
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (604) ] [ Notes plus anciennes (374) >> ]
Samedi 24 août 2024
Journal du samedi 24 août 2024 à 10:47
Je cherche à mieux comprendre la syntaxe let:close utilisée dans le contexte de Svelte, comme dans l'exemple suivant :
<Popover>
<PopoverButton>Solutions</PopoverButton>
<PopoverPanel let:close>
<button
on:click={async () => {
await fetch("/accept-terms", { method: "POST" });
close();
}}
>
Read and accept
</button>
<!-- ... -->
</PopoverPanel>
</Popover>
Ce code provient du projet svelte-headlessui.
À première vue, cette syntaxe me faisait penser aux <slot key={value}> dans Svelte 🤔.
Cette intuition s'est confirmée après avoir exploré le concept plus en détail à travers l'exemple suivant :
<!-- FancyList.svelte -->
<ul>
{#each items as item}
<li class="fancy">
<slot prop={item} />
</li>
{/each}
</ul>
<!-- App.svelte -->
<FancyList {items} let:prop={thing}>
<div>{thing.text}</div>
</FancyList>
Après avoir lu la section sur les <slot key={value}> , je me rends compte que je n'utilise presque jamais les slots, à l'exception des layout. C'est dommage, car je passe à côté d'une fonctionnalité très pratique.
Vendredi 23 août 2024
Journal du vendredi 23 août 2024 à 21:35
#JaiDécouvert le philosophe Alfred Korzybski dans le livre Systemantics.
Il a fondé la sémantique générale, logique de pensée fondée sur les mathématiques et la physique du tournant du siècle, une discipline pratique pour que chacun puisse prendre un recul critique sur les réactions (non verbales et verbales) à un « événement » au sens large (comprendre ses propres réactions, ainsi que les réactions des autres et leur interaction éventuelle).
Quelle différence entre une Issue et un Ticket ?
Je préfère ne pas utiliser le terme « ticket » pour traduire « issue » en anglais.
Il m'arrive cependant d'employer « ticket » uniquement pour désigner les demandes de support ou les bugs.
Les définitions proposées par le Wiktionary et Wikipedia semblent corroborer cette distinction :
« Billet comportant un numéro d’ordre de passage dans une file d’attente. »
« Une demande d'assistance, désignées ainsi dans le métier de l'assistance sous le nom de ticket. »
-- wikipedia
Le terme anglais « issue » a une portée bien plus large que celle de « ticket ». Il peut désigner :
ChatGPT me dit :
En français, le terme "issue" peut être traduit de différentes manières en fonction du contexte. Voici quelques traductions courantes :
- Problème : C'est la traduction la plus directe et souvent utilisée. Elle est appropriée si l'"issue" en question concerne un bug ou un défaut à corriger.
- Ticket : Ce terme est également couramment utilisé dans le contexte du suivi des tâches ou des bugs. Il est un peu plus neutre et peut désigner aussi bien un problème qu'une demande de fonctionnalité.
- Tâche : Si l'"issue" représente quelque chose à faire (comme une nouvelle fonctionnalité à développer), "tâche" peut être une bonne traduction.
- Demande : Ce terme peut être utilisé si l'"issue" est une requête ou une demande de changement.
En fonction du contexte précis, tu peux choisir le mot qui semble le plus approprié. Par exemple :
- Pour un bug : Problème ou Bug.
- Pour une nouvelle fonctionnalité : Tâche ou Demande.
- De manière générale, dans le cadre d'un système de gestion de projet : Ticket.
Le terme "issue" est parfois laissé tel quel en français dans certains contextes techniques, surtout dans des équipes habituées aux outils comme GitLab ou GitHub.
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Mercredi 21 août 2024
Journal du mercredi 21 août 2024 à 15:30
#JaiLu pour la première fois la page de la Web API nommée Intersection Observer API.
Dans un projet Svelte, je crée dynamiquement un composant qui est inséré dans un élément non Svelte :
component = new myComponent({
target: element,
props: {
foo: bar
}
});
Cette Web API m'a permis de déterminer la position d'un composant lorsque celui-ci est réellement attaché à la page web.
<script lang="js">
import { onMount } from "svelte";
export let rootElement;
onMount(() => {
const observer = new IntersectionObserver(
(entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
console.log(entry.boundingClientRect);
observer.disconnect();
}
});
}
);
observer.observe(rootElement);
});
</script>
<span bind:this={rootElement}>
...
</span>
Journal du mercredi 21 août 2024 à 10:53
#OnMaPartagé La Vélodyssé, je suis très intéressé par cet itinéraire de voyage à vélo.
Journal du mercredi 21 août 2024 à 10:37
Note de type snippets concernant docker compose et l'utilisation de la fonctionnalité healthcheck et depends_on.
Cette méthode évite que le service webapp démarre avant que les services postgres et redis soient prêts.
# Fichier docker-composexyml
services:
postgres:
image: postgres:16
...
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
redis:
image: redis:7
...
healthcheck:
test: ["CMD", "redis-cli", "ping"]
timeout: 10s
retries: 3
start_period: 10s
webapp:
image: ...
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
Ici la commande :
$ docker compose up -d webapp
s'assure du lancement de ses dépendances, les services postgres et redis.
De plus, si le Dockerfile du service webapp contient par exemple :
# Fichier Dockerfile
...
RUN apt update -y; apt install -y curl
...
HEALTHCHECK --interval=30s --timeout=10s --retries=3 CMD curl --fail http://localhost:3000 || exit 1
Alors, je peux lancer webapp avec :
$ docker compose up -d webapp --wait
Avec l'option --wait docker compose "rend la main" lorsque le service webapp est prêt à recevoir des requêtes.
Ressources :
Journal du mercredi 21 août 2024 à 10:16
#OnMaPartagé https://www.paat.ch/, communauté de Coliving Coworking.

Il semble possible d'organiser des sessions de coworking :
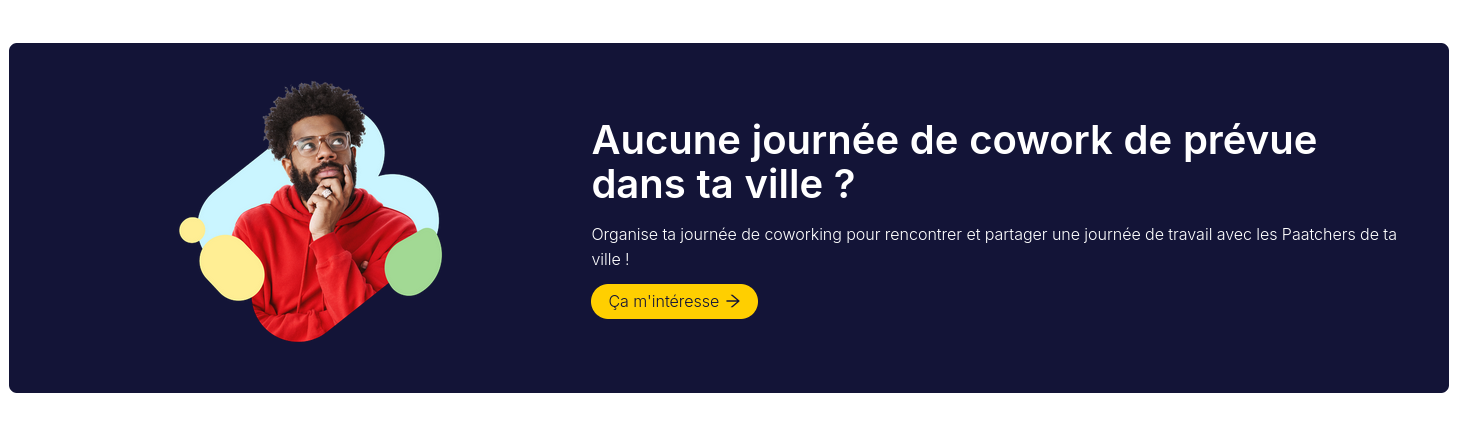
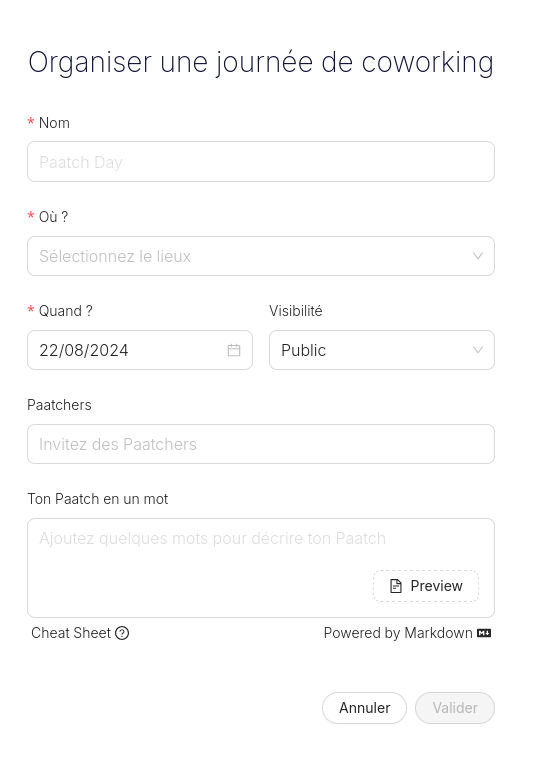
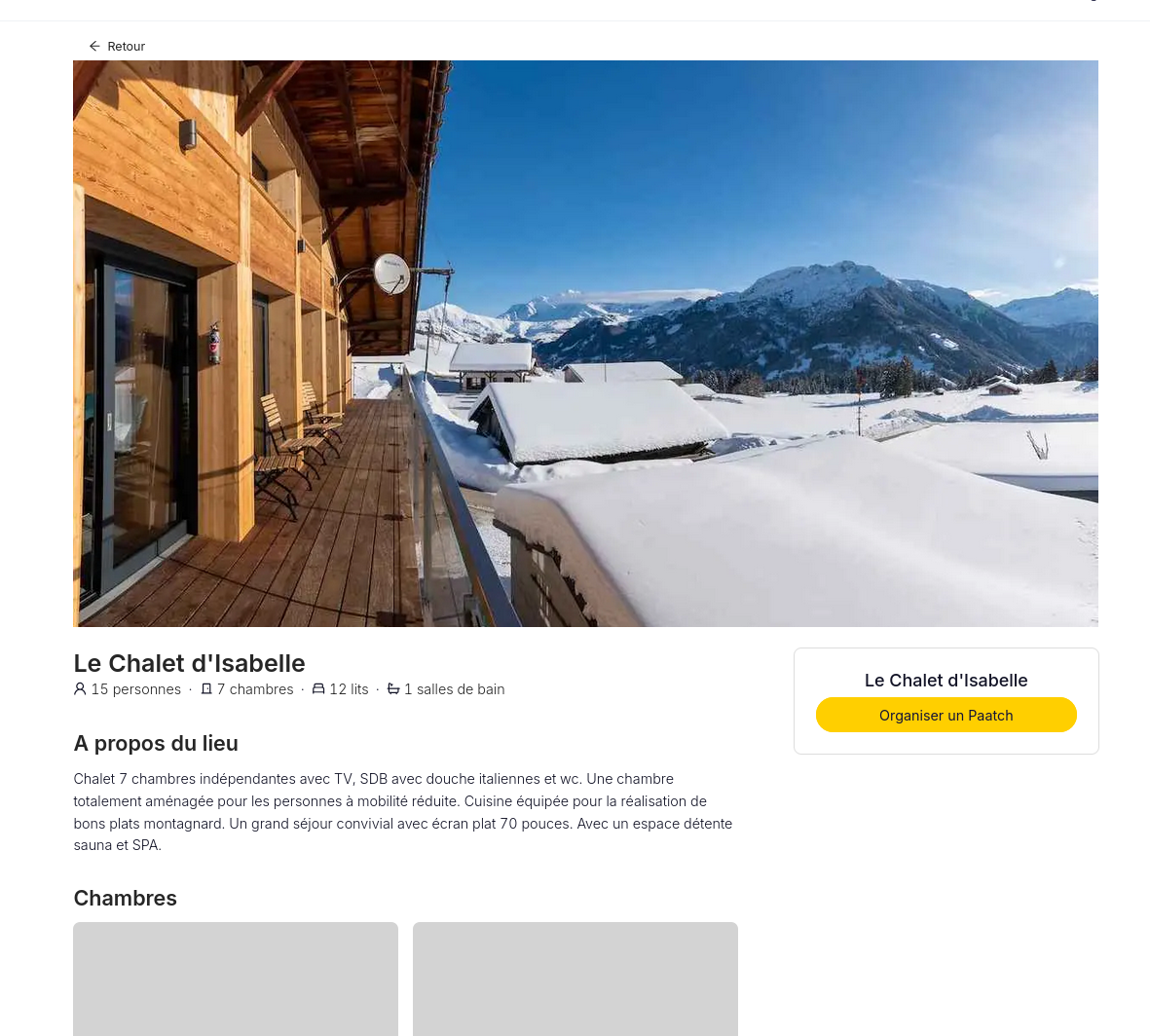
Je pense que ce site rassemble des logements propice au coworking :
Journal du mercredi 21 août 2024 à 10:08
#OnMaPartagé un nouvel article qui fait mention de Otium :
Jean-Miguel était l’invité de Gregory Pouy dans son Podcast Vlan! et définit l’otium, mot issu de l’Antiquité, comme “le loisir intelligent”. Il s’agit de “la part, dans le temps libre, utilisée pour développer sa conscience, tout ce qui permet d’avoir un rapport éclairé, lucide avec le monde extérieur et soi-même”.
-- from
Journal du mercredi 21 août 2024 à 09:53
#JaiDécouvert le browser Open source nommé Zen Browser basé sur Firefox qui reprends les principes de Arc (browser) (from)
Je viens de l'installer et de le lancer, il semble bien fonctionner. Je constate qu'il partage bien les extensions Firefox.
Toutefois, je n'ai pas trouvé comment effectuer des "split views", qui est la fonctionnalité qui m'intéresse le plus.
Je n'ai pas trouvé non plus comment activer le "Compact Mode".
J'arrête de tondre de Yak! pour le moment.
Journal du mercredi 21 août 2024 à 09:49
Je trouve le projet très bien réaliséfélicitations à l'auteur !
Je pense que ce projet partage en partie les mêmes objectifs que Datasette.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Mardi 20 août 2024
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:13
#JaiDécouvert cette citation de Alan Kay (from).
« Pop culture is all about identity and feeling like you're participating. It has nothing to do with cooperation, the past or the future — it's living in the present. I think the same is true of most people who write code for money. They have no idea where their culture came from." -- from
Traduction ChatGTP :
« La culture pop concerne avant tout l'identité et le fait de ressentir que l'on participe. Elle n'a rien à voir avec la coopération, le passé ou le futur — c'est vivre dans le présent. Je pense que c'est la même chose pour la plupart des personnes qui écrivent du code pour de l'argent. Elles n'ont aucune idée de l'origine de leur culture. »
Source de cette citation : https://web.archive.org/web/20120715041026/http://www.drdobbs.com/architecture-and-design/interview-with-alan-kay/240003442?pgno=1
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
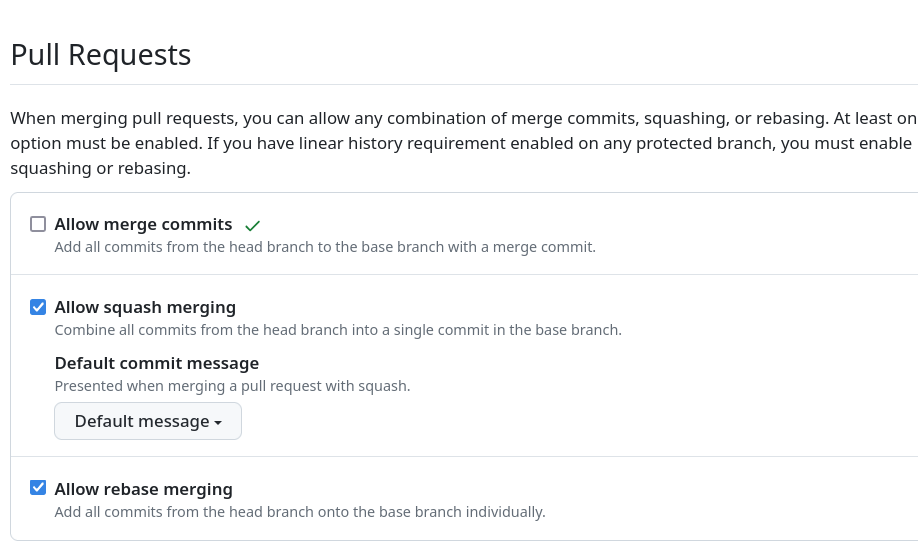
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
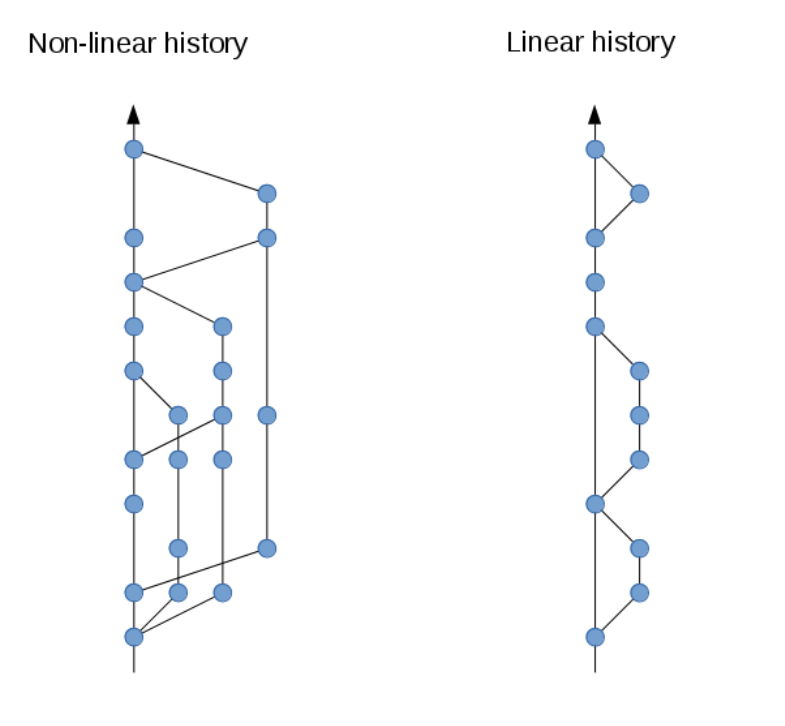
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.
Journal du mardi 20 août 2024 à 17:37
#JaiDécouvert un article très intéressant qui répertorie les difficultés classiques rencontrées par les développeurs avec git rebase, ainsi que des solutions pour y remédier :git rebase: what can go wrong?.
Journal du mardi 20 août 2024 à 17:27
#JaiDécouvert ce guide pour Git : Flight rules for Git.
Je le trouve excellent 👌.
Et voici une autre article intéressant au sujet de Git rebase : git rebase in depth.
Journal du mardi 20 août 2024 à 16:09
#JaiDécouvert Waymarked Trails pour les randonnées basé sur OpenStreetMap.
Journal du mardi 20 août 2024 à 14:35
#OnMaPartagé la pratique suivante quand un projet utilise Mise : convertir tous les fichiers .tool-versions vers le format de configuration natif de Mise.mise.toml. Cette conversion permet d'éviter d'éventuels problèmes de compatibilité entre Mise et Asdf.
It supports the same .tool-versions files that you may have used with asdf and uses asdf plugins. It will not, however, reuse existing asdf directories (so you'll need to either reinstall them or move them), and 100% compatibility is not a design goal.
-- from
En utilisant le format .mise.toml l'utilisateur comprends qu'il doit utiliser Mise.
#JaiDécidé d'ajouter cette pratique dans ma doctrine d'artisan développeur.
Journal du mardi 20 août 2024 à 10:40
Un ami ma partager cette adresse de coworking que j'avais déjà identifié lors d'un footing à la Cité internationale universitaire de Paris : L'Égyptien Café Coworking.
Il me dit que y a du café, Internet, des prises, que c'est parfait pour coworker.
Journal du mardi 20 août 2024 à 09:47
Dans ce thread Fediverse #JaiDécouvert LeBureau.coop.
Une société coopérative de gestion de noms de domaine (registrar).
La vidéo "Les noms de domaine pour se réapproprier Internet" de Arthur Vuillard à Pas Sage en Seine (à partir de 25min) contient une présentation de ce projet.
J'y ai au passage découvert la coopérative Hasshbang.
Dans ma #todo-list :
- [ ] Transférer un de mes noms de domaine vers LeBureau.coop pour tester ;
- [ ] Acheter des parts pour devenir sociétaire soutien.
Journal du mardi 20 août 2024 à 09:46
#JaiLu les slides Mozilla va-t-il sauver le web ?.
Je suis attristé par la gouvernance de Mozilla 😭.
Journal du mardi 20 août 2024 à 09:33
#JaiLu Software estimates have never worked and never will
Je suis en accord — depuis très longtemps — avec le contenu de cet article.
Give up on estimates, and embrace the alternative method for making software by using budgets, or appetites, as we call them in our Shape Up methodology.
Cette méthode fait parti de ma doctrine d'artisan développeur.
Lundi 19 août 2024
Journal du lundi 19 août 2024 à 21:03
Je teste Zed editor, sous Fedora.
$ flatpak install flathub dev.zed.Zed
Journal du lundi 19 août 2024 à 17:21
#JaiDécouvert https://github.com/romkor/svelte-portal (from ChatGPT).
Vraiment trop pratique !
Journal du lundi 19 août 2024 à 16:28
Dans l'introduction de la documentation de bits-ui, #JaiDécouvert encore une autre #librairie de composants UI pour Svelte : melt.
Journal du lundi 19 août 2024 à 15:52
#Jadore le projet shadcn-svelte. Je trouve l'expérience développeur (DX) excellente ❤️.
Journal du lundi 19 août 2024 à 15:28
Je souhaite setup Tailwind CSS dans un projet SvelteKit avec svelte-add.
https://svelte-add.com/adder/tailwindcss
Mais ne comprends pas pourquoi, svelte-add semble ne plus fonctionner comme avant, il ne modifie pas mon projet SvelteKit existant, mais il souhaite l'écraser 🤔.
$ pnpx svelte-add@latest tailwindcss
svelte-add version 2.7.3
┌ Welcome to Svelte Add!
│
◇ Create new Project?
│ No
│
└ Exiting.
En attendant de comprendre pourquoi, je vais setup Tailwind CSS manuellement en suivante cette documentation https://tailwindcss.com/docs/guides/sveltekit.
Je découvre Kopia, une alternative à Restic
Alexandre m'a partagé Kopia, logiciel Open source de backup, alternatif à restic.
7000 likes GitHub versus 25000 likes pour Restic.
Je constate que Kopia est développé principalement par 2 développeurs et je constate le même nombre pour Restic.
J'ai parcouru cette page qui date de 2 ans : How Do Kopia Features Compare to Other Backup Software?.
En 2022, il semble que restic ne supportait pas la compression de données, mais je constate via cette Pull Request Implement compression support que cette feature est maintenant intégrée à restic.
#JaiLu en partie le thread Hacker News : Kopia: Fast and secure open-source backup software.
Initially I thought this was a corporate project and was looking for the monetization model, but then I found https://github.com/kopia/kopia/blob/master/GOVERNANCE.md
I feel like the project might benefit from making their governance model more prominent on the website.
-- from
D'après ces commentaires, Kopia est lent à la restauration :
Used it for a while, recently tried to restore some things and it failed, taking a really long time to restore some snapshots compared to other things I've tried. Switched to restic instead. Really like what kopia is but I'll wait a few more years before considering it for something, but right now I'm happy with restic.
This has been my experience too with Kopia.
I tried to restore a ~200 GB file (stored remotely on a Hetzner Storage Box), and it failed (or at least did not finish after being left for ~20 hours; there was also no progress indicator or status I could find in the UI).
I also tried to restore a folder with about ~32 GB of data in it, and that also failed (the UI did report an error, but I don't recall it being useful).
Also, in general use, the UI would get disconnected from the repository every few days, and sometimes the backup overview list would show folders as being size 0 (which maybe indicated they failed; they showed up with an "incomplete" [or similar] tag in the UI).
-- from
Il semble que l'outil Veloro utilisait restic et ait migré vers Kopia :
One thing I will mention is that other backup projects have switched from Restic to Kopia. Velero from VMware comes to mind.
-- from
À ce sujet, j'ai vu Unified Repository & Kopia Integration Design et je n'ai pas tout compris.
Alexandre m'a appris que Veloro supporte pour le moment Kopia et restic mais que le support restic est en train d'être supprimé : Deprecate Restic.
Voilà l'origine du nom 🙂 :
"Kopia" means "copy" in Swedish and probably more Nordic languages, too.
-- from
J'ai vu ce commentaire :
Personally, I've had some issues with Kopia.
I found their explanation here:
Still not solved after many years :(
Ma doctrine pour le moment : je vais rester sur restic.
Journal du lundi 19 août 2024 à 11:27
#JaiLu "Les mathématiques de l'argument d'autorité #DébattonsMieux" de Lê Nguyên Hoang, je trouve cela très intéressant, bien que, après une première lecture, je n'aie saisi qu'une infime partie de l'article.
L'article présente un théorème bayésien qui stipule :
- Si vous êtes bayésien,
- si vous supposez qu'une autorité a eu accès aux mêmes données que vous et à plus encore,
- si vous êtes sûr que l'autorité parle de manière honnête,
- si vous pensez qu'une autorité est aussi bayésienne avec le même a priori que vous, alors vous devez croire tout ce que l'autorité dit.
#JaiDécouvert John Geanakoplos, Herakles Polemarchakis et John Harsanyi cités dans cet article.
Samedi 17 août 2024
Journal du samedi 17 août 2024 à 16:09
Je viens de créer Projet 13 - "POC Elasticsearch sur un PKM".
Journal du samedi 17 août 2024 à 15:21
Je repository GitHub officiel des images Docker de Elasticsearch se trouve ici : https://github.com/elastic/elasticsearch/tree/main/distribution/docker.
Journal du samedi 17 août 2024 à 15:15
En lien avec Elasticsearch, #JaiDécouvert :
- https://github.com/searchkit/searchkit
- https://opensource.reactivesearch.io/
- https://github.com/appbaseio/dejavu/
qui sont plus ou moins des équivalents à InstantSearch (from).
Journal du samedi 17 août 2024 à 15:00
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
-- from
#JeMeDemande également si pg_search, Typesense et Meilisearch peuvent réaliser la même chose que ce qui est décrit dans Elastic Search: Highlighting Text That Contains HTML Tags.
En ce qui concerne Typesense, j'ai consulté l'issue Feature Request - Ignore any HTML tags when searching but still return response with HTML included, ce qui me laisse penser que cette fonctionnalité n'est pas prise en charge.
Pour Meilisearch, la discussion Ignore HTML tags at search m'a également conduit à la conclusion que cette fonctionnalité n'est pas encore implémentée. J'ai aussi appris qu'Algolia permet d'ignorer les balises HTML lors de la recherche : Algolia ignores HTML tags during search.
Quant à pg_search, mes recherches sur les mots-clés HTML dans les dépôts pg_search et Tantivy (Tantivy) n'ont rien donné. Il semble donc que la fonctionnalité de surlignage du texte contenant des balises HTML ne soit pas prise en charge par pg_search.
Contenu de ce constat, je vais peut-être redonner une chance à Elasticsearch malgré mon aversion pour la JVM 🤔.
Journal du samedi 17 août 2024 à 14:50
Depuis le début des années 2000, j'éprouve une certaine aversion dès que je suis confronté à une technologie basée sur Java. Pourquoi ? Parce que, à tort ou à raison, j'ai remarqué que les applications Java sont souvent très longues à démarrer et consomment une quantité excessive de RAM.
Je pense par exemple à Logstash, dont la lenteur était insupportable, que j'ai fini par remplacer d'abord par Fluentd, puis par Vector.
Je pense également à Eclipse IDE.
Et bien sûr, aux serveurs Jakarta EE.
Journal du samedi 17 août 2024 à 12:53
Ce matin, j'ai enfin pris le temps de parcourir attentivement la documentation d'Elasticsearch pour comparer ses fonctionnalités à celles de Meilisearch, Typesense et pg_search.
J'ai lu Text analysis overview de Elasticsearch.
Je note ici les étapes de l'Text analysis que j'ai des difficultés à retenir :
- Tokenization
- Token filtering (voir dans Anatomy of an analyzer)
- Normalization (search engine)
- Stemmer token filter (search engine)
- Character filters reference
- Customize text analysis
J'ai parcouru la liste des différents types des Built-in analyzer reference de Elasticsearch.
Je retiens le concept de stop analyzer.
#JeMeDemande l'usage du Keyword analyzer 🤔.
Je trouve le Pattern analyzer intéressant.
En lisant Fingerprint analyzer je découvre l'algorithme fingerprinting décrit dans la documentation de OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint. Je garde cela dans un coin de mon esprit, il se peut que cela me soit utile à l'avenir 🤔.
Je découvre que Elasticsearch (sans doute Lucene 🤔) propose beauoup de token filtering différent qui peuvent être combinés : Apostrophe, ASCII folding, CJK bigram, CJK width, Classic, Common grams, Conditional, Decimal digit, Delimited payload, Dictionary decompounder, Edge n-gram, Elision, Fingerprint, Flatten graph, Hunspell, Hyphenation decompounder, Keep types, Keep words, Keyword marker, Keyword repeat, KStem, Length, Limit token count, Lowercase, MinHash, Multiplexer, N-gram, Normalization, Pattern capture, Pattern replace, Phonetic, Porter stem, Predicate script, Remove duplicates, Reverse, Shingle, Snowball, Stemmer, Stemmer override, Stop, Synonym, Synonym graph, Trim, Truncate, Unique, Uppercase, Word delimiter, Word delimiter graph.
J'ai lu Stemmer token filter que je considère comme très important pour un moteur de recherche efficace.
#JaiDécouvert le support de Synonym graph token filter.
Je lis HTML strip character filter, fonctionnalité que je juge très utile.
Je lis qu'Elasticsearch propose de nombreuses méthodes de query, entre autres :
- Query DSL
- EQL search
- ES QL
- et même SQL
- Scripting
Tout cela est très riche !
J'ai lu Highlighting
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
Journal du samedi 17 août 2024 à 11:59
Je viens de comprendre que dans le domaine des full-text search engine les notions de Facets et Aggregations sont liées.
La fonctionnalité facets sont basés les fonctionnalités aggregations des full-text search engine.
Vendredi 16 août 2024
Journal du vendredi 16 août 2024 à 14:46
#Jaime observer les reviews des scripts vidéo de Lê Nguyên Hoang : https://github.com/lenhoanglnh/manuscripts/pull/29 🙂.
Journal du vendredi 16 août 2024 à 13:17
J'ai relu cette note de David Larlet :
Silk = documentation et tests
Markdown based document-driven web API testing.
La rapidité d’exécution d’un outil écrit en Go est toujours surprenante, j’ai eu besoin de vérifier que les tests étaient bien passés pour être sûr de son bon fonctionnement… Mon expérience me montre qu’une documentation qui n’est pas testée/proche du code n’est jamais synchronisée et conduit à des frustrations pour les utilisateurs. Silk est un moyen de faire cela directement depuis votre markdown, ça me rappelle d’une certaine manière le couple docutils/reStructuredText. En rapide. Et je ne saurais trop insister sur l’importance d’avoir une suite de tests rapide pour qu’elle reste pertinente.
Raconter une histoire dans vos tests est plus verbeux mais assurément plus intéressant pour la personne qui cherchera à comprendre ce que vous avez implémenté. Il y a de grandes chances que ce soit vous. Le README du dépôt est un exemple de ce qui peut être réalisé.
Je pense que ce billet a participer à ma sensibilitasion à la notion de colocated documentation.
Journal du vendredi 16 août 2024 à 13:06
Dans ma note Keep it simple, stupid le plus longtemps possible j'ai écris :
Je me souviens de la quête vers le minimaliste dans le code de David Larlet : « Est-ce qu’il est possible d'enlever des couches dans la stack ? »
Je viens d'essayer de retrouver ces articles, mais ce n'est pas facile tellement les articles de David Larlet sont nombreux.
Pour le moment j'ai retrouvé les extraits ci-dessous ceci en lien avec le sujet.
Paternité
- Ajouter des couches
- Changer des couches
- Enlever des couches
- Changer des couches
- Mettre des couches
J’en suis à l’étape 3 dans ma maturité en tant que développeur. La paternité change les priorités et je pense qu’elle a un grand rôle dans le fait de vouloir remettre le focus sur la valeur apportée plus que sur la technique. Me battre pour une meilleure expérience utilisateur plutôt que contre un framework, chercher à se faire plaisir davantage via ce qui est produit que par un contentement technique.
Lorsque j’expérimente aujourd’hui, ce n’est plus pour découvrir une nouvelle bibliothèque mais pour trouver de nouveaux moyens de simplifier un problème. Dans ce contexte, il est intéressant de re-questionner la page blanche (cache), de re-challenger certaines bonnes pratiques communément admises (cache).
Autre extrait :
Leftpad
Every package that you use adds yet another dependency to your project. Dependencies, by their very name, are things you need in order for your code to function. The more dependencies you take on, the more points of failure you have. Not to mention the more chance for error: have you vetted any of the programmers who have written these functions that you depend on daily?
J’étais en train de préparer cette intervention lorsque le fiasco leftpad est arrivé dans l’écosystème NPM. Du coup, j’ai eu immédiatement plein d’articles faisant une ode à la simplicité, à la réduction de dépendances et mettant en garde contre les couches d’abstraction. Merci Azer Koçulu, je pouvais difficilement rêver mieux :-). Je ne vais pas tirer sur l’ambulance mais ça illustre presque trop bien mon propos.
as your project progresses, your team’s productivity will drop because of all the complexity and dependencies. You’ll need more people to maintain it, and more people with specific knowledge to maintain it. If your lead developers leave, you’re dead. You should be fighting complexity and not embracing it. Every added framework, and even library, makes your project more difficult to maintain. Avoid unnecessary frameworks and libraries from day one.
Jusqu’où aller dans cette démarche ? Par où commencer ?
Autre extrait :
Maybe it’s not too late for you, though. Perhaps, like me, you aren’t feeling particularly overworked. But are you feeling irritable, tired, and apathetic about the work you need to do? Are you struggling to concentrate on simple tasks?
Then maybe what you’re feeling is burnout, too.
J’ai travaillé pendant un an et demi avec Mozilla sur la partie paiement du Marketplace puis sur le site des extensions de Firefox. Et depuis un an avec Etalab sur la plateforme datagouv. Dans les deux situations, j’ai passé davantage de temps à lutter contre les outils plutôt qu’à les apprécier pour le travail rendu. C’est terrible car ceux-ci sont censés théoriquement faire gagner du temps mais sur le long terme cela se révèle être faux dans mon cas.
Je me demande si je ne suis pas en train de faire un burnout technique, non pas par trop de travail mais par manque de contrôle dans mes outils.
Autre extrait :
The aesthetic microlith
Growth for the sake of growth is the ideology of the cancer cell.
Edward Abbey
Toutes ces raisons m’ont amené à étudier une nouvelle piste. Cette appellation est une combinaison du Majestic Monolith (cache) et des microservices. Je me persuade qu’il y a une voie différente entre ces deux extrêmes. Une voie qui limite les fuites d’abstraction (cache) afin de réduire la dette technique et de favoriser l’inclusion de nouveaux membres dans une équipe. Une voie qui ne demande pas de réécrire la moitié de l’application tous les six mois car une nouvelle montée en version majeure n’est pas rétro-compatible. Une voie où l’on ne raisonne plus en termes de features et de bugs mais d’expérience utilisateur et de satisfaction pour l’ensemble des parties prenantes. Un environnement qui permet de faire une pause dans les développements afin de prendre le temps de davantage considérer les besoins des personnes qui utilisent le produit.
We all want things to be simpler. But we may not know what to sacrifice in order to achieve that goal.
Dans cette recherche de simplicité, j’ai essayé de remettre en question chaque concept de programmation, chaque bonne pratique, chaque bibliothèque, chaque ligne de code. J’ai essayé de produire un prototype qui soit un peu plus conséquent que celui proposé à Confoo pour voir jusqu’où cela pouvait aller. Ce qu’il me manque c’est non pas du temps de développement mais du temps de vie du projet pour analyser les effets produits sur le moyen terme. Je devrais avoir l’occasion d’expérimenter cela avec scopyleft prochainement, ça sent la trilogie.
À court terme en tout cas, c’est extrêmement plus fun à coder et l’on arrive au résultat finalement aussi rapidement. Cela devient une matière beaucoup plus malléable, dont on connait les forces et les faiblesses car le périmètre est réduit. En contrepartie, certains cas aux limites vont être écartés et l’expérience de certains utilisateurs se dégrade plus rapidement. Ce n’est pas que le coût de prise en compte soit énorme, il s’agit davantage de le prendre en considération lorsque le besoin est réel.
Autre extrait :
Maintenance
Capitalism excels at innovation but is failing at maintenance, and for most lives it is maintenance that matters more
Innovation is overvalued. Maintenance often matters more (cache)
Le problème ici c’est que je n’ai jamais rencontré de projet qui réduisent leur complexité dans le temps. Que ce soit via des itérations de retrait ou des réécritures complètes on arrive toujours à des usines à gaz si l’on ne s’est pas fixé en amont — de manière consentie par toutes les parties prenantes — les budgets évoqués plus haut. Pourtant en restant à l’échelle du microlith, la maintenance se trouverait potentiellement réduite de beaucoup.
Si l’on s’en tient à l’estimation selon laquelle la maintenance représente 67% d’un produit (cache), il devient important de trouver comment réduire ce coût.
Autre extrait :
Frameworks, API et prolétarisation
La présentation 6 reasons why APIs are reshaping your business fait l’analogie du développement Web avec l’industrie automobile et le passage de l’artisanat à l’intégration de pièces toutes faites.
Si le passage aux frameworks JavaScript et CSS a entraîné la perte de savoir des développeurs front-end et leur prolétarisation, le passage aux API va avoir le même effet sur les développeurs back-end, ceux-ci devenant de simples intégrateurs de solutions existantes s’éloignant de la problématique métier et de ses données pour se perdre dans les couches du pragmatisme. N’oubliez pas qu’en facilitant le travail de la machine, on finit par être remplacé par la machine, c’est ce que nous réserve l’industrialisation du Web. Et ça me rend nostalgique.
Autre extrait :
A system where you can delete parts without rewriting others is often called loosely coupled, but it’s a lot easier to explain what one looks like rather than how to build it in the first place.
Even hardcoding a variable once can be loose coupling, or using a command line flag over a variable. Loose coupling is about being able to change your mind without changing too much code.
Write code that is easy to delete, not easy to extend (cache)
Partant de ce constat, j’ai essayé de produire une stack minimaliste qui comportent très peu de dépendances qui peuvent évoluer en fonction du besoin. De cette manière, on accède à un LEAN technique : l’ajout de complexité architecturale en fonction du besoin uniquement.
Le code produit accorde une place importante à l’esthétique et à la modularité sans endommager la compréhension de l’ensemble grâce à la documentation et aux tests.
Autre extrait :
Thus teams are often confronting the uncomfortable choice between a risky refactoring operation and clean amputation. The best developers can be positively gleeful about amputating a diseased piece of code (even when it’s their own baby, so to speak), recognizing that it’s often the best choice for the overall health of the project. Better a single module should die than continue to bog down the rest of the project.
…
The organic, evolutionary nature of code also highlights the importance of getting your APIs right. By virtue of their public visibility, APIs can exert a lot of influence on the future growth of the codebase. A good API acts like a trellis, coaxing the code to grow where you want it. A bad API is like a cancer, and it will metastasize all over your codebase.
L’intérêt de partir d’un périmètre aussi restreint est de pouvoir se ré-interroger à chaque nouvel ajout sur sa pertinence, cela constitue une base itérative sans renoncer au plaisir technique. Le code est lisible et explicable en quelques heures pour des personnes ayant un faible niveau et il n’y a pas besoin de télécharger la moitié d’internet pour faire tourner une page web. Ma démarche est de renoncer à la complexité par défaut qui est prônée par tous les frameworks actuels, l’ajout de dépendances doit se faire au moment du besoin.
La durée de vie d’une composition de technologies est forcément réduite et demande de se ré-interroger à échéances régulières sur sa pertinence. Toute la difficulté actuelle est de pouvoir allonger ces échéances pour trouver le bon ratio entre focus et exploration. Plus vous bâtirez sur des concepts simples, universels et standardisés, plus vous aurez de chances de pouvoir être conservateur dans votre choix technique. Et plus vous serez inclusif auprès des potentiels contributeurs.
Journal du vendredi 16 août 2024 à 11:39
#JaiLu la note de David Larlet nommée Initiateurs et mainteneurs.
There are two roles for any project: starters and maintainers. People may play both roles in their lives, but for some reason I’ve found that for a single project it’s usually different people. Starters are good at taking a big step in a different direction, and maintainers are good at being dedicated to keeping the code alive.
…
I am definitely a starter. I tend to be interested in a lot of various things, instead of dedicating myself to a few concentrated areas. I’ve maintained libraries for years, but it’s always a huge source of guilt and late Friday nights to catch up on a backlog of issues.
Je suis également un initiateur. J’aime créer de nouvelles choses en expérimentant des usages et des techniques. Lorsque je me retrouve dans un rôle de mainteneur, j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses. Or l’apprentissage nait de l’échec et du test des limites. C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. À moins que la maintenance soit un vestige du passé (cache).
-- from
Ces réflexions résonnent profondément en moi 🤗, car ce sont des questions et des pensées qui m'habitent depuis de nombreuses années.
« j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses »
Pour éviter cette tendance à complexifier l’existant, j'utilise la stratégie suivante. Lorsque je ressens le besoin d'expérimenter ou d'apprendre quelque chose de nouveau, je le fais au travers des side projects personnels ou dans le cadre de POC (Proof of Concept) et Spike officiellement décidés en équipe. C'est entre autres pour cette raison que j'avais proposé de mettre en place les Spike and Learn Day.
Cette approche me permet de satisfaire ma curiosité et mon envie d'apprendre, tout en maintenant l'utilisation de Boring Technology pour les projets critiques ou ceux menés en équipe. Ainsi, je parviens à éviter le piège du Resume Driven Development.
J'aime bien la distinction suivante :
« There are two roles for any project: starters and maintainers »
Jusqu'à présent, j'ai tendance à utiliser le terme solo développeurs pour les "starters" et team développeurs pour les "maintainers".
Petite anecdote amusante : lors de mon expérience chez Spacefill, j'avais proposé de nommer le rôle des développeurs d'expérience au sein de l'équipe les "maintainers" 😉.
« C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. »
C'est une réflexion que j'ai moi-même eue par le passé.
Je crois en effet que les solo développeurs apprécient particulièrement les microservices et les multi repositories car cela leur permet d'éviter les contraintes d'équipes.
Cela leur permet d'explorer des nouveaux langages et frameworks et d'échaper aux revues de code.
À mes yeux, cette approche favorise davantage l'individualisme que la cohésion d'équipe.
J'ai également remarqué que c'est souvent lors des phases de storming du modèle de Tuckman que les développeurs semblent se tourner vers les microservices comme une forme d'évitement des défis collectifs. Cette stratégie peut sembler séduisante, mais elle risque de renforcer les silos et de freiner la collaboration au sein de l'équipe 🤔.
Journal du vendredi 16 août 2024 à 11:30
#JaiDécouvert l'expression Core-stack developer dans cet article de David Larlet :
… when in doubt, focus on the core. When in doubt, learn CSS over any sort of tooling around CSS. Learn JavaScript instead of React or Angular or whatever other library seems hot at the moment. Learn HTML. Learn how browsers work. Learn how connections are established over the network.
The reason for focusing on the core has nothing to do with the validity of any of those other frameworks, libraries or tools. On the contrary, focusing on the core helps you to recognize the strengths and limitations of these tools and abstractions. A developer with a solid understanding of vanilla JavaScript can shift fairly easily from React to Angular to Ember. More importantly, they are well equipped to understand if the shift should be made at all. You can’t necessarily say the same thing about an INSERT-NEW-HOT-FRAMEWORK-HERE developer.
Building your core understanding of the web and the underlying technologies that power it will help you to better understand when and how to utilize abstractions.
That’s part one of dealing with the rapid pace of the web.
À défaut d’être complet (full) en raison de l’effervescence technique difficile à suivre au quotidien, il me semble de plus en plus pertinent de miser sur le cœur (core) des technologies utilisées. Comprendre et maîtriser les bases avant tout pour pouvoir ponctuellement et rapidement se spécialiser en fonction du besoin. Connaître ES6 vous servira ces 10 prochaines années, savoir utiliser React sera obsolète l’année prochaine. Sages développeurs, investissez.
-- from
Core-stack developer me fait penser à Choose Boring Technology et à mon article nommé Sur quelles compétences j'ai décidé ou non d'investir mon temps ?. Je me rends compte rétrospectivement que j'ai listé ma core-stack 🙂.
Journal du vendredi 16 août 2024 à 11:12
Je viens de lire la note "EndOfPage" de David Larlet dans laquelle il explique pourquoi il arrête de publier des articles en Anglais et retourne à sa langue native, le Français.
I decided to switch from English to French as my blogging language so this post is the last one in English for a few reasons:
- I started to write in English to somehow extend my audience given that I went to Japan and only a very few Japanese people are reading French. I’m pretty sure no Japanese at all ever read that page so I can consider this as a failure, I realized way too late that integration is before all about working together in Japan :-).
- It looks like Craig Kerstiens is the only one reading English-only across my few readers (thank you!), probably because my vocabulary and grammar are so bad or my thoughts far from those of another country. Anyway, trying to think in English was a good experiment but now I need to improve myself via discussion, not unidirectional writing anymore.
- ...
- I want to be involved locally, from OpenData to (micro)events, and to interact with my French peers. Moreover, I’m trying something new with Scopyleft and I’m sure that feedback about that adventure is more valuable for French people too.
Je vous vois demain !
-- from
Je trouve ce retour d'expérience particulièrement intéressant.
Traduction ChatGPT :
J'ai décidé de passer de l'anglais au français pour mes publications de blog, et ce post sera le dernier en anglais, pour plusieurs raisons :
- J'avais commencé à écrire en anglais pour élargir mon audience, notamment parce que je vivais au Japon et que très peu de Japonais lisent le français. Il se trouve que probablement aucun Japonais n'a jamais lu cette page, donc je considère cela comme un échec. J'ai réalisé bien trop tard que l'intégration au Japon passe avant tout par le travail collaboratif.
- Il semble que Craig Kerstiens soit le seul à lire mes articles en anglais parmi mes rares lecteurs (merci à lui !), probablement parce que mon vocabulaire et ma grammaire laissent à désirer, ou que mes pensées sont trop éloignées de celles d'autres cultures. Quoi qu'il en soit, essayer de réfléchir en anglais a été une bonne expérience, mais je ressens maintenant le besoin de m'améliorer à travers des discussions plutôt que par une écriture unidirectionnelle.
- ...
- Je souhaite m'impliquer localement, de l'OpenData aux (micro)événements, et interagir avec mes pairs francophones. De plus, je me lance dans une nouvelle aventure avec Scopyleft, et je suis convaincu que les retours d'expérience seront plus pertinents pour un public français.
Je vous dis à demain !
[ << Notes plus récentes (604) ] | [ Notes plus anciennes (374) >> ]