
Git
Ressouces :
Journaux liées à cette note :
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :
2014-2018 approche alternative avec Atomic Project
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "CoreOS de 2013 à 2018".
La première version d'Atomic Project paraît en 2014, avec rpm-ostree comme élément central, développé principalement par Colin Walters de Red Hat.
rpm-ostree utilise libostree comme fondation, composant qui lui confère "toute sa puissance".
OSTree composant central de Atomic Project
Colin Walters a créé libostree en 2011 pour les besoins de GNOME Continuous.
libostree est un outil qui s'inspire de Git, mais se spécialise dans la gestion d'arbres de fichiers complets de système d'exploitation.
Principales différences avec Git :
- Aucune copie lors des checkouts : libostree repose sur des hardlinks, donc pas de working copy du fait de l'immutabilité des fichiers.
- libostree préserve les contextes SELinux, les xattrs, les uid/gid, ainsi que des timestamps précis
- libostree peut gérer les device nodes (
/dev/zero,/dev/null…), les sockets (/run/systemd/notify...), et tous les types de fichiers d'un filesystem d'OS - Un mécanisme de déduplication
- …
Avec OSTree, pas besoin de double partition
À la différence de CoreOS Container Linux qui utilisait le système de mise à jour A/B (seamless) system updates, Fedora Atomic Host (puis Fedora CoreOS) n'a pas besoin de deux partitions grâce à libostree.
Lors d'un upgrade, libostree réalise un "checkout" en utilisant la commande ostree-admin-deploy .
Puis grub communique au kernel le paramètre ostree= qui détermine sur quel déploiement booter.
Voici les avantages de l'utilisation de libostree par rapport au système A/B (seamless) system updates :
- libostree permet de conserver plusieurs déploiements, sans se limiter à 2
- Grâce au système de déduplication, libostree consomme beaucoup moins d'espace disque
- Grâce au téléchargement uniquement des deltas, les mises à jour sont très rapides
Néanmoins, alors que libostree offre techniquement la possibilité de créer autant de déploiements que souhaité, d'après mes tests, Fedora CoreOS semble actuellement limité à 2 déploiements seulement.
J'ai trouvé cette issue qui aborde ce sujet : support configuring host to retain more than two deployments.
rpm-ostree
Les utilisateurs d'Fedora Atomic Host n'interagissent pas directement avec libostree mais avec rpm-ostree.
rpm-ostree s'appuie sur les librairies libostree et libdnf pour installer des packages RPM et propose de nombreuses commandes d'administration de l'OS :
stephane@stephane-coreos:~$ rpm-ostree
Usage:
rpm-ostree [OPTION…] COMMAND
Builtin Commands:
apply-live Apply pending deployment changes to booted deployment
cancel Cancel an active transaction
cleanup Clear cached/pending data
compose Commands to compose a tree
db Commands to query the RPM database
deploy Deploy a specific commit
finalize-deployment Unset the finalization locking state of the staged deployment and reboot
initramfs Enable or disable local initramfs regeneration
initramfs-etc Add files to the initramfs
install Overlay additional packages
kargs Query or modify kernel arguments
override Manage base package overrides
rebase Switch to a different tree
refresh-md Generate rpm repo metadata
reload Reload configuration
reset Remove all mutations
rollback Revert to the previously booted tree
search Search for packages
status Get the version of the booted system
uninstall Remove overlayed additional packages
upgrade Perform a system upgrade
usroverlay Apply a transient overlayfs to /usr
Note suivante : "Fusion de CoreOS et Atomic Project en 2018.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du mardi 26 août 2025 à 21:45
Voici une note pour présenter la seconde #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
J'ai tout d'abord implémenté dans ce commit un mécanisme qui exécute du code JavaScript automatiquement après chaque git push.
Pour cela, j'ai choisi de me baser sur le mécanisme Server-Side Hooks natif de Git : post-receive.
Voici le contenu de ce script hook en Bash :
#!/bin/bash
while read oldrev newrev refname; do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
curl -X POST \
-H "Content-Type: application/json" \
-d "{
\"oldrev\": \"${oldrev}\",
\"newrev\": \"${newrev}\",
\"refname\": \"${refname}\",
\"branch\": \"${branch}\",
\"repository\": \"$(basename $(pwd))\"
}" \
"${POST_RECIEVE_HOOK_URL}" >> /dev/null
done
Chaque événement git push déclenche un appel HTTP vers le endpoint http://localhost:3334/post_recieve_hook_url/ exposé par le serveur NodeJS. Le payload contient notamment :
oldrev: l'identifiant du dernier commit présent dans le repository avant le pushnewrev: l'identifiant du commit le plus récent envoyé lors du push
L'intervalle entre oldrev et newrev permet d'identifier précisément l'ensemble des commits qui ont été poussés lors de cette opération.
J'ai ensuite implémenté une version SvelteKit iso-fonctionnelle de node-git-http-server. Voici le repository poc-node-git-server-in-sveltekit .
Contrairement à ce que j'avais prévu initialement, pour cette implémentation, je ne me suis pas basé sur SvelteKit Custom Server, mais sur la fonctionnalité Server hooks : src/hooks.server.js#L11.
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
2026-04-02 : étudier Beads comme source d'inspiration ou outil à intégrer.
Journal du mardi 06 mai 2025 à 13:42
Suite à la lecture du thread "jj tips and tricks" Lobster, je suis tombé dans un rabbit hole (1h30) : #JaiLu les articles ci-dessous au sujet de Jujutsu.
- "What I've learned from jj" (134 commentaires Hacker News et 57 commentaires Lobster)
- Et ses sous-articles :
- "jj tips and tricks"
Quelques commentaires au sujet de l'article "What I've learned from jj"
Along with describing and making new changes, jj squash allows you to take some or all of the current change and “squash” it into another revision. This is usually the immediate parent, but can be any revision.
...
With jj squash, the current change is pushed into whatever target revision you want. And if that change has children, they’ll all be automatically rebased to incorporate the updated code, no additional work is needed.
J'ai hâte de tester si, à l'usage, c'est sensiblement plus simple qu'avec Git 🤔.
Conflict resolution
One of the consequences of being able to modify changes in-place is that all subsequent changes need to be rebased to account for the updated parent. If there were a sequence
s -> t -> u -> vand you’d modifiedt, jj will automatically rebase the rest:s -> t' -> u' -> v'. This includes conflicts, if any arise. The difference from git is that conflicts are not a stop-the-world event! You’ll see in the jj log output that changes have a conflict, but it won’t prevent a command (like an explicit or implicit rebase) from running to completion. You get to choose when and how to resolve the conflicts afterward. I found this a surprising benefit: rebases are already less stressful because of how easyundois, but now I’m no longer interrupted and forced to resolve conflicts immediately.
Cette simplicité annoncée me surprend vraiment. J'ai du mal à imaginer le fonctionnement, sans doute parce que je suis trop habitué à utiliser Git. J'ai l'impression que c'est de la magie !
J'ai hâte de tester !
... efforts to add
Change-IDas a supported header in git itself to enable durable change tracking on top of commits.
J'ai découvert cette initiative, je trouve cela très intéressant👌.
Un commentaire au sujet de l'article "First-class conflicts"
First-class conflicts
...
Unlike most other VCSs, Jujutsu can record conflicted states in commits. For example, if you rebase a commit and it results in a conflict, the conflict will be recorded in the rebased commit and the rebase operation will succeed. You can then resolve the conflict whenever you want. Conflicted states can be further rebased, merged, or backed out. Note that what's stored in the commit is a logical representation of the conflict, not conflict markers; rebasing a conflict doesn't result in a nested conflict markers (see technical doc for how this works).
Je trouve cela très intéressant.
Voici une commande pour extraire un patch avec l'inclusion des "Conflict markers" (je n'ai pas encore testé) :
$ jj diff --include-conflicts > conflicts.patch
Un commentaire au sujet de l'article "In Praise of Stacked PRs"
“Stacked PRs” is the practice of breaking up a large change into smaller, individually reviewable PRs which can depend on each other, forming a DAG.
Je suis ravi de découvrir que le terme "Stacked PRs" existe pour décrire le concept que j'expliquais souvent quand j'étais chez Spacefill.
En lisant ces articles, #JaiDécouvert :
git-rerere- Mercurial Changset Evolution
git-machete- git-stack (
git-stack) - GitBulter (https://github.com/gitbutlerapp/gitbutler)
et j'ai "redécouvert" :
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du samedi 07 décembre 2024 à 19:04
En travaillant sur Projet 19, #JaiDécouvert le projet git-branchless (https://github.com/arxanas/git-branchless).
High-velocity, monorepo-scale workflow for Git.
Je n'ai pas encore compris à quoi cela sert.
La fonctionnalité "Activité" de GitLab me manque dans GitHub
La fonctionnalité "Activité" de GitLab me manque dans GitHub.
Voici trois exemples concrets de fonctionnement de cette fonctionnalité, dans trois contextes différents.
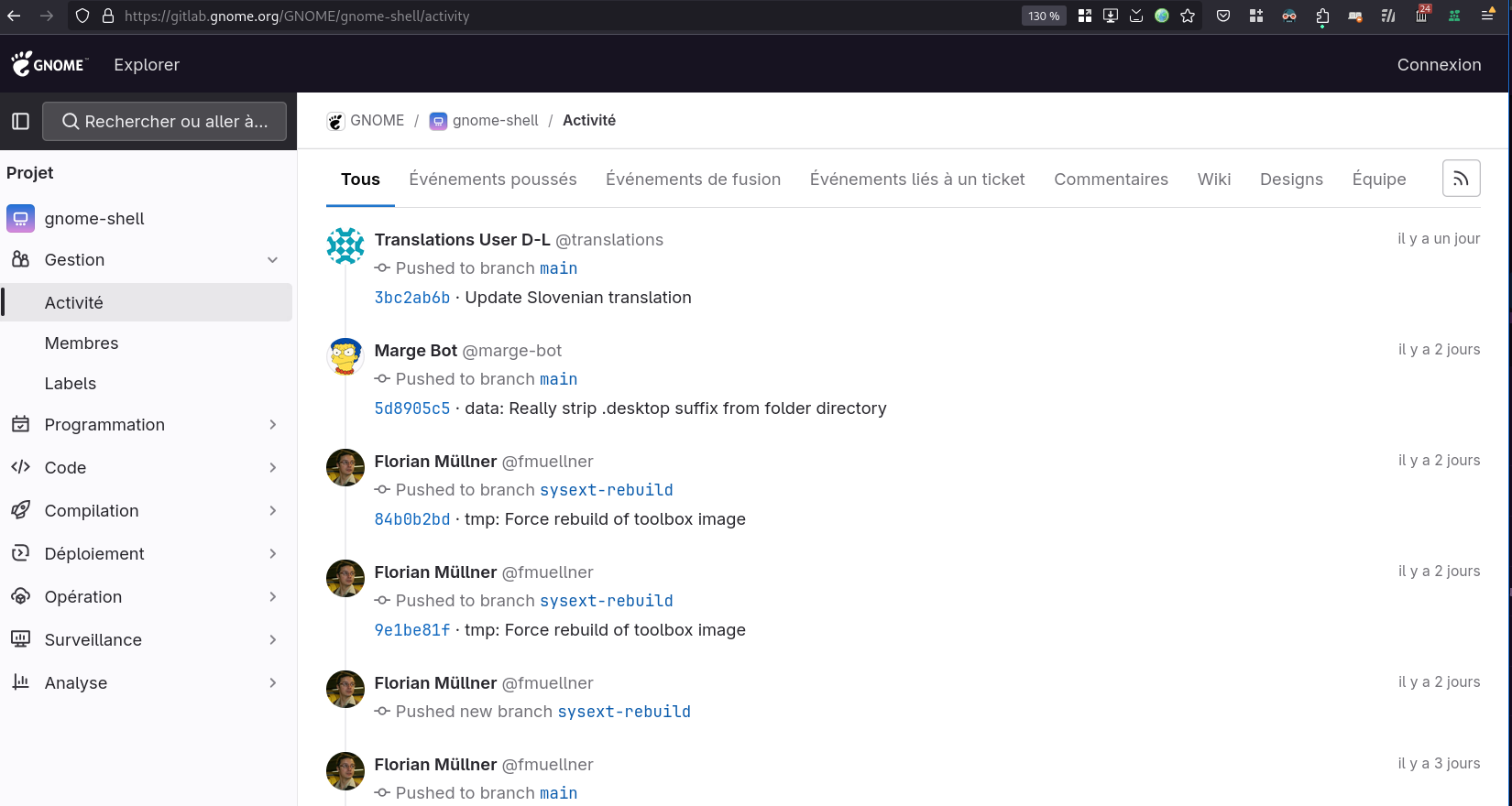
Le premier, dans le projet GNOME Shell :
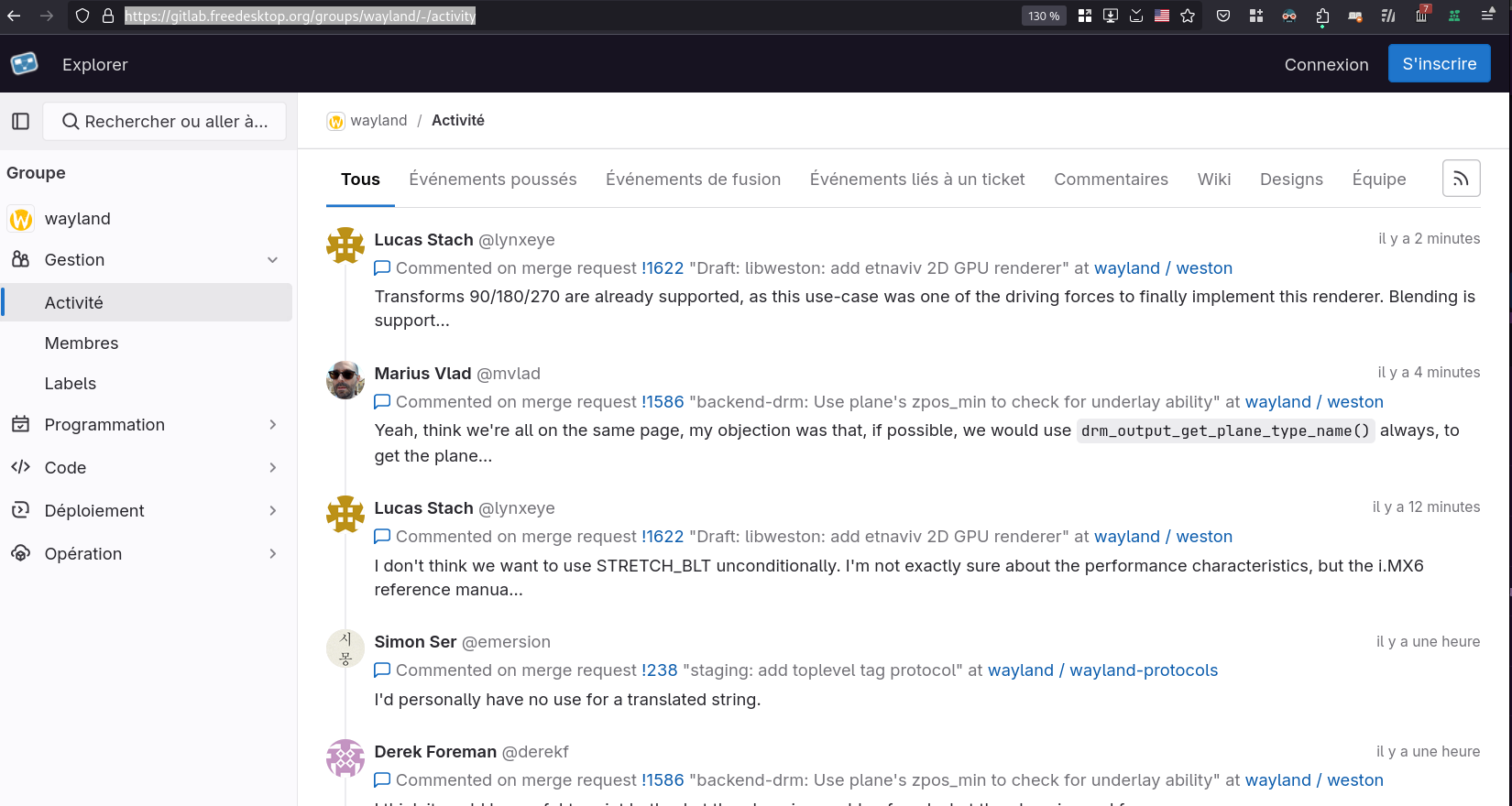
Le second, dans le groupe Wayland : https://gitlab.freedesktop.org/groups/wayland/-/activity
Et le troisième, pour l'utilisateur Lucas Stach: https://gitlab.freedesktop.org/users/lynxeye/activity
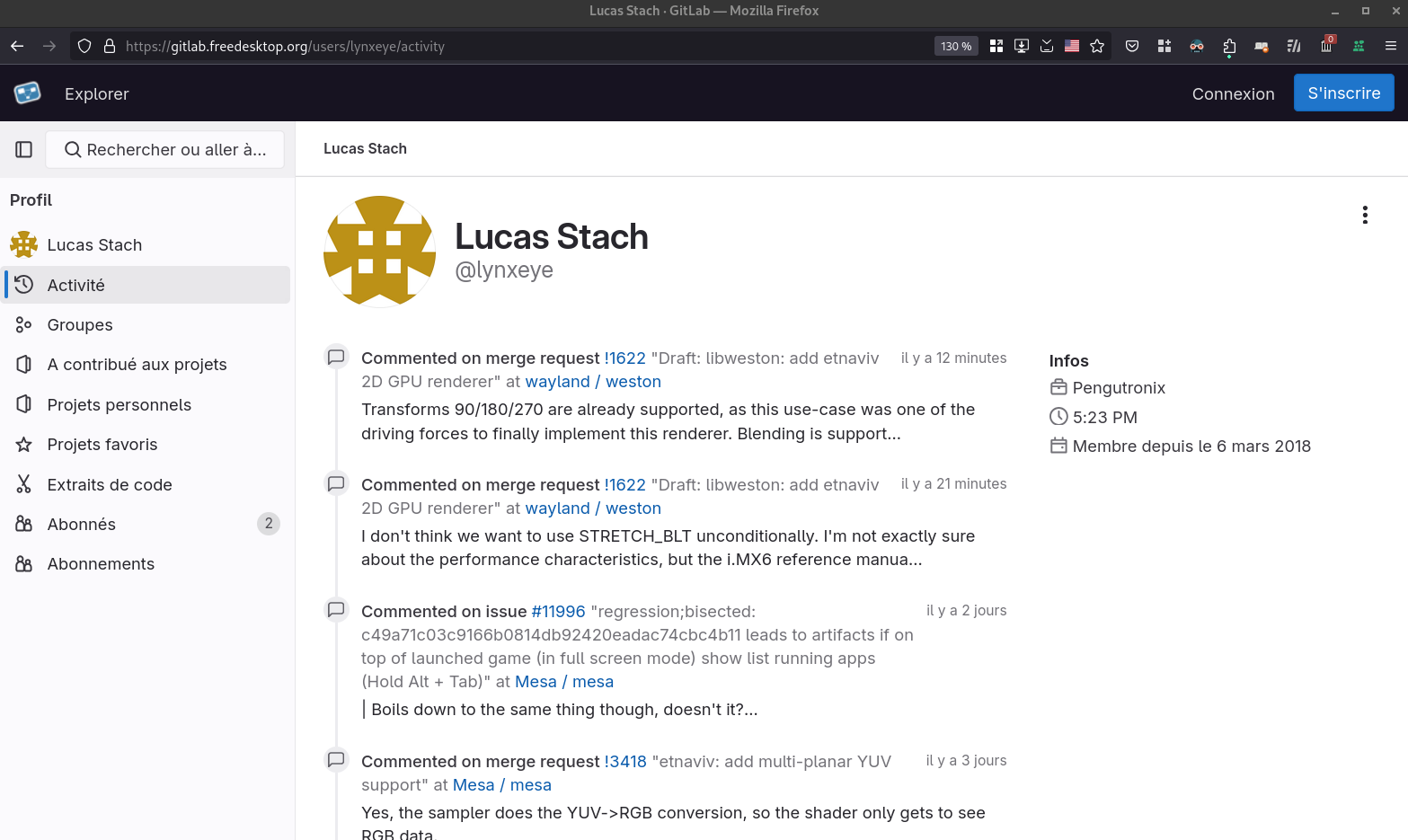
Je trouve cette fonctionnalité très utile quand on travaille sur un projet. Elle permet d'avoir une vue d'ensemble de ce qui s'est passé sur un projet sur une période. Elle vient en complément de l'historique Git qui est limité aux changements effectués sur le code source.
Dans certaines situations, je sais qu'un collègue travaille sur un sujet qui me concerne et la fonctionnalité "Activité" me permet de mieux comprendre où il en est, de suivre facilement ce qu'il fait.
Cette fonctionnalité "Activité" permet de pratiquer la stigmergie.
J'utilise aussi cette fonctionnalité lors de la rédaction d'un rapport d'activité ou d'un message de Daily Scrum. Elle m'aide à retrouver précisément ce que j'ai fait dernièrement.
Je trouve la page "Contribution activity" d'un user GitHub limité, par exemple, elle ne contient pas l'historique des commentaires.
Même chose au niveau d'un projet, dans la page "Pulse", par exemple : https://github.com/sveltejs/kit/pulse.
Je viens de regarder du côté de Codeberg / Forgejo : <https://codeberg.org/forgejo/forgejo/activity. Même constat que pour GitHub, les informations sont très réduites.