
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (0) >> ]
Journal du samedi 08 juin 2024 à 10:35
Dans 2024-06-06_1047 #JaiDécidé d'utiliser le terme Inference Engines pour définir la fonction ou la catégorie de Llama.cpp.
J'ai échangé avec un ami au sujet des NPU et j'ai dit que j'avais l'impression que ces puces sont spécialés pour exécuter des Inference Engines, c'est-à-dire, effectuer des calculs d'inférence à partir de modèles.
Après vérification, dans cet article je lis :
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed to accelerate artificial intelligence and machine learning applications, including artificial neural networks and machine vision.
et je comprends que mon impression était fausse. Il semble que les NPU ne sont pas seulement dédiés aux opérations d'exécution d'inférence, mais semblent être optimisés aussi pour faire de l'entrainement 🤔.
Un ami me précise :
Inference Engines
Pour moi, c'est un terme très générique qui couvre tous les aspects du machine learning, du deep learning et des algorithmes type LLM mis en œuvre.
et il me partage l'article Wikipedia Inference engine que je n'avais pas lu quand j'avais rédigé 2024-06-06_1047, honte à moi 🫣.
Dans l'article Wikipedia Inference engine je lis :
In the field of artificial intelligence, an inference engine is a software component of an intelligent system that applies logical rules to the knowledge base to deduce new information.
et
Additionally, the concept of 'inference' has expanded to include the process through which trained neural networks generate predictions or decisions. In this context, an 'inference engine' could refer to the specific part of the system, or even the hardware, that executes these operations.
Je comprends qu'un Inference Engines n'effectue pas l'entrainement de modèles.
Pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Le contenu de l'article Wikipedia Llama.cpp augmente mon niveau de confiance dans ce choix de vocabulaire :
llama.cpp is an open source software library written in C++, that performs inference on various Large Language Models such as Llama
Journal du jeudi 06 juin 2024 à 22:57
#JeMeDemande quelles sont les différences entre les modèles qui terminent par "rien", par -instruct et par -chat.
This brings us to the heart of the innovation behind the wildly popular ChatGPT: it uses an enhancement of GPT3 that (besides having a lot more parameters), was explicitly fine-tuned on instructions (and dialogs more generally) -- this is referred to as instruction-fine-tuning or IFT for short. In addition to fine-tuning instructions/dialogs, the models behind ChatGPT (i.e., GPT-3.5-Turbo and GPT-4) are further tuned to produce responses that align with human preferences (i.e. produce responses that are more helpful and safe), using a procedure called Reinforcement Learning with Human Feedback (RLHF). (from)
Journal du jeudi 06 juin 2024 à 16:20
En travaillant sur 2024-06-06_1047 :
- #JaiDécouvert https://github.com/PABannier/bark.cpp - Suno AI's Bark model in C/C++ for fast text-to-speech (from)
- #JaiDécouvert https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from)
- #JaiLu au sujet de GGUF :
Hugging Face Hub supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework.
https://huggingface.co/docs/hub/gguf
- #JaiDécouvert llama : add pipeline parallelism support by slaren autrement dit « Multi-GPU pipeline parallelism support » (from)
- #JaiDécouvert https://github.com/ggerganov/whisper.cpp de Georgi Gerganov
- #JaiDécouvert https://github.com/ggerganov/llama.cpp/discussions/3471
- #JaiDécouvert la Merge Request d'ajout du support de ROCm Port : ROCm Port 1087 (from)
- #JaiDécouvert Basic Vim plugin for llama.cpp
- #JaiDécouvert https://github.com/rgerganov/ggtag par le même auteur que Llama.cpp, c'est-à-dire Georgi Gerganov
- #JaiDécouvert Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- #JaiDécouvert : d'après ce que j'ai compris la librairie ggml est le composant de base de Llama.cpp et Whisper.cpp
- #JaiDécouvert que Georgi Gerganov a lancé sa société nommée https://ggml.ai (from) et que celle-ci est financé entre autre part Nat Friedman ! Ha ha, encore lui 😍.
ggml.ai is a company founded by Georgi Gerganov to support the development of ggml. Nat Friedman and Daniel Gross provided the pre-seed funding.
We are currently seeking to hire full-time developers that share our vision and would like to help advance the idea of on-device inference. If you are interested and if you have already been a contributor to any of the related projects, please contact us at jobs@ggml.ai
- #JaiDécouvert Text-to-phoneme-to-speech https://twitter.com/ConcreteSciFi/status/1641166275446714368, j'adore 🙂
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de Llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé Llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que Llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits Llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de Llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur Llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à Llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme Llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, Llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

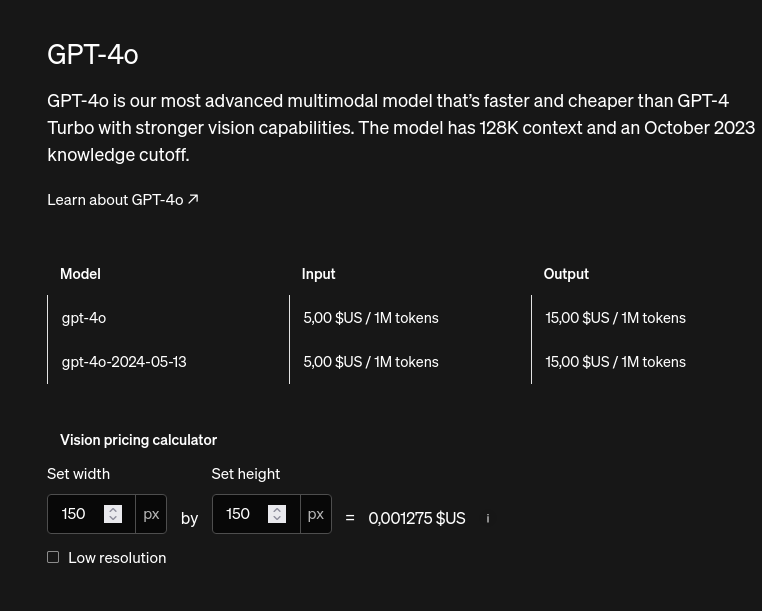
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo
Je vous partage une réflexion que je viens d'avoir.
- Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo (mon moteur de recherche actuel).
- Je commence souvent par dégrossir une question avec ChatGPT, puis j'utilise mon moteur de recherche pour vérifier l'information avec une source que je juge "fiable".
- À d'autres moments, je préfère un article Wikipédia ou une documentation de référence plus exhaustive ou structurée — question d'habitude, sans doute — que la réponse de ChatGPT.
Suite à cela, je me suis dit que Google doit très rapidement revoir ses produits. Sinon, il est fort probable que Google perde énormément de revenus.
Je me suis ensuite demandé à quoi pourrait ressembler un produit Google basé sur un LLM qui remplacerait totalement ou en partie Google Search. Là, j'ai pensé directement à l'intégration de publicité à l'intérieur des réponses du LLM de Google 😱.
- Les publicités pourraient être intégrées de manière subtile sous forme de conseil dans les réponses.
- Je ne pourrais plus utiliser de bloqueurs de publicité comme uBlock Origin 😟.
- La situation pourrait être encore pire : Google pourrait se faire financer par des États, des grandes entreprises ou des milliardaires pour nous influencer légèrement via les réponses du LLM.
Je pense plus que jamais qu'il est important pour l'avenir de construire des modèles #open-source, auditables et reproductibles.
Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
#JeMeDemande combien me coûterait la réalisation du #POC suivant :
- Déploiement de Llama.cpp sur une GPU Instances de Scaleway;
- 3h d'expérimentation;
- Shutdown de l'instance.
🤔.
Tarifs :
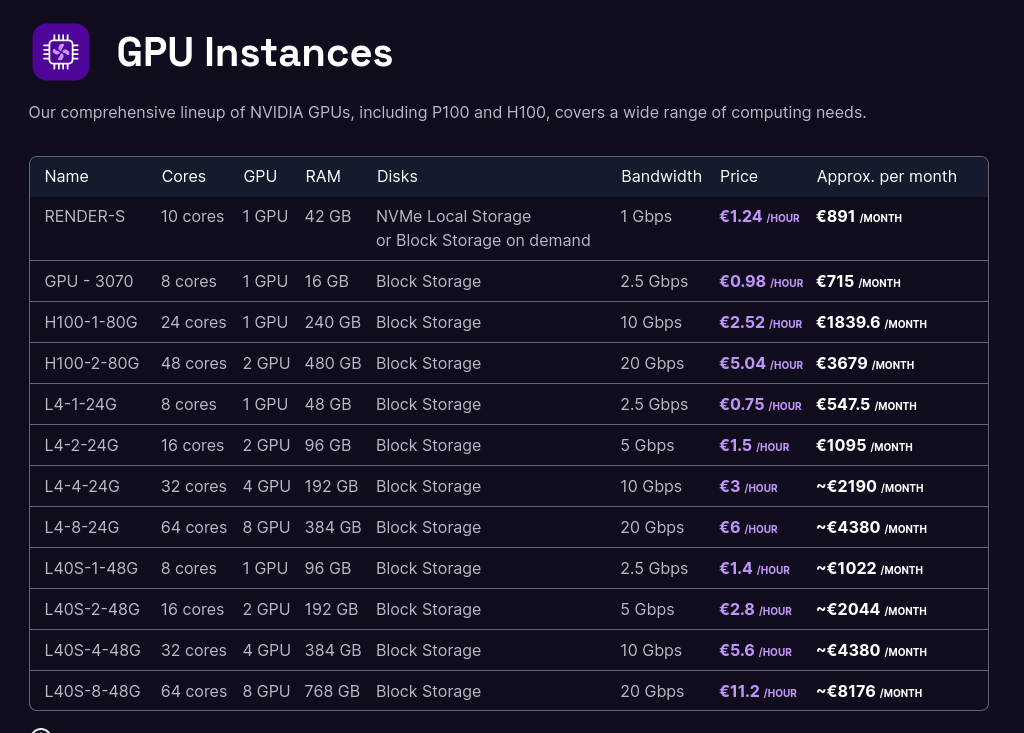
Dans un premier temps, j'aimerais me limiter aaux instances les moins chères :
- GPU-3070 à environ 1 € / heure
- L4-1-24G à 0.75 € / heure
- et peut-être RENDER-S à 1,24 € / heure
Tous ces prix sont hors taxe.
- L'instance GPU-3070 a seulement 16GB de Ram, #JeMeDemande si le résultat serait médiocre ou non.
- Je lis que l'instance L4-1-24G contient un GPU NVIDIA L4 Tensor Core GPU avec 24GB de Ram.
- Je lis que l'instance Render S contient un GPU Dedicated NVIDIA Tesla P100 16GB PCIe avec 42GB de Ram.
Au moment où j'écris ces lignes, Scaleway a du stock de ces trois types d'instances :
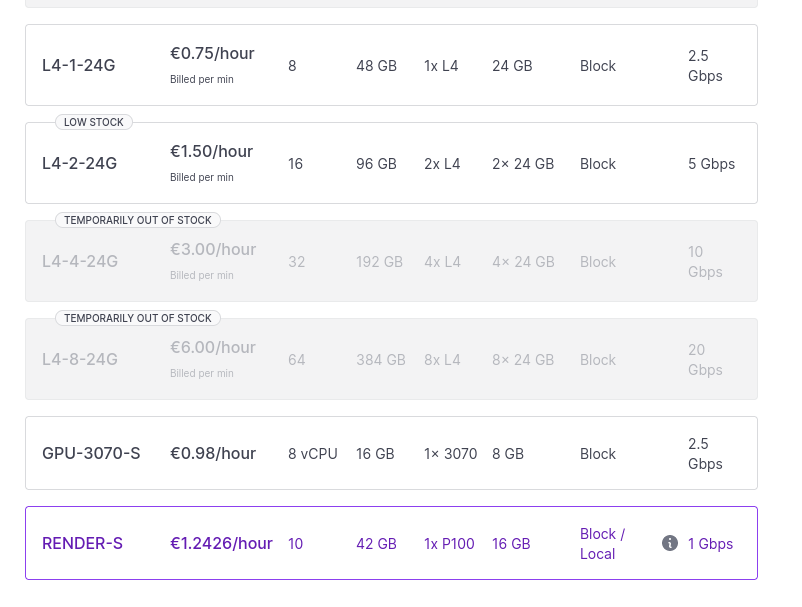
- #JeMeDemande comment je pourrais me préparer en amont pour installer rapidement sur le serveur un environnement pour faire mes tests.
- #JeMeDemande s'il existe des tutoriaux tout prêts pour faire ce type de tâches.
- #JeMeDemande combien de temps prendrait le déploiement.
Si je prends 2h pour l'installation + 3h pour faire des tests, cela ferait 5h au total.
J'ai cherché un peu partout, je n'ai pas trouvé de coût "caché" de setup de l'instance.
Le prix de cette expérience serait entre 4,5 € et 7,44 € TTC.
- #PremièreActionConcrète pour réaliser cette expérimentation : chercher s'il existe des tutoriaux d'installation de Llama.cpp sur des instances GPU Scaleway.
- #JeMeDemande combien me coûterait l'achat de ce type de machine.
- #JeMeDemande à partir de combien d'heures d'utilisation l'achat serait plus rentable que la location.
- Si par exemple, j'utilise cette machine 3h par jour, je me demande à partir de quelle date cette machine serait rentabilisée et aussi, #JeMeDemande si cette machine ne serait totalement obsolète ou non à cette date 🤔.
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.
Journal du samedi 20 janvier 2024 à 17:22
#JaiLu le README de Ollama https://github.com/ollama/ollama
Journal du mercredi 07 juin 2023 à 19:37
#JaiDécouvert le projet PrivateGPT (https://github.com/zylon-ai/private-gpt).
Cela fait plusieurs mois que je souhaite trouver une solution pour self hosted une alternative à ChatGPT. J'ai bien envie de tester ce projet.
Basé à Mountain View.
https://github.com/ollama/ollama
Get up and running with Llama 3.1, Mistral, Gemma 2, and other large language models.
Ollama est un Inference Engine (comme LLama.cpp).
Dépôt GitHub : https://github.com/zylon-ai/private-gpt
Dépôt GitHub : https://github.com/vllm-project/vllm
Nom alternatifs à "Inference Engines" :
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, j'ai décidé d'utiliser le terme Inference Engines.
Update du 2024-06-08 : suite à 2024-06-08_1035, pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Exemples de "Inference Engines" :
Article Wikipedia : https://en.wikipedia.org/wiki/LLM-as-a-Judge
Papier de recheche Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena datant du 24 décembre 2023.
Projet 20 - "Créer un POC d'un RAG"
Date de la création de cette note : 2024-12-20.
Quel est l'objectif de ce projet ?
Je souhaite réaliser un POC qui setup un Retrieval-augmented generation (RAG) qui permet d'aller chercher des informations dans des documents.
Fonctionnalités que j'aimerais arriver à implémenter :
- Le LLM doit pouvoir indiquer précisément ses sources pour chaque réponse.
- Le LLM devrait être en mesure de s’inspirer du style des documents importés dans le RAG.
- Les informations importées dans le RAG doivent avoir une priorité absolue sur les connaissances préexistantes du moteur LLM.
Je souhaite me baser sur LLaMa.
Dans ce projet, je souhaite aussi étudier les coûts d'hébergement d'un RAG.
Documents à importer dans le RAG ?
Mes critères de sélection sont les suivants :
- Des documents récents, contenant de préférence des informations inconnues des modèles LLaMa.
- Des documents en français.
- Des documents en libre accès.
- Si possible, avec peu de tableaux.
J’avais envisagé d’importer des threads de Hacker News via https://hnrss.github.io/, mais je préfère réaliser mes tests en français.
J’ai également exploré https://fr.wikinews.org, mais le projet contient malheureusement trop peu d’articles.
Finalement, je pense importer les 10 derniers articles disponibles sur https://www.projets-libres.org/interviews/.
Autres projets en lien avec celui-ci
Pourquoi je souhaite réaliser ce projet ?
Je souhaite implémenter un RAG depuis que j'ai commencé à utiliser ChatGPT — début 2023 (par exemple, ici ou ici).
Alexandre souhaite aussi réaliser ce type de POC : https://github.com/Its-Alex/backlog/issues/25.
Je pense qu'un RAG me serait utile pour interroger mon Personal knowledge management. Un RAG m'aurait été utile quand j'étais président du club de Tennis de Table d'Issy-les-Moulineaux.
De plus, j'ai plusieurs projets professionnels qui pourraient bénéficier d'un RAG.
Repository de ce projet :
rag-poc(je n'ai pas encore créé ce repository)
Liste de tâches
- [ ] Étudier kotaemon. Après cette étude, à moins d'avoir découvert des éléments bloquants :
- [ ] Réaliser un POC de kotaemon
- [ ] Étudier llama_index
Ressources :
- Augmenter ChatGPT avec le RAG de Science4All (version texte)
- https://github.com/topics/rag
- https://github.com/run-llama/llama_index
- https://github.com/run-llama/llama_parse
- https://www.youtube.com/watch?v=u5Vcrwpzoz8
- https://ollama.com/blog/embedding-models
- https://github.com/Cinnamon/kotaemon (voir note 2025-01-03_1545)
Open WebUI est une interface web de conversation IA.
User-friendly WebUI for LLMs (Formerly Ollama WebUI)
Dépôt GitHub : https://github.com/open-webui/open-webui
Documentation : https://docs.openwebui.com
Site officiel : https://llm-stats.com/
Dépôt GitHub : https://github.com/JonathanChavezTamales/llm-leaderboard
Site officiel : https://lmarena.ai/
Un modèle LLM développé par Google.
Article Wikipedia : https://en.wikipedia.org/wiki/Language_model_benchmark
Les LLM Benchmark sont utilisés par les leaderboard du type LLM-Stats.com.
Quelques exemples de LLM Benchmark :
Site officiel : https://vast.ai/
Article Wikipedia : https://fr.wikipedia.org/wiki/Grok_(IA)
Site officiel : https://www.llm-prices.com
Voir aussi models.dev.
Site : https://models.dev/
Voir aussi llm-prices.
Dépôt GitHub : https://github.com/promptfoo/promptfoo
Un modèle LLM de Mistral AI.
Note de release de Mistral Small 3.1 sortie le 17 mai 2025 : https://mistral.ai/news/mistral-small-3-1
Documentation :
Annonce de support les LLM tools par OpenAI en juin 2023 : "Function calling and other API updates".
Documentation LLM function calling de OpenAI : https://platform.openai.com/docs/guides/function-calling
Dépôt GitHub : https://github.com/langchain-ai/langsmith-sdk
Plateforme pour effectuel du LLM Eval.
Ressources :
Prompts que j'utilise :
Site officiel : https://aider.chat
Aider lets you pair program with LLMs to start a new project or build on your existing codebase.
Notes de Simon Willison au sujet de Aider : https://simonwillison.net/search/?tag=aider
Voir aussi : aider-ce.
Projet de Simon Willison :
A CLI tool and Python library for interacting with OpenAI, Anthropic’s Claude, Google’s Gemini, Meta’s Llama and dozens of other Large Language Models, both via remote APIs and with models that can be installed and run on your own machine.
Dépôt GitHub : https://github.com/simonw/llm
Voir aussi : AIChat
Dépôt GitHub : https://github.com/sigoden/aichat
Voir aussi llm (cli).
METR is a research nonprofit which evaluates frontier AI models to help companies and wider society understand AI capabilities and what risks they pose.
Site officiel : https://www.tbench.ai/
Dernière page.