
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (800) ] [ Page suivante (3108) >> ]
Journal du mardi 06 août 2024 à 09:14
Je me pose à nouveau la question suivante en Svelte : first, last, even, odd field in {#each} loop.
Journal du mardi 06 août 2024 à 08:45
#JaiDécouvert la commande psql nommé \ir :
\iror\include_relativefilenameThe \ir command is similar to \i, but resolves relative file names differently. When executing in interactive mode, the two commands behave identically. However, when invoked from a script, \ir interprets file names relative to the directory in which the script is located, rather than the current working directory.
-- from
J'ai trouvé cette commande via Fwd: psql include file using relative path.
Cela faisait des années que j'avais besoin de cette fonctionnalité et, étrangement, je ne l'ai découverte seulement aujourd'hui 🤔.
Exemple d'utilisation https://github.com/stephane-klein/sklein-pkm-engine/blob/8938d7a2c19ed8f741bd38162882e9517c739c30/sqls/init.sql#L36
Journal du lundi 05 août 2024 à 22:57
« #JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔. » -- from
Je viens de lire le thread suivant : [Question: difference between Lezer and tree-sitter](# Question: difference between Lezer and tree-sitter).
This system's approach is heavily influenced by tree-sitter, a similar system written in C and Rust, and several papers by Tim Wagner and Susan Graham on incremental parsing (1, 2). It exists as a different system because it has different priorities than tree-sitter—as part of a JavaScript system, it is written in JavaScript, with relatively small library and parser table size. It also generates more compact in-memory trees, to avoid putting too much pressure on the user's machine. -- from
Journal du lundi 05 août 2024 à 16:41
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
J'essaie d'implémenter un "Replacing Dectorator" CodeMirror basé sur une recheche syntaxTree.
J'essaie de m'inspirer de /examples/decoration/checkbox.ts.
Journal du lundi 05 août 2024 à 15:20
Je regarde le site web de lezer https://lezer.codemirror.net/ et je constate qu'il a le même look que CodeMirror.
J'en déduis qu'il est sans doute développé par les mêmes développeur que CodeMirror.
#JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔.
Journal du lundi 05 août 2024 à 14:58
Le projet SilverBullet.mb utilise le terme Transclusion : https://silverbullet.md/Transclusions
Transclusions are an extension of the Markdown syntax enabling inline embedding of content.
The general syntax is
![[path]].
Journal du lundi 05 août 2024 à 14:52
Dans le cadre du Projet 8 - "CodeMirror, conceal, Svelte", j'essaie de m'inspirer du code source de SilverBullet.mb.
#JeMeDemande si l'implémentation de la fonctionnalité conceal sur les wikilink se trouve ici 🤔.
Je constate ici que l'implémentation ne prend pas en charge directement la recherche des de la syntax [[wikilink]] via, par exemple, une regex, mais l'implémentation semble utiliser un parser Markdown.
Je constate ici que SilverBullet.mb est basé sur la lib lezer. Ce qui me semble normal, parce que le plugin lang-markdown utilise aussi lezer.
Je ne trouve aucune mention de wikilink dans le code source de /lezer-parser/markdown/, par conséquent, je pense que ce type d'élément a été implémenté dans le code source de SilverBullet.mb.
Journal du dimanche 04 août 2024 à 22:03
Suite à la lecture de l'article Project Metrics, #JaiLu :
Journal du dimanche 04 août 2024 à 21:27
Voici quelques notes suite à ma lecture de l'article Project Metrics.
Jusqu'à présent, je n'avais fait qu'un survol rapide du projet git-metrics. D'après son nom, je pensais qu'il s'agissait d'un outil permettant de générer des statistiques à partir des données d'un dépôt git.
Je me trompais : ce projet a une tout autre vocation.
git-metrics permet, tout comme git notes, d'intégrer des métadonnées directement dans un dépôt git.
Journal du samedi 03 août 2024 à 11:53
Suite à l'écriture de 2024-08-03_1018, une idée m'est venue : pourquoi ne pas lancer un service d'email en France basé sur le code source de Forward Email ?
Les principales différences avec Forward Email seraient les suivantes :
- Hébergement en France, soumis au droit français
- Transparence totale sur l'identité des auteurs
L'objectif serait d'entreprendre cette démarche de manière transparente avec l'équipe de Forward Email et de leur reverser une partie des revenus générés.
Journal du samedi 03 août 2024 à 10:42
#JaiDécouvert le projet Uptime (from).
Upptime is the Open source Status et Uptime pages and status page, powered entirely by GitHub Actions, Issues, and Pages. It's made with 💚 by Anand Chowdhary, supported by Pabio.
Je trouve l'idée de baser le service entièrement sur GitHub Actions ingénieuse, bien que la dépendance totale à GitHub me dérange un peu 🤔.
Journal du samedi 03 août 2024 à 10:18
Un ami, m'a posé des questions au sujet de Fastmail que j'utilise.
Je profite de cette question pour lui partager le service Forward Email.
#Jadore ce projet pour les raisons suivantes :
- Je trouve le site web super complet, avec une rédaction précise et complète.
- La documentation est à mes yeux parfaites !
- Un service pour des utilisateurs qui ont un mindset de hackers.
- Grande transparence et précision sur l'offre.
- Je n'ai pas identifié de dark pattern.
Je suis envieux de ce projet. J'ai souvent partagé avec mes amis mon désir de lancer un service de messagerie électronique, et Forward Email est exactement le projet que j'aurais rêvé de réaliser.
Je lis ici :
No. Prices will never increase. Unlike other companies, we will never shutdown our service either.
Cette déclaration me laisse perplexe.
Elle semble présomptueuse. Comment peut-on affirmer que les prix n'augmenteront jamais, même en cas de forte inflation, d'augmentation du prix de l'énergie, etc. ?
Et comment garantir que ce service ne sera jamais arrêté ? Les auteurs de cette déclaration ne sont-ils pas soumis aux aléas de la vie, sont-ils immortels ?
Le service semble être effectivement totalement Open source, https://github.com/forwardemail/forwardemail.net. De plus, l'organisation GitHub contient 20 autres projets supplémentaires
J'ai consulter webarchive pour en savoir un peu plus sur l'histoire du projet.
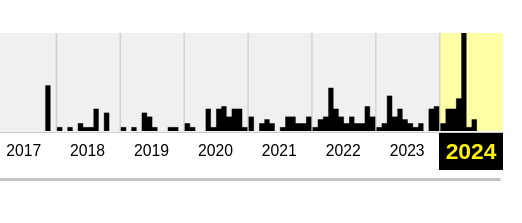
Voici ce que j'ai appris.
- Premier commit public le 6 novembre 2017
- En novembre 2017, je lis ici :
How is it free
I built this for myself and use it regularly. I feel bad that people are using free closed-source forwarding services and risking their privacy and security. I also know that most of these services if not all of them don't offer all the features that come with mine. If this thing really takes off I might ask for donations or do a pay-what-you-want model to cover server costs.
Je comprends que l'auteur a réalisé ce projet avant tout pour lui même.
À cette époque, l'auteur utilisait de pseudo "niftylettuce" et proposé un Patreon pour soutenir le projet.
- C'est en 2020, sans doute pendant le contexte de Covid qu'une offre à $3 a été lancé.
- En 2020, le développeur principal est toujours nommé "niftylettuce".
- En 2021, je constate que le pseudo "niftylettuce" a disparu, je ne sais pas pourquoi.
Le service est régi par les lois de l'État du Delaware.
J'ai des difficultés à déterminer si ce projet est maintenu par une seule personne ou par une équipe.
Est-ce que le compte GitHub niftylettuce a été remplacé par titanism ?
Est-ce que titanism est un compte d'équipe ou le compte d'un utilisateur individuel ?
Je n'ai trouvé aucune information sur "Forwardemail" sur LinkedIn.
Je n'ai pas trouvé de trace des tweets mentionnés dans la section Témoignages.
En conclusion, j'apprécie énormément la réalisation technique de ce projet et j'aimerais vraiment migrer de Fastmail vers Forward Email. Cependant, le manque de transparence sur l'identité des membres du projet me rend réticent. Si le projet était plus clair sur l'identité de ses membres, je ferais cette transition avec bien moins d'hésitation.
Journal du vendredi 02 août 2024 à 17:13
J'ai l'impression que ce projet ressemble avec GitGuardian.
#OnMaPartagé https://github.com/hadolint/hadolint
Journal du vendredi 02 août 2024 à 14:11
J'ai partagé la note au sujet des Quick Fixes du 31 juillet 2024 à un ami — profil Développeur sénior, Architecte informatique, plus de 20 ans d'expérience — et voici ma réponse à ses commentaires.
« Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais. » -- from
« Je confirme ... remettre à plus tard, reviens à dire que ce ne sera jamais fait. Quand t'as un ticket dans le backlog qui s'appelle "C'était pas terrible faudrait refaire mieux .." et qui n'a pas été touché depuis 6 mois, tu sais que tu peux le foutre à la benne. » -- mon ami
🙂.
« a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique. » -- from
« Oui, mais ça ne marche que dans les équipes en mode produit ... pas dans les équipes qui fournissent du "service" 😉 » -- mon ami
Je pense que tu as malheureusement raison.
C'est pour cela que je pense qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que passer par des ESN.
C'est pourquoi je crois qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que de passer par des ESN. Je pense à des projets comme Louvois (projet), SIRHEN (projet), ou ONP (projet).
Journal du vendredi 02 août 2024 à 13:40
Je souhaite partager une réflexion sur un risque potentiel lié à l'usage des spikes.
Lorsque les équipes réalisent des spikes avec un taux de réussite très élevé, il existe un risque significatif que les développeurs et les stakeholders commencent progressivement à considérer ces spikes comme des issues ordinaires. Si cela se produit, les caractéristiques et l'utilité intrinsèques des spikes risquent d'être compromises :
- Les développeurs pourraient se sentir obligés de réussir chaque spike ;
- Ils pourraient alors être tentés d'augmenter la qualité de réalisation de leurs spikes, transformant ainsi des explorations en livrables de production ;
- Les stakeholders, quant à eux, pourraient ne plus prendre en compte le risque d'échec des spikes dans leur stratégie.
Pour ces raisons, je rappelle régulièrement aux stakeholders que l'échec fait partie intégrante des spikes et qu'il est essentiel de préserver cette caractéristique pour maintenir leur véritable utilité.
Journal du vendredi 02 août 2024 à 10:40
J'ai partagé la note au sujet des Quick Fixes du 31 juillet 2024 à un ami — profil Product Manager — et voici ma réponse à ses commentaires.
« Ce que je retiens principalement et qui est, à mon avis, sous-estimé, c’est l’impact psychologique de travailler dans le chaos et d’avoir l’impression d’une dette insurmontable. Pour moi, la motivation et le sens de ce qu’on fait, c’est vraiment l’enjeu clé. Je pense donc qu’il est essentiel d’avoir une gestion saine et transparente de tout ça, le quick fix est néfaste à long terme. » -- mon ami
Je trouve cela intéressant que tu soulignes "l'impact psychologique" 👍️. Je partage cet avis et cela rejoint cette partie de ma note :
« D'après mon expérience, lorsque le développement d'une application est fait en équipe, l'accumulation de Quick Fixes entraîne rapidement :
- Une perte de contrôle — analogie "des sables mouvants" dans l'article.
- Un risque de perte de confiance de l'équipe, surtout des nouveaux venus en période de storming : voir le concept sociologique de l'hypothèse de la vitre brisée. » -- (from)
Ensuite :
« Sur la question des explorations/spikes, je suis partagé. De ma modeste expérience, ça n’a jamais été concluant. Ça ne permet pas de valider une quelconque « pain » business qu’on n’aurait pas pu valider d’une autre manière. » -- mon ami
Je comprends ton point de vue.
Comme toi, autant que je me souvienne, je n'ai jamais participé à une exploration de produit réussie destinée aux utilisateurs B2B ou B2C.
Je pense qu'il y a deux raisons à cela : la première est que, de mon point de vue, ces expériences n'étaient pas réalisées avec le niveau de rigueur nécessaire.
La seconde est que ce type d'activité est intrinsèquement difficile à mener.
Cependant, j'ai réalisé des spikes produits — objectifs d'explorations de features — avec succès pour des utilisateurs internes — stakeholder.
Ces spikes m'ont permis plusieurs choses :
- De rendre concrètes des idées pas toujours comprises par des descriptions verbales ;
- De gagner la confiance des stakeholders, et d'éviter une longue période de vaporware ;
- De créer un artefact facilitant la convergence d'un groupe — développeurs, product managers, stakeholders — vers un objectif commun.
« et ça n’aide pas franchement la tech à débroussailler les écueils techniques. » -- mon ami
Mon expérience concernant les spikes techniques est différente. Pour moi, c'est une méthode qui fonctionne sans hésitation.
Ce que j'observe sur moi-même et je pense chez d'autres personnes :
- Les spikes mettent moins de pression aux développeurs sur des tâches complexes.
- Les spikes réduisent l'Effet Ikea des développeurs. Ils savent que c'est un spike et que sa solution sera probablement abandonnée.
- Les spikes réduisent l'entêtement, facilitant la pratique du timeboxing.
- Les spikes indiquent clairement aux développeurs qu'on n'attend pas une fonctionnalité finie et sans bug.
(Voir aussi ma note à propos d'un risque potentiel lié à l'usage des spikes).
J’ai pas encore avancé dans ma réflexion là-dessus, mais j’ai l’impression qu’un projet, s’il est important, doit être conduit proprement dès le départ. Si on n’a pas le temps de le faire proprement, c’est que c’était pas nécessaire, et ça va ajouter de la complexité inutilement.
Je te rejoins très fortement sur cette dernière phrase 👍️.
Journal du mercredi 31 juillet 2024 à 17:33
#JeMeDemande comment définir la largeur d'une image dans Obsidian.
J'ai commencé par faire une recheche sur le forum d'Obsidian : image size.
Et j'ai trouvé ma réponse. La syntax Markdown suivante fonctionne :

🙂
Journal du mercredi 31 juillet 2024 à 11:11
Une amie m'a demandé ce que je pense de cette déclaration :
« Selon moi, la résolution de problème se déroule en deux étapes : d'abord, on traite les symptômes. Si le problème persiste, on prend plus de temps pour en identifier et résoudre la cause profonde.
Cette doctrine est particulièrement adapté aux Startup ».
Cette question de fait penser à la citation du chapitre "Quick Fixes Become Quicksand" du livre Practices of an Agile Developer :
« You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine. »
De mon expérience — dans le domaine du software engineering —, le bon dosage de l'usage des Quick Fixes, QuickWin est une source de désacord classique au sein d'une organisation.
Et ceci arrive d'autant plus lorsqu'une équipe est dans sa période de storming.
La lecture du chapitre Quick Fixes Become Quicksand en 2007 m'a beaucoup marqué et ne m'a jamais quitté depuis, je peux dire qu'il fait parti de ma doctrine d'artisan développeur.
Voici-ci dessous les screenshot et la version texte de ce chapiter.
(cliquer ici pour voir ces screenshots en grand)

Voici la version texte de ce chapitre.
Quick Fixes Become Quicksand
You don't need to really understand that piece of code; it seems, to work OK as is. Oh, but it just needs one small tweak. Just add one to the result, and it works. Go ahead and put that in; it's probably fine.”
We've all been there. There's a bug, and there's time pressure. The quick fix seems to work— just add one or ignore that last entry in the list, and it works OK for now. But what happens next distinguishes good programmers from crude hackers.
The crude hacker leaves the code as is and quickly moves on to the next problem.
The good programmer will go to the next step and try to understand why that +1 is necessary, and—more important—what else is affected.
Now this might sound like a contrived, even silly, example, except that it really happened — on a large scale. A former client of Andy's had this very problem. None of the developers or architects understood the underlying data model of their domain, and over the course of several years the code base became littered with thousands of +1 and -1 corrections. Trying to add features or fix bugs in that mess was a hair-pulling nightmare (and indeed, many of the developers had gone bald by then).
But like most catastrophes, it didn't get like that all at once. Instead, it happened one quick fix at a time. Each quick fix — which ignored the pervasive, underlying problem — added up to a swamp-like morass of quicksand that eventually sucked the life out of the project.
« Beware of land mines »
Shallow hacks are the problem — those quick changes that you make under pressure without a deep understanding of the true problem and any possible consequences. It's easy to fall prey to this temptation: the quick fix is a very seductive proposition. With a short enough lens, it looks like it works. But in any longer view, you may as well be walking across a field strewn with land mines. You might make it halfway across — or even more — and everything seems fine. But sooner or later...
As soon as that quick hack goes in, the clarity of the code goes down. Once a number of those pile up, clarity is out the window, and opacity takes over. You've probably worked places where they say, “Whatever you do, don’t touch that module of code. The guy who wrote it is no longer here, and no one knows how it works.” There's no clarity. The code is opaque, and no one can understand it.
You can't possibly be agile with that kind of baggage. But some agile techniques can help prevent this from happening. We'll look at these in more depth in later chapters, but here's a preview.
Isolation is dangerous; don’t let your developers write code in complete isolation (see Practice 40, Practice Collective Ownership, on page 155). If team members take the time to read the code that their colleagues write, they can ensure that it's readable and understandable—and isn’t laced with arbitrary “+1s and -1s”. The more frequently you read the code, the better. These ongoing code reviews not only help make the code understandable but they are also one of the most effective ways of spotting bugs (see Practice 44, Review Code, on page 165).
The other major technique that can help prevent opaque code is unit testing. Unit testing helps you naturally layer the code into manageable pieces, which results in better designed, clearer code. Further into the project, you can go back and read the unit tests — they're a kind of executable documentation (see Practice 19, Put Angels on Your Shoulders, on page 78). Unit tests allow you to look at smaller, more comprehensible modules of code and help you get a thorough understanding by running and working with the code.
Conseil de petit ange : A Don't fall for the quick hack. Invest the energy to keep code clean and out in the open.
What It Feels Like
It feels like the code is well lit; there are no dark corners in the project. You may not know every detail of every piece of code or every step of every algorithm, but you have a good general working knowledge. No code is cordoned off with police tape or “Keep Out” signs.
Keeping Your Balance
- You need to understand how a piece of code works, but you don't necessarily have to become an expert at it. Know enough to work with it effectively, but don't make a career of it.
- If a team member proclaims that a piece of code is too hard for anyone else to understand, then it will be too hard for anyone (including the original author) to maintain. Simplify it.
- Never kludge in a fix without understanding. The +1/-1 syndrome starts innocently enough but rapidly escalates into an opaque mess. Fix the problem, not the symptom.
- Most nontrivial systems are too complex for any one person to understand entirely. You need to have a high-level understanding of most of the parts in order to understand what pieces of the system interact with each other, in addition to a deeper understanding of the particular parts on which you're working.
- If the system has already become an opaque mess, follow the advice given in Practice 4, Damn the Torpedoes, Go Ahead, on page 23.
Andy Says : Understand Process. Too
Although we're talking about understanding code, and especially understanding code well before you make changes to it, the same argument holds for your team’s methodology or development process.
You have to understand the development methodology in use on your team. You have to understand how the methodology in place is supposed to work, why things are the way they are, and how they got that way.
Only with that understanding can you begin to make changes effectively.
Mon point de vue plus détaillé
Voici une version plus personnelle de ma philosophie — ma doctrine d'artisan développeur — à ce sujet. Je précise qu'elle est bien plus longue que ce que j'avais prévu et qu'elle dépasse la question de départ de mon ami… oui, je suis tombé dans un Yak! 🙂.
J'accepte d'utiliser des Quick Fixes — même sans bien comprendre le problème — dans les situations suivantes :
- Dans un Proof of Concept ou un code exploratoire ;
- Dans une application ou un composant d'application destiné à être rapidement abandonné ;
- En cas d'urgence, si le bug impacte les clients. Dans ce cas, j'applique un Quick Fixes en production, puis, je m'efforce, dans un second temps, de comprendre et de corriger correctement le problème par la suite ;
- Si je suis solo développeur sur l'application et que celle-ci n'est pas critique pour le client.
D'après mon expérience, lorsque le développement d'une application est fait en équipe, l'accumulation de Quick Fixes entraîne rapidement :
-
Une perte de contrôle — analogie "des sables mouvants" dans l'article.
-
Un risque de perte de confiance de l'équipe, surtout des nouveaux venus en période de storming : voir le concept sociologique de l'hypothèse de la vitre brisée.
-
Risque de "game over de la partie de Tetris", voir l'article La dette technique est comme une partie de Tetris.
Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais.
En 20 ans d'expérience, j'ai toujours travaillé dans des organisations où l'urgence était la norme. L'urgence permanente est tout ce que j'ai connu. Je pense que cela reflète la nature humaine.
Ainsi, la déclaration « Oui, mais nous, c'est différent, tu comprends, on n'a pas le temps » n'a pas de sens à mes yeux, car c'est le cas pour tout le monde.
Avec le temps, j'ai construit la doctrine suivante pour gérer les Quick Fixes et donc la dette technique en équipes :
- a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique.
- b. Si une dette jugée critique ne peut pas être traitée durant ce temps imparti, je propose de l'expliquer au Product Management et éventuellement à la direction afin qu'un choix stratégique soit fait pour lui allouer plus de temps en la priorisant comme objectif de Sprint (scrum).
Par expérience, j'observe que si la règle a est appliquée, alors la situation b se produit exceptionnellement.
L'itération pour éviter de tomber dans l'overthinking et l'overengineering !
Je pense qu'un certain nombre de leaders de startup créent un climat d'urgence pour éviter que les développeurs tombent dans de l'overthinking et de l'overengineering.
Bien que cette approche soit compréhensible, j'ai personnellement une autre méthode pour éviter ces écueils sans recourir à l'urgence.
Ma solution pour éviter de tomber dans ces travers sont :
- l'itération ;
- le time boxing, autrement dit l'utilisation de spikes ou la définition de l'appétit d'un sprint ;
- sensibiliser les développeurs aux Yak!.
Par itération, j'entends la livraison du plus petit Incrément (Scrum) possible et sa mise en production dès que possible.
Le choix du plus petit incrément possible doit être associé aux principes Keep it simple, stupid! (KISS) et You aren't gonna need it (YAGNI).
L'esprit marathon en meuthe plutôt que des courses de 100m !
Comme le dit la Loi de Gall, je pense que :
Un système complexe qui fonctionne se trouve invariablement avoir évolué depuis un système simple qui fonctionnait. La proposition inverse se révèle également exacte : Un système complexe développé de A à Z ne fonctionne jamais et vous n'arriverez jamais à le faire fonctionner. Vous devez recommencer depuis le début, en commençant par un système simple.
Ici j'entends par "système complexe" à la fois le logiciel et l'organisation humaine.
Je crois également à « New systems mean new problems ».
Depuis des années, j'observe de nombreuses startups en situation d'urgence vivre des cycles sans fin de reboot — une fois par an ou tous les deux ans —, accompagnés d'un turnover élevé.
Les projets sont constamment recommencés à zéro, avec de nouvelles équipes.
Je doute fortement que le pari de la vitesse — la course de 100m — soit plus efficace que celui du marathon.
Attention à bien identifier les projets et phases d'explorations !
Il m'est arrivé à plusieurs reprises de ne pas identifier correctement les signaux faibles indiquant qu'un projet dont j'avais la responsabilité devait en réalité être traité comme un projet d'exploration..
Je pense que les projets d'exploration ne doivent pas être traités comme des courses de 100 mètres, mais plutôt comme des spikes — prototypes.
J'insiste sur l'utilisation du terme Spike pour bien communiquer :
- Aux décideurs — stakeholder — que l'implémentation de ce projet n'est pas destinée à être conservée sur le long terme. Si l'exploration est concluante, le projet sera recommencé à zéro et attribué à une équipe dédiée.
- Aux développeurs qu'ils peuvent échouer, que le code peut contenir des bugs et être développé avec une grande dette technique.
- Aux utilisateurs qu'il est fort probable que l'application contienne des bugs ou que l'User experience ne soit pas optimale.
Ces messages sont souvent difficiles à faire passer, et c'est sans doute pour se protéger que les développeurs choisissent souvent de traiter le projet comme un projet pérenne de long terme plutôt que comme un spike.
De plus, je constate que les décideurs pensent souvent que leur idée est valide et ne jugent pas utile de réaliser des prototypes. Ce n'est souvent qu'après 1 ou 2 ans de vie de la startup que les décideurs considèrent rétrospectivement que les premières versions étaient des prototypes. Problème : ces premières versions n'ont pas été développées comme des prototypes.
Journal du mardi 30 juillet 2024 à 16:33
Free and Open Source Machine Translation API. Self hosted, offline capable and easy to setup.
Qui utilise Argos Translate :
Open Source offline translation library written in Python.
Qui utilise OpenNMT.
Open source ecosystem for neural machine translation and neural sequence learning.
#JeMeDemande quelle est la différence en termes de qualité de traduction et de consommation d'énergie entre la technologie OpenNMT et les modèles de langage classiques tels que Llama 🤔.
Un ami m'a dit que DeepL utilise un Neural Machine Translation. Ce que semble confirmer cette source.
Journal du mardi 30 juillet 2024 à 14:55
Je viens de créer Projet 12 - "Implémentation nodemailer-scaleway-transport".
Journal du mardi 30 juillet 2024 à 12:02
Aujourd'hui, je repense à la vidéo de Scrum Life Management d'équipe - le modèle de Tuckman (Forming, Storming, Norming, Performing) au sujet du modèle de Tuckman et ses phases de développement de l'équipe :
Je me demande s'il est préférable de faire le maximum pour passer les phases storming et norming en présentiel 🤔.
Je rappelle aussi que tous les modèles sont faux, mais certains sont utiles.
Journal du mardi 30 juillet 2024 à 09:51
J'ai visité à nouveau le site Feedback Company et je continue à #JeMePoseLaQuestion de la qualité de ce genre de service 🤔.
Journal du dimanche 28 juillet 2024 à 14:02
#JaiÉcouté ( #Réécouté ) Épisode 2-4 - Guildes et compagnonnage, défendre son métier au Moyen Âge.
Suite à cette écoute, j'ai cherché d'autre conférence de Julie Claustre et #JaiÉcouté Travailler en ville au Moyen Âge, conférence de Julie Claustre du mercredi 13 décembre 2017.
#JaiDécouvert et #JeMeSuisAbonné à la chaine Musée de Cluny : https://www.youtube.com/@museeclunymoyenage.
J'ai ensuite découvert cette conférence de Cécile Sabathier : Travailler sur les chantiers au Moyen Âge, conférence de Cécile Sabathier du mercredi 17 janvier 2018 que j'ai trouvé très intéressante (Sociologie du travail et Histoire du travail).
Journal du dimanche 28 juillet 2024 à 11:59
Nouvelle #iteration du Projet 11 - "Première version d'un moteur web PKM".
Voici ce que j'ai implémenté dans la sklein-pkm-engine (lien vers la version du 28 juillet 2024, 12h00) :
- [x] Implémentation d'un script qui injecte des nanoid dans le frontmatter de toutes les notes ;
- [x] Implémentation d'un script qui injecte
type: fleeting_notedans toutes les notes qui se trouvent dans le dossier/Notes éphémères/; - [x] Implémentation d'un script qui injecte
type: evergreen_noteà toutes les notes sanstype; - [x] Implémentation d'un script qui injecte
created_at: ISO 8601sur les Fleeting Note ; - [x]
/{note_filename}/(sans.md) affiche une seule Fleeting Note ; - [x]
/liste de toutes les Fleeting Note de la plus récente à la plus ancienne ; - [x] Afficher les Fleeting Note liées aux Evergreen Note en bas des Evergreen Note ;
- [x] Rendering des
WikiLink; - [x] Rendering des
#tags; - [x] Support des fichiers binaires (image…)
J'ai déployé cette projet sur https://notes.develop.sklein.xyz/.
Voici à quoi cela ressemble :
Prochaines itérations :
- [ ] Activer l'attribue
loading="lazy"sur les images ; - [ ] Ajouter de la pagination sur
/; - [ ] Rendering markdown :
- [ ] Rendering des simples liens;
- [ ] Rendering des codes sources.
- [ ]
/tags/{tag_name}/; - [ ] Affichage des tags derrière l'heure :
 ;
; - [ ] Permettre de remplacer les tages du type
JaiDécouvertparJ'ai découvertpour simplifier la lecture.
Journal du dimanche 28 juillet 2024 à 09:43
Je viens d'apprendre que l'option -N de ssh permet de ne pas ouvrir une session shell interactive sur le serveur distant.
Option très utile lors de l'ouverture de tunnels ssh.
Exemple :
ssh -L 8080:localhost:80 user@host -N
Journal du dimanche 28 juillet 2024 à 09:14
Pour des raisons Developer eXperience — convivialité — j'apprécie d'avoir la possibilité de me connecter facilement à un serveur PostgreSQL distant, par exemple, pour :
- Simplement ouvrir un terminal interactif psql ;
- Exécuter un fichier SQL local sur un serveur distant ;
- Exécuter un script local, Python, JavaScript ou autre sur un serveur distant.
Cependant, par choix déontologique, je préfère ne jamais ouvrir PostgreSQL sur l'extérieur.
Je me limite à ouvrir uniquement les services SSH et HTTP sur l'extérieur.
Pour contourner cette limitation, j'utilise des tunnels SSH pour accéder à mes serveurs PostgreSQL distants.
Dans ce dossier /deployment/develop, voici mes scripts idiosyncrasiques que j'ai l'habitude d'utiliser pour ouvrir ou fermer mes tunnels SSH :
Voici un exemple d'utilisation :
$ ./scripts/open_ssh_tunnel_postgres.sh
$ ./scripts/enter-in-pg.sh ../../init.sql
$ ../../import.js
$ ./scripts/close_ssh_tunnel_postgres.sh
Dans les scripts open_ssh_tunnel_postgres.sh et close_ssh_tunnel_postgres.sh, j'utilise simplement nohup pour exécuter ssh en tâche de fond et récuperer son PID.
Journal du samedi 27 juillet 2024 à 14:00
#JaiLu le thread Hacker News "An experiment in UI density created with Svelte | Hacker News" et j'ai trouvé cela très intéressant.
Le bon dosage de la densité d'affichage est un élément très important dans mon expérience utilisateur.
#JaiDécouvert la librairie frontend web nommée DataTables (https://datatables.net/) implémentée en Javascript basée sur jQuery.
I'd like to think projects like these are somehow signaling a return to well designed but information dense, space saving interfaces ...
The amount of bloat, whitespace, extra spacing, "air" and other such waste — starting with (now Google-dead) "Material Design" has been egregious. —
#JaiDécouvert Perspective (https://perspective.finos.org/), j'aime beaucoup la densité des grilles. Voici un exemple en full screen : https://perspective.finos.org/blocks/editable/index.html.
J'aime sa densité et sa vitesse de rendu 👌.
This is interesting because it proves something to me about my vision and visual comprehension.
The "Grid" view is absolutely fine for me. The "Table" view is unworkable.
Intéressant 🤔.
J'ai regardé une partie de la vidéo de présentation du Bloomberg Terminal (https://www.youtube.com/watch?v=2ee-x6IXWK8), j'ai trouvé l'UI très intéressante.
Journal du vendredi 26 juillet 2024 à 15:08
#OnMaPartagé Storj, une solution de Object Storage alternative à Backblaze, Scaleway Object Storage…
Get faster cloud object storage at 90% less cost than AWS S3 while dramatically reducing your data’s carbon footprint.

J'ai vérifié, Storj semble bien supporter l'API S3 : https://storj.dev/dcs/objects
Journal du jeudi 25 juillet 2024 à 16:56
Rich Harris explains this clearly. JSDoc for writing a lib. TypeScript for writing an app. (from)
Ce conseil entre en opposition avec ce que j'ai écrit en octobre 2023 :
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Ce conseil entre aussi en opposition avec ce second élément que j'ai écrit en octobre 2023 :
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Je pense qu'il serait bon que je revoie ma doctrine d'artisan développeur sur ce sujet.
Journal du jeudi 25 juillet 2024 à 15:24
#JaiDécouvert shadcn-svelte et donc shadcn-ui.
En cherchant des informations au sujet de shadcn-ui, #JaiDécouvert ici Franken UI.
Dans la documentation de shadcn-ui je lis :
This is NOT a component library. It's a collection of re-usable components that you can copy and paste or use the CLI to add to your apps.
What do you mean not a component library?
It means you do not install it as a dependency. It is not available or distributed via npm, with no plans to publish it.
Je trouve cela intéressant, #Jaime .
Dans la page About de shadcn-svelte :
- #JaiDécouvert bits-ui une lib Svelte Headless components, utilisé par shadcn-svelte
- #JaiDécouvert cmdk-sv
- #JaiDécouvert Formsnap
Journal du mercredi 24 juillet 2024 à 13:30
Je viens de recevoir mon Shokz OpenMove, écouteur à conduction osseuse.

Voici mon bilan :
- Très agréable à porter : c'est léger et j'ai l'impression de ne rien porter ;
- Je me sens bien plus libre qu'avec un dispositif sur les oreilles ;
- Le volume est bon, bien que je pense ne rien entendre lorsque je passe l'aspirateur ;
- Je dois éviter de mettre le volume trop fort si j'écoute une personne avec une voix très grave, sinon, j'ai une sensation de vibration ;
- J'ai testé un appel téléphonique, et mon interlocuteur m'a bien entendu.
- Je constate que la solution conduction osseuse est bien plus efficace que la technologie Sidetone.
J'ai hâte de tester en visioconférence pour voir si je continue à parler dans le micro ou non 😉.
Ayant perdu un écouteur de mon Jabra Elite 5, je cherchais une alternative pour le remplacer. (from)
Au passage, je viens de retrouver mon écouteur 🙈.
Achat compulsif ? 🤔
Journal du mardi 23 juillet 2024 à 22:46
#JaiDécouvert https://github.com/idealclover/RSS-OPML-to-Markdown
🎁 Convert RSS OPML file to Markdown - easy to read and share
Journal du mardi 23 juillet 2024 à 22:37
Je viens de créer la page Mon usage des réseaux sociaux.
Journal du mardi 23 juillet 2024 à 22:19
Je profite de la question 2024-07-23_2219 pour commencer la migration du contenu des issues :
- Écrire une page "garden" de liste des Subreddit que je suis et ce que j'y trouve
- Écrire un article pour expliquer les sites de contenu ou réseaux sociaux que j'utilise et je n'utilise pas
vers la page "Où est-ce que je m'informe, où est-ce que je vais chercher de la connaissance ?.
Journal du mardi 23 juillet 2024 à 21:08
« C'est quoi vos 3 meilleures sources de veille ? Par source j'entends,l'endroit ou vous allez chercher vos informations (Un channel reddit précis, un site précis, etc...) »
Voici mes habitudes quotidiennes de veille informatique, technologique et anglo-saxonne :
-
- En premier, je consulte https://lobste.rs/ ;
-
- Ensuite, Hacker News, soit directement via https://news.ycombinator.com/ ou alors via mon instance miniflux ;
-
- Ensuite, mon instance miniflux ;
-
- Ensuite, mon flux Fediverse : https://mamot.fr/deck/@stephane_klein.
Très souvent, je m'arrête à l'étape 2, car comme je lis surtout les commentaires, cela me prend beaucoup de temps.
Pour les actualités :
- Souvent https://www.youtube.com/@HugoDecrypte ;
- Souvent Le 6/9 de France Inter ;
- Et rarement Brief.me (je suis abonné).
Au quotidien :
- Mon flux YouTube (voir Je suis abonné à ces chaines YouTube) ;
- Et les Podcasts de Radio France.
Je n'utilise pas le feed de suggestion de YouTube, je consulte mes abonnements.
#JutilisePeu Twitter (de moins en moins).
- J'utilise actuellement Facebook uniquement comme un carnet d'adresse + quelque Goupe, je ne consulte presque jamais mon feed
- J'utilise LinkedIn uniquement comme un carnet d'adresse. Je ne consulte presque jamais mon feed
- TikTok
Journal du mardi 23 juillet 2024 à 16:27
Suite à cette limitation de Scaleway :
J'ai pourcouru la documentation et l'espace client de Scaleway et je pense qu'un utilisateur ne peux pas créer d'organisation supplémentaire. (from)
#JaiPosté https://feature-request.scaleway.com/posts/941/allow-a-user-to-create-multiple-organizations
Journal du mardi 23 juillet 2024 à 15:54
#JaiDécouvert que Scaleway a déployé en public beta une offre d'Managed Inference Service : Scaleway Managed Inference.
Added : Managed Inference is available in Public Beta
Managed Inference lets you deploy generative AI models and answer prompts from European end-consumers securely. Now available in public beta! (from)
C'est une alternative à Replicate.com.
Models now support longer and better conversations :
- All models on catalog now support conversations to their full context window (e.g Mixtral-8x7b up to 32K tokens, Llama3 up to 8k tokens).
- Llama3 70B is now available in FP8 quantization, INT8 is deprecated.
- Llama3 8b is now available in FP8 quantization, BF16 remains default.
L'offre est beaucoup moins large que celle de Replicate mais c'est un bon début 🙂.
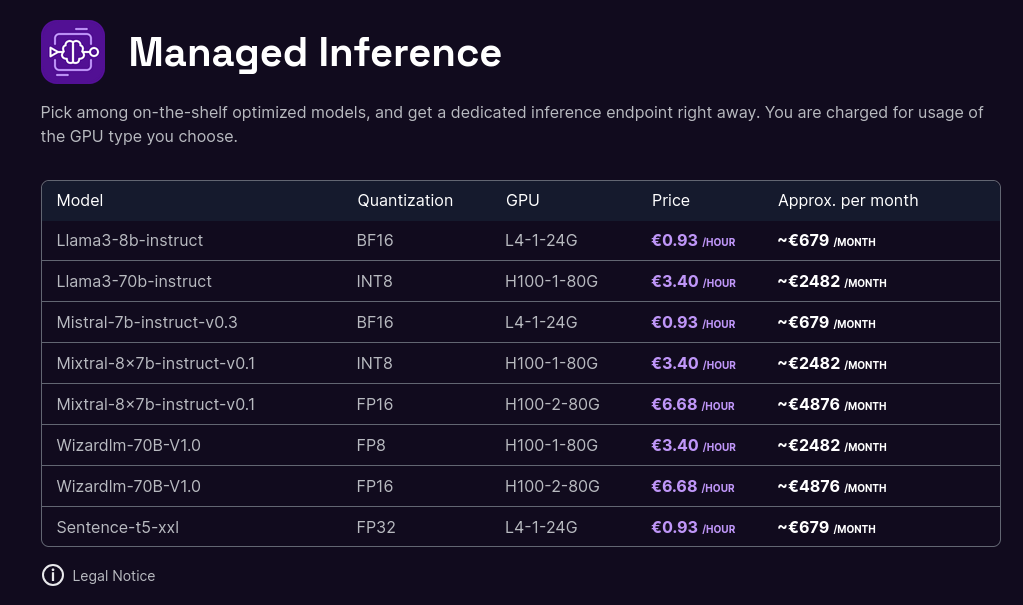
Tarif de l'offre de Scaleway :
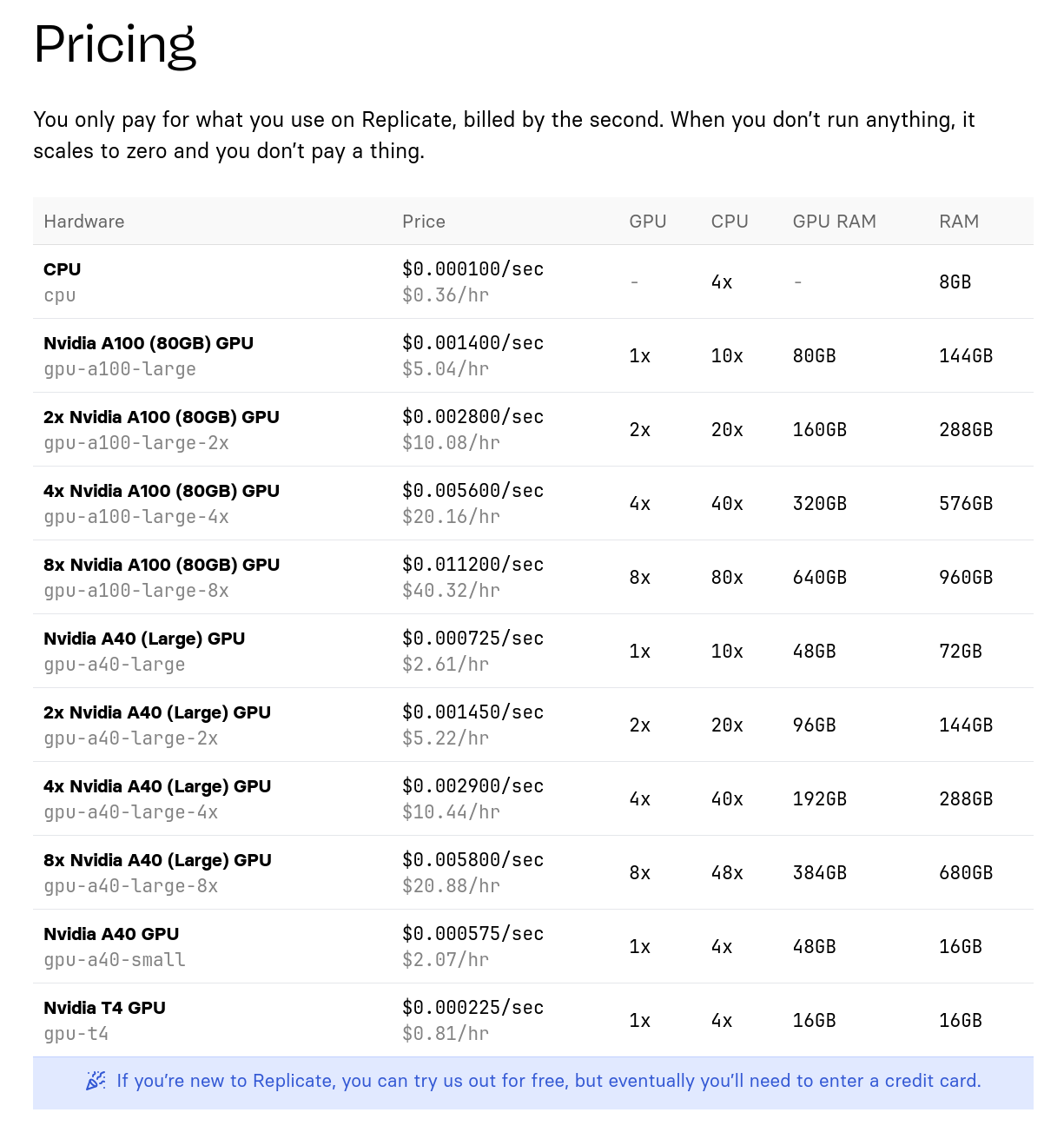
Tarif de l'offre de Replicate.com :
Bien que le matériel soit différent, j'essaie tout de même de faire une comparaison de prix :
- Scaleway : 0,93 € / heure pour une machine à 24Go de Ram GPU
- Replicate : 0,81 $ / heure pour une machine à 16GB de Ram GPU
Ensuite :
- Scaleway : 3,40 € / heure pour une machine à 80Go de Ram GPU
- Replicate : 5,04 € / heure pour une machine à 80Go de Ram GPU
Je précise, que je n'ai aucune idée si ma comparaison a du sens ou non.
Je n'ai pas creusé plus que cela le sujet.
Note en lien avec 2024-05-17_1257.
Journal du mardi 23 juillet 2024 à 15:38
Je dois créer une Organization Scaleway pour un client.
Je souhaite que ce client soit propriétaire de l'organisation.
Je souhaite pouvoir administrer totalement cette organisation, mais je souhaite aussi pouvoir quitter cette organisation.
Je lis ici :
An Organization is made of one or several Projects. When you create your Scaleway account, an Organization is automatically created, of which you are the Owner.
J'ai parcouru la documentation et l'espace client de Scaleway et je pense qu'un utilisateur ne peut pas créer d'organisation supplémentaire.
D'après ce que j'observe, une Organization appartient à un user.
Partant de ce constat, voici la méthode que j'imagine afin de créer une organisation que je peux céder.
- Je crée une organisation avec une adresse mail spécifique, du type
contact+ownernomduclient@stephane-klein.info - J'invite mon client dans cette organisation
- Si besoin, je m'invite moi-même via une autre adresse mail, exemple
contact+nomduclient@stephane-klein.info - Plus tard, je peux changer l'adresse mail dans "Edit your account profile" pour céder l'organization à l'adresse mail du client.
Suite à cette limitation, j'ai posté Allow a user to create multiple organizations sur Scaleway Feature Request.
Journal du mardi 23 juillet 2024 à 09:48
Ayant perdu un écouteur de mon Jabra Elite 5, je suis en train d'étudier par quoi le remplacer.
L'hiver dernier, j'ai croisé un utilisateur de casque à conduction osseuse, il était fan.
Je viens de passer un peu de temps à étudier les modèles vendu sur Amazon et #JaiDécouvert la marque Skokz.
Je découvre ici qu'il existe de type de technologie d'écoute à oreilles libres : conduction osseuse et DirectPitch.
#JaiCommandé le modèle Shokz OpenMove à 89,95 €.
Journal du lundi 22 juillet 2024 à 15:15
Merci à Alexandre de m'avoir partagé le projet Mailpit une alternative à Maildev ou MailCatcher.
Journal du vendredi 19 juillet 2024 à 23:51
Suite à la lecture de https://github.com/passlock-dev/svelte-passkeys j'ai envie de tester Passkey.
Journal du vendredi 19 juillet 2024 à 23:40
#JaiLu What's new in Svelte: July 2024
#JaiLu What's new in Svelte: June 2024
Tons of work on the migrate tool to make migrating to Svelte 5 syntax easier
J'ai hâte de tester pour constater les changements dans le code et aussi constater si cela cette outil fonctionne correctement ou non 🤔.