
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (450) ] [ Page suivante (3458) >> ]
Le support des variables d'environments de Mise est limité, je continue à utiliser direnv
J'ai décidé d'utiliser la fonctionnalité "mise
env._source" pendant quelques semaines pour me faire une opinion.-- (from)
J'ai déjà rencontré un problème : il n'est pas possible de lancer des outils installés via Mise dans un script lancé par _.source.
Voici un exemple, j'ai ce fichier .envrc.sh :
export SERVER1_IP=$(terraform output --json | jq -r '.server1_public_ip | .value')
Terraform est installé avec Mise :
[env]
_.source = "./.envrc.sh"
[tools]
terraform="1.9.8"
Quand je lance mise set, j'ai cette erreur :
$ mise set
.envrc.sh: line 6: terraform: command not found
J'ai trouvé une issue pour traiter cette limitation : "Use mise tools in env template".
En attendant que cette issue soit implémentée, j'ai décidé de continuer d'utiliser direnv.
2024-12-19 : suite à la cloture de l'issue indiquée dans cette note, j'ai publié la note Je pense maintenant pouvoir remplacer Direnv par Mise 🤞.
Journal du mercredi 06 novembre 2024 à 17:10
En travaillant sur la note 2024-11-06_1631, j'ai découvert les commandes shell suivantes mises à disposition par direnv que je trouve intéressantes :
Je remplace direnv par la fonctionnalité env._source proposée Mise
Depuis avril 2019, j'utilise direnv dans pratiquement tous mes projets de développement informatique.
Ce matin je me suis demandé si avec les nouvelles fonctionnalités de gestion des variables d'environnement de Mise, je pouvais simplifier mes development kit 🤔.
Comme vous pouvez le voir dans install-and-configure-direnv-with-mise-skeleton, actuellement mes development kit contiennent deux étapes de modifications de .bash_profile ou .zshrc. Exemple avec Zsh :
- Une étape pour configurer Mise :
$ echo 'eval "$(~/.local/bin/mise activate zsh)"' >> ~/.zshrc
$ source ~/.zsrhrc
- Seconde étape pour configurer direnv :
$ echo -e "\neval \"\$(direnv hook zsh)\"" >> ~/.zshrc
$ source ~/.zsrhrc
Voici la version simplifiée de ce skeleton basé sur "mise env._source", avec une étape de configuration en moins :
https://github.com/stephane-klein/install-and-configure-mise-skeleton
Voici le contenu du fichier .mise.toml :
[env]
_.source = "./.envrc.sh"
et le contenu de .envrc.sh :
export HELLO_WORLD=foo
J'ai fait le choix de nommer ce fichier .envrc.sh plutôt que .envrc afin d'éviter des problèmes de compatibilité pour les utilisateurs qui ont direnv installé.
J'ai vérifié que les variables d'environnements "parents" sont bien conservées en cas de changement de variable d'environnement par Mise dans un sous dossier.
#JeMeDemande si je vais rencontrer des régressions par rapport à direnv 🤔.
J'ai décidé d'utiliser la fonctionnalité "mise env._source" pendant quelques semaines pour me faire une opinion.
Update : voir 2024-11-06_2109.
development kit skeleton d'installation de direnv
Voici un dépôt GitHub qui contient les instructions que j'indiquais dans mes development kit, avant 2024, pour installer et configurer direnv, sous MacOS.
https://github.com/stephane-klein/install-and-configure-direnv-with-asdf-skeleton
Dans ce skeleton, direnv est installé avec asdf, voir le fichier racine ./.tool-versions
Et voici un exemple de skeleton, que j'utilise depuis novembre 2023, basé sur Mise :
https://github.com/stephane-klein/install-and-configure-direnv-with-mise-skeleton
Dans ce second skeleton, direnv est installé avec Mise, voir le fichier racine ./.mise.toml.
Pourquoi j'utilise direnv dans mes development kit ?
Dans cette note, je souhaite expliquer pourquoi j'utilise et j'aime utiliser direnv.
Je suis toujours en train d'essayer de créer des development kit me permettant de travailler dans un environnements de développement toujours plus agréable.
J'ai découvert direnv en 2017 et j'ai commencé à l'utiliser dans un projet en avril 2019.
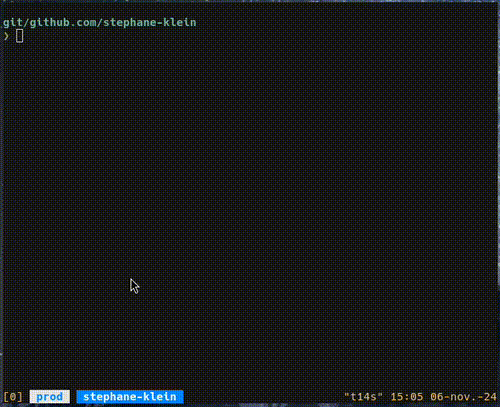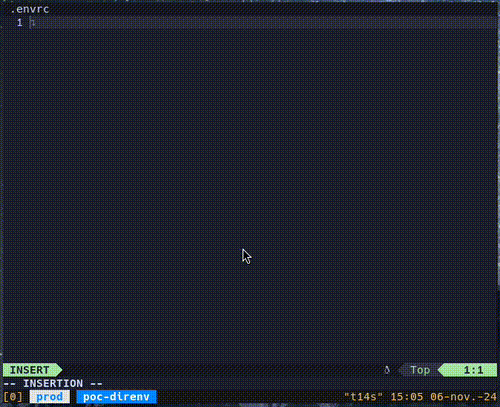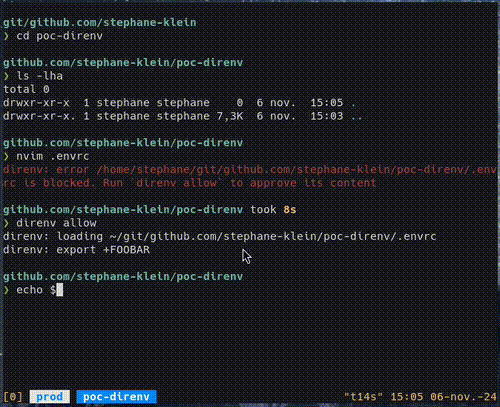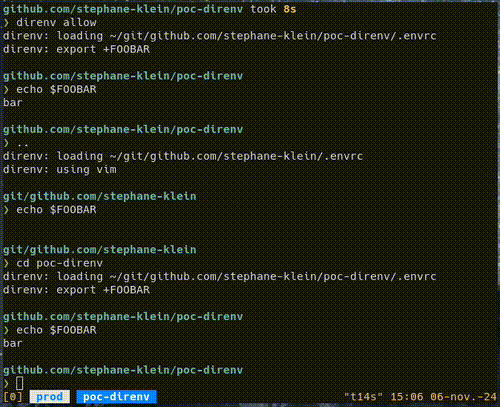
direnv s'utilise dans un shell, il charge et décharge automatiquement les variables d'environnement spécifiées dans un fichier .envrc lorsqu'on entre et quitte un répertoire.
Exemple :
Voici les use cases listées sur le site officiel de direnv :
- Load 12factor apps environment variables
- Create per-project isolated development environments
- Load secrets for deployment
Voici quelques exemples concrets de mon utilisation de direnv :
- chargement automatique des paramètres de configuration et secret pour :
source .secret
export SCW_DEFAULT_ORGANIZATION_ID="...." # Get it, in https://console.scaleway.com/organization/settings
export SCW_ACCESS_KEY="..."
# This variable environments are used by Grafana Grizzly
export GRAFANA_URL=http://grafana.$(terraform output --json | jq -r '.server3_public_ip | .value').nip.io
export GRAFANA_USER=admin
export GRAFANA_TOKEN=password
- dans un projet Javascript :
export POSTGRES_ADMIN_URL="postgres://postgres:password@localhost:5432/myapp"
export POSTGRES_URL="postgres://webapp:password@localhost:5432/myapp"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export SECRET="secret"
export APP_HOSTNAME="localhost"
export MAIL_FROM="noreply@example.com"
Les fichiers .envrc sont des scripts shell, il est possible comme dans l'exemple au-dessus, d'utiliser source .secret pour charger un autre fichier.
Je versionne toujours le fichier .envrc, tandis que j'ignore (.gitignore) les fichiers .secret contenant des informations sensibles qui ne doivent pas être publiés dans le repository git.
Après avoir installé un development kit, j'indique à l'utilisateur les instructions à suivre pour installer les éléments de base du projet, comme Mise, Docker…, et la mise en place des secrets.
Mon objectif est ensuite de permettre à l'utilisateur de l'environnement de développement d'interagir avec des « scripts helpers » sans nécessiter de configuration préalable, simplement en entrant ou sortant des dossiers. Les dossiers sont utilisés comme « workspace contexte ».
Voir aussi : development kit skeleton d'installation de direnv
À la recherche d'un environnement de développement sans le savoir : mes années 1999-2008
Je pense que je m'intéresse au sujet des "development environment" ou development kit depuis 1999.
À l'époque, même si je ne connaissais pas encore ces concepts, j'en ressentais déjà le besoin.
Par exemple, lorsque j'ai voulu contribuer au projet KDE, je cherchais des solutions et des bonnes pratiques pour organiser ma station de travail de manière à pouvoir compiler et installer KDE sans risquer de casser mon environnement de bureau.
Malheureusement, je n'y suis pas parvenu 😔.
Avec le recul, je réalise que ces pratiques étaient souvent transmises de manière informelle, principalement par des échanges oraux ou via des messages sur IRC. En somme, il s'agissait d'un véritable "bouche-à-oreille" numérique.
Je pense que la majorité des développeurs devaient faire face aux mêmes difficultés. Je pense aussi qu’ils devaient prendre beaucoup de temps à trouver leur propre méthode, année après année.
J’en ai eu une fois la confirmation. En 2002, je suis allé au FOSDEM, pour rencontrer entre autres David Faure, un core développeur français de KDE.
J’ai échangé avec lui et il m’a montré de nombreuses astuces qu’il utilisait… je n’ai pas tout compris, je n’ai pas réussi à les retenir…
J’en ai conclu que les développeurs avaient sans doute chacun leurs propres méthodes de développement non documentées.
Question qui me vient alors à l’esprit : alors qu'ils contribuent à des logiciels libres et partagent leur code source, pourquoi les développeurs ne partagent-ils pas aussi leurs environnements de développement ?
Journal du mercredi 06 novembre 2024 à 14:18
Je viens de réfléchir à l'usage des termes "development environment" et "development kit".
Je pense que le dépôt gitlab-development-kit est un "development kit" qui permet d'installer et configurer un "development environment" pour travailler sur le projet GitLab.
Upgarde de ma workstation de Fedora 40 à 41
Fedora 41 version stable est sortie le 29 octobre 2024, 7 jours plus tard, j'ai upgrade mon Thinkpad T14s AMD Gen 3 de la version 40 vers la version 41.
J'ai suivi la méthode officielle de mise à jour :
# dnf install dnf-plugin-system-upgrade
# dnf upgrade --refresh
# dnf clean all
# dnf system-upgrade download --releasever=41
# dnf system-upgrade reboot
et cela c'est déroulé avec succès.
Après 1h d'utilisation, je n'ai observé aucune régression.
J'espère que cette version va régler ce problème.
Voir aussi : Upgrade de ma workstation de Fedora 39 vers 40.
Journal du mardi 05 novembre 2024 à 11:34
En explorant la console de Scaleway, je viens de tomber sur la fonctionnalité suivante :
Scaleway Domains and DNS provides advanced features for traffic management using your DNS zone. It allows you to redirect users based on their geolocation, the load on your different servers, and more.
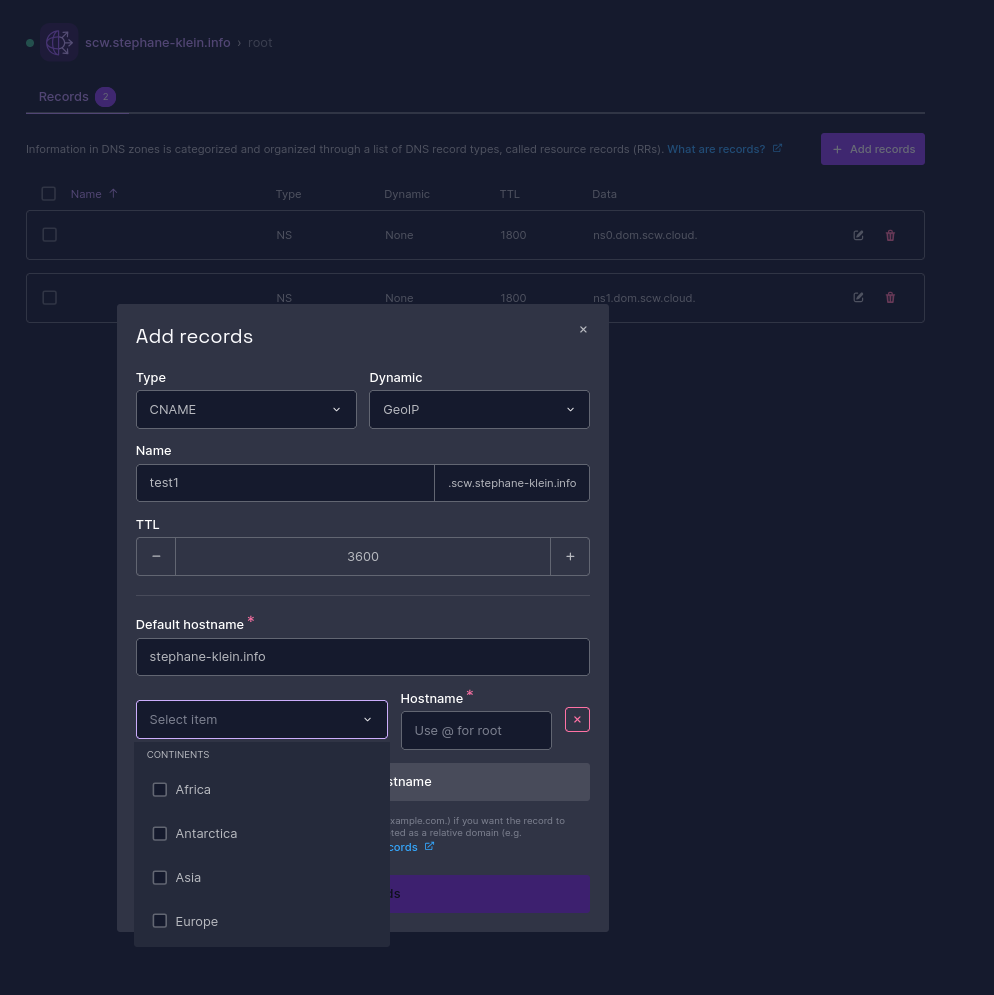
Je viens de réaliser que cela répond à une question que je me posais souvent entre 2000 et 2010 : comment les sites à portée mondiale parviennent-ils à répartir le trafic entre différents datacenters avec une URL unique, comme google.com ?
À l’époque, j’imaginais que ces acteurs utilisaient principalement le Round-robin DNS ou des algorithmes de répartition de charge avec HAProxy. mais je n'avais pas pensé à la possibilité que le serveur DNS puisse donner une réponse différente en fonction de l'IP de la personne qui fait la requête.
De plus, cette réponse peut dépendre de la localisation de l'IP (GeoIP).
Par exemple, depuis 2014, le serveur DNS Bind propose nativement la fonctionnalité "GeoIP Features".
J'ai lu aussi que les gros acteurs utilisent la méthode Anycast, mais cette méthode nécessite de gérer son propre Autonomous System.
Journal du mardi 05 novembre 2024 à 10:18
Lors d'un échange avec une amie, j'ai essayé de retrouver le terme employé par Tim Ferris pour désigner « un petit business en ligne automatisé qui rapporte régulièrement de l'argent sans demander trop de temps ou de maintenance à sa création pour générer ce revenu ».
J'ai retrouvé ce terme dans le livre The 4-Hour Workweek, il utilise le mot Muse. Exemple d'utilisation de Muse sur son blog : "Muse Examples".
Je viens de regarder les définitions de Muse en Anglais et je trouve les mêmes définitions qu'en français :
- Génie artistique, inspiration.
- (Par extension) Personne ou sentiment qui inspire un poète.
J'en déduis que la définition de Muse de Tim Ferris lui est personnelle, il a créé un mème.
Pourquoi Tim Ferris a choisi le mot "Muse" ? ChatGPT me répond ceci :
Tim Ferriss utilise le terme muse pour décrire ces entreprises parce qu’il voit ces projets comme une source d’inspiration et de liberté. Dans la mythologie grecque, les muses sont des déesses qui inspirent la créativité, l'art et la découverte. Ferriss reprend cette idée en adaptant le concept au monde de l’entrepreneuriat moderne. Il considère qu'une muse, en générant des revenus passifs, permet à l'entrepreneur de se libérer des contraintes financières et temporelles, et ainsi de se consacrer à des activités inspirantes et enrichissantes.
Pour Ferriss, une muse n’est pas seulement un business. Elle est le moyen d’accéder à un style de vie centré sur l’indépendance, la créativité et l'exploration. Le choix de ce mot évoque donc le rôle de catalyseur de liberté qu’elle joue dans la vie de ceux qui s’y lancent, leur permettant de créer un équilibre entre travail et passions.
Journal du lundi 04 novembre 2024 à 23:43
Un ami m'a partagé cet article : Google’s DeepMind is building an AI to keep us from hating each other .
L'article contient un lien vers le papier de recherche dont parle l'article : https://www.science.org/doi/10.1126/science.adq2852.
Voici le document PDF qui se trouve en lien de cet article : AI can help humans find common ground in democratic deliberation.
J'ai fait une recherche sur arXiv de chaque auteur de ce papier de recherche :
- Michael Henry Tessler
- Daniel Jarrett
- Hannah Sheahan
- Martin J. Chadwick
- Raphael Koster
- Georgina Evans
- Lucy Campbell-Gillingham
- Tantum Collins
- David Parkes
- Matthew Botvinick
- Christopher Summerfield
Suite à cela, j'ai découvert les preprint suivants :
Journal du lundi 04 novembre 2024 à 15:11
Dans l'article "Google’s DeepMind is building an AI to keep us from hating each other" j'ai découvert le philosophe Jürgen Habermas.
J'y ai ensuite découvert :
J'ai pris conscience que j'ai déjà croisé John Langshaw Austin dans le livre "L'argent mode d'emploi" de Paul Jorion. En 2010, j'avais découvert dans ce livre le concept de phrase performative (page 157).
On peut clarifier ce point en recourant à la notion de performatif telle que l'utilisent les linguistes. On doit cette notion au philosophe anglais John Langshaw Austin qui l'introduisit dans une allocution fameuse : How to Do Things with Words.
Journal du lundi 04 novembre 2024 à 11:39
Je viens de découvrir l'expression « pro bono » :
Le pro bono est une ancienne locution latine, provenant de « pro bono publico » signifiant « pour le bien public », qui désigne le travail réalisé à titre gracieux par un professionnel à destination d'une population défavorisée.
-- from
Journal du dimanche 03 novembre 2024 à 18:58
Dans le blog de Richard Jones, j'ai découvert nbdkit.
nbdkit is an NBD server. NBD — Network Block Device — is a protocol for accessing Block Devices (hard disks and disk-like things) over a Network.
-- from
Journal du dimanche 03 novembre 2024 à 18:35
Dans le tutoriel "Proxmox Template with Cloud Image and Cloud Init", #JaiDécouvert un usage de la commande virt-customize :
# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Je trouve cela extrêmement pratique, cela évite de devoir utiliser Packer pour personnaliser une image disque.
J'ai fait quelques recherches et j'ai appris que la fonctionnalité d'installation de package est ancienne, elle a été implémentée dans libguestfs en 2014 par Richard Jones, employé de chez Red Hat (auteur de libguestfs).
Journal du dimanche 03 novembre 2024 à 15:47
#JaiDécouvert que wal-g ne se limite pas au support de PostgreSQL : il prend également en charge MySQL, MS SQL Server, et ajoutera bientôt le support de MongoDB et Redis.
WAL-G is an archival restoration tool for PostgreSQL, MySQL/MariaDB, and MS SQL Server (beta for MongoDB and Redis).
-- from
Journal du dimanche 03 novembre 2024 à 12:33
En lisant la release note v3.0.3 de wal-g, j'ai découvert l'extension PostgreSQL nommée OrioleDB.
OrioleDB is a new storage engine for PostgreSQL, bringing a modern approach to database capacity, capabilities and performance to the world's most-loved database platform.
OrioleDB consists of an extension, building on the innovative table access method framework and other standard Postgres extension interfaces. By extending and enhancing the current table access methods, OrioleDB opens the door to a future of more powerful storage models that are optimized for cloud and modern hardware architectures.
Le projet OrioleDB a commencé en février 2022 par un développeur de Supabase : Alexander Korotkov.
Les commentaires de ce thread Hacker News semblent très enthousiastes https://news.ycombinator.com/item?id=30462695.
Dans la page "Introductions" de la documentation, je lis :
Differentiators
The key technical differentiations of OrioleDB are as follows:
No buffer mapping and lock-less page reading
In-memory pages in OrioleDB are connected with direct links to the storage pages. This eliminates the need for in-buffer mapping along with its related bottlenecks. Additionally, in OrioleDB in-memory page reading doesn't involve atomic operations. Together, these design decisions bring vertical scalability for Postgres to the whole new level.
MVCC is based on the UNDO log concept
In OrioleDB, old versions of tuples do not cause bloat in the main storage system, but eviction into the undo log comprising undo chains. Page-level undo records allow the system to easily reclaim space occupied by deleted tuples as soon as possible. Together with page-mergins, these mechanisms eliminate bloat in the majority of cases. Dedicated VACUUMing of tables is not needed as well, removing a significant and common cause of system performance deterioration and database outages.
Copy-on-write checkpoints and row-level WAL
OrioleDB utilizes copy-on-write checkpoints, which provides a structurally consistent snapshot of data every moment of time. This is friendly for modern SSDs and allows row-level WAL logging. In turn, row-level WAL logging is easy to parallelize (done), compact and suitable for active-active multimaster (planned).
J'ai lu le billet "Rethinking PostgreSQL buffer mapping for modern hardware architectures". Je pense avoir compris que l'implémentation actuelle de PostgreSQL utilise un "buffer mapping" autrefois bien adapté aux contraintes matérielles.
J'ai compris qu'OrioleDB propose une nouvelle approche, spécialement conçue pour tirer parti des SSD rapides, ce qui lui permet d’atteindre des performances nettement supérieures à celles de l’implémentation existante.
Journal du dimanche 03 novembre 2024 à 11:51
Avec la sortie de la version 17 de PostgreSQL, de nouvelles options de sauvegarde sont désormais disponibles : l'outil pg_basebackup (https://www.postgresql.org/docs/17/app-pgbasebackup.html) permet de réaliser les sauvegardes incrémentales, et un nouvel utilitaire, pg_combinebackup, permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
J'ai lu les articles suivants de Robert Haas, créateur de ces nouvelles fonctionnalités :
- Incremental Backup: What To Copy?
- #JaiDécouvert le projet ptrack.
- Incremental Backups: Evergreen and Other Use Cases
J'en ai profité aussi pour lire :
J'ai trouvé tous ces articles très intéressants, j'y ai appris beaucoup de choses.
Je me demande quel impact ces fonctionnalités auront ou ont déjà sur les outils existants comme pgBackRest, barman, et wal-g.
Autres ressources :
Impact sur pgBackRest ?
Voici ce que j'ai trouvé dans le projet pgBackRest.
We are aware of what's been committed to PG17.
-- from
Je comprends d'après ce commentaire que les auteurs de pgBackRest sont bien au courant des avancées de PostgreSQL 17.
Issue : WAL summarizer in pg 17 and incremental backups in pgbackrest ?.
We already support page-level (we call it block-level) incremental since v2.46 and it works for all versions of PostgreSQL supported by pgBackRest (>= 9.4), see https://pgbackrest.org/user-guide.html#backup/block.
We are planning to use the WAL summarizer to help us pick more optimal block sizes and cross-check timestamps but we are waiting for it to be a bit more stable. Also, the WAL summarizer output uses a lot of memory and is not the best fit for large databases with a lot of changes. We have some ideas on how to make that more efficient but have not had time to pursue it yet.
D'après ce commentaire, je pense avoir compris que les nouvelles fonctionnalités de backup incrémental de PostgreSQL 17 ne sont d'aucune utilité pour pgBackRest, qui implémente déjà cette fonctionnalité de manière efficace 🤔.
Impact sur barman ?
La version 3.11.0 de barman intègre des fonctionnalités liées aux nouvelles fonctionnalités de PostgreSQL 17.
Impact sur wal-g
J'ai n'ai trouvé aucune mention de pg_combinebackup, ni de pg_basebackup incremental dans le repository de wal-g.
J'ai l'impression qu'il est possible d'utiliser directement pg_basebackup pour effectuer des sauvegardes incrémentales de bases de données PostgreSQL. Cependant, je crains que cette idée soit un peu naïve.
Vers la fin de 2023, j'ai commencé à implémenter un POC de pgBackRest : https://github.com/stephane-klein/backlog/issues/322. J'ai pu réaliser une simulation complète de son utilisation dans ce dépôt : poc-pgbackrest. Cependant, je n'ai pas conservé un souvenir précis des raisons pour lesquelles mon expérience utilisateur n'a pas été satisfaisante, ce qui m'a dissuadé de déployer pgBackRest en production.
Après avoir constaté que barman intègre la fonctionnalité increment de pg_basebackup, j'ai envie de tester barman.
Journal du samedi 02 novembre 2024 à 23:44
Dans la vidéo "Conférence de Sébastien BROCA au Congrès ADULLACT 2014", vers le timecode 0:32 #JaiDécouvert la théorie nommée "Motivation crowding theory" :
« Quand les gens s'investissent dans une activité dont ils considèrent qu'elle a une valeur intrinsèque, leur offrir de l'argent peut affaiblir leur motivation en dépréciant ou en "excluant" leur intérêt intrinsèque ou leur engagement ».
Journal du samedi 02 novembre 2024 à 23:36
#JaiDécouvert Harvester qui me semble être une alternative moderne à Proxmox, basé sur KubeVirt et Longhorn.
J'ai regardé la vidéo Kubevirt: Et si Kubernetes orchestrait vos VMs? (Mickael ROGER) qui m'a découragé d'utiliser KubeVirt.
Journal du samedi 02 novembre 2024 à 12:52
Suite à quelques cherches, j'ai décidé d'utiliser "commander" plutôt que "yargs" dans sklein-pkm-engine : lien vers le commit.
Je trouve cette librairie minimaliste :
program
.option('--dry', 'Run in dry mode')
.parse();
console.log(program.opts());
Résultat de "commander vs inquirer vs meow vs yargs" :
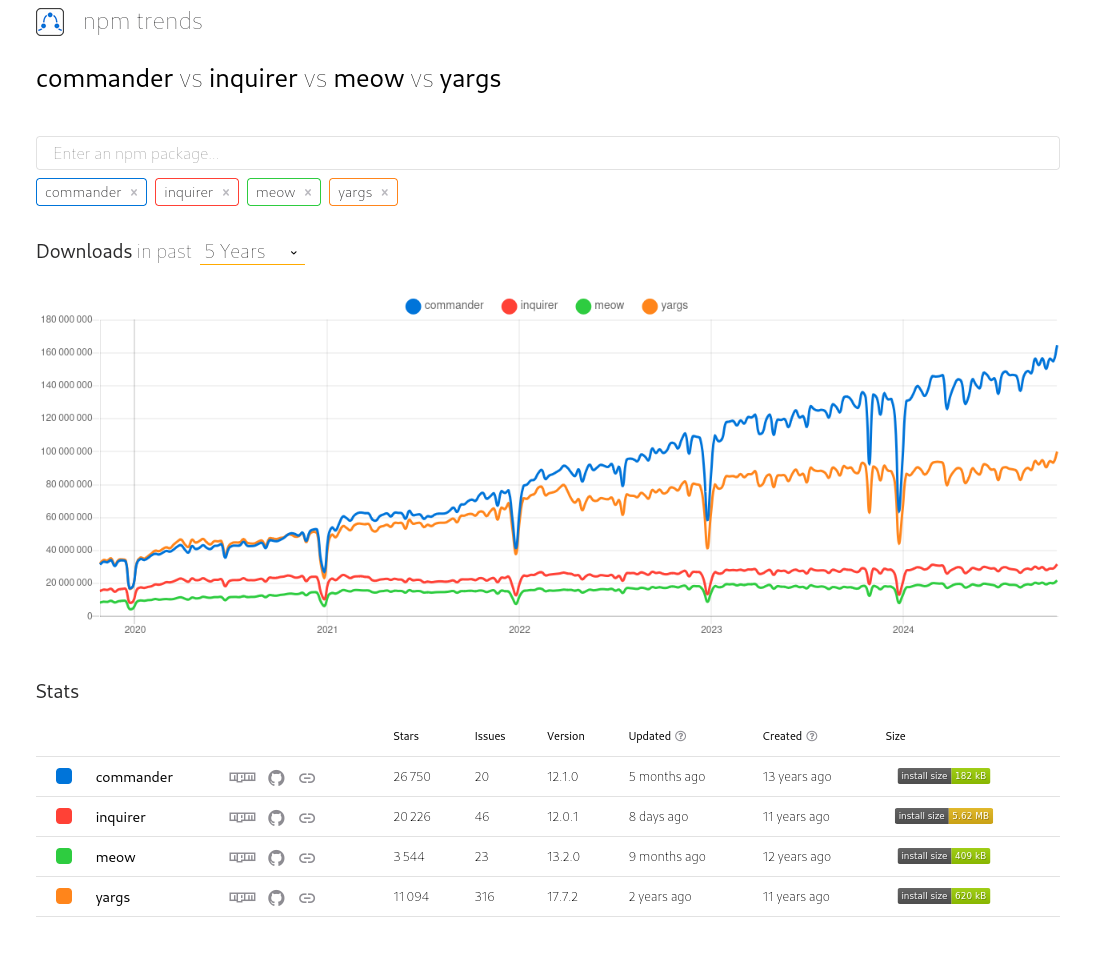
Journal du samedi 02 novembre 2024 à 12:20
Je cherche un équivalent de Listr2 en Golang, mais pour le moment je n'ai rien trouvé 😟.
Je viens de poster ce message sur le Subreddit Golang : I'm looking for an equivalent of listr2: beautiful CLI interfaces via easy and logical to implement task lists that feel lively and interactive
Subject: I'm looking for an equivalent of listr2: beautiful CLI interfaces via easy and logical to implement task lists that feel lively and interactive
Hi,
Do you know a Golang equivalent of the Javascript listr2 library?
My goal is to create a cli tool with the same rendering as demonstrated in the screencast on https://listr2.kilic.dev
Listr2:
Create beautiful CLI interfaces via easy and logical-to-implement task lists that feel alive and interactive.
Best regards,
Stéphane
Journal du samedi 02 novembre 2024 à 11:19
Dans la vidéo "Conférence de Sébastien BROCA au Congrès ADULLACT 2014", vers le timecode 0:32 #JaiDécouvert le mot Autotélisme.
Le psychologue Mihály Csíkszentmihályi emploie la notion d'autotélisme pour qualifier sa notion de flow. Dans son approche, l'expérience autotélique est à considérer comme l'aboutissement d'un état de concentration total, d'absorption mental, en direction d'une activité ou d'une action précise.
-- from
Définition dans Wiktionary :
- Qui n’entreprend une activité pour d’autre but que l’intense satisfaction qu’elle procure, en parlant d’une personne.
- Qui n’a d’autre but que soi-même, en parlant d’un objet artistique.
-- from
Journal du jeudi 31 octobre 2024 à 12:53
Je viens de faire ma première "contribution" à la coopérative social.coop 😉 : mon message posté dans le thread "TWG is exploring server hosting alternatives".
Journal du jeudi 31 octobre 2024 à 12:34
Note de comparaison de la localisation des serveurs Hetzner et Scaleway.
Pour Hetzner je lis ceci :
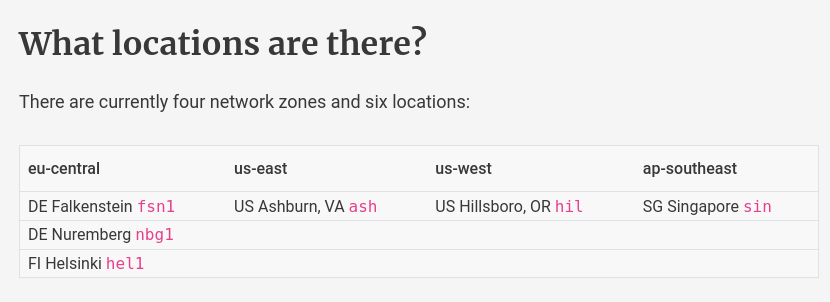
Pour Scaleway, je lis ici :
All Dedibox servers and associated services are hosted in our Paris & Amsterdam datacenters. We also have a Warsaw datacenter.
Journal du jeudi 31 octobre 2024 à 12:12
Dans l'article "Hetzner Considered Hostile: A PSA", j'ai découvert le terme anglais Threat actor et son article Wikipedia : Threat actor.
Qui peut être traduit en français par "acteurs malveillants ou "acteurs de menace".
Journal du jeudi 31 octobre 2024 à 11:35
En lisant le thread suivant TWG is exploring server hosting alternatives sur le Loomio de social.coop, #JaiDécouvert l'instance Mastodon nommée tenforward.social.
Contrairement à social.coop, l'instance tenforward.social n'est pas gouverné par une coopérative, mais elle est tout de même transparente :
- Les coûts fixes par mois et par an : Ten Forward Wiki
- Les dépenses mois par mois : Monthly Income and Expense Reports
- Data Backup Policies
- Ten Forward’s Status Page
Et un blog pour divers messages de communications : https://tenforward.blog.
Réflexions au sujet des notions d'"environnement", "instance" et "workspace"
Je suis en train d'implémenter un repository playground privé pour un client et je me demande comment bien nommer les choses.
Je souhaite implémenter dans ce playground, des dossiers qui permettent d'interagir avec différents types d'instance.
Je me suis interrogé sur les notions de « environnement » et « d'instance ». Je connais ces termes, mais j'ai souhaité étudier leur différence avec précision.
Environnement :
- Article Wiktionary français : environnement
(Informatique) Ensemble des matériels et logiciels sur lesquels sont exécutés les programmes d'une application.
- "On travaille dans un environnement Linux."
- Article Wiktionary français : environment
(Informatique) Environnement.
- "The primary prompt is changed to help us remember that this session is inside a chroot environment."
- Article Wikipedia anglais : Runtime environment
In computer programming, a runtime system or runtime environment is a sub-system that exists in the computer where a program is created, as well as in the computers where the program is intended to be run.
- Article Wikipedia anglais : Deployment environment
In software deployment, an environment or tier is a computer system or set of systems in which a computer program or software component is deployed and executed. In simple cases, such as developing and immediately executing a program on the same machine, there may be a single environment, but in industrial use, the development environment (where changes are originally made) and production environment (what end users use) are separated, often with several stages in between. This structured release management process allows phased deployment (rollout), testing, and rollback in case of problems.
Instance :
- Article Wiktionary Français : instance
(Réseaux informatiques) Copie d’un logiciel fournissant un service sur un réseau.
- "PeerTube est un logiciel. Ce logiciel, des personnes spécialisées (disons… Bernadette, l’université X et le club de karaté Y) peuvent l’installer sur un serveur. Cela donnera une « instance », c’est à dire un hébergement de PeerTube. Concrètement, héberger une instance crée un site web (disons BernadetTube.fr, UniversiTube.org ou KarateTube.net) sur lequel on peut regarder des vidéos et créer un compte pour interagir ou uploader ses propres contenus."
- Article Wikipedia Anglais : instance
- Instance (computer science), referring to any running process or to an object as an instance of a class.
- Instance can refer to a single virtual machine in a virtualized or cloud computing environment that provides operating-system-level virtualization.
ChatGPT me dit :
Dans un contexte DevOps, les termes environment et instance font référence à des concepts distincts :
- Un environment regroupe les ressources et la configuration nécessaires pour une étape spécifique du cycle de vie de développement.
- Une instance est une unité d'exécution de l'application, isolée, et potentiellement en plusieurs exemplaires au sein d'un même environnement.
À la suite de cette réflexion, j'ai implémenté un exemple de repository contenant plusieurs workspaces, permettant d'interagir avec des instances de différents types d'environnement.
Repository : project-workspaces-skeleton
Je l'ai organisé de la façon suivante :
$ tree
├── development
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── production
│ ├── local-workspace
│ │ └── README.md
│ └── remote-workspace
│ └── README.md
├── README.md
└── staging
├── local-workspace
│ └── README.md
└── remote-workspace
└── README.md
Voici quelques extraits du contenu des README.md.
development/local-workspace/README.md :
Local development environment workspace
Introduction
This workspace allows you locally launch the equivalent of remote development environment instances (applications, databases, etc.), within the GitOps paradigm.
This workspace provides scripts for injecting and initializing a database with demo data, or for copying the contents of remote instances to the local database.
This workspace is the right place if you want to work (fix bug, improve…) in isolation (without disturbing your colleagues) on development-type configuration changes.
This workspace is also useful for tinkering to better understand how this environment works.
Workspace configuration
...
production/remote-workspace/README.md :
Remote production environment workspace
Be careful when using scripts in this workspace, as you risk breaking production instances!
Introduction
This workspace allows you to interact with remote production environment instances (applications, databases, etc.) within the GitOps paradigm.
This workspace is designed, among other things, to store the configuration of production instances.
It includes scripts for deploying this configuration to remote instances and analysing the differences between the theoretical or desired configuration and that actually deployed.
With Git, these configurations are versioned, making it possible to track changes made over time on these instances.
Furthermore, this paradigm allows modifications to be proposed in the form of Pull Requests, simplifying collaborative work.Workspace configuration
...
Je pense que ce skeleton va me servir de base pour de futurs repository de projets.
Journal du mercredi 30 octobre 2024 à 10:21
Je garde trace dans cette notes de deux plugins Asdf / Mise que j'ai utilisé avec succès ces deux derniers jours.
Le premier, pour installer la cli de Hasura : asdf-hasura
$ mise plugin add hasura-cli https://github.com/gurukulkarni/asdf-hasura.git
Contenu de .mise.toml :
[tools]
hasura-cli = "2.43.0"
$ mise install
$ hasura version
INFO hasura cli version=v2.43.0
Le second, pour installer Gitleaks : asdf-gitleaks
$ mise plugin add gitleaks https://github.com/jmcvetta/asdf-gitleaks.git
Contenu de .mise.toml :
[tools]
gitleaks = "8.21.2"
$ mise install
$ gitleaks --version
gitleaks version 8.21.2
Je viens de publier un nouveau playground pour tester Hasura : hasura-graphql-engine-playground.
Journal du mardi 29 octobre 2024 à 12:20
Après quelques heures d'utilisation de Hasura, j'ai l'impression que le projet manque de soin :
Journal du mardi 29 octobre 2024 à 10:26
Note de comparaison de la documentation Hasura version 2 versus PostGraphile.
J'essaie d'exposer une mutation GraphQL qui exécute et retourne de résultat d'une fonction PL/pgSQL.
Postgraphile
Voici le parcours pour découvrir comment implémenter cette fonctionnalité dans PostGraphile :
-
- J'ouvre la page documentation : https://www.graphile.org/postgraphile/introduction/
-
- Je vois dans la navigation de droite, "Opération", ensuite "Functions".
-
- J'ouvre la page "Functions"
-
- Je clique sur la page "Custom Mutations"
Et sur cette page je peux lire une explication du fonctionnement et un exemple :
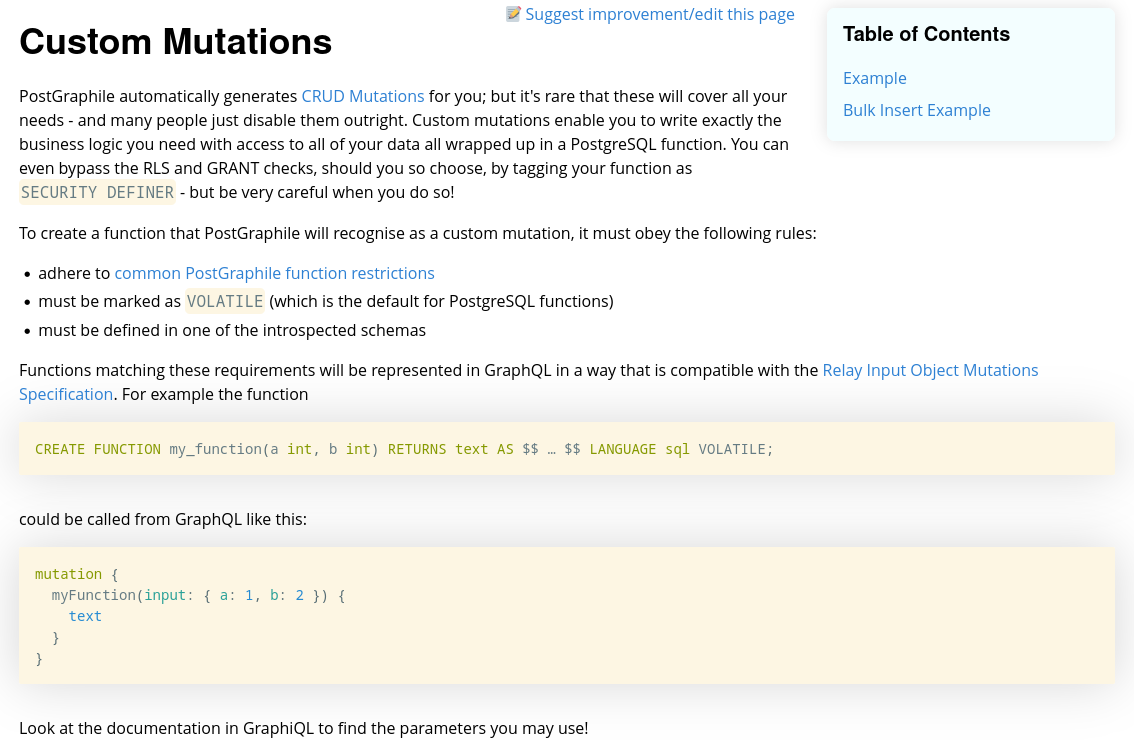
Hasura
Voici le parcours pour découvrir comment implémenter cette fonctionnalité dans Hasura :
-
- J'ouvre la documentation https://hasura.io/docs/2.0/index/
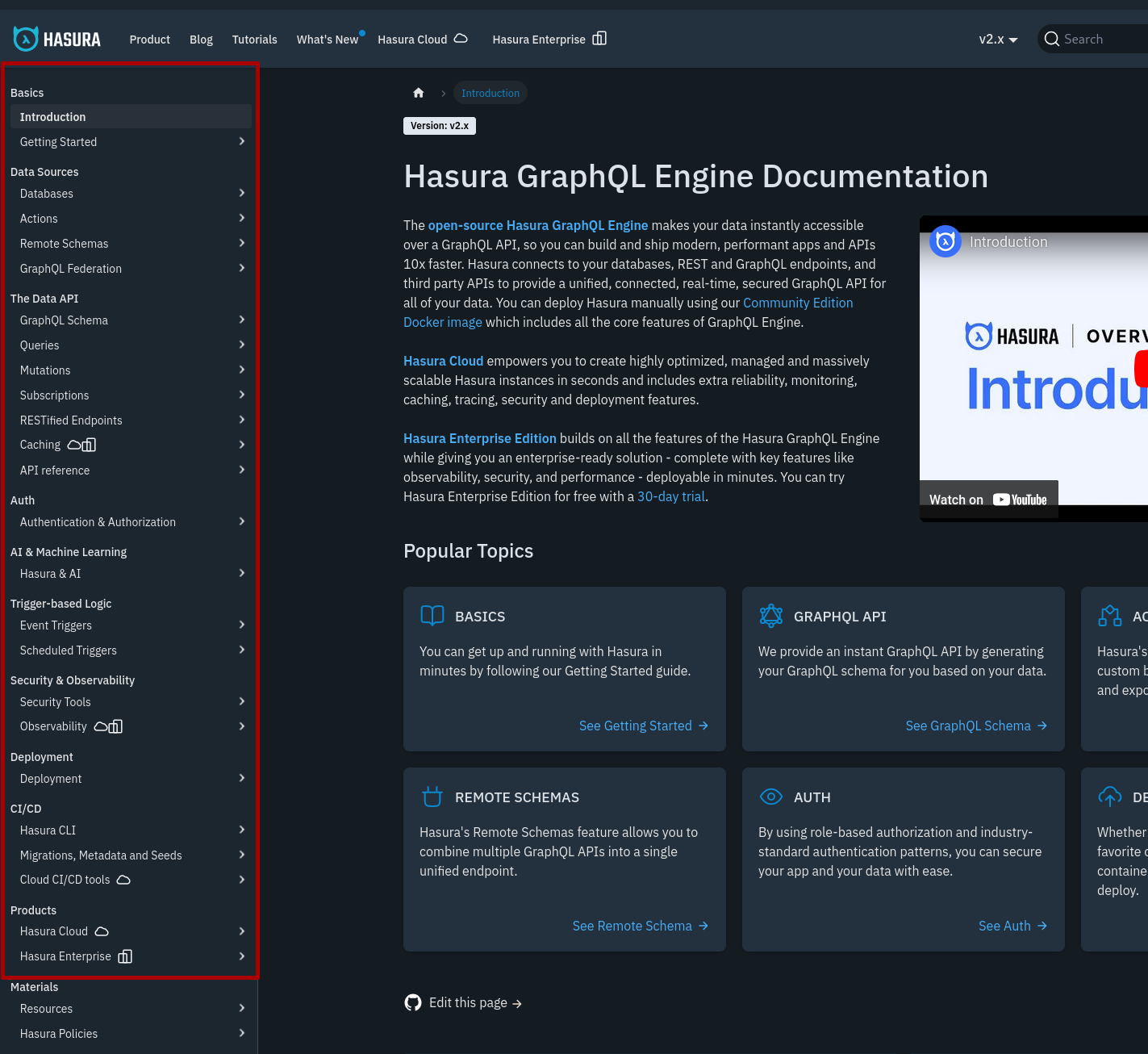
-
- Contrairement à la navigation de la documentation de PostGraphile qui affiche directement les mots clés "Function" et "Custom Mutation", j'ai eu quelques difficultés à trouver la page qui contient ce que je cherche. Cela s'explique par le fait que Hasura propose plus de fonctionnalités que PostGraphile et plus d'abstractions.
-
- En explorant, j'ai fini par trouver la section en ouvrant les sections "GraphQL Schema" => "Postgres".
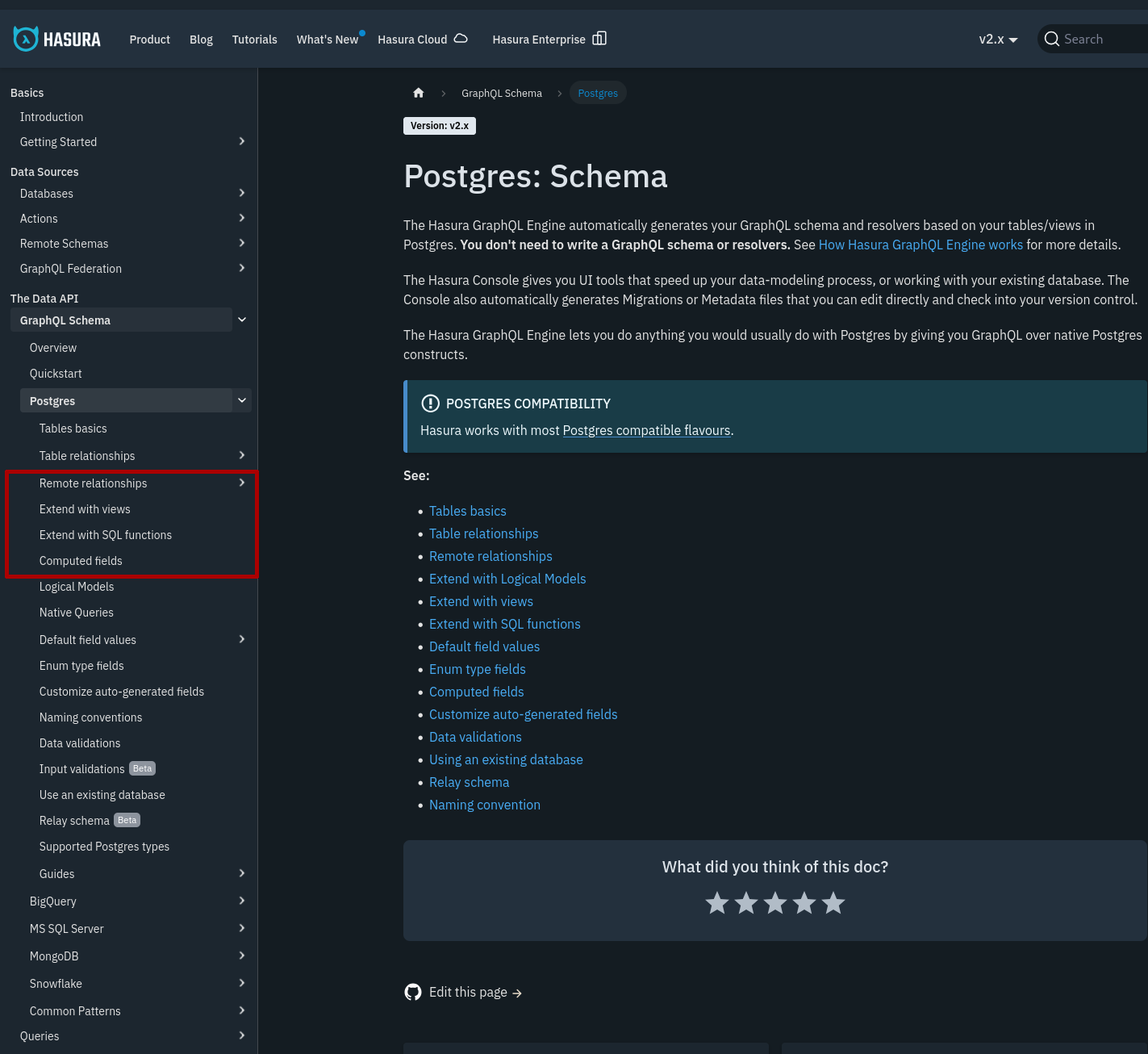
-
- J'ouvre la page "Extend with SQL functions"
Journal du lundi 28 octobre 2024 à 18:30
Été 2021, j'ai essayé d'utiliser PostgREST dans un projet professionnel, mais j'ai abandonné cette option en raison de trop nombreuses limitations rencontrées.
Depuis, je constate que PostgREST a beaucoup évolué : CHANGELOG.md.
Cela pourrait valoir la peine que je redonne une chance à ce projet lors de ma prochaine réalisation d'une API REST.
#JeMeDemande si la bonne santé du projet est liée au sponsoring de Supabase.
Sur la page Patreon du projet, je constate qu'il reçoit 1375 € de don récurrent par mois.
Journal du lundi 28 octobre 2024 à 14:56
Je rassemble ici quelques notes au sujet de projet Hasura.
À l'origine, Hasura était uniquement un moteur GraphQL open-source qui se branchait directement sur une base de données PostgreSQL. Le projet a commencé en 2018, bien que le site web soit plus ancien — 2015.
D'après le dépôt GitHub, les premiers développeurs d'Hasura sont Shahidh K Muhammed, Vamshi Surabhi, Aravind Shankar et Rakesh Emmadi, tous basés à Bangalore, en Inde.
En 2019, dans un cadre professionnel, j'ai choisi d'utiliser un autre moteur GraphQL : PostGraphile.
Début 2020, j'avais également identifié Hasura et Supabase comme alternatives.
J'avais choisi d'utiliser PostGraphile pour plusieurs raisons :
- Supabase était encore un jeune projet, lancé en octobre 2019.
- Hasura était codé en Haskell, un langage que je ne maîtrise pas. En revanche, PostGraphile, développé en JavaScript, m'inspirait plus confiance, car je savais que j'avais les compétences nécessaires si je devais intervenir sur son code source, par exemple, pour corriger un bug.
- D'autre part, PostGraphile n'était pas financé par des Venture capital, ce qui m'inspirait bien plus confiance sur son avenir que Supabase et Hasura.
- J'apprécie énormément la façon de travailler de Benjie. J'apprécie sa manière d'organiser ses projets, ses documentations et ses choix techniques. Je pense que notre doctrine est assez similaire.
Quatre plus tard, je constate que PostGraphile a choisi de rester concentré sur un seul objectif : être un moteur GraphQL, tandis que Supabase et Hasura, bénéficiant d'un financement par des Venture capital, ont diversifié leurs offres.
Alors que PostGraphile se limite au support de PostgreSQL, Hasura peut se connecter à Mysql, MongoDB, Clickhouse, Elasticsearch…
Et d'après la documentation, Hasura permet d'exposer, en plus d'une API GraphQL, une API REST (RESTified Endpoints).
Journal du lundi 28 octobre 2024 à 11:45
On m'a partagé : https://paris-atlas-historique.fr/.
Site dédié à la représentation de l'évolution historique de Paris, tout particulièrement sous son aspect spatial.
Journal du dimanche 27 octobre 2024 à 23:51
Dans cette page, #JaiDécouvert ansible-pull qui pourtant existe depuis 2013 !
Journal du dimanche 27 octobre 2024 à 21:09
Nouvelle #iteration du Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram.
J'ai eu des difficultés à trouver comment déployer avec Proxmox des Virtual instance basées sur Ubuntu Cloud Image.
J'ai trouvé réponse à mes questions dans cet article : "Perfect Proxmox Template with Cloud Image and Cloud Init".
Mais depuis, j'ai trouvé un meilleur tutoriel : "Linux VM Templates in Proxmox on EASY MODE using Prebuilt Cloud Init Images!".
Création d'un template Ubuntu LTS
J'ai exécuté les commandes suivantes en SSH sur mon serveur NUC i3 pour créer un template de VM Proxmox.
root@nuci3:~# apt update -y && apt install libguestfs-tools jq -y
root@nuci3:~# wget https://cloud-images.ubuntu.com/noble/current/noble-server-cloudimg-amd64.img
Ancienne commande qui contient une erreur à ne pas utilisé, plus d'information dans la note 2024-12-23_1939 :
root@nuci3:~# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
root@nuci3:~# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
root@nuci3:~# qm create 8000 --memory 2048 --core 2 --name ubuntu-cloud-template --net0 virtio,bridge=vmbr0
root@nuci3:~# qm disk import 8000 noble-server-cloudimg-amd64.img local-lvm
transferred 3.5 GiB of 3.5 GiB (100.00%)
transferred 3.5 GiB of 3.5 GiB (100.00%)
Successfully imported disk as 'unused0:local-lvm:vm-8000-disk-0'
root@nuci3:~# rm noble-server-cloudimg-amd64.img
root@nuci3:~# qm set 8000 --scsihw virtio-scsi-pci --scsi0 local-lvm:vm-8000-disk-0
update VM 8000: -scsi0 local-lvm:vm-8000-disk-0 -scsihw virtio-scsi-pci
root@nuci3:~# qm set 8000 --ide2 local-lvm:cloudinit
update VM 8000: -ide2 local:cloudinit
Formatting '/var/lib/vz/images/8000/vm-8000-cloudinit.qcow2', fmt=qcow2 cluster_size=65536 extended_l2=off preallocation=metadata compression_type=zlib size=4194304 lazy_refcounts=off refcount_bits=16
ide2: successfully created disk 'local:8000/vm-8000-cloudinit.qcow2,media=cdrom'
generating cloud-init ISO
(liste des paramètres cloud-init)
root@nuci3:~# qm set 8000 --ipconfig0 "ip6=auto,ip=dhcp"
root@nuci3:~# qm set 8000 --sshkeys ~/.ssh/authorized_keys
root@nuci3:~# qm set 8000 --ciuser stephane
root@nuci3:~# qm set 8000 --cipassword password # optionnel, seulement en phase de debug
root@nuci3:~# qm set 8000 --boot c --bootdisk scsi0
update VM 8000: -boot c -bootdisk scsi0
root@nuci3:~# qm set 8000 --serial0 socket --vga serial0
update VM 8000: -serial0 socket -vga serial0
root@nuci3:~# qm set 8000 --agent enabled=1
root@nuci3:~# qm set 8000 --ciupgrade 0
root@nuci3:~# qm template 8000
Renamed "vm-8000-disk-0" to "base-8000-disk-0" in volume group "pve"
Logical volume pve/base-8000-disk-0 changed.
WARNING: Combining activation change with other commands is not advised.
Création d'une Virtual Instance
root@nuci3:~# qm clone 8000 100 --name server1
root@nuci3:~# qm start 100
root@nuci3:~# qm guest cmd 100 network-get-interfaces | jq -r '.[] | select(.name == "eth0") | .["ip-addresses"][0] | .["ip-address"]'
192.168.1.64
$ ssh stephane@192.168.1.64
The authenticity of host '192.168.1.64 (192.168.1.64)' can't be established.
ED25519 key fingerprint is SHA256:OJHcY3GHOsm3I4qcsYFc6V4qePNxVS4iAOBsDjeLM7o.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '192.168.1.64' (ED25519) to the list of known hosts.
Welcome to Ubuntu 24.04.1 LTS (GNU/Linux 6.8.0-45-generic x86_64)
...
Journal du dimanche 27 octobre 2024 à 20:55
J'ai écouté la vidéo "Live Géologie 15 janvier 2023 : Spécial Mont St Michel, Cartogr. du manteau, 100 sites IUGS/UNESCO" ce qui m'a permis de découvrir la chaine de Géologie nommée GÉO Logique.
Journal du vendredi 25 octobre 2024 à 20:51
#JaiDécouvert la fonctionnalité Tablespaces de PostgreSQL.
Tablespaces in PostgreSQL allow database administrators to define locations in the file system where the files representing database objects can be stored. Once created, a tablespace can be referred to by name when creating database objects.
By using tablespaces, an administrator can control the disk layout of a PostgreSQL installation. This is useful in at least two ways. First, if the partition or volume on which the cluster was initialized runs out of space and cannot be extended, a tablespace can be created on a different partition and used until the system can be reconfigured.
Pour le moment, je n'en ai aucune utilité.
AWS RDS playground et fixe du problème pg_dumpall
En 2019, j'ai rencontré un problème lors de l'exécution de pg_dumpall sur une base de données PostgreSQL hébergée sur AWS RDS. À l'époque, ce problème était "la goutte d'eau" qui m'avait empressé de migrer de RDS vers une instance PostgreSQL self hosted avec une simple image Docker dans un docker-compose.yml, mais je digresse, ce n'est pas le sujet de cette note.
Aujourd'hui, j'ai fait face à nouveau à ce problème, mais cette fois, j'ai décidé de prendre le temps pour bien comprendre le problème et d'essayer de le traiter.
Pour cela, j'ai implémenté et publié un playground nommé rds-playground.
Je peux le dire maintenant, j'ai trouvé une solution à mon problème 🙂.
Ce playground contient :
- Un exemple de déploiement d'une base de données AWS RDS avec Terraform.
- Un script qui permet d'importer avec succès la base de données AWS RDS vers une instance locale de PostgreSQL, en incluant les rôles.
Au départ, je pensais que le problème venait d'un problème de configuration des rôles du côté de AWS RDS ou alors que je n'utilisais pas le bon user. J'ai ensuite compris que c'était une fausse piste.
J'ai ensuite découvert ce billet : "Using pg_dumpall with AWS RDS Postgres".
For those interested, RDS Postgres (by design) doesn't allow you to read
pg_authid, which was earlier necessary for pg_dumpall to work.
J'ai compris que pour exécuter un pg_dumpall sur une instance RDS, il est impératif d'utiliser l'option --no-role-passwords.
Autre subtilité : sur une instance RDS, le rôle SUPERUSER est attribué au rôle rlsadmin, tandis que cette option est supprimé du rôle postgres.
ALTER ROLE postgres WITH NOSUPERUSER INHERIT CREATEROLE
CREATEDB LOGIN NOREPLICATION NOBYPASSRLS VALID UNTIL 'infinity';
Par conséquent, j'ai décidé d'utiliser le même nom d'utilisateur superuser pour l'instance locale PostgreSQL :
services:
postgres:
image: postgres:13.15
environment:
POSTGRES_USER: rdsadmin
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
...
Pour aller plus loin, je vous invite à suivre le README.md de rds-playground.
Journal du vendredi 25 octobre 2024 à 09:38
Dans le thread Hacker News "Rsbuild – A Better Vite?" #JaiDécouvert :
- Rsbuild : The Rspack-based build tool. It's fast, out-of-the-box and extensible.
- SWC : (stands for Speedy Web Compiler) is a super-fast TypeScript / JavaScript compiler written in Rust.
- VoidZero : a company dedicated to building an open-source, high-performance, and unified development toolchain for the JavaScript ecosystem.
- Oxc : is building a parser, Linter, formatter,, transformer, minifier, resolver ... all written in Rust.
- Rolldown : Rolldown is a JavaScript/TypeScript bundler written in Rust intended to serve as the future bundler used in Vite.
Voici ce que j'ai compris.
Tous ces outils sont écrits en Rust.
Rsbuild est une alternative à : Vite, Create React App et Vue CLI et qui offre d'excellente performance (les tâches de build… sont exécutées bien plus rapidement).
Jiahan Chen, développeur de chez ByteDance, a commencé le projet Rsbuild en octobre 2023.
Dans le thread HackerNews je lis ce commentaire :
The better, faster, Rust-powered Vite is… Vite.
J'ai creusé le sujet et j'ai compris que le créateur de Vite, Evan You a fondé une société nommée VoidZero, composée de core développeurs des projets Oxc, Vite, Rolldown.
Accel a injecté 4,6 millions de dollars dans VoidZero avec comme objectif de financer le développement de Rolldown qui sera intégré dans une future version de Vite.
D'après ce que j'ai compris, Rolldown utilise Oxc.
Je me demande si Accel envisage de tirer des bénéfices directs de VoidZero ou si cette initiative relève davantage du mécénat. Du côté des intérêts indirects : plusieurs sociétés du portefeuille d'Accel utilisent la stack Javascript, ce qui permet de financer et de mutualiser le développement d'outils clés.
Voici les points principaux que je retiens. Rsbuild semble une alternative performante Vite qui est utilisable dès aujourd'hui.
Le projet Vite est bien structuré et financé, ce qui lui permettra de sortir une nouvelle version optimisée.
Pour ma part, j’espère voir le projet VoidZero réussir afin d’éviter une dilution des efforts au sein de la communauté Javascript dans une multitude de projets.
Journal du jeudi 24 octobre 2024 à 14:34
Je viens de visiter Naples et à mon retour, je me suis lancé dans la recherche de quelques vidéos au sujet de cette ville.
Je suis tombé sur "Naples: misère et beauté" que j'ai trouvé intéressante et qui m'a permis de découvrir la chaine YouTube nommée Barbare Civilisé.
J'ai ensuite voulu en savoir plus sur cette chaîne et j'ai grandement apprécié le contenu des vidéos suivantes :
Journal du mercredi 23 octobre 2024 à 10:53
#JaiDécidé d'utiliser dans mes README l'expression figurée anglaise "Smoke test".
Journal du lundi 21 octobre 2024 à 22:36
J'étudie Oils (shell) afin de me faire une idée si il pourrait être un bon compromis entre l'utilisation de Bash et Ansible pour l'implémentation de script de déploiement pour de toute petite infrastructure.
Journal du dimanche 20 octobre 2024 à 22:50
Nouvelle #iteration du Projet 14 - Script de base d'installation d'un serveur Ubuntu LTS.
Il y a quelques jours, j'ai migré de vagrant-hostmanger vers vagrant-dns. J'ai ensuite souhaité mettre en œuvre Grizzly, mais j'ai rencontré un problème.
J'ai installé une version binaire statiquement liée de Grizzly à l'aide de Mise. Dans cette version, Go ne fait pas appel à la fonction getaddrinfo pour la résolution des noms d'hôte. Au lieu de cela, Go se limite à lire les informations de configuration DNS dans /etc/resolv.conf (champ nameserver) et les entrées de /etc/hosts.
Cela signifie que les serveurs DNS gérés par systemd-resolved ne sont pas pris en compte 😭.
Pour régler ce problème, j'utilise en même temps vagrant-dns et Vagrant Host Manager : voici le commit.
J'active uniquement ici le paramètre config.hostmanager.manage_host = true et je laisse vagrant-dns résoudre les hostnames à l'intérieur des machines virtuelles et des containers Docker.
Journal du dimanche 20 octobre 2024 à 21:47
#JaiLu 20 years of Linux on the Desktop (part 1) de Ploum, j'y ai appris des choses, comme :
At the start of 2004, I was contacted by Sébastien Bacher, a Debian developer who told me that he had read my "Perfect Desktop" essay months ago and forwarded it to someone who had very similar ideas. And lots of money. So much money that they were already secretly working on it and, now that it was starting to take shape, they were interested in my feedback about the very alpha version.
Chose amusante, j'ai vécu la même expérience que Ploum pendant ma jeunesse :
I had been one of those teenagers invited everywhere to "fix" the computer. Neighbours, friends, family. Yes, that kind of nerdy teenager. You probably know what I mean. But I was tired of installing cracked antivirus and cleaning infested Microsoft Windows computers, their RAM full of malware, their CPU slowing to a crawl, with their little power LED begging me to alleviate their suffering.
Journal du dimanche 20 octobre 2024 à 21:46
#JaiDécouvert le concept de Machine de Rube Goldberg (from).
Journal du dimanche 20 octobre 2024 à 21:42
En lisant le thread Reddit "Desktop version 2024.10.0 is no longer free software · Issue #11611 · bitwarden/clients" #JaiDécouvert Psono.
Open Source Self Hosted Password Manager for Companies
Secure self-hosted solution for businesses
-- from
Journal du dimanche 20 octobre 2024 à 10:04
La version 5 de Svelte vient de sortir : 5.0.0.
Il y a un an, j'avais lu le billet Introducing runes. Depuis, j'ai suivi ce sujet de loin.
J'aimerais tester et apprendre à utiliser la fonctionnalité rune.
#JeMeDemande dans quel projet 🤔. Est-ce que je préfère refactorer vers rune le projet sklein-pkm-engine ou gibbon-replay 🤔. Je pense que ces deux projets utilisent trop peu de "reactive state".
Je souhaite prochainement débuter le projet que j'ai présenté dans 2023-10-28_2008. Je pense que ça serait une bonne occasion pour créer mon premier projet 100% TypeScript avec Svelte 5 avec Rune.
Journal du dimanche 20 octobre 2024 à 10:03
Oxen is a lightning fast data version control system for structured and unstructured machine learning datasets.