
docker compose
Journaux liées à cette note :
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Journal du jeudi 01 mai 2025 à 16:22
Je continue mon travail de mise à niveau en Kubernetes.
Je viens de réaliser que Helmfile ne fait pas directement partie du projet Helm. Je trouve cela surprenant. Ces deux projets sont réalisés par deux equipes différentes :
- Dépôt GitHub de Helm : https://github.com/helm/helm/
- Développeurs principaux :
- Matt Butcher basé aux États-Unis
- Adam Reese basé aux États-Unis
- Développeurs principaux :
- Dépôt GitHub de Helmfile : https://github.com/helmfile/helmfile/
- Développeurs principaux :
- Yusuke Kuoka basé au Japon
- yxxhero basé en Chine
- Développeurs principaux :
D'après ce que je comprends, si je simplifie, Helmfile est pour Helm l'équivalent de ce qu'est docker-compose.yml pour Docker.
Je m'intéresse aujourd'hui à Helmfile parce que je souhaite effectuer une tâche qui correspond au use-case numéro 2 décrit dans la documentation :
ArgoCD has support for kustomize/manifests/helm chart by itself. Why bother with Helmfile?
The reasons may vary:
1.You do want to manage applications with ArgoCD, while letting Helmfile manage infrastructure-related components like Calico/Cilium/WeaveNet, Linkerd/Istio, and ArgoCD itself.2.You want to review the exact K8s manifests being applied on pull-request time, before ArgoCD syncs.3.This is often better than using a kind of HelmRelease custom resources that obfuscates exactly what manifests are being applied, which makes reviewing harder.
Suite à cette lecture, voici comment j'ai mis en application une partie du use-case 2.
J'ai ce helmfile.yaml :
environments:
dev:
values:
- version: 6.1.0
production:
values:
- version: 6.1.0
---
repositories:
- name: open-webui
url: https://helm.openwebui.com/
---
releases:
- name: openwebui
namespace: {{ .Namespace }}
chart: open-webui/open-webui
values:
- ./env.d/{{ .Environment.Name }}/values.yaml
version: {{ .Values.version }}
Et ensuite, j'ai exécuté :
$ helmfile template -e dev --output-dir-template $(pwd)/gitops/{{.Release.Name}}
Adding repo open-webui https://helm.openwebui.com/
"open-webui" has been added to your repositories
Templating release=openwebui, chart=open-webui/open-webui
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service.yaml
wrote .../gitops/openwebui/open-webui/templates/service.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/deployment.yaml
wrote .../gitops/openwebui/open-webui/templates/workload-manager.yaml
wrote .../gitops/openwebui/open-webui/templates/ingress.yaml
Cela me permet ensuite de pouvoir observer avec précision ce qui va être déployé par ArgoCD.
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ai, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ai j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du mardi 27 août 2024 à 14:23
#JaiLu en partie le thread Hacker News Dokku: My favorite personal serverless platform.
- https://github.com/skateco/skate
- dokploy
- kamal
- ptah.sh (sous licence fair source)
J'ai apprécié ce tableau de comparaison de fonctionnalités entre dokploy, CapRover, Dokku et Coolify.
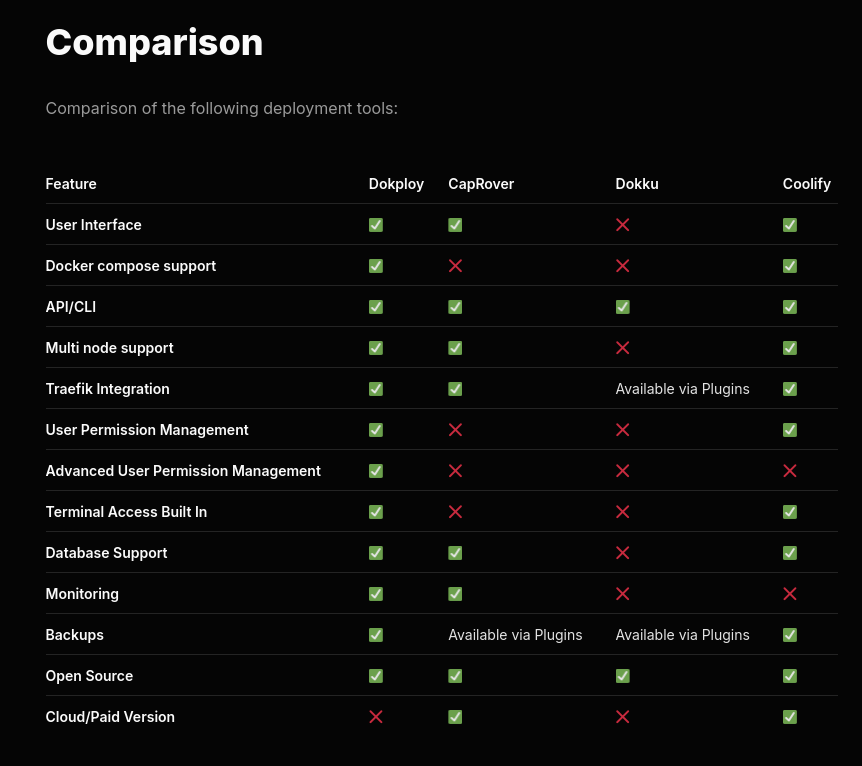
C'est la ligne "Docker compose support" qui a attiré mon attention.
Je reste très attaché au support de docker compose qui je trouve est une spécification en même temps simple, complète et flexible qui ne m'a jamais déçu ces 9 dernières années.
Attention, je n'ai pas bien compris si Dokku est réellement open source ou non 🤔.
Je constate que Dokploy est basé sur Docker Swarm.
Dokploy leverages Docker Swarm to orchestrate and manage container deployments for your applications, providing an intuitive interface for monitoring and control.
-- from
Choix qui me paraît surprenant puisque Docker Swarm est officieusement déprécié.
Je me suis demandé si K3s pourrait être une alternative à Docker Swarm 🤔.
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.
Journal du mercredi 21 août 2024 à 10:37
Note de type snippets concernant docker compose et l'utilisation de la fonctionnalité healthcheck et depends_on.
Cette méthode évite que le service webapp démarre avant que les services postgres et redis soient prêts.
# Fichier docker-composexyml
services:
postgres:
image: postgres:16
...
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
redis:
image: redis:7
...
healthcheck:
test: ["CMD", "redis-cli", "ping"]
timeout: 10s
retries: 3
start_period: 10s
webapp:
image: ...
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
Ici la commande :
$ docker compose up -d webapp
s'assure du lancement de ses dépendances, les services postgres et redis.
De plus, si le Dockerfile du service webapp contient par exemple :
# Fichier Dockerfile
...
RUN apt update -y; apt install -y curl
...
HEALTHCHECK --interval=30s --timeout=10s --retries=3 CMD curl --fail http://localhost:3000 || exit 1
Alors, je peux lancer webapp avec :
$ docker compose up -d webapp --wait
Avec l'option --wait docker compose "rend la main" lorsque le service webapp est prêt à recevoir des requêtes.
Ressources :