
Kubernetes
Article Wikipedia anglais : https://en.wikipedia.org/wiki/Kubernetes
Journaux liées à cette note :
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Quelques outils CoreOS : coreos-installer, graphe de migration et zincati
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Fusion de CoreOS et Atomic Project en 2018".
coreos-installer
L'outil coreos-installer est un composant essentiel de Fedora CoreOS. Il propose différentes méthodes pour installer Fedora CoreOS.
La commande coreos-installer download permet de télécharger tout type de version de CoreOS, sous différents formats, par exemple iso, raw, qemu, cloud image, etc (toutes celles présentes dans la page download).
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée vers un disque. Cette commande est par exemple disponible à la fin du boot d'une image ISO. Contrairement à Fedora Silverblue qui propose d'installer la distribution avec Anaconda, l'installation de CoreOS s'effectue en cli via coreos-installer install.
Ensuite, la commande coreos-installer install permet d'installer la version téléchargée sur un disque. Cette commande est notamment accessible après le démarrage d'une image ISO. Contrairement à Fedora Silverblue qui utilise l'installateur graphique Anaconda, CoreOS s'installe exclusivement en cli via coreos-installer install.
Toutefois, coreos-installer permet de préparer une installation automatique. La commande coreos-installer iso customize modifie une image ISO existante pour y intégrer directement une configuration ignition, rendant l'installation entièrement automatisée au démarrage.
Voici un exemple dans mon playground : atomic-os-playground/create-coreos-custom-iso.sh.
coreos-installer pxe permet aussi d'effectuer une configuration automatique par réseau, via PXE, mais je ne l'ai pas testé.
Graphe de migration de versions
Lors de mes tests d'upgrade de CoreOS à partir d'une ancienne release (environ n-10), j'ai constaté que la transition vers la dernière version ne se faisait pas directement mais nécessitait le passage par des versions intermédiaires.
J'ai découvert que CoreOS maintient un graphe qui définit le parcours d'upgrade requis. Certaines versions intermédiaires doivent être installées pour gérer des breaking changes, comme la migration de configurations.
zincati
Un autre composant important de Fedora CoreOS est zincati, le service responsable de l'exécution des mises à jour automatiques.
zincati décide d'effectuer les mises à jour en fonction du seuil de prudence de déploiement (rollout_wariness) et de la stratégie de mise à jour : immediate ou periodic (plage horaire définie dans la semaine).
CoreOS utilisant par défaut la stratégie immediate, zincati détecte automatiquement les nouvelles releases dès le premier démarrage et lance immédiatement leur téléchargement, suivi d'un redémarrage.
Le téléchargement par deltas rend l'upgrade vers la dernière release très rapide.
zincati permet également de coordonner les mises à jour de plusieurs serveurs, fonctionnalité particulièrement utile dans le contexte d'un cluster Kubernetes. Je n'ai pas encore testé cette fonctionnalité.
Note suivante : "composefs, un filesystem spécialement créé pour les besoins des distributions atomic".
Journal du lundi 22 septembre 2025 à 21:26
Dans le cadre du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab", j'étudie CoreOS.
Dans la page "Fedora CoreOS Release Notes stable" je vois quelques packages mis en avant :
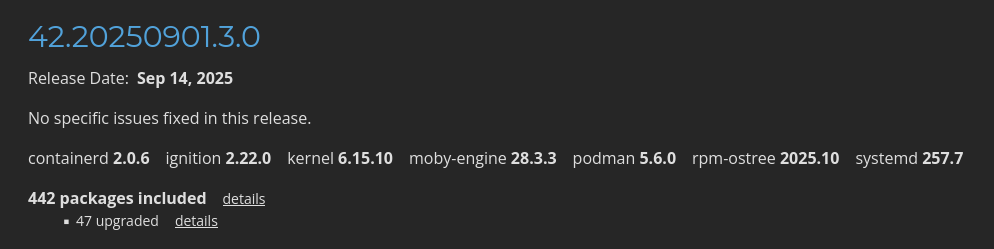
Je constate que CoreOS installe par défaut containerd, moby-engine et podman.
Information de type #mémento #mémo au sujet de containerd, moby-engine et podman.
- Kubernetes intéragie directement avec containerd.
- Depuis 2017, Docker est basé sur containerd + moby-engine. Sous Fedora, la commande
dockerest installée par le packagedocker-cli. - podman est une alternative rootless à Docker. podman n'est pas basé sur containerd, ni moby-engine.
Est-ce qu'une fonction Open WebUI peut importer une autre fonction Open WebUI ?
J'ai essayé de comprendre si une fonction Open WebUI pouvait importer le code d'une autre fonction Open WebUI.
La réponse est non. Je vais tenter dans cette note d'expliquer pourquoi.
(j'ai aussi publié une version de cette note en anglais dans la section "discussions" de Open WebUI)
Open WebUI propose de méthode pour créer ou mettre à jour une fonction Open WebUI sur une instance en production : via l'interface web d'administration, ou via l'API REST.
Une instance production fait référence à Open WebUI hébergé sur une Virtual machine ou un Cluster Kubernetes, par opposition à une instance locale lancée en mode développement.
Dans un premier temps, j'ai essayé d'importer dans Open WebUI les deux fichiers suivants :
# utils.py
def add(a, b):
return a + b
# hello_world.py
from pydantic import BaseModel, Field
from .utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le fichier hello_world.py contient un import de utils.add implémenté dans le premier fichier.
L'importation du premier fichier est refusée par Open WebUI parce que class Pipe: est absent de utils.py.
J'ai ensuite trompé Open WebUI en ajoutant une classe Pipe fictive das le fichier utils.py et l'importation a réussi.
Ensuite l'import de hello_world.py a échoué parce que Open WebUI n'arrive pas a effectué l'import from .utils import add. J'ai ensuite effectué plusieurs tentatives d'import absolut, par exemple from open_webui.utils import add… mais sans succès.
J'ai pris un peu de temps pour étudier l'implémentation d'Open WebUI et j'ai identifié cette section de code :
module_name = f"tool_{tool_id}"
module = types.ModuleType(module_name)
sys.modules[module_name] = module
Ce code permet à Open WebUI de charger dynamiquement le code source des modules qui sont stockés dans la base de données.
Un esprit tordu pourrait en pratique importer une fonction chargé dynamiquement dans un autre module dynamique, par exemple :
from tool_utils import add
Mais cette méthode ne correspond pas à l'usage normal d'Open WebUI.
Pour implémenter des fonctions "modulaires", Open WebUI conseille d'utiliser la fonctionnalité "Pipelines" :
Welcome to Pipelines, an Open WebUI initiative. Pipelines bring modular, customizable workflows to any UI client supporting OpenAI API specs – and much more! Easily extend functionalities, integrate unique logic, and create dynamic workflows with just a few lines of code.
Pour les personnes qui souhaitent vraiment effectuer des imports dans des fonctions Open WebUI sans utiliser la fonction Pipelines, il existe tout de même une solution que j'ai implémentée dans la branche test-if-openwebui-function-support-import.
Voici le contenu de /functions/hello_world.py :
from pydantic import BaseModel, Field
from open_webui.shared.utils import add
class Pipe:
class Valves(BaseModel):
pass
def __init__(self):
self.valves = self.Valves()
def pipe(self, body: dict):
print("body", body)
return f"Hello, World! {add(1, 2)}"
Le contenu de /shared/utils.py
def add(a, b):
return a + b
Pour rendre accessible /shared/utils.py dans l'instance d'Open WebUI lancé loculement, j'ai configuré de volume mounts suivante dans mon /docker-compose.yml :
openwebui:
image: ghcr.io/open-webui/open-webui:0.6.15
restart: unless-stopped
volumes:
- ./shared/:/app/backend/open_webui/shared/
ports:
- "3000:8080"
Ensuite, si je souhaite pouvoir déployer en production cette fonction Open WebUI et le module utils.py, il sera nécessaire de build une image Docker customisé d'Open WebUI pour y inclure le fichier /shared/utils.py.
Cette méthode peut fonctionner, mais cela reste un "hack" non conseillé. Il est préférable d'utiliser la méthode "Pipelines".
Avril 2025, quelle est mon expérience Kubernetes ?
J'ai commencé à utiliser Kubernetes pour la première fois en janvier 2016. C'était dans un cadre professionnel, quand je travaillais chez Tech-Angels / Gemnasium.
Mes deux premiers projets étaient les suivants :
- Opérer et continuer à améliorer un cluster de 3 nodes basé sur OpenShift (surcouche Kubernetes de Red Hat) qui permettait d'héberger les services web de nos clients.
L'objectif était de fournir un service un peu comme Heroku, c'est-à-dire permettre un déploiement via un simple "git push".
Avec le recul, l'objectif ressemblait à ce que propose actuellement Clever Cloud. - Implémenter une version OnPremise de Gemnasium propulsée par Kubernetes.
En janvier 2016, Kubernetes était un projet très jeune, avec seulement 20 mois d'existence depuis la sortie de la première version 0.2.
L'écosystème était bien plus petit que maintenant. Par exemple, Helm n'était pas encore populaire.
J'ai commencé par installer la version 1.1 de Kubernetes avec les playbooks officiels Ansible.
Ce fut une expérience difficile, avec de nombreux crashs de clusters, tout particulièrement lors des montées en version.
L'expérience fut très enrichissante. Cela m'a permis de monter en compétence avec Docker, Kubernetes, Ceph…
J'ai ensuite utilisé Kubernetes de novembre 2018 à avril 2019, dans la team Kubernetes Kapsule de Scaleway.
La mission de cette équipe était de créer un produit qui permettait de déployer des clusters Kubernetes managés.
Je suis arrivé dans cette équipe 10 mois après le début du projet. J'ai contribué au projet pendant 5 mois, jusqu'au lancement du produit en production.
Cette fois encore, une partie du travail était de déployer des clusters Kubernetes from "scatch".
Expérience intéressante : j'ai appris à déployer des clusters Kubernetes via Kubernetes !
L'implémentation était inspirée de la méthode présentée dans cet article : Gardener - The Kubernetes Botanist.
Depuis avril 2019, je n'ai plus opéré de cluster Kubernetes. J'ai seulement continué à suivre de loin les actualités de cet écosystème. Je n'ai plus eu d'expérience pratique.
Maintenant que j'ai rejoint une mission dont le produit est déployé sur Kubernetes, je souhaite mettre à jour mes compétences pratiques dans ce domaine.
Voici quelques sujets sur lesquels je souhaite monter en compétence ces prochains mois :
- M'entrainement à utiliser et à créer des Helm Charts
- Déployer un ArgoCD pour apprendre à bien l'utiliser
- Jouer avec k3s
- Tester Postgres Operator
- Étudier et tester https://tilt.dev/
- kind (https://kind.sigs.k8s.io/)
- Grafana Tanka
- kustomize (https://github.com/kubernetes-sigs/kustomize)
Journal du jeudi 17 avril 2025 à 12:02
Alexandre m'a partagé le projet Postgres Operator, que j'avais peut-être croisé par le passé, mais que j'avais oublié.
Postgres Operator permet entre autres de déployer des instances PostgreSQL dans un cluster Kubernetes mais aussi de mettre en place des systèmes de backup logique et backup binaire.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du lundi 09 septembre 2024 à 16:03
Alexandre m'a partagé le projet Grafana Tanka.
Flexible, reusable and concise configuration for Kubernetes.
Je découvre ce thread Hacker News que je n'ai pas pris le temps de lire : Tanka: Our way of deploying to Kubernetes.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.