
Ubuntu
Ubuntu est une distribution Linux.
Journaux liées à cette note :
net-tools est déprécié, je dois remplacer "lsof -i" par "ss -tlnp"
J'utilise habituellement lsof -i | grep "8080" pour identifier le processus qui écoute sur le port 8080.
Comme je le mentionnais dans 2025-07-04_1614, j'ai appris net-tools au début des années 2000 et j'ai gardé cette habitude depuis.
D'après Claude Sonnet 4.5, iproute2 est devenu le standard dans Debian, Ubuntu et Fedora vers 2013-2015. net-tools a été supprimé de l'installation par défaut entre 2017 et 2018.
lsof (pour LiSt Open Files) interroge /proc pour récupérer les informations. Cette implémentation, comme tous les outils net-tools, est ancienne et n'utilise pas l'API moderne Netlink.
En 2025, la méthode recommandée pour identifier les processus écoutant des ports est cette commande iproute2 (code source) :
$ ss -tlnp | grep 8080
-t: TCP sockets-l: Listening sockets uniquement-n: Affichage numérique (pas de résolution DNS)-p: Affiche les processus
J'ai écrit cette note et bridge-utils est déprécié, je dois remplacer "brctl" par "ip link" pour m'aider à adopter les commandes modernes iproute2.
Pour apprendre cette nouvelle commande, j'ai ajouté la carte-mémoire suivante dans Anki :
Rocky Linux semble reproduire CentOS de manière plus fidèle que AlmaLinux
Hier, j'ai écrit la note "AlmaLinux ou Rocky Linux ?".
En ce moment, je suis en train d'approfondir mes connaissances sur le fonctionnement des différents network backend de QEMU et j'en ai profité pour comparer le comportement d'Ubuntu, AlmaLinux, Rocky Linux et CentOS.
J'ai lancé QEMU avec le paramètre qemu ... -nic user avec chacune de ces distributions et voici les résultats de ip addr dans chacune de ces VMs:
Ubuntu :
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
inet 10.0.2.15/24 metric 100 brd 10.0.2.255 scope global dynamic ens3
valid_lft 83314sec preferred_lft 83314sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic mngtmpaddr noprefixroute
valid_lft 86087sec preferred_lft 14087sec
inet6 fe80::5054:ff:fe12:3456/64 scope link
valid_lft forever preferred_lft forever
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute ens3
valid_lft 83596sec preferred_lft 83596sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86379sec preferred_lft 14379sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
CentOS :
$ sudo ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: ens3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute ens3
valid_lft 86341sec preferred_lft 86341sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86342sec preferred_lft 14342sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
$ ip addr
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:12:34:56 brd ff:ff:ff:ff:ff:ff
altname enp0s3
altname ens3
altname enx525400123456
inet 10.0.2.15/24 brd 10.0.2.255 scope global dynamic noprefixroute eth0
valid_lft 84221sec preferred_lft 84221sec
inet6 fec0::5054:ff:fe12:3456/64 scope site dynamic noprefixroute
valid_lft 86053sec preferred_lft 14053sec
inet6 fe80::5054:ff:fe12:3456/64 scope link noprefixroute
valid_lft forever preferred_lft forever
Ce que j'observe :
- Rocky Linux et CentOS semblent se comporter de manière identique :
- une interface réseau nommée
ens3qui signifie : ethernet slot 3 - et les noms alternatifs :
enp0s3qui signifie : ethernet, PCI bus 0, slot 3enx525400123456qui signifie : ethernet +x+ la adresse MAC sans les:
- une interface réseau nommée
- Ubuntu :
- une interface réseau nommée
ens3 - et un nom alternatif :
enp0s3
- une interface réseau nommée
- AlmaLinux :
- une interface réseau nommée
eth0 - et les noms alternatifs :
ens3enp0s3enx525400123456
- une interface réseau nommée
Voici les configurations de GRUB_CMDLINE_LINUX_DEFAULT :
Rocky Linux et CentOS :
GRUB_CMDLINE_LINUX_DEFAULT="console=ttyS0,115200n8 no_timer_check crashkernel=1G-4G:192M,4G-64G:256M,64G-:512M"
GRUB_CMDLINE_LINUX="console=tty0 console=ttyS0,115200n8 no_timer_check biosdevname=0 net.ifnames=0"
Ubuntu :
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
Conclusion de cette analyse : il me semble que Rocky Linux cherche à reproduire CentOS de manière très fidèle, alors qu'AlmaLinux se permet davantage de libertés dans son approche.
De 2000 à 2016, j'ai essentiellement déployé la distribution Linux Debian sur mes serveurs et après cette date des Ubuntu LTS.
Depuis 2022, j'utilise une Fedora sur ma workstation. Distribution que je maitrise et que j'apprécie de plus en plus.
J'envisage peut-être d'utiliser une distribution de la famille Fedora sur mes serveurs personnels.
J'avais suivi de loin les événements autour de CentOS en décembre 2020 :
- 8 décembre 2020 : CentOS Project shifts focus to CentOS Stream
- 16 décembre 2020 : Rocky Linux: A CentOS replacement by the CentOS founder
J'ai enfin compris l'origine du nom Rocky Linux :
"Thinking back to early CentOS days... My cofounder was Rocky McGaugh. He is no longer with us, so as a H/T to him, who never got to see the success that CentOS came to be, I introduce to you...Rocky Linux"
J'aime beaucoup cet hommage 🤗 !
J'ai étudié AlmaLinux et il me semble que cette distribution est principalement développée par l'entreprise CloudLinux, une entreprise à but lucratif qui vend du support Linux.
Personnellement, je trouve le positionnement d'AlmaLinux peu "fair-play" envers Red Hat : Red Hat investit massivement dans le développement de Red Hat Enterprise Linux et AlmaLinux récupère ce travail gratuitement pour ensuite vendre du support commercial en concurrence directe.
À mon avis, si une entreprise souhaite un vrai support sur une distribution de la famille Red Hat, elle devrait se tourner vers Red Hat Enterprise Linux et acheter du support directement à Red Hat plutôt qu'à CloudLinux.
Suite à ce constat, j'ai décidé d'utiliser Rocky Linux plutôt qu'AlmaLinux.
21h30 : j'ai reçu le message suivant sur Mastodon :
@stephane_klein you have things quite backwards. AlmaLinux is a non-profit foundation while Rocky is owned 100% by Greg kurtzer and they have over $100M in venture capital funding.
AlmaLinux has a community-elected board.
Suite à ce message, j'ai essayé d'en savoir plus, mais il est difficile d'y voir clair.
Par exemple : I’m confused about the different organizational structure when it comes to Rocky and Alma.
La page "AlmaLinux OS Foundation " que j'ai consultée m'a particulièrement plu.
J'ai révisé ma position, j'ai décidé d'utiliser AlmaLinux plutôt que Rocky Linux.
2025-12-02 : j'ai révisé ma position, pour des serveurs de production, j'ai décidé d'utiliser la version stable de CoreOS, plutôt que AlmaLinux ou Rocky Linux.
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
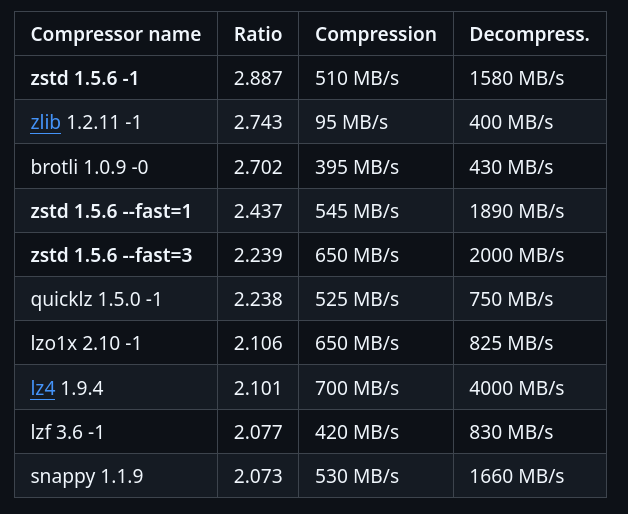
Benchmark sur le dépôt officiel de Zstandard :
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Journal du vendredi 11 octobre 2024 à 20:28
J'ai mis à jour mon repository vagrant-virtualbox-fedora vers Ubuntu 24.04 LTS.
Qu'est-ce que RPM Fusion et pourquoi ce nom ?
Jusqu'à ce soir, j'installais sous Fedora des packages qui vennait du dépôt RPM Fusion sans vraiment avoir étudié ce qu'était-ce repository. Je viens de me renseigner et voici ce que j'ai appris.
"RPM Fusion" est l'équivalent des dépôts "contrib et non-free" chez Debian ou "universe et multiverse" chez Ubuntu.
Le terme "Fusion" dans "RPM Fusion" fait référence à l'origine du dépôt. RPM Fusion est né de la fusion de plusieurs dépôts tiers qui existaient avant sa création en 2007-2008, tels que : Livna, Freshrpms et Dribble.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.