
Claude
Journaux liées à cette note :
Journal du dimanche 16 novembre 2025 à 11:06
Je viens d'écouter une nouvelle vidéo de Monsieur Phi au sujet des LLM : "L'autonomie des IA expliquée aux humains". Je l'ai trouvée excellente, tout comme celle que j'avais mentionnée dans la note de décembre 2024.
J'ai apprécié tout particulièrement :
- L'analogie du « Le paradigme du micro-trottoir », que je trouve frapante.
- La présentation de l'étude de METR sur la progression exponentielle de la capacité à résoudre des tâches longues.
- La présentation des résultats du concours AtCoder, expliquée par Passe-Science.
- La présentation de l'article sur l'émergence de désalignement quand on entraîne un modèle sur du code vulnérable : https://www.emergent-misalignment.com.
- La présentation de l'article sur la falsification d'alignement et Claude soucieux du bien-être animal : https://www.anthropic.com/research/alignment-faking.
J'ai découvert que le livre de Monsieur Phi, "La parole aux machines - Philosophie des grands modèles de langage" est enfin sorti ! Je viens de l'acheter 🙂.
L'utilisation de OSTree par Flatpak
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "composefs, un filesystem spécialement créé pour les besoins des distributions atomic"
En étudiant libostree, j'ai découvert que Flatpak est construit sur OSTree depuis sa création : voir page Flatpak documentation - Under the Hood.
Flatpak utilise la fonctionnalité pull d'OSTree pour télécharger l'intégralité des applications depuis un repository OSTree, ou des deltas pour les mises à jour.
Depuis la version 0.6.0 de 2016, Flatpak supporte aussi le téléchargement au format OCI.
Voici un exemple de repository Flatpak configuré sur mon workspace :
$ flatpak remotes -d
Name Title URL Collection ID Subset Filter Priority Options Com… Descript… Homepage Icon
fedora Fedora Flatpaks oci+https://registry.fedoraproject.org - - - 1 system,oci - - - -
flathub Fedora Flathub Selection https://dl.flathub.org/repo/ - - - 1 system Sel… Selected… https://flathub.org/ https://dl.flathub.org/repo/logo.svg
flathub Flathub https://dl.flathub.org/repo/ - - - 1 user Cen… Central … https://flathub.org/ https://dl.flathub.org/repo/logo.svg
On peut voir que Flathub est un serveur libostree et le registry registry.fedoraproject.org utilise le format OCI.
Sans entrer dans les détails (ce serait trop long pour cette note), libostree est la raison pour laquelle Flatpak est plus performant que Snap basé sur squashfs.
Selon Claude.ia, Flatpak offre par rapport à Snap : un démarrage des applications 2 à 3 fois plus rapide, 60-80% de bande passante en moins sur les mises à jour, et 30-40% d'espace disque économisé.
Note suivante : "Support OCI de CoreOS (image pull & updates)".
J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux
Pendant mon travail d'étude pratique de IPv6, #JaiDécouvert le projet Containerlab :
Containerlab was meant to be a tool for provisioning networking labs built with containers. It is free, open and ubiquitous. No software apart from Docker is required! As with any lab environment it allows the users to validate features, topologies, perform interop testing, datapath testing, etc. It is also a perfect companion for your next demo. Deploy the lab fast, with all its configuration stored as a code -> destroy when done.
Projet qui a commencé en 2020 et semble principalement développé par un développeur de chez Nokia.
D'après ce que j'ai compris, Containerlab me permet de facilement créer des réseaux dans un simulateur.
Je me souviens que je cherchais ce type d'outil en 2018, quand je travaillais sur un projet baremetal as service chez Scaleway.
Voici un exemple de fichier créé par Claude.ia pour simuler un environnement composé de deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Je précise que je n'ai pas encore testé ce fichier. J'ignore donc s'il fonctionne correctement.
name: dual-network-ipv6-lab
topology:
nodes:
# Routeur avec IPv6
router:
kind: linux
image: alpine:latest
exec:
# Activer IPv6
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- sysctl -w net.ipv6.conf.all.forwarding=1
# Adresses IPv6 sur les interfaces
- ip -6 addr add 2001:db8:1::1/64 dev eth1
- ip -6 addr add 2001:db8:2::1/64 dev eth2
# IPv4 en parallèle (dual-stack)
- ip addr add 192.168.1.1/24 dev eth1
- ip addr add 192.168.2.1/24 dev eth2
- echo 1 > /proc/sys/net/ipv4/ip_forward
# Réseau A (2001:db8:1::/64)
vm-a1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::10/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.10/24 dev eth1
- ip route add default via 192.168.1.1
vm-a2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::11/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.11/24 dev eth1
- ip route add default via 192.168.1.1
vm-a3:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::12/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.12/24 dev eth1
- ip route add default via 192.168.1.1
# Réseau B (2001:db8:2::/64)
vm-b1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::10/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.10/24 dev eth1
- ip route add default via 192.168.2.1
vm-b2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::11/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.11/24 dev eth1
- ip route add default via 192.168.2.1
links:
# Réseau A
- endpoints: ["router:eth1", "vm-a1:eth1"]
- endpoints: ["router:eth1", "vm-a2:eth1"]
- endpoints: ["router:eth1", "vm-a3:eth1"]
# Réseau B
- endpoints: ["router:eth2", "vm-b1:eth1"]
- endpoints: ["router:eth2", "vm-b2:eth1"]
J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes
Un ami m'a posé la question suivante :
J'aimerais ton avis sur l'utilisation des LLM au quotidien (hors code). Les utilises-tu ? En tires-tu quelque chose de positif ? Quelles en sont les limites ?
Je vais tenter de répondre à cette question dans cette note.
Danger des LLMs : le risque de prolétarisation
Mon père et surtout mon grand-père m'ont inculqué par tradition familiale la valeur du savoir-faire. Plus tard, Bernard Stiegler m'a donné les outils théoriques pour comprendre cet enseignement à travers le concept de processus de prolétarisation.
La prolétarisation est, d’une manière générale, ce qui consiste à priver un sujet (producteur, consommateur, concepteur) de ses savoirs (savoir-faire, savoir-vivre, savoir concevoir et théoriser).
Ici, j'utilise la définition de prolétaire suivante :
Personne qui ne possède plus ses savoirs, desquels elle a été dépossédée par l’utilisation d’une technique.
En analysant mon parcours, je réalise que ma quête d'autonomie technique et de compréhension — en somme, ma recherche d'émancipation — a systématiquement guidé mes choix, comme le fait d'avoir pris le chemin du logiciel libre en 1997.
Sensibilisé à ces questions, j'ai immédiatement perçu les risques dès que j'ai découvert la puissance des LLM mi 2023 .
J'utilise les LLMs comme des amis expert d'un domaine
Les LLMs sont pour moi des pharmakons : ils sont à la fois un potentiel remède et un poison. J'essaie de rester conscient de leurs toxicités.
J'ai donc décidé d'utiliser les IA générative de texte comme je le ferais avec un ami expert d'un domaine.
Concrètement, je continue d'écrire la première version de mes notes, mails, commentaires, messages de chat ou issues sans l'aide d'IA générative de texte.
C'est seulement dans un second temps que je consulte un LLM, comme je le ferais avec un ami expert : pour lui demander un commentaire, lui poser une question ou lui demander une relecture.
J'utilise les IA générative de texte par exemple pour :
- vérifier si mon texte est explicite et compréhensible
- obtenir des suggestions d'amélioration de ma rédaction
Tout comme avec un ami, je lui partage l'intégralité de mon texte pour donner le contexte, et ensuite je lui pose des questions ciblées sur une phrase ou un paragraphe spécifique. Cette méthode me permet de mieux cadrer ses réponses.
À ce sujet, voir mes notes suivantes :
- Idée d'application de réécriture de texte assistée par IA
- Prompt - Reformulation de paragraphes pour mon notes.sklein.xyz
Par respect pour mes interlocuteurs, je ne demande jamais à un LLM de rédiger un texte à ma place.
 (source)
(source)
Lorsque je trouve pertinent un contenu produit par un LLM, je le partage en tant que citation en indiquant clairement la version du modèle qui l'a généré. Je le cite comme je citerai les propos d'un humain.
En résumé, je ne m'attribue jamais les propos générés par un LLM. Je n'utilise jamais un LLM comme un écrivain fantôme.
Seconde utilisation : exploration de sujets
J'utilise aussi les LLMs pour explorer des sujets.
Je dirais que cela me permet de faire l'expérience de ce que j'appellerais "de la sérendipité dirigée".
Par exemple, je lui expose une idée et comme à un ami, je lui demande si cela a du sens pour lui, qu'est-ce que cela lui évoque et très souvent, je découvre dans ses réponses des auteurs ou des concepts que je n'ai jamais entendus parler.
J'utilise beaucoup les LLMs pour obtenir un "overview" avec une orientation très spécifique, sur des sujets tech, politique, historique…
Je l'utilise aussi souvent pour comprendre l'origine des noms des projets, ce qui me permet de mieux m'en souvenir.
Voir aussi cette note que j'ai publiée en mai 2024 : Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo.
Les limites ?
En matière d'exploration, je pense que les LLMs sont d'une qualité exceptionnelle pour cette tâche. Je n'ai jamais expérimenté quelque chose d'aussi puissant. Peut-être que j'obtiendrais de meilleurs résultats en posant directement des questions à des experts mondiaux dans les domaines concernés, mais la question ne se pose pas puisque je n'ai pas accès à ces personnes.
Pour l'aide à la rédaction, il me semble que c'est nettement plus efficace que ce qu'un ami serait en mesure de proposer. Même si ce n'est pas parfait, je ne pense pas qu'un LLMs soit en mesure de deviner précisément, par lui-même, ce que j'ai l'intention d'exprimer. Il n'y a pas de magie : il faut que mes idées soient suffisamment claires dans mon cerveau pour être formulées de façon explicite. En ce qui concerne ces tâches, je constate d'importantes différences entre les modèles. Actuellement, Claude Sonnet 4 reste mon préféré pour la rédaction En revanche, j'obtiens de moins bons résultats avec les modèles chain-of-thought, ce qui est sans doute visible dans les LLM Benchmark.
Par contre, dès que je m'éloigne des questions générales pour aborder la résolution de problèmes précis, j'obtiens pour le moment des résultats très faibles. Je remarque quotidiennement des erreurs dans le domaine tech, comme :
- des paramètres inexistants
- des parties de code qui ne s'exécutent pas
- ...
Comment a évolué mon utilisation des LLMs depuis 2023 ?
J'ai publié sur https://data.sklein.xyz mes statistiques d'utilisation des LLMs de janvier 2023 à mai 2025.
Ces statistiques ne sont plus représentatives à partir de juin 2025, parce que j'ai commencé à utiliser fortement Open WebUI couplé à OpenRouter et aussi LMArena. J'aimerais prendre le temps d'intégrer les statistiques de ces plateformes prochainement.
Comme on peut le voir sur https://data.sklein.xyz, mon usage de ChatGPT a réellement démarré en avril 2024, pour évoluer vers une consommation mensuelle d'environ 300 threads.
Je suis surpris d'avoir si peu utilisé ChatGPT entre avril 2023 et janvier 2024 🤔. Je l'utilisais peut-être en mode non connecté et dans ce cas, j'ai perdu toute trace de ces interactions.
Voir aussi ma note : Estimation de l'empreinte carbone de mon usage des IA génératives de textes.
Combien je dépense en inférence LLM par mois ?
De mars à septembre 2024, 22 € par mois pour ChatGPT.
De mars à mai 2025, 22 € par mois pour Claude.ia.
Depuis juin 2025, je pense que je consomme moins de 10 € par mois, depuis que je suis passé à OpenRouter. Plus d'informations à ce sujet dans : Quelle est mon utilisation d'OpenRouter.ia ?
J'aurais encore beaucoup à dire sur le sujet des LLMs, mais j'ai décidé de m'arrêter là pour cette note.
Pour aller plus loin sur ce sujet, sous un angle très technique, je conseille cette série d'articles sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
- Nouvelles sur l’IA de juin 2025
Et toutes mes notes associées au tag : #llm
Quelle est mon utilisation d'OpenRouter.ia ?
Alexandre m'a posé la question suivante :
Pourquoi utilises-tu openrouter.ai ? Quel est son intérêt principal pour toi ?
Je vais tenter de répondre à cette question dans cette note.
(Un screencast est disponible en fin de note)
Historique de mon utilisation des IA génératives payantes
Pour commencer, je pense qu’il est utile de revenir sur l’histoire de mon usage des IA génératives de texte payantes, afin de mieux comprendre ce qui m’a amené à utiliser openrouter.ai.
En juin 2023, j'ai expérimenté l'API ChatGPT dans ce POC poc-api-gpt-generate-demo-datas et je me rappelle avoir brûlé mes 10 € de crédit très rapidement.
Cette expérience m'a mené à la conclusion que pour utiliser des LLM dans le futur, je devrais passer par du self-hosting.
C'est pour cela que je me suis fortement intéressé à Llama.cpp en 2024, comme l'illustrent ces notes :
- 2024 janvier : J'ai lu le README.md de Ollama
- 2024 mai : Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
- 2024 mai : Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
- 2024 juin : Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
J'ai souscrit à ChatGPT Plus pour environ 22 € par mois de mars à septembre 2024.
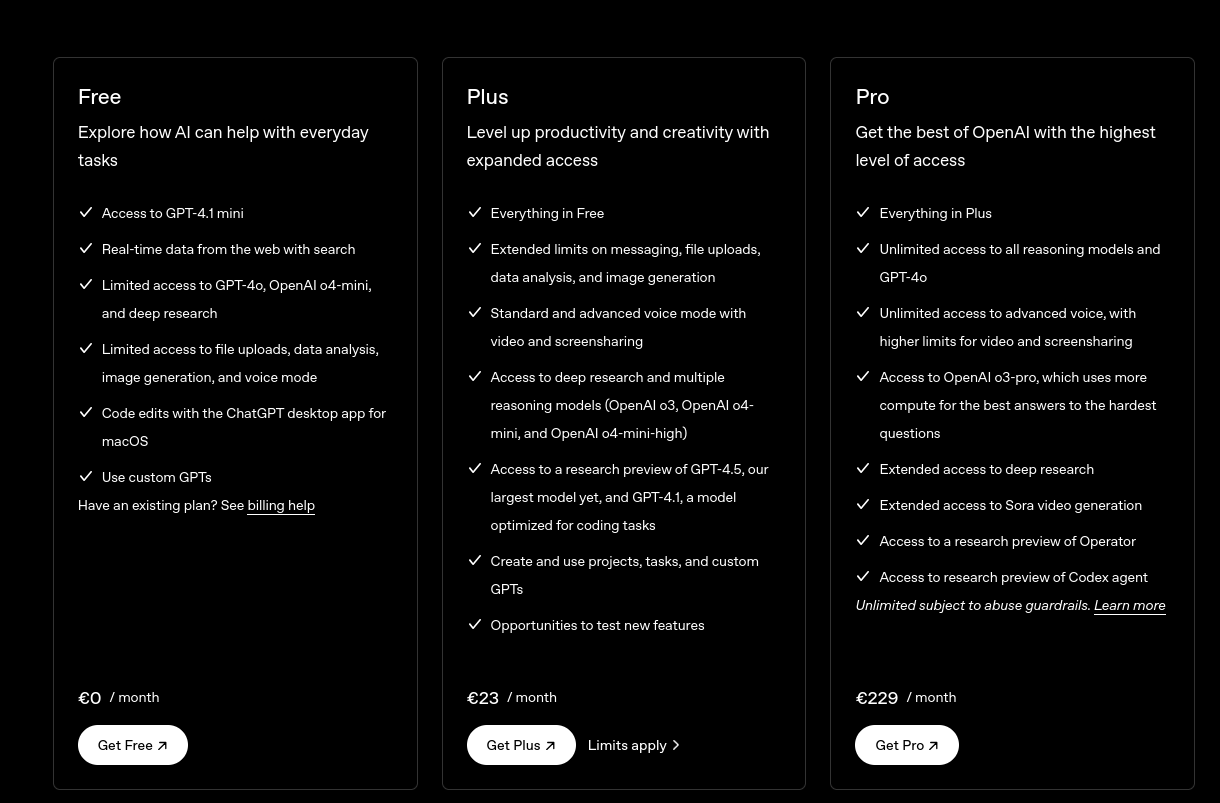
Je pensais que cette offre était probablement bien plus économique que l'utilisation directe de l'API ChatGPT. Avec du recul, je pense que ce n'était pas le cas.
Après avoir lu plusieurs articles sur Anthropic — notamment la section Historique de l'article Wikipédia — et constaté les retours positifs sur Claude Sonnet (voir la note 2025-01-12_1509), j’ai décidé de tester Claude.ia pendant un certain temps.
Le 3 mars 2025, je me suis abonné à l'offre Claude Pro à 21,60 € par mois.
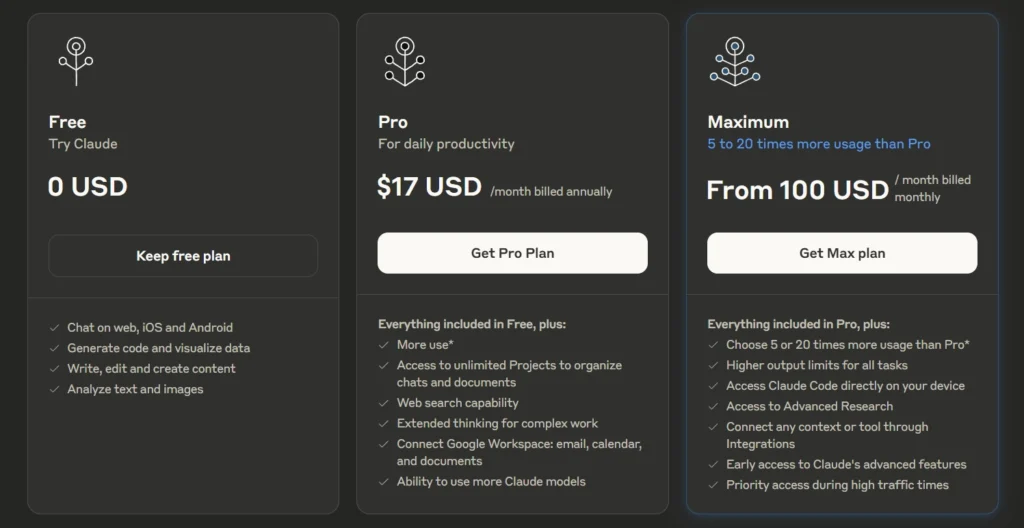
Durant cette même période, j'ai utilisé avante.nvim connecté à Claude Sonnet via le provider Copilot, voir note : J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot.
En revanche, comme je l’indique ici , je n’ai jamais réussi à trouver, dans l’interface web de GitHub, mes statistiques d’utilisation ni les quotas associés à Copilot. J’avais en permanence la crainte de découvrir un jour une facture salée.
Au mois d'avril 2025, j'ai commencé à utiliser Scaleway Generative APIs connecté à Open WebUI : voir note 2025-04-25_1833.
Pour résumer, ma situation en mai 2025 était la suivante
- Je pensais que l'utilisation des API directes d'OpenAI ou d'Anthropic était hors de prix.
- Je payais un abonnement mensuel d'un peu plus de 20 € pour un accès à Claude.ia via leur agent conversationnel web
- Je commençais à utiliser Scaleway Generative APIs avec accès à un nombre restreint de modèles
- Étant donné que je souscrivais à un abonnement, je ne pouvais pas facilement passer d'un provider à un autre. Quand je décidais de prendre un abonnement Claude.ia alors j'arrêtais d'utiliser ChatGPT.
En mai 2025, j'ai commencé sans conviction à m'intéresser à OpenRouter
J'ai réellement pris le temps de tester OpenRouter le 30 mai 2025. J'avais déjà croisé ce projet plusieurs fois auparavant, probablement dans la documentation de Aider, llm (cli) et sans doute sur le Subreddit LocalLLaMa.
Avant de prendre réellement le temps de le tester, en ligne de commande et avec Open WebUI, je n'avais pas réellement compris son intérêt.
Je ne comprenais pas l'intérêt de payer 5% de frais supplémentaires à openrouter.ai pour accéder aux modèles payants d'OpenAI ou Anthropic 🤔 !
Au même moment, je m'interrogeais sur les limites de quotas de tokens de l'offre Claude Pro.
For Individual Power Users: Claude Pro Plan
- All Free plan features.
- Approximately 5 times more usage than the Free plan.
- ...
J'étais très surpris de constater que la documentation de l'offre Claude Pro , contrairement à celle de l'API, ne précisait aucun chiffre concernant les limites de consommation de tokens.
Même constat du côté de ChatGPT :
ChatGPT Plus
- Toutes les fonctionnalités de l’offre gratuite
- Limites étendues sur l’envoi de messages, le chargement de fichiers, l’analyse de données et la génération d’images
- ...
Je me souviens d'avoir effectué diverses recherches sur Reddit à ce sujet, mais sans succès.
J'ai interrogé Claude.ia et il m'a répondu ceci :
L'offre Claude Pro vous donne accès à environ 3 millions de tokens par mois. Ce quota est remis à zéro chaque mois et vous permet d'utiliser Claude de manière plus intensive qu'avec le plan gratuit.
Aucune précision n'est donnée concernant une éventuelle répartition des tokens d'input et d'output, pas plus que sur le modèle LLM qui est sélectionné.
J'ai fait ces petits calculs de coûts sur llm-prices :
- En prenant l'hypothèse de 1 million de tokens en entrée et 2 millions en sortie :
- Le modèle Claude Sonnet 4 coûterait environ
$33. - Le modèle Claude Haiku coûterait environ
$2,75.
- Le modèle Claude Sonnet 4 coûterait environ
J'en ai déduit que le prix des abonnements n'est peut-être pas aussi économique que je le pensais initialement.
Après cela, j'ai calculé le coût de plusieurs de mes discussions sur Claude.ia. J'ai été surpris de voir que les prix étaient bien inférieurs à ce que je pensais : seulement 0,003 € pour une petite question, et environ 0,08 € pour générer un texte de 5000 mots.
J'ai alors pris la décision de tester openrouter.ai avec 10 € de crédit. Je me suis dit : "Au pire, si openrouter.ai est inutile, je perdrai seulement 0,5 €".
Je pensais que je n'avais pas à me poser de questions tant qu'openrouter.ai ne me coûtait qu'un ou deux euros par mois.
Suite à cette décision, j'ai commencé à utiliser openrouter.ai avec Open WebUI en utilisant ce playground : open-webui-deployment-playground.
Ensuite, je me suis lancé dans « Projet 30 - "Setup une instance personnelle d'Open WebUI connectée à OpenRouter" » pour héberger cela un peu plus proprement.
Et dernièrement, j'ai connecté avante.nvim à OpenRouter : Switch from Copilot to OpenRouter with Gemini 2.0 Flash for Avante.nvim.
Après plus d'un mois d'utilisation, voici ce que OpenRouter m'apporte
Entre le 30 mai et le 15 juillet 2025, j'ai consommé $14,94 de crédit. Ce qui est moindre que l'abonnement de 22 € par mois de Claude Pro.
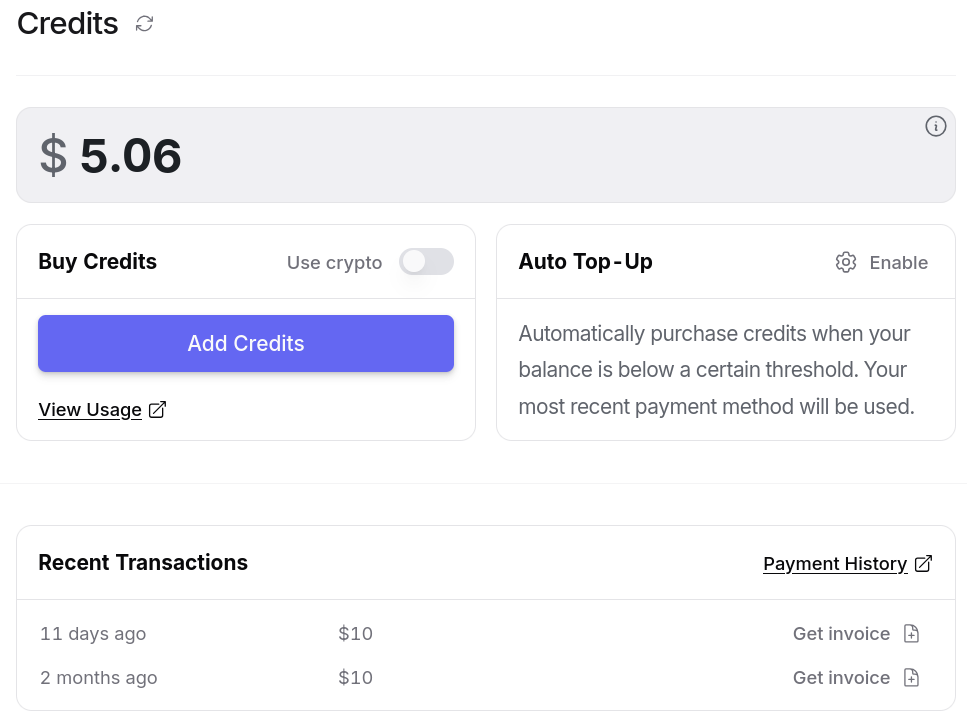
D'après mes calculs basés sur https://data.sklein.xyz, en utilisant OpenRouter j'aurais dépensé :
- mars 2025 :
$3.07 - avril 2025 :
$2,76 - mai 2025 :
$2,32
Ici aussi, ces montants sont bien moindres que les 22 € de l'abonnement Claude Pro.
En utilisant OpenRouter, j'ai accès facilement à plus de 400 instances de models, dont la plupart des modèles propriétaires, comme ceux de OpenAI, Claude, Gemini, Mistral AI…
Je n'ai plus à me poser la question de prendre un abonnement chez un provider ou un autre.
Je dépose simplement des crédits sur openrouter.ai et après, je suis libre d'utiliser ce que je veux.
openrouter.ai me donne l'opportunité de tester différents modèles avec plus de liberté.
J'ai aussi accès à énormément de modèles gratuitement, à condition d'accepter que ces providers exploitent mes prompts pour de l'entrainement. Plus de détail ici : Privacy, Logging, and Data Collection.
Tout ceci est configurable dans l'interface web de OpenRouter :
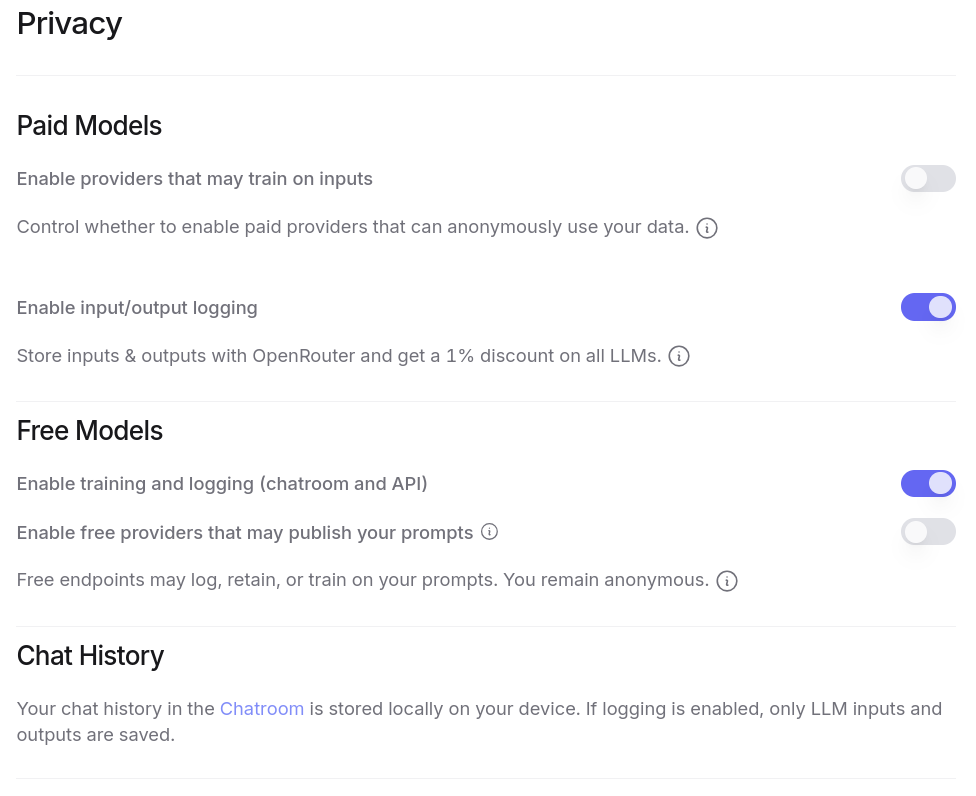
Je peux générer autant de clés d'API que je le désire. Et ce que j'apprécie particulièrement, c'est la possibilité de paramétrer des quotas de crédits spécifiques pour chaque clé ❤️.
OpenRouter me donne bien entendu accès aux fonctionnalités avancées des modèles, par exemple Structured Outputs with LLM, ou "tools" :
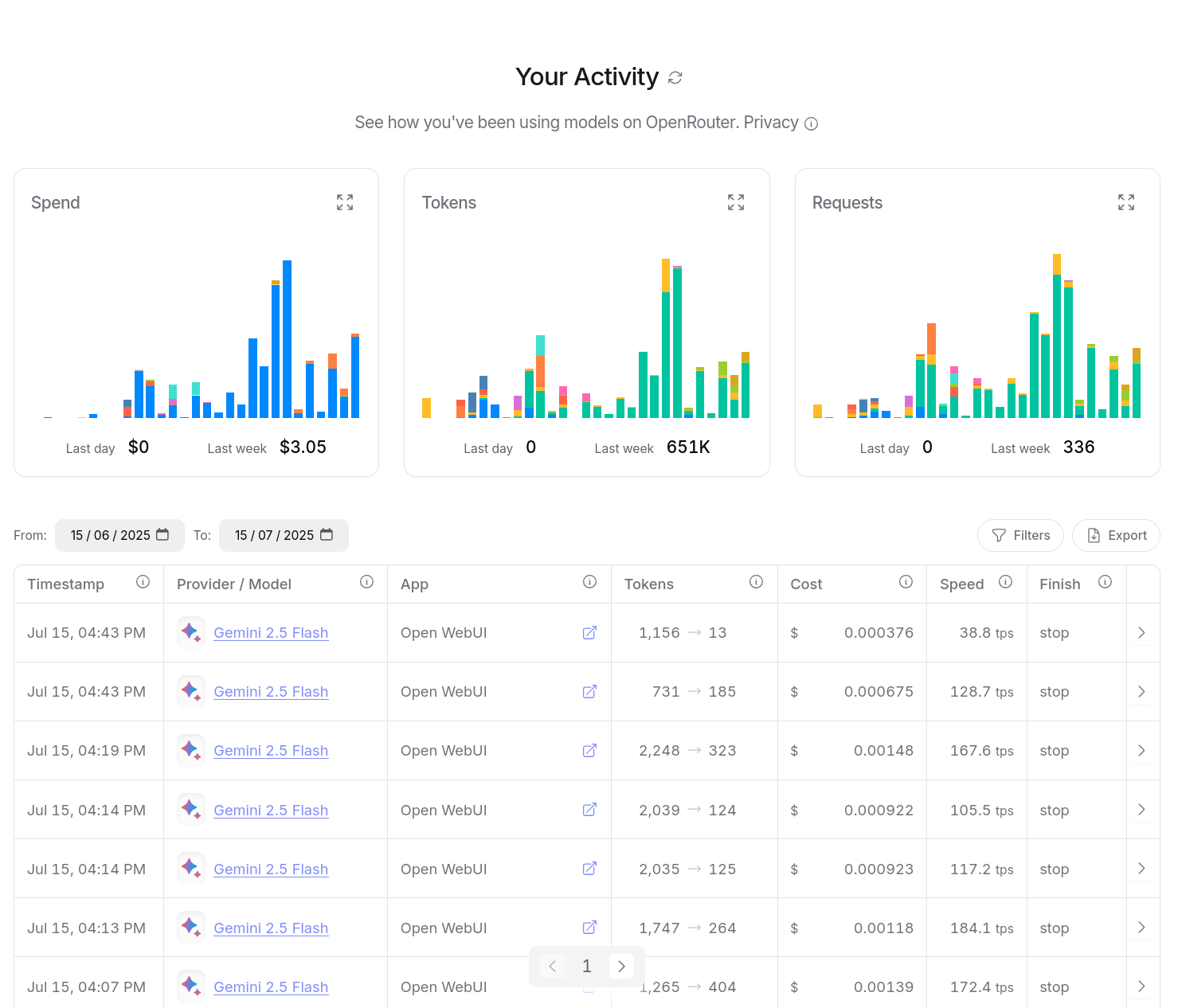
J'ai aussi accès à un dashboard d'activité, je peux suivre avec précision mes consommations :
Je peux aussi utiliser OpenRouter dans mes applications, avec llm (cli), avante.nvim… Je n'ai plus à me poser de question.
Et voici un petit screencast de présentation de openrouter.ai :
Une extension browser pour exporter ses threads Claude.ia et ChatGPT
Actuellement, et à ma connaissance, les APIs de Claude.ia et ChatGPT ne proposent pas de fonctionnalité d'export de l'historique des conversations de leur interface web de chat.
J'imagine deux approches pour réaliser cet export malgré tout : développer un script qui réalise une forme de Web Scraping ou intégrer cette fonctionnalité directement dans une extension navigateur plutôt que dans un script autonome. L'extension browser présente l'avantage de simplifier la gestion de l'authentification.
Après 30 minutes de recherche sur GitHub, du style "export chatgpt", j'ai trouvé claude-chatgpt-backup-extension. Cette extension permet l'export d'une ou plusieurs conversations Claude.ia et une conversation à la fois ChatGPT.
Je l'ai testée, elle fonctionne correctement 🙂.
Je viens de proposer cette Pull Request pour ajouter le support de l'export ChatGPT en mode bulk : Add bulk export feature for ChatGPT conversations.
Cette extension pourrait me servir de base de travail pour l'idée de projet "Aggregator - Backup Numeric Conversation System".
Voici les prochaines issues d'amélioration que j'imagine pour un fork de cette extension :
- Affichage conditionnel des boutons d'export Claude.ia uniquement quand l'utilisateur est connecté sur https://claude.ai/ (même principe pour ChatGPT).
- Afficher une barre de progression lors des bulk exportations.
- Proposer une option d'export au format YAML, sous une forme plus facile à lire pour les humains, avec moins d'informations techniques que le format JSON natif proposé actuellement.
- Tenter un refactoring pour simplifier la base de code actuelle.
- Développer une option permettant l'export vers des services Object Storage qui implémentent l'API S3.
- Créer un mock serveur API REST et permettre l'export des données vers ce serveur.
Aggregator - Backup Numeric Conversation System
Ce matin, j'ai eu l' #idée et l’envie de créer une appli d'archivage et de centralisation de toutes mes conversations numériques.
L'objectif ? Rassembler en un seul endroit, dans une interface web minimaliste, toutes mes discussions provenant de :
- ChatGPT
- Claude.ia
- Open WebUI
- Mes threads Mattermost
- Mes Mail
Le support des threads serait utile pour Mattermost et les mails. J'aimerais pouvoir sauvegarder tous ces messages au format brut original et en Markdown. Une fonction pour partager un message ou un thread serait aussi sympa.
Pour la persistance des données, je pense utiliser ElasticSearch avec son moteur vectoriel. Un LLM pourrait assigner automatiquement des tags à chaque conversation. J'aimerais que l'interface web soit minimaliste, orientée vitesse et exploration.
Pour la postérité, toutes ces données devraient être exportées en continu dans un Object Storage, sous un format YAML facilement compréhensible.
Je me demande si ce type d’application existe en Open source ou closed-source 🤔.
Journal du mardi 29 avril 2025 à 22:36
Depuis un an que j'effectue des missions Freelance, j'ai régulièrement besoin d'effectuer des changements dans des projets pour intégrer mes pratiques development kit, telles que l'utilisation de Mise, .envrc, docker-compose.yml, un README guidé, etc.
Généralement, ces missions Freelance sont courtes et je ne suis pas missionné pour faire des propositions d'amélioration de l'environnements de développement.
En un an, j'ai été confronté à cette problématique à cinq reprises.
Jusqu'à présent, j'ai utilisé la méthode suivante :
- J'ai intégré mon development kit dans une branche
sklein-devkit - Cette branche m'a ensuite servi de base pour créer des branches destinées à traiter mes issues, nommées sous la forme
sklein-devkit-issue-xxx - Et pour finir, je transfère mes commits avec
git cherry-pickdans une branche du typeissue-xxxque je soumettais dans une Merge Request ou Pull Request.
À la base, ce workflow de développement n'est pas très agréable à utiliser, et devient particulièrement complexe lorsque je dois effectuer des git pull --rebase sur la branche sklein-devkit !
Dans les semaines à venir, pour le projet Albert Conversation, je dois trouver une solution élégante pour gérer un cas similaire. Il s'agit de maintenir des modifications (série de patchs) du projet https://github.com/open-webui/open-webui qui :
- seront soit intégrées au projet upstream après plusieurs semaines ou mois
- soit resteront spécifiques au projet Albert Conversation et ne seront jamais intégrées en upstream, comme par exemple l'intégration du Système de Design de l'État.
Je me souviens avoir été marqué par l'histoire du projet Real-Time Linux mentionnée dans l'épisode 118 du podcast de Clever Cloud : les développeurs de Real-Time Linux ont maintenu pendant 20 ans toute une série de patchs avant de finir par être intégrés dans le kernel upstream (source : la conférence "PREEMPT_RT over the years") !
Voici la liste des patchs maintenus par l'équipe Real-Time Linux :
└── patches
├── 0001-arm-Disable-jump-label-on-PREEMPT_RT.patch
├── 0001-ARM-vfp-Provide-vfp_state_hold-for-VFP-locking.patch
├── 0001-drm-i915-Use-preempt_disable-enable_rt-where-recomme.patch
├── 0001-hrtimer-Use-__raise_softirq_irqoff-to-raise-the-soft.patch
├── 0001-powerpc-Add-preempt-lazy-support.patch
├── 0001-sched-Add-TIF_NEED_RESCHED_LAZY-infrastructure.patch
├── 0002-ARM-vfp-Use-vfp_state_hold-in-vfp_sync_hwstate.patch
├── 0002-drm-i915-Don-t-disable-interrupts-on-PREEMPT_RT-duri.patch
├── 0002-locking-rt-Remove-one-__cond_lock-in-RT-s-spin_trylo.patch
├── 0002-powerpc-Large-user-copy-aware-of-full-rt-lazy-preemp.patch
├── 0002-sched-Add-Lazy-preemption-model.patch
├── 0002-timers-Use-__raise_softirq_irqoff-to-raise-the-softi.patch
├── 0002-tracing-Record-task-flag-NEED_RESCHED_LAZY.patch
├── 0003-ARM-vfp-Use-vfp_state_hold-in-vfp_support_entry.patch
├── 0003-drm-i915-Don-t-check-for-atomic-context-on-PREEMPT_R.patch
├── 0003-locking-rt-Add-sparse-annotation-for-RCU.patch
├── 0003-riscv-add-PREEMPT_LAZY-support.patch
├── 0003-sched-Enable-PREEMPT_DYNAMIC-for-PREEMPT_RT.patch
├── 0003-softirq-Use-a-dedicated-thread-for-timer-wakeups-on-.patch
├── 0004-ARM-vfp-Move-sending-signals-outside-of-vfp_state_ho.patch
├── 0004-drm-i915-Disable-tracing-points-on-PREEMPT_RT.patch
├── 0004-locking-rt-Annotate-unlock-followed-by-lock-for-spar.patch
├── 0004-sched-x86-Enable-Lazy-preemption.patch
├── 0005-drm-i915-gt-Use-spin_lock_irq-instead-of-local_irq_d.patch
├── 0005-sched-Add-laziest-preempt-model.patch
├── 0006-drm-i915-Drop-the-irqs_disabled-check.patch
├── 0007-drm-i915-guc-Consider-also-RCU-depth-in-busy-loop.patch
├── 0008-Revert-drm-i915-Depend-on-PREEMPT_RT.patch
├── 0053-serial-8250-Switch-to-nbcon-console.patch
├── 0054-serial-8250-Revert-drop-lockdep-annotation-from-seri.patch
├── Add_localversion_for_-RT_release.patch
├── ARM__Allow_to_enable_RT.patch
├── arm-Disable-FAST_GUP-on-PREEMPT_RT-if-HIGHPTE-is-als.patch
├── ARM__enable_irq_in_translation_section_permission_fault_handlers.patch
├── netfilter-nft_counter-Use-u64_stats_t-for-statistic.patch
├── POWERPC__Allow_to_enable_RT.patch
├── powerpc_kvm__Disable_in-kernel_MPIC_emulation_for_PREEMPT_RT.patch
├── powerpc_pseries_iommu__Use_a_locallock_instead_local_irq_save.patch
├── powerpc-pseries-Select-the-generic-memory-allocator.patch
├── powerpc_stackprotector__work_around_stack-guard_init_from_atomic.patch
├── powerpc__traps__Use_PREEMPT_RT.patch
├── riscv-add-PREEMPT_AUTO-support.patch
├── sched-Fixup-the-IS_ENABLED-check-for-PREEMPT_LAZY.patch
├── series
├── sysfs__Add__sys_kernel_realtime_entry.patch
└── tracing-Remove-TRACE_FLAG_IRQS_NOSUPPORT.patch
46 files
J'ai été impressionné, je me suis demandé comment cette équipe a réuissi à gérer ce projet aussi complexe sur une si longue durée sans finir par se perdre !
Real-Time Linux n'est pas le seul projet qui propose des versions patchées du kernel, c'est le cas aussi du projet Xen, Openvz, etc.
J'ai essayé de comprendre le workflow de développement de ces projets. Avec l'aide de Claude.ia, il semble que ces projets utilisent un outil comme quilt qui permet de gérer des séries de patchs.
Il semble aussi que Debian utilise quilt pour gérer des patchs ajoutés aux packages :
Quilt has been incorporated into dpkg, Debian's package manager, and is one of the standard source formats supported from the Debian "squeeze" release onwards.
J'ai creusé un peu de sujet et à l'aide de Claude.ia j'ai découvert des alternatives "modernes" à quilt.
- Git lui-même :
git format-patchpour créer des séries de patchesgit ampour appliquer des patchesgit range-diffpour comparer des séries de patches- Branches de fonctionnalités +
git rebase -ipour organiser les commits
- Stacked Git (https://stacked-git.github.io/) :
- Topgit (https://github.com/mackyle/topgit) :
- Gère des changements de code sous forme de piles (stacks)
- Permet de maintenir des patches à long terme pour des forks
- Git Patchwork - (https://github.com/getpatchwork/patchwork) :
- Système de gestion et suivi des patches envoyés par email
- Utilisé par le noyau Linux et d'autres projets open source
- Guilt (http://repo.or.cz/w/guilt.git) :
- Jujutsu :
- Système de contrôle de version moderne basé sur Git
- Meilleure gestion des branches et séries de patches
- Git Series (https://github.com/git-series/git-series) :
- Outil pour travailler avec des séries de patches Git
- Permet de suivre l'évolution des séries au fil du temps
Après avoir jeté un œil sur chacun de ces projets, j'envisage de créer un playground pour tester Stacked Git.
Journal du vendredi 25 avril 2025 à 18:33
Au mois de janvier, j'ai écrit :
Voici mes prochaines #intentions d'amélioration de ma workstation :
- ...
- Essayer de remplacer les services ChatGPT ou Claude.ia par Open WebUI.
- ...
Le hasard de la vie fait que je commence une mission professionnelle pour la DINUM en lien avec Open WebUI : Ablert Conversation.
Au mois de décembre, j'ai déjà installé et testé rapidement Open WebUI connecté à Scaleway Generative APIs, mais je n'ai pas pris le temps de le faire avec rigueur.
Dans les prochains jours, je souhaite réaliser les projets suivants :
Journal du mercredi 05 mars 2025 à 21:51
J'utilise LibreWolf depuis le 4 jours.
Je rencontre un problème sur le site Claude.ia. Après la génération de quelques lignes de réponses, l'opération s'arrête et LibreWolf se bloque — freeze. Après quelques secondes, le message d'erreur suivant apparaît :
« This page is slowing down LibreWolf. To speed up your browser, stop the page ».
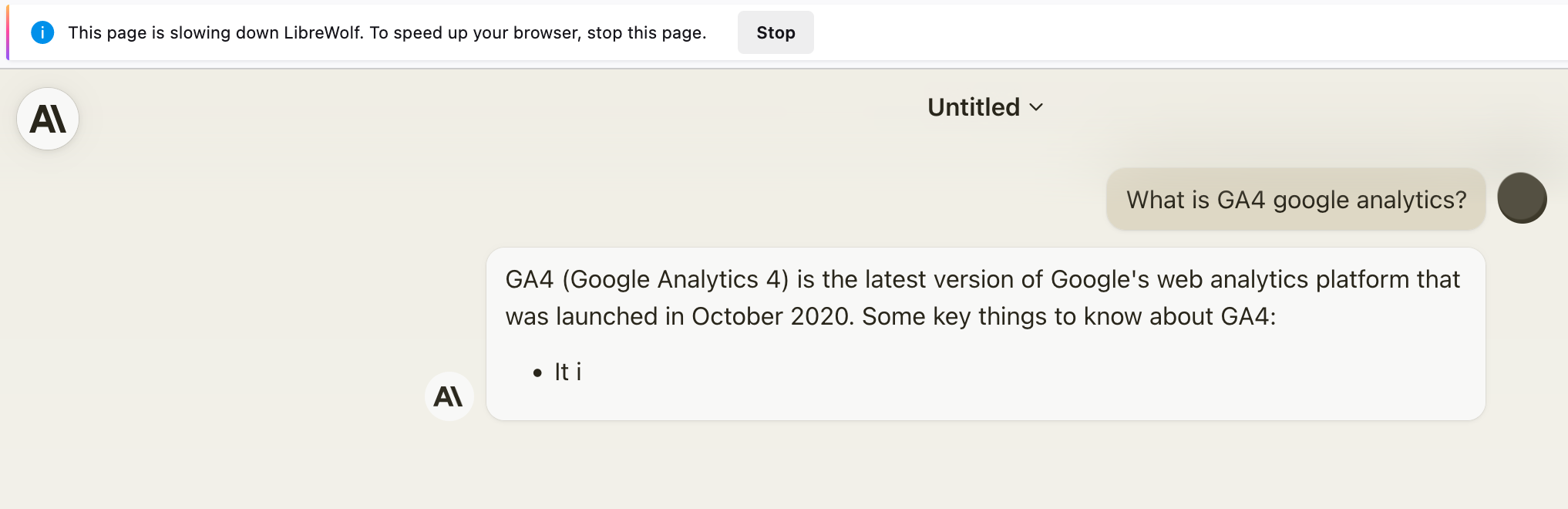
J'ai trouvé une solution ici.
Issue upstream à ce sujet : LibreWolf sometimes freezes when Claude AI writes responses in chat - librewolf/issues - Codeberg.org
J'ai ajouté https://claude.ai dans la liste des exceptions de protection renforcée contre le pistage.
Après cela, les "freeze" ont disparu.

2025-03-11 : même en ayant ajouté l'exception de protection renforcée, je rencontre toujours le problème 🤨 (voir mon commentaire).
J'ai toutefois corrigé le problème grâce à la configuration suivante : https://github.com/stephane-klein/dotfiles/commit/5791e3fe2044df33e5391674c13b237dd573aef4.