
Mise
Mise est un "tooling version management", il permet d'installer la plupart des outils nécessaire au bon fonctionnement d'un development environment. Il permet de "pin" les versions précises de ces outils.
Avec direnv et Docker, Mise fait parti des briques de fondactions que j'utilise pour créer mes development kit.
Site officiel : https://mise.jdx.dev
Journaux liées à cette note :
Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code
Cette après-midi, DeepSeek V4 Flash (via OpenCode) a fait une boulette dans mon projet homelab.sklein.xyz !

En voulant corriger le Helmfile de déploiement de Hindsight, il a lancé :
$ mise run destroy-cnpg-hindsight
sans réaliser que cette task Mise allait lancer la commande suivante :
helmfile -f helmfile/helmfile.yaml.gotmpl destroy
sans remarquer que mon fichier helmfile/helmfile.yaml.gotmpl contenait tous mes services et pas seulement cnpg-hindsight !
Ce qui est marrant, c'est qu'après le « Oups », il a tout de suite essayé de se rattraper. Heureusement, je suis au début de l'installation de mon homelab — rien d'important à perdre — et j'ai pu tester que la restauration du backup continu de CloudNativePG basé sur barman fonctionne bien.
DeepSeek V4 Flash n'est pas à blâmer : je ne l'ai pas aidé avec mes instructions, je lui ai tendu un piège.
Suite à cet incident sans gravité, j'ai pris conscience que faire travailler un agent de coding sur un projet d'Infrastructure as code est bien plus risqué que sur un projet de développement cloisonné, sans accès à la production.
J'ai commencé par ajouter ces quelques lignes dans mon fichier AGENTS.md :
## Safety Rules
- **Never run any `destroy-*` script or `helmfile destroy` command without explicit user confirmation** in the same conversation turn. Always ask first.
- If you must run `helmfile destroy`, always use `--selector name=<release>` to target only one release.
- When in doubt about a command's destructiveness, ask before executing.
Ensuite, j'ai remarqué que l'agent plan de OpenCode avait par défaut un accès trop large au tool bash pour un projet d'Infrastructure as code, je me suis lancé dans le renforcement des permissions :
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"plan": {
"permission": {
"bash": {
"*": "ask",
"kubectl get *": "allow",
"kubectl describe *": "allow",
"kubectl logs *": "allow",
"kubectl top *": "allow",
"tofu plan*": "allow",
"tofu show*": "allow",
"tofu output*": "allow",
"tofu state*": "allow",
"helm list*": "allow",
"helm status*": "allow",
"helm diff*": "allow",
"helmfile *list*": "allow",
"helmfile *status*": "allow",
"helmfile *diff*": "allow",
"git log*": "allow",
"git diff*": "allow",
"git status": "allow",
"git show*": "allow",
"jj log*": "allow",
"jj diff*": "allow",
"jj status": "allow",
"ls*": "allow",
"find*": "allow"
}
}
}
}
}
Ensuite, je me suis demandé s'il existait des solutions clé en main de limitation d'accès aux commandes cli, du même style que rtk, pour autoriser seulement des commandes de lecture sans risque.
#JaiDécouvert Prempti et agentsh. Je me suis demandé si l'intégration de l'un de ces outils n'allait pas entrer en conflit avec rtk. En étudiant les issues sur la sécurité de rtk, j'ai découvert que : rtk contourne le système de permissions d'OpenCode.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
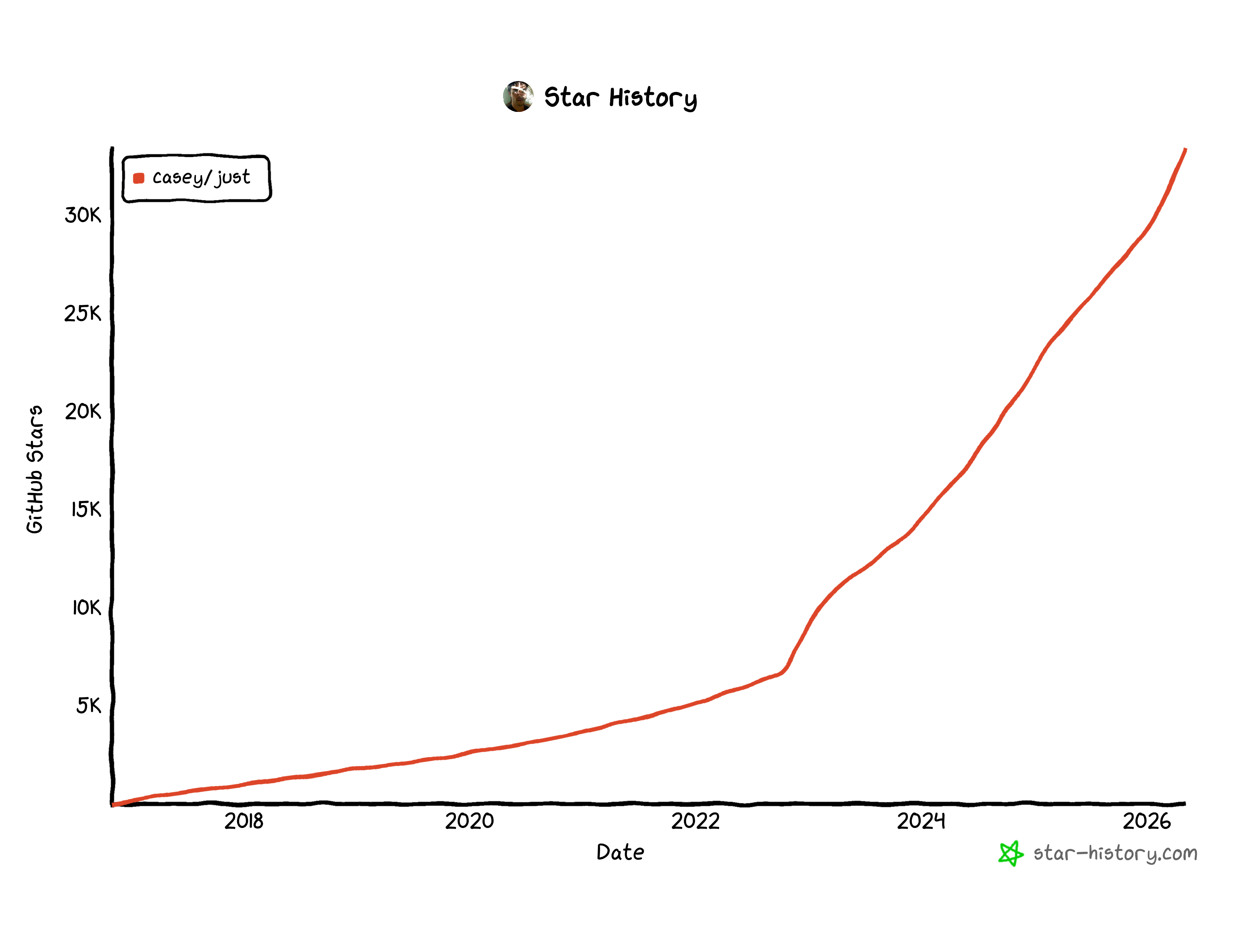
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
J'ai découvert snip et rtk et testé rtk (reduce LLM usage)
Le 13 avril 2026, j'ai découvert le projet snip :
Quelques semaines plus tard, le 29 avril, Alexandre m'a fait découvrir rtk, une alternative à snip.
rtk est un projet Rust dont le développement a commencé le 18 janvier 2026. snip, quant à lui, est un projet Golang initié par un français basé à la Réunion le 15 février 2026, directement inspiré de rtk.
Voici comment le projet snip compare les deux projets :
Design Philosophy
snip chose a fundamentally different approach to LLM token reduction: filters are data, not code. The binary is the engine, filters are YAML data files, and the two evolve independently.
rtk (Rust) snip (Go) Filter authoring Write Rust, recompile, wait for release Write YAML, drop in a folder, done Filter format Compiled into the binary Declarative YAML, engine and filters evolve independently Custom filters Fork the repo, add Rust code Create a .yamlfile in~/.config/snip/filters/Concurrency 2 OS threads Goroutines (lightweight, no thread pool) SQLite Requires CGO + C compiler Pure Go driver, static binary, no dependencies Cross-compilation Per-target C toolchain GOOS=linux GOARCH=arm64 go buildPipeline actions Built-in strategies 19 composable actions (keep, remove, regex, JSON, state machine...) Contributing Rust knowledge required YAML knowledge sufficient Both tools solve the same problem: reducing AI token costs from verbose CLI output. snip's bet is that extensibility wins. When anyone can write a filter in 5 minutes without touching Go or Rust, the filter ecosystem grows faster.
Voici à quoi ressemble un filtre dans rtk : https://github.com/rtk-ai/rtk/blob/master/src/filters/jj.toml.
Et voici l'équivalent pour snip : https://github.com/edouard-claude/snip/blob/master/filters/jj.yaml.
Je trouve la possibilité d'ajouter de nouvelles commandes à snip simplement en créant un fichier YAML intéressante, mais pour le moment je ne sais pas si j'en aurai besoin.
D'autre part, rtk est supporté par Mise : https://mise-versions.jdx.dev/tools/rtk.
Par conséquent, j'ai décidé de tester la configuration de rtk avec OpenCode. Voici le commit d'intégration à sklein-devbox : https://github.com/stephane-klein/sklein-devbox-chezmoi/commit/0fa4917ee2f31605f8d124223ec650961bf057b6.
Voici comment j'ai initialisé le plugin OpenCode pour rtk :
$ rtk init -g --opencode
OpenCode plugin installed (global).
OpenCode: /home/sklein/.config/opencode/plugins/rtk.ts
Restart OpenCode. Test with: git status
--- Telemetry ---
RTK collects anonymous usage metrics once per day to improve filters.
What: command names (not arguments), token savings, OS, version
Why: prioritize filter development for the most-used commands
Who: RTK AI Labs, contact@rtk-ai.app
Rights: disable anytime with `rtk telemetry disable`,
request erasure with `rtk telemetry forget`
Details: https://github.com/rtk-ai/rtk/blob/main/docs/TELEMETRY.md
Enable anonymous telemetry? [y/N] y
Telemetry enabled. Disable anytime: rtk telemetry disable
Et voici un exemple d'utilisation :
$ opencode run "Quels sont les derniers changements de ce projet ?"
> build · minimax-m2.5
$ rtk git log --oneline -10
0fffe04 Remove mode -x dot_config/tmux/scripts/executable_current-path.sh
832f03b Add peeble/ to Chezignore # <m-r> Reset Message
0fa4917 Setup rtk to reduces OpenCode LLM token consumption
983b77d s6-overlay migration to Pebble (#25)
1f7cbcd Start Mise eval before atuin to fix a bug
c8e6194 Remove gopass and GPG agent management since both services start automatically on first use
71e64e1 Enable Mise environment activation so Neovim can access Mise-managed tools
679f53f Purge empty mise installs/ dirs to force reinstall of incomplete tools
4c32db8 Extract init process into standalone script
8258ab9 Add infomation messages in init scripts
...
Je constate que la commande rtk git log est correctement utilisée par OpenCode.
Voici ce que m'affiche la commande rtk gain :
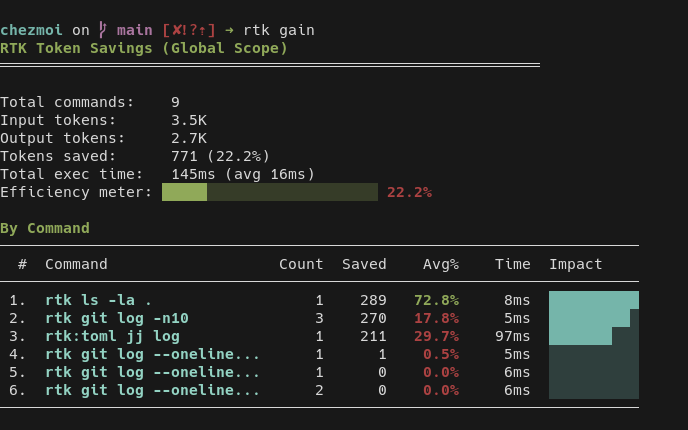
Pour le moment ceci n'est pas représentatif, car je viens de l'installer et j'ai lancé uniquement des tests fictifs.
Je compte publier une note de bilan d'ici quelques semaines pour analyser si c'est vraiment impactant ou non.
J'ai découvert la méthode NVIM_APPNAME qui permet de lancer des instances cloisonnées de Neovim
Il y a plus d'un an, j'ai écrit cette note où je décrivais la méthode que j'avais trouvée après plusieurs itérations pour lancer plusieurs instances Neovim cloisonnées.
J'ai publié cette méthode dans neovim-playground, qui ressemble à ceci :
export XDG_CONFIG_HOME=$(PWD)/config/
export XDG_DATA_HOME=$(PWD)/local/share/
export XDG_STATE_HOME=$(PWD)/local/state/
export XDG_CACHE_HOME=$(PWD)/local/cache/
Je me suis senti un peu bête aujourd'hui en découvrant dans la documentation officielle de Neovim qu'il existe une méthode officielle pour isoler une instance Neovim :
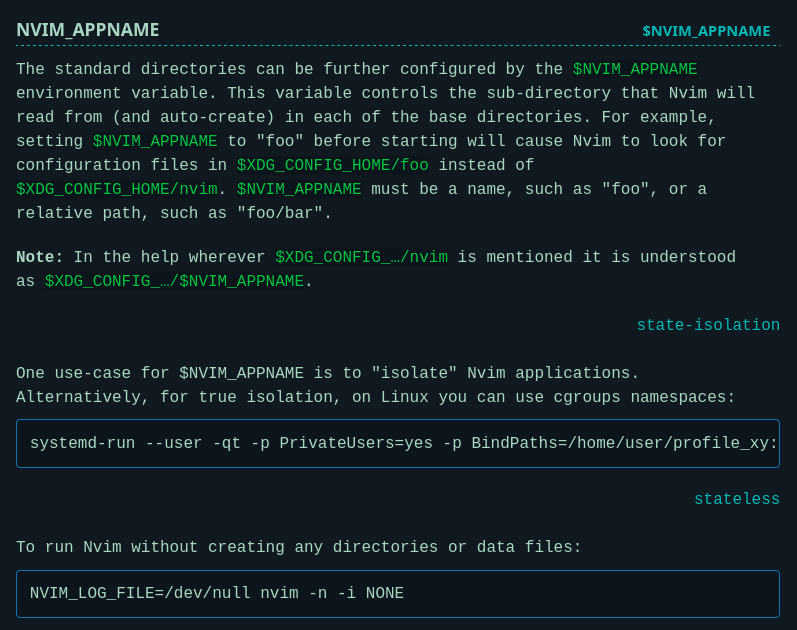
Cette fonctionnalité a été ajoutée dans la version 0.9.0 d'avril 2023, suite à une demande d'utilisateurs qui avaient le même besoin que moi, décrite dans cette issue : NVIM_APPNAME: isolated configuration profiles
Dans cette documentation, #JaiDécouvert comment lancer une application dans un namespace cgroups :
$ systemd-run --user -qt -p PrivateUsers=yes -p BindPaths=/home/user/profile_xy:/home/user/.config/nvim nvim
Je trouve cela plutôt simple.
Coïncidence : j'ai découvert systemd-run il y a 3 mois et depuis, je croise cette commande de plus en plus souvent.
Comme je souhaite lancer un environnement cloisonné Neovim tout en conservant l'accès aux outils de mon terminal (comme ceux installés avec Mise), j'ai choisi d'utiliser la méthode basée sur NVIM_APPNAME.
J'ai testé cette méthode avec succès dans neovim-playground (commit).
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
En attendant de trouver un repository Mise pour PostgreSQL Client Applications
À ce jour, je n'ai pas trouvé de repository Mise ou Asdf pour installer les "Client Applications" de PostgreSQL, par exemple : psql, pg_dump, pg_restore.
Il existe asdf-postgres, mais ce projet me pose quelques problèmes :
- L'installation basée sur le code source de PostgreSQL avec une phase de compilation qui peut être longue et consommer beaucoup d'espace disque.
- L'intégralité de PostgreSQL est installée alors que je n'ai besoin que des "Client Applications".
#JaimeraisUnJour créer une repository Mise ou Asdf qui permet d'installer les "Client Applications" en mode binaire. Pour le moment, je n'ai aucune idée sur quels binaires me baser 🤔.
En attendant de créer ou de trouver ce repository, voici ci-dessous mes méthodes actuelles d'installation des "PostgreSQL Client Applications".
Sous MacOS
Sous MacOS, j'utilise Brew pour installer le package libpq qui contient les "PostgreSQL Client Applications".
$ brew install libpq
ou alors pour l'installation d'une version spécifique :
$ brew install libpq@17.4
Sous Fedora
Sous Fedora, j'installe le package PostgreSQL client proposé sur la page "Downloads" officielle de PostgreSQL.
Cette méthode me permet d'installer précisément une version majeure précise de PostgreSQL :
Voici les instructions pour installer la dernière version de PostgreSQL 17 sous Fedora 41 :
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/F-41-x86_64/pgdg-fedora-repo-latest.noarch.rpm
$ sudo rpm --import https://download.postgresql.org/pub/repos/yum/keys/PGDG-RPM-GPG-KEY-Fedora
$ sudo dnf update -y
Le package nommé postgresql17 contient uniquement les "PostgreSQL Client Applications" :
$ dnf info postgresql17
Mise à jour et chargement des dépôts :
Dépôts chargés.
Paquets installés
Nom : postgresql17
Epoch : 0
Version : 17.4
Version : 1PGDG.f41
Architecture : x86_64
Taille une fois installé : 10.7 MiB
Source : postgresql17-17.4-1PGDG.f41.src.rpm
Dépôt d'origine : pgdg17
Résumé : PostgreSQL client programs and libraries
URL : https://www.postgresql.org/
Licence : PostgreSQL
Description : PostgreSQL is an advanced Object-Relational database management system (DBMS).
: The base postgresql package contains the client programs that you'll need to
: access a PostgreSQL DBMS server. These client programs can be located on the
: same machine as the PostgreSQL server, or on a remote machine that accesses a
: PostgreSQL server over a network connection. The PostgreSQL server can be found
: in the postgresql17-server sub-package.
:
: If you want to manipulate a PostgreSQL database on a local or remote PostgreSQL
: server, you need this package. You also need to install this package
: if you're installing the postgresql17-server package.
Fournisseur : PostgreSQL Global Development Group
$ dnf repoquery -l postgresql17 | grep "/bin"
Mise à jour et chargement des dépôts :
Dépôts chargés.
/usr/pgsql-17/bin/clusterdb
/usr/pgsql-17/bin/createdb
/usr/pgsql-17/bin/createuser
/usr/pgsql-17/bin/dropdb
/usr/pgsql-17/bin/dropuser
/usr/pgsql-17/bin/pg_basebackup
/usr/pgsql-17/bin/pg_combinebackup
/usr/pgsql-17/bin/pg_config
/usr/pgsql-17/bin/pg_createsubscriber
/usr/pgsql-17/bin/pg_dump
/usr/pgsql-17/bin/pg_dumpall
/usr/pgsql-17/bin/pg_isready
/usr/pgsql-17/bin/pg_receivewal
/usr/pgsql-17/bin/pg_restore
/usr/pgsql-17/bin/pg_waldump
/usr/pgsql-17/bin/pg_walsummary
/usr/pgsql-17/bin/pgbench
/usr/pgsql-17/bin/psql
/usr/pgsql-17/bin/reindexdb
/usr/pgsql-17/bin/vacuumdb
Installation de ce package :
$ sudo dnf install postgresql17
$ psql --version
psql (PostgreSQL) 17.4
Journal du mardi 25 février 2025 à 14:20
Alexandre vient de partager ce thread : « Asdf Version Manager Has Been Re-Written in Golang »
Je découvre que Asdf n'est pas mort ! La version 0.16.0 publié le 30 janvier 2025 a été réécrite en Golang !
La raison principale semble être une volonté d'amélioration de la vitesse de Asdf :
With improvements ranging from 2x-7x faster than asdf version 0.15.0!
Depuis cette date, Mise a publié un benchmark qui compare la vitesse d'exécution de Asdf et Mise : https://mise.jdx.dev/dev-tools/comparison-to-asdf.html#asdf-in-go-0-16.
Comme mon ami Alexandre, certains utilisateurs sont inquiets de voir Mise faire trop de choses :
I tried mise a while back, and the main reason I went away from it is like you said, it does too much. It tries to be asdf, direnv and a task runner. I just want a tool manager, and is the reason why I switched to aquaproj/aqua.
J'ai migré de Asdf vers Mise en novembre 2023 et pour le moment, je n'ai pas envie, ni de raison pratique particulière pour retourner à Asdf.
De plus, je suis plutôt satisfait d'avoir remplacé direnv par Mise, voir Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Je viens de découvrir le projet Fastlane (https://fastlane.tools/).
Je pense que c'est l'outil qui me manquait pour suivre le paradigme configuration as code dans mon "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor".
Ce projet a commencé en 2014 par Felix Krause et repris par Google en 2017 : « fastlane is joining Google - Felix Krause ».
Mais, je découvre que Google semble avoir arrêter de financer le développement du projet en 2023 : Google is no longer sponsoring Fastlane | Hacker News.
Depuis, le projet semble être toujours actif avec de nombreuses release : https://github.com/fastlane/fastlane/releases.
Fonctionnalités de Fastlane qui m'intéressent tout particulièrement :
Fastlane permet aussi d'automatiser de nombreuses autres tâches que je n'ai pas encore pris le temps d'explorer : https://docs.fastlane.tools/actions/.
Installation de Fastlane avec Mise que j'ai testée sous Fedora et MacOS :
[tools]
ruby = '3.1.6' # for fastlane
fastlane = "2.226.0"
[alias]
fastlane = "https://github.com/mollyIV/asdf-fastlane.git"
(Toujours aussi pénibles ces outils développés en Ruby 😔)
À noter que sous MacOS j'ai dû lancer :
$ mise install -f fastlane
Parce que lors du premier lancement de mise install, j'ai l'impression qu'il a essayé d'installer fastlane avec l'instance ruby native de l'OS.
J'ai cherché s'il existe une option pour préciser que fastlane doit utiliser ruby installé par Mise, mais je n'ai pas trouvé.
17:05 - Solution pour contourner le problème mentionné ci-dessus :
$ mise install ruby
$ mise install
Journal du mercredi 05 février 2025 à 18:32
Un ami m'a fait découvrir uv (https://github.com/astral-sh/uv).
Je trouve cela amusant de constater que Rust prend en charge de plus en plus d'outils pour différents langages 😉.
Le projet a commencé fin 2023.
Voici un thread Hacker News de 200 commentaires à ce sujet qui date de février 2024 : Uv: Python packaging in Rust .
L'article de ce thread contient beaucoup d'éléments intéressants : https://astral.sh/blog/uv
Son nom uv semble être une référence à uvloop.
J'en ai profité pour migrer le playground mise-python-flask-playground de pip vers uv : https://github.com/stephane-klein/mise-python-flask-playground/commit/2f1678798cfc6749dcfdb514a8fe4a3e54739844.
J'ai lancé une installation et effectivement, sa rapidité est très impressionnante :
$ uv pip install -r requirements.txt
Resolved 15 packages in 245ms
Prepared 15 packages in 176ms
Installed 15 packages in 37ms
+ alembic==1.14.1
+ blinker==1.9.0
+ click==8.1.8
+ flask==3.1.0
+ flask-migrate==4.1.0
+ flask-sqlalchemy==3.1.1
+ greenlet==3.1.1
+ itsdangerous==2.2.0
+ jinja2==3.1.5
+ mako==1.3.9
+ markupsafe==3.0.2
+ psycopg2-binary==2.9.10
+ sqlalchemy==2.0.37
+ typing-extensions==4.12.2
+ werkzeug==3.1.3
uv ne propose pas seulement une amélioration de l'installation de packages Python, mais propose beaucoup d'autres choses comme :
- L'installation de Python : https://docs.astral.sh/uv/guides/install-python/
Pour cette partie, dans un but d'unification, je continuerai à utiliser Mise pour installer une version précise de Python. De plus, Mise intègre nativement UV : https://mise.jdx.dev/mise-cookbook/python.html#mise-uv
- Système pour lancer des scripts Python : https://docs.astral.sh/uv/guides/scripts/
Exemple :
$ uv run example.py
Je pense avoir compris que cela lance ce script avec les dépendances du virtual environment du projet. Un peu comme fonctionne npm, yarn ou pnpm qui permet aux scripts d'utiliser les packages présents dans ./node_modules/.
- Permet de lancer des outils : https://docs.astral.sh/uv/guides/tools/
Par exemple, le linter Python ruff, exemple :
$ uv tool run ruff
- uv met à disposition des images Docker : https://docs.astral.sh/uv/guides/integration/docker/
J'ai un peu parcouru la documentation de pyproject.toml : https://packaging.python.org/en/latest/guides/writing-pyproject-toml/.
J'ai lu aussi la section uv - Locking environments.
Suite à ces lectures, j'ai migré le playground mise-python-flask-playground vers pyproject.toml : https://github.com/stephane-klein/mise-python-flask-playground/commit/c17216464778df4bc00bf782d5a889cb3f198051.
Je ne suis pas certain que ces commandes soient une bonne pratique :
$ uv pip compile requirements.in -o requirements.txt
$ uv pip install -r requirements.txt
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)