
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (700) ] [ Page suivante (3208) >> ]
Journal du lundi 26 août 2024 à 22:10
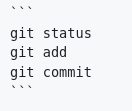
Lorsque vous collaborez avec moi et partagez du code source ou des extraits de terminal dans un logiciel compatible avec le format Markdown, tel que GitHub, GitLab, Mattermost, Zulip, etc., je vous encourage à entourer vos extraits avec des balises ```. Par exemple :
De même, pour les citations de texte en prose, utilisez les caractères > au début de chaque ligne, comme illustré ci-dessous :
> Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse justo neque, facilisis ut commodo in, auctor at tellus. Morbi non mattis risus. In vehicula risus felis, ac ullamcorper magna consequat et.
> Sed finibus, lorem a rutrum pulvinar, magna urna rutrum tortor, eget faucibus dolor enim sit amet lacus. Nulla pulvinar ligula eu leo rhoncus faucibus.
Ce qui produira :
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Suspendisse justo neque, facilisis ut commodo in, auctor at tellus. Morbi non mattis risus. In vehicula risus felis, ac ullamcorper magna consequat et. Sed finibus, lorem a rutrum pulvinar, magna urna rutrum tortor, eget faucibus dolor enim sit amet lacus. Nulla pulvinar ligula eu leo rhoncus faucibus.
Ces deux recommandations permettent d'améliorer le confort de lecture de vos messages.
Voir aussi je préfère recevoir les extraits de vos textes au format texte plutôt que sous forme de captures d'écran.
Journal du lundi 26 août 2024 à 21:59
Alexandre m'a partagé JS Dates Are About to Be Fixed
Many people think that by working with UTC or communicating dates in ISO format, they are safe; however, this is not correct, as information is still lost.
Oui ! J'ai souvent fait l'erreur !
La librairie : Temporal
Journal du lundi 26 août 2024 à 16:41
#JaiDécouvert l'expression "Pont aux ânes".
(Éducation) Obstacle apparent qui n’en est pas un, qui rebute les élèves les moins doués.
-- wiktionary
Journal du lundi 26 août 2024 à 15:09
Lorsque vous collaborez avec moi, je préfère recevoir les extraits de vos textes Markdown, vos codes sources, et le contenu de votre terminal au format texte plutôt que sous forme de captures d'écran.
Voici ci-dessous six inconvénients liés à l'utilisation de captures d'écran.
1. Impossibilité de copier le contenu
Lorsque vous partagez des lignes de commande, des configurations ou des messages d'erreur en capture d'écran, je ne peux pas copier le contenu pour le tester ou effectuer des recherches. Cela m'oblige à ressaisir manuellement le texte, avec le risque d'introduire des erreurs.
De plus, il m'est impossible de citer précisément une partie de votre contenu lors de nos échanges.
2. Impossible de cliquer sur les liens
3. Recherche inefficace
Les outils comme GitHub, GitLab, Slack, Zulip, Mattermost, Signal, WhatsApp, ainsi que les moteurs de recherche dans les pages des navigateurs, ne permettent pas de rechercher du texte présent dans des images. Le format texte, en revanche, est entièrement indexable et facilitera la recherche d'informations.
4. Consommation de mémoire multipliée par 100
Les captures écrans consomment beaucoup plus d'espace disque que du texte.
Prenons l'exemple d'un extrait de terminal au format texte :
# docker info
Client: Docker Engine - Community
Version: 27.1.2
Context: default
Debug Mode: false
Plugins:
buildx: Docker Buildx (Docker Inc.)
Version: v0.16.2
Path: /usr/libexec/docker/cli-plugins/docker-buildx
compose: Docker Compose (Docker Inc.)
Version: v2.29.1
Path: /usr/libexec/docker/cli-plugins/docker-compose
Server:
Containers: 194
Running: 194
Paused: 0
Stopped: 0
Images: 34
Server Version: 27.1.2
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: systemd
Cgroup Version: 2
Cet extrait consomme 682 octets de mémoire.
Je viens de vérifier : une capture d'écran équivalente consomme 83 000 octets de mémoire, soit 121 fois plus d'espace disque qu'un simple extrait de texte. Pour ceux qui utilisent des écrans haute résolution, comme les écrans Retina, cette consommation peut même être multipliée par 4.
Il est regrettable de saturer 100 fois plus rapidement l'espace disque sur des services comme GitHub, GitLab, Slack, Zulip, Mattermost, etc., pour une expérience utilisateur finalement moins optimale.
5. Chargement moins rapide des pages
Ceci est surtout impactant pour les issues ou Merge Request avec beaucoup de commentaires.
6. Occupation excessive de l'espace écran
Les captures d'écran, en particulier celles prises sur des écrans Retina, occupent souvent un espace d'écran excessif dans la fenêtre du navigateur, rendant la lecture des commentaires plus difficile et nuisant à la fluidité de la navigation.
Journal du dimanche 25 août 2024 à 18:58
Dans le thread Lobster Printing the web, part 2: HTML and CSS for printing books
#JaiDécouvert plusieurs la propriétés CSS :
The orphans property specifies the minimum number of line boxes in a block container that must be left in a fragment before a fragmentation break. The widows property specifies the minimum number of line boxes of a block container that must be left in a fragment after a break. Examples of how they are used to control fragmentation breaks are given below.
-- from
et
In addition to the specific CSS counter for page, you can use counter(pages) to get the total number of pages.
-- from
et
We are going to make use of the
string-setproperty defined in the CSS Generated Content for Paged Media Module which is still a working draft at the W3C.-- from
#JaiDécouvert aussi le projet Paged.js.
Paged.js is an Open source library to display paginated content in the browser and to generate print books using web technology.
-- from
Journal du dimanche 25 août 2024 à 12:44
En cherchant des informations au sujet de l'origine de la fonctionnalité compose watch, #JaiDécouvert Tilt (from).
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
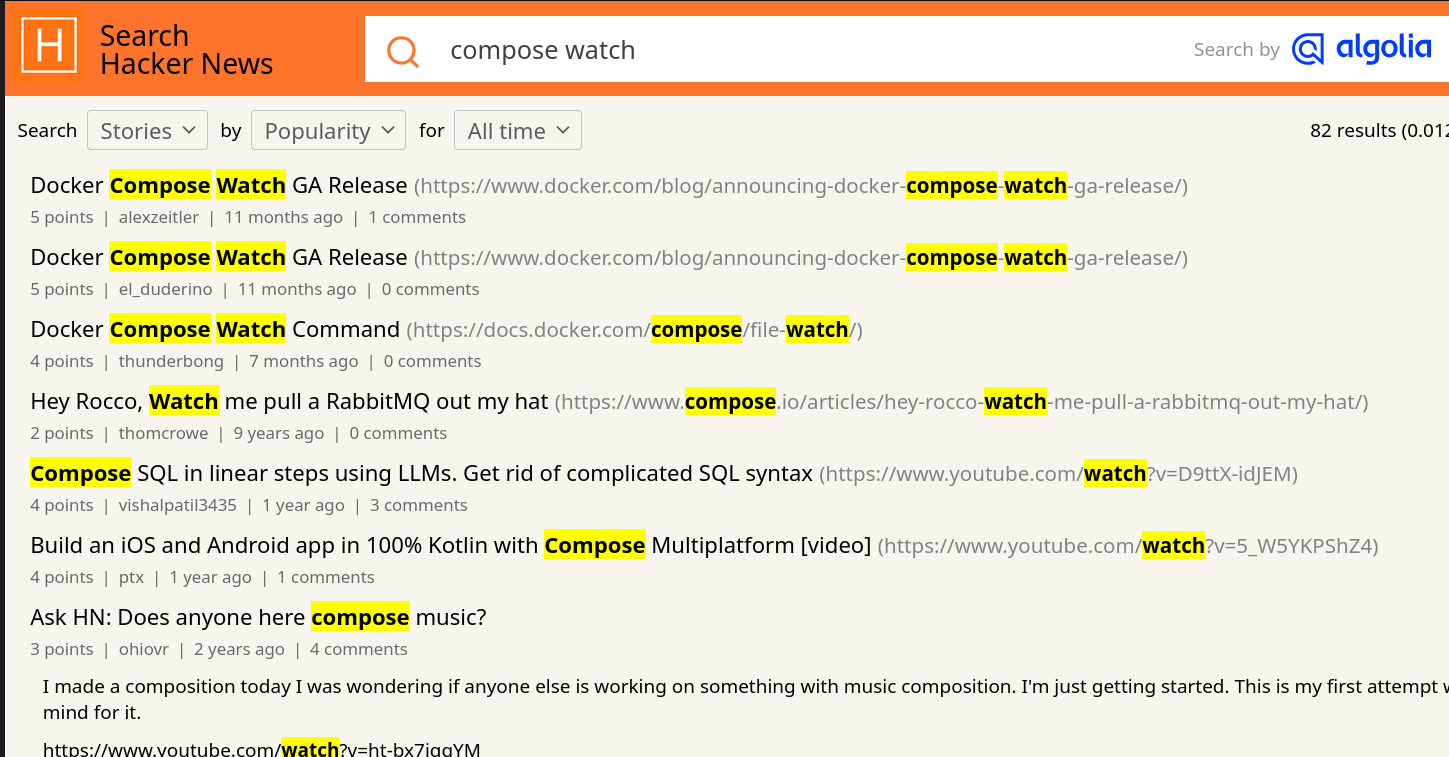
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.
Journal du samedi 24 août 2024 à 21:58
#JaiLu Agir contre les appels commerciaux sur LinuxFr.
#JaiDécouvert EGBG Anti-Telemarketing Contre-scénario et leur super affiche : https://egbg.home.xs4all.nl/EGBGcontrescenario.pdf
J'ai remplacé DoisJeRépondre par SpamBlocker sur mon Android.
Journal du samedi 24 août 2024 à 10:47
Je cherche à mieux comprendre la syntaxe let:close utilisée dans le contexte de Svelte, comme dans l'exemple suivant :
<Popover>
<PopoverButton>Solutions</PopoverButton>
<PopoverPanel let:close>
<button
on:click={async () => {
await fetch("/accept-terms", { method: "POST" });
close();
}}
>
Read and accept
</button>
<!-- ... -->
</PopoverPanel>
</Popover>
Ce code provient du projet svelte-headlessui.
À première vue, cette syntaxe me faisait penser aux <slot key={value}> dans Svelte 🤔.
Cette intuition s'est confirmée après avoir exploré le concept plus en détail à travers l'exemple suivant :
<!-- FancyList.svelte -->
<ul>
{#each items as item}
<li class="fancy">
<slot prop={item} />
</li>
{/each}
</ul>
<!-- App.svelte -->
<FancyList {items} let:prop={thing}>
<div>{thing.text}</div>
</FancyList>
Après avoir lu la section sur les <slot key={value}> , je me rends compte que je n'utilise presque jamais les slots, à l'exception des layout. C'est dommage, car je passe à côté d'une fonctionnalité très pratique.
Journal du vendredi 23 août 2024 à 21:35
#JaiDécouvert le philosophe Alfred Korzybski dans le livre Systemantics.
Il a fondé la sémantique générale, logique de pensée fondée sur les mathématiques et la physique du tournant du siècle, une discipline pratique pour que chacun puisse prendre un recul critique sur les réactions (non verbales et verbales) à un « événement » au sens large (comprendre ses propres réactions, ainsi que les réactions des autres et leur interaction éventuelle).
Quelle différence entre une Issue et un Ticket ?
Je préfère ne pas utiliser le terme « ticket » pour traduire « issue » en anglais.
Il m'arrive cependant d'employer « ticket » uniquement pour désigner les demandes de support ou les bugs.
Les définitions proposées par le Wiktionary et Wikipedia semblent corroborer cette distinction :
« Billet comportant un numéro d’ordre de passage dans une file d’attente. »
« Une demande d'assistance, désignées ainsi dans le métier de l'assistance sous le nom de ticket. »
-- wikipedia
Le terme anglais « issue » a une portée bien plus large que celle de « ticket ». Il peut désigner :
ChatGPT me dit :
En français, le terme "issue" peut être traduit de différentes manières en fonction du contexte. Voici quelques traductions courantes :
- Problème : C'est la traduction la plus directe et souvent utilisée. Elle est appropriée si l'"issue" en question concerne un bug ou un défaut à corriger.
- Ticket : Ce terme est également couramment utilisé dans le contexte du suivi des tâches ou des bugs. Il est un peu plus neutre et peut désigner aussi bien un problème qu'une demande de fonctionnalité.
- Tâche : Si l'"issue" représente quelque chose à faire (comme une nouvelle fonctionnalité à développer), "tâche" peut être une bonne traduction.
- Demande : Ce terme peut être utilisé si l'"issue" est une requête ou une demande de changement.
En fonction du contexte précis, tu peux choisir le mot qui semble le plus approprié. Par exemple :
- Pour un bug : Problème ou Bug.
- Pour une nouvelle fonctionnalité : Tâche ou Demande.
- De manière générale, dans le cadre d'un système de gestion de projet : Ticket.
Le terme "issue" est parfois laissé tel quel en français dans certains contextes techniques, surtout dans des équipes habituées aux outils comme GitLab ou GitHub.
Journal du vendredi 23 août 2024 à 12:35
Depuis des années, j'essaie de suivre avec rigueur la doctrine suivante dans les projets utilisant le workflow Trunk-Based Development.
- La branche trunk doit toujours être stable et contenir uniquement du code fonctionnel.
- Le code obsolète ou inutilisé doit être supprimé de la branche trunk.
- Aucun code commenté ne doit figurer dans la branche trunk.
- La branche trunk ne contient pas de tests qui échouent.
Pourquoi ?
- Pour éviter qu'un développeur perde du temps à essayer de faire fonctionner quelque chose qui n'est pas en état de marche.
- Pour éviter qu'un développeur refactore du code mort — j'ai observé à nouveau cela, il n'y a pas longtemps 😔. Quand le développeur fini par le découvrir, il est généralement très frustré.
- Pour éviter l'installation et la mise à jour de bibliothèques qui alourdissent inutilement le projet.
- Pour prévenir une perte de confiance dans le projet (voir l'hypothèse de la vitre brisée).
Et si j'ai besoin de ce code plus tard ?
Tout d'abord, je vous réponds "YAGNI" 🙂.
Plus sérieusement, ma réponse est que votre code ne sera pas perdu étant donné qu'il est versionné dans votre repository.
Si le code commenté est en cours de développement, alors je suggère d'extraire ce code en préparation dans une Merge Request et de la merger quand elle sera prête.
Trouvez le bon équilibre
Un morceau de code commenté ou un test qui échouent peut tout à fait rester dans trunk sur une courte période. Dans ce cas, je conseille d'ajouter en commentaire un lien vers l'issue de dette technique qui détaille l'action prévue.
Journal du mercredi 21 août 2024 à 15:30
#JaiLu pour la première fois la page de la Web API nommée Intersection Observer API.
Dans un projet Svelte, je crée dynamiquement un composant qui est inséré dans un élément non Svelte :
component = new myComponent({
target: element,
props: {
foo: bar
}
});
Cette Web API m'a permis de déterminer la position d'un composant lorsque celui-ci est réellement attaché à la page web.
<script lang="js">
import { onMount } from "svelte";
export let rootElement;
onMount(() => {
const observer = new IntersectionObserver(
(entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
console.log(entry.boundingClientRect);
observer.disconnect();
}
});
}
);
observer.observe(rootElement);
});
</script>
<span bind:this={rootElement}>
...
</span>
Journal du mercredi 21 août 2024 à 10:53
#OnMaPartagé La Vélodyssé, je suis très intéressé par cet itinéraire de voyage à vélo.
Journal du mercredi 21 août 2024 à 10:37
Note de type snippets concernant docker compose et l'utilisation de la fonctionnalité healthcheck et depends_on.
Cette méthode évite que le service webapp démarre avant que les services postgres et redis soient prêts.
# Fichier docker-composexyml
services:
postgres:
image: postgres:16
...
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
redis:
image: redis:7
...
healthcheck:
test: ["CMD", "redis-cli", "ping"]
timeout: 10s
retries: 3
start_period: 10s
webapp:
image: ...
depends_on:
postgres:
condition: service_healthy
redis:
condition: service_healthy
Ici la commande :
$ docker compose up -d webapp
s'assure du lancement de ses dépendances, les services postgres et redis.
De plus, si le Dockerfile du service webapp contient par exemple :
# Fichier Dockerfile
...
RUN apt update -y; apt install -y curl
...
HEALTHCHECK --interval=30s --timeout=10s --retries=3 CMD curl --fail http://localhost:3000 || exit 1
Alors, je peux lancer webapp avec :
$ docker compose up -d webapp --wait
Avec l'option --wait docker compose "rend la main" lorsque le service webapp est prêt à recevoir des requêtes.
Ressources :
Journal du mercredi 21 août 2024 à 10:16
#OnMaPartagé https://www.paat.ch/, communauté de Coliving Coworking.

Il semble possible d'organiser des sessions de coworking :
Je pense que ce site rassemble des logements propice au coworking :
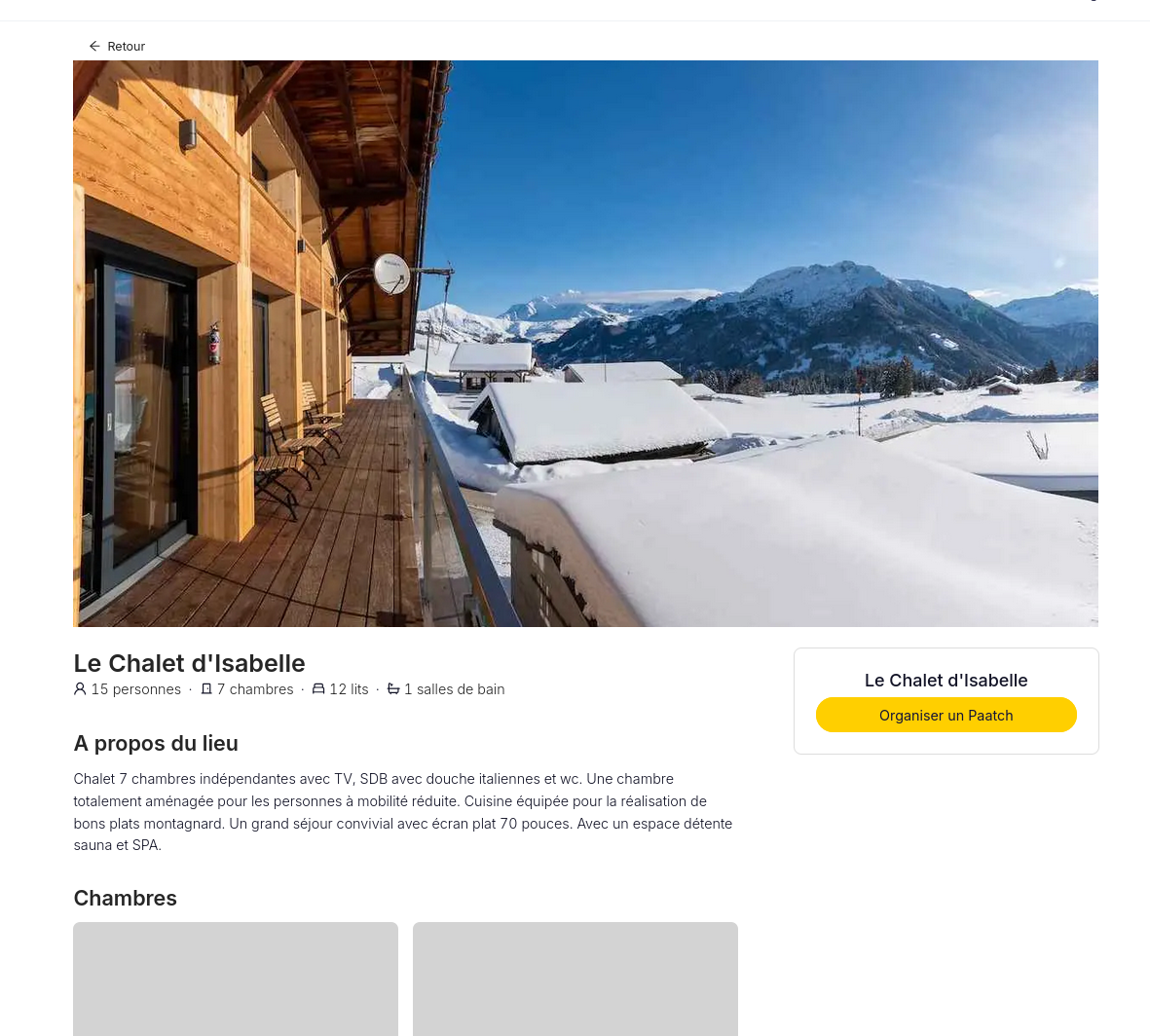
Journal du mercredi 21 août 2024 à 10:08
#OnMaPartagé un nouvel article qui fait mention de Otium :
Jean-Miguel était l’invité de Gregory Pouy dans son Podcast Vlan! et définit l’otium, mot issu de l’Antiquité, comme “le loisir intelligent”. Il s’agit de “la part, dans le temps libre, utilisée pour développer sa conscience, tout ce qui permet d’avoir un rapport éclairé, lucide avec le monde extérieur et soi-même”.
-- from
Journal du mercredi 21 août 2024 à 09:53
#JaiDécouvert le browser Open source nommé Zen Browser basé sur Firefox qui reprends les principes de Arc (browser) (from)
Je viens de l'installer et de le lancer, il semble bien fonctionner. Je constate qu'il partage bien les extensions Firefox.
Toutefois, je n'ai pas trouvé comment effectuer des "split views", qui est la fonctionnalité qui m'intéresse le plus.
Je n'ai pas trouvé non plus comment activer le "Compact Mode".
J'arrête de tondre de Yak! pour le moment.
Journal du mercredi 21 août 2024 à 09:49
Je trouve le projet très bien réaliséfélicitations à l'auteur !
Je pense que ce projet partage en partie les mêmes objectifs que Datasette.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Journal du mardi 20 août 2024 à 23:26
Je tente ici de présenter la notion de Git Commit dit "cavalier" en la reliant au concept de Cavalier Législatif.
Un cavalier législatif est un article de loi qui introduit des dispositions qui n'ont rien à voir avec le sujet traité par le projet de loi.
Ces articles sont souvent utilisés afin de faire passer des dispositions législatives sans éveiller l'attention de ceux qui pourraient s'y opposer.
-- from
Dans le contexte de développement logiciel, un Commit Cavalier désigne un commit inséré dans une Pull Request ou Merge Request qui n’a aucun lien direct avec l’objectif principal de celle-ci.
Cette pratique pose les problèmes suivants :
- Cela rend la Merge Request plus difficile à review ;
- Cela rend la Merge Request plus longue à review ;
- Cela lance des discussions sans lien avec l'objectif de la Merge Request ;
- Le Commit Cavalier devient "invisible" au reste de l'équipe ;
- L'auteur peut mettre la pression au reviewer pour merger son Commit Cavalier sous prétexe que la Merge Request doit être mergé rapidement.
Il va sans dire que cette pratique a le don de m'irriter profondément. Par respect pour mon reviewer et mon équipe, je veille scrupuleusement à ne jamais soumettre de commit cavalier.
Journal du mardi 20 août 2024 à 18:13
#JaiDécouvert cette citation de Alan Kay (from).
« Pop culture is all about identity and feeling like you're participating. It has nothing to do with cooperation, the past or the future — it's living in the present. I think the same is true of most people who write code for money. They have no idea where their culture came from." -- from
Traduction ChatGTP :
« La culture pop concerne avant tout l'identité et le fait de ressentir que l'on participe. Elle n'a rien à voir avec la coopération, le passé ou le futur — c'est vivre dans le présent. Je pense que c'est la même chose pour la plupart des personnes qui écrivent du code pour de l'argent. Elles n'ont aucune idée de l'origine de leur culture. »
Source de cette citation : https://web.archive.org/web/20120715041026/http://www.drdobbs.com/architecture-and-design/interview-with-alan-kay/240003442?pgno=1
Journal du mardi 20 août 2024 à 18:05
Depuis 2012, je pratique exclusivement le Git Rebase Workflow pour tous mes projets de développement.
Concrètement :
- J'utilise
git pull --rebasequand je travaille dans une branche, généralement une Pull Request ou Merge Request ; - Je pousse régulièrement des commits en "work in progress" au fil de l'avancée de mon travail dans ma branche de développement avec la commande
git commit -m "WIP"; git push; - Une fois le travail terminé, je squash mes commits à l'aide de
git rebase -i HEAD~[NUMBER OF COMMITS]; - Ensuite, je rédige un commit message qui contient la description du changement et le numéro de l'issue ou de la merge request
git commit --amend; - Enfin, j'effectue un Merge en Fast-Forward en utilisant l'interface de GitHub ou GitLab.
Pour cela, je paramètre GitLab de la façon suivante (navigation "Settings" => "General") :

Ou alors je paramètre GitHub de la façon suivante (navigation "Settings" => "General")
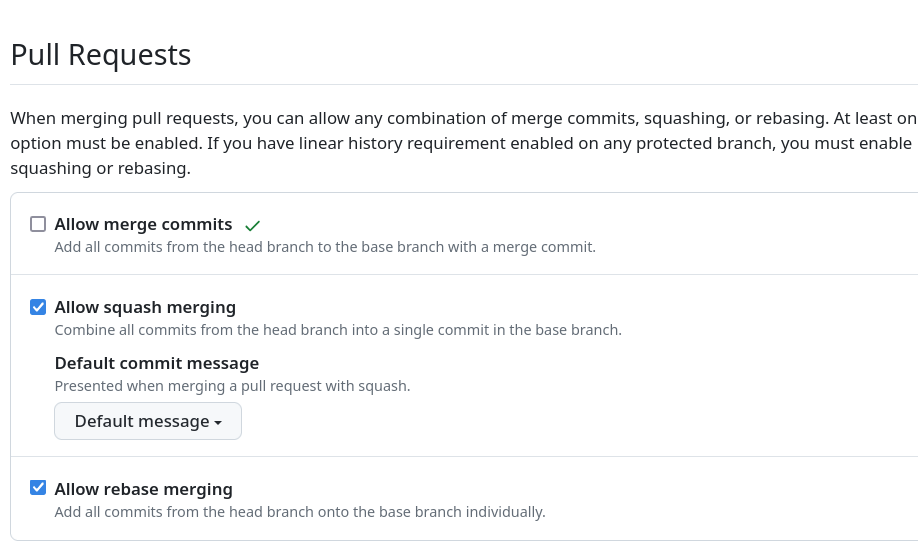
Les avantages de cette pratique
L'approche Rebase + Squash + Merge Fast-Forard permet de maintenir l'historique de changements linéaire, rendant celui-ci plus facile à lire et à comprendre.
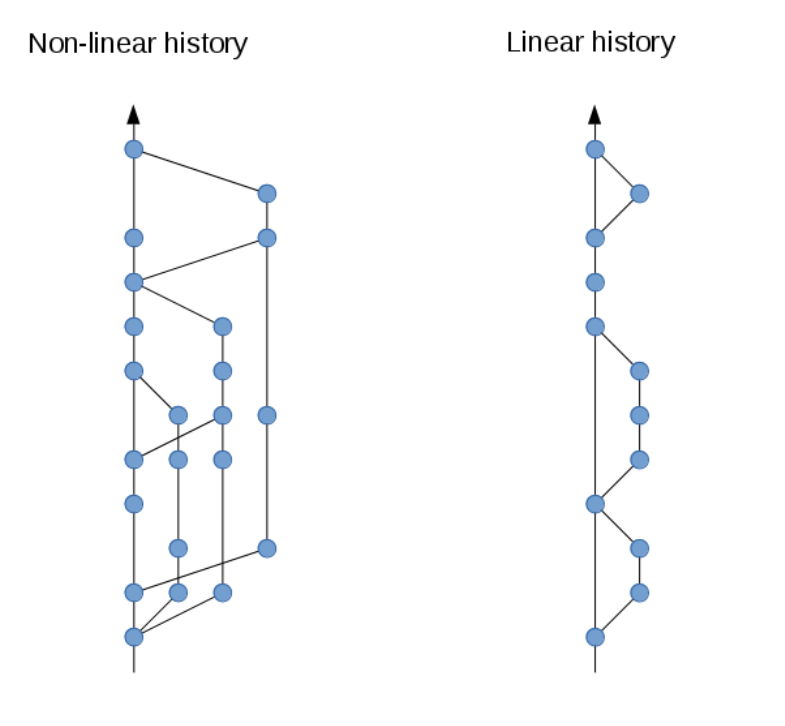
L'historique ne contient aucun commit de fusion inutile.
Cela facilite la mise en place d'Intégration Continue.
Tous les problèmes, bugs, et conflits sont traités dans les branches, dans les Merge Request et jamais dans la branche main qui se doit d'être toujours stable, ce qui améliore grandement le travail en équipe.
Ce workflow est particulièrement puissant lorsque l'historique linéaire ne contient que des commit dit "atomic", c’est-à-dire : 1 issue = 1 merge request = 1 commit. Un commit est considéré comme "atomic" lorsqu'il ne contient qu'un seul type de changement cohérent, tel qu'une correction de bug, un refactoring ou l'implémentation d'une seule fonctionnalité.
À de rares exceptions près, le code source de la branche main doit rester stable et cohérent tout au long de l'historique des commits.
Cette discipline favorise un travail collaboratif de qualité, rendant plus compréhensible l'évolution du projet.
De plus, l'atomicité des commits facilite la revue des Merge Request et permet d'éviter les Commits Cavaliers.
Généralement je couple ce Git workflow au workflow nommé Trunk-Based Development.
Journal du mardi 20 août 2024 à 17:37
#JaiDécouvert un article très intéressant qui répertorie les difficultés classiques rencontrées par les développeurs avec git rebase, ainsi que des solutions pour y remédier :git rebase: what can go wrong?.
Journal du mardi 20 août 2024 à 17:27
#JaiDécouvert ce guide pour Git : Flight rules for Git.
Je le trouve excellent 👌.
Et voici une autre article intéressant au sujet de Git rebase : git rebase in depth.
Journal du mardi 20 août 2024 à 16:09
#JaiDécouvert Waymarked Trails pour les randonnées basé sur OpenStreetMap.
Journal du mardi 20 août 2024 à 14:35
#OnMaPartagé la pratique suivante quand un projet utilise Mise : convertir tous les fichiers .tool-versions vers le format de configuration natif de Mise.mise.toml. Cette conversion permet d'éviter d'éventuels problèmes de compatibilité entre Mise et Asdf.
It supports the same .tool-versions files that you may have used with asdf and uses asdf plugins. It will not, however, reuse existing asdf directories (so you'll need to either reinstall them or move them), and 100% compatibility is not a design goal.
-- from
En utilisant le format .mise.toml l'utilisateur comprends qu'il doit utiliser Mise.
#JaiDécidé d'ajouter cette pratique dans ma doctrine d'artisan développeur.
Journal du mardi 20 août 2024 à 10:40
Un ami ma partager cette adresse de coworking que j'avais déjà identifié lors d'un footing à la Cité internationale universitaire de Paris : L'Égyptien Café Coworking.
Il me dit que y a du café, Internet, des prises, que c'est parfait pour coworker.
J'ai découvert le registrar coopératif nommé LeBureau.coop
Dans ce thread Fediverse #JaiDécouvert LeBureau.coop.
Une société coopérative de gestion de noms de domaine (registrar).
La vidéo "Les noms de domaine pour se réapproprier Internet" de Arthur Vuillard à Pas Sage en Seine (à partir de 25min) contient une présentation de ce projet.
J'y ai au passage découvert la coopérative Hasshbang.
Dans ma #todo-list :
- [ ] Transférer un de mes noms de domaine vers LeBureau.coop pour tester ;
- [ ] Acheter des parts pour devenir sociétaire soutien.
Journal du mardi 20 août 2024 à 09:46
#JaiLu les slides Mozilla va-t-il sauver le web ?.
Je suis attristé par la gouvernance de Mozilla 😭.
Journal du mardi 20 août 2024 à 09:33
#JaiLu Software estimates have never worked and never will
Je suis en accord — depuis très longtemps — avec le contenu de cet article.
Give up on estimates, and embrace the alternative method for making software by using budgets, or appetites, as we call them in our Shape Up methodology.
Cette méthode fait parti de ma doctrine d'artisan développeur.
Journal du lundi 19 août 2024 à 21:03
Je teste Zed editor, sous Fedora.
$ flatpak install flathub dev.zed.Zed
Journal du lundi 19 août 2024 à 17:21
#JaiDécouvert https://github.com/romkor/svelte-portal (from ChatGPT).
Vraiment trop pratique !
Journal du lundi 19 août 2024 à 16:28
Dans l'introduction de la documentation de bits-ui, #JaiDécouvert encore une autre #librairie de composants UI pour Svelte : melt.
Journal du lundi 19 août 2024 à 15:52
#Jadore le projet shadcn-svelte. Je trouve l'expérience développeur (DX) excellente ❤️.
Journal du lundi 19 août 2024 à 15:28
Je souhaite setup Tailwind CSS dans un projet SvelteKit avec svelte-add.
https://svelte-add.com/adder/tailwindcss
Mais ne comprends pas pourquoi, svelte-add semble ne plus fonctionner comme avant, il ne modifie pas mon projet SvelteKit existant, mais il souhaite l'écraser 🤔.
$ pnpx svelte-add@latest tailwindcss
svelte-add version 2.7.3
┌ Welcome to Svelte Add!
│
◇ Create new Project?
│ No
│
└ Exiting.
En attendant de comprendre pourquoi, je vais setup Tailwind CSS manuellement en suivante cette documentation https://tailwindcss.com/docs/guides/sveltekit.
Je découvre Kopia, une alternative à Restic
Alexandre m'a partagé Kopia, logiciel Open source de backup, alternatif à restic.
7000 likes GitHub versus 25000 likes pour Restic.
Je constate que Kopia est développé principalement par 2 développeurs et je constate le même nombre pour Restic.
J'ai parcouru cette page qui date de 2 ans : How Do Kopia Features Compare to Other Backup Software?.
En 2022, il semble que restic ne supportait pas la compression de données, mais je constate via cette Pull Request Implement compression support que cette feature est maintenant intégrée à restic.
#JaiLu en partie le thread Hacker News : Kopia: Fast and secure open-source backup software.
Initially I thought this was a corporate project and was looking for the monetization model, but then I found https://github.com/kopia/kopia/blob/master/GOVERNANCE.md
I feel like the project might benefit from making their governance model more prominent on the website.
-- from
D'après ces commentaires, Kopia est lent à la restauration :
Used it for a while, recently tried to restore some things and it failed, taking a really long time to restore some snapshots compared to other things I've tried. Switched to restic instead. Really like what kopia is but I'll wait a few more years before considering it for something, but right now I'm happy with restic.
This has been my experience too with Kopia.
I tried to restore a ~200 GB file (stored remotely on a Hetzner Storage Box), and it failed (or at least did not finish after being left for ~20 hours; there was also no progress indicator or status I could find in the UI).
I also tried to restore a folder with about ~32 GB of data in it, and that also failed (the UI did report an error, but I don't recall it being useful).
Also, in general use, the UI would get disconnected from the repository every few days, and sometimes the backup overview list would show folders as being size 0 (which maybe indicated they failed; they showed up with an "incomplete" [or similar] tag in the UI).
-- from
Il semble que l'outil Veloro utilisait restic et ait migré vers Kopia :
One thing I will mention is that other backup projects have switched from Restic to Kopia. Velero from VMware comes to mind.
-- from
À ce sujet, j'ai vu Unified Repository & Kopia Integration Design et je n'ai pas tout compris.
Alexandre m'a appris que Veloro supporte pour le moment Kopia et restic mais que le support restic est en train d'être supprimé : Deprecate Restic.
Voilà l'origine du nom 🙂 :
"Kopia" means "copy" in Swedish and probably more Nordic languages, too.
-- from
J'ai vu ce commentaire :
Personally, I've had some issues with Kopia.
I found their explanation here:
Still not solved after many years :(
Ma doctrine pour le moment : je vais rester sur restic.
Journal du lundi 19 août 2024 à 11:27
#JaiLu "Les mathématiques de l'argument d'autorité #DébattonsMieux" de Lê Nguyên Hoang, je trouve cela très intéressant, bien que, après une première lecture, je n'aie saisi qu'une infime partie de l'article.
L'article présente un théorème bayésien qui stipule :
- Si vous êtes bayésien,
- si vous supposez qu'une autorité a eu accès aux mêmes données que vous et à plus encore,
- si vous êtes sûr que l'autorité parle de manière honnête,
- si vous pensez qu'une autorité est aussi bayésienne avec le même a priori que vous, alors vous devez croire tout ce que l'autorité dit.
#JaiDécouvert John Geanakoplos, Herakles Polemarchakis et John Harsanyi cités dans cet article.
Journal du samedi 17 août 2024 à 16:09
Je viens de créer Projet 13 - "POC Elasticsearch sur un PKM".
Journal du samedi 17 août 2024 à 15:21
Je repository GitHub officiel des images Docker de Elasticsearch se trouve ici : https://github.com/elastic/elasticsearch/tree/main/distribution/docker.
Journal du samedi 17 août 2024 à 15:15
En lien avec Elasticsearch, #JaiDécouvert :
- https://github.com/searchkit/searchkit
- https://opensource.reactivesearch.io/
- https://github.com/appbaseio/dejavu/
qui sont plus ou moins des équivalents à InstantSearch (from).