
Agent Skills
Site officiel : https://agentskills.io
Journaux liées à cette note :
J'ai découvert cc-safety-net : des hooks pour sécuriser les agents IA
Suite à ma note "Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code", une amie m'a mise sur la piste des hooks pour intégrer efficacement le blocage de l'exécution de commandes dangereuses dans mon harness.
claude-code-hooks
Elle utilise Claude Code et je pense qu'elle utilise le projet claude-code-hooks (lien direct), et plus précisément son script block-dangerous-commands.js.
Ce projet est présenté dans le billet Claude Code's Most Underrated Feature: Hooks du 25 janvier 2026, que j'ai pris le temps de lire avec attention.
Après lecture, ce billet confirme la piste suggérée par mon amie : les hooks semblent être la solution la plus répandue pour bloquer les commandes dangereuses.
J'ai découvert cc-safety-net
J'ai ensuite cherché une solution "clé en main" équivalente à block-dangerous-commands.js pour OpenCode et suis tombée sur cc-safety-net (lien direct), un projet qui a même démarré un peu avant claude-code-hooks (source) :
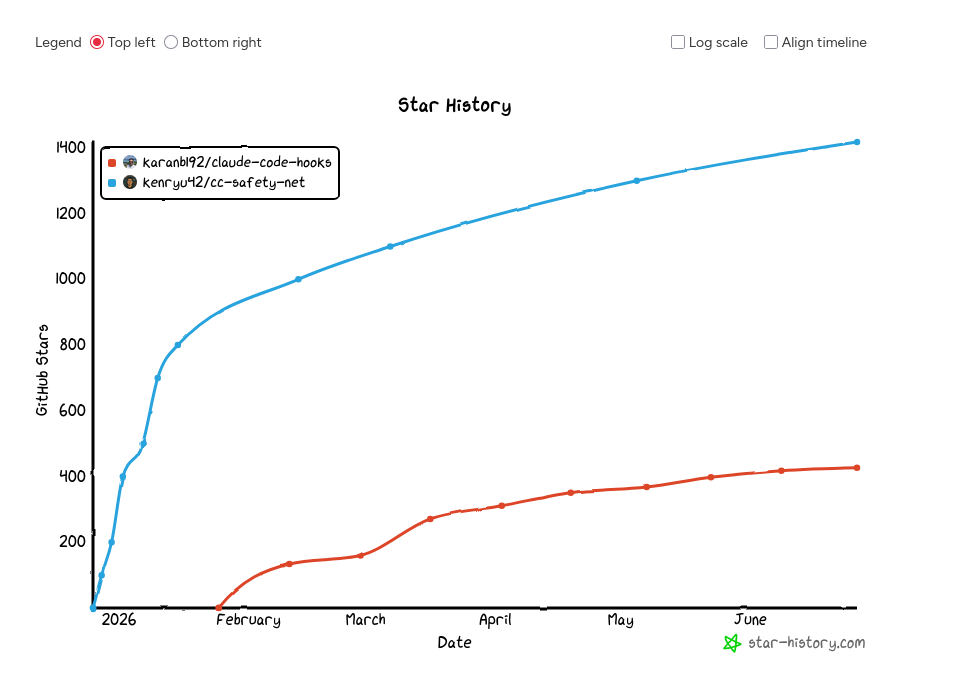
Le nom cc-safety-net combine l'abréviation de Claude Code ("cc") et "safety net", qui veut dire "filet de sécurité".
cc-safety-net ne se limite pas à Claude Code et OpenCode : il prend aussi en charge Codex, Gemini CLI, GitHub Copilot CLI et Kimi Code.
J'ai installé cc-safety-net
J'ai installé cc-safety-net sur mon instance OpenCode. Bien qu'il ne soit pas visible dans la liste des plugins de l'interface OpenCode — ce qui semble normal — il fonctionne correctement d'après mes tests :
$ git init
$ touch file1.md
$ git add file1.md
$ git commit -m "First import"
$ touch file2.md
$ opencode run --agent="build" "exécute git reset --hard"
> build · deepseek-v4-flash
✗ git reset --hard failed
Error: BLOCKED by CC Safety Net
Reason: git reset --hard destroys all uncommitted changes permanently. Use 'git stash' first.
Command: git reset --hard
If this operation is truly needed, ask the user for explicit permission and have them run the command manually.
La commande `git reset --hard` est bloquée par le CC Safety Net car elle détruit irréversiblement les changements non commités.
**Alternatives :**
- `git stash` pour sauvegarder les changements avant de reset
- Exécute la commande toi-même manuellement si tu confirms vouloir tout perdre
Que veux-tu faire ?
Par défaut, cc-safety-net contient peu de règles : il bloque les commandes de suppression sur le système de fichiers et git, comme documenté ici : "blocked-commands".
Après la lecture de la page "allowed-commands", j'ai cru que cc-safety-net proposait aussi un mode whitelist. En réalité, il fonctionne seulement en mode blocklist — pas de mode "tout bloquer" avec un système de whitelist.
Pour le moment, j'ai décidé d'activer le mode par défaut de cc-safety-net.
Création de rulebooks pour mon projet homelab
Ce que je trouve très intéressant avec cc-safety-net, c'est la possibilité d'ajouter facilement des "Custom Rules" grâce aux "rulebooks". Cette fonctionnalité est jeune, à peine 3 semaines. Pour le moment, je n'ai trouvé que 2 "rulebooks" sur GitHub.
J'ai utilisé le skill /cc-safety-net pour créer mes "rulebooks" pour les commandes kubectl, helmfile, tofu et mise de mon projet homelab.sklein.xyz.
Pas sans difficulté : le skill a dû corriger plusieurs erreurs de syntaxe dans les fichiers json qu'il a générés. Je ne sais pas si c'est normal. Mais à la fin, ça a fonctionné.
Je viens de configurer tout cela, je n'ai aucun retour d'expérience, j'essaierai d'en donner un d'ici une semaine.
Encore un problème avec rtk !
Par contre, j'ai découvert que cc-safety-net a lui aussi des difficultés avec rtk : [Bug]: rtk bypasses safety net.
Pour les secrets, je compte tester Rehydra
Contrairement à claude-code-hooks, cc-safety-net ne propose pas de hooks pour cacher les secrets à l'agent.
#JaiDécouvert le projet rehydra qui me semble très intéressant :
PII security for AI workflows, coding agents and browser workloads. Detects, replaces, encrypts, and rehydrates back when needed.
cc-safety-net versus agentsh ?
J'ai seulement survolé le sujet, mais j'ai l'impression que agentsh analyse et intercepte ce qui se passe directement au niveau du système d'exploitation, du système de fichiers, réseau, et processus. Il n'agit pas au niveau applicatif, il n'a pas besoin de comprendre ce que fait en théorie la commande, il observe réellement son action sur l'OS.
Pour le moment je pense que cc-safety-net est une bonne première étape de sécurité pour mes besoins. Mais agentsh a attiré ma curiosité, peut-être que je le testerai prochainement.
Remerciement
Merci à mon amie CC de m'avoir mise sur la piste des hooks 🤗.
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
L'exécution de promptfoo eval donne ceci :
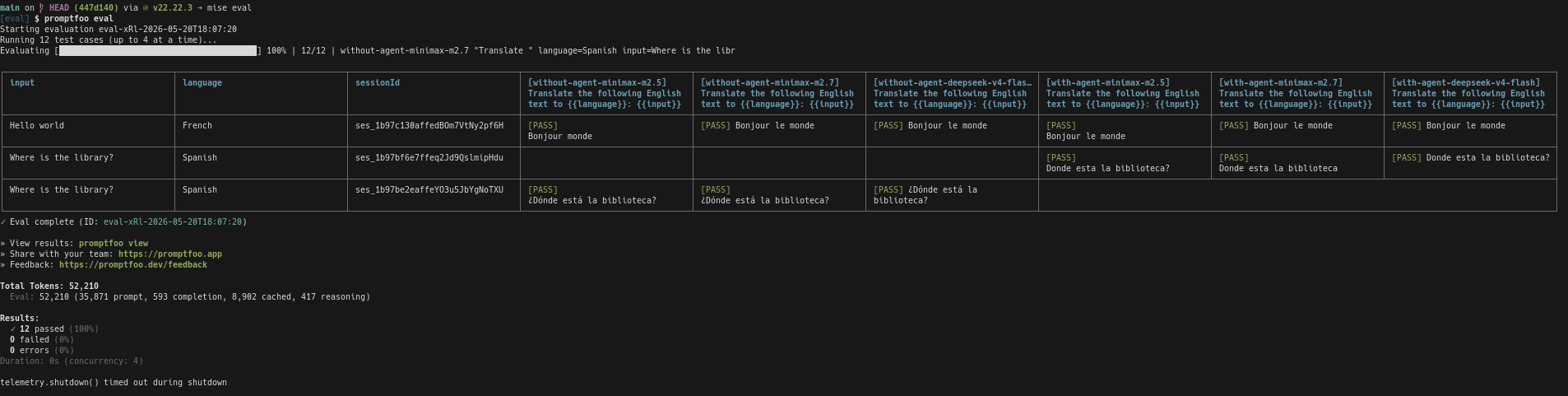
Et voici ce qu'affiche promptfoo viewer dans un browser :
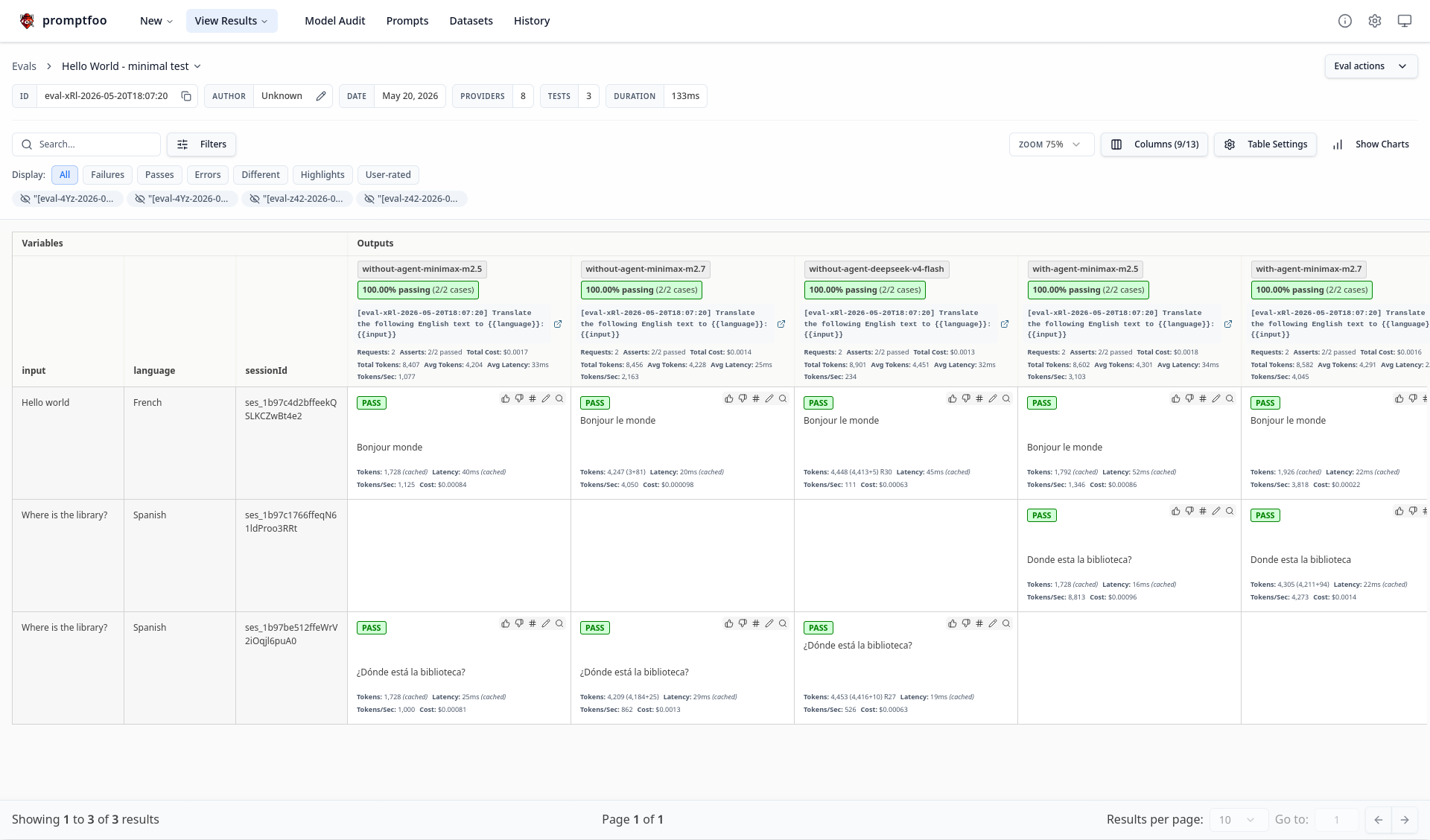
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
Comment "harness" s'est répandu en IA et pourquoi ce terme a été choisi
Le week-end dernier, j'ai commencé à chercher d'où venait le terme harness et pourquoi il a été choisi pour désigner ce concept dans les AI agents comme OpenCode ou Claude Code.
Cette note est le résultat de ce travail de recherche, basé sur des échanges avec Sonnet 4.6, des lectures de commentaires Hacker News et divers articles sur le sujet.
En novembre 2025, Anthropic a publié l'article « Effective Harnesses for Long-Running Agents », qui utilise explicitement « agent harness » dans le sens moderne.
Le terme « harness engineering » semble avoir été popularisé par Mitchell Hashimoto dans la section 5 de son billet publié le 5 février 2026. Il y décrit une pratique qu'il a développée au fil de son usage des agents IA :
Je ne sais pas s'il existe un terme largement accepté par l'industrie pour cela, mais j'en suis venu à appeler cela « harness engineering ». C'est l'idée que chaque fois qu'on constate qu'un agent commet une erreur, on prend le temps de concevoir une solution pour que l'agent ne commette plus jamais cette erreur. Je n'ai pas besoin d'inventer de nouveaux termes ici ; s'il en existe un autre, je m'y joindrai.
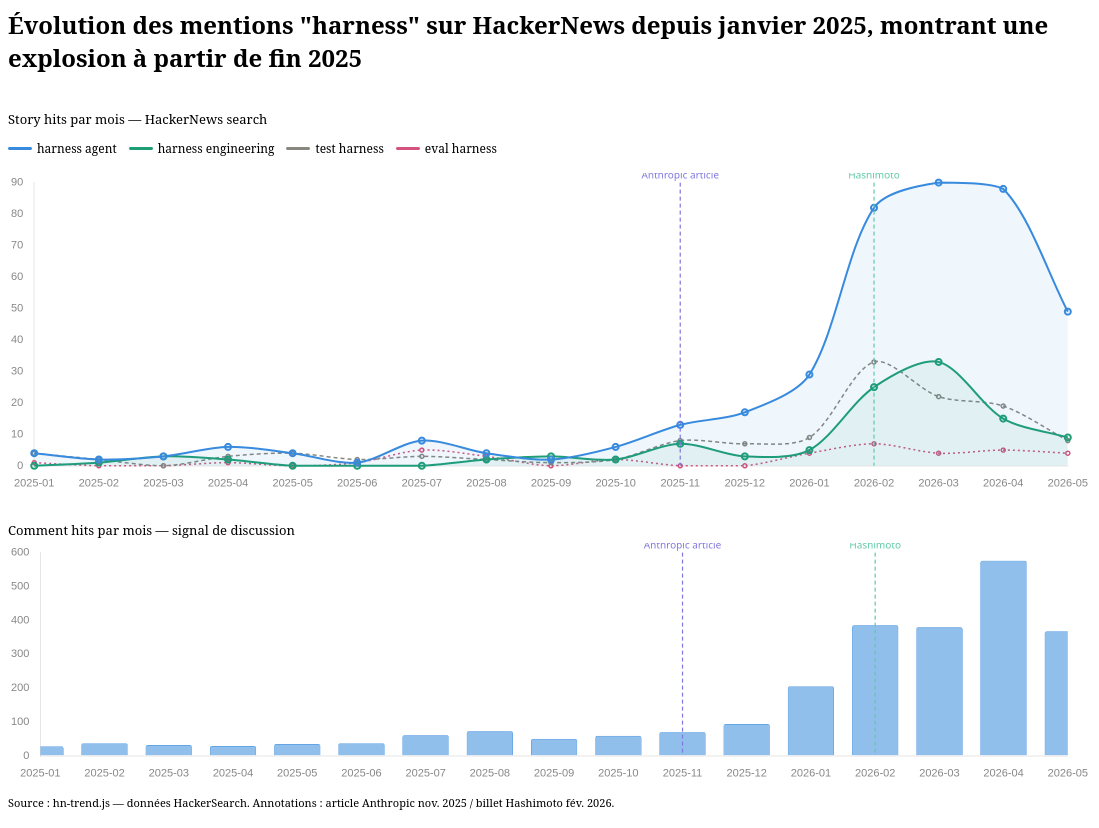 Données extraites avec hackernews-trends-poc.
Données extraites avec hackernews-trends-poc.
Jusqu'à présent, je pensais à tort que l'analogie du harnais correspondait simplement à l'équipement qu'on pose sur un cheval, sans saisir la pertinence de ce terme, par manque de culture de cette langue. En anglais, on trouve les expressions « harness the sun » ou « harness the wind ». Voici la définition du verbe harness :
Verb
harness (third-person singular simple present harnesses, present participle harnessing, simple past and past participle harnessed)
- (transitive) To place a harness on something; to tie up or restrain. Synonym: tackle
« They harnessed the horse to the post. »- (transitive) To capture, control or put to use. « Imagine what might happen if it were possible to harness solar energy fully. »
- (transitive) To equip with armour.
Le terme français qui me semble le plus proche du verbe harness serait « canaliser » ou « dompter ».
Le terme harness désigne donc l'action de canaliser et d'orienter la puissance d'un LLM vers un objectif souhaité.
Avant l'usage du terme harness dans le domaine de l'AI — que ce soit pour agent harness, harness engineering ou LM Evaluation Harness — j'ai découvert en travaillant sur cette note qu'il était déjà utilisé en software engineering, principalement dans l'expression test harness. Il me semble que c'était d'ailleurs l'usage principal du mot dans notre domaine, bien avant qu'il ne soit repris pour les agents IA.
Les concepts que je pense avoir identifiés et que je retiens
- Le harness est un artefact à installer et configurer dans OpenCode. Il est composé de :
- Le harness engineering est le processus humain d'amélioration itérative du harness. Quand l'utilisateur observe une erreur de l'agent, il modifie ou ajoute des fichiers
AGENTS.md,SKILLS.md, des outils MCP ou des configurations pour qu'elle ne se reproduise plus. Ce terme désigne le processus, par opposition au harness qui est l'artefact. - Agent-eval-harness est un outil externe au harness permettant de lancer des sortes de tests unitaires. Il est utilisé pendant les phases de harness engineering pour valider les modifications de façon contrôlée et reproductible.
Cette note ne traite pas de la boucle agent en elle-même — j'ai documenté ce concept séparément ici :
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise.
Le concept de harness vient encadrer cette boucle pour la configurer et la contraindre, mais il ne la définit pas. Comprendre la boucle aide à saisir ce qu'orchestre le harness.
Extrait d'un article de Sebastian Raschka :
Pour clarifier les concepts :
- LLM : le modèle brut de prédiction du prochain token
- Modèle de raisonnement : un LLM optimisé pour produire des traces de raisonnement intermédiaires et se vérifier davantage
- Agent : une boucle qui combine un modèle avec des outils, de la mémoire et des retours d'environnement
- Agent harness : le scaffold logiciel autour d'un agent qui gère le contexte, l'utilisation des outils, les prompts, l'état et le flux de contrôle
- Coding harness : un cas particulier d'agent harness ; un harness spécifique au génie logiciel qui gère le contexte du code, les outils, l'exécution et les retours itératifs
Quelques articles que j'ai lus avec attention :
- Effective harnesses for long-running agents — Anthropic, nov. 2025
- My AI Adoption Journey — Mitchell Hashimoto, fév. 2026
- Components of a Coding Agent — Sebastian Raschka, avr. 2026
En explorant le sujet de harness, je constate que, comme beaucoup de concepts, sa définition peut varier selon les sources et les communautés. Par exemple, l'article Components of a Coding Agent de Sebastian Raschka semble en proposer une définition plus large que Mitchell Hashimoto.
Pour le moment, je souhaite adopter la version de Mitchell Hashimoto, que j'arrive mieux à appréhender et dont je parviens mieux à délimiter le périmètre : un dispositif qui canalise la fougue du LLM, comme le harnais canalise le cheval sauvage.
Comment déclencher des questions interactives dans OpenCode et ClaudeCode ?
Cela fait plusieurs mois que je me demande comment fonctionne le mécanisme de questions interactives présent dans OpenCode et Claude Code.
Plus précisément, je me demande comment je peux déclencher, de manière certaine, des questions interactives dans mes SKILLS.md.
Dans cet exemple :
> Pose-moi la question pour savoir si je suis une femme ou un homme.
Es-tu une femme ou un homme ?
OpenCode ne me pose pas cette question de manière interactive, la question est posée sous la forme de "texte libre".
J'ai cherché à en savoir plus et voici ce que j'ai trouvé.
Le mécanisme de questions interactives est déclenché par un tool.
- Chez Claude Code, ce tool est nommé "
AskUserQuestion" - Et chez OpenCode, ce tool est nommé simplement "
question"
Et voici le contenu des descriptions de ces tools (qui jouent le rôle de prompt) :
- Pour OpenCode : https://github.com/anomalyco/opencode/blob/dev/packages/opencode/src/tool/question.txt
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- When `custom` is enabled (default), a "Type your own answer" option is added automatically; don't include "Other" or catch-all options
- Answers are returned as arrays of labels; set `multiple: true` to allow selecting more than one
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
- Pour Claude Code : https://github.com/Piebald-AI/claude-code-system-prompts/blob/main/system-prompts/tool-description-askuserquestion.md
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- Users will always be able to select "Other" to provide custom text input
- Use multiSelect: true to allow multiple answers to be selected for a question
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
Plan mode note: In plan mode, use this tool to clarify requirements or choose between approaches BEFORE finalizing your plan. Do NOT use this tool to ask "Is my plan ready?" or "Should I proceed?" - use ${EXIT_PLAN_MODE_TOOL_NAME} for plan approval. IMPORTANT: Do not reference "the plan" in your questions (e.g., "Do you have feedback about the plan?", "Does the plan look good?") because the user cannot see the plan in the UI until you call ${EXIT_PLAN_MODE_TOOL_NAME}. If you need plan approval, use ${EXIT_PLAN_MODE_TOOL_NAME} instead.
Aucun des deux prompts ne dit quand ne pas poser les questions en texte libre. Les deux disent "use this tool when you need to ask questions" — mais le modèle juge lui-même si la situation justifie le tool ou une réponse textuelle directe.
Pour être certain que l'agent IA pose une question en mode interactif, il faut lui demander explicitement de l'utiliser, par exemple, avec la mention (use question tool) ou dans cet exemple :
Utilise le tool question pour me poser deux questions :
1. Mon sexe (homme, femme, autre)
2. Mon prénom, avec "Stéphane" comme première option suggérée, et une option pour saisir autre chose
Autres ressources :
- Le code source du tool
questionde OpenCode : https://github.com/anomalyco/opencode/blob/e3c983c21f925fef4b03f46a06663f1b29cfed34/packages/opencode/src/tool/question.ts - https://github.com/vtemian/octto - un plugin permettant de créer des formulaires avancés, avec gestion de branches et 14 types de saisie. À noter : l'interface s'ouvre dans un navigateur, ce qui casse le flux TUI.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals. Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).