
sklein-pkm-engine
Dépôt GitHub : https://github.com/stephane-klein/sklein-pkm-engine
Cette application est le moteur de mon Personal knowledge management : https://notes.sklein.xyz.
Note initale de ce projet : Projet 11 - "Première version d'un moteur web PKM".
Journaux liées à cette note :
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Journal du samedi 21 décembre 2024 à 16:10
Je viens d'améliorer l'implémentation du moteur de recherche de mon sklein-pkm-engine.
Voici un screencast de présentation du résultat :
Le commit de changement : https://github.com/stephane-klein/sklein-pkm-engine/commit/71210703fe626bd455b2ec7774167d9a637e4972
Je suis passé de :
query_string: {
query: queryString,
default_field: "content_html"
}
à ceci :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Les fonctionnalités de recherche d'Elasticsearch sont nombreuses. Pour les parcourir, je conseille ce point d'entrée de la documentation Search in Depth.
Même après avoir fini mon implémentation de la fonction recherche, je dois avouer que je tâtonne sur le sujet. Je suis loin de maitriser le sujet.
Au départ, après lecture de ce paragraphe :
If you don’t need to support a query syntax, consider using the
matchquery. If you need the features of a query syntax, use thesimple_query_stringquery, which is less strict.
J'ai fait un refactoring de query_string vers simple_query_string (lien vers la documentation).
Mon objectif était d'arriver à implémenter la fonctionnalité Query-Time Search-as-You-Type avec de la recherche floue (fuzzy).
J'ai commencé par essayer la syntax foobar~* mais j'ai appris qu'il n'était pas possible d'utiliser ~ (fuzzy) en couplé avec * 😔 (documentation vers la syntax). Sans doute pour de bonnes raisons, liées à des problèmes de performance.
J'ai ensuite découpé ma requête en 3 conditions :
baseQuery.body.query.bool.must.push({
bool: {
should: [
{
simple_query_string: {
query: queryString,
fields: ["content_html"],
boost: 3
}
},
{
simple_query_string: {
query: queryString.split(' ').map(word => (word.length >= 3) ? `${word}*` : undefined).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
},
{
simple_query_string: {
query: queryString.split(' ').map(
word => {
if (word.length >= 5) { return `${word}~2`; }
else if (word.length >= 3) { return `${word}~1`; }
else return undefined;
}
).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
}
],
minimum_should_match: 1
}
}
Cette implémentation fonctionne, mais je rencontrais des problèmes de performance aléatoires que je n'ai pas pris le temps d'essayer de comprendre la cause.
À force de tâtonnement, j'ai fini par choisir la solution basée sur multi_match (documentation de référence) :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Documentation de référence du paramètre fuzziness : Fuzzy query.
Documentation de la valeur AUTO : Common options - Fuzziness
Malheureusement, ici aussi, je ne peux pas utiliser fuzziness avec phrase_prefix :
The fuzziness parameter cannot be used with the phrase or phrase_prefix type.
En finissant cette note, je viens de découvrir cet exemple dans la documentation.
J'ai l'impression de comprendre qu'en utilisant le tokenizer ngram je pourrais faire des Fuzzy Search sans utiliser l'option fuzziness 🤔.
J'ai commencé l'implémentation dans la branche ngram-tokenizer mais je m'arrête là pour aujourd'hui. En tout, ce weekend, j'ai passé 4h30 sur ce sujet 😮.
J'espère tester cette implémentation d'ici à quelques jours.
Je souhaite aussi essayer prochainement de migrer de Elasticsearch vers OpenSearch.
Journal du samedi 21 décembre 2024 à 14:17
Je viens de corriger dans mon sklein-pkm-engine, un problème d'expérience utilisateur que m'avait remonté Alexandre sur la page détail d'une note.
Par exemple sur la note : https://notes.sklein.xyz/2024-12-19_1709/

Le lien sur le tag dev-kit pointait vers https://notes.sklein.xyz/diaries/?tags=dev-kit. Conséquence : les Evergreen Note n'étaient pas listés dans les résultats. Ce comportement était perturbant pour l'utilisateur.
J'ai modifié l'URL sur les tags pour les faire pointer vers https://notes.sklein.xyz/search/?tags=dev-kit, page qui affiche tous types de notes.
Journal du mardi 03 décembre 2024 à 23:57
Suite de 2024-12-03_2213. J'ai réussi à implémenter le support Pandoc style markdown attributes dans sklein-pkm-engine.
Le package markdown-it-attrs fonctionne parfaitement bien.
Par contre, le plugin markdown-attributes semble ne pas fonctionner sur les dernières versions de Obsidian.
Journal du mardi 03 décembre 2024 à 22:13
Suite à 2024-11-13_2147, j'ai implémenté l'amélioration du rendu des "citations", voici un exemple :
Texte de la citation.
J'ai utilisé la librairie markdown-it-callouts.
Par contre, l'implémentation actuelle contient un bug. Je souhaite appliquer ce style css uniquement au lien de la source de la citation :

Pour cela, j'aimerais pouvoir spécifier en markdown une classe source sur le lien qui pointe vers la source de la citation.
J'ai trouvé markdown-it-attrs qui me permettrait d'implémenter une syntax Pandoc-style markdown attributes :
> [!quote]
>
> Texte de la citation.
>
> [source](http://example.com){.source}
Le plugin Obsidian markdown-attributes semble implémenter cette syntax.
Je souhaite tester si ce plugin fonctionne bien et si oui, je vais essayer d'intégrer markdown-it-attrs dans sklein-pkm-engine.
Journal du mercredi 13 novembre 2024 à 21:47
Actuellement, dans sklein-pkm-engine, les "citations" sont affichées comme ceci :
Je souhaite modifier ce rendu pour réaliser quelque chose ressemblant à ceci :

Ma source d'inspiration est le blog de gwern.net.
gwern.net utilise la syntax de quote suivante (exemple) :
<div class="epigraph">
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
</div>
Étant donné que j'édite notes.sklein.xyz avec Obsidian, je ne peux pas utiliser la même syntax.
En remplacement, je pense utiliser la syntax "Callouts", par exemple :
> [!quote]
>
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
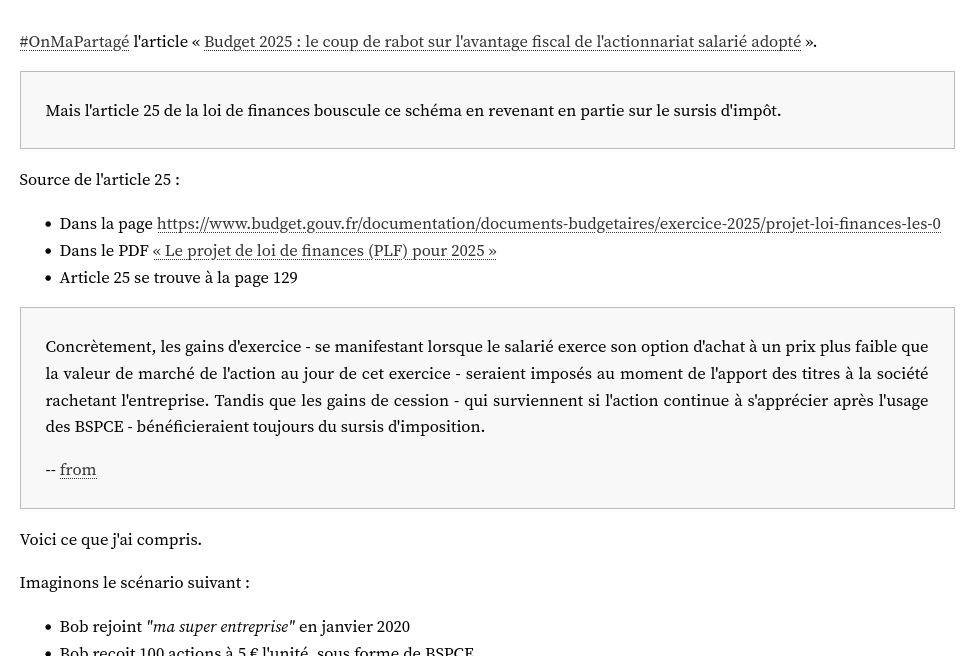
Qui donne le rendu suivant dans Obsidian :
#réflexion : j'ai l'intuition qu'à terme, une utilisation SilverBullet.mb à la place d'Obsidian m'offrirait bien plus de flexibilité.
Journal du samedi 02 novembre 2024 à 12:52
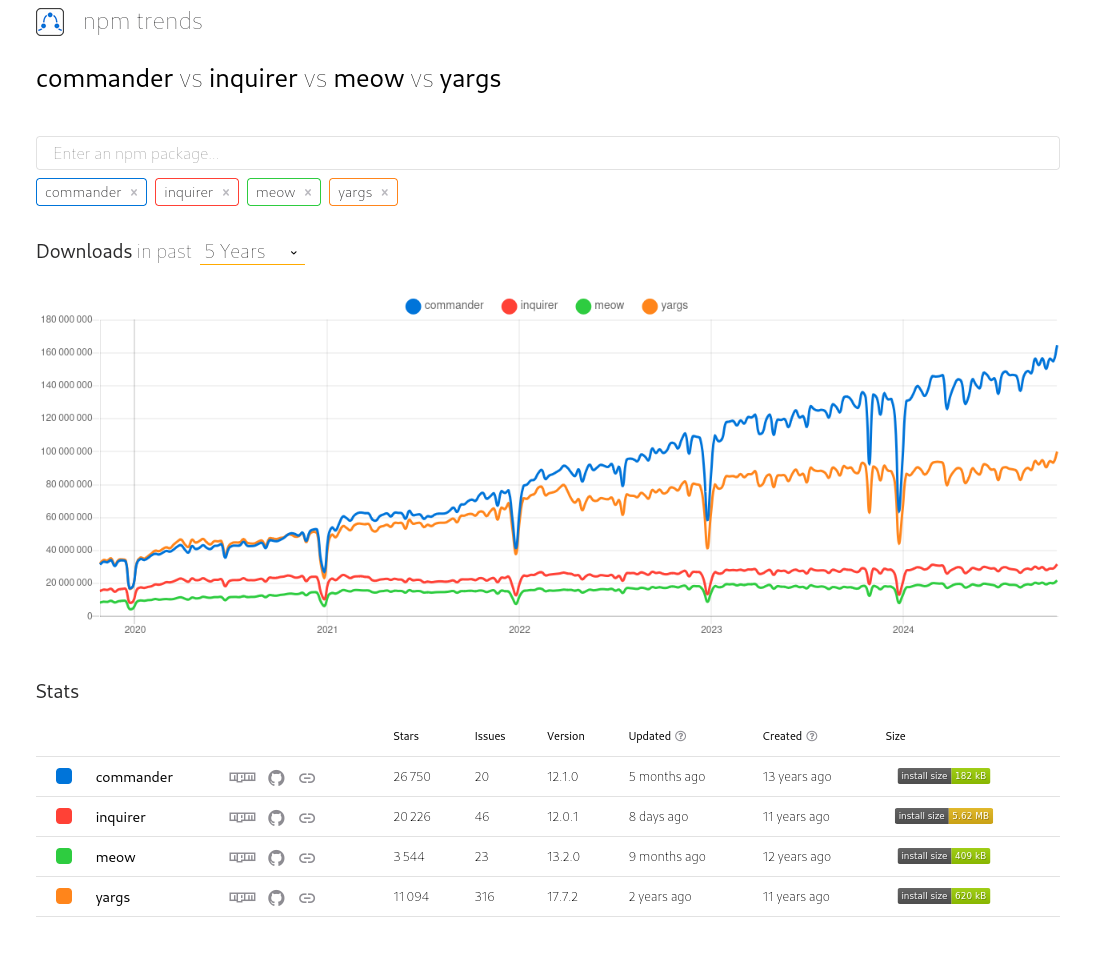
Suite à quelques cherches, j'ai décidé d'utiliser "commander" plutôt que "yargs" dans sklein-pkm-engine : lien vers le commit.
Je trouve cette librairie minimaliste :
program
.option('--dry', 'Run in dry mode')
.parse();
console.log(program.opts());
Résultat de "commander vs inquirer vs meow vs yargs" :
Journal du dimanche 20 octobre 2024 à 10:04
La version 5 de Svelte vient de sortir : 5.0.0.
Il y a un an, j'avais lu le billet Introducing runes. Depuis, j'ai suivi ce sujet de loin.
J'aimerais tester et apprendre à utiliser la fonctionnalité rune.
#JeMeDemande dans quel projet 🤔. Est-ce que je préfère refactorer vers rune le projet sklein-pkm-engine ou gibbon-replay 🤔. Je pense que ces deux projets utilisent trop peu de "reactive state".
Je souhaite prochainement débuter le projet que j'ai présenté dans 2023-10-28_2008. Je pense que ça serait une bonne occasion pour créer mon premier projet 100% TypeScript avec Svelte 5 avec Rune.
Je souhaite afficher une barre de progression d'importation dans le script import-to-es-database.js du projet sklein-pkm-engine.
Je souhaite afficher deux lignes :
- Première ligne : barre de progression d'importation ;
- Seconde ligne : action en cours de traitement.
Je viens d'étudier les librairies blessed, ora et cli-progress et je pense que cli-progress est celle qui conviendra de mieux pour atteindre mon objectif.
Par contre, cli-progress ne semble pas supporter la présence d'un retour à la ligne dans le paramètre format :
const bar = new cliProgress.SingleBar({
format: "Progress | {bar} | {percentage}% || {value}/{total} items\nProcessing: {currentAction}",
barCompleteChar: "\u2588",
barIncompleteChar: "\u2591",
hideCursor: true,
clearOnComplete: false,
linewrap: false
});
Finalement, non satisfait de cli-progress, je suis parti vers la #library listr2 (https://github.com/listr2/listr2).
Voici le résultat :
Voici le code source de ma mise en œuvre de Listr2 : https://github.com/stephane-klein/sklein-pkm-engine/blob/9bca16344dca075c595ceebb82b91bbbd3a267ff/import-to-es-database.js#L49.
J'ai trouvé la librairie très agréable à utiliser.