Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (3879) >> ]
Fusion de CoreOS et Atomic Project en 2018
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "2014-2018 approche alternative avec Atomic Project".
Suite au rachat de la société CoreOS par Red Hat en 2018, les projets CoreOS Container Linux et Fedora Atomic Host ont fusionné en juillet 2019 pour donner Fedora CoreOS.
D'après mon analyse, mise à part ignition, le projet Fedora CoreOS est construit sur les bases de Fedora Atomic Host et n'a gardé de CoreOS Container Linux que le nom "CoreOS".
Cette nouvelle distribution Fedora CoreOS reste atomic et immutable comme l'ancien CoreOS Container Linux, mais utilise désormais rpm-ostree et OSTree (au lieu du système dual partition A/B), et permet le package layering si nécessaire. La philosophie "100% conteneurs" reste encouragée, mais n'est plus une contrainte absolue.
Voici une chronologie sur l'histoire de CoreOS que m'a proposée Claude Sonnet 4.5 :
2013-2017: CoreOS Container Linux
├─ Atomic ✓ (dual partition)
├─ Immutable ✓
└─ Package layering ✗
2014-2018: Fedora/RHEL Atomic Host
├─ Atomic ✓ (OSTree)
├─ Immutable ✓
└─ Package layering ✓ (rpm-ostree)
2018: Rachat CoreOS par Red Hat
2019+: Fedora CoreOS (fusion des deux)
├─ Atomic ✓ (OSTree)
├─ Immutable ✓
├─ Package layering ✓ (possible mais découragé)
└─ Philosophie: conteneurs first, mais flexible
Note suivante : "Quelques outils CoreOS : coreos-installer, graphe de migration et zincati".
Je fais mon retour dans l'écosystème React, j'ai découvert Jotai et Zustand
Dans le code source de mon projet professionnel, #JaiDécouvert la librairie ReactJS nommée Jotai (https://jotai.org).
Les atom de Jotai ressemblent aux fonctionnalités Svelte Store. Jotai permet entre autres d'éviter de faire du props drilling.
Pour en savoir plus sur l'intérêt de Jotai versus "React context (useContext + useState)", je vous conseille la lecture d'introduction de la page Comparison de la documentation Jotai. J'ai trouvé la section "Usage difference" très simple à comprendre.
Cette découverte est une bonne surprise pour moi, car les atom de Jotai reproduisent l'élégance syntaxique des Store de Svelte, ce qui améliore mon confort de développement en ReactJS. #JaiLu ce thread Hacker News en lien avec le sujet : "I like Svelte more than React (it's store management)".
Je tiens toutefois à préciser que si Jotai améliore significativement mon expérience de développeur (DX) avec ReactJS, cela reste une solution de gestion d'état au sein du runtime ReactJS. En comparaison, le compilateur Svelte génère du code optimisé natif qui reste intrinsèquement plus performant à l'exécution.
Exemple Svelte :
import { writable, derived } from 'svelte/store';
const count = writable(0);
const doubled = derived(count, $count => $count * 2);
// Usage dans component
$count // auto-subscription
Exemple ReactJS basé sur Jotai :
import { atom } from 'jotai';
const countAtom = atom(0);
const doubledAtom = atom(get => get(countAtom) * 2);
// Usage dans component
const [count] = useAtom(countAtom);
J'ai lu la page "Comparison" de Jotai pour mieux comprendre la place qu'a Jotai dans l'écosystème ReactJS.
#JaiDécouvert deux autres librairies développées par la même personne, Daishi Kato : Zustand et Valtio. D'après ce que j'ai compris, Daishi a développé ces librairies dans cet ordre :
- Zustand en juin 2019 - voir "How Zustand Was Born"
- La première version de Jotai en septembre 2020 - voir "How Jotai Was Born"
- La première version de Valtio en mars 2021 - voir "How Valtio Was Born"
J'ai aussi découvert Recoil développé par Facebook, mais d'après son entête GitHub celle-ci semble abandonnée. Une migration de Recoil vers Jotai semble être conseillée.
J'aime beaucoup comment Daishi Kato choisit le nom de ses librairies, la méthode est plutôt simple 🙂 :
Comme mentionné plus haut, Jotai ressemble à Recoil alors que Zustand ressemble à Redux :
Analogy
Jotai is like Recoil. Zustand is like Redux.
...
How to structure state
Jotai state consists of atoms (i.e. bottom-up). Zustand state is one object (i.e. top-down).
Même en lisant la documentation Comparison, j'ai eu de grandes difficulté à comprendre quand préférer Zustand à Jotai.
En lisant la documentation, Jotai me semble toujours plus simple à utiliser que Zustand.
Avec l'aide de Claude Sonnet 4.5, je pense avoir compris quand préférer Zustand à Jotai.
Exemple Zustand
Dans l'exemple Zustand suivant, la fonction addToCart modifie plusieurs parties du state useCartStore en une seule transaction :
import { create } from 'zustand'
const useCartStore = create((set) => ({
user: null,
cart: [],
notifications: [],
addToCart: (product) => set((state) => {
return {
cart: [...state.cart, product],
notifications: (
state.user
? [...state.notifications, { type: 'cart_updated' }]
: state.notifications
)
};
};
}));
Et voici un exemple d'utilisation de addToCart dans un composant :
function ProductCard({ product }) {
// Sélectionner uniquement l'action addToCart
const addToCart = useCartStore((state) => state.addToCart);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Exemple Jotai
Voici une implémentation équivalente basée sur Jotai :
import { atom } from 'jotai';
const userAtom = atom(null);
const cartAtom = atom([]);
const notificationsAtom = atom([]);
export const addToCartAtom = atom(
null,
(get, set, product) => {
const user = get(userAtom);
const cart = get(cartAtom);
const notifications = get(notificationsAtom);
set(cartAtom, [...cart, product]);
if (user) {
set(notificationsAtom, [...notifications, { type: 'cart_updated' }]);
}
}
);
Et voici un exemple d'utilisation de useToCartAtom dans un composant :
import { useSetAtom } from 'jotai';
import { addToCartAtom } from 'addToCartAtom';
function ProductCard({ product }) {
// Récupérer uniquement l'action (pas la valeur)
const addToCart = useSetAtom(addToCartAtom);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Ces deux exemples montrent que Zustand est plus élégant et probablement plus performant que Jotai pour gérer des actions qui conditionnent ou modifient plusieurs parties du state simultanément.
#JaiLu le thread SubReddit ReactJS "What do you use for global state management? " et j'ai remarqué que Zustand semble plutôt populaire.
En rédigeant cette note, j'ai découvert Valtio qui semble être une alternative à MobX. Je prévois d'étudier ces deux librairies dans une future note.
Journal du dimanche 19 octobre 2025 à 11:20
Dans l'historique de mon projet professionnel, #JaiDécouvert immer. J'ai constaté que Jotai propose une extension permettant d'utiliser immer. Pour le moment, je n'ai aucune idée de son intérêt, je n'ai pas pris le temps d'étudier ce sujet.
Journal du dimanche 19 octobre 2025 à 11:16
Ici dans la documentation Jotai, #JaiDécouvert Waku. Je n'ai pas pris le temps de l'étudier.
Journal du samedi 18 octobre 2025 à 12:18
En étudiant la librairie Jotai, #JaiDécouvert le terme "props drilling" :
Passing props is a great way to explicitly pipe data through your UI tree to the components that use it.
But passing props can become verbose and inconvenient when you need to pass some prop deeply through the tree, or if many components need the same prop. The nearest common ancestor could be far removed from the components that need data, and lifting state up that high can lead to a situation called “prop drilling”.
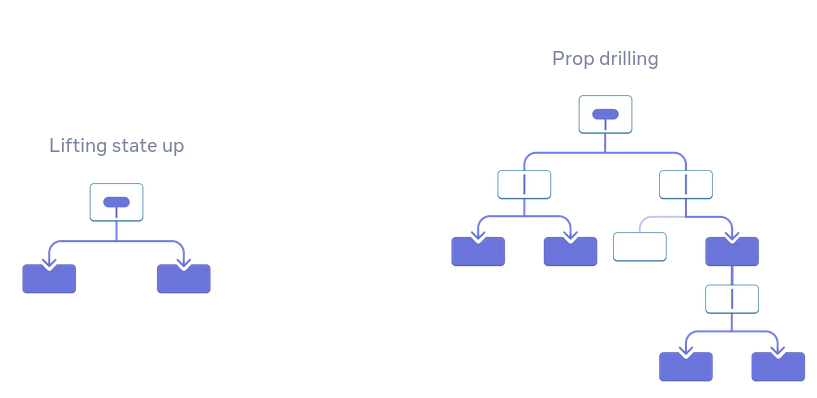
Le terme props drilling est très présent dans le SubReddit ReactJS : https://old.reddit.com/r/reactjs/search?q=drilling&restrict_sr=on&include_over_18=on.
Journal du jeudi 16 octobre 2025 à 00:32
#JaiDécouvert les conférences Fedora annuelles nommées : Flock (https://fedoraproject.org/flock/)
2014-2018 approche alternative avec Atomic Project
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "CoreOS de 2013 à 2018".
La première version d'Atomic Project paraît en 2014, avec rpm-ostree comme élément central, développé principalement par Colin Walters de Red Hat.
rpm-ostree utilise libostree comme fondation, composant qui lui confère "toute sa puissance".
OSTree composant central de Atomic Project
Colin Walters a créé libostree en 2011 pour les besoins de GNOME Continuous.
libostree est un outil qui s'inspire de Git, mais se spécialise dans la gestion d'arbres de fichiers complets de système d'exploitation.
Principales différences avec Git :
- Aucune copie lors des checkouts : libostree repose sur des hardlinks, donc pas de working copy du fait de l'immutabilité des fichiers.
- libostree préserve les contextes SELinux, les xattrs, les uid/gid, ainsi que des timestamps précis
- libostree peut gérer les device nodes (
/dev/zero,/dev/null…), les sockets (/run/systemd/notify...), et tous les types de fichiers d'un filesystem d'OS - Un mécanisme de déduplication
- …
Avec OSTree, pas besoin de double partition
À la différence de CoreOS Container Linux qui utilisait le système de mise à jour A/B (seamless) system updates, Fedora Atomic Host (puis Fedora CoreOS) n'a pas besoin de deux partitions grâce à libostree.
Lors d'un upgrade, libostree réalise un "checkout" en utilisant la commande ostree-admin-deploy .
Puis grub communique au kernel le paramètre ostree= qui détermine sur quel déploiement booter.
Voici les avantages de l'utilisation de libostree par rapport au système A/B (seamless) system updates :
- libostree permet de conserver plusieurs déploiements, sans se limiter à 2
- Grâce au système de déduplication, libostree consomme beaucoup moins d'espace disque
- Grâce au téléchargement uniquement des deltas, les mises à jour sont très rapides
Néanmoins, alors que libostree offre techniquement la possibilité de créer autant de déploiements que souhaité, d'après mes tests, Fedora CoreOS semble actuellement limité à 2 déploiements seulement.
J'ai trouvé cette issue qui aborde ce sujet : support configuring host to retain more than two deployments.
rpm-ostree
Les utilisateurs d'Fedora Atomic Host n'interagissent pas directement avec libostree mais avec rpm-ostree.
rpm-ostree s'appuie sur les librairies libostree et libdnf pour installer des packages rpm et propose de nombreuses commandes d'administration de l'OS :
stephane@stephane-coreos:~$ rpm-ostree
Usage:
rpm-ostree [OPTION…] COMMAND
Builtin Commands:
apply-live Apply pending deployment changes to booted deployment
cancel Cancel an active transaction
cleanup Clear cached/pending data
compose Commands to compose a tree
db Commands to query the RPM database
deploy Deploy a specific commit
finalize-deployment Unset the finalization locking state of the staged deployment and reboot
initramfs Enable or disable local initramfs regeneration
initramfs-etc Add files to the initramfs
install Overlay additional packages
kargs Query or modify kernel arguments
override Manage base package overrides
rebase Switch to a different tree
refresh-md Generate rpm repo metadata
reload Reload configuration
reset Remove all mutations
rollback Revert to the previously booted tree
search Search for packages
status Get the version of the booted system
uninstall Remove overlayed additional packages
upgrade Perform a system upgrade
usroverlay Apply a transient overlayfs to /usr
Note suivante : "Fusion de CoreOS et Atomic Project en 2018.
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows".
Première version de CoreOS Container Linux en 2013
La première version de CoreOS Container Linux sortie en 2013 utilisé la méthode A/B (seamless) system updates inspirée de manière transparente à Chrome OS :
Upgrading CoreOS is a bit different than the usual distros. Our update system is based on ChromeOS. The big difference is that we have two root partitions; lets call them root A and root B. Initially your system is booted into the root A partition and CoreOS begins talking to the update service to find out about new updates. If there is an update available it is downloaded and installed to root B.
D'après ce repository coreos/coreos-overlay, CoreOS Container Linux était basé sur les packages de Gentoo.
Première version d'Ignition en 2016
En avril 2016, l'équipe CoreOS a publié la première version de ignition, outil toujours utilisé en 2025 par Fedora CoreOS.
Ignition is a utility created to manipulate disks during the initramfs. This includes partitioning disks, formatting partitions, writing files (regular files, systemd units, etc.), and configuring users. On first boot, Ignition reads its configuration from a source of truth (remote URL, network metadata service, hypervisor bridge, etc.) and applies the configuration.
ignition est un système qui ressemble à cloud-init, mais qui est exécuté seulement une seule fois, lors du premier boot et est lancé en tout premier, avant même systemd.
Depuis 2019, les fichiers json ignition ne sont plus édités manuellement grâce à l'outil butane qui convertit des fichiers YAML butane en fichiers json ignition.
Voici la documentation de butane qui vous permet de voir les actions que peut effectuer ignition : https://coreos.github.io/butane/specs/.
À la différence de cloud-init, ignition fonctionne à un niveau plus bas. La spec Butane Fedora CoreOS v1.6.0 permet par exemple de configurer les partitions, le Raid, LUKS encryption…
Voici dans mon playground un exemple de son utilisation : atomic-os-playground/create-coreos-custom-iso.sh.
Note suivante : "2014-2018 approche alternative avec Atomic Project".
Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Ajout de packages dans des distributions atomiques".
Chrome OS et Android implémentent la stratégie de double partition A/B (seamless) system updates.
Cette technologie offre des mises à jour complètement transparentes en arrière-plan et un redémarrage immédiat.
En revanche, contrairement à la solution CoreOS (méthode détaillée dans cette note), cette méthode a pour inconvénient de consommer deux fois plus d'espace de stockage.
MacOS s'appuie sur les snapshots de son filesystem APFS (fonctionnalité qu'offre aussi btrfs). Cela garantit un retour en arrière rapide vers la version antérieure si des problèmes surviennent.
En revanche, l'upgrade se termine durant le reboot, pouvant prendre de 2 à 5 minutes, alors que le redémarrage reste instantané avec Chrome OS, Android, CoreOS ou Fedora Silverblue.
Comme d'habitude, je n'arrive pas à trouver des informations précises sur le fonctionnement interne de MS Windows 😔. D'après Claude Sonnet 4, le système de mise à jour de Windows 10 et Windows 11, baptisé Unified Update Platform (UUP), semble plutôt daté : pas d'A/B (seamless) system updates, absence d'atomicité, installation longue lors du reboot (10 à 30 minutes), possibilité d'échec en cours de processus, rollback complexe, aucun système de snapshot comparable à MacOS. J'ai du mal à croire ce bilan tellement catastrophique, ce qui m'amène à questionner sur l'exactitude des informations rapportées par Claude Sonnet 4.
D'après cette documentation particulièrement riche et mes recherches complémentaires, je pense que la stack libostree + composefs (avec zstd:chunked ) tel qu'implémenté dans Fedora CoreOS est probablement la technologie de mise à jour la plus avancée actuellement disponible.
Avant de présenter le fonctionnement du système de mise à jour de Fedora CoreOS en 2025, je vais retracer l'évolution technique de cette solution.
Note suivante : "CoreOS de 2013 à 2018".
Ajout de packages dans des distributions atomiques
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Peu à peu depuis 2015, le terme immutable est remplacé par atomic".
Je constate que la plupart des personnes avec qui j'échange pensent qu'une distribution immutable ne permet que d'exécuter des containers Docker ou des applications Flatpak.
En réalité, grâce à la technologie libostree, il est possible d'installer des packages Fedora sur une instance Fedora CoreOS.
Voici un exemple sous Fedora CoreOS que j'ai réalisé avec le playground suivant : https://github.com/stephane-klein/atomic-os-playground.
Je commence par regarder l'état de l'OS avec rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:43:23 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Je constate que la version 42.20250901.3.0 identifiée par le commit sha256:d196ab...ae10c1 est installée.
Cette version correspond au moment où j'écris cette note à la dernière release du stream stale listé sur cette page https://fedoraproject.org/coreos/release-notes?arch=x86_64&stream=stable.
Maintenant, j'utilise rpm-ostree install … pour installer neovim.
stephane@stephane-coreos:~$ sudo rpm-ostree install neovim
Checking out tree 1e5b81c... done
Enabled rpm-md repositories: fedora-cisco-openh264 updates fedora updates-archive
Updating metadata for 'fedora-cisco-openh264'... done
Updating metadata for 'updates'... done
Updating metadata for 'fedora'... done
Updating metadata for 'updates-archive'... done
Importing rpm-md... done
rpm-md repo 'fedora-cisco-openh264'; generated: 2025-03-19T16:53:39Z solvables: 6
rpm-md repo 'updates'; generated: 2025-09-27T01:07:36Z solvables: 24410
rpm-md repo 'fedora'; generated: 2025-04-09T11:06:59Z solvables: 76879
rpm-md repo 'updates-archive'; generated: 2025-09-27T01:38:59Z solvables: 44216
Resolving dependencies... done
Will download: 40 packages (121.6 MB)
Downloading from 'updates'... done
Downloading from 'fedora'... done
Importing packages... done
Checking out packages... done
Running systemd-sysusers... done
Running pre scripts... done
Running post scripts... done
Running posttrans scripts... done
Writing rpmdb... done
Writing OSTree commit... done
Staging deployment... done
Added:
binutils-2.44-6.fc42.x86_64
compat-lua-libs-5.1.5-28.fc42.x86_64
...
neovim-0.11.4-1.fc42.x86_64
...
Changes queued for next boot. Run "systemctl reboot" to start a reboot
Neovim a bien été installé, mais je dois reboot pour l'utiliser. Voici ce que me dit rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:48:33 UTC)
Deployments:
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Diff: 40 added
LayeredPackages: neovim
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
La pastille ● m'indique la version (nommée déploiement) actuellement utilisée par l'instance.
Lors du démarrage du serveur, grub est configuré pour booter sur le premier déploiement de la liste. Exemple :
Une fois le serveur démarré, je peux voir que la version 42.20250901.3.0 est toujours utilisée, mais avec en plus un layer qui contient le package neovim :
[stephane@stephane-coreos ~]$ rpm-ostree status
rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 13:04:36 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
LayeredPackages: neovim
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Neovim est bien accessible :
[stephane@stephane-coreos ~]$ nvim --version
nvim --version
NVIM v0.11.4
Build type: RelWithDebInfo
LuaJIT 2.1.1748459687
Run "nvim -V1 -v" for more info
Avec la commande rpm-ostree apply-live il est même possible de commencer à utiliser le package sans avoir à reboot.
Cette fonctionnalité doit se limité à des petits utilitaires. Pour les composants systèmes, il est conseillé d'effectuer un reboot.
Note suivante : "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows".
Peu à peu depuis 2015, le terme immutable est remplacé par atomic
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "En 2016, j'ai testé Fedora Atomic Host, une expérience pénible".
Après avoir étudié et testé CoreOS pendant une semaine, je réalise que la plupart des informations que j'avais entendues sur cette distribution, et plus généralement sur les immutables ou atomiques, étaient approximatives et m'ont conduit à des erreurs de compréhension.
Quelques exemples de propos que j'ai entendus de la part d'amis sur ce sujet.
En 2025 :
« Une distribution readonly ça empêchait pas mal de choses. Je n'ai pas creusé, je n'y connais rien, mais j'ai vu beaucoup de gens se plaindre. »
ou encore 2024 :
Les distributions immuables (comme feu CoreOS) garantissent une cohérence ultime. Pas de gestion de paquets, donc ni ajout ni suppression ni mises à jour possibles. Tout est gravé dans le marbre. Pour protéger le marbre, la partition racine est montée en lecture seule. Note suivante : "Ajout de packages dans des distributions atomiques". Le choix est extrême, mais l’idée est de servir de socle pour une abstraction de plus haut niveau. Imaginé pour les conteneurs, ils peuvent aussi gérer des machines virtuelles.
Pour mettre à jour, il suffit de redémarrer sur une nouvelle version. Techniquement, il y a deux partitions bootables, la courante, en lecture seule, la version suivante sur laquelle on a appliqué des patchs, soit n et n+1. Si le redémarrage de mise à jour se passe mal, rembobinage sur la dernière version connue comme stable.
Ma première erreur consistait à penser que distribution atomic et distribution immutable désignaient la même chose.
Les distributions immutables ont les caractéristiques suivantes :
- Système de fichiers racine en lecture seule
- Protection contre les modifications accidentelles
- Peut ou non avoir des mises à jour transactionnelles
Les distributions atomics ont les caractéristiques suivantes :
- Toujours immutable (par nature)
- Mises à jour transactionnelles (tout ou rien)
- Capacité de rollback complet
- Basé sur des images système versionnées (généralement OSTree)
Les distributions atomic modernes, telles que Fedora CoreOS, Fedora Silverblue permettent en plus :
- La modification de l'image de manière transactionnelle, par exemple d'installer des packages supplémentaires via rpm-ostree
- Personnalisation tout en gardant les bénéfices de l'approche atomic
En 2016, lors de ma première utilisation de Fedora Atomic Host, j'avais compris que cette distribution était immutable comme CoreOS, sans réaliser qu'elle était aussi atomic. Contrairement à CoreOS qui interdisait tout ajout de packages système, Fedora Atomic Host permettait déjà via rpm-ostree d'installer des packages de manière transactionnelle (package layering), tout en conservant les bénéfices des mises à jour atomiques et du rollback.
À l'époque, CoreOS mettait l'accent sur son approche "100% conteneurs" et son immutabilité stricte, ce qui m'avait fait passer à côté de cette différence importante.
D'après ce que j'ai compris, la terminologie autour des distributions immutables et atomic a évolué au fil du temps. Si les concepts techniques sont bien définis (immutabilité du système, mises à jour transactionnelles), leur usage dans la communication a varié selon les projets et les époques. J'ai l'impression que cette ambiguïté persiste aujourd'hui.
Note suivante : "Ajout de packages dans des distributions atomiques".
En 2016, j'ai testé Fedora Atomic Host, une expérience pénible
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
J'ai eu mon premier contact avec une distribution dite "Atomic" ou "Immutable" en 2016.
On m'avait donné accès à une instance de la distribution Fedora Atomic Host de Atomic Project (page "Introduction to Project Atomic" de 2016).
On m'avait présenté le concept ainsi : « Il s'agit d'une distribution atomic immutable où tu ne peux rien installer directement sur l'OS. L'avantage ? Un système très stable et sécurisé. L'approche est 100% centrée sur le paradigme des containers Docker. Besoin d'un outil cli ? Tu utilises un container Docker. »
L'expérience a été pénible pour moi. Par exemple, je n'avais même pas accès à vim.
Je me sentais bloqué à chaque étape.
Je comprenais l'intérêt du concept et il me séduisait théoriquement, mais en pratique, l'expérience était vraiment désagréable.
Cela explique pourquoi jusqu'à cette semaine, 9 ans après, je n'ai jamais retouché à ce type de distribution tout en gardant un œil sur leurs développements.
Note suivante : "Peu à peu depuis 2015, le terme immutable est remplacé par atomic".
J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈
Le 22 septembre, j'ai commencé à explorer CoreOS, sans me douter que j'allais tomber dans un tel rabbit hole 🙈.
J'ai commencé une note qui dépasse maintenant 4000 mots, et après plus de 3 semaines, je ne l'ai toujours pas publiée.
Ce soir, je reviens à la méthode itérative qui me permet de garder la motivation. J'ai décidé de découper cette note en plusieurs petites notes, accessibles depuis cette note qui fait office de sommaire.
Liste en vrac des technologies mentionnées dans ces notes : CoreOS, libostree, rpm-ostree, butane, ignition, zincati, coreos-installer, composefs, OCI, Fedora Silverblue, Atomic OS, bootc, Universal Blue, Flatpak.
Sommaire des notes en lien avec CoreOS :
- "En 2016, j'ai testé Fedora Atomic Host, une expérience pénible"
- "Peu à peu depuis 2015, le terme immutable est remplacé par atomic"
- "Ajout de packages dans des distributions atomiques"
- "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows"
- "CoreOS de 2013 à 2018"
- "2014-2018 approche alternative avec Atomic Project"
- "Fusion de CoreOS et Atomic Project en 2018"
- "Quelques outils CoreOS : coreos-installer, graphe de migration et zincati"
- "composefs, un filesystem spécialement créé pour les besoins des distributions atomic"
- "L'utilisation de OSTree par Flatpak"
- "Support OCI de CoreOS (image pull & updates)"
- "Convergence vers Bootc"
Journal du lundi 13 octobre 2025 à 22:12
Dans cette issue, #JaiDécouvert le projet Kairos (https://kairos.io).
Journal du samedi 11 octobre 2025 à 10:27
À la position 24min20 de la vidéo This Week in Svelte, Ep. 119 , #JaiDécouvert la nouvelle section "Packages" du site officiel de Svelte. Cette initiative me semble utile : elle offre une liste de packages considérés comme "standard" par la communauté Svelte.
J'ai consulté la Merge Request qui ajoute la section "Packages" en pensant y trouver des explications sur le process et les critères d'inclusion d'un package dans cette liste, mais je n'ai rien trouvé 🤷♂️.
Journal du mercredi 08 octobre 2025 à 14:38
Il y a quelques jours, j'ai découvert osquery. Aujourd'hui, je découvre ici que l'agent du service Oneleet utilise osquery.
Cependant, son usage et son intérêt me semblent assez limités pour le moment 🤔 : https://docs.oneleet.com/oneleet-agent/data-collection .
Journal du mercredi 08 octobre 2025 à 14:29
#JaiDécouvert le nom officiel des attaques par social engineering suivantes :
Journal du lundi 29 septembre 2025 à 18:57
#OnMaPartagé ce projet d'imprimante Open source : Open Printer.
J'adore l'idée 🙂.
Articles qui parlent de ce projet :
- The Open Printer Is a Raspberry Pi Zero W-Powered, Fully-Open, Highly-Flexible Inkjet Printer
- Reddit : One Step Closer to an All-in-one Modern Word Processor: A Compact, Open-Source Printer/
Pour le moment, aucun commentaire sur Hacker News :
Journal du vendredi 26 septembre 2025 à 14:12
Dans l'article "Bilan des Journées du Logiciel Libre 2025" du blog du LeBureau.coop, j'ai découvert et j'ai écouté la #vidéo "(Ne) détruisons (pas) le capitalisme avec une coopérative - Agnès Haasser et Arthur Vuillard" des Journées du Logiciel Libre 2025.
J'y ai appris de nombreuses précisions au sujet des SCOP, SCIC, CAE…
Journal du mercredi 24 septembre 2025 à 18:03
Dans ce billet du blog de Bluefin #JaiDécouvert Bazaar (https://github.com/kolunmi/bazaar).
Bazaar is a new app store for GNOME with a focus on discovering and installing applications and add-ons from Flatpak remotes, particularly Flathub ...
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Bazaar est une alternative à l'application officielle GNOME nommée gnome-software.
Contrairement à gnome-software qui est basée sur PackageKit et gère différents types de packages (rpm, DEB, Flatpak, Snap, etc.), Bazaar a un périmètre plus limité et se concentre exclusivement sur les packages Flatpak.
Dans un premier temps, je me suis demandé quel était l'intérêt de créer une nouvelle GUI pour installer des packages, pourquoi l'auteur n'a pas choisi de contribuer à gnome-software ?
J'ai trouvé une réponse dans ce thread.
Bazaar est une application avec une vision tranchée :
- support uniquement le repository Flathub (qui contient seulement des packages Flatpak) ;
- mise en avant de solution pour faire des donations.
Cette vision a permis à l'auteur de créer Bazaar en mai 2025, à partir de zéro, avec une implémentation plus direct (pas de support PackageKit…).
Cela lui a permis aussi de se consacrer fortement sur l'expérience utilisateur.
Après avoir testé l'application, je constate que contrairement à gnome-software, toutes les tâches s'exécutent de manière asynchrone. À la différence de gnome-software, Bazaar évite de recharger constamment l'index des packages après chaque opération , ce qui rend l'expérience utilisateur excellente 🙂.
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Je tiens tout de même à préciser que la version 49 de gnome-software a fait des progrès à ce sujet, un gros travail de refactoring a été fait sur 3 ans (73 Merge Request 😮) pour apporter le support de threading dans gnome-software.
Je pense utiliser Bazaar dans Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora".
Journal du mercredi 24 septembre 2025 à 17:11
Dans la documentation de Flight Control #JaiDécouvert le terme ClickOps :
Features and use cases Flight Control aims to support:
- Declarative APIs well-suited for GitOps management.
- ...
- Web UI to manage and monitor devices and applications for ClickOps management.
- ...
Je trouve que ClickOps constitue une terminologie plus rigoureuse pour désigner ce qu'on appelle communément clickodrome.
Journal du mardi 23 septembre 2025 à 22:41
Un ami vient de me partager l'application Android et iOS nommée Saracroche (https://cbouvat.com/saracroche/) :
Saracroche est une application open source iOS et Android qui bloque les appels indésirables. Elle utilise la fonctionnalité native de blocage d'appels pour empêcher les appels provenant de numéros gênants, comme ceux utilisés pour le démarchage commercial ou les arnaques.
J'adore le nom de l'application 😉.
J'ai lu les articles suivants :
- Sarah qui ? Ça raccroche !
- Saracroche, l'appli libre par un frenchy usé par les appels indésirables, pour iOS
Depuis août 2024, j'utilise SpamBlocker. À ce stade, il me semble que l'avantage principal de Saracroche réside dans sa disponibilité sur iOS.
Cela fait longtemps que je n'ai plus d'appels indésirables sur mon Fairphone 5 - 5G.
Pour le moment, je ne vois pas l'intérêt de tester Saracroche.
Journal du mardi 23 septembre 2025 à 16:23
En vrac, quelques projets que je viens de découvrir :
L'origine du nom "Fedora Silverblue"
La lecture du document "Team Silverblue - The Origins " m'a appris de nombreuses choses sur les origines de la distribution Fedora Silverblue.
Avant 2018, le prédécesseur de Fedora Silverblue s'appelait "Fedora Atomic Workstation", défini comme : "image-mode container-based Fedora Workstation based on rpm-ostree".
À ses débuts, Fedora Atomic Workstation était un side project, développé et utilisé par quelques membres seulement de l'équipe Project Atomic (version du site de 2017).
Durant la conférence DevConf.CZ de janvier 2018, des participants ont présenté leur projet "Atomic Desktop". Suite à cette présentation, Owen Taylor, Sanja Bonic et Matthias Clasen ont créé un Special interest group (SIG) dédié à ce sujet dans la communauté Fedora : https://fedoraproject.org/wiki/SIGs/AtomicDesktops.
Voici comment le nom "Team Silverblue" a été choisi 2018 par Matthias Clasen et Sanja Bonic :
Couldn’t you come up with a better name?
No.
And in more detail: Matthias and Sanja have vetted over 150 words and word combination for something suitable, starting with tree names and going to atoms, physics, nature, landscapes.
Several other people have been asked to contribute. The entire process lasted for roughly 2 months, culminating in an open discussion of naming in the SIG meeting on April 16.
On April 19, Matthias and Sanja decided for the name Team Silverblue, because it was :
- available on Twitter, GitHub, and as a .org domain
- makes sense and sounds nice within the Fedora realm (color alignment)
- opens up fun and entertaining ways to have swag (silver-blue wigs, sports jerseys with the logo on it, phrasing like “Go, Team Silverblue!”, “Want to join the Team and improve Silverblue?”)
- works as Fedora Silverblue or Team Silverblue without losing branding investment
"Team Silverblue" a ensuite donné le nom Fedora Silverblue.
Le document indique que Red Hat a acquis CoreOS juste quelques jours après le lancement de cette idée de projet par les développeurs. S'agit-il d'une coïncidence heureuse 🤔 ? Le document ne le précise pas.
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du lundi 22 septembre 2025 à 21:26
Dans le cadre du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab", j'étudie CoreOS.
Dans la page "Fedora CoreOS Release Notes stable" je vois quelques packages mis en avant :
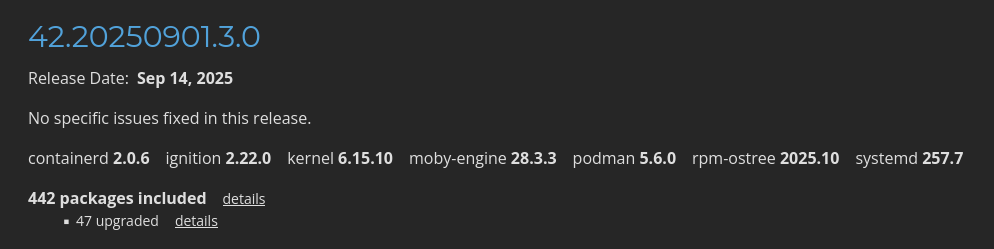
Je constate que CoreOS installe par défaut containerd, moby-engine et podman.
Information de type #mémento #mémo au sujet de containerd, moby-engine et podman.
- Kubernetes intéragie directement avec containerd.
- Depuis 2017, Docker est basé sur containerd + moby-engine. Sous Fedora, la commande
dockerest installée par le packagedocker-cli. - podman est une alternative rootless à Docker. podman n'est pas basé sur containerd, ni moby-engine.
Journal du lundi 22 septembre 2025 à 17:50
#JaiDécouvert la page Project MINI RACK : https://mini-rack.jeffgeerling.com
Ce sujet m'intéresse, car je cherche une solution élégante pour remplacer ce bazar !

Journal du lundi 22 septembre 2025 à 17:30
Je viens de publier le "Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab"".
Journal du lundi 22 septembre 2025 à 16:27
Dans le projet Homepage, #JaiDécouvert le projet Open-Meteo : https://open-meteo.com
Open-Meteo is an open-source weather API and offers free access for non-commercial use. No API key required. Start using it n
Mémento au sujet de QEMU et de sa configuration réseau
Note de type #mémento #mémo au sujet des fonctionnalités network de QEMU.
Pour bien comprendre le fonctionnement de la configuration network de QEMU, il est important de bien saisir deux concepts :
- les "virtual network device" (
-device) - les "network backend" (
-netdev)
There are two parts to networking within QEMU:
- the virtual network device that is provided to the guest (e.g. a PCI network card).
- the network backend that interacts with the emulated NIC (e.g. puts packets onto the host's network).
Voici toute la liste des network backend supportés par QEMU :
$ qemu-system-x86_64 -netdev help
Available netdev backend types:
socket
stream
dgram
hubport
tap
user
l2tpv3
bridge
af-xdp
vhost-user
vhost-vdpa
Dans cette note, je m'intéresse uniquement aux backend user, tap et bridge.
Le network backend user permet uniquement des accès sortant de la machine virtuelle vers Internet, mais pas l'inverse sans configurer un forwarding de port.
La configuration s'effectue via les options -netdev et -device :
$ qemu-system-x86_64 \
... \
-netdev user,id=n1 \ # configuration du network backend
-device e1000,netdev=n1 \ # virtual network device
...
La version 2.12 de QEMU (2018) propose une alternative plus simplifiée avec l'option -nic. Voici une exemple équivalent à la configuration ci-dessus :
$ qemu-system-x86_64 \
... \
-nic user,model=e1000
La version 2.12 de QEMU (2018) propose une alternative plus simplifiée avec l'option -nic. Voici un exemple équivalent à la configuration ci-dessus :
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
valid_lft 47067sec preferred_lft 47067sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86251sec preferred_lft 14251sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
En approfondissant mes recherches, j'ai appris que quand le network backend user est configuré, QEMU prend en charge nativement les fonctionnalités DHCP et NAT. Il répond aux requêtes DHCP de la VM démarrée et gère aussi le routage IP en mode NAT.
On peut voir ici deux adresses IPv6 attachées à l'interface eth0 :
fec0::5054:ff:fe12:3456/64fe80::5054:ff:fe12:3456/64
Une fois développées, ces deux adresses correspondent à :
fec0:0000:0000:0000:5054:00ff:fe12:3456fe80:0000:0000:0000:5054:00ff:fe12:3456
Après avoir regardé cette vidéo, je pense avoir compris que dans une IPv6, la moitié gauche représente systématiquement un réseau (ici fe80:0000:0000:0000), nommé aussi "network prefix" ou "routing prefix", tandis que la partie de droite (ici 5054:00ff:fe12:3456) correspond à une adresse d'interface.
La partie interface de ces deux adresses est identique : 5054:00ff:fe12:3456.
Cette adresse d'interface est générée par conversion EUI-64 de l'adresse MAC 52:54:00:12:34:56 => 5054:00ff:fe12:3456.
Exemple de génération d'une autre adresse IPv6 si j'ajoute une interface réseau supplémentaire à la machine virtuelle :
3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:57 brd ff:ff:ff:ff:ff:ff
altname enp0s4
altname ens4
altname enx525400123457
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth1
valid_lft 86388sec preferred_lft 86388sec
inet6 fec0::5054:ff:fe12:3457/64 scope site dynamic noprefixroute
valid_lft 86389sec preferred_lft 14389sec
inet6 fe80::5054:ff:fe12:3457/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Ici on peut voir que la conversion EUI-64 de 52:54:00:12:34:57 donne 5054:ff:fe12:3457.
Par rapport au fonctionnement d'IPv4, je trouve que le mécanisme de génération automatique des adresses d'interface réseau d'IPv6 très bien conçu 👌.
Je m'intéresse maintenant aux préfixes d'adresses IPv6 fec0::/10 et fe80::/10.
Le préfixe fe80::/10 est réservé aux adresses Link-Local. Ces adresses sont automatiquement configurées sur toutes les interfaces IPv6 actives et permettent une communication uniquement au sein du même segment réseau.
Exemple, dans le schéma ci-dessous, tous les serveurs présents sur le réseau A sont joignables via l'adresse Link-Local.
Cependant, les serveurs A n'ont pas la possibilité d'atteindre les serveurs B via Link-Local.
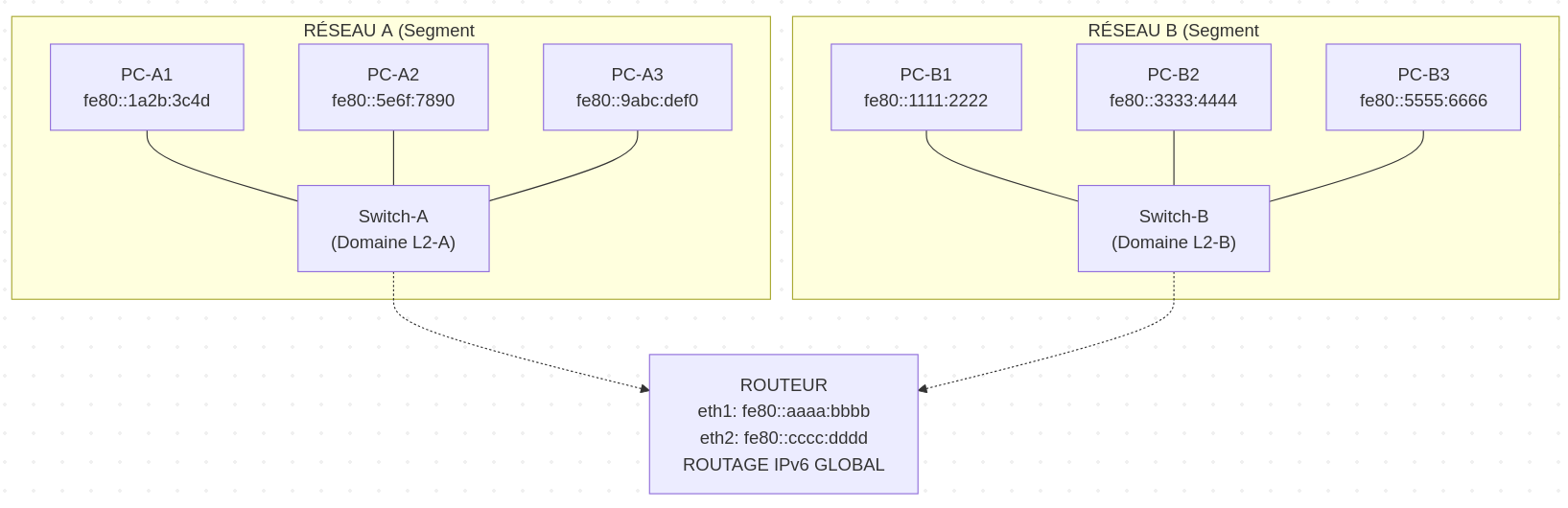
Journal du dimanche 21 septembre 2025 à 12:50
Après un an d'utilisation de mon Shokz OpenMove, j'ai enfin pris le temps de mettre en place l'appairage multipoint . Cela marche impeccablement, et je trouve cette fonctionnalité vraiment pratique, voire même indispensable 🙂 !
#JeMeDemande pourquoi le mode multipoint n'est pas activé pas défaut 🤔.
Dans l'épisode "141 L’IA c’est comme les patates, il faut la faire garder pour la faire adopter" du podcast Clever Cloud, #JaiDécouvert la spécification agents.md (https://agents.md).
J'ai l'impression que AGENTS.md ressemble à la fonctionnalité CONVENTIONS.md du projet Aider.
J'ai trouvé une issue à ce sujet dans le projet Aider : Does Aider support AGENT.md or PLAN.md?.
Journal du vendredi 19 septembre 2025 à 16:51
Dans ma note du 2025-07-24_2231 au sujet de Containerlab je disais :
Je viens de poster le message suivant l'espace de discussion GitHub de Containerlab : « Does Containerlab support the creation of topologies with multiple subnets? ».
J'espère que le créateur de Containerlab pourra me suggérer une solution à mon problème, car je n'ai pas réussi à l'identifier dans la documentation 🤷♂️.
Depuis, j'ai eu une réponse et j'ai réussi à fixer mon problème : https://github.com/srl-labs/containerlab/discussions/2718#discussioncomment-14457884
Voici le résultat : https://github.com/srl-labs/containerlab/discussions/2814
Je ne suis pas satisfait de cette simulation, car de mon point de vue les Linux bridge créé par Docker configure trop de chose automatiquement.
Par exemple, l'IP 2001:db8:a:1::1 est automatiquement créé et assigné au bridge network-a.
De plus, je ne suis pas satisfait de cette simulation parce que containerlab configure automatiquement des routes au niveau de l'hôte pour interconnecter les réseaux Docker network-a, network-b et network-c, alors que dans un environnement réel, cette connectivité serait gérée par les équipements réseau de la topologie.
J'envisage peut-être de tester Mininet pour effectuer des simulations IPv6.
Journal du vendredi 19 septembre 2025 à 11:21
En mars 2025, j'ai pris la décision de contribuer financièrement à la hauteur de 10$ par mois au projet Servo (via Open Collective).
Aujourd'hui, j'ai eu la bonne surprise de découvrir l'article "Your Donations at Work: Funding Josh Matthews' Contributions to Servo".
The Servo project is excited to share that long-time maintainer Josh Matthews (@jdm) is now working part-time on improving the Servo contributor experience.
À l'heure actuelle, 287 contributeurs soutiennent Servo sur GitHub (montant non communiqué) et 388 personnes sur Open Collective pour 67 404 $ par an.
Je pense que la somme totale entre Open Collective et GitHub atteint probablement les 120 000 $ annuels.
Comparé aux 670 000 $ de revenus de Zig, les contributions pour Servo restent nettement plus modestes.
J'espère que la communauté Servo s'inspirera de la transparence de Zig : 2025 Financial Report and Fundraiser .
Dans cet article, #JaiDécouvert l'initiative Outreachy.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
J'ai découvert l'outil de build Javascript avec cache remote nommé "nx"
En étudiant un projet privé professionnel, #JaiDécouvert le projet nx qui est comme Turborepo un outil de build pour Javascript et TypeScript.
Pour commencer, je dois préciser que je n'apprécie pas du tout comment le projet se présente. On voit partout :
Cela me donne l'impression que ce "pitch" a été créé par une équipe marketing 🙉 !
J'ai découvert ce tout petit thread Hacker News qui date du 18 août 2022 sur Hacker News qui, je trouve, explique très bien le but de Nx :
I'm a core team member of Nx (nx.dev) and one of the core features we implemented quite a while ago, is "computation caching". Basically to speed up things, we get all the input to a given computation, which our case as a devtool means running your Jest tests, Webpack/esbuild/... build etc, and cache the result (logs & potential build artifacts).
Next time when the same computation is run, we look it up and restore it from the cache, obviously tremendously improving the speed of the run. The real value is when you distribute that cache among co-workers, CI agents etc., which you can do with Nx Cloud (nx.app).
We had played with the idea of potentially mapping this to CO2 emissions. If you start saving a lot of computation, this reduces the number of times a machine gets spin up & executed on your CI. Well, earlier this week we aggregated some stats of how much time we saved and we were pretty by the result ourselves!
I summed it up in this blog article: https://blog.nrwl.io/helping-the-environment-by-saving-two-centuries-of-compute-time-feea8e1ce22?source=friends_link&sk=9b1259d0b171a7b95ebe95b3795660b5
But basically we saved:
- last 7 days: ~5 years of compute time
- last 30 days: ~23 years
- since beginning of Nx Cloud: ~200 years
Je pense que ces mesures font référence à ce qu'on peut voir dans ce screenshot :
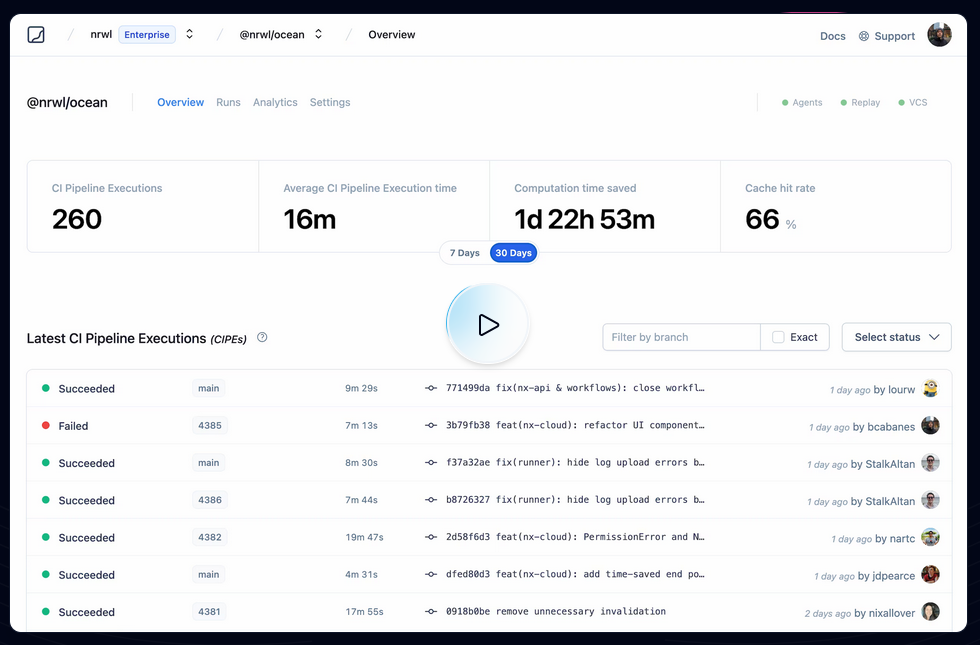
Je trouve cela très intéressant. Après avoir testé Bazel sans résultat concluant, sur la période 2018 à 2022, j'ai souvent cherché un outil comme Nx ou Turborepo, c'est-à-dire :
- Build distribué en parallèle sur différentes machines
- Partage de cache entre l'équipe de développement et les pipelines CI/CD
By default, Nx caches task results locally. The biggest benefit of caching comes from using remote caching in CI, where you can share the cache between different runs. Nx comes with a managed remote caching solution built on top of Nx Cloud.
To enable remote caching, connect your workspace to Nx Cloud by running the following command...
Je me demande si Nx permet de self host un composant de remote caching et si oui, je me demande si ce composant est open source ou non 🤔.
À noter que Turborepo permet de self host son propre service de remote cache : voir Turborepo - Remote Cache Self-hosting.
D'après mes recherches, Nx a été créé en juillet 2017, par Victor Savkin, un ancien développeur d'Angular chez Google. Selon cette description :
Software Engineer at Google (San Francisco Bay Area) between Jul 2014 - Dec 2016
One of the main developers of Angular 2. I've developed the dependency injection, change detection, forms, and router modules.
je pense que c'est pendant cette mission qu'il a eu l'idée de créer nx.
En janvier 2018, un second développeur Jason Jean, l'a rejoint sur le projet.
J'ai l'impression que Victor Savkin le CEO, n'a plus le temps de développer sur le projet depuis juillet 2023. Je pense que c'est à partir de là que le projet a eu de la traction.
Quel impact Tailwind CSS a-t-il sur la taille des pages d'un site de contenu ?
En février 2023, j'écrivais ceci :
Par ailleurs, je m'interroge sur l'impact du paradigme Tailwind CSS (utility CSS) concernant l'empreinte mémoire des pages.
J'ai le sentiment que la profusion d'attributsclass="..."va probablement augmenter considérablement la taille des pages.
#JaimeraisUnJour prendre le temps de mesurer cet aspect.
Cette question continue de me trotter dans la tête et mon intuition a évolué au fil du temps. J'ai maintenant l'intuition qu'une compression Brotli fonctionnerait efficacement avec le code Tailwind CSS.
Ce matin j'ai enfin pris le temps de faire des mesures.
J'ai choisi d'effectuer mes mesures sur le site de Blast qui est un site de contenu implémenté en Tailwind CSS.
Voici les mesures que j'ai effectuées :
- Home page https://www.blast-info.fr
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
453 Ko - Taille mémoire du HTML du
body, récupéré avec l'inspecteur Firefox via "copier l'intérieur du HTML" :178Ko - En supprimant tous les attributs
class="...", je passe à145Ko, soit une empreinte brute des attributsclassde33Ko(environ 18% du body) - Taille mémoire du texte seul :
5ko(2%) - Taille du body compressé Brotli :
25Ko - Taille du body sans attributs
class="..."compressé Brotli :23Ko, soit2Kopour les attributs classe (environ8%)
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
- Page intérieure https://www.blast-info.fr/articles/2025/macron-bayrou-vers-un-jour-sans-fin-I0AwyT5KTf6_0ywKmLShVQ
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
404 Ko - Taille mémoire brute du HTML du
body, récupéré avec l'inspecteur Firefox via "copier l'intérieur du HTML" :281ko - En supprimant tous les attributs
class="...", je passe à251Ko, soit une empreinte brute des attributsclassde30Ko(environ 10% du body) - Taille mémoire du texte seul :
34ko(environ 12%) - Taille du body compressé Brotli :
43Ko - Taille du body sans attributs
class="..."compressé Brotli :40Ko, soit3Kopour les attributs classe (environ6%)
- Taille mémoire brute (non compressée) de la page complète sans dépendances :
Une fois compressé, la partie Tailwind CSS représente 2Ko à 3Ko par page. Il faut noter que ces valeurs constituent probablement une estimation haute, car un site utilisant le paradigme CSS traditionnel emploie généralement aussi des class="…" dans ses pages HTML.
Mon constat : je pense que le surcout de Tailwind CSS sur la taille des pages d'un site de contenu demeure négligeable après compression.
Une autre question que je me pose : quel est l'impact de Tailwind CSS sur l'utilisation mémoire du navigateur ?
Journal du samedi 30 août 2025 à 20:17
Je viens de publier : Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch".
Journal du samedi 30 août 2025 à 16:50
#JaiDécouvert la formalisation du concept de content-modeling as code :
Bilan de mon temps de travail de ma première année de Freelance
Après ma note "Retour XP posts LinkedIn et mes canaux d'acquisition de mission Freelance", voici ma seconde note bilan de ma première année d'activité Freelance.
En 2022, ma dernière année complète en CDI qui me sert de référence, j'ai travaillé 219 jours. Cette année-là, 6 jours fériés sur 10 sont tombés en semaine et j'ai pris en tout 35 jours de congé.
Pour ma première année de Freelance, du 1er juillet 2024 au 30 juin 2025 :
- J'ai travaillé l'équivalent de 206 journées complètes :
- J'ai facturé 168 jours de prestation
- À cela s'ajoute 39 journées complètes non facturées. Il s'agit soit de prestations supplémentaires que je n'ai pas facturées, soit du temps consacré à la prospection et aux échanges avec des prospects.
- 266 jours où j'ai travaillé plus de 30min
- 288 jours où j'ai travaillé au moins 1min
- 59 jours de vacances officielles, dont 18 qui sont tombés en weekend, donc j'ai posé l'équivalent de 41 jours de congés. Pendant ces 59 jours, j'ai au moins travaillé 18 jours durant plus de 30 minutes.
Si je fais le bilan, pour ma première année, j'ai travaillé 13 jours de moins que ma dernière année en CDI, pour un chiffre d'affaires qui correspond approximativement à un CDI à 75 K€ brut par an.
Répartition des jours que j'ai facturée de juillet 2024 à fin mai 2025 :

Journal du mercredi 27 août 2025 à 09:57
Dans le livre "Politikon - Tout ce qu'il faut savoir sur les idéologies qui ont façonné notre monde", #JaiDécouvert le mouvement philosopique nommé le "convivialisme".
Autour du noyau du M.A.U.S.S. s'élabore depuis quelques années une idéologie politique qui ambitionne de s'opposer massivement à l'idéologie économique dominante : le convivialisme. Plusieurs manifestes et ouvrages sont parus et ont été soutenus par de nombreuses personnalités internationales aussi différentes que Noam Chomsky, Jean-Claude Michéa, Chantal Mouffe ou Edgar Morin.
Le terme « convivialisme » trouve sa source dans l'ouvrage La convivialité du philosophe Ivant Illich.
Il s'agit ici de penser une société fondée sur une volonté commune de vivre ensemble en dehors du principe de l'utilité à maximiser et de l'illimitation de la croissance économique.
Journal du mardi 26 août 2025 à 21:45
Voici une note pour présenter la seconde #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
J'ai tout d'abord implémenté dans ce commit un mécanisme qui exécute du code JavaScript automatiquement après chaque git push.
Pour cela, j'ai choisi de me baser sur le mécanisme Server-Side Hooks natif de Git : post-receive.
Voici le contenu de ce script hook en Bash :
#!/bin/bash
while read oldrev newrev refname; do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
curl -X POST \
-H "Content-Type: application/json" \
-d "{
\"oldrev\": \"${oldrev}\",
\"newrev\": \"${newrev}\",
\"refname\": \"${refname}\",
\"branch\": \"${branch}\",
\"repository\": \"$(basename $(pwd))\"
}" \
"${POST_RECIEVE_HOOK_URL}" >> /dev/null
done
Chaque événement git push déclenche un appel HTTP vers le endpoint http://localhost:3334/post_recieve_hook_url/ exposé par le serveur NodeJS. Le payload contient notamment :
oldrev: l'identifiant du dernier commit présent dans le repository avant le pushnewrev: l'identifiant du commit le plus récent envoyé lors du push
L'intervalle entre oldrev et newrev permet d'identifier précisément l'ensemble des commits qui ont été poussés lors de cette opération.
J'ai ensuite implémenté une version SvelteKit iso-fonctionnelle de node-git-http-server. Voici le repository poc-node-git-server-in-sveltekit .
Contrairement à ce que j'avais prévu initialement, pour cette implémentation, je ne me suis pas basé sur SvelteKit Custom Server, mais sur la fonctionnalité Server hooks : src/hooks.server.js#L11.
Retour XP posts LinkedIn et mes canaux d'acquisition de mission Freelance
J'ai prévu de publier quelques notes de bilan de ma première année d'activité Freelance. Voici la première, une note d'analyse de mes canaux d'acquisition de missions.
Il y a environ un an, fin septembre 2024, j'ai publié 3 posts sur LinkedIn dans le but de faire connaître ma nouvelle activité Freelance :
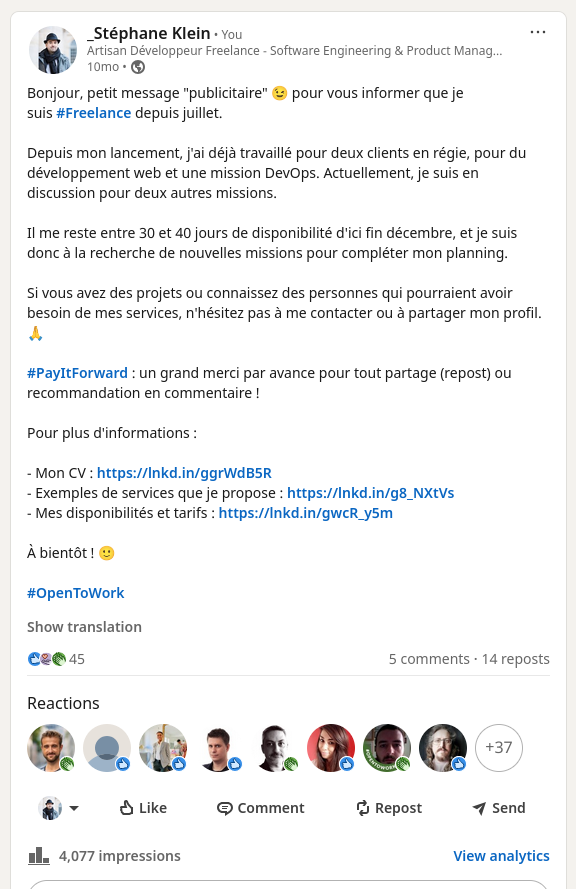
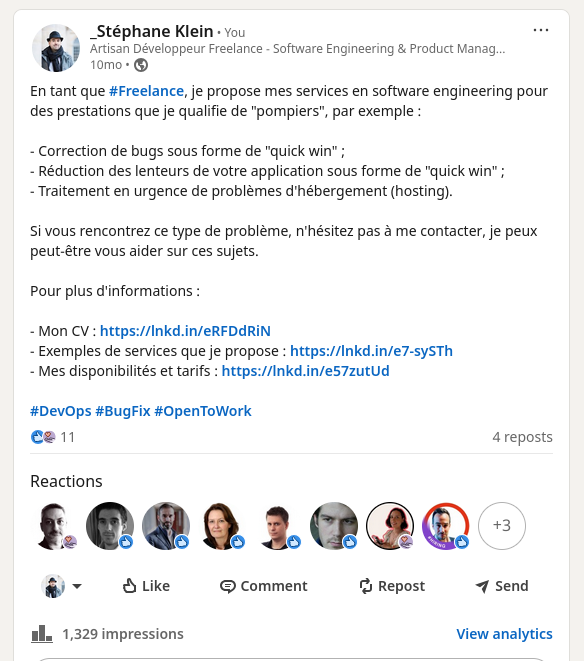
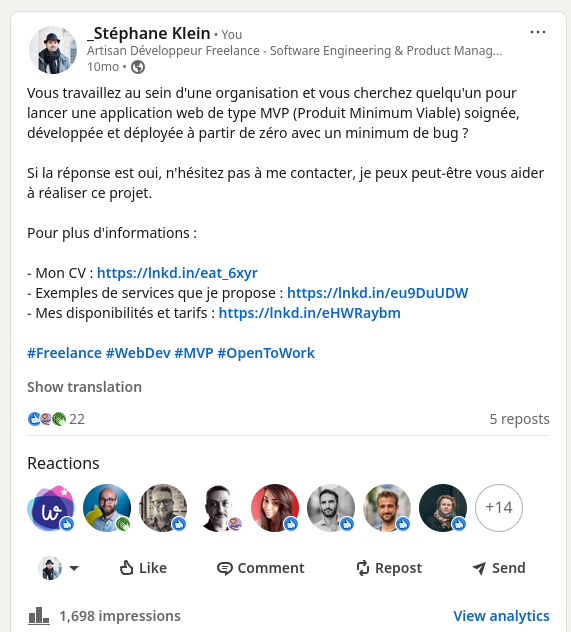
Bien que ces messages aient généré 78 réactions, 23 reposts et 7163 impressions cumulées, ils ne m'ont apporté aucune mission directe.
Cependant, j'ai observé qu'ils ont efficacement informé l'ensemble de mon réseau professionnel de ma nouvelle activité.
Malgré cet échec sur ce canal d'acquisition, j'ai tout de même facturé 168 jours de prestation sur une période de 12 mois, du 1er juillet 2024 (jour du dépôt légal de ma micro-entreprise) au 30 juin 2025, en utilisant d'autres approches d'acquisition client.
Voici la répartition de ces 168 jours selon le canal d'acquisition :
- Mon réseau direct, des anciens collègues très proches : 3 clients pour un total de 98 jours
- Des candidatures spontanées : 2 clients pour un total de 50 jours
- Recommandation indirecte d'un client qui n'était pas dans mon cercle de connaissance avant d'avoir travaillé avec lui : 1 client pour un total de 20 jours
Je n'ai reçu aucune proposition de mission sur Malt, pas même un message. Mon taux journalier de 700 € est peut-être trop élevé, ou alors c'est un problème de positionnement de profil. Je dois reconnaitre que je n'ai fait aucun effort à améliorer mon profil Malt depuis ma dernière phase d'optimisation présentée dans cette note du 25 septembre 2024.
Je n'ai répondu à aucune annonce de mission.
J'ai fait seulement deux candidatures spontanées et toutes les deux ont abouti.
Pour la première, j'ai ciblé un service que j'apprécie beaucoup et dont je suis client depuis presque 10 ans. J'avais repéré par leurs posts qu'ils avaient peut-être un budget pour des missions de développement.
Pour la seconde, j'ai visé un collectif que j'avais identifié il y a plus de 10 ans et pour lequel j'avais toujours eu envie de travailler.
Dans les deux cas, mes messages étaient parfaitement sincères, très éloignés des modèles de lettres de motivation qu'on trouve en ligne. J'avais fait mes recherches sur ces organisations et j'ai soigneusement détaillé mes motivations ainsi que les compétences que je pouvais leur apporter.
En repensant à ma stratégie d'acquisition de missions Freelance, je constate qu'elle ressemble étonnamment à ma façon d'obtenir mes CDI durant ma carrière :
- J'ai répondu à une annonce d'emploi
- J'ai répondu à une annonce d'emploi (Jobboard : Lolix)
- Une amie proche m'a contacté pour une mission
- Un ami proche m'a contacté pour un emploi
- Une amie proche m'a contactée pour un emploi
- J'ai ciblé une organisation en contactant une connaissance d'une communauté
- J'ai lancé une bouteille à la mer à une connaissance d'une communauté
- J'ai eu une proposition autour d'une bière alors que je n'avais rien prévu
- J'ai lancé une bouteille à la mer à une connaissance d'une communauté
Voir aussi : Bilan de mon temps de travail de ma première année de Freelance
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Journal du samedi 23 août 2025 à 18:29
Je viens de publier : Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
Journal du samedi 23 août 2025 à 14:13
Dans l'épisode "Une nouvelle histoire du Moyen Âge, avec Florian Mazel " de la web radio Storiavoce, #JaiDécouvert l'ouvrage collectif dirigé par Florian Mazel : "Nouvelle Histoire du Moyen Âge" (https://www.seuil.com/ouvrage/nouvelle-histoire-du-moyen-age-collectif/9782021460353 ).
L'émission m'a donné envie de l'acheter et de le feuilleter.
Journal du mardi 19 août 2025 à 11:05
Ces derniers jours, j'ai lu :
- le thread Hacker News : "Sunny days are warm: why LinkedIn rewards mediocrity"
- et le billet "Le personal branding, c’est fini " de Laëtitia Vitaud
à propos de LinkedIn.
Cela me rassure d'observer que d'autres partagent mon opinion sur la médiocrité générale des posts LinkedIn.
Dès les années 2010, j'avais remarqué une dérive : la plupart des gens cherchaient à gonfler leur réseau en acceptant toutes les connexions, y compris de parfaits inconnus.
Selon moi, LinkedIn devrait représenter les relations authentiques entre les gens. J'ai toujours suivi cette règle personnelle pour accepter une connexion : si je croise cette personne dans la rue, est-ce que je prendrais le temps de la saluer ?
J'utilise LinkedIn essentiellement comme carnet d'adresses et base de données de CV dynamiques, ainsi que pour comprendre la structure et la dynamique des organisations.
En revanche, je consulte très peu mon feed. Pour éviter de le voir, j'ai installé l'extension Browser "LinkedIn Feed Locker".
J'ai découvert Badsender, une agence spécialisée en e-mailing et email deliverability
Il y a quelques semaines, un ami m'a demandé si je connaissais quelqu'un pour réaliser un audit Email deliverability. N'ayant personne de confiance à lui recommander dans ce domaine, je lui ai proposé de faire moi-même une prestation d'une demi-journée sur le sujet, malgré le fait que ce ne soit pas mon cœur de métier.
Pendant mes études, pour monter en compétence sur ce sujet (voir mes notes dans Email deliverability), j'ai découvert l'agence "d'emailing" nommée Badsender (https://www.badsender.com) via leur excellent billet sur BIMI.
Badsender, c’est une équipe de 10 spécialistes du numérique dotés d’une forte expertise en emailing et newsletter. Nous intervenons sur toute la chaîne email : délivrabilité, conseils stratégiques, rédaction, conception et production de campagnes.
J'ai beaucoup apprécié leur démarche de transparence : "Cap à 9 mois : Quel cap dans les 9 prochains mois ?".
J'ai beaucoup aimé le contenu de leurs billets d'analyse de newletters : https://www.badsender.com/newsletter/exemples/.
J'ai l'impression que Sébastien Fischer a produit la majorité des bons articles de Badsender pendant sa période chez eux (2021-2024).
En étudiant les dépôts de comptes sur INPI jusqu'à 2019 et les profils LinkedIn, il me semble que Badsender repose principalement sur 3 experts, notamment Jonathan Loriaux , le fondateur qui paraît avoir une solide expérience en Email deliverability.
Avec leur marge brute de 2019 d'environ 220 K€ et un panier moyen qui tourne autour de 2000 €, j'estime leur portefeuille client entre 100 et 150 comptes.
Après mon audit de délivrabilité d'e-mail pour mon client, si mon tarif à la journée est trop élevé, si mes disponibilités ne correspondent pas à ses besoins, ou s'il souhaite établir un partenariat à long terme avec un prestataire, alors je lui recommanderai sans doute de se tourner vers l'agence Badsender ou Sébastien Fischer.
Je vais informer Badsender de la publication de cette note pour savoir si elle contient des informations qui leur posent un problème.
Pour le moment, je n'ai pas d'avis sur l'intérêt des services d'email warming
Je continue mes explorations sur l'Email deliverability avec cette note dédiée à l'email warming (pour rappel, mes notes précédentes : 2025-08-04_1449, 2025-08-08_2222, 2025-08-14_2229).
Quel est le fonctionnement technique des services d'email warming ?
L'email warming consiste à établir progressivement une réputation positive pour une nouvelle adresse e-mail, d'un nouveau domaine ou d'une nouvelle IP SMTP auprès des ESP.
Mon hypothèse sur le fonctionnement de ces services :
- Ces plateformes créent en premier lieu des comptes e-mail chez un maximum d'email service providers (Gmail, Yahoo (Mail), Fastmail, La Poste (mail)…).
- Elles expédient graduellement, sur plusieurs jours, des e-mails vers ces adresses, avec des contenus variés.
- Elles simulent via un headless browser des interactions utilisateur dans les webmails de ces boîtes : ouverture de mails, clics sur des liens, etc.
J'imagine qu'elles doivent créer des scénarios aléatoires au niveau des timings et des actions pour éviter d'être trop facilement détectées par les email service providers 🤔.
J'ai essayé d'en savoir plus sur l'efficacité de l'email warming. J'ai effectué des recherches sur le Subreddit EmailMarketing. J'ai par exemple trouvé les threads suivants :
- Do I need to warm up domain before sending behavioral emails?
- What exactly has email warming changed for you?
- Is there any evidence that domain/IP warm up actually works?
Une minorité d'utilisateurs (exemple ) affirment que l'email warming est un scam, tandis qu'une majorité soutient que l'email warming reste indispensable pour toute nouvelle adresse e-mail. Cependant, je me demande si ces avis positifs ne viennent pas principalement des fournisseurs de services d'email warming 🤔.
Idéalement, j'aimerais trouver une étude d'un cas concret, menée par quelqu'un dont je ne pourrais pas questionner la crédibilité. Sinon, il me reste l'option de mener un test par moi-même.
Les systèmes SPF, DKIM, et DMARC me paraissent efficaces, mais les outils non officiels d'inbox placement et d'email warming ressemblent plutôt à du bricolage dans un écosystème incomplet.
Ces pratiques obscures me font penser à l'univers du SEO.
Il s'agit d'un système de coévolution antagoniste, semblable au jeu du chat et de la souris, ou plus précisément, un jeu séquentiel à somme variable avec des composantes antagonistes.
Dans ce genre d'écosystème, chaque acteur investit massivement en énergie pour maintenir le statu quo. Je trouve cette dynamique absurde et n'y vois aucun intérêt.
Concernant les tarifs, je trouve que le prix de MailReach est correct, $25 par mois pour "faire chauffer" une adresse mail :