
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (850) ] [ Page suivante (3058) >> ]
Journal du vendredi 19 juillet 2024 à 23:16
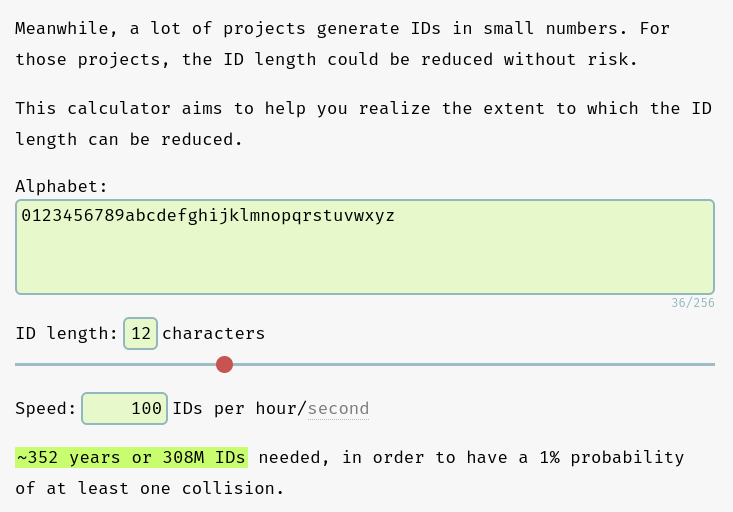
Pour la génération de nanoid du Projet 11, j'ai choisi les paramètres suivants :
const nanoid = customAlphabet('0123456789abcdefghijklmnopqrstuvwxyz', 12);
D'après les calculs effectués sur https://zelark.github.io/nano-id-cc/, à raison de 100 nouvelles notes par jour (ce qui est irréaliste), sur 352 années, le risque de doublon d'id est de 1%, ce qui est largement acceptable 😉.
Journal du vendredi 19 juillet 2024 à 22:44
Je viens de publier Projet 11 - "Première version d'un moteur web PKM".
Journal du vendredi 19 juillet 2024 à 18:07
#JaiDécouvert le terme Inkling (from : Spaced repetition may be a helpful tool to incrementally develop inklings) qui signifie :
Le terme "inkling" en anglais signifie une vague idée ou une intuition.
Journal du vendredi 19 juillet 2024 à 18:06
#JaiDécouvert Timeful Texts de Andy Matuschak.
Consider texts like the Bible and the Analects of Confucius. People integrate ideas from those books into their lives over time — but not because authors designed them that way. Those books work because they’re surrounded by rich cultural activity. Weekly sermons and communities of practice keep ideas fresh in readers’ minds and facilitate ongoing connections to lived experiences. This is a powerful approach for powerful texts, requiring extensive investment from readers and organizers. We can’t build cathedrals for every book. Sophisticated readers adopt similar methods to study less exalted texts, but most people lack the necessary skills, drive, and cultural contexts. How might we design texts to more widely enable such practices?
Cela rejoint une réflexion que j'ai eue concernant les documentations d'onboarding ou handbook d'organisation.
Problème
Il est courant de demander à aux nouveaux employés d'une startup de lire la documentation d'onboarding ou le handbook de l'organisation.
En pratique, je trouve cela peu efficace. Les premiers jours ou heures dans une nouvelle organisation sont souvent à la fois excitants et stressants. C'est une période où les individus cherchent à créer des liens, à rencontrer les autres et à comprendre qui est qui. Conséquence : je pense qu'il est difficile d'entrer en deepflow de lecture pendant cette période. Les personnes onboardé survolent la documentation et je trouve cela tout à fait justifié.
D'autre part, les informations détaillées contenues dans ces documents n'auront que peu de signification au début et ne deviendront pertinentes qu'après plusieurs semaines passées au sein de l'organisation. Et malheureusement, je constate que si les autres membres de l'équipe ne l'invitent pas, la personne onboardé retourne rarement elle-même consulter des détails bien utiles dans la documentation.
Solution humaine
Pour pallier ce problème, lors de ma dernière expérience, j'ai mis en place un système de parrain attribué à chaque nouvelle personne. Le parrain était là pour répondre à toutes les questions du nouvel arrivant et le rediriger vers les bonnes sections de la documentation.
Idée technique
En 2022, j'imaginais un système basé sur un chatbot (pour Slack ou autre) qui enverrait, de manière espacée dans le temps des liens vers des sections de la documentation à lire.
Ce chatbot pourrait aussi poser des questions, pour vérifier si la personne est au courant d'éléments contenus dans la documentation.
Cela ressemble au projet Timeful Texts 🤔.
[!Note au lecture] Pour bien comprendre le lien, je vous invite à lire l'intégralité de l'article et pas seulement l'extrait cité au début de cette note.
Journal du vendredi 19 juillet 2024 à 17:48
Il y a un an, j'envisageais de self hosted une alternative à Pocket, par exemple Shiori, Wallabag et pour finir, j'avais une préférence pour Linkding.
Maintenant que j'utilise un Personal knowledge management, je ne trouve plus d'intérêt à utiliser un logiciel de bookmark manager.
À la place, j'utiliser le tag #JaiDécouvert… et si je trouve de l'intérêt au lien, je crée une Evergreen Note.
Journal du vendredi 19 juillet 2024 à 17:35
J'ai passé 10min à étudier ce projet, je n'ai pas vraiment compris ses caractéristiques, mais j'y ai trouvé des choses qui ont attiré ma curiosité. #JaimeraisUnJour prendre du temps pour étudier Atomic Data en profondeur.
En lien avec Systèmes d’organisation des connaissances.
Journal du vendredi 19 juillet 2024 à 12:35
Je suis surpris de ne pas trouver de Hub note dans Taxonomie des types de notes de Andy et Taxonomie des types de notes listé dans le livre « How to Make Notes and Write ».
Journal du vendredi 19 juillet 2024 à 10:49
Note au sujet de mon usage des Notes éphémères est imprécis.
En avril 2024, j'ai décidé d'utilisé le wording "Notes éphémères" présent dans la taxonomie des types de notes listé dans le livre « How to Make Notes and Write ».
Mais j'ai bien conscient que mon usage de ces notes est pour le moment imprécis, je ne sais pas si je dois classer mes Notes éphémères dans la catégorie Daily working log ou Writing inbox de Taxonomy of note types. Je pense que je mélenge ces deux concepts.
En plus de ces Notes éphémères publiques, j'écris aussi des notes éphèmeres dans un Vault Obsidian privé.
Journal du jeudi 18 juillet 2024 à 21:27
#JaiLu commencé à lire https://notes.andymatuschak.org/Evergreen_notes de Andy's working notes.
Voir aussi Evergreen Note.
Journal du jeudi 18 juillet 2024 à 21:03
#JaiDécouvert un portail qui contient de nombreuses conférences scientifiques : https://portal.sciencesconf.org/browse/list
Journal du mercredi 17 juillet 2024 à 22:53
Dans la page Wikipedia de Paul Otlet #JaiDécouvert Classification décimale universelle et Classification décimale de Dewey.
Journal du mercredi 17 juillet 2024 à 21:19
Dans la vidéo FAQ – juillet 2017 de Monsieur Phi #JaiDécouvert L’Encyclopédie Philosophique.
Journal du mercredi 17 juillet 2024 à 21:07
Dans la vidéo FAQ – juillet 2017 de Monsieur Phi, il conseille le #livre L'influence de l'odeur des croissants chauds sur la bonté humaine de Ruwen Ogien qui traite de la philosophie morale.
Journal du mercredi 17 juillet 2024 à 18:13
Je pense avoir retrouvé le site que Thibaut Giraud mentionne fréquemment, dédié à la philosophie analytique : la Stanford Encyclopedia of Philosophy ou l'Internet Encyclopedia of Philosophy.
Journal du mercredi 17 juillet 2024 à 17:46
En cherchant la définition de mot Diaphories, #JaiDécouvert le #livre : L'Homme-trace - Inscriptions corporelles et techniques.
Journal du mercredi 17 juillet 2024 à 17:25
#JaiDécouvert Luciano Floridi (from)
Floridi s'est fait connaître comme l'un des plus importants théoriciens de la philosophie de l'information et éthique de l'informatique, reconnu comme une autorité dans le domaine de la philosophie sur Internet. (from).
Luciano Floridi enseigne comme professeur associé de logique et d’épistémologie au département de philosophie de l'université de Bari. (from)
Journal du mercredi 17 juillet 2024 à 17:23
Je tente de comprendre la signification du mot Diaphories que j'ai découvert dans l'article Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret.
Après avoir partiellement lu :
- #JaiLu Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
- #JaiLu Quelques révisions du concept d’information.
- Cette citation :
"La donnée correspond, quant à elle, à ce qui n’est pas uniforme (à ce qui est « diaphora/différent ») ; bref il s’agit d’une variable : « une donnée est un fait supposé qui procède d’une différence ou d’un manque d’uniformité dans un contexte »" (source).
Je constate que je ne suis pas certain d'avoir bien compris la signification de Diaphories.
Voici un exemple pour illustrer ce que je pense avoir compris : imaginons une pelouse totalement uniforme. Si cette pelouse contient une fleur, cet élément, différent (du grec ancien διαφορά, diaphorá (« différence, distinction »)) de l'homogénéité de la pelouse, est une information. Sa couleur, sa localisation… sont des données, des Diaphories.
Journal du mardi 16 juillet 2024 à 13:44
#JaiLu Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret publié sur HAL.
La documentation personnelle peut être définie comme la documentation élaborée par un individu pour lui-même, de manière idiosyncrasique.
#JaiDécouvert le mot Idiosyncrasique.
#JeMeDemande si la condition « pour lui-même » est dépassable ou non 🤔.
(Psychologie) Caractères propres au comportement d’un individu particulier. (from).
Élaborer une documentation personnelle permet d’organiser le processus de « signifiance » (Leleu-Merviel, 2010) pour construire des connaissances (voir figure 1).
#JaiDécouvert la chercheuse Sylvie Leleu-Merviel.
#JeSouhaite lire Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
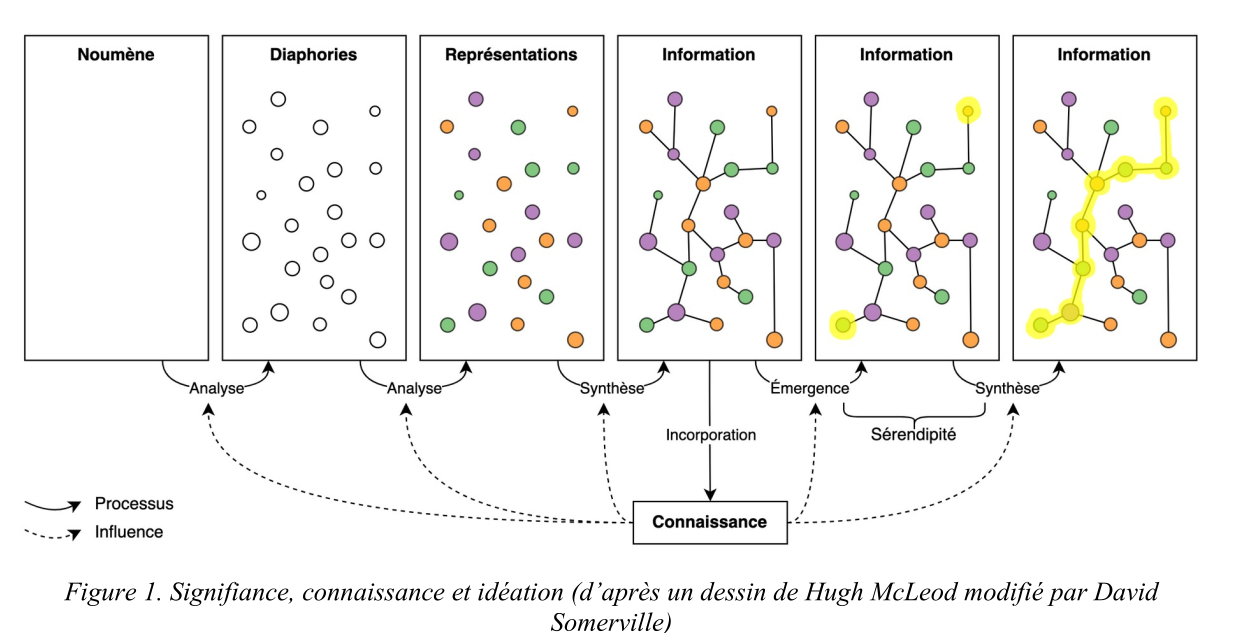 #JaiDécouvert les mots Noumène, Noème et Diaphories.
#JaiDécouvert les mots Noumène, Noème et Diaphories.
Comme l’écrit Latour (dans « Pensée retenue, pensée distribuée »), la pensée n’est pas « retenue » dans l’unique cerveau du penseur, mais « distribuée » dans un ensemble d’acteurs et d’actants – un « milieu de savoir » selon l’expression de Le Deuff : données et documents, individus et collectifs, lieux, évènements et dispositifs divers.
#JaiDécouvert Traité de documentation de Paul Otlet.
#JaiDécouvert Robert Estivals et Communicology.
L’approche hypertextuelle présente plusieurs avantages par rapport aux graphes de connaissance, notamment une mise en œuvre plus simple et une plus grande expressivité. Cette méthode produit ce que Stiegler (Le concept d’ « Idiotexte » : esquisses - 2010) appelle un idiotexte, c’est-à-dire la textualisation d’une mémoire personnelle. L’utilité primaire de cette méthode, pour l’individu qui crée sa documentation personnelle, est de multiplier les chemins vers une même information, via des connexions riches en signification et facilement réactivées.
#JaiDécouvert idiotexte, j'ai lu l'article mentionné et je ne l'ai pas compris 🙅♀️.
Cette méthode présente également un intérêt pour les recherches sur les systèmes d’organisation des connaissances (SOC). Mazzocchi (2018) définit les SOC comme des ensembles de termes ou concepts interreliés, outils intermédiaires entre des humains et des collections de données et documents. Dans la méthode que nous avons décrite, la création d’un graphe documentaire correspond à la fois à la création d’une collection de documents – les fiches – et d’un SOC – les catégories de fiches et de liens utilisées dans le graphe.
#JaiDécouvert Systèmes d’organisation des connaissances (SOC).
D’abord, cette méthode est orientée par la subjectivité : les choix qui guident l’élaboration du graphe sont basés sur la mémorabilité, critère hautement subjectif.
Ok, j'ai bien compris 👌.
Par exemple, des catégories de fiches peuvent être modifiées, supprimées ou ajoutées progressivement pour orienter la manière dont fonctionne la remémoration.
Ok, j'ai bien compris 👌.
#JaiDécouvert L’épistémologie sociale (from)
J'ai pris le temps de regarder https://www.arthurperret.fr/glossaire-indexation.html, j'ai trouvé des choses intéressantes, du vocabulaire pour nommer des éléments techniques des CMS.
Ces configurations affectent la manière dont nous remémorons les choses : nous nous disons par exemple « J’ai mentionné ce concept dans telle publication » ou bien « C’est untel qui m’a recommandé cette méthode ». Ces connexions idiosyncrasiques sont facilement réactivées car elles reposent sur des éléments ayant une grande « mémorabilité » – terme qui renvoie aux arts de la mémoire et que nous entendons ici comme une qualité déterminée subjectivement, de manière réflexive, à partir de situations essentiellement contingentes, qui modifient notre « comportement informationnel ».
Je comprends très bien ce qui est exprimé et cela correspond à mon expérience vécu.
Journal du mardi 16 juillet 2024 à 09:57
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
- Extraction des tags présents dans le corps des notes.
C'est fait 🙂 : Extract tags from note bodies to create and associate them with the note
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
C'est fait 🙂 : Implementation of a markdown-to-html rendering function that takes tags and wikilinks into account
J’ai préparé une première ébauche, mais étant incertain de la manière dont je vais intégrer cette fonctionnalité avec pg_search ou Typesense, j’ai décidé de ne pas continuer à la développer pour le moment : Implementation of a function that transforms markdown content into plain text.
Journal du lundi 15 juillet 2024 à 15:25
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search.- Créer un repository GitHub nommé
obsidian-vault-to-typesense.- Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc
C'est fait 🙂.
Après cela, je souhaite implémenter dans
obsidian-vault-to-apache-age-pocles fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]).
C'est implémenté par ce commit 🙂.
Je ne suis pas satisfait de l'implémentation de cette partie et celle-ci.
Journal du lundi 15 juillet 2024 à 14:45
Dans l'épisode Combien d'argent il faut pour être vraiment riche … du Podcast Le Trilliard #JaiDécouvert le #livre The Gatekeepers: How the White House Chiefs of Staff Define Every Presidency. Je trouve le sujet intéressant, #UnJourPeuxÊtre je prendrais le temps de le lire.
Journal du dimanche 14 juillet 2024 à 12:11
Avec l'intégration de pg_search et Typesense, j'ai bien conscience de m'être un peu perdu dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search. - Créer un repository GitHub nommé
obsidian-vault-to-typesense. - Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc.
Après cela, je souhaite implémenter dans obsidian-vault-to-apache-age-poc les fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]). - Extraction des tags présents dans le corps des notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en texte brut, sans lien, destiné à être injecté dans un moteur de recherche comme pg_search ou Typesense.
Après avoir traité ces tâches, je souhaite travailler sur un moteur de rendu HTML basé sur SvelteKit, obsidian-vault-to-apache-age-poc et sans doute obsidian-vault-to-typesense.
Journal du dimanche 14 juillet 2024 à 10:26
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans 2024-07-10_0941 je disais :
je souhaite tester l'intégration de Typesense à
obsidian-vault-to-apache-age-pocen complément de pg_search.
Voici un screencast du résulat de cette implémentation de InstantSearch connecté à Typesense :
Journal du dimanche 14 juillet 2024 à 10:08
#JeMeDemande comment Typesense gère le contenu HTML présent dans les champs textes. Ignore-t-il ou non les balises HTML ?
Ici dans la documentation, j'ai trouvé un lien vers l'issue intitulée Feature Request - Ignore any HTML tags when searching but still return response with HTML included.
La solution proposée ne me satisfait pas à 100% :
For a simple solution you could introduce an artificial field where all html tags are removed.
Idéalement, j'aimerais que cette fonctionnalité soit directement prise en charge par Typesense.
Journal du samedi 13 juillet 2024 à 21:52
#JaiDécouvert typesense-dashboard :
A Typesense Dashboard to manage and browse collections.
Journal du samedi 13 juillet 2024 à 10:34
#JaiLu ce manuscrit de Lê Nguyên Hoang : Une astuce bayésienne pour identifier l'expertise.
En particulier, un argument bayésien montre bel et bien que les affirmations bien plus populaires que ceux qu'on croit ont tendance à être souvent juste --- en tout cas dans un monde où les humains réfléchissent correctement, ou plutôt, conformément aux lois des probabilités.
🤔
J'ai lu plusieurs fois la section "Le théorème de la popularité insoupçonnée d'une vérité" et pour le moment, je n'ai toujours pas réussi à comprendre le raisonnement. Cela me demande beaucoup de concentration !
Eh bien, le scrutin proposé par Prelec, Seung et McCoy, qu'ils appellent le vote du candidat "surprenamment populaire" consiste à calculer, pour chaque candidat X, tous les ratios de ce genre, où X est comparé à des alternatives Y, en comparant les prédictions pro-Y chez les pro-X aux prédications pro-X chez les pro-Y.
Voir aussi Bayésianisme.
Journal du vendredi 12 juillet 2024 à 13:46
#OnMaPartagé l'information suivante Évolution des taux de cotisations sociales des auto-entrepreneurs .
Depuis le 1er juillet 2024, la loi prévoit que le taux global de cotisations de 21,1 % évolue progressivement sur une période de trois ans, selon le calendrier suivant :
- du 1er juillet au 31 décembre 2024 : 23,1 % ;
- du 1er janvier au 31 décembre 2025 : 24,6 % ;
- à partir du 1er janvier 2026 : 26,1 %.
Ce qui fait une augmentation totale de 5%.
Source du changement : Décret n° 2024-484 du 30 mai 2024 modifiant les taux globaux de cotisations et contributions de certains travailleurs indépendants exerçant dans le cadre de la microentreprise
J'ai essayé de comprendre les motivations derrière ce changement.
J'ai découvert que la Fédération nationale des auto-entrepreneurs (FNAE) se bat depuis plusieurs années pour la retraite complémentaire (la CIPAV) des micro-entropeneurs :
- En 2021 : « La FNAE continue à se battre pour la retraite complémentaire des microentrepreneurs passés au régime général et pour lesquels aucune cotisation retraite complémentaire n’est appelée depuis 2018. Elle réclame une clé de répartition du forfait social. »
- En 2022 : « Retraite : après l’obtention d’une clé de répartition claire du forfait social mais la FNAE continue de se mobiliser pour les PLNR et les retraites complémentaires des années précédentes depuis 2018 ».
- En 2023 : « la bataille continue pour assurer aux microentrepreneurs leur droit à la retraite complémentaire, de façon rétroactive depuis 2018 pour tous, et pour les PLNR (Professions libérales non réglementées) dont la cotisation à la retraite complémentaire n’est pas comptée dans le forfait social. »
Sur le site de la FNAE, j'ai trouvé l'article Retraite complémentaire d’auto-entrepreneur : enfin des droits en profession libérale ! qui donne beaucoup d'explications :
Le 1er juillet 2024 sera à marquer d’une croix (blanche ?) pour les auto entrepreneurs libéraux, puisqu’ils cotiseront enfin pour leur retraite complémentaire d’autoentrepreneur.
J'ai regardé ma dernière fiche de paie en CDI et j'ai l'impression que les taux de cotisations sociale de retraite complémentaire était : 12,4 %.
12 % me semble bien supérieur à 5 % de cotisations de retraite complémentaire pour les micro-entrepreneurs.
Conclusion : il me semble extrêmement probable que c'est la FNAE qui est à l'origine de ce changement et non pas Bruno Le Maire ministre de l'Économie.
Journal du vendredi 12 juillet 2024 à 10:57
Suite de 2024-07-11_1929 :
Suite à ce constat, je vais essayer de setup InstantSearch dans le projet
obsidian-vault-to-apache-age-poc.
J'ai trouvé "typesense-instantsearch-demo (without NPM or YARN)" qui va me servir de base.
11:10 : J'ai une première version de InstantSearch qui fonctionne mais avec plein d'imperfection.
Journal du vendredi 12 juillet 2024 à 10:17
#JaiDécouvert que InstantSearch propose une version "vanilla JS". Jusqu'à présent, je pensais que seuls React, Vue et Angular étaient proposés.
Journal du jeudi 11 juillet 2024 à 19:29
J'ai essayé d'utiliser TypeSense-Minibar dans obsidian-vault-to-apache-age-poc et je constate que TypeSense-Minibar est limité à un usage bien précis : effectuer une recherche sur un schema généré par Docsearch.
La limitation se trouve ici.
query_by: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content',
include_fields: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content,url_without_anchor,url,id',
highlight_full_fields: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content',
Pour un usage autre que Docsearch, je pense qu'il faut utiliser InstantSearch.
Je constate ici que je peux configurer query_by :
...
additionalSearchParameters: {
query_by: "name,description,categories",
},
...
Suite à ce constat, je vais essayer de setup InstantSearch dans le projet obsidian-vault-to-apache-age-poc.
Journal du mercredi 10 juillet 2024 à 22:29
#JaiDécouvert la fonctionnalité Semantic Search de Typesense :
Typesense supports the ability to do semantic search out-of-the-box, using built-in Machine Learning models or you can also use external ML models like OpenAI, PaLM API and Vertex AI API.
Journal du mercredi 10 juillet 2024 à 21:36
Je suis en train d'étudier Typesense et j'ai la sensation que :
- la documentation de Typesense est plus agréable à lire que celle de Meilisearch ;
- la documentaion de Typesense est plus complète, plus précise que celle de Meilisearch ;
- Typesense est plus complet que Meilisearch.
#Jaime cette la section "What is the difference between Typesense Cloud and Self-Hosted version?".
Journal du mercredi 10 juillet 2024 à 19:38
#JaiDécouvert la documentation PostgreSQL nommée https://pgpedia.info/.
Journal du mercredi 10 juillet 2024 à 19:09
#JaiDécouvert Citation Style Language, pour le moment je n'ai pas pris de temps de comprendre à quoi cela sert précisément (from)
Journal du mercredi 10 juillet 2024 à 11:38
Suite à 2024-07-10_1121, #JeSouhaite tester Cosma avec le contenu de https://notes.sklein.xyz.
Journal du mercredi 10 juillet 2024 à 11:21
#JaiLu Écrire autrement : réflexion croisées sur Mardown
En SHS, les logiciels de traitement de texte (comme LibreOffice Writer, Microsoft Word et Google Docs) sont utilisés par la ma‐ jorité des auteurs et des éditeurs. … leur modèle économique est souvent défavorable à l'utilisateur ; …
La maniabilité des textes en Markdown permet de circuler de façon plus fluide dans sa production écrite et de la mobiliser au fil de différents contextes de recherche (communications scientifiques, articles de recherche, notes, supports de cours, etc.). Le temps de traitement et le travail de mise en forme des textes ainsi produits sont de ce fait rationalisés. L’ensemble de ces étapes constitue un écosystème de travail global et intégré.
Markdown a été pensé pour le Web : c'est une sorte de « sténographie » de HTML.
À la façon d'un wiki personnel, cette documentation regroupe tous les documents dans lesquels on travaille : fiches de lecture, notes terminologiques, brouillons d'idées, etc. C'est l'espace de travail dans Zettlr ou le "vault" dans Obsidian. L'idée centrale est de travailler avec des notes organisées de manière non-linéaire, qui se font référence les unes aux autres. Périodiquement, une idée émerge : un lien nou‐ veau entre deux choses (ou plus). Les notes servent d'aide-mémoire et d'espace de réflexion/idéation.
Outils cités dans l'article :
- #JaiDécouvert https://github.com/peterpeterparker/stylo
- Marp
- #JaiDécouvert https://ia.net/presenter (j'adore)
- #JaiDécouvert https://cosma.arthurperret.fr/
#JaiDécouvert le mot cosmoscope.
Journal du mercredi 10 juillet 2024 à 11:03
#JeDécouvre ce site perso https://www.arthurperret.fr/ de Arthur Perret, j'aime beaucoup le style. (from).
Dans ses papiers de recherche #JaiDécouvert ces papiers :
Journal du mercredi 10 juillet 2024 à 09:41
Suite à 2024-07-09_0846 (Projet 5) et suite à la publication de poc-meilisearch-blog-sveltekit en 2023, je souhaite tester l'intégration de Typesense à obsidian-vault-to-apache-age-poc en complément de pg_search.
J'ai bien conscience que Typesense fait doublon avec pg_search, mais mon objectif dans ce projet est de comparer les résultats de Typesense avec ceux de pg_search.
J'espère que cet environnement de travail me permettra d'itérer afin de répondre à cette question.
Idéalement, j'aimerais uniquement utiliser pg_search afin de mettre en œuvre un seul serveur de base de données et de bénéficier de la mise à jour automatique de l'index du moteur de recherche :
A BM25 index must be created over a table before it can be searched. This index is strongly consistent, which means that new data is immediately searchable across all connections. Once an index is created, it automatically stays in sync with the underlying table as the data changes. (from)
Journal du mardi 09 juillet 2024 à 18:38
#OnMaPartagé Comment nous avons développé un outil d’édition collaborative sur mesure pour nos journalistes
Comme je n'ai pas trouvé le code source du projet Echo, j'ai posé cette question sur LinkedIn :
Tout d'abord, félicitations pour cet article et le développement de ce projet 👍️.
J'ai cherché ce projet sur GitHub, mais je n'ai rien trouvé. Est-ce que le projet Echo est closed-source ?
Journal du mardi 09 juillet 2024 à 09:52
#JaimeraisUnJour installer et tester le moteur de recherche décentralisé https://yacy.net/.
#JeLis le thread YaCy, a distributed Web Search Engine, based on a peer-to-peer network | Hacker News
- Je suis tombé sur ce commentaire que je trouve intéressant
Journal du mardi 09 juillet 2024 à 08:46
Dans le cadre de mon travail sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément, ma tentative d'utiliser pg_search pour y intégrer un moteur de recherche, j'ai creusé le sujet InstantSearch.
Typesense permet d'utiliser InstantSearch via un adaptateur :
At Typesense, we've built an adapter (opens new window) that lets you use the same Instantsearch widgets as is, but send the queries to Typesense instead. (from)
Ici j'ai découvert des alternatives à InstantSearch :
- typesense-minibar
- autocomplete (aussi créé par Algolia)
- docsearch (aussi créé par Algolia)
#JeMeDemande comment utiliser InstantSearch ou TypeSense-Minibar avec pg_search.
N'ayant pas trouvé de réponse, #JaiPublié How can I implement InstantSearch, Typesense-Minibar or Docsearch with pg_search?.