
NodeJS
Journaux liées à cette note :
J'ai découvert Adminer, alternative à PhpMyAdmin et je me suis intéressé à OPCache
En travaillant sur un playground d'étude de Podman Quadlets, dans le README.md de l'image Docker mariadb, #JaiDécouvert le projet Adminer (https://www.adminer.org) qui semble être l'équivalent de PhpMyAdmin, mais sous la forme d'un fichier unique.
Je découvre aussi que contrairement à PhpMyAdmin, Adminer n'est pas limité à Mysql / MariaDB, il supporte aussi PostgreSQL.
En regardant le dépôt GitHub d'Adminer, je découvre que le gros fichier PHP de 496 kB est le résultat de la concaténation de nombreux fichiers php.
Ça me rassure, parce que je me demandais comment l'édition d'un fichier unique de cette taille pouvait être humainement gérable.
Je trouve astucieux ce mode de déploiement d'un projet PHP sous forme d'un seul fichier qui me fait penser à la méthode Golang. Cependant, je me pose des questions sur la performance de cette technique étant donné que PHP fonctionne en mode process-per request (CGI), ce qui signifie que ce gros fichier PHP est interprété à chaque action sur la page 🤔.
En creusant un peu le sujet avec Claude Sonnet 4.5, je découvre que depuis la version 5.5 de PHP, OPCache améliore significativement la vitesse des requêtes PHP, sans pour autant atteindre celle de Golang, NodeJS, Python ou Ruby qui utilisent des serveurs HTTP intégrés. La consommation mémoire reste supérieure dans des conditions d'implémentation comparables.
Avec OPCache, Adminer semble rester performant malgré l'utilisation d'un fichier unique.
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
Journal du mardi 26 août 2025 à 21:45
Voici une note pour présenter la seconde #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push".
J'ai tout d'abord implémenté dans ce commit un mécanisme qui exécute du code JavaScript automatiquement après chaque git push.
Pour cela, j'ai choisi de me baser sur le mécanisme Server-Side Hooks natif de Git : post-receive.
Voici le contenu de ce script hook en Bash :
#!/bin/bash
while read oldrev newrev refname; do
branch=$(git rev-parse --symbolic --abbrev-ref $refname)
curl -X POST \
-H "Content-Type: application/json" \
-d "{
\"oldrev\": \"${oldrev}\",
\"newrev\": \"${newrev}\",
\"refname\": \"${refname}\",
\"branch\": \"${branch}\",
\"repository\": \"$(basename $(pwd))\"
}" \
"${POST_RECIEVE_HOOK_URL}" >> /dev/null
done
Chaque événement git push déclenche un appel HTTP vers le endpoint http://localhost:3334/post_recieve_hook_url/ exposé par le serveur NodeJS. Le payload contient notamment :
oldrev: l'identifiant du dernier commit présent dans le repository avant le pushnewrev: l'identifiant du commit le plus récent envoyé lors du push
L'intervalle entre oldrev et newrev permet d'identifier précisément l'ensemble des commits qui ont été poussés lors de cette opération.
J'ai ensuite implémenté une version SvelteKit iso-fonctionnelle de node-git-http-server. Voici le repository poc-node-git-server-in-sveltekit .
Contrairement à ce que j'avais prévu initialement, pour cette implémentation, je ne me suis pas basé sur SvelteKit Custom Server, mais sur la fonctionnalité Server hooks : src/hooks.server.js#L11.
Journal du dimanche 24 août 2025 à 12:42
Je viens de publier la première #iteration du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push" dans le repository node-git-http-server.
L'implémentation d'un serveur Git HTTP via Apache ou nginx, en s'appuyant sur git-http-backend , paraît plutôt simple à réaliser.
Comme mon objectif est d'intégrer cette fonctionnalité dans le projet sklein-pkm-engine et que j'ai une préférence pour les monolith, j'ai exploré les solutions basées sur NodeJS.
J'ai dans un premier temps étudié le projet node-git-http-server et ensuite node-git-server.
Ces deux projets semblent peu actifs.
J'ai échoué à faire fonctionner le projet node-git-server, probablement à cause d'une erreur de ma part — j'ai sans doute oublié d'initialiser au préalable les dépôts Git en mode bare.
Par la suite, en utilisant Claude Sonnet 4, j'ai créé une implémentation basée uniquement sur les modules natifs de NodeJS et l'exécutable git-http-backend , sans recourir à aucun package NodeJS externe.
Voici le résultat : node-git-http-server/server.js.
Prochaines étapes
- Implémenter un système qui exécute du code JavaScript automatiquement après chaque
git push, en lui transmettant la branche concernée et la liste des nouveaux commits publiés. - Implémenter une déclinaison de ce projet dans un SvelteKit Custom Server.
Journal du mercredi 07 mai 2025 à 14:22
Ici dans le code source de Open WebUI, #JaiDécouvert Pyodide :
Pyodide is a Python distribution for the browser and NodeJS based on WebAssembly.
Journal du mercredi 12 février 2025 à 10:44
En travaillant sur le projet Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker", j'ai découvert que PostgreSQL propose deux protocoles de communication :
- Le premier est le plus connu "Frontend/Backend Protocol". C'est celui qui est utilisé par la commande
psqlou les librairies telles que Postgres.js (en NodeJS), Psycopg (en Python)… - Le second nommé "Streaming Replication Protocol"
Sans vraiment comprendre, en 2020, j'avais activé le protocole streaming replication dans ce POC postgresql-streaming-replication-playground. Mais je n'avais jamais pris conscience de l'existence de ce second protocole.
Les développeurs de PostgreSQL semblent avoir décidé de créer un second protocole parce qu'ils n'ont pas du tout le même objectif.
Streaming Replication Protocol est optimisé dans la transmission des WAL et des snapshots (copie de l'intégralité du dossier PGDATA).
Le protocole Streaming Replication Protocol est entre autres utilisé par pg_basebackup, barman, pgBackRest, ou Patroni.
Comment activer Streaming Replication Protocol ?
Les images Docker Postgres setup par défaut le fichier pg_hba.conf suivant :
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
host all all all scram-sha-256
J'ai compris que par défaut, toutes ces lignes configurent l'accès au Frontend/Backend Protocol.
Seules les lignes qui contiennent replication configurent l'accès au Streaming Replication Protocol.
Pour permettre l'accès au Streaming Replication Protocol par réseau TCP/IP en dehors du container Docker il est nécessaire d'ajouter la ligne suivante :
host replication all all scram-sha-256
Suite à cette découverte, j'ai repensé à :
Pour faire face à ce problème, j'ai exploré fin 2023 une solution basée sur pgBackRest : Implémenter un POC de pgBackRest.
Je suis plus ou moins arrivé au bout de ce POC mais je n'ai pas été satisfait du résultat.
Je n'ai pas réussi à configurer pgBackRest en "pure Docker sidecar".
De plus, j'ai trouvé la restauration du backup difficile à exécuter.
et je me suis demandé si mon échec de configuration de pgBackRest en Docker sidecar n'était pas seulement dû au fait que je n'avais pas activé Streaming Replication Protocol 🤔.
La réponse semble être "oui" et "non".
Je suis tombé sur l'issue suivante : pgbackrest with postgresql in docker.
The problem might be harder than you think unfortunately. If the pgBackRest process is running on the VM (docker host), it will try to connect to PG locally using the unix socket, not the tcp "localhost" connection.
Je pense comprendre que pgBackRest ne permet pas d'utiliser des INET sockets pour communiquer avec PostgreSQL.
Toutefois, je me dis que je pourrais partager le volume PGDATA avec le sidecar pgBackRest pour lui donner accès à l'Unix Socket du Streaming Replication Protocol 🤔.
Entre mon exploration de pg_basebackup, mes envies de tester barman et de continuer mon POC pgBackRest… je me dis que je ne suis pas encore au bout de ce Yak!.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du mercredi 29 janvier 2025 à 11:55
#JaiDécouvert Nitro (https://nitro.build/)
Next Generation Server Toolkit.
Create web servers with everything you need and deploy them wherever you prefer.
D'après ce que j'ai compris, Nitro est un serveur http en NodeJS qui a été spécialement conçu pour Nuxt.js.
Nitro a été introduit fin 2021 dans la version 3 de Nuxt.
Nitro fait partie de l'écosystème UnJS.
Je découvre l'existence de UnJS Ecosystem. #JeMeDemande si ce projet a un lien avec VoidZero 🤔.
Je viens de vérifier, SvelteKit ne semble pas utiliser Nitro. Nitro semble être utilisé uniquement par Nuxt.js.
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres
Pourquoi faire un refactoring de Nuxt.js vers HTMX ? 🤔
En étudiant l'annonce Développeur(se) back-end en CDI de Brief.me j'ai été intrigué par :
Je me suis demandé quelle est la motivation de passer d'un framework de type Nuxt.js, NextJS ou SvelteKit à htmx 🤔.
J'utilise SvelteKit depuis deux ans, qui est comparable Nuxt.js, principalement en mode SSR avec Hydration, et je suis totalement satisfait. Ma Developer eXperience est excellente. Je trouve ce framework minimaliste, conforme au principe Keep it simple, stupid! (KISS), et performant.
Après réflexion, j'ai réalisé que mon expérience de développeur (DX) serait moindre si j'héritais d'un backend codé dans un langage autre que Javascript : Python, PHP, Ruby, Golang…
Et Brief.me semble être dans ce cas de figure :
- Back-end : Django, PostgreSQL, RabbitMQ, Celery
- Front-end : HTMX
- Tests : pytest
- Infra : Platform.sh
Je me suis connecté à mon compte Brief.me et en regardant ce que me retourne Wappalyzer, je constate que le site est effectivement propulsé par Nuxt.js, VueJS.
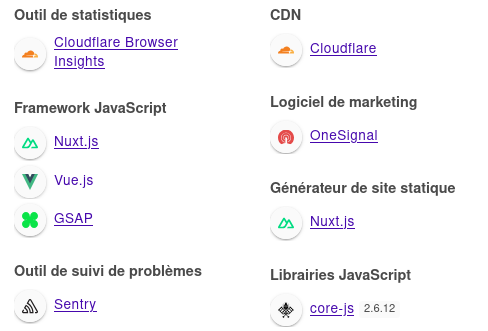

En regardant ce qu'il se passe dans l'onglet Réseau de mon navigateur, je constate que https://app.brief.me est un site web de type SPA. Le contenu des articles est chargé via l'api https://www.brief.me/api/ qui est propulsée par Django REST framework.
Si je résume, la stack est la suivante : PostgreSQL => Django => Django REST framework <=> Nuxt.js => Rendu HTML via VueJS.
Je suppose que ce qui motive la migration de Nuxt.js vers HTMX est la suppression de couches.
Plus précisément, je suppose que l'équipe tech de Brief.me souhaite supprimer les couches suivantes :
Et utiliser simplement le système de template de Django en SSR pour afficher le contenu des articles et implémenter les quelques éléments dynamiques côté browser avec HTMX.
De mon point de vue, ceci a pour avantage de largement simplifier la stack, de simplifier le déploiement et d'accélérer le chargement des pages.
Ma conclusion : la librairie HTMX semble être un choix très pertinent quand elle est utilisée dans une stack non NodeJS.