
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (13 notes) :
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du jeudi 29 mai 2025 à 00:04
Dans ma note Bilan de poc-sveltekit-custom-server je finis par ceci :
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Voici ce que je viens de publier :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Bilan de poc-sveltekit-custom-server
Contexte et objectifs
Dans le projet gibbon-replay, j'ai besoin d'exécuter une tâche une fois par jour pour supprimer des anciennes sessions.
gibbon-replay utilise une base de données SQLite qui ne dispose pas nativement de fonctionnalité de type Time To Live, comme on peut trouver dans Clickhouse.
SQLite ne propose pas non plus d'équivalent à pg_cron — ce qui est tout à fait normal étant donnée que SQLite est une librairie et non pas un service à part entière.
Le projet gibbon-replay est un monolith (j'aime les monoliths !) et je souhaite conserver ce choix.
Face à ces contraintes, une solution consiste à intégrer une solution comme Cron for Node.js directement dans l'application gibbon-replay.
Je pense que je dois implémenter cela dans un SvelteKit Custom Server, ce qui me permettrait d'exécuter cette tâche de purge à intervalles réguliers tout en conservant l'architecture monolithique.
Il y a quelques jours, j'ai décidé de tester cette idée dans un POC nommé : poc-sveltekit-custom-server.
J'ai aussi décidé d'expérimenter un objectif supplémentaire dans ce POC : lancer la migration du modèle de données dès le lancement du monolith et non plus lors de la première requête HTTP reçue par le service.
Enfin, je souhaitais ne pas dégrader l'expérience développeur (DX), c'est à dire, je souhaitais pouvoir continuer à simplement utiliser :
$ pnpm run dev
ou
$ pnpm run build
$ pnpm run preview
sans différence avec un projet SvelteKit "vanilla".
Résultats du POC et enseignements
Tout d'abord, le POC fonctionne parfaitement 🙂, sans dégrader l'expérience développeur (DX), qui ressemble à ceci :
$ mise install
$ pnpm install
$ pnpm run load-seed-data
Start data model migration…
Data model migration completed
Start load seed data...
seed data loaded
Lancement du projet en mode développement :
$ pnpm run dev
Start data model migration…
Data model migration completed
Server started on http://localhost:5173 in development mode
Lancement du projet "buildé" :
$ pnpm run build
$ pnpm run preview
Start data model migration…
Data model migration completed
Server started on http://localhost:3000 in production mode
Les migrations et les données "seed.sql" se trouvent dans le dossier /sqls/.
Le SvelteKit Custom Server est implémenté dans le fichier src/server.js et il ressemble à ceci :
import express from 'express';
import cron from 'node-cron';
import db, { migrate } from '@lib/server/db.js';
const isDev = process.env.ENV !== 'production';
migrate(); // Lancement de la migration du modèle de donnée dès de lancement du serveur
// Configuration d'une tâche exécuté toutes les heures
cron.schedule(
'0 * * * *',
async () => {
console.log('Start task...');
console.log(db().query('SELECT * FROM posts'));
console.log('Task executed');
}
);
async function createServer() {
const app = express();
...
Personnellement, je trouve cela simple et minimaliste.
Point de difficulté
SvelteKit utilise des "module alias", comme par exemple $lib.
Problème, par défaut, ces "module alias" ne sont pas configurés lors de l'exécution de node src/server.js.
Pour me permettre d'importer dans src/server.js des modules de src/lib/server/* comme :
import db, { migrate } from '@lib/server/db.js';
j'ai utilisé la librairie esm-module-alias.
Ceci complexifie un peu le projet, j'ai dû configurer ceci dans /package.json :
{
"scripts": {
"dev": "ENV=development node --loader esm-module-alias/loader --no-warnings src/server.js",
"preview": "ENV=production node --loader esm-module-alias/loader --no-warnings build/server.js",
...
"aliases": {
"@lib": "src/lib/"
}
}
- ajout de
--loader esm-module-alias/loader --no-warnings - et la section
aliases
Et dans /vite.config.js :
export default defineConfig({
plugins: [sveltekit()],
resolve: {
alias: {
'@lib': path.resolve('./src/lib')
}
}
});
- ajout de
alias
Le fichier src/server.js contient du code spécifique en fonction de son contexte d'exécution ("dev" ou "buildé") :
if (isDev) {
const { createServer: createViteServer } = await import('vite');
const vite = await createViteServer({
server: { middlewareMode: true },
appType: 'custom'
});
app.use(vite.middlewares);
} else {
const { handler } = await import('./handler.js');
app.use(handler);
}
En mode "dev" il utilise Vite et en "buildé" il utilise le fichier build/handler.js généré par SvelteKit build en mode SSR.
Le fichier src/server.js est copié vers le dossier /build/ lors de l'exécution de pnpm run build.
J'ai testé le bon fonctionnement du POC dans un container Docker.
J'ai intégré au projet un deployment-playground : https://github.com/stephane-klein/poc-sveltekit-custom-server/tree/main/deployment-playground.
La suite...
Je souhaite rédiger cette note en anglais et la publier sur https://github.com/sveltejs/kit/discussions et https://old.reddit.com/r/sveltejs/ afin :
- d'avoir des retours d'expérience
- de découvrir des méthodes alternatives
- et partager la méthode que j'ai utilisée, qui sera peut-être utile à d'autres développeurs Svelte 🙂
Update du 2025-05-29 à 00:07 - Je viens de publier ceci :
- https://github.com/sveltejs/kit/discussions/13841
- https://old.reddit.com/r/sveltejs/comments/1kxtz1u/custom_sveltekit_server_dev_production_with/?
2025-05-29 : voir J'ai découvert la fonctionnalité SvelteKit Shared hooks init
Journal du mercredi 07 mai 2025 à 14:22
Ici dans le code source de Open WebUI, #JaiDécouvert Pyodide :
Pyodide is a Python distribution for the browser and NodeJS based on WebAssembly.
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Dans l'application web que je développe pour Value Props, je n'utilise actuellement aucune librairie de configuration pour l'app.
J'utilise uniquement process.env.CONFIG_PARAM || "default value".
En contexte, cela ressemble à ceci.
import nodemailer from "nodemailer";
let transporter;
if (process.env?.SMTP_USER && process.env?.SMTP_PASS) {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: true,
auth: {
user: process.env.SMTP_USER,
pass: process.env.SMTP_PASS
}
});
} else {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: false
});
}
export default transporter;
Je commence maintenant à utiliser des paramètres de configuration à différents endroits. Conséquence, je me dis que c'est peut-être maintenant le bon moment pour utiliser une librairie de configuration du type Convict.
Pourquoi j'ai cité Convict ? Parce que c'était le choix que j'avais fait en 2019, dans le projet gibbon-mail.
#JeMeDemande qu'elle est en 2024, la librairie [Javascript] de type environment-variables, configuration-management la plus populaire actuellement.
Pour répondre à cette question, j'ai commencé à faire une recherche sur npm trends et il m'a proposé la suggestion suivante config vs configstore vs convict vs cross-env vs dotenv
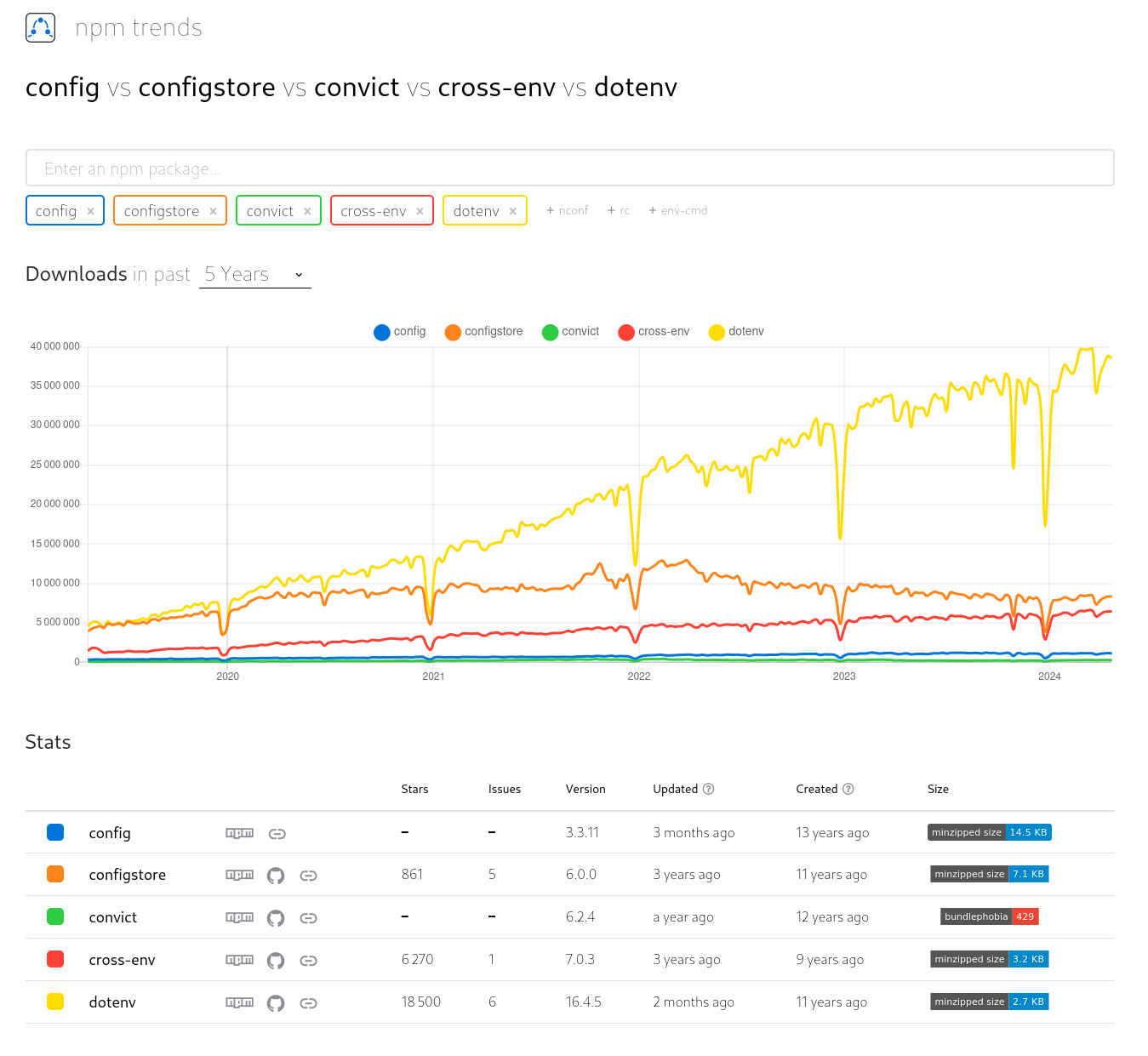
dotenv semble se détacher assez franchement.
dotenv et cross-env sont listés dans Delightful Node.js packages and resources.
Je constate que cross-env est abandonné et conseille ici de migrer vers env-cmd.
Je vais demander avis à des amis, mais pour le moment, je pense que je vais utiliser dotenv.
Quelque heure plus tard :
Site officiel : https://nitro.build/
Next Generation Server Toolkit.
Create web servers with everything you need and deploy them wherever you prefer.
Site web https://github.com/motdotla/dotenv
L'outil direnv permet nativement de charger des fichiers .env, simplement avec :
# fichier .envrc
dotenv .env
Site officiel : https://uptime.kuma.pet/
Dépôt GitHub : https://github.com/louislam/uptime-kuma
Démo : https://status.kuma.pet/
Voir par exemple : https://github.com/euberdeveloper/esm-module-alias
Dépôt GitHub : https://github.com/gabrielcsapo/node-git-server
Site officiel : https://fastify.dev
Dernière page.