
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (801) ] [ Notes plus anciennes (258) >> ]
Dimanche 28 juillet 2024
Journal du dimanche 28 juillet 2024 à 09:14
Pour des raisons Developer eXperience — convivialité — j'apprécie d'avoir la possibilité de me connecter facilement à un serveur PostgreSQL distant, par exemple, pour :
- Simplement ouvrir un terminal interactif psql ;
- Exécuter un fichier SQL local sur un serveur distant ;
- Exécuter un script local, Python, JavaScript ou autre sur un serveur distant.
Cependant, par choix déontologique, je préfère ne jamais ouvrir PostgreSQL sur l'extérieur.
Je me limite à ouvrir uniquement les services SSH et HTTP sur l'extérieur.
Pour contourner cette limitation, j'utilise des tunnels SSH pour accéder à mes serveurs PostgreSQL distants.
Dans ce dossier /deployment/develop, voici mes scripts idiosyncrasiques que j'ai l'habitude d'utiliser pour ouvrir ou fermer mes tunnels SSH :
Voici un exemple d'utilisation :
$ ./scripts/open_ssh_tunnel_postgres.sh
$ ./scripts/enter-in-pg.sh ../../init.sql
$ ../../import.js
$ ./scripts/close_ssh_tunnel_postgres.sh
Dans les scripts open_ssh_tunnel_postgres.sh et close_ssh_tunnel_postgres.sh, j'utilise simplement nohup pour exécuter ssh en tâche de fond et récuperer son PID.
Samedi 27 juillet 2024
Journal du samedi 27 juillet 2024 à 14:00
#JaiLu le thread Hacker News "An experiment in UI density created with Svelte | Hacker News" et j'ai trouvé cela très intéressant.
Le bon dosage de la densité d'affichage est un élément très important dans mon expérience utilisateur.
#JaiDécouvert la librairie frontend web nommée DataTables (https://datatables.net/) implémentée en Javascript basée sur jQuery.
I'd like to think projects like these are somehow signaling a return to well designed but information dense, space saving interfaces ...
The amount of bloat, whitespace, extra spacing, "air" and other such waste — starting with (now Google-dead) "Material Design" has been egregious. —
#JaiDécouvert Perspective (https://perspective.finos.org/), j'aime beaucoup la densité des grilles. Voici un exemple en full screen : https://perspective.finos.org/blocks/editable/index.html.
J'aime sa densité et sa vitesse de rendu 👌.
This is interesting because it proves something to me about my vision and visual comprehension.
The "Grid" view is absolutely fine for me. The "Table" view is unworkable.
Intéressant 🤔.
J'ai regardé une partie de la vidéo de présentation du Bloomberg Terminal (https://www.youtube.com/watch?v=2ee-x6IXWK8), j'ai trouvé l'UI très intéressante.
Vendredi 26 juillet 2024
Journal du vendredi 26 juillet 2024 à 15:08
#OnMaPartagé Storj, une solution de Object Storage alternative à Backblaze, Scaleway Object Storage…
Get faster cloud object storage at 90% less cost than AWS S3 while dramatically reducing your data’s carbon footprint.

J'ai vérifié, Storj semble bien supporter l'API S3 : https://storj.dev/dcs/objects
Jeudi 25 juillet 2024
Journal du jeudi 25 juillet 2024 à 16:56
Rich Harris explains this clearly. JSDoc for writing a lib. TypeScript for writing an app. (from)
Ce conseil entre en opposition avec ce que j'ai écrit en octobre 2023 :
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Ce conseil entre aussi en opposition avec ce second élément que j'ai écrit en octobre 2023 :
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Je pense qu'il serait bon que je revoie ma doctrine d'artisan développeur sur ce sujet.
Journal du jeudi 25 juillet 2024 à 15:24
#JaiDécouvert shadcn-svelte et donc shadcn-ui.
En cherchant des informations au sujet de shadcn-ui, #JaiDécouvert ici Franken UI.
Dans la documentation de shadcn-ui je lis :
This is NOT a component library. It's a collection of re-usable components that you can copy and paste or use the CLI to add to your apps.
What do you mean not a component library?
It means you do not install it as a dependency. It is not available or distributed via npm, with no plans to publish it.
Je trouve cela intéressant, #Jaime .
Dans la page About de shadcn-svelte :
- #JaiDécouvert bits-ui une lib Svelte Headless components, utilisé par shadcn-svelte
- #JaiDécouvert cmdk-sv
- #JaiDécouvert Formsnap
Mercredi 24 juillet 2024
Journal du mercredi 24 juillet 2024 à 13:30
Je viens de recevoir mon Shokz OpenMove, écouteur à conduction osseuse.

Voici mon bilan :
- Très agréable à porter : c'est léger et j'ai l'impression de ne rien porter ;
- Je me sens bien plus libre qu'avec un dispositif sur les oreilles ;
- Le volume est bon, bien que je pense ne rien entendre lorsque je passe l'aspirateur ;
- Je dois éviter de mettre le volume trop fort si j'écoute une personne avec une voix très grave, sinon, j'ai une sensation de vibration ;
- J'ai testé un appel téléphonique, et mon interlocuteur m'a bien entendu.
- Je constate que la solution conduction osseuse est bien plus efficace que la technologie Sidetone.
J'ai hâte de tester en visioconférence pour voir si je continue à parler dans le micro ou non 😉.
Ayant perdu un écouteur de mon Jabra Elite 5, je cherchais une alternative pour le remplacer. (from)
Au passage, je viens de retrouver mon écouteur 🙈.
Achat compulsif ? 🤔
Mardi 23 juillet 2024
Journal du mardi 23 juillet 2024 à 22:46
#JaiDécouvert https://github.com/idealclover/RSS-OPML-to-Markdown
🎁 Convert RSS OPML file to Markdown - easy to read and share
Journal du mardi 23 juillet 2024 à 22:37
Je viens de créer la page Mon usage des réseaux sociaux.
Journal du mardi 23 juillet 2024 à 22:19
Je profite de la question 2024-07-23_2219 pour commencer la migration du contenu des issues :
- Écrire une page "garden" de liste des Subreddit que je suis et ce que j'y trouve
- Écrire un article pour expliquer les sites de contenu ou réseaux sociaux que j'utilise et je n'utilise pas
vers la page "Où est-ce que je m'informe, où est-ce que je vais chercher de la connaissance ?".
Journal du mardi 23 juillet 2024 à 21:08
« C'est quoi vos 3 meilleures sources de veille ? Par source j'entends,l'endroit ou vous allez chercher vos informations (Un channel reddit précis, un site précis, etc...) »
Voici mes habitudes quotidiennes de veille informatique, technologique et anglo-saxonne :
-
- En premier, je consulte https://lobste.rs/ ;
-
- Ensuite, Hacker News, soit directement via https://news.ycombinator.com/ ou alors via mon instance miniflux ;
-
- Ensuite, mon instance miniflux ;
-
- Ensuite, mon flux Fediverse : https://mamot.fr/deck/@stephane_klein.
Très souvent, je m'arrête à l'étape 2, car comme je lis surtout les commentaires, cela me prend beaucoup de temps.
Pour les actualités :
- Souvent https://www.youtube.com/@HugoDecrypte ;
- Souvent Le 6/9 de France Inter ;
- Et rarement Brief.me (je suis abonné).
Au quotidien :
- Mon flux YouTube (voir Je suis abonné à ces chaines YouTube) ;
- Et les Podcasts de Radio France.
Je n'utilise pas le feed de suggestion de YouTube, je consulte mes abonnements.
#JutilisePeu Twitter (de moins en moins).
- J'utilise actuellement Facebook uniquement comme un carnet d'adresse + quelque Goupe, je ne consulte presque jamais mon feed
- J'utilise LinkedIn uniquement comme un carnet d'adresse. Je ne consulte presque jamais mon feed
- TikTok
Journal du mardi 23 juillet 2024 à 16:27
Suite à cette limitation de Scaleway :
J'ai pourcouru la documentation et l'espace client de Scaleway et je pense qu'un utilisateur ne peux pas créer d'organisation supplémentaire. (from)
#JaiPosté https://feature-request.scaleway.com/posts/941/allow-a-user-to-create-multiple-organizations
Journal du mardi 23 juillet 2024 à 15:54
#JaiDécouvert que Scaleway a déployé en public beta une offre d'Managed Inference Service : Scaleway Managed Inference.
Added : Managed Inference is available in Public Beta
Managed Inference lets you deploy generative AI models and answer prompts from European end-consumers securely. Now available in public beta! (from)
C'est une alternative à Replicate.com.
Models now support longer and better conversations :
- All models on catalog now support conversations to their full context window (e.g Mixtral-8x7b up to 32K tokens, Llama3 up to 8k tokens).
- Llama3 70B is now available in FP8 quantization, INT8 is deprecated.
- Llama3 8b is now available in FP8 quantization, BF16 remains default.
L'offre est beaucoup moins large que celle de Replicate mais c'est un bon début 🙂.
Tarif de l'offre de Scaleway :
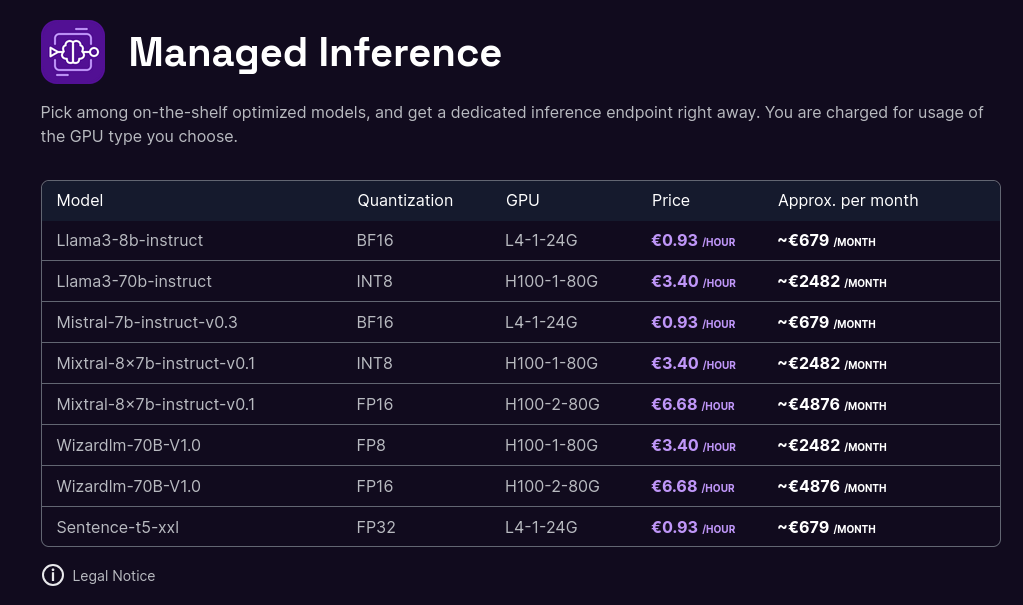
Tarif de l'offre de Replicate.com :
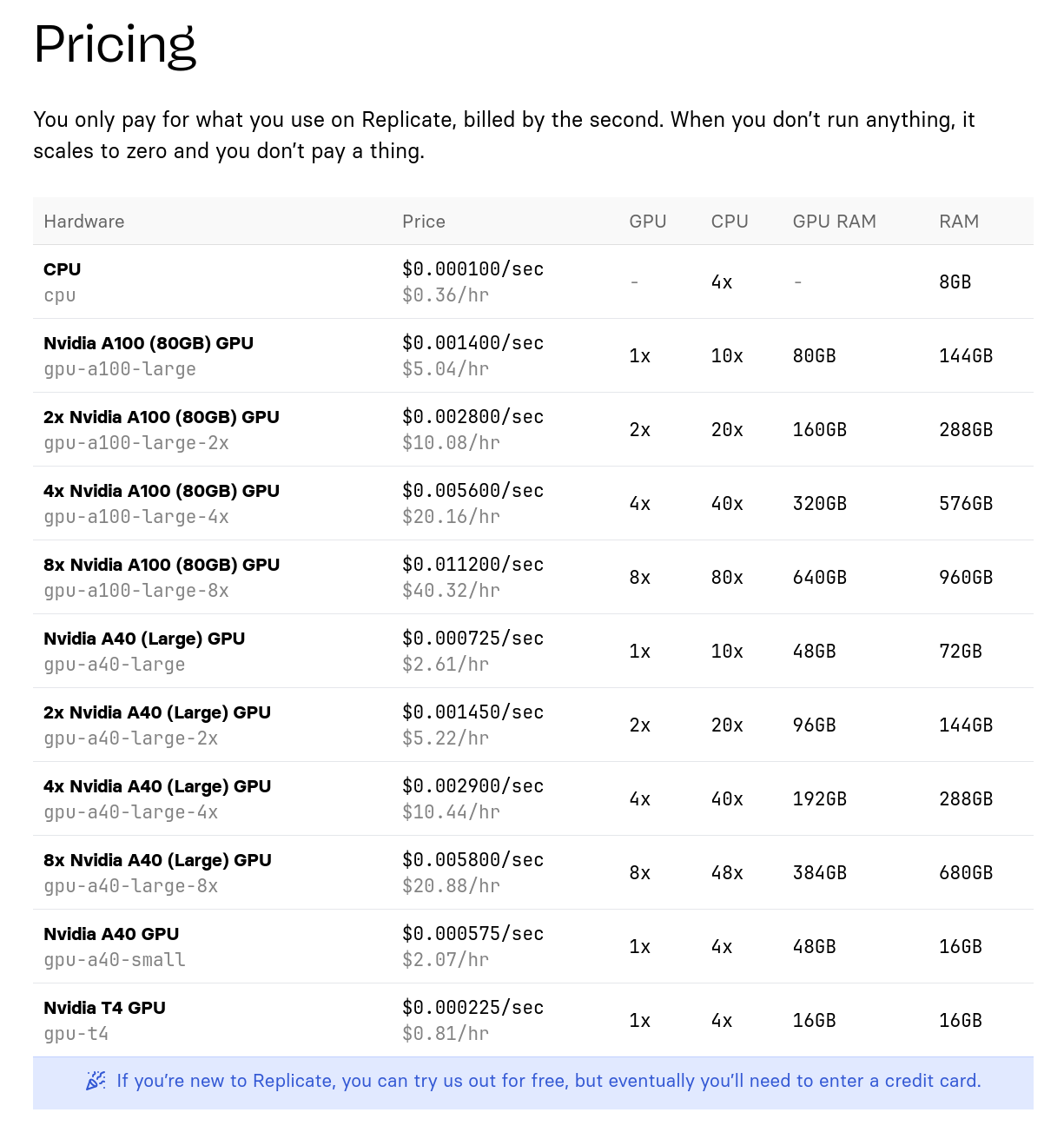
Bien que le matériel soit différent, j'essaie tout de même de faire une comparaison de prix :
- Scaleway : 0,93 € / heure pour une machine à 24Go de Ram GPU
- Replicate : 0,81 $ / heure pour une machine à 16GB de Ram GPU
Ensuite :
- Scaleway : 3,40 € / heure pour une machine à 80Go de Ram GPU
- Replicate : 5,04 € / heure pour une machine à 80Go de Ram GPU
Je précise, que je n'ai aucune idée si ma comparaison a du sens ou non.
Je n'ai pas creusé plus que cela le sujet.
Note en lien avec 2024-05-17_1257.
Journal du mardi 23 juillet 2024 à 15:38
Je dois créer une Organization Scaleway pour un client.
Je souhaite que ce client soit propriétaire de l'organisation.
Je souhaite pouvoir administrer totalement cette organisation, mais je souhaite aussi pouvoir quitter cette organisation.
Je lis ici :
An Organization is made of one or several Projects. When you create your Scaleway account, an Organization is automatically created, of which you are the Owner.
J'ai parcouru la documentation et l'espace client de Scaleway et je pense qu'un utilisateur ne peut pas créer d'organisation supplémentaire.
D'après ce que j'observe, une Organization appartient à un user.
Partant de ce constat, voici la méthode que j'imagine afin de créer une organisation que je peux céder.
- Je crée une organisation avec une adresse mail spécifique, du type
contact+ownernomduclient@stephane-klein.info - J'invite mon client dans cette organisation
- Si besoin, je m'invite moi-même via une autre adresse mail, exemple
contact+nomduclient@stephane-klein.info - Plus tard, je peux changer l'adresse mail dans "Edit your account profile" pour céder l'organization à l'adresse mail du client.
Suite à cette limitation, j'ai posté Allow a user to create multiple organizations sur Scaleway Feature Request.
Journal du mardi 23 juillet 2024 à 09:48
Ayant perdu un écouteur de mon Jabra Elite 5, je suis en train d'étudier par quoi le remplacer.
L'hiver dernier, j'ai croisé un utilisateur de casque à conduction osseuse, il était fan.
Je viens de passer un peu de temps à étudier les modèles vendu sur Amazon et #JaiDécouvert la marque Skokz.
Je découvre ici qu'il existe de type de technologie d'écoute à oreilles libres : conduction osseuse et DirectPitch.
#JaiCommandé le modèle Shokz OpenMove à 89,95 €.
Lundi 22 juillet 2024
Journal du lundi 22 juillet 2024 à 15:15
Merci à Alexandre de m'avoir partagé le projet Mailpit une alternative à Maildev ou MailCatcher.
Samedi 20 juillet 2024
Vendredi 19 juillet 2024
Journal du vendredi 19 juillet 2024 à 23:51
Suite à la lecture de https://github.com/passlock-dev/svelte-passkeys j'ai envie de tester Passkey.
Journal du vendredi 19 juillet 2024 à 23:40
#JaiLu What's new in Svelte: July 2024
#JaiLu What's new in Svelte: June 2024
Tons of work on the migrate tool to make migrating to Svelte 5 syntax easier
J'ai hâte de tester pour constater les changements dans le code et aussi constater si cela cette outil fonctionne correctement ou non 🤔.
Journal du vendredi 19 juillet 2024 à 23:16
Pour la génération de nanoid du Projet 11, j'ai choisi les paramètres suivants :
const nanoid = customAlphabet('0123456789abcdefghijklmnopqrstuvwxyz', 12);
D'après les calculs effectués sur https://zelark.github.io/nano-id-cc/, à raison de 100 nouvelles notes par jour (ce qui est irréaliste), sur 352 années, le risque de doublon d'id est de 1%, ce qui est largement acceptable 😉.
Journal du vendredi 19 juillet 2024 à 22:44
Je viens de publier Projet 11 - "Première version d'un moteur web PKM".
Journal du vendredi 19 juillet 2024 à 18:07
#JaiDécouvert le terme Inkling (from : Spaced repetition may be a helpful tool to incrementally develop inklings) qui signifie :
Le terme "inkling" en anglais signifie une vague idée ou une intuition.
Journal du vendredi 19 juillet 2024 à 18:06
#JaiDécouvert Timeful Texts de Andy Matuschak.
Consider texts like the Bible and the Analects of Confucius. People integrate ideas from those books into their lives over time — but not because authors designed them that way. Those books work because they’re surrounded by rich cultural activity. Weekly sermons and communities of practice keep ideas fresh in readers’ minds and facilitate ongoing connections to lived experiences. This is a powerful approach for powerful texts, requiring extensive investment from readers and organizers. We can’t build cathedrals for every book. Sophisticated readers adopt similar methods to study less exalted texts, but most people lack the necessary skills, drive, and cultural contexts. How might we design texts to more widely enable such practices?
Cela rejoint une réflexion que j'ai eue concernant les documentations d'onboarding ou handbook d'organisation.
Problème
Il est courant de demander à aux nouveaux employés d'une startup de lire la documentation d'onboarding ou le handbook de l'organisation.
En pratique, je trouve cela peu efficace. Les premiers jours ou heures dans une nouvelle organisation sont souvent à la fois excitants et stressants. C'est une période où les individus cherchent à créer des liens, à rencontrer les autres et à comprendre qui est qui. Conséquence : je pense qu'il est difficile d'entrer en deepflow de lecture pendant cette période. Les personnes onboardé survolent la documentation et je trouve cela tout à fait justifié.
D'autre part, les informations détaillées contenues dans ces documents n'auront que peu de signification au début et ne deviendront pertinentes qu'après plusieurs semaines passées au sein de l'organisation. Et malheureusement, je constate que si les autres membres de l'équipe ne l'invitent pas, la personne onboardé retourne rarement elle-même consulter des détails bien utiles dans la documentation.
Solution humaine
Pour pallier ce problème, lors de ma dernière expérience, j'ai mis en place un système de parrain attribué à chaque nouvelle personne. Le parrain était là pour répondre à toutes les questions du nouvel arrivant et le rediriger vers les bonnes sections de la documentation.
Idée technique
En 2022, j'imaginais un système basé sur un chatbot (pour Slack ou autre) qui enverrait, de manière espacée dans le temps des liens vers des sections de la documentation à lire.
Ce chatbot pourrait aussi poser des questions, pour vérifier si la personne est au courant d'éléments contenus dans la documentation.
Cela ressemble au projet Timeful Texts 🤔.
[!Note au lecture] Pour bien comprendre le lien, je vous invite à lire l'intégralité de l'article et pas seulement l'extrait cité au début de cette note.
Journal du vendredi 19 juillet 2024 à 17:48
Il y a un an, j'envisageais de self hosted une alternative à Pocket, par exemple Shiori, Wallabag et pour finir, j'avais une préférence pour Linkding.
Maintenant que j'utilise un Personal knowledge management, je ne trouve plus d'intérêt à utiliser un logiciel de bookmark manager.
À la place, j'utiliser le tag #JaiDécouvert… et si je trouve de l'intérêt au lien, je crée une Evergreen Note.
Journal du vendredi 19 juillet 2024 à 17:35
J'ai passé 10min à étudier ce projet, je n'ai pas vraiment compris ses caractéristiques, mais j'y ai trouvé des choses qui ont attiré ma curiosité. #JaimeraisUnJour prendre du temps pour étudier Atomic Data en profondeur.
En lien avec Systèmes d’organisation des connaissances.
Journal du vendredi 19 juillet 2024 à 12:35
Je suis surpris de ne pas trouver de Hub note dans Taxonomie des types de notes de Andy et Taxonomie des types de notes listé dans le livre « How to Make Notes and Write ».
Journal du vendredi 19 juillet 2024 à 10:49
Note au sujet de mon usage des Notes éphémères est imprécis.
En avril 2024, j'ai décidé d'utilisé le wording "Notes éphémères" présent dans la taxonomie des types de notes listé dans le livre « How to Make Notes and Write ».
Mais j'ai bien conscient que mon usage de ces notes est pour le moment imprécis, je ne sais pas si je dois classer mes Notes éphémères dans la catégorie Daily working log ou Writing inbox de Taxonomy of note types. Je pense que je mélenge ces deux concepts.
En plus de ces Notes éphémères publiques, j'écris aussi des notes éphèmeres dans un Vault Obsidian privé.
Jeudi 18 juillet 2024
Journal du jeudi 18 juillet 2024 à 21:27
#JaiLu commencé à lire https://notes.andymatuschak.org/Evergreen_notes de Andy's working notes.
Voir aussi Evergreen Note.
Journal du jeudi 18 juillet 2024 à 21:03
#JaiDécouvert un portail qui contient de nombreuses conférences scientifiques : https://portal.sciencesconf.org/browse/list
Mercredi 17 juillet 2024
Journal du mercredi 17 juillet 2024 à 22:53
Dans la page Wikipedia de Paul Otlet #JaiDécouvert Classification décimale universelle et Classification décimale de Dewey.
Journal du mercredi 17 juillet 2024 à 21:19
Dans la vidéo FAQ – juillet 2017 de Monsieur Phi #JaiDécouvert L’Encyclopédie Philosophique.
Journal du mercredi 17 juillet 2024 à 21:07
Dans la vidéo FAQ – juillet 2017 de Monsieur Phi, il conseille le #livre L'influence de l'odeur des croissants chauds sur la bonté humaine de Ruwen Ogien qui traite de la philosophie morale.
Journal du mercredi 17 juillet 2024 à 18:13
Je pense avoir retrouvé le site que Thibaut Giraud mentionne fréquemment, dédié à la philosophie analytique : la Stanford Encyclopedia of Philosophy ou l'Internet Encyclopedia of Philosophy.
Journal du mercredi 17 juillet 2024 à 17:46
En cherchant la définition de mot Diaphories, #JaiDécouvert le #livre : L'Homme-trace - Inscriptions corporelles et techniques.
Journal du mercredi 17 juillet 2024 à 17:25
#JaiDécouvert Luciano Floridi (from)
Floridi s'est fait connaître comme l'un des plus importants théoriciens de la philosophie de l'information et éthique de l'informatique, reconnu comme une autorité dans le domaine de la philosophie sur Internet. (from).
Luciano Floridi enseigne comme professeur associé de logique et d’épistémologie au département de philosophie de l'université de Bari. (from)
Journal du mercredi 17 juillet 2024 à 17:23
Je tente de comprendre la signification du mot Diaphories que j'ai découvert dans l'article Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret.
Après avoir partiellement lu :
- #JaiLu Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
- #JaiLu Quelques révisions du concept d’information.
- Cette citation :
"La donnée correspond, quant à elle, à ce qui n’est pas uniforme (à ce qui est « diaphora/différent ») ; bref il s’agit d’une variable : « une donnée est un fait supposé qui procède d’une différence ou d’un manque d’uniformité dans un contexte »" (source).
Je constate que je ne suis pas certain d'avoir bien compris la signification de Diaphories.
Voici un exemple pour illustrer ce que je pense avoir compris : imaginons une pelouse totalement uniforme. Si cette pelouse contient une fleur, cet élément, différent (du grec ancien διαφορά, diaphorá (« différence, distinction »)) de l'homogénéité de la pelouse, est une information. Sa couleur, sa localisation… sont des données, des Diaphories.
Mardi 16 juillet 2024
Journal du mardi 16 juillet 2024 à 13:44
#JaiLu Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret publié sur HAL.
La documentation personnelle peut être définie comme la documentation élaborée par un individu pour lui-même, de manière idiosyncrasique.
#JaiDécouvert le mot Idiosyncrasique.
#JeMeDemande si la condition « pour lui-même » est dépassable ou non 🤔.
(Psychologie) Caractères propres au comportement d’un individu particulier. (from).
Élaborer une documentation personnelle permet d’organiser le processus de « signifiance » (Leleu-Merviel, 2010) pour construire des connaissances (voir figure 1).
#JaiDécouvert la chercheuse Sylvie Leleu-Merviel.
#JeSouhaite lire Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
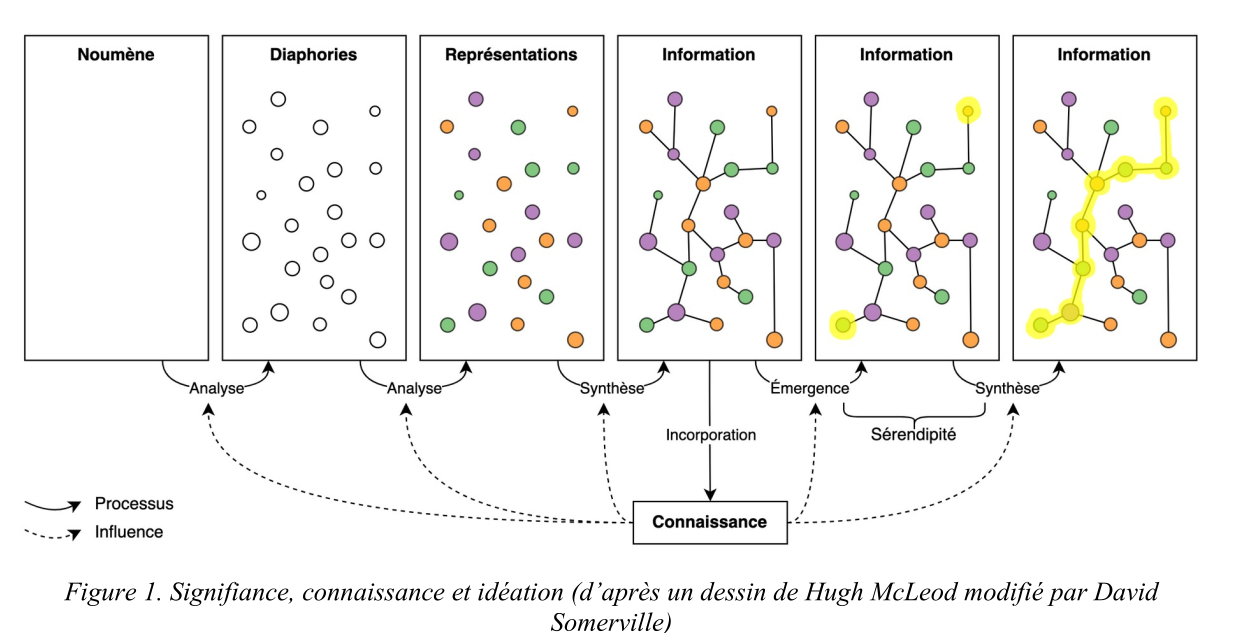 #JaiDécouvert les mots Noumène, Noème et Diaphories.
#JaiDécouvert les mots Noumène, Noème et Diaphories.
Comme l’écrit Latour (dans « Pensée retenue, pensée distribuée »), la pensée n’est pas « retenue » dans l’unique cerveau du penseur, mais « distribuée » dans un ensemble d’acteurs et d’actants – un « milieu de savoir » selon l’expression de Le Deuff : données et documents, individus et collectifs, lieux, évènements et dispositifs divers.
#JaiDécouvert Traité de documentation de Paul Otlet.
#JaiDécouvert Robert Estivals et Communicology.
L’approche hypertextuelle présente plusieurs avantages par rapport aux graphes de connaissance, notamment une mise en œuvre plus simple et une plus grande expressivité. Cette méthode produit ce que Stiegler (Le concept d’ « Idiotexte » : esquisses - 2010) appelle un idiotexte, c’est-à-dire la textualisation d’une mémoire personnelle. L’utilité primaire de cette méthode, pour l’individu qui crée sa documentation personnelle, est de multiplier les chemins vers une même information, via des connexions riches en signification et facilement réactivées.
#JaiDécouvert idiotexte, j'ai lu l'article mentionné et je ne l'ai pas compris 🙅♀️.
Cette méthode présente également un intérêt pour les recherches sur les systèmes d’organisation des connaissances (SOC). Mazzocchi (2018) définit les SOC comme des ensembles de termes ou concepts interreliés, outils intermédiaires entre des humains et des collections de données et documents. Dans la méthode que nous avons décrite, la création d’un graphe documentaire correspond à la fois à la création d’une collection de documents – les fiches – et d’un SOC – les catégories de fiches et de liens utilisées dans le graphe.
#JaiDécouvert Systèmes d’organisation des connaissances (SOC).
D’abord, cette méthode est orientée par la subjectivité : les choix qui guident l’élaboration du graphe sont basés sur la mémorabilité, critère hautement subjectif.
Ok, j'ai bien compris 👌.
Par exemple, des catégories de fiches peuvent être modifiées, supprimées ou ajoutées progressivement pour orienter la manière dont fonctionne la remémoration.
Ok, j'ai bien compris 👌.
#JaiDécouvert L’épistémologie sociale (from)
J'ai pris le temps de regarder https://www.arthurperret.fr/glossaire-indexation.html, j'ai trouvé des choses intéressantes, du vocabulaire pour nommer des éléments techniques des CMS.
Ces configurations affectent la manière dont nous remémorons les choses : nous nous disons par exemple « J’ai mentionné ce concept dans telle publication » ou bien « C’est untel qui m’a recommandé cette méthode ». Ces connexions idiosyncrasiques sont facilement réactivées car elles reposent sur des éléments ayant une grande « mémorabilité » – terme qui renvoie aux arts de la mémoire et que nous entendons ici comme une qualité déterminée subjectivement, de manière réflexive, à partir de situations essentiellement contingentes, qui modifient notre « comportement informationnel ».
Je comprends très bien ce qui est exprimé et cela correspond à mon expérience vécu.
Journal du mardi 16 juillet 2024 à 09:57
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
- Extraction des tags présents dans le corps des notes.
C'est fait 🙂 : Extract tags from note bodies to create and associate them with the note
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
C'est fait 🙂 : Implementation of a markdown-to-html rendering function that takes tags and wikilinks into account
J’ai préparé une première ébauche, mais étant incertain de la manière dont je vais intégrer cette fonctionnalité avec pg_search ou Typesense, j’ai décidé de ne pas continuer à la développer pour le moment : Implementation of a function that transforms markdown content into plain text.
Lundi 15 juillet 2024
Journal du lundi 15 juillet 2024 à 15:25
Suite de 2024-07-14_1211 en lien avec Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search.- Créer un repository GitHub nommé
obsidian-vault-to-typesense.- Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc
C'est fait 🙂.
Après cela, je souhaite implémenter dans
obsidian-vault-to-apache-age-pocles fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]).
C'est implémenté par ce commit 🙂.
Je ne suis pas satisfait de l'implémentation de cette partie et celle-ci.
Journal du lundi 15 juillet 2024 à 14:45
Dans l'épisode Combien d'argent il faut pour être vraiment riche … du Podcast Le Trilliard #JaiDécouvert le #livre The Gatekeepers: How the White House Chiefs of Staff Define Every Presidency. Je trouve le sujet intéressant, #UnJourPeuxÊtre je prendrais le temps de le lire.
Dimanche 14 juillet 2024
Journal du dimanche 14 juillet 2024 à 12:11
Avec l'intégration de pg_search et Typesense, j'ai bien conscience de m'être un peu perdu dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Pour résoudre ce problème, j'ai décidé de :
- Créer un repository GitHub nommé
obsidian-vault-to-pg_search. - Créer un repository GitHub nommé
obsidian-vault-to-typesense. - Supprimer les intégrations pg_search et Typesense de
obsidian-vault-to-apache-age-poc.
Après cela, je souhaite implémenter dans obsidian-vault-to-apache-age-poc les fonctionnalités suivantes :
- Création des liaisons entre les notes basées sur les wikilink (
[[Internal links]]). - Extraction des tags présents dans le corps des notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en HTML avec les bons liens HTML vers les tags et autres notes.
- Implémentation d'une fonction qui transforme le corps markdown d'une note en texte brut, sans lien, destiné à être injecté dans un moteur de recherche comme pg_search ou Typesense.
Après avoir traité ces tâches, je souhaite travailler sur un moteur de rendu HTML basé sur SvelteKit, obsidian-vault-to-apache-age-poc et sans doute obsidian-vault-to-typesense.
Journal du dimanche 14 juillet 2024 à 10:26
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans 2024-07-10_0941 je disais :
je souhaite tester l'intégration de Typesense à
obsidian-vault-to-apache-age-pocen complément de pg_search.
Voici un screencast du résulat de cette implémentation de InstantSearch connecté à Typesense :
Journal du dimanche 14 juillet 2024 à 10:08
#JeMeDemande comment Typesense gère le contenu HTML présent dans les champs textes. Ignore-t-il ou non les balises HTML ?
Ici dans la documentation, j'ai trouvé un lien vers l'issue intitulée Feature Request - Ignore any HTML tags when searching but still return response with HTML included.
La solution proposée ne me satisfait pas à 100% :
For a simple solution you could introduce an artificial field where all html tags are removed.
Idéalement, j'aimerais que cette fonctionnalité soit directement prise en charge par Typesense.
[ << Notes plus récentes (801) ] | [ Notes plus anciennes (258) >> ]