
notes.sklein
Le site web https://notes.sklein.xyz est mon Personal knowledge management.
Première note publiée le 18 avril 2024.
Depuis le 2 octobre 2024, https://notes.sklein.xyz est propulsé par sklein-pkm-engine.
Journaux liées à cette note :
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du vendredi 03 janvier 2025 à 12:59
Dans ce thread du forum de SilverBullet.mb #JaiDécouvert l'outil Nutshell (https://ncase.me/nutshell/) :

Je trouve cela très ingénieux.
#JeMeDemande comment je pourrais tirer parti de cette fonctionnalité dans notes.sklein.xyz 🤔.
Journal du mercredi 13 novembre 2024 à 21:47
Actuellement, dans sklein-pkm-engine, les "citations" sont affichées comme ceci :
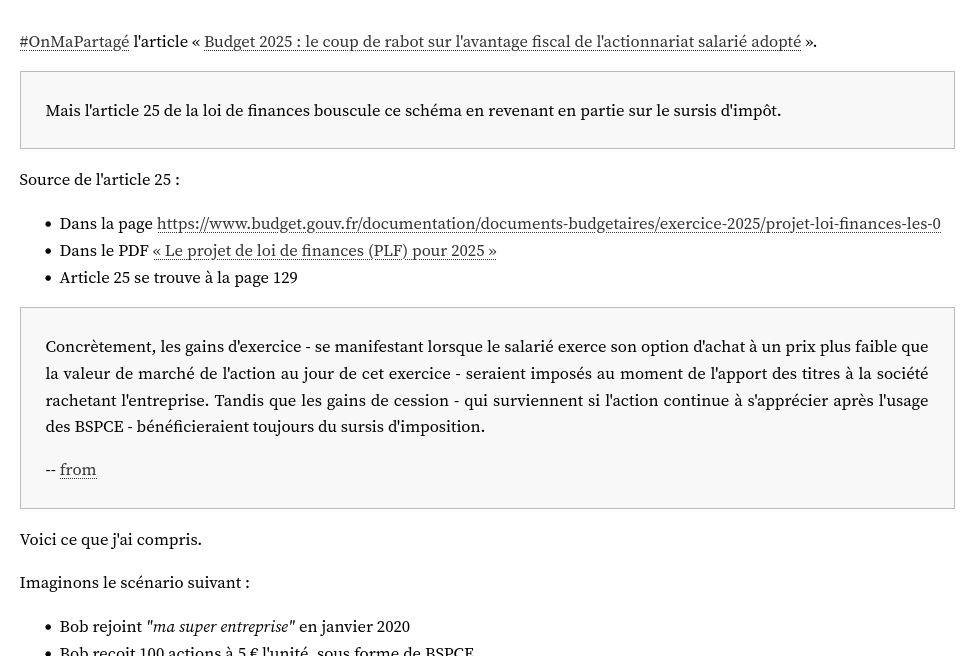
Je souhaite modifier ce rendu pour réaliser quelque chose ressemblant à ceci :

Ma source d'inspiration est le blog de gwern.net.
gwern.net utilise la syntax de quote suivante (exemple) :
<div class="epigraph">
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
</div>
Étant donné que j'édite notes.sklein.xyz avec Obsidian, je ne peux pas utiliser la même syntax.
En remplacement, je pense utiliser la syntax "Callouts", par exemple :
> [!quote]
>
> Beware of bugs in the above code; I have only proved it correct, not tried it.
>
> [Donald Knuth](https://www-cs-faculty.stanford.edu/~knuth/faq.html)
Qui donne le rendu suivant dans Obsidian :
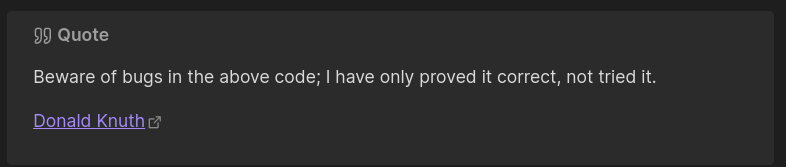
#réflexion : j'ai l'intuition qu'à terme, une utilisation SilverBullet.mb à la place d'Obsidian m'offrirait bien plus de flexibilité.
Journal du vendredi 11 octobre 2024 à 10:24
#JaiLu l'article Wikipedia Prise de décision et #JaiDécouvert le tableau suivant qui définit :
- Décisions stratégiques
- Décisions tactiques
- Décisions opérationnelles
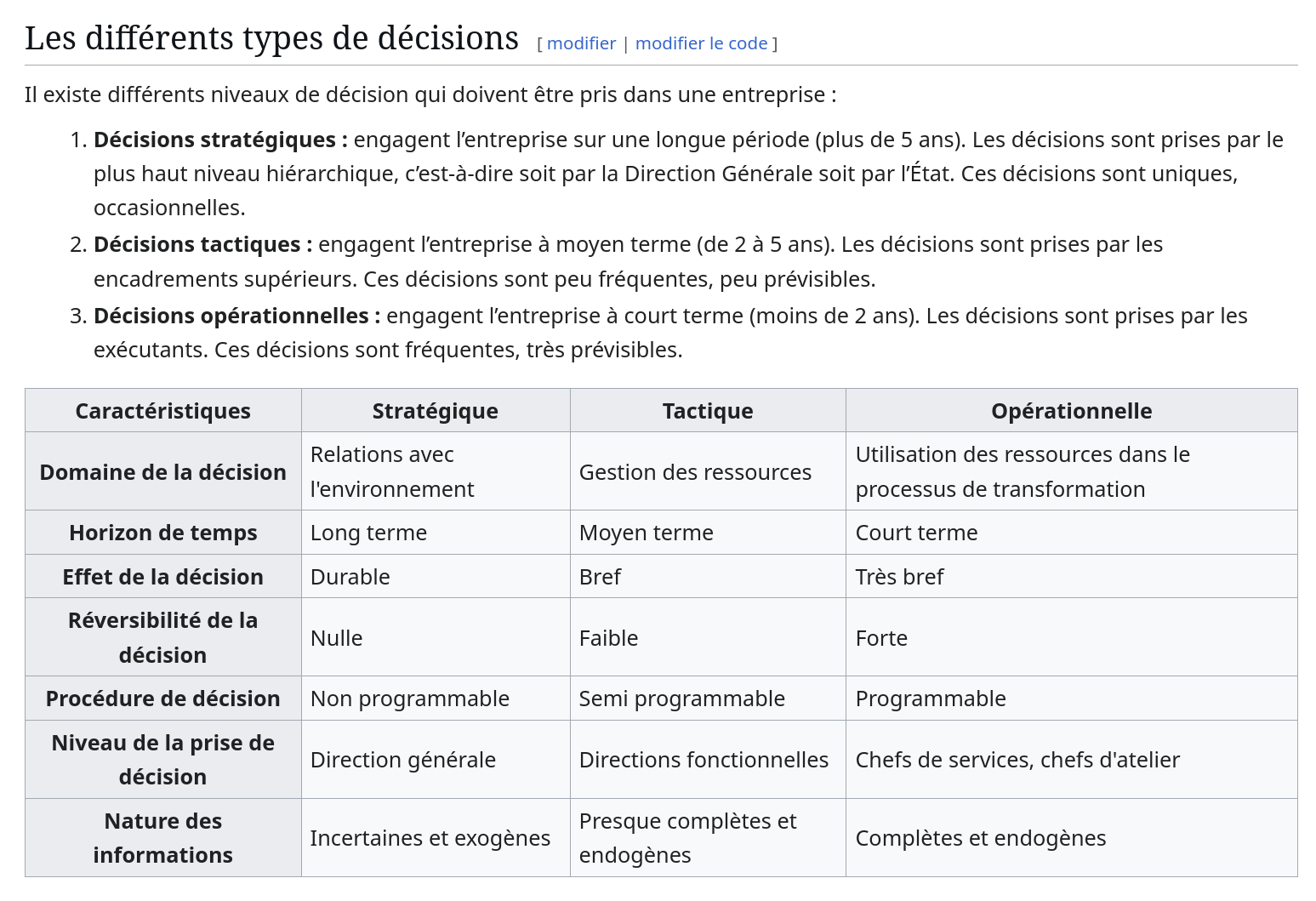
Cette information m’intéresse, car, avec le temps, j’ai constaté qu’il existe de nombreuses définitions de stratégie et tactique selon les contextes : que ce soit dans le domaine militaire, le sport, ou encore l’agilité…
J'ai pour objectif de centraliser, ici sur notes.sklein.xyz, les différentes définitions de ces termes au fil de mes découvertes.
Je vois ici que Loomio a commencé à intégrer de l'AI pour la transcription d'audio.
Journal du mercredi 02 octobre 2024 à 18:07
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
J'ai traité les tâches décrites dans ma dernière note.
- Comme me l'a signalé à plusieurs reprises Alexandre, je dois améliorer le rendu responsive sur smartphone. Jusqu'à présent, je n'ai pas encore consacré de temps à ce sujet.
- Je dois améliorer le script d'import des données dans Elasticsearch. Pour le moment, ici, je commence par supprimer toutes les données avant d'effectuer l'importation des données.
Problème : les pages ne sont plus accessibles pendant l'exécution de ce script.
J'ai enfin publié sklein-pkm-engine sur https://notes.sklein.xyz.
En mars 2024, j'écrivais :
Pour le moment, j'utilise Obsidian Quartz pour déployer https://notes.sklein.xyz.
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Début mai 2024, je suis tombé dans ce Yak!, j'y ai consacré 93 heures en tout, soit l'équivalent d'environ 15 jours de travail étalés sur 8 semaines.
J'ai enfin supprimé Obsidian Quartz
J'ai changé plusieurs fois de direction :
- j'ai exploré une implémentation basée sur Apache Age,
- ensuite pg_search,
- ensuite Typesense
- et pour finir, j'ai opté pour une implémentation basée sur Elasticsearch (voir détail dans Projet 13).
Je viens d'essayer de réaliser un screencast de présentation de la version actuelle de sklein-pkm-engine, mais le résultat de mon discours était vraiment trop déstructuré pour être publié. J'essaierai de publier un screencast prochainement.
Je viens de tenter de réaliser un screencast pour présenter la version actuelle de sklein-pkm-engine, mais mon discours était trop désorganisé pour être publié. Je souhaite enregistrer une nouvelle version prochainement.
Prochains objectifs concernant le projet sklein-pkm-engine :
- Traiter les dernières tâches que j'avais listées dans Projet 11 - "Première version d'un moteur web PKM" ;
- Dresser une liste des corrections de bug et des améliorations que je souhaite apporter à notes.sklein.xyz.
Journal du mardi 01 octobre 2024 à 11:55
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
Dans ma dernière itération du 31 août 2024, j'écrivais ceci :
Voici quelque erreur d'User Interface que je souhaite corriger.
Sur ce screenshot, les notes actuellement séparé par des
<hr />ne sont pas facilement identifiable.

Depuis, j'ai travaillé dans la branche experimentation-ui et pour le moment, j'ai le résultat suivant :

Je pense que les délimitations des notes sont maintenant mieux identifiables.
Problème User Interface que j'ai identifié : je pense que la présence d'un lien sur le titre de la note n'est pas facilement "découvrable".
Mon objectif est toujours le suivant :
Maintenant mon objectif est d'apporter le minimum de petite amélioration me permettant de remplacer l'instance notes.sklein.xyz propulsé actuellement par Obsidian Quartz par une version propulsé par
sklein-pkm-engine.-- from
Voici la liste des choses que je dois implémenter pour atteindre cet objectif.
- Comme me l'a signalé à plusieurs reprises Alexandre, je dois améliorer le rendu responsive sur smartphone. Jusqu'à présent, je n'ai pas encore consacré de temps à ce sujet.
- Je dois améliorer le script d'import des données dans Elasticsearch. Pour le moment, ici, je commence par supprimer toutes les données avant d'effectuer l'importation des données.
Problème : les pages ne sont plus accessibles pendant l'exécution de ce script.
Je pense qu'après avoir traité ces deux tâches, je pourrais abandonner Obsidian Quartz et seulement ensuite implémenter toutes les idées pour améliorer mon Personal knowledge management "viewer".
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du mercredi 22 mai 2024 à 12:45
On me demande où j'en suis dans mon expérience notes.sklein.xyz ?
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Aujourd'hui c'est toujours le cas. Quand je veux déployer je lance le script deployment/scripts/build-and-push.sh.
Je disais aussi :
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
Je ne suis toujours pas satisfait du rendu de notes.sklein.xyz mais je suis satisfait de l'expérience car j'arrive à produire et partager du contenu facilement.
Pour le moment, je pense que produire du contenu est plus important que de soigner le rendu. Le jour où j'aurai beaucoup de contenu, une amélioration de la forme, de la navigation et des fonctionnalités aura alors plus de valeur pour moi.
Je disais aussi :
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Suite à cela, j'ai créé Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et j'ai seulement travailé un tout petit peu sur cette expérience.
#JaimeraisUnJour un jour setup un RAG sur notes.sklein.xyz.
Est-ce que je suis satisfait du client Obsidian ? Je réponds que parfois oui, parfois non. Il m'agace par moments, et j'aimerais prendre le temps de "parfaitement configurer" Obsidian.nvim.