
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (300) ] [ Page suivante (3629) >> ]
Journal du lundi 03 février 2025 à 17:18
Je viens de publier le thread suivant sur Pragmatic Entrepreneurs Forum : https://forum.pragmaticentrepreneurs.com/t/micro-entreprise-a-quel-moment-je-dois-declarer-la-tva-est-ce-que-la-declaration-doit-seffectuer-en-fonction-de-la-date-demission-de-la-facture-ou-alors-de-sa-date-dencaissement/23606
Mon premier message :
Micro-entreprise, à quel moment je dois déclarer la TVA ? Est-ce que la déclaration doit s'effectuer en fonction de la date d'émission de la facture ou alors de sa date d'encaissement ?
Bonjour,
Le 28 janvier, j'ai envoyé le message suivant à mon "Service impôts des entreprises".
Je partage ici, "afin de documenter" le processus au fur et à mesure des réponses que je reçois.
Bonjour,
J'ai commencé mon activité en micro-entreprise au 1ᵉʳ juillet 2024.
À ce jour, voici ce que j'ai facturé :
- 4 juillet 2024, 10 000 € net sans TVA (encaissé)
- 6 septembre 2024, 10 000 € net sans TVA (encaissé)
- 13 novembre 2024, 10 000 € net sans TVA (encaissé le 29 novembre 2024)
- 20 décembre 2024, 10 000 € TTC, dont 2 000 € de TVA (encaissé le 20 janvier 2025)
J'ai lu que la TVA est applicable si je dépasse 34 400 € en prestations de services.
Dans le doute, j'ai commencé à appliquer la TVA à partir de ma 4ᵉ facture.
Questions :
- a.Est-ce que je suis dans les "règles" en ayant appliqué la TVA à ma 4ᵉ facture ?
- b. À quel moment je vais devoir déclarer les 2000 € de TVA de ma 4ᵉ facture ?
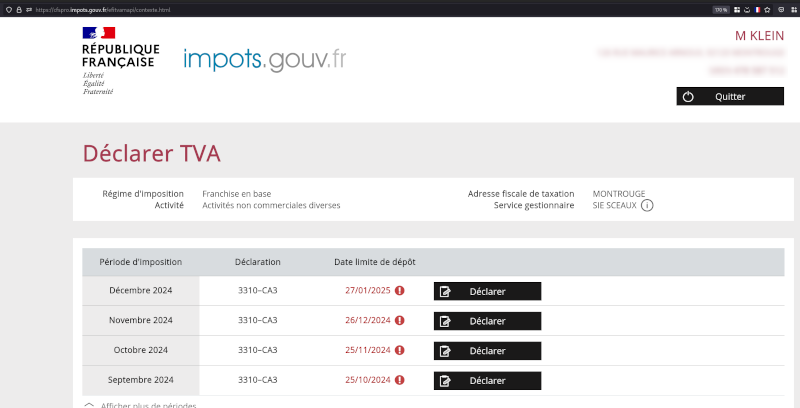
- c. Pouvez-vous me confirmer que ma déclaration devrait se faire sur la page web indiquée dans le screenshot en pièce jointe ?
- d. Est-ce que la déclaration doit s'effectuer en fonction de la date d'émission de la facture ou alors sa date d'encaissement ?
Cordialement, Stéphane Klein Tel: xx xx xx xx xx
Mon second message :
Le 3 février, j'ai reçu la réponse suivante :
Bonjour,
Je vous remercie d'envoyer une lettre d'option à la TVA datée et signée en spécifiant le régime demandé.
En vous remerciant de votre attention.
Mes commentaires au sujet de cette réponse :
- Je trouve cela dommage que l'agent n'ait répondu à aucune de mes 4 questions 😔
- Je trouve dommage que l'agent ne m'ai pas donné de lien vers
- une documentation au sujet de cette lettre d'option à la TVA
- un modèle de lettre ;
- Je trouve cela dommage que je doive rédiger une lettre plutôt que déclarer des champs dans un formulaire. Je pense que la méthode basée sur une lettre augmente la charge de l'administration, est source d'erreur, est difficilement automatisable…
Quelques remarques sur cette réponse :
- L’agent n’a répondu à aucune de mes quatre questions 😔.
- Aucune ressource n’est fournie pour mieux comprendre cette demande :
- Pas de lien vers une documentation expliquant cette lettre d’option à la TVA.
- Pas de modèle de lettre proposé.
- Il est regrettable que cette démarche passe par une lettre plutôt qu’un formulaire dédié. Je pense qu'un formulaire éviterait des erreurs, réduirait la charge administrative et faciliterait l’automatisation.
Je me demande comment je pourrais faire remonter ces retours à l’administration. Ces améliorations sont peut-être déjà prévues dans leur feuille de route, ou bien l’administration manque tout simplement de moyens pour les mettre en place 🤔.
Prochaine étape : essayer de trouver un modèle de lettre d'option à la TVA.
Journal du jeudi 30 janvier 2025 à 12:02
Note de type #aide-mémoire : contrairement à ~/.zprofile, .zshenv est chargé même lors de l'exécution d'une session ssh en mode non interactif, par exemple :
$ ssh user@host 'echo "Hello, world!"'
Je me suis intéressé à ce sujet parce que mes scripts exécutés par ssh dans le cadre du projet /poc-capacitor/ n'avaient pas accès aux outils mis à disposition par Homebrew et Mise.
J'ai creusé le sujet et j'ai découvert que .zprofile était chargé seulement dans les cas suivants :
- « login shell »
- « interactive shell »
Un login shell est un shell qui est lancé lors d'une connexion utilisateur. C'est le type de shell qui exécute des fichiers de configuration spécifiques pour préparer l'environnement utilisateur. Un login shell se comporte comme si tu te connectais physiquement à une machine ou à un serveur.
Un shell interactif est un shell dans lequel tu peux entrer des commandes de manière active, et il attend des entrées de ta part. Un shell interactif est conçu pour interagir avec l'utilisateur et permet de saisir des commandes, d'exécuter des programmes, de lancer des scripts, etc.
Suite à cela, dans ce commit "Move zsh config from .zprofile to .zshenv", j'ai déplacé la configuration de Homebrew et Mise de ~/.zprofile vers .zshenv.
Cela donne ceci une fois configuré :
$ cat .zshenv
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
Mais, attention, « As /etc/zshenv is run for all instances of zsh ». Je pense que ce n'est pas forcément une bonne idée d'appliquer cette configuration sur une workstation, parce que cela peut "ralentir" légèrement le système en lançant inutilement ces commandes.
ChatGPT me conseille cette configuration pour éviter cela :
# Ne charge Brew et Mise que si on est dans un shell interactif ou SSH
if [[ -t 1 || -n "$SSH_CONNECTION" ]]; then
eval "$(/opt/homebrew/bin/brew shellenv)"
eval "$(mise activate zsh)"
fi
Journal du mercredi 29 janvier 2025 à 22:22
En étudiant Pi-hole, je découvre le terme "DNS sinkhole" :
A DNS sinkhole, also known as a sinkhole server, Internet sinkhole, or Blackhole DNS is a Domain Name System (DNS) server that has been configured to hand out non-routable addresses for a certain set of domain names.
...
Another use is to block ad serving sites, either using a host's file-based sinkhole or by locally running a DNS server (e.g., using a Pi-hole). Local DNS servers effectively block ads for all devices on the network.
Journal du mercredi 29 janvier 2025 à 16:29
Alexandre m'a fait remarquer que GitLab a activé par défaut une extension Markdown de génération automatique de TOC :
A table of contents is an unordered list that links to subheadings in the document. You can add a table of contents to issues, merge requests, and epics, but you can’t add one to notes or comments.
Add one of these tags on their own line to the description field of any of the supported content types:
[[_TOC_]] or [TOC]
- Markdown files.
- Wiki pages.
- Issues.
- Merge requests.
- Epics.
Je trouve cela excellent que cette extension Markdown soit supportée un peu partout, en particulier les issues, Merge Request… 👍️.
Cette fonctionnalité a été ajoutée en mars 2020 🫢 ! Comment j'ai pu passer à côté ?
GitHub permet d'afficher un TOC au niveau des README, mais je viens de vérifier, GitHub ne semble pas supporter cette extension TOC Markdown au niveau des issues… Pull Request…
Journal du mercredi 29 janvier 2025 à 11:55
#JaiDécouvert Nitro (https://nitro.build/)
Next Generation Server Toolkit.
Create web servers with everything you need and deploy them wherever you prefer.
D'après ce que j'ai compris, Nitro est un serveur http en NodeJS qui a été spécialement conçu pour Nuxt.js.
Nitro a été introduit fin 2021 dans la version 3 de Nuxt.
Nitro fait partie de l'écosystème UnJS.
Je découvre l'existence de UnJS Ecosystem. #JeMeDemande si ce projet a un lien avec VoidZero 🤔.
Je viens de vérifier, SvelteKit ne semble pas utiliser Nitro. Nitro semble être utilisé uniquement par Nuxt.js.
Journal du mardi 28 janvier 2025 à 15:26
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Après 16 jours d'utilisation d'avante.nvim et comme je le disais dans cette note mon retour est positif, mis à part le bug suivant : bug: non-streaming output never shows.
Pour le moment, je n'arrive pas à comprendre dans quelle condition ce bug arrive 🤔.
Je n'ai pas encore pris le temps de creuser le sujet. J'espère que l'issue va rapidement être résolue. 🤞.
Journal du mardi 28 janvier 2025 à 13:49
Alexandre me dit : « Le contenu de Speed of Code Reviews (https://google.github.io/eng-practices/review/reviewer/speed.html) ressemble à ce dont tu faisais la promotion dans notre précédente équipe ».
En effet, après lecture, les recommandations de cette documentation font partie de ma doctrine d'artisan développeur.
Note: j'ai remplacé CL qui signifie Changelist par Merge Request.
When code reviews are slow, several things happen:
- The velocity of the team as a whole is decreased. Yes, the individual who doesn’t respond quickly to the review gets other work done. However, new features and bug fixes for the rest of the team are delayed by days, weeks, or months as each Merge Request waits for review and re-review.
- Developers start to protest the code review process. If a reviewer only responds every few days, but requests major changes to the Merge Request each time, that can be frustrating and difficult for developers. Often, this is expressed as complaints about how “strict” the reviewer is being. If the reviewer requests the same substantial changes (changes which really do improve code health), but responds quickly every time the developer makes an update, the complaints tend to disappear. Most complaints about the code review process are actually resolved by making the process faster.
- Code health can be impacted. When reviews are slow, there is increased pressure to allow developers to submit Merge Request that are not as good as they could be. Slow reviews also discourage code cleanups, refactorings, and further improvements to existing Merge Request.
J'ai fait le même constat et je trouve que cette section explique très bien les conséquences 👍️.
How Fast Should Code Reviews Be?
If you are not in the middle of a focused task, you should do a code review shortly after it comes in.
One business day is the maximum time it should take to respond to a code review request (i.e., first thing the next morning).
Following these guidelines means that a typical Merge Request should get multiple rounds of review (if needed) within a single day.
Je partage et recommande cette pratique 👍️.
If you are too busy to do a full review on a Merge Request when it comes in, you can still send a quick response that lets the developer know when you will get to it, suggest other reviewers who might be able to respond more quickly.
👍️
Large Merge Request
If somebody sends you a code review that is so large you’re not sure when you will be able to have time to review it, your typical response should be to ask the developer to split the Merge Request into several smaller Merge Requests that build on each other, instead of one huge Merge Request that has to be reviewed all at once. This is usually possible and very helpful to reviewers, even if it takes additional work from the developer.
Je partage très fortement cette recommandation et je pense que c'est celle que j'avais le plus de difficulté à faire accepter par les nouveaux développeurs.
Quand je code, j'essaie de garder à l'esprit que mon objectif est de faciliter au maximum le travail du reviewer plutôt que de chercher à minimiser mes propres efforts.
J'ai sans doute acquis cet état d'esprit du monde open source. En effet, l'un des principaux défis lors d'une contribution à un projet open source est de faire accepter son patch par le mainteneur. On comprend rapidement qu'un patch doit être simple à comprendre et rapide à intégrer pour maximiser ses chances d'acceptation.
Un bon patch doit remplir un objectif unique et ne contenir que les modifications strictement nécessaires pour l'atteindre.
Je suis convaincu que si une équipe de développeurs applique ces principes issus de l'open source dans leur contexte professionnel, leur efficacité collective s'en trouvera grandement améliorée.
Par ailleurs, une Merge Request de taille réduite présente plusieurs avantages concrets :
- elle est non seulement plus simple à rebase,
- mais elle a aussi plus de chances d'être mergée rapidement.
Cela permet à l'équipe de bénéficier plus rapidement des améliorations apportées, qu'il s'agisse de corrections de bugs ou de nouvelles fonctionnalités.
Journal du lundi 27 janvier 2025 à 11:49
En lisant la documentation de lazy.nvim, #JaiDécouvert que la bonne pratique n'est pas celle-ci :
{
"folke/todo-comments.nvim",
config = function()
require("todo-comments").setup({})
end,
},
Mais simplement celle-ci :
{ "folke/todo-comments.nvim", opts = {} },
Journal du lundi 27 janvier 2025 à 10:51
Il y a plus de deux ans, j'avais écrit la note suivante :
En plus de les oublier régulièrement, je trouve ces deux commandes pas pratiques.
Je dois utiliser ctrl-w H pour transformer des windows horizontaux en verticaux et ctrl-w J pour transformer des windows verticaux en horizontaux. Cela fait deux raccourcis alors que j'aimerais en utiliser un seul.
Ce matin, #JaiDécidé d'essayer d'utiliser winshift.nvim (https://github.com/sindrets/winshift.nvim).
Voici mon commit de changement de mon dotfiles : https://github.com/stephane-klein/dotfiles/commit/5d6f798538ac16ab8a308d4da26913306b0cff82
J'ai testé un peu winshift.nvim. C'est parfait 🙂, ce plugin correspond parfaitement à mes besoins et il est très facile à utiliser !
Journal du vendredi 24 janvier 2025 à 19:00
Dans l'article Wikipedia IPv6, j'ai découvert le terme addresse de Liaison Locale ou Link-Local, qui est utilisé pour communiquer avec des hôtes du réseau physique local.
Ces adresses commences par fe80::....
Certains préfixes d’adresses IPv6 jouent des rôles particuliers :
Description Terme anglais Détail Préfixe IPv6 Équivalent IPv4 Boucle Locale Node-local
LoopbackAdresse de bouclage, utilisée lorsqu'un hôte se parle à lui-même (ex : envoi de données entre 2 programmes sur cet hôte). ::1/128 127.0.0.0/8 (principalement 127.0.0.1) Liaison Locale Link-Local Envoi individuel sur liaison locale (RFC 4291). Obligatoire et indispensable au bon fonctionnement du protocole. fe80::/10 169.254.0.0/16 ... ... ... ... ...
Journal du jeudi 23 janvier 2025 à 14:37
#JaiDécouvert Moshi (https://github.com/kyutai-labs/moshi).
Moshi is a speech-text foundation model and full-duplex spoken dialogue framework. It uses Mimi, a state-of-the-art streaming neural audio codec.
Moshi models two streams of audio: one corresponds to Moshi, and the other one to the user. At inference, the stream from the user is taken from the audio input, and the one for Moshi is sampled from the model's output. Along these two audio streams, Moshi predicts text tokens corresponding to its own speech, its inner monologue, which greatly improves the quality of its generation.
Journal du mardi 21 janvier 2025 à 10:45
Alexandre m'a fait découvrir testssl.sh (https://github.com/testssl/testssl.sh) :
testssl.shis a free command line tool which checks a server's service on any port for the support of TLS/SSL ciphers, protocols as well as some cryptographic flaws.
Voici ci-dessous le résultat pour mon domaine sklein.xyz.
Je lis : Overall Grade: A+
Quelques précisions concernant la configuration derrière sklein.xyz :
- J'utilise un certificat Let's Encrypt, validé par la méthode challenge HTTP-01
- Ce certificat est généré par nginx-proxy acme-companion et utilisé par nginx-proxy (la configuration)
$ docker run --rm -ti drwetter/testssl.sh sklein.xyz
#####################################################################
testssl.sh version 3.2rc3 from https://testssl.sh/dev/
This program is free software. Distribution and modification under
GPLv2 permitted. USAGE w/o ANY WARRANTY. USE IT AT YOUR OWN RISK!
Please file bugs @ https://testssl.sh/bugs/
#####################################################################
Using OpenSSL 1.0.2-bad [~183 ciphers]
on 43cf528ca9c5:/home/testssl/bin/openssl.Linux.x86_64
Start 2025-01-21 09:45:05 -->> 51.159.34.231:443 (sklein.xyz) <<--
rDNS (51.159.34.231): 51-159-34-231.rev.poneytelecom.eu.
Service detected: HTTP
Testing protocols via sockets except NPN+ALPN
SSLv2 not offered (OK)
SSLv3 not offered (OK)
TLS 1 not offered
TLS 1.1 not offered
TLS 1.2 offered (OK)
TLS 1.3 offered (OK): final
NPN/SPDY not offered
ALPN/HTTP2 h2, http/1.1 (offered)
Testing cipher categories
NULL ciphers (no encryption) not offered (OK)
Anonymous NULL Ciphers (no authentication) not offered (OK)
Export ciphers (w/o ADH+NULL) not offered (OK)
LOW: 64 Bit + DES, RC[2,4], MD5 (w/o export) not offered (OK)
Triple DES Ciphers / IDEA not offered
Obsoleted CBC ciphers (AES, ARIA etc.) not offered
Strong encryption (AEAD ciphers) with no FS not offered
Forward Secrecy strong encryption (AEAD ciphers) offered (OK)
Testing server's cipher preferences
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
-
SSLv3
-
TLSv1
-
TLSv1.1
-
TLSv1.2 (no server order, thus listed by strength)
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 521 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
x9f DHE-RSA-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
xcca8 ECDHE-RSA-CHACHA20-POLY1305 ECDH 521 ChaCha20 256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xccaa DHE-RSA-CHACHA20-POLY1305 DH 2048 ChaCha20 256 TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 521 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
x9e DHE-RSA-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLSv1.3 (no server order, thus listed by strength)
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
Has server cipher order? no
(limited sense as client will pick)
Testing robust forward secrecy (FS) -- omitting Null Authentication/Encryption, 3DES, RC4
FS is offered (OK) TLS_AES_256_GCM_SHA384 TLS_CHACHA20_POLY1305_SHA256 ECDHE-RSA-AES256-GCM-SHA384 DHE-RSA-AES256-GCM-SHA384
ECDHE-RSA-CHACHA20-POLY1305 DHE-RSA-CHACHA20-POLY1305 TLS_AES_128_GCM_SHA256 ECDHE-RSA-AES128-GCM-SHA256
DHE-RSA-AES128-GCM-SHA256
Elliptic curves offered: prime256v1 secp384r1 secp521r1 X25519 X448
Finite field group: ffdhe2048 ffdhe3072 ffdhe4096 ffdhe6144 ffdhe8192
TLS 1.2 sig_algs offered: RSA+SHA224 RSA+SHA256 RSA+SHA384 RSA+SHA512 RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
TLS 1.3 sig_algs offered: RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
Testing server defaults (Server Hello)
TLS extensions (standard) "renegotiation info/#65281" "server name/#0" "EC point formats/#11" "status request/#5" "supported versions/#43"
"key share/#51" "supported_groups/#10" "max fragment length/#1" "application layer protocol negotiation/#16"
"extended master secret/#23"
Session Ticket RFC 5077 hint no -- no lifetime advertised
SSL Session ID support yes
Session Resumption Tickets no, ID: yes
TLS clock skew Random values, no fingerprinting possible
Certificate Compression none
Client Authentication none
Signature Algorithm SHA256 with RSA
Server key size RSA 4096 bits (exponent is 65537)
Server key usage Digital Signature, Key Encipherment
Server extended key usage TLS Web Server Authentication, TLS Web Client Authentication
Serial 048539E72F864A52E28F6CBEFF15527F75C5 (OK: length 18)
Fingerprints SHA1 5B966867DF42BC654DA90FADFDB93B6C77DD7053
SHA256 E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
Common Name (CN) sklein.xyz (CN in response to request w/o SNI: letsencrypt-nginx-proxy-companion )
subjectAltName (SAN) cv.stephane-klein.info garden.stephane-klein.info sklein.xyz stephane-klein.info
Trust (hostname) Ok via SAN and CN (SNI mandatory)
Chain of trust Ok
EV cert (experimental) no
Certificate Validity (UTC) 63 >= 30 days (2024-12-26 08:40 --> 2025-03-26 08:40)
ETS/"eTLS", visibility info not present
Certificate Revocation List --
OCSP URI http://r11.o.lencr.org
OCSP stapling offered, not revoked
OCSP must staple extension --
DNS CAA RR (experimental) not offered
Certificate Transparency yes (certificate extension)
Certificates provided 2
Issuer R11 (Let's Encrypt from US)
Intermediate cert validity #1: ok > 40 days (2027-03-12 23:59). R11 <-- ISRG Root X1
Intermediate Bad OCSP (exp.) Ok
Testing HTTP header response @ "/"
HTTP Status Code 302 Moved Temporarily, redirecting to "https://sklein.xyz/fr/"
HTTP clock skew 0 sec from localtime
Strict Transport Security 365 days=31536000 s, just this domain
Public Key Pinning --
Server banner nginx/1.27.1
Application banner --
Cookie(s) (none issued at "/") -- maybe better try target URL of 30x
Security headers --
Reverse Proxy banner --
Testing vulnerabilities
Heartbleed (CVE-2014-0160) not vulnerable (OK), no heartbeat extension
CCS (CVE-2014-0224) not vulnerable (OK)
Ticketbleed (CVE-2016-9244), experiment. not vulnerable (OK), no session ticket extension
ROBOT Server does not support any cipher suites that use RSA key transport
Secure Renegotiation (RFC 5746) supported (OK)
Secure Client-Initiated Renegotiation not vulnerable (OK)
CRIME, TLS (CVE-2012-4929) not vulnerable (OK)
BREACH (CVE-2013-3587) no gzip/deflate/compress/br HTTP compression (OK) - only supplied "/" tested
POODLE, SSL (CVE-2014-3566) not vulnerable (OK), no SSLv3 support
TLS_FALLBACK_SCSV (RFC 7507) No fallback possible (OK), no protocol below TLS 1.2 offered
SWEET32 (CVE-2016-2183, CVE-2016-6329) not vulnerable (OK)
FREAK (CVE-2015-0204) not vulnerable (OK)
DROWN (CVE-2016-0800, CVE-2016-0703) not vulnerable on this host and port (OK)
make sure you don't use this certificate elsewhere with SSLv2 enabled services, see
https://search.censys.io/search?resource=hosts&virtual_hosts=INCLUDE&q=E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
LOGJAM (CVE-2015-4000), experimental not vulnerable (OK): no DH EXPORT ciphers, no common prime detected
BEAST (CVE-2011-3389) not vulnerable (OK), no SSL3 or TLS1
LUCKY13 (CVE-2013-0169), experimental not vulnerable (OK)
Winshock (CVE-2014-6321), experimental not vulnerable (OK)
RC4 (CVE-2013-2566, CVE-2015-2808) no RC4 ciphers detected (OK)
Running client simulations (HTTP) via sockets
Browser Protocol Cipher Suite Name (OpenSSL) Forward Secrecy
------------------------------------------------------------------------------------------------
Android 6.0 TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 7.0 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 8.1 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 253 bit ECDH (X25519)
Android 9.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 10.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 11 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 12 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 79 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 101 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 66 (Win 8.1/10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 100 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
IE 6 XP No connection
IE 8 Win 7 No connection
IE 8 XP No connection
IE 11 Win 7 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win 8.1 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win Phone 8.1 No connection
IE 11 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Edge 15 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
Edge 101 Win 10 21H2 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Safari 12.1 (iOS 12.2) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 13.0 (macOS 10.14.6) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 15.4 (macOS 12.3.1) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Java 7u25 No connection
Java 8u161 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Java 11.0.2 (OpenJDK) TLSv1.3 TLS_AES_128_GCM_SHA256 256 bit ECDH (P-256)
Java 17.0.3 (OpenJDK) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
go 1.17.8 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
LibreSSL 2.8.3 (Apple) TLSv1.2 ECDHE-RSA-CHACHA20-POLY1305 253 bit ECDH (X25519)
OpenSSL 1.0.2e TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
OpenSSL 1.1.0l (Debian) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
OpenSSL 1.1.1d (Debian) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
OpenSSL 3.0.3 (git) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
Apple Mail (16.0) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Thunderbird (91.9) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Rating (experimental)
Rating specs (not complete) SSL Labs's 'SSL Server Rating Guide' (version 2009q from 2020-01-30)
Specification documentation https://github.com/ssllabs/research/wiki/SSL-Server-Rating-Guide
Protocol Support (weighted) 100 (30)
Key Exchange (weighted) 90 (27)
Cipher Strength (weighted) 90 (36)
Final Score 93
Overall Grade A+
Done 2025-01-21 09:46:08 [ 66s] -->> 51.159.34.231:443 (sklein.xyz) <<--
Journal du lundi 20 janvier 2025 à 23:57
Suite de 2025-01-20_1028.
Via ce message, j'ai lu le billet "Le statut d’entrepreneur salarié au sein d’une coopérative d’activité et d’emploi (CAE) – Timothée Goguely".
J'y ai découvert l'annuaire des CAE : https://www.les-cae.coop/trouver-une-cae
Journal du lundi 20 janvier 2025 à 22:28
J'ai récupéré l'archive de mes posts, je vais sans doute les publiers avec l'un des outils listés dans Awesome Mastodon - Archiving.
Voilà, je viens de publier mon archive de mon ancien compte Mastodon : http://archives.sklein.xyz/mamot.fr/.
Pour réaliser cette archive, j'ai utilisé Posty (https://posty.1sland.social/).
Journal du lundi 20 janvier 2025 à 10:28
Un ami vient de me partager le site web de l'association L'Échappée Belle : https://lechappeebelle.team/.
En lisant les pages suivantes :
- Journal de Décisions
- Status
- Liste d'arrivée nouvelleau membre
- Morceaux de contrat de prestation
- Nos expériences
- Menace juridique
Je pense avoir compris que les membres de cette association l'utilisent pour faire une sorte de portage salarial.
Cela permet à des indépendants d'être salariés, de mutualiser les frais comptables, bancaires…
Je ne savais pas qu'une association loi 1901 pouvait être utilisée pour un fonctionnement proche du portage salarial. C’est une solution astucieuse pour mutualiser les frais tout en offrant une flexibilité structurelle.
J'aime beaucoup leur pratique, par exemple, la forme de leur "Journal de Décisions", la rédaction de la page "Menace juridique".
CAE, SCOP ou asso ?
CAE ça a l’air plus relou que SCOP alors qu’en SCOP à priori on peut avoir ce qu’on veut en ayant tou.te.es le statut de gérant non salarié mais rémunéré. Mais on est théoriquement en attente d’une ultime réponse de l’avocat sur la SCOP. Du coup, on (David et Sabine) n’a pas envie d’attendre cette réponse pour passer sous un statut salarié ou assimilé, donc on choisit de créer une association au moins pour commencer, parce que c’est théoriquement facile, rapide et non coûteux à créer. On verra si on la transforme plus tard en SCOP ou si on reste sous le statut d’association.
Après étude de CAE versus SCOP, il me semble qu’une CAE conviendrait mieux à leur projet.
Je pense qu'une SCOP est idéale pour des structures qui exploitent des outils de production, comme des boulangeries ou des usines.
Je trouve ce projet d’association inspirant, et je tiens à féliciter les fondateurs! 👏
Journal du dimanche 19 janvier 2025 à 21:33
Dans cette vidéo, #JaiDécouvert que Sébastien Canavet de la chaine YouTube Vous Avez Le Droit a publié en 2013 chez PUF le livre Droit des logiciels: Logiciels privatifs et logiciels libres.
Journal du dimanche 19 janvier 2025 à 18:27
#JaiDécouvert la chaine YouTube : Le Grand Virage (https://www.youtube.com/@legrandvirage).
Pour le moment j'ai uniquement regardé la vidéo : Documentaire - Rennes de Château le grand virage.
Appliquer une configuration nftables avec un rollback automatique de sécurité
Voici une astuce pour appliquer une configuration nftables en toute sécurité, pour éviter tout risque d'être "enfermé dehors".
Je commence par m'assurer que le fichier de configuration ne contient pas d'erreur de syntaxe ou autre :
# nft -c -f /etc/nftables.conf
Sauvegarder la configuration actuelle :
# nft list ruleset > /root/nftables-backup.conf
Application de la configuration avec un rollback automatique exécuté après 200 secondes :
# (sleep 200 && nft -f /root/nftables-backup.conf) & sudo nft -f /etc/nftables.conf
Après cette commande, j'ai 200 secondes pour tester si j'ai toujours bien accès au serveur.
Si tout fonctionne bien, alors je peux exécuter la commande suivante pour désactiver le rollback :
# pkill -f "sleep 200"
Journal du dimanche 19 janvier 2025 à 11:24
#iteration Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram :
Être capable d'exposer sur Internet un port d'une VM.
Voici comment j'ai atteint cet objectif.
Pour faire ce test, j'ai installé un serveur http nginx sur une VM qui a l'IP 192.168.1.236.
Cette IP est attribuée par le DHCP installé sur mon routeur OpenWrt. Le serveur hôte Proxmox est configuré en mode bridge.
Ma Box Internet Bouygues sur 192.168.1.254 peut accéder directement à cette VM 192.168.1.236.
Pour exposer le serveur Proxmox sur Internet, j'ai configuré mon serveur Serveur NUC i3 gen 5 en tant que DMZ host.
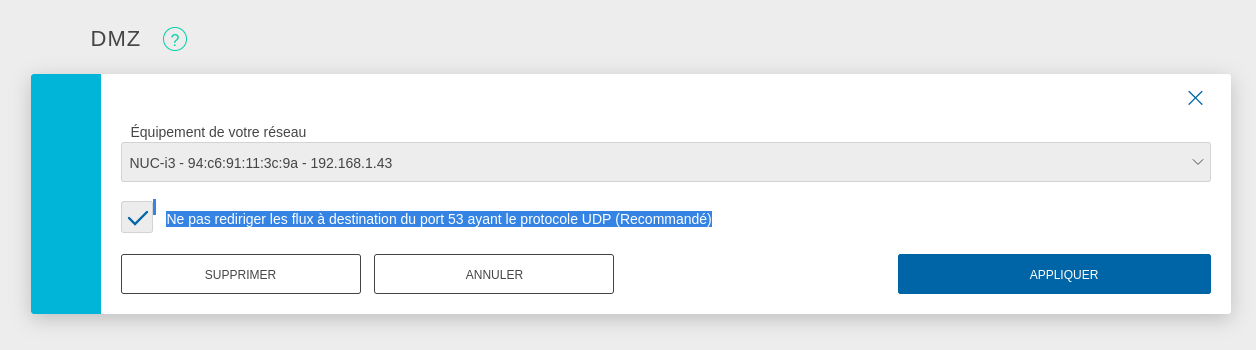
J'ai suivi la recommandation pour éviter une attaque du type : DNS amplification attacks
DNS amplification attacks involves an attacker sending a DNS name lookup request to one or more public DNS servers, spoofing the source IP address of the targeted victim.
Avec cette configuration, je peux accéder en ssh au Serveur NUC i3 gen 5 depuis Internet.
J'ai tout de suite décidé d'augmenter la sécurité du serveur ssh :
# cat <<'EOF' > /etc/ssh/sshd_config.d/sklein.conf
Protocol 2
PasswordAuthentication no
PubkeyAuthentication yes
AuthenticationMethods publickey
KbdInteractiveAuthentication no
X11Forwarding no
# systemctl restart ssh
J'ai ensuite configuré le firewall basé sur nftables pour mettre en place quelques règles de sécurité et mettre en place de redirection de port du serveur hôte Proxmox vers le port 80 de la VM 192.168.1.236.
nftables est installé par défaut sur Proxmox mais n'est pas activé. Je commence par activer nftables :
root@nuci3:~# systemctl enable nftables
root@nuci3:~# systemctl start nftables
Voici ma configuration /etc/nftables.conf, je me suis fortement inspiré des exemples présents dans ArchWiki : https://wiki.archlinux.org/title/Nftables#Server
# cat <<'EOF' > /etc/nftables.conf
flush ruleset;
table inet filter {
# Configuration from https://wiki.archlinux.org/title/Nftables#Server
set LANv4 {
type ipv4_addr
flags interval
elements = { 10.0.0.0/8, 172.16.0.0/12, 192.168.0.0/16, 169.254.0.0/16 }
}
set LANv6 {
type ipv6_addr
flags interval
elements = { fd00::/8, fe80::/10 }
}
chain input {
type filter hook input priority filter; policy drop;
iif lo accept comment "Accept any localhost traffic"
ct state invalid drop comment "Drop invalid connections"
ct state established,related accept comment "Accept traffic originated from us"
meta l4proto ipv6-icmp accept comment "Accept ICMPv6"
meta l4proto icmp accept comment "Accept ICMP"
ip protocol igmp accept comment "Accept IGMP"
udp dport mdns ip6 daddr ff02::fb accept comment "Accept mDNS"
udp dport mdns ip daddr 224.0.0.251 accept comment "Accept mDNS"
ip saddr @LANv4 accept comment "Connections from private IP address ranges"
ip6 saddr @LANv6 accept comment "Connections from private IP address ranges"
tcp dport ssh accept comment "Accept SSH on port 22"
tcp dport 8006 accept comment "Accept Proxmox web console"
udp sport bootpc udp dport bootps ip saddr 0.0.0.0 ip daddr 255.255.255.255 accept comment "Accept DHCPDISCOVER (for DHCP-Proxy)"
}
chain forward {
type filter hook forward priority filter; policy accept;
}
chain output {
type filter hook output priority filter; policy accept;
}
}
table nat {
chain prerouting {
type nat hook prerouting priority dstnat;
tcp dport 80 dnat to 192.168.1.236;
}
chain postrouting {
type nat hook postrouting priority srcnat;
masquerade
}
}
EOF
Pour appliquer en toute sécurité cette configuration, j'ai suivi la méthode indiquée dans : "Appliquer une configuration nftables avec un rollback automatique de sécurité".
Après cela, voici les tests que j'ai effectués :
- Depuis mon réseau local :
- Test d'accès au serveur Proxmox via ssh :
ssh root@192.168.1.43 - Test d'accès au serveur Proxmox via la console web : https://192.168.1.43:8006
- Test d'accès au service http dans la VM :
curl -I http://192.168.1.236
- Test d'accès au serveur Proxmox via ssh :
- Depuis Internet :
Voilà, tout fonctionne correctement 🙂.
Prochaines étapes :
- Être capable d'accéder depuis Internet via IPv6 à une VM
- Je souhaite arrive à effectuer un déploiement d'une Virtual instance via Terraform
Journal du vendredi 17 janvier 2025 à 19:02
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Après 5 jours d'utilisation, mon retour est positif. Je trouve avante.nvim très agréable à utiliser et GitHub Copilot avec Claude Sonnet 3.5 m'assiste efficacement 🙂.
Pour le moment, le seul reproche que je peux faire à avante.nvim, c'est que je ne peux pas utiliser Neovim (me balader dans le code, éditer un fichier) pendant qu'une réponse est en train d'être rédigée dans la sidebar.
J'ai trouvé cette issue qui semble correspondre à ce problème : feature: Cursor Movement Issue During Chat Response Generation.
Journal du vendredi 17 janvier 2025 à 12:03
Suite de ma note 2025-01-15_1350.
Voici la réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Journal du vendredi 17 janvier 2025 à 11:58
#JeMeDemande s'il est possible d'installer des serveurs Scaleway Elastic Metal avec des images d'OS préalablement construites avec Packer 🤔.
Je viens de poser la question suivante : Is it possible to create Elastic Metal OS images with Packer and use it to create a Elastic Metal serveurs?
En français :
Bonjour,
Je sais qu'il est possible de créer des images d'OS avec Packer utilisables lors de la création d'instance Scaleway (voir https://www.scaleway.com/en/docs/tutorials/deploy-instances-packer-terraform/).
De la même manière, je me demande s'il est possible de créer des images d'OS avec Packer pour installer des serveurs Elastic Metal .
Question : est-il possible de créer des images Elastic Metal avec Packer et d'utiliser celle-ci pour créer des serveurs Elastic Metal ?
Si c'est impossible actuellement, pensez-vous qu'il soit possible de l'implémenter ? Ou alors, est-ce que des limitations techniques de Elastic Metal rendent impossible cette fonctionnalité ?
Bonne journée, Stéphane
Je viens d'envoyer cette demande au support de Scaleway.
Journal du mercredi 15 janvier 2025 à 14:55
#JaiDécouvert que le site Scaleway Feature Requests est propulsé par Fiber (https://fider.io/), développé principalement pour Guilherme Oenning, un irelandais, qui se qualifie de « Solopreneur building in public ». Il a aussi créé aptabase et SEO Gets.
Journal du mercredi 15 janvier 2025 à 13:50
Suite de la note 2025-01-14_2152 au sujet de Scaleway Domains and DNS.
Dans l'e-mail « External domain name validation » que j'ai reçu, je lis :
Alternative validation process (if your current registrar doesn't offer basic DNS service):
Please set your nameservers at your registrar to:
9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud
J'ai essayé cette méthode alternative pour le sous-domaine scw.stephane-klein.info :
Voici les DNS Records correspondants :
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
scw.stephane-klein.info. 1 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
J'ai vérifié ma configuration :
$ dig NS scw.stephane-klein.info @ali.ns.cloudflare.com
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns0.dom.scw.cloud.
scw.stephane-klein.info. 300 IN NS 9ca08f37-e2c8-478d-bb0e-8a525db976b9.ns1.dom.scw.cloud.
J'ai attendu plus d'une heure et cette méthode de validation n'a toujours pas fonctionné.
Je pense que cela ne fonctionne pas 🤔.
Je vais créer un ticket de support Scaleway pour savoir si c'est un bug ou si j'ai mal compris comment cela fonctionne.
2025-01-17 : réponse que j'ai reçu :
Notre équipe produit est revenue vers nous pour nous indiquer qu’en effet il y a un défaut de documentation.
Ce process alternatif ne fonctionne que sur la racine des domaines pas sur un sous domaine.
C’était pour les tlds qui ne donnent pas de DNS par défaut aux clients.
Conclusion : la documentation était imprécise, ce que j'ai essayé de réaliser ne peut pas fonctionner.
Journal du mardi 14 janvier 2025 à 21:52
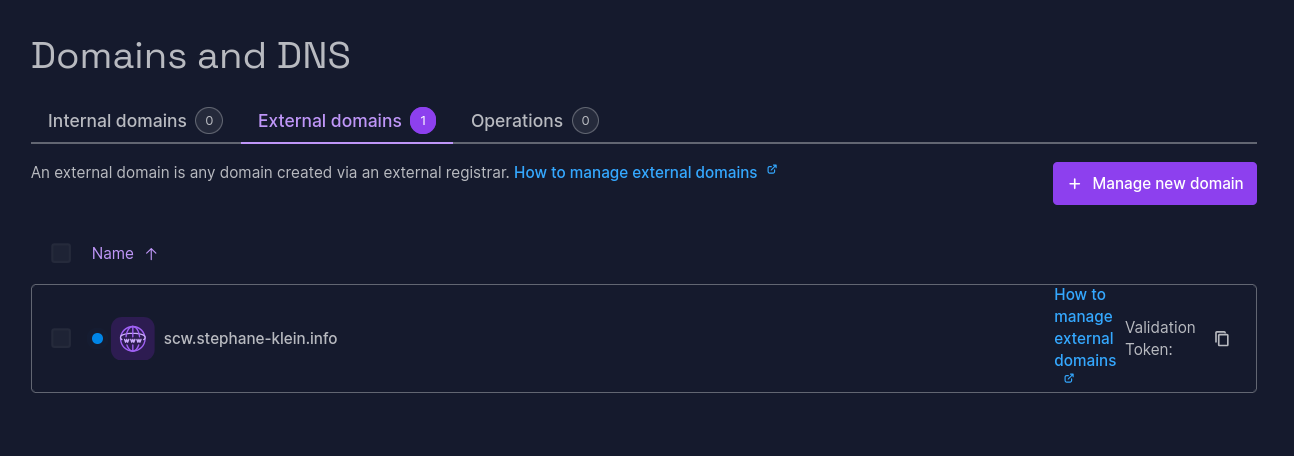
J'ai réalisé un test pour vérifier que la délégation DNS par le managed service de Scaleway nommé Domains and DNS (lien direct) fonctionne correctement pour un sous-domaine tel que testscaleway.stephane-klein.info.
Je commence par suivre les instructions du how to : How to add an external domain to Domains and DNS.
Sur la page https://console.scaleway.com/domains/internal/create :
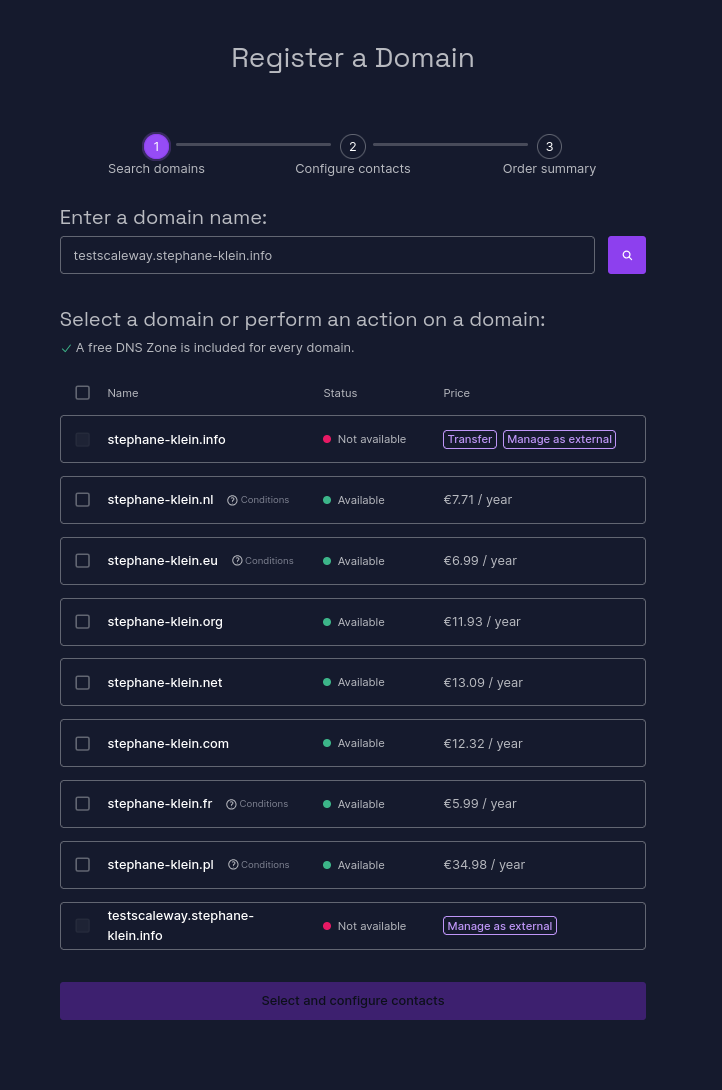
Je sélectionne la dernière entrée « Manage as external ».
Ensuite :
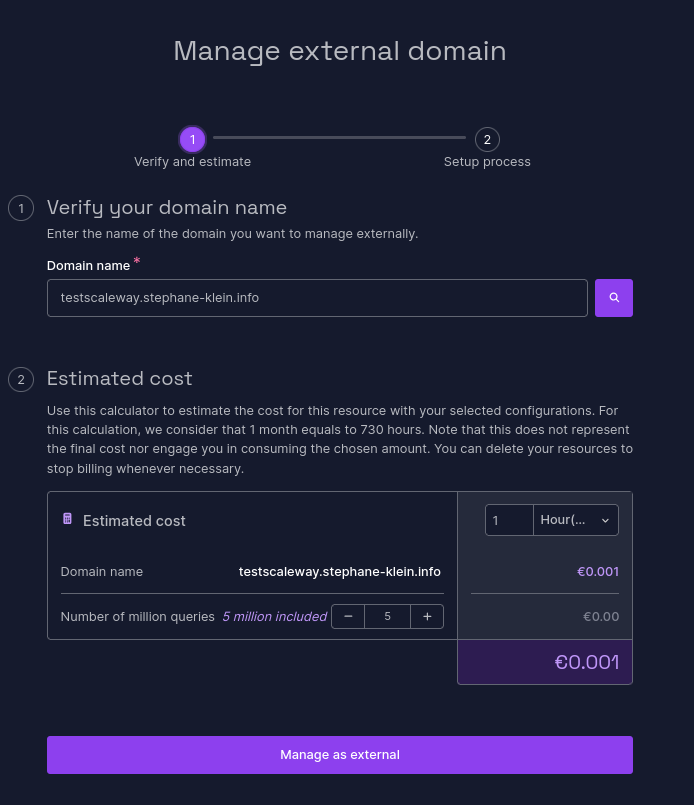

J'ai ajouté le DNS Record suivant à mon serveur DNS géré par cloudflare :
_scaleway-challenge.testscaleway.stephane-klein.info. 1 IN TXT "dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Vérification :
$ dig TXT _scaleway-challenge.testscaleway.stephane-klein.info +short
"dd7e7931-56d6-4e04-bcd7-e358821e63dd"
Je n'ai aucune idée de la fréquencede passage du job Scaleway qui effectue la vérification de l'entrée TXT :
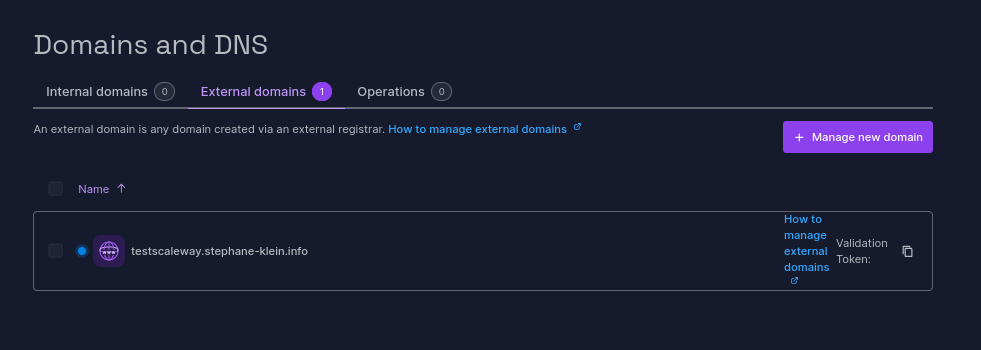
J'ai ajouté mon domaine à 22h22 et il a été validé à 22h54 :
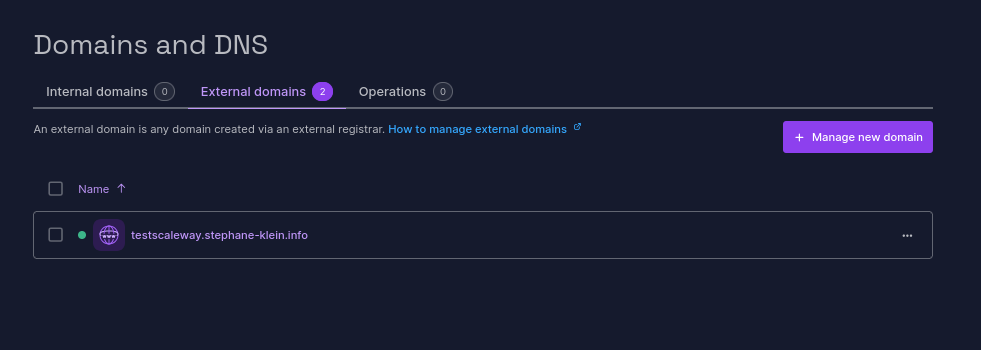
Ensuite, j'ai ajouté les DNS Records suivants :
testscaleway.stephane-klein.info. 1 IN NS ns1.dom.scw.cloud.
testscaleway.stephane-klein.info. 1 IN NS ns0.dom.scw.cloud.
Vérification :
$ dig NS testscaleway.stephane-klein.info +short
ns0.dom.scw.cloud.
ns1.dom.scw.cloud.
Ensuite, j'ai configuré dans la console Scaleway, le DNS Record :
test1 3600 IN A 8.8.8.8
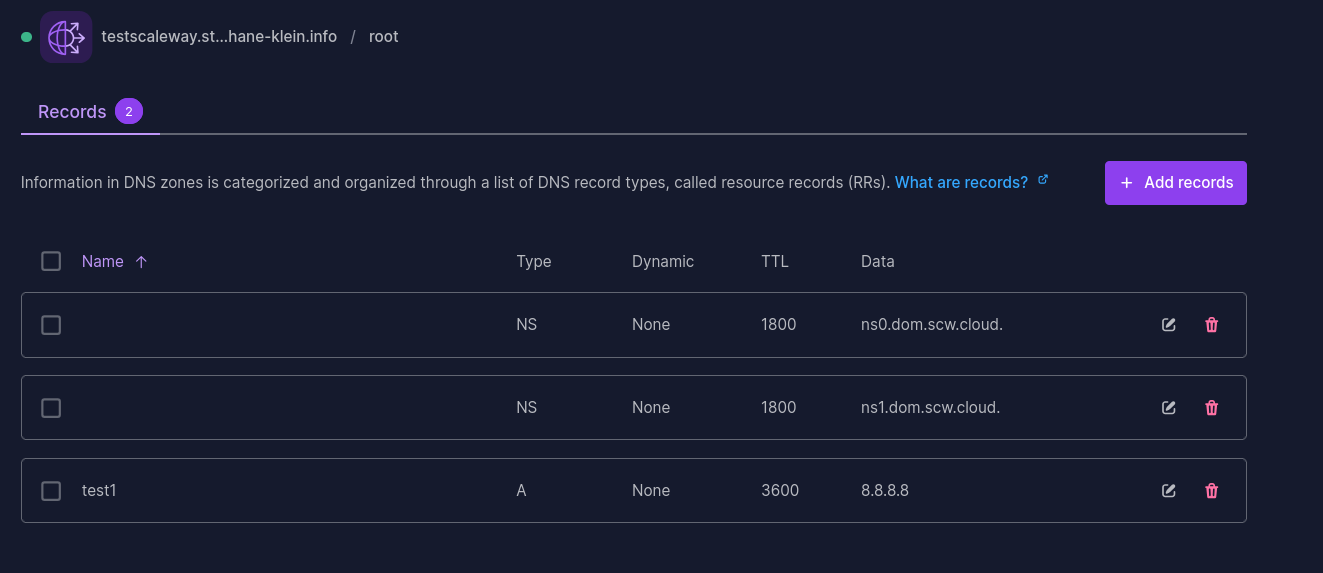
Vérification :
$ dig test1.testscaleway.stephane-klein.info +short
8.8.8.8
Conclusion : la réponse est oui, le managed service Scaleway Domains and DNS permet la délégation de sous-domaines 🙂.
Journal du mardi 14 janvier 2025 à 15:08
Je viens de découvrir une nouvelle option de configuration Mise :
# .mise.toml
[tools]
node = "20.18.1"
"npm:typescript" = "5.7.3"
Comment l'indique la documentation de Mise, "npm:...." = "..." permet d'installer n'importe quel package npm dans un projet géré par Mise.
Concrètement, ici tsc est accessible directement dans le PATH dans le dossier où est placé .mise.toml.
Quelle est la fonction de "/deployment-playground/" dans mes projets ?
L'objectif de cette note est d'expliquer ce que sont les dossiers /deployment-playground/ et ma pratique consistant à les intégrer dans la plupart de mes projets de développement web.
Je pense me souvenir que j'ai commencé à intégrer ce type de dossier vers 2018.
Au départ, je nommais ce dossier /demo/ dont l'objectif était le suivant : permettre à un développeur de lancer localement le plus rapidement possible une instance de démo complète de l'application.
Pour cela, ce dossier contenait généralement :
- Un
docker-compose.ymlqui permettait le lancer tous les services à partir des dernières images Docker déjà buildé. Soit les images de la version de l'environnement de développement, staging ou production. - Un script d'injection de données de fixtures ou de données spécifiques de démonstration.
- Mise à disposition des logins / password d'un ou plusieurs comptes utilisateurs.
Cet environnement était configuré au plus proche de la configuration de production.
Avec le temps, j'ai constaté que mon utilisation de ce dossier a évolué. Petit à petit, je m'en servais pour :
- Aider les développeurs à comprendre le processus de déploiement de l'application en production, en fournissant une représentation concrète des résultats des scripts de déploiement.
- Permettre aux développeurs de tester localement la bonne installation de l'application, afin de reproduire les conditions de production en cas de problème.
- Faciliter l'itération locale sur l'amélioration ou le refactoring de la méthode de déploiement.
- Et bien d'autres usages.
J'ai finalement décidé de renommer ce dossier deployment-playground, un bac à sable pour "jouer" localement avec la configuration de production de l'application.
Je ne peux pas vous partager mes exemples beaucoup plus complets qui sont hébergés sur des dépôts privés, mais voici quelques exemples minimalistes dans mes dépôts publics :
- https://github.com/stephane-klein/sveltekit-user-auth-postgres-rls-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-ssr-skeleton/tree/main/deployment-playground
- https://github.com/stephane-klein/gibbon-replay/tree/main/deployment-playground
- https://github.com/stephane-klein/sveltekit-tendaro-webshell-skeleton/tree/main/deployment-playground
J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot
Note d' #iteration du Projet 21 - "Rechercher un AI code assistant qui ressemble à Cursor mais pour Neovim".
J'ai réussi à installer avante.nvim, voici le commit de changement de mon dotfiles : "Add Neovim Avante AI Code assistant".
Suite à la lecture de :
Since auto-suggestions are a high-frequency operation and therefore expensive, it is recommended to specify an inexpensive provider or even a free provider: copilot
et ma note 2025-01-12_2026, #JaiDécidé de connecter avante.nvim à GitHub Copilot.
J'ai suivi les instructions de README.md de avante.nvim et voici les difficultés que j'ai rencontrées.
Contexte : j'utilise lazy.nvim avec la méthode kickstart.nvim.
- Ici j'ai appliqué cette configuration :
opts = {
provider = "copilot",
auto_suggestions_provider = "copilot",
copilot = {
model = "claude-3.5-sonnet"
}
},
- Ce commentaire n'indique pas explicitement que je devais ajouter ici cette initialisation de copilot.lua :
{
"zbirenbaum/copilot.lua",
config = function()
require("copilot").setup({})
end
},
Après installation des plugins (Lazy sync), il faut lancer :Copilot auth pour initialiser l'accès à votre instance de GitHub Copilot. C'est très simple, il suffit de suivre les instructions à l'écran.
Pour le moment, j'ai uniquement fait un test de commentaire d'un script : « Est-ce que ce script contient des erreurs ? » :
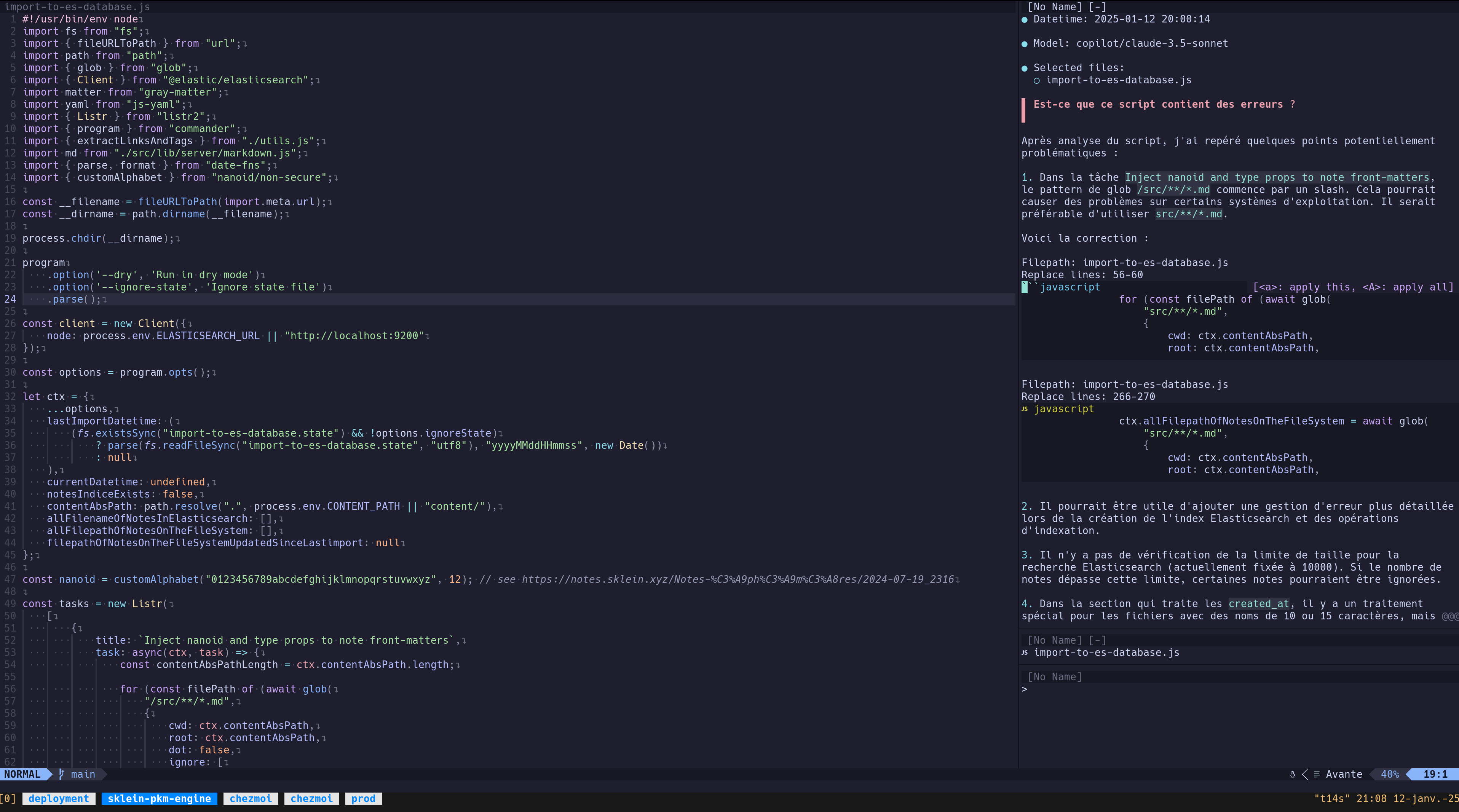
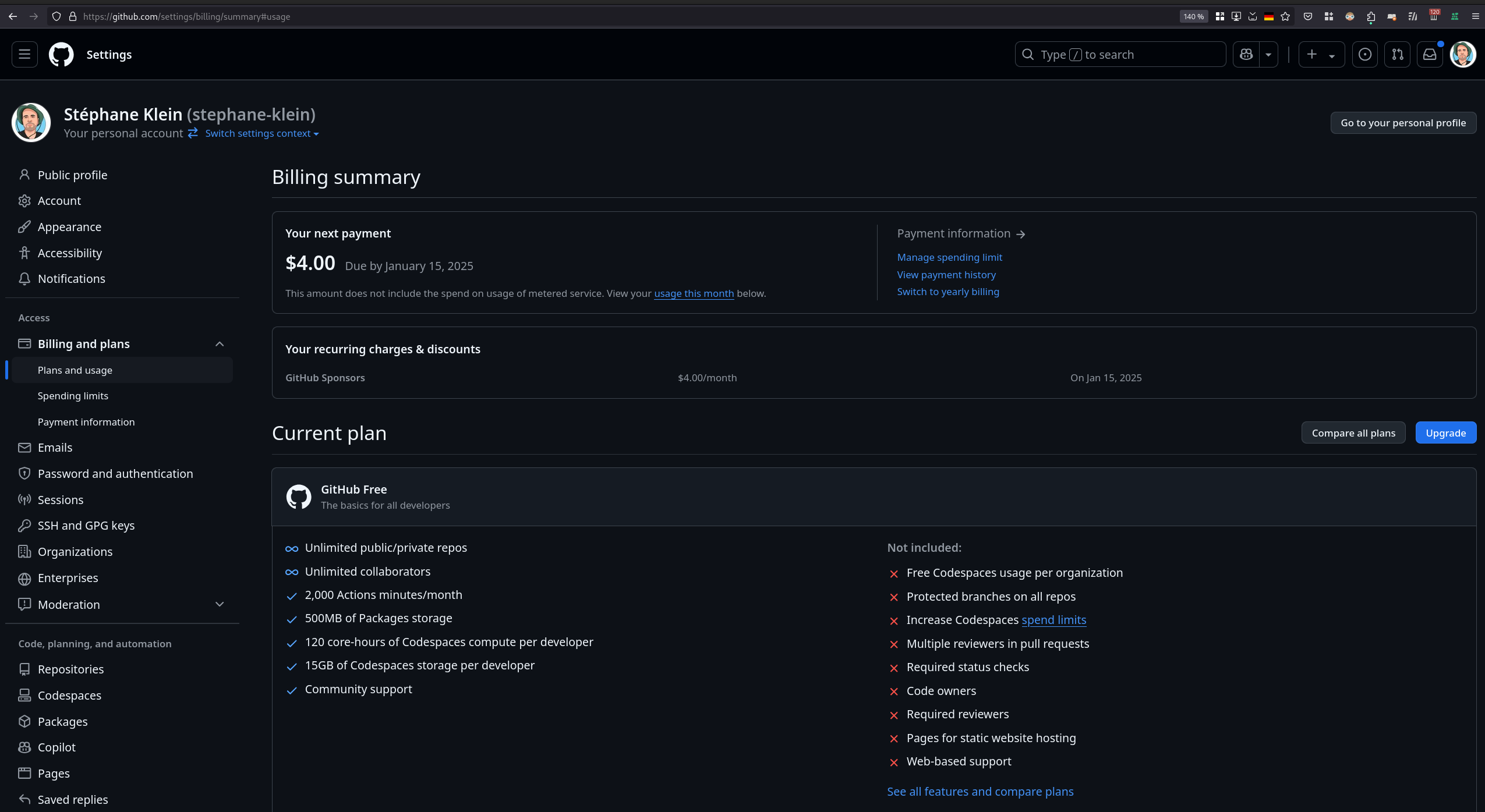
J'ai ensuite tenté de consulter mon rapport d'utilisation de GitHub Copilot pour vérifier l'état de mes quotas, mais je n'ai pas réussi à trouver ces informations :
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Journal du dimanche 12 janvier 2025 à 20:26
Suite à la lecture de :
Since auto-suggestions are a high-frequency operation and therefore expensive, it is recommended to specify an inexpensive provider or even a free provider: copilot
j'ai un peu étudié GitHub Copilot.
J'ai commencé par lire l'article Wikipedia "Microsoft Copilot" pour creuser pour la première fois ce sujet. Jusqu'à présent, Copilot était pour moi synonyme de GitHub Copilot, mais je me trompais totalement !
#JaiLu l'article Wikipedia GitHub Copilot.
J'ai ensuite parcouru les dernières entrées de GitHub Changelog.
- #JaiDécouvert que OpenAI o1 est déjà disponible dans GitHub Copilot : OpenAI o1 is now available in GitHunb Models.
Il y a quelques jours, j'avais vu le thread Hacker News : GitHub Copilot is now available for free
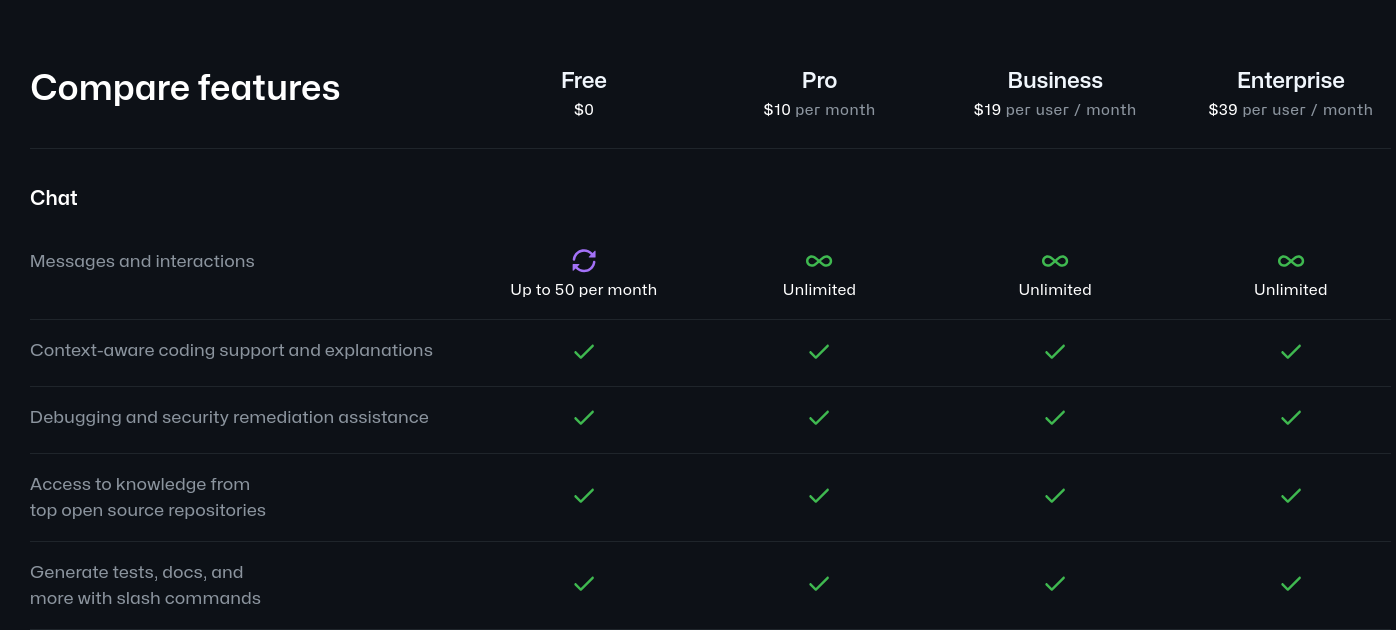
J'ai l'impression que « 50 messages and interactions » est très peu… mais tout de même utile pour tester comment cela fonctionne.
Par contre je trouve que 10 dollars par mois en illimité est très abordable.
Je découvre ici que Microsoft supporte officiellement un plugin GitHub Copilot pour Neovim : copilot.vim.
Je découvre la page de paramétrage de GitHub Copilot : https://github.com/settings/copilot
Journal du dimanche 12 janvier 2025 à 16:38
J'ai résolu mon problème d'hier : « Panne clavier : soudainement, la touche "v" de mon Thinkpad affiche "m" » 🙂.
En moins de 24h, j'ai reçu une réponse d'un employé de Lenovo à mon message (posté un weekend) :
2. Perform a Power Drain:
- Shut down your laptop.
- Disconnect the power adapter and any external devices.
- Press and hold the power button for about 30 seconds to drain any residual power.
- Reconnect the power adapter and turn on your laptop to see if the issue persists.
J'ai suivi ces instructions et la panne est corrigée, le clavier de mon Thinkpad T14s fonctionne parfaitement 🙂.
Ce n'est pas la première fois que je trouve des réponses très précises sur le Forum officiel Lenovo :
- Random screen flickering on T14s Gen 3 AMD in Fedora 37
- T14 Gen1 AMD with kernel 6.1.12 thermal: Invalid critical threshold (0) & No valid trip found
- No external USB-C monitor detection on my Thinkpad T14s AMD Gen3 powered by Fedora 38
Des ingénieurs de chez Lenovo répondent très régulièrement sur ce forum, par exemple :
It seems like you have the same panel as some of the other users who have reported this issue. Disabling PSR is currently the recommended workaround until a proper fix is available. AMD is actively working on this issue and we are hoping to have a solution soon. I will keep you updated on any progress.
C'est quelque chose que j'apprécie.
Je pense que je pourrais retrouver la même expérience sur le forum de Framework (laptop) : https://community.frame.work/.
#JeMeDemande si je pourrais échanger avec des techniciens de chez Apple, DELL…
Journal du dimanche 12 janvier 2025 à 15:09
J'ai lu ici que Salvatore Sanfilippo conseille Claude Sonnet 3.5 :
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
Journal du dimanche 12 janvier 2025 à 12:56
Je viens de publier : Projet 21 - "Rechercher un AI code assistant qui ressemble à Cursor mais pour Neovim".
J'ai découvert « Timeline of AI model releases in 2024 »
#JaiDécouvert et #JaiLu le document "Timeline of AI model releases in 2024" (via) (LLM):
(Cliquez sur ce lien pour voir tous les mois)
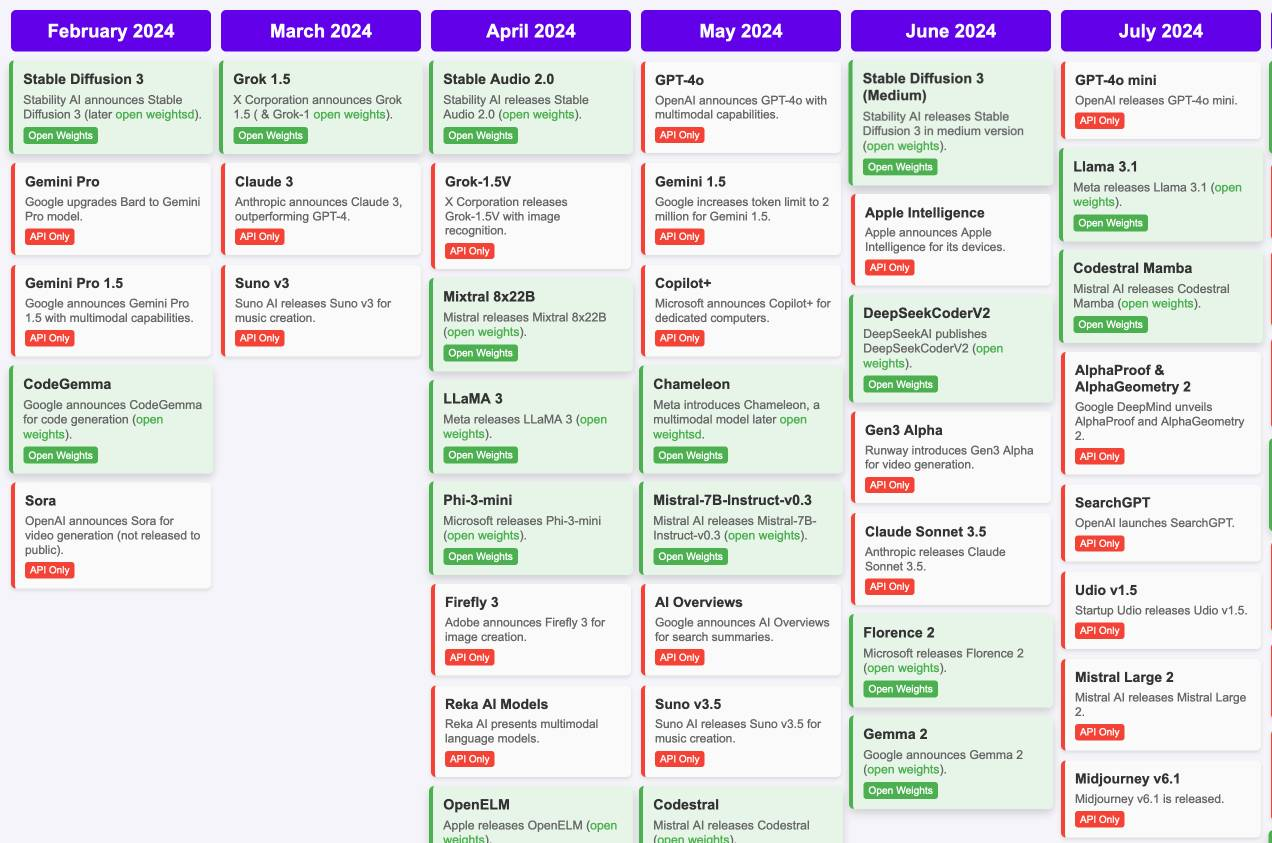
#UnJourPeuxÊtre je prendrais le temps d'étudier les différences de chacun de ces modèles.
Journal du dimanche 12 janvier 2025 à 00:14
Voici mes prochaines #intentions d'amélioration de ma workstation :
- Après avoir observé l'environement desktop d'Alexandre, cela m'a donné envie de tester Zen Browser.
- Installer, configurer et tester Ghostty.
- Étudier, installer, configurer un AI code assistant qui ressemble à Cursor mais pour Neovim, voici-ci les plugins que j'aimerais tester :
- Peut-être apprendre à utiliser Jujutsu - A Git-compatible VCS that is both simple and powerful.
- J'aimerais trouver un équivalent à rofi ou fuzzel pour GNOME Shell.
#JeMeDemande si la fonctionnalité "GNOME Shell Search Provider" me permettrait de réaliser cet objectif 🤔.
Ou alors, est-ce que GNOME Shell permet nativement de lancer des scripts shells 🤔. - Essayer de remplacer les services ChatGPT ou Claude.ia par Open WebUI.
- Peut-être remplacer zsh par fish shell.
Journal du samedi 11 janvier 2025 à 23:25
#JaiDécouvert "Void", une alternative à l'éditeur de code "Cursor" : "Show HN: Void, an open-source Cursor/GitHub Copilot alternative ".
Dans les commentaires, #JaiDécouvert Supermaven, mais je n'ai pas pris le temps de l'étudier.
Journal du samedi 11 janvier 2025 à 21:28
Suite à mon problème de clavier son mon Thinkpad T14s : "Suddenly, the “v” key on my Thinkpad T14s Gen 3 returns keycode 47 instead of 55, hardware failure?", je teste l'outil keyd, qui permet de reconfigurer des touches de clavier.
Je souhaite utiliser la touche <Caps-Lock> pour afficher . et <Shift>+<Caps-Lock> par :.
Je commence par installer le package keyd pour Fedora (comme documenté ici) :
$ sudo dnf copr enable alternateved/keyd
$ sudo dnf install keyd
Je défini le fichier de configuration pour mapper <Caps-Lock> vers la touche <v> :
$ sudo tee /etc/keyd/default.conf > /dev/null <<EOF
[ids]
*
[main]
capslock = v
EOF
Je lance le service keyd :
$ sudo systemctl enable --now keyd
Et voila, ça fonctionne, il faut juste que je prenne l'habitude à taper la touche <Caps-Lock> à la place de <.>. Je me demande combien de temps cela va me prendre !
Panne clavier : soudainement, la touche "v" de mon Thinkpad affiche "m"
Depuis ce matin, la touche <v> du clavier de mon Thinkpad T14s ne fonctionne plus normalement. Maintenant, la touche <v> affiche <m> et la touche <m> affiche toujours <m> 🤔 (en Azerty ISO Layout).
Au départ, j'ai pensé que j'avais un problème au niveau de mon OS (Fedora), que la configuration du clavier qui avait changé par erreur…
J'ai branché mon clavier externe et je constate qu'il n'a pas de problème, la touche <v> affiche <v>.
Pourtant, tout fonctionnait bien quelques minutes avant. J'ai fait des mises à jour d'OS et de firmware il y a plus d'une semaine.
J'ai shutdown totalement le laptop, j'ai relancé et le problème était toujours présent 🤔.
J'ai ensuite redémarré et je suis entré dans l'outil de diagnostic Lenovo (touche <F10> au démarrage) et là, horreur, le problème est aussi présent dans le BIOS 😯😭.
Voici une vidéo : https://youtu.be/88335YSr6AQ
J'ai démonté la touche <v> pour la nettoyer sans grand espoir, étant donné qu'elle fonctionnait mécaniquement très bien. J'ai eu ensuite d'énormes difficultés à la remonter… et maintenant elle a un petit défaut 😭.
Désespéré, j'ai posté deux messages :
- Sur le forum Lenovo : Suddenly, the “v” key on my Thinkpad T14s Gen 3 returns keycode 47 instead of 55, hardware failure?
- Sur Reddit : Suddenly, the “v” key on my Thinkpad T14s Gen 3 returns keycode 47 instead of 55, hardware failure?
Mon thread Fediverse : https://social.coop/@stephane_klein/113811173930863045
Je croise les doigts ! 🤞
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
Benchmark sur le dépôt officiel de Zstandard :
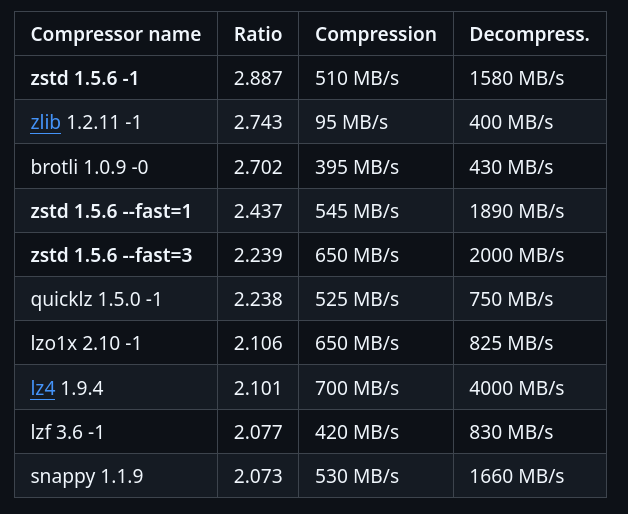
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Journal du jeudi 09 janvier 2025 à 13:13
Nouvelle #iteration sur le Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Je viens de push le commit feat(android): implemented webview and configured deeplinks. J'ai passé en tout, 11 heures sur cette itération.
Je souhaite, dans cette note de type DevLog, présenter les difficultés et les erreurs rencontrées dans cette itération.
Étape 1 : mise en place d'un dummy website totalement statique
The Capacitor application in this POC displays the content of a demonstration website, with the HTML content located in the
./dummy-website/folder.
This website is served by an HTTP Nginx server, launched usingdocker-compose.yml.
Pour faire très simple, j'ai choisi de créer un faux site totalement statique, qui sera affiché dans une webview de l'application smartphone.
Ce site contient juste 2 pages HTML ; celui-ci est exposé par un serveur HTTP nginx, lancé via un docker-compose.yml.
Étape 2 : Expose dummy website on Internet
En première étape, j'ai dû mettre en place une méthode pour facilement exposer sur Internet un dummy website lancé localement :
Expose dummy website on Internet
Why?
The Android and iOS emulators do not have direct and easy access to the HTTP service (dummy website) exposed on http://localhost:8080.To overcome this issue, I use "cloudflared tunnel". You can also use other solutions, such as sish or ngrok Developer Preview. For more information, you can refer to the following note (in French): 2025-01-06_2105
Comme expliqué ci-dessus, cette contrainte est nécessaire afin de permettre à l'émulateur Android et à l'émulateur iOS (lancé sur une instance Scaleway Apple Silicon) aussi bien que sur mon smartphone physique personnel, d'accéder aux dummy website avec un support https.
Ceci était d'autant plus nécessaire, pour remplir les contraintes de configuration de la fonctionnalité Deep Linking with Universal and App Links.
C'est pour cela que j'ai dernièrement publié les notes suivantes : 2024-12-28_1621, 2024-12-28_1710, 2024-12-31_1853 et Alternatives managées à ngrok Developer Preview.
Pour simplifier la configuration de ce projet (poc-capacitor), j'ai décidé d'utiliser "cloudflared tunnel" en mode non connecté.
J'ai installé cloudflared avec Mise (voir la configuration ici).
Pour rendre plus pratique le lancement et l'arrêt du tunnel cloudflare, j'ai implémenté deux scripts :
Voici ce que cela donne à l'usage :
$ ./scripts/start-cloudflare-http-tunnel.sh Starting the tunnel... …wait… …wait… …wait… Tunnel started successfully: https://moral-clause-interesting-broadway.trycloudflare.comTo stop the tunnel, you can execute:
$ ./scripts/stop-cloudflare-http-tunnel.sh Stopping the tunnel (PID: 673143)... Tunnel stopped successfully.
Étape 3 : configuration de la webview Capacitor
En réalité, par erreur, j'ai configuré la webview Capacitor après l'implémentation de la partie App links.
Au départ, je pensais qu'un simple window.location.href = process.env.START_URL; était suffisant pour afficher le site web dans l'application. En réalité, cette commande a pour effet d'ouvrir la page HTML dans le browser par défaut du smartphone. Je ne m'en étais pas tout de suite rendu compte.
Dans Capacitor, pour créer une webview dans une application, il est nécessaire l'utiliser la fonction InAppBrowser.openInWebView(... du package @capacitor/inappbrowser.
Voici l'implémentation dans le fichier /src/js/online-webview.js :
window.Capacitor.Plugins.InAppBrowser.openInWebView({ url: startUrl, options: { // See https://github.com/ionic-team/capacitor-os-inappbrowser/blob/e5bee40e9b942da0d4dad872892f5e7007d87e75/src/defaults.ts#L33 // Constant values are in https://github.com/ionic-team/capacitor-os-inappbrowser/blob/e5bee40e9b942da0d4dad872892f5e7007d87e75/src/definitions.ts showToolbar: false, showURL: false, clearCache: true, clearSessionCache: true, mediaPlaybackRequiresUserAction: false, // closeButtonText: 'Close', // toolbarPosition: 'TOP', // ToolbarPosition.TOP // showNavigationButtons: true, // leftToRight: false, customWebViewUserAgent: 'capacitor webview', android: { showTitle: false, hideToolbarOnScroll: false, viewStyle: 'BOTTOM_SHEET', // AndroidViewStyle.BOTTOM_SHEET startAnimation: 'FADE_IN', // AndroidAnimation.FADE_IN exitAnimation: 'FADE_OUT', // AndroidAnimation.FADE_OUT allowZoom: false }, iOS: { closeButtonText: 'DONE', // DismissStyle.DONE viewStyle: 'FULL_SCREEN', // iOSViewStyle.FULL_SCREEN animationEffect: 'COVER_VERTICAL', // iOSAnimation.COVER_VERTICAL enableBarsCollapsing: true, enableReadersMode: false } } });
Les paramètres dans options permettent de configurer la webview. J'ai choisi de désactiver un maximum de fonctionnalités.
En implémentant cette partie, j'ai rencontré trois difficultés :
- Avec la version
1.0.2du packages, j'ai rencontré ce bug "Bug- Android App crashing after adding this plugin, j'ai perdu presque 1 heure avant de le découvrir, pour fixer cela, j'ai choisi le QuickWin d'installer la version1.0.1. - J'ai mis un peu de temps pour trouver les paramètres passés dans
options - J'ai trouvé
allowZoom: falsepour supprimer l'affichage des boutons de zoom dans la webview
Étape 4 : setup de la partie App Links
Après avoir lu la page "Deep Linking with Universal and App Links", c'était la partie que je trouvais la plus difficile, mais en pratique, ce n'est pas très compliqué.
J'ai passé 5h30 sur cette partie, mais j'ai fait plusieurs erreurs.
Cette configuration se passe en 3 étapes.
Génération du fichier .well-known/assetlinks.json
La première consiste à générer le fichier le fichier dummy-website/.well-known/assetlinks.json qui est exposé par le serveur HTTP du dummy website.
Cette opération est documentée dans la partie "Create Site Association File".
Son contenu ressemble à ceci :
[
{
"relation": [
"delegate_permission/common.handle_all_urls"
],
"target": {
"namespace": "android_app",
"package_name": "$PACKAGE_NAME",
"sha256_cert_fingerprints": ["$SHA256_FINGERPRINT"]
}
}
]
Il a une fonction de sécurité, il permet d'éviter de créer des applications malveillantes qui s'ouvriraient automatiquement sur des URLs sans lien avec l'application.
Il permet de dire « l'URL de ce site web peut automatiquement ouvrir l'application $PACKAGE_NAME » qui est signée avec la clé publique $SHA256_FINGERPRINT.
J'ai implémenté le script /scripts/generate-dev-assetlinks.sh qui permet automatiquement de générer ce fichier.
Lorsque j'ai travaillé sur cette partie, j'ai fait l'erreur de générer un certificat (voir le script /scripts/generate-dev-assetlinks.sh). Or, ce n'est pas la bonne méthode en mode développement.
Par défaut, Android met à disposition un certificat de développement dans ${HOME}/.android/debug.keystore.
La commande suivante me permet d'extraire la clé publique :
SHA256_FINGERPRINT=$(keytool -list -v \ -keystore "${HOME}/.android/debug.keystore" \ -alias "androiddebugkey" \ # password par défaut -storepass "android" 2>/dev/null | grep "SHA256:" | awk '{print $2}')
Configuration de AndroidManifest.xml
Comme indiqué ici, voici les lignes que j'ai ajoutées dans /android/app/src/main/AndroidManifest.xml.tmpl :
<intent-filter android:autoVerify="true"> <action android:name="android.intent.action.VIEW" /> <category android:name="android.intent.category.DEFAULT" /> <category android:name="android.intent.category.BROWSABLE" /> <data android:scheme="https" /> <data android:host="{{ .Env.ALLOW_NAVIGATION }}" /> </intent-filter>
Petite digression sur mon usage des templates dans ce projet.
J'utilise gomplate pour générer des fichiers dynamiquement à partir de 4 templates (.tmpl) et des variables d'environnement configurées entre autres dans .envrc.
La génération des fichiers se trouve ici :
gomplate -f capacitor.config.json.tmpl -o capacitor.config.json gomplate -f android/app/build.gradle.tmpl -o android/app/build.gradle gomplate -f android/app/src/main/AndroidManifest.xml.tmpl -o android/app/src/main/AndroidManifest.xml gomplate -f android/app/src/main/strings.xml.tmpl -o android/app/src/main/res/values/strings.xml
Les principaux éléments dynamiques sont :
export APP_NAME=myapp
export PACKAGE_NAME="xyz.sklein.myapp"
export START_URL=$(cat .cloudflared_tunnel_url)
export ALLOW_NAVIGATION=$(echo "$START_URL" | sed -E 's#https://([^/]+).*#\1#')
START_URL contient l'URL publique générée par cloudflared tunnel qui change à chaque lancement du tunnel.
Support deep links via l'interception de l'événement appUrlOpen
Troisième étape de la configuration de App links.
let timeoutId = setTimeout(() => { openInWebView(process.env.START_URL); }, 200); window.Capacitor.Plugins.App.addListener('appUrlOpen', (event) => { clearTimeout(timeoutId); openInWebView(event.url); });
Cela permet d'implémenter la fonction deep links. Exemple : si l'utilisateur du smartphone clique sur l'URL https://dummysite/deep/ alors l'application va directement s'ouvrir sur la page /deep/ du dummy website.
Commandes utiles
La commande suivante permet de demander à l'OS Android de lancer une nouvelle "vérification" du fichier dummy-website/.well-known/assetlinks.json :
$ adb shell pm verify-app-links --re-verify ${PACKAGE_NAME}
Note : le fichier .cloudflared_tunnel_url contient l'URL du tunnel cloudflare qui expose le dummy website.
La commande suivante permet d'afficher la configuration actuelle App Link d'une application :
$ adb shell pm get-app-links ${PACKAGE_NAME} xyz.sklein.myapp: ID: 100ba7e3-b978-49ac-926c-8e6ec6810f5c Signatures: [AF:AE:25:7F:ED:98:49:A3:E0:23:B3:BE:92:08:84:A5:82:D1:80:AA:E0:A4:A3:D3:A0:E2:18:D6:70:05:67:ED] Domain verification state: association-pending-belt-acute.trycloudflare.com: verified
La commande suivante permet de tester le lancement de l'application à partir d'une URL passée en paramètre :
$ adb shell am start -W -a android.intent.action.VIEW -d "$(cat .cloudflared_tunnel_url)" Starting: Intent { act=android.intent.action.VIEW dat=https://sc-lo-welsh-injury.trycloudflare.com/... } Status: ok LaunchState: COLD Activity: xyz.sklein.myapp/.MainActivity TotalTime: 1258 WaitTime: 1266 Complete
Cela fonctionne aussi avec une sous-page, par exemple : "$(cat .cloudflared_tunnel_url)/deep/?query=foobar".
Dans l'émulateur, Chrome ne lance pas les App Link !
Je pense que ce piège m'a fait perdre 2 h (sur les 5 h passées sur cette implémentation) !
Si j'ouvre l'URL du dummy website dans Chrome, l'application n'est pas lancée.
Mais, si j'ouvre l'URL dans l'application qui se nomme "Google", celle accessible via la barre de recherche en bas ce ce screenshot, l'App Link est bien pris en compte.

Problème : je testais mon application seulement dans Chrome. Et la fonctionnalité App Links ne fonctionnait pas. C'est seulement quand j'ai installé l'application sur mon smartphone physique personnel que j'ai constaté que App Links fonctionnait sous "Firefox Android".
J'ai constaté aussi que sur mon smartphone, Chrome n'ouvrait aucune application sur les URLs youtube.com, reddit.com, github.com…
D'après ce que je pense avoir compris, la liste des applications qui peuvent ouvrir les App Links est listée dans la section "Settings => Apps => Default apps" :
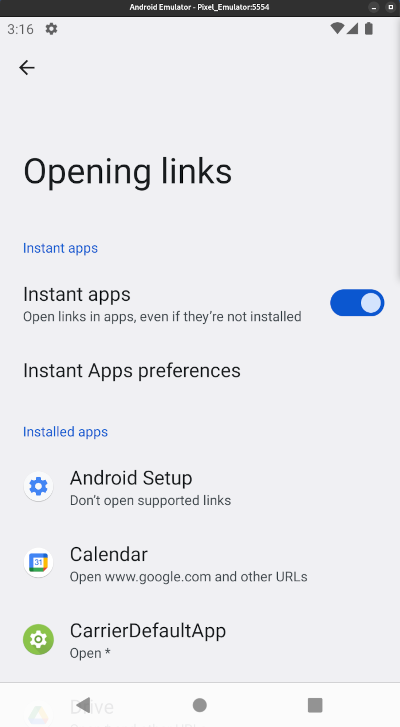
J'ai fait des expériences sur 3 différents smartphones Android d'amis et à ce jour, je n'ai pas encore compris comment cela fonctionne. J'ai l'impression que c'est lié au browser par défaut configuré, mais j'ai trouvé des exceptions.
En tout cas, ce piège m'a fait perdre beaucoup de temps !
Note finale
Pour le moment, je n'ai pas eu besoin de configurer @capacitor/app-launcher, mais je pense que cela sera utile pour permettre à l'application d'ouvrir d'autres applications à partir d'une URL.
J'ai scripté pratiquement toutes les actions de ce projet.
ChatGPT m'a bien servi tout au long de cette implémentation.
Alternatives managées à ngrok Developer Preview
Dans la note 2024-12-31_1853, j'ai présenté sish-playground qui permet de self host sish.
Je souhaite maintenant lister des alternatives à ngrok qui proposent des services gérés.
Quand je parle d'alternative à ngrok, il est question uniquement de la fonctionnalité d'origine de ngrok en 2013 : exposer des serveurs web locaux (localhost) sur Internet via une URL publique. ngrok nomme désormais ce service "Developer Preview".
Offre managée de sish
Les développeurs de sish proposent un service managé à 2 € par mois.
Ce service permet l'utilisation de noms de domaine personnalisés : https://pico.sh/custom-domains#tunssh.
Test de la fonctionnalité "Developer Preview" de ngrok
J'ai commencé par créer un compte sur https://ngrok.com.
Ensuite, une fois connecté, la console web de ngrok m'invite à installer le client ngrok. Voici la méthode que j'ai suivie sur ma Fedora :
$ wget https://bin.equinox.io/c/bNyj1mQVY4c/ngrok-v3-stable-linux-amd64.tgz -O ~/Downloads/ngrok-v3-stable-linux-amd64.tgz
$ sudo tar -xvzf ~/Downloads/ngrok-v3-stable-linux-amd64.tgz -C /usr/local/bin
$ ngrok --help
ngrok version 3.19.0
$ ngrok config add-authtoken 2r....RN
$ ngrok http http://localhost:8080
ngrok (Ctrl+C to quit)
👋 Goodbye tunnels, hello Agent Endpoints: https://ngrok.com/r/aep
Session Status online
Account Stéphane Klein (Plan: Free)
Version 3.19.0
Region Europe (eu)
Web Interface http://127.0.0.1:4040
Forwarding https://2990-2a04-cec0-107a-ea02-74d7-2487-cc11-f4d2.ngrok-free.app -> http://localhost:8080
Connections ttl opn rt1 rt5 p50 p90
0 0 0.00 0.00 0.00 0.00
Cette fonctionnalité de ngrok est gratuite.
Toutefois, pour pouvoir utiliser un nom de domaine personnalisé, il est nécessaire de souscrire à l'offre "personal" à $8 par mois.
Test de la fonctionnalité Tunnel de Cloudflare
Pour exposer un service local sur Internet via une URL publique avec cloudflared, je pense qu'il faut suivre la documentation suivante : Create a locally-managed tunnel (CLI).
J'ai trouvé sur cette page, le package rpm pour installer cloudflared sous Fedora :
$ wget https://github.com/cloudflare/cloudflared/releases/latest/download/cloudflared-linux-x86_64.rpm -O /tmp/cloudflared-linux-x86_64.rpm
$ sudo rpm -i /tmp/cloudflared-linux-x86_64.rpm
$ cloudflared --version
cloudflared version 2024.12.2 (built 2024-12-19-1724 UTC)
Voici comment exposer un service local sur Internet via une URL publique avec cloudflared sans même créer un compte :
$ cloudflared tunnel --url http://localhost:8080
...
Requesting new quick Tunnel on trycloudflare.com...
Your quick Tunnel has been created! Visit it at (it may take some time to be reachable):
https://manufacturer-addressing-surgeon-tried.trycloudflare.com
Après cela, le service est exposé sur Internet sur l'URL suivante : https://manufacturer-addressing-surgeon-tried.trycloudflare.com.
Voici maintenant la méthode pour exposer un service sur un domaine spécifique.
Pour cela, il faut que le nom de domaine soit géré pour les serveurs DNS de cloudflare.
Au moment où j'écris cette note, c'est le cas pour mon domaine stephane-klein.info :
$ dig NS stephane-klein.info +short
ali.ns.cloudflare.com.
sri.ns.cloudflare.com.
Ensuite, il faut lancer :
$ cloudflared tunnel login
Cette commande ouvre un navigateur, ensuite il faut se connecter à cloudflare et sélectionner le nom de domaine à utiliser, dans mon cas j'ai sélectionné stephane-klein.info.
Ensuite, il faut créer un tunnel :
$ cloudflared tunnel create mytunnel
Tunnel credentials written to /home/stephane/.cloudflared/61b0e52f-13e3-4d57-b8da-6c28ff4e810b.json. …
La commande suivante, connecte le tunnel mytunnel au hostname mytunnel.stephane-klein.info :
$ cloudflared tunnel route dns mytunnel mytunnel.stephane-klein.info
2025-01-06T17:52:10Z INF Added CNAME mytunnel.stephane-klein.info which will route to this tunnel tunnelID=67db5943-1f16-4b4a-a307-e8ceeb01296c
Et, voici la commande pour exposer un service sur ce tunnel :
$ cloudflared tunnel --url http://localhost:8080 run mytunnel
Après cela, le service est exposé sur Internet sur l'URL suivante : https://mytunnel.stephane-klein.info.
Pour finir, voici comment détruire ce tunnel :
$ cloudflared tunnel delete mytunnel
J'ai essayé de trouver le prix de ce service, mais je n'ai pas trouvé. Je pense que ce service est gratuit, tout du moins jusqu'à un certain volume de transfert de données.
Journal du lundi 06 janvier 2025 à 12:35
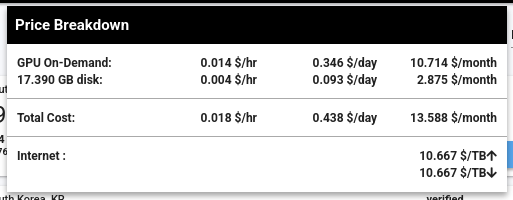
#JaiDécouvert Vast.ai (https://vast.ai/) :
Vast.ai is the market leader in low-cost cloud GPU rental.
Use one simple interface to save 5-6X on GPU compute.
J'aimerais faire des Benchmarks de Inference Engines sur le serveur suivant à 14 $ par mois, qui contient une RTX 4090 avec 24 GB de Ram.

Journal du dimanche 05 janvier 2025 à 13:51
Note de type #mémento.
Bien que gnome-software prenne en charge (code source) l'upgrade des firmware avec fwupd en mode GUI, j'aime effectuer ces mises à jour en ligne de commande.
Voici les commandes fwupd utiles.
Tout d'abord, pour m'aider à retenir le nom de cet outil : "fwupd" est tout simplement la contraction de "firmware update".
Pour rafraîchir la liste des firmwares disponibles :
$ sudo fwupdmgr refresh
Pour obtenir la liste des mises à jour disponibles :
$ sudo fwupdmgr get-updates
Pour installer les mises à jour disponibles :
$ sudo fwupdmgr update
Journal du samedi 04 janvier 2025 à 16:43
#JaiDécouvert l'opérateur satisfies en TypeScript, ajouté en novembre 2022, dans la version 4.9.
Je pense avoir compris son utilité et son usage.
Journal du vendredi 03 janvier 2025 à 15:45
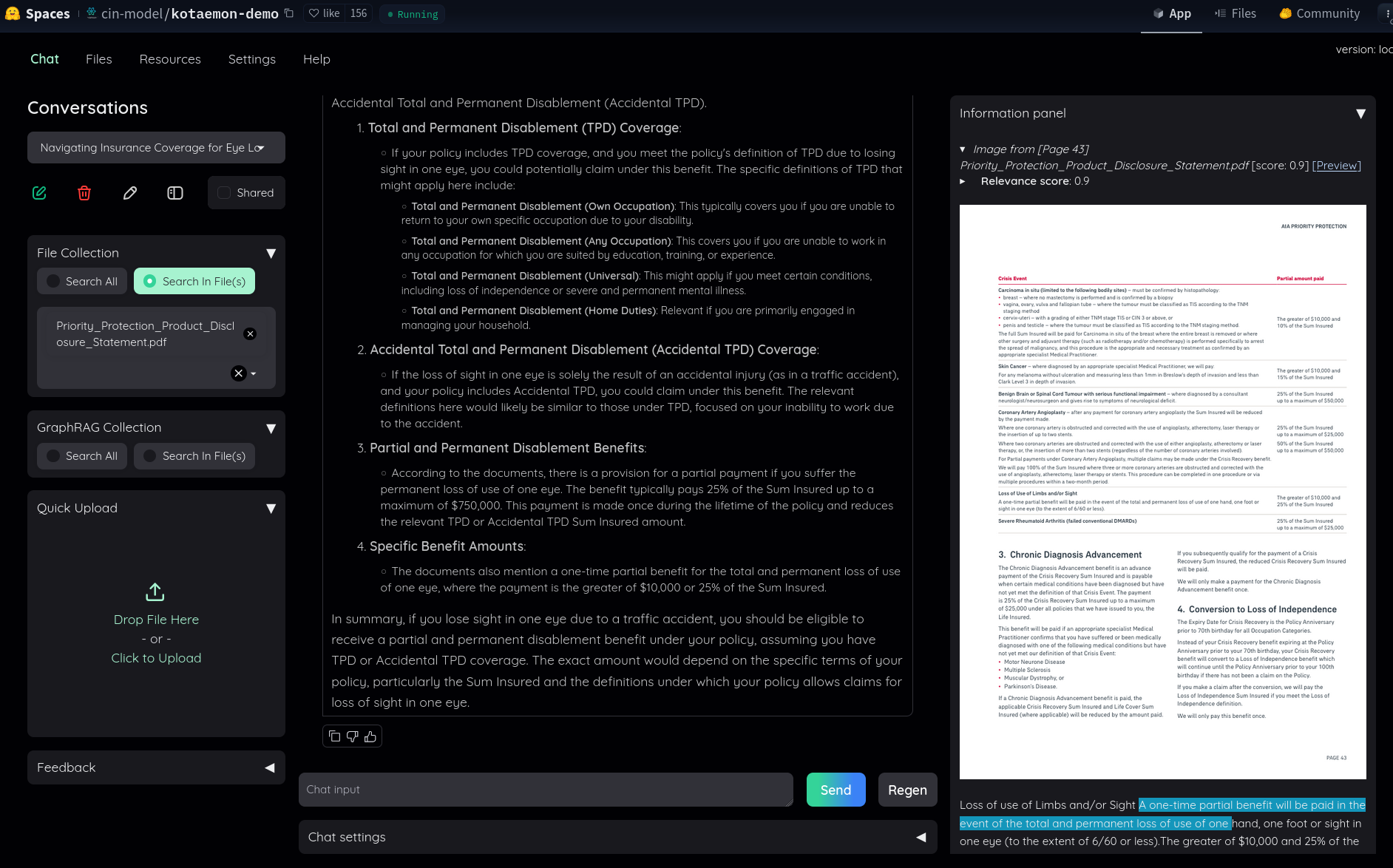
Dans ce thread Hacker News, #JaiDécouvert le RAG kotaemon (https://github.com/Cinnamon/kotaemon).
J'ai fait un simple test sur "Live Demo", j'ai trouvé le résultat très intéressant :
Dans le README, #JaiDécouvert GraphRAG (https://github.com/microsoft/graphrag), nano-graphrag (https://github.com/gusye1234/nano-graphrag) et LightRAG (https://github.com/HKUDS/LightRAG).
J'ai compris que kotaemon peut fonctionner avec nano-graphrag, LightRAG et GraphRAG et que nano-graphrag était recommandé.
J'ai lu :
Support for Various LLMs: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via
ollamaandllama-cpp-python).
J'ai l'impression que kotaemon est un outil de RAG complet, prêt à l'emploi, contrairement à llama_index qui se positionne davantage comme une bibliothèque de plus bas niveau.
Dans le Projet 20 - "Créer un POC d'un RAG", je pense commencer par tester kotaemon.
Je me demande si Obsidian ou SilverBullet pourraient tirer parti de la norme "URL text fragment" 🤔
#JeMeDemande si Obsidian ou SilverBullet.mb supportent la syntax URL text fragment 🤔.
Claude.ia m'a appris que les URL text fragment se nomment aussi des "deep linking to text".
J'ai effectué les recherches suivantes sur GitHub :
- « obsidian deep linking » et j'ai trouvé :
deep-notesmais le README "vide" ne m'a pas donné envie de le tester
- « obsidian fragment » mais je n'ai rien trouvé de pertinent
J'ai effectué les recherches suivantes sur https://forum.obsidian.md :
- « deep link » et j'ai trouvé :
- En lisant "Link to Block does not work with non-default themes" #JaiDécouvert la fonctionnalité d'Obsidian nommée "Link to a block in a note" qui est à l'usage très pratique.
- « fragment » et j'ai trouvé :
- "I think text fragment could be very useful in Obsidian" qui correspond à la question que je me pose.
Pour le moment, je pense qu'avec Obsidian la seule solution est d'utiliser la fonctionnalité "Link to a block in a note".
Voici mes recherches concernant SilverBullet.mb.
Dans la page "Links" j'ai trouvé la fonctionnalité "Anchors."
J'ai effectué les recherches suivantes sur https://community.silverbullet.md:
et je n'ai rien trouvé d'intéressant.
J'ai ensuite effectué des recherches sur GitHub :
je n'ai rien trouvé d'intéressant non plus.
J'ai posté le message suivant sur « I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔 ».
Version française :
Il y a quelques jours, j'ai découvert la fonctionnalité URL text fragment (ma note à ce sujet en français). Depuis, j'utilise l'extension Firefox "Link to Text Fragment" pour partager des liens précis et je trouve cela très simple d'usage.
J'ai bien identifié la fonctionnalité Anchors de Silverbullet pour créer un lien vers une position précise dans une page interne à SilverBullet.
Je me demande si SilverBullet pourrait tirer parti de la norme "URL text fragment" 🤔.
J'imagine une syntaxe du type
[[MyPage#:~:text=foobar]].Pour le moment, j'ai du mal à imaginer les avantages /inconvénients de cette idée de fonctionnalité par rapport à l'utilisation de "Anchors".
J'ai cherché si Obsidian supportait les URL text fragment, je constate que non.
Chez Obsidian l'équivalent de Anchors semble être Link to a block in a note.Quelle est votre intuition à ce sujet ?
Version anglaise :
A few days ago, I discovered the URL text fragment feature (my note about this in french). Since then, I've been using the Firefox extension “Link to Text Fragment” to share specific links, and I find it very easy to use.
I did identify Silverbullet's Anchors feature for linking to a specific position on a SilverBullet internal page.
I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔.
I can imagine a syntax like
[[MyPage#:~:text=foobar]].For now, I'm struggling to imagine the advantages/disadvantages of this feature idea compared to using “Anchors”.
I've looked to see if Obsidian supports URL text fragments, and find that it doesn't.
Obsidian's equivalent of Anchors seems to be Link to a block in a note.What's your feeling about this?
Journal du vendredi 03 janvier 2025 à 12:59
Dans ce thread du forum de SilverBullet.mb #JaiDécouvert l'outil Nutshell (https://ncase.me/nutshell/) :

Je trouve cela très ingénieux.
#JeMeDemande comment je pourrais tirer parti de cette fonctionnalité dans notes.sklein.xyz 🤔.
J'ai publié deux nouveaux playgrounds :
Cela fait depuis 2018 que je souhaite tester la génération d'un certificat de type "wildcard" avec le challenge DNS-01 de la version 2 de ACME.
Bonne nouvelle, j'ai testé avec succès cette fonctionnalité dans le playground : dnsrobocert-playground.
Est-ce que je vais généraliser l'usage de certificats wildcard générés avec un challenge DNS-01 à la place de multiples challenge HTTP-01 ?
Pour le moment, je n'en ai aucune idée. J'ai utilisé un challenge DNS-01 pour déployer sish.
L'avantage d'un certificat wildcard réside dans le fait qu'il n'a besoin d'être généré qu'une seule fois et peut ensuite être utilisé pour tous les sous-domaines. Toutefois, il doit être mis à jour tous les 90 jours.
Actuellement, je n'ai pas trouvé de méthode pratique pour automatiser son déploiement.
Par exemple, pour nginx, il serait nécessaire d'automatiser l'upload du certificat dans le volume du conteneur nginx, ainsi que l'exécution de la commande nginx -s reload pour recharger le certificat.
Concernant le second playground, j'ai réussi à déployer avec succès sish.
Voici un exemple d'utilisation :
$ ssh -p 2222 -R test:80:localhost:8080 playground.stephane-klein.info
Press Ctrl-C to close the session.
Starting SSH Forwarding service for http:80. Forwarded connections can be accessed via the following methods:
HTTP: http://test.playground.stephane-klein.info
HTTPS: https://test.playground.stephane-klein.info
Je trouve l'usage plutôt simple.
Je compte déployer sish sur sish.stephane-klein.info pour mon usage personnel.
Journal du mardi 31 décembre 2024 à 18:21
Suite à la lecture de ce pouet, #JaiLu le billet de blog d'Emmanuele Bassi "The Mirror" qui traite de GObject et d'une stratégie d'amélioration.
Je n'ai pas compris l'intégralité de ce que j'ai lu. Cependant, l'écosystème Linux Desktop est un sujet qui me passionne depuis des années et je continue à me cultiver sur le sujet.
Journal du mardi 31 décembre 2024 à 17:12
Dans le billet de blog d'Emmanuele Bassi "The Mirror", j'ai découvert l'expression informatique "Flag day".
Releasing GLib 3.0 today would necessitate breaking API in the entirety of the GNOME stack and further beyond; it would require either a hard to execute “flag day”, or an impossibly long transition, reverberating across downstreams for years to come.
L'article Wikipédia donne la définition suivante :
A flag day, as used in system administration, is a change which requires a complete restart or conversion of a sizable body of software or data. The change is large and expensive, and—in the event of failure—similarly difficult and expensive to reverse.
D'après ce que j'ai compris, un "Flag day" désigne un déploiement complexe où plusieurs systèmes doivent être mis à jour simultanément, sans possibilité de retour en arrière. C'est une approche risquée, car elle implique une transition brutale entre l'ancien et le nouveau système, souvent difficile à gérer dans des environnements interdépendants.
Un "Flag day" s'oppose à une migration en douceur.
C'est une situation que j'essaie d'éviter autant que possible. Des méthodes comme les Feature toggle ou l'introduction d'un système de versionnement permettent d'effectuer des migrations douces, par petites itérations, testables et sans interruption de service.
Concernant l'origine de cette expression, je lis :
This systems terminology originates from a major change in the Multics operating system's definition of ASCII, which was scheduled for the United States holiday, Flag Day, on June 14, 1966.
Je pense qu'à l'avenir, je vais utiliser cette expression.