
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (0) >> ]
Journal du jeudi 04 juillet 2024 à 22:27
#JeLis la section Example: Decorations de CodeMirror qui je pense me sera très utile pour Projet 8.
#JaiDécouvert ici MatchDecorator. Je pense devoir utiliser MatchDecorator pour implémenter Projet 8.
#JaiDécouvert l'article [Learning CodeMirror] que #JeSouhaite lire.
L'implémentation dans SilverBullet.mb de la fonctionnalité décrite dans Projet 8 se trouve ici.
Journal du dimanche 23 juin 2024 à 22:22
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211 et 2024-06-23_1057.
#JaiCompris en lisant ceci que pg_search se nommait apparavant pg_bm25.
#JaiDécouvert que Tantivy — lib sur laquelle est construit pg_search — et Apache Lucene utilisent l'algorithme de scoring nommé BM25.
Okapi BM25 est une méthode de pondération utilisée en recherche d'information. Elle est une application du modèle probabiliste de pertinence, proposé en 1976 par Robertson et Jones. (from)
Je suis impressionné qu'en 2024, l'algorithme qui je pense est le plus performant utilisé dans les moteurs de recherche ait été mis au point en 1976 😮.
#JaiDécouvert pgfaceting - Faceted query acceleration for PostgreSQL using roaring bitmaps .
J'ai finallement réussi à installer pg_search à l'image Docker postgres:16 : https://github.com/stephane-klein/pg_search_docker.
J'ai passé 3h pour réaliser cette image Docker, je trouve que c'est beaucoup trop 🫣.
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
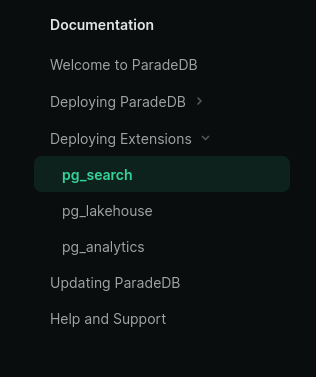
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Journal du jeudi 20 juin 2024 à 22:11
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans cette version du 20 juin j'ai implémenté :
- Importation des fichiers dans des nodes de type
notesdans un graph. - Le contenu des notes dans une table
public.notes - Les aliases dans la table
public.note_aliases - Importation des tags et leurs liaisons vers les notes dans un graph.
Au stade où j'en suis, je suis encore loin d'être en capacité de juger si le moteur de graph — Age — me sera utile ou non pour réaliser des requêtes simplement 🤔.
Prochaine fonctionnalités que je souhaite implémenter dans ce projet :
- [ ] Recherche de type fuzzy search sur les
Note.title,aliasetTag.namebasé sur la méthode Levenshtein du module fuzzystrmatch - [ ] Recherche plain text sur le contenu des Notes basé sur pg_search
Dans la liste des features de pg_search je lis :
- Autocomplete
- Fuzzy search
Je pense donc intégrer pg_search avant fuzzystrmatch. Peut-être que je n'aurais pas besoin d'utiliser fuzzystrmatch.
Journal du dimanche 16 juin 2024 à 17:08
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
#JeMeDemande si la convention est de nommer les nodes au singulier ou au pluriel, par exemple Note ou Notes 🤔.
D'après cette documentation, je comprends que la convention semble être le singulier.
Journal du samedi 08 juin 2024 à 17:08
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Alors que je travaille sur cette partie du projet, je relis la documentation de pg_dumpall et je constate à nouveau que cette commande ne supporte pas les différents formats de sortie que propose pg_dump 😡.
C'est pénible… du coup, j'ai enfin pris le temps de chercher si il existe une solution alternative et #JaiDécouvert pg_back :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
C'est parfait, c'est exactement ce que je cherche 👌.
Mais je découvre aussi les fonctionnalités suivantes :
- Pre-backup and post-backup hooks
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure or a remote host with SFTP
Conséquence : #JeMeDemande si j'ai encore besoin de restic dans Projet 7 🤔.
Je viens de lire ici :
In addition to the N previous backups, it would be nice to keep N' weekly backups and N'' monthly backups, to be able to look back into the far past.
C'est une fonctionnalité supporté par restic, donc pour le moment, je choisis de continuer à utiliser restic.
Pour le moment, #JaiDécidé d'intégrer simplement pg_back dans restic-pg_dump-docker en remplacement de pg_dumpall et de voir par la suite si je simplifie ce projet ou non.
Journal du vendredi 07 juin 2024 à 17:12
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Hasard du calendrier, mon ami Alexandre travaille en ce moment sur un projet nommé restic-ftp-docker.
Quelle différence avec restic-pg_dump-docker ?
Principale différence d'objectif entre ces deux projets :
restic-ftp-dockersauvegarde via restic le contenu d'un dossier vers un espace FTP.restic-pg_dump-dockersauvegarde via restic le contenu d'une base de données PostgreSQL. Le contenu de la base de données est exporté avec la commande standard pg_dump de PostgreSQL. La sauvegarde peut être envoyée vers tous les storages supportés par rclone.
#JaiDécidé de reprendre un maximum d'élément du projet restic-ftp-docker dans restic-pg_dump-docker.
#JeSouhaite proposer une Pull Request à restic-ftp-docker pour étendre ce projet à tous les storages supporté par rclone et ne plus le limité au storage ftp.
Journal du mercredi 22 mai 2024 à 10:33
Je viens de finir Projet 6 - "SvelteFlow playground", voici un screencast de démonstration du résultat :
J'ai passé 5h27 sur ce projet.
Code source de ce projet https://github.com/stephane-klein/svelteflow-playground
Ma plus grosse difficulté a été de trouver comment implémenter les containtes liaison.
Pour le moment, je doute que mon implémentation respecte les bonnes pratiques d'utilisation de la librairie. Je pense que je vais découvrir le "bon" usage — tel que imaginé par Moritz Klack — de la librarie au fur et à mesure de mon utilisation.
Journal du mardi 21 mai 2024 à 16:22
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
17:00 : J'ai réussi à ajouter un CustomNode (commit).
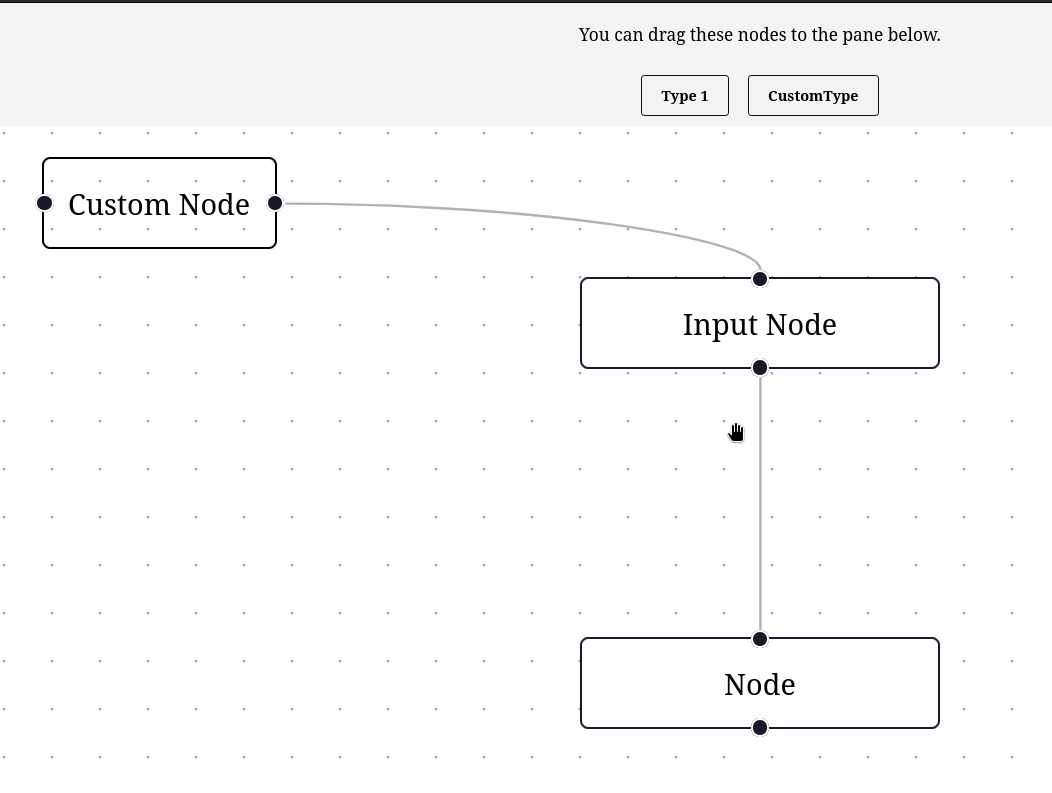
23:00 : Dans ce commit, j'ai réussi à définir des contraintes de liaisons. Il n'est plus possible de lier deux nodes du même type.

Journal du lundi 20 mai 2024 à 11:01
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
Je me suis inspiré de l'exemple Drag and Drop pour implémenter ce commit, ce qui donne ceci :
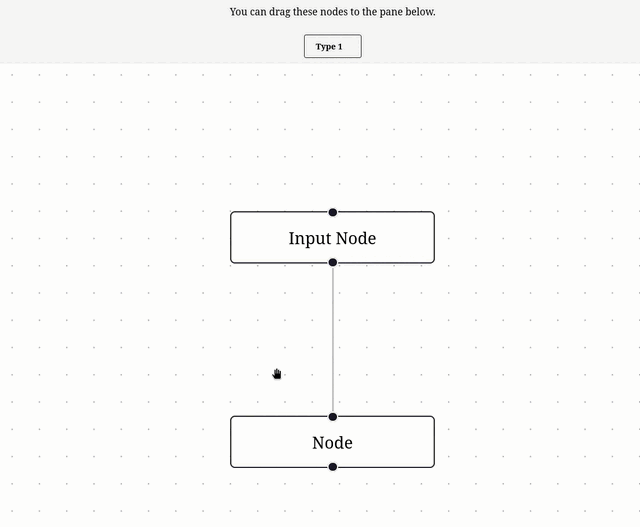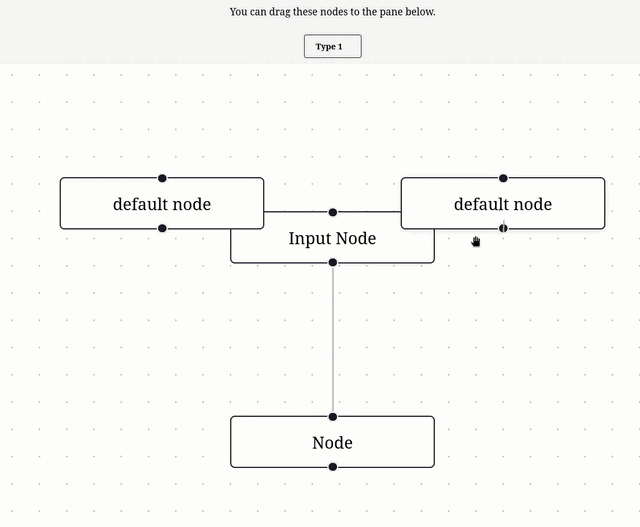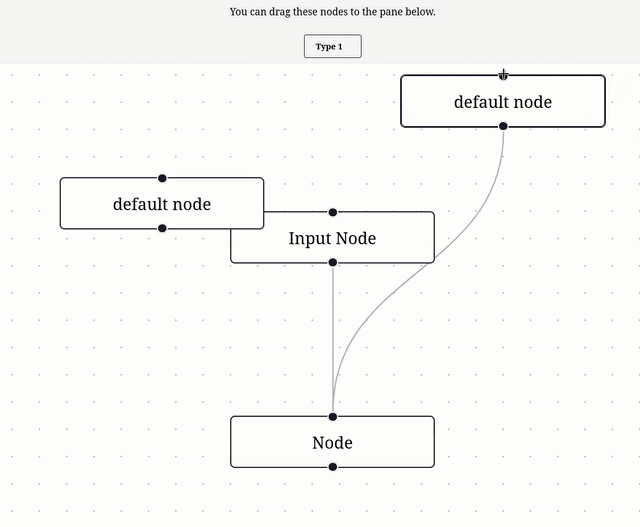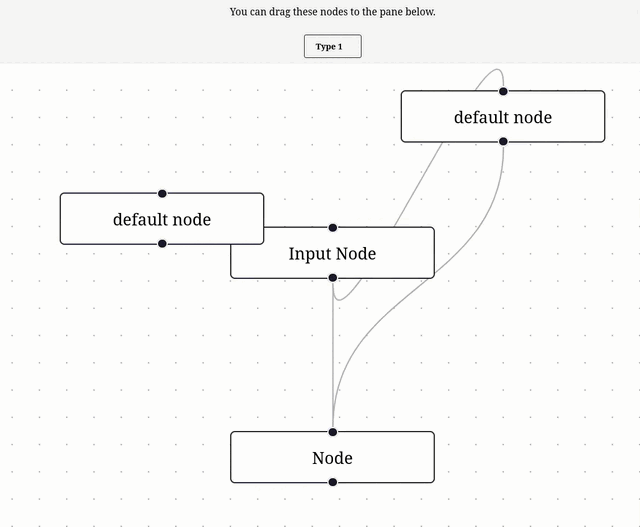
11:19 : Prochaine étape, lire et comprendre Theming – Svelte Flow.
11:32 :
- J'ai trouvé ce projet https://github.com/theonlytechnohead/patchcanvas/ qui peut me servir de source d'inspiration.
- #JeMeDemande si je dois implémenter un composant de type
<Handle />pour définir des contraintes de liaisons entre les nodes 🤔.
12:29 :
Journal du jeudi 16 mai 2024 à 09:44
Voici ma dernière itération du Projet -1 "CodeMirror, autocomplétion, Svelte".
Code source https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc
Journal du vendredi 10 mai 2024 à 08:37
#JeMeDemande si le code de SilverBullet.mb pourrait m'inspirer dans mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai l'impression que le code qui m'intéresse se trouve vers ici.
Je pense que CompletionTooltip est la classe qui est responsable de l'affichage du "completion picker".
09:56 : J'ai réussi à afficher un "completion picker" minimaliste :
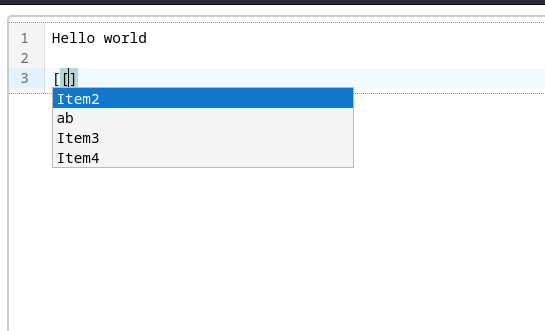
10:02 : Prochaines itérations :
- [ ] Essayer d'implémenter le chargement de la liste d'items de suggestion de manière dynamique. Je souhaite obtenir cette liste via une requête GET http, sur l'url
/get-suggestions/. Cette fonctionnalité est souvent nommée « remote data fetch » (exemple ici). - [ ] Essayer d'implémenter un chargement dynamique d'items de manière progressif. Au lieu de charger toutes la listes des items, l'objectif et de les charger au fur et à mesure, par exemple en petit paquets de 100 items). L'objectif de cette tache ressemble à https://github.com/vtaits/react-select-async-paginate.
Journal du jeudi 02 mai 2024 à 22:57
J'ai traité Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age".
Le résultat se trouve ici https://github.com/stephane-klein/apache-age-playground.
J'ai réussi à écrire plusieurs requêtes Cypher, mais je suis très loin de maitriser ce langage. Pour le moment, je me base principalement sur les exemples donnés dans la documentation.
Journal du mardi 30 avril 2024 à 23:04
Je continue mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte".
Voici le résultat de ma dernière itération :
#JeMeDemande si CodeMirror implémente une fonctionnalité comme conceal de Neovim 🤔. J'ai trouvé :
Première itération d'un POC de CodeMirror avec l'autocomplétion
#JaiPublié https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc qui contient mes 2 premières heures de travail sur le #POC Projet 1 - "CodeMirror, autocomplétion, Svelte".
J'ai réussi à setup le projet, mais pour le moment, je n'arrive pas à bien configurer la fonctionnalité autocomplete de CodeMirror. Par exemple, je n'arrive pas à ne pas afficher les caractères [[ dans le popup qui affiche la liste des suggestions.
Idéalement, pour expliquer, j'aimerais réaliser un screencast.
Je pense que ce POC va me prendre du temps. Je pense que je vais devoir étudier en profondeur l'API de @codemirror/autocomplete.
#SiJeDevaisParier, mon estimation de durée 🤔 serait de 8h à 20h de travail.
Journal du lundi 11 mars 2024 à 08:33
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
Je vais essayer d'implémenter ce DSL dans https://github.com/stephane-klein/postgres-tags-model-poc/issues/8
Journal du dimanche 10 mars 2024 à 10:29
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai rédigé la version Française du billet que je souhaite publier : https://a51nxj8cxk.joplinusercontent.com/shares/c0UzIdTp2nlP0H1R7I4o5F.
Version anglaise du billet : https://a51nxj8cxk.joplinusercontent.com/shares/qCbq5t9WA3o4xr8b5CgZjW.
Proposition de titre en FR : "Demande de conseils pour convertir une query filter string sur des tags en SQL, exemple "(tag1 and tag2) or tag3" en SQL"
Proposition de titre en EN : "Need advice on how to convert a filter string query on tags in SQL, for example "(tag1 and tag2) or tag3" in SQL?"
J'ai posté le billet sur https://old.reddit.com/r/PostgreSQL/comments/1bb6qvj/need_advice_on_how_to_convert_a_filter_string/? et aussi sur https://sklein.xyz/fr/posts/2024-03-10_demande-de-conseils-pour-convertir-une-query-filter-string-sur-des-tags-en-sql/
On m'a partagé Peggy qui me semble en effet, intéressant.
Journal du samedi 09 mars 2024 à 10:22
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
#JaiLu Google Search Operators: The Complete List (44 Advanced Operators)
Je constate que le langage de query de Google support OR, AND, les (……)… En résumé, toutes les fonctionnalités que je souhaite.
Dans l'article How to use advanced syntax on DuckDuckGo Search je comprends que le langage de query de DuckDuckGo supporte les fonctionnalités que je souhaite, mais avec une syntax intéressante, sans doute pratique, mais je la juge moins explicite que celle de Google.
J'ai lu la page Log queries de Loki et je ne la trouve pas adaptée à mon besoin. Cette syntax est trop puissante. Je souhaite quelque chose de plus limité, qui permette seulement d'effectuer des filtres basés sur des tags.
J'ai lu la page Filtering projects de GitHub et je constate que ce langage de query est trop limité, ne correspond pas à mon besoin.
La syntax de recherche de Lobsters est trop limitée par rapport à mon besoin https://lobste.rs/search
Concernant Jira, j'ai commencé ma lecture sur cette page Use advanced search with Jira Query Language (JQL), j'ai ensuite lu :
Le "Jira Query Language (JQL)" est très puissant, même trop puissant par rapport à mon besoin.
J'ai lu la page Filtering de Meilisearch.
La syntaxe est puissante, intéressante.
Après avoir étudié les query search syntax de Google, Duckduckgo, Melisearch, Loki, GitHub, Jira, Lobster je constate que mon besoin est un peu spécifique, car je souhaite effectuer des filtrages seulement sur les lables.
Le moteur de syntaxe qui ressemble le plus à ce que je cherche est le langage de syntaxe de Google.
Mon objectif est de pouvoir appliquer des règles d'appartenance sur les tags.
Journal du lundi 29 janvier 2024 à 11:09
#iteration Projet GH-339 - Implémenter un POC de Automerge.
J'ai une première version de https://github.com/stephane-klein/automerge-playground en vrac, mais qui fonctionne 🙂.
Todo :
- [ ] Ranger le repository, cleaner le code ;
- [ ] Mettre à jour le README pour y inclure un scénario compréhensible ;
- [ ] Essayer de faire une version Golang en m'inspirant de https://github.com/astromechza/automerge-experiments/.
J'aimerais à terme réaliser à partir de ce POC un outil comme Toggl basé sur Automerge, avec une version Web + TUI.
Journal du mercredi 10 janvier 2024 à 17:11
#iteration Projet GH-360 - Implémenter un POC de Fuzzy Search en PostgreSQL.
#JaiDécouvert que l'extension fuzzystrmatch implémente plusieurs algorithmes :
- Soundex => article Wikipedia : Soundex
- Daitch-Mokotoff Soundex => article Wikipedia : Daitch–Mokotoff Soundex
- Levenshtein => article Wikipedia : Levenshtein distance
- Metaphone => article Wikipedia : Metaphone
- Double Metaphone
Journal du lundi 21 août 2023 à 11:57
Pour le moment, j'ai passé 17h sur le Projet GH-289 - Créer un simulateur de manque à gagner suite à une rupture conventionnelle, licenciement économique ou licenciement simple.
Je ne comprends pas comment j'ai fait pour y passer autant de temps.
Peut-être le cumul de la recherche d'information juridique, le refactoring UX de la page 🤔.
À noter que je ne suis pas satisfait de cette version de l'UX.
Le projet est déployé sur Vercel à l'adresse suivante : https://comparateur-rupture-conventionnelle-cdi.sklein.xyz/
Dernière page.