
PostgreSQL
Quelques notes au sujet de PostgreSQL :
Journaux liées à cette note :
J'ai découvert Adminer, alternative à PhpMyAdmin et je me suis intéressé à OPCache
En travaillant sur un playground d'étude de Podman Quadlets, dans le README.md de l'image Docker mariadb, #JaiDécouvert le projet Adminer (https://www.adminer.org) qui semble être l'équivalent de PhpMyAdmin, mais sous la forme d'un fichier unique.
Je découvre aussi que contrairement à PhpMyAdmin, Adminer n'est pas limité à Mysql / MariaDB, il supporte aussi PostgreSQL.
En regardant le dépôt GitHub d'Adminer, je découvre que le gros fichier PHP de 496 kB est le résultat de la concaténation de nombreux fichiers php.
Ça me rassure, parce que je me demandais comment l'édition d'un fichier unique de cette taille pouvait être humainement gérable.
Je trouve astucieux ce mode de déploiement d'un projet PHP sous forme d'un seul fichier qui me fait penser à la méthode Golang. Cependant, je me pose des questions sur la performance de cette technique étant donné que PHP fonctionne en mode process-per request (CGI), ce qui signifie que ce gros fichier PHP est interprété à chaque action sur la page 🤔.
En creusant un peu le sujet avec Claude Sonnet 4.5, je découvre que depuis la version 5.5 de PHP, OPCache améliore significativement la vitesse des requêtes PHP, sans pour autant atteindre celle de Golang, NodeJS, Python ou Ruby qui utilisent des serveurs HTTP intégrés. La consommation mémoire reste supérieure dans des conditions d'implémentation comparables.
Avec OPCache, Adminer semble rester performant malgré l'utilisation d'un fichier unique.
Première description du gestionnaire de projet de mes rêves
Introduction
Cela fait depuis 2022 que je souhaite prototyper un outil de gestion de tâches (issues) avec certaines fonctionnalités que je n'ai trouvées dans aucun outils Open source ou closed-source.
En novembre 2022, j'ai commencé le tout début d'un modèle de données PostgreSQL, mais je n'ai pas continué.
Je souhaite, dans cette note, présenter mon idée de prototype, présenter les fonctionnalités que j'aimerais implémenter.
Nom du projet : Projet 24 - Prototyper le gestionnaire de projet de mes rêves
Ces idées de fonctionnalité sont tirées de besoin personnel que j'ai rencontré depuis 2018, dans mes différents projets professionnel en équipe.
Pour réduire mon temps de rédaction de cette note et la publier au plus tôt, je ne souhaite pas détailler ici l'origine de ces besoins.
Je souhaite juste décrire quelques fonctionnalités que je souhaite et quelque détail technique sans expliquer l'origine de mon besoin.
Sources d'inspiration
Mes principales sources d'inspiration :
- Certaines fonctionnalités issues et projects de GitHub et ses dernières améliorations.
- Certaines fonctionnalités Plan and track work de GitLab.
- Certaines fonctionnalités de Basecamp, par exemple, j'adore les Hill Charts (https://basecamp.com/hill-charts).
- Certaines fonctionnalités de Linear.
- Certaines fonctionnalités de OpenProject
Je me projette d'utiliser Projet 24 dans les framework de gestion de projets suivants :
Ainsi qu'avec la technologie sociale Sociocratie 3.0.
Liste de fonctionnalités en vrac
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
- Permettre d'attribuer à une issue une estimation basse et haute de temps d'implémentation.
- Permettre d'activer un Hill Charts sur toute issue.
- Permettre d'indiquer un niveau d'approximation d'une issue
- Permettre aux lectures d'une issue d'indiquer leur niveau de compréhension de l'issue
- Permettre de configurer la taille maximum en mots d'une issue. Pour forcer un certain niveau de synthèse.
- Permettre de calculer le poids d'une issue en faisant la somme basse et haute de toutes ses dépendances.
- Système inspiré de Tinder pour prioriser les issues. L'application présente deux issues choisies selon un algorithme Elo et invite l'utilisateur à désigner celle qu'il considère comme prioritaire.
- Implémenter un système de tags d'issues personnalisés où chaque utilisateur peut créer ses propres étiquettes. La visibilité de ces tags serait configurable : mode privé pour un usage personnel ou mode partagé pour les rendre disponibles aux autres utilisateurs.
- Permettre de créer des portfolios d'issue par utilisateurs.
- Pas de séparation des entités Epic (gestion de projet logiciel) / Issue contrairement à ce que fait GitLab.
- Permettre d'utilisation d'une extension Browser pour enrichir les pages GitHub, GitLab, Linear ou Forgejo avec les fonctionnalités de Projet 24.
- Permettre au Projet 24 d'améliorer une instance privé Forgejo avec un wrapper HTTP.
- Système de dashboard pratiquement identique à GitHub projects.
- Système de commentaire comme GitHub, mais avec un système de thread.
- Support de wikilink et alias au niveau de toutes les ressources texte.
- Support d'une fonctionnalité de publication de notes éphémères attachées à chaque utilisateur.
- Permettre la création d'issues ou de notes "flottantes". Une issue "flottante" n'appartient à aucune ressource spécifique — elle n'est rattachée ni à un projet, ni à un groupe. Cette fonctionnalité me semble essentielle et je compte la détailler dans une note dédiée prochainement.
- Proposer une extension Browser qui détecte automatiquement les issues liées à l'URL de la page actuelle. Cela permettrait d'accéder rapidement aux issues ou notes "flottantes" selon le contexte de navigation.
- Très bon support Markdown, contrairement aux implémentations de Slack, Notion ou Linear. Il devrait être possible de basculer entre le mode d'édition riche et le mode markdown. Le contenu copié doit générer du markdown valide dans le presse-papier.
- Respect strict des conventions Web : permettre l'ouverture de toutes les pages dans un nouvel onglet, etc.
- Mettre l'accent sur la performance de rendu des pages. Implémenter en priorité un système de métriques pour mesurer les temps de rendu.
- Proposer un système de génération de titre d'issue et de tag basé sur un LLM.
- Mettre en place un système qui utilise un LLM pour proposer automatiquement des titres d'issues et des tags.
- Alimenter une base de données vectorielle avec les descriptions d'issues et leurs commentaires pour activer la recherche sémantique.
Expérience utilisateur
Comme SilverBullet.mb, un outil fait dans un premier temps pour les hackers.
Détails techniques
- Stockage dans Elasticsearch pour faciliter les recherches par tags et plain text.
- Utilisation de nanoid de 5 caractères pour identifier les issues.
- Utilisation de Git hook pre-receive côté serveur pour importer des données (issues, notes, etc)
Idée d'application de réécriture de texte assistée par IA
En travaillant sur mon prompt de reformulation de paragraphes pour mon notes.sklein.xyz, j'ai réalisé que l'expérience utilisateur des chat IA ne semble pas optimale pour ce type d'activité.
Voici quelques idées #idée pour une application dédiée à cet usage :
- Utilisation de deux niveaux de prompt :
- Un niveau général sur le style personnel
- Un niveau spécifique à l'objectif particulier
- Interface à deux zones texte :
- Une zone repliée par défaut contenant le ou les prompts
- Une seconde zone pour le texte à modifier
- Sélection de mots alternatifs comme dans DeepL : une fois qu'un mot de remplacement est choisi, le reste de la phrase s'adapte automatiquement en conservant au maximum la structure originale.
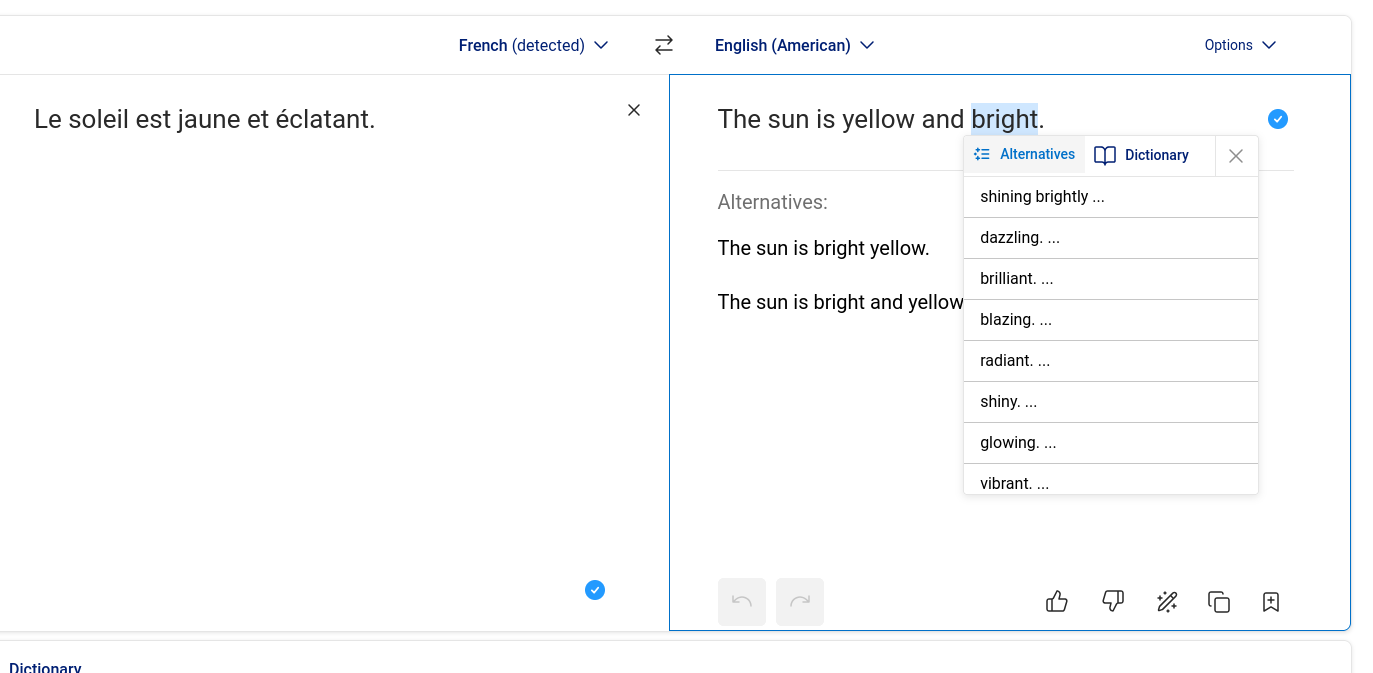
- Sélection flexible : permettre de sélectionner non seulement un mot isolé, mais aussi plusieurs mots consécutifs ou des paragraphes entiers.
- Support parfait du markdown.
À ce jour, je n'ai pas croisé d'application de ce type, #JaimeraisUnJour investir plus de temps pour approfondir cette recherche.
Quelques idées pour implémenter cette application :
- Connecté à OpenRouter
- Utilisation de Svelte, SvelteKit, ProseMirror, PostgreSQL, bits-ui
- Utilisation de la fonctionnalité Structured Outputs (LLM) (https://platform.openai.com/docs/guides/structured-outputs)
Journal du vendredi 18 avril 2025 à 11:40
Cela fait des années que je m'intéresse au sujet des solutions de sauvegarde en continu de bases de données PostgreSQL.
Dans cette note, le terme "sauvegarde en continu" ne signifie pas Point In Time Recovery.
Jusqu'à présent, je me suis toujours concentré sur la méthode "mainstream", qui consiste principalement à effectuer un backup binaire couplé avec une sauvegarde continue du WAL. Par exemple des solutions basées sur pg_basebackup, pgBackRest ou barman.
Une autre solution consiste à déployer une seconde instance PostgreSQL en mode streaming replication.
Une troisième solution que #JaimeraisUnJour tester : mettre en place une sauvegarde incrémentale basée sur le filesystème btrfs.
Plus précisément, la commande btrfs-send. La documentation de Dalibo mentionne cette méthode de sauvegarde.
Samedi dernier, j'ai imaginé une autre méthode qui me plait beaucoup par sa relative flexibilité et sa simplicité.
Elle consisterait à sauvegarder des tables de manière granulaire à intervalle de temps régulier vers un Object Storage à l'aide d'un Foreign Data Wrapper.
Pour cela, j'ai identifié parquet_s3_fdw, basé sur le format Apache Parquet qui permet de lire et d'écrire des données sur un bucket Object Storage.
Features
- Support SELECT of parquet file on local file system or Amazon S3.
- Support INSERT, DELETE, UPDATE (Foreign modification).
- Support MinIO access instead of Amazon S3.
J'ai utilisé de nombreuses fois Foreign Data Wrapper pour copier de manière granulaire des données entre deux bases de données PostgreSQL.
J'ai trouvé cette méthode très pratique, en particulier la possibilité de pouvoir utiliser un "pattern" SQL de copie du type :
INSERT INTO clients_local (id, nom, email, date_derniere_maj)
SELECT
d.client_id,
d.nom_client,
d.email_client,
CURRENT_TIMESTAMP
FROM
distant.clients_distant d
WHERE
d.date_modification > (SELECT MAX(date_derniere_maj) FROM clients_local)
ON CONFLICT (id) DO UPDATE
SET
nom = EXCLUDED.nom,
email = EXCLUDED.email,
date_derniere_maj = EXCLUDED.date_derniere_maj;
#JaimeraisUnJour réaliser un POC de cette idée basée sur parquet_s3_fdw.
Journal du vendredi 18 avril 2025 à 10:31
Il existe deux familles de méthodes de backup d'une base de données PostgreSQL :
- Backup logique
- Backup binaire à "chaud et à froid"
Voici une présentation simplifiée des différences entre ces deux modes de sauvegarde, qui peut comporter certaines imprécisions dues à cette vulgarisation.
Un backup logique est effectué par pg_dump sur une instance PostgreSQL en cours d'exécution (nommée "à chaud"). pg_dump supporte plusieurs formats d'archivage dont plain et custom.
Le format plain génère un fichier SQL classique, lisible "humainement".
Le format custom génère un fichier binaire, qui est plus flexible et a une taille bien plus réduite que le format plain. Il est toujours possible de générer un fichier SQL comme plain à partir d'un fichier custom : avec la commande pg_restore -f output.sql fichier_custom.
Il est possible de réaliser des sauvegardes et restaurations à "distance", via le protocole classique PostgreSQL Frontend Backend Protocol.
Il est possible d'importer un backup logique vers une instance PostgreSQL de version différente, en général plus récente.
Un backup binaire peut être effectué à "chaud" ou à "froid". En simplifiant, cela consiste à sauvegarder les fichiers PostgreSQL du filesystem et optionnellement sauvegarder aussi les journaux (WAL) de PostgreSQL. Pour effectuer un backup binaire, il existe la commande officielle pg_basebackup, mais aussi d'autres solutions plus complètes, comme pgBackRest ou barman.
Les systèmes de backup binaire de PostgreSQL ont l'avantage de pouvoir restaurer une sauvegarde à un point précis dans le temps (fonctionnalité PITR).
Je constate que la mise en place d'un backup binaire est plus complexe à mettre en place qu'un backup logique.
Voici mon POC le plus avancé concernant les backup binaire : poc-pg_basebackup_incremental.
Actuellement, pour sauvegarder des instances PostgreSQL, j'utilise pg_back-docker-sidecar qui est une solution de backup logique, basé sur pg_back, déployé sous la forme d'un Docker sidecar.
J'envisage aussi d'expérimenter une méthode basée sur parquet_s3_fdw que j'ai décrite dans 2025-04-18_1140.
Pour des informations plus approfondies à propos de ces sujets, je vous conseille la documentation de ces formations de Dalibo :
Journal du jeudi 17 avril 2025 à 12:02
Alexandre m'a partagé le projet Postgres Operator, que j'avais peut-être croisé par le passé, mais que j'avais oublié.
Postgres Operator permet entre autres de déployer des instances PostgreSQL dans un cluster Kubernetes mais aussi de mettre en place des systèmes de backup logique et backup binaire.
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.
En attendant de trouver un repository Mise pour PostgreSQL Client Applications
À ce jour, je n'ai pas trouvé de repository Mise ou Asdf pour installer les "Client Applications" de PostgreSQL, par exemple : psql, pg_dump, pg_restore.
Il existe asdf-postgres, mais ce projet me pose quelques problèmes :
- L'installation basée sur le code source de PostgreSQL avec une phase de compilation qui peut être longue et consommer beaucoup d'espace disque.
- L'intégralité de PostgreSQL est installée alors que je n'ai besoin que des "Client Applications".
#JaimeraisUnJour créer une repository Mise ou Asdf qui permet d'installer les "Client Applications" en mode binaire. Pour le moment, je n'ai aucune idée sur quels binaires me baser 🤔.
En attendant de créer ou de trouver ce repository, voici ci-dessous mes méthodes actuelles d'installation des "PostgreSQL Client Applications".
Sous MacOS
Sous MacOS, j'utilise Brew pour installer le package libpq qui contient les "PostgreSQL Client Applications".
$ brew install libpq
ou alors pour l'installation d'une version spécifique :
$ brew install libpq@17.4
Sous Fedora
Sous Fedora, j'installe le package PostgreSQL client proposé sur la page "Downloads" officielle de PostgreSQL.
Cette méthode me permet d'installer précisément une version majeure précise de PostgreSQL :
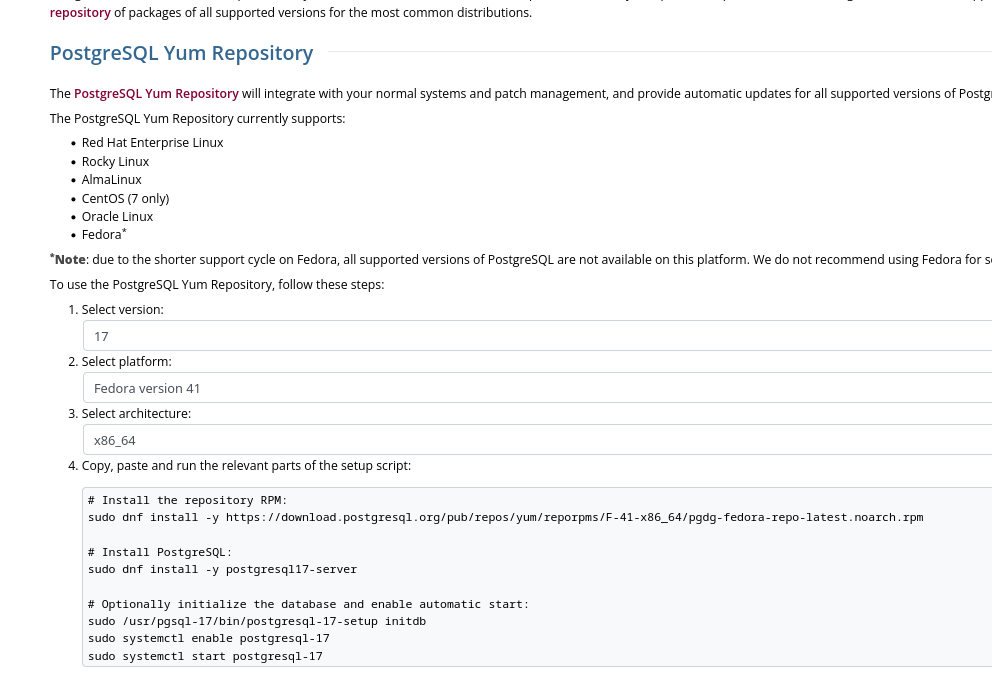
Voici les instructions pour installer la dernière version de PostgreSQL 17 sous Fedora 41 :
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/F-41-x86_64/pgdg-fedora-repo-latest.noarch.rpm
$ sudo rpm --import https://download.postgresql.org/pub/repos/yum/keys/PGDG-RPM-GPG-KEY-Fedora
$ sudo dnf update -y
Le package nommé postgresql17 contient uniquement les "PostgreSQL Client Applications" :
$ dnf info postgresql17
Mise à jour et chargement des dépôts :
Dépôts chargés.
Paquets installés
Nom : postgresql17
Epoch : 0
Version : 17.4
Version : 1PGDG.f41
Architecture : x86_64
Taille une fois installé : 10.7 MiB
Source : postgresql17-17.4-1PGDG.f41.src.rpm
Dépôt d'origine : pgdg17
Résumé : PostgreSQL client programs and libraries
URL : https://www.postgresql.org/
Licence : PostgreSQL
Description : PostgreSQL is an advanced Object-Relational database management system (DBMS).
: The base postgresql package contains the client programs that you'll need to
: access a PostgreSQL DBMS server. These client programs can be located on the
: same machine as the PostgreSQL server, or on a remote machine that accesses a
: PostgreSQL server over a network connection. The PostgreSQL server can be found
: in the postgresql17-server sub-package.
:
: If you want to manipulate a PostgreSQL database on a local or remote PostgreSQL
: server, you need this package. You also need to install this package
: if you're installing the postgresql17-server package.
Fournisseur : PostgreSQL Global Development Group
$ dnf repoquery -l postgresql17 | grep "/bin"
Mise à jour et chargement des dépôts :
Dépôts chargés.
/usr/pgsql-17/bin/clusterdb
/usr/pgsql-17/bin/createdb
/usr/pgsql-17/bin/createuser
/usr/pgsql-17/bin/dropdb
/usr/pgsql-17/bin/dropuser
/usr/pgsql-17/bin/pg_basebackup
/usr/pgsql-17/bin/pg_combinebackup
/usr/pgsql-17/bin/pg_config
/usr/pgsql-17/bin/pg_createsubscriber
/usr/pgsql-17/bin/pg_dump
/usr/pgsql-17/bin/pg_dumpall
/usr/pgsql-17/bin/pg_isready
/usr/pgsql-17/bin/pg_receivewal
/usr/pgsql-17/bin/pg_restore
/usr/pgsql-17/bin/pg_waldump
/usr/pgsql-17/bin/pg_walsummary
/usr/pgsql-17/bin/pgbench
/usr/pgsql-17/bin/psql
/usr/pgsql-17/bin/reindexdb
/usr/pgsql-17/bin/vacuumdb
Installation de ce package :
$ sudo dnf install postgresql17
$ psql --version
psql (PostgreSQL) 17.4
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Journal du vendredi 21 mars 2025 à 15:15
Note de type #mémento pour calculer la taille des tables PostgreSQL.
Commande pour calculer la taille de la base de données entière :
postgres=# select pg_size_pretty(pg_database_size('postgres'));
pg_size_pretty
----------------
74 GB
Commande pour voir les détails table par table :
SELECT
nspname AS "schema",
pg_class.relname AS "table",
pg_size_pretty(pg_total_relation_size(pg_class.oid)) AS "total_size",
pg_size_pretty(pg_relation_size(pg_class.oid)) AS "data_size",
pg_size_pretty(pg_indexes_size(pg_class.oid)) AS "index_size",
pg_stat_user_tables.n_live_tup AS "rows",
pg_size_pretty(
pg_total_relation_size(pg_class.oid) /
(pg_stat_user_tables.n_live_tup + 1)
) AS "total_row_size",
pg_size_pretty(
pg_relation_size(pg_class.oid) /
(pg_stat_user_tables.n_live_tup + 1)
) AS "row_size"
FROM
pg_stat_user_tables
JOIN
pg_class
ON
pg_stat_user_tables.relid = pg_class.oid
JOIN
pg_catalog.pg_namespace AS ns
ON
pg_class.relnamespace = ns.oid
ORDER BY
pg_total_relation_size(pg_class.oid) DESC;
schema | table | total_size | data_size | index_size | rows | total_row_size | row_size
--------+-----------------+------------+------------+------------+---------+----------------+------------
public | table1 | 72 GB | 1616 MB | 1039 MB | 7456403 | 10 kB | 227 bytes
public | table2 | 1153 MB | 754 MB | 399 MB | 2747998 | 440 bytes | 287 bytes
public | table3 | 370 MB | 8192 bytes | 47 MB | 8 | 41 MB | 910 bytes
public | table4 | 232 kB | 136 kB | 56 kB | 422 | 561 bytes | 329 bytes
(7 rows)