
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (300) ] [ Page suivante (126) >> ]
Journal du mardi 10 septembre 2024 à 12:48
#JaiLu L'option ControlMaster de ssh_config.
J'y ai découvert l'open ControlMaster de OpenSSH.
Journal du lundi 09 septembre 2024 à 21:33
#JaiLu Windows NT vs. Unix: A design comparison (from).
Je ne connais rien au kernel MS Windows, j'ai trouvé cela intéressant.
Journal du dimanche 08 septembre 2024 à 21:32
#JaiDécouvert Mini Spreadsheet Component with Svelte 5 : sveltejs.
Très minimaliste et sympatique 🙂.
Journal du dimanche 08 septembre 2024 à 20:18
Detect bots/crawlers/spiders using the user agent string
Journal du dimanche 08 septembre 2024 à 11:15
#JaiDécouvert Window.sessionStorage
L'objet global
sessionStorageest similaire àWindow.localStorage, à la différence que les données enregistrées dans sessionStorage ont une durée vie limitée et expirent à la fin de la session de navigation actuelle....
En revanche, une session de navigation n'est valable que pour le contexte de navigation actuel, c'est-à-dire que le fait d'ouvrir une page dans un nouvel onglet ou dans une nouvelle fenêtre provoquera l'initialisation d'une nouvelle session de navigation, ce qui diffère du comportement des sessions utilisant des cookies.
-- from
Je vais avoir besoin de sessionStorage pour le projet Idée d'un outil de session recoding web minimaliste basé sur rrweb.
2024-09-14 : j'ai nommé ce projet gibbon-replay.
Journal du dimanche 08 septembre 2024 à 11:03
#JaiDécouvert le nom du concept "dichotomie du contrôle" (from).
Je n'ai pas trouvé d'article Wikipedia sur ce sujet.
La "dichotomie du contrôle" est un principe clé dans la philosophie stoïcienne, notamment développé par Épictète. Elle distingue entre ce qui est en notre pouvoir et ce qui ne l'est pas. Selon les Stoïciens, seules nos propres actions, nos jugements et nos choix (notamment comment nous répondons aux impressions externes) sont sous notre contrôle. Tout le reste — y compris la richesse, la santé, ou l'opinion des autres — est considéré comme étant en dehors de notre pouvoir et, par conséquent, ne devrait pas influencer notre tranquillité d'esprit.
Le concept est central dans les enseignements d'Épictète, qui insiste sur l'importance de se concentrer uniquement sur ce qui dépend de nous, afin de mener une vie vertueuse et en accord avec la nature. Cette approche est explorée dans ses "Entretiens" et d'autres textes stoïciens, et constitue une base de la pratique stoïcienne pour atteindre la paix intérieure et la résilience face aux événements extérieurs.
-- from ChatGPT
Journal du samedi 07 septembre 2024 à 21:44
#JaiLu ce thread Hacker News : Rrweb – record and replay debugger for the web.
#JaiDécouvert highlight.io, replay.io, Zipy et wirequery qui semblent être des alternatives à Posthog et OpenReplay.
Tous ces outils sont basés sur rrweb.
wirequery semble être un projet 100% open source.
#JaiDécouvert un autre projet basé sur rrweb : RecordOnce pour générer des tutoriels.
Journal du samedi 07 septembre 2024 à 11:53
#JaiDécouvert le package goatcounter-js pour directement charger le code JavaScript de Goatcounter. Ce qui, je pense, permet d'éviter le blocage de chargement de ce script par uBlock Origin.
Journal du jeudi 05 septembre 2024 à 11:52
#JaiLu The SOC2 Starting Seven (from)
First: for us, SOC2 is about sales. You will run into people with other ideas of what SOC2 is about. Example: “SOC2 will help you get your security house in order and build a foundation for security engineering”. No. Go outside, turn around three times, and spit. Compliance is a byproduct of security engineering. Good security engineering has little to do with compliance. And SOC2 is not particularly good. So keep the concepts separate.
-- from
😉
Suite à cela, j'ai lu l'article Wikipédia sur System and Organization Controls.
This is not an instruction guide for getting SOC2-certified. Though: that guide would be mercifully short: “find $15,000, talk to your friends who have gotten certified, get referred to the credible auditor that treated your friends the best, and offer them the money, perhaps taped to the boom box playing Peter Gabriel you hold aloft outside their offices”.
-- from
😉
If there is one thing to understand about SOC2 audits, it’s: SOC2 is about documentation, not reality.
-- from
🙈
Puis ils vous remettront un questionnaire de 52 000 lignes appelé Liste de demandes d'informations (IRL), basé d'une manière occulte sur ce que vous leur avez dit que vous faisiez. Vous le remplirez. Vous aurez quelques réunions, puis vous leur enverrez un chèque. Le nom de votre entreprise figurera sur un rapport.
-- from
🙈
PRs, Protected Branches, and CI/CD
Enable Protected Branches for your master/deployment branches in Github. Set up a CI system and run all your deploys through it. Require reviews for PRs that merge to production. Make your CI run some tests; it probably doesn’t much matter to your auditor which tests.
We probably didn’t even need to tell you this. It’s how most professional engineering shops already run. But if you’re a 3-person team, get it set up now and you won’t have to worry about it when your team sprawls and new process is a nightmare to establish.
-- from
J'implémente systématiquement ce workflow dès que je travaille en équipe. Cependant, je me demande à partir de combien de développeurs cela devient réellement pertinent. Avant de lire cet article, je pensais que cela valait la peine à partir de trois développeurs.
À noter que ma motivation première de mise en place de ce workflow n'est pas la sécurité, mais la fluidité de développement en équipe et d'éviter les bugs.
Centralized Logging
Sign up for or set up a centralized logging service. It doesn’t matter which. Pipe all your logs to it. Set up some alerts – again, at this stage, it doesn’t matter which; you just want to build up the muscle.
-- from
Pour cela, j'utilise Grafana avec Loki branché sur un Object Storage.
The AWS console is evil. Avoid the AWS console.
Instead, deploy everything with Terraform (or whatever the cool kids are using, but it’s probably still just Terraform). Obviously, keep your Terraform configs in Github.
C'est aussi l'une de mes premières motivations pour utiliser Terraform ! 😊
#JaiDécouvert Munki, MicroDMD, NanoMDM qui sont des MDM.
Web Application Firewalls: Most SOC2’d firms don’t use them, and most WAFs don’t work at all.
-- from
🙂
Endpoint Protection and AV: You have MDM and macOS/Windows full complement of security features and a way to force them enabled, you’re covered. AV software is a nightmare; avoid it while you can.
-- from
🙂
Journal du jeudi 05 septembre 2024 à 10:37
« Laminar - Open-Source observability, analytics, evals and prompt chains for complex LLM apps. ».
Premier post de l'auteur à ce sujet sur hackers : Laminar – fast Rust backend and monitoring for AI applications
Journal du jeudi 05 septembre 2024 à 10:29
#JaiDécouvert BABLR qui semble être une alternative à Language Server Protocol (LSP) (from).
Journal du mardi 03 septembre 2024 à 12:52
#JaiDécouvert le blog Andrew Walpole (from).
J'aime bien la présentation de son CV : https://andrewwalpole.com/resume/
Journal du dimanche 01 septembre 2024 à 17:50
#JaiDécouvert que des fontes de caractères sont distribuées directement via npm.
Par exemple, la police de caractères source-serif utilisé par gwern.net, sous licence SIL Open Font est disponible via ce package npm https://www.npmjs.com/package/source-serif.
En creusant un peu plus le sujet, #JaiDécouvert https://fontsource.org qui est le projet qui semble packager toutes ces polices de caractères sur npm.
Journal du dimanche 01 septembre 2024 à 11:28
Dans le podcast Les gens de + de 30 ANS devraient TOUS savoir ça avec Gregoire Gibault de Major Mouvement et Léa Pateras-Pescara j'ai découvert la fonction des collagènes.
Quand on est stressé, on perd du magnésium.
#JaiDécouvert le laboratoire français de compléments alimentaires nommé NHCO.
Journal du vendredi 30 août 2024 à 15:24
#JaiDécouvert et je viens de tester le plugin Obsidian https://github.com/czottmann/obsidian-blockquote-levels. Je suis content, cela fait plusieurs mois que j'étais frustré de ne pas pouvoir indenter des "blockquote" sur plusieurs niveaux !
This plugin for Obsidian adds commands for increasing/decreasing the blockquote level of the current line or selection(s).
Journal du vendredi 30 août 2024 à 08:49
J'ai découvert et j'ai lu ce long document au sujet de Qwant : https://scratched-delivery-09e.notion.site/Qwant-petit-pr-cis-d-une-escroquerie-en-bande-organis-e-98300251bfeb44c49720025a15206e90
Journal du mercredi 28 août 2024 à 11:31
Je cherche depuis plusieurs années une solution pour surveiller la date d'expiration des noms de domaine en analysant le contenu de Whois.
#JaiDécouvert cet exporter Prometheus qui correspond exactement à mon besoin : https://github.com/shift/domain_exporter
En examinant l'historique du projet, je constate qu'il a été lancé en 2017. Il me semble pourtant avoir recherché ce type d'exporter en 2019 sans le trouver. Peut-être n'était-il pas encore assez mature à ce moment-là 🤔.
J'ai identifié aussi les projets suivants :
- https://github.com/casnerano/domain-exporter qui semble confidentiel et moins complet, peut-être un simple POC ;
- https://github.com/sorrowless/whois-exporter écrit en Python avec un seul commit... Peut-être que son auteur n'avait pas connaissance de https://github.com/shift/domain_exporter 🤔.
Pour le moment, je n'ai pas encore trouvé de dashboards Grafana pour cet exporter.
Journal du mercredi 28 août 2024 à 09:46
#JaiLu la documentation de UnoCSS.
Tailwind CSS is a PostCSS plugin, while UnoCSS is an isomorphic engine with a collection of first-class integrations with build tools (including a PostCSS plugin). This means UnoCSS can be much more flexible to be used in different places (for example, CDN Runtime, which generates CSS on the fly) and have deep integrations with build tools to provide better HMR, performance, and developer experience (for example, the Inspector).
-- Why UnoCSS?
Si je souhaite utiliser UnoCSS tout en conservant une compatibilité Tailwind CSS je dois utiliser Uno preset :
This preset is compatible with Tailwind CSS and Windi CSS, you can refer to their documentation for detailed usage.
#JaiDécouvert les features innovantes de UnoCSS :
<button
bg="blue-400 hover:blue-500 dark:blue-500 dark:hover:blue-600"
text="sm white"
font="mono light"
p="y-2 x-4"
border="2 rounded blue-200"
>
Button
</button>
Est l'équivalent de :
<button class="bg-blue-400 hover:bg-blue-500 text-sm text-white font-mono font-light py-2 px-4 rounded border-2 border-blue-200 dark:bg-blue-500 dark:hover:bg-blue-600">
Button
</button>
<text-red> red text </text-red>
<flex> flexbox </flex>
I'm feeling <i-line-md-emoji-grin /> today!
Est l'équivalent de :
<span class="text-red"> red text </span>
<div class="flex"> flexbox </div>
I'm feeling <span class="i-line-md-emoji-grin"></span> today!
Je trouve ces syntaxes élégantes, mais, à ma connaissance, elles sont très peu courantes. Si je me mets à la place d'un développeur "onbordé" dans un nouveau projet utilisant le "attributify mode" et Tagify mode, je crains que cela puisse être un choc pour lui. Il me faudrait probablement plusieurs semaines avant que mon cerveau s'habitue à interpréter automatiquement cette syntaxe.
Je me demande donc si le gain final est réellement positif ou négatif.
Pour le moment, j'ai décidé que n'utiliserait pas les fonctionnalités "attributify mode" et Tagify mode.
Journal du mardi 27 août 2024 à 14:23
#JaiLu en partie le thread Hacker News Dokku: My favorite personal serverless platform.
- https://github.com/skateco/skate
- dokploy
- kamal
- ptah.sh (sous licence fair source)
J'ai apprécié ce tableau de comparaison de fonctionnalités entre dokploy, CapRover, Dokku et Coolify.
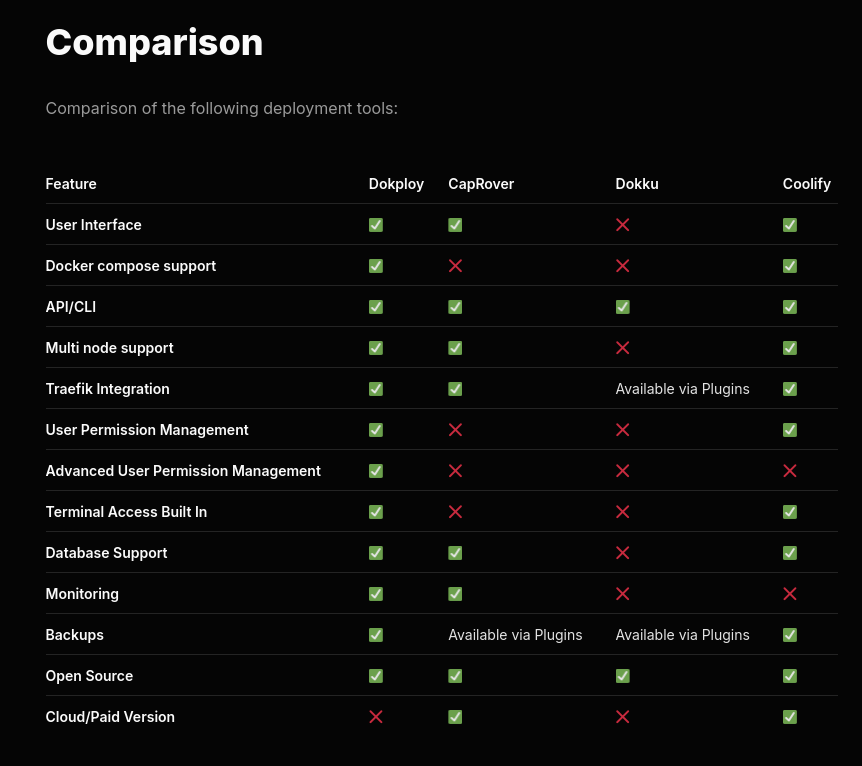
C'est la ligne "Docker compose support" qui a attiré mon attention.
Je reste très attaché au support de docker compose qui je trouve est une spécification en même temps simple, complète et flexible qui ne m'a jamais déçu ces 9 dernières années.
Attention, je n'ai pas bien compris si Dokku est réellement open source ou non 🤔.
Je constate que Dokploy est basé sur Docker Swarm.
Dokploy leverages Docker Swarm to orchestrate and manage container deployments for your applications, providing an intuitive interface for monitoring and control.
-- from
Choix qui me paraît surprenant puisque Docker Swarm est officieusement déprécié.
Je me suis demandé si K3s pourrait être une alternative à Docker Swarm 🤔.
Journal du mardi 27 août 2024 à 14:06
Suite à une réflexion sur les solutions de chiffrement coté browser, #JaiDécouvert https://age-online.com/ :
Easily pass around secure data with age (everything is in-browser, powered by WASM, data does not go ANYWHERE).
Toujours sur le même sujet, #JaiDécouvert libsodium et libsodium.js.
#JaiDécouvert aussi que age utilise pour le chiffrement symétrique l'algorithme ChaCha20-Poly1305, qui est aussi proposé par libsodium.
Journal du mardi 27 août 2024 à 10:33
#JaiDécouvert le mouvement Copie Publique (from)
Ce mouvement formalise et donne un nom à une pratique que j'ai essayé maintes fois de mettre en place par le passé sans succès.
À l'avenir, Copie Publique m'aidera dans mon travail d'évangélisation.
Journal du lundi 26 août 2024 à 16:41
#JaiDécouvert l'expression "Pont aux ânes".
(Éducation) Obstacle apparent qui n’en est pas un, qui rebute les élèves les moins doués.
-- wiktionary
Journal du dimanche 25 août 2024 à 18:58
Dans le thread Lobster Printing the web, part 2: HTML and CSS for printing books
#JaiDécouvert plusieurs la propriétés CSS :
The orphans property specifies the minimum number of line boxes in a block container that must be left in a fragment before a fragmentation break. The widows property specifies the minimum number of line boxes of a block container that must be left in a fragment after a break. Examples of how they are used to control fragmentation breaks are given below.
-- from
et
In addition to the specific CSS counter for page, you can use counter(pages) to get the total number of pages.
-- from
et
We are going to make use of the
string-setproperty defined in the CSS Generated Content for Paged Media Module which is still a working draft at the W3C.-- from
#JaiDécouvert aussi le projet Paged.js.
Paged.js is an Open source library to display paginated content in the browser and to generate print books using web technology.
-- from
Journal du dimanche 25 août 2024 à 12:44
En cherchant des informations au sujet de l'origine de la fonctionnalité compose watch, #JaiDécouvert Tilt (from).
Journal du dimanche 25 août 2024 à 11:00
Alexandre m'a fait découvrir la fonctionnalité Compose Watch ajoutée en septembre 2023 dans la version 2.22.0 de docker compose.
Compose supports sharing a host directory inside service containers. Watch mode does not replace this functionality but exists as a companion specifically suited to developing in containers.
More importantly, watch allows for greater granularity than is practical with a bind mount. Watch rules let you ignore specific files or entire directories within the watched tree.
For example, in a JavaScript project, ignoring the node_modules/ directory has two benefits:
Performance. File trees with many small files can cause high I/O load in some configurations
Multi-platform. Compiled artifacts cannot be shared if the host OS or architecture is different to the container
-- from
Je suis très heureux de l'introduction de cette fonctionnalité, même si je n'ai pas encore eu l'occasion de la tester. Bien que je trouve qu'elle arrive un peu tardivement 😉.
Je suis surpris d'observer que cette fonction a généré très peu de réaction sur Hacker News 🤔.
Je n'ai rien trouvé non plus sur Reddit, ni sur Lobster 🤔.
Sans doute pour cela que je n'ai pas vu la sortie de cette fonctionnalité.
Je pense avoir retrouvé la première Pull Request de la fonctionnalité compose watch : [ENV-44] introduce experimental watch command (skeletton) #10163.
Je constate que compose watch est basé sur fsnotify.
Je constate ici qu'un système de "debounce" est implémenté.
Je pense que c'est cette fonction qui effectue la copie des fichiers, mais je n'en suis pas certain et je ai mal compris son fonctionnement.
Entre 2015 et 2019, j'ai rencontré de nombreux problèmes de performance liés aux volumes de type "bind" sous MacOS (et probablement aussi sous MS Windows) :
volumes:
- ./src/:/src/
Les performances étaient désastreuses pour les projets Javascript avec leurs node_modules volumineux.
Exécuter des commandes telles que npm install ou npm run build prenait parfois 10 à 50 fois plus de temps que sur un système natif ! Je précise que ce problème de performance était inexistant sous GNU Linux.
Pour résoudre ce problème pour les utilisateurs de MacOS, j'ai exploré plusieurs stratégies de development environment, comme l'utilisation de Vagrant avec différentes méthodes de montage, dont certaines reposaient sur une approche similaire à celle de Compose Watch, c'est-à-dire la surveillance des fichiers (fsnotify…) et leur copie.
N'ayant trouvé aucune solution pleinement satisfaisante, j'ai finalement adopté la stratégie Asdf, puis Mise, qui me convient parfaitement aujourd'hui.
Cela signifie que, dans mes environnements de développement, je n'utilise plus Docker pour les services sur lesquels je développe, qu'ils soient implémentés en JavaScript, Python ou Golang...
En revanche, j'utilise toujours Docker pour les services complémentaires tels que PostgreSQL, Redis, Elasticsearch, etc.
Est-ce que la fonctionnalité Compose Watch remettra en question ma stratégie basée sur Mise ? Pour l'instant, je ne le pense pas, car je ne rencontre aucun inconvénient majeur avec ma configuration actuelle et l'expérience développeur (DX) est excellente.
Journal du samedi 24 août 2024 à 21:58
#JaiLu Agir contre les appels commerciaux sur LinuxFr.
#JaiDécouvert EGBG Anti-Telemarketing Contre-scénario et leur super affiche : https://egbg.home.xs4all.nl/EGBGcontrescenario.pdf
J'ai remplacé DoisJeRépondre par SpamBlocker sur mon Android.
Journal du vendredi 23 août 2024 à 21:35
#JaiDécouvert le philosophe Alfred Korzybski dans le livre Systemantics.
Il a fondé la sémantique générale, logique de pensée fondée sur les mathématiques et la physique du tournant du siècle, une discipline pratique pour que chacun puisse prendre un recul critique sur les réactions (non verbales et verbales) à un « événement » au sens large (comprendre ses propres réactions, ainsi que les réactions des autres et leur interaction éventuelle).
Journal du mercredi 21 août 2024 à 09:53
#JaiDécouvert le browser Open source nommé Zen Browser basé sur Firefox qui reprends les principes de Arc (browser) (from)
Je viens de l'installer et de le lancer, il semble bien fonctionner. Je constate qu'il partage bien les extensions Firefox.
Toutefois, je n'ai pas trouvé comment effectuer des "split views", qui est la fonctionnalité qui m'intéresse le plus.
Je n'ai pas trouvé non plus comment activer le "Compact Mode".
J'arrête de tondre de Yak! pour le moment.
Journal du mercredi 21 août 2024 à 09:49
Je trouve le projet très bien réaliséfélicitations à l'auteur !
Je pense que ce projet partage en partie les mêmes objectifs que Datasette.
Journal du mercredi 21 août 2024 à 09:39
Après avoir rédigé la note Commit Cavalier, #JaiDécouvert le concept de des projets de loi omnibus.
« Depuis les années 1980, cependant, les projets de loi omnibus sont devenus plus courants : ces projets de loi contiennent des dispositions, parfois importantes, sur un éventail de domaines politiques. »
-- from
Ceci m'a fait penser aux Merge Requests qui contiennent de nombreux petits commits, souvent de refactoring, qu'il serait fastidieux de passer en revue individuellement.
Je pense que je vais nommer ces Merge Request, des Merge Request Omnibus, ce néologisme sera une de mes marques idiosyncrasiques 😉.
J'ai donc décidé de baptiser ces Merge Requests des Merge Requests Omnibus. Ce néologisme deviendra l'une de mes marques idiosyncrasiques 😉.
Journal du mardi 20 août 2024 à 18:13
#JaiDécouvert cette citation de Alan Kay (from).
« Pop culture is all about identity and feeling like you're participating. It has nothing to do with cooperation, the past or the future — it's living in the present. I think the same is true of most people who write code for money. They have no idea where their culture came from." -- from
Traduction ChatGTP :
« La culture pop concerne avant tout l'identité et le fait de ressentir que l'on participe. Elle n'a rien à voir avec la coopération, le passé ou le futur — c'est vivre dans le présent. Je pense que c'est la même chose pour la plupart des personnes qui écrivent du code pour de l'argent. Elles n'ont aucune idée de l'origine de leur culture. »
Source de cette citation : https://web.archive.org/web/20120715041026/http://www.drdobbs.com/architecture-and-design/interview-with-alan-kay/240003442?pgno=1
Journal du mardi 20 août 2024 à 17:37
#JaiDécouvert un article très intéressant qui répertorie les difficultés classiques rencontrées par les développeurs avec git rebase, ainsi que des solutions pour y remédier :git rebase: what can go wrong?.
Journal du mardi 20 août 2024 à 17:27
#JaiDécouvert ce guide pour Git : Flight rules for Git.
Je le trouve excellent 👌.
Et voici une autre article intéressant au sujet de Git rebase : git rebase in depth.
Journal du mardi 20 août 2024 à 16:09
#JaiDécouvert Waymarked Trails pour les randonnées basé sur OpenStreetMap.
J'ai découvert le registrar coopératif nommé LeBureau.coop
Dans ce thread Fediverse #JaiDécouvert LeBureau.coop.
Une société coopérative de gestion de noms de domaine (registrar).
La vidéo "Les noms de domaine pour se réapproprier Internet" de Arthur Vuillard à Pas Sage en Seine (à partir de 25min) contient une présentation de ce projet.
J'y ai au passage découvert la coopérative Hasshbang.
Dans ma #todo-list :
- [ ] Transférer un de mes noms de domaine vers LeBureau.coop pour tester ;
- [ ] Acheter des parts pour devenir sociétaire soutien.
Journal du lundi 19 août 2024 à 17:21
#JaiDécouvert https://github.com/romkor/svelte-portal (from ChatGPT).
Vraiment trop pratique !
Journal du lundi 19 août 2024 à 16:28
Dans l'introduction de la documentation de bits-ui, #JaiDécouvert encore une autre #librairie de composants UI pour Svelte : melt.