
Ma doctrine d'artisan développeur
Je suis adpte du paradigme suivant : Don’t Build A General Purpose API To Power Your Own Front End
Journaux liées à cette note :
Certification HDS : ce que j'ai appris en creusant pour un ami
Un ami, professionnel libéral de santé, a vibe codé une application de gestion pour ses patients actuellement hébergée sur Supabase. Il souhaite migrer vers un Hébergeur de Données de Santé — il a notamment vu que Scaleway propose des services certifiés HDS — et m'a demandé si je connaissais un développeur pour l'accompagner dans ce projet.
J'ai croisé la notion de HDS pour la première fois en 2016, chez Tech-Angels. Depuis, j'ai suivi le sujet de loin sans jamais creuser.
Je profite de sa demande pour étudier le sujet en profondeur avant de lui répondre, et publier une note de ce que j'aurai appris.
Hébergeur de Données de Santé, c'est quoi ?
Toute personne physique ou morale qui héberge des données de santé à caractère personnel recueillies à l’occasion d’activités de prévention, de diagnostic, de soins ou de suivi médico-social pour le compte de personnes physiques ou morales à l'origine de la production ou du recueil de ces données ou pour le compte du patient lui-même, doit être agréée ou certifiée à cet effet.
Texte de loi : article L.1111-8 du Code de la santé publique
Qu'est-ce qu'une donnée de santé (DDS) ?
Avant d'aller plus loin, j'ai eu besoin de comprendre précisément ce qu'est une "donnée de santé".
La CNIL distingue trois catégories (source) :
- Les données de santé par nature : antécédents médicaux, diagnostics, traitements, résultats d'examens, ordonnances, comptes-rendus d'hospitalisation.
- Les données qui deviennent des données de santé par croisement : le poids ou le nombre de pas seuls ne le sont pas, mais croisés avec d'autres mesures (tension artérielle, apports caloriques), ils le deviennent.
- Les données qui deviennent des données de santé par leur usage : un rendez-vous chez un médecin, à lui seul, n'est pas une donnée de santé — mais le motif de la consultation, si.
Concrètement, dans l'application de mon ami, cela inclut probablement les noms des patients, leurs comptes-rendus, leurs ordonnances, les notes de suivi, et potentiellement les créneaux de rendez-vous liés à des actes de soins. Ce n'est pas seulement la « base médicale » au sens strict — c'est tout ce qui, relié à une personne identifiée, révèle qu'elle a reçu ou consulté pour des soins.
Un document médical sans identifiant, est-ce encore une donnée de santé ?
Une question qui m'est tout de suite venue à l'esprit : un document médical sans identifiant — pas de nom, pas de numéro de patient — est-ce encore une donnée de santé ?
La réponse dépend de la possibilité de ré-identification. Si le document est véritablement anonymisé, qu'il n'existe aucun moyen raisonnable de le relier à une personne, alors ce n'est plus une donnée de santé à caractère personnel — ça sort du périmètre du RGPD et du HDS.
Mais en pratique, c'est très difficile de le rendre vraiment anonyme. Un diagnostic rare, une date de traitement, ou un hôpital spécifique croisés avec d'autres sources, peuvent permettre de ré-identifier la personne.
La CNIL considère qu'une donnée est « personnelle » dès qu'il existe des « moyens raisonnablement susceptibles » de ré-identification.
Je pense qu'une bonne méthode pour estimer si c'est une DDS ou non, est de se mettre dans la peau d'un détective privé : si on me donnait ce document et tous les indices disponibles (date, hôpital, pathologie rare…), est-ce que je pourrais remonter à la personne ? Si la réponse est oui, c'est une donnée de santé. La question n'est donc pas « y a-t-il un nom dans le document ? » mais « quelqu'un, avec les moyens raisonnables, pourrait-il retrouver à qui ça appartient ? ».
Quels liens entre PII et DDS ?
Pour faire le lien avec les PII : toute Données de santé (DDS) est une PII, mais l'inverse n'est pas vrai. Un nom, une adresse email ou une adresse IP sont des PII parce qu'ils permettent d'identifier une personne.
Une donnée de santé est une PII qui révèle en plus quelque chose sur l'état de santé de cette personne. La distinction importe parce que le régime juridique n'est pas le même : les DDS sont soumises au RGPD comme les PII, mais avec des protections supplémentaires — secret médical, consentement explicite, obligation d'hébergement certifié HDS.
Qui est le "responsable de traitement" ?
Pour comprendre à qui s'applique la certification HDS, j'ai eu besoin de creuser la notion de "responsable de traitement" au sens du RGPD. Je croise ce terme régulièrement, je pense le comprendre dans les grandes lignes, mais j'ai voulu comprendre précisément où se situent les frontières.
D'après ce que j'ai compris, le responsable de traitement est la personne morale (ou la personne physique en entreprise individuelle) qui décide quoi faire avec les données personnelles. C'est elle qui détermine pourquoi on collecte les données et comment on les traite. Ce n'est pas l'individu (le médecin, l'infirmière) — c'est la structure juridique qui a la relation de soin avec le patient.
Concrètement :
| Situation | Responsable de traitement | Pourquoi ? |
|---|---|---|
| Médecin salarié à l'hôpital | L'hôpital (personne morale) | C'est l'hôpital qui a la relation avec le patient, pas le médecin individuellement |
| Médecin dans un cabinet en SARL | La SARL (personne morale) | C'est la SARL qui signe les contrats et est responsable en cas de fuite |
| Médecin libéral en entreprise individuelle | Le médecin (personne physique) | Il n'y a pas de structure intermédiaire |
| Cabinet médical | Le cabinet (personne morale) | Le cabinet détermine les règles de gestion du système d'information |
| Doctolib | Non — c'est un sous-traitant | Doctolib est un moyen de communication entre le médecin et le patient, comme un téléphone amélioré |
| Scaleway | Non — c'est un hébergeur | Scaleway fournit l'infrastructure, il ne traite pas les données pour ses propres fins |
| Un développeur freelance qui maintient le serveur | Non — c'est un sous-traitant | Il administre l'infrastructure pour le compte du responsable de traitement |
Cette distinction est cruciale pour comprendre la certification HDS. La loi dit que l'hébergement doit être certifié quand il est fait "pour le compte de" un responsable de traitement. Si tu es toi-même le responsable de traitement, tu n'héberges pas pour un tiers — tu héberges pour toi-même alors pas besoin de certification HDS (mais tu restes soumis au RGPD).
C'est pour ça qu'un médecin qui gère son propre dossier patient n'a pas besoin de HDS, mais qu'un hébergeur qui stocke les données pour le compte de ce médecin doit être certifié.
Un cas limite : les services médicaux numériques
Le cas des services médicaux numériques comme Poppins — "le dispositif médical numérique à domicile pour les enfants dyslexiques" — est compliqué. Qui est le responsable de traitement ?
La réponse dépend de qui décide quoi faire avec les données :
- Si Poppins décide quelles données collecter et comment les utiliser (recherche, amélioration du produit) alors Poppins est responsable de traitement
- Si l'orthophoniste décide quelles données utiliser pour le suivi du patient alors l'orthophoniste est responsable de traitement
- Si les deux ont un rôle de décision → co-responsabilité (article 26 RGPD)
Où est la documentation officielle HDS ?
La documentation officielle est trouvable sur le site https://esante.gouv.fr/ => "Produits et services" => "HDS" => "Les référentiels de la procédure de certification".
La documentation HDS est nommée "référentiel de certifications HDS", elle est disponible au format PDF à cette adresse https://esante.gouv.fr/sites/default/files/media_entity/documents/referentiel_certification_hds---fr--v2.pdf.
Je n'ai pas trouvé de version HTML de ce document.
D'après ce que j'ai compris, ce sont des personnes de l'Agence du Numérique en Santé (ANS) qui ont rédigé les 29 pages du référentiel de certifications HDS.
Ce référentiel a été officialisé dans le Journal Officiel le 16 mai 2024 https://www.legifrance.gouv.fr/jorf/id/JORFTEXT000049537692 par un ministre délégué à la santé. Ce document remplace la version précédente de 2018.
Et voici le communiqué de presse de l'ANS : Publication au Journal Officiel du référentiel de certification HDS : souveraineté des données et améliorations du référentiel.
Je suis ravi de lire la section Focus sur l’ajout d’exigences relatives à la souveraineté des données qui indique :
L’hébergement physique des données de santé doit être réalisé exclusivement sur le territoire d’un pays situé au sein de l’Espace Economique Européen.
🙂
Les 6 activités du référentiel HDS
Est considérée comme une activité d'hébergement de données de santé à caractère personnel sur support numérique ... des activités suivantes :
- La mise à disposition et le maintien en condition opérationnelle de sites physiques permettant d'héberger l'infrastructure matérielle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure matérielle du système d'information utilisé pour le traitement de données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de l'infrastructure virtuelle du système d'information utilisé pour le traitement des données de santé ;
- La mise à disposition et le maintien en condition opérationnelle de la plateforme d'hébergement d'applications du système d'information ;
- L'administration et l'exploitation du système d'information contenant les données de santé ;
- La sauvegarde des données de santé
Cette liste, reformulée en activités concrètes :
| # | Activité |
|---|---|
| 1 | Gestion des sites physiques : datacenters, baies serveurs, climatisation, alimentation électrique, sécurité des locaux |
| 2 | Gestion de l'infrastructure matérielle : serveurs physiques, stockage, câblage réseau, commutation |
| 3 | Gestion de l'infrastructure virtuelle : machines virtuelles, réseaux virtuels, stockage virtuel, hyperviseurs |
| 4 | Gestion de la plateforme applicative : bases de données managées, conteneurs, serveurs d'application |
| 5 | Gestion des sauvegardes : sauvegardes automatisées, stockage hors site, restauration |
| 6 | Administration et exploitation du SI : supervision, mises à jour, gestion des accès, support technique, astreinte |
Il y a un point important que j'ai mis du temps à saisir : l'obligation de certification ne s'applique qu'à l'hébergement de données de santé pour un tiers qui est responsable de traitement.
Par conséquent, un professionnel de santé qui auto-héberge ses propres données n'a pas besoin de certification HDS pour les activités de cette liste qu'il administre lui-même.
Un exemple concret
Imaginons un cabinet de médecin, qui développe une application web qui contient des données de santé. Cette application est à destination de ses utilisateurs finaux, ses patients.
L'application web est codée en JavaScript avec PostgreSQL pour la persistance des données.
Pour le déploiement, le développeur employé directement par le cabinet de médecin fait le choix de déployer le tout sur une Virtual machine Scaleway.
D'après la version du 18 juin 2026 de la page "L’hébergement des données de santé et la certification HDS" de la documentation Scaleway, voici la liste des services certifiés HDS :

Les composants de fondations les plus importants sont bien certifiés. Je note au passage que l'offre "Managed Database for PostgreSQL and MySQL" n'est pas certifiée pour le moment.
Ceci n'est pas grave dans mon exemple si je déploie directement une image Docker de PostgreSQL directement sur la Virtual machine. Les sauvegardes peuvent être déposées dans Scaleway Object Storage qui lui est certifié.
Le cabinet de médecin devra souscrire un plan de support niveau Business à 250 € par mois pour pouvoir ensuite signer un contrat HDS :

Ensuite, Scaleway remettra au cabinet de médecin (son client) un document de garantie HDS, conformément au chapitre 8 du référentiel :
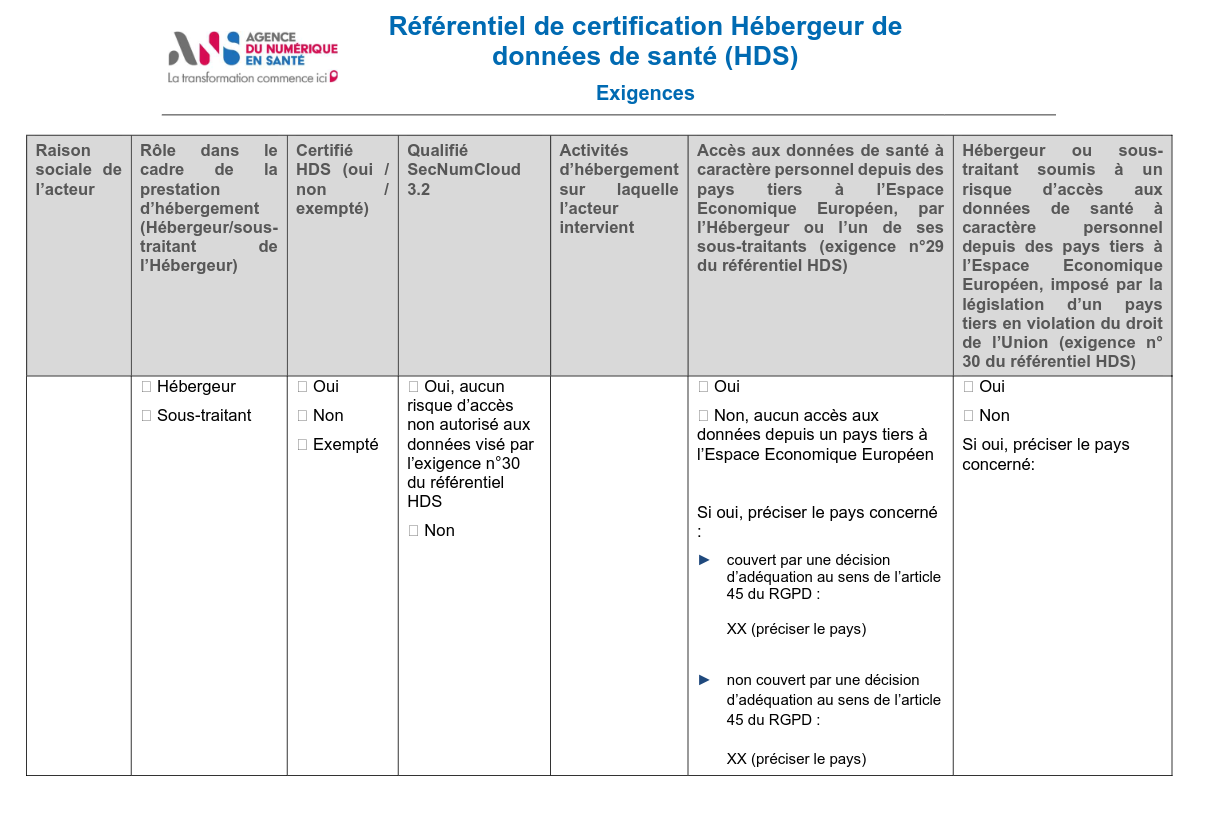
Voici à quoi pourrait ressembler ce document : "Exemple fictif d'une garantie de certification HDS de Scaleway".
Ensuite, les DevOps salariés directement du cabinet de santé déploient, maintiennent, administrent l'application sur les Virtual machine de Scaleway sans que le cabinet de médecin n'ait besoin de certification HDS car il n'est pas un hébergeur de données parce qu'il ne vend pas son service à d'autres professionnels. Seuls les patients directs utilisent son service.
Employé vs freelance : une distinction absurde mais légale
Il y a un point que j'ai mis du temps à saisir, et qui me paraît absurde mais qui est juridiquement cohérent.
Un employé (CDD ou CDI) du cabinet de santé qui gère le serveur, fait les mises à jour et les sauvegardes n'a pas besoin de certification HDS. Il fait partie de l'organisation du responsable de traitement — il n'est pas un sous-traitant.
Le même développeur, faisant exactement le même travail (SSH, mises à jour, sauvegardes), mais en freelance vendant 5 heures de prestation, a besoin de la certification HDS pour l'activité 5 (administration et exploitation). Pourquoi ? Parce qu'il est une entité séparée, un sous-traitant au sens RGPD, qui assure une activité d'hébergement pour le compte d'un tiers responsable de traitement.
La distinction ne se fait pas sur la nature du travail, mais sur le statut juridique de la personne qui le fait :
- Employé du cabinet (CDD/CDI) avec accès SSH → pas de HDS, il fait partie du responsable de traitement
- Freelance avec accès SSH permanent → HDS requis, il est sous-traitant et assure l'activité 5
Le cas du freelance qui livrerait uniquement du code
Si le freelance se contente de fournir du code — application, scripts d'infrastructure, configs de déploiement — et qu'il push tout dans un repo Git sans jamais avoir accès au serveur, à la base de données ni aux données, alors il n'assure aucune des 6 activités d'hébergement. Il livre un produit (du code), il n'opère pas un service.
Le test légal reste le même : "le fait d'assurer pour le compte du responsable de traitement tout ou partie des activités suivantes." Le verbe clé est "assurer" — c'est-à-dire exécuter, opérer, maintenir en condition opérationnelle. Les 6 activités décrivent des opérations sur l'infrastructure et le système, pas de la production de code.
La frontière se joue sur un point précis : qui appuie sur le bouton "déployer" ?
- Si c'est un employé du cabinet de santé qui contrôle l'outil de déploiement (par exemple ArgoCD) et déclenche les déploiements → freelance = livreur de code → pas de HDS
- Si le freelance a accès à cet outil et déclenche lui-même les déploiements → il participe à l'exploitation (activité 5) → HDS requis
Combien coûte une certification HDS pour les activités 4, 5 et 6 ?
J'ai cherché le processus officiel pour obtenir la certification HDS, voici ce que j'ai retenu :
- Mettre en place un Système de Management de la Sécurité de l'Information (SMSI) conforme à ISO 27001 (politique de sécurité, analyse de risques, gestion des accès, plan de continuité) — prérequis obligatoire.
- Choisir un organisme certificateur accrédité Comité français d'accréditation (Cofrac) (BSI, AFNOR, Bureau Veritas, LRQA…).
- Audit sur site en deux volets : conformité ISO 27001, puis exigences HDS spécifiques.
- Correction des non-conformités relevées.
- Obtention du certificat (valable 3 ans, avec audit de surveillance annuel).
J'ai volontairement laissé de côté le contenu concret du SMSI et de la norme ISO 27001 — je les connais mal. Cette note m'a donné envie d'explorer le sujet en profondeur, mais je le ferai dans une note séparée pour ne pas allonger encore celle-ci.
Les coûts typiques pour une TPE (< 10 personnes) :
| Poste | Estimation |
|---|---|
| Mise en place SMSI (conseil externe) | 2 000 – 6 000 € |
| Audit initial COFRAC (ISO 27001 + HDS) | 8 000 – 15 000 € |
| Audits de surveillance annuels (×2) | 2 000 – 5 000 € |
| Sous-total coûts externes | 12 000 – 26 000 € |
| Coût interne du salarié (100 – 200 h à 500 €/j soit ~70 €/h super brut) | 7 000 – 14 000 € |
| Total sur 3 ans | 19 000 – 40 000 € |
Estimation en temps humain (pour une personne seule, en charge de tout) :
| Étape | Effort humain estimé | Durée calendrier estimée |
|---|---|---|
| Mise en place SMSI (rédaction, procédures, analyse de risques, choix des outils) | 40 – 100 heures | 2 – 4 mois |
| Choix du certificateur et préparation du dossier | 15 – 30 heures | 3 – 6 semaines |
| Audit initial (sur site + préparation) | 15 – 30 heures | 1 – 2 semaines |
| Correction des non-conformités | 20 – 60 heures | 2 – 6 semaines |
| Obtention du certificat + 1er audit de surveillance | 10 – 30 heures | 1 – 2 mois |
| Total (avec SMSI ou maturité existante) | 100 – 250 heures | 6 – 9 mois |
| Total (sans SMSI préalable) | 200 – 400 heures | 12 – 18 mois |
Sources
Les fourchettes de coûts et de durées ci-dessus sont des estimations de Fermi calculées par MiMO-V2-Pro, recalibrées pour coller aux données publiées :
- Legiscope — Certification HDS hébergeur de données de santé 2026 (Dr. Thiébaut Devergranne, 23 mai 2026) : fourchette de 20 000 à 35 000 € sur 3 ans pour une TPE. Durée de 6 à 9 mois si l'organisation dispose déjà d'un SMSI ou d'une maturité ISO 27001 ; 12 à 18 mois sans SMSI préalable (dont 9-12 mois pour la certification ISO 27001 seule).
- Galeon — Certification HDS en 2026 (21 avril 2026) : « Les audits représentent généralement plusieurs dizaines de milliers d'euros, auxquels s'ajoutent les coûts internes de préparation et de mise en conformité. »
Je pense que des outils de service d'automatisation de conformité du type Oneleet que j'ai testés, peuvent accélérer le processus de mise en place d'un SMSI pour obtenir une certification ISO 27001.
Le risque sécurité du code vibe codé
Ça me fait un peu peur, honnêtement. Mon ami a vibe codé une application qui contient des données de santé. Et payer les frais importants d'une agence de développeur certifiée HDS n'aurait aucun sens dans ce contexte d'une application amateur sur mesure.
Qu'est-ce que je vais répondre à mon ami ?
D'abord, son idée d'hébergement chez Scaleway va coûter cher ! Déjà 250 € par mois rien que pour le plan de support Business.
Pour éviter cela, une solution serait d'auto-héberger l'application chez soi, dans son bureau, sur un petit serveur. Tant qu'on n'héberge pas pour un tiers, il n'y a pas besoin de certification HDS.
Mais il ne pourra pas demander à un développeur freelance d'administrer ce serveur. Dès qu'un freelance intervient sur l'infrastructure (accès SSH, mises à jour, sauvegardes), il assure l'activité 5 du référentiel HDS — et il devrait être certifié ! Et le coût de la certification pour administrer ce serveur, pour une seule instance, sera bien trop élevé.
Autre solution : embaucher un développeur en CDD pour toute intervention. C'est légalement possible sans HDS, mais c'est lourd à gérer et coûteux.
Réflexion sur le Vibe coding : libération ou prolétarisation ?
En tant qu'artisan développeur, je trouve amusant d'observer plusieurs de mes amis vibe coder des applications sur mesure pour leur besoin.
Pour le moment je n'ai pas cherché à savoir s'ils essaient de comprendre le code produit, ou si le code reste une boîte noire dont ils se fichent tant que ça marche. Mais c'est un phénomène socialement intéressant, et je ne sais pas si c'est une bonne nouvelle ou non.
Si le vibe coding reste un outil d'appropriation, si la personne comprend ce qu'elle fait, peut modifier, adapter, expliquer — alors c'est un acte de déprolétarisation : il reprend le contrôle sur ses outils de travail.
Mais si le code reste opaque, s'il ne s'agit que de produire sans comprendre, alors le vibe coding n'est qu'une nouvelle forme de prolétarisation. Le savoir ne passe plus par la machine au sens de Bernard Stiegler — il passe par l'IA, et la personne reste aussi démunie que devant si l'outil disparaît ou change, c'est de la désindividuation au sens de Bernard Stiegler. La personne n'a pas acquis de savoir, elle a acquis un résultat, elle "consomme".
C'est ce qui fait de ces outils des pharmakons : ils peuvent désindividuer autant qu'ils peuvent aider à s'individuer, selon l'usage qu'on en fait.
J'ai développé cette réflexion dans "J'utilise les LLMs comme des amis experts et jamais comme des écrivains fantômes" et dans "Ma lutte contre mon affaiblissement cognitif". En résumé, j'essaie personnellement d'éviter cette prolétarisation : plutôt que de consommer l'IA pour produire des choses, j'essaie de groker — comprendre en profondeur, pas seulement obtenir un résultat.
Enlever des couches : mon chemin de Make vers de simples scripts Bash
Je profite d'une discussion entre deux amis au sujet de just et make pour partager mon point de vue et mes pratiques sur ce sujet.
Je tiens tout de suite à préciser que c'est un sujet qui me tient à cœur, parce qu'il m'irrite fortement : j'ai lutté pendant des années avec la mauvaise Developer eXperience de l'outil make dans mes projets, et je continue à voir tant de développeurs s'entêter à utiliser un outil dont la raison d'être est la résolution de dépendances basée sur les timestamps de fichiers — or, il me semble que cette fonctionnalité n'est probablement jamais utilisée, sauf dans les projets C ou C++.
Tout d'abord, je souhaite commencer par lister quelques éléments de complexité des makefile.
Quelques exemples de complexité accidentelle apportée par Make
- Chaque ligne est un sous-shell indépendant et ça c'est super pénible, exemple :
# Le "cd" n'a aucun effet sur la ligne suivante
broken-cd:
cd /tmp
ls # ← liste le répertoire original, pas /tmp
Une solution de contournement est d'utiliser des backslashes pour continuer la ligne, mais cela complique la lisibilité :
build:
cd /tmp && \
ls && \
echo "done"
- Par défaut, Make utilise
shet non pas bash ou zsh et ne supporte pas la construction[[ ]], les tableaux, etc qui cassent silencieusement. Exemple de code qui ne fonctionne pas :
check-env:
@if [[ -z "$(ENV)" ]]; then \
echo "ENV is not set"; \
exit 1; \
fi
@echo "ENV = $(ENV)"
- L'indentation du contenu des rules doit être une tabulation (pas des espaces)
- Les
$doivent être doublés pour le shell, sinon make l'interprète, exemple :
greet:
@MSG="Hello $(APP_NAME)" && \ # $(APP_NAME) → résolu par make ✓
echo $$MSG # $$MSG → variable bash du sous-shell ✓
@echo $(MSG) # $(MSG) → make cherche "MSG" → vide ! ✗
# Piège 3 : le $ doit être doublé pour bash, sinon make l'interprète
list:
@for i in 1 2 3; do echo $$i; done # ✓ correct
@for i in 1 2 3; do echo $i; done # ✗ make interprète $i → vide
- Le préfixe "-" permet d'ignorer les erreurs d'une commande est une convention propre à makefile, sans équivalent dans Bash
clean:
-rm -rf build/ # sans "-", make s'arrête si build/ n'existe pas
-docker rmi $(APP_NAME)
- Par défaut, make affiche chaque commande avant de l'exécuter. Pour le supprimer, il faut préfixer chaque ligne avec
@:
build:
echo "Building..." # affiche : echo "Building..." puis : Building...
@echo "Building..." # affiche seulement : Building...
Du coup, dans la pratique, on se retrouve à préfixer toutes les lignes avec @ :
deploy:
@echo "Deploying..."
@docker build -t myapp .
@kubectl apply -f k8s/
- Nécessité d'ajouter des
.PHONY
Pourquoi tant de difficulté pour lancer de simples commandes ?
À chaque fois que je rencontrais des problèmes avec make, je culpabilisais. Je me disais que c'était de ma faute, que tout le monde utilisait make et qu'il devait y avoir une bonne raison. Je voyais bien que mon expérience de développeur (DX) était mauvaise, que je n'avais pas besoin de résolution de dépendance… mais je me disais que je devais utiliser make, et que mon erreur était de ne pas avoir pris le temps de lire sa documentation.
Alors je replongeais régulièrement dans les 16 chapitres de la documentation de make et je me demandais pourquoi je devais apprendre la syntaxe de make en plus de celle de bash. Et au final, je finissais même par détester Bash en plus de make.
Pourquoi tout cela était-il aussi compliqué, alors que je voulais seulement lancer de simples commandes et intégrer quelques conditions dans mes scripts ?
La recherche d'alternative
En 2018, la douleur des makefiles revenait souvent dans nos discussions en interne, au sein de mon équipe, et on cherchait régulièrement des alternatives. Parmi les pistes étudiées :
- Task, en Golang, apparu en 2017 — je l'ai testé et ai fortement envisagé de l'adopter
- Pydoit, en Python, démarré en 2008
- Rake, en Ruby, lancé en 2003 — alors que je ne maîtrise pas le Ruby et que, par goût personnel, j'évite au maximum d'intégrer ce type de projet dans mes stacks
- CMake, qu'un collègue avait exploré
Fin 2018, la prise de conscience
Fin 2018, je ne me souviens plus pour quelle raison, en parcourant le code source de Terraform, je suis tombé sur le dossier scripts/) de Terraform.
├── ...
├── Makefile
├── ...
├── scripts
│ ├── build.sh
│ ├── changelog-links.sh
│ ├── changelog.sh
│ ├── copyright.sh
│ ├── debug-terraform
│ ├── exhaustive.sh
│ ├── gofmtcheck.sh
│ ├── gogetcookie.sh
│ ├── goimportscheck.sh
│ ├── staticcheck.sh
│ ├── syncdeps.sh
│ └── version-bump.sh
└── ...
Et un fichier makefile minimaliste qui lance simplement des fichiers Bash :
$ cat Makefile
protobuf:
go run ./tools/protobuf-compile .
fmtcheck:
"$(CURDIR)/scripts/gofmtcheck.sh"
importscheck:
"$(CURDIR)/scripts/goimportscheck.sh"
staticcheck:
"$(CURDIR)/scripts/staticcheck.sh"
exhaustive:
"$(CURDIR)/scripts/exhaustive.sh"
[...snip...]
Et, ce jour-là, je me suis senti très stupide d'avoir passé tant de temps à trouver une solution qui était en réalité très simple, à portée de main !
Je pense aussi que le fait que cette méthode ait été utilisée par Mitchell Hashimoto en personne, dans Terraform, m'a probablement donné une sorte d'autorisation d'utiliser cette approche.
J'ai compris que je pouvais simplement me passer de make.
2019 à 2026 : utilisation de simples scripts Bash
Suite à ma prise de conscience de fin 2018, j'ai appliqué un principe que je nomme "enlever des couches" : plutôt que d'ajouter une technologie pour résoudre un problème, réfléchir à ce que peut enlever pour réduire la complexité — et, par la même, peut-être supprimer le problème lui-même. C'est une vigilance consciente contre le biais cognitif du cargo cult : la tendance à reproduire des pratiques par habitude ou imitation, sans vraiment les comprendre ni les justifier.
En appliquant ce principe, il m'a semblé que je pouvais simplement enlever make — sans avoir à le remplacer par un outil tel que Task qui aurait été une couche supplémentaire dont je n'avais probablement pas besoin.
J'ai même pris conscience qu'en plaçant tous mes scripts dans un dossier ./scripts/, je bénéficiais nativement de l'autocomplétion de mes commandes par le filesystem — tout comme ce que proposait aussi make.
Par exemple :
make updevenait./scripts/up.shmake builddevenait./scripts/build.shmake cleandevenait./scripts/clean.sh- etc.
Et surtout, je pouvais désormais pleinement me concentrer sur ma maîtrise de Bash pour améliorer l'expérience de développeur (DX) de mes kits de développement.
L'astuce du cd automatique
Pour exécuter ces commandes sans se préoccuper du dossier courant, j'ai ajouté la ligne suivante au début de chaque script :
cd "$(dirname "$0")/../"
Cela permet de lancer ./scripts/up.sh depuis la racine du projet comme depuis un sous-répertoire (cd subproject && ../scripts/up.sh), et le script s'exécutera toujours depuis le dossier parent de scripts.
Voici le boilerplate code qu'utilise la quasi-totalité de mes scripts :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
...
Mais "make" est un standard ?
L'argument revient souvent : « make est un standard, tout le monde le connaît, un nouveau contributeur saura immédiatement quoi faire. ».
Seulement voilà : la partie « standard » de make, celle que tout le monde utilise réellement, c'est make <target> — et c'est exactement ce que fait ./scripts/<target>.sh, sans syntaxe supplémentaire, sans pièges de tabulations, sans résolution de dépendances par timestamps dont on ne veut probablement pas.
Il me semble que cet argument touche au cargo cult : on place un Makefile à la racine du projet par habitude, sans vraiment tirer parti des capacités qui justifient l'existence même de make.
De plus, si l'on parle de standard, bash est probablement au moins aussi universel que make. Et écrire un script bash est sans doute plus accessible pour un développeur que d'apprendre les subtilités du makefile ($ doublés, sous-shells, .PHONY, @, -, etc.).
Il me semble donc que l'argument du "standard" est légitime — mais mon choix de ne plus utiliser make n'est pas un obstacle pour autant : si ./scripts/up.sh est clairement documenté dans le README, je pense que n'importe quel développeur comprendra sans difficulté son usage et sa fonction. Pas besoin de connaître make pour exécuter un script bash dont le nom est explicite.
Retour d'expérience : 4 ans, de 2 à 10 développeurs
J'ai utilisé cette méthode avec succès pendant 4 ans, en passant de 2 à 10 développeurs, sans que j'aie constaté de friction. À ma connaissance, personne n'a eu de difficulté avec ce système d'exécution des scripts et, il me semble, personne ne m'a suggéré de les remplacer par autre chose.
Et Just, alors ?
J'ai découvert just en 2022, puis je l'ai vu gagner en popularité à partir de 2023 (199 commentaires sur HackerNews) :
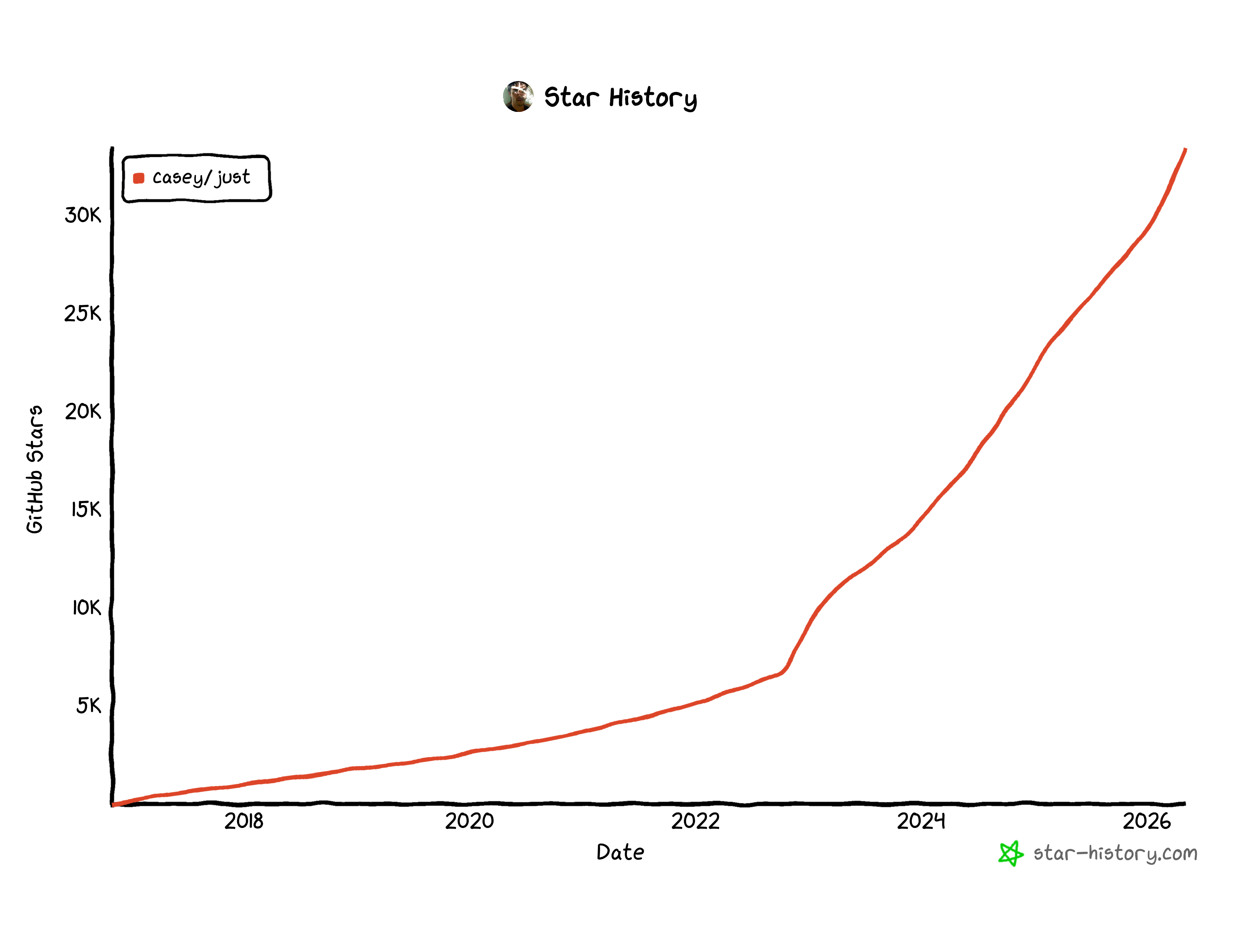
J'ai failli me laisser tenter. Mais je n'avais aucune douleur avec mes scripts, j'étais pleinement satisfait — et conformément au principe d'enlever des couches, ajouter une couche supplémentaire n'avait aucun intérêt.
D'autre part, just est riche en fonctionnalités et sa documentation est déjà importante : il me semble que c'est beaucoup à apprendre pour un outil dont je n'ai pas besoin.
Et puis j'ai craqué pour Mise Tasks
Je suis un grand utilisateur de Mise et dernièrement ce projet a ajouté la fonctionnalité Tasks. Et au grand désespoir de mon ami Alexandre — qui me fait régulièrement remarquer cette contradiction —, j'ai craqué, j'ai commencé à utiliser cette fonctionnalité en janvier 2026. Je n'ai pas d'argument solide à avancer ; sans doute un mélange de curiosité et d'affection pour Mise.
Contrairement à just, la fonctionnalité task de Mise reste minimaliste et est compatible avec mon paradigme : le if dans l'exemple ci-dessous est du Bash standard — pas besoin de $$, de \, de sous-shells par ligne. J'écris du Bash et rien d'autre.
D'autre part, Mise est déjà au cœur de mes development kit, je l'utilise à depuis 2023 à la place de Asdf pour installer du tooling de développement. Depuis 1 an, j'ai remplacé direnv par Mise. Par conséquent, ce n'est pas une dépendance en plus à ajouter à mes projets.
Mise task supporte trois syntaxes pour définir des tasks.
Dans le fichier .mise.toml, en ligne simple :
[tasks.build]
run = "pnpm run build"
Ou en bloc multiligne :
[tasks.clean]
run = """
if [ "$1" = "--with-lint" ]; then
mise run lint
fi
pnpm run test
"""
Ou alors, via des scripts dans le dossier mise-tasks/, par exemple mise-tasks/build :
#!/usr/bin/env bash
#MISE description="Build the web application"
pnpm run build
Voici un extrait de Mise tasks mises en œuvre dans un vrai projet :
$ mise task
Name Description
build-cli Build the sklein-devbox CLI application
build-image Build the sklein-devbox container image
[...snip...]
up Start the devbox container
Le code source est consultable ici : https://github.com/stephane-klein/sklein-devbox/blob/main/.mise.toml
C'est important pour moi de préciser que j'ai bien conscience que Mise Tasks est une couche de plus — et que ça contredit ma doctrine « enlever des couches ».
Dans un projet d'équipe, je partirais par défaut sur des scripts Bash simples, sans Mise task. Je n'intégrerais Mise task que s'il y a un consensus fort de l'équipe — et je ne l'imposerais pas.
Remerciements
Je remercie mes deux amis de m'avoir motivé à écrire cette note — c'est un sujet que je souhaitais traiter depuis 2019 (j'avais même créé une issue à ce sujet dans mon ancien backlog).
J'ai découvert le terme "test sociable"
Alexandre m'a fait découvrir aujourd'hui le terme "test sociable" versus "test solitaire", documenté ici par Martin Fowler.
Je connaissais déjà cette problématique sans en avoir le vocabulaire. Je la décrivais comme du "couplage dans le test" : un test qui couvre plusieurs unités à la fois peut échouer pour une raison indirecte, ce qui rend difficile l'identification de la vraie cause.
Je savais que la solution habituelle est d'utiliser des mocks pour isoler l'unité testée. Cela rend les tests mieux ciblés, mais aussi plus fastidieux à écrire.
Martin Fowler semble préférer les tests sociables par défaut, et ne recourt aux mocks que quand c'est nécessaire (non-déterminisme, lenteur, ressource externe instable). Je partage cette doctrine.
Cette note est la suite de la note "J'ai créé fedora-rpm-copr-playground pour apprendre à publier des packages RPM sur Fedora COPR" :
Pour être tout à fait transparent, en rédigeant cette note, j'ai découvert les méthodes tito et Packit.
Je compte mettre à jour
stephane-klein/fedora-rpm-copr-playgroundpour les tester et ensuite publier une nouvelle note de compte rendu.
Voici ce que Claude Sonnet 4.6 m'a appris au sujet des méthodes Tito et Packit :
Tito (~2008) est issu de l'équipe Red Hat Network / Spacewalk. C'est un outil local de gestion du cycle de vie RPM : il gère le tagging Git (
tito tag), incrémente la version dans le.spec, génère automatiquement les changelogs depuis l'historique Git et produit des SRPMs. Ce sont des opérations que le développeur invoque manuellement sur sa workstation, avant de committer et pousser son travail.Packit (~2019) est un projet Red Hat conçu pour l'ère CI/CD GitHub/GitLab. Son rôle est d'orchestrer automatiquement les builds RPM (via COPR), et optionnellement les soumissions Koji et les updates Bodhi pour les projets intégrés à la distribution officielle Fedora, en réaction à des événements upstream (push, PR, release, ou création d'un tag). Il peut également mettre à jour le changelog à partir des commits, mais cette opération intervient au moment où il prépare la mise à jour vers le dist-git Fedora — non pas comme étape explicite du workflow local du développeur.
La différence fondamentale entre les deux n'est donc pas tant dans quand le build est déclenché — les deux peuvent travailler sur tag — que dans comment le workflow de tagging est géré : avec Tito, c'est le développeur qui crée le tag depuis sa workstation, alors que Packit suppose que le tag existe déjà et déclenche automatiquement le build sur l'infrastructure Fedora (Copr, Koji ou Bodhi selon la configuration) à sa création ou à tout autre événement upstream configuré.
Les deux sont des projets Red Hat gravitant autour de l'écosystème Fedora/RPM, sans que l'un soit le successeur de l'autre. Tito lui-même recommande aujourd'hui Packit pour automatiser les Bodhi updates. Beaucoup de projets Fedora les utilisent d'ailleurs conjointement : Tito pour gérer le versioning et le tagging en local, Packit pour automatiser la distribution en aval.
J'ai intégré Packit à fedora-rpm-copr-playground, dans la branche bash-packit.
Avant de pouvoir utiliser Packit pour build un package RPM d'un projet qui se trouve dans un repository GitHub, il est nécessaire de suivre un certain nombre d'étapes détaillées dans le "Packit Upstream Onboarding Guide" :
- Activer l'application GitHub nommée "Packit-as-a-Service" : https://packit.dev/docs/guide/#github
- Ensuite suivre l'étape "Approval" — j'ai perdu du temps dans le playground parce que j'étais totalement passé à côté de cette étape : https://packit.dev/docs/guide/#2-approval
Voici l'issue GitHub qui a permis l'approbation de mon compte : https://github.com/packit/notifications/issues/716 - Créer un projet COPR et ajouter des permissions "admin" à "packit" (voir ligne 18).
J'ai automatisé cette étape avec le script
/init-copr-project.sh.
Ensuite, j'ai intégré le fichier /.packit.yaml à la racine de mon playground, avec le contenu suivant :
specfile_path: rpm/hello-bash.spec
upstream_package_name: hello-bash
downstream_package_name: hello-bash
upstream_tag_template: "v{version}"
actions:
create-archive:
- bash rpm/create-archive.sh
jobs:
- job: copr_build
trigger: release
owner: stephaneklein
project: hello-bash-packit
targets:
- fedora-42
- fedora-43
- fedora-44
preserve_project: true
Je ne vais pas détailler ici le contenu de ce fichier, je vous renvoie vers la documentation officielle :
La configuration trigger: release dans .packit.yaml signifie qu'il faut créer une release GitHub pour obtenir un package. Pour cela j'utilise de script /release.sh qui exécute :
gh release create "$VERSION" --title "Release $VERSION" --generate-notes
Une fois la commande suivante exécutée :
$ ./release.sh v1.0.15
L'exécution du job de génération du package SRPM est visible sur le backend Packit à cette adresse : https://dashboard.packit.dev/jobs/srpm
Une fois ce job terminé, c'est ensuite le backend COPR qui s'occupe de construire les packages RPM pour toutes les distributions indiquées dans le fichier .packit.yaml :
En conclusion, j'ai réussi à configurer Packit pour construire mes packages RPM. Cependant, la configuration est plus complexe que la méthode make_srpm. Selon moi, Packit est à utiliser pour les packages destinés à être intégrés officiellement à Fedora, tandis que make_srpm convient mieux pour les autres.
J'ai découvert class-variance-authority et tailwinds-variants
Jusqu'à présent, pour la gestion conditionnelle des classes CSS dans mes projets ReactJS ou Svelte, j'utilisais clsx.
Pour Svelte en particulier, j'utilise souvent directement le mécanisme conditionnel natif de l'attribut "class" du framework.
Aujourd'hui, dans un projet professionnel ReactJS, #JaiDécouvert la librairie conditionnelle class-variance-authority.
Cette librairie existe depuis debut 2022 et voici un exemple d'utilisation de class-variance-authority :
<script>
import { cva } from 'class-variance-authority';
const button = cva(
'font-semibold rounded', // équivalent au paramètre `base:` utlisé par tailwind-variants
{
variants: {
intent: {
primary: 'bg-blue-500 text-white hover:bg-blue-600',
secondary: 'bg-gray-200 text-gray-900 hover:bg-gray-300'
},
size: {
sm: 'px-3 py-1 text-sm',
md: 'px-4 py-2 text-base',
lg: 'px-6 py-3 text-lg'
}
},
compoundVariants: [
{
intent: 'primary',
size: 'lg',
class: 'uppercase tracking-wide' // <= appliqué seulement si intent="primary" et size="lg"
}
],
defaultVariants: {
intent: 'primary',
size: 'md'
}
}
);
export let intent = 'primary';
export let size = 'md';
</script>
<button class={button({ intent, size })}>
<slot />
</button>
Je trouve cette approche plus élégante que clsx pour des besoins complexes, comme la création d'un design system.
Dans la même famille de librairie, il existe aussi tailwind-merge que j'avais déjà identifié mais sans avoir jamais pris le temps d'étudier. Ses fonctionnalités sont très simples et minimalistes :
Merge Tailwind CSS classes without style conflicts
Claude Sonnet 4.5 m'a fait découvrir tailwind-variants, une alternative à class-variance-authority. Cette lib est spécifique à Tailwind CSS mais offre de meilleures performances et des fonctionnalités supplémentaires par rapport à class-variance-authority.
Le projet a été créé début 2023, soit environ 1 an après class-variance-authority.
Voici un tableau comparant les fonctionnalités de tailwind-variants et class-variance-authority :
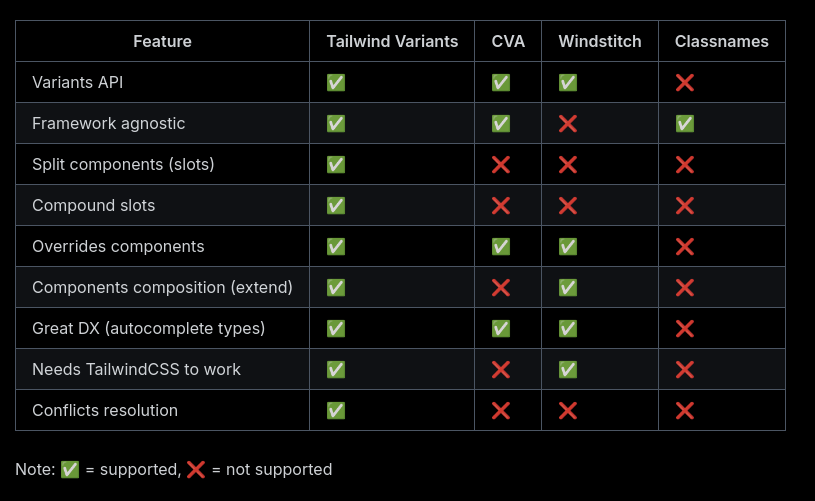
La dernière section de la page Tailwind Variants - Comparison explique l'historique de la lib avec class-variance-authority et les raisons qui ont motivé sa création.
Après quelques difficultés, je pense avoir saisi l'intérêt de la fonctionnalité "slots", disponible dans tailwind-variants mais absente de class-variance-authority.
Si un jour je dois créer des composants de design system avancés dans un projet ReactJS ou Svelte, je pense que j'utiliserai tailwind-variants.
De 2000 à 2016, j'ai essentiellement déployé la distribution Linux Debian sur mes serveurs et après cette date des Ubuntu LTS.
Depuis 2022, j'utilise une Fedora sur ma workstation. Distribution que je maitrise et que j'apprécie de plus en plus.
J'envisage peut-être d'utiliser une distribution de la famille Fedora sur mes serveurs personnels.
J'avais suivi de loin les événements autour de CentOS en décembre 2020 :
- 8 décembre 2020 : CentOS Project shifts focus to CentOS Stream
- 16 décembre 2020 : Rocky Linux: A CentOS replacement by the CentOS founder
J'ai enfin compris l'origine du nom Rocky Linux :
"Thinking back to early CentOS days... My cofounder was Rocky McGaugh. He is no longer with us, so as a H/T to him, who never got to see the success that CentOS came to be, I introduce to you...Rocky Linux"
J'aime beaucoup cet hommage 🤗 !
J'ai étudié AlmaLinux et il me semble que cette distribution est principalement développée par l'entreprise CloudLinux, une entreprise à but lucratif qui vend du support Linux.
Personnellement, je trouve le positionnement d'AlmaLinux peu "fair-play" envers Red Hat : Red Hat investit massivement dans le développement de Red Hat Enterprise Linux et AlmaLinux récupère ce travail gratuitement pour ensuite vendre du support commercial en concurrence directe.
À mon avis, si une entreprise souhaite un vrai support sur une distribution de la famille Red Hat, elle devrait se tourner vers Red Hat Enterprise Linux et acheter du support directement à Red Hat plutôt qu'à CloudLinux.
Suite à ce constat, j'ai décidé d'utiliser Rocky Linux plutôt qu'AlmaLinux.
21h30 : j'ai reçu le message suivant sur Mastodon :
@stephane_klein you have things quite backwards. AlmaLinux is a non-profit foundation while Rocky is owned 100% by Greg kurtzer and they have over $100M in venture capital funding.
AlmaLinux has a community-elected board.
Suite à ce message, j'ai essayé d'en savoir plus, mais il est difficile d'y voir clair.
Par exemple : I’m confused about the different organizational structure when it comes to Rocky and Alma.
La page "AlmaLinux OS Foundation " que j'ai consultée m'a particulièrement plu.
J'ai révisé ma position, j'ai décidé d'utiliser AlmaLinux plutôt que Rocky Linux.
2025-12-02 : j'ai révisé ma position, pour des serveurs de production, j'ai décidé d'utiliser la version stable de CoreOS, plutôt que AlmaLinux ou Rocky Linux.
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
J'ai lu le très bon billet d'Athoune sur Kloset, moteur de stockage de backup de Plakar
Il y a un an, Alexandre m'avait fait découvrir Kopia : Je découvre Kopia, une alternative à Restic.
Ma conclusion était :
Ma doctrine pour le moment : je vais rester sur restic.
En septembre 2024, j'ai découvert rustic, un clone de restic recodé en Rust. Pour le moment, je n'ai aucun avis sur rustic.
Il y a quelques semaines, Athoune m'a fait découvrir Plakar, mais je n'avais pas encore pris le temps d'étudier ce que cet outil de backup apportait de plus que restic que j'ai l'habitude d'utiliser.
Depuis, Athoune a eu la bonne idée d'écrire un article très détaillé sur Plakar, enfin, surtout son moteur de stockage avant-gardiste nommé Kloset : "Kloset sur la table de dissection" (au minimum 30 minutes de lecture).
Ce que je retiens, c'est que Kloset propose un système de déduplication plus performant que par exemple celui de restic qui est basé sur Rabin Fingerprints :
For creating a backup, restic scans the source directory for all files, sub-directories and other entries. The data from each file is split into variable length Blobs cut at offsets defined by a sliding window of 64 bytes. The implementation uses Rabin Fingerprints for implementing this Content Defined Chunking (CDC). An irreducible polynomial is selected at random and saved in the file config when a repository is initialized, so that watermark attacks are much harder.
Files smaller than 512 KiB are not split, Blobs are of 512 KiB to 8 MiB in size. The implementation aims for 1 MiB Blob size on average.
For modified files, only modified Blobs have to be saved in a subsequent backup. This even works if bytes are inserted or removed at arbitrary positions within the file.
Au moment où j'écris ces lignes, je n'ai aucune idée des différences ou des points communs entre l'algorithme Rolling hash dont parle l'article et Rabin Fingerprints qu'utilise restic.
Chose suprernante, je trouve très peu de citations de Plakar ou kloset sur Hacker News ou Lobster :
- Recherche avec "Plakar"
- Hacker News
- dans les stories
- Mars 2021 : March 2021: backups with Plakar – poolp.org : 0 commentaire
- Octobre 2024 : Open source distributed, versioned backups with encryption and deduplication : 0 commentaires
- Mars 2025 : CDC Attack Mitigation in Plakar : 0 commentaires
- dans les commentaires
- dans les stories
- Lobsters => rien
- Hacker News
- Recherche avec "Kloset"
- Hacker News :
- Lobsters => rien
Je tiens à remercier Athoune pour l'écriture, qui m'a permis de découvrir de nombreuses choses 🤗.
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.