
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (1000) ] [ Notes plus anciennes (69) >> ]
Lundi 13 mai 2024
Journal du lundi 13 mai 2024 à 19:07
Suite de Je m'interroge, pourquoi tant de beaux projets sont codés en Closure ?.
Encore Nautilus time-blocking tool que je trouve intéressant, codé en Closure : https://nautilus-omnibus.web.app
Voici les arguments que donne ici l'auteur de ce logiciel pour expliquer pourquoi il a choisi Closure :
It has to be said that Clojurescript is an excellent fit for text-based Roam. The Nautilus code in Clojurescript is, in a way, one “big function,” transforming text (task list) into another text (SVG code), which renders the spiral. What I enjoy most about working with Clojure is the mindset where code and data are almost one. With REPL, you can easily evaluate parts of the code for debugging and even rewrite code on the fly.
Hooray, and now Nautilus is finally part of the extensions menu in Roam Depot and it already has several hundred users. More are joining daily.
Fonctionnalité cluster and edit de OpenRefine
Il y a quelques semaines, #JaiDécouvert le #logiciel OpenRefine, qui permet de réaliser des tâches de #data-curation , plus précisément de #data-cleaning — mais pas seulement.
#JaimeraisUnJour prendre le temps d'essayer de nettoyer mes données Toggl avec OpenRefine.
Je lis ici que je peux manipuler plusieurs type de format de données :
From these sources, you can load any of the following file formats:
- comma-separated values (CSV) or text-separated values (TSV)
- Fixed-width columns
- JSON
et
OpenRefine can connect to PostgreSQL, MySQL, MariaDB, and SQLite database systems
Je souhaite particulièrement tester la fonctionnalité cluster and edit de OpenRefine et surtout les différentes méthode de clustering.
Dimanche 12 mai 2024
Opération de nettoyage, curation de mes données Toggl
Je souhaite nettoyer ( #data-cleaning, #data-curation ) une année de données que j'ai collectées avec l'application Toggl.
Chaque ligne de données ressemble à ceci :
start: "2024-05-12 09:00"
stop: "2024-05-12 09:23"
duration: 1380
description: "Rédaction d'une note éphémères au sujet du netoyage de données"
tags:
- écriture
- clean-data
Voici les opérations de nettoyage que j'aimerais réaliser :
- homogénéifier le contenu du champ "description" ;
- ajouter ou supprimer des tags sur une liste de lignes sélectionnées par l'application d'un filtre.
Jusqu'à présent, j'effectue ce nettoyage via l'application web Toggl. Cela n'est pas très agréable pour les raisons suivantes :
- Je trouve l'application très lente, ce qui m'insupporte !
- La saisie au clavier dans un champ input est lente.
- La recherche d'un tag est lente.
- ...
- Je ne peux pas sélectionner rapidement plusieurs lignes avec le clavier, je dois cliquer sur une case à cocher sur chaque ligne.
#JaimeraisUnJour trouver une méthode efficace et agréable pour réaliser mes tâches que #data-curation.
Vendredi 10 mai 2024
Journal du vendredi 10 mai 2024 à 19:47
Le 29 avril, j'ai suivi deux mauvaises pratiques : imposer mon emploi du temps aux autres, demander de l'aide avant de documenter mon problème.
En résumé : commencer par du synchrone avant de l'asynchrone.
Voici ci-dessous ce qu'il s'est passé le 29 avril.
Je reçois un e-mail du cabinet comptable qui s'occupe du club de Tennis de Table.
J'apprends qu'il manque encore des informations pour clôturer l'exercice comptable 2022-2023 !
Je culpabilise et j'ai la volonté de clore tout de suite ce dossier déjà très en retard !
Fini la procrastination ! Je constate rapidement qu'il me manque des informations, que je ne suis en mesure de répondre aux questions du cabinet comptable.
J'ai besoin d'aide et je commence par suivre une bonne pratique :
- je commence par rédiger un email pour expliquer les éléments dont j'ai besoin pour clôturer le dossier ;
- j'envoie ce e-mail à Nicolas, Ludovic et Grégoire ;
- ensuite, je leur envoie un message privé à chacun, dans l'espoir d'avoir une réponse rapidement et peut-être de traiter ce problème dans l'heure.
J'ai quelques échanges par chat, mais aucun d'entre eux n'est disponible — ce qui est tout à fait normal, ce n'est pas leur priorité.
Je fais quelques progrès dans ma recherche d'information et je découvre un nouveau problème dans un des logiciels de gestion de remboursement de notes de frais.
C'est à ce moment là que je commence la mauvaise pratique 🫣.
Le problème que je rencontre est difficile à expliquer et au lieu de réaliser tout de suite un screencast, j'envoie le message suivant à Ludovic « Je peux t'embêter 10min en visio » ?
Il me répond que non, il n'est pas disponible.
Mon erreur ? Étant pressé, souhaitant absolument finir le sujet dans la journée, j'ai essayé de forcer mes collaborateurs à passer en mode synchrone, leur imposant mon emploi du temps !
Quelle était la bonne pratique à suivre ?
- Commencer par réaliser un screencast pour bien expliquer le problème.
- Partager ce screencast à Nicolas, Ludovic et à toute autre personne à qui je demanderai de l'aide sur ce sujet.
- Laisser Nicolas et Ludovic étudier ce sujet en asynchrone.
Quels sont les bénéfices de suivre une méthode asynchrone ?
- Respecter l'emploi du temps de mes amis en n'essayant pas de leur imposer mon emploi du temps !
- Garder une trace numérique du problème à résoudre ! Je ne l'ai pas fait et 10 jours plus tard, au moment où j'écris ces lignes, je ne me souviens plus avec précision quelle était ma difficulté. Je vais devoir passer du temps à retrouver quel était mon problème.
Pourquoi je suis tombé dans mes travers, cette mauvaise pratique ?
- Je pense que c'est parce que j'avais la volonté et l'illusion de clore rapidement — dans la journée — ce dossier.
Journal du vendredi 10 mai 2024 à 08:37
#JeMeDemande si le code de SilverBullet.mb pourrait m'inspirer dans mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai l'impression que le code qui m'intéresse se trouve vers ici.
Je pense que CompletionTooltip est la classe qui est responsable de l'affichage du "completion picker".
09:56 : J'ai réussi à afficher un "completion picker" minimaliste :
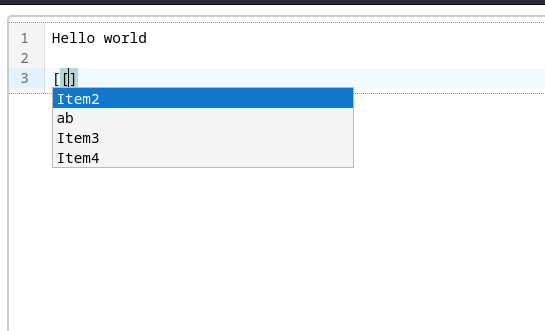
10:02 : Prochaines itérations :
- [ ] Essayer d'implémenter le chargement de la liste d'items de suggestion de manière dynamique. Je souhaite obtenir cette liste via une requête GET http, sur l'url
/get-suggestions/. Cette fonctionnalité est souvent nommée « remote data fetch » (exemple ici). - [ ] Essayer d'implémenter un chargement dynamique d'items de manière progressif. Au lieu de charger toutes la listes des items, l'objectif et de les charger au fur et à mesure, par exemple en petit paquets de 100 items). L'objectif de cette tache ressemble à https://github.com/vtaits/react-select-async-paginate.
Mardi 7 mai 2024
Journal du mardi 07 mai 2024 à 16:06
#JaiPublié ce bug report Request_uri missing in proxy_pass (nginx proxy) Obsidian Publish configuration documentation sur le forum de Obsidian.
Journal du mardi 07 mai 2024 à 10:09
Suite de ma note 2024-05-06_1051.
Du mercredi 8 au lundi 13 mai, je vais faire 5 jours de vélo, une petite partie de la véloroute Véloscénie, de Argentan à Dol-de-Bretagne en passant par Le Mont-Saint-Michel.
Soit 174km au total, en 5 jours :
- mercredi : 30 km
- jeudi : 37 km
- vendredi : 40 km
- samedi : 45 km
- dimanche : 22 km
Ce sont des petites distances, cela nous laissera du temps pour faire des détours.
Carte à jour avec toutes les informations sur des markers : https://umap.openstreetmap.fr/en/map/argentan-vers-mont-saint-michel-en-velo_1051084#10/48.6148/-1.0410
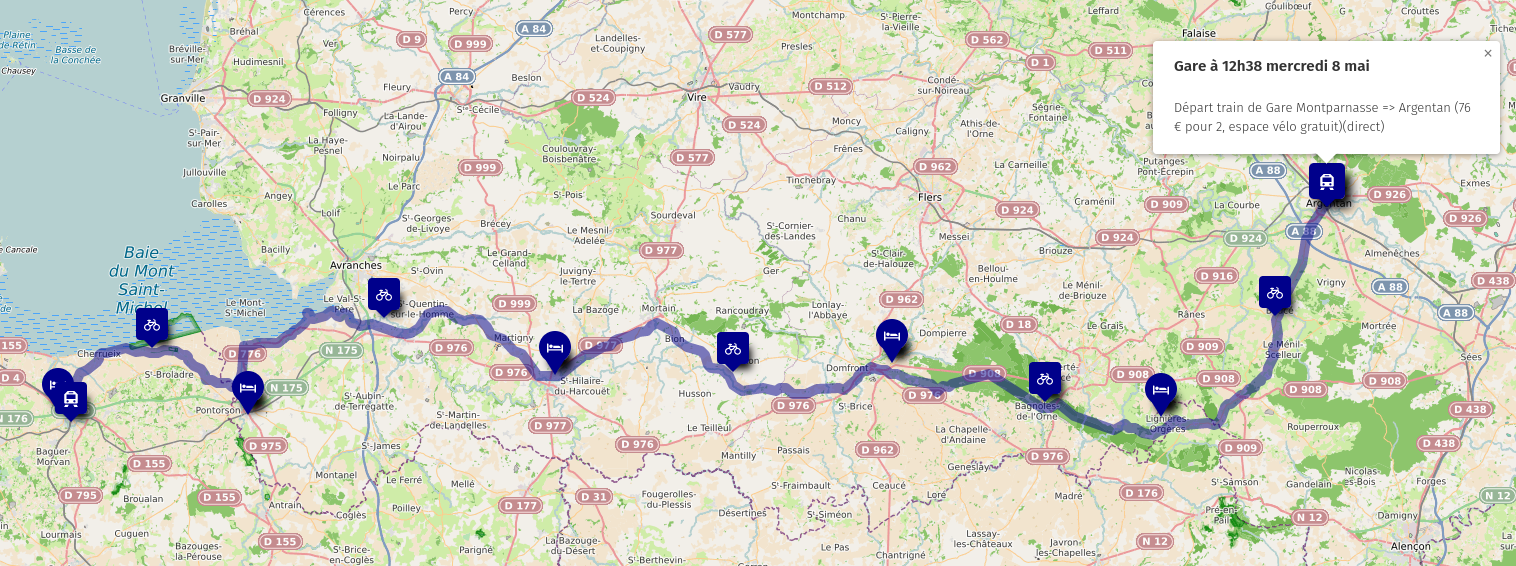
Timeline
Mercredi 8 mai (météo - pas de pluie, 11°c à 9h, 18°c à 16h) :
- 8h00 : Réveil
- 9h00 : Départ de Montrouge, vers chez Paulette (28min de métro). Stéphane part de son coté en vélo (16min de vélo).
- 9h30 : Enlévement de la location vélo Sarah chez Paulette à l'adresse suivante 115 rue Brancion, 75015 Paris
- 10h00 : Départ pour trajet en vélo de Paulette vers gare Montparnasse
- 10h30 : Arrivé à la gare Montparnasse
- 10h54 : Départ train de Gare Montparnasse => Argentan (76 € pour 2, espace vélo gratuit)(direct)
- 12h38 : Arrivé à Argentan
- 13h00 : Déjeuner
- 14h00 : Course pour diner ?
- 14h00 : Départ en vélo vers Lignieres Orgeres, trajet de 30km, à 10km/h, ça fait 3h de trajet
- 18h00 : Arrivé sur Lignieres Orgeres
- 19h00 : Les Herbages de Beauvais (adresse : Lieu dit de Beauvais 53140 Lignieres Orgeres) 75 € pour 2, avec petit dejeuner compris
- Diner : Attention, j'ai l'impression qu'il n'y a aucun restaurant dans cette zone. (edit : pas grave, le gite fait table d'hôte, 25 € par personnes boissons et apéritif inclus)
Jeudi 9 mai (météo - pas de pluie, 12°c à 9h, 19°c à 16h):
- 8h30 : Petit déjeuner à Les Herbages de Beauvais
- 9h30 : Départ en vélo vers Domfront, trajet de 37 km, à 10km/h ça fait moins de 4h de trajet
- 12h00 : Déjeuner, je pense qu'il y a des restaurant sur le trajet :
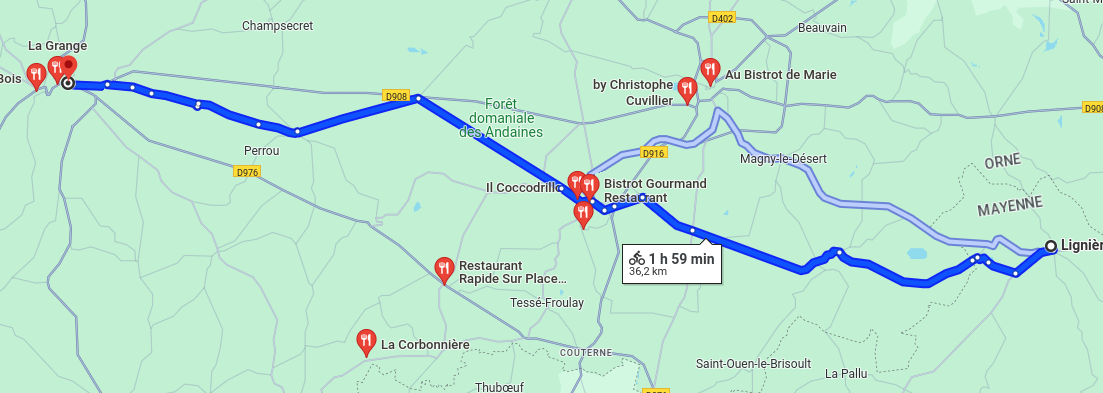
- 19h00 : Chambres d'Hôtes Belle Vallee à Domfront (adresse) 100 € pour 2, avec petit déjeuner inclus.
- 19h30 : Il y a des restaurant pour le diner.
Vendredi 10 mai (météo - pas de pluie, 14°c à 9h, 21°c à 16h):
- 8h30 : Petit déjeuner à Chambres d'Hôtes Belle Vallee à Domfront
- 9h30 : Départ en vélo vers Saint-Hilaire-du-Harcouet, trajet 40 km, à 10 km/h, ça fait moins de 4h de trajet
- 12h00 : Je pense qu'il y aura de quoi déjeuner
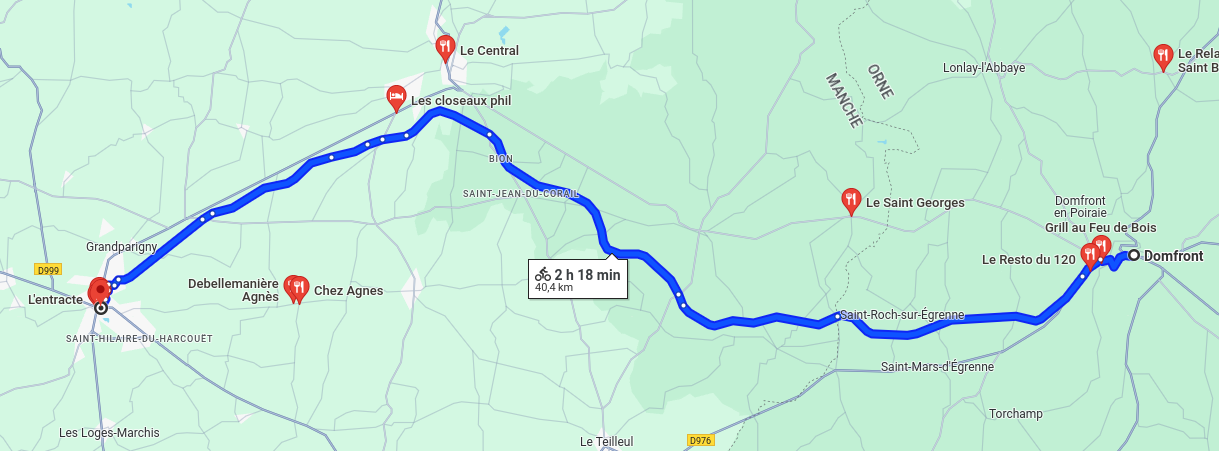
- 19h00 : Nuit à Chambre Airbnb à 20 Rue Fulgence Bienvenue, 50600 Grandparigny, 60 € pour 2, sans petit déjeuner
Samedi 11 mai (météo - pas de pluie, 16°c à 9h, 26°c à 17h) :
- 8h30 : Petit déjeuner à Chambre Airbnb (à confirmer)
- 9h30 : Départ en vélo vers Saint-Georges-de-Gréhaigne, trajet de 45 km, à 10 km/h, ça fait moins de 5h de trajet
- 19h00 : Hôtel Ariane à Pontorson, adresse 50 Bd Clemenceau, 50170 Pontorson, 88 € pour 2, sans petit déjeuner
Dimanche 12 mai (météo - pluie l'après midi et le soir, 15°c à 8h, 21°c à 12h) :
- 9h00 : Départ en vélo vers Mont-Dol, trajet de 22 km, à 10 km/h, ça fait moins de 2h de trajet
- 19h00 : Chambres d'hôtes La Bégaudière, adresse 12 La Bégaudière 35120 Mont-Dol, 78 € pour 2, petit déjeuner inclus.
Lundi 13 mai (météo - pluie, 14°c à 8h, 15°c à 14h):
- 8h30 : Petite déjeuner à Chambres d'hôtes La Bégaudière
- 17h30 : Arrivé à la gare Dol De Bretagne
- 17h58 : Départ train Dol De Bretagne vers Paris Montparnasse (222 € pour 2, espace vélo payant inclus)(direct)
- 20h19 : Arrivé à Paris Montparnasse
Mardi 14 mai :
- 9h30 : Rendre le vélo de Sarah
Détail location vélo pour Sarah chez Paulette :
- VTC électrique - Taille : M : 166 €
- Sacoches Arrière (Paire) : 22 €
- Panier avant : 13 €
Total : 202 €
Le paramétrage de `search_path` PostgreSQL dans docker-compose ne fonctionne pas 🤨
Je suis en train de travailler sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et je rencontre une difficulté.
J'utilise cette configuration docker-compose.yml :
services:
postgres:
image: apache/age:PG16_latest
restart: unless-stopped
ports:
- 5432:5432
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
PGOPTIONS: "--search_path='ag_catalog,public'"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Je ne comprends pas pourquoi, j'ai l'impression que le paramètre PGOPTIONS: "--search_path=''" ne fonctionne plus.
$ ./scripts/enter-in-pg.sh
postgres=# SHOW search_path ;
search_path
-----------------
"$user", public
(1 ligne)
postgres=#
La valeur de search_path devrait être ag_catalog,public.
J'ai testé avec l'image Docker image: postgres:16, j'observe le même problème.
Je suis surpris parce que je pense me souvenir que cette syntaxe fonctionnait ici en septembre 2023 🤔.
#JeMeDemande comment corriger ce problème 🤔.
#JaiLu docker - Can't set schema_name in dockerized PostgreSQL database - Stack Overflow
09:07 : #ProblèmeRésolu par https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/commit/0b1cef3a725550269583ddb514fa3fff1932e89d
Lundi 6 mai 2024
Journal du lundi 06 mai 2024 à 15:23
#JaiPublié le playground https://github.com/stephane-klein/mermaid-sveltekit-playground parce que j'ai besoin de faire une intégration Mermaid dans mon projet Value Props.
Ce playground n'a que peu d'intérêt pour le moment, mis à part de confirmer que je n'ai pas eu de difficulté à initialiser Mermaid dans un projet SvelteKit.
Journal du lundi 06 mai 2024 à 13:56
#OnMePoseLaQuestion suivante :
C'est quoi ta stats de temps moyenne d'écriture de notes éphémères ?
Entre le 29 avril au 6 mai inclus, j'ai passé 7h pour publier 40 notes éphémères et 5 projets, soit environ 10 minutes par note…
Journal du lundi 06 mai 2024 à 13:31
Dans l'émission de France Inter 1804. Bonaparte et l’exécution du duc d’Enghien je découvre le mot codicille.
Journal du lundi 06 mai 2024 à 11:57
Je vais sans doute mal exprimer cette pensée, mais j'essaie tout de même.
J'ai l'impression que je suis une personne plus nostalgique que la majorité des personnes.
Il est très important pour moi de ne pas perdre ma mémoire, mes souvenirs, mon passé.
Je connais des personnes qui écrivent un journal intime.
Une page par jour ou par semaine, et cela, depuis plus de dix ans !
Je suis envieux, j'aurais aimé faire cela, mais je n'ai jamais eu la rigueur et j'ai toujours pensé que c'était trop tard — je trouve cette pensée très stupide.
Je ne tiens pas de journal intime, néanmoins, je souhaite, autant que possible, ne pas perdre mes informations numériques qui me permettent de garder de petites traces et m'aident à retrouver mes souvenirs. Quelques exemples :
- mes photos stockées dans Google Photos. La plupart des photos contiennent une date précise et une localisation ;
- mes e-mails, SMS, WhatApp, Signal, Mattermost, Slack, Matrix, Jabber… ;
- mes traces de déplacement Google Maps ;
- quand je dois me séparer d'un objet qui a fait partie de ma vie, je prends une photo avant de le jeter, pour ne pas l'oublier.
Malheureusement, j'ai déjà perdu beaucoup d'informations numériques, comme :
- mes e-mails Yahoo de 1998 à 2004 ;
- mes échanges Jabber (XMPP) de 2006 à 2015 ;
- mes échanges Slack professionnels ;
- plein de veielle photos ;
- des vieux SMS de 1996 à 2015 ;
- …
Quand je prends conscience de perdre ces informations, de perdre ces souvenirs, je pense mourir un peu. Personnellement, perdre mon passé, c'est un peu comme mourir un petit peu.
Toutes ces données sont importantes pour moi, bien que j'aie conscience qu'il y a peu de chance que je les consulte à la fin de ma vie… qu'elles me seront sans doute inutiles. J'ai aussi conscience que la collecte et la sauvegarde de ces informations demande bien trop d'effort par rapport à leur utilité.
Je ne suis "personne", je n'ai aucun intérêt à écrire plus tard mes mémoires… alors à quoi bon garder tout cela ?
Par moments, j'essaie de m'autopersuader de l'utilité de cette pratique en qualifiant cela comme une activité artistique. Si c'est de "l'art", je n'ai pas besoin de trouver d'utilité.
J'ai très peur du jour où je commencerai à perdre mes capacités cognitives et ma mémoire — ce moment a peut-être déjà commencé 🤔😱.
Je pense, en écrivant ces mots, au film Still Alice, qui m'avait beaucoup marqué.
J'ai l'impression que pour beaucoup de personnes, perdre ses souvenirs n'est pas quelque chose de très important.
#JeMePoseLaQuestion si cette impression correspond à la réalité ou non, je vais poser la question à des amis…
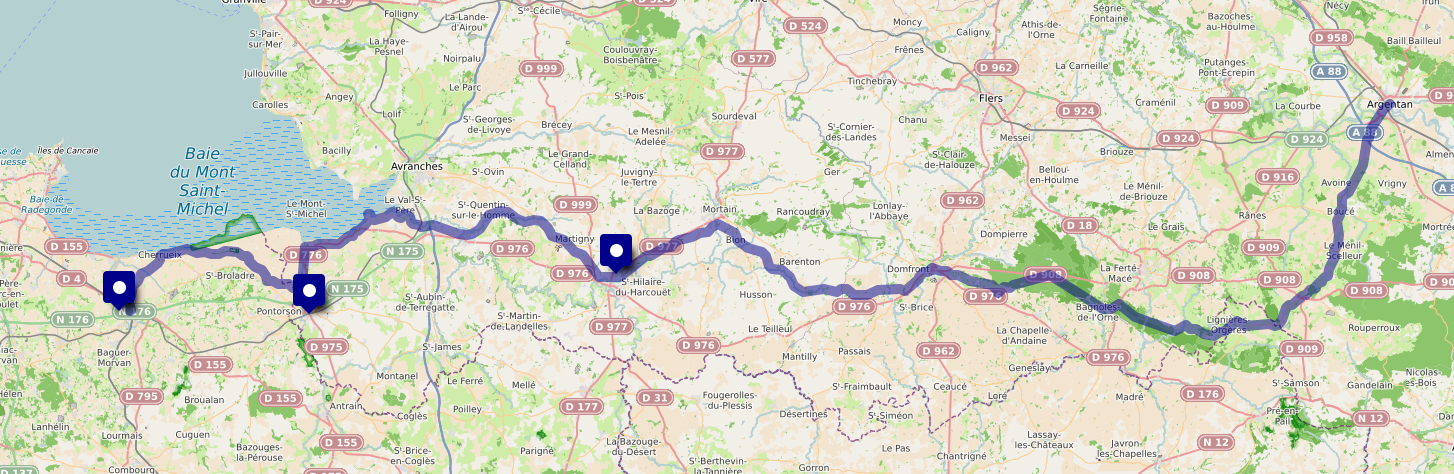
5 jours à vélo de Argentan à Dol-De-Bretagne
Du mercredi 8 au lundi 13 mai, je vais faire 5 jours de vélo, une petite partie de la véloroute Véloscénie, de Argentan à Dol-de-Bretagne en passant par Le Mont-Saint-Michel.
Soit 174km au total, en 5 jours. Je pense que cela ne va pas être bien difficile.
Voici le trajet : http://u.osmfr.org/m/1051084/
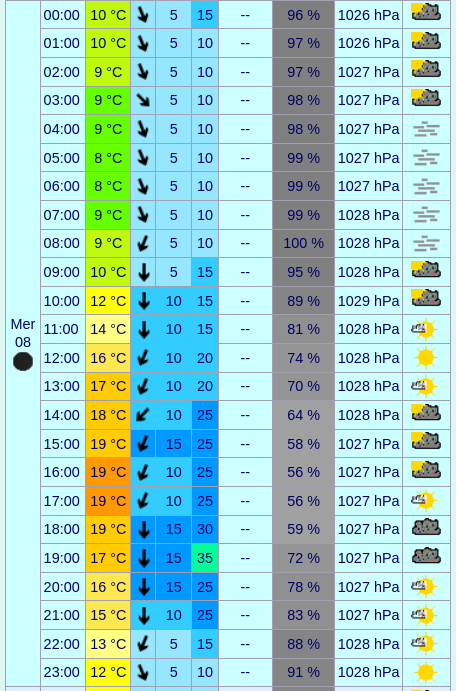
Par contre, je suis inquiet pour la météo. Voici ce que me dit le modèle Prévisions plus fines (ICON-EU) de Meteo Ciel :
Mercredi :
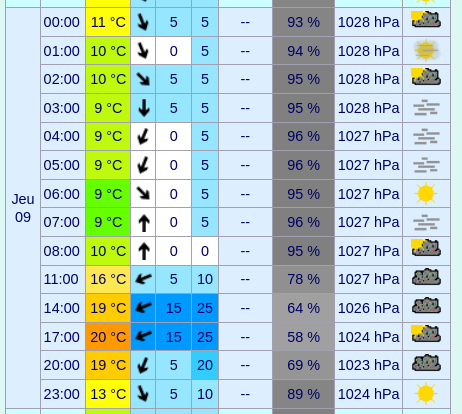
Jeudi :
Vendredi :
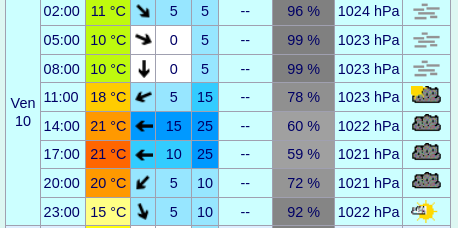
Pas de pluie les 3 premiers jours, 14°C environ les matins et entre 19 et 21°c au plus chaud dans l'après-midi.
Le modèle Tendances météo à 10 jours me dit :

Si ces prédictions s'avèrent, peut-être que nous allons pouvoir éviter la pluie !
Vendredi 3 mai 2024
Dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age", j'utilise les librairies remark mais pour le moment, je les trouve bien plus difficiles à utiliser que gray-matter couplé avec markdown-it.
Par exemple, je souhaite extraire dans un dict le contenu frontmatter de fichiers markdown, ainsi que la partie body.
Avec remark j'ai écrit avec difficulté le code suivant :
#!/usr/bin/env node
import { glob } from "glob";
import fs from 'fs';
import { unified } from 'unified';
import markdown from 'remark-parse';
import frontmatter from 'remark-frontmatter';
import extract from 'remark-extract-frontmatter';
import { parse } from 'yaml';
import stringify from 'remark-stringify';
const processor = unified()
.use(markdown)
.use(frontmatter, ['yaml'])
.use(extract, { yaml: parse })
.use(stringify);
const processMarkdown = async (filename) => {
const fileContent = fs.readFileSync(filename);
const result = await processor.process(fileContent);
const body = result.toString().split(/---\s*$/m)[2] || '';
return {
frontmatter: result.data,
body: body.trim()
};
};
for (const filename of (await glob("content/**/*.md"))) {
processMarkdown(filename).then(data => {
console.log('Frontmatter:', data.frontmatter);
console.log('Body:', data.body);
});
}
Et voici mon implémentation avec gray-matter :
#!/usr/bin/env node
import { glob } from "glob";
import matter from "gray-matter";
import yaml from "js-yaml";
for (const filename of (await glob("content/**/*.md"))) {
console.log(matter.read(filename, {
engines: {
yaml: (s) => yaml.load(s, { schema: yaml.JSON_SCHEMA })
}
}));
}
Je préfère sans hésitation cette seconde implémentation.
#JaiDécidé d'utiliser gray-matter.
#JeMeDemande quels seraient les avantages que j'aurai à utiliser remark 🤔.
Journal du vendredi 03 mai 2024 à 15:25
En lisant l'article RootDB - une application web de reporting, auto-hebergée - LinuxFr.org #JaiDécouvert RootDB qui est un outil de #data-analytics #data-visualisation #Business-Intelligence.
En regardant rapidement les repositories GitHub, j'ai l'impression que ce projet vient tout juste d'être libéréré. Il est codé en PHP et me semble être limité à MariaDB.
Pour le moment, ce projet ne m'intéresse pas.
Il vient s'ajouter à ma liste des autres outils du même type : Datasette, Observable, Gitbi, Evidence, Metabase et Redash.
Journal du vendredi 03 mai 2024 à 11:24
#JaiDécouvert via l'outil de Product Management nommé Productboard.
Jeudi 2 mai 2024
Journal du jeudi 02 mai 2024 à 23:15
#JeMeDemande les librairies qui existent pour afficher des graphes basés sur les résultats retournées par une base de données orienté graphe, comme Apache Age.
#JeMeDemande si je peux arriver à faire quelque chose avec la librairie Svelte suivante : https://svelteflow.dev/
Autre librairies :
Obsidian Quartz utilise d3js : https://github.com/jackyzha0/quartz/blob/v4/quartz/components/scripts/graph.inline.ts
Journal du jeudi 02 mai 2024 à 22:57
J'ai traité Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age".
Le résultat se trouve ici https://github.com/stephane-klein/apache-age-playground.
J'ai réussi à écrire plusieurs requêtes Cypher, mais je suis très loin de maitriser ce langage. Pour le moment, je me base principalement sur les exemples donnés dans la documentation.
Journal du jeudi 02 mai 2024 à 21:56
Dans le cadre de Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age" #JeSouhaite essayer de setup https://github.com/apache/age-viewer.
J'ai l'impression que l'image Docker n'a pas été publié https://github.com/apache/age-viewer/issues/118.
$ git clone git@github.com:apache/age-viewer.git .
$ docker build . -t stephaneklein/age-viewer:8a7f0be2513e2aa4b2caf3d9833f4e2707f0001d
$ docker push stephaneklein/age-viewer:8a7f0be2513e2aa4b2caf3d9833f4e2707f0001d
J'ai pushé l'image sur https://hub.docker.com/r/stephaneklein/age-viewer
Journal du jeudi 02 mai 2024 à 21:34
Je suis en train de travailler sur Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age" mais pour le moment, je regrette de ne pas prendre le temps de bien lire toute cette documentation https://age.apache.org/age-manual/master/index.html pour apprendre Cypher. Je ne comprends pas pourquoi je ne fais pas cette effort alors que le sujet m'intéresse 🤔.
Journal du jeudi 02 mai 2024 à 19:37
#OnMaPartagé ce projet https://pts-project.org/ :
The PiRogue Tool Suite is an open-source consensual digital forensic analysis and incident response solution that empowers organizations with comprehensive tools for network traffic analysis, mobile forensics, knowledge management, and artifact handling.
J'ai l'impression que c'est un outil lié à la sécurité informatique, mais après une première lecture de 2min, je ne comprends pas très bien ni son utilité ni son usage 🤔.
Mercredi 1 mai 2024
Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Finalement, contraiment à ce que j'avais décidé ici, je n'ai pas utilisé Convict dans mon application Value Props propulsé par SvelteKit.
J'ai "simplement" utilisé la vite-plugin-environment pour définir la valeur par défaut des variables d'environnement de configuration utilisées par l'application.
Exemple :
// vite.config.js
import { defineConfig } from "vite";
import EnvironmentPlugin from 'vite-plugin-environment'
import { sveltekit } from "@sveltejs/kit/vite";
export default defineConfig({
plugins: [
EnvironmentPlugin({
POSTGRES_URL: "postgres://webapp:password@localhost:5432/myapp",
Y_WEBSOCKET_URL: "ws://localhost:1234",
SMTP_HOST: "127.0.0.1",
SMTP_POST: 1025,
SECRET: "secret"
}),
sveltekit()
]
});;
Et voici un exemple d'utilisation de ces paramètres de configuration :
// src/lib/server/db.js
import postgres from "postgres";
const sql = postgres(process.env.POSTGRES_URL);
export default sql;
Rien de plus, je n'ai ni utilisé Convict ni dotenv, j'ai pu suivre le principe KISS.
J'ai décidé de continuer à utiliser la lib Convict de configuration management
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Après avoir parcouru la documentation de env-cmd et dotenv
Après avoir réalisé que je n'avais rencontré aucun problème avec node-convict et que j'avais même pris du plaisir à l'utiliser.
Suite au feedback d'un ami qui me dit :
J'aime beaucoup convict qu'on a utilisé dans gibbon-mail
Et qui me rappelle que dotenv est très orienté "fichier de conf" alors que lui comme moi suivons plutôt la doctrine "variable d'env" (The Twelve-Factors App).
#JaiDécidé que je n'allais suivre la mode, que je vais continuer à utiliser Convict.
Une heure plus tard, j'ai changé d'avis Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Journal du mercredi 01 mai 2024 à 16:37
En étudiant le projet dotenv — ici, ici et ici — je découvre que son auteur est un Indie Hacker, qui opère à lui tout seul le service SaaS dotenv (partie payante "Vault").
C'est typiquement ce type de projet que j'aurais aimé créer ! Mais je n'ai pas eu l'idée, bien qu'elle semble tellement évidente après l'avoir observée !
Je me demande s'il a beaucoup d'utilisateurs 🤔.
J'ai trouvé son compte sur Indie Hackers, mais je ne trouve aucune information, cependant j'ai l'impression en lisant ce billet qu'il a lancé ce service en 2022, ce que semble confirmer la page contribution du repository dotenv-vault.
J'ai ensuite trouvé ce compte, il semble qu'en 2022, quelque temps après le lancement du projet, il générait 750$ de revenus par mois.
Mais, depuis, le projet semble avoir gagné beaucoup d'utilisateurs :
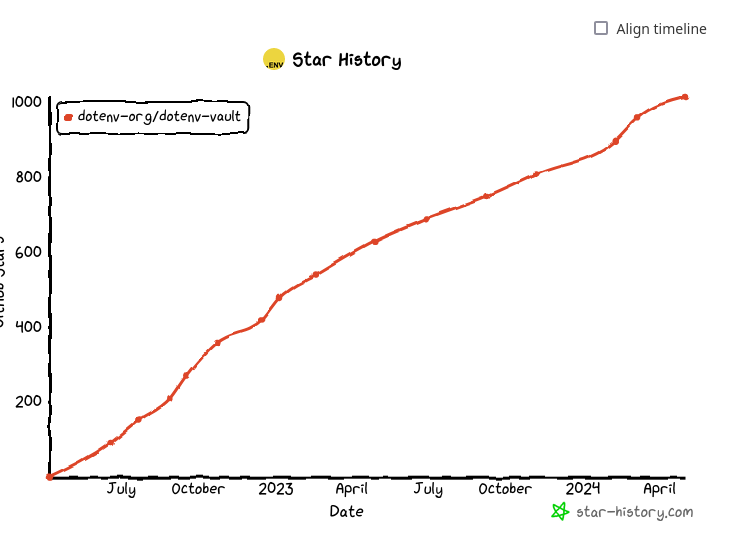
Je trouve que le marketing positioning du projet dotenv est très bien présenté
Je trouve que le site web https://www.dotenv.org du projet dotenv est un bel exemple de Marketing positonning. Voici pourquoi :
- la page de pricing compare clairement le prix de dotenv-vault avec ses concurrents directs :
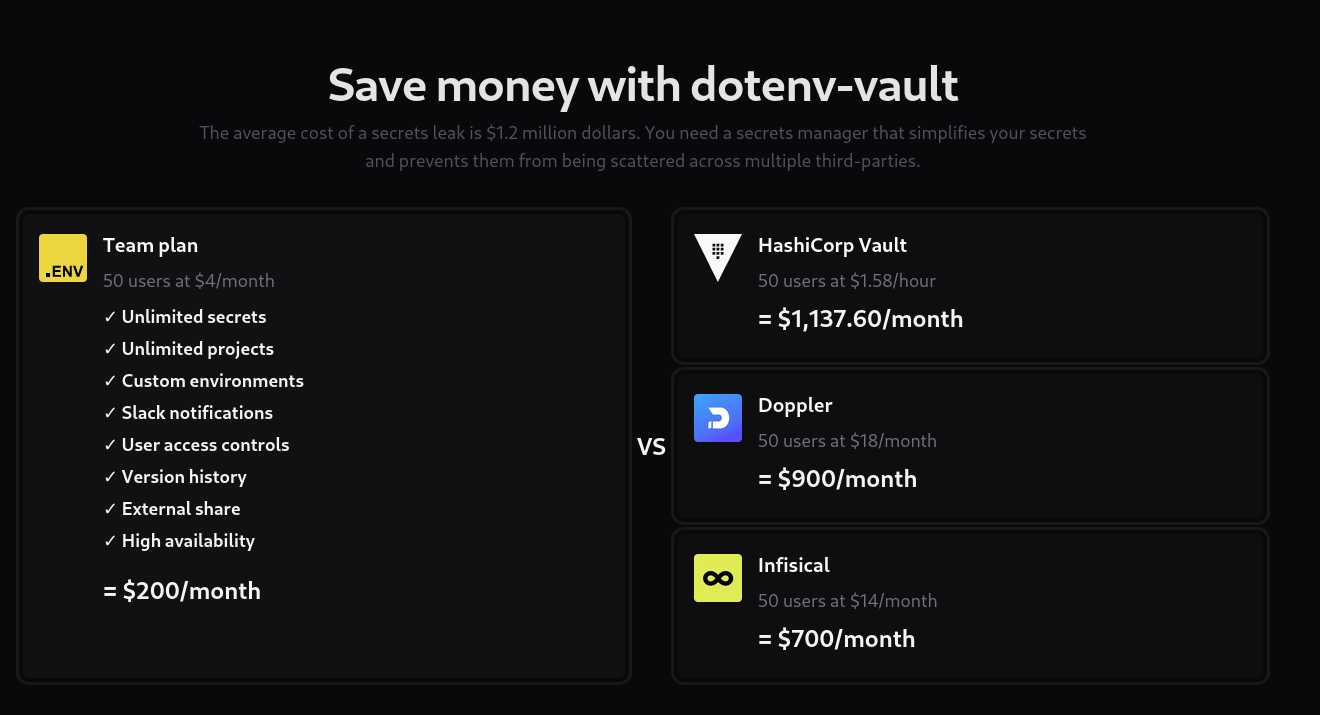
- Le blog de dotenv-vault contient plusieurs articles de blog détaillés de comparaison entre la proposition de valeur de dotenv-vault et celle de chacun de ses concurrents majeurs :
Journal du mercredi 01 mai 2024 à 16:06
Je suis en train de lire la documentation de dotenv-vault, j'ai beau relire plusieurs fois cette documentation, je n'arrive pas à comprendre où est stocker la configuration 🤔.
5 minutes après, je pense avoir compris, la libraire dotenv-vault est basé sur le service SaaS https://www.dotenv.org/.
5 minutes après, #JaiLu Dotenv Vault vs Infisical | Dotenv.
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Dans l'application web que je développe pour Value Props, je n'utilise actuellement aucune librairie de configuration pour l'app.
J'utilise uniquement process.env.CONFIG_PARAM || "default value".
En contexte, cela ressemble à ceci.
import nodemailer from "nodemailer";
let transporter;
if (process.env?.SMTP_USER && process.env?.SMTP_PASS) {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: true,
auth: {
user: process.env.SMTP_USER,
pass: process.env.SMTP_PASS
}
});
} else {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: false
});
}
export default transporter;
Je commence maintenant à utiliser des paramètres de configuration à différents endroits. Conséquence, je me dis que c'est peut-être maintenant le bon moment pour utiliser une librairie de configuration du type Convict.
Pourquoi j'ai cité Convict ? Parce que c'était le choix que j'avais fait en 2019, dans le projet gibbon-mail.
#JeMeDemande qu'elle est en 2024, la librairie [Javascript] de type environment-variables, configuration-management la plus populaire actuellement.
Pour répondre à cette question, j'ai commencé à faire une recherche sur npm trends et il m'a proposé la suggestion suivante config vs configstore vs convict vs cross-env vs dotenv
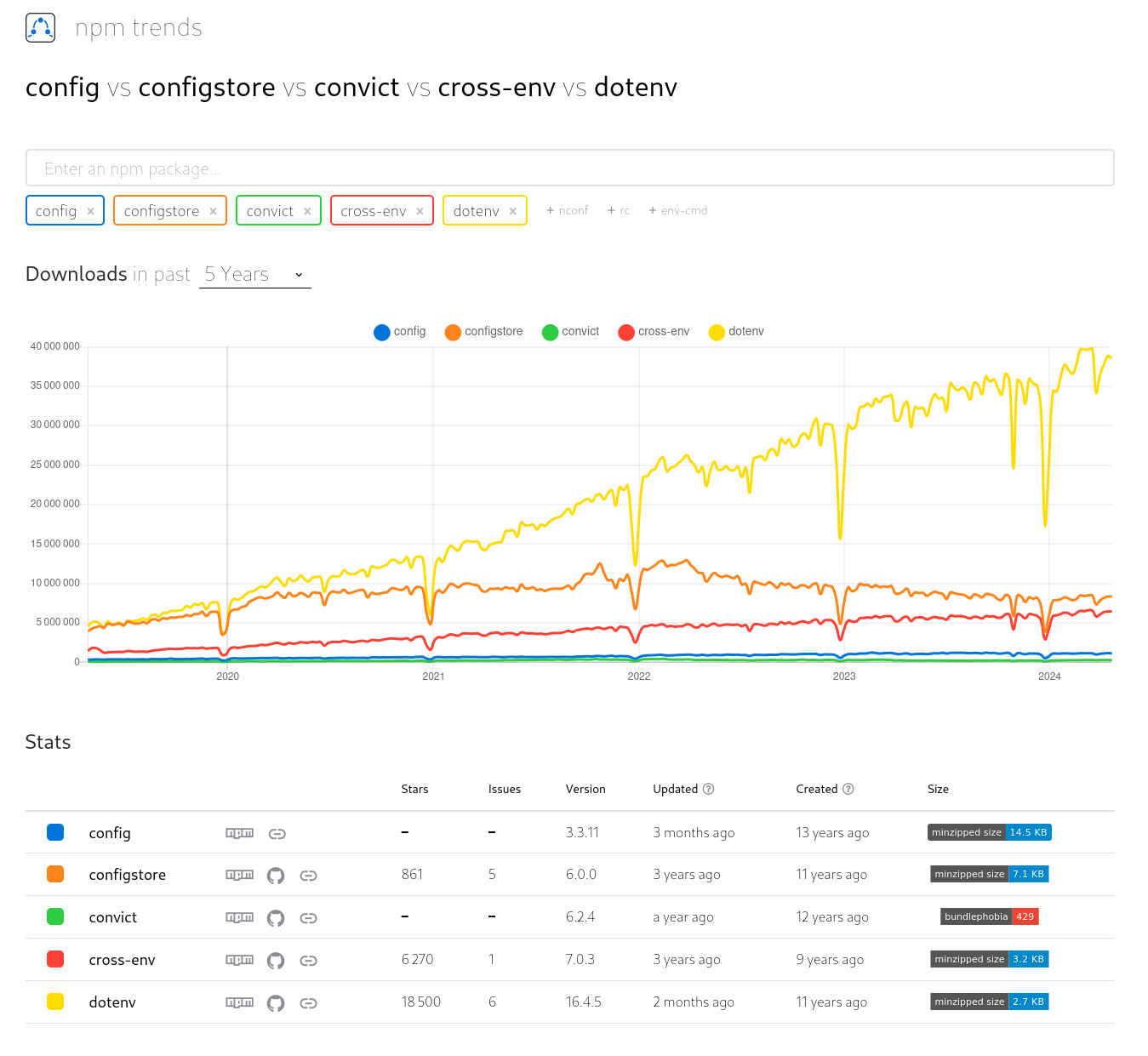
dotenv semble se détacher assez franchement.
dotenv et cross-env sont listés dans Delightful Node.js packages and resources.
Je constate que cross-env est abandonné et conseille ici de migrer vers env-cmd.
Je vais demander avis à des amis, mais pour le moment, je pense que je vais utiliser dotenv.
Quelque heure plus tard :
Journal du mercredi 01 mai 2024 à 14:05
En lien avec 2024-05-01_1205 :
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Je n'ai pas réussi à trouver mention de fonctionnalité de loop ou condition dans la documentation du plugin Obsidian Templater mais après lecture de ces deux threads :
il semble que Templater supporte bien les fonctionnalités permettant d'implémenter des loop et condition dans un template.
Je pense que cela va me servir de source d'inspiration pour 2024-05-01_1205.
Je découvre la newsletter de l'émission "Le dessous des cartes"
#JaiDécouvert vient le partage d'un ami, l'existance de la Newsletter de l'émission Le dessous des cartes.
Émission que j'adore mais je réalise que je ne la regarde pas assez !
Pour tenter de résoudre ce problème, j'ai essayé d'ajouter le flux RSS de l'émission à mon instance miniflux, mais malheureusement, le flux RSS du site semble ne pas fonctionner 😔.
Finalement, je me suis abonné à la newsletter, bien que j'aurais préféré un abonnement RSS.
Journal du mercredi 01 mai 2024 à 13:05
En lien avec 2024-05-01_1205, dans le code source du plugin Obsidian nommé Templater, #JaiDécouvert la librairie Javascript rusty_engine :
A Javascript templating engine in WASM
En dehors de l'aspect performance, je me demande si cette librairie serait plus adaptée à mes besoins que EJS 🤔.
Journal du mercredi 01 mai 2024 à 12:05
#JeMeDemande si la librairie mdsvex me permet d'implémenter de manière agréable des nouveaux components qui ont la capacité d'aller chercher des données en backend, typiquement une base de données PostgreSQL.
J'aimerais que la requête soit décrite directement dans le markdown.
Je souhaite aussi que le composant soit rendu seulement côté serveur (SSR).
J'aimerais pouvoir implémenter quelque chose comme :
# Mon titre
Mon paragraphe
``sql posts
SELECT title FROM posts ORDER BY created_at LIMIT 10
``
<ul>
{#each posts as post}
<li>{post}</li>
{/each}
</ul>
(inspiration de https://evidence.dev/).
#JeMeDemande si mdsvex serait adapté pour cet objectif.
Je viens de voir ce thread Thoughts on Mdsvex moving away from Unified : sveltejs. Il contient un lien vers Penguin-flavoured markdown · pngwn/MDsveX · Discussion #293 · GitHub qui me semble intéressant #JaimeraisUnJour prendre le temps de le lire.
Autre thread What remark and rehype plugins are people using? · pngwn/MDsveX · Discussion #354 · GitHub.
#JeMeDemande si remark ou markdown-it serait mieux adapté pour atteindre mon objectif 🤔.
#JaiDécouvert (ou plutôt redécouvert) https://github.com/unifiedjs.
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Evidence semble implémenter un mécanisme qui ressemble à mon objectif et est codé en Svelte.
Journal du mercredi 01 mai 2024 à 11:05
Voici une liste non exhaustive de média que je n'utilise pas comme source d'information :
- Medium
- salons Discord
Et une première liste non exhaustive de mes sources d'informations :
- Univers Hacker
- Ma agréateur perso miniflux self hosted
- https://lobste.rs/
- https://news.ycombinator.com/
- https://lwn.net/ (j'ai une version payante)
- Fediverse https://mamot.fr/deck/getting-started
- https://old.reddit.com/
- https://linuxfr.org/
- Actualité générale :
Voir aussi Je suis abonné à ces chaines YouTube - Jardin numérique de Stéphane Klein/.
Cette note éhémères est très incomplète, je l'ai noté rapidement sur le vif.
#JaimeraisUnJour réaliser un document bien plus exaustif.
Journal du mercredi 01 mai 2024 à 10:05
En faisant la recheche suivant sur le subreddit Svelte : "markdown" #JaiDécouvert ici le projet Sveltia :
Alternative to Netlify/Decap CMS. Modern, fast, lightweight, Git-based headless CMS. Free & open source. UX-driven development. Made with Svelte.
#JaiDécouvert aussi ici le projet Sanity :
Sanity Studio – Rapidly configure content workspaces powered by structured content
basé sur ReactJS, après une première lecture rapide, je ne n'arrive pas à comprendre si c'est un #headless-cms ou non 🙅♀️.
En lien : l'issue de mon backlog nommée Étudier, tester, mettre en oeuvre tina.io
Je découvre "Carta" (Svelte Markdown editor)
En faisant la recheche suivant sur le subreddit Svelte : "markdown" #JaiDécouvert ici la librairie carta :
A lightweight, fast and extensible Svelte Markdown editor and viewer.
La démo se trouve ici : https://beartocode.github.io/carta/
#JeMeDemande si je dois tester cette librairie pour réaliser l'objectif du projet Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai regardé le code source de l'extension Slash et j'ai l'impression que je pourrais m'inspirer de cette implémentation pour créer une extension permettant d'implémenter un "sélécteur de ressource", "à la" Obsidian pour le projet Value Props 🤔.
Mardi 30 avril 2024
Journal du mardi 30 avril 2024 à 23:04
Je continue mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte".
Voici le résultat de ma dernière itération :
#JeMeDemande si CodeMirror implémente une fonctionnalité comme conceal de Neovim 🤔. J'ai trouvé :
D'après toi, quel problème a cherché à résoudre Svelte ?
D'après toi, quel problème a cherché à résoudre Svelte ?
Comme le dit ici Richard Harris :
The first version of Svelte was all about testing a hypothesis — that a purpose-built compiler could generate rock-solid code that delivered a great user experience. The second was a small upgrade that tidied things up a bit.
Je pense que la réponse se trouve dans ce billet https://svelte.dev/blog/frameworks-without-the-framework
D'après ce que j'ai compris il voulait tester si une librairie compilé pourrait :
- Générer des projets plus petit
- Générer des projets plus rapide
- Apporté des choses élégantes
Après les résultats de ce POC et 8 ans plus tard, je pense que les réponses à ces questions étaient oui.
J'ai lu ce billet il y a plusieurs année, je n'ai pas pris le temps de le relire.
Tu utilises quoi pour publier ton Obsidian sur notes.sklein.xyz ?
Pour le moment, j'utilise Obsidian Quartz pour déployer https://notes.sklein.xyz.
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Je me demande si LogSeq utilise CodeMirror 🤔
En pensant au projet Projet -1 "CodeMirror, autocomplétion, Svelte", je me suis demandé si le projet OpenSource LogSeq utilise ou non CodeMirror.
Je suis aller voir le code source et j'ai constaté que la réponse est oui, LogSeq utilise CodeMirror. J'ai un peu plus creusé et je suis tombé dans cette partie du code qui je pense implémente la fonctionnalité d'auto complétion de l'éditeur de LogSeq.
Problème 😔, je n'ai aucune connaissance dans le langage Closure et il m'est difficile de comprendre cette implémentation et de m'en servir dans mon POC.
Svelte n'a pas de runtime, il est compilé
D'après ce que j'ai compris, les framework framework VueJS et ReactJS utilisent des runtime. Ce n'est pas le cas de Svelte qui est un framework qui nécessite une phase de compilation, il n'utilise pas de runtime.
C'est une différence majeure entre les frameworks VueJS et ReactJS versus Svelte.
Je dis cela avec des pincettes, mais il me semble que cela permet à Svelte d'implémenter des solutions "élégantes" non possibles avec runtime. À vérifier…
Aller plus loin sur ce sujet :
-
Extrait de Svelte 3: Rethinking reactivity :
Svelte is a component framework — like React or Vue — but with an important difference. Traditional frameworks allow you to write declarative state-driven code, but there's a penalty: the browser must do extra work to convert those declarative structures into DOM operations, using techniques like virtual DOM diffing that eat into your frame budget and tax the garbage collector.
Instead, Svelte runs at build time, converting your components into highly efficient imperative code that surgically updates the DOM. As a result, you're able to write ambitious applications with excellent performance characteristics.
-
Frameworks without the framework: why didn't we think of this sooner? You can't write serious applications in vanilla JavaScript without hitting a complexity wall. But a compiler can do it for you.
Pourquoi j'apprécie le framework SvelteKit ?
La partie que je préfère de plus dans le framework SvelteKit ce sont les fonctionnalités décrient dans la section Routing et Advanced routing de la documentation de SvelteKit.
Si vous survolez ces pages de documentation, vous allez peut-être me poser la question « ok et alors, c'est quoi le truc cool ? ». Je ne vais pas vous répondre maintenant, parce que c'est intégralité de ces deux pages de documentations qui faut lire avec une très grande attention. En utilisant SvelteKit dans plusieurs projets, j'ai appris à découvrir toutes les petites subtilités du système de rooting de SvelteKit.
#JaimeraisUnJour prendre le temps de paraphraser avec mes mots cette documentation pour partager avec vous l'enthousiasme que j'ai à l'égard de SvelteKit.
Est-ce que Nuxt ou NextJS sont moins élégants que SvelteKit ? Pour le moment, je ne sais pas, je n'ai pas pris assez de temps pour pousser assez loin la comparaison. C'est l'objectif de Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit".
Un ami est heureux d'utiliser Nuxt (VueJS), je suis heureux pour lui 🙂
Un ami me partage la satisfaction qu'il a à utiliser la version 3 de Nuxt :
Nuxt3 est devenu magnifique avec le combo Nuxt/Font, Nuxt/i18n, Tailwind CSS, sa couche server pour proxy une api sous le boisseau. Ça en fait un framework redoutable.
Suite à la lecture de ce commentaire, #JeMeDemande s'il est autant satisfait de Nuxt3 que je le suis de SvelteKit 🤔.
Je souhaite depuis longtemps — début 2023 — réaliser ces deux projets :
- Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit"
- Projet 3 - "Réaliser un petit projet basé sur Nuxt pour le comparer avec SvelteKit"
pour être en capacité de donner mon opinion éclairée de comparaison entre ces trois frameworks NextJS, Nuxt et SvelteKit.
Pour le moment, je me contente de recevoir avec plaisir le bonheur de mon ami et je garde en mémoire son expérience, pour la partager le jour où un ami de demandera mon avis au sujet de Nuxt.
Première itération d'un POC de CodeMirror avec l'autocomplétion
#JaiPublié https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc qui contient mes 2 premières heures de travail sur le #POC Projet 1 - "CodeMirror, autocomplétion, Svelte".
J'ai réussi à setup le projet, mais pour le moment, je n'arrive pas à bien configurer la fonctionnalité autocomplete de CodeMirror. Par exemple, je n'arrive pas à ne pas afficher les caractères [[ dans le popup qui affiche la liste des suggestions.
Idéalement, pour expliquer, j'aimerais réaliser un screencast.
Je pense que ce POC va me prendre du temps. Je pense que je vais devoir étudier en profondeur l'API de @codemirror/autocomplete.
#SiJeDevaisParier, mon estimation de durée 🤔 serait de 8h à 20h de travail.
Lundi 29 avril 2024
Journal du lundi 29 avril 2024 à 16:04
Quand je dois gérer seul, et d'autant plus en équipe, une grosse quantité de documents administratifs, je rencontre des difficultés pour classer les fichiers et retrouver ces fichiers dans une base hiérarchique.
J'ai déjà écrit sur ce problème dans l'issue suivante : Écrire un billet de réflexion au sujet des forces et faiblesses du classement de documents dans des dossiers versus un système à plat avec des tags.
Voici ce que j'écrivais le 6 août 2023 :
Difficultés que j'ai rencontrées ces derniers mois (sous forme de bullet point) :
- en situation pro :
- difficultés à construire une taxinomie (organisation et namming des dossiers, sous dossiers) pour classer les documents "Ressource Humaine" de mon équipe
- difficulté à naviguer dans cette taxinomie
- types de documents classés
- contrat de travail
- promesse d'embauche
- budget
- avenant de contrat de travail
- ces documents étaient classés dans le Google Drive de la société
- difficultés pour coopérer
- mes collaborateurs avaient des difficultés à comprendre rapidement la taxinomie
- la responsable RH archivait les mêmes documents dans un dossier "à elle", elle utilisait sa propre taxonomie
- je souhaitais "merger" ces deux dossiers, mais comme aucune taxinomie n'est évidente, nous n'avons même pas pris le temps d'essayer de "merger" nos dossiers
- dans une assiociation
- j'ai hérité d'un Google Drive avec une taxinomie définie par l'ancien président du club
- j'ai des difficultés à retrouver les documents
- exemples :
- est-ce qu'une fiche de paie doit être classée dans le dossier "comptabilité" ou "administratif" ?
- comment lister tous les documents qui concernent le joueur John Doe ?
- comment lister tous les documents de la saison 2022/2023 ?
Actuellement, mon intuition de réponse à ce problème est :
- ne pas mettre en oeuvre une taxinomie, mais utiliser un thésaurus, c'est-à-dire :
- organiser "à plat" (sans dossier) les documents
- attribuer des tags (labels) sur ces documents
- dans une "sidebar" :
- proposer des recherches sauvegardées, exemples :
- contrats de travailles
- John Doe
- 2022/2023
- ...
- permettre aussi de lister des tags favoris dans cette sidebar
Aujourd'hui, #JeMeDemande si Obsidian pourrait être adapté pour ranger des documents administratifs.
Avec ce type d'outil, il serait possible de ranger les documents dans de la "prose".
Cela permettrait de retrouver ces documents via plusieurs méthodes, avec du contexte autour du document….
#JeMeDemande s'il est possible d'attacher des tags à des pièces jointes 🤔.
Journal du lundi 29 avril 2024 à 11:04
Dans l'application web de mon projet Value Props, j'utilise la librairie sveltekit-i19n qui propose la fonctionnalité suivante :
Module-based – your translations are loaded for visited pages only (and only once!)
Actuellement, j'ai configuré les modules suivants :
❯ tree src/lib/translations
src/lib/translations
├── en
│ ├── all_data.json
│ ├── buttons.json
│ ├── login.json
│ ├── menu.json
│ ├── my_password.json
│ ├── my_preferences.json
│ ├── question_answers.json
│ ├── question_setup.json
│ ├── question_status.json
│ ├── space_data.json
│ ├── space_edit.json
│ ├── space.json
│ ├── space_members.json
│ ├── space_questions.json
│ ├── spaces.json
│ ├── space_slides.json
│ └── space_status.json
├── fr
│ ├── all_data.json
│ ├── buttons.json
│ ├── login.json
│ ├── menu.json
│ ├── my_password.json
│ ├── my_preferences.json
│ ├── question_answers.json
│ ├── question_setup.json
│ ├── question_status.json
│ ├── space_data.json
│ ├── space_edit.json
│ ├── space.json
│ ├── space_members.json
│ ├── space_questions.json
│ ├── spaces.json
│ ├── space_slides.json
│ └── space_status.json
├── index.js
├── lang.json
└── README.md
3 directories, 37 files
Je viens à nouveau de me casser la tête parce que j'ai besoin d'une traduction présente dans le module space_data dans une page qui ne fait pas partie de ce module.
Cela m'arrive très très souvent et je m'en veux, je n'ai pas respecté le principe YAGNI !
Dès le début d'l'implémentation de cette application, j'ai voulu faire les choses "bien" et j'ai commencé à utiliser la fonctionnalité "module" de la librairie !
Je suis persuadé que c'est une optimisation inutile pour le moment. Le découpage en module est difficile.
Encore une expérience qui me confirme que je dois toujours suivre par défaut le principe suivant du Zen of Python :
Flat is better than nested.
Je pense me créer pour ce projet une tâche de dette technique, de refactoring dont le but sera de migrer tous les modules vers un seul module — un seul fichier).
Seulement, le jour où je travaillerai sur la performance de chargement des pages, je réfléchirai à un découpage "intelligent" des traductions en modules.
Journal du lundi 29 avril 2024 à 10:04
Dans le livre How to Make Notes and Write, je lis :
You should read with a pen in your hand and enter… short hints of what you feel… may be useful; for this be the best method of imprinting [them] in your memory. — #BenjaminFranklin
J'aimerais suivre ce conseil.
Depuis des années, je n'arrive pas à mettre en place cette pratique à cause des difficultés suivantes :
- Je ne pratique pas la prise de notes sur papier.
- Je lis souvent sur mon smartphone, dans le canapé, dans le lit, dans le metro… et dans ce contexte, il m'est difficile de prendre des notes.
- Quand je lis un livre papier, je suis généralement allongé, je ne lis pas sur une table et dans ce contexte, il m'est difficile de prendre des notes.
- De par mon éducation, je n'aime pas écrire sur un livre, j'ai l'impression de le dégrader. Je sais que c'est sans doute une mauvaise habitude que cela n'a pas d'importance.
- La prise de notes sur une liseuse Kindle n'est pas pratique.
J'aime prendre des notes avec un clavier.
Je pense que je devrais lire sur une table, avec mon laptop ouvert.
#JeMePoseLaQuestion : dans ce cas, est-ce que je dois arrêter de lire quand je ne suis pas dans ce contexte de lecture 🤔 .
À propos de cette citation, ChatGPT me dit :
The quote you mentioned from Benjamin Franklin, advising to read with a pen in hand and jot down useful notes, appears to be a slightly altered version of a passage from his writings. The more commonly cited version of this quote is: "I would advise you to read with a pen in hand, and enter in a little book short hints of what you find that is curious, or that may be useful; for this will be the best method of imprinting such particulars in your memory." This advice underscores the importance of actively engaging with reading material to enhance memory retention and personal learning.
It seems that this particular expression of thought isn't directly sourced from Franklin's most famous works like "Poor Richard's Almanack" or "The Autobiography of Benjamin Franklin." Instead, it reflects a general principle he emphasized about the value of learning and recording insights for personal development. This approach to learning was typical of Franklin's style, promoting continuous personal improvement and practical application of knowledge.
For more details on the context or variations of this quote, you might find it helpful to explore collections of Franklin's lesser-known writings or advice, where such insights often appear.
Samedi 27 avril 2024
Journal du samedi 27 avril 2024 à 22:55
Ici sur #Fediverse, #JaiDécouvert le #livre How to Make Notes and Write de Dan Allosso.
#JaiLu les chapitres suivants :
I.Main Body1.Inspiration, Interest, Anxiety 52.Writing is Thinking 143.Working with Ideas 224.Highlighting and Taking Notes
Pour le moment je trouve cela très intéressants. Je vais essayer de mettre cela en pratique, si possible en mode WorkInPublic.
Jeudi 25 avril 2024
Journal du jeudi 25 avril 2024 à 20:44
Le 25 octobre 2020, j'ai commandé et installé un serveur Dedibox (Start-2-S-SSD - Intel® C2350 (Avoton) - 4 GB DDR3 - 1x 120 GB SSD) que j'ai nommé perier
Position du serveur : Datacenter: AMS1, Room: Hall 6 12, Rack: 6.12.53, Block: C, Position: 8.
Prix de cette machine : 5,48 € TCC par mois, 66 € / an.
Coût total entre octobre 2020 et avril 2024 : 42 mois x 5,48 € = 230 €.
Aucune panne, pendant 42 mois.
J'utilisais cette machine principalement pour du stockage web statique.
J'y hébergeais https://sklein.xyz.
Ce jeudi 25 avril 2024, cette machine est tombée en panne, réponse du support :
Navré de la situation, il s'agit d'une erreur matérielle qui ne permet pas la récupération de données. Pourriez-vous vérifier l'état de vos sauvegardes.
Chose surprenante, le même modèle de serveur de mon ami AM a, lui aussi, une panne matérielle, exactement au même moment que moi.
Autre chose surprenante, la panne est tombée le même jour que cet incident déclaré sur https://status.scaleway.com/ :
[DEDIBOX] - Switch down in AMS1 Hall 6 rack B53
Resolved - This incident is resolved
Apr 25, 14:28 CEST
Investigating - Dedibox switch located in AMS1 Hall 6 rack B53 is currently down
Apr 25, 10:20 CEST
Le support m'a dit qu'il n'y a aucun lien entre cette panne et la panne matérielle de mon serveur.
J'en doute 🤔.
Je ne suis pas surpris de cette panne, d'après mes souvenirs, cette machine était reconditionnée, très vieille, j'avais bien conscience qu'une panne pouvait arriver à tout moment.
C'est la première fois que j'ai ce type de panne définitive depuis que j'utilise des serveurs dédiés Dedibox Scaleway, depuis 2006.
Au passage, j'ai perdu tout mon contenu de https://stats.sklein.xyz/
Samedi 13 avril 2024
Journal du samedi 13 avril 2024 à 20:00
#OnMaPartagé et #JaiÉcouté l'intégralité de André Comte-Sponville, la philosophie au service du bonheur de André Compte-Sponville. Je l'ai tellement appricié que je l'ai partagé à plusieurs amis. Je l'ai écouté au moins 3 fois.
Sujets abordés :
- 02:07 Une enfance malheureuse
- 06:23 La responsabilité du malheur
- 09:09 L’hystérie : mythe ou réalité ?
- 13:06 L’expérience de psychanalyse
- 14:46 Rencontrer la philosophie
- 16:28 Perdre la foi
- 23:16 La quête de sens
- 28:23 La peur de rater sa vie
- 31:04 Les échecs
- 32:03 L’échec amoureux
- 32:36 La réussite de ses proches
- 34:15 Doit-on accepter d’être malheureux ?
- 40:12 Le deuil
- 44:37 Relâcher nos attentes
- 47:43 Le réel est-il condamné à nous décevoir ?
- 51:27 Vivre sa vie ou rêver sa vie ?
- 01:06:02 L’échec politique
- 01:09:39 Affiner ses positions politiques
- 01:15:21 Comment progresser ?
[ << Notes plus récentes (1000) ] | [ Notes plus anciennes (69) >> ]