
C
Journaux liées à cette note :
Mes observations sur la popularité historique des langages de programmation
Un ami m'a partagé la vidéo Most Popular Programming Languages: Data from 1958 to 2025 (Most Popular Programming Languages). Pour quelqu'un comme moi qui a une grande curiosité pour l'histoire de l'informatique, c'est amusant de regarder ça 🙂.
J'ai lu la description de la vidéo pour essayer d'en savoir plus sur la véracité de ce qui est présenté :
Dans cette vidéo, je présente une chronologie détaillée des langages de programmation les plus utilisés de 1958 à 2025, basée sur une analyse approfondie des données. Les classements historiques reposent sur une combinaison d'enquêtes nationales agrégées, du nombre de livres pédagogiques publiés sur chaque langage, et de la fréquence à laquelle ces langages sont mentionnés dans les publications mondiales dédiées aux logiciels et aux technologies. Pour les années récentes, les classements ont été ajustés à partir de données issues de plusieurs indices de popularité des langages de programmation, des tendances d'accès aux dépôts GitHub, et d'enquêtes auprès des développeurs.
La popularité dans ce classement est définie par le nombre de développeurs maîtrisant ou apprenant activement chaque langage. L'échelle est normalisée sur une valeur relative de 100, permettant des comparaisons cohérentes entre les langages et les périodes.
L'emoji flamme représente les langages qui ont atteint la première place au moins une fois. L'emoji tête de mort représente les langages qui ne sont plus officiellement maintenus et ne disposent plus d'une communauté de développeurs active.
Plusieurs erreurs ont été corrigées par rapport à la vidéo précédente. J'ai également étendu la chronologie de près d'une décennie, en remontant à 1958, et ajouté de nouvelles données pour 2023, 2024 et 2025.
Vos retours sont toujours les bienvenus. Une suggestion de sujet ? Envoyez-moi un message !
Quelques observations personnelles sur l'évolution des langages présentés dans la vidéo :
- Fortran et Cobol : Je pensais que Cobol était dominant, mais je découvre que non, je suis surpris, Fortran semble avoir toujours été devant. J'ai toujours beaucoup plus entendu parler de Cobol que Fortran.
- Pascal : L'un de mes premiers amours en programmation, avant Python. Je n'imaginais pas que Pascal avait été numéro 1 à partir de 1980.
J'observe que quand j'ai appris Pascal vers 1991-1992, le langage C l'avait déjà dépassé depuis 1985. - Ada : Je ne m'attendais pas à le voir aussi populaire à la fin des années 1980, et encore moins à le voir passer devant Pascal en 1988. Et au passage, un langage conçu par Jean Ichbiah, un Français, au sein de CII-Honeywell-Bull : une entreprise à capitaux mixtes franco-américains — sur commande du Pentagone.
- C : C'est impressionnant de voir comment C a tout écrasé de 1990 à 1995 !
- Perl : Il a eu sa petite heure de gloire jusqu'en 1997, avant l'arrivée de PHP. C'était juste avant que je commence le développement web. En regardant l'évolution de Perl dans la vidéo, on devine assez bien comment Java et PHP ont ensuite tué Perl sur le web.
- Visual Basic : Curieusement, il n'a jamais vraiment dominé malgré les apparences. À la fin des années 1990, j'avais pourtant l'impression que tout le monde en faisait.
- Java et PHP : C'est au début de ma carrière professionnelle, en 2001, que Java commence à être hégémonique. Mais ce qui est intéressant, c'est de voir PHP se défendre très bien face à lui.
- Python : Il commence à monter en 2006, ce qui correspond exactement à l'année où je commence à me perfectionner sérieusement dans ce langage.
- Javascript : En 2012, j'avais clairement senti une forte montée en puissance de JS avec l'arrivée de NodeJS — j'avais même publié Réflexions à propos de Node.js et de JavaScript plus globalement le 18 avril 2012 sur LinuxFr.
- Python vs Javascript : Je suis vraiment surpris de voir Python doubler JavaScript en 2017, puis Java en 2018. J'imagine que cela doit être l'effet de l'IA — TensorFlow et compagnie. Je suis surpris de constater que Javascript n'a jamais été numéro 1 !
- Golang : J'ai commencé à l'utiliser en 2015, et je suis content de voir qu'il pointe le bout de son nez dans le top 12 en 2019. J'ai une sorte d'affection pour ce langage, j'apprécie beaucoup ses valeurs.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
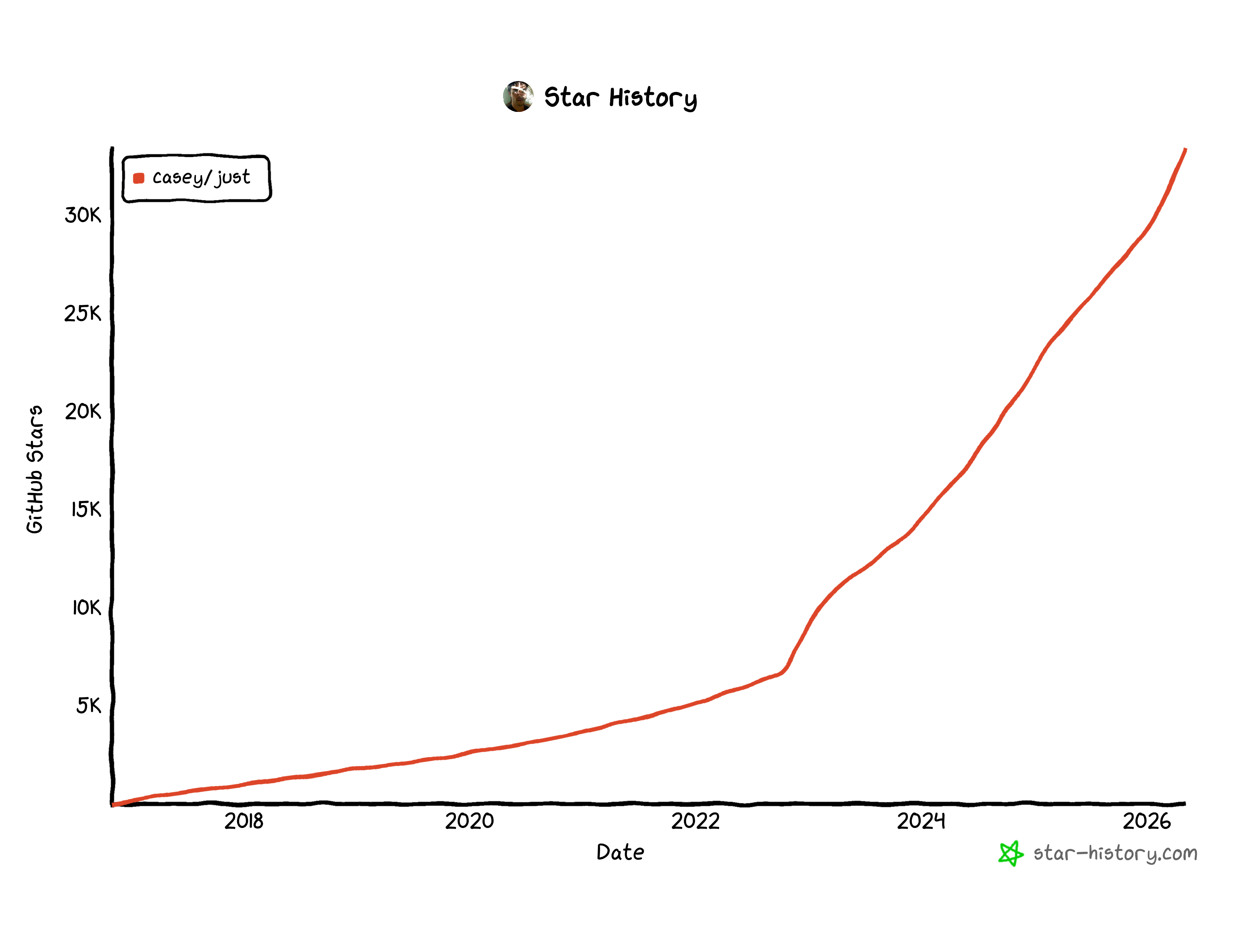
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
J'ai découvert upterm qui permet de partager facilement une session terminal à distance
J'ai cherché une solution pour partager facilement une session shell de ma workstation à un collègue.
Je connais les solutions suivantes :
$ ngrok tcp 22
Donne : tcp://0.tcp.ngrok.io:12345
# Connexion : ssh user@0.tcp.ngrok.io -p 12345
- Tmate, un fork de tmux patché, en C, projet qui a débuté en 2007
- cloudflared
#JaiDécouvert aujourd'hui les solutions upterm et bore.
Le projet upterm a commencé en 2019 et est codé en Golang. Le projet bore est plus jeune, il a commencé 2022 et est codé en rust.
J'ai testé bore puis upterm. J'ai retenu upterm pour les raisons suivantes :
- upterm propose directement un package RPM, contrairement à bore
- Le serveur relais public de upterm était significativement plus réactif que celui de bore lors de mes tests
- upterm propose nativement une session partagée entre deux utilisateurs, alors que bore est spécialisé dans la création de tunnels TCP. Il est possible de configurer bore pour lancer automatiquement des sessions partagées via un script tmux lancé par ssh, mais c'est moins pratique que upterm
Voici une démonstration de upterm :
$ sudo dnf install -y https://github.com/owenthereal/upterm/releases/download/v0.20.0/upterm_linux_amd64.rpm
Je peux ensuite autoriser la clé publique ssh de l'utilisateur invité :
$ upterm host --authorized-keys PATH_TO_PUBLIC_KEY
ou directement via son username GitHub :
$ upterm host --github-user username
Pour donner accès à une session terminal :
$ upterm host
The authenticity of host 'uptermd.upterm.dev (2a09:8280:1::3:4b89)' can't be established.
ED25519 key fingerprint is SHA256:9ajV8JqMe6jJE/s3TYjb/9xw7T0pfJ2+gADiBIJWDPE.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
╭─ Session: LiZaF6eKfCTxNeFSEt7B ─╮
┌──────────────────┬─────────────────────────────────────────────┐
│ Command: │ /usr/bin/zsh │
│ Force Command: │ n/a │
│ Host: │ ssh://uptermd.upterm.dev:22 │
│ Authorized Keys: │ n/a │
│ │ │
│ ➤ SSH Command: │ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev │
└──────────────────┴─────────────────────────────────────────────┘
╰─ Run 'upterm session current' to display this again ─╯
🤝 Accept connections? [y/n] (or <ctrl-c> to force exit)
✅ Starting to accept connections...
L'utilisateur invité accède à ce terminal simplement avec :
$ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev
upterm maintient une liste de sessions ouvertes, consultable avec :
$ upterm session list
📡 Active Sessions (1)
═══════════════════════
┌───┬──────────────────────┬──────────────┬─────────────────────────────┐
│ │ SESSION ID │ COMMAND │ HOST │
├───┼──────────────────────┼──────────────┼─────────────────────────────┤
│ * │ DumRFGF6AuinQjzwBf0E │ /usr/bin/zsh │ ssh://uptermd.upterm.dev:22 │
└───┴──────────────────────┴──────────────┴─────────────────────────────┘
💡 Tips:
• Use 'upterm session current' to see details
• Use 'upterm session info <SESSION_ID>' for specific session
Journal du lundi 12 août 2024 à 13:25
Quel est mon rapport aux langages typés ?
Pour bien comprendre mon approche des langages typés, il est utile de revenir sur mon parcours.
Enfant, j'ai commencé par du Locomotive Basic (non typé), j'ai ensuite fait beaucoup de Turbo Pascal (typé) et un peu de C, C++ (typé).
À cette époque, je préférais les langages typés pour des raisons de performances.
En 2000, j'ai vraiment aimé utiliser à nouveau des langages non typés, comme PHP et surtout Python qui a été pendant très longtemps mon langage de prédilection.
J'ai à nouveau beaucoup pratiqué un langage typé de 2013 à 2018 : Golang.
Aujourd'hui, je considère qu'il est souvent plus facile et plus rapide de programmer dans un langage non typé, notamment grâce au Duck Typing. Cependant, je reconnais que les langages typés offrent des avantages indéniables, notamment en matière de refactoring de code.
Je pense qu'il est préférable d'utiliser un langage typé sur un projet critique.
Je pense qu'il est préférable d'utiliser un langage typé pour les programmes qui manipule des données complexes et divers.
C'est, par exemple, pour cela que ne suis pas un utilisateur de MongoDB. Je préfère une base de données PostgreSQL où tout est bien typé.
Il ne me viendrait pas à l'esprit d'implémenter une base de données ou un moteur web dans un langage non typé.
Par contre, je suis moins convaincu par l'utilisation d'un langage typé pour les applications d'interface utilisateur lourde ou web.
Lorsqu'une équipe de développement travaillant sur un code commun atteint une certaine taille — je n'ai aucune idée de ce nombre — je suis convaincu qu'il devient préférable d'utiliser un langage typé.