
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
Résultat de la recherche (2338 notes) :
Vendredi 31 juillet 2026
Pourquoi je me suis désintéressé des projets portés par Canonical à partir de 2014
J'ai commencé à utiliser Debian en juin 2001 avec la version 2.2 Potato. J'ai découvert fin 2004 le projet Ubuntu porté par l'entreprise Canonical et ça m'a tout de suite plu. En avril 2005, j'ai migré avec la version Ubuntu 5.04 Hoary Hedgehog.
Je trouvais cela incroyable qu'un milliardaire, Mark Shuttleworth, lui-même développeur Debian, investisse une grande partie de sa fortune dans le Linux Desktop.
J'étais adepte de Canonical : j'utilisais et promouvais Bazaar, Launchpad, puis Upstart en 2006.
À cette époque, j'aurais rêvé de travailler chez Canonical que j'admirais, mais je n'ai pas tenté ma chance : mon niveau d'anglais ne le permettait pas.
Ma confiance en Canonical a commencé à basculer vers 2012-2013. Je constatais qu'ils étaient seuls à coder Unity sans contribuer à GNOME Shell, à maintenir Upstart alors que systemd gagnait du terrain. La polémique autour de Dash fin 2012 a ajouté au malaise. Mais le vrai point de bascule a été en 2013, quand Canonical a décidé de lancer Mir de son côté et d'abandonner Wayland.
Voici les projets de Canonical qui n'ont pas réussi à s'imposer :
-
Bazaar : outil de gestion de versions distribué pour le développement logiciel
- Projet alternatif devenu mainstream : Git
- Lancement : 26 mars 2005
- Date mainstream Git : 7 avril 2005 (premier commit) ; adoption massive ~2008-2010
- Mort : Dernière release stable 2016 ; support Launchpad totalement arrêté le 1er septembre 2025
-
Upstart : système d'init pour Linux, remplaçant SysV
- Projet alternatif devenu mainstream : systemd
- Lancement : 24 août 2006 (Ubuntu 6.10)
- Date mainstream systemd : 6 juillet 2010 (version 1) ; adoption massive ~2014-2015
- Mort : Annonce d'abandon le 14 février 2014 ; remplacé effectivement dans Ubuntu 15.04 (avril 2015)
-
Mir : serveur d'affichage graphique pour le desktop Linux
- Projet alternatif devenu mainstream : Wayland
- Lancement : Annoncé le 4 mars 2013
- Date mainstream Wayland : 30 septembre 2008 ; adoption par GNOME, KDE ~2015-2017
- Mort (desktop) : 5 avril 2017 (reconverti ensuite vers l'IoT/embarqué, toujours maintenu dans ce créneau)
-
Unity : environnement de bureau pour Ubuntu
- Projet alternatif devenu mainstream : GNOME Shell
- Lancement : ~2010 (Ubuntu 10.10 Netbook Edition, puis 11.04 desktop)
- Date mainstream GNOME Shell : 6 avril 2011 (GNOME 3.0)
- Mort : 5 avril 2017
-
Snap : système de packaging universel pour Linux
- Projet alternatif devenu mainstream : Flatpak
- Lancement : 2014-2016 (lancé avec Ubuntu Core/16.04)
- Date mainstream Flatpak : mars 2015 (sous le nom xdg-app), renommé mai 2016 ; adoption par Fedora ~2016-2018
- Toujours actif en 2026 (coexiste avec Flatpak)
Hors d'Ubuntu, seul cloud-init a réussi à s'imposer.
Dans la communauté du logiciel libre, une critique revient souvent sur Canonical, celle de garder la mainmise sur ses projets, d'utiliser un projet comme levier pour renforcer l'adoption de ses autres projets, et de freiner les contributions avec des CLA restrictifs comme le Canonical Contributor Agreement. C'est un constat que je partage. Je pense que ces pratiques, qui rendent les projets non conviviaux au sens d'Ivan Illich, expliquent en grande partie pourquoi ils échouent. Canonical n'a pas le savoir-faire de Red Hat pour construire une communauté qui porte un projet.
C'est triste à dire, mais depuis ce constat, j'en suis venu à penser qu'adopter un projet porté par Canonical, c'est parier sur le mauvais cheval. Depuis 2014, je ne m'intéresse plus du tout à leurs projets.
Dimanche 19 juillet 2026
Journal du dimanche 19 juillet 2026 à 14:36
Je viens de rédiger Projet 38 - "POC champ de recherche enrichi avec CodeMirror et conceal".
Vendredi 26 juin 2026
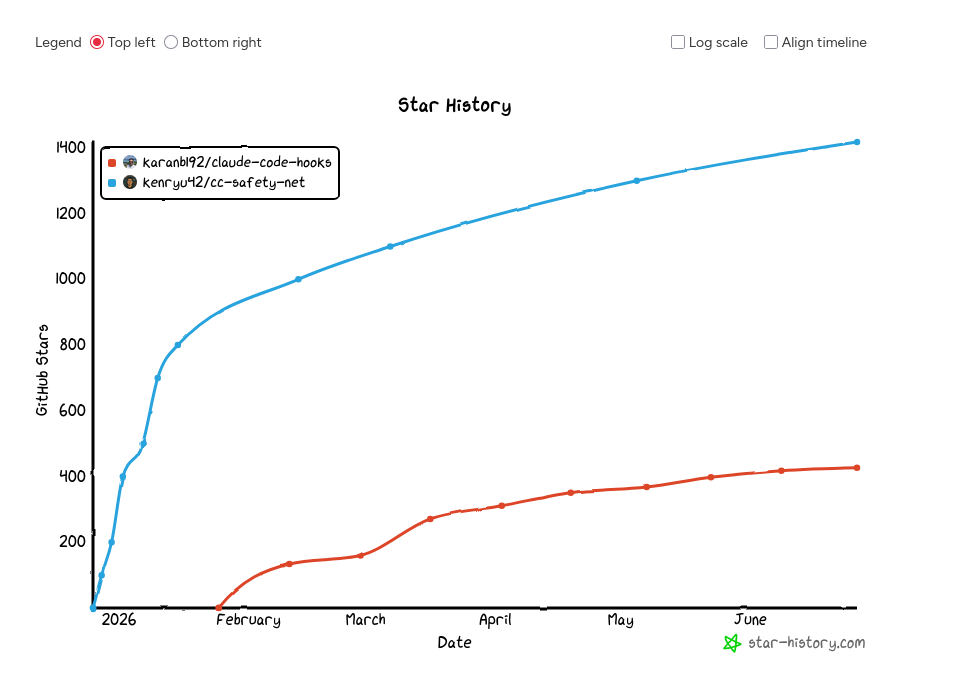
J'ai découvert cc-safety-net : des hooks pour sécuriser les agents IA
Suite à ma note "Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code", une amie m'a mise sur la piste des hooks pour intégrer efficacement le blocage de l'exécution de commandes dangereuses dans mon harness.
claude-code-hooks
Elle utilise Claude Code et je pense qu'elle utilise le projet claude-code-hooks (lien direct), et plus précisément son script block-dangerous-commands.js.
Ce projet est présenté dans le billet Claude Code's Most Underrated Feature: Hooks du 25 janvier 2026, que j'ai pris le temps de lire avec attention.
Après lecture, ce billet confirme la piste suggérée par mon amie : les hooks semblent être la solution la plus répandue pour bloquer les commandes dangereuses.
J'ai découvert cc-safety-net
J'ai ensuite cherché une solution "clé en main" équivalente à block-dangerous-commands.js pour OpenCode et suis tombée sur cc-safety-net (lien direct), un projet qui a même démarré un peu avant claude-code-hooks (source) :
Le nom cc-safety-net combine l'abréviation de Claude Code ("cc") et "safety net", qui veut dire "filet de sécurité".
cc-safety-net ne se limite pas à Claude Code et OpenCode : il prend aussi en charge Codex, Gemini CLI, GitHub Copilot CLI et Kimi Code.
J'ai installé cc-safety-net
J'ai installé cc-safety-net sur mon instance OpenCode. Bien qu'il ne soit pas visible dans la liste des plugins de l'interface OpenCode — ce qui semble normal — il fonctionne correctement d'après mes tests :
$ git init
$ touch file1.md
$ git add file1.md
$ git commit -m "First import"
$ touch file2.md
$ opencode run --agent="build" "exécute git reset --hard"
> build · deepseek-v4-flash
✗ git reset --hard failed
Error: BLOCKED by CC Safety Net
Reason: git reset --hard destroys all uncommitted changes permanently. Use 'git stash' first.
Command: git reset --hard
If this operation is truly needed, ask the user for explicit permission and have them run the command manually.
La commande `git reset --hard` est bloquée par le CC Safety Net car elle détruit irréversiblement les changements non commités.
**Alternatives :**
- `git stash` pour sauvegarder les changements avant de reset
- Exécute la commande toi-même manuellement si tu confirms vouloir tout perdre
Que veux-tu faire ?
Par défaut, cc-safety-net contient peu de règles : il bloque les commandes de suppression sur le système de fichiers et git, comme documenté ici : "blocked-commands".
Après la lecture de la page "allowed-commands", j'ai cru que cc-safety-net proposait aussi un mode whitelist. En réalité, il fonctionne seulement en mode blocklist — pas de mode "tout bloquer" avec un système de whitelist.
Pour le moment, j'ai décidé d'activer le mode par défaut de cc-safety-net.
Création de rulebooks pour mon projet homelab
Ce que je trouve très intéressant avec cc-safety-net, c'est la possibilité d'ajouter facilement des "Custom Rules" grâce aux "rulebooks". Cette fonctionnalité est jeune, à peine 3 semaines. Pour le moment, je n'ai trouvé que 2 "rulebooks" sur GitHub.
J'ai utilisé le skill /cc-safety-net pour créer mes "rulebooks" pour les commandes kubectl, helmfile, tofu et mise de mon projet homelab.sklein.xyz.
Pas sans difficulté : le skill a dû corriger plusieurs erreurs de syntaxe dans les fichiers json qu'il a générés. Je ne sais pas si c'est normal. Mais à la fin, ça a fonctionné.
Je viens de configurer tout cela, je n'ai aucun retour d'expérience, j'essaierai d'en donner un d'ici une semaine.
Encore un problème avec rtk !
Par contre, j'ai découvert que cc-safety-net a lui aussi des difficultés avec rtk : [Bug]: rtk bypasses safety net.
Pour les secrets, je compte tester Rehydra
Contrairement à claude-code-hooks, cc-safety-net ne propose pas de hooks pour cacher les secrets à l'agent.
#JaiDécouvert le projet rehydra qui me semble très intéressant :
PII security for AI workflows, coding agents and browser workloads. Detects, replaces, encrypts, and rehydrates back when needed.
cc-safety-net versus agentsh ?
J'ai seulement survolé le sujet, mais j'ai l'impression que agentsh analyse et intercepte ce qui se passe directement au niveau du système d'exploitation, du système de fichiers, réseau, et processus. Il n'agit pas au niveau applicatif, il n'a pas besoin de comprendre ce que fait en théorie la commande, il observe réellement son action sur l'OS.
Pour le moment je pense que cc-safety-net est une bonne première étape de sécurité pour mes besoins. Mais agentsh a attiré ma curiosité, peut-être que je le testerai prochainement.
Remerciement
Merci à mon amie CC de m'avoir mise sur la piste des hooks 🤗.
Jeudi 25 juin 2026
rtk contourne le système de permissions d'OpenCode
En étudiant la compatibilité de Prempti avec rtk (voir cette note : "Danger des permissions par défaut d'OpenCode sur un projet d'infrastructure as code"), j'ai découvert ici que rtk contourne les règles de permissions de OpenCode ! Mais aussi Claude Code d'après ce que j'ai compris.
J'ai testé et c'est vrai ! Voici mon test.
J'ai rtk installé et configuré pour OpenCode au niveau global, avec rtk init -g --opencode.
Voici à quoi ressemble le dossier de mon projet de test :
$ tree -a
.
├── .opencode
│ └── opencode.json
└── foobar
2 directories, 2 files
$ cat .opencode/opencode.json
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"build": {
"permission": {
"bash": {
"git *": "deny",
}
}
},
}
}
La commande git est interdite à l'agent build.
Je lance :
$ opencode run --agent="build" "exécute la commande unix 'git status'"
> build · deepseek-v4-flash
$ rtk git status
* No commits yet on main
?? .opencode/
?? foobar
Pas encore de commit sur `main`. Fichiers non suivis : `.opencode/` et `foobar`.
rtk a réussi à lancer la commande git status !
Voici un test sans rtk :
$ mv ~/.config/opencode/plugins/rtk.ts /tmp/rtk.ts
$ opencode run --agent="build" "exécute la commande unix 'git status'"
> build · deepseek-v4-flash
✗ git status failed
Error: The user has specified a rule which prevents you from using this specific tool call. Here are some of the relevant rules [{"permission":"*","action":"allow","pattern":"*"},{"permission":"bash","action":"allow","pattern":"*"},{"permission":"bash","pattern":"git *","action":"deny"}]
La commande `git status` est bloquée par une règle de permission qui interdit les commandes `git *` dans bash.
Souhaites-tu autoriser cette commande ?
Sans rtk, le système de permissions d'OpenCode fonctionne parfaitement, l'exécution de git status est interdite.
D'après mes recherches snip a le même problème de sécurité.
Je pense que pour le moment je vais arrêter d'utiliser rtk 🤔.
Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code
Cette après-midi, DeepSeek V4 Flash (via OpenCode) a fait une boulette dans mon projet homelab.sklein.xyz !

En voulant corriger le Helmfile de déploiement de Hindsight, il a lancé :
$ mise run destroy-cnpg-hindsight
sans réaliser que cette task Mise allait lancer la commande suivante :
helmfile -f helmfile/helmfile.yaml.gotmpl destroy
sans remarquer que mon fichier helmfile/helmfile.yaml.gotmpl contenait tous mes services et pas seulement cnpg-hindsight !
Ce qui est marrant, c'est qu'après le « Oups », il a tout de suite essayé de se rattraper. Heureusement, je suis au début de l'installation de mon homelab — rien d'important à perdre — et j'ai pu tester que la restauration du backup continu de CloudNativePG basé sur barman fonctionne bien.
DeepSeek V4 Flash n'est pas à blâmer : je ne l'ai pas aidé avec mes instructions, je lui ai tendu un piège.
Suite à cet incident sans gravité, j'ai pris conscience que faire travailler un agent de coding sur un projet d'Infrastructure as code est bien plus risqué que sur un projet de développement cloisonné, sans accès à la production.
J'ai commencé par ajouter ces quelques lignes dans mon fichier AGENTS.md :
## Safety Rules
- **Never run any `destroy-*` script or `helmfile destroy` command without explicit user confirmation** in the same conversation turn. Always ask first.
- If you must run `helmfile destroy`, always use `--selector name=<release>` to target only one release.
- When in doubt about a command's destructiveness, ask before executing.
Ensuite, j'ai remarqué que l'agent plan de OpenCode avait par défaut un accès trop large au tool bash pour un projet d'Infrastructure as code, je me suis lancé dans le renforcement des permissions :
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"plan": {
"permission": {
"bash": {
"*": "ask",
"kubectl get *": "allow",
"kubectl describe *": "allow",
"kubectl logs *": "allow",
"kubectl top *": "allow",
"tofu plan*": "allow",
"tofu show*": "allow",
"tofu output*": "allow",
"tofu state*": "allow",
"helm list*": "allow",
"helm status*": "allow",
"helm diff*": "allow",
"helmfile *list*": "allow",
"helmfile *status*": "allow",
"helmfile *diff*": "allow",
"git log*": "allow",
"git diff*": "allow",
"git status": "allow",
"git show*": "allow",
"jj log*": "allow",
"jj diff*": "allow",
"jj status": "allow",
"ls*": "allow",
"find*": "allow"
}
}
}
}
}
Ensuite, je me suis demandé s'il existait des solutions clé en main de limitation d'accès aux commandes cli, du même style que rtk, pour autoriser seulement des commandes de lecture sans risque.
#JaiDécouvert Prempti et agentsh. Je me suis demandé si l'intégration de l'un de ces outils n'allait pas entrer en conflit avec rtk. En étudiant les issues sur la sécurité de rtk, j'ai découvert que : rtk contourne le système de permissions d'OpenCode.
Mercredi 24 juin 2026
J'ai découvert que hindsight vient de "hind" (arrière) + "sight" (vue)
En étudiant le projet Hindsight, #JaiDécouvert un nouveau mot #anglais : hindsight, qui se traduit par "recul" en français.
Etymology : from hind + sight, 19th c. Compare Latinate retrospect.
Noun : hindsight
- Realization or understanding of the significance and nature of events after they have occurred.
Le mot hind anglais signifie :
MiMO-V2-Pro m'a confirmé que c'est normal que je ne connaissais pas ce mot : en anglais courant, on utilise back — que je connais, bien entendu — pour dire "arrière" de manière générale. Hind est un mot spécialisé un peu vieilli, principalement utilisé dans le contexte anatomique des animaux.
Je trouve que ce nom est très bien choisi pour le projet Hindsight qui est un Agent memory system.
Vendredi 19 juin 2026
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
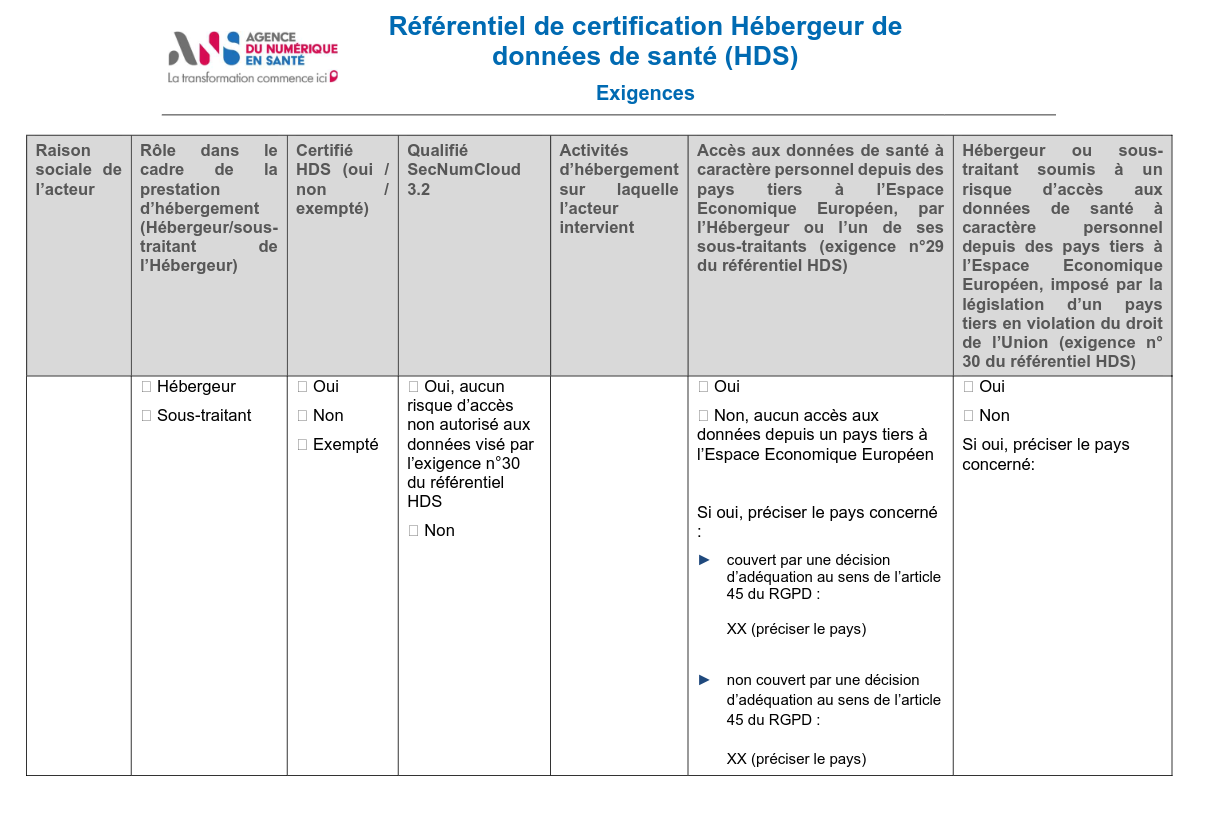
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
Vendredi 29 mai 2026
Mes observations sur la popularité historique des langages de programmation
Un ami m'a partagé la vidéo Most Popular Programming Languages: Data from 1958 to 2025 (Most Popular Programming Languages). Pour quelqu'un comme moi qui a une grande curiosité pour l'histoire de l'informatique, c'est amusant de regarder ça 🙂.
J'ai lu la description de la vidéo pour essayer d'en savoir plus sur la véracité de ce qui est présenté :
Dans cette vidéo, je présente une chronologie détaillée des langages de programmation les plus utilisés de 1958 à 2025, basée sur une analyse approfondie des données. Les classements historiques reposent sur une combinaison d'enquêtes nationales agrégées, du nombre de livres pédagogiques publiés sur chaque langage, et de la fréquence à laquelle ces langages sont mentionnés dans les publications mondiales dédiées aux logiciels et aux technologies. Pour les années récentes, les classements ont été ajustés à partir de données issues de plusieurs indices de popularité des langages de programmation, des tendances d'accès aux dépôts GitHub, et d'enquêtes auprès des développeurs.
La popularité dans ce classement est définie par le nombre de développeurs maîtrisant ou apprenant activement chaque langage. L'échelle est normalisée sur une valeur relative de 100, permettant des comparaisons cohérentes entre les langages et les périodes.
L'emoji flamme représente les langages qui ont atteint la première place au moins une fois. L'emoji tête de mort représente les langages qui ne sont plus officiellement maintenus et ne disposent plus d'une communauté de développeurs active.
Plusieurs erreurs ont été corrigées par rapport à la vidéo précédente. J'ai également étendu la chronologie de près d'une décennie, en remontant à 1958, et ajouté de nouvelles données pour 2023, 2024 et 2025.
Vos retours sont toujours les bienvenus. Une suggestion de sujet ? Envoyez-moi un message !
Quelques observations personnelles sur l'évolution des langages présentés dans la vidéo :
- Fortran et Cobol : Je pensais que Cobol était dominant, mais je découvre que non, je suis surpris, Fortran semble avoir toujours été devant. J'ai toujours beaucoup plus entendu parler de Cobol que Fortran.
- Pascal : L'un de mes premiers amours en programmation, avant Python. Je n'imaginais pas que Pascal avait été numéro 1 à partir de 1980.
J'observe que quand j'ai appris Pascal vers 1991-1992, le langage C l'avait déjà dépassé depuis 1985. - Ada : Je ne m'attendais pas à le voir aussi populaire à la fin des années 1980, et encore moins à le voir passer devant Pascal en 1988. Et au passage, un langage conçu par Jean Ichbiah, un Français, au sein de CII-Honeywell-Bull : une entreprise à capitaux mixtes franco-américains — sur commande du Pentagone.
- C : C'est impressionnant de voir comment C a tout écrasé de 1990 à 1995 !
- Perl : Il a eu sa petite heure de gloire jusqu'en 1997, avant l'arrivée de PHP. C'était juste avant que je commence le développement web. En regardant l'évolution de Perl dans la vidéo, on devine assez bien comment Java et PHP ont ensuite tué Perl sur le web.
- Visual Basic : Curieusement, il n'a jamais vraiment dominé malgré les apparences. À la fin des années 1990, j'avais pourtant l'impression que tout le monde en faisait.
- Java et PHP : C'est au début de ma carrière professionnelle, en 2001, que Java commence à être hégémonique. Mais ce qui est intéressant, c'est de voir PHP se défendre très bien face à lui.
- Python : Il commence à monter en 2006, ce qui correspond exactement à l'année où je commence à me perfectionner sérieusement dans ce langage.
- Javascript : En 2012, j'avais clairement senti une forte montée en puissance de JS avec l'arrivée de NodeJS — j'avais même publié Réflexions à propos de Node.js et de JavaScript plus globalement le 18 avril 2012 sur LinuxFr.
- Python vs Javascript : Je suis vraiment surpris de voir Python doubler JavaScript en 2017, puis Java en 2018. J'imagine que cela doit être l'effet de l'IA — TensorFlow et compagnie. Je suis surpris de constater que Javascript n'a jamais été numéro 1 !
- Golang : J'ai commencé à l'utiliser en 2015, et je suis content de voir qu'il pointe le bout de son nez dans le top 12 en 2019. J'ai une sorte d'affection pour ce langage, j'apprécie beaucoup ses valeurs.
Dimanche 24 mai 2026
Journal du dimanche 24 mai 2026 à 13:15
#JaiDécouvert ici encore des alternatives supplémentaires à pgfmt, pg_propre :
Mercredi 20 mai 2026
Premier test minimaliste de Promptfoo avec le provider OpenCode SDK
Depuis au moins novembre 2025, je cherche à rédiger mes prompts, mes fichiers AGENTS.md, mes fichiers SKILLS.md — et plus largement mon harness OpenCode — avec une méthode rigoureuse et contrôlée. J'ai découvert dans cette issue le nom du mécanisme que j'essaie de mettre en place : agent-eval-harness, terme plutôt simple et explicite.
En février, je disais :
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Quelques mois plus tard, j'ai enfin implémenté un premier POC utilisant Promptfoo couplé avec le provider OpenCode SDK : https://github.com/stephane-klein/opencode-promptfoo-poc.
Cette première itération est volontairement minimaliste. J'ai testé :
- 3 LLMs (dans 2 configurations chacune)
- 3 cas de test
L'intégralité de mon évaluation tient dans un seul fichier promptfooconfig.yaml :
# yaml-language-server: $schema=https://promptfoo.dev/config-schema.json
description: "Hello World - minimal test"
providers:
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "without-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-minimax-m2.7"
config:
provider_id: opencode-go
model: minimax-m2.7
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
- id: opencode:sdk
label: "with-agent-deepseek-v4-flash"
config:
provider_id: opencode-go
model: deepseek-v4-flash
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
prompts:
- "Translate the following English text to {{language}}: {{input}}"
tests:
- vars:
language: French
input: Hello world
assert:
- type: contains-all
value:
- "Bonjour"
- "monde"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: contains-any
value:
- "Donde esta la biblioteca"
providers:
- "with-agent*"
- vars:
language: Spanish
input: Where is the library?
assert:
- type: not-contains-any
value:
- "Donde esta la biblioteca"
providers:
- "without-agent*"
L'exécution de promptfoo eval donne ceci :
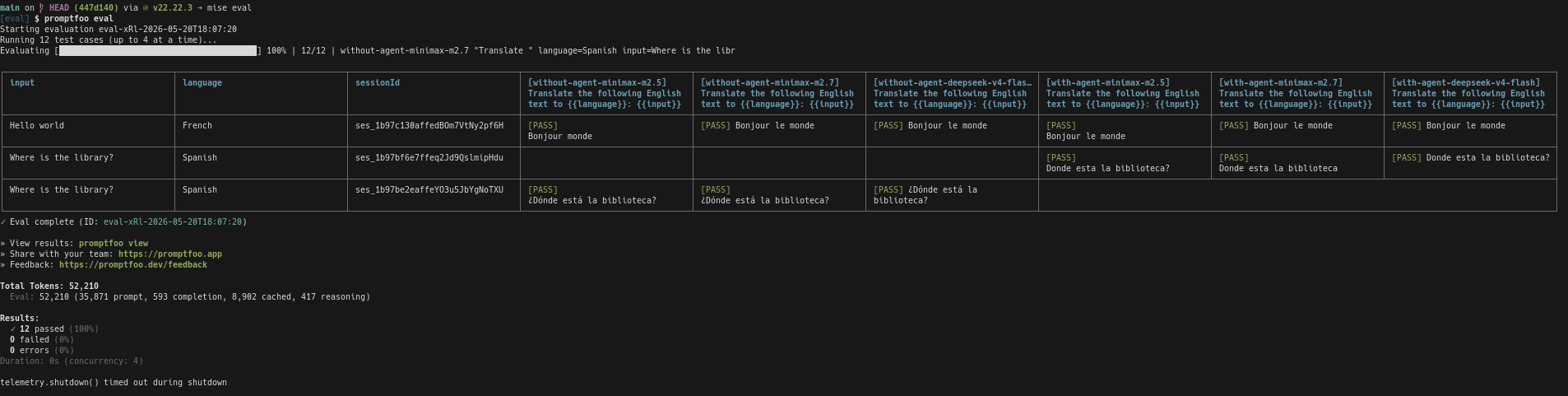
Et voici ce qu'affiche promptfoo viewer dans un browser :
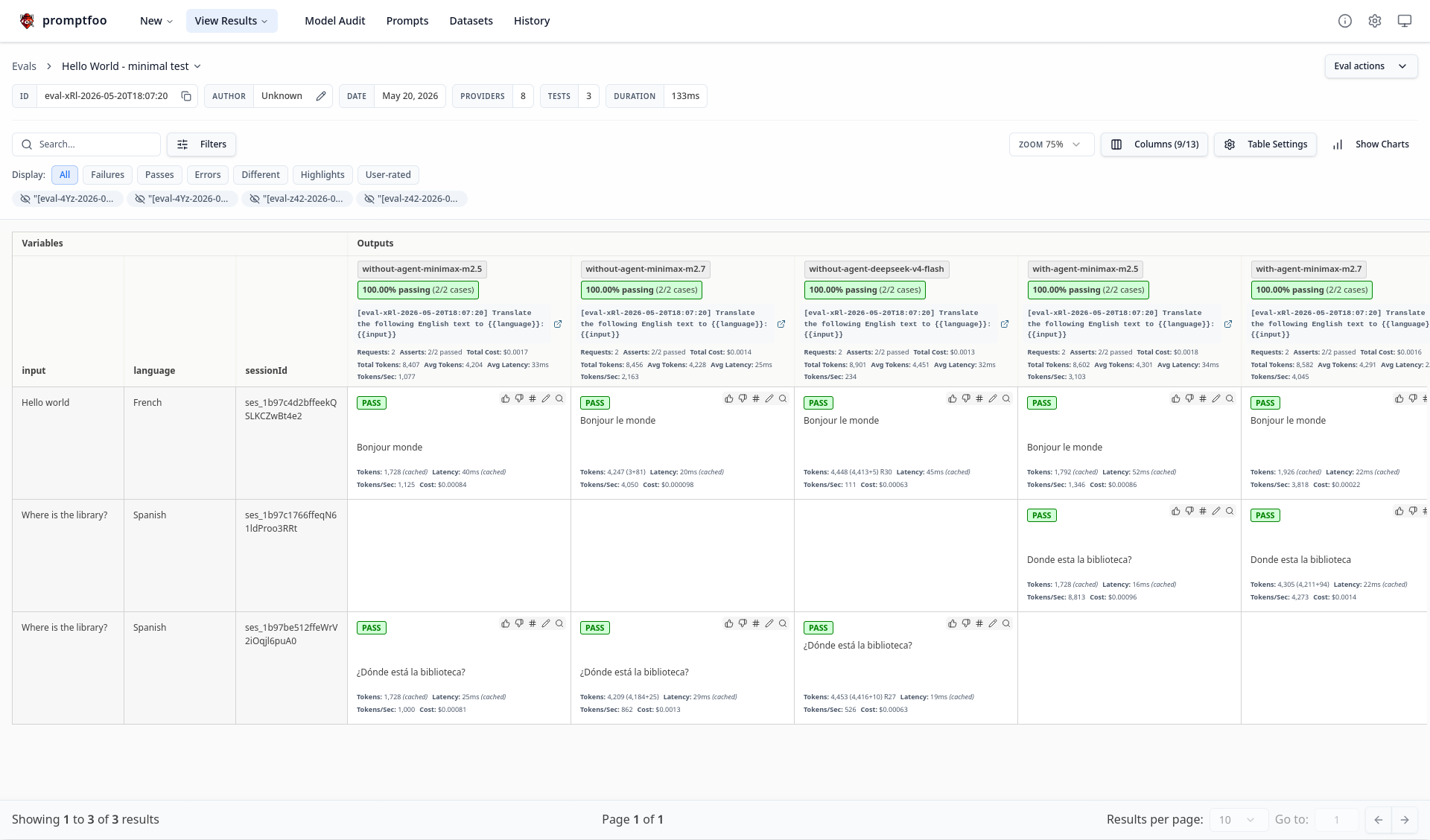
Dans mes tests, j'ai mis en œuvre uniquement contains-all et contains-any, mais Promptfoo propose beaucoup d'autres « Deterministic metrics ».
Promptfoo propose aussi de nombreuses assertions effectuées par des modèles de langage, les « Model-graded metrics », dont la plupart peuvent être qualifiées de LLM-as-a-Judge. Je ne les ai pas encore testées.
Je n'ai pas non plus exploré l'évaluation de « Chat conversations / threads ». Par ailleurs, en examinant la documentation du provider OpenCode SDK, j'ai constaté ce qui me semble être une limitation : il n'est probablement pas possible de changer d'agent dans un thread, c'est-à-dire d'alterner entre le mode plan et le mode build, comme on le ferait dans un usage normal de OpenCode.
Mais après réflexion, il me semble que cette limitation n'est pas importante. Dans un test d'évaluation, chaque cas est un appel unique à l'agent, avec l'historique complet de la conversation fourni en contexte — il n'est pas nécessaire de simuler un flux interactif multi-tours avec alternance d'agents.
Dans ce POC, je configure le provider OpenCode SDK pour qu'il utilise le dossier de configuration ./config/opencode du repository, afin que le harness évalué soit précisément celui qui est versionné, et afin de ne pas subir de perturbation par la configuration OpenCode globale.
Quand j'ai démarré ce POC, j'ai essayé d'indiquer différentes configurations OpenCode au niveau des tests, pour tester différents fichiers AGENTS.md. Mais j'ai constaté que la configuration OpenCode ne peut être définie qu'une seule fois, ici, via une variable d'environnement XDG_CONFIG_HOME.
J'ai mis un certain temps à réaliser que je pouvais procéder autrement, en plaçant les fichiers AGENTS.md dans différents working_dir. Les working_dir se configurent au niveau des providers, voici deux exemples :
- id: opencode:sdk
label: "without-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir1/
- id: opencode:sdk
label: "with-agent-minimax-m2.5"
config:
provider_id: opencode-go
model: minimax-m2.5
apiKey: "{{env.OPENCODE_API_KEY}}"
working_dir: ./workdir2/
Cela permet de charger et de tester ./workdir1/AGENTS.md ou ./workdir2/AGENTS.md. Il est possible d'utiliser la même méthode pour évaluer différents SKILLS.md.
Pour le moment, je ne sais pas encore si Promptfoo est un bon outil pour mettre au point mon harness.
Avant de poursuivre mes tests de harness engineering avec Promptfoo, j'aimerais tester agent-catalog-eval pour voir si cet outil serait plus simple à mettre en œuvre.
Samedi 16 mai 2026
Comment "harness" s'est répandu en IA et pourquoi ce terme a été choisi
Le week-end dernier, j'ai commencé à chercher d'où venait le terme harness et pourquoi il a été choisi pour désigner ce concept dans les AI agents comme OpenCode ou Claude Code.
Cette note est le résultat de ce travail de recherche, basé sur des échanges avec Sonnet 4.6, des lectures de commentaires Hacker News et divers articles sur le sujet.
En novembre 2025, Anthropic a publié l'article « Effective Harnesses for Long-Running Agents », qui utilise explicitement « agent harness » dans le sens moderne.
Le terme « harness engineering » semble avoir été popularisé par Mitchell Hashimoto dans la section 5 de son billet publié le 5 février 2026. Il y décrit une pratique qu'il a développée au fil de son usage des agents IA :
Je ne sais pas s'il existe un terme largement accepté par l'industrie pour cela, mais j'en suis venu à appeler cela « harness engineering ». C'est l'idée que chaque fois qu'on constate qu'un agent commet une erreur, on prend le temps de concevoir une solution pour que l'agent ne commette plus jamais cette erreur. Je n'ai pas besoin d'inventer de nouveaux termes ici ; s'il en existe un autre, je m'y joindrai.
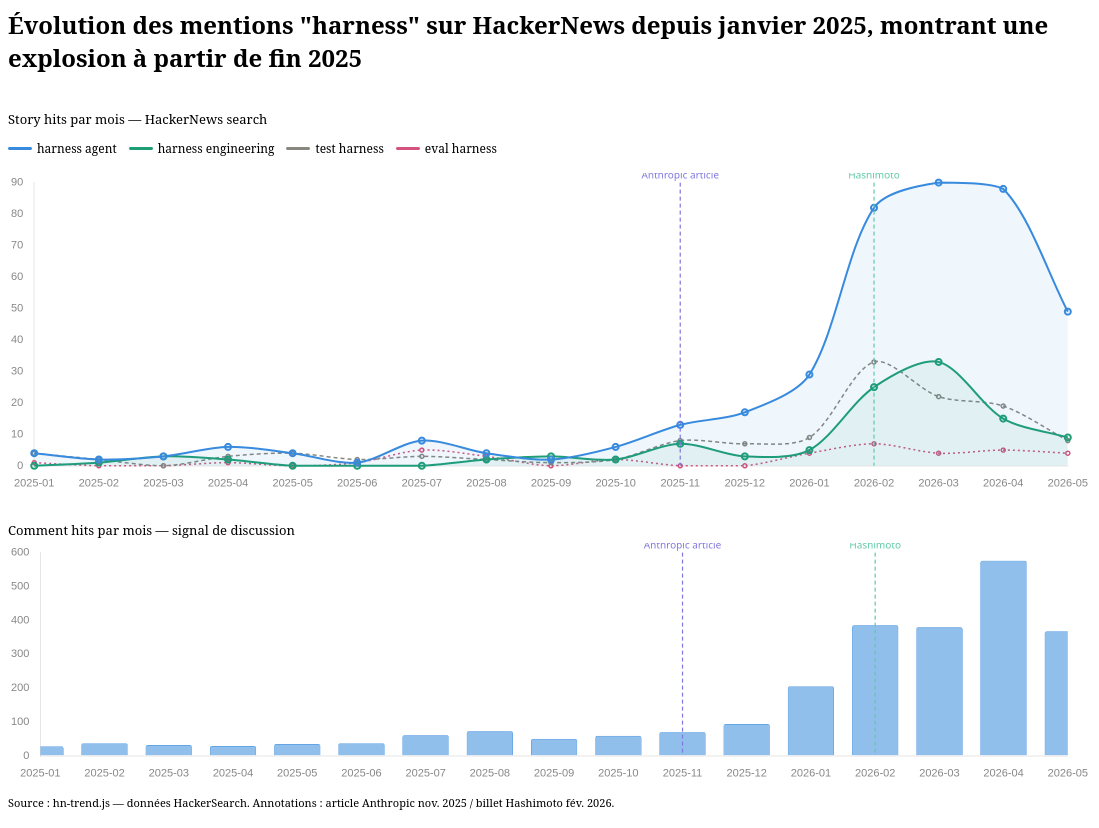 Données extraites avec hackernews-trends-poc.
Données extraites avec hackernews-trends-poc.
Jusqu'à présent, je pensais à tort que l'analogie du harnais correspondait simplement à l'équipement qu'on pose sur un cheval, sans saisir la pertinence de ce terme, par manque de culture de cette langue. En anglais, on trouve les expressions « harness the sun » ou « harness the wind ». Voici la définition du verbe harness :
Verb
harness (third-person singular simple present harnesses, present participle harnessing, simple past and past participle harnessed)
- (transitive) To place a harness on something; to tie up or restrain. Synonym: tackle
« They harnessed the horse to the post. »- (transitive) To capture, control or put to use. « Imagine what might happen if it were possible to harness solar energy fully. »
- (transitive) To equip with armour.
Le terme français qui me semble le plus proche du verbe harness serait « canaliser » ou « dompter ».
Le terme harness désigne donc l'action de canaliser et d'orienter la puissance d'un LLM vers un objectif souhaité.
Avant l'usage du terme harness dans le domaine de l'AI — que ce soit pour agent harness, harness engineering ou LM Evaluation Harness — j'ai découvert en travaillant sur cette note qu'il était déjà utilisé en software engineering, principalement dans l'expression test harness. Il me semble que c'était d'ailleurs l'usage principal du mot dans notre domaine, bien avant qu'il ne soit repris pour les agents IA.
Les concepts que je pense avoir identifiés et que je retiens
- Le harness est un artefact à installer et configurer dans OpenCode. Il est composé de :
- Le harness engineering est le processus humain d'amélioration itérative du harness. Quand l'utilisateur observe une erreur de l'agent, il modifie ou ajoute des fichiers
AGENTS.md,SKILLS.md, des outils MCP ou des configurations pour qu'elle ne se reproduise plus. Ce terme désigne le processus, par opposition au harness qui est l'artefact. - Agent-eval-harness est un outil externe au harness permettant de lancer des sortes de tests unitaires. Il est utilisé pendant les phases de harness engineering pour valider les modifications de façon contrôlée et reproductible.
Cette note ne traite pas de la boucle agent en elle-même — j'ai documenté ce concept séparément ici :
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise.
Le concept de harness vient encadrer cette boucle pour la configurer et la contraindre, mais il ne la définit pas. Comprendre la boucle aide à saisir ce qu'orchestre le harness.
Extrait d'un article de Sebastian Raschka :
Pour clarifier les concepts :
- LLM : le modèle brut de prédiction du prochain token
- Modèle de raisonnement : un LLM optimisé pour produire des traces de raisonnement intermédiaires et se vérifier davantage
- Agent : une boucle qui combine un modèle avec des outils, de la mémoire et des retours d'environnement
- Agent harness : le scaffold logiciel autour d'un agent qui gère le contexte, l'utilisation des outils, les prompts, l'état et le flux de contrôle
- Coding harness : un cas particulier d'agent harness ; un harness spécifique au génie logiciel qui gère le contexte du code, les outils, l'exécution et les retours itératifs
Quelques articles que j'ai lus avec attention :
- Effective harnesses for long-running agents — Anthropic, nov. 2025
- My AI Adoption Journey — Mitchell Hashimoto, fév. 2026
- Components of a Coding Agent — Sebastian Raschka, avr. 2026
En explorant le sujet de harness, je constate que, comme beaucoup de concepts, sa définition peut varier selon les sources et les communautés. Par exemple, l'article Components of a Coding Agent de Sebastian Raschka semble en proposer une définition plus large que Mitchell Hashimoto.
Pour le moment, je souhaite adopter la version de Mitchell Hashimoto, que j'arrive mieux à appréhender et dont je parviens mieux à délimiter le périmètre : un dispositif qui canalise la fougue du LLM, comme le harnais canalise le cheval sauvage.
Samedi 9 mai 2026
gh-issue-sync: sync GitHub issues locally and back
gh-issue-sync is a command line tool that syncs GitHub issues to local Markdown files for offline editing, batch updates, and integration with coding agents.
Pull issues locally, refine them until you are satisfied, and sync changes back. Also useful for offline access to your issues.
C'est un outil qui répond à un besoin que j'ai depuis 2018 : préparer avec un process précis des issues GitLab ou GitHub en draft, dans un format texte versionnable, particulièrement utile pendant la phase de meta-spec-writing.
C'est pour répondre à ce besoin que j'avais spécifié les fonctionnalités suivantes dans Projet 24 - Prototyper le gestionnaire de projet de mes rêves :
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
Je trouve curieux de voir émerger des projets comme Beads en octobre 2025 ou gh-issue-sync en décembre 2025, portés par la mouvance Specs Driven Development des agents IA, alors que j'explore ce formalisme depuis environ 2010. Ce qui m'intrigue surtout : pourquoi les développeurs s'intéressent à la spécification maintenant, et pas avant ? J'ai commencé à rédiger des choses à ce sujet, que je souhaite publier.
Le 15 mars dernier, j'ai créé des commandes OpenCode issue-create.md, issue-pull.md, issue-push.md, issue-update.md dont l'objectif était plus ou moins identique à gh-issue-sync : rédiger une issue dans un fichier local, la raffiner, puis l'envoyer vers GitHub. J'ai utilisé ces commandes pour créer les issues du projet sklein-devbox : https://github.com/stephane-klein/sklein-devbox/issues.
En l'état, je ne suis pas satisfait de mon expérience de développeur (DX). Il me semble que la fonctionnalité SKILL.md de gh-issue-sync offre probablement une meilleure architecture que l'utilisation des commandes OpenCode.
Ces prochains jours, je compte tester gh-issue-sync pour un éventuel remplacement. À plus long terme, j'aimerais pousser plus loin le sujet en testant Beads.
Vendredi 8 mai 2026
Comment déclencher des questions interactives dans OpenCode et ClaudeCode ?
Cela fait plusieurs mois que je me demande comment fonctionne le mécanisme de questions interactives présent dans OpenCode et Claude Code.
Plus précisément, je me demande comment je peux déclencher, de manière certaine, des questions interactives dans mes SKILLS.md.
Dans cet exemple :
> Pose-moi la question pour savoir si je suis une femme ou un homme.
Es-tu une femme ou un homme ?
OpenCode ne me pose pas cette question de manière interactive, la question est posée sous la forme de "texte libre".
J'ai cherché à en savoir plus et voici ce que j'ai trouvé.
Le mécanisme de questions interactives est déclenché par un tool.
- Chez Claude Code, ce tool est nommé "
AskUserQuestion" - Et chez OpenCode, ce tool est nommé simplement "
question"
Et voici le contenu des descriptions de ces tools (qui jouent le rôle de prompt) :
- Pour OpenCode : https://github.com/anomalyco/opencode/blob/dev/packages/opencode/src/tool/question.txt
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- When `custom` is enabled (default), a "Type your own answer" option is added automatically; don't include "Other" or catch-all options
- Answers are returned as arrays of labels; set `multiple: true` to allow selecting more than one
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
- Pour Claude Code : https://github.com/Piebald-AI/claude-code-system-prompts/blob/main/system-prompts/tool-description-askuserquestion.md
Use this tool when you need to ask the user questions during execution. This allows you to:
1. Gather user preferences or requirements
2. Clarify ambiguous instructions
3. Get decisions on implementation choices as you work
4. Offer choices to the user about what direction to take.
Usage notes:
- Users will always be able to select "Other" to provide custom text input
- Use multiSelect: true to allow multiple answers to be selected for a question
- If you recommend a specific option, make that the first option in the list and add "(Recommended)" at the end of the label
Plan mode note: In plan mode, use this tool to clarify requirements or choose between approaches BEFORE finalizing your plan. Do NOT use this tool to ask "Is my plan ready?" or "Should I proceed?" - use ${EXIT_PLAN_MODE_TOOL_NAME} for plan approval. IMPORTANT: Do not reference "the plan" in your questions (e.g., "Do you have feedback about the plan?", "Does the plan look good?") because the user cannot see the plan in the UI until you call ${EXIT_PLAN_MODE_TOOL_NAME}. If you need plan approval, use ${EXIT_PLAN_MODE_TOOL_NAME} instead.
Aucun des deux prompts ne dit quand ne pas poser les questions en texte libre. Les deux disent "use this tool when you need to ask questions" — mais le modèle juge lui-même si la situation justifie le tool ou une réponse textuelle directe.
Pour être certain que l'agent IA pose une question en mode interactif, il faut lui demander explicitement de l'utiliser, par exemple, avec la mention (use question tool) ou dans cet exemple :
Utilise le tool question pour me poser deux questions :
1. Mon sexe (homme, femme, autre)
2. Mon prénom, avec "Stéphane" comme première option suggérée, et une option pour saisir autre chose
Autres ressources :
- Le code source du tool
questionde OpenCode : https://github.com/anomalyco/opencode/blob/e3c983c21f925fef4b03f46a06663f1b29cfed34/packages/opencode/src/tool/question.ts - https://github.com/vtemian/octto - un plugin permettant de créer des formulaires avancés, avec gestion de branches et 14 types de saisie. À noter : l'interface s'ouvre dans un navigateur, ce qui casse le flux TUI.
Jeudi 7 mai 2026
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
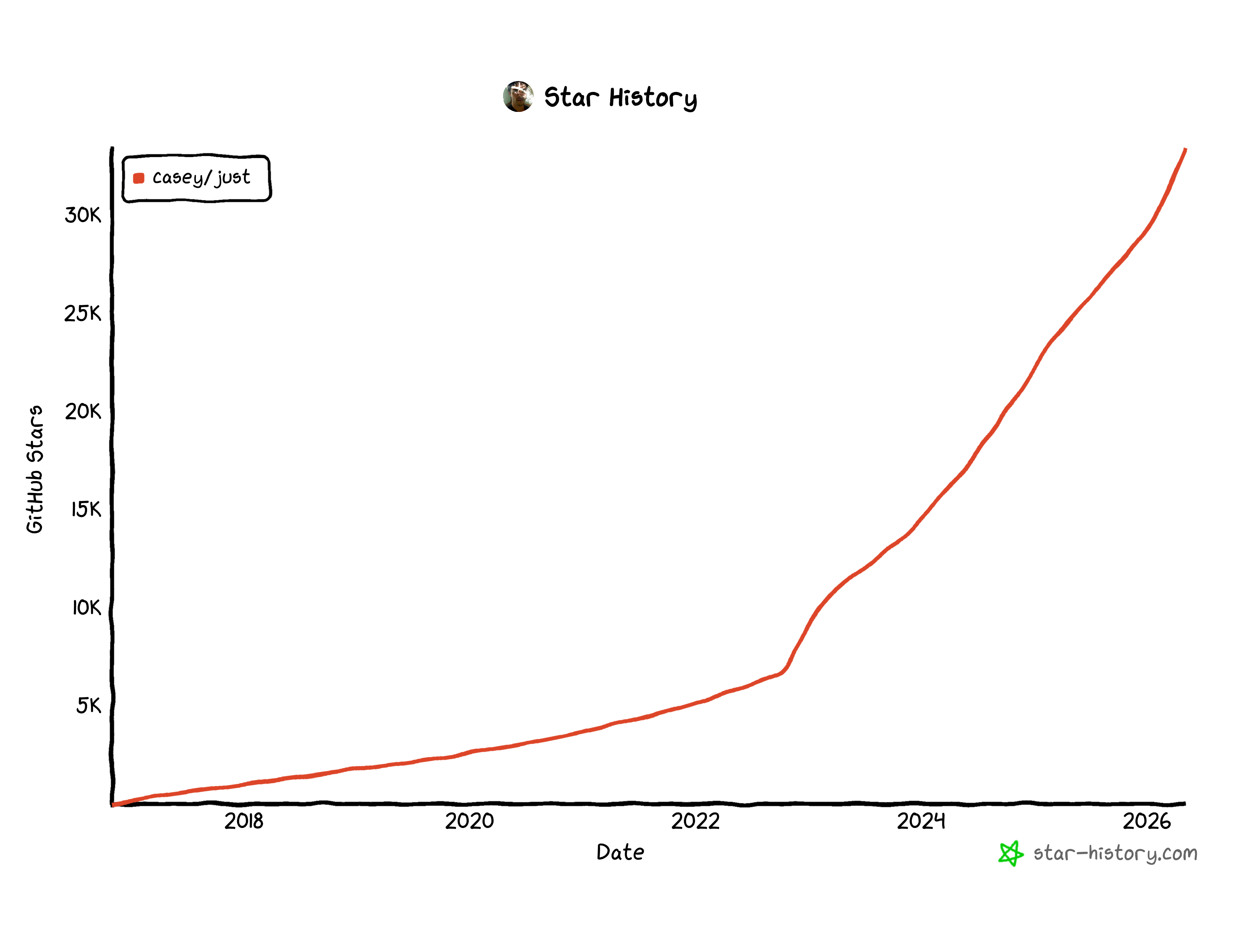
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
Journal du jeudi 07 mai 2026 à 00:06
Je viens de publier Projet 37 - "Application de répétition espacée, comme Anki, assistée par LLM".
En rédigeant cette note, j'ai découvert Mochi qui est une alternative closed-source à Anki et qui intègre un serveur MCP (mcp-mochi) qui devrait permettre de créer les cards avec un LLM. J'envisage de tester cet outil.
Lundi 4 mai 2026
J'ai découvert snip et rtk et testé rtk (reduce LLM usage)
Le 13 avril 2026, j'ai découvert le projet snip :
Quelques semaines plus tard, le 29 avril, Alexandre m'a fait découvrir rtk, une alternative à snip.
rtk est un projet Rust dont le développement a commencé le 18 janvier 2026. snip, quant à lui, est un projet Golang initié par un français basé à la Réunion le 15 février 2026, directement inspiré de rtk.
Voici comment le projet snip compare les deux projets :
Design Philosophy
snip chose a fundamentally different approach to LLM token reduction: filters are data, not code. The binary is the engine, filters are YAML data files, and the two evolve independently.
rtk (Rust) snip (Go) Filter authoring Write Rust, recompile, wait for release Write YAML, drop in a folder, done Filter format Compiled into the binary Declarative YAML, engine and filters evolve independently Custom filters Fork the repo, add Rust code Create a .yamlfile in~/.config/snip/filters/Concurrency 2 OS threads Goroutines (lightweight, no thread pool) SQLite Requires CGO + C compiler Pure Go driver, static binary, no dependencies Cross-compilation Per-target C toolchain GOOS=linux GOARCH=arm64 go buildPipeline actions Built-in strategies 19 composable actions (keep, remove, regex, JSON, state machine...) Contributing Rust knowledge required YAML knowledge sufficient Both tools solve the same problem: reducing AI token costs from verbose CLI output. snip's bet is that extensibility wins. When anyone can write a filter in 5 minutes without touching Go or Rust, the filter ecosystem grows faster.
Voici à quoi ressemble un filtre dans rtk : https://github.com/rtk-ai/rtk/blob/master/src/filters/jj.toml.
Et voici l'équivalent pour snip : https://github.com/edouard-claude/snip/blob/master/filters/jj.yaml.
Je trouve la possibilité d'ajouter de nouvelles commandes à snip simplement en créant un fichier YAML intéressante, mais pour le moment je ne sais pas si j'en aurai besoin.
D'autre part, rtk est supporté par Mise : https://mise-versions.jdx.dev/tools/rtk.
Par conséquent, j'ai décidé de tester la configuration de rtk avec OpenCode. Voici le commit d'intégration à sklein-devbox : https://github.com/stephane-klein/sklein-devbox-chezmoi/commit/0fa4917ee2f31605f8d124223ec650961bf057b6.
Voici comment j'ai initialisé le plugin OpenCode pour rtk :
$ rtk init -g --opencode
OpenCode plugin installed (global).
OpenCode: /home/sklein/.config/opencode/plugins/rtk.ts
Restart OpenCode. Test with: git status
--- Telemetry ---
RTK collects anonymous usage metrics once per day to improve filters.
What: command names (not arguments), token savings, OS, version
Why: prioritize filter development for the most-used commands
Who: RTK AI Labs, contact@rtk-ai.app
Rights: disable anytime with `rtk telemetry disable`,
request erasure with `rtk telemetry forget`
Details: https://github.com/rtk-ai/rtk/blob/main/docs/TELEMETRY.md
Enable anonymous telemetry? [y/N] y
Telemetry enabled. Disable anytime: rtk telemetry disable
Et voici un exemple d'utilisation :
$ opencode run "Quels sont les derniers changements de ce projet ?"
> build · minimax-m2.5
$ rtk git log --oneline -10
0fffe04 Remove mode -x dot_config/tmux/scripts/executable_current-path.sh
832f03b Add peeble/ to Chezignore # <m-r> Reset Message
0fa4917 Setup rtk to reduces OpenCode LLM token consumption
983b77d s6-overlay migration to Pebble (#25)
1f7cbcd Start Mise eval before atuin to fix a bug
c8e6194 Remove gopass and GPG agent management since both services start automatically on first use
71e64e1 Enable Mise environment activation so Neovim can access Mise-managed tools
679f53f Purge empty mise installs/ dirs to force reinstall of incomplete tools
4c32db8 Extract init process into standalone script
8258ab9 Add infomation messages in init scripts
...
Je constate que la commande rtk git log est correctement utilisée par OpenCode.
Voici ce que m'affiche la commande rtk gain :
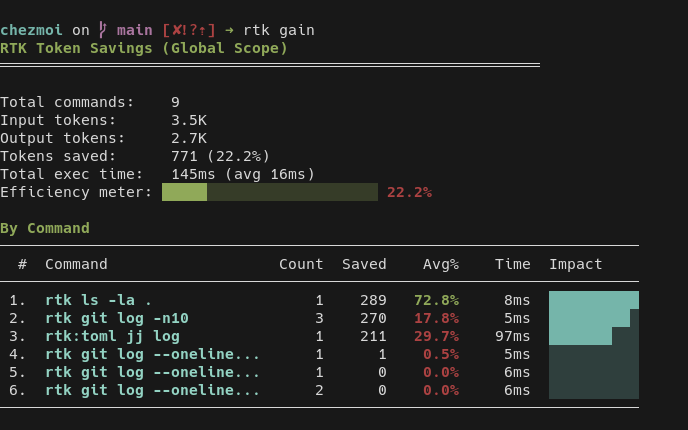
Pour le moment ceci n'est pas représentatif, car je viens de l'installer et j'ai lancé uniquement des tests fictifs.
Je compte publier une note de bilan d'ici quelques semaines pour analyser si c'est vraiment impactant ou non.
J'ai découvert le terme "test sociable"
Alexandre m'a fait découvrir aujourd'hui le terme "test sociable" versus "test solitaire", documenté ici par Martin Fowler.
Je connaissais déjà cette problématique sans en avoir le vocabulaire. Je la décrivais comme du "couplage dans le test" : un test qui couvre plusieurs unités à la fois peut échouer pour une raison indirecte, ce qui rend difficile l'identification de la vraie cause.
Je savais que la solution habituelle est d'utiliser des mocks pour isoler l'unité testée. Cela rend les tests mieux ciblés, mais aussi plus fastidieux à écrire.
Martin Fowler semble préférer les tests sociables par défaut, et ne recourt aux mocks que quand c'est nécessaire (non-déterminisme, lenteur, ressource externe instable). Je partage cette doctrine.
Samedi 2 mai 2026
J'ai découvert Beads, Dolt et DoltgreSQL
En parcourant awesome-opencode, je suis tombé sur opencode-beads, qui m'a fait découvrir le projet Beads :
Beads is a distributed graph issue tracker for AI agents, powered by Dolt.
J'ai passé un peu de temps à parcourir la documentation du projet et je vois beaucoup de choses intéressantes et qui rejoignent les idées que j'ai pour "Projet 24 - Prototyper le gestionnaire de projet de mes rêves".
Ce projet m'a aussi fait découvrir Dolt :
Dolt is a SQL database that you can fork, clone, branch, merge, push and pull just like a Git repository.
et DoltgreSQL :
From the creators of Dolt, the world's first version controlled SQL database, comes DoltgreSQL, the postgres-flavored version of Dolt. It's a SQL database that you can branch and merge, fork and clone, push and pull just like a Git repository. Connect to your Doltgres server just like any Postgres database to read or modify schema and data. Version control functionality is exposed in SQL via system tables, functions, and procedures.
Lundi 27 avril 2026
Journal du lundi 27 avril 2026 à 16:27
Je viens de rédiger une nouvelle idée de projet : Projet 36 - "toggl-pg-mirror — Agréger mon historique de temps dans PostgreSQL".
Dimanche 26 avril 2026
Comment je me renseigne sur un nouveau modèle LLM en 4 étapes
Voici le process que je suis lorsque je découvre un nouveau modèle LLM et que je souhaite en savoir plus à son propos.
Étape 1 : blog de Simon Willison
Je commence par jeter un œil rapide sur le blog de Simon Willison, car cela fait plusieurs années que je le suis et j'apprécie son expertise et ses analyses de modèles.
Étape 2 : les articles de Artificial Analysis
Ensuite je regarde les articles (https://artificialanalysis.ai/articles) d'Artificial Analysis, pour voir s'ils ont publié un nouvel article sur ce modèle. Généralement, ils sont très réactifs. Voici un exemple concernant Kimi K2.6 : Kimi K2.6: The new leading open weights model.
J'aime beaucoup la structure de leurs articles.
Tout d'abord, une section synthétique avec des informations majeures du modèle :

Ensuite, la position du nouveau modèle pour différents leaderboards :
Étape 3 : Analyse des commentaires HackerNews
En troisième étape, j'utilise le moteur de recherche de Hacker News pour identifier le thread qui traite du modèle. Voici par exemple celui à propos de Kimi K2.6: Advancing open-source coding et ses 371 commentaires.
À partir de l'url de ce thread, je lance le prompt suivant dans Claude Desktop connecté au serveur MCP fetch lancé localement :
Utilise `fetch_html` pour récupérer https://news.ycombinator.com/item?id=47835735
**Étape 1 — Récupération complète**
- Récupère la première page avec `fetch_html` et lis le nombre total de commentaires indiqué en début de page — ce nombre est ta cible obligatoire
- Le contenu étant probablement tronqué (limite 200 000 caractères), enchaîne les appels successifs en incrémentant `start_index` de 200 000 à chaque fois :
- `fetch_html(url, start_index=0, max_length=200000)`
- `fetch_html(url, start_index=200000, max_length=200000)`
- `fetch_html(url, start_index=400000, max_length=200000)`
- … jusqu'à ce que la réponse soit vide
- **Tu dois avoir récupéré 100% des commentaires avant de passer à l'étape suivante.** Vérifie que le nombre de commentaires extraits correspond au compteur initial — si ce n'est pas le cas, continue à paginer.
**Étape 2 — Analyse exhaustive**
Analyse **chacun des commentaires sans exception** exclusivement sous l'angle des **modèles LLM** mentionnés. Aucun commentaire ne doit être ignoré ou échantillonné.
Pour chaque modèle cité, synthétise :
- **Points forts** relevés par les commentateurs
- **Points faibles** ou limitations mentionnées
- **Cas d'usage Coding** : performance en génération de code, débogage, complétion, etc.
- **Cas d'usage Intelligence générale** : raisonnement, compréhension, tâches polyvalentes, etc.
- **Benchmarks mentionnés** : scores, classements ou comparaisons chiffrées associés à ce modèle
**Étape 3 — Synthèse**
Présente le résultat sous forme de **deux tableaux comparatifs markdown** :
1. **Tableau Coding** — colonnes : Modèle | Points forts | Points faibles | Benchmarks coding
2. **Tableau Intelligence générale** — colonnes : Modèle | Points forts | Points faibles | Benchmarks généralistes
Puis ajoute :
1. Une section **"Comparaison directe entre modèles"** synthétisant les confrontations explicites faites par les commentateurs (quel modèle bat quel autre, sur quoi, dans quel contexte), en distinguant coding vs intelligence générale
2. Une section **"Benchmarks en discussion"** listant les benchmarks cités, leur crédibilité perçue par la communauté, et les modèles qu'ils avantagent ou désavantagent — en précisant s'il s'agit de benchmarks coding (HumanEval, SWE-bench…) ou généralistes (MMLU, GPQA…)
Seuls les commentaires sans aucune mention de modèle spécifique sont à ignorer.
Ce qui m'a donné le résultat suivant : Analyse par Sonnet 4.6 des commentaires Hacker News à propos de Kimi K2.6.
Étape 4 : quelques semaines plus tard
Quelques semaines plus tard, je consulte toutes les sorties de modèle du mois dans l'article Nouvelles sur l'IA du site LinuxFR pour avoir une revue complète de l'écosystème.
Je suis ravi de voir l'offre de modèles OpenCode Go s'enrichir semaine après semaine
Le 12 mars 2026, quand j'ai commencé à utiliser OpenCode Go, seuls 3 modèles étaient disponibles : MiniMax M2.5, Kimi K2.5 et GLM-5. J'ai depuis eu l'agréable surprise de voir arriver de nouveaux modèles Open Weights, souvent dès le lendemain de leur publication.
Aujourd'hui, l'offre est bien plus vaste :
- 18 mars, ajout de MiniMax M2.7
- 19 mars OpenCode supprime le support d'accès à l'offre Claude Pro
- 2 avril, ajout de MiMo-V2-Pro et MiMo-V2-Omni de Xiaomi
- 7 avril, ajout de GLM-5.1
- 15 avril, ajout de Qwen 3.5 Plus et Qwen3.6 Plus
- 20 avril, ajout de Kimi K2.6
- 22 avril, ajout de MiMo v2.5 et MiMo v2.5 Pro de Xiaomi
- 24 avril, ajout de DeepSeek V4 Pro et DeepSeek V4 Flash
Et depuis, j'ai pris la fâcheuse habitude — un peu par FoMo, je l'avoue — de consulter presque une fois par jour le compte Twitter de OpenCode (https://xcancel.com/opencode/) pour voir si un nouveau modèle est sorti.
Après 45 jours d'utilisation de OpenCode Go à 10$ par mois, je n'ai jamais été limité par les quotas
Comme je l'avais décidé dans ma note de découverte de OpenCode Go, j'utilise OpenCode Go depuis le 12 mars 2026.
Voici mes coûts d'utilisation par jour du mois de mars :
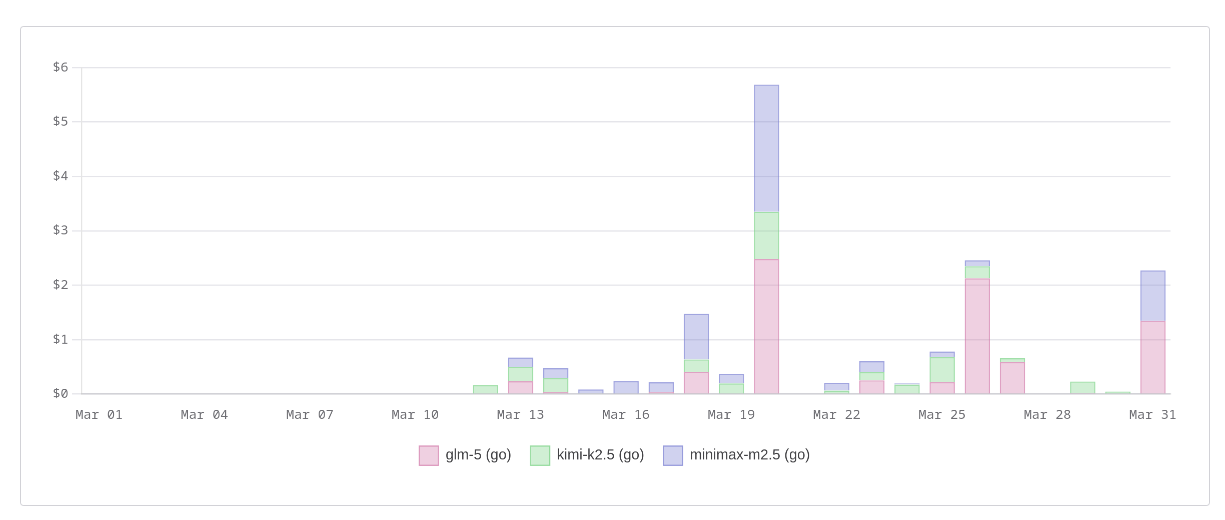
Et ceux du mois d'avril :
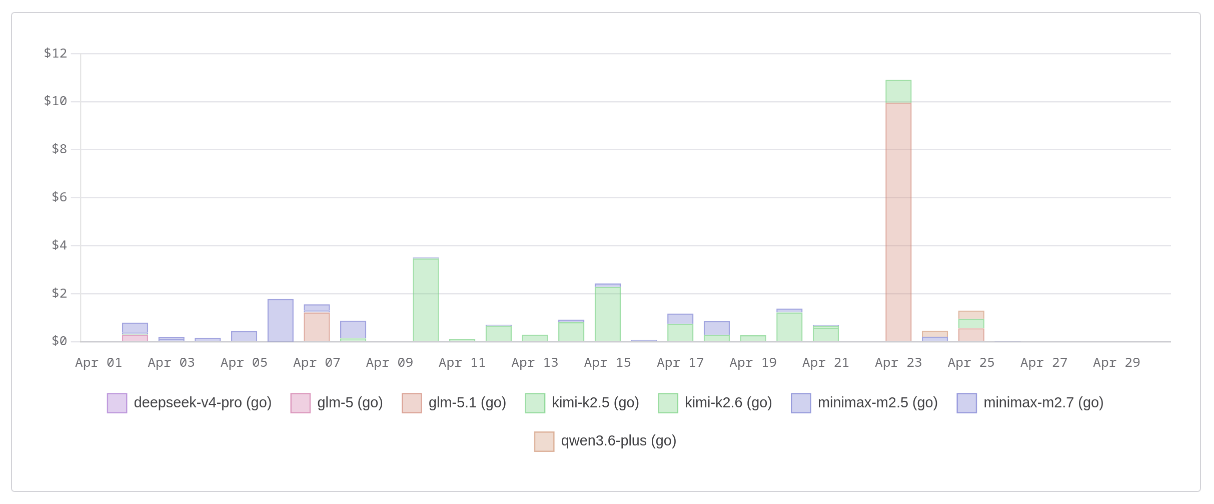
Mais attention, la lecture de ce graphe peut être trompeuse : ces montants correspondent au coût réel de l'offre OpenCode Zen, de type Pay-As-You-Go. Concrètement, je paie 10 $/mois avec l'offre OpenCode Go, qui me donne l'équivalent d'environ 60 $ de crédits Zen.
Après environ 14 jours sur mon abonnement d'avril — soit près de la moitié du mois —, j'ai consommé 35 % de mon quota. Pour le mois de mars, je n'ai pas de chiffre précis en tête, mais il me semble que j'avais atteint environ 60 %.
En 45 jours d'utilisation, je n'ai jamais atteint les limitations des fenêtres de 5 h, ni les limites hebdomadaires.
Samedi 25 avril 2026
Alexandre m'a partagé le chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp publié en 2019.
Il sait que j'apprécie cette méthode — j'ai lu le livre vers 2021-2022 — et me l'a envoyé parce qu'il ne comprend pas bien comment je peux adhérer à cette méthode alors qu'elle semble aller à l'encontre de ce qu'on a pratiqué ensemble.
Tout d'abord, je commence par préciser que Shape Up semble mélanger les notions de issue tracker et Product Backlog (voir note "Confusion entre issue tracker et backlog, et comment gérer la masse d'issues").
Ensuite, la méthode ne dit pas "no backlog", mais "no backlog commun" :
Des listes décentralisées
On n'a pas à choisir entre un backlog encombrant et ne rien retenir du passé. Chacun peut continuer à suivre pitchs, bugs, demandes ou idées de son côté, sans liste centrale.
Le support peut maintenir une liste des demandes ou problèmes qui reviennent souvent. Le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur. Les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion. Il n'y a ni backlog unique ni liste centrale, et aucune de ces listes n'alimente directement le processus des paris.
Shape Up ne m'apparaît pas comme une méthode qui interdit de partager des listes d'issues entre sous-groupes — c'est visible quand le texte dit que « le produit suit les idées qu'il espère pouvoir façonner dans un cycle futur » et que « les développeurs tiennent une liste de bugs qu'ils aimeraient corriger dès qu'ils en ont l'occasion ».
Ce qui me semble central dans Shape Up, ce n'est probablement pas tant le rejet d'un issue tracker commun. À mon sens, le cœur de la méthode réside ici :
Quelques paris potentiels
Que fait-on à la place ? Avant chaque cycle de six semaines, on organise une table des paris (betting table) où les parties prenantes décident ce qu'elles vont faire dans le cycle suivant. À cette table, on examine les pitchs des six dernières semaines — ou ceux que quelqu'un a délibérément ressortis et défendus à nouveau.
Rien d'autre n'est sur la table. Pas de longue liste d'idées à passer en revue. Pas de temps perdu à entretenir un backlog d'anciennes idées.
Cela signifie que si une issue n'a pas de "sponsor", c'est-à-dire, personne qui la met en avant, alors elle ne sera jamais priorisée. Les pitchs sont examinés à la betting table, mais Shape Up n'a pas de process continu de revue des issues en tant que backlog.
C'est pour moi l'idée la plus importante de ce chapitre par rapport à Scrum "mainstream" et cela ne me perturbe pas, car dans ma pratique Scrum, comme je le disais dans une précédente note, une issue sans sponsor n'a pratiquement aucune chance d'être sélectionnée lors d'un Sprint Planning :
Le triage régulier des issues (fermer et prioriser) est un travail laborieux, extrêmement difficile à maintenir dans la durée dès lors qu'un issue tracker contient beaucoup d'issues. Si je peux témoigner d'une chose, c'est que je n'ai probablement jamais réussi à le faire, ni vu quelqu'un y parvenir.
Imaginons un bug remonté il y a 8 mois sur l'export PDF.
- Scénario Scrum classique : le bug traîne dans le backlog, priorité "moyenne". À chaque Sprint Planning, le Product Owner fait défiler la liste, le voit, se dit "pas critique cette fois", et le repousse. Le bug survit parce qu'il est dans le système, pas parce qu'il est défendu.
- Scénario Shape Up : le bug n'existe nulle part dans un backlog central. Si un développeur pense qu'il vaut la peine d'y consacrer un cycle, il doit le re-pitcher activement à la prochaine betting table. Si personne ne le fait, le bug disparaît du radar — pas par décision active de le fermer, mais par absence de sponsor.
Dans ma pratique de Scrum, j'intègre déjà un betting table lors du Sprint Planning, et seules les issues proposées au sprint par un sponsor sont étudiées, par conséquent, cela me semble assez proche de ce que propose Shape Up.
Je préfère Shape Up à Scrum sur ce point précis de la betting table : il me semble que cette approche est plus honnête et reflète probablement mieux ce qui se passe réellement sur le terrain.
Confusion entre issue tracker et backlog, et comment gérer la masse d'issues
À la fin de la note "Collecter les sujets dans un issue tracker pour ne pas se répéter", je disais :
Un backlog est une liste d'items souvent extraits de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
Est-ce que toutes les issues ouvertes du issue tracker sont un backlog ? La réponse est non.
J'ai vu plusieurs fois des Product Managers arriver dans une organisation et être effrayés par la quantité d'issues présentes dans l'issue tracker — ils essayaient de passer en revue toutes les issues, pensant qu'il s'agissait du backlog.
Il me semble que cette confusion entre issue tracker et backlog est très classique — j'ai moi-même probablement entretenu cette confusion.
Les personnes issues de la culture open source sont habituées aux issue tracker, tandis que les Product Managers sont généralement plus familiers avec les Product Backlog.
Face à toutes ces issues, certains Product Managers font des choix radicaux pour garder la maîtrise :
- fermer très rapidement toutes les issues non prioritaires
- interdire l'utilisation d'un issue tracker
- ignorer l'issue tracker et travailler dans un autre outil
Je ne conseille pas ces approches : elles suppriment d'un bloc ce qui fait la valeur d'un issue tracker (voir "Collecter les sujets dans un issue tracker pour ne pas se répéter").
À la place, je conseille dans un premier temps de ne pas se préoccuper de l'intégralité des issues, et de se concentrer uniquement sur les issues indiquées par ses collègues ainsi que sur celles que l'on a soi-même créées.
Pour suivre ces issues et constituer son backlog, je conseille d'utiliser des labels — sur GitLab, j'utilise par exemple backlog, backlog-stephane, next-sprint, next-next-sprint. Ces labels, combinés à des vues kanban, permettent à chaque membre de créer un backlog à partir d'un sous-ensemble restreint d'issues.
Cette approche par labels fonctionne, mais le problème est que ce workflow exige une rigueur importante et un protocole commun d'équipe — difficile à mettre en place sans un leadership fort qui l'impulse et le maintient.
C'est pour améliorer cette expérience utilisateur, que j'ai intégré les fonctionnalités suivantes dans la description du gestionnaire de projet de mes rêves :
- Permettre de créer des portfolios d'issue par utilisateurs.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
De plus, j'imagine aussi une fonctionnalité permettant de « cacher » les issues, ou du moins de les rendre moins facilement accessibles aux nouveaux arrivants — non pas pour en interdire l'accès, mais pour réduire le bruit visuel et éviter qu'ils ne soient effrayés au point, après ce traumatisme, de les ignorer totalement.
Le triage régulier des issues (fermer et prioriser) est un travail laborieux, extrêmement difficile à maintenir dans la durée dès lors qu'un issue tracker contient beaucoup d'issues. Si je peux témoigner d'une chose, c'est que je n'ai probablement jamais réussi à le faire, ni vu quelqu'un y parvenir.
Concernant la fermeture des issues, certains projets configurent un système qui ferme automatiquement les issues après un certain temps sans activité. Personnellement, à la place de cela, je préfère un système qui poste un commentaire dans l'issue qui notifie et demande au créateur s'il juge qu'elle est toujours pertinente. En cas de non réponse après un temps imparti, l'issue peut être clôturée automatiquement.
Pour la priorisation des issues, toujours dans la description du gestionnaire de projet de mes rêves, j'ai imaginé la fonctionnalité suivante :
Collecter les sujets dans un issue tracker pour ne pas se répéter
En essayant de répondre à une question d'un ami au sujet du chapitre 7 « Bets, Not Backlogs » du livre Shape Up de Basecamp, j'ai cherché à mettre des mots sur les raisons qui me poussent à utiliser un issue tracker, une pratique que j'expérimente depuis plus de 15 ans. Cette note est le résultat de cette réflexion.
Pendant 5 ans, de 2018 à 2023, j'ai utilisé GitLab comme outil de issue tracker, en équipe, dans deux organisations différentes.
Avant d'aller plus loin, il me semble utile de montrer concrètement les types d'issue présentes dans ces trackers (voir aussi ces labels) :
- Bug — corriger un comportement qui ne correspond pas à ce qui est attendu
- Feature — implémenter une nouvelle fonctionnalité
- Enhancement — améliorer une capacité existante ; DoD : le comportement amélioré est mesurable ou observable
- Knowledge Gap — répondre à une question sans réponse accessible ; DoD : répondre à la question, indiquer comment trouver la réponse à cette question, si l'information n'était pas documentée, alors la documenter ou améliorer la documentation existante
- Spike — explorer une question technique ou une hypothèse incertaine dans un temps imparti ; DoD : du code est livré, une décision binaire est posée (concluante / non concluante) et documentée dans l'issue
- Enabler — préparer le terrain technique pour qu'une ou plusieurs issues futures soient implémentables en moins de 10h ; DoD : mergé sur main sans régression, les issues qu'il débloque sont identifiées
- User story développeur — exprimer un besoin d'infrastructure ou d'outillage interne sous forme de user story dont le "user" est un développeur ; DoD : code produit, environnement de développement amélioré, documentation ajoutée, etc.
- meta-spec-writing — décomposer un périmètre flou en issues actionnables ; DoD : les issues enfants sont créées, estimées et prêtes pour le sprint planning
- Sprint planning — préparer et documenter une session de sprint planning ; DoD : date, participants et issues candidates documentés avant la réunion, décisions prises et issues assignées documentées après
- Sprint retrospective — préparer et documenter une session de rétrospective ; DoD : date et sujets à aborder documentés avant la réunion, décisions et actions correctives documentées après, chaque action corrective génère une issue de suivi
Pourquoi je crée systématiquement une issue ?
Mon approche consiste à créer une issue dès qu'une idée, un bug ou un sujet émerge — même sans intention de le traiter immédiatement.
C'est un point qui me tient à cœur, parce qu'il m'agace profondément de voir les mêmes sujets resurgir sans cesse sans jamais être vraiment travaillés.
J'ai souvent observé dans les open spaces des conversations de 10-20 minutes autour d'un sujet où chacun y va de son opinion, de son intuition, de ses mises en garde et de ses objections, puis retourne à ses activités… pour recommencer le même débat deux jours plus tard. Tout ce qui a été dit est perdu et rarement approfondi.
Ces "conversations de couloir" récurrentes sont un symptôme classique de non-décision : personne ne bloque explicitement, personne n'avance vraiment — la discussion tourne en boucle, invisible et non tracée. Dans certains cas, elles dégénèrent en Stop Energy : les mêmes objections ressurgissent à chaque fois, épuisant le porteur de l'idée sans jamais produire de résolution.
Je préfère de loin créer l'issue avant toute conversation. À défaut, quand j'assiste à une discussion informelle qui tourne en rond, je la crée à chaud, y dépose les idées échangées, et la partage aux participants pour vérifier que j'ai bien retranscrit. La prochaine fois que le sujet resurgit, j'invite chacun à la lire et ajouter son commentaire ou voter "+1".
L'issue devient un espace formel où chacun peut argumenter et enrichir le fil à son rythme ; le Sprint Planning devient le moment de délibération légitime où l'équipe arbitre collectivement si l'issue doit être traitée dans le nouveau sprint ou non.
Cette rigueur n'est pas simple à tenir : quand l'équipe a l'habitude de tout régler à l'oral, créer une issue peut passer pour de la lourdeur bureaucratique. Je la tiens malgré tout, parce que le coût de la répétition me paraît plus élevé que celui du traçage. Surtout, à long terme, cela évite le brouillard organisationnel.
Cette utilisation d'un issue tracker s'inspire du monde du logiciel libre, où des issues peuvent rester ouvertes des années, voire des décennies, et servent de mémoire collective pour comprendre la complexité d'une demande, les trade-offs, les ressources disponibles.
Quand cette méthode est appliquée pendant plusieurs années dans une organisation, un issue tracker peut contenir des centaines voire des milliers d'issues ouvertes, mais ceci ne pose pas de problème car ces issues ne constituent pas un backlog.
Un backlog est une liste d'items extraits et sélectionnés de l'ensemble des issues de l'issue tracker — un sous-ensemble volontairement restreint et de meilleure qualité. Priorisée, maintenue à jour et régulièrement affiné, cette liste représente le travail potentiel sérieusement envisagé pour le produit. Lors du Sprint Planning, les parties prenantes — développeurs, produit et autres contributeurs concernés — discutent et arbitrent ensemble les priorités pour décider quels items intégreront le Sprint Backlog.
Vendredi 10 avril 2026
J'ai découvert pgfmt, un formater de code SQL
A PostgreSQL SQL formatter with multiple style options.
pgfmt parses SQL using tree-sitter PostgreSQL and reformats it according to one of several well-known style guides. Formatting is powered by libpgfmt.
Ce formatter supporte plusieurs types de style de formatage. Pour le moment, le formatage "river" est celui qui se rapproche le plus de mon style.
Je pense qu'il serait même possible de créer mon propre style de formatage en modifiant ce projet à l'aide d'un agentic coding tool 🤔.
Journal du vendredi 10 avril 2026 à 10:21
Dans Postgres Weekly numéro 643 #JaiDécouvert rpg :
rpg — modern Postgres terminal written in Rust. psql-compatible, with built-in DBA diagnostics and AI assistant
La liste des fonctionnalités de rpg me donne envie de le tester pour voir si, à l'usage, il est une bonne alternative à psql, pgcli ou usql.
Features
- psql-compatible —
\-commands are standard psql meta-commands (\d,\dt,\copy,\watch, ...);/-commands are rpg extensions — both AI and non-AI. Same muscle memory, clearly distinct additions.- Active Session History —
/ashlive wait event timeline with drill-down; pg_ash history integration- AI assistant —
/ask,/fix,/explain,/optimize,/text2sql,/yolo- DBA diagnostics — 15+
/dbacommands: activity, locks, bloat, indexes, vacuum, replication, config- Schema-aware completion — tab completion for tables, columns, functions, keywords
- Lua plugin system — extend rpg with custom
/-commands written in Lua- TUI pager — scrollable pager for large result sets
- Syntax highlighting — SQL keywords, strings, operators; EXPLAIN plans; color-coded errors/warnings
- Markdown output —
\pset format markdownfor docs-ready table output- Named queries — save and recall frequent queries
- Session persistence — history and settings preserved across sessions
- Multi-host failover —
-h host1,host2tries each in order, first success wins- SSH tunnel — connect through bastion hosts without manual port-forwarding
- Config profiles — per-project
.rpg.toml- Shell backtick substitution — dynamic prompts via
PROMPT1='[git branch --show-current] %/ # '- Status bar — connection info, transaction state, timing
- Cross-platform — single static binary: Linux, macOS, Windows (x86_64 + aarch64)
Lundi 6 avril 2026
Jeudi 2 avril 2026
J'ai découvert MimiMax M2.7, qui semble équivalent à GLM-5 pour un tiers du prix
#JaiDécouvert la sortie de MiniMax M2.7 le 18 mars 2026 : https://www.minimax.io/news/minimax-m27-en.
Pour donner du contexte, j'utilise depuis le 12 mars 2026 les modèles GLM-5, Kimi K2.5 et MiniMax M2.5 via l'offre OpenCode Go. Je n'ai pas comparé rigoureusement ces modèles avec Sonnet 4.6 et Opus 4.6, mais pour le moment, je suis satisfait de ces modèles. J'ai même l'impression que MiniMax M2.5, le moins cher, suffit pour la majorité de mes besoins.
J'ai lu l'article "MiniMax M2.7 Review: Is It Worth the Hype?", mais c'est finalement MiniMax M2.7: Everything you need to know qui m'a été le plus utile, voici sa traduction :
MiniMax a publié MiniMax-M2.7, offrant une intelligence de niveau GLM-5 pour moins d'un tiers du coût
MiniMax-M2.7 de @MiniMax_AI obtient un score de 50 sur l'Artificial Analysis Intelligence Index, une amélioration de 8 points par rapport à MiniMax-M2.5, publié il y a un mois. Cette amélioration est portée par une performance améliorée sur les tâches agentiques du monde réel et une réduction des hallucinations. MiniMax-M2.7 est désormais devant MiMo-V2-Pro (Reasoning, 49) et Kimi K2.5 (Reasoning, 47), et équivalent à GLM-5 (Reasoning, 50) tout en utilisant 20% de tokens de sortie en moins et coûtant moins d'un tiers du prix pour fonctionner. MiniMax-M2.7 est un modèle uniquement raisonnement et maintient le même prix par token que MiniMax-M2.5.
Points clés :
➤ Performance solide sur les tâches agentiques du monde réel : MiniMax-M2.7 atteint un Elo GDPval-AA de 1494, une amélioration significative par rapport à MiniMax-M2.5 (1203) et devant MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406) et Kimi K2.5 (Reasoning, 1283). Il reste derrière les modèles de pointe tels que GPT-5.4 (xhigh, 1667) et Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606).
- Réduction des hallucinations : MiniMax-M2.7 obtient un score de +1 sur l'AA-Omniscience Index, contre -40 pour MiniMax-M2.5. Cela le place en compétition avec GPT-5.2 (xhigh, -1) et GLM-5 (Reasoning, +2), et bien devant Kimi K2.5 (Reasoning, -8). L'amélioration par rapport à M2.5 est entièrement due à la réduction des hallucinations, ce qui signifie que le modèle est plus susceptible de s'abstenir de répondre lorsqu'il ne connaît pas la réponse, plutôt que de deviner. M2.7 atteint un taux d'hallucination de 34%, inférieur à Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) et Gemini 3.1 Pro Preview (50%).
- Gains sur la plupart des évaluations par rapport à MiniMax-M2.5 : En dehors des améliorations du GDPval-AA et de l'AA-Omniscience notées ci-dessus, MiniMax-M2.7 progresse en HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.) et LCR (+3 p.p.). Nous avons constaté une régression notable en τ²-Bench (-11 p.p.).>
- Utilisation accrue de tokens : MiniMax-M2.7 a utilisé environ 87M tokens de sortie pour exécuter l'Artificial Analysis Intelligence Index, en hausse de 55% par rapport à MiniMax-M2.5 (environ 56M). Il reste plus efficace en tokens que d'autres modèles tels que GLM-5 (Reasoning, 110M) et Kimi K2.5 (Reasoning, environ 89M).
- Rentabilité de pointe : MiniMax-M2.7 a coûté 176 $ pour exécuter l'Artificial Analysis Intelligence Index, maintenant le même prix de 0,30 $/1,20 $ par million de tokens d'entrée/sortie que M2.5. Cela le place sur la frontière de Pareto de notre graphique Intelligence vs. Coût. À titre de référence, GLM-5 (Reasoning) a coûté 547 $ à intelligence équivalente, Kimi K2.5 (Reasoning) 371 $, et Gemini 3 Flash Preview (Reasoning) 278 $.
Détails clés du modèle :
- Fenêtre de contexte : 200K tokens (équivalent à MiniMax-M2.5).
- Tarification : 0,30 $/1,20 $ par million de tokens d'entrée/sortie (inchangé par rapport à MiniMax-M2.5).
- Disponibilité : API propriétaire MiniMax uniquement.
- Modalité : Entrée et sortie de texte uniquement (pas de multimodalité).
- Licence : MiniMax n'a pas annoncé si MiniMax-M2.7 sera en open weights. MiniMax-M2.5 est disponible sous licence MIT.
MiniMax M2.7 a été intégré dans l'offre OpenCode Go, par conséquent, je vais tester ce modèle dans mes projets OpenCode.
Jeudi 26 mars 2026
Journal du jeudi 26 mars 2026 à 14:47
#JaiDécouvert https://keepachangelog.com, un guide pour maintenir les changelog de ses projets.
Mercredi 25 mars 2026
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
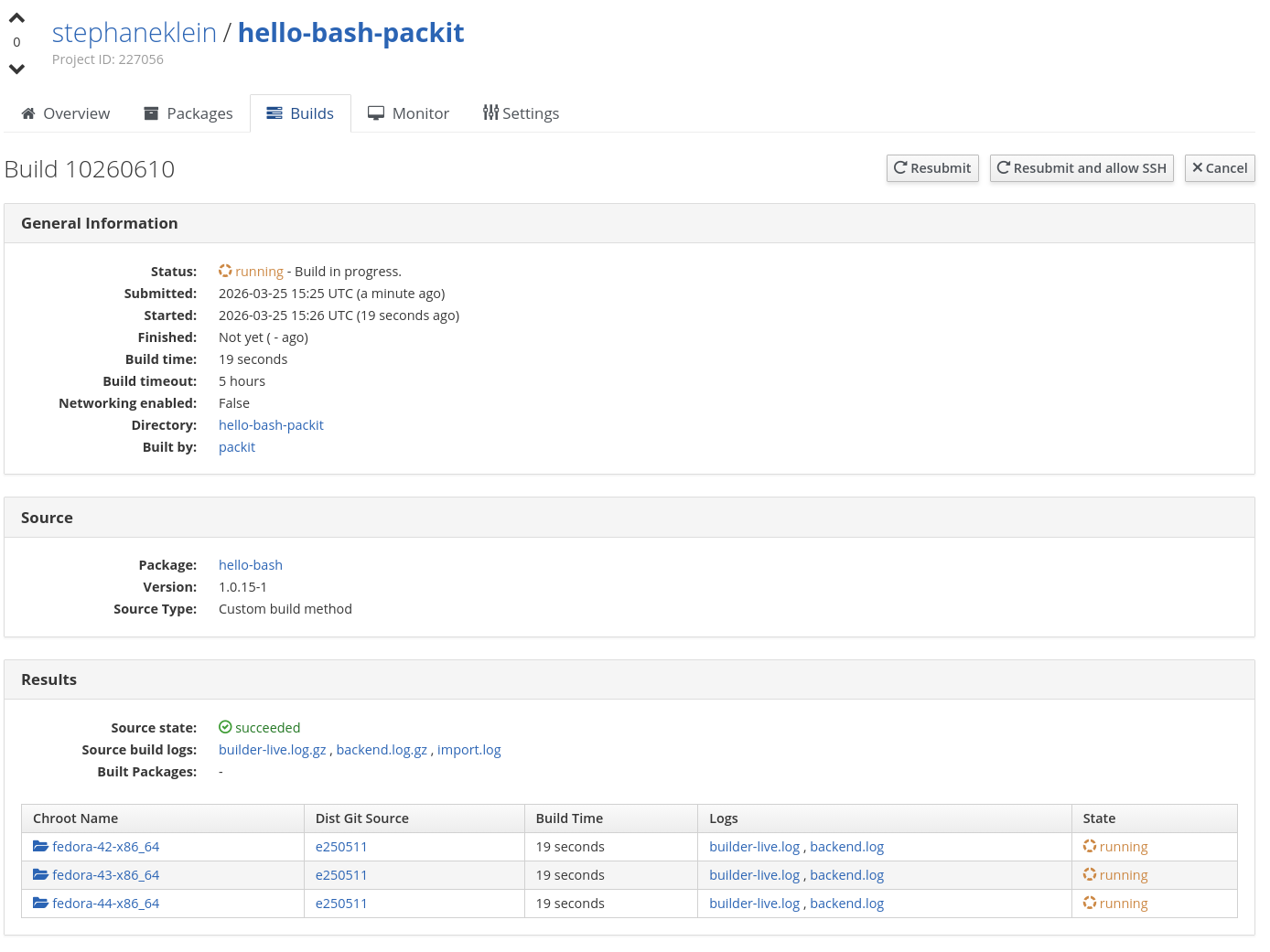
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
Mardi 24 mars 2026
Version courte : ceci est un message à caractère publicitaire — une contribution de 20 €, ou même seulement 5 €, pour financer l'interview de Thomas Hobbes par Monsieur Phi !
Ça se passe sur Ulule : https://fr.ulule.com/le-late-show-du-siecle---une-emission-de-monsieur-phi/news/premier-palier-atteint---merci-472520/
Maintenant, la version un peu plus longue.
J'ai adoré les interviews de philosophes de l'Antiquité par MrPhi dans PhilosopherView (lien direct) — Socrate, Diogène, Platon, Aristote, Sénèque, Épicure, Pyrrhon d'Elis et Sextus Empiricus.

Vraiment, je suis totalement fan : dès qu'un nouvel épisode sort, je me précipite pour l'écouter. Je trouve que c'est excellent, tant sur le fond que sur la forme.
Si vous ne connaissez pas, allez-y, et n'ayez pas peur : ils sont à la fois très accessibles et détaillés.
Si vous connaissez déjà, vous serez peut-être intéressé par le futur projet de Thibaut (alias MrPhi) : Le Late Show du Siècle : Une émission de Monsieur Phi.
Le premier épisode — une interview de Descartes en personne par Élisabeth de Bohême — est déjà financé à hauteur de 60 K€, avec le soutien de 1 239 personnes !
Le prochain palier à atteindre est l'interview de Thomas Hobbes !
Vous vous dites peut-être que 60 K€ par épisode, c'est très cher. Dans ce cas, je vous invite à regarder cette vidéo de présentation du projet par MrPhi : Le plus gros projet de ma chaîne !.
Personnellement, je suis le travail de MrPhi depuis bientôt 10 ans, principalement via ses vidéos. J'ai aussi beaucoup aimé ses deux livres — à tel point que j'ai déjà offert 2 exemplaires de « Curiosités philosophiques : De Platon à Russell » (lien) et 3 exemplaires de « La parole aux machines - Philosophie des grands modèles de langage » (lien), qui aborde les LLM sous l'angle de la philosophie de l'esprit (école analytique).
Il s'agit probablement du créateur de contenu en qui j'ai le plus confiance, car depuis tout ce temps, il fait preuve d'une intransigeance absolue sur la qualité — que ce soit dans ses vidéos, ses livres, son choix des sources ou la rigueur de ses arguments.
Alors, si vous voulez faire plaisir à mon moi du futur 🤗, vous pouvez contribuer à ce projet — même 5 € — pour que je puisse me délecter 😋 des interviews de Hobbes, Spinoza, etc.
Lundi 23 mars 2026
J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR
Introduction
Après trois ans à repousser ce projet, je me suis enfin lancé en janvier 2026 dans la création de paquets RPM pour Fedora COPR.
J'ai créé et publié les packages aichat-git (repository) et text-to-audio (repository). L'expérience a été beaucoup plus simple et rapide que je le pensais. Les agents IA simplifient certes ce genre de tâche, mais même sans eux, le code reste plutôt minimaliste.
Pourquoi est-ce que je me suis intéressé à ce sujet ? Au départ, c'était pour distribuer qemu-compose sous forme de package RPM (voir issue).
Pour bien maîtriser ces opérations, la semaine dernière, je suis reparti de zéro et j'ai implémenté et publié le playground : fedora-rpm-copr-playground. Voici les objectifs de ce playground :
- Générer un package pour distribuer un simple script Bash qui affiche un "Hello world" (dans la branche
bash). - Générer un package pour distribuer une application Golang qui affiche un "Hello world" (dans la branche
golang)
Pour chacun de ces packages, j'ai testé trois méthodes de build :
- build du package RPM 100% local
- build du package SRPM en local, puis upload sur Fedora COPR qui génère les RPM pour plusieurs plateformes et architectures (x86_64, aarch64, etc.)
- une méthode basée à 100% sur Fedora COPR à partir des sources d'un dépôt GitHub, déclenchée automatiquement par un script GitHub Actions
Cette note documente ce playground et rassemble les difficultés que j'ai rencontrées. Le README.md reste consultable si vous préférez suivre un exemple pas à pas.
Le fichier .spec
Le point central pour créer un package RPM est le fichier .spec /rpm/hello-bash.spec :
#
Name: hello-bash
Version: 1.0.7
Release: 1%{?dist}
Summary: A simple Hello World bash script
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: hello-bash
BuildArch: noarch
%description
A simple "Hello World" Bash script packaged as an RPM for Fedora COPR.
%prep
# Nothing to prepare, source is ready
%build
# Nothing to build, it's a bash script
%install
mkdir -p %{buildroot}/%{_bindir}
cp %{SOURCE0} %{buildroot}/%{_bindir}/hello-bash
chmod 755 %{buildroot}/%{_bindir}/hello-bash
%files
%{_bindir}/hello-bash
%changelog
* Thu Mar 19 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les lignes importantes dans ce fichier :
BuildArch: noarch, étant donnée que c'est un simple script, ce package n'est pas dépendant de l'architecture (processeur).- La section
%install - La section
%files
La syntaxe du format .spec peut sembler étrange en 2026. Elle date de 1995 — avant même l'existence de YAML (2001) et JSON (1999). Cette ancienneté explique les %... et %{...} qui peuvent paraitre cryptiques aujourd'hui.
Historiquement, le champ Source0 pointe vers une archive (généralement un tar.gz), contenant les sources du projet. Pour des cas simples, comme ici avec le script Bash, Source0 peut directement référencer le fichier source.
J'ai aussi implémenté une variante bash-multifiles dans le playground, pour tester le packaging de plusieurs scripts accompagnés d'un fichier de documentation. J'y indique les fichiers via Source0:, Source1:, Source2:, puis je les copie dans %install avec %{SOURCE0}, %{SOURCE1}, %{SOURCE2}. Cela fonctionne correctement, bien qu'au-delà de trois ou quatre fichiers, je pense qu'il soit probablement plus pratique d'utiliser une archive.
Build local du package RPM
Le script /build.sh suivant permet de générer un package RPM :
#!/bin/bash
set -e
TOPDIR="$(pwd)/rpmbuild"
mkdir -p "$TOPDIR"/{BUILD,RPMS,SRPMS,SOURCES,SPECS}
echo "Copying source to SOURCES..."
cp hello-bash "$TOPDIR/SOURCES/"
echo "Building RPM..."
rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec
echo ""
echo "Build complete!"
echo "RPM: $TOPDIR/RPMS/noarch/"
Il commence par préparer la structure de dossier suivante :
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
├── SPECS
└── SRPMS
Ensuite les fichiers à packager sont copiés dans rpmbuild/SOURCES
/rpmbuild/
├── BUILD
├── RPMS
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
Pour finir, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-bash.spec génère à la fois le package SRPM (source RPM) et le RPM binaire. L'option -ba signifie "build all". Pour générer uniquement le SRPM, il faudrait utiliser -bs (build source). Ici, comme le package contient un script Bash, il est de type noarch :
/rpmbuild/
├── BUILD
├── RPMS
│ └── noarch
│ └── hello-bash-1.0.7-1.fc42.noarch.rpm
├── SOURCES
│ ├── hello-bash
├── SPECS
└── SRPMS
└── hello-bash-1.0.7-1.fc42.src.rpm
Publication sur Fedora COPR
Le playground contient un second script qui permet de publier le package sur Fedora COPR, ce qui permet de rendre accessible publiquement son package.
Voici comment cette méthode fonctionne. Tout d'abord, il faut créer un compte et un projet sur Fedora COPR. Dans le playground, j'ai implémenté le script init-copr-project.sh basé sur copr-cli, qui me permet d'automatiser la création du projet (paradigme GitOps).
$ copr-cli create "hello-bash" \
--description "A simple Hello World Bash script packaged as an RPM (auto-build on tags)" \
--chroot fedora-42-x86_64 \
--chroot fedora-43-x86_64 \
--chroot fedora-44-x86_64
Dans cet exemple, je demande à COPR de builder les packages du projet pour les distributions fedora-42-x86_64, fedora-43-x86_64, fedora-44-x86_64.
Après avoir configuré le projet COPR, je lance le script /build-copr.sh qui exécute :
copr-cli build "hello-bash" /rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
Le premier paramètre "hello-bash" est le nom du projet et le second est le package source SRPM préalablement construit localement par le script /build.sh.
Voici ce que donne l'exécution de ./build-copr.sh côté cli :
$ ./build-copr.sh
...
Build complete!
RPM: /home/stephane/git/github.com/stephane-klein/fedora-rpm-copr-playground/.worktree/bash/rpmbuild/RPMS/noarch/
Uploading package ./rpmbuild/SRPMS/hello-bash-1.0.6-1.fc42.src.rpm
|################################| 8.5 kB 47.1 kB/s eta 0:00:00
Build was added to hello-bash:
https://copr.fedorainfracloud.org/coprs/build/10252699
Created builds: 10252699
Watching build(s): (this may be safely interrupted)
08:59:15 Build 10252699: pending
08:59:45 Build 10252699: running
09:00:15 Build 10252699: starting
09:00:46 Build 10252699: running
Voici ce qui est visible sur l'interface web de COPR, https://copr.fedorainfracloud.org/coprs/stephaneklein/hello-bash/builds/ :
Une fois le build des packages terminé, il est facile d'installer le package avec les commandes suivantes :
$ sudo dnf copr enable -y stephaneklein/hello-bash
$ sudo dnf install -y hello-bash
$ hello-bash
Hello World
Automatisation GitOps avec COPR
Et pour finir, j'ai implémenté dans le playground l'automatisation complète de la compilation et publication des packages sur l'infrastructure COPR.
Pour cela, dans le script init-copr-project.sh j'ai déclaré l'URL du repository qui contient le code source :
...
copr-cli add-package-scm "$COPR_PROJECT" \
--name hello-bash \
--clone-url https://github.com/stephane-klein/fedora-rpm-copr-playground.git \
--commit bash \
--subdir . \
--spec rpm/hello-bash.spec \
--type git \
--method make_srpm \
--webhook-rebuild on
Le paramètre --commit bash permet de définir la branche Git à utiliser comme source.
Le paramètre --method make_srpm, qui permet à l'utilisateur d'utiliser un script personnalisé de génération du SRPM, à placer dans /.copr/Makefile à la racine du dépôt avec une cible srpm, exemple :
specfile = rpm/hello-bash.spec
.PHONY: srpm
srpm: $(specfile)
mkdir -p /tmp/copr-srpm-build
cp rpm/hello-bash.spec /tmp/copr-srpm-build/hello-bash.spec
cp -r . /tmp/copr-srpm-build/source/
cd /tmp/copr-srpm-build && \
rpmbuild -bs hello-bash.spec \
--define "_topdir /tmp/copr-srpm-build/rpmbuild" \
--define "dist .fc42" \
--define "_sourcedir /tmp/copr-srpm-build/source"
cp /tmp/copr-srpm-build/rpmbuild/SRPMS/*.src.rpm $(outdir)
Je ne souhaite pas détailler ici d'autres méthodes comme tito ou Packit, mais la méthode make_srpm est la plus flexible, elle permet de contrôler entièrement comment le SRPM est construit.
Une fois tout ceci configuré, il est possible de rebuild le package directement en cliquant sur le bouton "Rebuild" sur l'interface web de COPR :
Dernière étape : j'ai implémenté un build automatique qui est déclenchée par un appel curl dans le job GitHub Actions /.github/workflows/trigger-copr-build.yml, dont voici le contenu :
name: Trigger Copr Build
on:
push:
tags:
- '*'
jobs:
trigger-copr-build:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Verify tag is on bash branch
run: |
if ! git branch -r --contains ${{ github.ref_name }} | grep -q "origin/bash"; then
echo "Tag ${{ github.ref_name }} is not on branch bash"
exit 1
fi
- name: Trigger Copr webhook
run: |
curl -X POST https://copr.fedorainfracloud.org/webhooks/custom/226325/3cf20247-820b-4050-bfb1-593b01a6996f/hello-bash/
Ce job est exécuté à chaque publication d'un nouveau Git tag, suivi d'une vérification que le tag provient bien de la branche bash.
Claude Sonnet 4.6 m'a suggéré l'existence d'une méthode de polling de dépôt Git intégrée à COPR, mais je n'ai trouvé aucune trace de celle-ci dans la documentation.
J'ai aussi essayé d'utiliser la méthode basée sur les webhooks GitHub de COPR, mais je n'ai pas réussi à la faire fonctionner. L'interface de GitHub m'indiquait à chaque fois une erreur dans la réponse des calls HTTP. C'est pour cela que j'ai fini par déclencher le webhook custom via un job GitHub Actions.
Package d'un projet en Golang
Le playground contient aussi le packaging d'une application en Golang, consultable dans la branche golang.
Voici le contenu du fichier /golang/rpm/hello-golang.spec :
Name: hello-golang
Version: 1.0.10
Release: 1%{?dist}
Summary: A simple Hello World Go application
License: MIT
URL: https://github.com/stephane-klein/fedora-rpm-copr-playground
Source0: %{name}-%{version}.tar.gz
BuildRequires: golang >= 1.21
%description
A simple "Hello World" Go application packaged as an RPM for Fedora COPR.
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
%install
mkdir -p %{buildroot}%{_bindir}
cp %{name} %{buildroot}%{_bindir}/
%files
%{_bindir}/%{name}
%changelog
* Fri Mar 20 2026 Stéphane Klein <contact@stephane-klein.info> - 1.0.0-1
- Initial release
Les principales différences avec la version pour Bash :
- Absence de
BuildArch: noarch - Présence de
BuildRequires: golang >= 1.21 - Et l'ajout des instructions suivantes :
%prep
%autosetup
%build
go build -ldflags "-X main.version=%{version}" -o %{name}
Peu de changement au niveau du script /build-rpm-locally.sh, qui génère ces fichiers :
rpmbuild
├── BUILD
├── RPMS
│ └── x86_64
│ ├── hello-golang-1.0.10-1.fc42.x86_64.rpm
│ ├── hello-golang-debuginfo-1.0.10-1.fc42.x86_64.rpm
│ └── hello-golang-debugsource-1.0.10-1.fc42.x86_64.rpm
├── SOURCES
│ ├── hello-golang-1.0.10
│ │ ├── go.mod
│ │ └── main.go
│ └── hello-golang-1.0.10.tar.gz
├── SPECS
└── SRPMS
└── hello-golang-1.0.10-1.fc42.src.rpm
Cette fois, plus rien dans le dossier RPMS/noarch/, la commande rpmbuild --define "_topdir $TOPDIR" -ba rpm/hello-golang.spec build le package pour la distribution de la workstation du développeur.
Pour le reste, je n'ai pas identifié de différence majeure entre la version Bash et la version Golang
La suite… méthode Tito et Packit
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour stephane-klein/fedora-rpm-copr-playground pour les tester et ensuite publier une nouvelle note de compte rendu.
Jeudi 12 mars 2026
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Journal du jeudi 12 mars 2026 à 11:18
En étudiant l'offre OpenCode Go, je suis tombé sur une page marketing du service ApiYi : « Is the OpenCode GO Plan Worth Buying? $10/Month 3 Model Tests + 5 Major Alternative Solutions Compared ».
En analysant le contenu avec Sonnet 4.6, j'ai compris qu'ApiYi fonctionne vraisemblablement comme une solution de contournement à destination du marché chinois : les utilisateurs qui ne peuvent pas acheter directement auprès d'Anthropic — en raison des risques de bannissement liés aux adresses IP et aux moyens de paiement chinois — y trouvent un accès indirect aux modèles.
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Mercredi 11 mars 2026
J'ai découvert le terme « Architecture à médaillon » — un concept DataOps
Alexandre m'a fait découvrir, via cet article, le terme « Architecture à médaillon » — un concept que je pratiquais déjà sans savoir le nommer.
Mardi 10 mars 2026
Serveur MCP web fetch local sous Claude Desktop pour contourner les blocages IP de certains sites
Mon installation de Claude Desktop sous Fedora était principalement motivée par l'exécution locale du tool "Web fetch tool" d'Anthropic, afin de contourner le blocage des IP d'Anthropic par certains sites web.
Après avoir passé en revue une demi-douzaine de serveurs MCP de type « web fetch », j'ai retenu zcaceres/fetch-mcp, implémenté en Javascript, qui, après quelques heures d'utilisation, semble bien fonctionner.
Voici mon fichier ~/.config/Claude/claude_desktop_config.json après configuration du serveur MCP :
{
"mcpServers": {
"fetch": {
"command": "npx",
"args": ["mcp-fetch-server"],
"env": {
"DEFAULT_LIMIT": "0"
}
}
},
"isUsingBuiltInNodeForMcp": false,
"isDxtAutoUpdatesEnabled": false,
"preferences": {
"coworkScheduledTasksEnabled": true,
"ccdScheduledTasksEnabled": true,
"coworkWebSearchEnabled": true,
"sidebarMode": "chat"
}
}
zcaceres/fetch-mcp supporte différents types de formats de fetching :
All tools accept the following common parameters:
- fetch_html — Fetch a website and return its raw HTML content.
- fetch_markdown — Fetch a website and return its content converted to Markdown.
- fetch_txt — Fetch a website and return plain text with HTML tags, scripts, and styles removed.
- fetch_json — Fetch a URL and return the JSON response.
- fetch_readable — Fetch a website and extract the main article content using Mozilla Readability, returned as Markdown. Strips navigation, ads, and boilerplate. Ideal for articles and blog posts.
- fetch_youtube_transcript — Fetch a YouTube video's captions/transcript. Uses
yt-dlpif available, otherwise extracts directly from the page. Accepts an additionallangparameter (default:"en") to select the caption language.
C'est le LLM qui choisit quel tool utiliser. J'ai demandé à Claude Sonnet 4.6 comment il effectuait son choix : par défaut, il utilise fetch_markdown ; lorsqu'il sait qu'un site contient des publicités, une sidebar, etc. — généralement les sites de presse —, il utilise fetch_readable.
J'ai observé que les tools fetch_markdown, fetch_readable et fetch_json fonctionnent bien, mais fetch_youtube_transcript n'a pas fonctionné chez moi. D'après les logs, ce tool semble contenir un bug. #JaimeraisUnJour essayer de le corriger.
Dimanche 8 mars 2026
J'ai installé Claude Desktop sous Fedora
Anthropic ne propose pas de version GNU Linux de Claude Desktop.
#JaiDécouvert le projet Claude Desktop for Linux qui a repackagé la version de Claude Desktop Windows pour GNU Linux. Ce projet propose des packages pour Debian, Fedora, ArchLinux et NixOS.
Je l'ai installé avec succès sous Fedora avec les commandes suivantes trouvé ici :
$ sudo curl -fsSL https://aaddrick.github.io/claude-desktop-debian/rpm/claude-desktop.repo -o /etc/yum.repos.d/claude-desktop.repo
$ sudo dnf install claude-desktop
J'ai ensuite testé la connexion de Claude Desktop au Filesystem MCP Server lancé en local :
Seul élément négatif pour l'instant : la version Desktop ne permet pas d'utiliser l'extension Claude Counter (extension), contrairement à la version web.
Vendredi 6 mars 2026
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals. Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
Jeudi 5 mars 2026
Samedi 28 février 2026
Renouvellement de ma contribution financière à la coopérative Mastodon social.coop
Avec 4 mois de retard, je viens de renouveler pour 12,00 £ GBP (13,70 €) un abonnement d'un an à l'Instance Mastodon social.coop qui héberge mon compte https://social.coop/@stephane_klein.
Voici les recettes et dépenses de l'année 2025 :
Pour 2025 :
- Recettes : 15 088 €
- Dépenses : 9 603 €
J'ai été surpris de ne pas avoir reçu de rappel de renouvellement de contribution. Pour en savoir plus, j'ai posté ici et ici le message suivant :
Titre : Question sur le processus de renouvellement des contributions
Bonjour,
Le 8 octobre 2024, j'ai fait une contribution de 36,00 £ GBP pour rejoindre la coopérative social.coop.
Le temps a passé et aujourd'hui, je viens de penser à renouveler ma contribution financière, à la hauteur de 12,00 £ GBP.
Je suis surpris de n'avoir reçu aucun message de demande de renouvellement de contribution financière. Je ne pense pas avoir reçu de mail, je n'ai rien vu sur l'interface de https://social.coop, et rien non plus sur https://opencollective.com.
J'ai trouvé et lu la page Wiki "Social.coop registration process" mais je n'ai trouvé aucune documentation concernant le "renouvellement".
J'ai quelques questions :
- est-ce normal de ne pas recevoir de rappel ?
- la coopérative laisse-t-elle délibérément les membres renouveler leur contribution à leur propre rythme, sans relance, en faisant confiance à leur engagement ?
Suggestion : que pensez-vous de documenter le fonctionnement du process de renouvellement sur les pages ?
- https://join.social.coop/registration-form.html
- et/ou dans une page wiki sur https://git.coop/social.coop/community/docs/-/wikis/home
Bonne journée, Stéphane
Mise à jour le 2026-02-28 à 18:09, j'ai posté :
Suite au commentaire d'Eliott :
That's interesting, when I registered I signed up for a recurring annual membership
J'ai vérifié mes transactions sur OpenCollective et j'ai constaté qu'un paiement récurrent est bien actif et qu'un prélèvement automatique a bien été effectué à la date anniversaire :
https://opencollective.com/socialcoop/contributions/797022
Mon erreur : j'avais complètement oublié avoir souscrit à un abonnement — et non réalisé un simple paiement ponctuel.
Désolé pour le bruit 😔.
Vendredi 27 février 2026
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Jeudi 26 février 2026
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?
Dans une note de juillet 2025, j'évoquais ne pas avoir trouvé d'information sur les limites de consommation de tokens de l'offre "Pro" de Claude.
J'avais observé empiriquement qu'avec mon usage de Claude Sonnet à l'époque, l'API directe était plus avantageuse qu'un abonnement Pro :
Entre le 30 mai et le 15 juillet 2025, j'ai consommé
$14,94de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
En 2026, avec la forte augmentation de l'usage des AI code assistant de type Claude Code ou OpenCode, la consommation de tokens a explosé, ce qui change la donne.
Je me pose à nouveau la question suivante : « Est-ce que les abonnements sont maintenant réellement plus économiques que l'utilisation directe de l'API ? ».
Cette semaine, j'ai effectué de nouvelles recherches pour en savoir plus sur les limites des abonnements Claude et cette fois, j'ai trouvé dans ce thread Reddit des informations.
Dans cette article, l'auteur explique les résultats qu'il a trouvé par reverse engineering.
Attention, l'unité "credits" est différente de "tokens". La définition de crédit est donné un peu plus loin dans cette note.
Le plan 20× n'est pas aussi avantageux qu'on pourrait le croire. Sur le site d'Anthropic, toutes les mentions « 20× plus d'utilisation* » comportent cet astérisque gênant. Les limites de session de cinq heures sont bien 20× plus élevées qu'en Pro, mais la vraie question est : quelle quantité de travail peut-on en tirer ? La réponse est : seulement deux fois plus par semaine que le plan 5×.
En revanche, le plan 5× offre un excellent rapport qualité-prix. Il tient largement ses promesses. C'est le point idéal du tableau tarifaire. Vous obtenez une limite de session six fois plus élevée que Pro (et non cinq), et plus de huit fois la limite hebdomadaire (davantage que l'éponyme cinq).
Tier Credits/5h Credits/week Pro 550,000 (1×) 5,000,000 (1×) Max 5× 3,300,000 (6×) 41,666,700 (8.33×) Max 20× 11,000,000 (20×) 83,333,300 (16.67×) Comparés aux tarifs de l'API, tous les abonnements semblent fantastiques. Les estimations de valeur dans le tableau sont des bornes inférieures, car la mise en cache rend l'équivalent API effectif encore plus favorable (je l'expliquerai dans un moment). Dans tous les cas, si vous pouvez utiliser un abonnement plutôt que l'API, foncez.
Tier Price Credits/month Opus-rate tokens Equivalent API cost Pro $20 21.7M 32.5M in or 6.5M out $163 (8.1×) Max 5× $100 180.6M 270.9M in or 54.2M out $1,354 (13.5×) Max 20× $200 361.1M 541.7M in or 108.3M out $2,708 (13.5×)
Voici un autre avantage de l'abonnement versus l'API :
Les lectures de cache. Elles sont entièrement gratuites.
Cela rend la balance encore plus favorable aux abonnements. Dans une boucle agentique (par exemple Claude Code), le modèle effectue des dizaines d'appels d'outils par tour. Après chaque appel d'outil, le modèle est invoqué à nouveau. Lecture du cache sur l'intégralité du contexte. L'API facture 10% pour chaque lecture ; les abonnements ne facturent rien. Ça s'accumule vite, comme nous allons le voir dans un instant.
Les écritures de cache sont également moins chères : elles coûtent 1,25×/2× le prix d'entrée sur l'API, tandis que sur l'abonnement elles sont facturées au prix d'entrée normal. Chaque tour de conversation est écrit dans le cache avant de pouvoir être lu, ce qui a donc aussi son importance.
Voici le lien entre credit et tokens :
Ce sont les unités utilisées en interne pour suivre la consommation de votre abonnement. « Crédits » est mon nom arbitraire pour ça — ces valeurs n'apparaissent pas directement dans un champ de l'API, donc il n'y a pas de mot évident pour les désigner. Je trouve que « crédits » sonne bien.
Comment passe-t-on des crédits aux tokens ? Voici la formule :
credits_used = ceil(input_tokens × input_rate + output_tokens × output_rate)...et les valeurs à y insérer :
Modèle Crédits/token en entrée Crédits/token en sortie Haiku 2/15 = 0,133... 10/15 = 2/3 = 0,666... Sonnet 6/15 = 2/5 = 0,4 30/15 = 2 Opus 10/15 = 2/3 = 0,666... 50/15 = 10/3 = 3,333... Les valeurs spécifiques semblent assez arbitraires, mais les ratios entre elles reflètent la tarification de l'API : la sortie coûte 5× l'entrée, vous paierez 5× plus pour Opus que pour Haiku, etc.
Après la lecture de cet article, il est clair que je vais utiliser principalement un abonnement Claude plutôt que des tokens d'API. Cependant, l'accès à un LLM par abonnement est moins flexible qu'une OpenAI Chat Completions compatible API.
Par exemple, je ne peux pas connecter Open WebUI, LibreChat ou toute autre application qui nécessite un accès direct à un LLM.
Mi-janvier 2026, j'ai lu ce thread à propos d'un "hack" utilisé par OpenCode pour accéder directement à l'API Anthropic avec un abonnement Claude. Ça m'a donné l'idée de chercher des outils de type "proxy" capables d'exposer une OpenAI Chat Completions compatible API à partir d'un abonnement Claude.
En fouillant sur Reddit, dans ce thread, j'ai trouvé les projets suivants :
Je compte tester ces deux projets dans les semaines à venir.
Dimanche 15 février 2026
Journal du dimanche 15 février 2026 à 15:23
#JaiDécouvert l'effet Zeigarnik que je n'arrive pas encore à bien maîtriser.
#JaiDécouvert aussi l'effet What the hell ou en français l'effet "Et puis merde".
Mardi 10 février 2026
Dimanche 8 février 2026
Je prends enfin le temps d'écrire ce texte pour trois raisons :
- Communiquer les informations du faire-part
- Remercier toutes les personnes qui m'ont témoigné leur soutien.
- Publier le discours que je souhaite prononcer à la cérémonie
Voici le faire-part publié dans Le Républicain Lorrain et Ouest France du 30 janvier 2026, que je me suis permis d'enrichir de quelques informations :
Laillé - Vern-sur-Seiche - Flévy - Metz - Thionville
Stéphane, Aurélie, ses enfants ; Elora, sa petite-fille ; Christian Klein, le père de ses enfants
ont la douleur de vous faire part du décès de Madame Françoise DEGAUGUE - KLEIN
Elle s'est éteinte le mardi 27 janvier 2026 à 23h55, à Bourg-des-Comptes à proximité de Rennes, entourée des siens et de son amie Marie-Annick, paisiblement et sans souffrance, après avoir lutté courageusement depuis le 31 juillet 2025 contre une leucémie.
Elle repose du vendredi 30 janvier au lundi 2 février à la chambre funéraire à Guichen.
Un dernier hommage lui sera rendu le lundi 9 février 2026, à 11 h 30, au crématorium de Vern-sur-Seiche.
Pas de fleurs, des dons en faveur de l'association Leucémie Espoir 35 seront préférés.
Tout d'abord, je tiens à remercier toutes les personnes qui m'ont écrit entre le 15 et le 27 janvier pour apporter leur soutien et leur tendresse à ma maman. J'ai bien pris soin de lui transmettre tous vos messages, écrits ou oraux. Merci infiniment 🙏. Françoise est restée lucide jusqu'au dernier jour et je suis certain que cela lui a fait très plaisir.
Merci à toutes les personnes qui se sont adressées à moi directement pour m'apporter leur soutien. Je suis infiniment touché par leur nombre et leur diversité : des personnes dont je ne pensais plus compter assez pour qu'elles m'écrivent, de la famille éloignée et même des amis de ma maman qui m'étaient totalement inconnus. Cette humanité m'a beaucoup ému.
Merci, sans ordre d'importance :
- Aux membres de ma famille proche 🤗
- Aux membres de ma famille plus éloignée 🤗
- À toutes les personnes du comité des fêtes et sages de Laillé, l'équipe d'organisation de la braderie, ses voisines, etc. 🤗
- Au club de Tennis de Table de Vern où maman était arbitre ces 2 dernières années 🤗
- Au COJEP Tennis de Table en Lorraine où maman était dans l'équipe de direction depuis le début des années 1990 🤗
- À de nombreux pongistes de Thionville, Montigny-les-Metz, Issy-les-Moulineaux et de mon club actuel de Châtillon 🤗
- À mon ancienne équipe de National 3 🤗
- À des anciens collègues de Spacefill et isWebdesign 🤗
- À une camarade de primaire de Flevy et une camarade de collège 🤗
- Et à toutes les autres personnes qui m'ont écrit 🤗
Le discours que j'espère arriver à prononcer, demain, lundi 9 février à 11h30, au crématorium de Vern-sur-Seiche.
Maman,
Tu es née en 1954 et tu as passé tes premières années à Casablanca, au Maroc. Tes parents étaient arrivés au Maroc depuis la France à la fin de la guerre.
Tu étais la petite dernière d'une famille de quatre enfants.
Tu as perdu ton père en 1963, alors que tu n'avais que neuf ans. Tu me parlais souvent de lui. Tu en gardais un tendre souvenir.
Je veux te dire merci pour tous les beaux souvenirs d'enfance : les moments à Metz, puis à Flévy. Je me souviens de tant d'étés merveilleux. J'étais très heureux.
Merci aussi de m'avoir toujours accompagné au tennis de table. Et pour les vacances à Argelès-sur-Mer.
Ces dernières années, tu avais choisi de vivre en Bretagne, à Laillé depuis 2021. Tu t'y étais créé un nouveau cercle d'amis. J'ai l'impression que tu étais heureuse ces dernières années.
J'ai eu la chance de t'emmener à Londres en 2008. Je sais que tu en rêvais depuis longtemps.
En 2017, nous sommes allés à Casablanca revoir ta maison d'enfance. Avec du recul, c'était pas grand-chose pour moi, mais je sais combien c'était important pour toi. Je suis heureux d'avoir pu faire ça. La photo devant ta maison d'enfance... je sais l'émotion qu'elle t'a apportée.
Malgré tout, j'ai des regrets. On avait des projets. Je pensais qu'on avait du temps.
L'Écosse, la baie de Somme, la Savoie... tous ces voyages qu'on n'a pas faits. Le temps nous a manqué.
Je suis terriblement triste que tu n'aies pu profiter que cinq jours de ta petite maison à Chef-Chef, en bord de mer. On devait passer quelques jours ensemble. La maladie a tout annulé. Je n'aurai qu'un seul souvenir là-bas avec toi : un jour froid et pluvieux de novembre.
Je me souviens de notre dernière balade dans les beaux petits chemins de Laillé, le 31 mai 2025. J'étais incapable d'imaginer que ce serait la dernière. Ça me semble encore irréel.
J'ai eu la chance d'être auprès de toi une dizaine de jours pour t'accompagner, entouré de ma sœur et de mon père. C'était un beau cadeau d'être tous ensemble.
Je suis rassuré que tu sois partie sans souffrance.
Le jour où tu m'as téléphoné pour m'annoncer la fin, tu m'as dit : « Crois-moi, je me suis battue, battue, mais là c'est fini. Pardonne-moi, mais j'abandonne. »
Je te comprends. Ça a été dur. Tu peux partir maintenant. Rejoindre ton papa qui t'attend depuis plus de 60 ans.
Je remercie les équipes soignantes de l'hôpital. Elles ont été remarquables d'humanité et de professionnalisme.
Je remercie toutes les personnes qui ont envoyé des messages à Françoise ces dernières semaines. J'ai pris soin de les lui transmettre. Cela m'a beaucoup touché.
Et pour finir, un grand et tendre merci à Marie-Annick.
Cet événement me rappelle combien la vie est courte et précieuse. J’en prends pleinement conscience seulement depuis 3 semaines !
Au revoir, maman.
Je ne suis pas croyant, mais je te souhaite d'être heureuse là où tu es.
J'espère que tu peux me voir.
Je te dis merci.
À bientôt. Attends-moi quelques dizaines d'années, et je te retrouverai.
Je t'aime.
































Mercredi 4 février 2026
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :
Pas de notes plus récentes | [ Notes plus anciennes (1144) >> ]