
Recherche
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (600) ] [ Page suivante (3308) >> ]
Journal du mardi 24 septembre 2024 à 15:48
#OnMaPartagé Looker Studio qui est un renommage de Data Studio.
Looker Studio est un logiciel de Data visualization, comme Metabase, Observable…
Pour le moment, mon coup de cœur reste Observable.
Journal du mardi 24 septembre 2024 à 13:07
#JaiLu un excellent article sur NATS : NATS de A à Y du blog Une tasse de café de Quentin Joly.
J'aime beaucoup les fonctionnalités cli de NATS, très pratiques pour faire des démos ou des tests.
J'y ai découvert les requêtes synchrones de NATS : Core NATS - Request-Reply.
À la fin de l'article, j'ai découvert Nex (NATS Execution Engine) :
The NATS Execution Engine (we'll just call it Nex most of the time) is an optional add-on to NATS that overlays your existing NATS infrastructure, giving you the ability to deploy and run workloads.
...
While you can build virtually any kind of application with Nex, the core building blocks are made up of two fundamental types of workloads: services and functions.
...
Nex functions are small and can be deployed either as Javascript functions or as WebAssembly modules.
Je découvre aussi que Nex utilise Firecracker.
Je suis un peu embêté, car je réalise que cela fait 2 ans que j'ai très envie d'utiliser NATS. J'espère ne pas tomber prochainement dans les travers du Resume Driven Development 🙈.
À la suite de la lecture de cet article, j'ai offert un petit café à Quentin Joly.
Journal du lundi 23 septembre 2024 à 17:12
PostgreSQL zero-downtime migrations made easy.
#JaiLu en partie ce thread Hacker News de 2023.
Après avoir lu partiellement la documentation, j'ai l'impression que pgroll est simple à utiliser pour des migrations qui restent simples.
J'ai lu la section Raw SQL et #JeMeDemande si pgroll reste pratique à utiliser pour des migrations complexes, par exemple, split d'une table en plusieurs tables, merge de tables…
Je ne suis pas très motivé pour apprendre un nouveau DSL, c'est-à-dire, le format de migrations de pgroll à la place des instructions DDL (Data Definition Language) SQL (create, alter…).
Pour le moment, j'ai réussi à réaliser "à la main" des migrations en douceur : mise en place de view, de triggers… qui sont par la suite supprimés.
Je pense que pgroll serait très pratique avec une fonctionnalité Skew Protection pour un projet où les déploiements en production en journée sont fréquents et qui ne souhaite pas imposer aux utilisateurs de rafraîchir leurs pages.
Journal du samedi 21 septembre 2024 à 11:42
Je souhaite essayer de créer un #playground qui intègre UnoCSS et qui permet de builder un fichier HTML qui contient toutes les dépendances.
Journal du samedi 21 septembre 2024 à 11:22
#JaiDécouvert better-sqlite3-migrate, #JeShouhaiteTester dans gibbon-replay.
#JaiDécouvert aussi better-sqlite3-helper qui propose un mécanisme de migration de base de données SQLite.
#JaiDécouvert aussi la méthode suivante, un peu plus "raw" : https://github.com/n1ru4l/character-overlay/blob/ed7b2e1a1f18982196b41fb544067db54cef433f/server/migrateDatabase.ts#L10
Journal du samedi 21 septembre 2024 à 11:13
#JaiLu Convince me to use better-sqlite3 qui explique pourquoi utiliser better-sqlite3 plutôt que node-sqlite3.
Journal du samedi 21 septembre 2024 à 11:09
#JaiDécouvert la fonctionnalité "PRAGMA schema version" de SQLite : https://www.sqlite.org/pragma.html#pragma_schema_version (from).
Journal du samedi 21 septembre 2024 à 10:46
J'aime utiliser la syntax de query de Postgres.js basé sur ES2015 tagged template string, par exemple :
const result = await sql`SELECT * FROM name = ${name}`;
Je cherche la même chose pour SQLite et #JaiDécouvert https://github.com/blakeembrey/sql-template-tag.
J'ai redécouvert squid et postguard.
Je pense que postguard est surtout utile avec TypeScript.
Journal du vendredi 20 septembre 2024 à 18:15
#OnMaPartagé l'article Wikipedia nommé Malleus Maleficarum.
#JaiDécouvert le mot Démonologie.
Journal du vendredi 20 septembre 2024 à 10:25
#JaiDécouvert et un peu étudié Temporal (workflow management).
D'après ce que j'ai compris, Temporal a été initialement développé par les auteurs (Maxim Fateev et Samar Abbas) de Cadence.
Je me souviens d'avoir étudié Cadence vers 2019. J'ai l'impression que ce projet est encore très actif. #JeMeDemande quelles sont les réelles différences entre Temporal et Cadence 🤔.
Une première réponse à ma question :
- Temporal supporte les langages Go, Java, PHP, Python, TypeScript, dotNET alors que Cadence est limitée aux langages Go et Java.
- Cadence propose une UI nommée
cadence-webqui semble plus minimaliste quetemporalio/ui.
D'après ce que j'ai lu, Temporal est totalement open-source, sous licence MIT. L'entreprise Temporal propose une version hébergée (managée) nommée Temporal Cloud.
#JaiDécouvert un exemple de projet d'Order Management System codé en Go et basé sur Temporal : https://github.com/temporalio/reference-app-orders-go.
Je n'ai pas étudié le code source, mais c'est un sujet qui m'intéresse, étant donné que j'ai travaillé par le passé sur le développement d'un Order Management System 😉.
Journal du jeudi 19 septembre 2024 à 09:56
#OnMaPartagé ce repository pour déployer n8n avec Ollama.
Journal du jeudi 19 septembre 2024 à 09:55
#JaiLu ce commentaire que j'ai trouvé très intéressant au sujet de NATS.
Journal du jeudi 19 septembre 2024 à 09:54
#JaiDécouvert Comic Mono (from), j'aime bien 🙂.
Journal du jeudi 19 septembre 2024 à 09:49
J'ai redécouvert les lois de Goodhart et de Campbell (from), en lien avec l'effet Cobra.
Journal du mardi 17 septembre 2024 à 18:48
Suite de 2024-09-17_1707.
Mon but est toujours de convertir une donnée datetime UTC vers la timezone du navigateur.
L'équivalent du code :
return Temporal.PlainDateTime
.from(value)
.toZonedDateTime('UTC')
.withTimeZone(
Intl.DateTimeFormat().resolvedOptions().timeZone
)
.toString({
offset: 'never',
timeZoneName: 'never'
})
.replace('T', ' ');
avec date-fns est :
import { format } from 'date-fns';
import { fromZonedTime, toZonedTime } from 'date-fns-tz';
return format(
toZonedTime(
fromZonedTime(value, "UTC"),
Intl.DateTimeFormat().resolvedOptions().timeZone
),
"yyyy-mm-dd HH:MM:SS"
);
Ce qui m'évite de devoir utiliser .replace('T', ' ').
Par contre, j'aurais bien aimé pouvoir utiliser une syntax du style :
return (
fromZonedTime(value, "UTC")
.toZonedTime(Intl.DateTimeFormat().resolvedOptions().timeZone)
.format("yyyy-mm-dd HH:MM:SS")
);
ce qui ne semble pas possible avec dns-fns.
Luxon semble proposer une syntax plus agréable :
import { DateTime } from 'luxon';
return DateTime
.fromISO(value, { zone: 'UTC' })
.setZone(Intl.DateTimeFormat().resolvedOptions().timeZone)
.toFormat('yyyy-MM-dd HH:mm:ss');
Journal du mardi 17 septembre 2024 à 17:07
Ici, dans le projet gibbon-replay, j'ai utilisé la librairie Temporal.
import { Temporal } from 'temporal-polyfill';
return Temporal.PlainDateTime
.from(value)
.toZonedDateTime('UTC')
.withTimeZone(
Intl.DateTimeFormat().resolvedOptions().timeZone
)
.toString({
offset: 'never',
timeZoneName: 'never'
})
.replace('T', ' ');
Le but est de convertir une donnée datetime UTC vers la timezone du navigateur.
Cependant, j'ai été déçu de constater qu'il n'existe pas de fonction de formatage intégrée similaire à celle de date-fns pour formater une date/heure.
Je trouve dommage de devoir utiliser .replace('T', ' '); pour supprimer le caractère T dans la date formatée.
Journal du lundi 16 septembre 2024 à 17:54
#JaiLu Trois candidats retenus pour racheter 49% des data centers d'Iliad
Si les résultats opérationnels, selon les ratios du marché, impliquerait une valorisation à hauteur de 700 millions, Iliad table pour sa part pour près d’un milliard. L’investisseur devra par ailleurs s’engager sur des investissements de 2.5 milliards d’euros sur dix ans. D’autant qu’Iliad entend ajouter des nouveaux centres à sa flotte d’ici à 2026, ce qui devrait permettre d’accroître les résultats opérationnels de sa filiale de 50%.
Dans cet article, j'ai trouvé le lien vers un article plus ancien, qui date du 27 juin 2024 : Iliad met en vente 49% de ses data centers pour réduire sa dette.
Iliad espère recevoir les premières offres indicatives des candidats d’ici au 31 juillet, précise le quotidien d’enquête sur la politique. Sur les 15 data centers que possède OPCORE en France et en Pologne, 14 seraient concernés par cette ouverture de capital. Cette information confirme les révélations de L’informé en janvier 2024.
-- from
Journal du dimanche 15 septembre 2024 à 10:38
#JaiDécouvert https://github.com/ghostdevv/svelte-hamburgers
Je l'ai utilisé dans https://sklein.xyz.
Journal du samedi 14 septembre 2024 à 22:53
#JaiDécouvert better-sqlite3, je vais sans doute l'utiliser dans gibbon-replay à la place de Redis.
Journal du samedi 14 septembre 2024 à 20:04
Dans le cadre du projet gibbon-replay, j'ai étudié sendBeacon pour traiter l'erreur NS_BINDING_ABORTED

qui a lieu ici lors de l'exécution de fetch lors d'événements beforeunload :
window.addEventListener('beforeunload', save);
C'est-à-dire, quand l'utilisateur quitte la page.
Dans ce commit, j'ai remplacé fetch par navigator.sendBeacon.
Journal du samedi 14 septembre 2024 à 18:18
#JaiDécouvert https://meet.hn, je me suis inscrit, mais je ne suis pas encore présent sur la carte.
Journal du vendredi 13 septembre 2024 à 17:40
#JaiDécouvert l'acronyme Consent Management Provider, Axeptio est un outil de CMP.
Journal du vendredi 13 septembre 2024 à 10:23
Après une mise en pratique plus approfondie, la technique présentée dans pnpm workspace et Docker build n'a pas fonctionné comme je l'attendais.
À cause de cette ligne du /demosite/pnpm-lock.yaml :
dependencies:
gibbon-replay-js:
specifier: 0.2.0
version: link:../packages/gibbon-replay-js
Pour générer un fichier pnpm-lock.yaml qui contient :
gibbon-replay-js:
specifier: 0.2.0
version: 0.2.0
j'ai créé un script nommé demosite/scripts/generate-local-pnpm-lock-file.sh qui contient :
#!/usr/bin/env bash
# This script generates a pnpm-lock.yaml file in the local directory,
# without including dependencies from workspace projects.
# For example, the version of gibbon-replay-js installed is the version
# published on npmjs.
# This point is crucial to ensure the correct operation of the docker build
# command when creating the Docker image of the demo-site project.
set -e
cd "$(dirname "$0")/../"
export npm_config_link_workspace_packages=false
export npm_config_prefer_workspace_packages=false
export npm_config_shared_workspace_lockfile=false
pnpm install --lockfile-only
Cela me permet de générer un fichier pnpm-lock.yaml qui sera présent dans le dossier /demosite/ et utilisé lors de l'exécution de Docker build.
En complément de cela, j'utilise les paramètres suivants dans /demosite/.npmrc :
link-workspace-packages=true
prefer-workspace-packages=true
shared-workspace-lockfile=true
cela permet en phase de "développement", c'est-à-dire en dehors du build Docker, d'utiliser le fichier pnpm-lock.yaml à la racine et la version locale du package packages/gibbon-replay-js.
Tout cela me paraît un peu complexe, mais pour l'instant, je n'ai pas trouvé de méthode alternative permettant de configurer un environnement de développement répondant à ces deux exigences :
- En mode développement, utiliser directement le code du
packages/gibbon-replay-jssans qu'aucune action ne soit requise de la part du développeur. - Pouvoir générer l'image Docker en une seule commande.
Je suis ouvert à toute suggestion 🙂 (contact@stephane-klein.info).
pnpm workspace et Docker build
J'écris cette note pour me souvenir pourquoi j'ai paramétré .npmrc avec les options suivantes :
link-workspace-packages=true
prefer-workspace-packages=true
shared-workspace-lockfile=false
Sans l'option link-workspace-packages=true, je devais configurer package.json comme ceci
"gibbon-replay-js": "workspace:*"
pour que /demosite utilise le package local /packages/gibbon-replay-js.
Cette contrainte me posait un problème, parce que /demosite/Dockerfile ne pouvait pas être buildé.
L'option link-workspace-packages=true permet de configurer la dépendance suivante
"gibbon-replay-js": "0.2.0"
qui pourra être installé correctement lors du build de l'image Docker.
Attention, cette version de gibbon-replay-js doit avoir préalablement été publiée sur npm registry.
Seconde option qui m'a été utile : shared-workspace-lockfile=false.
Avec cette option, pnpm install génère les fichiers /demosite/pnpm-lock.yaml et /app/pnpm-lock.yaml, fichiers indispensables pour build les images Docker.
Journal du jeudi 12 septembre 2024 à 19:14
#JaiDécouvert cet article pnpm "Working with Docker".
J'y ai découvert corepack.
Pour le moment, je ne comprends pas l'avantage d'utiliser :
FROM node:20-slim AS base
ENV PNPM_HOME="/pnpm"
ENV PATH="$PNPM_HOME:$PATH"
RUN corepack enable
plutôt que :
FROM node:20-slim AS base
RUN npm install -g pnpm@9.10
🤔
Dans ce Dockerfile j'ai tout de même utilisé cette technique pour tester.
J'ai utilisé le système de cache store de pnpm :
RUN --mount=type=cache,id=pnpm,target=/pnpm/store pnpm install --prod --frozen-lockfile
Je me suis posé la question de partage le cache de ma workstation :
$ pnpm store path
/home/stephane/.local/share/pnpm/store/v3
Mais je ne pense pas que cela soit une bonne idée dans le cas où cette image est buildé par une CI.
Journal du mercredi 11 septembre 2024 à 11:14
Dans la branche gibbon-replay-js du projet Idée d'un outil de session recoding web minimaliste basé sur rrweb, j'ai essayé sans succès d'extraire du code dans un package Javascript.
Pour le moment l'import suivant ne fonctionne pas :
import gibbonReplayJs from 'gibbon-replay-js';
Quand je lance pnpm run build, j'ai l'erreur suivante :
$ pnpm run build
...
x Build failed in 336ms
error during build:
src/routes/(record)/+layout.svelte (2:11): "default" is not exported by "packages/gibbon-replay-js/dist/index.js", imported by "src/routes/(record)/+layout.svelte".
file: /home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/src/routes/(record)/+layout.svelte:2:11
1: <script>
2: import gibbonReplayJs from 'gibbon-replay-js';
Et quand je lance pnpm run dev, j'ai l'erreur suivante :
$ pnpm run dev
...
11:21:21 [vite] Error when evaluating SSR module /packages/gibbon-replay-js/dist/index.js:
|- ReferenceError: exports is not defined
at eval (/home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/packages/gibbon-replay-js/dist/index.js:5:23)
at instantiateModule (file:///home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/node_modules/.pnpm/vite@5.4.3/node_modules/vite/dist/node/chunks/dep-BaOMuo4I.js:52904:11)
11:21:21 [vite] Error when evaluating SSR module /src/routes/(record)/+layout.svelte:
|- ReferenceError: exports is not defined
at eval (/home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/packages/gibbon-replay-js/dist/index.js:5:23)
at instantiateModule (file:///home/stephane/git/github.com/stephane-klein/gibbon-replay-poc/node_modules/.pnpm/vite@5.4.3/node_modules/vite/dist/node/chunks/dep-BaOMuo4I.js:52904:11)
Suite à cette frustration, j'ai envie de créer un projet, sans doute nommé javascript-package-playground dans lequel je souhaite étudier les sujets suivants :
- mise en place d'une librairie
/packages/lib1/qui contient une librairie javascript, qui peut être importé avec la méthode ECMAScript Modules ; - mise en place d'une app NodeJS dans
/services/app1_nodejs/qui utiliselib1; - mise en place d'une app SvelteKit dans
/services/app2_sveltekit/qui utiliselib1dans un fichier coté server et dans une page web coté browser ; - mise en place d'une librairie
/packages/lib2qui utiliselib1
Je souhaite décliner ces 2 libs et 2 apps sous plusieurs déclinaisons d'implémentation :
- avec le build basé sur tsc
- avec le build basé sur esbuild
- avec le build basé sur Babel (Javascript)
- et sans build
Et le tout encore dans deux déclinaisons : Javascript et TypeScript.
Je ne souhaite pas supporter CommonJS qui est sur le déclin, remplacé par ECMAScript Modules.
Dans ce playground, je souhaite aussi me perfectionner dans l'usage de pnpm link et pnpm workspace.
#JeMeDemande si ces connaissances sont totalement maitrisées et évidentes chez mes amis développeurs Javascript 🤔 et s'ils les considèrent comme "basiques".
Journal du mercredi 11 septembre 2024 à 09:28
#JaiDécouvert NestedText (from).
Même en lisant la section Alternatives - YAML, je ne comprends pas encore précisément l'intérêt du projet. Je ne trouve pas YAML plus simple que NestedText.
Journal du mardi 10 septembre 2024 à 17:55
Un ami m'a partagé Reclaim-the-Stack. J'aime bien l'initiative, mais pour mes besoins spécifiques, qui sont bien plus modestes, je préfère opter pour une solution plus minimaliste, comme Kamal.
Journal du mardi 10 septembre 2024 à 17:51
#JaiLu l'article de DHH : Design for the web without Figma.
This is perhaps the biggest, open secret to the productivity and viability of our two-person teams at 37signals. All our web designers work directly with the native materials of HTML, CSS, and usually even a fair bit of JavaScript and Ruby. The design process and its iterations flow through updates to the real code that runs the real app, and, as quickly as possible, against real data.
Voici encore une pratique à contre-courant de DHH, que je suis moi aussi depuis des années.
Journal du mardi 10 septembre 2024 à 17:24
J'avais bien vu passer la news de sortie de Writebook, mais j'étais passé totalement à côté de la sortie du concept de Once.com de Basecamp.
Pour le moment, Once.com propose deux services de type SaaS without the aaS :
J'aime bien le concept de Finished software, cela me fait penser à Hare. J'aimerais utiliser davantage de logiciels qui ne nécessitent jamais de mises à jour, sauf pour les corrections de bugs.
Dans l'article Campfire is SaaS without the aaS, je lis :
It hasn’t even been a week since we started selling Campfire under the new ONCE model, but we’ve already sold more than quarter of a million dollars worth of this beautifully simple installable chat system.
Si c’est exact, 250 000 $ représentent 836 ventes, ce qui est vraiment impressionnant en moins d'une semaine !
Ce que j'apprécie particulièrement chez DHH, c'est son franc-parler et surtout son courage à aller à contre-courant. Par exemple, il défend le self-hosting, n’utilise pas TypeScript, et prône le SaaS without the aaS...
Journal du mardi 10 septembre 2024 à 17:10
#JaiLu l'article de DHH : Merchants of complexity.
Je vous encourage à lire cet article, car il exprime une opinion que je partage depuis de nombreuses années.
J'aime bien l'expression merchants of complexity.
Cela rejoint ma doctrine qui consiste à enlever des couches, réduire la complexité, suivre le principe Keep it simple, stupid!, éviter le Cargo cult programming !
Journal du mardi 10 septembre 2024 à 15:05
#JaiDécouvert restic-exporter : « Prometheus exporter for the Restic backup system ».
Journal du mardi 10 septembre 2024 à 13:20
#JaiDécouvert l'option "append-only" mode de restic.
#JaiDécouvert rustic, un clone de restic implémenté en Rust (from).
Journal du mardi 10 septembre 2024 à 12:48
#JaiLu L'option ControlMaster de ssh_config.
J'y ai découvert l'open ControlMaster de OpenSSH.
Journal du lundi 09 septembre 2024 à 21:33
#JaiLu Windows NT vs. Unix: A design comparison (from).
Je ne connais rien au kernel MS Windows, j'ai trouvé cela intéressant.
Journal du lundi 09 septembre 2024 à 16:03
Alexandre m'a partagé le projet Grafana Tanka.
Flexible, reusable and concise configuration for Kubernetes.
Je découvre ce thread Hacker News que je n'ai pas pris le temps de lire : Tanka: Our way of deploying to Kubernetes.
Journal du lundi 09 septembre 2024 à 15:59
Dans cette note, je souhaite présenter ma doctrine de mise à jour d'OS de serveurs.
Je ne traiterai pas ici de la stratégie d'upgrade pour un Cluster Kubernetes.
La mise à jour d'un serveur, par exemple, sous un OS Ubuntu LTS, peut être effectuée avec les commandes suivantes :
sudo apt upgrade -y- ou
sudo apt dist-upgrade -y(plus risqué) - ou
sudo do-release-upgrade(encore plus risqué)
L'exécution d'un sudo apt upgrade -y peut :
- Installer une mise à jour de docker, entraînant une interruption des services sur ce serveur de quelques secondes à quelques minutes.
- Installer une mise à jour de sécurité du kernel, nécessitant alors un redémarrage du serveur, ce qui entraînera une coupure de quelques minutes.
Une montée de version de l'OS via sudo do-release-upgrade peut prendre encore plus de temps et impliquer des ajustements supplémentaires.
Bien que ces opérations se déroulent généralement sans encombre, il n'y a jamais de certitude totale, comme l'illustre l'exemple de la Panne informatique mondiale de juillet 2024.
Sachant cela, avant d'effectuer la mise à jour d'un serveur, j'essaie de déterminer quelles seraient les conséquences d'une coupure d'une journée de ce serveur.
Si je considère que ce risque de coupure est inacceptable ou ne serait pas accepté, j'applique alors la méthode suivante pour réaliser mon upgrade.
Je n'effectue pas la mise à jour le serveur existant. À la place, je déploie un nouveau serveur en utilisant mes scripts automatisés d'Infrastructure as code / GitOps.
C'est pourquoi je préfère éviter de nommer les serveurs d'après le service spécifique qu'ils hébergent (voir aussi Pets vs Cattle). Par exemple, au lieu de nommer un serveur gitlab.servers.example.com, je vais le nommer server1.servers.example.com et configurer gitlab.servers.example.com pour pointer vers server1.servers.example.com.
Ainsi, en cas de mise à jour de server1.servers.example.com, je crée un nouveau serveur nommé server(n+1).servers.example.com.
Ensuite, je lance les scripts de déploiement des services qui étaient présents sur server1.servers.example.com.
Idéalement, j'utilise mes scripts de restauration des données depuis les sauvegardes des services de server1.servers.example.com, ce qui me permet de vérifier leur bon fonctionnement.
Ensuite, je prépare des scripts rsync pour synchroniser rapidement les volumes entre server1.servers.example.com et server(n+1).servers.example.com.
Je teste que tout fonctionne bien sur server(n+1).servers.example.com.
Si tout fonctionne correctement, alors :
- J'arrête les services sur
server(n+1).servers.example.com; - J'exécute le script de synchronisation
rsyncdeserver1.servers.example.comversserver(n+1).servers.example.com; - Je relance les services sur
server(n+1).servers.example.com - Je modifie la configuration DNS pour faire pointer les services de
server1.servers.example.comversserver(n+1).servers.example.com - Quelques jours après cette intervention, je décommissionne
server1.servers.example.com.
Cette méthode est plus longue et plus complexe qu'une mise à jour directe de l'OS sur le server1.servers.example.com, mais elle présente plusieurs avantages :
- Une grande sécurité ;
- L'opération peut être faite tranquillement, sans stress, avec de la qualité ;
- Une durée de coupure limitée et maîtrisée ;
- La possibilité de confier la tâche en toute sécurité à un nouveau DevOps ;
- La garantie du bon fonctionnement des scripts de déploiement automatisé ;
- La vérification de l'efficacité des scripts de restauration des sauvegardes ;
- Un test concret des scripts et de la documentation du Plan de reprise d'activité.
Si le serveur à mettre à jour fonctionne sur une Virtual instance, il est également possible de cloner la VM et de tester la mise à niveau. Cependant, je préfère éviter cette méthode, car elle ne permet pas de valider l'efficacité des scripts de déploiement.
Journal du lundi 09 septembre 2024 à 15:00
Dans cette note, j'essaie autant que possible de comparer des offres Bare-metal server, Elastic Metal et Virtual Instances de Scaleway, pour une puissance égale.
Je lis ici que les Virtual Instances "Workload-Optimized - POP2HC" sont exécutés sur des serveurs « AMD EPYC™ 7003 Series processors ».
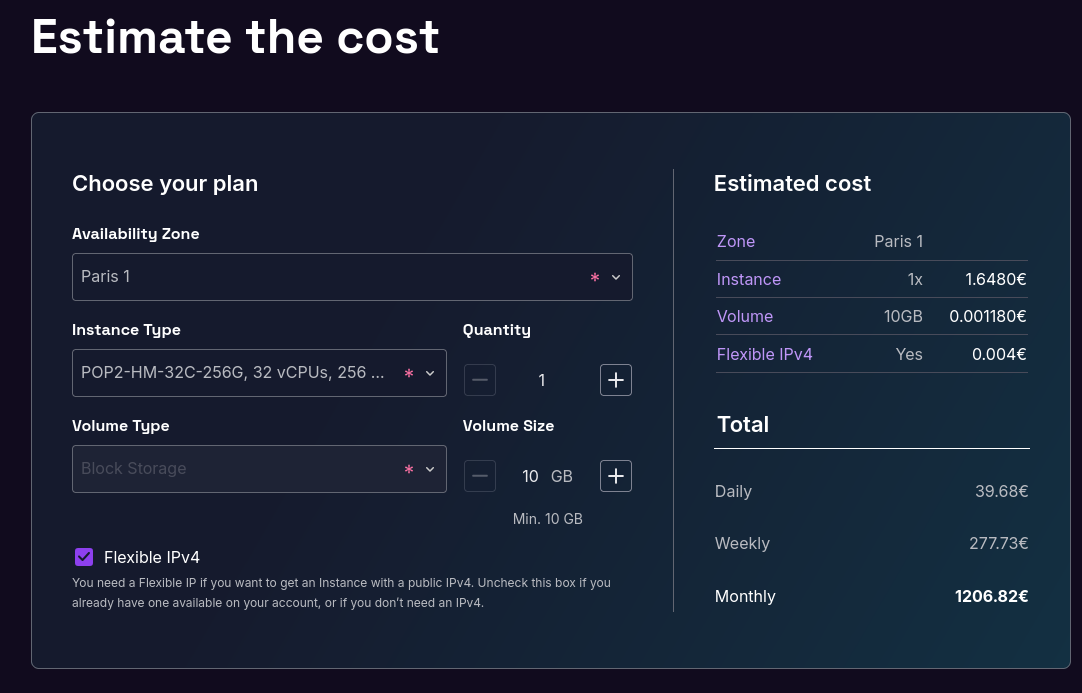
Le serveur Dedibox Core-9-L avec un CPU "AMD EPYC 7313P" fait partie de la famille des 7003, équivalent je pense aux serveurs qui font tourner les Virtual Instances POP3HC.

Coté Elastic Metal, j'ai identifié le modèle EM-I210E-NVME avec un processeur de la famille 7003 : "AMD EPYC 7313P".
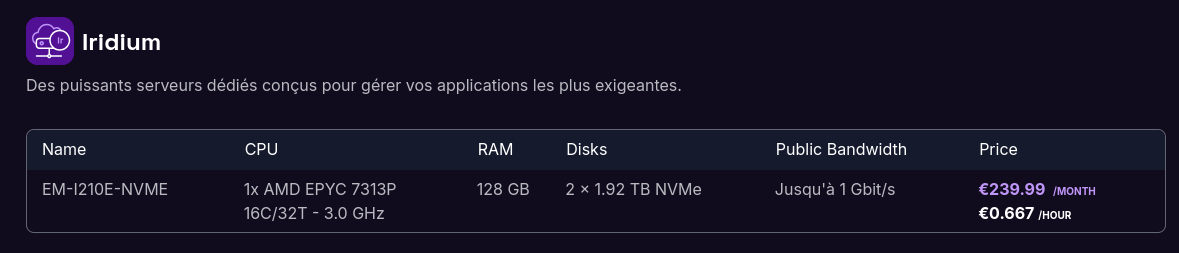
Tarif de ce serveur avec un engagement au mois : 239,99 € / mois et sans cet engagement : environ 480 € / mois.
Si je fais un bilan de comparaison :
- Dedibox
Core-9-L: 249 € / mois avec 256 GB de Ram et 3x1TB, engagement au mois. À cela il faut ajouter 329.99 € de frais de setup. - Elastic Metal
EM-I210E-NVME: 239 € / mois avec 128 GB de Ram et 2x1.9 TB, engagement au mois. À cela il faut ajouter 239,99 € de frais de setup. - Elastic Metal
EM-I210E-NVME: 480 € / mois avec 128 GB de Ram et 2x1.9 TB, engagement à l'heure - Virtual Instances
POP2HC: 1464 € / mois, avec 256 GB de Ram et 3TB de volume
À puissance égale, une Virtual Instances est approximativement 6 fois plus cher qu'une Dedibox (sans prise en compte des frais de setup Dedibox qui s'élèvent à 329 €).
Il est important de noter que je pourrais manquer d'informations concernant les serveurs hébergeant les Virtual Instances, ce qui pourrait entraîner des erreurs dans mon analyse.
Je tiens également à préciser qu'une Virtual Instance offre, en théorie, une meilleure fiabilité grâce à la possibilité — toujours en théorie — de migrer à chaud d'un serveur à un autre.
Journal du dimanche 08 septembre 2024 à 21:32
#JaiDécouvert Mini Spreadsheet Component with Svelte 5 : sveltejs.
Très minimaliste et sympatique 🙂.
Journal du dimanche 08 septembre 2024 à 20:18
Detect bots/crawlers/spiders using the user agent string