
direnv
direnv is an extension for your shell. It augments existing shells with a new feature that can load and unload environment variables depending on the current directory.
Site officiel : https://direnv.net/
direnv charge automatiquement les variables d'environnement présentes dans les fichiers .envrc du dossier courant et, optionnellement, des dossiers parents.
Journaux liées à cette note :
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
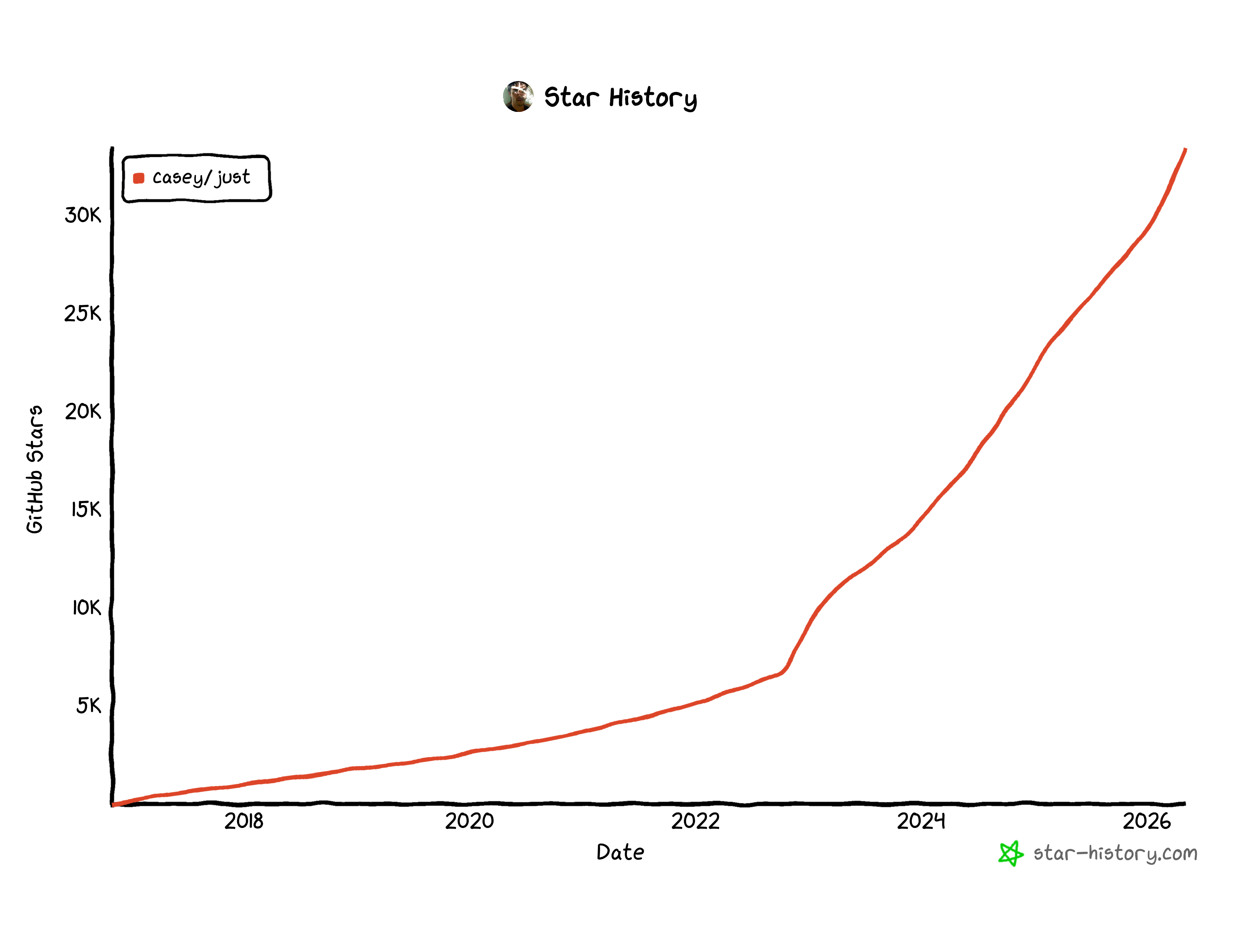
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du mardi 25 février 2025 à 14:20
Alexandre vient de partager ce thread : « Asdf Version Manager Has Been Re-Written in Golang »
Je découvre que Asdf n'est pas mort ! La version 0.16.0 publié le 30 janvier 2025 a été réécrite en Golang !
La raison principale semble être une volonté d'amélioration de la vitesse de Asdf :
With improvements ranging from 2x-7x faster than asdf version 0.15.0!
Depuis cette date, Mise a publié un benchmark qui compare la vitesse d'exécution de Asdf et Mise : https://mise.jdx.dev/dev-tools/comparison-to-asdf.html#asdf-in-go-0-16.
Comme mon ami Alexandre, certains utilisateurs sont inquiets de voir Mise faire trop de choses :
I tried mise a while back, and the main reason I went away from it is like you said, it does too much. It tries to be asdf, direnv and a task runner. I just want a tool manager, and is the reason why I switched to aquaproj/aqua.
J'ai migré de Asdf vers Mise en novembre 2023 et pour le moment, je n'ai pas envie, ni de raison pratique particulière pour retourner à Asdf.
De plus, je suis plutôt satisfait d'avoir remplacé direnv par Mise, voir Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞
Le 6 novembre 2024, j'ai publié la note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
L'issue indiquée dans cette note a été cloturée il y a 3 jours : Use mise tools in env template · Issue #1982.
Voici le contenu de changement de la documentation : https://github.com/jdx/mise/pull/3598/files#diff-e8cfa8083d0343d5a04e010a9348083f7b64035c407faa971074c6f0e8d0d940
Ce qui signifie que je vais pouvoir maintenant utiliser terraform installé via Mise dans le fichier .envrc :
[env]
_.source = { value = "./.envrc.sh", tools = true }
[tools]
terraform="1.9.8"
Après avoir installé la dernière version de Mise, j'ai testé cette configuration dans repository suivant : install-and-configure-mise-skeleton.
Le fichier .envrc suivant a fonctionné :
export HELLO_WORLD=foo3
export NOW=$(date)
export TERRAFORM_VERSION=$(terraform --version | head -n1)
Exemple :
$ mise trust
$ echo $TERRAFORM_VERSION
Terraform v1.9.8
Je n'ai pas trouvé de commande Mise pour recharger les variables d'environnement du dossier courant, sans quitter le dossier. Avec direnv, pour effectuer un rechargement je lançais : direnv allow.
À la place, j'ai trouvé la méthode suivante :
$ source .envrc
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Journal du dimanche 08 décembre 2024 à 22:19
Je viens de rencontrer l'outil envdir (à ne pas confondre avec direnv) et son modèle de stockage de variables d'environnement, que je trouve très surprenant !
direnv ou dotenv utilisent de simples fichiers texte pour stocker les variables d'environnements, par exemple :
export POSTGRES_URL="postgres://postgres:password@localhost:5432/postgres"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export MAIL_FROM="noreply@example.com"
Contrairement à ces deux outils, pour définir ces quatre variables, le modèle de stockage de envdir nécessite la création de 4 fichiers :
$ tree .
.
├── MAIL_FROM
├── POSTGRES_URL
├── SMTP_HOST
└── SMTP_PORT
1 directory, 4 files
$ cat POSTGRES_URL
postgres://postgres:password@localhost:5432/postgres
$ cat SMTP_HOST
127.0.0.1
$ cat SMTP_PORT
1025
$ cat MAIL_FROM
127.0.0.1
Je trouve ce modèle fort peu pratique. Contrairement à un simple fichier unique, le modèle de envdir présente certaines limitations :
- Organisation : il ne permet pas de structurer librement l'ordre ou de regrouper visuellement les variables.
- Lisibilité : l'ensemble de la configuration est plus difficile à visualiser d'un seul coup d'œil.
- Manipulation : copier ou coller son contenu n'est pas aussi direct qu'avec un fichier texte.
- Documentation : les commentaires ne peuvent pas être inclus pour expliquer les variables.
- Rapidité : la saisie ou la modification de plusieurs variables demande plus de temps, chaque variable étant dans un fichier distinct.
J'ai été particulièrement intrigué par le choix fait par l'auteur de envdir. Sa décision semble vraiment surprenante.
envdir fait partie du projet daemontools, créé en 1990. Ainsi, il est bien plus ancien que dotenv, qui a été lancé autour de 2010, et direnv, qui date de 2014.
Si je me remets dans le contexte des années 1990, je pense que le modèle de envdir a été avant tout motivé par une simplicité d'implémentation plutôt que d'utilisation. En effet, il est plus facile de lister les fichiers d'un répertoire et de charger leur contenu que de développer un parser de fichiers.
Je pense qu'en 2024, envdir n'a plus sa place dans un environnement informatique moderne. Je recommande vivement de le remplacer par des solutions plus récentes, comme devenv ou direnv.
Personnellement, j'utilise direnv dans tous mes projets.
Journal du mercredi 04 décembre 2024 à 14:56
Alexandre a eu un breaking change avec Mise : https://github.com/jdx/mise/issues/3338.
Suite à cela, j'ai découvert que Mise va prévilégier l'utilisation du backend aqua plutôt que Asdf :
we are actively moving tools in the registry away from asdf where possible to backends like aqua and ubi which don't require plugins.
J'ai découvert au passage que Mise supporte de plus en plus de backend, par exemple Ubi et vfox.
Je constate qu'il commence à y avoir une profusion de "tooling version management" : Asdf,Mise, aqua, Ubi, vfox !
Je pense bien qu'ils ont chacun leurs histoires, leurs forces, leurs faiblesses… mais j'ai peur que cela me complique mon affaire : comment arriver à un consensus de choix de l'un de ces outils dans une équipe 🫣 ! Chaque développeur aura de bons arguments pour utiliser l'un ou l'autre de ces outils.
Constatant plusieurs fois que le développeur de Mise a fait des breaking changes qui font perdre du temps aux équipes, mon ami et moi nous sommes posés la question si, au final, il ne serait pas judicieux de revenir à Asdf.
D'autre part, au départ, Mise était une simple alternative plus rapide à Asdf, mais avec le temps, Mise prend en charge de plus en plus de fonctionnalités, comme une alternative à direnv , un système d'exécution de tâches, ou mise watch.
Souvent, avec des petits défauts très pénibles, voir par exemple, ma note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
Alexandre s'est ensuite posé la question d'utiliser un jour le projet devenv, un outil qui va encore plus loin, basé sur le système de package Nix.
Le projet devenv me fait un peu peur au premier abord, il gère "tout" :
- Comme Asdf et Mise : l'installation des outils, packages et langages
- Support de scripts "helper"
- Intégration de Docker
- Support de process
- Support du SDK Android
Il fait énormément de choses et je crains que la barrière à l'entrée soit trop haute et fasse fuir beaucoup de développeurs 🤔.
Tout cela me fait un peu penser à Bazel (utilisé par Google), Pants (utilisé par Twitter), Buck (utilisé par Facebook) et Please.
Tous ces outils sont puissants, je les ai étudiés en 2018 sans arrivée à les adopter.
Pour le moment, mes development kit nécessitent les compétences suivantes :
- Comprendre les rudiments d'un terminal Bash ;
- Arriver à installer et à utiliser Mise et direnv ;
- Maitriser Docker ;
- Savoir lire et écrire des scripts Bash de niveau débutant.
Déjà, ces quatre prérequis posent quelques fois des difficultés d'adoption.
Le support des variables d'environments de Mise est limité, je continue à utiliser direnv
J'ai décidé d'utiliser la fonctionnalité "mise
env._source" pendant quelques semaines pour me faire une opinion.-- (from)
J'ai déjà rencontré un problème : il n'est pas possible de lancer des outils installés via Mise dans un script lancé par _.source.
Voici un exemple, j'ai ce fichier .envrc.sh :
export SERVER1_IP=$(terraform output --json | jq -r '.server1_public_ip | .value')
Terraform est installé avec Mise :
[env]
_.source = "./.envrc.sh"
[tools]
terraform="1.9.8"
Quand je lance mise set, j'ai cette erreur :
$ mise set
.envrc.sh: line 6: terraform: command not found
J'ai trouvé une issue pour traiter cette limitation : "Use mise tools in env template".
En attendant que cette issue soit implémentée, j'ai décidé de continuer d'utiliser direnv.
2024-12-19 : suite à la cloture de l'issue indiquée dans cette note, j'ai publié la note Je pense maintenant pouvoir remplacer Direnv par Mise 🤞.
Journal du mercredi 06 novembre 2024 à 17:10
En travaillant sur la note 2024-11-06_1631, j'ai découvert les commandes shell suivantes mises à disposition par direnv que je trouve intéressantes :
Je remplace direnv par la fonctionnalité env._source proposée Mise
Depuis avril 2019, j'utilise direnv dans pratiquement tous mes projets de développement informatique.
Ce matin je me suis demandé si avec les nouvelles fonctionnalités de gestion des variables d'environnement de Mise, je pouvais simplifier mes development kit 🤔.
Comme vous pouvez le voir dans install-and-configure-direnv-with-mise-skeleton, actuellement mes development kit contiennent deux étapes de modifications de .bash_profile ou .zshrc. Exemple avec Zsh :
- Une étape pour configurer Mise :
$ echo 'eval "$(~/.local/bin/mise activate zsh)"' >> ~/.zshrc
$ source ~/.zsrhrc
- Seconde étape pour configurer direnv :
$ echo -e "\neval \"\$(direnv hook zsh)\"" >> ~/.zshrc
$ source ~/.zsrhrc
Voici la version simplifiée de ce skeleton basé sur "mise env._source", avec une étape de configuration en moins :
https://github.com/stephane-klein/install-and-configure-mise-skeleton
Voici le contenu du fichier .mise.toml :
[env]
_.source = "./.envrc.sh"
et le contenu de .envrc.sh :
export HELLO_WORLD=foo
J'ai fait le choix de nommer ce fichier .envrc.sh plutôt que .envrc afin d'éviter des problèmes de compatibilité pour les utilisateurs qui ont direnv installé.
J'ai vérifié que les variables d'environnements "parents" sont bien conservées en cas de changement de variable d'environnement par Mise dans un sous dossier.
#JeMeDemande si je vais rencontrer des régressions par rapport à direnv 🤔.
J'ai décidé d'utiliser la fonctionnalité "mise env._source" pendant quelques semaines pour me faire une opinion.
Update : voir 2024-11-06_2109.
development kit skeleton d'installation de direnv
Voici un dépôt GitHub qui contient les instructions que j'indiquais dans mes development kit, avant 2024, pour installer et configurer direnv, sous MacOS.
https://github.com/stephane-klein/install-and-configure-direnv-with-asdf-skeleton
Dans ce skeleton, direnv est installé avec asdf, voir le fichier racine ./.tool-versions
Et voici un exemple de skeleton, que j'utilise depuis novembre 2023, basé sur Mise :
https://github.com/stephane-klein/install-and-configure-direnv-with-mise-skeleton
Dans ce second skeleton, direnv est installé avec Mise, voir le fichier racine ./.mise.toml.