
prolétarisation
Le processus de prolétarisation est un concept très important dans ma façon de voir le monde.
Voici une interview de Bernard Stiegler à ce sujet (qui d'après ce billet semble dater de 2011) :
https://arsindustrialis.org/vocabulaire-proletarisation
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Rappelons tout d’abord que Marx ne dit pas que le prolétariat est la classe ouvrière : il dit que la classe ouvrière est la première classe à être touchée par la prolétarisation. Les prolétaires n’ont pas disparu : la prolétarisation, c’est à dire la perte des savoirs, a au contraire envahi « toutes les couches de la société ». Privé de savoir, le prolétaire est privé de travail, s’il est vrai que travailler c’est s’individuer en individuant son milieu de travail et en se co-individuant avec des collègues de travail, c’est à dire en formant avec eux un milieu associé. Le prolétaire est l’employé d’un milieu dissocié. Le prolétaire, dit Simondon, est désindividué par la machine qui a grammatisé et automatisé son savoir.
Au cours du XXe siècle cependant, ce qui est prolétarisé n’est plus seulement le savoir-faire du producteur : c’est aussi le savoir-vivre du consommateur. Le consommateur ainsi prolétarisé ne produit pas ses propres modes d’existence : ceux-ci lui sont imposés par le marketing qui a transformé son mode de vie en mode d’emploi.
La crise de 2008 a mis en évidence que ce sont aussi désormais les concepteurs et les décideurs qui sont prolétarisés : l’automatisation issue des « systèmes d’aide à la décision », tels les programmes informatiques de trading qui grammatisent unilatéralement les points de vue économiques et financiers dominants (renforçant souvent des processus entropiques – comme l’avait déjà montré une étude du crack boursier de 1987 réalisée par Catherine Distler, et comme le soulignait récemment Paul Jorion – processus entropiques qui constituent la base technologique de ce que l’on avait appelé « la pensée unique »), généralisent la situation qui s’était installée avec les systèmes informatiques nucléaires, où la prise de décision politique et militaire, formalisée dans les appareils de surveillance électronique, est court-circuitée par la performance de l’arsenal informatisé.
Que la grammatisation induise à travers le développement de ses stades successifs une prolétarisation n’est pourtant pas une fatalité : c’est une question pharmacologique, où l’alternative relève de ce que nous appelons une pharmacologie positive. De nos jours, cette question se pose avec une radicalité absolument inédite précisément dans la mesure où la prolétarisation atteint chacun d’entre nous, installant en chacun de nous les effets ravageurs de la « bêtise systémique », atteignant toutes les fonctions sociales, des plus humbles aux plus décisives. C’est pourquoi nous faisons de la déprolétarisation généralisée l’enjeu fondamental de l’économie de la contribution.
Autre définition donnée par Bernard Stiegler :
Le prolétariat, ça n’est pas la classe ouvrière, ça n’est pas les gens pauvres. La définition du prolétariat par Marx, c’est ceux qui perdent leur savoir, parce que leur savoir est extériorisé dans les machines. La prolétarisation des travailleurs manuels, décrite la première fois par Adam Smith 80 ans avant Marx, c’est le fait qu’avec les machines qui deviennent programmables, par exemple le métier Jacquard, le savoir qui était entre les mains de la fileuse qui fabriquait le tissu passe dans la machine à travers un programme qui est d’ailleurs l’origine du programme informatique, donc c’est une histoire très importante.
Journaux liées à cette note :
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
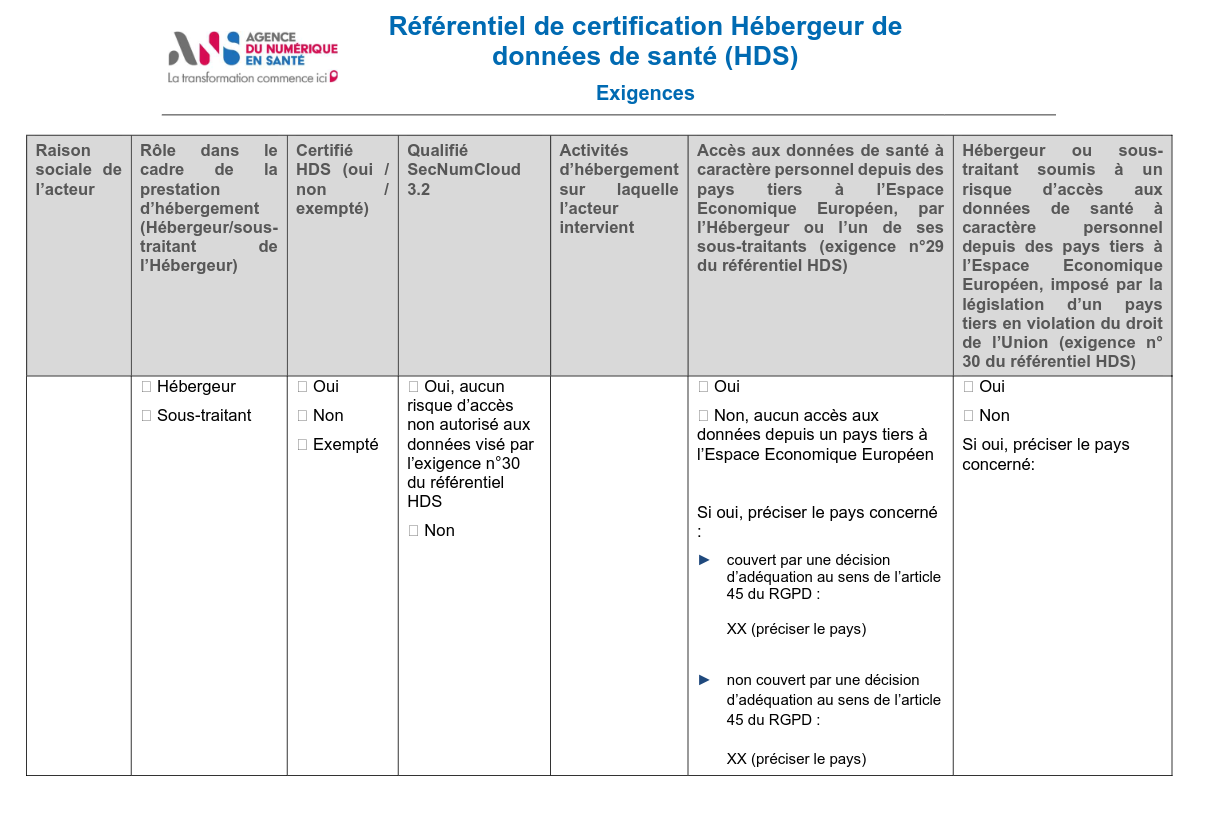
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
Ma lutte contre mon affaiblissement cognitif
#JaiLu cet excellent billet de Tristan Nitot qui traite du processus de prolétarisation : L'IA fait elle de nous des prolétaires ?.
Il rejoint totalement ce que je disais dans ma note : J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes.
Cela pose la question de la façon dont on aborde l’IA : peut-on profiter de l’IA sans y laisser son intelligence ?
À cette question, ma réponse imparfaite est celle-ci : j'essaie d'utiliser, autant que possible, les IA générative de texte comme un ami expert d'un domaine. J'essaie de ne jamais lui faire faire mon travail à ma place.
J'essaie de résister à l'injonction néolibérale d'effectuer chaque tâche le plus rapidement possible au nom de la rentabilité immédiate. Pour cela, tous les jours, j'essaie de trouver un équilibre entre la vitesse et prendre le temps de comprendre, de maîtriser les concepts et d'exécuter les gestes techniques. C'est loin d'être facile !
Pour lutter contre mon affaiblissement cognitif, j'essaie depuis quelques semaines d'intégrer Anki dans mes habitudes quotidiennes.
Mon objectif : créer une carte-mémoire pour chaque tâche que je délègue à un LLM alors que je devrais pouvoir l'accomplir moi-même.
Pour le moment, je n'ai pas la discipline pour respecter cet objectif, mais j'y travaille.
J'ai bien conscience que ma pratique est hétérodoxe. J'observe autour de moi que la tendance est la course à l'automatisation du maximum de tâches par l'IA. Je souhaite rester un artisan.
#JaiLu aussi le billet "Prolétarisation" de Carnets de La Grange.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ai.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Journal du vendredi 16 août 2024 à 13:06
Dans ma note Keep it simple, stupid le plus longtemps possible j'ai écris :
Je me souviens de la quête vers le minimaliste dans le code de David Larlet : « Est-ce qu’il est possible d'enlever des couches dans la stack ? »
Je viens d'essayer de retrouver ces articles, mais ce n'est pas facile tellement les articles de David Larlet sont nombreux.
Pour le moment j'ai retrouvé les extraits ci-dessous ceci en lien avec le sujet.
Paternité
- Ajouter des couches
- Changer des couches
- Enlever des couches
- Changer des couches
- Mettre des couches
J’en suis à l’étape 3 dans ma maturité en tant que développeur. La paternité change les priorités et je pense qu’elle a un grand rôle dans le fait de vouloir remettre le focus sur la valeur apportée plus que sur la technique. Me battre pour une meilleure expérience utilisateur plutôt que contre un framework, chercher à se faire plaisir davantage via ce qui est produit que par un contentement technique.
Lorsque j’expérimente aujourd’hui, ce n’est plus pour découvrir une nouvelle bibliothèque mais pour trouver de nouveaux moyens de simplifier un problème. Dans ce contexte, il est intéressant de re-questionner la page blanche (cache), de re-challenger certaines bonnes pratiques communément admises (cache).
Autre extrait :
Leftpad
Every package that you use adds yet another dependency to your project. Dependencies, by their very name, are things you need in order for your code to function. The more dependencies you take on, the more points of failure you have. Not to mention the more chance for error: have you vetted any of the programmers who have written these functions that you depend on daily?
J’étais en train de préparer cette intervention lorsque le fiasco leftpad est arrivé dans l’écosystème NPM. Du coup, j’ai eu immédiatement plein d’articles faisant une ode à la simplicité, à la réduction de dépendances et mettant en garde contre les couches d’abstraction. Merci Azer Koçulu, je pouvais difficilement rêver mieux :-). Je ne vais pas tirer sur l’ambulance mais ça illustre presque trop bien mon propos.
as your project progresses, your team’s productivity will drop because of all the complexity and dependencies. You’ll need more people to maintain it, and more people with specific knowledge to maintain it. If your lead developers leave, you’re dead. You should be fighting complexity and not embracing it. Every added framework, and even library, makes your project more difficult to maintain. Avoid unnecessary frameworks and libraries from day one.
Jusqu’où aller dans cette démarche ? Par où commencer ?
Autre extrait :
Maybe it’s not too late for you, though. Perhaps, like me, you aren’t feeling particularly overworked. But are you feeling irritable, tired, and apathetic about the work you need to do? Are you struggling to concentrate on simple tasks?
Then maybe what you’re feeling is burnout, too.
J’ai travaillé pendant un an et demi avec Mozilla sur la partie paiement du Marketplace puis sur le site des extensions de Firefox. Et depuis un an avec Etalab sur la plateforme datagouv. Dans les deux situations, j’ai passé davantage de temps à lutter contre les outils plutôt qu’à les apprécier pour le travail rendu. C’est terrible car ceux-ci sont censés théoriquement faire gagner du temps mais sur le long terme cela se révèle être faux dans mon cas.
Je me demande si je ne suis pas en train de faire un burnout technique, non pas par trop de travail mais par manque de contrôle dans mes outils.
Autre extrait :
The aesthetic microlith
Growth for the sake of growth is the ideology of the cancer cell.
Edward Abbey
Toutes ces raisons m’ont amené à étudier une nouvelle piste. Cette appellation est une combinaison du Majestic Monolith (cache) et des microservices. Je me persuade qu’il y a une voie différente entre ces deux extrêmes. Une voie qui limite les fuites d’abstraction (cache) afin de réduire la dette technique et de favoriser l’inclusion de nouveaux membres dans une équipe. Une voie qui ne demande pas de réécrire la moitié de l’application tous les six mois car une nouvelle montée en version majeure n’est pas rétro-compatible. Une voie où l’on ne raisonne plus en termes de features et de bugs mais d’expérience utilisateur et de satisfaction pour l’ensemble des parties prenantes. Un environnement qui permet de faire une pause dans les développements afin de prendre le temps de davantage considérer les besoins des personnes qui utilisent le produit.
We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
Dans cette recherche de simplicité, j’ai essayé de remettre en question chaque concept de programmation, chaque bonne pratique, chaque bibliothèque, chaque ligne de code. J’ai essayé de produire un prototype qui soit un peu plus conséquent que celui proposé à Confoo pour voir jusqu’où cela pouvait aller. Ce qu’il me manque c’est non pas du temps de développement mais du temps de vie du projet pour analyser les effets produits sur le moyen terme. Je devrais avoir l’occasion d’expérimenter cela avec scopyleft prochainement, ça sent la trilogie.
À court terme en tout cas, c’est extrêmement plus fun à coder et l’on arrive au résultat finalement aussi rapidement. Cela devient une matière beaucoup plus malléable, dont on connait les forces et les faiblesses car le périmètre est réduit. En contrepartie, certains cas aux limites vont être écartés et l’expérience de certains utilisateurs se dégrade plus rapidement. Ce n’est pas que le coût de prise en compte soit énorme, il s’agit davantage de le prendre en considération lorsque le besoin est réel.
Autre extrait :
Maintenance
Capitalism excels at innovation but is failing at maintenance, and for most lives it is maintenance that matters more
Innovation is overvalued. Maintenance often matters more (cache)
Le problème ici c’est que je n’ai jamais rencontré de projet qui réduisent leur complexité dans le temps. Que ce soit via des itérations de retrait ou des réécritures complètes on arrive toujours à des usines à gaz si l’on ne s’est pas fixé en amont — de manière consentie par toutes les parties prenantes — les budgets évoqués plus haut. Pourtant en restant à l’échelle du microlith, la maintenance se trouverait potentiellement réduite de beaucoup.
Si l’on s’en tient à l’estimation selon laquelle la maintenance représente 67% d’un produit (cache), il devient important de trouver comment réduire ce coût.
Autre extrait :
Frameworks, API et prolétarisation
La présentation 6 reasons why APIs are reshaping your business fait l’analogie du développement Web avec l’industrie automobile et le passage de l’artisanat à l’intégration de pièces toutes faites.
Si le passage aux frameworks JavaScript et CSS a entraîné la perte de savoir des développeurs front-end et leur prolétarisation, le passage aux API va avoir le même effet sur les développeurs back-end, ceux-ci devenant de simples intégrateurs de solutions existantes s’éloignant de la problématique métier et de ses données pour se perdre dans les couches du pragmatisme. N’oubliez pas qu’en facilitant le travail de la machine, on finit par être remplacé par la machine, c’est ce que nous réserve l’industrialisation du Web. Et ça me rend nostalgique.
Autre extrait :
A system where you can delete parts without rewriting others is often called loosely coupled, but it’s a lot easier to explain what one looks like rather than how to build it in the first place.
Even hardcoding a variable once can be loose coupling, or using a command line flag over a variable. Loose coupling is about being able to change your mind without changing too much code.
Write code that is easy to delete, not easy to extend (cache)
Partant de ce constat, j’ai essayé de produire une stack minimaliste qui comportent très peu de dépendances qui peuvent évoluer en fonction du besoin. De cette manière, on accède à un LEAN technique : l’ajout de complexité architecturale en fonction du besoin uniquement.
Le code produit accorde une place importante à l’esthétique et à la modularité sans endommager la compréhension de l’ensemble grâce à la documentation et aux tests.
Autre extrait :
Thus teams are often confronting the uncomfortable choice between a risky refactoring operation and clean amputation. The best developers can be positively gleeful about amputating a diseased piece of code (even when it’s their own baby, so to speak), recognizing that it’s often the best choice for the overall health of the project. Better a single module should die than continue to bog down the rest of the project.
…
The organic, evolutionary nature of code also highlights the importance of getting your APIs right. By virtue of their public visibility, APIs can exert a lot of influence on the future growth of the codebase. A good API acts like a trellis, coaxing the code to grow where you want it. A bad API is like a cancer, and it will metastasize all over your codebase.
L’intérêt de partir d’un périmètre aussi restreint est de pouvoir se ré-interroger à chaque nouvel ajout sur sa pertinence, cela constitue une base itérative sans renoncer au plaisir technique. Le code est lisible et explicable en quelques heures pour des personnes ayant un faible niveau et il n’y a pas besoin de télécharger la moitié d’internet pour faire tourner une page web. Ma démarche est de renoncer à la complexité par défaut qui est prônée par tous les frameworks actuels, l’ajout de dépendances doit se faire au moment du besoin.
La durée de vie d’une composition de technologies est forcément réduite et demande de se ré-interroger à échéances régulières sur sa pertinence. Toute la difficulté actuelle est de pouvoir allonger ces échéances pour trouver le bon ratio entre focus et exploration. Plus vous bâtirez sur des concepts simples, universels et standardisés, plus vous aurez de chances de pouvoir être conservateur dans votre choix technique. Et plus vous serez inclusif auprès des potentiels contributeurs.