
Journaux
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
Résultat de la recherche (35 notes) :
Mercredi 3 décembre 2025
Journal du mercredi 03 décembre 2025 à 06:58
#JaiDécouvert usql (https://github.com/xo/usql) qui semble être une alternative à pgcli, écrit en Golang.
Je ne l'ai pas encore testé.
Vendredi 18 avril 2025
Journal du vendredi 18 avril 2025 à 11:40
Cela fait des années que je m'intéresse au sujet des solutions de sauvegarde en continu de bases de données PostgreSQL.
Dans cette note, le terme "sauvegarde en continu" ne signifie pas Point In Time Recovery.
Jusqu'à présent, je me suis toujours concentré sur la méthode "mainstream", qui consiste principalement à effectuer un backup binaire couplé avec une sauvegarde continue du WAL. Par exemple des solutions basées sur pg_basebackup, pgBackRest ou barman.
Une autre solution consiste à déployer une seconde instance PostgreSQL en mode streaming replication.
Une troisième solution que #JaimeraisUnJour tester : mettre en place une sauvegarde incrémentale basée sur le filesystème btrfs.
Plus précisément, la commande btrfs-send. La documentation de Dalibo mentionne cette méthode de sauvegarde.
Samedi dernier, j'ai imaginé une autre méthode qui me plait beaucoup par sa relative flexibilité et sa simplicité.
Elle consisterait à sauvegarder des tables de manière granulaire à intervalle de temps régulier vers un Object Storage à l'aide d'un Foreign Data Wrapper.
Pour cela, j'ai identifié parquet_s3_fdw, basé sur le format Apache Parquet qui permet de lire et d'écrire des données sur un bucket Object Storage.
Features
- Support SELECT of parquet file on local file system or Amazon S3.
- Support INSERT, DELETE, UPDATE (Foreign modification).
- Support MinIO access instead of Amazon S3.
J'ai utilisé de nombreuses fois Foreign Data Wrapper pour copier de manière granulaire des données entre deux bases de données PostgreSQL.
J'ai trouvé cette méthode très pratique, en particulier la possibilité de pouvoir utiliser un "pattern" SQL de copie du type :
INSERT INTO clients_local (id, nom, email, date_derniere_maj)
SELECT
d.client_id,
d.nom_client,
d.email_client,
CURRENT_TIMESTAMP
FROM
distant.clients_distant d
WHERE
d.date_modification > (SELECT MAX(date_derniere_maj) FROM clients_local)
ON CONFLICT (id) DO UPDATE
SET
nom = EXCLUDED.nom,
email = EXCLUDED.email,
date_derniere_maj = EXCLUDED.date_derniere_maj;
#JaimeraisUnJour réaliser un POC de cette idée basée sur parquet_s3_fdw.
Journal du vendredi 18 avril 2025 à 10:31
Il existe deux familles de méthodes de backup d'une base de données PostgreSQL :
- Backup logique
- Backup binaire à "chaud et à froid"
Voici une présentation simplifiée des différences entre ces deux modes de sauvegarde, qui peut comporter certaines imprécisions dues à cette vulgarisation.
Un backup logique est effectué par pg_dump sur une instance PostgreSQL en cours d'exécution (nommée "à chaud"). pg_dump supporte plusieurs formats d'archivage dont plain et custom.
Le format plain génère un fichier SQL classique, lisible "humainement".
Le format custom génère un fichier binaire, qui est plus flexible et a une taille bien plus réduite que le format plain. Il est toujours possible de générer un fichier SQL comme plain à partir d'un fichier custom : avec la commande pg_restore -f output.sql fichier_custom.
Il est possible de réaliser des sauvegardes et restaurations à "distance", via le protocole classique PostgreSQL Frontend Backend Protocol.
Il est possible d'importer un backup logique vers une instance PostgreSQL de version différente, en général plus récente.
Un backup binaire peut être effectué à "chaud" ou à "froid". En simplifiant, cela consiste à sauvegarder les fichiers PostgreSQL du filesystem et optionnellement sauvegarder aussi les journaux (WAL) de PostgreSQL. Pour effectuer un backup binaire, il existe la commande officielle pg_basebackup, mais aussi d'autres solutions plus complètes, comme pgBackRest ou barman.
Les systèmes de backup binaire de PostgreSQL ont l'avantage de pouvoir restaurer une sauvegarde à un point précis dans le temps (fonctionnalité PITR).
Je constate que la mise en place d'un backup binaire est plus complexe à mettre en place qu'un backup logique.
Voici mon POC le plus avancé concernant les backup binaire : poc-pg_basebackup_incremental.
Actuellement, pour sauvegarder des instances PostgreSQL, j'utilise pg_back-docker-sidecar qui est une solution de backup logique, basé sur pg_back, déployé sous la forme d'un Docker sidecar.
J'envisage aussi d'expérimenter une méthode basée sur parquet_s3_fdw que j'ai décrite dans 2025-04-18_1140.
Pour des informations plus approfondies à propos de ces sujets, je vous conseille la documentation de ces formations de Dalibo :
Jeudi 17 avril 2025
Journal du jeudi 17 avril 2025 à 12:02
Alexandre m'a partagé le projet Postgres Operator, que j'avais peut-être croisé par le passé, mais que j'avais oublié.
Postgres Operator permet entre autres de déployer des instances PostgreSQL dans un cluster Kubernetes mais aussi de mettre en place des systèmes de backup logique et backup binaire.
Lundi 14 avril 2025
J'ai publié le projet "pg_back-docker-sidecar"
Je viens de terminer une première itération de travail sur Projet 27 - "Créer un POC de pg_back".
Le résultat se trouve dans le repository GitHub : pg_back-docker-sidecar
J'ai passé en tout 17 h 30 sur ce projet, écriture de notes incluse.
Ce projet a évolué par rapport à mon objectif initial :
Initialement, dans ce dépôt, je voulais tester l'implémentation de
pg_backdéployé dans un conteneur Docker comme un « sidecar » pour sauvegarder une base de données PostgreSQL déployée via Docker.Et progressivement, j'ai changé l'objectif de ce projet. Il contient maintenant
- le code source pour construire une image Docker Sidecar nommée
stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload- un tutoriel étape par étape qui présente tous les aspects de l'utilisation de ce conteneur
- un espace de travail qui me permet de contribuer au projet pg_back en amont :
./src/
Voici tous les éléments testés dans le tutoriel :
pg_backest dépolyé dans un Docker sidecar- L'instance PostgreSQL est sauvegardée dans une instance Minio
- Les archives sont chiffrées avec age
- Les archives sont générées au format
custom - J'ai documenté une méthode pour télécharger une archive dans un dossier du workspace du développeur
- J'ai documenté une méthode pour restaurer l'archive dans un serveur PostgreSQL déployé via Docker
- J'ai testé le fonctionnement du système d'expiration des archives
- J'ai testé la fonctionnalité de "purge" automatique
Éléments que j'ai implémentés
L'image Docker proposée par pg_back ne contient pas de scheduler de type cron et ne suit pas les recommandations The Twelve-Factors App.
J'ai décidé d'implémenter ma propre image Docker stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload avec les ajouts suivants :
- Support de configuration basé sur des variables d'environnement, par exemple :
pg_back:
image: stephaneklein/pg_back-docker-sidecar:2.5.0-delete-local-file-after-upload
environment:
POSTGRES_HOST: postgres1
POSTGRES_PORT: 5432
POSTGRES_USER: postgres
POSTGRES_DBNAME: postgres
POSTGRES_PASSWORD: password
BACKUP_CRON: ${BACKUP_CRON:-0 3 * * *}
UPLOAD: "s3"
UPLOAD_PREFIX: "foobar"
...
- Intégration de Supercronic pour exécuter pg_back régulièrement, une fonctionnalité de type cron
Patch envoyé en upstream
J'ai proposé deux patchs à pg_back :
- Add upload_prefix option to pg_back.conf example file
- Add the --delete-local-file-after-upload to delete local file after upload
Le premier patch est totalement mineur.
Dans la version actuelle 2.5.0 de pg_back, les archives dump ne sont pas supprimées du filesystem de container après l'upload vers l'Object Storage.
Ce choix me perturbe, car je préfère éviter de surcharger le disque avec des fichiers d'archives volumineux qui risquent de saturer l'espace disponible.
Pour éviter cela, j'ai implémenté "Add the --delete-local-file-after-upload to delete local file after upload" qui permet de supprimer les fichiers intermédiaires après upload.
Bilan
J'ai réussi à effectuer un cycle complet de la sauvegarde à la restauration.
J'ai décidé d'utiliser pg_back pour mes sauvegardes PostgreSQL automatique vers Object Storage.
J'ai déprécié le projet restic-pg_dump-docker pour inviter à utiliser pg_back.
Idée d'amélioration
#JaimeraisUnJour créer et implémenter les issues suivantes.
1. Implémenter une commande pg_back snapshots pour lister les snapshots sous une forme facilement lisible par un humain. Actuellement, le retour de la commande ressemble à ceci :
$ pg_back --list-remote s3
foobar/hba_file_2025-04-14T14:58:08Z.out.age
foobar/hba_file_2025-04-14T14:58:39Z.out.age
foobar/ident_file_2025-04-14T14:58:08Z.out.age
foobar/ident_file_2025-04-14T14:58:39Z.out.age
foobar/pg_globals_2025-04-14T14:58:08Z.sql.age
foobar/pg_globals_2025-04-14T14:58:39Z.sql.age
foobar/pg_settings_2025-04-14T14:58:08Z.out.age
foobar/pg_settings_2025-04-14T14:58:39Z.out.age
foobar/postgres_2025-04-14T14:58:08Z.dump.age
foobar/postgres_2025-04-14T14:58:39Z.dump.age
Je ne trouve pas ce rendu agréable à lire. J'aimerais afficher quelque chose qui ressemble à la sortie de restic. Par exemple :
$ pg_back snapshots
ID Date Folder
---------------------------------------
40dc1520 2025-04-14 14:58:08 foobar
79766175 2025-04-14 14:58:39 foobar
2. Implémenter un système de suppressions des archives basé sur des règles plus avancées, comme celle de restic
3. Implémenter un refactoring vers cobra pour utiliser des sous-commandes (subcommands) et éviter le mélange entre paramètres et commandes.
En attendant de trouver un repository Mise pour PostgreSQL Client Applications
À ce jour, je n'ai pas trouvé de repository Mise ou Asdf pour installer les "Client Applications" de PostgreSQL, par exemple : psql, pg_dump, pg_restore.
Il existe asdf-postgres, mais ce projet me pose quelques problèmes :
- L'installation basée sur le code source de PostgreSQL avec une phase de compilation qui peut être longue et consommer beaucoup d'espace disque.
- L'intégralité de PostgreSQL est installée alors que je n'ai besoin que des "Client Applications".
#JaimeraisUnJour créer une repository Mise ou Asdf qui permet d'installer les "Client Applications" en mode binaire. Pour le moment, je n'ai aucune idée sur quels binaires me baser 🤔.
En attendant de créer ou de trouver ce repository, voici ci-dessous mes méthodes actuelles d'installation des "PostgreSQL Client Applications".
Sous MacOS
Sous MacOS, j'utilise Brew pour installer le package libpq qui contient les "PostgreSQL Client Applications".
$ brew install libpq
ou alors pour l'installation d'une version spécifique :
$ brew install libpq@17.4
Sous Fedora
Sous Fedora, j'installe le package PostgreSQL client proposé sur la page "Downloads" officielle de PostgreSQL.
Cette méthode me permet d'installer précisément une version majeure précise de PostgreSQL :
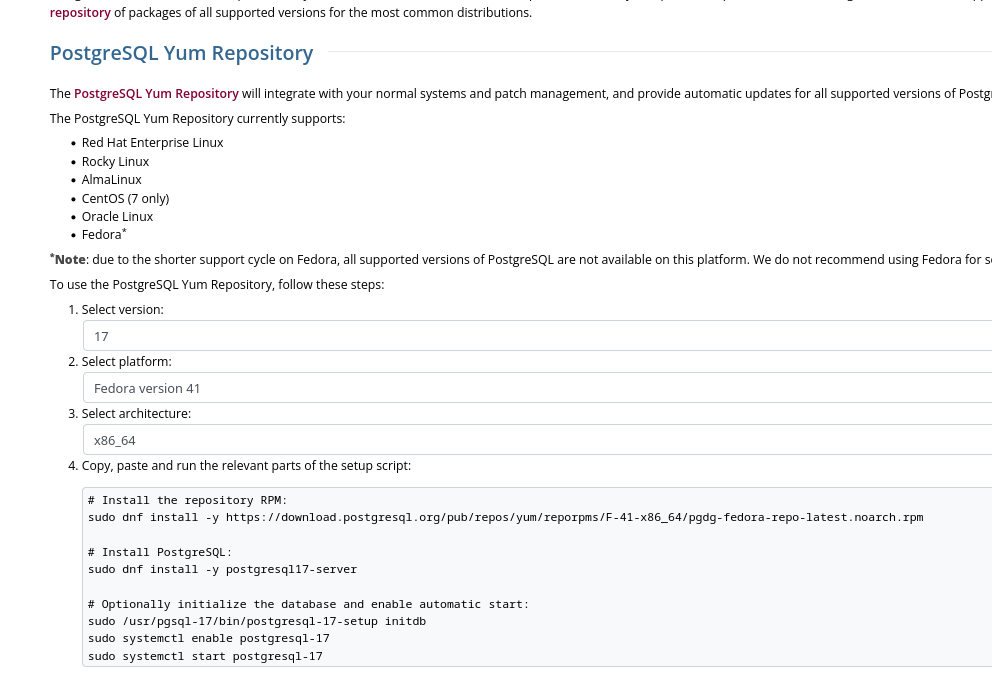
Voici les instructions pour installer la dernière version de PostgreSQL 17 sous Fedora 41 :
$ sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/F-41-x86_64/pgdg-fedora-repo-latest.noarch.rpm
$ sudo rpm --import https://download.postgresql.org/pub/repos/yum/keys/PGDG-RPM-GPG-KEY-Fedora
$ sudo dnf update -y
Le package nommé postgresql17 contient uniquement les "PostgreSQL Client Applications" :
$ dnf info postgresql17
Mise à jour et chargement des dépôts :
Dépôts chargés.
Paquets installés
Nom : postgresql17
Epoch : 0
Version : 17.4
Version : 1PGDG.f41
Architecture : x86_64
Taille une fois installé : 10.7 MiB
Source : postgresql17-17.4-1PGDG.f41.src.rpm
Dépôt d'origine : pgdg17
Résumé : PostgreSQL client programs and libraries
URL : https://www.postgresql.org/
Licence : PostgreSQL
Description : PostgreSQL is an advanced Object-Relational database management system (DBMS).
: The base postgresql package contains the client programs that you'll need to
: access a PostgreSQL DBMS server. These client programs can be located on the
: same machine as the PostgreSQL server, or on a remote machine that accesses a
: PostgreSQL server over a network connection. The PostgreSQL server can be found
: in the postgresql17-server sub-package.
:
: If you want to manipulate a PostgreSQL database on a local or remote PostgreSQL
: server, you need this package. You also need to install this package
: if you're installing the postgresql17-server package.
Fournisseur : PostgreSQL Global Development Group
$ dnf repoquery -l postgresql17 | grep "/bin"
Mise à jour et chargement des dépôts :
Dépôts chargés.
/usr/pgsql-17/bin/clusterdb
/usr/pgsql-17/bin/createdb
/usr/pgsql-17/bin/createuser
/usr/pgsql-17/bin/dropdb
/usr/pgsql-17/bin/dropuser
/usr/pgsql-17/bin/pg_basebackup
/usr/pgsql-17/bin/pg_combinebackup
/usr/pgsql-17/bin/pg_config
/usr/pgsql-17/bin/pg_createsubscriber
/usr/pgsql-17/bin/pg_dump
/usr/pgsql-17/bin/pg_dumpall
/usr/pgsql-17/bin/pg_isready
/usr/pgsql-17/bin/pg_receivewal
/usr/pgsql-17/bin/pg_restore
/usr/pgsql-17/bin/pg_waldump
/usr/pgsql-17/bin/pg_walsummary
/usr/pgsql-17/bin/pgbench
/usr/pgsql-17/bin/psql
/usr/pgsql-17/bin/reindexdb
/usr/pgsql-17/bin/vacuumdb
Installation de ce package :
$ sudo dnf install postgresql17
$ psql --version
psql (PostgreSQL) 17.4
Vendredi 11 avril 2025
Journal du vendredi 11 avril 2025 à 10:24
Suite à 2025-04-10_2034, je viens de créer le Projet 27 - "Créer un POC de pg_back".
Jeudi 10 avril 2025
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Vendredi 21 mars 2025
Journal du vendredi 21 mars 2025 à 15:15
Note de type #mémento pour calculer la taille des tables PostgreSQL.
Commande pour calculer la taille de la base de données entière :
postgres=# select pg_size_pretty(pg_database_size('postgres'));
pg_size_pretty
----------------
74 GB
Commande pour voir les détails table par table :
SELECT
nspname AS "schema",
pg_class.relname AS "table",
pg_size_pretty(pg_total_relation_size(pg_class.oid)) AS "total_size",
pg_size_pretty(pg_relation_size(pg_class.oid)) AS "data_size",
pg_size_pretty(pg_indexes_size(pg_class.oid)) AS "index_size",
pg_stat_user_tables.n_live_tup AS "rows",
pg_size_pretty(
pg_total_relation_size(pg_class.oid) /
(pg_stat_user_tables.n_live_tup + 1)
) AS "total_row_size",
pg_size_pretty(
pg_relation_size(pg_class.oid) /
(pg_stat_user_tables.n_live_tup + 1)
) AS "row_size"
FROM
pg_stat_user_tables
JOIN
pg_class
ON
pg_stat_user_tables.relid = pg_class.oid
JOIN
pg_catalog.pg_namespace AS ns
ON
pg_class.relnamespace = ns.oid
ORDER BY
pg_total_relation_size(pg_class.oid) DESC;
schema | table | total_size | data_size | index_size | rows | total_row_size | row_size
--------+-----------------+------------+------------+------------+---------+----------------+------------
public | table1 | 72 GB | 1616 MB | 1039 MB | 7456403 | 10 kB | 227 bytes
public | table2 | 1153 MB | 754 MB | 399 MB | 2747998 | 440 bytes | 287 bytes
public | table3 | 370 MB | 8192 bytes | 47 MB | 8 | 41 MB | 910 bytes
public | table4 | 232 kB | 136 kB | 56 kB | 422 | 561 bytes | 329 bytes
(7 rows)
Jeudi 13 février 2025
Journal du jeudi 13 février 2025 à 14:50
Suite à ce commentaire et celui-ci, je m'adresse dans cette note à Anarcat (francophone) et Martín Marqués pour expliquer ce que j'essaie de faire dans le POC https://github.com/stephane-klein/poc-barman, ce que j'ai réussi à faire et présenter aussi mes difficultés.
J'ai traduit cette note en anglais et je l'ai postée sur "GitHub Barman discussion" : https://github.com/EnterpriseDB/barman/discussions/1067.
Mon objectif dans le repository poc-barman est d'essayer d'utiliser barman dans un container Docker sidecar pour sauvegarder un container PostgreSQL.
Une de mes contraintes est d'effectuer un minimum de changements au niveau du container PostgreSQL que je souhaite sauvegarder. Je souhaite pouvoir utiliser une image Docker PostgreSQL mainstream https://hub.docker.com/_/postgres, sans changement.
Je souhaite utiliser le mode de sauvegarde de barman nommé streaming backups method: backup_method = postgres qui se base sur la commande pg_basebackup (commande officielle intégrée à PostgreSQL).
Je souhaite utiliser la nouvelle fonctionnalité pg_basebackup --incremental... de la version 17 de PostgreSQL.
Voici ma configuration de barman : https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/docker-compose.yml#L15
Et voici ma configuration de PostgreSQL 17 :
- https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/docker-compose.yml#L15
- et https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/init-barman.sh#L1
J'ai implémenté un script nommé ./scripts/reset.sh qui effectue un test de bout automatiquement.
Voici son screencast :
Voici ce qu'il fait :
- Il coupe tous les containers et efface les volumes
- Il lance les containers
postgres1etbarmanet injecte quelques données danspostgres1 - Il initialise
barman - Il effectue une sauvegarde complète de
postgres1 - Il restaure la sauvegarde vers
postgres2et lancepostgres2et affiche les données de la tabledummy - Il effectue une sauvegarde incrémentielle après avoir injecté quelques nouvelles données dans
postgres1 - Il restaure la sauvegarde de
postgres1en utilisantpg_combinebackupverspostgres2préalablement coupé et effacé - Ici j'ai un échec au lancement de
postgres2basé sur la restauration de la sauvegarde incrémentielle
Questions que je me pose :
- Pourquoi la restauration basée sur la sauvegarde incrémentielle échoue ?
- Est-ce que mon scénario de test d'usage de barman est correct, est-ce qu'il me manque des étapes ou est-ce que je fais des opérations non nécessaires ?
- Est-ce que j'ai fait des erreurs importantes ?
Voici ci-dessous la version anglaise posté ici.
Subject: Streaming Incremental Backup Configuration with PostgreSQL 17 using Docker Sidecar
Hello,
In the poc-barman repository, I'm trying to use barman in a Docker sidecar container to backup a PostgreSQL container.
One of my constraints is to make minimal changes to the PostgreSQL container that I want to backup. I want to be able to use a mainstream Docker PostgreSQL image https://hub.docker.com/_/postgres, without modifications.
I want to use the barman backup mode called streaming backups method: backup_method = postgres which is based on the pg_basebackup command (official command integrated into PostgreSQL).
I want to use the new pg_basebackup --incremental... feature from PostgreSQL version 17.
Here is my barman configuration: https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/docker-compose.yml#L15
And here is my PostgreSQL 17 configuration:
- https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/docker-compose.yml#L15
- and https://github.com/stephane-klein/poc-barman/blob/4df58ecc5af6d2d1f7607c364400f8c5ba012496/init-barman.sh#L1
I implemented a script called ./scripts/reset.sh that performs an end-to-end test automatically.
Here's its screencast:
Here's what it does:
- It stops all containers and erases the volumes
- It starts the
postgres1andbarmancontainers and injects some data intopostgres1 - It initializes
barman - It performs a full backup of
postgres1 - It restores the backup to
postgres2, startspostgres2, and displays the data from thedummytable - It performs an incremental backup after injecting some new data into
postgres1 - It restores
postgres1backup usingpg_combinebackuptopostgres2which was previously stopped and erased - Here I have a failure when starting
postgres2based on the incremental backup restoration
Questions:
- Why does the restoration based on the incremental backup fail?
- Is my barman usage test scenario correct, am I missing steps or am I performing unnecessary operations?
- Have I made any significant mistakes?
Best regards,
Stephane
Journal du jeudi 13 février 2025 à 14:09
Suite de mes notes 2025-02-09_1705, 2025-02-12_1044, 2025-02-12_1511, 2025-02-12_1534 et 2025-02-12_2305 au sujet de barman pour sauvegarder des bases de données PostgreSQL
Je ne sais pas pourquoi je dois lancer
select pg_switch_wal();.
J'ai découvert dans ce commentaire qu'il existe une commande nommée : barman switch-wal.
Je pense avoir compris qu'avant d'exécuter barman backup… il est nécessaire d'exécuter :
$ barman switch-wal
$ barman cron
$ barman check postgres1
Server postgres1:
PostgreSQL: OK
superuser or standard user with backup privileges: OK
PostgreSQL streaming: OK
wal_level: OK
replication slot: OK
directories: OK
retention policy settings: OK
backup maximum age: OK (no last_backup_maximum_age provided)
backup minimum size: OK (0 B)
wal maximum age: OK (no last_wal_maximum_age provided)
wal size: OK (0 B)
compression settings: OK
failed backups: OK (there are 0 failed backups)
minimum redundancy requirements: OK (have 0 backups, expected at least 0)
pg_basebackup: OK
pg_basebackup compatible: OK
pg_basebackup supports tablespaces mapping: OK
systemid coherence: OK (no system Id stored on disk)
pg_receivexlog: OK
pg_receivexlog compatible: OK
receive-wal running: OK
archiver errors: OK
$ barman backup postgres1 --immediate-checkpoint
Starting backup using postgres method for server postgres1 in /var/lib/barman/postgres1/base/20250213T100353
Backup start at LSN: 0/4000000 (000000010000000000000004, 00000000)
Starting backup copy via pg_basebackup for 20250213T100353
Copy done (time: 1 second)
Finalising the backup.
This is the first backup for server postgres1
WAL segments preceding the current backup have been found:
000000010000000000000002 from server postgres1 has been removed
Backup size: 22.3 MiB
Backup end at LSN: 0/6000000 (000000010000000000000006, 00000000)
Backup completed (start time: 2025-02-13 10:03:53.072228, elapsed time: 1 second)
Processing xlog segments from streaming for postgres1
000000010000000000000003
000000010000000000000004
WARNING: IMPORTANT: this backup is classified as WAITING_FOR_WALS, meaning that Barman has not received yet all the required WAL files for the backup consistency.
This is a common behaviour in concurrent backup scenarios, and Barman automatically set the backup as DONE once all the required WAL files have been archived.
Hint: execute the backup command with '--wait'
total 4.0K
$ ls /var/lib/barman/postgres1/base/ -lha
total 8.0K
drwxr-xr-x 1 barman barman 60 Feb 13 10:00 .
drwxr-xr-x 1 barman barman 88 Feb 13 09:59 ..
drwxr-xr-x 1 barman barman 30 Feb 13 09:59 20250213T095917
$ barman list-backups postgres1
postgres1 20250213T103723 - F - Thu Feb 13 10:37:24 2025 - Size: 22.3 MiB - WAL Size: 0 B - WAITING_FOR_WALS
J'ai réussi dans le POC https://github.com/stephane-klein/poc-barman à dérouler toutes les étapes du backup complet jusqu'à la restauration d'une base de données.
Toutefois, pour le moment, je n'ai toujours pas réussi à restaurer un backup incrémental 🙁.
À cet endroit, j'ai l'erreur suivante :
$ docker compose up postgres2
postgres2-1 | PostgreSQL Database directory appears to contain a database; Skipping initialization
postgres2-1 |
postgres2-1 | 2025-02-13 13:20:07.594 UTC [1] LOG: starting PostgreSQL 17.2 (Debian 17.2-1.pgdg120+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit
postgres2-1 | 2025-02-13 13:20:07.594 UTC [1] LOG: listening on IPv4 address "0.0.0.0", port 5432
postgres2-1 | 2025-02-13 13:20:07.594 UTC [1] LOG: listening on IPv6 address "::", port 5432
postgres2-1 | 2025-02-13 13:20:07.596 UTC [1] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
postgres2-1 | 2025-02-13 13:20:07.598 UTC [1] LOG: could not open directory "pg_tblspc": No such file or directory
postgres2-1 | 2025-02-13 13:20:07.600 UTC [29] LOG: database system was interrupted; last known up at 2025-02-13 13:20:03 UTC
postgres2-1 | 2025-02-13 13:20:07.643 UTC [29] LOG: could not open directory "pg_tblspc": No such file or directory
postgres2-1 | 2025-02-13 13:20:07.643 UTC [29] LOG: starting backup recovery with redo LSN 0/8000028, checkpoint LSN 0/8000080, on timeline ID 1
postgres2-1 | 2025-02-13 13:20:07.643 UTC [29] LOG: could not open directory "pg_tblspc": No such file or directory
postgres2-1 | 2025-02-13 13:20:07.649 UTC [29] FATAL: could not open directory "pg_tblspc": No such file or directory
postgres2-1 | 2025-02-13 13:20:07.651 UTC [1] LOG: startup process (PID 29) exited with exit code 1
postgres2-1 | 2025-02-13 13:20:07.651 UTC [1] LOG: aborting startup due to startup process failure
postgres2-1 | 2025-02-13 13:20:07.652 UTC [1] LOG: database system is shut down
Mercredi 12 février 2025
Journal du mercredi 12 février 2025 à 23:05
Suite de ma note 2025-02-12_1511.
J'ai passé 5h40 sur un POC de barman, mais je n'ai pas eu beaucoup plus de succès qu'avec pgBackRest. Décidément, ces outils ne m'aiment pas 😔.
Repository du POC : https://github.com/stephane-klein/poc-barman
La commande barman check streaming-server retourne le message WAL archive: FAILED (please make sure WAL shipping is setup). Pour fixer cette erreur, je dois faire les manipulations suivantes que je trouve bizarre :
$ ./scripts/enter-in-pg1.sh
postgres=# select pg_switch_wal();
pg_switch_wal
---------------
0/206A330
(1 row)
et ensuite :
$ docker compose exec barman bash
root@5482aa5f8420:/# su barman
barman@5482aa5f8420:/$ barman cron
Starting WAL archiving for server streaming-server
barman@5482aa5f8420:/$ barman check streaming-server
Server streaming-server:
PostgreSQL: OK
superuser or standard user with backup privileges: OK
PostgreSQL streaming: OK
wal_level: OK
replication slot: OK
directories: OK
retention policy settings: OK
backup maximum age: OK (no last_backup_maximum_age provided)
backup minimum size: OK (0 B)
wal maximum age: OK (no last_wal_maximum_age provided)
wal size: OK (0 B)
compression settings: OK
failed backups: OK (there are 0 failed backups)
minimum redundancy requirements: OK (have 0 backups, expected at least 0)
pg_basebackup: OK
pg_basebackup compatible: OK
pg_basebackup supports tablespaces mapping: OK
systemid coherence: OK (no system Id stored on disk)
pg_receivexlog: OK
pg_receivexlog compatible: OK
receive-wal running: OK
archiver errors: OK
Je ne sais pas pourquoi je dois lancer select pg_switch_wal();.
J'ai pourtant configuré checkpoint_timeout='60s' :
command: >
postgres
-c wal_level=replica
-c summarize_wal=on
-c checkpoint_timeout='60s'
-c max_wal_size='100MB'
Je pensais que ce paramètre effectuait la même action que pg_switch_wal(); mais je constate que non.
Aussi, je constate que je dois aussi lancer pg_switch_wal(); pour que la commande suivante se termine :
barman@5482aa5f8420:/$ barman backup streaming-server --wait
Starting backup using postgres method for server streaming-server in /var/lib/barman/streaming-server/base/20250212T221703
Backup start at LSN: 0/5000B40 (000000010000000000000005, 00000B40)
Starting backup copy via pg_basebackup for 20250212T221703
Copy done (time: 1 second)
Finalising the backup.
Backup size: 22.3 MiB
Backup end at LSN: 0/7000000 (000000010000000000000007, 00000000)
Backup completed (start time: 2025-02-12 22:17:03.190492, elapsed time: 1 second)
Waiting for the WAL file 000000010000000000000007 from server 'streaming-server'
Processing xlog segments from streaming for streaming-server
000000010000000000000005
Processing xlog segments from streaming for streaming-server
000000010000000000000006
Je ne comprends pas non plus pourquoi.
Journal du mercredi 12 février 2025 à 15:11
Je pense comprendre que pgBackRest ne permet pas d'utiliser des INET sockets pour communiquer avec PostgreSQL.
Toutefois, je me dis que je pourrais partager le volume
PGDATAavec le sidecar pgBackRest pour lui donner accès à l'Unix Socket du Streaming Replication Protocol 🤔.
Je viens de me rappeler que pgBackRest a une seconde contrainte qui semble l'empêcher de fonctionner en Docker sidecar :
Backing up a running PostgreSQL cluster requires WAL archiving to be enabled. Note that at least one WAL segment will be created during the backup process even if no explicit writes are made to the cluster.
pg-primary:/etc/postgresql/15/demo/postgresql.conf⇒ Configure archive settings :archive_command = 'pgbackrest --stanza=demo archive-push %p' archive_mode = on max_wal_senders = 3 wal_level = replica
Cela signifie que l'exécutable pgbackrest doit être installé dans l'image Docker PostgreSQL.
Cela me pose un problème parce que mon objectif est de pouvoir utiliser un système de sauvegarde en Docker sidecar sans avoir à utiliser une image Docker PostgreSQL modifiée.
Cette contrainte ne semble pas présente avec barman qui propose 3 méthodes de backup :
La méthode postgres utilise pg_basebackup et je pense qu'elle peut fonctionner en Docker sidecar.
#JaiDécidé d'explorer cette piste.
Dimanche 9 février 2025
Journal du dimanche 09 février 2025 à 17:05
J'utilise depuis 2019 les containers Docker suivant en sidecar pour sauvegarder automatiquement et régulièrement directement un volume Docker et un volume PostgreSQL :
restic-pg_dump-docker est très pratique et facile d'usage, voici un exemple d'utilisation dans un docker-compose.yml :
restic-pg-dump:
image: stephaneklein/restic-pg_dump:latest
environment:
AWS_ACCESS_KEY_ID: "admin"
AWS_SECRET_ACCESS_KEY: "password"
RESTIC_REPOSITORY: "s3:http://minio:9000/bucket1"
RESTIC_PASSWORD: secret
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
POSTGRES_HOST: postgres
POSTGRES_DB: postgres
postgres:
image: postgres:16.1
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Il suffit de configurer les paramètres d'accès à l'instance PostgreSQL à sauvegarder et ceux de l'Object Storage où uploader les backups. Rien de plus, 😉.
Pour plus de paramètres, voir la section Configuration du README.md.
Cependant, je ne suis pas totalement satisfait de restic-pg_dump-docker. Cet outil effectue seulement des sauvegardes complètes de la base de données.
Ceci ne pose généralement pas trop de problème quand la base de données est d'une taille modeste, mais c'est bien plus compliqué dès que celle-ci fait, par exemple, plusieurs centaines de mégas.
Pour faire face à ce problème, j'ai exploré fin 2023 une solution basée sur pgBackRest : Implémenter un POC de pgBackRest.
Je suis plus ou moins arrivé au bout de ce POC mais je n'ai pas été satisfait du résultat.
Je n'ai pas réussi à configurer pgBackRest en "pure Docker sidecar".
De plus, j'ai trouvé la restauration du backup difficile à exécuter.
Un élément a changé depuis septembre 2024. Comme je le disais dans cette note 2024-11-03_1151, la version 17 de PostgreSQL propose de nouvelles options de sauvegarde :
- l'outil pg_basebackup qui permet de réaliser les sauvegardes incrémentales,
- et un nouvel utilitaire, pg_combinebackup, qui permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
Cette nouvelle méthode semble apporter certains avantages par rapport aux solutions basées sur WAL comme pgBackRest ou barman.
Une consommation d'espace réduite :
In this mailing list thread on the Postgres-hackers mailing list, Jakub from EDB ran a test. This is a pgbench test. The idea is that the data size doesn't really change much throughout this test. This is a 24 hour long test. At the start the database is 3.3GB. At the end, the database is 4.3GB. Then, as it's running, it's continuously running pgbench workloads. In those 24 hours, if you looked at the WAL archive, there were 77 GB of WAL produced.
That's a lot of WAL to replay if you wanted to restore to a particular point in time within that timeframe!
Jakub ran one full backup in the beginning and then incremental backups every two hours. The full backup in the beginning is 3.4 GB, but then all the 11 other backups are 3.5 in total, they're essentially one 10th of a full backup size.
Une vitesse de restauration grandement accélérée :
A 10x time safe
What Jakub tested then was the restore to a particular point in time. Previously, to restore to a particular point in time would take more than an hour to replay the WAL versus in this case because we have more frequent, incremental backups, it's going to be much, much faster to restore. In this particular test case 78 minutes compared to 4 minutes. This is a more than a 10 times improvement in recovery time. Of course you won't necessarily always see this amount of benefit, but I think this shows why you might want to do this. It is because you want to enable more frequent backups and incremental backups are the way to do that.
Nombre 2024 j'ai passé un peu de temps à étudier les solutions de backup qui utilisent la nouvelle fonctionnalité de PostgreSQL 17, mais je n'avais rien trouvé
Je viens à nouveau de chercher dans les archives de Postgre Weely, sur GitHub, sur le forum de Restic, etc., et je n'ai rien trouvé d'intéressant.
#JaiDécidé de prendre les choses en main et de faire évoluer le projet restic-pg_dump-docker pour y ajouter le support du backup incrémental de PostgreSQL 17.
Voir : Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker".
Mardi 3 décembre 2024
Journal du mardi 03 décembre 2024 à 16:31
#JaiDécouvert la fonctionnalité "Table Partitioning" de PostgreSQL.
Je connaissais la possibilité de faire du database sharding avec PostgreSQL, en utilisant la fonctionnalité create_distributed_table de Citus — je n'ai jamais mis cela en pratique — mais je ne connaissais pas fonctionnalité native PostgreSQL de Table Partitining.
En PostgreSQL, une table partitionnée est une table divisée en plusieurs sous-tables appelées partitions, qui permettent de gérer efficacement de grandes quantités de données. Cette fonctionnalité est utile pour améliorer les performances des requêtes, simplifier l'archivage, ou encore gérer la répartition des données.
Avantages des tables partitionnées
Performances améliorées :
- Les requêtes peuvent être plus rapides grâce au pruning des partitions (PostgreSQL n'interroge que les partitions pertinentes).
- Les index sont plus légers car chaque partition peut avoir ses propres index.
Maintenance simplifiée :
- Vous pouvez archiver ou supprimer des partitions entières sans impacter le reste des données.
- Les opérations comme
VACUUMouANALYZEsont effectuées indépendamment sur chaque partition.
Cette fonctionnalité a été ajoutée dans la version 10 de PostgreSQL, en 2017.
J'ai aussi découvert qu'il est possible d'utiliser des Table Partitioning avec des Foreign Data Wrapper, par exemple, pour stocker certaines partitions sur des serveurs distants. Je pense que c'est une alternative à Citus, sans doute moins performante.
Vendredi 22 novembre 2024
Journal du vendredi 22 novembre 2024 à 21:37
Voici une stratégie pour contourner dans une certaine mesure la limitation Hasura que j'ai décrite dans la note 2024-11-22_1703.
Remplacer :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
par :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
GRANT SELECT ON TABLE foobar TO hasurauser;
ALTER TABLE foobar ENABLE ROW LEVEL SECURITY;
CREATE POLICY deny_untrusted_user ON foobar
FOR SELECT USING (current_user != 'hasurauser');
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
Vendredi 15 novembre 2024
Journal du vendredi 15 novembre 2024 à 16:44
Je viens d'apprendre que pg_dumpall de PostgreSQL n'exporte pas les passwords des utilisateurs.
Les users sont biens exporter, mais les passwords doivent être reconfigurées ensuite via la commande :
ALTER USER myuser WITH PASSWORD 'newsecret';
Dimanche 3 novembre 2024
Journal du dimanche 03 novembre 2024 à 12:33
En lisant la release note v3.0.3 de wal-g, j'ai découvert l'extension PostgreSQL nommée OrioleDB.
OrioleDB is a new storage engine for PostgreSQL, bringing a modern approach to database capacity, capabilities and performance to the world's most-loved database platform.
OrioleDB consists of an extension, building on the innovative table access method framework and other standard Postgres extension interfaces. By extending and enhancing the current table access methods, OrioleDB opens the door to a future of more powerful storage models that are optimized for cloud and modern hardware architectures.
Le projet OrioleDB a commencé en février 2022 par un développeur de Supabase : Alexander Korotkov.
Les commentaires de ce thread Hacker News semblent très enthousiastes https://news.ycombinator.com/item?id=30462695.
Dans la page "Introductions" de la documentation, je lis :
Differentiators
The key technical differentiations of OrioleDB are as follows:
No buffer mapping and lock-less page reading
In-memory pages in OrioleDB are connected with direct links to the storage pages. This eliminates the need for in-buffer mapping along with its related bottlenecks. Additionally, in OrioleDB in-memory page reading doesn't involve atomic operations. Together, these design decisions bring vertical scalability for Postgres to the whole new level.
MVCC is based on the UNDO log concept
In OrioleDB, old versions of tuples do not cause bloat in the main storage system, but eviction into the undo log comprising undo chains. Page-level undo records allow the system to easily reclaim space occupied by deleted tuples as soon as possible. Together with page-mergins, these mechanisms eliminate bloat in the majority of cases. Dedicated VACUUMing of tables is not needed as well, removing a significant and common cause of system performance deterioration and database outages.
Copy-on-write checkpoints and row-level WAL
OrioleDB utilizes copy-on-write checkpoints, which provides a structurally consistent snapshot of data every moment of time. This is friendly for modern SSDs and allows row-level WAL logging. In turn, row-level WAL logging is easy to parallelize (done), compact and suitable for active-active multimaster (planned).
J'ai lu le billet "Rethinking PostgreSQL buffer mapping for modern hardware architectures". Je pense avoir compris que l'implémentation actuelle de PostgreSQL utilise un "buffer mapping" autrefois bien adapté aux contraintes matérielles.
J'ai compris qu'OrioleDB propose une nouvelle approche, spécialement conçue pour tirer parti des SSD rapides, ce qui lui permet d’atteindre des performances nettement supérieures à celles de l’implémentation existante.
Journal du dimanche 03 novembre 2024 à 11:51
Avec la sortie de la version 17 de PostgreSQL, de nouvelles options de sauvegarde sont désormais disponibles : l'outil pg_basebackup (https://www.postgresql.org/docs/17/app-pgbasebackup.html) permet de réaliser les sauvegardes incrémentales, et un nouvel utilitaire, pg_combinebackup, permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
J'ai lu les articles suivants de Robert Haas, créateur de ces nouvelles fonctionnalités :
- Incremental Backup: What To Copy?
- #JaiDécouvert le projet ptrack.
- Incremental Backups: Evergreen and Other Use Cases
J'en ai profité aussi pour lire :
J'ai trouvé tous ces articles très intéressants, j'y ai appris beaucoup de choses.
Je me demande quel impact ces fonctionnalités auront ou ont déjà sur les outils existants comme pgBackRest, barman, et wal-g.
Autres ressources :
Impact sur pgBackRest ?
Voici ce que j'ai trouvé dans le projet pgBackRest.
We are aware of what's been committed to PG17.
-- from
Je comprends d'après ce commentaire que les auteurs de pgBackRest sont bien au courant des avancées de PostgreSQL 17.
Issue : WAL summarizer in pg 17 and incremental backups in pgbackrest ?.
We already support page-level (we call it block-level) incremental since v2.46 and it works for all versions of PostgreSQL supported by pgBackRest (>= 9.4), see https://pgbackrest.org/user-guide.html#backup/block.
We are planning to use the WAL summarizer to help us pick more optimal block sizes and cross-check timestamps but we are waiting for it to be a bit more stable. Also, the WAL summarizer output uses a lot of memory and is not the best fit for large databases with a lot of changes. We have some ideas on how to make that more efficient but have not had time to pursue it yet.
D'après ce commentaire, je pense avoir compris que les nouvelles fonctionnalités de backup incrémental de PostgreSQL 17 ne sont d'aucune utilité pour pgBackRest, qui implémente déjà cette fonctionnalité de manière efficace 🤔.
Impact sur barman ?
La version 3.11.0 de barman intègre des fonctionnalités liées aux nouvelles fonctionnalités de PostgreSQL 17.
Impact sur wal-g
J'ai n'ai trouvé aucune mention de pg_combinebackup, ni de pg_basebackup incremental dans le repository de wal-g.
J'ai l'impression qu'il est possible d'utiliser directement pg_basebackup pour effectuer des sauvegardes incrémentales de bases de données PostgreSQL. Cependant, je crains que cette idée soit un peu naïve.
Vers la fin de 2023, j'ai commencé à implémenter un POC de pgBackRest : https://github.com/stephane-klein/backlog/issues/322. J'ai pu réaliser une simulation complète de son utilisation dans ce dépôt : poc-pgbackrest. Cependant, je n'ai pas conservé un souvenir précis des raisons pour lesquelles mon expérience utilisateur n'a pas été satisfaisante, ce qui m'a dissuadé de déployer pgBackRest en production.
Après avoir constaté que barman intègre la fonctionnalité increment de pg_basebackup, j'ai envie de tester barman.
Mardi 29 octobre 2024
Journal du mardi 29 octobre 2024 à 10:26
Note de comparaison de la documentation Hasura version 2 versus PostGraphile.
J'essaie d'exposer une mutation GraphQL qui exécute et retourne de résultat d'une fonction PL/pgSQL.
Postgraphile
Voici le parcours pour découvrir comment implémenter cette fonctionnalité dans PostGraphile :
-
- J'ouvre la page documentation : https://www.graphile.org/postgraphile/introduction/
-
- Je vois dans la navigation de droite, "Opération", ensuite "Functions".
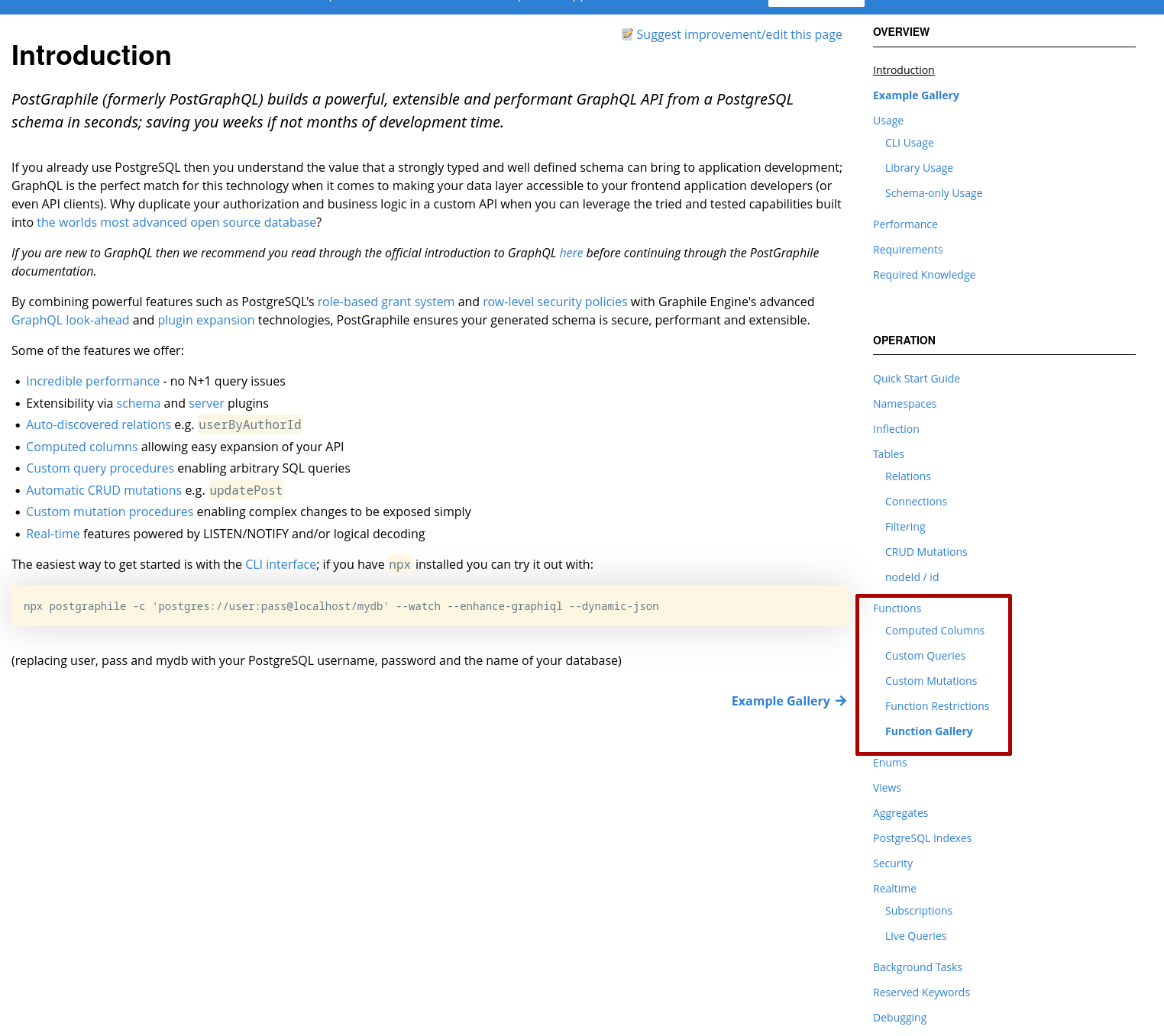
-
- J'ouvre la page "Functions"
-
- Je clique sur la page "Custom Mutations"
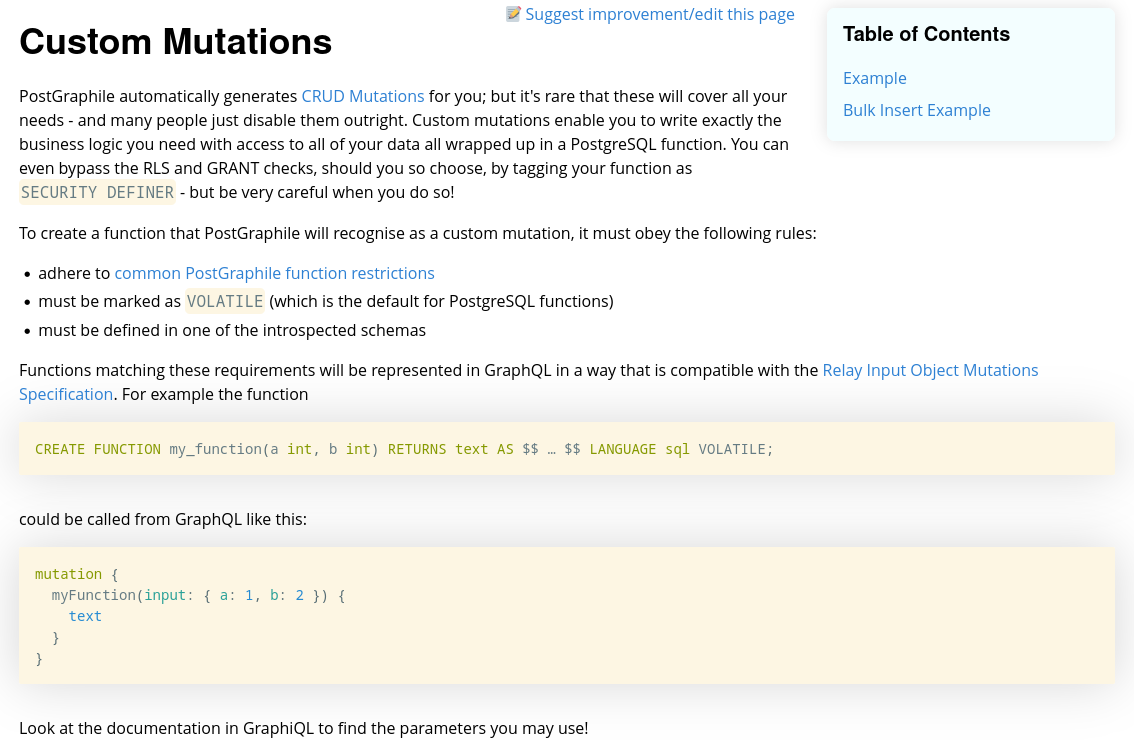
Et sur cette page je peux lire une explication du fonctionnement et un exemple :
Hasura
Voici le parcours pour découvrir comment implémenter cette fonctionnalité dans Hasura :
-
- J'ouvre la documentation https://hasura.io/docs/2.0/index/
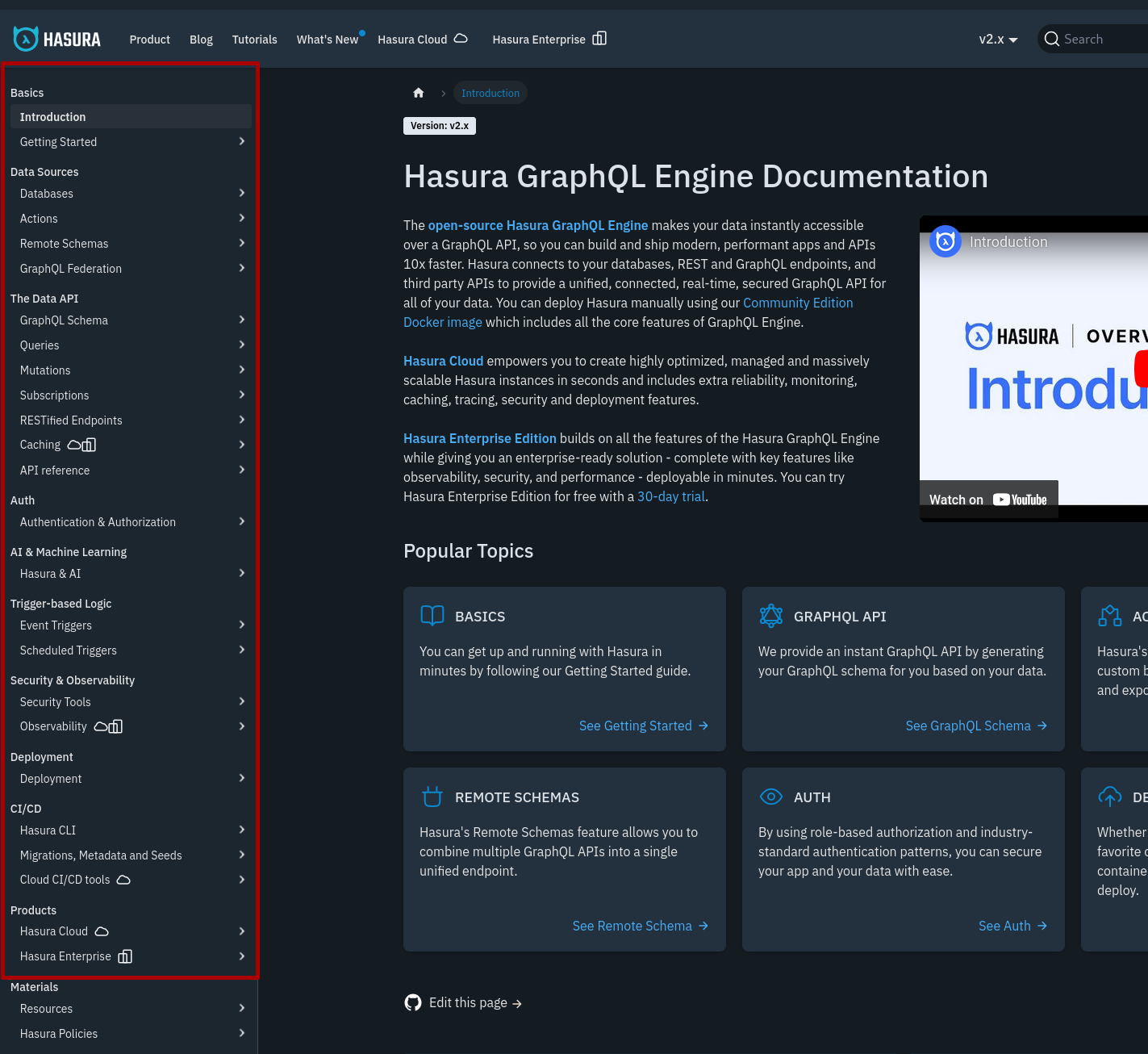
-
- Contrairement à la navigation de la documentation de PostGraphile qui affiche directement les mots clés "Function" et "Custom Mutation", j'ai eu quelques difficultés à trouver la page qui contient ce que je cherche. Cela s'explique par le fait que Hasura propose plus de fonctionnalités que PostGraphile et plus d'abstractions.
-
- En explorant, j'ai fini par trouver la section en ouvrant les sections "GraphQL Schema" => "Postgres".
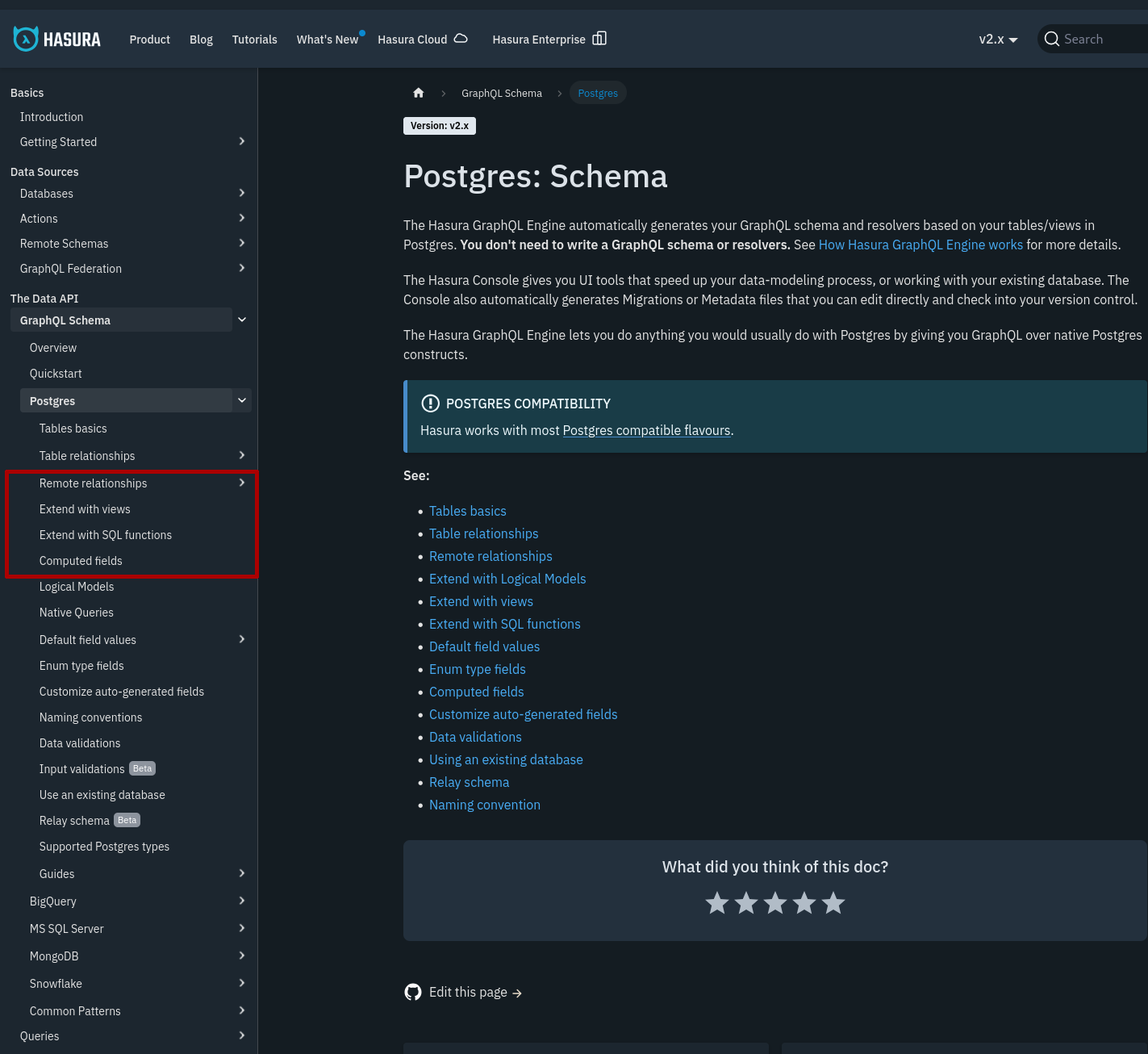
-
- J'ouvre la page "Extend with SQL functions"
Vendredi 25 octobre 2024
Journal du vendredi 25 octobre 2024 à 20:51
#JaiDécouvert la fonctionnalité Tablespaces de PostgreSQL.
Tablespaces in PostgreSQL allow database administrators to define locations in the file system where the files representing database objects can be stored. Once created, a tablespace can be referred to by name when creating database objects.
By using tablespaces, an administrator can control the disk layout of a PostgreSQL installation. This is useful in at least two ways. First, if the partition or volume on which the cluster was initialized runs out of space and cannot be extended, a tablespace can be created on a different partition and used until the system can be reconfigured.
Pour le moment, je n'en ai aucune utilité.
Vendredi 18 octobre 2024
Journal du vendredi 18 octobre 2024 à 18:37
#JaiDécouvert https://github.com/dhth/schemas.
Inspect PostgreSQL schemas in the terminal.
Mardi 24 septembre 2024
Journal du mardi 24 septembre 2024 à 16:01
Alexandre m'a partagé le billet Postgres webhooks with pgstream.
J'y découvre pgstream et wal2json.
Pour le moment, je ne vois pas à quoi cela pourrait bien me servir, mais je garde cet outil dans un coin de ma tête.
C'est amusant de voir que j'ai découvert hier un autre projet des mêmes auteurs que pgstream : pgroll.
Lundi 23 septembre 2024
Journal du lundi 23 septembre 2024 à 17:12
PostgreSQL zero-downtime migrations made easy.
#JaiLu en partie ce thread Hacker News de 2023.
Après avoir lu partiellement la documentation, j'ai l'impression que pgroll est simple à utiliser pour des migrations qui restent simples.
J'ai lu la section Raw SQL et #JeMeDemande si pgroll reste pratique à utiliser pour des migrations complexes, par exemple, split d'une table en plusieurs tables, merge de tables…
Je ne suis pas très motivé pour apprendre un nouveau DSL, c'est-à-dire, le format de migrations de pgroll à la place des instructions DDL (Data Definition Language) SQL (create, alter…).
Pour le moment, j'ai réussi à réaliser "à la main" des migrations en douceur : mise en place de view, de triggers… qui sont par la suite supprimés.
Je pense que pgroll serait très pratique avec une fonctionnalité Skew Protection pour un projet où les déploiements en production en journée sont fréquents et qui ne souhaite pas imposer aux utilisateurs de rafraîchir leurs pages.
Mardi 13 août 2024
Journal du mardi 13 août 2024 à 21:32
#iteration du Projet GH-382 - Je cherche à convertir en SQL des query de filtre basé sur un système de "tags".
J'ai enfin analysé la Merge Request qui m'a été envoyé par un ami 🤗 : https://github.com/stephane-klein/postgres-tags-model-poc/pull/9
6 mois plus tard, j'ai fini l'implémentation de la première version du "Query string javascript parser" : https://github.com/stephane-klein/postgres-tags-model-poc/commit/f0f363b78c136e8e67a38f95b5c627d874537949
Pour la coloration syntaxique des fichiers Peggy sous Neovim, j'utilise avec succès https://github.com/TheGrandmother/peggy-vim : https://github.com/stephane-klein/dotfiles/commit/20cba4ba646a0793f66f9b19788920a4ff1f1838
Mardi 6 août 2024
Journal du mardi 06 août 2024 à 08:45
#JaiDécouvert la commande psql nommé \ir :
\iror\include_relativefilenameThe \ir command is similar to \i, but resolves relative file names differently. When executing in interactive mode, the two commands behave identically. However, when invoked from a script, \ir interprets file names relative to the directory in which the script is located, rather than the current working directory.
-- from
J'ai trouvé cette commande via Fwd: psql include file using relative path.
Cela faisait des années que j'avais besoin de cette fonctionnalité et, étrangement, je ne l'ai découverte seulement aujourd'hui 🤔.
Exemple d'utilisation https://github.com/stephane-klein/sklein-pkm-engine/blob/8938d7a2c19ed8f741bd38162882e9517c739c30/sqls/init.sql#L36
Samedi 6 juillet 2024
Journal du samedi 06 juillet 2024 à 15:15
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, 2024-06-23_1057 et 2024-06-23_2222.
Pour le projet obsidian-vault-to-apache-age-poc je souhaite créer une image Docker qui intègre les extensions pg_search et Apache Age à une image PostgreSQL.
Pour réaliser cela, je vais me baser sur ce travail préliminaire https://github.com/stephane-klein/pg_search_docker.
#JaiDécidé de créer un repository GitHub nommé apache-age-docker, qui contiendra un Dockerfile pour builder une image Docker PostgreSQL 16 qui intègre la release "Release v1.5.0 for PG16" de l'extension Postgres Apage Age.
Dimanche 23 juin 2024
Journal du dimanche 23 juin 2024 à 22:22
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211 et 2024-06-23_1057.
#JaiCompris en lisant ceci que pg_search se nommait apparavant pg_bm25.
#JaiDécouvert que Tantivy — lib sur laquelle est construit pg_search — et Apache Lucene utilisent l'algorithme de scoring nommé BM25.
Okapi BM25 est une méthode de pondération utilisée en recherche d'information. Elle est une application du modèle probabiliste de pertinence, proposé en 1976 par Robertson et Jones. (from)
Je suis impressionné qu'en 2024, l'algorithme qui je pense est le plus performant utilisé dans les moteurs de recherche ait été mis au point en 1976 😮.
#JaiDécouvert pgfaceting - Faceted query acceleration for PostgreSQL using roaring bitmaps .
J'ai finallement réussi à installer pg_search à l'image Docker postgres:16 : https://github.com/stephane-klein/pg_search_docker.
J'ai passé 3h pour réaliser cette image Docker, je trouve que c'est beaucoup trop 🫣.
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
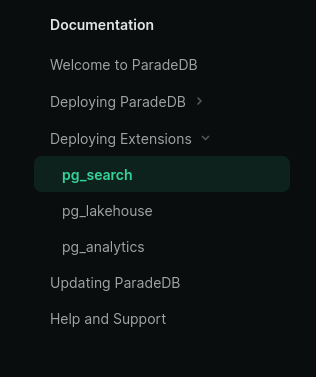
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Jeudi 20 juin 2024
Journal du jeudi 20 juin 2024 à 22:11
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans cette version du 20 juin j'ai implémenté :
- Importation des fichiers dans des nodes de type
notesdans un graph. - Le contenu des notes dans une table
public.notes - Les aliases dans la table
public.note_aliases - Importation des tags et leurs liaisons vers les notes dans un graph.
Au stade où j'en suis, je suis encore loin d'être en capacité de juger si le moteur de graph — Age — me sera utile ou non pour réaliser des requêtes simplement 🤔.
Prochaine fonctionnalités que je souhaite implémenter dans ce projet :
- [ ] Recherche de type fuzzy search sur les
Note.title,aliasetTag.namebasé sur la méthode Levenshtein du module fuzzystrmatch - [ ] Recherche plain text sur le contenu des Notes basé sur pg_search
Dans la liste des features de pg_search je lis :
- Autocomplete
- Fuzzy search
Je pense donc intégrer pg_search avant fuzzystrmatch. Peut-être que je n'aurais pas besoin d'utiliser fuzzystrmatch.
Samedi 8 juin 2024
Journal du samedi 08 juin 2024 à 17:04
#JeLis pour la première fois https://github.com/postgrespro/pg_probackup
J'ai en même temps découvert https://github.com/postgrespro/ptrack mais je n'ai pas pris le temps de bien comprendre son rôle.
Mercredi 5 juin 2024
Journal du mercredi 05 juin 2024 à 11:29
#JeMeDemande s'il existe un meilleur moteur de recherche que https://www.postgresql.org/search/?u=%2Fdocs%2F16%2F&q=on+conflict 🤔.
J'ai fait quelques recherches, pour le moment, je n'ai rien trouvé 😟.
Mardi 7 mai 2024
Le paramétrage de `search_path` PostgreSQL dans docker-compose ne fonctionne pas 🤨
Je suis en train de travailler sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et je rencontre une difficulté.
J'utilise cette configuration docker-compose.yml :
services:
postgres:
image: apache/age:PG16_latest
restart: unless-stopped
ports:
- 5432:5432
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
PGOPTIONS: "--search_path='ag_catalog,public'"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Je ne comprends pas pourquoi, j'ai l'impression que le paramètre PGOPTIONS: "--search_path=''" ne fonctionne plus.
$ ./scripts/enter-in-pg.sh
postgres=# SHOW search_path ;
search_path
-----------------
"$user", public
(1 ligne)
postgres=#
La valeur de search_path devrait être ag_catalog,public.
J'ai testé avec l'image Docker image: postgres:16, j'observe le même problème.
Je suis surpris parce que je pense me souvenir que cette syntaxe fonctionnait ici en septembre 2023 🤔.
#JeMeDemande comment corriger ce problème 🤔.
#JaiLu docker - Can't set schema_name in dockerized PostgreSQL database - Stack Overflow
09:07 : #ProblèmeRésolu par https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/commit/0b1cef3a725550269583ddb514fa3fff1932e89d
Mercredi 10 janvier 2024
Journal du mercredi 10 janvier 2024 à 17:11
#iteration Projet GH-360 - Implémenter un POC de Fuzzy Search en PostgreSQL.
#JaiDécouvert que l'extension fuzzystrmatch implémente plusieurs algorithmes :
- Soundex => article Wikipedia : Soundex
- Daitch-Mokotoff Soundex => article Wikipedia : Daitch–Mokotoff Soundex
- Levenshtein => article Wikipedia : Levenshtein distance
- Metaphone => article Wikipedia : Metaphone
- Double Metaphone
Lundi 12 juin 2023
Journal du lundi 12 juin 2023 à 13:48
Voici le repository de la première version de mon POC qui avait pour objectif d'implémenter un système de tags en PostgreSQL, en me basant sur l'article "Tags and Postgres Arrays, a Purrrfect Combination" : https://github.com/stephane-klein/postgres-tags-model-poc.
Fin de la liste des notes.