
workstation
Journaux liées à cette note :
Via Claude Sonnet 4.5, j'ai découvert l'existance des projets croc et Magic Wormhole.
Ces deux projets permettent de partager des fichiers entre deux machines.
Voici un tableau comparatif :
Caractéristique Magic Wormhole croc Langage Python Go (plus rapide) Reprise transfert ❌ ✅ Multi-fichiers ❌ (un par un) ✅ Vitesse Bon Meilleur Maturité Plus ancien, stable Plus récent, actif Stdin/stdout ✅ Excellent ✅ Bon
J'ai décidé de tester croc.
Sur ma workstation Fedora, j'ai lancé :
$ sudo dnf install -y croc
$ croc --version
croc version v9.6.4-1fce28e
$ croc send --text "Foobar"
Sending 'text' (6 B)
Code is: 8834-lady-protect-senator
On the other computer run
croc 8834-lady-protect-senator
Sur une seconde machine :
$ croc --yes 8834-lady-protect-senator
Receiving text message (6 B)
Receiving (<-192.168.1.108:9009)
Foobar
Ça fonctionne bien, je garde cet outil dans ma boîte à outils 🙂.
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "Support OCI de CoreOS (image pull & updates)".
Colin Walters, le principal développeur de libostree a initié le projet bootc en mars 2021. J'ai découvert le projet bootc en début d'année et lisant des articles liés à systemd.
La vision de bootc est assez simple : rendre la création d'images de système d'exploitation aussi simple que la création d'images de conteneurs d'applications tout en utilisant les mêmes outils. Pour avoir un peu de contexte historique, je conseille l'article lwn de juin 2024 : Making containers bootable for fun and profit
Les images bootc utilisent la même technologie de stockage que les images des container classique : OCI.
D'après ce que j'ai compris, ce type d'image bootc ne porte pas nom officiellle, elles sont nommés aussi bien "bootc image", que "bootable container image" ou "bootable OCI image".
En janvier 2025, Red Hat a transféré le projet bootc à la CNCF. Le but est de permettre à toutes les distributions de l'adopter comme standard, indépendamment de Red Hat.
Parmis les distributions qui ont adopté bootc, trois retiennent mon attention :
- fedora-bootc
- fedora-coreos (mais attention, cette version n'est pas encore prête à être utilisé)
- Bluefin du projet Universal Blue
Au moment où j'écris ces lignes, je pense migrer d'ici quelques mois ma workstation vers une distribution Desktop bootc, probablement Bluefin, qui est déjà disponible, ou Fedora Silverblue, une fois que son support bootc sera finalisé.
J'aurai donc certainement l'occasion de tester en pratique comment créer des images bootc personnalisées.
Voici diverses ressources que j'ai trouvées concernant le support bootc pour Fedora Silverblue :
- Issue dans "Fedora Atomic Desktops / SIG Issue Tracker" :
- Pages dans "Fedora Project Wiki" :
- Section "First step towards Bootable Containers: dnf5 and bootc" dans l'article "What’s new for Fedora Atomic Desktops in Fedora 41"
Je compte aussi tester bootc et tout particulièrement Bluefin dans le cadre de mon "Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora"".
Publication du projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"
Je viens de terminer le "Projet 33 - "POC serveur Git HTTP qui injecte du contenu dans OpenSearch"" en 25h.
Si j'inclus le travail préliminaire du Projet 32 - "POC serveur Git HTTP avec exécution de scripts au push", cela représente 34h au total.
Voici le repository avec le résultat final : https://github.com/stephane-klein/poc-content-repository-git-to-opensearch.
J'ai réussi à implémenter preque tous les éléments que j'avais prévu :
- Un serveur Git HTTP supportant les opérations push et pull
- Après chaque git push, injection automatique des données reçues vers une base de données OpenSearch
- Intégration d'un système de job queue minimaliste qui permet de traiter les tâches d'importation des données Git vers OpenSearch de manière asynchrone. Cela permet entre autres de rendre l'opération git push non bloquante.
- Le modèle de données doit permettre l'accès au contenu de plusieurs branches.
- Upload des fichiers binaires vers un serveur Minio tout concervant leurs metadata (chemin, branche, etc) dans OpenSearch.
- La suppression d'une branche ou d'un commit doit aussi supprimer les données présentes dans OpenSearch et Minio.
- Utilisation de la librairie nodegit.
Le seul élément que je n'ai pas testé est celui-ci :
- L'accès aux données via l'API de OpenSearch ne doit pas être perturbé pendant les phases d'importation de données depuis Git.
Je précise d'emblée que l'implémentation de la fonctionnalité d'exploration web du content repository manque actuellement d'élégance.
Les dossiers suivants contiennent une quantité importante de code dupliqué :
src/routes/[...pathname]/,src/routes/branches/[branch_name]/[...pathname]/- et
src/routes/r/[revision]/[...pathname]/
src/routes
├── branches
│ ├── [branch_name]
│ │ ├── history
│ │ │ ├── +page.server.js
│ │ │ └── +page.svelte
│ │ ├── +page.server.js
│ │ ├── +page.svelte
│ │ └── [...pathname]
│ │ ├── +page.server.js
│ │ └── +page.svelte
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
├── [...pathname]
│ ├── +page.server.js
│ ├── +page.svelte
│ └── raw
│ └── +server.js
└── r
├── +page.server.js
└── [revision]
├── history
│ ├── +page.server.js
│ └── +page.svelte
├── +page.server.js
├── +page.svelte
└── [...pathname]
├── +page.server.js
├── +page.svelte
└── raw
Pour le moment, je n'ai pas encore trouvé comment éviter cette duplication de manière élégante.
J'ai pensé à 3 approches pour améliorer cette implémentation :
- Factoriser la logique de query des fichiers
+page.server.jsdans une fonction partagée. - Migrer complètement ces pages d'exploration vers
src/hooks.server.js(avec les Server hooks de SvelteKit ).
Comme cette partie n'était pas au cœur du projet, j'ai préféré ne pas y investir davantage de temps.
Dans ce projet, j'ai utilisé pour la première fois OpenSearch, le fork de Elasticsearch. J'ai dû faire quelques adaptations par rapport à Elasticsearch mais rien de vraiment complexe.
J'ai utilisé la librairie @opensearch-project/opensearch avec succès, bien aidé par Claude Sonnet 4 pour écrire mes query OpenSearch.
J'aimerais mieux maîtriser l'api de OpenSearch et Elasticsearch, mais je ne les utilise pas suffisamment.
Cette dépendance à un LLM pour écrire ces requêtes me contrarie, je me sens prolétaire et j'ai le sentiment de perdre l'habitude de l'effort. Je pense à cette recherche "Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task" et cela me préoccupe.
J'ai développé un système de job queue minimaliste en NodeJS avec une persistance basée sur des fichiers json simples : src/lib/server/job-queue.js.
Ma recherche avec Claude Sonnet 4 n'a révélé aucune librairie minimaliste existante qui se contente de fichiers pour la persistance.
Cette implémentation me paraît suffisamment robuste pour répondre à l'objectif que je me suis fixé.
J'ai implémenté la fonction importRevision avec nodegit pour parcourir toutes les entrées d'une révision Git du repository et les importer dans OpenSearch.
Claude Sonnet 4 m'a encore été d'une grande aide, me permettant d'éviter de passer trop de temps dans la documentation d'API de NodeGit, qui reste assez minimaliste.
Mon expérience de 2015 avec git2go sur le projet CmsHub avait été nettement plus laborieuse, à l'époque pré-LLM. Cela dit, j'avais quand même réussi. 🙂
L'implémentation du endpoint /src/routes/post_recieve_hook_url/+server.js n'a pas été très difficile.
J'ai réussi à implémenter le support de git push --force sans trop de difficulté.
Qu'est-ce qui t'a amené à choisir OpenSearch pour ce projet, plutôt qu'un autre type de base de données ?
Suite à de multiples expérimentations durant l'été 2024 (voir 2024-08-17_1253 ou Projet 5), j'ai sélectionné Elasticsearch comme moteur de base de données pour sklein-pkm-engine.
La puissance du moteur de query d'Elasticsearch m'a vraiment séduit, comme on peut le voir dans cette implémentation. Ça me paraît beaucoup plus souple que ce que j'avais développé avec postgres-tags-model-poc.
J'ai donc décidé d'explorer les possibilités d'Elasticsearch ou de son fork OpenSearch comme moteur de base de données de content repository. J'ai décidé d'en faire mon option par défaut tant que je ne rencontre pas d'obstacle majeur ou de point bloquant.
La partie où j'ai le plus hésité concerne le choix du modèle de données OpenSearch pour stocker efficacement le versioning Git.
J'ai décidé d'utiliser deux indexes distincts : files et commits :
await client.indices.create({
index: "files",
body: {
mappings: {
properties: {
content: {
type: "text"
},
mimetype: {
type: 'keyword'
},
commits: {
type: 'object',
dynamic: 'true'
}
}
}
}
});
await client.indices.create({
index: "commits",
body: {
mappings: {
properties: {
index: {
type: 'integer'
},
time: {
type: 'date',
format: 'epoch_second'
},
message: {
type: "text"
},
parents: {
type: 'keyword'
},
entries: {
type: 'object',
dynamic: 'true',
},
branches: {
type: 'keyword'
}
}
}
}
});
Après import des données depuis le repository dummy-content-repository-solar-system, voici ce qu'on trouve dans files :
[
{
_index: 'files',
_id: '2f729046cb0f02820226c1183aa04ab20ceb857d',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'mars.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'mars.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '1be731144f49282c43b5e7827bef986a52723a71',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'venus.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'venus.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/index.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/index.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/index.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
_score: 1,
_source: {
commits: {
'4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/lune.md',
a9272695d179e70cca15e89f1632b8fb76112dca: 'terre/lune.md',
d9bffc3da0c91366dda54fefa01383b109554054: 'terre/lune.md'
},
mimetype: 'text/markdown; charset=utf-8'
}
},
{
_index: 'files',
_id: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
_score: 1,
_source: {
commits: { '4da69e469145fe5603e57b9e22889738d066a5e2': 'terre/terre.jpg' },
mimetype: 'image/jpeg'
}
}
]
et voici un exemple de contenu de commits :
[
{
_index: 'commits',
_id: '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa',
_score: 1,
_source: { index: 1, time: 1757420855, branches: [ 'main' ], parents: [] }
},
{
_index: 'commits',
_id: '4da69e469145fe5603e57b9e22889738d066a5e2',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/terre.jpg': {
oid: '97ef5b8f52f85c595bf17fac6cbec856ce80bd4a',
contentType: 'image/jpeg'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 4,
time: 1757429173,
branches: [ 'main' ],
parents: [ 'd9bffc3da0c91366dda54fefa01383b109554054' ]
}
},
{
_index: 'commits',
_id: 'd9bffc3da0c91366dda54fefa01383b109554054',
_score: 1,
_source: {
entries: {
'venus.md': {
oid: '1be731144f49282c43b5e7827bef986a52723a71',
contentType: 'text/markdown; charset=utf-8'
},
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'mars.md': {
oid: '2f729046cb0f02820226c1183aa04ab20ceb857d',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 3,
time: 1757421171,
branches: [ 'main' ],
parents: [ 'a9272695d179e70cca15e89f1632b8fb76112dca' ]
}
},
{
_index: 'commits',
_id: 'a9272695d179e70cca15e89f1632b8fb76112dca',
_score: 1,
_source: {
entries: {
'terre/lune.md': {
oid: '153d9d6e9dfedb253c624c9f25fbdb7d8691a042',
contentType: 'text/markdown; charset=utf-8'
},
'terre/index.md': {
oid: 'ccc921b7a66f18e98f4887189824eefe83c7e0b3',
contentType: 'text/markdown; charset=utf-8'
}
},
index: 2,
time: 1757420956,
branches: [ 'main' ],
parents: [ '7ce2ab6f8d29fec0348342d95bfe71899dcb44fa' ]
}
}
]
Ensuite, je mise beaucoup sur la puissance du moteur de requête d'OpenSearch pour récupérer efficacement les données à afficher.
Voici l'exemple de src/routes/[...pathname]/+page.server.js qui permet d'afficher le contenu d'un fichier de la branche main.
Première requête :
const responseOid = await client().search({
index: 'commits',
body: {
query: {
bool: {
must: [
{
term: {
branches: 'main'
}
},
{
exists: {
field: `entries.${params.pathname}`
}
}
]
}
},
_source: [`entries.${params.pathname}`]
}
});
Seconde requête qui utilise la réponse de la première :
const responseFile = await client().get({
index: 'files',
id: responseOid.body.hits.hits[0]._source.entries[params.pathname].oid,
_source: ['content', 'mimetype']
});
Basé sur l'expérience de ce projet, je souhaite améliorer sklein-pkm-engine pour permettre la mise à jour de notes.sklein.xyz avec mes données locales uniquement via git push, sans avoir besoin d'installer quoi que ce soit sur ma workstation.
Je pense que cette implémentation sera bien plus simple que le Projet 33, car je ne prévois pas d'inclure le support dans un premier temps. Peut-être que je supporterai les branches dans un second temps.
De 2000 à 2016, j'ai essentiellement déployé la distribution Linux Debian sur mes serveurs et après cette date des Ubuntu LTS.
Depuis 2022, j'utilise une Fedora sur ma workstation. Distribution que je maitrise et que j'apprécie de plus en plus.
J'envisage peut-être d'utiliser une distribution de la famille Fedora sur mes serveurs personnels.
J'avais suivi de loin les événements autour de CentOS en décembre 2020 :
- 8 décembre 2020 : CentOS Project shifts focus to CentOS Stream
- 16 décembre 2020 : Rocky Linux: A CentOS replacement by the CentOS founder
J'ai enfin compris l'origine du nom Rocky Linux :
"Thinking back to early CentOS days... My cofounder was Rocky McGaugh. He is no longer with us, so as a H/T to him, who never got to see the success that CentOS came to be, I introduce to you...Rocky Linux"
J'aime beaucoup cet hommage 🤗 !
J'ai étudié AlmaLinux et il me semble que cette distribution est principalement développée par l'entreprise CloudLinux, une entreprise à but lucratif qui vend du support Linux.
Personnellement, je trouve le positionnement d'AlmaLinux peu "fair-play" envers Red Hat : Red Hat investit massivement dans le développement de Red Hat Enterprise Linux et AlmaLinux récupère ce travail gratuitement pour ensuite vendre du support commercial en concurrence directe.
À mon avis, si une entreprise souhaite un vrai support sur une distribution de la famille Red Hat, elle devrait se tourner vers Red Hat Enterprise Linux et acheter du support directement à Red Hat plutôt qu'à CloudLinux.
Suite à ce constat, j'ai décidé d'utiliser Rocky Linux plutôt qu'AlmaLinux.
21h30 : j'ai reçu le message suivant sur Mastodon :
@stephane_klein you have things quite backwards. AlmaLinux is a non-profit foundation while Rocky is owned 100% by Greg kurtzer and they have over $100M in venture capital funding.
AlmaLinux has a community-elected board.
Suite à ce message, j'ai essayé d'en savoir plus, mais il est difficile d'y voir clair.
Par exemple : I’m confused about the different organizational structure when it comes to Rocky and Alma.
La page "AlmaLinux OS Foundation " que j'ai consultée m'a particulièrement plu.
J'ai révisé ma position, j'ai décidé d'utiliser AlmaLinux plutôt que Rocky Linux.
2025-12-02 : j'ai révisé ma position, pour des serveurs de production, j'ai décidé d'utiliser la version stable de CoreOS, plutôt que AlmaLinux ou Rocky Linux.
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.
Journal du vendredi 25 avril 2025 à 18:33
Au mois de janvier, j'ai écrit :
Voici mes prochaines #intentions d'amélioration de ma workstation :
- ...
- Essayer de remplacer les services ChatGPT ou Claude.ai par Open WebUI.
- ...
Le hasard de la vie fait que je commence une mission professionnelle pour la DINUM en lien avec Open WebUI : Ablert Conversation.
Au mois de décembre, j'ai déjà installé et testé rapidement Open WebUI connecté à Scaleway Generative APIs, mais je n'ai pas pris le temps de le faire avec rigueur.
Dans les prochains jours, je souhaite réaliser les projets suivants :
Journal du vendredi 07 février 2025 à 14:03
Pendant l'année 2014, Athoune m'a fait découvrir les concepts DevOps "Baking" et "Frying".
Je le remercie, car ce sont des concepts que je considère très importants pour comprendre les différents paradigmes de déploiement.
Je n'ai aucune idée dans quelles conditions il avait découvert ces concepts. J'ai essayé de faire des recherches limitées à l'année 2014 et je suis tombé sur cette photo :
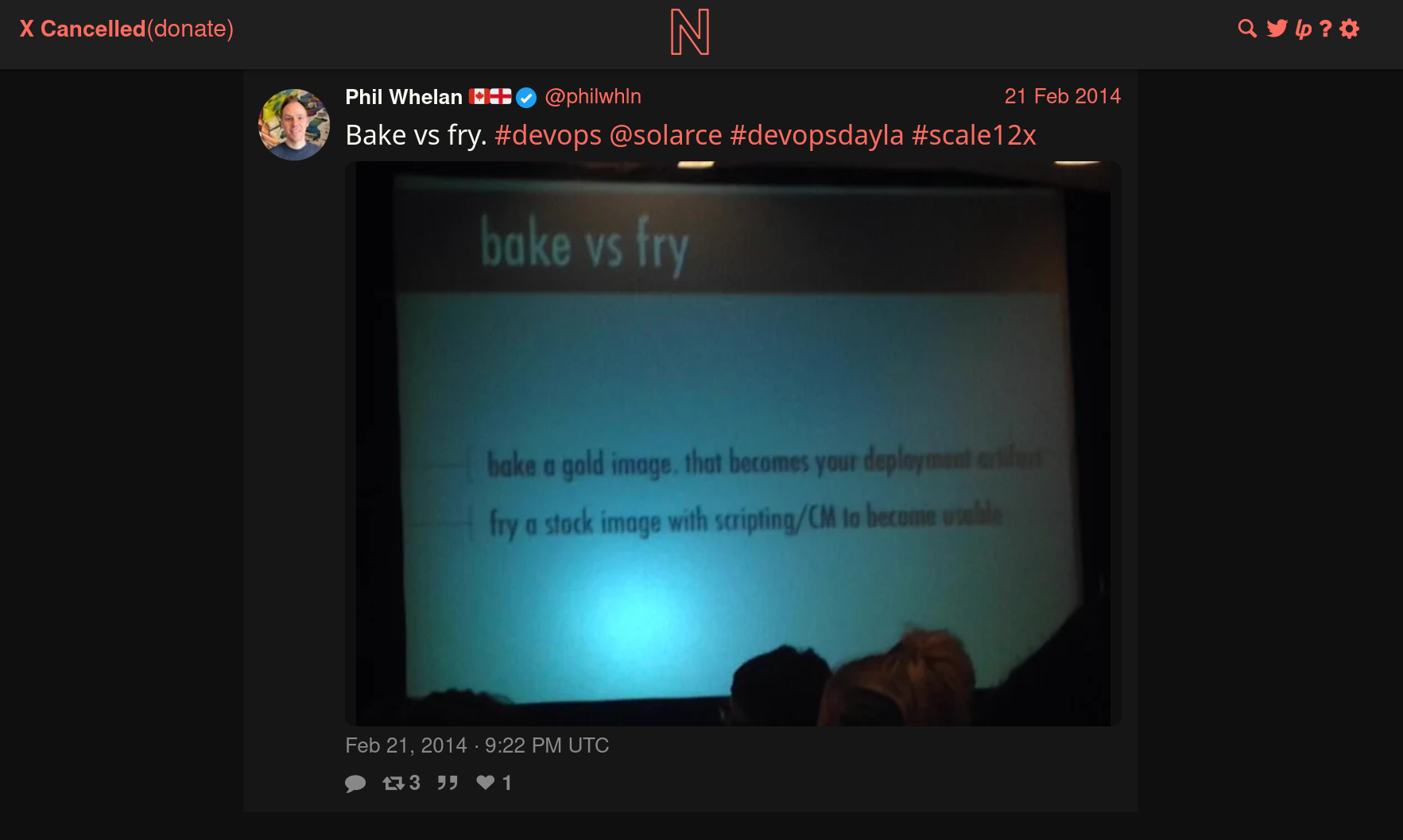
J'en déduis que cela devait être un sujet à la méthode dans l'écosystème DevOps de 2014.
Cet ami me l'avait très bien expliqué avec une analogie du type :
« Le baking en DevOps, c’est comme dans un restaurant où les plats sont préparés en cuisine et ensuite apportés tout prêt salle à la table du client. Le frying, c’est comme si le plat était préparé directement en salle sur la table du client. »
Bien que cette analogie ne soit pas totalement rigoureuse, elle m'a bien permis de saisir, en 2014, le paradigme Docker qui consiste à préparer des images de container en amont. Ce paradigme permet d'installer, de configurer ces images "en cuisine", donc pas sur les serveurs de production, "de goûter les plats" et de les envoyer ensuite de manière prédictible sur le serveur de production.
Ces images peuvent être construites soit sur la workstation du développeur ou mieux, sur des serveurs dédiés à cette fonction, comme Gitlab-Runner…
Définitions proposées par LLaMa :
Baking (ou "Image Baking") : Il s'agit de créer une image de serveur prête à l'emploi, avec tous les logiciels et les configurations nécessaires déjà installés et configurés. Cette image est ensuite utilisée pour déployer de nouveaux serveurs, qui seront ainsi identiques et prêts à fonctionner immédiatement. L'avantage de cette approche est qu'elle permet de réduire le temps de déploiement et d'assurer la cohérence des environnements.
Frying (ou "Server Frying") : Il s'agit de déployer un serveur "nu" et de le configurer et de l'installer à la volée, en utilisant des outils d'automatisation tels que Ansible, Puppet ou Chef. Cette approche permet de personnaliser la configuration de chaque serveur en fonction des besoins spécifiques de l'application ou du service.
Exemple :
Cas d'usage Baking Frying Docker Construire une image complète ( docker build) et la stocker dans un registreLancer un conteneur minimal et installer les dépendances au démarrage. Machines virtuelles (VMs) Créer une image VM avec Packer et la déployer telle quelle Démarrer une VM de base et appliquer un script d’installation à la volée CI/CD Compiler et packager une application en image prête à être déployée Construire l’application à chaque déploiement sur la machine cible
En 2014, lorsque le concept de baking m’a été présenté, j’ai immédiatement été enthousiasmé, car il répondait à trois problèmes que je cherchais à résoudre :
- Réduire les risques d’échec d’une installation sur le serveur de production
- Limiter la durée de l’indisponibilité (pendant la phase d’installation)
- Éviter d'augmenter la charge du serveur durant les opérations de build lors de l’installation
Depuis, j'évite au maximum le frying et j'ai intégré le baking dans ma doctrine d'artisan développeur.
Comment tu déploies tes containers Docker en production sans Kubernetes ?
Début novembre un ami me posait la question :
Quand tu déploies des conteneurs en prod, sans k8s, tu fais comment ?
Après 3 mois d'attente, voici ma réponse 🙂.
Mon contexte
Tout d'abord, un peu de contexte. Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Cela dit, j'ai également eu à gérer des infrastructures comportant plusieurs serveurs : 10, 20, 30 serveurs. Ces serveurs étaient généralement utilisés pour héberger une infrastructure de soutien (Platform infrastructure) à destination des développeurs. Par exemple :
- Environnements de recettage
- Serveurs pour faire tourner Gitlab-Runner
- Sauvegarde des données
- Etc.
Ce contexte montre que je n'ai jamais eu à gérer le déploiement de services à très forte charge, comme ceux que l'on trouve sur des plateformes telles que Deezer, le site des impôts, Radio France, Meetic, la Fnac, Cdiscount, France Travail, Blablacar, ou encore Doctolib. La méthode que je décris dans cette note ne concerne pas ce type d'infrastructure.
Ma méthode depuis 2015
Dans cette note, je ne vais pas retracer l'évolution complète de mes méthodes de déploiement, mais plutôt me concentrer sur deux d'entre elles : l'une que j'utilise depuis 2015, et une déclinaison adoptée en 2020.
Voici les principes que j'essaie de suivre et qui constituent le socle de ma doctrine en matière de déploiement de services :
- Je m'efforce de suivre le modèle Baking autant que possible (voir ma note 2025-02-07_1403), sans en faire une approche dogmatique ou extrémiste.
- J'applique les principes de The Twelve-Factors App.
- Je privilégie le paradigme Remote Task Execution, ce qui me permet d'adopter une approche GitOps.
- J'utilise des outils d'orchestration prenant en charge le mode push (voir note 2025-02-07_1612), comme Ansible, et j'évite le mode pull.
En pratique, j'utilise Ansible pour déployer un fichier docker-compose.yml sur le serveur de production et ensuite lancer les services.
Je précise que cette note ne traite pas de la préparation préalable du serveur, de l'installation de Docker, ni d'autres aspects similaires. Afin de ne pas alourdir davantage cette note, je n'aborde pas non plus les questions de Continuous Integration ou de Continuous Delivery.
Imaginons que je souhaite déployer le lecteur RSS Miniflux connecté à un serveur PostgreSQL.
Voici les opérations effectuées par le rôle Ansible à distance sur le serveur de production :
-
- Création d'un dossier
/srv/miniflux/
- Création d'un dossier
-
- Upload de
/srv/miniflux/docker-compose.ymlavec le contenu suivant :
- Upload de
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: password
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:password@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: secret
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
-
- Depuis le dossier
/srv/miniflux/lancement de la commandedocker compose up -d --remove-orphans --wait --pull always
- Depuis le dossier
Voilà, c'est tout 🙂.
En 2020, j'enlève "une couche"
J'aime enlever des couches et en 2020, je me suis demandé si je pouvais pratiquer avec élégance la méthode Remote Execution sans Ansible.
Mon objectif était d'utiliser seulement ssh et un soupçon de Bash.
Voici le résultat de mes expérimentations.
J'ai besoin de deux fichiers.
_payload_deploy_miniflux.shdeploy_miniflux.sh
Voici le contenu de _payload_deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
PROJECT_FOLDER="/srv/miniflux/"
mkdir -p ${PROJECT_FOLDER}
cat <<EOF > ${PROJECT_FOLDER}docker-compose.yaml
services:
postgres:
image: postgres:17
restart: unless-stopped
environment:
POSTGRES_DB: miniflux
POSTGRES_USER: miniflux
POSTGRES_PASSWORD: {{ .Env.MINIFLUX_POSTGRES_PASSWORD }}
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ['CMD', 'pg_isready']
interval: 10s
start_period: 30s
miniflux:
image: miniflux/miniflux:2.2.5
ports:
- 8080:8080
environment:
DATABASE_URL: postgres://miniflux:{{ .Env.MINIFLUX_POSTGRES_PASSWORD }}@postgres/miniflux?sslmode=disable
RUN_MIGRATIONS: 1
CREATE_ADMIN: 1
ADMIN_USERNAME: johndoe
ADMIN_PASSWORD: {{ .Env.MINIFLUX_ADMIN_PASSWORD }}
healthcheck:
test: ["CMD", "/usr/bin/miniflux", "-healthcheck", "auto"]
depends_on:
postgres:
condition: service_healthy
volumes:
postgres:
name: miniflux_postgres
EOF
cd ${PROJECT_FOLDER}
docker compose pull
docker compose up -d --remove-orphans --wait
Voici le contenu de deploy_miniflux.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
gomplate -f _payload_deploy_miniflux.sh | ssh root@$SERVER1_IP 'bash -s'
J'utilise gomplate pour remplacer dynamiquement les secrets dans le script _payload_deploy_miniflux.sh.
En conclusion, pour déployer une nouvelle version, j'ai juste à exécuter :
$ ./deploy_miniflux.sh
Je trouve cela minimaliste et de plus, l'exécution est bien plus rapide que la solution Ansible.
Ce type de script peut ensuite être exécuté aussi bien manuellement par un développeur depuis sa workstation, que via GitLab-CI ou même Rundeck.
Pour un exemple plus détaillé, consultez ce repository : https://github.com/stephane-klein/poc-bash-ssh-docker-deployement-example
Bien entendu, si vous souhaitez déployer votre propre application que vous développez, vous devez ajouter à cela la partie baking, c'est-à-dire, le docker build qui prépare votre image, l'uploader sur un Docker registry… Généralement je réalise cela avec GitLab-CI/CD ou GitHub Actions.
Objections
Certains DevOps me disent :
- « Mais on ne fait pas ça pour de la production ! Il faut utiliser Kubernetes ! »
- « Comment ! Tu n'utilises pas Kubernetes ? »
Et d'autres :
- « Il ne faut au grand jamais utiliser
docker-composeen production ! »
Ne jamais utiliser docker compose en production ?
J'ai reçu cette objection en 2018. J'ai essayé de comprendre les raisons qui justifiaient que ce développeur considère l'usage de docker compose en production comme un Antipattern.
Si mes souvenirs sont bons, je me souviens que pour lui, la bonne méthode conscistait à déclarer les états des containers à déployer avec le module Ansible docker_container (le lien est vers la version de 2018, depuis ce module s'est grandement amélioré).
Je n'ai pas eu plus d'explications 🙁.
J'ai essayé d'imaginer ses motivations.
J'en ai trouvé une que je ne trouve pas très pertinente :
- Uplodaer un fichier
docker-compose.ymlen production pour ensuite lancer des fonctions distantes sur celui-ci est moins performant que manipulerdocker-engineà distance.
J'en ai imaginé une valable :
- En déclarant la configuration de services Docker uniquement dans le rôle Ansible cela garantit qu'aucun développeur n'ira modifier et manipuler directement le fichier
docker-compose.ymlsur le serveur de production.
Je trouve que c'est un très bon argument 👍️.
Cependant, cette méthode a à mes yeux les inconvénients suivants :
- Je maitrise bien mieux la syntaxe de docker compose que la syntaxe du module Ansible community.docker.docker_container
- J'utilise docker compose au quotidien sur ma workstation et je n'ai pas envie d'apprendre une syntaxe supplémentaire uniquement pour le déploiement.
- Je pense que le nombre de développeurs qui maîtrisent docker compose est suppérieur au nombre de ceux qui maîtrisent le module Ansible
community.docker.docker_container. - Je ne suis pas utilisateur maximaliste de la méthode Remote Execution. Dans certaines circonstances, je trouve très pratique de pouvoir manipuler docker compose dans une session ssh directement sur un serveur. En période de stress ou de debug compliqué, je trouve cela pratique. J'essaie d'être assez rigoureux pour ne pas oublier de reporter mes changements effectués directement le serveur dans les scripts de déploiements (configuration as code).
Tu dois utiliser Kubernetes !
Alors oui, il y a une multitude de raisons valables d'utiliser Kubernetes. C'est une technologie très puissante, je n'ai pas le moindre doute à ce sujet.
J'ai une expérience dans ce domaine, ayant utilisé Kubernetes presque quotidiennement dans un cadre professionnel de janvier 2016 à septembre 2017. J'ai administré un petit cluster auto-managé composé de quelques nœuds et y ai déployé diverses applications.
Ceci étant dit, je rappelle mon contexte :
Cela fait 25 ans que je travaille sur des projets web, et tous les projets sur lesquels j'ai travaillé pouvaient être hébergés sur un seul et unique serveur baremetal ou une Virtual machine, sans jamais nécessiter de scalabilité horizontale.
Je n'ai jamais eu besoin de serveurs avec plus de 96Go de RAM pour faire tourner un service en production. Il convient de noter que, dans 80% des cas, 8 Go ou 16 Go étaient largement suffisants.
Je pense que faire appel à Kubernetes dans ce contexte est de l'overengineering.
Je dois avouer que j'envisage d'expérimenter un usage minimaliste de K3s (attention au "3", je n'ai pas écrit k8s) pour mes déploiements. Mais je sais que Kubernetes est un rabbit hole : Helm, Kustomize, Istio, Helmfile, Grafana Tanka… J'ai peur de tomber dans un Yak!.
D'autre part, il existe déjà un pourcentage non négligeable de développeur qui ne maitrise ni Docker, ni docker compose et dans ces conditions, faire le choix de Kubernetes augmenterait encore plus la barrière à l'entrée permettant à des collègues de pouvoir comprendre et intervenir sur les serveurs d'hébergement.
C'est pour cela que ma doctrine d'artisan développeur consiste à utiliser Kubernetes seulement à partir du moment où je rencontre des besoins de forte charge, de scalabilité.
Playground qui présente comment je setup un projet Python Flask en 2025
Je pense que cela doit faire depuis 2015 que je n'ai pas développé une application en Python Flask !
Entre 2008 et 2015, j'ai beaucoup itéré dans mes méthodes d'installation et de setup de mes environnements de développement Python.
D'après mes souvenirs, si je devais dresser la liste des différentes étapes, ça donnerai ceci :
- 2006 : aucune méthode, j'installe Python 🙂
- 2007 : je me bats avec setuptools et distutils (mais ça va, c'était plus mature que ce que je pouvais trouver dans le monde PHP qui n'avait pas encore imaginé composer)
- 2008 : je trouve la paie avec virtualenv
- 2010 : j'ai peur d'écrire des scripts en Bash alors à la place, j'écris un script
bootstrap.pydans lequel j'essaie d'automatiser au maximum l'installation du projet - 2012 : je me bats avec buildout pour essayer d'automatiser des éléments d'installation. Avec le recul, je réalise que je n'ai jamais rien compris à buildout
- 2012 : j'utilise Vagrant pour fixer les éléments d'installation, je suis plutôt satisfait
- 2015 : je suis radicale, j'enferme tout l'environnement de dev Python dans un container de développement, je monte un path volume pour exposer le code source du projet dans le container. Je bricole en
entrypointavec la commande "sleep".
Des choses ont changé depuis 2015.
Mais, une chose que je n'ai pas changée, c'est que je continue à suivre le modèle The Twelve-Factors App et je continue à déployer tous mes projets packagé dans des images Docker. Généralement avec un simple docker-compose.yml sur le serveur, ou alors Kubernetes pour des projets de plus grande envergure… mais cela ne m'arrive jamais en pratique, je travaille toujours sur des petits projets.
Choses qui ont changé : depuis fin 2018, j'ai décidé de ne plus utiliser Docker dans mes environnements de développement pour les projets codés en NodeJS, Golang, Python…
Au départ, cela a commencé par uniquement les projets en NodeJS pour des raisons de performance.
J'ai ensuite découvert Asdf et plus récemment Mise. À partir de cela, tout est devenu plus facilement pour moi.
Avec Asdf, je n'ai plus besoin "d'enfermer" mes projets dans des containers Docker pour fixer l'environnement de développement, les versions…
Cette introduction est un peu longue, je n'ai pas abordé le sujet principal de cette note 🙂.
Je viens de publier un playground d'un exemple de projet minimaliste Python Flask suivant mes pratiques de 2025.
Voici son repository : mise-python-flask-playground
Ce playground est "propulsé" par Docker et Mise.
J'ai documenté la méthode d'installation pour :
- Linux (Fedora (distribution que j'utilise au quotidien) et Ubuntu)
- MacOS avec Brew
- MS Windows avec WSL2
Je précise que je n'ai pas eu l'occasion de tester l'installation sous Windows, hier j'ai essayé, mais je n'ai pas réussi à installer WSL2 sous Windows dans un Virtualbox lancé sous Fedora. Je suis à la recherche d'une personne pour tester si mes instructions d'installation sont valides ou non.
Briques technologiques présentes dans le playground :
- La dernière version de Python installée par Mise, voir .mise.toml
- Une base de données PostgreSQL lancé par Docker
- J'utilise named volumes comme expliqué dans cette note : 2024-12-09_1550
- Flask-SQLAlchemy
- Flask-Migrate
- Une commande
flask initdbavec Click pour reset la base de données - Utiliser d'un template Jinja2 pour qui affiche les
usersen base de données
Voici quelques petites subtilités.
Dans le fichier alembic.ini j'ai modifié le paramètre file_template parce que j'aime que les fichiers de migration soient classés par ordre chronologique :
[alembic]
# template used to generate migration files
file_template = %%(year)d%%(month).2d%%(day).2d_%%(hour).2d%%(minute).2d%%(second).2d_%%(slug)s
20250205_124639_users.py
20250205_125437_add_user_lastname.py
Ici le port de PostgreSQL est généré dynamiquement par docker compose :
postgres:
image: postgres:17
...
ports:
- 5432 # <= ici
Avec cela, fini les conflits de port quand je lance plusieurs projets en même temps sur ma workstation.
L'URL vers le serveur PostgreSQL est générée dynamiquement par le script get_postgres_url.sh qui est appelé par le fichier .envrc. Tout cela se passe de manière transparente.
J'initialise ici les extensions PostgreSQL :
def init_db():
db.drop_all()
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "uuid-ossp"'))
db.session.execute(db.text('CREATE EXTENSION IF NOT EXISTS "unaccent"'))
db.session.commit()
db.create_all()
et ici dans la première migration :
def upgrade():
op.execute('CREATE EXTENSION IF NOT EXISTS "uuid-ossp";')
op.execute('CREATE EXTENSION IF NOT EXISTS "unaccent";')
op.create_table('users',
sa.Column('id', sa.Integer(), autoincrement=True, nullable=False),
sa.Column('firstname', sa.String(), nullable=False),
sa.PrimaryKeyConstraint('id')
)
Journal du jeudi 30 janvier 2025 à 12:02
Note de type #aide-mémoire : contrairement à ~/.zprofile, .zshenv est chargé même lors de l'exécution d'une session ssh en mode non interactif, par exemple :
$ ssh user@host 'echo "Hello, world!"'
Je me suis intéressé à ce sujet parce que mes scripts exécutés par ssh dans le cadre du projet /poc-capacitor/ n'avaient pas accès aux outils mis à disposition par Homebrew et Mise.
J'ai creusé le sujet et j'ai découvert que .zprofile était chargé seulement dans les cas suivants :
- « login shell »
- « interactive shell »
Un login shell est un shell qui est lancé lors d'une connexion utilisateur. C'est le type de shell qui exécute des fichiers de configuration spécifiques pour préparer l'environnement utilisateur. Un login shell se comporte comme si tu te connectais physiquement à une machine ou à un serveur.
Un shell interactif est un shell dans lequel tu peux entrer des commandes de manière active, et il attend des entrées de ta part. Un shell interactif est conçu pour interagir avec l'utilisateur et permet de saisir des commandes, d'exécuter des programmes, de lancer des scripts, etc.
Suite à cela, dans ce commit "Move zsh config from .zprofile to .zshenv", j'ai déplacé la configuration de Homebrew et Mise de ~/.zprofile vers .zshenv.
Cela donne ceci une fois configuré :
$ cat .zshenv
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
Mais, attention, « As /etc/zshenv is run for all instances of zsh ». Je pense que ce n'est pas forcément une bonne idée d'appliquer cette configuration sur une workstation, parce que cela peut "ralentir" légèrement le système en lançant inutilement ces commandes.
ChatGPT me conseille cette configuration pour éviter cela :
# Ne charge Brew et Mise que si on est dans un shell interactif ou SSH
if [[ -t 1 || -n "$SSH_CONNECTION" ]]; then
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
fi