
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (750) ] [ Page suivante (3158) >> ]
Journal du samedi 17 août 2024 à 15:00
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
-- from
#JeMeDemande également si pg_search, Typesense et Meilisearch peuvent réaliser la même chose que ce qui est décrit dans Elastic Search: Highlighting Text That Contains HTML Tags.
En ce qui concerne Typesense, j'ai consulté l'issue Feature Request - Ignore any HTML tags when searching but still return response with HTML included, ce qui me laisse penser que cette fonctionnalité n'est pas prise en charge.
Pour Meilisearch, la discussion Ignore HTML tags at search m'a également conduit à la conclusion que cette fonctionnalité n'est pas encore implémentée. J'ai aussi appris qu'Algolia permet d'ignorer les balises HTML lors de la recherche : Algolia ignores HTML tags during search.
Quant à pg_search, mes recherches sur les mots-clés HTML dans les dépôts pg_search et Tantivy (Tantivy) n'ont rien donné. Il semble donc que la fonctionnalité de surlignage du texte contenant des balises HTML ne soit pas prise en charge par pg_search.
Contenu de ce constat, je vais peut-être redonner une chance à Elasticsearch malgré mon aversion pour la JVM 🤔.
Journal du samedi 17 août 2024 à 14:50
Depuis le début des années 2000, j'éprouve une certaine aversion dès que je suis confronté à une technologie basée sur Java. Pourquoi ? Parce que, à tort ou à raison, j'ai remarqué que les applications Java sont souvent très longues à démarrer et consomment une quantité excessive de RAM.
Je pense par exemple à Logstash, dont la lenteur était insupportable, que j'ai fini par remplacer d'abord par Fluentd, puis par Vector.
Je pense également à Eclipse IDE.
Et bien sûr, aux serveurs Jakarta EE.
Journal du samedi 17 août 2024 à 12:53
Ce matin, j'ai enfin pris le temps de parcourir attentivement la documentation d'Elasticsearch pour comparer ses fonctionnalités à celles de Meilisearch, Typesense et pg_search.
J'ai lu Text analysis overview de Elasticsearch.
Je note ici les étapes de l'Text analysis que j'ai des difficultés à retenir :
- Tokenization
- Token filtering (voir dans Anatomy of an analyzer)
- Normalization (search engine)
- Stemmer token filter (search engine)
- Character filters reference
- Customize text analysis
J'ai parcouru la liste des différents types des Built-in analyzer reference de Elasticsearch.
Je retiens le concept de stop analyzer.
#JeMeDemande l'usage du Keyword analyzer 🤔.
Je trouve le Pattern analyzer intéressant.
En lisant Fingerprint analyzer je découvre l'algorithme fingerprinting décrit dans la documentation de OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint. Je garde cela dans un coin de mon esprit, il se peut que cela me soit utile à l'avenir 🤔.
Je découvre que Elasticsearch (sans doute Lucene 🤔) propose beauoup de token filtering différent qui peuvent être combinés : Apostrophe, ASCII folding, CJK bigram, CJK width, Classic, Common grams, Conditional, Decimal digit, Delimited payload, Dictionary decompounder, Edge n-gram, Elision, Fingerprint, Flatten graph, Hunspell, Hyphenation decompounder, Keep types, Keep words, Keyword marker, Keyword repeat, KStem, Length, Limit token count, Lowercase, MinHash, Multiplexer, N-gram, Normalization, Pattern capture, Pattern replace, Phonetic, Porter stem, Predicate script, Remove duplicates, Reverse, Shingle, Snowball, Stemmer, Stemmer override, Stop, Synonym, Synonym graph, Trim, Truncate, Unique, Uppercase, Word delimiter, Word delimiter graph.
J'ai lu Stemmer token filter que je considère comme très important pour un moteur de recherche efficace.
#JaiDécouvert le support de Synonym graph token filter.
Je lis HTML strip character filter, fonctionnalité que je juge très utile.
Je lis qu'Elasticsearch propose de nombreuses méthodes de query, entre autres :
- Query DSL
- EQL search
- ES QL
- et même SQL
- Scripting
Tout cela est très riche !
J'ai lu Highlighting
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
Journal du samedi 17 août 2024 à 11:59
Je viens de comprendre que dans le domaine des full-text search engine les notions de Facets et Aggregations sont liées.
La fonctionnalité facets sont basés les fonctionnalités aggregations des full-text search engine.
Journal du vendredi 16 août 2024 à 14:46
#Jaime observer les reviews des scripts vidéo de Lê Nguyên Hoang : https://github.com/lenhoanglnh/manuscripts/pull/29 🙂.
Journal du vendredi 16 août 2024 à 13:17
J'ai relu cette note de David Larlet :
Silk = documentation et tests
Markdown based document-driven web API testing.
La rapidité d’exécution d’un outil écrit en Go est toujours surprenante, j’ai eu besoin de vérifier que les tests étaient bien passés pour être sûr de son bon fonctionnement… Mon expérience me montre qu’une documentation qui n’est pas testée/proche du code n’est jamais synchronisée et conduit à des frustrations pour les utilisateurs. Silk est un moyen de faire cela directement depuis votre markdown, ça me rappelle d’une certaine manière le couple docutils/reStructuredText. En rapide. Et je ne saurais trop insister sur l’importance d’avoir une suite de tests rapide pour qu’elle reste pertinente.
Raconter une histoire dans vos tests est plus verbeux mais assurément plus intéressant pour la personne qui cherchera à comprendre ce que vous avez implémenté. Il y a de grandes chances que ce soit vous. Le README du dépôt est un exemple de ce qui peut être réalisé.
Je pense que ce billet a participer à ma sensibilitasion à la notion de colocated documentation.
Journal du vendredi 16 août 2024 à 13:06
Dans ma note Keep it simple, stupid le plus longtemps possible j'ai écris :
Je me souviens de la quête vers le minimaliste dans le code de David Larlet : « Est-ce qu’il est possible d'enlever des couches dans la stack ? »
Je viens d'essayer de retrouver ces articles, mais ce n'est pas facile tellement les articles de David Larlet sont nombreux.
Pour le moment j'ai retrouvé les extraits ci-dessous ceci en lien avec le sujet.
Paternité
- Ajouter des couches
- Changer des couches
- Enlever des couches
- Changer des couches
- Mettre des couches
J’en suis à l’étape 3 dans ma maturité en tant que développeur. La paternité change les priorités et je pense qu’elle a un grand rôle dans le fait de vouloir remettre le focus sur la valeur apportée plus que sur la technique. Me battre pour une meilleure expérience utilisateur plutôt que contre un framework, chercher à se faire plaisir davantage via ce qui est produit que par un contentement technique.
Lorsque j’expérimente aujourd’hui, ce n’est plus pour découvrir une nouvelle bibliothèque mais pour trouver de nouveaux moyens de simplifier un problème. Dans ce contexte, il est intéressant de re-questionner la page blanche (cache), de re-challenger certaines bonnes pratiques communément admises (cache).
Autre extrait :
Leftpad
Every package that you use adds yet another dependency to your project. Dependencies, by their very name, are things you need in order for your code to function. The more dependencies you take on, the more points of failure you have. Not to mention the more chance for error: have you vetted any of the programmers who have written these functions that you depend on daily?
J’étais en train de préparer cette intervention lorsque le fiasco leftpad est arrivé dans l’écosystème NPM. Du coup, j’ai eu immédiatement plein d’articles faisant une ode à la simplicité, à la réduction de dépendances et mettant en garde contre les couches d’abstraction. Merci Azer Koçulu, je pouvais difficilement rêver mieux :-). Je ne vais pas tirer sur l’ambulance mais ça illustre presque trop bien mon propos.
as your project progresses, your team’s productivity will drop because of all the complexity and dependencies. You’ll need more people to maintain it, and more people with specific knowledge to maintain it. If your lead developers leave, you’re dead. You should be fighting complexity and not embracing it. Every added framework, and even library, makes your project more difficult to maintain. Avoid unnecessary frameworks and libraries from day one.
Jusqu’où aller dans cette démarche ? Par où commencer ?
Autre extrait :
Maybe it’s not too late for you, though. Perhaps, like me, you aren’t feeling particularly overworked. But are you feeling irritable, tired, and apathetic about the work you need to do? Are you struggling to concentrate on simple tasks?
Then maybe what you’re feeling is burnout, too.
J’ai travaillé pendant un an et demi avec Mozilla sur la partie paiement du Marketplace puis sur le site des extensions de Firefox. Et depuis un an avec Etalab sur la plateforme datagouv. Dans les deux situations, j’ai passé davantage de temps à lutter contre les outils plutôt qu’à les apprécier pour le travail rendu. C’est terrible car ceux-ci sont censés théoriquement faire gagner du temps mais sur le long terme cela se révèle être faux dans mon cas.
Je me demande si je ne suis pas en train de faire un burnout technique, non pas par trop de travail mais par manque de contrôle dans mes outils.
Autre extrait :
The aesthetic microlith
Growth for the sake of growth is the ideology of the cancer cell.
Edward Abbey
Toutes ces raisons m’ont amené à étudier une nouvelle piste. Cette appellation est une combinaison du Majestic Monolith (cache) et des microservices. Je me persuade qu’il y a une voie différente entre ces deux extrêmes. Une voie qui limite les fuites d’abstraction (cache) afin de réduire la dette technique et de favoriser l’inclusion de nouveaux membres dans une équipe. Une voie qui ne demande pas de réécrire la moitié de l’application tous les six mois car une nouvelle montée en version majeure n’est pas rétro-compatible. Une voie où l’on ne raisonne plus en termes de features et de bugs mais d’expérience utilisateur et de satisfaction pour l’ensemble des parties prenantes. Un environnement qui permet de faire une pause dans les développements afin de prendre le temps de davantage considérer les besoins des personnes qui utilisent le produit.
We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
Dans cette recherche de simplicité, j’ai essayé de remettre en question chaque concept de programmation, chaque bonne pratique, chaque bibliothèque, chaque ligne de code. J’ai essayé de produire un prototype qui soit un peu plus conséquent que celui proposé à Confoo pour voir jusqu’où cela pouvait aller. Ce qu’il me manque c’est non pas du temps de développement mais du temps de vie du projet pour analyser les effets produits sur le moyen terme. Je devrais avoir l’occasion d’expérimenter cela avec scopyleft prochainement, ça sent la trilogie.
À court terme en tout cas, c’est extrêmement plus fun à coder et l’on arrive au résultat finalement aussi rapidement. Cela devient une matière beaucoup plus malléable, dont on connait les forces et les faiblesses car le périmètre est réduit. En contrepartie, certains cas aux limites vont être écartés et l’expérience de certains utilisateurs se dégrade plus rapidement. Ce n’est pas que le coût de prise en compte soit énorme, il s’agit davantage de le prendre en considération lorsque le besoin est réel.
Autre extrait :
Maintenance
Capitalism excels at innovation but is failing at maintenance, and for most lives it is maintenance that matters more
Innovation is overvalued. Maintenance often matters more (cache)
Le problème ici c’est que je n’ai jamais rencontré de projet qui réduisent leur complexité dans le temps. Que ce soit via des itérations de retrait ou des réécritures complètes on arrive toujours à des usines à gaz si l’on ne s’est pas fixé en amont — de manière consentie par toutes les parties prenantes — les budgets évoqués plus haut. Pourtant en restant à l’échelle du microlith, la maintenance se trouverait potentiellement réduite de beaucoup.
Si l’on s’en tient à l’estimation selon laquelle la maintenance représente 67% d’un produit (cache), il devient important de trouver comment réduire ce coût.
Autre extrait :
Frameworks, API et prolétarisation
La présentation 6 reasons why APIs are reshaping your business fait l’analogie du développement Web avec l’industrie automobile et le passage de l’artisanat à l’intégration de pièces toutes faites.
Si le passage aux frameworks JavaScript et CSS a entraîné la perte de savoir des développeurs front-end et leur prolétarisation, le passage aux API va avoir le même effet sur les développeurs back-end, ceux-ci devenant de simples intégrateurs de solutions existantes s’éloignant de la problématique métier et de ses données pour se perdre dans les couches du pragmatisme. N’oubliez pas qu’en facilitant le travail de la machine, on finit par être remplacé par la machine, c’est ce que nous réserve l’industrialisation du Web. Et ça me rend nostalgique.
Autre extrait :
A system where you can delete parts without rewriting others is often called loosely coupled, but it’s a lot easier to explain what one looks like rather than how to build it in the first place.
Even hardcoding a variable once can be loose coupling, or using a command line flag over a variable. Loose coupling is about being able to change your mind without changing too much code.
Write code that is easy to delete, not easy to extend (cache)
Partant de ce constat, j’ai essayé de produire une stack minimaliste qui comportent très peu de dépendances qui peuvent évoluer en fonction du besoin. De cette manière, on accède à un LEAN technique : l’ajout de complexité architecturale en fonction du besoin uniquement.
Le code produit accorde une place importante à l’esthétique et à la modularité sans endommager la compréhension de l’ensemble grâce à la documentation et aux tests.
Autre extrait :
Thus teams are often confronting the uncomfortable choice between a risky refactoring operation and clean amputation. The best developers can be positively gleeful about amputating a diseased piece of code (even when it’s their own baby, so to speak), recognizing that it’s often the best choice for the overall health of the project. Better a single module should die than continue to bog down the rest of the project.
…
The organic, evolutionary nature of code also highlights the importance of getting your APIs right. By virtue of their public visibility, APIs can exert a lot of influence on the future growth of the codebase. A good API acts like a trellis, coaxing the code to grow where you want it. A bad API is like a cancer, and it will metastasize all over your codebase.
L’intérêt de partir d’un périmètre aussi restreint est de pouvoir se ré-interroger à chaque nouvel ajout sur sa pertinence, cela constitue une base itérative sans renoncer au plaisir technique. Le code est lisible et explicable en quelques heures pour des personnes ayant un faible niveau et il n’y a pas besoin de télécharger la moitié d’internet pour faire tourner une page web. Ma démarche est de renoncer à la complexité par défaut qui est prônée par tous les frameworks actuels, l’ajout de dépendances doit se faire au moment du besoin.
La durée de vie d’une composition de technologies est forcément réduite et demande de se ré-interroger à échéances régulières sur sa pertinence. Toute la difficulté actuelle est de pouvoir allonger ces échéances pour trouver le bon ratio entre focus et exploration. Plus vous bâtirez sur des concepts simples, universels et standardisés, plus vous aurez de chances de pouvoir être conservateur dans votre choix technique. Et plus vous serez inclusif auprès des potentiels contributeurs.
Journal du vendredi 16 août 2024 à 11:39
#JaiLu la note de David Larlet nommée Initiateurs et mainteneurs.
There are two roles for any project: starters and maintainers. People may play both roles in their lives, but for some reason I’ve found that for a single project it’s usually different people. Starters are good at taking a big step in a different direction, and maintainers are good at being dedicated to keeping the code alive.
…
I am definitely a starter. I tend to be interested in a lot of various things, instead of dedicating myself to a few concentrated areas. I’ve maintained libraries for years, but it’s always a huge source of guilt and late Friday nights to catch up on a backlog of issues.
Je suis également un initiateur. J’aime créer de nouvelles choses en expérimentant des usages et des techniques. Lorsque je me retrouve dans un rôle de mainteneur, j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses. Or l’apprentissage nait de l’échec et du test des limites. C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. À moins que la maintenance soit un vestige du passé (cache).
-- from
Ces réflexions résonnent profondément en moi 🤗, car ce sont des questions et des pensées qui m'habitent depuis de nombreuses années.
« j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses »
Pour éviter cette tendance à complexifier l’existant, j'utilise la stratégie suivante. Lorsque je ressens le besoin d'expérimenter ou d'apprendre quelque chose de nouveau, je le fais au travers des side projects personnels ou dans le cadre de POC (Proof of Concept) et Spike officiellement décidés en équipe. C'est entre autres pour cette raison que j'avais proposé de mettre en place les Spike and Learn Day.
Cette approche me permet de satisfaire ma curiosité et mon envie d'apprendre, tout en maintenant l'utilisation de Boring Technology pour les projets critiques ou ceux menés en équipe. Ainsi, je parviens à éviter le piège du Resume Driven Development.
J'aime bien la distinction suivante :
« There are two roles for any project: starters and maintainers »
Jusqu'à présent, j'ai tendance à utiliser le terme solo développeurs pour les "starters" et team développeurs pour les "maintainers".
Petite anecdote amusante : lors de mon expérience chez Spacefill, j'avais proposé de nommer le rôle des développeurs d'expérience au sein de l'équipe les "maintainers" 😉.
« C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. »
C'est une réflexion que j'ai moi-même eue par le passé.
Je crois en effet que les solo développeurs apprécient particulièrement les microservices et les multi repositories car cela leur permet d'éviter les contraintes d'équipes.
Cela leur permet d'explorer des nouveaux langages et frameworks et d'échaper aux revues de code.
À mes yeux, cette approche favorise davantage l'individualisme que la cohésion d'équipe.
J'ai également remarqué que c'est souvent lors des phases de storming du modèle de Tuckman que les développeurs semblent se tourner vers les microservices comme une forme d'évitement des défis collectifs. Cette stratégie peut sembler séduisante, mais elle risque de renforcer les silos et de freiner la collaboration au sein de l'équipe 🤔.
Journal du vendredi 16 août 2024 à 11:30
#JaiDécouvert l'expression Core-stack developer dans cet article de David Larlet :
… when in doubt, focus on the core. When in doubt, learn CSS over any sort of tooling around CSS. Learn JavaScript instead of React or Angular or whatever other library seems hot at the moment. Learn HTML. Learn how browsers work. Learn how connections are established over the network.
The reason for focusing on the core has nothing to do with the validity of any of those other frameworks, libraries or tools. On the contrary, focusing on the core helps you to recognize the strengths and limitations of these tools and abstractions. A developer with a solid understanding of vanilla JavaScript can shift fairly easily from React to Angular to Ember. More importantly, they are well equipped to understand if the shift should be made at all. You can’t necessarily say the same thing about an INSERT-NEW-HOT-FRAMEWORK-HERE developer.
Building your core understanding of the web and the underlying technologies that power it will help you to better understand when and how to utilize abstractions.
That’s part one of dealing with the rapid pace of the web.
À défaut d’être complet (full) en raison de l’effervescence technique difficile à suivre au quotidien, il me semble de plus en plus pertinent de miser sur le cœur (core) des technologies utilisées. Comprendre et maîtriser les bases avant tout pour pouvoir ponctuellement et rapidement se spécialiser en fonction du besoin. Connaître ES6 vous servira ces 10 prochaines années, savoir utiliser React sera obsolète l’année prochaine. Sages développeurs, investissez.
-- from
Core-stack developer me fait penser à Choose Boring Technology et à mon article nommé Sur quelles compétences j'ai décidé ou non d'investir mon temps ?. Je me rends compte rétrospectivement que j'ai listé ma core-stack 🙂.
Journal du vendredi 16 août 2024 à 11:12
Je viens de lire la note "EndOfPage" de David Larlet dans laquelle il explique pourquoi il arrête de publier des articles en Anglais et retourne à sa langue native, le Français.
I decided to switch from English to French as my blogging language so this post is the last one in English for a few reasons:
- I started to write in English to somehow extend my audience given that I went to Japan and only a very few Japanese people are reading French. I’m pretty sure no Japanese at all ever read that page so I can consider this as a failure, I realized way too late that integration is before all about working together in Japan :-).
- It looks like Craig Kerstiens is the only one reading English-only across my few readers (thank you!), probably because my vocabulary and grammar are so bad or my thoughts far from those of another country. Anyway, trying to think in English was a good experiment but now I need to improve myself via discussion, not unidirectional writing anymore.
- ...
- I want to be involved locally, from OpenData to (micro)events, and to interact with my French peers. Moreover, I’m trying something new with Scopyleft and I’m sure that feedback about that adventure is more valuable for French people too.
Je vous vois demain !
-- from
Je trouve ce retour d'expérience particulièrement intéressant.
Traduction ChatGPT :
J'ai décidé de passer de l'anglais au français pour mes publications de blog, et ce post sera le dernier en anglais, pour plusieurs raisons :
- J'avais commencé à écrire en anglais pour élargir mon audience, notamment parce que je vivais au Japon et que très peu de Japonais lisent le français. Il se trouve que probablement aucun Japonais n'a jamais lu cette page, donc je considère cela comme un échec. J'ai réalisé bien trop tard que l'intégration au Japon passe avant tout par le travail collaboratif.
- Il semble que Craig Kerstiens soit le seul à lire mes articles en anglais parmi mes rares lecteurs (merci à lui !), probablement parce que mon vocabulaire et ma grammaire laissent à désirer, ou que mes pensées sont trop éloignées de celles d'autres cultures. Quoi qu'il en soit, essayer de réfléchir en anglais a été une bonne expérience, mais je ressens maintenant le besoin de m'améliorer à travers des discussions plutôt que par une écriture unidirectionnelle.
- ...
- Je souhaite m'impliquer localement, de l'OpenData aux (micro)événements, et interagir avec mes pairs francophones. De plus, je me lance dans une nouvelle aventure avec Scopyleft, et je suis convaincu que les retours d'expérience seront plus pertinents pour un public français.
Je vous dis à demain !
Journal du jeudi 15 août 2024 à 20:00
Depuis que j'utilise @tabler/icons-svelte pour intégrer des tabler-icons sur un projet SvelteKit SSR, je rencontre d'énormes problèmes de performance en mode développement (pnpm run dev).
Pour traiter le problème, j'ai essayé ce hack indiqué dans l'issue Slow experience in SvelteKit, mais cela ne fonctionne pas.
Toujours dans cette issue, #JaiDécouvert Iconify.
Je pense me souvenir d'avoir commencé à utiliser tabler-icons comme alternative Open source à Font Awesome.
J'ai lu la page page raconte l'histoire du projet et j'apprends que le projet s'est réellement lancé en 2020.
Iconify est devenu un projet Open source en 2021 :
In mid 2022 plans changed, thanks to people showing interest in sponsoring open source development.
The new plan is to:
- Open source everything, encourage developers to create their own open source solutions that use Iconify.
- Rely on sponsors to finance development.
-- from
Mais, d'après la page contributors le projet semble toujours très majoritairement développé par Vjacheslav Trushkin.
Je lis aussi :
Unlike fonts, it downloaded data only for icons used on page, rendered pixel perfect SVG. (from)
Par contre, je pense comprendre qu'Iconify n'est pas un projet de création d'icônes, mais un framework qui regroupe énormément d'icônes.
Par exemple, j'ai constaté qu'Iconify intègre entre autres :
Iconify propose des composants icônes pour Svelte : Iconify for Svelte.
Mais, je lis :
Loads icons on demand. No need to bundle icons, component will automatically load icon data for icons that you use from Iconify API. -- from
Cette technique « Loads icons on demand » ne me plait pas. Je souhaite réduire au maximum les latences dans mes applications web.
J'ai continué mes recherches.
#JaiLu Icon library for svelte? : sveltejs
#JaiDécouvert unplugin-icons (from).
unplugin-icons est un projet qui a commencé en 2021 et qui est basé sur Iconify.
Je constate que unplugin-icons propose une configuration SvelteKit.
J'ai testé et cela semble très bien fonctionner 🙂.
Le site https://icones.js.org permet de facilement copier-coller le code Javascript pour intégrer une icône. Par exemple, un click sur "Unplugin Icons" :
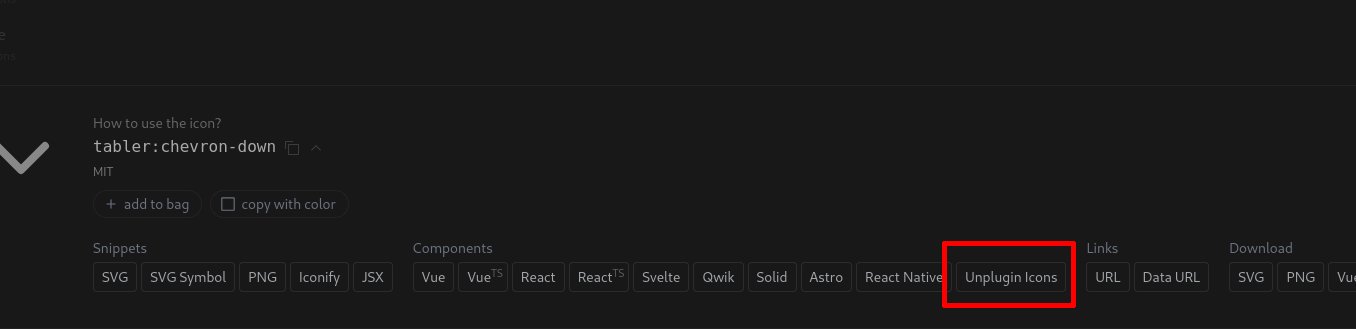
permet de copier :
import TablerChevronDown from '~icons/tabler/chevron-down'
Je ne constate aucun problème de lenteur au mode développement (pnpm run dev) et aucun chargement réseau externe des icônes dans la version de production.
#JaiDécidé d'adopter cette librairie pour gérer les icons de mes projets SvelteKit.
Journal du jeudi 15 août 2024 à 19:08
#JaiDécouvert la #library classix un équivalent à clsx mais :
String expressions have a few benefits over objects:
- A faster typing experience
- A more intuitive syntax (conditions first)
- else support through ternary operators
What's more, by leveraging them, classix provides:
- A simpler and consistent API
- A smaller library size
- Better performance
-- from
Après avoir vu cela, j'ai creusé un peu le sujet et #JaiDécouvert que clsx a sorti une nouvelle release après la création de classix : https://github.com/lukeed/clsx/releases/tag/v2.1.0
Add new
clsx/litesubmodule for string-only usage: 1a49142This is a 140b version of clsx that is ideal for Tailwind and/or React contexts, which typically follow this clsx usage pattern.
clsx('foo bar', props.maybe && 'conditional classes', props.className);
Qui, d'après ce que je comprends, reprend en partie l'implémentation de classix.
Afin d'éviter un effet de balkanisation, je vais utiliser clsx.
Journal du jeudi 15 août 2024 à 16:00
#iteration Projet 11 - "Première version d'un moteur web PKM".
Le nombre de tags listé sur ce screenshot est limité par un flex-wrap: wrap + height: 2em + overflow: hidden.
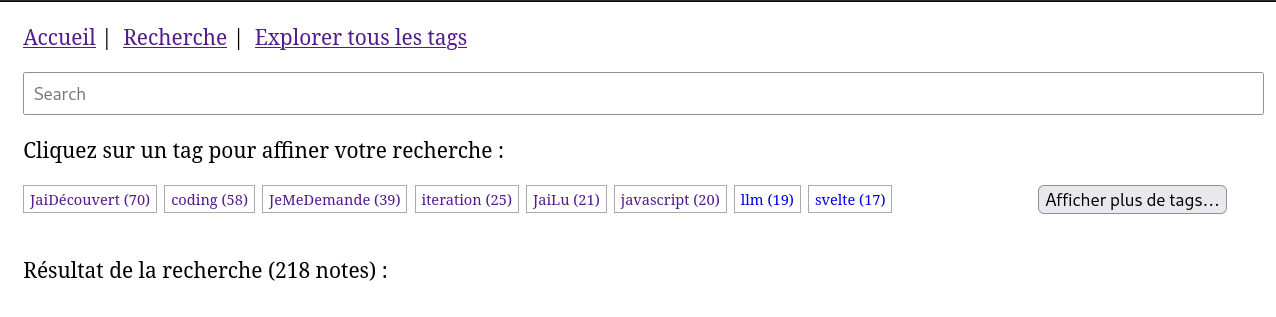
Problème : j'aimerais que le bouton "Afficher plus de tags…" soit affiché directement à droite du dernier tag (ici "Svelte").
Je souhaite limiter le nombre de tags affiché non pas via du css (overflow: hidden), mais via une action Svelte.
J'aimerais pouvoir utiliser cette svelte/action comme ceci :
<ul use:ItemOverflowLimiter={{itemClass: "tag"}}>
{#each data.tags as tag}
<li class="tag">
<a
href={`/search/?tags=${tag.name}`}
>{tag.name} ({tag.note_counts})</a>
</li>
{/each}
<li>Afficher plus de tags…</li>
</ul>
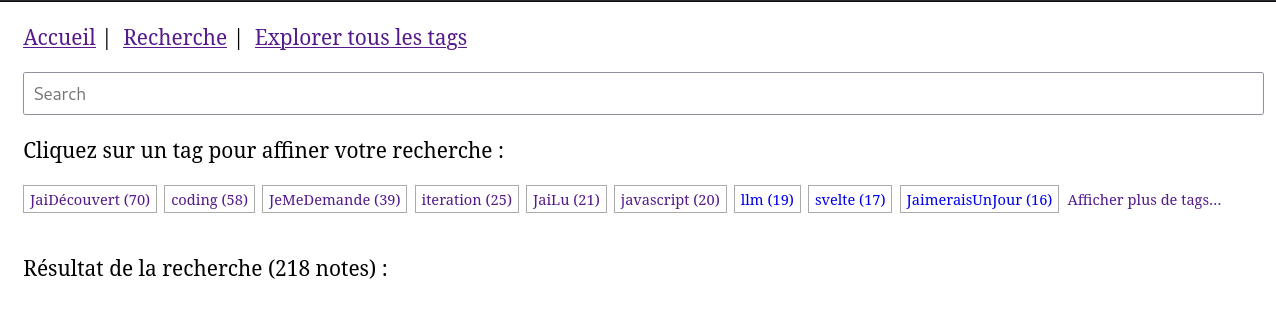
1 heure plus tard, j'ai réussi à atteindre mon objectif avec ce commit.
Voici le résulat 🙂 :
Voici le code de la fonction svelte/action ItemOverflowLimiter.js :
export default function ItemOverflowLimiter(node, options) {
let destroyAllNextItems = false;
let itemsToDestroy = [];
// search width of items to keep
let widthItemsToKeep = 0;
for (let item of node.children) {
if (
(options?.itemClass) &&
(!item.classList.contains(options.itemClass))
) {
widthItemsToKeep += item.clientWidth;
}
}
for (let item of node.children) {
if (destroyAllNextItems) {
if (
(!options?.itemClass) ||
(item.classList.contains(options.itemClass))
) {
itemsToDestroy.push(item);
}
} else if (
(item.offsetTop > 0) ||
(item.offsetLeft + item.clientWidth > (node.clientWidth - widthItemsToKeep))
) {
itemsToDestroy.push(item);
destroyAllNextItems = true;
}
}
for (let item of itemsToDestroy) {
item.remove();
}
}
Je trouve les svelte/action très agréable à utiliser.
Journal du jeudi 15 août 2024 à 12:32
#Jaime beaucoup cette élement UX :

Visible par exemple tout en bas de cette page : https://gwern.net/rubiks-cube-claude
Journal du jeudi 15 août 2024 à 10:48
Nouvelle #iteration de Projet 11 - "Première version d'un moteur web PKM".
En haut de cette page, j'aimerais afficher quelques tags.
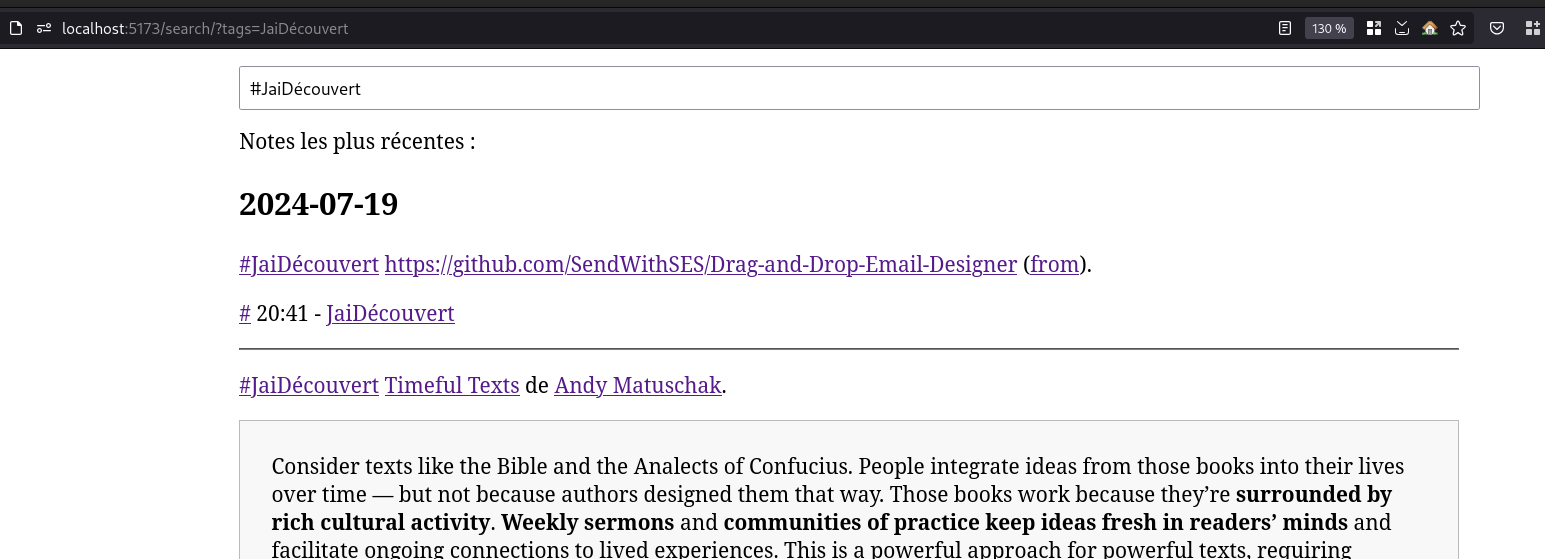
En peu de la même manière que sur ce site :
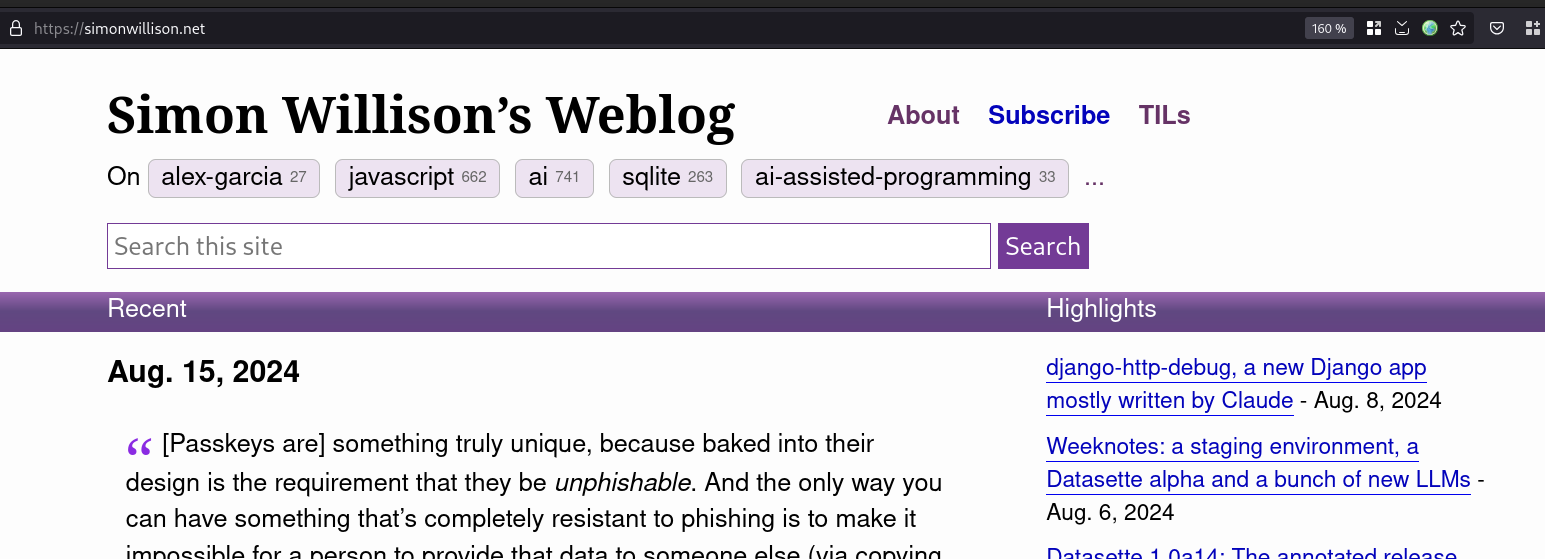
Dans cette #iteration , j'affiche tous les tags, mais la liste est trop longue.
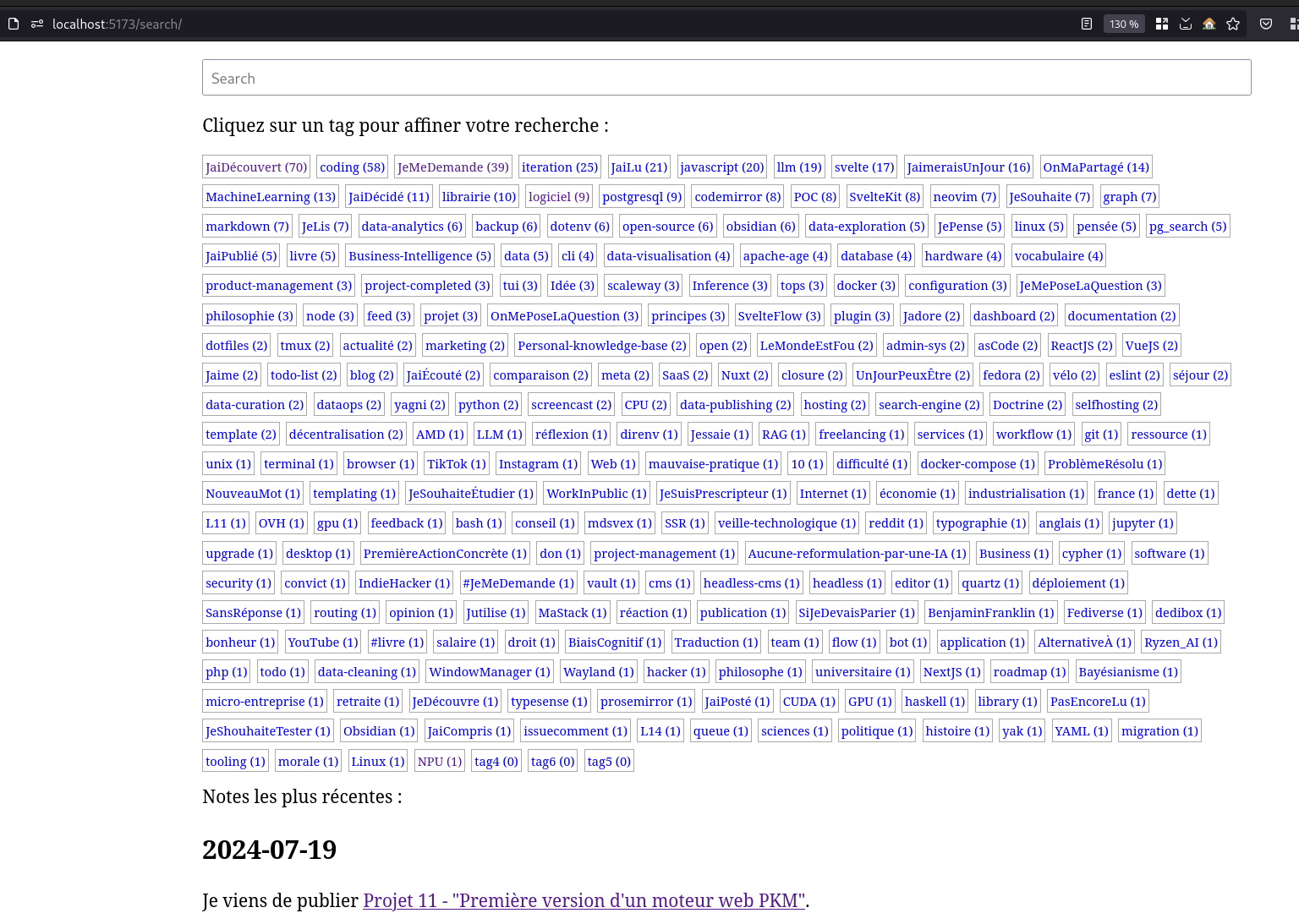
Sur ce screenshot, seules les deux premières lignes de tags sont affichées avec un fondu transparent sur la seconde ligne.
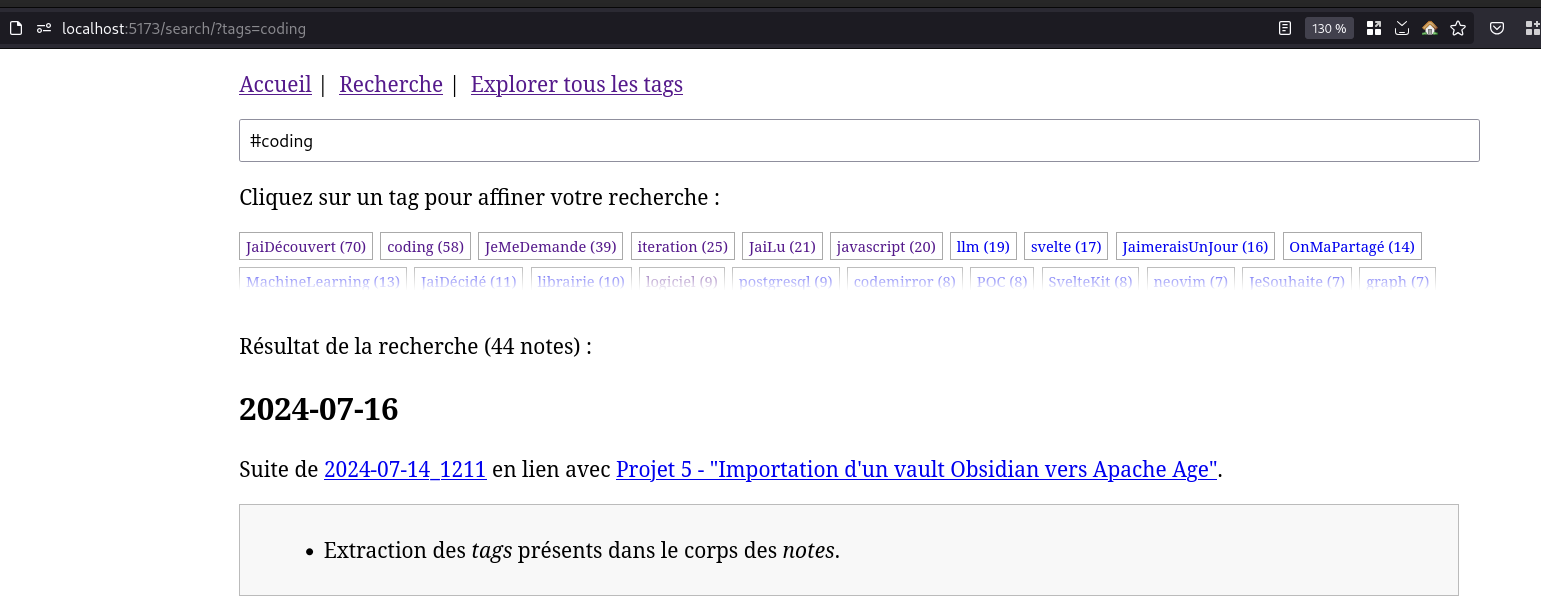
Je ne suis pas convaincu de la pertinence du fondu transparent.
Je pense que cela attire le regard d'une manière excessif sur un élément d'UI secondaire.
Je pense qu'il est préférable d'afficher une seule ligne 🤔.
Je pense ajouter à la fin d'un tags un élément UX inspiré par :
Journal du jeudi 15 août 2024 à 10:46
#JaiDécouvert https://gwern.net/resorter mais je ne l'ai pas encore lu.
Journal du mercredi 14 août 2024 à 15:11
Suite à mon poste 2024-08-14_1423, un ami m'a fait découvrir le projet OpenConnect.
OpenConnect is a free and open-source cross-platform multi-protocol virtual private network (VPN) client software which implement secure point-to-point connections.
Il me dit :
« C'est client qui a pour but de se connecter a n'importe quelle VPN et il a une plus grosse communauté. Avec plus d'options généralement niveau UI. »
Il me dit qu'il utilise OpenConnect avec NetworkManager-openconnect.
Il faudra que je teste.
Journal du mercredi 14 août 2024 à 14:23
Je dois passer par un VPN pour accéder à un projet professionnel.
Ce VPN est propulsé par OpenVPN.
Ma workstation tourne sous Fedora, sous GNOME.
J'ai réussi à configurer facilement l'accès OpenVPN via NetworkManager-openvpn via l'import de fichier .ovpn.
Cependant, cette méthode de configuration m'a posé un problème : le routage par défaut était dirigé vers le VPN. Conséquence, l'intégration de mon accès à Internet passait par le réseau VPN qui était bien plus lent que mon accès Internet.
Ceci était très frustrant.
De plus, cette configuration ajoutait une charge réseau supplémentaire inutile au VPN.
J'ai essayé d'utiliser l'option "N'utiliser cette connexion que pour les ressources sur ce réseau" mais cela n'a pas fonctionné.
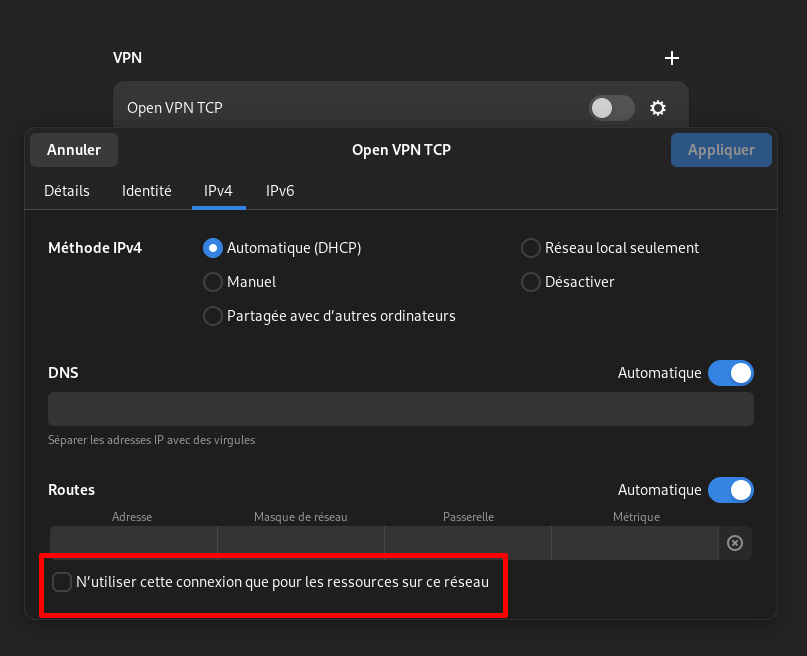
Peut-être un problème DNS 🤔.
J'ai donc choisi une autre stratégie. J'ai configuré cela sans GUI.
Voici le skeleton de mon dossier de connexion au VPN : https://github.com/stephane-klein/openvpn-client-skeleton (celui-ci ne contient aucun secret).
Ce projet me permet :
- D'utiliser le serveur DNS présent dans le réseau privé seulement pour un certain type de sous domaine.
- Le VPN est utilisé uniquement pour les serveurs qui se trouvent à l'intérieur du réseau privé. Par exemple, je ne passe pas par ce VPN pour accéder à Internet.
- La totalité de cette configuration est basé sur des fichiers et est scripté (pratique GitOps)
- OpenVPN client est managé par SystemD
Voir aussi 2024-08-14_1511.
Journal du mercredi 14 août 2024 à 12:05
Cela fait 25 ans que je travaille dans le domaine du web, et je viens seulement de prendre conscience de la différence entre un Domain name registrar et un Domain name registry 🙈.
Jusqu'à présent, j'avais tendance à les considérer comme synonymes.
Par exemple, des entreprises comme Gandi ou BookMyName sont exclusivement des Domain name registrar. Elles ne jouent pas le rôle de Domain name registry.
En revanche, certaines entreprises cumulent les deux fonctions, à savoir être à la fois registrar et registry.
C'est le cas de https://www.identity.digital/, qui est à la fois un registrar et registry pour des gTLDs comme le .systems.
Un autre exemple est Team Internet, qui non seulement opère en tant que registry pour le domaine ".xyz", mais agit également en tant que registrar.
Journal du mercredi 14 août 2024 à 12:01
#JaiDécouvert l'existence du gTLDs .systems, qui est disponible depuis 2014.
Journal du mardi 13 août 2024 à 21:32
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai enfin analysé la Merge Request qui m'a été envoyé par un ami 🤗 : https://github.com/stephane-klein/postgres-tags-model-poc/pull/9
6 mois plus tard, j'ai fini l'implémentation de la première version du "Query string javascript parser" : https://github.com/stephane-klein/postgres-tags-model-poc/commit/f0f363b78c136e8e67a38f95b5c627d874537949
Pour la coloration syntaxique des fichiers Peggy sous Neovim, j'utilise avec succès https://github.com/TheGrandmother/peggy-vim : https://github.com/stephane-klein/dotfiles/commit/20cba4ba646a0793f66f9b19788920a4ff1f1838
Journal du mardi 13 août 2024 à 16:32
Je suis victime du bug suivant depuis 2 ou 3 jours sous ma Fedora :
Unexpected Logouts and System Instability: The second, more critical issue I’ve been facing is unexpected system logouts. Over the past two days, my screen has suddenly gone black as if the system has shut down. After less than a second, the login screen reappears, and upon logging in, I find that all my applications have closed. Yesterday, August 11, 2024, this happened twice within a three-minute span. Today, August 12, 2024, while studying with only Firefox open, I suspended my laptop and left.
-- from
J'en apprends plus ici :
A new regression for AMD APU’s is present in kernel 6.10 that wil cause intermittent full system crashes in combination with Mesa 24.1.5. The only option is to power down and restart the machine.
Kernel 6.9 is unaffected.
Issue upstream : https://gitlab.freedesktop.org/drm/amd/-/issues/3497
Je vais donc reboot sous un kernel 6.9 🤷♂️.
Je suis sûr qu'Alexandre va me dire qu'il n'a aucun problème sous ArchLinux ! Mais je ne le croirai pas, c'est un bug upstream !
Voir aussi ma doctrine Linux Desktop.
2024-08-22 : J'ai posté ce message AMD APU regression (full halt) on kernel 6.10 - how to best report?
2024-09-12 : J'ai posté ce message How to list Mesa versions included in my flatpak applications?
2024-10-15 : J'ai posté ce message.
Journal du mardi 13 août 2024 à 10:41
Deux amis m'ont partagé un thread Hacker News : Postgres.new: In-browser Postgres with an AI interface.
Je viens de prendre le temps de tester postgres.new.
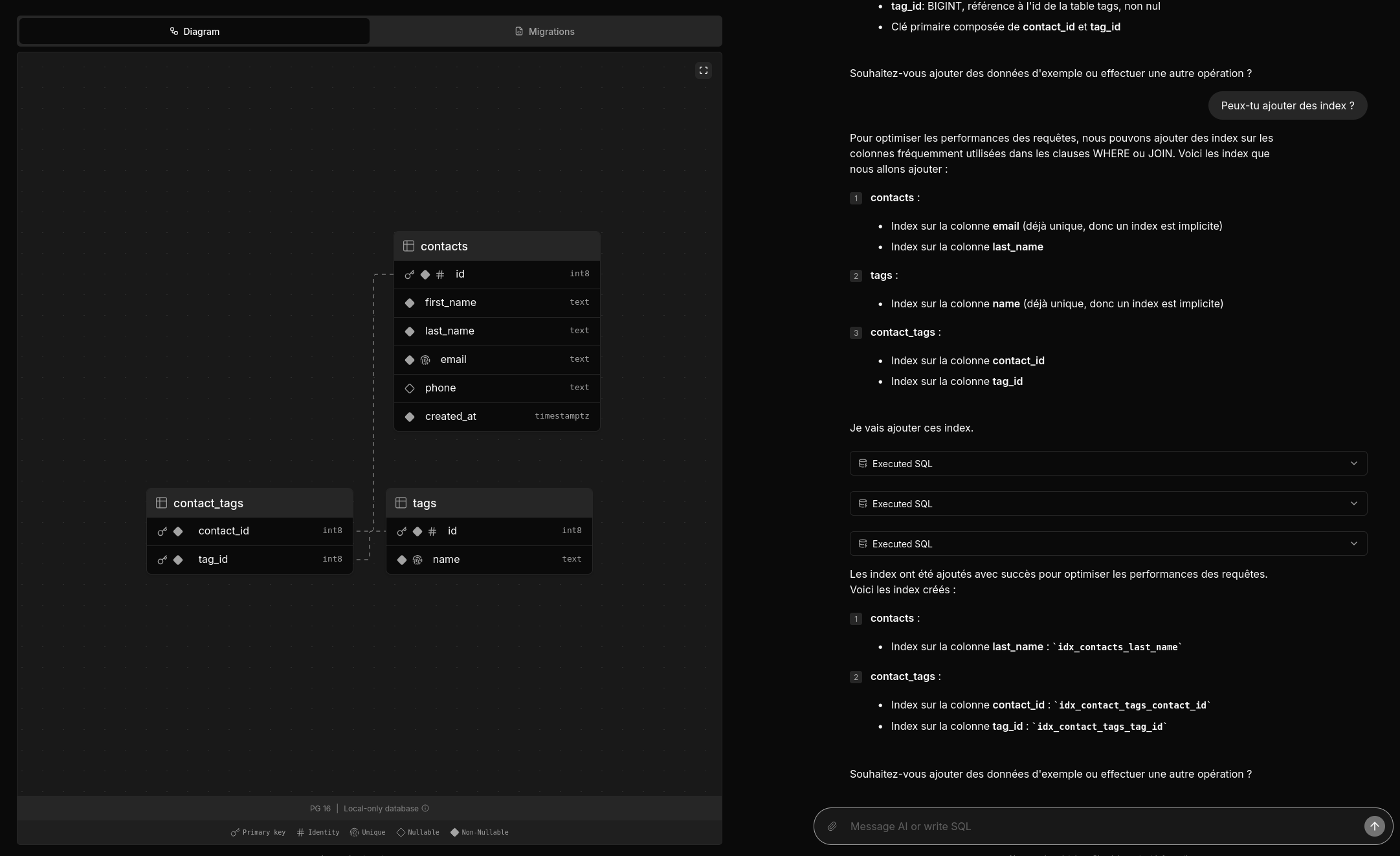
Voici une vidéo officielle : https://www.youtube.com/watch?v=ooWaPVvljlU
#Jadore ! Je trouve l'UX très bonne, j'aime l'onglet "Migrations", les explications données dans la colonne de droite.
Le projet est 100% Open source, voici le dépôt GitHub : https://github.com/supabase-community/postgres-new
Très beau travail !
Je me demande combien de temps ce projet a été implémenté 🤔.
1 mois et demi d'après la page contributors.
Mais je constate que le premier commit est plutôt conséquent, je pense que le projet était initialement intégré dans un mono repository.
Concernant l'implémentation, je lis :
All queries in postgres.new run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
👍️
How is this possible? PGlite, a WASM version of PostgreSQL that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
La partie LLM n'est pas mentionnée, #JeMeDemande comment elle est implémentée 🤔.
Je pense avoir trouvé ma réponse ici :
We pair PGlite with an LLM (currently GPT-4o) and give it full reign over the database with unrestricted permissions. (from)
Je lis :
RAG / pgvector: PGLite supports pgvector, so you can ask the LLM to create embeddings for RAG. The site uses transformers.js to create embeddings inside the browser.
Je n'ai pas tout compris 🤔.
#JaiDécouvert transformers.js.
J'ai lu ce commentaire :
It is a neat tech demo but it clearly shows the limits of AI:
- I got it to generate invalid SQL resulting in errors - it merely generates reasonable SQL, but in my case it generated to disjoint set of tables…. - In practice you have tot review all code - It can point you into the wrong direction. Novel systems often have something smart/abstract in there. This system creates mostly Straightforward simple systems. That’s not where the value is
All in all, it’s not worth it to me. Writing code myself is easier than having to review LLM code
Within our organization we have forbidden full LLM merge request because more often than not the code was suboptimal. And had sneaky bugs/mistakes.
I’m not saying these can’t be overcome. But not with current LLM design. They mostly generate stuff they have seen and are bad as truly new stuff.
Personnellement, cela ne me surprend pas et cela ne remet pas en question, à mes yeux, l'intérêt de cet outil.
Je pense l'utiliser pour concevoir une ébauche de base de données.
Je pense qu'il pourra me fournir de bonnes suggestions pour les noms de tables et de champs, et même inclure des champs auxquels je n'aurais peut-être pas pensé.
Journal du lundi 12 août 2024 à 23:21
#JaiLu pour la première fois la syntax de recherche de GitHub : Searching issues and pull requests.
Je la trouve à la fois complète et intuitive.
Cependant, j'ai remarqué que les opérateurs and et or, ainsi que l'utilisation des parenthèses, ne sont pas pris en charge.
Journal du lundi 12 août 2024 à 13:25
Quel est mon rapport aux langages typés ?
Pour bien comprendre mon approche des langages typés, il est utile de revenir sur mon parcours.
Enfant, j'ai commencé par du Locomotive Basic (non typé), j'ai ensuite fait beaucoup de Turbo Pascal (typé) et un peu de C, C++ (typé).
À cette époque, je préférais les langages typés pour des raisons de performances.
En 2000, j'ai vraiment aimé utiliser à nouveau des langages non typés, comme PHP et surtout Python qui a été pendant très longtemps mon langage de prédilection.
J'ai à nouveau beaucoup pratiqué un langage typé de 2013 à 2018 : Golang.
Aujourd'hui, je considère qu'il est souvent plus facile et plus rapide de programmer dans un langage non typé, notamment grâce au Duck Typing. Cependant, je reconnais que les langages typés offrent des avantages indéniables, notamment en matière de refactoring de code.
Je pense qu'il est préférable d'utiliser un langage typé sur un projet critique.
Je pense qu'il est préférable d'utiliser un langage typé pour les programmes qui manipule des données complexes et divers.
C'est, par exemple, pour cela que ne suis pas un utilisateur de MongoDB. Je préfère une base de données PostgreSQL où tout est bien typé.
Il ne me viendrait pas à l'esprit d'implémenter une base de données ou un moteur web dans un langage non typé.
Par contre, je suis moins convaincu par l'utilisation d'un langage typé pour les applications d'interface utilisateur lourde ou web.
Lorsqu'une équipe de développement travaillant sur un code commun atteint une certaine taille — je n'ai aucune idée de ce nombre — je suis convaincu qu'il devient préférable d'utiliser un langage typé.
Journal du lundi 12 août 2024 à 11:45
Je pense que depuis 2013 environ, je me classe dans la catégorie des artisans développeurs de type conservateurs.
Je m'efforce de suivre une une doctrine centrée sur le principe du Choose Boring Technology.
Je ne crois plus aux "techniques miracles" (No Silver Bullet).
J'ai vu trop de projet souffrir de pratique telles que le Resume Driven Development ou de Cargo cult programming.
Voir aussi : Keep it simple, stupid le plus longtemps possible.
Journal du lundi 12 août 2024 à 11:32
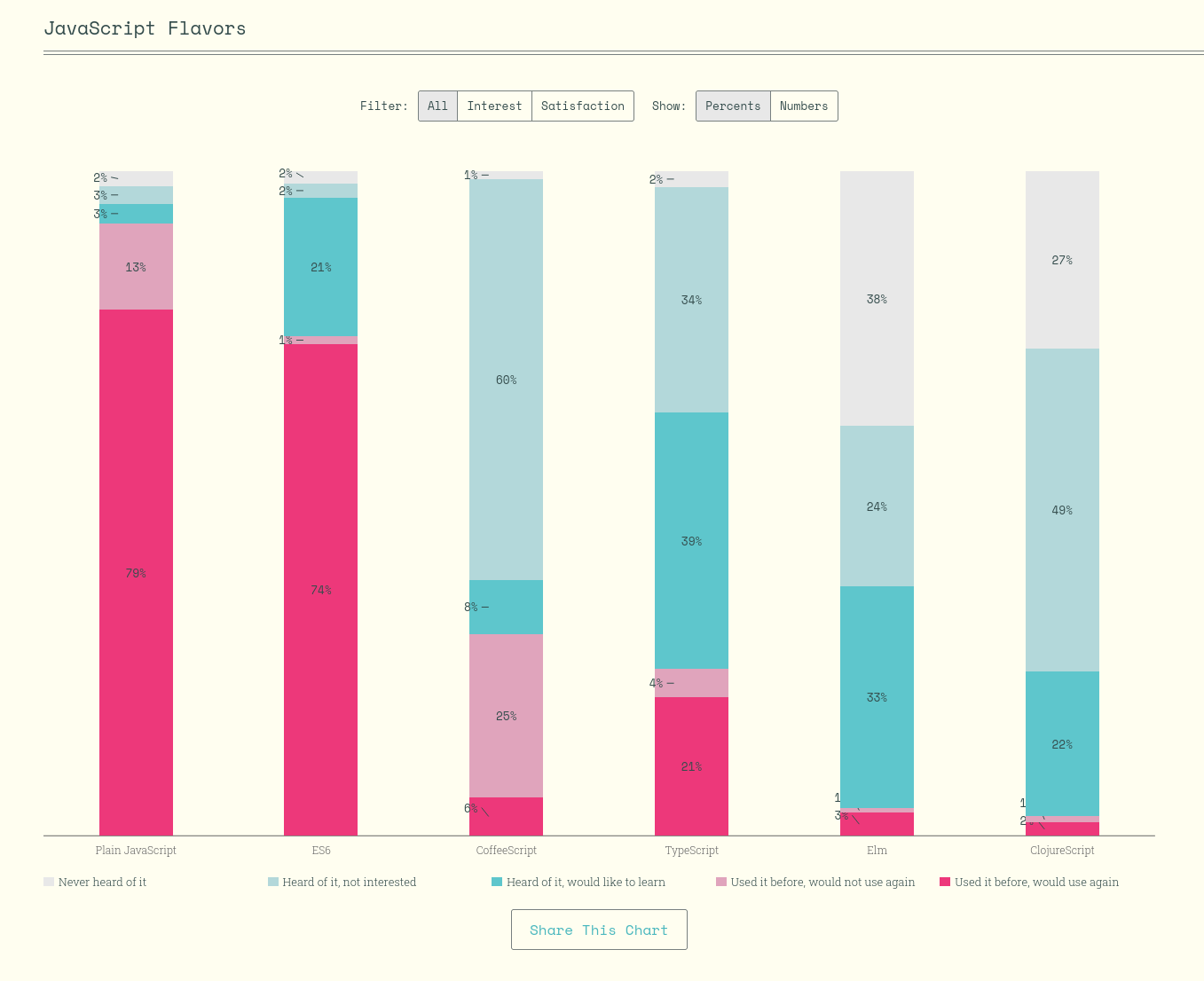
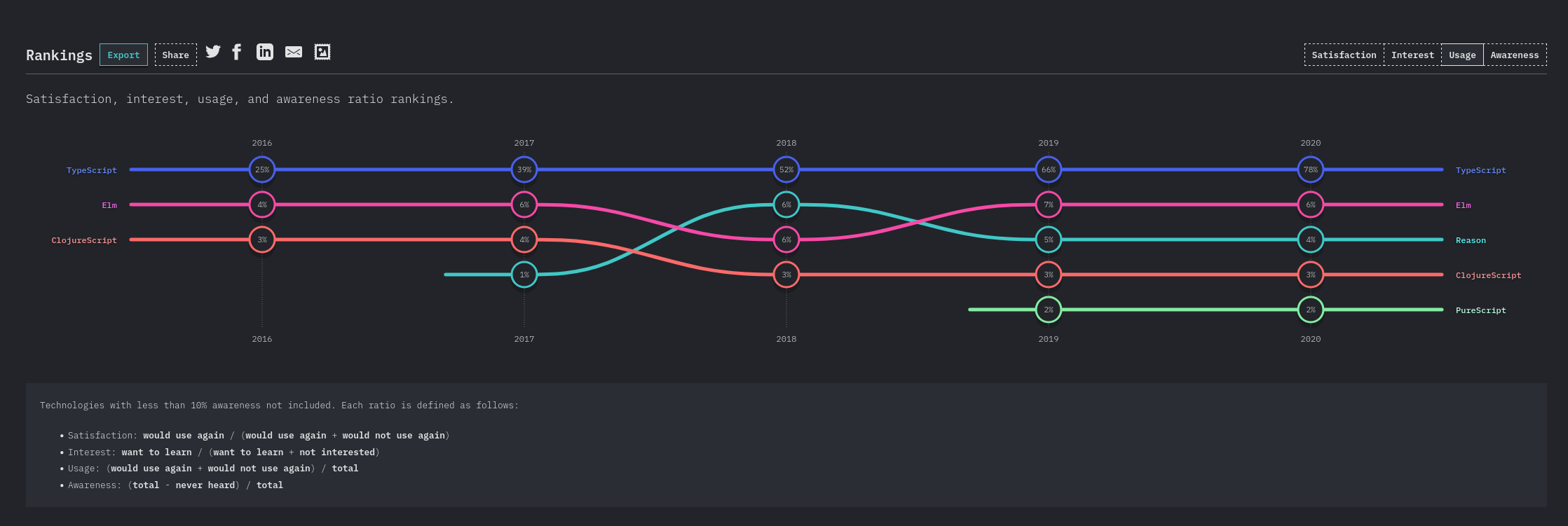
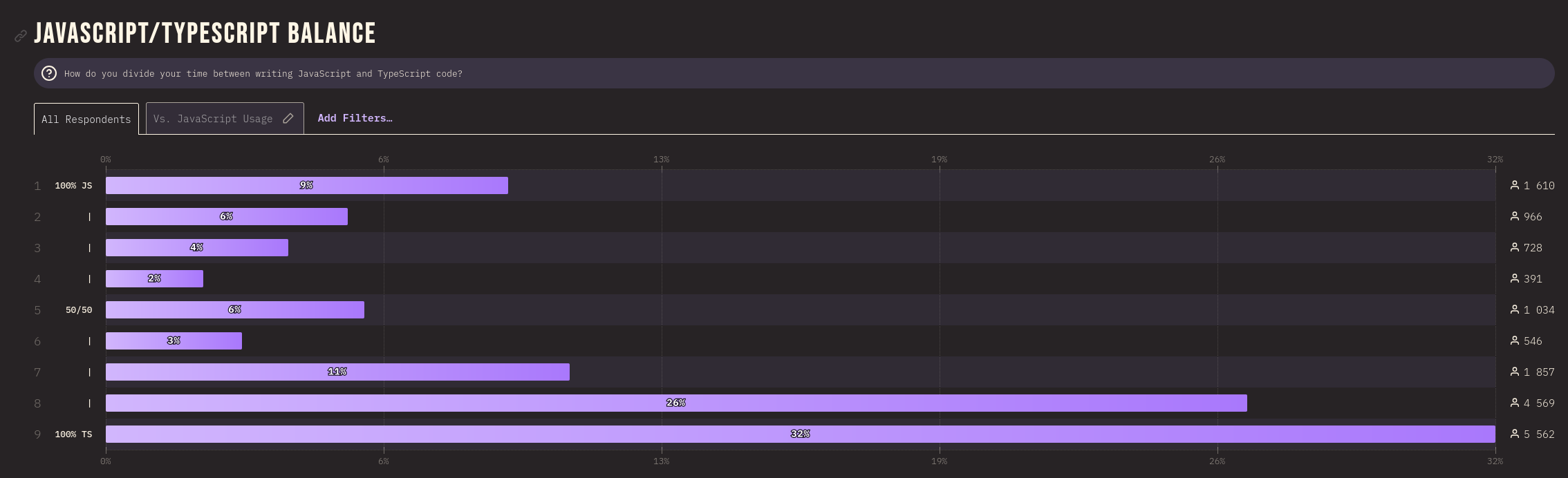
Je ressamble ici quelques notes au sujet de l'évolution de usage de TypeScript dans le temps.
Ces informations proviennent de State of JavaScript .
Année 2016
https://2016.stateofjs.com/2016/flavors/
Année 2020
JavaScript flavors usage :
https://2020.stateofjs.com/en-US/technologies/javascript-flavors/
Année 2022
https://2022.stateofjs.com/en-US/usage/#js_ts_balance

Année 2023
https://2023.stateofjs.com/en-US/usage/#js_ts_balance
Journal du lundi 12 août 2024 à 11:09
#JaiLu le thread Hacker News Turbo 8 is dropping TypeScript.
Quelques extraits :
I highly recommend reading the PR discussion for this.
https://github.com/hotwired/turbo/pull/971
Some summary:
- forced through without any discussion
- many maintainers raising questions, but no answers
- random changes attached to the PR (formatters, etc)
Wherever you land on types, I think we can agree that this is not an ideal way to make a change to a larger open source project. This has all the hallmarks of an executive decision made on a whim, and forced through at the last minute. Lead maintainers certainly have the right to make big changes on a whim, but giving people some notice before breaking other projects and having good communication is true leadership.
After using TypeScript I could never go back. The amount of times it's saved me or got me up to speed quickly is countless. It does come with a cost and god the error messages are just awful sometimes but I'd die before I ever work in a js only project again.
I wonder if type annotations (JSDoc) on plain JS could be the way to go. Lint, but don’t compile. This should work seamlessly with NPM modules etc.
Journal du lundi 12 août 2024 à 11:04
Voici un extrait de l'article Turbo 8 is dropping TypeScript de David Heinemeier Hansson (DHH de Basecamp) :
This isn't a plea to convert anyone of anything, though. As I discussed in Programming types and mindsets, very few programmers are typically interested in having their opinion on typing changed. Most programmers find themselves drawn strongly to typing or not quite early in their career, and then spend the rest of it rationalizing The Correct Choice to themselves and others.
Je trouve ce point de vue intéressant.
Voir aussi : TypeScript
Journal du dimanche 11 août 2024 à 21:20
Suite à ma note 2024-08-10_1726 en lien avec le Projet 11 - "Première version d'un moteur web PKM", #JaiDécidé de ne pas implémenter les pages /tags/{tag_name}/. À la place, je souhaite que les a href des tags point vers l'url suivante : /search/?tags=tagname.
Journal du dimanche 11 août 2024 à 20:33
#JaiDécouvert le concept Obsidian nommé Higher-Order Notes (from).
#JaiLu Concept notes are higher-order notes, not permanent Zettels et je n'ai rien appris d'intéressant..
Journal du dimanche 11 août 2024 à 20:21
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du samedi 10 août 2024 à 16:08
#JeSouhaiteTester https://zotlit.aidenlx.top/ qui est un plugin pour coupler Zotero à Obsidian.
Journal du samedi 10 août 2024 à 12:45
Depuis avril 2024, je m'intéresse au sujet des Personal knowledge management et Zettelkasten. J'ai remarqué que Zotero occupe une place importante dans les workflows des utilisateurs de PKM.
Conséquence : #JaiDécidé de tester Zotero , afin de déterminer s'il peut m'être utile et comment l'intégrer efficacement dans mon propre workflow.
Journal du jeudi 08 août 2024 à 17:22
Après 11h48 de travail, j'ai enfin réussi à achever mon Projet 8 - "CodeMirror, conceal, Svelte".
Consultez de détailler dans le README du repository : https://github.com/stephane-klein/svelte-codemirror-conceal-poc.
Journal du jeudi 08 août 2024 à 15:18
#JaiLu La France laboratoire de la Silicon Valley 2.0
Tous mes amis me confirment qu’avec la baisse du système éducatif, nous sommes sur notre avant-dernière génération d’ingénieurs de très haut niveau. Cette génération aurait pu être déployée sur les sujets régaliens, notamment la Défense. Mais en travaillant pour les grandes entreprises américaines, ils vont par procuration travailler sur la Défense américaine. Ils aideront aussi les retraités américains à garantir leur retraite (grâce à un NASDAQ avec des valeurs florissantes).
Intéressant comme point de vue 🤔.
Sur le court terme, elle apporte du capital, mais sur le long terme, je ne suis plus sûr que nous aurons la capacité de faire tourner le pays dans 10 ou 20 ans, car les meilleurs d’une génération auront travaillé pour résoudre les problèmes de la Silicon Valley.
🤔.
Journal du jeudi 08 août 2024 à 15:01
#JaiLu https://x.com/tariqkrim/status/1821205699898060995
#JaiLu Pourquoi la tech française va droit dans le mur (2ème partie)
J’ai découvert récemment que Canal Plus, autrefois leader incontesté du décodeur, s’appuie désormais sur l’Apple TV pour sa distribution. -- from
En effet, bel échec 🤷♂️.
#JeSouhaite lire La France laboratoire de la Silicon Valley 2.0.
Il ne serait pas idiot que la France, l’Angleterre, les Pays-Bas et l’Italie travaillent en commun de la prochaine génération de puces et de logiciels open source pour permettre de concevoir la prochaine génération d’infrastructures résilientes dont la guerre en Ukraine a fait l’éclatante démonstration de la nécessité.
Avec la chute possible de Mozilla dont les financements pourraient être arrêtés suite à la décision de justice sur Google, il ne serait pas idiot non plus d’imaginer un projet de browser européen pensé nativement pour la vie privée et totalement open source et open CPU. -- from
C'est la stratégie à laquelle je rêve depuis 20 ans ! 🙏
À part à la gendarmerie nationale, il n’y a eu aucune vision sur le futur du desktop en France. On continue de dépenser de l’argent pour maintenir une technologie des années 90. -- from
Je dis 👍️x100.
En ne protégeant pas le web ouvert, pourtant créé en Europe, nous avons laissé les entreprises qui veulent distribuer leurs applications sur mobile aux mains de deux apps stores qui vampirisent 30 % de la valeur créée depuis 15 ans.
Quand on prend la peine d’y réfléchir un instant, notre quotidien numérique est désormais totalement défini par des entreprises extérieures à la France, par une centaine de product managers en Californie que nous ne connaissons pas.
👍️
Journal du jeudi 08 août 2024 à 08:40
#JaiDécouvert que GoCardLess propose une API permettant de récupérer l'historique de transactions de plus de 900 banques : Bank Account Data.
Je vais m'inscrire pour la tester.
Note : L'accès Woob ne permet plus de se connecter à BPLC.
Journal du mardi 06 août 2024 à 17:43
#OnMaPartagé le #mot Otium.
L’otium n’est pas simplement un temps de relâchement, d'oisiveté ou de flânerie.
Il est ce qu’on pourrait appeler le loisir fécond et studieux, un temps que l'on consacre à s'améliorer soi-même, à progresser pour accéder à une compréhension du monde plus grande.
Il ne sert aucun but, si ce n’est celui de s’élever et de s’améliorer en tant qu’individu.
Une exploration complètement désintéressée qui le classerait dans la catégorie des activités dites “inutiles” de nos jours.
D’ailleurs, ce n’est pas un hasard si ce mot-là n’a pas vraiment de traduction dans notre langue moderne, c’est peut-être parce qu’il a simplement disparu de notre conception du monde.
Ce que nous appelons aujourd’hui “loisir” est tout ce qui se regroupe derrière l’idée d’un plaisir immédiat, à consommer. Un temps pour s’échapper de soi et de ses problèmes du quotidien. Un loisir-opium si l’on reprend l’analogie.
Le concept d'otium, s’il a été popularisé sous l’Empire romain, est né pendant la Grèce antique. On l’appelait la skholè.
Pour les Grecs, la skhôlè est le temps libre dans lequel se construit la capacité à argumenter, l’esprit critique, la capacité de jugement…
Bref, c’est le creuset qui a permis de créer le concept même de Citoyens capables de décider de leur avenir. C’est tout simplement l’idée fondatrice de la démocratie !
-- from
Dans cet article :
Journal du mardi 06 août 2024 à 16:48
Projet 8 - "CodeMirror, conceal, Svelte", je découvre ici la méthode pour déclarer un Widget CodeMirror vide :
export const invisibleDecoration = Decoration.replace({});
Journal du mardi 06 août 2024 à 14:27
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
#JaiDécouvert lezer-markdown-obsidian qui correspond à ce que j'ai besoin pour 2024-08-06_1140.
Je viens de voir ici une propriété complete :
class FootnoteReferenceParser implements LeafBlockParser {
...
complete(cx: BlockContext, leaf: LeafBlock) {
cx.addLeafElement(
leaf,
cx.elt(
"FootnoteReference",
leaf.start,
leaf.start + leaf.content.length,
[
cx.elt("FootnoteMark", leaf.start, leaf.start + 2),
cx.elt("FootnoteLabel", leaf.start + 2, this.labelEnd - 2),
cx.elt("FootnoteMark", this.labelEnd - 2, this.labelEnd),
...cx.parser.parseInline(
leaf.content.slice(this.labelEnd - leaf.start),
this.labelEnd
),
]
)
);
return true;
}
}
Dans le Projet 1 - "CodeMirror, autocomplétion, Svelte", #JeMeDemande si je ne suis pas passé à coté d'une meilleur méthode pour implémenter de l'auto complétiion dans CodeMirror 🤔.
Journal du mardi 06 août 2024 à 11:40
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
J'essaie d'implémenter un "Replacing Dectorator" CodeMirror basé sur une recheche
syntaxTree. -- from
J'essaie de m'inspirer de ces implémentations lezer-parser/markdown/src/extension.ts#L10 et /silverbulletmd/silverbullet/common/markdown_parser/parser.ts#L30.