
agent conversationnel
Exemples d'agent conversationnel :
Exemple d'interface web de conversation IA :
Journaux liées à cette note :
Journal du jeudi 12 mars 2026 à 00:51
J'ai regroupé dans cette note les feedbacks que j'ai reçus à propos de ma note « Ma cartographie de l'écosystème LLM de 2026 ». En principe, je considère que mes notes éphémères sont immuables, mais je vais cette fois me permettre d'y apporter quelques corrections et d'en tracer les changements dans la présente note.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs connectent leurs applications aux LLMs en passant par une Web API qui respecte généralement la convention OpenAI Chat Completions compatible API.
Un ami m'a dit : « Plus personne ne fait de "completion", on migre tous vers la Responses API. »
Jusqu'à présent, je ne m'étais jamais vraiment penché sur les spécifications d'API des AI providers. Je m'étais contenté d'utiliser des bibliothèques IA et des AI Frameworks, en supposant naïvement qu'des outils comme Aider, llm (cli), Open WebUI ou OpenCode s'appuyaient tous sur l'OpenAI Chat Completions compatible API, et que les nouvelles fonctionnalités — tools, prompt caching, etc. — s'intégraient simplement via de nouveaux champs dans le JSON. Après analyse, ce n'est pas le cas.
L'API "completions" est d'ailleurs désormais classée dans la section « Legacy » de la documentation d'OpenAI, et OpenAI cherche à imposer un nouveau standard avec Open Responses.
La lecture de l'article OpenAI Responses API vs. Chat Completions vs. Messages API confirme que trois formats d'API dominent aujourd'hui :
Today, three API formats dominate how AI Agents talk to LLMs:
- OpenAI's Chat Completions API — the de facto standard, universally supported
- OpenAI's Responses API — the newer, agent-oriented evolution with built-in tools and state management
- Anthropic's Messages API — Claude's native interface, with capabilities like extended thinking and prompt caching
Mistral AI, de son côté, semble encore s'appuyer sur l'OpenAI Chat Completions compatible API : son endpoint reste POST /v1/chat/completions.
Je comprends mieux maintenant, pourquoi des frameworks comme l'AI SDK proposent une implémentation par provider : chaque API diverge suffisamment pour nécessiter un adaptateur dédié 😯.
Je constate que OpenRouter proposes les trois API :
POST https://openrouter.ai/api/v1/chat/completions(lien vers la documentation)POST https://openrouter.ai/api/v1/responses(lien vers la documentation)POST https://openrouter.ai/api/v1/messages(lien vers la documentation)
C'est là l'un des intérêts d'OpenRouter : une abstraction unifiée au-dessus d'une multitude d'AI providers.
Voici la nouvelle version de mon paragraphe :
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Mon ami m'a aussi fait remarquer :
« Tu utilises interchangeablement "LLM" et "le produit". Dans "De nombreux LLMs permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes", c'est pas le LLM lui-même, c'est le wrapper autour qui fait ça — le LLM s'en fiche. »
J'avais en effet manqué de rigueur à plusieurs endroits ; j'ai corrigé ma note.
Autre retour :
Dans ton histoire de middle tu peux aussi parler de prompt répétition : Prompt Repetition Improves Non-Reasoning LLMs.
Je ne connaissais pas cette astuce. J'ai ajouté cette phrase dans ma note :
« Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour. »
Autre retour :
« Tes notes sur le prompt caching pourraient être plus précises. C'est utile pour plus de cas, mais il ne faut pas vraiment y penser comme à un cache software. »
En effet, je vois un autre usage évident : une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur.
J'ai ajouté ce paragraphe à ma note :
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
J'ai reçu le retour suivant d'une autre personne :
Je crois qu'en plus d'utiliser des Inferences Engines les AIs providers utilisent aussi des Workload Managers, Mistral avait mis https://github.com/SchedMD/slurm dans ses offres d'emploi compute
D'après ce que j'ai compris, Slurm Workload Manager est un projet qui a commencé en 2002, généralement utilisé sur des clusters High-performance computing (HPC) pour lancer de gros traitements de calcul, qui peuvent durer plusieurs heures ou même des jours, sur du matériel mutualisé entre plusieurs laboratoires de recherche.
J'ai trouvé cette mention dans une offre d'emploi qui semble aller dans le sens de cette hypothèse :
Now, it would be ideal if you also had:
• Experience with HPC workload managers (Slurm) and distributed storage systems (Lustre, Ceph)
Je pense que Mistral AI utilise Slurm pour leur offre Compute - built infrastructure for AI builders, qui permet à leurs clients de créer ou de fine-tuner des modèles.
Je ne pense pas que Slurm soit utilisé pour leur offre AI provider : c'est un ordonnanceur batch conçu pour des jobs longs et prévisibles, alors que l'inférence requiert une faible latence et la capacité à traiter des requêtes à la volée — deux patterns fondamentalement différents. Par conséquent, je n'ai pas inclus ce sujet dans ma cartographie de l'écosystème LLM de 2026.
Une troisième personne m'a fait des retours :
Il y un concept important que tu ne cites pas, c'est l'embedding (vectorisation).
En effet, j'ai oublié d'en parler. Je viens d'ajouter le paragraphe suivant dans ma note :
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Cette même personne m'a aussi partagé :
je suis dans une phase d'exploration du Specs Driven Development.
Je connais la méthode, bien que je n'aie jamais remarqué qu'elle portait un nom : Specs Driven Development (SDD). Je pense que j'ai plus ou moins suivi cette méthode dans le fichier AGENTS.md de mon projet qemu-compose.
Je prépare très souvent mes specs quand je suis dans le métro ou quand je marche. Je réalise que mes notes publiques de projets me sont de plus en plus utiles comme base de spécification à soumettre aux LLMs, comme par exemple celle-ci : Première description du gestionnaire de projet de mes rêves.
J'ai fait quelques recherches sur le sujet du Specs Driven Development et je suis tombé sur le thread Hacker News « Spec-Driven Development: The Waterfall Strikes Back » ainsi que sur la section « Do you do spec-driven development? » d'un billet de blog. La pratique ne semble pas faire consensus. Je n'ai pas encore d'avis tranché sur la question.
Au passage, j'ai découvert ici deux autres noms de concepts : Verified Spec-Driven Development (VSDD) et Verification-Driven Development (VDD).
Je n'ai pas ajouté ces informations dans ma note de cartographie.
En rédigeant cette note, je me suis rendu compte que j'avais oublié quelques sujets.
J'ai ajouté un paragraphe sur le reranking :
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence.- Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
J'ai aussi ajouté un paragraphe sur chain-of-thought (CoT) :
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètreeffort.
Les modèles Claude Sonnet et Opus4.xadaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
Et pour finir, j'ai ajouté un paragraphe à propos des API de type "Batch" :
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples :
POST /v1/messages/batchespour Anthropic,POST /batchespour OpenAI, ouPOST /v1/batch/jobspour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard. Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Ma cartographie de l'écosystème LLM de mars 2026
Dans cette hub note, j'essaie de cartographier les principaux concepts et composants de l'écosystème LLM, d'en clarifier les relations et d'affiner mon vocabulaire. Les dates et la dimension historique sont volontairement absentes — cette note décrit l'écosystème tel qu'il est en 2026, pas comment il en est arrivé là.
À la base, on trouve les laboratoires de recherche — OpenAI, Anthropic, Mistral AI, DeepSeek, Qwen Team, etc. — qui entraînent et publient les modèles. Ces modèles sont ensuite instanciés par des AI providers — Vertex AI (Google), Bedrock (AWS), Scaleway Generative APIs, chutes.ai, etc — qui les rendent accessibles via une API. La plupart des LLM producers jouent également ce rôle d'AI provider pour leurs propres modèles.
OpenRouter est également un AI provider, mais d'un type particulier : c'est un proxy qui s'intercale devant de nombreux AI providers pour offrir un point d'accès et une facturation unifiés.
Les AI providers instancient des Inference Engines — llama.cpp, vLLM, SGLang, ExLlamaV2, etc. — sur leurs serveurs, en y chargeant les poids d'un LLM.
Ces serveurs coûtent très cher, environ 30 000 € pour des H200, 40 000 € pour des B200, 50 000 € pour des B300. Les GPU de ces serveurs sont gravés par TSMC, tandis que la mémoire HBM est produite principalement par SK Hynix.
Si je simplifie, il existe deux familles de LLM, les modèles denses et les modèles Mixture of Experts (MoE). Ces derniers permettent un coût d'inférence réduit à paramètres totaux équivalents.
Généralement le grand public accède aux AI providers via leurs agents conversationnels web — ChatGPT, Claude, Le Chat, etc.
Les développeurs, eux, connectent leurs applications aux AI provider via une Web API : ces APIs respectaient initialement la convention OpenAI Chat Completions compatible API, mais les APIs ont progressivement divergé.
OpenAI cherche à imposer un standard commun avec Open Responses, tandis qu'Anthropic suit sa propre voie avec sa Messages API.
Beaucoup d'AI providers proposent deux modes de facturation : un abonnement donnant accès à leur agent conversationnel web, et un mode Pay-As-You-Go (à l'usage) donnant accès à leur Web API.
Le texte saisi par l'utilisateur dans un agent conversationnel web est transmis à l'API de l'AI provider au sein d'un prompt, qui contient également le System Prompt (LLM), l'historique de la conversation, et éventuellement du contexte additionnel. La taille maximale de l'ensemble prompt et réponse est nommée context window, exprimée en tokens.
Lorsque l'application enrichit ce prompt avec des données externes — issues d'une base de données vectorielle, d'une base de données relationnelle, d'un moteur de recherche full-text ou d'un moteur de recherche web — on nomme cette technique : RAG (Retrieval-Augmented Generation).
Pour écrire des données dans une base de données vectorielle, il est nécessaire de passer par une étape de vectorisation en utilisant un modèle d'embedding, comme par exemple Cohere Embed v3 multilingual, Voyage AI Text Embeddings ou text-embedding-3-large d'OpenAI. La vectorisation est également requise au moment d'effectuer la requête dans la base de données — avec impérativement le même modèle que celui utilisé lors de l'indexation.
Les modèles d'embedding sont nettement plus légers et économiques qu'un LLM. Ils peuvent être exécutés sur CPU pour des usages courants, sans nécessiter de GPU.
Depuis 2022, les RAG avancés suivent le pattern "Retrieve, rerank, Generate". L'étape de reranking peut être effectuée via deux méthodes :
- Des modèles spécialisés de reranking, comme Cohere Rerank, ou Voyage AI Rerankers, qui sont légers, rapides. Ils prennent en entrée la
queryet la liste de documents candidats et produisent un score de pertinence. - Ou directement des LLMs généralistes, potentiellement plus précis sur des domaines spécifiques non couverts par les données d'entraînement des modèles de reranking, mais plus coûteux en latence et en tokens.
Beaucoup de LLMs ont tendance à moins bien utiliser les informations situées au milieu d'un très long contexte — ce problème est nommé lost in the middle. Cela pénalise notamment les RAG, dont les chunks pertinents injectés en milieu de contexte risquent d'être sous-exploités par le modèle. Certains LLMs modernes comme Gemini 2.5 Pro ou GLM-5 ne sont plus victimes du lost in the middle sur de longs contextes. Jusqu'en 2025, répéter le prompt améliorait les résultats sur les modèles non-raisonnants. La question reste ouverte pour les LLMs de début 2026 : aucune étude publiée ne le confirme ni ne l'infirme à ce jour.
La technique d'activation de raisonnement chain-of-thought (CoT) par prompting sur les LLMs classiques est connue
depuis 2022.
Depuis o1 d'OpenAI en septembre 2024, les modèles sont entraînés spécifiquement pour le raisonnement via RL, on parle de Reasoning Language Model (RLM). L'utilisateur peut contrôler le niveau d'effort de raisonnement via le paramètre effort.
Les modèles Claude Sonnet et Opus 4.x adaptent dynamiquement l'effort de raisonnement en fonction de la complexité de la tâche — Anthropic nomme cela hybrid reasoning.
De nombreux AI provider permettent de configurer des tools qui permettent au modèle d'appeler des fonctions externes. Un tool est décrit sous la forme d'une structure JSON, constituée des champs name, description, input_schema. En fonction du contenu des messages, le LLM peut prendre la décision de demander l'exécution d'un ou plusieurs tools. Cette demande se matérialise dans le JSON de sa réponse (voir exemple).
Il existe deux types de tools :
- des built-in tools, fournis et exécutés par le AI provider — Web search, Web fetch, Code execution, Memory, etc.
- des custom tools, définis par le développeur via le Function calling, dont l'exécution est prise en charge par l'application.
La facturation des built-in tools est généralement incluse dans les abonnements des AI providers. Par contre, elles sont généralement facturées individuellement dans l'offre Pay-As-You-Go.
La majorité des AI providers supportent le standard Structured Outputs d'OpenAI pour garantir une réponse conforme à un JSON Schema précis.
Anthropic, quant à lui, ne supporte pas ce standard mais permet tout de même la génération de réponses structurées en JSON en passant par un tool.
Une application est qualifiée d'AI agent lorsqu'un LLM y prend de façon autonome des décisions en boucle pour atteindre un objectif — en appelant des tools, en consultant des sources via RAG, ou en déléguant à des sous-agents. La boucle s'arrête lorsque l'objectif est atteint ou qu'une intervention humaine est requise. En poussant l'idée, on peut dire qu'un assistant IA conversationnel basique, sans tools ni boucle, est la forme la plus minimaliste d'un AI agent. Les assistants conversationnels modernes comme ChatGPT ou Claude sont quant à eux devenus de véritables agents à part entière.
Les Inference Engines sont par nature stateless — chaque requête est traitée de façon indépendante, sans mémoire des échanges précédents. Certains AI providers proposent néanmoins du prompt caching : lorsqu'une portion du prompt est identique d'une requête à l'autre — même ordre, même contenu, token pour token — elle est mise en cache pour une courte durée, ce qui réduit à la fois la latence et le coût. C'est particulièrement utile pour les AI coding agents, dont les longues boucles agentiques répètent à chaque étape le même system prompt et le même historique de conversation.
Ce système de prompt caching peut être utile aussi pour une application métier qui envoie de nombreuses requêtes différentes partageant toutes le même long system prompt. Plutôt que de retraiter ces tokens à chaque fois, le provider les garde en cache côté serveur. En fonction du contexte d'utilisation de l'application, il est possible de choisir plusieurs durées de cache, par exemple Anthropic propose 5min ou 1h.
À noter que le prompt caching n'est pas un cache logiciel classique au sens applicatif : c'est une optimisation transparente et implicite côté inférence, sans gestion de clés ni invalidation manuelle.
La plupart des AI providers proposent une API asynchrone de type "batch" — exemples : POST /v1/messages/batches pour Anthropic, POST /batches pour OpenAI, ou POST /v1/batch/jobs pour Mistral AI.
Ces APIs sont conçues pour des tâches non temps-réel, avec un délai de traitement pouvant aller jusqu'à 24h, en échange d'une réduction de 50% sur le tarif standard.
Elles disposent par ailleurs de rate limits séparés des quotas synchrones, ce qui permet de soumettre de gros volumes sans impacter les appels temps-réel.
Le protocole MCP standardise la définition, la découverte et l'exécution de tools exposés par des serveurs externes.
Cela permet de connecter un AI agent à des centaines de serveurs MCP sans avoir à écrire la moindre ligne de code.
Cela permet aussi à n'importe quel développeur de publier un serveur MCP pour rendre son service accessible aux AI agents.
La logique est proche des API REST, à la différence que les interfaces MCP sont conçues pour être utilisées par des AI agents plutôt que par des développeurs.
Les AI agents devenant de plus en plus complexes à orchestrer, les développeurs s'appuient sur des frameworks agentiques — Vercel AI SDK, LangGraph, VoltAgent, etc. — pour gérer les boucles, la mémoire, les tools et l'observabilité.
Les développeurs utilisent des AI coding agents dans des agentic coding tools comme Claude Code, OpenCode, etc. Ces agents utilisent massivement les tools et chargent du contexte projet depuis des fichiers AGENTS.md — un standard collaboratif initié par Sourcegraph, OpenAI et Google.
Les AI coding agents peuvent également charger dynamiquement des « compétences » depuis des fichiers SKILL.md, un format introduit par Anthropic.
Lorsqu'il utilise un agentic coding tool comme Claude Code ou OpenCode, le développeur peut choisir quel type d'AI coding agent utiliser selon la nature de la tâche — certains moins coûteux pour les tâches simples, d'autres plus capables pour les tâches complexes. Par exemple pour OpenCode on trouve : agent build, agent plan, agent general, agent explore. Chez Claude Code : agent explore, agent plan, agent general-purpose. Ces agents peuvent également travailler en essaim : un agent orchestrateur décompose le travail et délègue des sous-tâches à plusieurs sous-agents exécutés en parallèle.
Certains agents conversationnels web, comme ChatGPT, Claude, etc., proposent des fonctionnalités de "memory layers" basées sur des tools spécifiques. Ces implémentations restent à ce jour plus opaques et moins puissantes que les services dédiés comme mem0, Graphiti, Letta, etc.
Les services de couche mémoire persistante utilisent généralement une architecture hybride combinant une base de données vectorielle et une base de données de graphe : la base vectorielle stocke des informations sémantiques probabilistes et le graphe stocke des informations symboliques. Ces deux types de données permettent de fournir à un agent IA un meilleur contexte.
Les développeurs peuvent tester leurs prompts et leurs AI agents avec des outils d'évaluation, comme Promptfoo, trulens, etc. Ces outils sont nommés LLM Evals ou harnais (harness). Cela ressemble un peu à des tests unitaires, mais à la différence de ces derniers, qui sont déterministes, les LLM Evals évaluent la qualité des réponses des LLMs de manière probabiliste, généralement en utilisant un LLM-as-a-Judge.
Des laboratoires de recherche en AI privés — OpenAI avec SimpleQA et PaperBench, Google DeepMind avec IFEval et FACTS Grounding, etc. — ou académiques (UC Berkeley avec Chatbot Arena, Princeton avec SWE-bench, Center for AI Safety avec GPQA et HLE) et des communautés (EleutherAI avec le LM Evaluation Harness, Hugging Face avec l'Open LLM Leaderboard) mettent au point des benchmarks pour publier des leaderboards publics. Les créateurs de LLM disposent également de benchmarks internes privés, dont les méthodologies et résultats ne sont pas communiqués de manière transparente.
2026-03-12 : des petites erreurs ont été corrigées et j'ai ajouté 7 paragraphes (détail des changements).
Anthropic sous-vend-il ses abonnements ou surtaxe-t-il son API ?
Comme je l'ai mentionné dans cette note, les abonnements Claude sont beaucoup plus économiques que l'offre par API :
- L'offre Pro à $20 est 8 fois moins chère que l'offre API (pay as you go) : $163
- L'offre Max 5x à $100 est 13,5 fois moins chère que l'offre API (pay as you go) : $1354
- L'offre Max 20x à $200 est 13,5 fois moins chère que l'offre API (pay as you go) : $2708
Un ami me demande à ce sujet :
Est-ce qu'ils sous-vendent leur abonnement (Claude Pro, Max…) ou est-ce qu'ils arnaquent en pay as you go (via l'API) ?
Je n'ai fait aucune recherche à ce sujet, mais voici les explications qui me viennent à l'esprit.
Toute organisation opérant un service numérique gourmand en ressources — qu'il s'agisse de puissance de calcul ou de stockage — doit trouver un équilibre pour rentabiliser une infrastructure coûteuse sur un usage moyen, tout en absorbant des pics de charge qu'il serait trop onéreux de provisionner en permanence, même lorsqu'ils sont prévisibles.
Par exemple, Twitter dans ses premières années (2007-2012) était célèbre pour sa page "Fail Whale" — une baleine affichée aux utilisateurs en lieu et place du service quand les serveurs saturaient. Les événements mondiaux en temps réel (élections, Coupe du monde) suffisaient à faire tomber la plateforme. Je n'ai aucune information interne de Twitter de cette époque, mais clairement, Twitter n'avait pas trouvé de bonne stratégie pour garantir une qualité de service qui puisse suivre sa croissance.
Une stratégie classique sur Internet pour maîtriser cette croissance est l'ouverture par invitation, comme Gmail en 2004 et Dropbox en 2008. Elle permet à l'organisation de contrôler le rythme d'adoption en distribuant des invitations au fur et à mesure qu'elle déploie de nouveaux serveurs.
L'inférence des services d'agent conversationnel est surtout consommatrice de computation — les GPU — et tous les utilisateurs souhaitent utiliser à fond leur limite de tokens, surtout avec les AI code assistant. Anthropic souhaite lisser l'usage de leurs GPU dans le temps, dans le mois. C'est pour cela qu'elle définit des quotas sur 5h et par semaine. Ces quotas leur permettent de lisser et de contrôler davantage l'usage de leur infrastructure.
Estimation de Fermi du coût d'un abonnement Claude Max 5x
Je me suis lancé dans une estimation de Fermi pour estimer le coût brut d'un abonnement Claude Max 5x.
Mon estimation s'appuie sur le modèle Qwen3-235B-A22B comme point de comparaison, faute de données publiques sur l'architecture interne de Claude Sonnet. Précision méthodologique importante : les benchmarks officiels de Qwen (SGLang) mesurent (tokens_input + tokens_output) / temps — c'est donc un throughput mixte, pas uniquement de la génération.
En croisant ces benchmarks avec les résultats de GPUStack sur H100, et avec l'aide de Sonnet 4.6, j'estime qu'un serveur Scaleway "H100-SXM-8-80G — 128 vCPUs — 8 GPUs — 960 GB" loué à 16 810 € / mois peut traiter environ 20 à 40 milliards de tokens d'entrée par mois selon la longueur moyenne des prompts, soit approximativement 30 000 millions de tokens.
Si j'estime qu'un abonnement Claude Max 5x permet de traiter environ 400 millions de tokens d'entrée par mois pour Sonnet, un seul serveur H100-SXM-8-80G peut alors servir :
30 000 M tokens / 400 M tokens = 75 utilisateurs
Si je pars du principe que Scaleway marge à 20% le prix du serveur, cela donne un coût infrastructure par utilisateur de :
16 810 € × 0,8 / 75 = ~179 € par utilisateur par mois
Ce qui fait presque le double du prix d'un abonnement Max 5x.
Je suppose que la majorité des abonnés n'utilisent pas leur quota à fond, et qu'Anthropic optimise son infrastructure bien au-delà de ce qu'on peut estimer depuis des benchmarks publics. Partant de là, j'ai l'impression que le prix des abonnements couvre à peu près le coût de leur infrastructure.
L'offre API oblige Anthropic à provisionner des serveurs supplémentaires pour absorber les pics de charge et garantir une bonne qualité de service, et je pense que c'est pour cela que le prix au token est plus élevé via l'API.
Ceci n'est bien sûr que mon estimation personnelle. Si l'un d'entre vous dispose d'une meilleure approche ou de données plus fiables, n'hésitez pas à me la partager : contact@stephane-klein.info.
Ma lutte contre mon affaiblissement cognitif
#JaiLu cet excellent billet de Tristan Nitot qui traite du processus de prolétarisation : L'IA fait elle de nous des prolétaires ?.
Il rejoint totalement ce que je disais dans ma note : J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes.
Cela pose la question de la façon dont on aborde l’IA : peut-on profiter de l’IA sans y laisser son intelligence ?
À cette question, ma réponse imparfaite est celle-ci : j'essaie d'utiliser, autant que possible, les IA générative de texte comme un ami expert d'un domaine. J'essaie de ne jamais lui faire faire mon travail à ma place.
J'essaie de résister à l'injonction néolibérale d'effectuer chaque tâche le plus rapidement possible au nom de la rentabilité immédiate. Pour cela, tous les jours, j'essaie de trouver un équilibre entre la vitesse et prendre le temps de comprendre, de maîtriser les concepts et d'exécuter les gestes techniques. C'est loin d'être facile !
Pour lutter contre mon affaiblissement cognitif, j'essaie depuis quelques semaines d'intégrer Anki dans mes habitudes quotidiennes.
Mon objectif : créer une carte-mémoire pour chaque tâche que je délègue à un LLM alors que je devrais pouvoir l'accomplir moi-même.
Pour le moment, je n'ai pas la discipline pour respecter cet objectif, mais j'y travaille.
J'ai bien conscience que ma pratique est hétérodoxe. J'observe autour de moi que la tendance est la course à l'automatisation du maximum de tâches par l'IA. Je souhaite rester un artisan.
#JaiLu aussi le billet "Prolétarisation" de Carnets de La Grange.
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ai.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis intéressé à llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
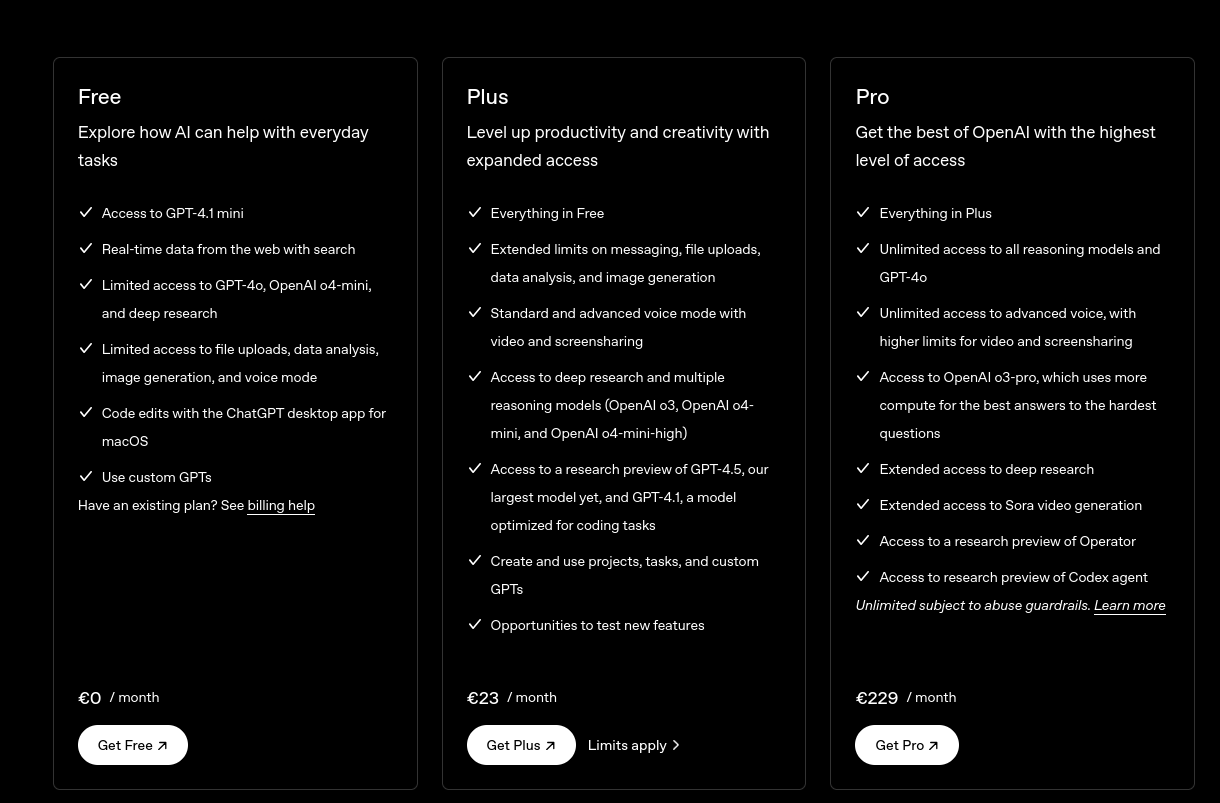
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ai pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
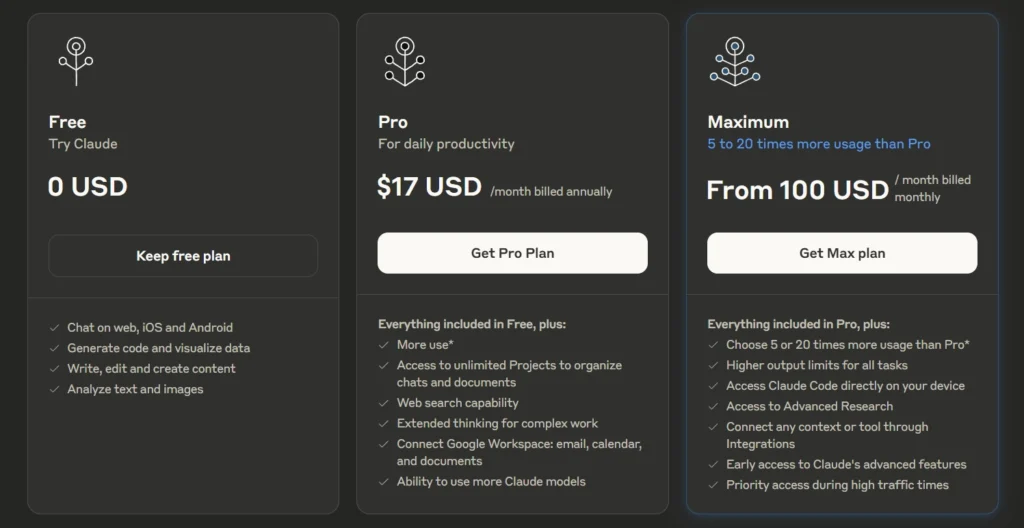
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ai via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ai alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ai et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ai. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
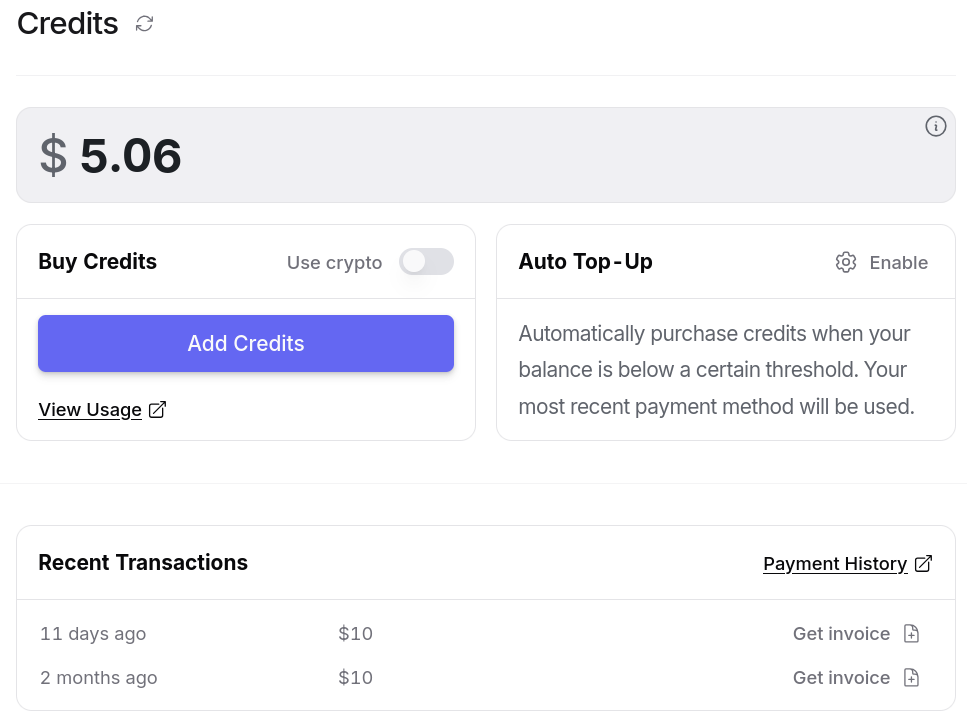
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
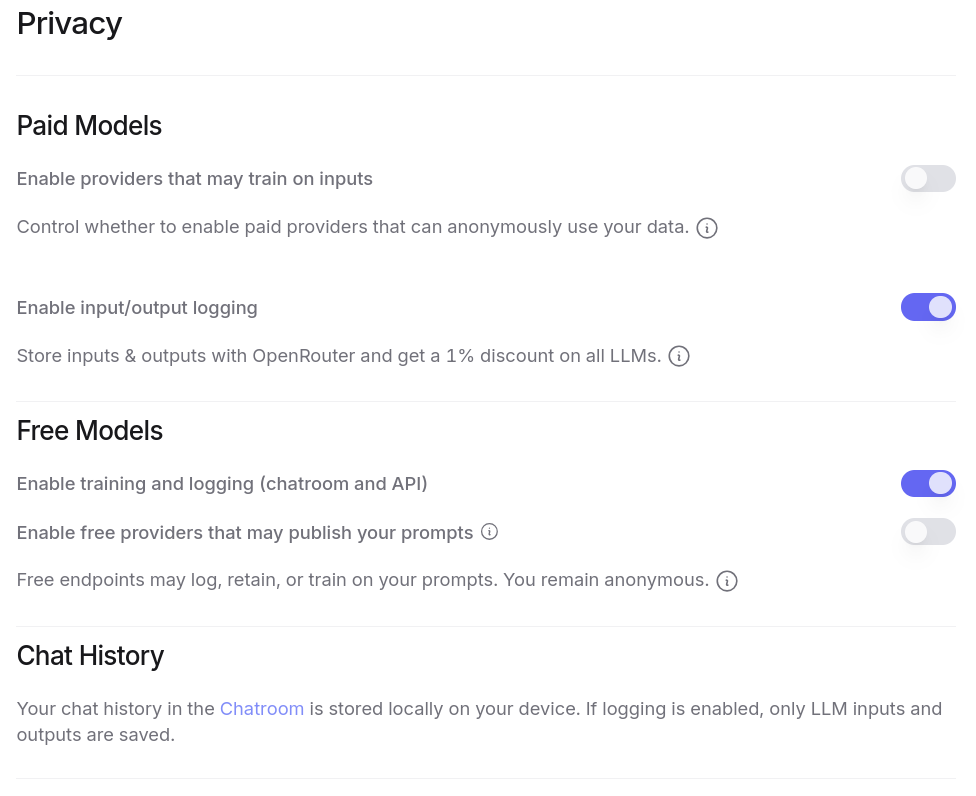
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs (LLM), ou "tools" :
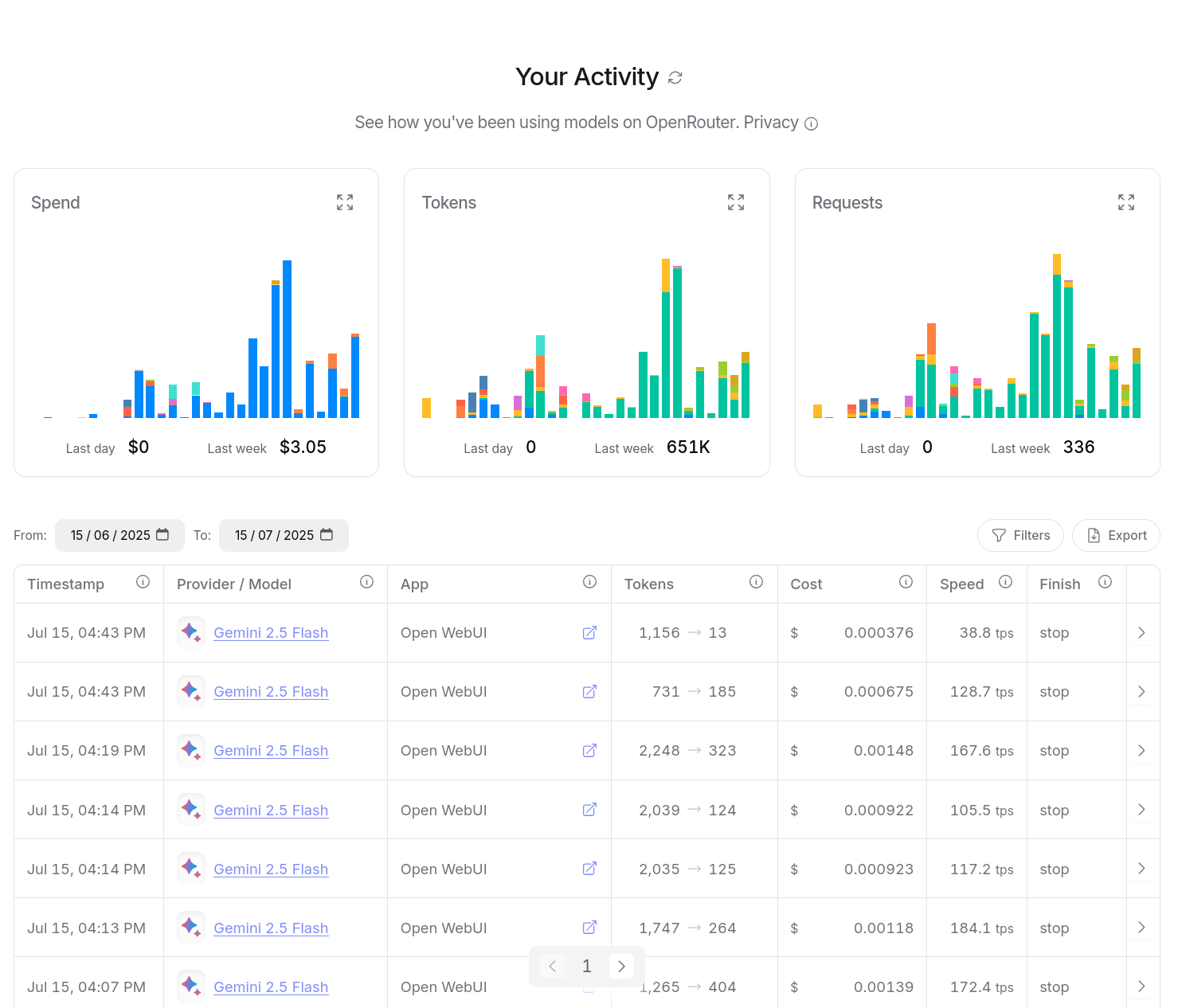
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Estimation de l'empreinte carbone de mon usage des IA génératives de textes
Je pense avoir entendu : « Une requête ChatGPT consomme l'équivalent de 10 recherches conventionnelles Google ! ».
Problème : je ne retrouve plus la source et cette comparaison me paraît manquer de rigueur. Par exemple, elle ne prend pas en compte le volume de tokens traités en entrée et en sortie.
Aujourd'hui, j'ai cherché à en savoir plus sur ce sujet et à vérifier cette déclaration.
J'ai d'abord cherché des informations sur l'émission de CO2 d'une recherche conventionnelle Google et j'ai trouvé ceci :
In 2009, The Guardian published an article about the carbon cost of Google search. Google had posted a rebuttal to the claim that every search emits 7 g of CO2 on their blog. What they claimed was that, in 2009, the energy cost was 0.0003 kWh per search, or 1 kJ. That corresponded to 0.2 g CO2, and I think that was indeed a closer estimate.
Si ma déclaration précédente est valide et qu'une recherche conventionnelle Google génère 0,2 g de CO2, alors une requête sur une IA générative de texte devrait sans doute produire environ 2g de CO2.
Attention, ces chiffres datent de 2009 : Google a probablement gagné en efficacité énergétique, mais a probablement aussi complexifié son algorithme.
En attendant de trouver des données plus récentes, j'ai choisi de partir de cette estimation pour cette note.
Ensuite, je me suis lancé dans des recherches sur l'estimation de la consommation CO2 des IA génératives de texte. J'ai effectué des recherches sur arXiv et je suis tombé sur cet article "How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference" qui date de mai 2025.
J'y ai trouvé ces graphes d'émission de CO2 par modèle en fonction du nombre de tokens en entrée et en sortie :

Pour Claude Sonnet 3.7 que j'ai fréquemment utilisé, je lis ceci :
- 100 in => 100 out : 0.4g
- 1k in => 1k out : 1g
- 10k in => 10k out : 2g
J'en conclus que l'ordre de grandeur de la déclaration que j'ai entendu semble réaliste.
(Mise à jour du 31 juillet : Mistral IA indique 1,14g pour 400 tokens pour Mistral Large 2)
En mai 2025, mes 299 threads ont consommé 19 129 tokens en entrée, soit 63 tokens par thread en moyenne. Mon usage d'IA générative de texte ce mois-là aurait généré approximativement 299 x 0,4g = 119g de CO2.
Pour mettre cela en perspective, j'ai estimé les émissions d'un trajet aller-retour Paris - Crest-Voland (Savoie) avec ma voiture :
- Trajet total :
620 km x 2=1240 km - Émissions constructeur (Dacia Sandero Stepway) : 140g CO2/km en WLTP en cycle mixte
Résultat : 1240km x 140g = 173 kg de CO2 pour mes déplacements hivernaux en Savoie.
Un seul voyage correspond à 121 ans de mon utilisation mensuelle actuelle d'IA générative de texte.
Mise à jour de 31 juillet, voir aussi : Équivalence de l'empreinte carbone de l'entrainement de Mistral Large 2.
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
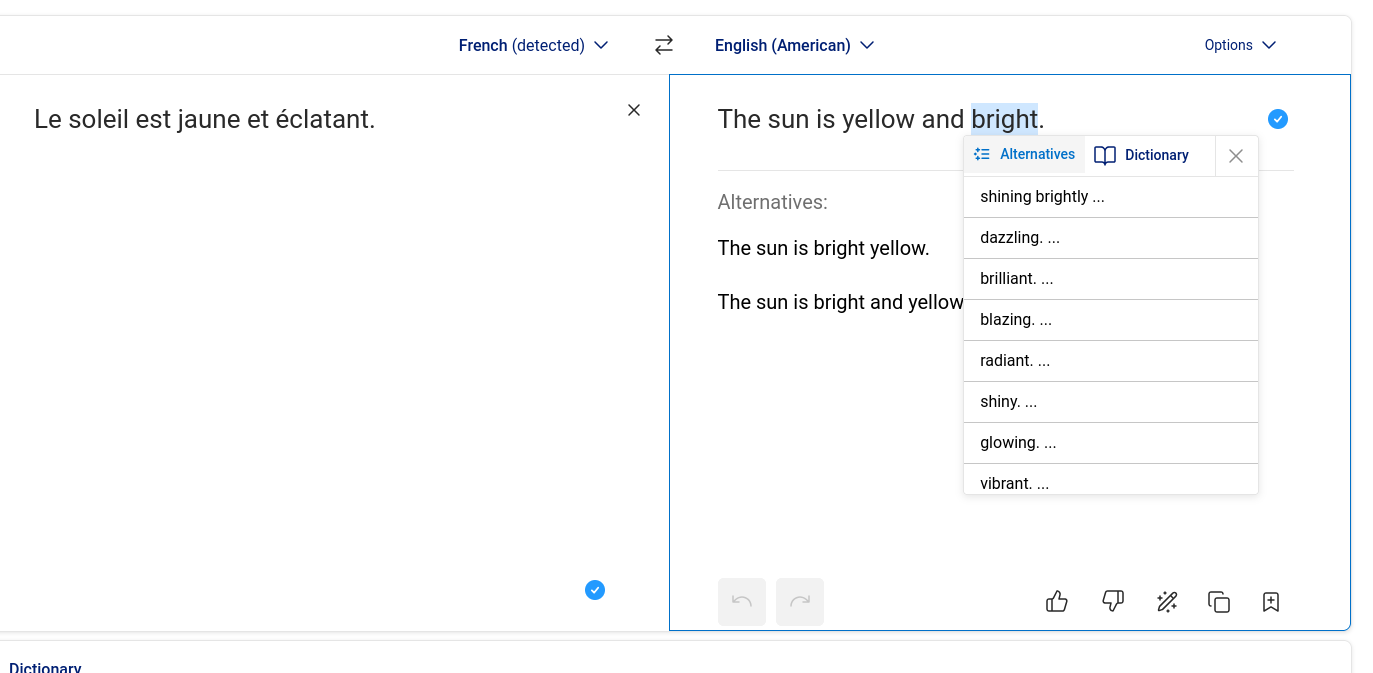
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Liste d'issues pour gibbon-replay de juin 2025
Mon objectif dans cette note est de rassembler une liste d'issues que j'ai à l'esprit pour le projet gibbon-replay.
Dans cette note, les issues sont décrites en moins de 280 caractères, de manière approximative et sans doute un peu idiosyncrasique. Elles sont présentées dans un ordre quelconque.
- Dans le README, expliquer pourquoi j’ai créé ce projet et son ambition. Indiquer clairement que l’objectif est de rester simple à déployer (architecture monolithique) et que les utilisateurs plus ambitieux peuvent se tourner vers des solutions comme Posthog ou OpenReplay.
- Toujours dans le README, indiquer comme dans l'introduction de SilverBullet : « gibbon-replay is optimized for people with a hacker mindset ».
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire total utilisé par l'ensemble des sessions. Issue GitHub : #4.
- [x] En tant qu'utilisateur, je peux visualiser l'espace mémoire consommé par chaque session individuellement.
- [x] En tant qu'utilisateur, je peux visualiser la durée de chaque session. Issue Github : #3.
- [x] En tant qu'utilisateur, je peux consulter, session par session, la présence ou non des actions utilisateur. Issue GitHub : #6.
- [ ] Optimiser la densité d'affichage de la liste des sessions en regroupant plusieurs données dans des cellules multilignes.
- En tant qu'utilisateur, dans la page liste des sessions, je peux appliquer un filtre sur les champs suivants : durée, taille mémoire ou mouvement de souris.
- En tant qu'utilisateur, dans la page détail d'une session, je peux visualiser les titres et les URLs des pages décrivant le parcours effectué par l'utilisateur.
- En tant qu'utilisateur, je peux visualiser un résumé textuel, du parcours utilisateur d'une session, rédigé par un agent conversationnel de petite taille.
- En tant qu'utilisateur avancé, je peux effectuer des recherches avancées sur le contenu des URLs présentes dans le parcours utilisateur. Par exemple, l'utilisateur peut saisir du code JavaScript qui permet de tester une condition sur toutes les URLs parcourues lors d'une session. Si la condition est positive, alors le résultat doit être sauvegardé dans un champ json de la session.
- En tant qu'utilisateur avancé, je peux rechercher des informations spécifiques dans le contenu des URLs présentes dans le parcours d'une session. Par exemple, je peux saisir un code JavaScript personnalisé pour tester une condition (comme la présence d'un
utm_sourceoucampaign) sur toutes les URLs parcourues. Si cette condition est vérifiée, les résultats correspondants sont stockés dans un champ json dans la session, permettant d'effectuer par la suite un filtre sur la liste des sessions. - User Story qui ressemble à la précédente : en tant qu'utilisateur avancé, je peux rechercher les balises HTML qui ont déclenché un événement "click" durant un parcours de session. Pour ce faire, il peut saisir du code JavaScript personnalisé pour tester une condition spécifique (comme la présence d'un attribut, d'une classe, etc.) sur ces balises. Les résultats de cette recherche sont enregistrés dans un champ JSON associé à la session, permettant d'effectuer par la suite un filtre sur la liste des sessions.
- En tant qu'utilisateur, je peux activer / désactiver l'envoi de notifications web sur des filtres de session, filtres avancés inclus.
- Permettre à une instance gibbon-replay d'enregistrer et de gérer plusieurs sites en même temps, en single-tenant.
- Ajouter un support multiutilisateurs — toujours en mode single-tenant. Permettre l'authentification par magic link et par username et password.
- Permettre la gestion des utilisateurs par API REST.
- Permettre de supprimer automatiquement des sessions en fonction de critères de filtres.
- En tant qu'utilisateur, je peux supprimer des sessions en mode batch.
Prochaine étape : créer ces issues plus détaillé dans : https://github.com/stephane-klein/gibbon-replay/issues