
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (851) ] [ Notes plus anciennes (208) >> ]
Samedi 13 juillet 2024
Journal du samedi 13 juillet 2024 à 21:52
#JaiDécouvert typesense-dashboard :
A Typesense Dashboard to manage and browse collections.
Journal du samedi 13 juillet 2024 à 10:34
#JaiLu ce manuscrit de Lê Nguyên Hoang : Une astuce bayésienne pour identifier l'expertise.
En particulier, un argument bayésien montre bel et bien que les affirmations bien plus populaires que ceux qu'on croit ont tendance à être souvent juste --- en tout cas dans un monde où les humains réfléchissent correctement, ou plutôt, conformément aux lois des probabilités.
🤔
J'ai lu plusieurs fois la section "Le théorème de la popularité insoupçonnée d'une vérité" et pour le moment, je n'ai toujours pas réussi à comprendre le raisonnement. Cela me demande beaucoup de concentration !
Eh bien, le scrutin proposé par Prelec, Seung et McCoy, qu'ils appellent le vote du candidat "surprenamment populaire" consiste à calculer, pour chaque candidat X, tous les ratios de ce genre, où X est comparé à des alternatives Y, en comparant les prédictions pro-Y chez les pro-X aux prédications pro-X chez les pro-Y.
Voir aussi Bayésianisme.
Vendredi 12 juillet 2024
Journal du vendredi 12 juillet 2024 à 13:46
#OnMaPartagé l'information suivante Évolution des taux de cotisations sociales des auto-entrepreneurs .
Depuis le 1er juillet 2024, la loi prévoit que le taux global de cotisations de 21,1 % évolue progressivement sur une période de trois ans, selon le calendrier suivant :
- du 1er juillet au 31 décembre 2024 : 23,1 % ;
- du 1er janvier au 31 décembre 2025 : 24,6 % ;
- à partir du 1er janvier 2026 : 26,1 %.
Ce qui fait une augmentation totale de 5%.
Source du changement : Décret n° 2024-484 du 30 mai 2024 modifiant les taux globaux de cotisations et contributions de certains travailleurs indépendants exerçant dans le cadre de la microentreprise
J'ai essayé de comprendre les motivations derrière ce changement.
J'ai découvert que la Fédération nationale des auto-entrepreneurs (FNAE) se bat depuis plusieurs années pour la retraite complémentaire (la CIPAV) des micro-entropeneurs :
- En 2021 : « La FNAE continue à se battre pour la retraite complémentaire des microentrepreneurs passés au régime général et pour lesquels aucune cotisation retraite complémentaire n’est appelée depuis 2018. Elle réclame une clé de répartition du forfait social. »
- En 2022 : « Retraite : après l’obtention d’une clé de répartition claire du forfait social mais la FNAE continue de se mobiliser pour les PLNR et les retraites complémentaires des années précédentes depuis 2018 ».
- En 2023 : « la bataille continue pour assurer aux microentrepreneurs leur droit à la retraite complémentaire, de façon rétroactive depuis 2018 pour tous, et pour les PLNR (Professions libérales non réglementées) dont la cotisation à la retraite complémentaire n’est pas comptée dans le forfait social. »
Sur le site de la FNAE, j'ai trouvé l'article Retraite complémentaire d’auto-entrepreneur : enfin des droits en profession libérale ! qui donne beaucoup d'explications :
Le 1er juillet 2024 sera à marquer d’une croix (blanche ?) pour les auto entrepreneurs libéraux, puisqu’ils cotiseront enfin pour leur retraite complémentaire d’autoentrepreneur.
J'ai regardé ma dernière fiche de paie en CDI et j'ai l'impression que les taux de cotisations sociale de retraite complémentaire était : 12,4 %.
12 % me semble bien supérieur à 5 % de cotisations de retraite complémentaire pour les micro-entrepreneurs.
Conclusion : il me semble extrêmement probable que c'est la FNAE qui est à l'origine de ce changement et non pas Bruno Le Maire ministre de l'Économie.
Journal du vendredi 12 juillet 2024 à 10:57
Suite de 2024-07-11_1929 :
Suite à ce constat, je vais essayer de setup InstantSearch dans le projet
obsidian-vault-to-apache-age-poc.
J'ai trouvé "typesense-instantsearch-demo (without NPM or YARN)" qui va me servir de base.
11:10 : J'ai une première version de InstantSearch qui fonctionne mais avec plein d'imperfection.
Journal du vendredi 12 juillet 2024 à 10:17
#JaiDécouvert que InstantSearch propose une version "vanilla JS". Jusqu'à présent, je pensais que seuls React, Vue et Angular étaient proposés.
Jeudi 11 juillet 2024
Journal du jeudi 11 juillet 2024 à 19:29
J'ai essayé d'utiliser TypeSense-Minibar dans obsidian-vault-to-apache-age-poc et je constate que TypeSense-Minibar est limité à un usage bien précis : effectuer une recherche sur un schema généré par Docsearch.
La limitation se trouve ici.
query_by: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content',
include_fields: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content,url_without_anchor,url,id',
highlight_full_fields: 'hierarchy.lvl0,hierarchy.lvl1,hierarchy.lvl2,hierarchy.lvl3,hierarchy.lvl4,hierarchy.lvl5,content',
Pour un usage autre que Docsearch, je pense qu'il faut utiliser InstantSearch.
Je constate ici que je peux configurer query_by :
...
additionalSearchParameters: {
query_by: "name,description,categories",
},
...
Suite à ce constat, je vais essayer de setup InstantSearch dans le projet obsidian-vault-to-apache-age-poc.
Mercredi 10 juillet 2024
Journal du mercredi 10 juillet 2024 à 22:29
#JaiDécouvert la fonctionnalité Semantic Search de Typesense :
Typesense supports the ability to do semantic search out-of-the-box, using built-in Machine Learning models or you can also use external ML models like OpenAI, PaLM API and Vertex AI API.
Journal du mercredi 10 juillet 2024 à 21:36
Je suis en train d'étudier Typesense et j'ai la sensation que :
- la documentation de Typesense est plus agréable à lire que celle de Meilisearch ;
- la documentaion de Typesense est plus complète, plus précise que celle de Meilisearch ;
- Typesense est plus complet que Meilisearch.
#Jaime cette la section "What is the difference between Typesense Cloud and Self-Hosted version?".
Journal du mercredi 10 juillet 2024 à 19:38
#JaiDécouvert la documentation PostgreSQL nommée https://pgpedia.info/.
Journal du mercredi 10 juillet 2024 à 19:09
#JaiDécouvert Citation Style Language, pour le moment je n'ai pas pris de temps de comprendre à quoi cela sert précisément (from)
Journal du mercredi 10 juillet 2024 à 11:38
Suite à 2024-07-10_1121, #JeSouhaite tester Cosma avec le contenu de https://notes.sklein.xyz.
Journal du mercredi 10 juillet 2024 à 11:21
#JaiLu Écrire autrement : réflexion croisées sur Mardown
En SHS, les logiciels de traitement de texte (comme LibreOffice Writer, Microsoft Word et Google Docs) sont utilisés par la ma‐ jorité des auteurs et des éditeurs. … leur modèle économique est souvent défavorable à l'utilisateur ; …
La maniabilité des textes en Markdown permet de circuler de façon plus fluide dans sa production écrite et de la mobiliser au fil de différents contextes de recherche (communications scientifiques, articles de recherche, notes, supports de cours, etc.). Le temps de traitement et le travail de mise en forme des textes ainsi produits sont de ce fait rationalisés. L’ensemble de ces étapes constitue un écosystème de travail global et intégré.
Markdown a été pensé pour le Web : c'est une sorte de « sténographie » de HTML.
À la façon d'un wiki personnel, cette documentation regroupe tous les documents dans lesquels on travaille : fiches de lecture, notes terminologiques, brouillons d'idées, etc. C'est l'espace de travail dans Zettlr ou le "vault" dans Obsidian. L'idée centrale est de travailler avec des notes organisées de manière non-linéaire, qui se font référence les unes aux autres. Périodiquement, une idée émerge : un lien nou‐ veau entre deux choses (ou plus). Les notes servent d'aide-mémoire et d'espace de réflexion/idéation.
Outils cités dans l'article :
- #JaiDécouvert https://github.com/peterpeterparker/stylo
- Marp
- #JaiDécouvert https://ia.net/presenter (j'adore)
- #JaiDécouvert https://cosma.arthurperret.fr/
#JaiDécouvert le mot cosmoscope.
Journal du mercredi 10 juillet 2024 à 11:03
#JeDécouvre ce site perso https://www.arthurperret.fr/ de Arthur Perret, j'aime beaucoup le style. (from).
Dans ses papiers de recherche #JaiDécouvert ces papiers :
Journal du mercredi 10 juillet 2024 à 09:41
Suite à 2024-07-09_0846 (Projet 5) et suite à la publication de poc-meilisearch-blog-sveltekit en 2023, je souhaite tester l'intégration de Typesense à obsidian-vault-to-apache-age-poc en complément de pg_search.
J'ai bien conscience que Typesense fait doublon avec pg_search, mais mon objectif dans ce projet est de comparer les résultats de Typesense avec ceux de pg_search.
J'espère que cet environnement de travail me permettra d'itérer afin de répondre à cette question.
Idéalement, j'aimerais uniquement utiliser pg_search afin de mettre en œuvre un seul serveur de base de données et de bénéficier de la mise à jour automatique de l'index du moteur de recherche :
A BM25 index must be created over a table before it can be searched. This index is strongly consistent, which means that new data is immediately searchable across all connections. Once an index is created, it automatically stays in sync with the underlying table as the data changes. (from)
Mardi 9 juillet 2024
Journal du mardi 09 juillet 2024 à 18:38
#OnMaPartagé Comment nous avons développé un outil d’édition collaborative sur mesure pour nos journalistes
Comme je n'ai pas trouvé le code source du projet Echo, j'ai posé cette question sur LinkedIn :
Tout d'abord, félicitations pour cet article et le développement de ce projet 👍️.
J'ai cherché ce projet sur GitHub, mais je n'ai rien trouvé. Est-ce que le projet Echo est closed-source ?
Journal du mardi 09 juillet 2024 à 09:52
#JaimeraisUnJour installer et tester le moteur de recherche décentralisé https://yacy.net/.
#JeLis le thread YaCy, a distributed Web Search Engine, based on a peer-to-peer network | Hacker News
- Je suis tombé sur ce commentaire que je trouve intéressant
Journal du mardi 09 juillet 2024 à 08:46
Dans le cadre de mon travail sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément, ma tentative d'utiliser pg_search pour y intégrer un moteur de recherche, j'ai creusé le sujet InstantSearch.
Typesense permet d'utiliser InstantSearch via un adaptateur :
At Typesense, we've built an adapter (opens new window) that lets you use the same Instantsearch widgets as is, but send the queries to Typesense instead. (from)
Ici j'ai découvert des alternatives à InstantSearch :
- typesense-minibar
- autocomplete (aussi créé par Algolia)
- docsearch (aussi créé par Algolia)
#JeMeDemande comment utiliser InstantSearch ou TypeSense-Minibar avec pg_search.
N'ayant pas trouvé de réponse, #JaiPublié How can I implement InstantSearch, Typesense-Minibar or Docsearch with pg_search?.
Lundi 8 juillet 2024
Journal du lundi 08 juillet 2024 à 09:52
Je cherche des informations à propos du modèle Phi-3.
Ici #JaiDécouvert Small Language Models (SLMs).
Journal du lundi 08 juillet 2024 à 09:38
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
#JeMeDemande quelles sont les projets alternatif à Outlines 🤔
J'ai trouvé :
- https://github.com/sgl-project/sglang (from)
- https://github.com/guidance-ai/guidance (from)
- https://github.com/eth-sri/lmql (from)
- https://python.langchain.com/v0.1/docs/modules/model_io/output_parsers/types/pydantic/ (from)
- https://github.com/ggerganov/llama.cpp/blob/master/grammars/README.md (from)
Dimanche 7 juillet 2024
Journal du dimanche 07 juillet 2024 à 15:59
#iteration sur le Projet 10 - "Mettre en oeuvre DotTXT AI".
16:00
#JeLis Coding For Structured Generation with LLMs
For those new to the blog: structured generation using Outlines (and soon .txt's products!) (from)
Je comprends que https://github.com/outlines-dev/outlines est simplement le repository du futur produit dottxt.
Je pense comprendre que structured generation est le nom officiel de l'objectif de l'outil dottxt.
16:23
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
16:31
#JeMeDemande comment utiliser outlines avec Replicate.com 🤔.
Je pense avoir ma réponse ici.
16:47
#JaiPosté How to use outlines with Replicate.com?
J'ai aussi posé la question sur https://replicate.com/support
Journal du dimanche 07 juillet 2024 à 15:11
L'année dernière, j'ai publié poc-api-gpt-generate-demo-datas, dont le but était de générer du contenu fictif pour un blog avec l'API de OpenAI.
J'étais moyennement satisfait du résultat, en particulier au niveau de la définition des contraintes de rendu : un fichier JSON.
Aujourd'hui, j'aimerais essayer de générer du contenu fictif d'un knowlege management system, créé par Obsidian, que j'aimerais utiliser pour le projet obsidian-vault-to-apache-age-poc.
Pour réaliser ce projet, j'aimerais essayer de mettre en œuvre :
- Outlines et/ou DotTXT AI (mentionné dans la note du 2024-06-06_1047)
- Replicate.com
Je viens de créer le Projet 10.
Samedi 6 juillet 2024
Journal du samedi 06 juillet 2024 à 15:15
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, 2024-06-23_1057 et 2024-06-23_2222.
Pour le projet obsidian-vault-to-apache-age-poc je souhaite créer une image Docker qui intègre les extensions pg_search et Apache Age à une image PostgreSQL.
Pour réaliser cela, je vais me baser sur ce travail préliminaire https://github.com/stephane-klein/pg_search_docker.
#JaiDécidé de créer un repository GitHub nommé apache-age-docker, qui contiendra un Dockerfile pour builder une image Docker PostgreSQL 16 qui intègre la release "Release v1.5.0 for PG16" de l'extension Postgres Apage Age.
Journal du samedi 06 juillet 2024 à 11:16
Je pense avoir terminé le projet Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Merci à Alexandre pour ses commits de GitHub Actions CI/CD et du support multi architectures publié sur Docker Hub : # stephaneklein/restic-pg_dump.
Je suis assez satisfait du résultat. Le projet a été réalisé avec soin et j'ai tenté de le simplifier au maximum.
Il reste cependant une dernière possibilité de simplification à implémenter : Suggestion : Remplacer Supercronic par Cronie.
Bilan du temps passé sur le Projet 7 :
- 8 sessions de travail entre le 5 juin et le 6 juillet 2024 ;
- Pour un total de 10h16.
Vendredi 5 juillet 2024
Jeudi 4 juillet 2024
Journal du jeudi 04 juillet 2024 à 22:27
#JeLis la section Example: Decorations de CodeMirror qui je pense me sera très utile pour Projet 8.
#JaiDécouvert ici MatchDecorator. Je pense devoir utiliser MatchDecorator pour implémenter Projet 8.
#JaiDécouvert l'article [Learning CodeMirror] que #JeSouhaite lire.
L'implémentation dans SilverBullet.mb de la fonctionnalité décrite dans Projet 8 se trouve ici.
Journal du jeudi 04 juillet 2024 à 15:44
Dans le cadre du projet Projet 8, je suis en train de lire la section "Guide" de la documentation CodeMirror. Je suis impressionné par le niveau de perfectionnement de ce projet.
Mardi 2 juillet 2024
Lundi 1 juillet 2024
Journal du lundi 01 juillet 2024 à 14:38
J'ai publié la première version d'un modèle de contrat freelance : Contrat cadre Freelance de Stéphane Klein (https://github.com/stephane-klein/contrats-freelance-sklein)
Samedi 29 juin 2024
Journal du samedi 29 juin 2024 à 23:31
#JaiDécouvert un nouveau Wayland Window Manager, nommé Niri d'un type particulier, c'est un scrollable-tiling Window Manager.
Journal du samedi 29 juin 2024 à 11:22
#JaiDécouvert https://rustdesk.com/ une solution alternative à TeamViewer.
J'ai décidé de tester RustDesk :
- J'ai installé avec succès RustDesk sous MacOS : https://rustdesk.com/docs/en/client/mac/
- J'ai installé RustDesk sous Fedora en installant directement le fichier Flatpak téléchargeable sur https://github.com/rustdesk/rustdesk/releases/tag/1.2.6
- J'ai vérifié, au moment où j'écris ces lignes, RustDesk ne semble pas disponible sur https://flathub.org/apps/search?q=rustdesk
- J'ai trouvé un Thread à ce sujet https://discourse.flathub.org/t/remote-desktop-control-rustdesk/2605/5
J'ai testé un accès via RustDesk depuis mon laptop Fedora vers un MacbookAir, via un réseau externe — j'ai utilisé ma connexion 4G — et cela a parfaitement fonctionné.
J'ai pu configurer un mot de passe permanent sur l'instance du MacbookAir, ainsi que le démarrage automatique RustDesk.
Tout semble parfait pour le moment.
Je constate que ce projet a démarré en septembre 2020.
J'ai installé et utilisé avec succès RustDesk pour contrôler un Desktop Windows à distance ainsi qu'un Smartphone Android à distance.
Journal du samedi 29 juin 2024 à 11:13
#JaiLu l'article intitulé Why the next GNOME Release will be one of the Best Ever.
Je pense que cet article offre une excellente vue d'ensemble des améliorations apportées à GNOME.
Vendredi 28 juin 2024
Journal du vendredi 28 juin 2024 à 17:07
#JaiDécouvert ce service en ligne pour payer des personne partout dans le monde https://www.deel.com/
Deel helps tens of thousands of companies expand globally with unmatched speed, flexibility and compliance. Get our all-in-one Global People Platform that simplifies the way you onboard, offboard, and everything else in between.
Ici je découvre des services alternatifs :
Mercredi 26 juin 2024
Journal du mercredi 26 juin 2024 à 13:31
Au mois de janvier 2024, #JaiDécouvert Slivev un outil alternatif à Reveal.js.
Presentation slides for developers 🧑💻👩💻👨💻
Lundi 24 juin 2024
Journal du lundi 24 juin 2024 à 11:56
#OnMaPartagé cette Étude de UFC-Que Choisir : Dark Pattens Dans l'E-Commerce. - Les interfaces trompeuses sur les places de marché en ligne.
Je ne l'ai pas encore lu, mais le sujet des dark pattern m'intéresse beaucoup.
#JaimeraisUnJour prendre le temps de lire l'intégralité de cette étude.
Dimanche 23 juin 2024
Journal du dimanche 23 juin 2024 à 22:22
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211 et 2024-06-23_1057.
#JaiCompris en lisant ceci que pg_search se nommait apparavant pg_bm25.
#JaiDécouvert que Tantivy — lib sur laquelle est construit pg_search — et Apache Lucene utilisent l'algorithme de scoring nommé BM25.
Okapi BM25 est une méthode de pondération utilisée en recherche d'information. Elle est une application du modèle probabiliste de pertinence, proposé en 1976 par Robertson et Jones. (from)
Je suis impressionné qu'en 2024, l'algorithme qui je pense est le plus performant utilisé dans les moteurs de recherche ait été mis au point en 1976 😮.
#JaiDécouvert pgfaceting - Faceted query acceleration for PostgreSQL using roaring bitmaps .
J'ai finallement réussi à installer pg_search à l'image Docker postgres:16 : https://github.com/stephane-klein/pg_search_docker.
J'ai passé 3h pour réaliser cette image Docker, je trouve que c'est beaucoup trop 🫣.
Journal du dimanche 23 juin 2024 à 11:20
#JaiDécouvert l'extension PostgreSQL : https://github.com/sraoss/pg_ivm (from)
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
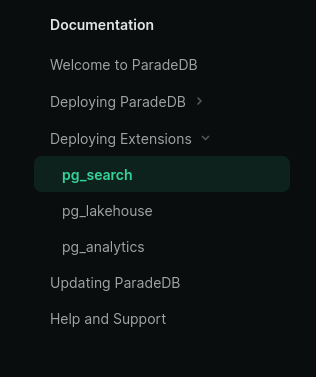
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Jeudi 20 juin 2024
Journal du jeudi 20 juin 2024 à 22:11
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans cette version du 20 juin j'ai implémenté :
- Importation des fichiers dans des nodes de type
notesdans un graph. - Le contenu des notes dans une table
public.notes - Les aliases dans la table
public.note_aliases - Importation des tags et leurs liaisons vers les notes dans un graph.
Au stade où j'en suis, je suis encore loin d'être en capacité de juger si le moteur de graph — Age — me sera utile ou non pour réaliser des requêtes simplement 🤔.
Prochaine fonctionnalités que je souhaite implémenter dans ce projet :
- [ ] Recherche de type fuzzy search sur les
Note.title,aliasetTag.namebasé sur la méthode Levenshtein du module fuzzystrmatch - [ ] Recherche plain text sur le contenu des Notes basé sur pg_search
Dans la liste des features de pg_search je lis :
- Autocomplete
- Fuzzy search
Je pense donc intégrer pg_search avant fuzzystrmatch. Peut-être que je n'aurais pas besoin d'utiliser fuzzystrmatch.
Journal du jeudi 20 juin 2024 à 18:36
Je ne sais pas quoi en pensé Argos Panoptès : la supervision de sites web simple et efficace - LinuxFr.org 🤔.
Journal du jeudi 20 juin 2024 à 00:14
#JaiLu Ask HN: Why do message queue-based architectures seem less popular now? | Hacker News.
Je trouve la question très intéressante.
Ce commentaire m'a bien fait rire :
Going to give the unpopular answer. Queues, Streams and Pub/Sub are poorly understood concepts by most engineers. They don't know when they need them, don't know how to use them properly and choose to use them for the wrong things. I still work with all of the above (SQS/SNS/RabbitMQ/Kafka/Google Pub/Sub).
I work at a company that only hires the best and brightest engineers from the top 3-4 schools in North America and for almost every engineer here this is their first job.
My engineers have done crazy things like:
- Try to queue up tens of thousands of 100mb messages in RabbitMQ instantaneously and wonder why it blows up.
- Send significantly oversized messages in RabbitMQ in general despite all of the warnings saying not to do this
- Start new projects in 2024 on the latest RabbitMQ version and try to use classic queues
- Creating quorum queues without replication policies or doing literally anything to make them HA.
- Expose clusters on the internet with the admin user being guest/guest.
- The most senior architect in the org declared a new architecture pattern, held an organization-wide meeting and demo to extol the new virtues/pattern of ... sticking messages into a queue and then creating a backchannel so that a second consumer could process those queued messages on demand, out of order (and making it no longer a queue). And nobody except me said "why are you putting messages that you need to process out of order into a queue?"...and the 'pattern' caught on!
- Use Kafka as a basic message queue
- Send data from a central datacenter to globally distributed datacenters with a global lock on the object and all operations on it until each target DC confirms it has received the updated object. Insist that this process is asynchronous, because the data was sent with AJAX requests.
As it turns out, people don't really need to do all that great of a job and we still get by. So tools get misused, overused and underused.
In the places where it's being used well, you probably just don't hear about it.
Edit: I forgot to list something significant. There's over 30 microservices in our org to every 1 engineer. Please kill me. I would literally rather Kurt Cobain myself than work at another organization that has thousands of microservices in a gigantic monorepo.
Mercredi 19 juin 2024
Journal du mercredi 19 juin 2024 à 10:56
Voici une liste de plateformes qui hébergent des publications scientiques dans le domaine des sciences socales :
En faisant cette recherche, #JaiDécouvert cette page Wikipedia : List of academic databases and search engines.
Mardi 18 juin 2024
Journal du mardi 18 juin 2024 à 22:09
#JaiDécouvert ici que le Le Parti radical est le premier partie politique qui a été fondé en France.
Journal du mardi 18 juin 2024 à 18:12
J'essaie de mettre de l'ordre dans ma configuration eslint et pour cela, j'essaie de migrer de l'ancien format de fichier de configuration .eslint.config.js vers le nouveau.
Le nouveau format de configuration est nommé "Flat Config" et l'ancien "Legacy Config".
Mon constat après avoir travaillé une demi-heure sur le sujet : je pense que je suis tombé dans un Yak! 🤣.
Pour le moment, j'ai l'impression que tout change. Pour arriver à effectuer la migration, je repars de zéro. J'ajoute un paramètre après l'autre afin d'avoir un truc fonctionnel et d'y comprendre quelque chose 🤷♂️.
"env": {
browser: true,
node: true,
es6: true,
es2020: true
}
semble être remplacer par des imports de https://github.com/sindresorhus/globals :
import globals from "globals";
export default [
{
languageOptions: {
ecmaVersion: 2022,
sourceType: "module",
globals: {
...globals.browser,
}
}
}
];
linebreak-style est déprécié, cette règle est déplacé dans le package ESLint Stylistic.
Je n'ai pas besoin de convertir la règle suivante :
linebreak-style: [error, unix]
étant donné qu'elle est activée par défaut.
#JeLis https://eslint.style/guide/why
With stylistic rules in ESLint, we are able to achieve similar formatting compatibility while retaining the original code style that reflects the authors/teams' intentions, and apply fixes in one go.
et je comprends que eslint semble pouvoir remplacer Prettier.
J'observe que eslint-stylistic est un nouveau projet qui date de septembre 2023.
Journal du mardi 18 juin 2024 à 17:39
J'utilise encore eslint 8.57.0 et non pas la version 9 et #JaiDécidé d'arrêter d'utiliser le format #YAML (.eslintrc.yaml) pour configurer eslint pour les raisons suivantes :
- eslint version 9 ne supporte le format #YAML .
- Je souhaite utiliser le fichier
svelte.config.jsdans la configuration eslint et cela n'est possible qu'avec le formateslint.config.js.
[ << Notes plus récentes (851) ] | [ Notes plus anciennes (208) >> ]