
Docker
Article Wikipedia : https://fr.wikipedia.org/wiki/Docker_(logiciel)
Journaux liées à cette note :
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Ajout de packages dans des distributions atomiques
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Peu à peu depuis 2015, le terme immutable est remplacé par atomic".
Je constate que la plupart des personnes avec qui j'échange pensent qu'une distribution immutable ne permet que d'exécuter des containers Docker ou des applications Flatpak.
En réalité, grâce à la technologie libostree, il est possible d'installer des packages Fedora sur une instance Fedora CoreOS.
Voici un exemple sous Fedora CoreOS que j'ai réalisé avec le playground suivant : https://github.com/stephane-klein/atomic-os-playground.
Je commence par regarder l'état de l'OS avec rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:43:23 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Je constate que la version 42.20250901.3.0 identifiée par le commit sha256:d196ab...ae10c1 est installée.
Cette version correspond au moment où j'écris cette note à la dernière release du stream stale listé sur cette page https://fedoraproject.org/coreos/release-notes?arch=x86_64&stream=stable.
Maintenant, j'utilise rpm-ostree install … pour installer neovim.
stephane@stephane-coreos:~$ sudo rpm-ostree install neovim
Checking out tree 1e5b81c... done
Enabled rpm-md repositories: fedora-cisco-openh264 updates fedora updates-archive
Updating metadata for 'fedora-cisco-openh264'... done
Updating metadata for 'updates'... done
Updating metadata for 'fedora'... done
Updating metadata for 'updates-archive'... done
Importing rpm-md... done
rpm-md repo 'fedora-cisco-openh264'; generated: 2025-03-19T16:53:39Z solvables: 6
rpm-md repo 'updates'; generated: 2025-09-27T01:07:36Z solvables: 24410
rpm-md repo 'fedora'; generated: 2025-04-09T11:06:59Z solvables: 76879
rpm-md repo 'updates-archive'; generated: 2025-09-27T01:38:59Z solvables: 44216
Resolving dependencies... done
Will download: 40 packages (121.6 MB)
Downloading from 'updates'... done
Downloading from 'fedora'... done
Importing packages... done
Checking out packages... done
Running systemd-sysusers... done
Running pre scripts... done
Running post scripts... done
Running posttrans scripts... done
Writing rpmdb... done
Writing OSTree commit... done
Staging deployment... done
Added:
binutils-2.44-6.fc42.x86_64
compat-lua-libs-5.1.5-28.fc42.x86_64
...
neovim-0.11.4-1.fc42.x86_64
...
Changes queued for next boot. Run "systemctl reboot" to start a reboot
Neovim a bien été installé, mais je dois reboot pour l'utiliser. Voici ce que me dit rpm-ostree status :
stephane@stephane-coreos:~$ rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 12:48:33 UTC)
Deployments:
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Diff: 40 added
LayeredPackages: neovim
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
La pastille ● m'indique la version (nommée déploiement) actuellement utilisée par l'instance.
Lors du démarrage du serveur, grub est configuré pour booter sur le premier déploiement de la liste. Exemple :
Une fois le serveur démarré, je peux voir que la version 42.20250901.3.0 est toujours utilisée, mais avec en plus un layer qui contient le package neovim :
[stephane@stephane-coreos ~]$ rpm-ostree status
rpm-ostree status
State: idle
AutomaticUpdatesDriver: Zincati
DriverState: active; periodically polling for updates (last checked Sat 2025-09-27 13:04:36 UTC)
Deployments:
● ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
LayeredPackages: neovim
ostree-remote-image:fedora:docker://quay.io/fedora/fedora-coreos:stable
Digest: sha256:d196ab492e7cadab00e26511cdc6b49c6602b399e1b6f8c5fd174329e1ae10c1
Version: 42.20250901.3.0 (2025-09-14T22:45:05Z)
Neovim est bien accessible :
[stephane@stephane-coreos ~]$ nvim --version
nvim --version
NVIM v0.11.4
Build type: RelWithDebInfo
LuaJIT 2.1.1748459687
Run "nvim -V1 -v" for more info
Avec la commande rpm-ostree apply-live il est même possible de commencer à utiliser le package sans avoir à reboot.
Cette fonctionnalité doit se limité à des petits utilitaires. Pour les composants systèmes, il est conseillé d'effectuer un reboot.
Note suivante : "Système de mise à jour d'Android, Chrome OS, MacOS et MS Windows".
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du lundi 22 septembre 2025 à 21:26
Dans le cadre du Projet 34 - "Déployer un cluster k3s et Kubevirt sous CoreOS dans mon Homelab", j'étudie CoreOS.
Dans la page "Fedora CoreOS Release Notes stable" je vois quelques packages mis en avant :
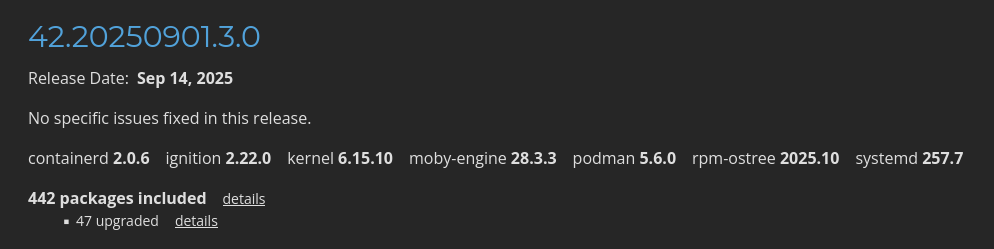
Je constate que CoreOS installe par défaut containerd, moby-engine et podman.
Information de type #mémento #mémo au sujet de containerd, moby-engine et podman.
- Kubernetes intéragie directement avec containerd.
- Depuis 2017, Docker est basé sur containerd + moby-engine. Sous Fedora, la commande
dockerest installée par le packagedocker-cli. - podman est une alternative rootless à Docker. podman n'est pas basé sur containerd, ni moby-engine.
Journal du vendredi 19 septembre 2025 à 16:51
Dans ma note du 2025-07-24_2231 au sujet de Containerlab je disais :
Je viens de poster le message suivant l'espace de discussion GitHub de Containerlab : « Does Containerlab support the creation of topologies with multiple subnets? ».
J'espère que le créateur de Containerlab pourra me suggérer une solution à mon problème, car je n'ai pas réussi à l'identifier dans la documentation 🤷♂️.
Depuis, j'ai eu une réponse et j'ai réussi à fixer mon problème : https://github.com/srl-labs/containerlab/discussions/2718#discussioncomment-14457884
Voici le résultat : https://github.com/srl-labs/containerlab/discussions/2814
Je ne suis pas satisfait de cette simulation, car de mon point de vue les Linux bridge créé par Docker configure trop de chose automatiquement.
Par exemple, l'IP 2001:db8:a:1::1 est automatiquement créé et assigné au bridge network-a.
De plus, je ne suis pas satisfait de cette simulation parce que containerlab configure automatiquement des routes au niveau de l'hôte pour interconnecter les réseaux Docker network-a, network-b et network-c, alors que dans un environnement réel, cette connectivité serait gérée par les équipements réseau de la topologie.
J'envisage peut-être de tester Mininet pour effectuer des simulations IPv6.
J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux
Pendant mon travail d'étude pratique de IPv6, #JaiDécouvert le projet Containerlab :
Containerlab was meant to be a tool for provisioning networking labs built with containers. It is free, open and ubiquitous. No software apart from Docker is required! As with any lab environment it allows the users to validate features, topologies, perform interop testing, datapath testing, etc. It is also a perfect companion for your next demo. Deploy the lab fast, with all its configuration stored as a code -> destroy when done.
Projet qui a commencé en 2020 et semble principalement développé par un développeur de chez Nokia.
D'après ce que j'ai compris, Containerlab me permet de facilement créer des réseaux dans un simulateur.
Je me souviens que je cherchais ce type d'outil en 2018, quand je travaillais sur un projet baremetal as service chez Scaleway.
Voici un exemple de fichier créé par Claude.ai pour simuler un environnement composé de deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Je précise que je n'ai pas encore testé ce fichier. J'ignore donc s'il fonctionne correctement.
name: dual-network-ipv6-lab
topology:
nodes:
# Routeur avec IPv6
router:
kind: linux
image: alpine:latest
exec:
# Activer IPv6
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- sysctl -w net.ipv6.conf.all.forwarding=1
# Adresses IPv6 sur les interfaces
- ip -6 addr add 2001:db8:1::1/64 dev eth1
- ip -6 addr add 2001:db8:2::1/64 dev eth2
# IPv4 en parallèle (dual-stack)
- ip addr add 192.168.1.1/24 dev eth1
- ip addr add 192.168.2.1/24 dev eth2
- echo 1 > /proc/sys/net/ipv4/ip_forward
# Réseau A (2001:db8:1::/64)
vm-a1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::10/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.10/24 dev eth1
- ip route add default via 192.168.1.1
vm-a2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::11/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.11/24 dev eth1
- ip route add default via 192.168.1.1
vm-a3:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::12/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.12/24 dev eth1
- ip route add default via 192.168.1.1
# Réseau B (2001:db8:2::/64)
vm-b1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::10/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.10/24 dev eth1
- ip route add default via 192.168.2.1
vm-b2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::11/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.11/24 dev eth1
- ip route add default via 192.168.2.1
links:
# Réseau A
- endpoints: ["router:eth1", "vm-a1:eth1"]
- endpoints: ["router:eth1", "vm-a2:eth1"]
- endpoints: ["router:eth1", "vm-a3:eth1"]
# Réseau B
- endpoints: ["router:eth2", "vm-b1:eth1"]
- endpoints: ["router:eth2", "vm-b2:eth1"]
Journal du jeudi 01 mai 2025 à 16:22
Je continue mon travail de mise à niveau en Kubernetes.
Je viens de réaliser que Helmfile ne fait pas directement partie du projet Helm. Je trouve cela surprenant. Ces deux projets sont réalisés par deux equipes différentes :
- Dépôt GitHub de Helm : https://github.com/helm/helm/
- Développeurs principaux :
- Matt Butcher basé aux États-Unis
- Adam Reese basé aux États-Unis
- Développeurs principaux :
- Dépôt GitHub de Helmfile : https://github.com/helmfile/helmfile/
- Développeurs principaux :
- Yusuke Kuoka basé au Japon
- yxxhero basé en Chine
- Développeurs principaux :
D'après ce que je comprends, si je simplifie, Helmfile est pour Helm l'équivalent de ce qu'est docker-compose.yml pour Docker.
Je m'intéresse aujourd'hui à Helmfile parce que je souhaite effectuer une tâche qui correspond au use-case numéro 2 décrit dans la documentation :
ArgoCD has support for kustomize/manifests/helm chart by itself. Why bother with Helmfile?
The reasons may vary:
1.You do want to manage applications with ArgoCD, while letting Helmfile manage infrastructure-related components like Calico/Cilium/WeaveNet, Linkerd/Istio, and ArgoCD itself.2.You want to review the exact K8s manifests being applied on pull-request time, before ArgoCD syncs.3.This is often better than using a kind of HelmRelease custom resources that obfuscates exactly what manifests are being applied, which makes reviewing harder.
Suite à cette lecture, voici comment j'ai mis en application une partie du use-case 2.
J'ai ce helmfile.yaml :
environments:
dev:
values:
- version: 6.1.0
production:
values:
- version: 6.1.0
---
repositories:
- name: open-webui
url: https://helm.openwebui.com/
---
releases:
- name: openwebui
namespace: {{ .Namespace }}
chart: open-webui/open-webui
values:
- ./env.d/{{ .Environment.Name }}/values.yaml
version: {{ .Values.version }}
Et ensuite, j'ai exécuté :
$ helmfile template -e dev --output-dir-template $(pwd)/gitops/{{.Release.Name}}
Adding repo open-webui https://helm.openwebui.com/
"open-webui" has been added to your repositories
Templating release=openwebui, chart=open-webui/open-webui
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service.yaml
wrote .../gitops/openwebui/open-webui/templates/service.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/deployment.yaml
wrote .../gitops/openwebui/open-webui/templates/workload-manager.yaml
wrote .../gitops/openwebui/open-webui/templates/ingress.yaml
Cela me permet ensuite de pouvoir observer avec précision ce qui va être déployé par ArgoCD.
Avril 2025, quelle est mon expérience Kubernetes ?
J'ai commencé à utiliser Kubernetes pour la première fois en janvier 2016. C'était dans un cadre professionnel, quand je travaillais chez Tech-Angels / Gemnasium.
Mes deux premiers projets étaient les suivants :
- Opérer et continuer à améliorer un cluster de 3 nodes basé sur OpenShift (surcouche Kubernetes de Red Hat) qui permettait d'héberger les services web de nos clients.
L'objectif était de fournir un service un peu comme Heroku, c'est-à-dire permettre un déploiement via un simple "git push".
Avec le recul, l'objectif ressemblait à ce que propose actuellement Clever Cloud. - Implémenter une version OnPremise de Gemnasium propulsée par Kubernetes.
En janvier 2016, Kubernetes était un projet très jeune, avec seulement 20 mois d'existence depuis la sortie de la première version 0.2.
L'écosystème était bien plus petit que maintenant. Par exemple, Helm n'était pas encore populaire.
J'ai commencé par installer la version 1.1 de Kubernetes avec les playbooks officiels Ansible.
Ce fut une expérience difficile, avec de nombreux crashs de clusters, tout particulièrement lors des montées en version.
L'expérience fut très enrichissante. Cela m'a permis de monter en compétence avec Docker, Kubernetes, Ceph…
J'ai ensuite utilisé Kubernetes de novembre 2018 à avril 2019, dans la team Kubernetes Kapsule de Scaleway.
La mission de cette équipe était de créer un produit qui permettait de déployer des clusters Kubernetes managés.
Je suis arrivé dans cette équipe 10 mois après le début du projet. J'ai contribué au projet pendant 5 mois, jusqu'au lancement du produit en production.
Cette fois encore, une partie du travail était de déployer des clusters Kubernetes from "scatch".
Expérience intéressante : j'ai appris à déployer des clusters Kubernetes via Kubernetes !
L'implémentation était inspirée de la méthode présentée dans cet article : Gardener - The Kubernetes Botanist.
Depuis avril 2019, je n'ai plus opéré de cluster Kubernetes. J'ai seulement continué à suivre de loin les actualités de cet écosystème. Je n'ai plus eu d'expérience pratique.
Maintenant que j'ai rejoint une mission dont le produit est déployé sur Kubernetes, je souhaite mettre à jour mes compétences pratiques dans ce domaine.
Voici quelques sujets sur lesquels je souhaite monter en compétence ces prochains mois :
- M'entrainement à utiliser et à créer des Helm Charts
- Déployer un ArgoCD pour apprendre à bien l'utiliser
- Jouer avec k3s
- Tester Postgres Operator
- Étudier et tester https://tilt.dev/
- kind (https://kind.sigs.k8s.io/)
- Grafana Tanka
- kustomize (https://github.com/kubernetes-sigs/kustomize)
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.
Journal du dimanche 09 février 2025 à 17:05
J'utilise depuis 2019 les containers Docker suivant en sidecar pour sauvegarder automatiquement et régulièrement directement un volume Docker et un volume PostgreSQL :
restic-pg_dump-docker est très pratique et facile d'usage, voici un exemple d'utilisation dans un docker-compose.yml :
restic-pg-dump:
image: stephaneklein/restic-pg_dump:latest
environment:
AWS_ACCESS_KEY_ID: "admin"
AWS_SECRET_ACCESS_KEY: "password"
RESTIC_REPOSITORY: "s3:http://minio:9000/bucket1"
RESTIC_PASSWORD: secret
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
POSTGRES_HOST: postgres
POSTGRES_DB: postgres
postgres:
image: postgres:16.1
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Il suffit de configurer les paramètres d'accès à l'instance PostgreSQL à sauvegarder et ceux de l'Object Storage où uploader les backups. Rien de plus, 😉.
Pour plus de paramètres, voir la section Configuration du README.md.
Cependant, je ne suis pas totalement satisfait de restic-pg_dump-docker. Cet outil effectue seulement des sauvegardes complètes de la base de données.
Ceci ne pose généralement pas trop de problème quand la base de données est d'une taille modeste, mais c'est bien plus compliqué dès que celle-ci fait, par exemple, plusieurs centaines de mégas.
Pour faire face à ce problème, j'ai exploré fin 2023 une solution basée sur pgBackRest : Implémenter un POC de pgBackRest.
Je suis plus ou moins arrivé au bout de ce POC mais je n'ai pas été satisfait du résultat.
Je n'ai pas réussi à configurer pgBackRest en "pure Docker sidecar".
De plus, j'ai trouvé la restauration du backup difficile à exécuter.
Un élément a changé depuis septembre 2024. Comme je le disais dans cette note 2024-11-03_1151, la version 17 de PostgreSQL propose de nouvelles options de sauvegarde :
- l'outil pg_basebackup qui permet de réaliser les sauvegardes incrémentales,
- et un nouvel utilitaire, pg_combinebackup, qui permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
Cette nouvelle méthode semble apporter certains avantages par rapport aux solutions basées sur WAL comme pgBackRest ou barman.
Une consommation d'espace réduite :
In this mailing list thread on the Postgres-hackers mailing list, Jakub from EDB ran a test. This is a pgbench test. The idea is that the data size doesn't really change much throughout this test. This is a 24 hour long test. At the start the database is 3.3GB. At the end, the database is 4.3GB. Then, as it's running, it's continuously running pgbench workloads. In those 24 hours, if you looked at the WAL archive, there were 77 GB of WAL produced.
That's a lot of WAL to replay if you wanted to restore to a particular point in time within that timeframe!
Jakub ran one full backup in the beginning and then incremental backups every two hours. The full backup in the beginning is 3.4 GB, but then all the 11 other backups are 3.5 in total, they're essentially one 10th of a full backup size.
Une vitesse de restauration grandement accélérée :
A 10x time safe
What Jakub tested then was the restore to a particular point in time. Previously, to restore to a particular point in time would take more than an hour to replay the WAL versus in this case because we have more frequent, incremental backups, it's going to be much, much faster to restore. In this particular test case 78 minutes compared to 4 minutes. This is a more than a 10 times improvement in recovery time. Of course you won't necessarily always see this amount of benefit, but I think this shows why you might want to do this. It is because you want to enable more frequent backups and incremental backups are the way to do that.
Nombre 2024 j'ai passé un peu de temps à étudier les solutions de backup qui utilisent la nouvelle fonctionnalité de PostgreSQL 17, mais je n'avais rien trouvé
Je viens à nouveau de chercher dans les archives de Postgre Weely, sur GitHub, sur le forum de Restic, etc., et je n'ai rien trouvé d'intéressant.
#JaiDécidé de prendre les choses en main et de faire évoluer le projet restic-pg_dump-docker pour y ajouter le support du backup incrémental de PostgreSQL 17.
Voir : Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker".