
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (350) ] [ Page suivante (76) >> ]
Je découvre Kopia, une alternative à Restic
Alexandre m'a partagé Kopia, logiciel Open source de backup, alternatif à restic.
7000 likes GitHub versus 25000 likes pour Restic.
Je constate que Kopia est développé principalement par 2 développeurs et je constate le même nombre pour Restic.
J'ai parcouru cette page qui date de 2 ans : How Do Kopia Features Compare to Other Backup Software?.
En 2022, il semble que restic ne supportait pas la compression de données, mais je constate via cette Pull Request Implement compression support que cette feature est maintenant intégrée à restic.
#JaiLu en partie le thread Hacker News : Kopia: Fast and secure open-source backup software.
Initially I thought this was a corporate project and was looking for the monetization model, but then I found https://github.com/kopia/kopia/blob/master/GOVERNANCE.md
I feel like the project might benefit from making their governance model more prominent on the website.
-- from
D'après ces commentaires, Kopia est lent à la restauration :
Used it for a while, recently tried to restore some things and it failed, taking a really long time to restore some snapshots compared to other things I've tried. Switched to restic instead. Really like what kopia is but I'll wait a few more years before considering it for something, but right now I'm happy with restic.
This has been my experience too with Kopia.
I tried to restore a ~200 GB file (stored remotely on a Hetzner Storage Box), and it failed (or at least did not finish after being left for ~20 hours; there was also no progress indicator or status I could find in the UI).
I also tried to restore a folder with about ~32 GB of data in it, and that also failed (the UI did report an error, but I don't recall it being useful).
Also, in general use, the UI would get disconnected from the repository every few days, and sometimes the backup overview list would show folders as being size 0 (which maybe indicated they failed; they showed up with an "incomplete" [or similar] tag in the UI).
-- from
Il semble que l'outil Veloro utilisait restic et ait migré vers Kopia :
One thing I will mention is that other backup projects have switched from Restic to Kopia. Velero from VMware comes to mind.
-- from
À ce sujet, j'ai vu Unified Repository & Kopia Integration Design et je n'ai pas tout compris.
Alexandre m'a appris que Veloro supporte pour le moment Kopia et restic mais que le support restic est en train d'être supprimé : Deprecate Restic.
Voilà l'origine du nom 🙂 :
"Kopia" means "copy" in Swedish and probably more Nordic languages, too.
-- from
J'ai vu ce commentaire :
Personally, I've had some issues with Kopia.
I found their explanation here:
Still not solved after many years :(
Ma doctrine pour le moment : je vais rester sur restic.
Journal du lundi 19 août 2024 à 11:27
#JaiLu "Les mathématiques de l'argument d'autorité #DébattonsMieux" de Lê Nguyên Hoang, je trouve cela très intéressant, bien que, après une première lecture, je n'aie saisi qu'une infime partie de l'article.
L'article présente un théorème bayésien qui stipule :
- Si vous êtes bayésien,
- si vous supposez qu'une autorité a eu accès aux mêmes données que vous et à plus encore,
- si vous êtes sûr que l'autorité parle de manière honnête,
- si vous pensez qu'une autorité est aussi bayésienne avec le même a priori que vous, alors vous devez croire tout ce que l'autorité dit.
#JaiDécouvert John Geanakoplos, Herakles Polemarchakis et John Harsanyi cités dans cet article.
Journal du samedi 17 août 2024 à 15:15
En lien avec Elasticsearch, #JaiDécouvert :
- https://github.com/searchkit/searchkit
- https://opensource.reactivesearch.io/
- https://github.com/appbaseio/dejavu/
qui sont plus ou moins des équivalents à InstantSearch (from).
Journal du samedi 17 août 2024 à 12:53
Ce matin, j'ai enfin pris le temps de parcourir attentivement la documentation d'Elasticsearch pour comparer ses fonctionnalités à celles de Meilisearch, Typesense et pg_search.
J'ai lu Text analysis overview de Elasticsearch.
Je note ici les étapes de l'Text analysis que j'ai des difficultés à retenir :
- Tokenization
- Token filtering (voir dans Anatomy of an analyzer)
- Normalization (search engine)
- Stemmer token filter (search engine)
- Character filters reference
- Customize text analysis
J'ai parcouru la liste des différents types des Built-in analyzer reference de Elasticsearch.
Je retiens le concept de stop analyzer.
#JeMeDemande l'usage du Keyword analyzer 🤔.
Je trouve le Pattern analyzer intéressant.
En lisant Fingerprint analyzer je découvre l'algorithme fingerprinting décrit dans la documentation de OpenRefine : https://openrefine.org/docs/technical-reference/clustering-in-depth#fingerprint. Je garde cela dans un coin de mon esprit, il se peut que cela me soit utile à l'avenir 🤔.
Je découvre que Elasticsearch (sans doute Lucene 🤔) propose beauoup de token filtering différent qui peuvent être combinés : Apostrophe, ASCII folding, CJK bigram, CJK width, Classic, Common grams, Conditional, Decimal digit, Delimited payload, Dictionary decompounder, Edge n-gram, Elision, Fingerprint, Flatten graph, Hunspell, Hyphenation decompounder, Keep types, Keep words, Keyword marker, Keyword repeat, KStem, Length, Limit token count, Lowercase, MinHash, Multiplexer, N-gram, Normalization, Pattern capture, Pattern replace, Phonetic, Porter stem, Predicate script, Remove duplicates, Reverse, Shingle, Snowball, Stemmer, Stemmer override, Stop, Synonym, Synonym graph, Trim, Truncate, Unique, Uppercase, Word delimiter, Word delimiter graph.
J'ai lu Stemmer token filter que je considère comme très important pour un moteur de recherche efficace.
#JaiDécouvert le support de Synonym graph token filter.
Je lis HTML strip character filter, fonctionnalité que je juge très utile.
Je lis qu'Elasticsearch propose de nombreuses méthodes de query, entre autres :
- Query DSL
- EQL search
- ES QL
- et même SQL
- Scripting
Tout cela est très riche !
J'ai lu Highlighting
#JeMeDemande comment Elasticsearch gère le support Highlighting (search-engine) avec du contenu qui intègre initialement des balises HTML 🤔.
J'ai trouvé la réponse dans cet article Elastic Search: Highlighting Text That Contains HTML Tags.
Journal du vendredi 16 août 2024 à 11:30
#JaiDécouvert l'expression Core-stack developer dans cet article de David Larlet :
… when in doubt, focus on the core. When in doubt, learn CSS over any sort of tooling around CSS. Learn JavaScript instead of React or Angular or whatever other library seems hot at the moment. Learn HTML. Learn how browsers work. Learn how connections are established over the network.
The reason for focusing on the core has nothing to do with the validity of any of those other frameworks, libraries or tools. On the contrary, focusing on the core helps you to recognize the strengths and limitations of these tools and abstractions. A developer with a solid understanding of vanilla JavaScript can shift fairly easily from React to Angular to Ember. More importantly, they are well equipped to understand if the shift should be made at all. You can’t necessarily say the same thing about an INSERT-NEW-HOT-FRAMEWORK-HERE developer.
Building your core understanding of the web and the underlying technologies that power it will help you to better understand when and how to utilize abstractions.
That’s part one of dealing with the rapid pace of the web.
À défaut d’être complet (full) en raison de l’effervescence technique difficile à suivre au quotidien, il me semble de plus en plus pertinent de miser sur le cœur (core) des technologies utilisées. Comprendre et maîtriser les bases avant tout pour pouvoir ponctuellement et rapidement se spécialiser en fonction du besoin. Connaître ES6 vous servira ces 10 prochaines années, savoir utiliser React sera obsolète l’année prochaine. Sages développeurs, investissez.
-- from
Core-stack developer me fait penser à Choose Boring Technology et à mon article nommé Sur quelles compétences j'ai décidé ou non d'investir mon temps ?. Je me rends compte rétrospectivement que j'ai listé ma core-stack 🙂.
Journal du jeudi 15 août 2024 à 20:00
Depuis que j'utilise @tabler/icons-svelte pour intégrer des tabler-icons sur un projet SvelteKit SSR, je rencontre d'énormes problèmes de performance en mode développement (pnpm run dev).
Pour traiter le problème, j'ai essayé ce hack indiqué dans l'issue Slow experience in SvelteKit, mais cela ne fonctionne pas.
Toujours dans cette issue, #JaiDécouvert Iconify.
Je pense me souvenir d'avoir commencé à utiliser tabler-icons comme alternative Open source à Font Awesome.
J'ai lu la page page raconte l'histoire du projet et j'apprends que le projet s'est réellement lancé en 2020.
Iconify est devenu un projet Open source en 2021 :
In mid 2022 plans changed, thanks to people showing interest in sponsoring open source development.
The new plan is to:
- Open source everything, encourage developers to create their own open source solutions that use Iconify.
- Rely on sponsors to finance development.
-- from
Mais, d'après la page contributors le projet semble toujours très majoritairement développé par Vjacheslav Trushkin.
Je lis aussi :
Unlike fonts, it downloaded data only for icons used on page, rendered pixel perfect SVG. (from)
Par contre, je pense comprendre qu'Iconify n'est pas un projet de création d'icônes, mais un framework qui regroupe énormément d'icônes.
Par exemple, j'ai constaté qu'Iconify intègre entre autres :
Iconify propose des composants icônes pour Svelte : Iconify for Svelte.
Mais, je lis :
Loads icons on demand. No need to bundle icons, component will automatically load icon data for icons that you use from Iconify API. -- from
Cette technique « Loads icons on demand » ne me plait pas. Je souhaite réduire au maximum les latences dans mes applications web.
J'ai continué mes recherches.
#JaiLu Icon library for svelte? : sveltejs
#JaiDécouvert unplugin-icons (from).
unplugin-icons est un projet qui a commencé en 2021 et qui est basé sur Iconify.
Je constate que unplugin-icons propose une configuration SvelteKit.
J'ai testé et cela semble très bien fonctionner 🙂.
Le site https://icones.js.org permet de facilement copier-coller le code Javascript pour intégrer une icône. Par exemple, un click sur "Unplugin Icons" :
permet de copier :
import TablerChevronDown from '~icons/tabler/chevron-down'
Je ne constate aucun problème de lenteur au mode développement (pnpm run dev) et aucun chargement réseau externe des icônes dans la version de production.
#JaiDécidé d'adopter cette librairie pour gérer les icons de mes projets SvelteKit.
Journal du jeudi 15 août 2024 à 19:08
#JaiDécouvert la #library classix un équivalent à clsx mais :
String expressions have a few benefits over objects:
- A faster typing experience
- A more intuitive syntax (conditions first)
- else support through ternary operators
What's more, by leveraging them, classix provides:
- A simpler and consistent API
- A smaller library size
- Better performance
-- from
Après avoir vu cela, j'ai creusé un peu le sujet et #JaiDécouvert que clsx a sorti une nouvelle release après la création de classix : https://github.com/lukeed/clsx/releases/tag/v2.1.0
Add new
clsx/litesubmodule for string-only usage: 1a49142This is a 140b version of clsx that is ideal for Tailwind and/or React contexts, which typically follow this clsx usage pattern.
clsx('foo bar', props.maybe && 'conditional classes', props.className);
Qui, d'après ce que je comprends, reprend en partie l'implémentation de classix.
Afin d'éviter un effet de balkanisation, je vais utiliser clsx.
Journal du jeudi 15 août 2024 à 10:46
#JaiDécouvert https://gwern.net/resorter mais je ne l'ai pas encore lu.
Journal du mercredi 14 août 2024 à 12:01
#JaiDécouvert l'existence du gTLDs .systems, qui est disponible depuis 2014.
Journal du mardi 13 août 2024 à 10:41
Deux amis m'ont partagé un thread Hacker News : Postgres.new: In-browser Postgres with an AI interface.
Je viens de prendre le temps de tester postgres.new.
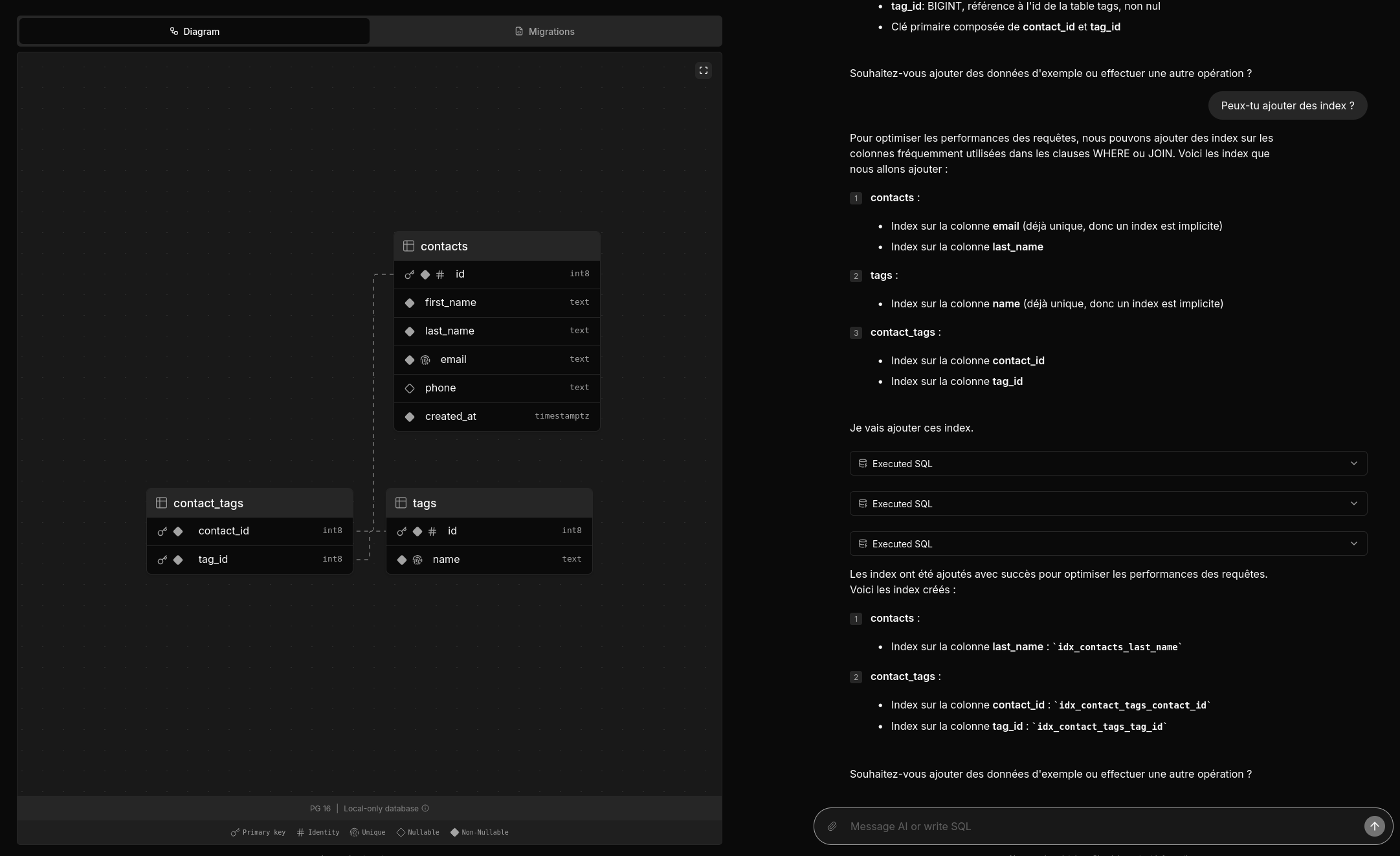
Voici une vidéo officielle : https://www.youtube.com/watch?v=ooWaPVvljlU
#Jadore ! Je trouve l'UX très bonne, j'aime l'onglet "Migrations", les explications données dans la colonne de droite.
Le projet est 100% Open source, voici le dépôt GitHub : https://github.com/supabase-community/postgres-new
Très beau travail !
Je me demande combien de temps ce projet a été implémenté 🤔.
1 mois et demi d'après la page contributors.
Mais je constate que le premier commit est plutôt conséquent, je pense que le projet était initialement intégré dans un mono repository.
Concernant l'implémentation, je lis :
All queries in postgres.new run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
👍️
How is this possible? PGlite, a WASM version of PostgreSQL that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
La partie LLM n'est pas mentionnée, #JeMeDemande comment elle est implémentée 🤔.
Je pense avoir trouvé ma réponse ici :
We pair PGlite with an LLM (currently GPT-4o) and give it full reign over the database with unrestricted permissions. (from)
Je lis :
RAG / pgvector: PGLite supports pgvector, so you can ask the LLM to create embeddings for RAG. The site uses transformers.js to create embeddings inside the browser.
Je n'ai pas tout compris 🤔.
#JaiDécouvert transformers.js.
J'ai lu ce commentaire :
It is a neat tech demo but it clearly shows the limits of AI:
- I got it to generate invalid SQL resulting in errors - it merely generates reasonable SQL, but in my case it generated to disjoint set of tables…. - In practice you have tot review all code - It can point you into the wrong direction. Novel systems often have something smart/abstract in there. This system creates mostly Straightforward simple systems. That’s not where the value is
All in all, it’s not worth it to me. Writing code myself is easier than having to review LLM code
Within our organization we have forbidden full LLM merge request because more often than not the code was suboptimal. And had sneaky bugs/mistakes.
I’m not saying these can’t be overcome. But not with current LLM design. They mostly generate stuff they have seen and are bad as truly new stuff.
Personnellement, cela ne me surprend pas et cela ne remet pas en question, à mes yeux, l'intérêt de cet outil.
Je pense l'utiliser pour concevoir une ébauche de base de données.
Je pense qu'il pourra me fournir de bonnes suggestions pour les noms de tables et de champs, et même inclure des champs auxquels je n'aurais peut-être pas pensé.
Journal du dimanche 11 août 2024 à 20:33
#JaiDécouvert le concept Obsidian nommé Higher-Order Notes (from).
#JaiLu Concept notes are higher-order notes, not permanent Zettels et je n'ai rien appris d'intéressant..
Journal du dimanche 11 août 2024 à 20:21
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du jeudi 08 août 2024 à 08:40
#JaiDécouvert que GoCardLess propose une API permettant de récupérer l'historique de transactions de plus de 900 banques : Bank Account Data.
Je vais m'inscrire pour la tester.
Note : L'accès Woob ne permet plus de se connecter à BPLC.
Journal du mardi 06 août 2024 à 17:43
#OnMaPartagé le #mot Otium.
L’otium n’est pas simplement un temps de relâchement, d'oisiveté ou de flânerie.
Il est ce qu’on pourrait appeler le loisir fécond et studieux, un temps que l'on consacre à s'améliorer soi-même, à progresser pour accéder à une compréhension du monde plus grande.
Il ne sert aucun but, si ce n’est celui de s’élever et de s’améliorer en tant qu’individu.
Une exploration complètement désintéressée qui le classerait dans la catégorie des activités dites “inutiles” de nos jours.
D’ailleurs, ce n’est pas un hasard si ce mot-là n’a pas vraiment de traduction dans notre langue moderne, c’est peut-être parce qu’il a simplement disparu de notre conception du monde.
Ce que nous appelons aujourd’hui “loisir” est tout ce qui se regroupe derrière l’idée d’un plaisir immédiat, à consommer. Un temps pour s’échapper de soi et de ses problèmes du quotidien. Un loisir-opium si l’on reprend l’analogie.
Le concept d'otium, s’il a été popularisé sous l’Empire romain, est né pendant la Grèce antique. On l’appelait la skholè.
Pour les Grecs, la skhôlè est le temps libre dans lequel se construit la capacité à argumenter, l’esprit critique, la capacité de jugement…
Bref, c’est le creuset qui a permis de créer le concept même de Citoyens capables de décider de leur avenir. C’est tout simplement l’idée fondatrice de la démocratie !
-- from
Dans cet article :
Journal du mardi 06 août 2024 à 14:27
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
#JaiDécouvert lezer-markdown-obsidian qui correspond à ce que j'ai besoin pour 2024-08-06_1140.
Je viens de voir ici une propriété complete :
class FootnoteReferenceParser implements LeafBlockParser {
...
complete(cx: BlockContext, leaf: LeafBlock) {
cx.addLeafElement(
leaf,
cx.elt(
"FootnoteReference",
leaf.start,
leaf.start + leaf.content.length,
[
cx.elt("FootnoteMark", leaf.start, leaf.start + 2),
cx.elt("FootnoteLabel", leaf.start + 2, this.labelEnd - 2),
cx.elt("FootnoteMark", this.labelEnd - 2, this.labelEnd),
...cx.parser.parseInline(
leaf.content.slice(this.labelEnd - leaf.start),
this.labelEnd
),
]
)
);
return true;
}
}
Dans le Projet 1 - "CodeMirror, autocomplétion, Svelte", #JeMeDemande si je ne suis pas passé à coté d'une meilleur méthode pour implémenter de l'auto complétiion dans CodeMirror 🤔.
Journal du mardi 06 août 2024 à 08:45
#JaiDécouvert la commande psql nommé \ir :
\iror\include_relativefilenameThe \ir command is similar to \i, but resolves relative file names differently. When executing in interactive mode, the two commands behave identically. However, when invoked from a script, \ir interprets file names relative to the directory in which the script is located, rather than the current working directory.
-- from
J'ai trouvé cette commande via Fwd: psql include file using relative path.
Cela faisait des années que j'avais besoin de cette fonctionnalité et, étrangement, je ne l'ai découverte seulement aujourd'hui 🤔.
Exemple d'utilisation https://github.com/stephane-klein/sklein-pkm-engine/blob/8938d7a2c19ed8f741bd38162882e9517c739c30/sqls/init.sql#L36
Journal du samedi 03 août 2024 à 10:42
#JaiDécouvert le projet Uptime (from).
Upptime is the Open source Status et Uptime pages and status page, powered entirely by GitHub Actions, Issues, and Pages. It's made with 💚 by Anand Chowdhary, supported by Pabio.
Je trouve l'idée de baser le service entièrement sur GitHub Actions ingénieuse, bien que la dépendance totale à GitHub me dérange un peu 🤔.
Journal du dimanche 28 juillet 2024 à 14:02
#JaiÉcouté ( #Réécouté ) Épisode 2-4 - Guildes et compagnonnage, défendre son métier au Moyen Âge.
Suite à cette écoute, j'ai cherché d'autre conférence de Julie Claustre et #JaiÉcouté Travailler en ville au Moyen Âge, conférence de Julie Claustre du mercredi 13 décembre 2017.
#JaiDécouvert et #JeMeSuisAbonné à la chaine Musée de Cluny : https://www.youtube.com/@museeclunymoyenage.
J'ai ensuite découvert cette conférence de Cécile Sabathier : Travailler sur les chantiers au Moyen Âge, conférence de Cécile Sabathier du mercredi 17 janvier 2018 que j'ai trouvé très intéressante (Sociologie du travail et Histoire du travail).
Journal du dimanche 28 juillet 2024 à 09:43
Je viens d'apprendre que l'option -N de ssh permet de ne pas ouvrir une session shell interactive sur le serveur distant.
Option très utile lors de l'ouverture de tunnels ssh.
Exemple :
ssh -L 8080:localhost:80 user@host -N
Journal du samedi 27 juillet 2024 à 14:00
#JaiLu le thread Hacker News "An experiment in UI density created with Svelte | Hacker News" et j'ai trouvé cela très intéressant.
Le bon dosage de la densité d'affichage est un élément très important dans mon expérience utilisateur.
#JaiDécouvert la librairie frontend web nommée DataTables (https://datatables.net/) implémentée en Javascript basée sur jQuery.
I'd like to think projects like these are somehow signaling a return to well designed but information dense, space saving interfaces ...
The amount of bloat, whitespace, extra spacing, "air" and other such waste — starting with (now Google-dead) "Material Design" has been egregious. —
#JaiDécouvert Perspective (https://perspective.finos.org/), j'aime beaucoup la densité des grilles. Voici un exemple en full screen : https://perspective.finos.org/blocks/editable/index.html.
J'aime sa densité et sa vitesse de rendu 👌.
This is interesting because it proves something to me about my vision and visual comprehension.
The "Grid" view is absolutely fine for me. The "Table" view is unworkable.
Intéressant 🤔.
J'ai regardé une partie de la vidéo de présentation du Bloomberg Terminal (https://www.youtube.com/watch?v=2ee-x6IXWK8), j'ai trouvé l'UI très intéressante.
Journal du jeudi 25 juillet 2024 à 15:24
#JaiDécouvert shadcn-svelte et donc shadcn-ui.
En cherchant des informations au sujet de shadcn-ui, #JaiDécouvert ici Franken UI.
Dans la documentation de shadcn-ui je lis :
This is NOT a component library. It's a collection of re-usable components that you can copy and paste or use the CLI to add to your apps.
What do you mean not a component library?
It means you do not install it as a dependency. It is not available or distributed via npm, with no plans to publish it.
Je trouve cela intéressant, #Jaime .
Dans la page About de shadcn-svelte :
- #JaiDécouvert bits-ui une lib Svelte Headless components, utilisé par shadcn-svelte
- #JaiDécouvert cmdk-sv
- #JaiDécouvert Formsnap
Journal du mardi 23 juillet 2024 à 22:46
#JaiDécouvert https://github.com/idealclover/RSS-OPML-to-Markdown
🎁 Convert RSS OPML file to Markdown - easy to read and share
Journal du mardi 23 juillet 2024 à 15:54
#JaiDécouvert que Scaleway a déployé en public beta une offre d'Managed Inference Service : Scaleway Managed Inference.
Added : Managed Inference is available in Public Beta
Managed Inference lets you deploy generative AI models and answer prompts from European end-consumers securely. Now available in public beta! (from)
C'est une alternative à Replicate.com.
Models now support longer and better conversations :
- All models on catalog now support conversations to their full context window (e.g Mixtral-8x7b up to 32K tokens, Llama3 up to 8k tokens).
- Llama3 70B is now available in FP8 quantization, INT8 is deprecated.
- Llama3 8b is now available in FP8 quantization, BF16 remains default.
L'offre est beaucoup moins large que celle de Replicate mais c'est un bon début 🙂.
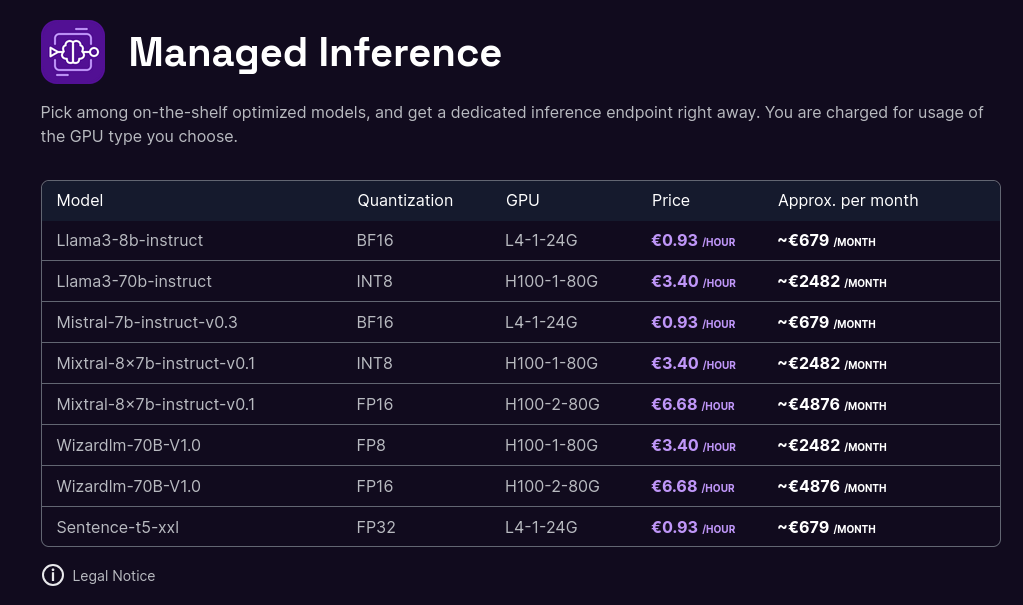
Tarif de l'offre de Scaleway :
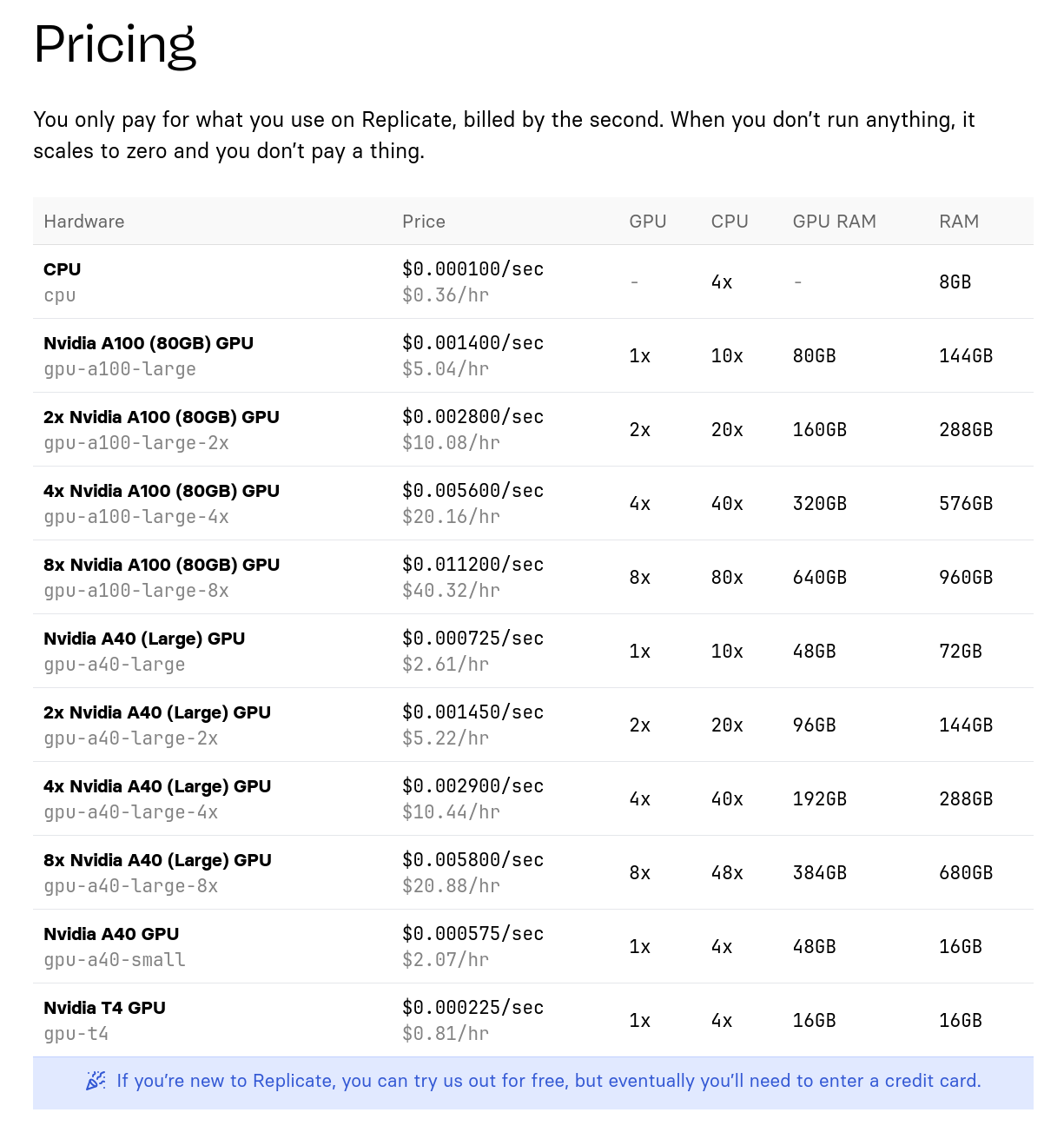
Tarif de l'offre de Replicate.com :
Bien que le matériel soit différent, j'essaie tout de même de faire une comparaison de prix :
- Scaleway : 0,93 € / heure pour une machine à 24Go de Ram GPU
- Replicate : 0,81 $ / heure pour une machine à 16GB de Ram GPU
Ensuite :
- Scaleway : 3,40 € / heure pour une machine à 80Go de Ram GPU
- Replicate : 5,04 € / heure pour une machine à 80Go de Ram GPU
Je précise, que je n'ai aucune idée si ma comparaison a du sens ou non.
Je n'ai pas creusé plus que cela le sujet.
Note en lien avec 2024-05-17_1257.
Journal du mardi 23 juillet 2024 à 09:48
Ayant perdu un écouteur de mon Jabra Elite 5, je suis en train d'étudier par quoi le remplacer.
L'hiver dernier, j'ai croisé un utilisateur de casque à conduction osseuse, il était fan.
Je viens de passer un peu de temps à étudier les modèles vendu sur Amazon et #JaiDécouvert la marque Skokz.
Je découvre ici qu'il existe de type de technologie d'écoute à oreilles libres : conduction osseuse et DirectPitch.
#JaiCommandé le modèle Shokz OpenMove à 89,95 €.
Journal du vendredi 19 juillet 2024 à 23:40
#JaiLu What's new in Svelte: July 2024
#JaiLu What's new in Svelte: June 2024
Tons of work on the migrate tool to make migrating to Svelte 5 syntax easier
J'ai hâte de tester pour constater les changements dans le code et aussi constater si cela cette outil fonctionne correctement ou non 🤔.
Journal du vendredi 19 juillet 2024 à 18:07
#JaiDécouvert le terme Inkling (from : Spaced repetition may be a helpful tool to incrementally develop inklings) qui signifie :
Le terme "inkling" en anglais signifie une vague idée ou une intuition.
Journal du vendredi 19 juillet 2024 à 18:06
#JaiDécouvert Timeful Texts de Andy Matuschak.
Consider texts like the Bible and the Analects of Confucius. People integrate ideas from those books into their lives over time — but not because authors designed them that way. Those books work because they’re surrounded by rich cultural activity. Weekly sermons and communities of practice keep ideas fresh in readers’ minds and facilitate ongoing connections to lived experiences. This is a powerful approach for powerful texts, requiring extensive investment from readers and organizers. We can’t build cathedrals for every book. Sophisticated readers adopt similar methods to study less exalted texts, but most people lack the necessary skills, drive, and cultural contexts. How might we design texts to more widely enable such practices?
Cela rejoint une réflexion que j'ai eue concernant les documentations d'onboarding ou handbook d'organisation.
Problème
Il est courant de demander à aux nouveaux employés d'une startup de lire la documentation d'onboarding ou le handbook de l'organisation.
En pratique, je trouve cela peu efficace. Les premiers jours ou heures dans une nouvelle organisation sont souvent à la fois excitants et stressants. C'est une période où les individus cherchent à créer des liens, à rencontrer les autres et à comprendre qui est qui. Conséquence : je pense qu'il est difficile d'entrer en deepflow de lecture pendant cette période. Les personnes onboardé survolent la documentation et je trouve cela tout à fait justifié.
D'autre part, les informations détaillées contenues dans ces documents n'auront que peu de signification au début et ne deviendront pertinentes qu'après plusieurs semaines passées au sein de l'organisation. Et malheureusement, je constate que si les autres membres de l'équipe ne l'invitent pas, la personne onboardé retourne rarement elle-même consulter des détails bien utiles dans la documentation.
Solution humaine
Pour pallier ce problème, lors de ma dernière expérience, j'ai mis en place un système de parrain attribué à chaque nouvelle personne. Le parrain était là pour répondre à toutes les questions du nouvel arrivant et le rediriger vers les bonnes sections de la documentation.
Idée technique
En 2022, j'imaginais un système basé sur un chatbot (pour Slack ou autre) qui enverrait, de manière espacée dans le temps des liens vers des sections de la documentation à lire.
Ce chatbot pourrait aussi poser des questions, pour vérifier si la personne est au courant d'éléments contenus dans la documentation.
Cela ressemble au projet Timeful Texts 🤔.
[!Note au lecture] Pour bien comprendre le lien, je vous invite à lire l'intégralité de l'article et pas seulement l'extrait cité au début de cette note.
Journal du vendredi 19 juillet 2024 à 17:35
J'ai passé 10min à étudier ce projet, je n'ai pas vraiment compris ses caractéristiques, mais j'y ai trouvé des choses qui ont attiré ma curiosité. #JaimeraisUnJour prendre du temps pour étudier Atomic Data en profondeur.
En lien avec Systèmes d’organisation des connaissances.
Journal du jeudi 18 juillet 2024 à 21:03
#JaiDécouvert un portail qui contient de nombreuses conférences scientifiques : https://portal.sciencesconf.org/browse/list
Journal du mercredi 17 juillet 2024 à 22:53
Dans la page Wikipedia de Paul Otlet #JaiDécouvert Classification décimale universelle et Classification décimale de Dewey.
Journal du mercredi 17 juillet 2024 à 21:19
Dans la vidéo FAQ – juillet 2017 de Monsieur Phi #JaiDécouvert L’Encyclopédie Philosophique.
Journal du mercredi 17 juillet 2024 à 17:46
En cherchant la définition de mot Diaphories, #JaiDécouvert le #livre : L'Homme-trace - Inscriptions corporelles et techniques.
Journal du mercredi 17 juillet 2024 à 17:25
#JaiDécouvert Luciano Floridi (from)
Floridi s'est fait connaître comme l'un des plus importants théoriciens de la philosophie de l'information et éthique de l'informatique, reconnu comme une autorité dans le domaine de la philosophie sur Internet. (from).
Luciano Floridi enseigne comme professeur associé de logique et d’épistémologie au département de philosophie de l'université de Bari. (from)
Journal du mardi 16 juillet 2024 à 13:44
#JaiLu Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret publié sur HAL.
La documentation personnelle peut être définie comme la documentation élaborée par un individu pour lui-même, de manière idiosyncrasique.
#JaiDécouvert le mot Idiosyncrasique.
#JeMeDemande si la condition « pour lui-même » est dépassable ou non 🤔.
(Psychologie) Caractères propres au comportement d’un individu particulier. (from).
Élaborer une documentation personnelle permet d’organiser le processus de « signifiance » (Leleu-Merviel, 2010) pour construire des connaissances (voir figure 1).
#JaiDécouvert la chercheuse Sylvie Leleu-Merviel.
#JeSouhaite lire Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
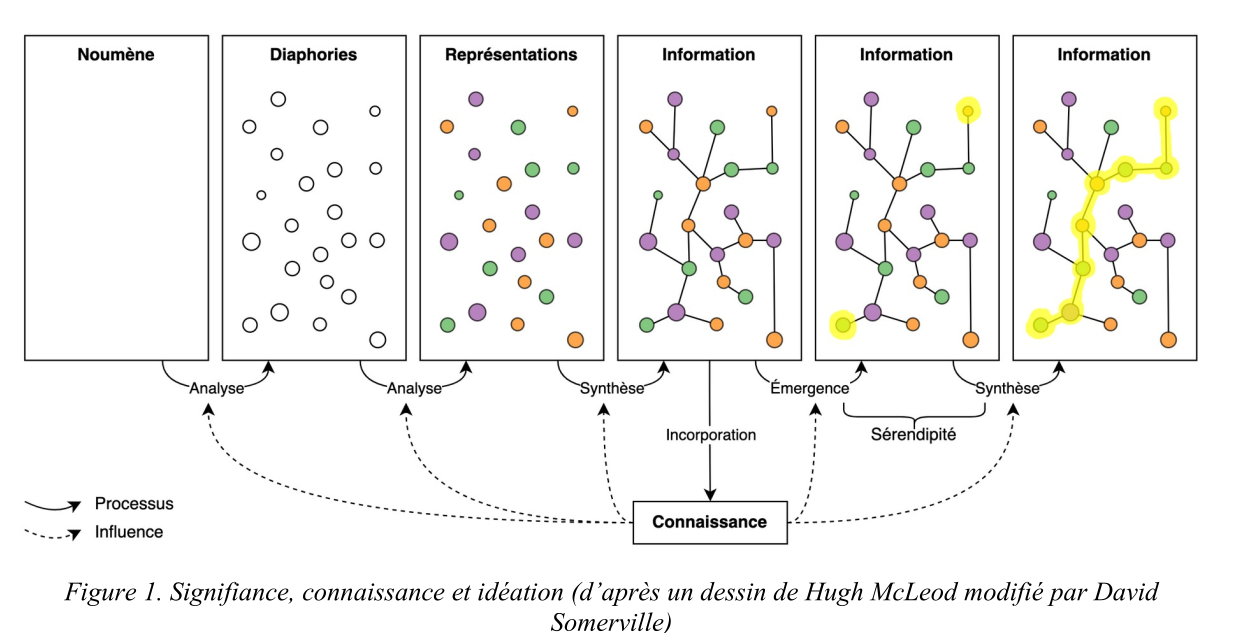 #JaiDécouvert les mots Noumène, Noème et Diaphories.
#JaiDécouvert les mots Noumène, Noème et Diaphories.
Comme l’écrit Latour (dans « Pensée retenue, pensée distribuée »), la pensée n’est pas « retenue » dans l’unique cerveau du penseur, mais « distribuée » dans un ensemble d’acteurs et d’actants – un « milieu de savoir » selon l’expression de Le Deuff : données et documents, individus et collectifs, lieux, évènements et dispositifs divers.
#JaiDécouvert Traité de documentation de Paul Otlet.
#JaiDécouvert Robert Estivals et Communicology.
L’approche hypertextuelle présente plusieurs avantages par rapport aux graphes de connaissance, notamment une mise en œuvre plus simple et une plus grande expressivité. Cette méthode produit ce que Stiegler (Le concept d’ « Idiotexte » : esquisses - 2010) appelle un idiotexte, c’est-à-dire la textualisation d’une mémoire personnelle. L’utilité primaire de cette méthode, pour l’individu qui crée sa documentation personnelle, est de multiplier les chemins vers une même information, via des connexions riches en signification et facilement réactivées.
#JaiDécouvert idiotexte, j'ai lu l'article mentionné et je ne l'ai pas compris 🙅♀️.
Cette méthode présente également un intérêt pour les recherches sur les systèmes d’organisation des connaissances (SOC). Mazzocchi (2018) définit les SOC comme des ensembles de termes ou concepts interreliés, outils intermédiaires entre des humains et des collections de données et documents. Dans la méthode que nous avons décrite, la création d’un graphe documentaire correspond à la fois à la création d’une collection de documents – les fiches – et d’un SOC – les catégories de fiches et de liens utilisées dans le graphe.
#JaiDécouvert Systèmes d’organisation des connaissances (SOC).
D’abord, cette méthode est orientée par la subjectivité : les choix qui guident l’élaboration du graphe sont basés sur la mémorabilité, critère hautement subjectif.
Ok, j'ai bien compris 👌.
Par exemple, des catégories de fiches peuvent être modifiées, supprimées ou ajoutées progressivement pour orienter la manière dont fonctionne la remémoration.
Ok, j'ai bien compris 👌.
#JaiDécouvert L’épistémologie sociale (from)
J'ai pris le temps de regarder https://www.arthurperret.fr/glossaire-indexation.html, j'ai trouvé des choses intéressantes, du vocabulaire pour nommer des éléments techniques des CMS.
Ces configurations affectent la manière dont nous remémorons les choses : nous nous disons par exemple « J’ai mentionné ce concept dans telle publication » ou bien « C’est untel qui m’a recommandé cette méthode ». Ces connexions idiosyncrasiques sont facilement réactivées car elles reposent sur des éléments ayant une grande « mémorabilité » – terme qui renvoie aux arts de la mémoire et que nous entendons ici comme une qualité déterminée subjectivement, de manière réflexive, à partir de situations essentiellement contingentes, qui modifient notre « comportement informationnel ».
Je comprends très bien ce qui est exprimé et cela correspond à mon expérience vécu.
Journal du lundi 15 juillet 2024 à 14:45
Dans l'épisode Combien d'argent il faut pour être vraiment riche … du Podcast Le Trilliard #JaiDécouvert le #livre The Gatekeepers: How the White House Chiefs of Staff Define Every Presidency. Je trouve le sujet intéressant, #UnJourPeuxÊtre je prendrais le temps de le lire.