
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (750) ] [ Notes plus anciennes (319) >> ]
Mercredi 14 août 2024
Journal du mercredi 14 août 2024 à 14:23
Je dois passer par un VPN pour accéder à un projet professionnel.
Ce VPN est propulsé par OpenVPN.
Ma workstation tourne sous Fedora, sous GNOME.
J'ai réussi à configurer facilement l'accès OpenVPN via NetworkManager-openvpn via l'import de fichier .ovpn.
Cependant, cette méthode de configuration m'a posé un problème : le routage par défaut était dirigé vers le VPN. Conséquence, l'intégration de mon accès à Internet passait par le réseau VPN qui était bien plus lent que mon accès Internet.
Ceci était très frustrant.
De plus, cette configuration ajoutait une charge réseau supplémentaire inutile au VPN.
J'ai essayé d'utiliser l'option "N'utiliser cette connexion que pour les ressources sur ce réseau" mais cela n'a pas fonctionné.
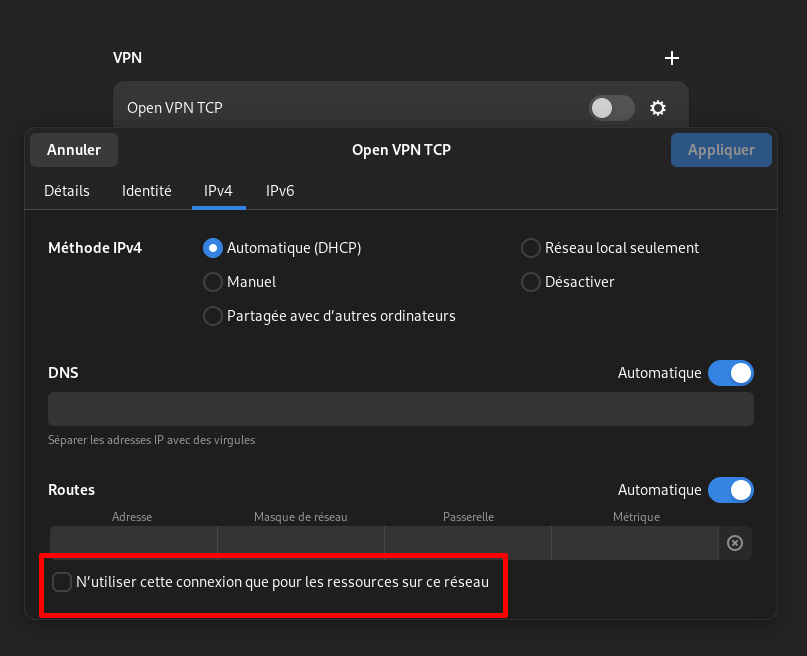
Peut-être un problème DNS 🤔.
J'ai donc choisi une autre stratégie. J'ai configuré cela sans GUI.
Voici le skeleton de mon dossier de connexion au VPN : https://github.com/stephane-klein/openvpn-client-skeleton (celui-ci ne contient aucun secret).
Ce projet me permet :
- D'utiliser le serveur DNS présent dans le réseau privé seulement pour un certain type de sous domaine.
- Le VPN est utilisé uniquement pour les serveurs qui se trouvent à l'intérieur du réseau privé. Par exemple, je ne passe pas par ce VPN pour accéder à Internet.
- La totalité de cette configuration est basé sur des fichiers et est scripté (pratique GitOps)
- OpenVPN client est managé par SystemD
Voir aussi 2024-08-14_1511.
Journal du mercredi 14 août 2024 à 12:05
Cela fait 25 ans que je travaille dans le domaine du web, et je viens seulement de prendre conscience de la différence entre un Domain name registrar et un Domain name registry 🙈.
Jusqu'à présent, j'avais tendance à les considérer comme synonymes.
Par exemple, des entreprises comme Gandi ou BookMyName sont exclusivement des Domain name registrar. Elles ne jouent pas le rôle de Domain name registry.
En revanche, certaines entreprises cumulent les deux fonctions, à savoir être à la fois registrar et registry.
C'est le cas de https://www.identity.digital/, qui est à la fois un registrar et registry pour des gTLDs comme le .systems.
Un autre exemple est Team Internet, qui non seulement opère en tant que registry pour le domaine ".xyz", mais agit également en tant que registrar.
Journal du mercredi 14 août 2024 à 12:01
#JaiDécouvert l'existence du gTLDs .systems, qui est disponible depuis 2014.
Mardi 13 août 2024
Journal du mardi 13 août 2024 à 21:32
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai enfin analysé la Merge Request qui m'a été envoyé par un ami 🤗 : https://github.com/stephane-klein/postgres-tags-model-poc/pull/9
6 mois plus tard, j'ai fini l'implémentation de la première version du "Query string javascript parser" : https://github.com/stephane-klein/postgres-tags-model-poc/commit/f0f363b78c136e8e67a38f95b5c627d874537949
Pour la coloration syntaxique des fichiers Peggy sous Neovim, j'utilise avec succès https://github.com/TheGrandmother/peggy-vim : https://github.com/stephane-klein/dotfiles/commit/20cba4ba646a0793f66f9b19788920a4ff1f1838
Journal du mardi 13 août 2024 à 16:32
Je suis victime du bug suivant depuis 2 ou 3 jours sous ma Fedora :
Unexpected Logouts and System Instability: The second, more critical issue I’ve been facing is unexpected system logouts. Over the past two days, my screen has suddenly gone black as if the system has shut down. After less than a second, the login screen reappears, and upon logging in, I find that all my applications have closed. Yesterday, August 11, 2024, this happened twice within a three-minute span. Today, August 12, 2024, while studying with only Firefox open, I suspended my laptop and left.
-- from
J'en apprends plus ici :
A new regression for AMD APU’s is present in kernel 6.10 that wil cause intermittent full system crashes in combination with Mesa 24.1.5. The only option is to power down and restart the machine.
Kernel 6.9 is unaffected.
Issue upstream : https://gitlab.freedesktop.org/drm/amd/-/issues/3497
Je vais donc reboot sous un kernel 6.9 🤷♂️.
Je suis sûr qu'Alexandre va me dire qu'il n'a aucun problème sous ArchLinux ! Mais je ne le croirai pas, c'est un bug upstream !
Voir aussi ma doctrine Linux Desktop.
2024-08-22 : J'ai posté ce message AMD APU regression (full halt) on kernel 6.10 - how to best report?
2024-09-12 : J'ai posté ce message How to list Mesa versions included in my flatpak applications?
2024-10-15 : J'ai posté ce message.
Journal du mardi 13 août 2024 à 10:41
Deux amis m'ont partagé un thread Hacker News : Postgres.new: In-browser Postgres with an AI interface.
Je viens de prendre le temps de tester postgres.new.
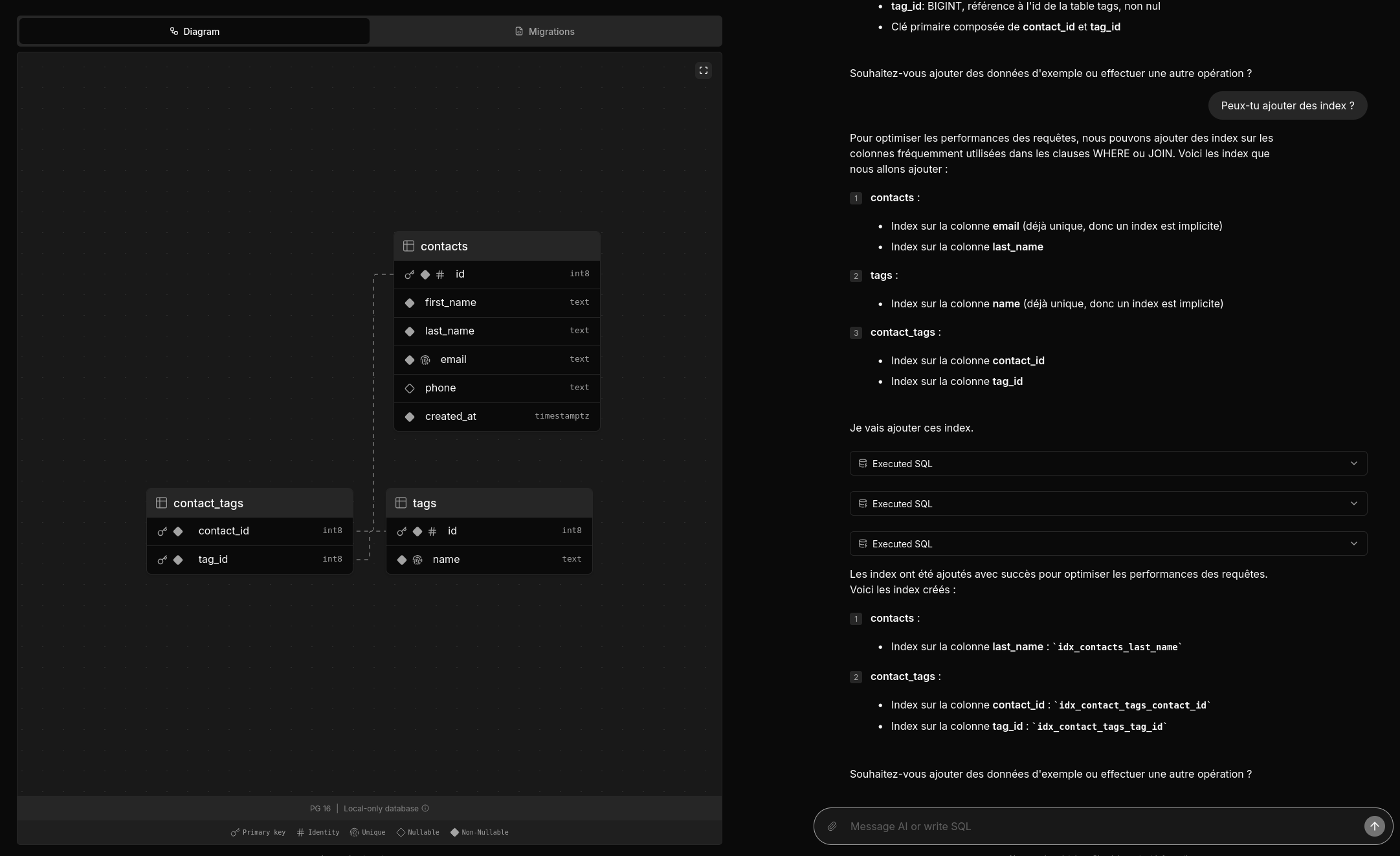
Voici une vidéo officielle : https://www.youtube.com/watch?v=ooWaPVvljlU
#Jadore ! Je trouve l'UX très bonne, j'aime l'onglet "Migrations", les explications données dans la colonne de droite.
Le projet est 100% Open source, voici le dépôt GitHub : https://github.com/supabase-community/postgres-new
Très beau travail !
Je me demande combien de temps ce projet a été implémenté 🤔.
1 mois et demi d'après la page contributors.
Mais je constate que le premier commit est plutôt conséquent, je pense que le projet était initialement intégré dans un mono repository.
Concernant l'implémentation, je lis :
All queries in postgres.new run directly in your browser. There’s no remote Postgres container or WebSocket proxy.
👍️
How is this possible? PGlite, a WASM version of PostgreSQL that can run directly in your browser. Every database that you create spins up a new instance of PGlite that exposes a fully-functional Postgres database. Data is stored in IndexedDB so that changes persist after refresh.
La partie LLM n'est pas mentionnée, #JeMeDemande comment elle est implémentée 🤔.
Je pense avoir trouvé ma réponse ici :
We pair PGlite with an LLM (currently GPT-4o) and give it full reign over the database with unrestricted permissions. (from)
Je lis :
RAG / pgvector: PGLite supports pgvector, so you can ask the LLM to create embeddings for RAG. The site uses transformers.js to create embeddings inside the browser.
Je n'ai pas tout compris 🤔.
#JaiDécouvert transformers.js.
J'ai lu ce commentaire :
It is a neat tech demo but it clearly shows the limits of AI:
- I got it to generate invalid SQL resulting in errors - it merely generates reasonable SQL, but in my case it generated to disjoint set of tables…. - In practice you have tot review all code - It can point you into the wrong direction. Novel systems often have something smart/abstract in there. This system creates mostly Straightforward simple systems. That’s not where the value is
All in all, it’s not worth it to me. Writing code myself is easier than having to review LLM code
Within our organization we have forbidden full LLM merge request because more often than not the code was suboptimal. And had sneaky bugs/mistakes.
I’m not saying these can’t be overcome. But not with current LLM design. They mostly generate stuff they have seen and are bad as truly new stuff.
Personnellement, cela ne me surprend pas et cela ne remet pas en question, à mes yeux, l'intérêt de cet outil.
Je pense l'utiliser pour concevoir une ébauche de base de données.
Je pense qu'il pourra me fournir de bonnes suggestions pour les noms de tables et de champs, et même inclure des champs auxquels je n'aurais peut-être pas pensé.
Lundi 12 août 2024
Journal du lundi 12 août 2024 à 23:21
#JaiLu pour la première fois la syntax de recherche de GitHub : Searching issues and pull requests.
Je la trouve à la fois complète et intuitive.
Cependant, j'ai remarqué que les opérateurs and et or, ainsi que l'utilisation des parenthèses, ne sont pas pris en charge.
Journal du lundi 12 août 2024 à 13:25
Quel est mon rapport aux langages typés ?
Pour bien comprendre mon approche des langages typés, il est utile de revenir sur mon parcours.
Enfant, j'ai commencé par du Locomotive Basic (non typé), j'ai ensuite fait beaucoup de Turbo Pascal (typé) et un peu de C, C++ (typé).
À cette époque, je préférais les langages typés pour des raisons de performances.
En 2000, j'ai vraiment aimé utiliser à nouveau des langages non typés, comme PHP et surtout Python qui a été pendant très longtemps mon langage de prédilection.
J'ai à nouveau beaucoup pratiqué un langage typé de 2013 à 2018 : Golang.
Aujourd'hui, je considère qu'il est souvent plus facile et plus rapide de programmer dans un langage non typé, notamment grâce au Duck Typing. Cependant, je reconnais que les langages typés offrent des avantages indéniables, notamment en matière de refactoring de code.
Je pense qu'il est préférable d'utiliser un langage typé sur un projet critique.
Je pense qu'il est préférable d'utiliser un langage typé pour les programmes qui manipule des données complexes et divers.
C'est, par exemple, pour cela que ne suis pas un utilisateur de MongoDB. Je préfère une base de données PostgreSQL où tout est bien typé.
Il ne me viendrait pas à l'esprit d'implémenter une base de données ou un moteur web dans un langage non typé.
Par contre, je suis moins convaincu par l'utilisation d'un langage typé pour les applications d'interface utilisateur lourde ou web.
Lorsqu'une équipe de développement travaillant sur un code commun atteint une certaine taille — je n'ai aucune idée de ce nombre — je suis convaincu qu'il devient préférable d'utiliser un langage typé.
Journal du lundi 12 août 2024 à 11:45
Je pense que depuis 2013 environ, je me classe dans la catégorie des artisans développeurs de type conservateurs.
Je m'efforce de suivre une une doctrine centrée sur le principe du Choose Boring Technology.
Je ne crois plus aux "techniques miracles" (No Silver Bullet).
J'ai vu trop de projet souffrir de pratique telles que le Resume Driven Development ou de Cargo cult programming.
Voir aussi : Keep it simple, stupid le plus longtemps possible.
Journal du lundi 12 août 2024 à 11:32
Je ressamble ici quelques notes au sujet de l'évolution de usage de TypeScript dans le temps.
Ces informations proviennent de State of JavaScript .
Année 2016
https://2016.stateofjs.com/2016/flavors/
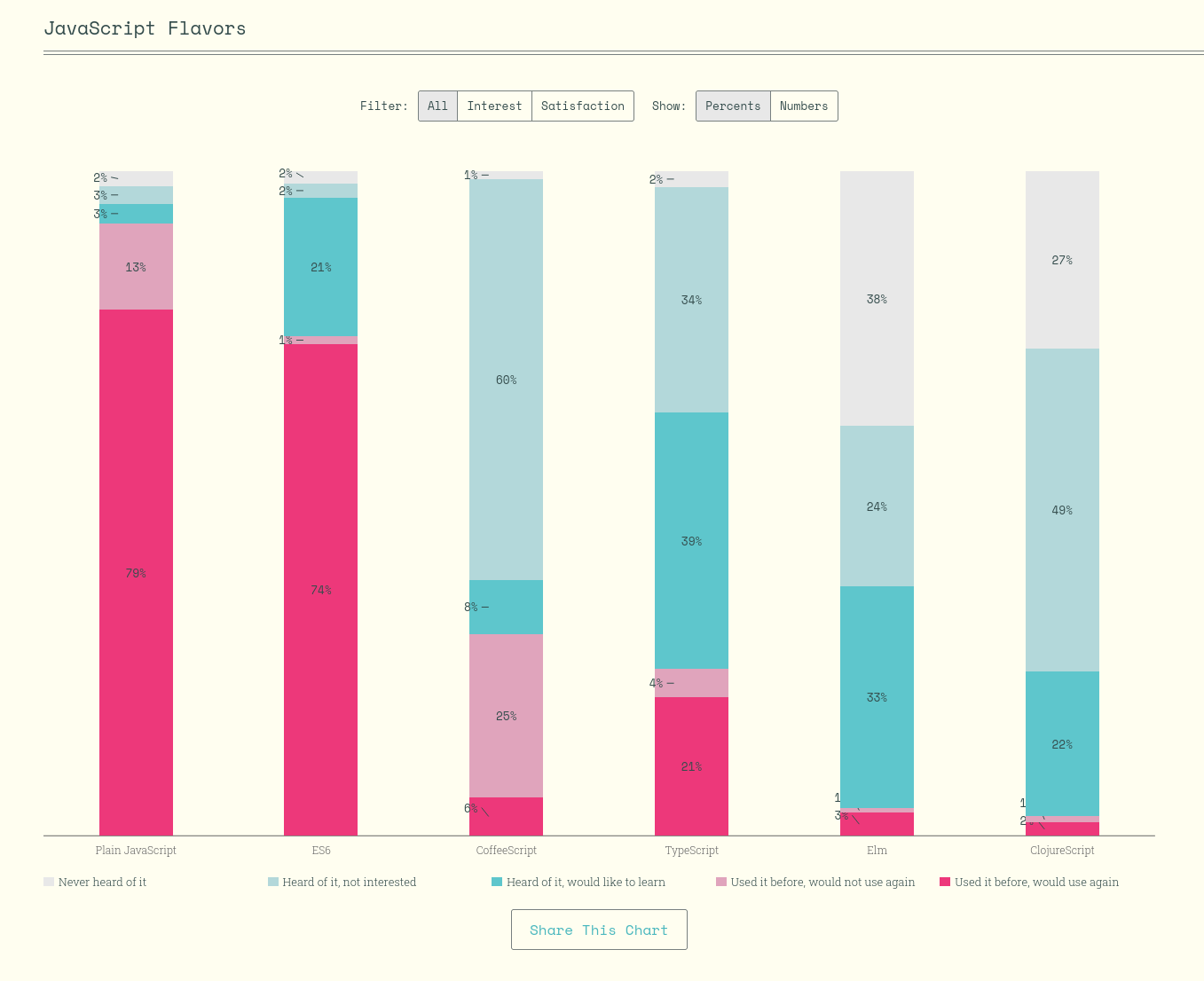
Année 2020
JavaScript flavors usage :
https://2020.stateofjs.com/en-US/technologies/javascript-flavors/
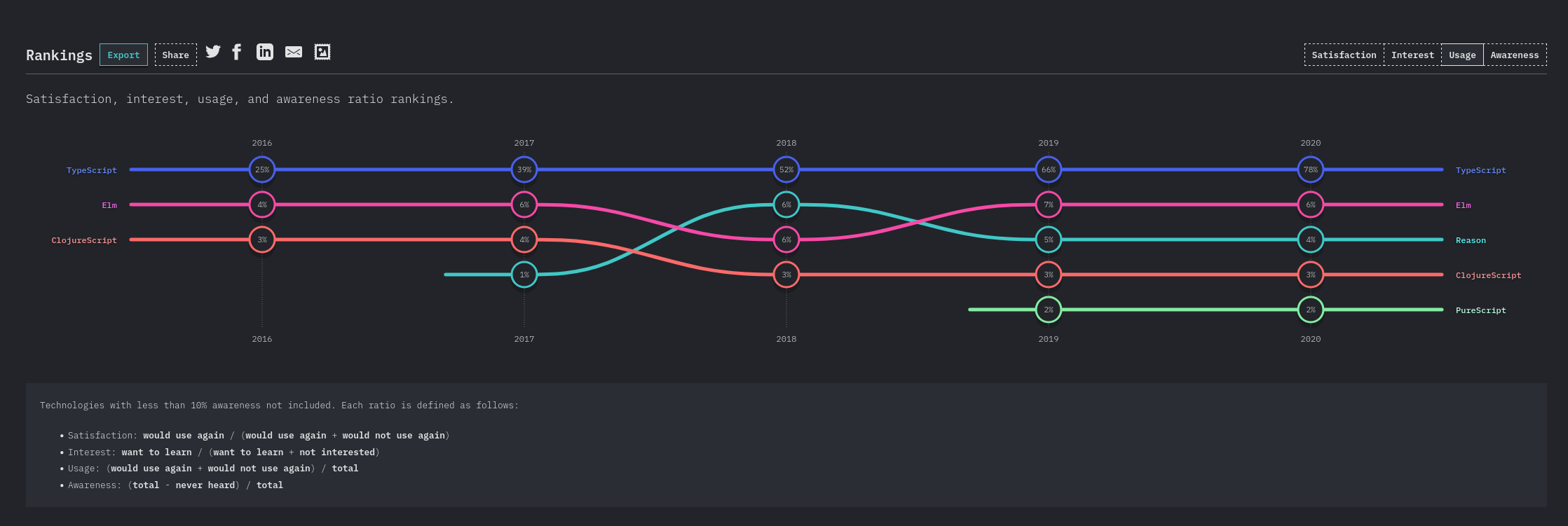
Année 2022
https://2022.stateofjs.com/en-US/usage/#js_ts_balance

Année 2023
https://2023.stateofjs.com/en-US/usage/#js_ts_balance
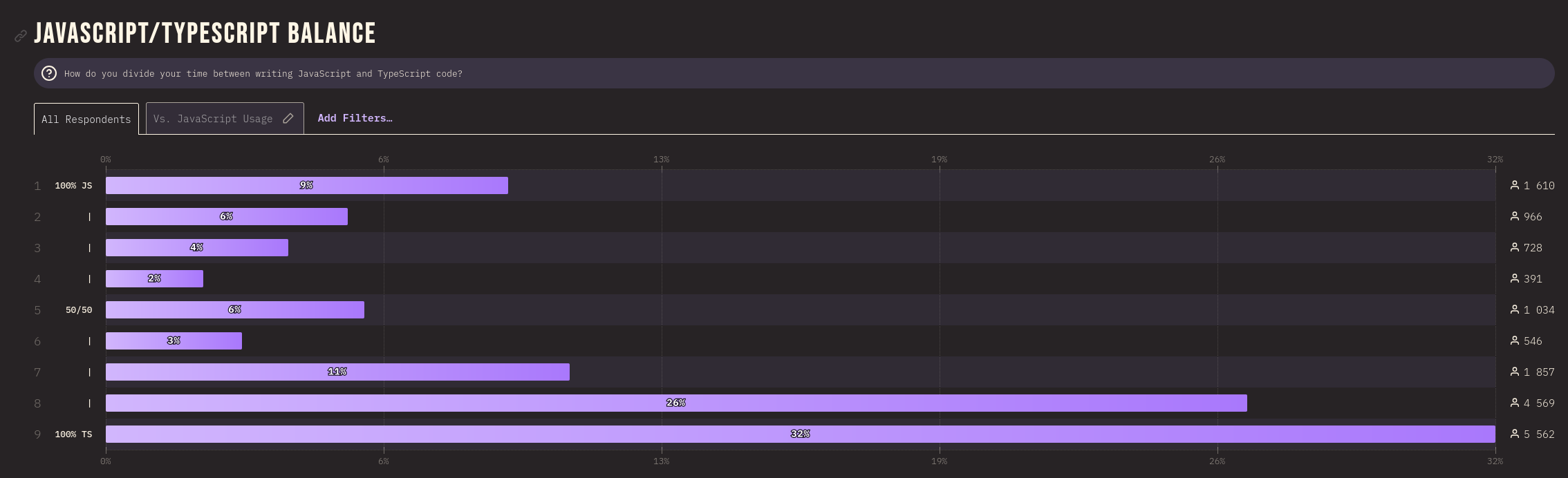
Journal du lundi 12 août 2024 à 11:09
#JaiLu le thread Hacker News Turbo 8 is dropping TypeScript.
Quelques extraits :
I highly recommend reading the PR discussion for this.
https://github.com/hotwired/turbo/pull/971
Some summary:
- forced through without any discussion
- many maintainers raising questions, but no answers
- random changes attached to the PR (formatters, etc)
Wherever you land on types, I think we can agree that this is not an ideal way to make a change to a larger open source project. This has all the hallmarks of an executive decision made on a whim, and forced through at the last minute. Lead maintainers certainly have the right to make big changes on a whim, but giving people some notice before breaking other projects and having good communication is true leadership.
After using TypeScript I could never go back. The amount of times it's saved me or got me up to speed quickly is countless. It does come with a cost and god the error messages are just awful sometimes but I'd die before I ever work in a js only project again.
I wonder if type annotations (JSDoc) on plain JS could be the way to go. Lint, but don’t compile. This should work seamlessly with NPM modules etc.
Journal du lundi 12 août 2024 à 11:04
Voici un extrait de l'article Turbo 8 is dropping TypeScript de David Heinemeier Hansson (DHH de Basecamp) :
This isn't a plea to convert anyone of anything, though. As I discussed in Programming types and mindsets, very few programmers are typically interested in having their opinion on typing changed. Most programmers find themselves drawn strongly to typing or not quite early in their career, and then spend the rest of it rationalizing The Correct Choice to themselves and others.
Je trouve ce point de vue intéressant.
Voir aussi : TypeScript
Dimanche 11 août 2024
Journal du dimanche 11 août 2024 à 21:20
Suite à ma note 2024-08-10_1726 en lien avec le Projet 11 - "Première version d'un moteur web PKM", #JaiDécidé de ne pas implémenter les pages /tags/{tag_name}/. À la place, je souhaite que les a href des tags point vers l'url suivante : /search/?tags=tagname.
Journal du dimanche 11 août 2024 à 20:33
#JaiDécouvert le concept Obsidian nommé Higher-Order Notes (from).
#JaiLu Concept notes are higher-order notes, not permanent Zettels et je n'ai rien appris d'intéressant..
Journal du dimanche 11 août 2024 à 20:21
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
Samedi 10 août 2024
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du samedi 10 août 2024 à 16:08
#JeSouhaiteTester https://zotlit.aidenlx.top/ qui est un plugin pour coupler Zotero à Obsidian.
Journal du samedi 10 août 2024 à 12:45
Depuis avril 2024, je m'intéresse au sujet des Personal knowledge management et Zettelkasten. J'ai remarqué que Zotero occupe une place importante dans les workflows des utilisateurs de PKM.
Conséquence : #JaiDécidé de tester Zotero , afin de déterminer s'il peut m'être utile et comment l'intégrer efficacement dans mon propre workflow.
Jeudi 8 août 2024
Journal du jeudi 08 août 2024 à 17:22
Après 11h48 de travail, j'ai enfin réussi à achever mon Projet 8 - "CodeMirror, conceal, Svelte".
Consultez de détailler dans le README du repository : https://github.com/stephane-klein/svelte-codemirror-conceal-poc.
Journal du jeudi 08 août 2024 à 15:18
#JaiLu La France laboratoire de la Silicon Valley 2.0
Tous mes amis me confirment qu’avec la baisse du système éducatif, nous sommes sur notre avant-dernière génération d’ingénieurs de très haut niveau. Cette génération aurait pu être déployée sur les sujets régaliens, notamment la Défense. Mais en travaillant pour les grandes entreprises américaines, ils vont par procuration travailler sur la Défense américaine. Ils aideront aussi les retraités américains à garantir leur retraite (grâce à un NASDAQ avec des valeurs florissantes).
Intéressant comme point de vue 🤔.
Sur le court terme, elle apporte du capital, mais sur le long terme, je ne suis plus sûr que nous aurons la capacité de faire tourner le pays dans 10 ou 20 ans, car les meilleurs d’une génération auront travaillé pour résoudre les problèmes de la Silicon Valley.
🤔.
Journal du jeudi 08 août 2024 à 15:01
#JaiLu https://x.com/tariqkrim/status/1821205699898060995
#JaiLu Pourquoi la tech française va droit dans le mur (2ème partie)
J’ai découvert récemment que Canal Plus, autrefois leader incontesté du décodeur, s’appuie désormais sur l’Apple TV pour sa distribution. -- from
En effet, bel échec 🤷♂️.
#JeSouhaite lire La France laboratoire de la Silicon Valley 2.0.
Il ne serait pas idiot que la France, l’Angleterre, les Pays-Bas et l’Italie travaillent en commun de la prochaine génération de puces et de logiciels open source pour permettre de concevoir la prochaine génération d’infrastructures résilientes dont la guerre en Ukraine a fait l’éclatante démonstration de la nécessité.
Avec la chute possible de Mozilla dont les financements pourraient être arrêtés suite à la décision de justice sur Google, il ne serait pas idiot non plus d’imaginer un projet de browser européen pensé nativement pour la vie privée et totalement open source et open CPU. -- from
C'est la stratégie à laquelle je rêve depuis 20 ans ! 🙏
À part à la gendarmerie nationale, il n’y a eu aucune vision sur le futur du desktop en France. On continue de dépenser de l’argent pour maintenir une technologie des années 90. -- from
Je dis 👍️x100.
En ne protégeant pas le web ouvert, pourtant créé en Europe, nous avons laissé les entreprises qui veulent distribuer leurs applications sur mobile aux mains de deux apps stores qui vampirisent 30 % de la valeur créée depuis 15 ans.
Quand on prend la peine d’y réfléchir un instant, notre quotidien numérique est désormais totalement défini par des entreprises extérieures à la France, par une centaine de product managers en Californie que nous ne connaissons pas.
👍️
Journal du jeudi 08 août 2024 à 08:40
#JaiDécouvert que GoCardLess propose une API permettant de récupérer l'historique de transactions de plus de 900 banques : Bank Account Data.
Je vais m'inscrire pour la tester.
Note : L'accès Woob ne permet plus de se connecter à BPLC.
Mardi 6 août 2024
Journal du mardi 06 août 2024 à 17:43
#OnMaPartagé le #mot Otium.
L’otium n’est pas simplement un temps de relâchement, d'oisiveté ou de flânerie.
Il est ce qu’on pourrait appeler le loisir fécond et studieux, un temps que l'on consacre à s'améliorer soi-même, à progresser pour accéder à une compréhension du monde plus grande.
Il ne sert aucun but, si ce n’est celui de s’élever et de s’améliorer en tant qu’individu.
Une exploration complètement désintéressée qui le classerait dans la catégorie des activités dites “inutiles” de nos jours.
D’ailleurs, ce n’est pas un hasard si ce mot-là n’a pas vraiment de traduction dans notre langue moderne, c’est peut-être parce qu’il a simplement disparu de notre conception du monde.
Ce que nous appelons aujourd’hui “loisir” est tout ce qui se regroupe derrière l’idée d’un plaisir immédiat, à consommer. Un temps pour s’échapper de soi et de ses problèmes du quotidien. Un loisir-opium si l’on reprend l’analogie.
Le concept d'otium, s’il a été popularisé sous l’Empire romain, est né pendant la Grèce antique. On l’appelait la skholè.
Pour les Grecs, la skhôlè est le temps libre dans lequel se construit la capacité à argumenter, l’esprit critique, la capacité de jugement…
Bref, c’est le creuset qui a permis de créer le concept même de Citoyens capables de décider de leur avenir. C’est tout simplement l’idée fondatrice de la démocratie !
-- from
Dans cet article :
Journal du mardi 06 août 2024 à 16:48
Projet 8 - "CodeMirror, conceal, Svelte", je découvre ici la méthode pour déclarer un Widget CodeMirror vide :
export const invisibleDecoration = Decoration.replace({});
Journal du mardi 06 août 2024 à 14:27
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
#JaiDécouvert lezer-markdown-obsidian qui correspond à ce que j'ai besoin pour 2024-08-06_1140.
Je viens de voir ici une propriété complete :
class FootnoteReferenceParser implements LeafBlockParser {
...
complete(cx: BlockContext, leaf: LeafBlock) {
cx.addLeafElement(
leaf,
cx.elt(
"FootnoteReference",
leaf.start,
leaf.start + leaf.content.length,
[
cx.elt("FootnoteMark", leaf.start, leaf.start + 2),
cx.elt("FootnoteLabel", leaf.start + 2, this.labelEnd - 2),
cx.elt("FootnoteMark", this.labelEnd - 2, this.labelEnd),
...cx.parser.parseInline(
leaf.content.slice(this.labelEnd - leaf.start),
this.labelEnd
),
]
)
);
return true;
}
}
Dans le Projet 1 - "CodeMirror, autocomplétion, Svelte", #JeMeDemande si je ne suis pas passé à coté d'une meilleur méthode pour implémenter de l'auto complétiion dans CodeMirror 🤔.
Journal du mardi 06 août 2024 à 11:40
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
J'essaie d'implémenter un "Replacing Dectorator" CodeMirror basé sur une recheche
syntaxTree. -- from
J'essaie de m'inspirer de ces implémentations lezer-parser/markdown/src/extension.ts#L10 et /silverbulletmd/silverbullet/common/markdown_parser/parser.ts#L30.
Journal du mardi 06 août 2024 à 09:14
Je me pose à nouveau la question suivante en Svelte : first, last, even, odd field in {#each} loop.
Journal du mardi 06 août 2024 à 08:45
#JaiDécouvert la commande psql nommé \ir :
\iror\include_relativefilenameThe \ir command is similar to \i, but resolves relative file names differently. When executing in interactive mode, the two commands behave identically. However, when invoked from a script, \ir interprets file names relative to the directory in which the script is located, rather than the current working directory.
-- from
J'ai trouvé cette commande via Fwd: psql include file using relative path.
Cela faisait des années que j'avais besoin de cette fonctionnalité et, étrangement, je ne l'ai découverte seulement aujourd'hui 🤔.
Exemple d'utilisation https://github.com/stephane-klein/sklein-pkm-engine/blob/8938d7a2c19ed8f741bd38162882e9517c739c30/sqls/init.sql#L36
Lundi 5 août 2024
Journal du lundi 05 août 2024 à 22:57
« #JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔. » -- from
Je viens de lire le thread suivant : [Question: difference between Lezer and tree-sitter](# Question: difference between Lezer and tree-sitter).
This system's approach is heavily influenced by tree-sitter, a similar system written in C and Rust, and several papers by Tim Wagner and Susan Graham on incremental parsing (1, 2). It exists as a different system because it has different priorities than tree-sitter—as part of a JavaScript system, it is written in JavaScript, with relatively small library and parser table size. It also generates more compact in-memory trees, to avoid putting too much pressure on the user's machine. -- from
Journal du lundi 05 août 2024 à 16:41
Suite de Projet 8 - "CodeMirror, conceal, Svelte".
J'essaie d'implémenter un "Replacing Dectorator" CodeMirror basé sur une recheche syntaxTree.
J'essaie de m'inspirer de /examples/decoration/checkbox.ts.
Journal du lundi 05 août 2024 à 15:20
Je regarde le site web de lezer https://lezer.codemirror.net/ et je constate qu'il a le même look que CodeMirror.
J'en déduis qu'il est sans doute développé par les mêmes développeur que CodeMirror.
#JeMeDemande si lezer sera un jour remplacé par tree-sitter compilé en WASM 🤔.
Journal du lundi 05 août 2024 à 14:58
Le projet SilverBullet.mb utilise le terme Transclusion : https://silverbullet.md/Transclusions
Transclusions are an extension of the Markdown syntax enabling inline embedding of content.
The general syntax is
![[path]].
Journal du lundi 05 août 2024 à 14:52
Dans le cadre du Projet 8 - "CodeMirror, conceal, Svelte", j'essaie de m'inspirer du code source de SilverBullet.mb.
#JeMeDemande si l'implémentation de la fonctionnalité conceal sur les wikilink se trouve ici 🤔.
Je constate ici que l'implémentation ne prend pas en charge directement la recherche des de la syntax [[wikilink]] via, par exemple, une regex, mais l'implémentation semble utiliser un parser Markdown.
Je constate ici que SilverBullet.mb est basé sur la lib lezer. Ce qui me semble normal, parce que le plugin lang-markdown utilise aussi lezer.
Je ne trouve aucune mention de wikilink dans le code source de /lezer-parser/markdown/, par conséquent, je pense que ce type d'élément a été implémenté dans le code source de SilverBullet.mb.
Dimanche 4 août 2024
Journal du dimanche 04 août 2024 à 22:03
Suite à la lecture de l'article Project Metrics, #JaiLu :
Journal du dimanche 04 août 2024 à 21:27
Voici quelques notes suite à ma lecture de l'article Project Metrics.
Jusqu'à présent, je n'avais fait qu'un survol rapide du projet git-metrics. D'après son nom, je pensais qu'il s'agissait d'un outil permettant de générer des statistiques à partir des données d'un dépôt git.
Je me trompais : ce projet a une tout autre vocation.
git-metrics permet, tout comme git notes, d'intégrer des métadonnées directement dans un dépôt git.
Samedi 3 août 2024
Journal du samedi 03 août 2024 à 11:53
Suite à l'écriture de 2024-08-03_1018, une idée m'est venue : pourquoi ne pas lancer un service d'email en France basé sur le code source de Forward Email ?
Les principales différences avec Forward Email seraient les suivantes :
- Hébergement en France, soumis au droit français
- Transparence totale sur l'identité des auteurs
L'objectif serait d'entreprendre cette démarche de manière transparente avec l'équipe de Forward Email et de leur reverser une partie des revenus générés.
Journal du samedi 03 août 2024 à 10:42
#JaiDécouvert le projet Uptime (from).
Upptime is the Open source Status et Uptime pages and status page, powered entirely by GitHub Actions, Issues, and Pages. It's made with 💚 by Anand Chowdhary, supported by Pabio.
Je trouve l'idée de baser le service entièrement sur GitHub Actions ingénieuse, bien que la dépendance totale à GitHub me dérange un peu 🤔.
Journal du samedi 03 août 2024 à 10:18
Un ami, m'a posé des questions au sujet de Fastmail que j'utilise.
Je profite de cette question pour lui partager le service Forward Email.
#Jadore ce projet pour les raisons suivantes :
- Je trouve le site web super complet, avec une rédaction précise et complète.
- La documentation est à mes yeux parfaites !
- Un service pour des utilisateurs qui ont un mindset de hackers.
- Grande transparence et précision sur l'offre.
- Je n'ai pas identifié de dark pattern.
Je suis envieux de ce projet. J'ai souvent partagé avec mes amis mon désir de lancer un service de messagerie électronique, et Forward Email est exactement le projet que j'aurais rêvé de réaliser.
Je lis ici :
No. Prices will never increase. Unlike other companies, we will never shutdown our service either.
Cette déclaration me laisse perplexe.
Elle semble présomptueuse. Comment peut-on affirmer que les prix n'augmenteront jamais, même en cas de forte inflation, d'augmentation du prix de l'énergie, etc. ?
Et comment garantir que ce service ne sera jamais arrêté ? Les auteurs de cette déclaration ne sont-ils pas soumis aux aléas de la vie, sont-ils immortels ?
Le service semble être effectivement totalement Open source, https://github.com/forwardemail/forwardemail.net. De plus, l'organisation GitHub contient 20 autres projets supplémentaires
J'ai consulter webarchive pour en savoir un peu plus sur l'histoire du projet.
Voici ce que j'ai appris.
- Premier commit public le 6 novembre 2017
- En novembre 2017, je lis ici :
How is it free
I built this for myself and use it regularly. I feel bad that people are using free closed-source forwarding services and risking their privacy and security. I also know that most of these services if not all of them don't offer all the features that come with mine. If this thing really takes off I might ask for donations or do a pay-what-you-want model to cover server costs.
Je comprends que l'auteur a réalisé ce projet avant tout pour lui même.
À cette époque, l'auteur utilisait de pseudo "niftylettuce" et proposé un Patreon pour soutenir le projet.
- C'est en 2020, sans doute pendant le contexte de Covid qu'une offre à $3 a été lancé.
- En 2020, le développeur principal est toujours nommé "niftylettuce".
- En 2021, je constate que le pseudo "niftylettuce" a disparu, je ne sais pas pourquoi.
Le service est régi par les lois de l'État du Delaware.
J'ai des difficultés à déterminer si ce projet est maintenu par une seule personne ou par une équipe.
Est-ce que le compte GitHub niftylettuce a été remplacé par titanism ?
Est-ce que titanism est un compte d'équipe ou le compte d'un utilisateur individuel ?
Je n'ai trouvé aucune information sur "Forwardemail" sur LinkedIn.
Je n'ai pas trouvé de trace des tweets mentionnés dans la section Témoignages.
En conclusion, j'apprécie énormément la réalisation technique de ce projet et j'aimerais vraiment migrer de Fastmail vers Forward Email. Cependant, le manque de transparence sur l'identité des membres du projet me rend réticent. Si le projet était plus clair sur l'identité de ses membres, je ferais cette transition avec bien moins d'hésitation.
Vendredi 2 août 2024
Journal du vendredi 02 août 2024 à 17:13
J'ai l'impression que ce projet ressemble avec GitGuardian.
#OnMaPartagé https://github.com/hadolint/hadolint
Journal du vendredi 02 août 2024 à 14:11
J'ai partagé la note au sujet des Quick Fixes du 31 juillet 2024 à un ami — profil Développeur sénior, Architecte informatique, plus de 20 ans d'expérience — et voici ma réponse à ses commentaires.
« Je tiens à préciser que la solution « On le fera plus tard quand on aura le temps » n'arrive jamais. » -- from
« Je confirme ... remettre à plus tard, reviens à dire que ce ne sera jamais fait. Quand t'as un ticket dans le backlog qui s'appelle "C'était pas terrible faudrait refaire mieux .." et qui n'a pas été touché depuis 6 mois, tu sais que tu peux le foutre à la benne. » -- mon ami
🙂.
« a. Durant toute la vie du projet, accorder entre 20 et 40% du temps — "de l'énergie" — au traitement de la dette technique. » -- from
« Oui, mais ça ne marche que dans les équipes en mode produit ... pas dans les équipes qui fournissent du "service" 😉 » -- mon ami
Je pense que tu as malheureusement raison.
C'est pour cela que je pense qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que passer par des ESN.
C'est pourquoi je crois qu'il est préférable que les services de l'État internalisent les compétences informatiques plutôt que de passer par des ESN. Je pense à des projets comme Louvois (projet), SIRHEN (projet), ou ONP (projet).
Journal du vendredi 02 août 2024 à 13:40
Je souhaite partager une réflexion sur un risque potentiel lié à l'usage des spikes.
Lorsque les équipes réalisent des spikes avec un taux de réussite très élevé, il existe un risque significatif que les développeurs et les stakeholders commencent progressivement à considérer ces spikes comme des issues ordinaires. Si cela se produit, les caractéristiques et l'utilité intrinsèques des spikes risquent d'être compromises :
- Les développeurs pourraient se sentir obligés de réussir chaque spike ;
- Ils pourraient alors être tentés d'augmenter la qualité de réalisation de leurs spikes, transformant ainsi des explorations en livrables de production ;
- Les stakeholders, quant à eux, pourraient ne plus prendre en compte le risque d'échec des spikes dans leur stratégie.
Pour ces raisons, je rappelle régulièrement aux stakeholders que l'échec fait partie intégrante des spikes et qu'il est essentiel de préserver cette caractéristique pour maintenir leur véritable utilité.
[ << Notes plus récentes (750) ] | [ Notes plus anciennes (319) >> ]