
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (22) >> ]
Journal du lundi 09 septembre 2024 à 21:33
#JaiLu Windows NT vs. Unix: A design comparison (from).
Je ne connais rien au kernel MS Windows, j'ai trouvé cela intéressant.
Journal du lundi 09 septembre 2024 à 16:03
Alexandre m'a partagé le projet Grafana Tanka.
Flexible, reusable and concise configuration for Kubernetes.
Je découvre ce thread Hacker News que je n'ai pas pris le temps de lire : Tanka: Our way of deploying to Kubernetes.
Journal du samedi 07 septembre 2024 à 21:44
#JaiLu ce thread Hacker News : Rrweb – record and replay debugger for the web.
#JaiDécouvert highlight.io, replay.io, Zipy et wirequery qui semblent être des alternatives à Posthog et OpenReplay.
Tous ces outils sont basés sur rrweb.
wirequery semble être un projet 100% open source.
#JaiDécouvert un autre projet basé sur rrweb : RecordOnce pour générer des tutoriels.
Journal du vendredi 06 septembre 2024 à 10:10
#JaiLu Is Linux collapsing under its own weight? On Rust for Linux, j'ai trouvé cela très intéressant (from).
À la suite de cette lecture, j'ai lu ce thread Lobster : https://lobste.rs/s/yx57uf/is_linux_collapsing_under_its_own_weight.
J'ai lu Rust for Linux revisited de Drew DeVault, bien que n'étant pas un spécialiste du sujet, je trouve son idée intéressante.
Journal du jeudi 05 septembre 2024 à 13:18
J'ai un peu parcouru la documentation de OpenBao, #JaimeraisUnJour faire un POC de cet outil.
Journal du jeudi 05 septembre 2024 à 11:52
#JaiLu The SOC2 Starting Seven (from)
First: for us, SOC2 is about sales. You will run into people with other ideas of what SOC2 is about. Example: “SOC2 will help you get your security house in order and build a foundation for security engineering”. No. Go outside, turn around three times, and spit. Compliance is a byproduct of security engineering. Good security engineering has little to do with compliance. And SOC2 is not particularly good. So keep the concepts separate.
-- from
😉
Suite à cela, j'ai lu l'article Wikipédia sur System and Organization Controls.
This is not an instruction guide for getting SOC2-certified. Though: that guide would be mercifully short: “find $15,000, talk to your friends who have gotten certified, get referred to the credible auditor that treated your friends the best, and offer them the money, perhaps taped to the boom box playing Peter Gabriel you hold aloft outside their offices”.
-- from
😉
If there is one thing to understand about SOC2 audits, it’s: SOC2 is about documentation, not reality.
-- from
🙈
Puis ils vous remettront un questionnaire de 52 000 lignes appelé Liste de demandes d'informations (IRL), basé d'une manière occulte sur ce que vous leur avez dit que vous faisiez. Vous le remplirez. Vous aurez quelques réunions, puis vous leur enverrez un chèque. Le nom de votre entreprise figurera sur un rapport.
-- from
🙈
PRs, Protected Branches, and CI/CD
Enable Protected Branches for your master/deployment branches in Github. Set up a CI system and run all your deploys through it. Require reviews for PRs that merge to production. Make your CI run some tests; it probably doesn’t much matter to your auditor which tests.
We probably didn’t even need to tell you this. It’s how most professional engineering shops already run. But if you’re a 3-person team, get it set up now and you won’t have to worry about it when your team sprawls and new process is a nightmare to establish.
-- from
J'implémente systématiquement ce workflow dès que je travaille en équipe. Cependant, je me demande à partir de combien de développeurs cela devient réellement pertinent. Avant de lire cet article, je pensais que cela valait la peine à partir de trois développeurs.
À noter que ma motivation première de mise en place de ce workflow n'est pas la sécurité, mais la fluidité de développement en équipe et d'éviter les bugs.
Centralized Logging
Sign up for or set up a centralized logging service. It doesn’t matter which. Pipe all your logs to it. Set up some alerts – again, at this stage, it doesn’t matter which; you just want to build up the muscle.
-- from
Pour cela, j'utilise Grafana avec Loki branché sur un Object Storage.
The AWS console is evil. Avoid the AWS console.
Instead, deploy everything with Terraform (or whatever the cool kids are using, but it’s probably still just Terraform). Obviously, keep your Terraform configs in Github.
C'est aussi l'une de mes premières motivations pour utiliser Terraform ! 😊
#JaiDécouvert Munki, MicroDMD, NanoMDM qui sont des MDM.
Web Application Firewalls: Most SOC2’d firms don’t use them, and most WAFs don’t work at all.
-- from
🙂
Endpoint Protection and AV: You have MDM and macOS/Windows full complement of security features and a way to force them enabled, you’re covered. AV software is a nightmare; avoid it while you can.
-- from
🙂
Journal du mercredi 04 septembre 2024 à 11:11
#JaiLu la page Wikipedia de Teleport.
Je pense que cela fait plus de 5 ans que #JeSouhaiteTester cet outil.
Journal du mercredi 04 septembre 2024 à 11:05
J'ai un regardé sshuttle.
Journal du dimanche 01 septembre 2024 à 10:42
Suite à des échanges avec Alexandre au sujet de la "position" et de l'usage de Ollama dans le domaine des LLM, j'ai pris un peu de temps pour essayer d'y voir plus clair.
#JaiLu ce thread Reddit : newbie confusion: LocalLM / AnythingLLM / llama.cpp / Lamafile / Ollama / openwebui All the same? : LocalLLM
Voici ma description d'Ollama. Ollama est un wrapper au-dessus de Llama.cpp afin de rendre son utilisation davantage User Friendly. Ollama est écrit en Golang.
D'après :
Supported backends
- llama.cpp project founded by Georgi Gerganov
-- from
et la présence de Llama.cpp directement dans le code source de Ollama
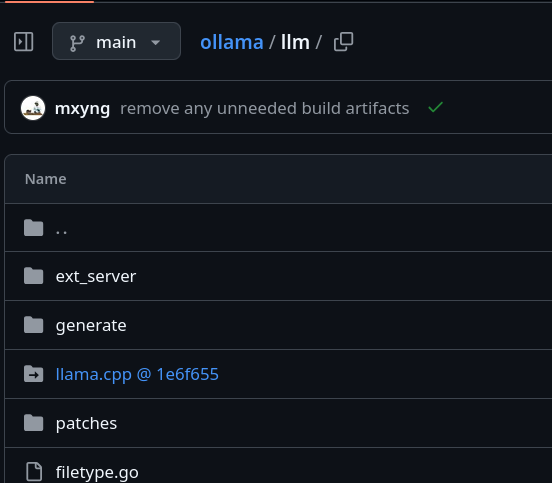
Je comprends que pour le moment, Ollama supporte uniquement le backend Llama.cpp.
Conclusion : je pense qu'il est préférable d'utiliser Ollama plutôt que directement Llama.cpp.
Journal du vendredi 30 août 2024 à 08:49
J'ai découvert et j'ai lu ce long document au sujet de Qwant : https://scratched-delivery-09e.notion.site/Qwant-petit-pr-cis-d-une-escroquerie-en-bande-organis-e-98300251bfeb44c49720025a15206e90
Journal du jeudi 29 août 2024 à 14:29
#JaiLu Prefer note titles with complete phrases to sharpen claims de Andy Matuschak.
Je pense que c'est une méthode importante pour tenir un bon Zettelkasten.
Journal du mercredi 28 août 2024 à 09:46
#JaiLu la documentation de UnoCSS.
Tailwind CSS is a PostCSS plugin, while UnoCSS is an isomorphic engine with a collection of first-class integrations with build tools (including a PostCSS plugin). This means UnoCSS can be much more flexible to be used in different places (for example, CDN Runtime, which generates CSS on the fly) and have deep integrations with build tools to provide better HMR, performance, and developer experience (for example, the Inspector).
-- Why UnoCSS?
Si je souhaite utiliser UnoCSS tout en conservant une compatibilité Tailwind CSS je dois utiliser Uno preset :
This preset is compatible with Tailwind CSS and Windi CSS, you can refer to their documentation for detailed usage.
#JaiDécouvert les features innovantes de UnoCSS :
<button
bg="blue-400 hover:blue-500 dark:blue-500 dark:hover:blue-600"
text="sm white"
font="mono light"
p="y-2 x-4"
border="2 rounded blue-200"
>
Button
</button>
Est l'équivalent de :
<button class="bg-blue-400 hover:bg-blue-500 text-sm text-white font-mono font-light py-2 px-4 rounded border-2 border-blue-200 dark:bg-blue-500 dark:hover:bg-blue-600">
Button
</button>
<text-red> red text </text-red>
<flex> flexbox </flex>
I'm feeling <i-line-md-emoji-grin /> today!
Est l'équivalent de :
<span class="text-red"> red text </span>
<div class="flex"> flexbox </div>
I'm feeling <span class="i-line-md-emoji-grin"></span> today!
Je trouve ces syntaxes élégantes, mais, à ma connaissance, elles sont très peu courantes. Si je me mets à la place d'un développeur "onbordé" dans un nouveau projet utilisant le "attributify mode" et Tagify mode, je crains que cela puisse être un choc pour lui. Il me faudrait probablement plusieurs semaines avant que mon cerveau s'habitue à interpréter automatiquement cette syntaxe.
Je me demande donc si le gain final est réellement positif ou négatif.
Pour le moment, j'ai décidé que n'utiliserait pas les fonctionnalités "attributify mode" et Tagify mode.
Journal du mardi 27 août 2024 à 14:23
#JaiLu en partie le thread Hacker News Dokku: My favorite personal serverless platform.
- https://github.com/skateco/skate
- dokploy
- kamal
- ptah.sh (sous licence fair source)
J'ai apprécié ce tableau de comparaison de fonctionnalités entre dokploy, CapRover, Dokku et Coolify.
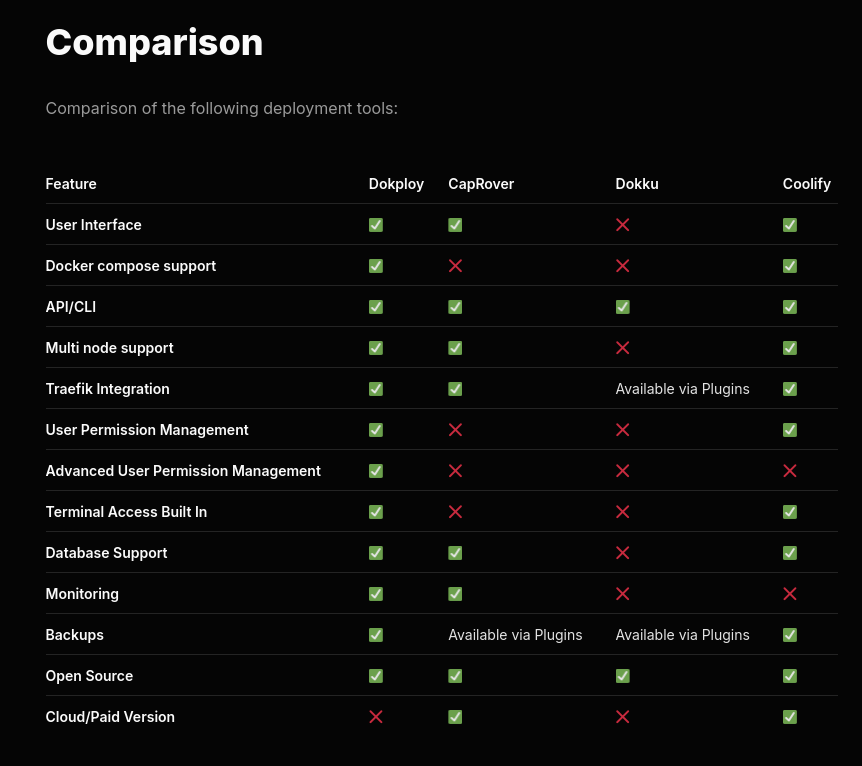
C'est la ligne "Docker compose support" qui a attiré mon attention.
Je reste très attaché au support de docker compose qui je trouve est une spécification en même temps simple, complète et flexible qui ne m'a jamais déçu ces 9 dernières années.
Attention, je n'ai pas bien compris si Dokku est réellement open source ou non 🤔.
Je constate que Dokploy est basé sur Docker Swarm.
Dokploy leverages Docker Swarm to orchestrate and manage container deployments for your applications, providing an intuitive interface for monitoring and control.
-- from
Choix qui me paraît surprenant puisque Docker Swarm est officieusement déprécié.
Je me suis demandé si K3s pourrait être une alternative à Docker Swarm 🤔.
Journal du mardi 27 août 2024 à 10:51
#JaiLu Le retour de la vengeance des luddites technophiles de Ploum.
On ne peut pas. Un écran tactile nécessite de le regarder. On ne peut pas acquérir des réflexes moteurs sur un écran tactile.
Je suis tout à fait d'accord.
On ne peut pas former des marins capables d’agir intuitivement en situation de stress si l’interface change tous les 6 mois pour cause de mise à jour.
👍️
Dessin humoristique montrant une dame cherchant à acheter un ticket de train et se voyant rétorquer de rentrer chez elle, de créer un compte sur la plateforme, d’acheter le ticket, de le transférer sur son smartphone et que ce sera plus facile (aide appréciée pour retrouver l’auteur)
👍️
Contrairement à ce que la propagande nous fait croire, le luddisme n’est pas une opposition à la technologie. C’est une opposition à une forme de technologie appartenant à une minorité utilisée pour exploiter la majorité.
En effet et je vais faire attention de ne plus utiliser luddisme en ce sens.
D’après mon expérience, pour la majorité des utilisateurs, c’est une terrible période de stress où on ne peut plus faire confiance, certaines choses doivent être réapprises. Quand elles n’ont pas tout simplement disparu.
Tout à fait d'accord, je trouve qu'il y a généralement trop de grosse mise à jour.
Dernier exemple, il y a quelque jour, l'application Radio France sous Android que j'utilisé a subi une mise à jour importante de l'User Interface qui a entraîné chez moi, en plus des bugs, des notifications incessantes en boucle.
J'ai pesté, je me suis demandé pourquoi ils n'avaient pas opté pour une mise à jour plus légère de la version précédente.
Ou alors, pourquoi ne pas avoir développé une seconde application, m'offrant une transition en douceur, à mon rythme, lorsque je me sentirais prêt.
J'ai l'impression que, de manière générale, les mises à jour des projets libres sont plus progressives, ce que j'apprécie particulièrement.
J’entends régulièrement que Telegram serait une messagerie chiffrée. Ce n’est pas et n’a jamais été le cas.
Ce qui est fou, c'est qu'à force d'entendre cette propagante, je vérifie environ tous les 3 mois si je suis dans l'erreur ou non.
Mais comment ce mensonge est-il devenu populaire ? Tout simplement parce que Telegram offre une possibilité de créer un « secret chat » qui lui est techniquement chiffré. Il y a donc moyen d’avoir une conversation secrète sur Telegram, en théorie. Mais en pratique ce n’est pas le cas, car :
- Ces conversations secrètes ne fonctionnent que pour les conversations directes, pas pour les groupes.
- Ces conversations secrètes sont difficiles à mettre en place
- Ces conversations secrètes ne sont pas par défaut
- Ces conversations secrètes n’utilisent pas les standards de l’industrie cryptographique, mais une solution « maison » développée par des personnes n’ayant aucune expertise cryptographique
- L’entreprise Telegram (et le gouvernement russe) savent quand et avec qui vous avez initié un chat secret. Et ils peuvent le recouper avec la partie non secrète (imaginez un instant le « On passe sur le chat secret pour discuter de ça ? »).
😔
Ce qui confirme l’adage (que j’ai inventé) :
J'adore 👍️.
Journal du samedi 24 août 2024 à 21:58
#JaiLu Agir contre les appels commerciaux sur LinuxFr.
#JaiDécouvert EGBG Anti-Telemarketing Contre-scénario et leur super affiche : https://egbg.home.xs4all.nl/EGBGcontrescenario.pdf
J'ai remplacé DoisJeRépondre par SpamBlocker sur mon Android.
Journal du mercredi 21 août 2024 à 15:30
#JaiLu pour la première fois la page de la Web API nommée Intersection Observer API.
Dans un projet Svelte, je crée dynamiquement un composant qui est inséré dans un élément non Svelte :
component = new myComponent({
target: element,
props: {
foo: bar
}
});
Cette Web API m'a permis de déterminer la position d'un composant lorsque celui-ci est réellement attaché à la page web.
<script lang="js">
import { onMount } from "svelte";
export let rootElement;
onMount(() => {
const observer = new IntersectionObserver(
(entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
console.log(entry.boundingClientRect);
observer.disconnect();
}
});
}
);
observer.observe(rootElement);
});
</script>
<span bind:this={rootElement}>
...
</span>
Journal du mardi 20 août 2024 à 09:46
#JaiLu les slides Mozilla va-t-il sauver le web ?.
Je suis attristé par la gouvernance de Mozilla 😭.
Journal du mardi 20 août 2024 à 09:33
#JaiLu Software estimates have never worked and never will
Je suis en accord — depuis très longtemps — avec le contenu de cet article.
Give up on estimates, and embrace the alternative method for making software by using budgets, or appetites, as we call them in our Shape Up methodology.
Cette méthode fait parti de ma doctrine d'artisan développeur.
Je découvre Kopia, une alternative à Restic
Alexandre m'a partagé Kopia, logiciel Open source de backup, alternatif à restic.
7000 likes GitHub versus 25000 likes pour Restic.
Je constate que Kopia est développé principalement par 2 développeurs et je constate le même nombre pour Restic.
J'ai parcouru cette page qui date de 2 ans : How Do Kopia Features Compare to Other Backup Software?.
En 2022, il semble que restic ne supportait pas la compression de données, mais je constate via cette Pull Request Implement compression support que cette feature est maintenant intégrée à restic.
#JaiLu en partie le thread Hacker News : Kopia: Fast and secure open-source backup software.
Initially I thought this was a corporate project and was looking for the monetization model, but then I found https://github.com/kopia/kopia/blob/master/GOVERNANCE.md
I feel like the project might benefit from making their governance model more prominent on the website.
-- from
D'après ces commentaires, Kopia est lent à la restauration :
Used it for a while, recently tried to restore some things and it failed, taking a really long time to restore some snapshots compared to other things I've tried. Switched to restic instead. Really like what kopia is but I'll wait a few more years before considering it for something, but right now I'm happy with restic.
This has been my experience too with Kopia.
I tried to restore a ~200 GB file (stored remotely on a Hetzner Storage Box), and it failed (or at least did not finish after being left for ~20 hours; there was also no progress indicator or status I could find in the UI).
I also tried to restore a folder with about ~32 GB of data in it, and that also failed (the UI did report an error, but I don't recall it being useful).
Also, in general use, the UI would get disconnected from the repository every few days, and sometimes the backup overview list would show folders as being size 0 (which maybe indicated they failed; they showed up with an "incomplete" [or similar] tag in the UI).
-- from
Il semble que l'outil Veloro utilisait restic et ait migré vers Kopia :
One thing I will mention is that other backup projects have switched from Restic to Kopia. Velero from VMware comes to mind.
-- from
À ce sujet, j'ai vu Unified Repository & Kopia Integration Design et je n'ai pas tout compris.
Alexandre m'a appris que Veloro supporte pour le moment Kopia et restic mais que le support restic est en train d'être supprimé : Deprecate Restic.
Voilà l'origine du nom 🙂 :
"Kopia" means "copy" in Swedish and probably more Nordic languages, too.
-- from
J'ai vu ce commentaire :
Personally, I've had some issues with Kopia.
I found their explanation here:
Still not solved after many years :(
Ma doctrine pour le moment : je vais rester sur restic.
Journal du lundi 19 août 2024 à 11:27
#JaiLu "Les mathématiques de l'argument d'autorité #DébattonsMieux" de Lê Nguyên Hoang, je trouve cela très intéressant, bien que, après une première lecture, je n'aie saisi qu'une infime partie de l'article.
L'article présente un théorème bayésien qui stipule :
- Si vous êtes bayésien,
- si vous supposez qu'une autorité a eu accès aux mêmes données que vous et à plus encore,
- si vous êtes sûr que l'autorité parle de manière honnête,
- si vous pensez qu'une autorité est aussi bayésienne avec le même a priori que vous, alors vous devez croire tout ce que l'autorité dit.
#JaiDécouvert John Geanakoplos, Herakles Polemarchakis et John Harsanyi cités dans cet article.
Journal du vendredi 16 août 2024 à 11:39
#JaiLu la note de David Larlet nommée Initiateurs et mainteneurs.
There are two roles for any project: starters and maintainers. People may play both roles in their lives, but for some reason I’ve found that for a single project it’s usually different people. Starters are good at taking a big step in a different direction, and maintainers are good at being dedicated to keeping the code alive.
…
I am definitely a starter. I tend to be interested in a lot of various things, instead of dedicating myself to a few concentrated areas. I’ve maintained libraries for years, but it’s always a huge source of guilt and late Friday nights to catch up on a backlog of issues.
Je suis également un initiateur. J’aime créer de nouvelles choses en expérimentant des usages et des techniques. Lorsque je me retrouve dans un rôle de mainteneur, j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses. Or l’apprentissage nait de l’échec et du test des limites. C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. À moins que la maintenance soit un vestige du passé (cache).
-- from
Ces réflexions résonnent profondément en moi 🤗, car ce sont des questions et des pensées qui m'habitent depuis de nombreuses années.
« j’ai tendance à complexifier l’existant et à le rendre moins stable par ma soif d’apprendre de nouvelles choses »
Pour éviter cette tendance à complexifier l’existant, j'utilise la stratégie suivante. Lorsque je ressens le besoin d'expérimenter ou d'apprendre quelque chose de nouveau, je le fais au travers des side projects personnels ou dans le cadre de POC (Proof of Concept) et Spike officiellement décidés en équipe. C'est entre autres pour cette raison que j'avais proposé de mettre en place les Spike and Learn Day.
Cette approche me permet de satisfaire ma curiosité et mon envie d'apprendre, tout en maintenant l'utilisation de Boring Technology pour les projets critiques ou ceux menés en équipe. Ainsi, je parviens à éviter le piège du Resume Driven Development.
J'aime bien la distinction suivante :
« There are two roles for any project: starters and maintainers »
Jusqu'à présent, j'ai tendance à utiliser le terme solo développeurs pour les "starters" et team développeurs pour les "maintainers".
Petite anecdote amusante : lors de mon expérience chez Spacefill, j'avais proposé de nommer le rôle des développeurs d'expérience au sein de l'équipe les "maintainers" 😉.
« C’est assez désastreux pour les projets et je pense que l’engouement pour les microservices est un complot des initiateurs en mal d’expérimentations au sein d’applications à maintenir. »
C'est une réflexion que j'ai moi-même eue par le passé.
Je crois en effet que les solo développeurs apprécient particulièrement les microservices et les multi repositories car cela leur permet d'éviter les contraintes d'équipes.
Cela leur permet d'explorer des nouveaux langages et frameworks et d'échaper aux revues de code.
À mes yeux, cette approche favorise davantage l'individualisme que la cohésion d'équipe.
J'ai également remarqué que c'est souvent lors des phases de storming du modèle de Tuckman que les développeurs semblent se tourner vers les microservices comme une forme d'évitement des défis collectifs. Cette stratégie peut sembler séduisante, mais elle risque de renforcer les silos et de freiner la collaboration au sein de l'équipe 🤔.
Journal du jeudi 15 août 2024 à 20:00
Depuis que j'utilise @tabler/icons-svelte pour intégrer des tabler-icons sur un projet SvelteKit SSR, je rencontre d'énormes problèmes de performance en mode développement (pnpm run dev).
Pour traiter le problème, j'ai essayé ce hack indiqué dans l'issue Slow experience in SvelteKit, mais cela ne fonctionne pas.
Toujours dans cette issue, #JaiDécouvert Iconify.
Je pense me souvenir d'avoir commencé à utiliser tabler-icons comme alternative Open source à Font Awesome.
J'ai lu la page page raconte l'histoire du projet et j'apprends que le projet s'est réellement lancé en 2020.
Iconify est devenu un projet Open source en 2021 :
In mid 2022 plans changed, thanks to people showing interest in sponsoring open source development.
The new plan is to:
- Open source everything, encourage developers to create their own open source solutions that use Iconify.
- Rely on sponsors to finance development.
-- from
Mais, d'après la page contributors le projet semble toujours très majoritairement développé par Vjacheslav Trushkin.
Je lis aussi :
Unlike fonts, it downloaded data only for icons used on page, rendered pixel perfect SVG. (from)
Par contre, je pense comprendre qu'Iconify n'est pas un projet de création d'icônes, mais un framework qui regroupe énormément d'icônes.
Par exemple, j'ai constaté qu'Iconify intègre entre autres :
Iconify propose des composants icônes pour Svelte : Iconify for Svelte.
Mais, je lis :
Loads icons on demand. No need to bundle icons, component will automatically load icon data for icons that you use from Iconify API. -- from
Cette technique « Loads icons on demand » ne me plait pas. Je souhaite réduire au maximum les latences dans mes applications web.
J'ai continué mes recherches.
#JaiLu Icon library for svelte? : sveltejs
#JaiDécouvert unplugin-icons (from).
unplugin-icons est un projet qui a commencé en 2021 et qui est basé sur Iconify.
Je constate que unplugin-icons propose une configuration SvelteKit.
J'ai testé et cela semble très bien fonctionner 🙂.
Le site https://icones.js.org permet de facilement copier-coller le code Javascript pour intégrer une icône. Par exemple, un click sur "Unplugin Icons" :
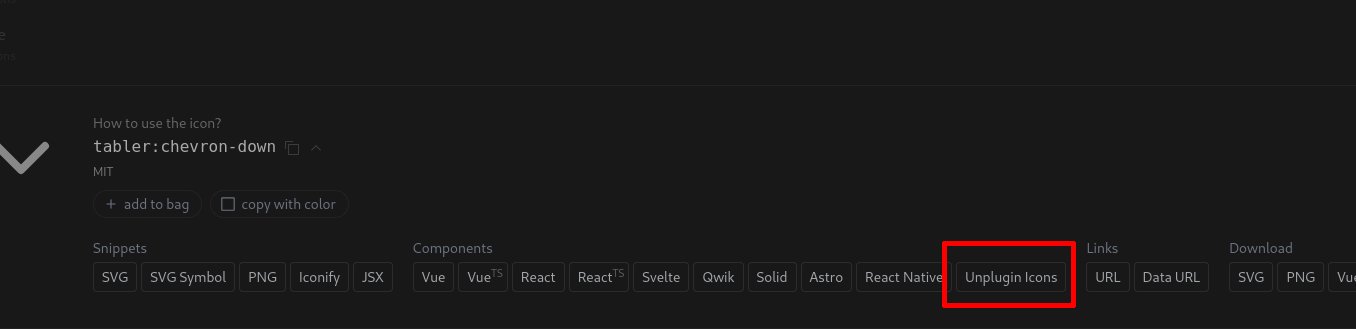
permet de copier :
import TablerChevronDown from '~icons/tabler/chevron-down'
Je ne constate aucun problème de lenteur au mode développement (pnpm run dev) et aucun chargement réseau externe des icônes dans la version de production.
#JaiDécidé d'adopter cette librairie pour gérer les icons de mes projets SvelteKit.
Journal du lundi 12 août 2024 à 23:21
#JaiLu pour la première fois la syntax de recherche de GitHub : Searching issues and pull requests.
Je la trouve à la fois complète et intuitive.
Cependant, j'ai remarqué que les opérateurs and et or, ainsi que l'utilisation des parenthèses, ne sont pas pris en charge.
Journal du lundi 12 août 2024 à 11:09
#JaiLu le thread Hacker News Turbo 8 is dropping TypeScript.
Quelques extraits :
I highly recommend reading the PR discussion for this.
https://github.com/hotwired/turbo/pull/971
Some summary:
- forced through without any discussion
- many maintainers raising questions, but no answers
- random changes attached to the PR (formatters, etc)
Wherever you land on types, I think we can agree that this is not an ideal way to make a change to a larger open source project. This has all the hallmarks of an executive decision made on a whim, and forced through at the last minute. Lead maintainers certainly have the right to make big changes on a whim, but giving people some notice before breaking other projects and having good communication is true leadership.
After using TypeScript I could never go back. The amount of times it's saved me or got me up to speed quickly is countless. It does come with a cost and god the error messages are just awful sometimes but I'd die before I ever work in a js only project again.
I wonder if type annotations (JSDoc) on plain JS could be the way to go. Lint, but don’t compile. This should work seamlessly with NPM modules etc.
Journal du dimanche 11 août 2024 à 20:33
#JaiDécouvert le concept Obsidian nommé Higher-Order Notes (from).
#JaiLu Concept notes are higher-order notes, not permanent Zettels et je n'ai rien appris d'intéressant..
Journal du samedi 10 août 2024 à 17:26
Dans mon PKM notes.sklein.xyz, #JeMeDemande quels sont les différences entre les tags et Wikilinks 🤔.
Les tags et les wikilinks me permettent tous les deux de retrouver une note à partir d'un ou plusieurs mots :
Contrairement aux tags, les wikilinks permettent :
- D'être documenté ;
- De proposer les alias.
Pour le moment, je ne vois pas d'avantage à utiliser des tags 🤔.
#JaiLu les threads suivants du forum Obsidian :
Links auto-refactor by default, and tags do not
This is a big one!
When you change the name of a file within Obsidian, all links to that folder will automatically change to be pointing to the right place. -- from
Je trouve que cette différence n'est pas négligeable 🤔.
#JaiDécouvert pjeby/tag-wrangler: Rename, merge, toggle, and search tags from the Obsidian tag pane (from).
People often debate the merits of using tags vs. page links to organize your notes. With tag pages, you can combine the best of both worlds: the visibility and fluid entry of tags, plus the centralized content and outbound linking of a page. -- from
Je trouve cette fonctionnalité intéressante, mais #JeMeDemande si l'utilisation de wikilinks ne serait pas une option plus simple 🤔.
Journal du jeudi 08 août 2024 à 15:18
#JaiLu La France laboratoire de la Silicon Valley 2.0
Tous mes amis me confirment qu’avec la baisse du système éducatif, nous sommes sur notre avant-dernière génération d’ingénieurs de très haut niveau. Cette génération aurait pu être déployée sur les sujets régaliens, notamment la Défense. Mais en travaillant pour les grandes entreprises américaines, ils vont par procuration travailler sur la Défense américaine. Ils aideront aussi les retraités américains à garantir leur retraite (grâce à un NASDAQ avec des valeurs florissantes).
Intéressant comme point de vue 🤔.
Sur le court terme, elle apporte du capital, mais sur le long terme, je ne suis plus sûr que nous aurons la capacité de faire tourner le pays dans 10 ou 20 ans, car les meilleurs d’une génération auront travaillé pour résoudre les problèmes de la Silicon Valley.
🤔.
Journal du jeudi 08 août 2024 à 15:01
#JaiLu https://x.com/tariqkrim/status/1821205699898060995
#JaiLu Pourquoi la tech française va droit dans le mur (2ème partie)
J’ai découvert récemment que Canal Plus, autrefois leader incontesté du décodeur, s’appuie désormais sur l’Apple TV pour sa distribution. -- from
En effet, bel échec 🤷♂️.
#JeSouhaite lire La France laboratoire de la Silicon Valley 2.0.
Il ne serait pas idiot que la France, l’Angleterre, les Pays-Bas et l’Italie travaillent en commun de la prochaine génération de puces et de logiciels open source pour permettre de concevoir la prochaine génération d’infrastructures résilientes dont la guerre en Ukraine a fait l’éclatante démonstration de la nécessité.
Avec la chute possible de Mozilla dont les financements pourraient être arrêtés suite à la décision de justice sur Google, il ne serait pas idiot non plus d’imaginer un projet de browser européen pensé nativement pour la vie privée et totalement open source et open CPU. -- from
C'est la stratégie à laquelle je rêve depuis 20 ans ! 🙏
À part à la gendarmerie nationale, il n’y a eu aucune vision sur le futur du desktop en France. On continue de dépenser de l’argent pour maintenir une technologie des années 90. -- from
Je dis 👍️x100.
En ne protégeant pas le web ouvert, pourtant créé en Europe, nous avons laissé les entreprises qui veulent distribuer leurs applications sur mobile aux mains de deux apps stores qui vampirisent 30 % de la valeur créée depuis 15 ans.
Quand on prend la peine d’y réfléchir un instant, notre quotidien numérique est désormais totalement défini par des entreprises extérieures à la France, par une centaine de product managers en Californie que nous ne connaissons pas.
👍️
Journal du dimanche 04 août 2024 à 22:03
Suite à la lecture de l'article Project Metrics, #JaiLu :
Journal du samedi 27 juillet 2024 à 14:00
#JaiLu le thread Hacker News "An experiment in UI density created with Svelte | Hacker News" et j'ai trouvé cela très intéressant.
Le bon dosage de la densité d'affichage est un élément très important dans mon expérience utilisateur.
#JaiDécouvert la librairie frontend web nommée DataTables (https://datatables.net/) implémentée en Javascript basée sur jQuery.
I'd like to think projects like these are somehow signaling a return to well designed but information dense, space saving interfaces ...
The amount of bloat, whitespace, extra spacing, "air" and other such waste — starting with (now Google-dead) "Material Design" has been egregious. —
#JaiDécouvert Perspective (https://perspective.finos.org/), j'aime beaucoup la densité des grilles. Voici un exemple en full screen : https://perspective.finos.org/blocks/editable/index.html.
J'aime sa densité et sa vitesse de rendu 👌.
This is interesting because it proves something to me about my vision and visual comprehension.
The "Grid" view is absolutely fine for me. The "Table" view is unworkable.
Intéressant 🤔.
J'ai regardé une partie de la vidéo de présentation du Bloomberg Terminal (https://www.youtube.com/watch?v=2ee-x6IXWK8), j'ai trouvé l'UI très intéressante.
Journal du jeudi 25 juillet 2024 à 16:56
Rich Harris explains this clearly. JSDoc for writing a lib. TypeScript for writing an app. (from)
Ce conseil entre en opposition avec ce que j'ai écrit en octobre 2023 :
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Ce conseil entre aussi en opposition avec ce second élément que j'ai écrit en octobre 2023 :
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Je pense qu'il serait bon que je revoie ma doctrine d'artisan développeur sur ce sujet.
Journal du vendredi 19 juillet 2024 à 23:40
#JaiLu What's new in Svelte: July 2024
#JaiLu What's new in Svelte: June 2024
Tons of work on the migrate tool to make migrating to Svelte 5 syntax easier
J'ai hâte de tester pour constater les changements dans le code et aussi constater si cela cette outil fonctionne correctement ou non 🤔.
Journal du jeudi 18 juillet 2024 à 21:27
#JaiLu commencé à lire https://notes.andymatuschak.org/Evergreen_notes de Andy's working notes.
Voir aussi Evergreen Note.
Journal du mercredi 17 juillet 2024 à 17:23
Je tente de comprendre la signification du mot Diaphories que j'ai découvert dans l'article Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret.
Après avoir partiellement lu :
- #JaiLu Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
- #JaiLu Quelques révisions du concept d’information.
- Cette citation :
"La donnée correspond, quant à elle, à ce qui n’est pas uniforme (à ce qui est « diaphora/différent ») ; bref il s’agit d’une variable : « une donnée est un fait supposé qui procède d’une différence ou d’un manque d’uniformité dans un contexte »" (source).
Je constate que je ne suis pas certain d'avoir bien compris la signification de Diaphories.
Voici un exemple pour illustrer ce que je pense avoir compris : imaginons une pelouse totalement uniforme. Si cette pelouse contient une fleur, cet élément, différent (du grec ancien διαφορά, diaphorá (« différence, distinction »)) de l'homogénéité de la pelouse, est une information. Sa couleur, sa localisation… sont des données, des Diaphories.
Journal du mardi 16 juillet 2024 à 13:44
#JaiLu Documenter la dimension sociale du travail de la connaissance : une approche hypertextuelle de Arthur Perret publié sur HAL.
La documentation personnelle peut être définie comme la documentation élaborée par un individu pour lui-même, de manière idiosyncrasique.
#JaiDécouvert le mot Idiosyncrasique.
#JeMeDemande si la condition « pour lui-même » est dépassable ou non 🤔.
(Psychologie) Caractères propres au comportement d’un individu particulier. (from).
Élaborer une documentation personnelle permet d’organiser le processus de « signifiance » (Leleu-Merviel, 2010) pour construire des connaissances (voir figure 1).
#JaiDécouvert la chercheuse Sylvie Leleu-Merviel.
#JeSouhaite lire Le sens aux interstices, émergence de reliances complexes de Sylvie Leleu-Merviel.
 #JaiDécouvert les mots Noumène, Noème et Diaphories.
#JaiDécouvert les mots Noumène, Noème et Diaphories.
Comme l’écrit Latour (dans « Pensée retenue, pensée distribuée »), la pensée n’est pas « retenue » dans l’unique cerveau du penseur, mais « distribuée » dans un ensemble d’acteurs et d’actants – un « milieu de savoir » selon l’expression de Le Deuff : données et documents, individus et collectifs, lieux, évènements et dispositifs divers.
#JaiDécouvert Traité de documentation de Paul Otlet.
#JaiDécouvert Robert Estivals et Communicology.
L’approche hypertextuelle présente plusieurs avantages par rapport aux graphes de connaissance, notamment une mise en œuvre plus simple et une plus grande expressivité. Cette méthode produit ce que Stiegler (Le concept d’ « Idiotexte » : esquisses - 2010) appelle un idiotexte, c’est-à-dire la textualisation d’une mémoire personnelle. L’utilité primaire de cette méthode, pour l’individu qui crée sa documentation personnelle, est de multiplier les chemins vers une même information, via des connexions riches en signification et facilement réactivées.
#JaiDécouvert idiotexte, j'ai lu l'article mentionné et je ne l'ai pas compris 🙅♀️.
Cette méthode présente également un intérêt pour les recherches sur les systèmes d’organisation des connaissances (SOC). Mazzocchi (2018) définit les SOC comme des ensembles de termes ou concepts interreliés, outils intermédiaires entre des humains et des collections de données et documents. Dans la méthode que nous avons décrite, la création d’un graphe documentaire correspond à la fois à la création d’une collection de documents – les fiches – et d’un SOC – les catégories de fiches et de liens utilisées dans le graphe.
#JaiDécouvert Systèmes d’organisation des connaissances (SOC).
D’abord, cette méthode est orientée par la subjectivité : les choix qui guident l’élaboration du graphe sont basés sur la mémorabilité, critère hautement subjectif.
Ok, j'ai bien compris 👌.
Par exemple, des catégories de fiches peuvent être modifiées, supprimées ou ajoutées progressivement pour orienter la manière dont fonctionne la remémoration.
Ok, j'ai bien compris 👌.
#JaiDécouvert L’épistémologie sociale (from)
J'ai pris le temps de regarder https://www.arthurperret.fr/glossaire-indexation.html, j'ai trouvé des choses intéressantes, du vocabulaire pour nommer des éléments techniques des CMS.
Ces configurations affectent la manière dont nous remémorons les choses : nous nous disons par exemple « J’ai mentionné ce concept dans telle publication » ou bien « C’est untel qui m’a recommandé cette méthode ». Ces connexions idiosyncrasiques sont facilement réactivées car elles reposent sur des éléments ayant une grande « mémorabilité » – terme qui renvoie aux arts de la mémoire et que nous entendons ici comme une qualité déterminée subjectivement, de manière réflexive, à partir de situations essentiellement contingentes, qui modifient notre « comportement informationnel ».
Je comprends très bien ce qui est exprimé et cela correspond à mon expérience vécu.
Journal du samedi 13 juillet 2024 à 10:34
#JaiLu ce manuscrit de Lê Nguyên Hoang : Une astuce bayésienne pour identifier l'expertise.
En particulier, un argument bayésien montre bel et bien que les affirmations bien plus populaires que ceux qu'on croit ont tendance à être souvent juste --- en tout cas dans un monde où les humains réfléchissent correctement, ou plutôt, conformément aux lois des probabilités.
🤔
J'ai lu plusieurs fois la section "Le théorème de la popularité insoupçonnée d'une vérité" et pour le moment, je n'ai toujours pas réussi à comprendre le raisonnement. Cela me demande beaucoup de concentration !
Eh bien, le scrutin proposé par Prelec, Seung et McCoy, qu'ils appellent le vote du candidat "surprenamment populaire" consiste à calculer, pour chaque candidat X, tous les ratios de ce genre, où X est comparé à des alternatives Y, en comparant les prédictions pro-Y chez les pro-X aux prédications pro-X chez les pro-Y.
Voir aussi Bayésianisme.
Journal du mercredi 10 juillet 2024 à 11:21
#JaiLu Écrire autrement : réflexion croisées sur Mardown
En SHS, les logiciels de traitement de texte (comme LibreOffice Writer, Microsoft Word et Google Docs) sont utilisés par la ma‐ jorité des auteurs et des éditeurs. … leur modèle économique est souvent défavorable à l'utilisateur ; …
La maniabilité des textes en Markdown permet de circuler de façon plus fluide dans sa production écrite et de la mobiliser au fil de différents contextes de recherche (communications scientifiques, articles de recherche, notes, supports de cours, etc.). Le temps de traitement et le travail de mise en forme des textes ainsi produits sont de ce fait rationalisés. L’ensemble de ces étapes constitue un écosystème de travail global et intégré.
Markdown a été pensé pour le Web : c'est une sorte de « sténographie » de HTML.
À la façon d'un wiki personnel, cette documentation regroupe tous les documents dans lesquels on travaille : fiches de lecture, notes terminologiques, brouillons d'idées, etc. C'est l'espace de travail dans Zettlr ou le "vault" dans Obsidian. L'idée centrale est de travailler avec des notes organisées de manière non-linéaire, qui se font référence les unes aux autres. Périodiquement, une idée émerge : un lien nou‐ veau entre deux choses (ou plus). Les notes servent d'aide-mémoire et d'espace de réflexion/idéation.
Outils cités dans l'article :
- #JaiDécouvert https://github.com/peterpeterparker/stylo
- Marp
- #JaiDécouvert https://ia.net/presenter (j'adore)
- #JaiDécouvert https://cosma.arthurperret.fr/
#JaiDécouvert le mot cosmoscope.
Journal du samedi 29 juin 2024 à 11:13
#JaiLu l'article intitulé Why the next GNOME Release will be one of the Best Ever.
Je pense que cet article offre une excellente vue d'ensemble des améliorations apportées à GNOME.
Journal du jeudi 20 juin 2024 à 00:14
#JaiLu Ask HN: Why do message queue-based architectures seem less popular now? | Hacker News.
Je trouve la question très intéressante.
Ce commentaire m'a bien fait rire :
Going to give the unpopular answer. Queues, Streams and Pub/Sub are poorly understood concepts by most engineers. They don't know when they need them, don't know how to use them properly and choose to use them for the wrong things. I still work with all of the above (SQS/SNS/RabbitMQ/Kafka/Google Pub/Sub).
I work at a company that only hires the best and brightest engineers from the top 3-4 schools in North America and for almost every engineer here this is their first job.
My engineers have done crazy things like:
- Try to queue up tens of thousands of 100mb messages in RabbitMQ instantaneously and wonder why it blows up.
- Send significantly oversized messages in RabbitMQ in general despite all of the warnings saying not to do this
- Start new projects in 2024 on the latest RabbitMQ version and try to use classic queues
- Creating quorum queues without replication policies or doing literally anything to make them HA.
- Expose clusters on the internet with the admin user being guest/guest.
- The most senior architect in the org declared a new architecture pattern, held an organization-wide meeting and demo to extol the new virtues/pattern of ... sticking messages into a queue and then creating a backchannel so that a second consumer could process those queued messages on demand, out of order (and making it no longer a queue). And nobody except me said "why are you putting messages that you need to process out of order into a queue?"...and the 'pattern' caught on!
- Use Kafka as a basic message queue
- Send data from a central datacenter to globally distributed datacenters with a global lock on the object and all operations on it until each target DC confirms it has received the updated object. Insist that this process is asynchronous, because the data was sent with AJAX requests.
As it turns out, people don't really need to do all that great of a job and we still get by. So tools get misused, overused and underused.
In the places where it's being used well, you probably just don't hear about it.
Edit: I forgot to list something significant. There's over 30 microservices in our org to every 1 engineer. Please kill me. I would literally rather Kurt Cobain myself than work at another organization that has thousands of microservices in a gigantic monorepo.
Journal du jeudi 06 juin 2024 à 22:57
#JeMeDemande quelles sont les différences entre les modèles qui terminent par "rien", par -instruct et par -chat.
This brings us to the heart of the innovation behind the wildly popular ChatGPT: it uses an enhancement of GPT3 that (besides having a lot more parameters), was explicitly fine-tuned on instructions (and dialogs more generally) -- this is referred to as instruction-fine-tuning or IFT for short. In addition to fine-tuning instructions/dialogs, the models behind ChatGPT (i.e., GPT-3.5-Turbo and GPT-4) are further tuned to produce responses that align with human preferences (i.e. produce responses that are more helpful and safe), using a procedure called Reinforcement Learning with Human Feedback (RLHF). (from)
Journal du jeudi 06 juin 2024 à 19:49
Suite à la lecture de Intel Unveils Lunar Lake Architecture #JaiLu l'article Wikipedia au sujet de NPU : https://en.wikipedia.org/wiki/AI_accelerator.
#JaiLu l'article Wikipedia au sujet des TPU de Google : https://en.wikipedia.org/wiki/Tensor_Processing_Unit
Il y a quelques jours, je me posais des questions au sujet du matériel spécialisé pour exécuter des Inference Engines. La page Puce d'accélération de réseaux de neurones est très intéressante à ce sujet.
Journal du jeudi 06 juin 2024 à 16:20
En travaillant sur 2024-06-06_1047 :
- #JaiDécouvert https://github.com/PABannier/bark.cpp - Suno AI's Bark model in C/C++ for fast text-to-speech (from)
- #JaiDécouvert https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from)
- #JaiLu au sujet de GGUF :
Hugging Face Hub supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework.
https://huggingface.co/docs/hub/gguf
- #JaiDécouvert llama : add pipeline parallelism support by slaren autrement dit « Multi-GPU pipeline parallelism support » (from)
- #JaiDécouvert https://github.com/ggerganov/whisper.cpp de Georgi Gerganov
- #JaiDécouvert https://github.com/ggerganov/llama.cpp/discussions/3471
- #JaiDécouvert la Merge Request d'ajout du support de ROCm Port : ROCm Port 1087 (from)
- #JaiDécouvert Basic Vim plugin for llama.cpp
- #JaiDécouvert https://github.com/rgerganov/ggtag par le même auteur que Llama.cpp, c'est-à-dire Georgi Gerganov
- #JaiDécouvert Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- #JaiDécouvert : d'après ce que j'ai compris la librairie ggml est le composant de base de Llama.cpp et Whisper.cpp
- #JaiDécouvert que Georgi Gerganov a lancé sa société nommée https://ggml.ai (from) et que celle-ci est financé entre autre part Nat Friedman ! Ha ha, encore lui 😍.
ggml.ai is a company founded by Georgi Gerganov to support the development of ggml. Nat Friedman and Daniel Gross provided the pre-seed funding.
We are currently seeking to hire full-time developers that share our vision and would like to help advance the idea of on-device inference. If you are interested and if you have already been a contributor to any of the related projects, please contact us at jobs@ggml.ai
- #JaiDécouvert Text-to-phoneme-to-speech https://twitter.com/ConcreteSciFi/status/1641166275446714368, j'adore 🙂
Journal du lundi 03 juin 2024 à 17:39
#JaiLu la page https://liquidex.house/programming/languages/lua (from) et au passage #JaiDécouvert le site perso https://liquidex.house/ que je trouve très intéressant dans sa forme.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

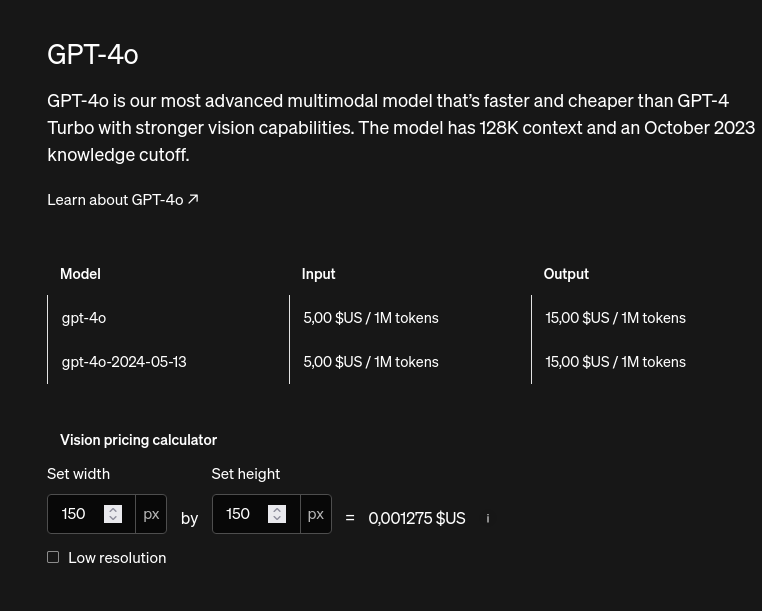
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
[ << Page précédente (50) ] | [ Page suivante (22) >> ]