
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (0) >> ]
Journal du mercredi 22 mai 2024 à 11:33
J'ai rapidement parcouru l'article "What UI density means and how to design for it" ainsi que les discussions sur HackerNews et Lobsters.
#JePense : En tant que utilisateur hacker, je suis attristé de constater — ce n'est qu'une impression — que les UI des applications mainstream semblent de plus en plus appauvries en termes de densité d'information. Mon propos concerne spécifiquement les applications desktop ; les applications smartphone ont d'autres contraintes, notamment la sélection avec le doigt.
#JeMeDemande si les contraintes des interfaces utilisateur en mode texte (TUI) permettent généralement une densité d'information plus élevée 🤔.
J'ai partagé cette réflexion dans ces deux commentaires : HackerNews et Lobsters
Journal du lundi 20 mai 2024 à 11:01
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
Je me suis inspiré de l'exemple Drag and Drop pour implémenter ce commit, ce qui donne ceci :
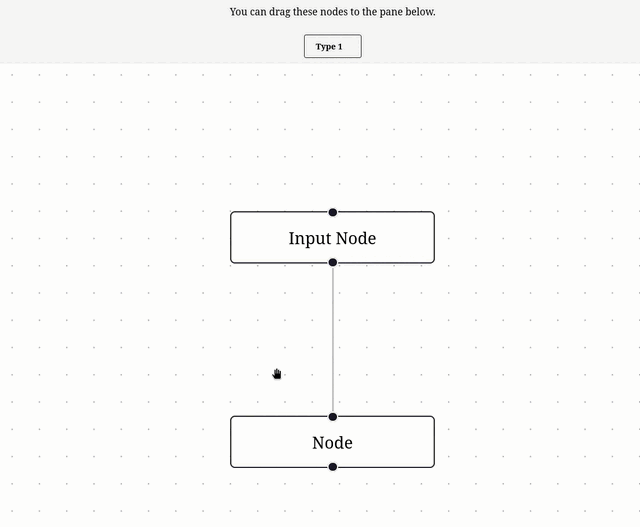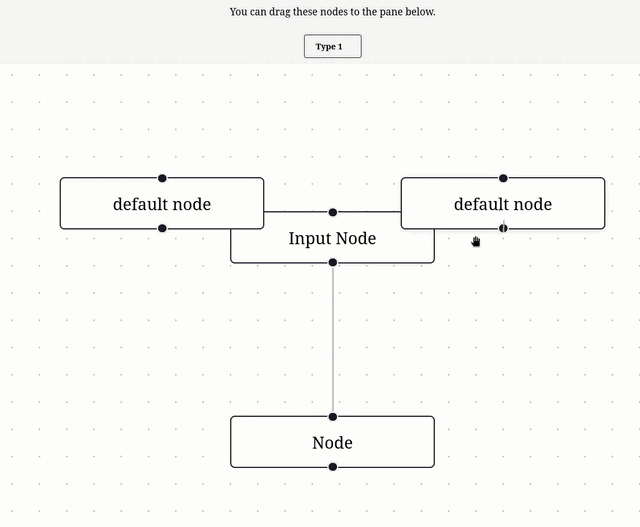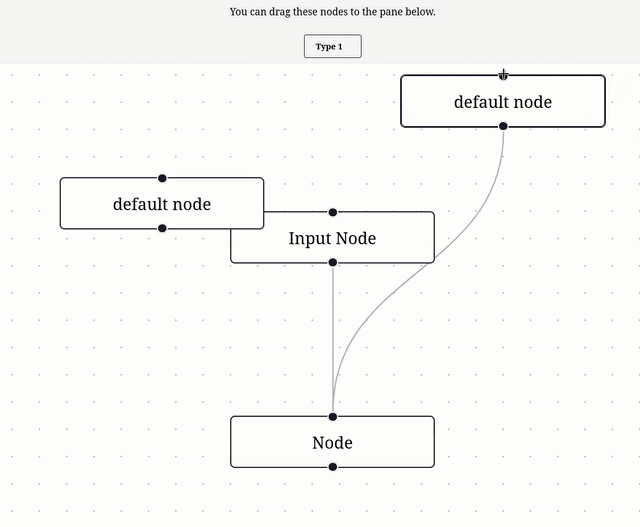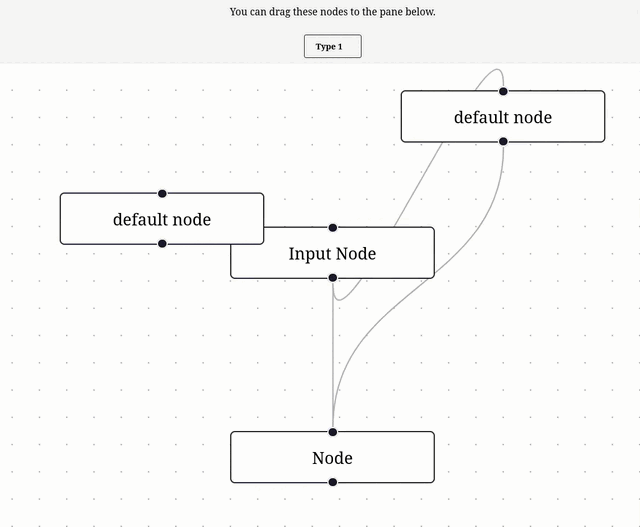
11:19 : Prochaine étape, lire et comprendre Theming – Svelte Flow.
11:32 :
- J'ai trouvé ce projet https://github.com/theonlytechnohead/patchcanvas/ qui peut me servir de source d'inspiration.
- #JeMeDemande si je dois implémenter un composant de type
<Handle />pour définir des contraintes de liaisons entre les nodes 🤔.
12:29 :
Journal du lundi 20 mai 2024 à 10:56
#JaiDécouvert https://keyshorts.com/ et #JeMeDemande si les stickers sont de meilleurs qualités que ceux de https://beaujoie.com/.
Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
#JeMeDemande combien me coûterait la réalisation du #POC suivant :
- Déploiement de Llama.cpp sur une GPU Instances de Scaleway;
- 3h d'expérimentation;
- Shutdown de l'instance.
🤔.
Tarifs :
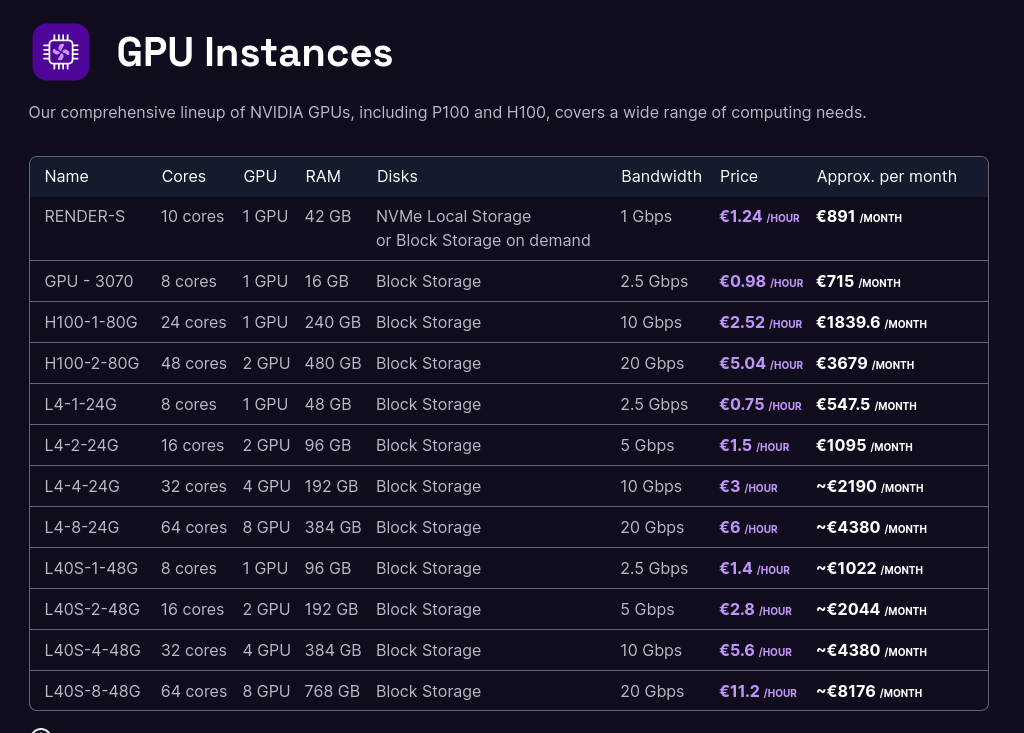
Dans un premier temps, j'aimerais me limiter aaux instances les moins chères :
- GPU-3070 à environ 1 € / heure
- L4-1-24G à 0.75 € / heure
- et peut-être RENDER-S à 1,24 € / heure
Tous ces prix sont hors taxe.
- L'instance GPU-3070 a seulement 16GB de Ram, #JeMeDemande si le résultat serait médiocre ou non.
- Je lis que l'instance L4-1-24G contient un GPU NVIDIA L4 Tensor Core GPU avec 24GB de Ram.
- Je lis que l'instance Render S contient un GPU Dedicated NVIDIA Tesla P100 16GB PCIe avec 42GB de Ram.
Au moment où j'écris ces lignes, Scaleway a du stock de ces trois types d'instances :
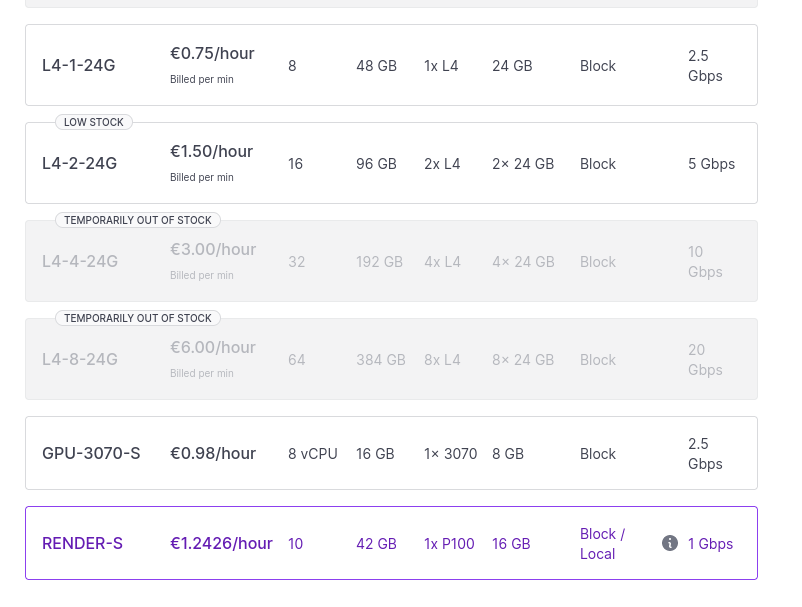
- #JeMeDemande comment je pourrais me préparer en amont pour installer rapidement sur le serveur un environnement pour faire mes tests.
- #JeMeDemande s'il existe des tutoriaux tout prêts pour faire ce type de tâches.
- #JeMeDemande combien de temps prendrait le déploiement.
Si je prends 2h pour l'installation + 3h pour faire des tests, cela ferait 5h au total.
J'ai cherché un peu partout, je n'ai pas trouvé de coût "caché" de setup de l'instance.
Le prix de cette expérience serait entre 4,5 € et 7,44 € TTC.
- #PremièreActionConcrète pour réaliser cette expérimentation : chercher s'il existe des tutoriaux d'installation de Llama.cpp sur des instances GPU Scaleway.
- #JeMeDemande combien me coûterait l'achat de ce type de machine.
- #JeMeDemande à partir de combien d'heures d'utilisation l'achat serait plus rentable que la location.
- Si par exemple, j'utilise cette machine 3h par jour, je me demande à partir de quelle date cette machine serait rentabilisée et aussi, #JeMeDemande si cette machine ne serait totalement obsolète ou non à cette date 🤔.
Journal du jeudi 16 mai 2024 à 08:36
#pensée : je travaille depuis plusieurs jours sur Projet -1 "CodeMirror, autocomplétion, Svelte" et je fais le constat que j'ai énormément de difficultés à comprendre et à utiliser la librairie #codemirror .
Bien que la documentation contienne déjà un certain nombre d'exemples, je constate que j'en ai besoin de beaucoup plus.
La documentation contient des exemples, mais la librairie est vaste et j'ai besoin de beaucoup plus d'exemples !
Comme je ne trouve pas mes réponses dans les exemples, je passe beaucoup de temps à :
- chercher dans le forum https://discuss.codemirror.net/
- chercher dans le code source https://github.com/codemirror/
- chercher dans les issues, par exemple https://github.com/search?q=org%3Acodemirror+bracket&type=issues
- à chercher dans le moteur de recherche global de GitHub https://github.com/search?q=codemirror+bracket&type=code
- à poser des questions à ChatGPT mais il me donne des réponses qui ne fonctionnent généralement pas
#JeMeDemande si je dois essayer de passer du temps à lire et comprendre le code source de #codemirror 🤔.
Mais, je sais qu'il m'est difficile de comprendre et de me faire une carte mentale d'une librairie de cette taille 🤔.
#JeMeDemande si mes amis développeurs arriveraient plus facilement que moi à comprendre le code source de #codemirror 🤔.
Journal du mercredi 15 mai 2024 à 22:45
Réflexion en travaillant sur 2024-05-15_2159 :
tmux is designed to be easy to script. Almost all commands work the same way when run using the
tmuxbinary as when run from a key binding or the command prompt inside tmux. (from)
Voici un exemple de ce que je trouve élégant dans le design de tmux.
Les commandes tmux, comme par exemple set :
- peut être exécuté via le shell avec l'exécutable
tmux:
$ tmux set -g window-status-current-format "Foobar"
- peut être utilisé dans le fichier de configuration
tmux.conf:
set -g window-status-current-format "Foobar"
- mais aussi en configurant un raccourcie clavier (ici cet exemple n'a pas trop de sens) :
bind-key x set -g window-status-current-format "Foobar"
C'est ce qui est expliqué ici :
Each command is named and can accept zero or more flags and arguments. They may be bound to a key with the bind-key command or run from the shell prompt, a shell script, a configuration file or the command prompt. For example, the same
set-optioncommand run from the shell prompt, from~/.tmux.confand bound to a key may look like:
$ tmux set-option -g status-style bg=cyanset-option -g status-style bg=cyanbind-key C set-option -g status-style bg=cyan
Le fonctionnement de tmux me fait aussi penser à i3 et sway…, plus précisément, les commandes utilisés dans leurs fichiers de configuration sont aussi exécutables via i3-msg commandname ou swaymsg commandename.
#JePense que c'est "çà" l'esprit Unix, des logiciels pour les utilisateurs qui ont un hacker mindset 🤔.
#JeMeDemande quels sont les autres logiciels qui suivent cet adn de tmux 🤔.
Journal du mercredi 15 mai 2024 à 18:25
#JeMeDemande quel est le #browser utilisé dans ce screencast : https://www.youtube.com/watch?v=ZiM1RM0DCgo

Je viens de lui poser la question : https://mamot.fr/@stephane_klein/112446033714935652
Journal du lundi 13 mai 2024 à 20:05
Note en lien avec Opération de nettoyage, curation de mes données Toggl et Fonctionnalité cluster and edit de OpenRefine.
Je pensais que Datasette pouvait être utilisé comme un outil de #data-curation mais je comprends que non, ce n'est pas dans "l'adn" du projet.
Voici ce que dit ici le développeur de Datasette :
For some developers, this is an odd choice - SQLite is an OLTP database, so why not support a few INSERT INTO or UPDATE statements?
The reasons, as laid out in that original blog post, are short and simple. For one, only handling read-only connections greatly reduces security risks. Datasette has SQL code execution as a first-class feature, so limiting any potential risk is important.
Plus, Datasette is a tool for publishing and exploring data. If you're investigating a government data dump or analyzing your city's annual budget, you don't want to edit data anyway!
J'ai trouvé ici une mention de OpenRefine par Simon Willison. J'y ai découvert datasette-reconcile mais pour le moment #JeMeDemande comment l'utiliser et à quoi cela pourrait me servir 🤔.
Journal du lundi 13 mai 2024 à 19:31
In my opinion you literally have about 5 seconds tops to get an idea across to most users on the internet
In "Don't Make Me Think!" (great book about UI/UX), they compare designing websites to designing roadside billboards; you have approximately the same time to get your point across to the viewer. (from)
Je comprends l'argument, je comprends pourquoi les auteurs disent cela, mais #JeMeDemande si cette "course" à la simplification nivelle le niveau par le bas.
Cela me fait aussi penser aux propos de cet article "Le marketing des logiciels, épisode 20240410 - LinuxFr.org".
Je pense aussi aux propos de Bernard Stiegler au sujet de pratiques marketing qui favorisent le « court-circuit de la pensée » — une altérération de notre capacité à penser de manière critique et approfondie — en jouant sur les pulsions.
Journal du vendredi 10 mai 2024 à 08:37
#JeMeDemande si le code de SilverBullet.mb pourrait m'inspirer dans mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai l'impression que le code qui m'intéresse se trouve vers ici.
Je pense que CompletionTooltip est la classe qui est responsable de l'affichage du "completion picker".
09:56 : J'ai réussi à afficher un "completion picker" minimaliste :
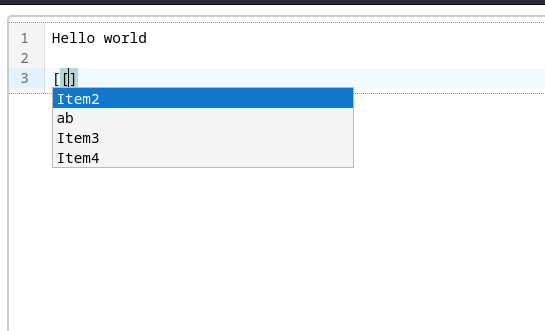
10:02 : Prochaines itérations :
- [ ] Essayer d'implémenter le chargement de la liste d'items de suggestion de manière dynamique. Je souhaite obtenir cette liste via une requête GET http, sur l'url
/get-suggestions/. Cette fonctionnalité est souvent nommée « remote data fetch » (exemple ici). - [ ] Essayer d'implémenter un chargement dynamique d'items de manière progressif. Au lieu de charger toutes la listes des items, l'objectif et de les charger au fur et à mesure, par exemple en petit paquets de 100 items). L'objectif de cette tache ressemble à https://github.com/vtaits/react-select-async-paginate.
Le paramétrage de `search_path` PostgreSQL dans docker-compose ne fonctionne pas 🤨
Je suis en train de travailler sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et je rencontre une difficulté.
J'utilise cette configuration docker-compose.yml :
services:
postgres:
image: apache/age:PG16_latest
restart: unless-stopped
ports:
- 5432:5432
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
PGOPTIONS: "--search_path='ag_catalog,public'"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Je ne comprends pas pourquoi, j'ai l'impression que le paramètre PGOPTIONS: "--search_path=''" ne fonctionne plus.
$ ./scripts/enter-in-pg.sh
postgres=# SHOW search_path ;
search_path
-----------------
"$user", public
(1 ligne)
postgres=#
La valeur de search_path devrait être ag_catalog,public.
J'ai testé avec l'image Docker image: postgres:16, j'observe le même problème.
Je suis surpris parce que je pense me souvenir que cette syntaxe fonctionnait ici en septembre 2023 🤔.
#JeMeDemande comment corriger ce problème 🤔.
#JaiLu docker - Can't set schema_name in dockerized PostgreSQL database - Stack Overflow
09:07 : #ProblèmeRésolu par https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/commit/0b1cef3a725550269583ddb514fa3fff1932e89d
Dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age", j'utilise les librairies remark mais pour le moment, je les trouve bien plus difficiles à utiliser que gray-matter couplé avec markdown-it.
Par exemple, je souhaite extraire dans un dict le contenu frontmatter de fichiers markdown, ainsi que la partie body.
Avec remark j'ai écrit avec difficulté le code suivant :
#!/usr/bin/env node
import { glob } from "glob";
import fs from 'fs';
import { unified } from 'unified';
import markdown from 'remark-parse';
import frontmatter from 'remark-frontmatter';
import extract from 'remark-extract-frontmatter';
import { parse } from 'yaml';
import stringify from 'remark-stringify';
const processor = unified()
.use(markdown)
.use(frontmatter, ['yaml'])
.use(extract, { yaml: parse })
.use(stringify);
const processMarkdown = async (filename) => {
const fileContent = fs.readFileSync(filename);
const result = await processor.process(fileContent);
const body = result.toString().split(/---\s*$/m)[2] || '';
return {
frontmatter: result.data,
body: body.trim()
};
};
for (const filename of (await glob("content/**/*.md"))) {
processMarkdown(filename).then(data => {
console.log('Frontmatter:', data.frontmatter);
console.log('Body:', data.body);
});
}
Et voici mon implémentation avec gray-matter :
#!/usr/bin/env node
import { glob } from "glob";
import matter from "gray-matter";
import yaml from "js-yaml";
for (const filename of (await glob("content/**/*.md"))) {
console.log(matter.read(filename, {
engines: {
yaml: (s) => yaml.load(s, { schema: yaml.JSON_SCHEMA })
}
}));
}
Je préfère sans hésitation cette seconde implémentation.
#JaiDécidé d'utiliser gray-matter.
#JeMeDemande quels seraient les avantages que j'aurai à utiliser remark 🤔.
Journal du jeudi 02 mai 2024 à 23:15
#JeMeDemande les librairies qui existent pour afficher des graphes basés sur les résultats retournées par une base de données orienté graphe, comme Apache Age.
#JeMeDemande si je peux arriver à faire quelque chose avec la librairie Svelte suivante : https://svelteflow.dev/
Autre librairies :
Obsidian Quartz utilise d3js : https://github.com/jackyzha0/quartz/blob/v4/quartz/components/scripts/graph.inline.ts
Journal du mercredi 01 mai 2024 à 16:06
Je suis en train de lire la documentation de dotenv-vault, j'ai beau relire plusieurs fois cette documentation, je n'arrive pas à comprendre où est stocker la configuration 🤔.
5 minutes après, je pense avoir compris, la libraire dotenv-vault est basé sur le service SaaS https://www.dotenv.org/.
5 minutes après, #JaiLu Dotenv Vault vs Infisical | Dotenv.
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Dans l'application web que je développe pour Value Props, je n'utilise actuellement aucune librairie de configuration pour l'app.
J'utilise uniquement process.env.CONFIG_PARAM || "default value".
En contexte, cela ressemble à ceci.
import nodemailer from "nodemailer";
let transporter;
if (process.env?.SMTP_USER && process.env?.SMTP_PASS) {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: true,
auth: {
user: process.env.SMTP_USER,
pass: process.env.SMTP_PASS
}
});
} else {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: false
});
}
export default transporter;
Je commence maintenant à utiliser des paramètres de configuration à différents endroits. Conséquence, je me dis que c'est peut-être maintenant le bon moment pour utiliser une librairie de configuration du type Convict.
Pourquoi j'ai cité Convict ? Parce que c'était le choix que j'avais fait en 2019, dans le projet gibbon-mail.
#JeMeDemande qu'elle est en 2024, la librairie [Javascript] de type environment-variables, configuration-management la plus populaire actuellement.
Pour répondre à cette question, j'ai commencé à faire une recherche sur npm trends et il m'a proposé la suggestion suivante config vs configstore vs convict vs cross-env vs dotenv
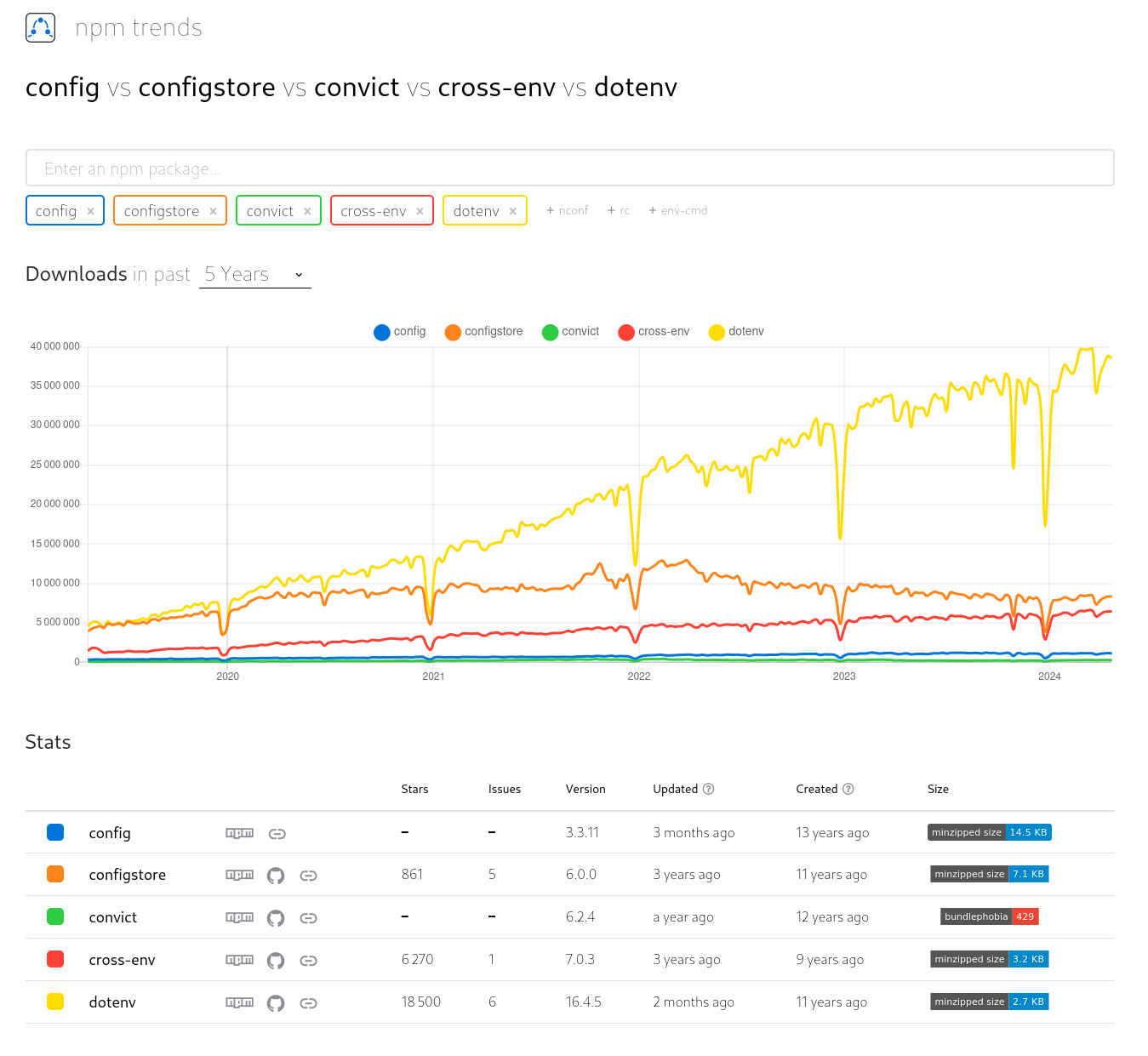
dotenv semble se détacher assez franchement.
dotenv et cross-env sont listés dans Delightful Node.js packages and resources.
Je constate que cross-env est abandonné et conseille ici de migrer vers env-cmd.
Je vais demander avis à des amis, mais pour le moment, je pense que je vais utiliser dotenv.
Quelque heure plus tard :
Journal du mercredi 01 mai 2024 à 14:05
En lien avec 2024-05-01_1205 :
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Je n'ai pas réussi à trouver mention de fonctionnalité de loop ou condition dans la documentation du plugin Obsidian Templater mais après lecture de ces deux threads :
il semble que Templater supporte bien les fonctionnalités permettant d'implémenter des loop et condition dans un template.
Je pense que cela va me servir de source d'inspiration pour 2024-05-01_1205.
Journal du mercredi 01 mai 2024 à 13:05
En lien avec 2024-05-01_1205, dans le code source du plugin Obsidian nommé Templater, #JaiDécouvert la librairie Javascript rusty_engine :
A Javascript templating engine in WASM
En dehors de l'aspect performance, je me demande si cette librairie serait plus adaptée à mes besoins que EJS 🤔.
Journal du mercredi 01 mai 2024 à 12:05
#JeMeDemande si la librairie mdsvex me permet d'implémenter de manière agréable des nouveaux components qui ont la capacité d'aller chercher des données en backend, typiquement une base de données PostgreSQL.
J'aimerais que la requête soit décrite directement dans le markdown.
Je souhaite aussi que le composant soit rendu seulement côté serveur (SSR).
J'aimerais pouvoir implémenter quelque chose comme :
# Mon titre
Mon paragraphe
``sql posts
SELECT title FROM posts ORDER BY created_at LIMIT 10
``
<ul>
{#each posts as post}
<li>{post}</li>
{/each}
</ul>
(inspiration de https://evidence.dev/).
#JeMeDemande si mdsvex serait adapté pour cet objectif.
Je viens de voir ce thread Thoughts on Mdsvex moving away from Unified : sveltejs. Il contient un lien vers Penguin-flavoured markdown · pngwn/MDsveX · Discussion #293 · GitHub qui me semble intéressant #JaimeraisUnJour prendre le temps de le lire.
Autre thread What remark and rehype plugins are people using? · pngwn/MDsveX · Discussion #354 · GitHub.
#JeMeDemande si remark ou markdown-it serait mieux adapté pour atteindre mon objectif 🤔.
#JaiDécouvert (ou plutôt redécouvert) https://github.com/unifiedjs.
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Evidence semble implémenter un mécanisme qui ressemble à mon objectif et est codé en Svelte.
Je découvre "Carta" (Svelte Markdown editor)
En faisant la recheche suivant sur le subreddit Svelte : "markdown" #JaiDécouvert ici la librairie carta :
A lightweight, fast and extensible Svelte Markdown editor and viewer.
La démo se trouve ici : https://beartocode.github.io/carta/
#JeMeDemande si je dois tester cette librairie pour réaliser l'objectif du projet Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai regardé le code source de l'extension Slash et j'ai l'impression que je pourrais m'inspirer de cette implémentation pour créer une extension permettant d'implémenter un "sélécteur de ressource", "à la" Obsidian pour le projet Value Props 🤔.
Journal du mardi 30 avril 2024 à 23:04
Je continue mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte".
Voici le résultat de ma dernière itération :
#JeMeDemande si CodeMirror implémente une fonctionnalité comme conceal de Neovim 🤔. J'ai trouvé :
Je me demande si LogSeq utilise CodeMirror 🤔
En pensant au projet Projet -1 "CodeMirror, autocomplétion, Svelte", je me suis demandé si le projet OpenSource LogSeq utilise ou non CodeMirror.
Je suis aller voir le code source et j'ai constaté que la réponse est oui, LogSeq utilise CodeMirror. J'ai un peu plus creusé et je suis tombé dans cette partie du code qui je pense implémente la fonctionnalité d'auto complétion de l'éditeur de LogSeq.
Problème 😔, je n'ai aucune connaissance dans le langage Closure et il m'est difficile de comprendre cette implémentation et de m'en servir dans mon POC.
Un ami est heureux d'utiliser Nuxt (VueJS), je suis heureux pour lui 🙂
Un ami me partage la satisfaction qu'il a à utiliser la version 3 de Nuxt :
Nuxt3 est devenu magnifique avec le combo Nuxt/Font, Nuxt/i18n, Tailwind CSS, sa couche server pour proxy une api sous le boisseau. Ça en fait un framework redoutable.
Suite à la lecture de ce commentaire, #JeMeDemande s'il est autant satisfait de Nuxt3 que je le suis de SvelteKit 🤔.
Je souhaite depuis longtemps — début 2023 — réaliser ces deux projets :
- Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit"
- Projet 3 - "Réaliser un petit projet basé sur Nuxt pour le comparer avec SvelteKit"
pour être en capacité de donner mon opinion éclairée de comparaison entre ces trois frameworks NextJS, Nuxt et SvelteKit.
Pour le moment, je me contente de recevoir avec plaisir le bonheur de mon ami et je garde en mémoire son expérience, pour la partager le jour où un ami de demandera mon avis au sujet de Nuxt.
Journal du lundi 29 avril 2024 à 16:04
Quand je dois gérer seul, et d'autant plus en équipe, une grosse quantité de documents administratifs, je rencontre des difficultés pour classer les fichiers et retrouver ces fichiers dans une base hiérarchique.
J'ai déjà écrit sur ce problème dans l'issue suivante : Écrire un billet de réflexion au sujet des forces et faiblesses du classement de documents dans des dossiers versus un système à plat avec des tags.
Voici ce que j'écrivais le 6 août 2023 :
Difficultés que j'ai rencontrées ces derniers mois (sous forme de bullet point) :
- en situation pro :
- difficultés à construire une taxinomie (organisation et namming des dossiers, sous dossiers) pour classer les documents "Ressource Humaine" de mon équipe
- difficulté à naviguer dans cette taxinomie
- types de documents classés
- contrat de travail
- promesse d'embauche
- budget
- avenant de contrat de travail
- ces documents étaient classés dans le Google Drive de la société
- difficultés pour coopérer
- mes collaborateurs avaient des difficultés à comprendre rapidement la taxinomie
- la responsable RH archivait les mêmes documents dans un dossier "à elle", elle utilisait sa propre taxonomie
- je souhaitais "merger" ces deux dossiers, mais comme aucune taxinomie n'est évidente, nous n'avons même pas pris le temps d'essayer de "merger" nos dossiers
- dans une assiociation
- j'ai hérité d'un Google Drive avec une taxinomie définie par l'ancien président du club
- j'ai des difficultés à retrouver les documents
- exemples :
- est-ce qu'une fiche de paie doit être classée dans le dossier "comptabilité" ou "administratif" ?
- comment lister tous les documents qui concernent le joueur John Doe ?
- comment lister tous les documents de la saison 2022/2023 ?
Actuellement, mon intuition de réponse à ce problème est :
- ne pas mettre en oeuvre une taxinomie, mais utiliser un thésaurus, c'est-à-dire :
- organiser "à plat" (sans dossier) les documents
- attribuer des tags (labels) sur ces documents
- dans une "sidebar" :
- proposer des recherches sauvegardées, exemples :
- contrats de travailles
- John Doe
- 2022/2023
- ...
- permettre aussi de lister des tags favoris dans cette sidebar
Aujourd'hui, #JeMeDemande si Obsidian pourrait être adapté pour ranger des documents administratifs.
Avec ce type d'outil, il serait possible de ranger les documents dans de la "prose".
Cela permettrait de retrouver ces documents via plusieurs méthodes, avec du contexte autour du document….
#JeMeDemande s'il est possible d'attacher des tags à des pièces jointes 🤔.
Journal du vendredi 06 octobre 2023 à 20:00
Cette après midi, j'hésite à migrer le projet sveltekit-tendaro-webshell-skeleton de Javascript vers TypeScript.
Je me demande si :
- cela en vaut la peine ;
- étant donné que je n'ai jamais fait pour de vrai un projet en TypeScript, est-ce que je ne risque pas de tomber dans un Yak! 🤔.
Actuellement ma doctrine concernant TypeScript est la suivante.
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.
Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Mais je me dis que je me trompe peut-être, peut-être que si j'essaie, je vais me rendre compte que j'aime bien cela et que cela me fera gagner du temps ou alors améliorera mon confort, mon plaisir de développement 🤔.
Tâches à faire si je souhaite migrer à TypeScript :
- [ ] Implémenter une déclinaison de
sveltekit-ssr-skeletonen TypeScript - [ ] Modifier mon environnement Neovim pour activer les fonctionnalités suivantes :
- [ ] Support de l'autocomplétion TypeScript
- [ ] Support de la détection des erreurs TypeScript
- [ ] Support des fonctions de refactoring TypeScript
- [ ] Affichage en "live" de la documentation des composants, fonctions…
Ressources à lire avant pour avancer sur ce sujet :
Journal du mardi 04 juillet 2023 à 17:35
#JaiDécouvert la fonctionnalité Skew Protection de Vercel : Introducing Skew Protection.
#JaiLu aussi Version Skew.
#JeMeDemande comment implémenter le même système que la fonctionnalité Skew Protection de Vercel en self hosted, par exemple, avec SvelteKit 🤔.
Journal du jeudi 29 décembre 2022 à 11:29
#JaiDécouvert la Mémoire transactive.
Quand je dis « j'aime travailler dans une équipe sur le long terme, tout devient fluide, elle a une culture commune… », #JeMeDemande si cela veut dire que j'aime la mémoire transactive 🤔.
#JeMeDemande si la mémoire transactive équivaut plus ou moins à une culture de travail ? 🤔.
Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker"
Date de la création de cette note : 2024-06-05.
Ce projet est terminé : voir 2024-07-06_1116.
Quel est l'objectif de ce projet ?
Bien que j'aie beaucoup travaillé de décembre 2023 janvier 2024 sur le projet Implémenter un POC de pgBackRest, je souhaite mettre à jour et améliorer le repository restic-pg_dump-docker.
Quelques tâches à réaliser :
- [x] Mettre à jour tous les composants ;
- [x] Publier le
Dockerfiledestephaneklein/restic-backup-docker; - [ ] Réaliser et publier un screencast ;
- [x] Améliorer le
README.md.
Pourquoi je souhaite réaliser ce projet ?
Pourquoi continuer ce projet alors que j'ai travaillé sur pgBackRest qui semble bien mieux ?
Pour plusieurs raisons :
- Je ne peux pas installer pgBackRest dans un « sidecar container Docker » — en tout cas, je n'ai pas trouvé comment réaliser cela 🤷♂️. Je dois utiliser un container Docker PostgreSQL qui intègre pgBackRest.
- Pour le moment, je ne comprends pas très bien la taille consommée par les "WAL segments" sauvegardés dans les buckets.
- Pour le moment, je ne sais pas combien de temps prend la restauration d'un backup d'une base de données d'une taille supérieure à un test. Par exemple, combien de temps prend la restauration d'une base de données de 100 Mo 🤔.
- Je ne suis pas rassuré de devoir lancer un cron —
supercronic— lancé partini
Bien que pgBackRest permette un backup en temps "réel" et est sans doute plus rapide que "ma" méthode "restic-pg_dump", pour toutes les raisons listée ci-dessus, je pense que la méthode "restic-pg_dump" est moins complexe à mettre en place et à utiliser.
#JeMeDemande si la fonctionnalité "incremental backups" la version 17 de PostgreSQL sera une solution plus pratique que pgBackRest et la méthode "restic-pg_dump" 🤔.
Repository de ce projet :
https://github.com/stephane-klein/restic-pg_dump-docker
Je vais travailler dans la branche nommée june-2024-working-session
Projet 21 - "Rechercher un AI code assistant qui ressemble à Cursor mais pour Neovim"
Date de la création de cette note : 12 janvier 2025.
Quel est l'objectif de ce projet ?
Étudier, installer et configurer un AI code assistant qui ressemble à Cursor mais pour Neovim.
- avante.nvim (https://github.com/yetone/avante.nvim)
- codecompanion.nvim (https://github.com/olimorris/codecompanion.nvim)
Pourquoi je souhaite réaliser ce projet ?
J'avais déjà envie de tester avante.nvim en août 2024.
Je constate que depuis plus de 6 mois, j'utilise de plus en plus ChatGPT ou Claude.ia lorsque je code ou je rédige des textes. Rien que pour la dernière semaine, j'ai compté 7 conversations par jour.
Je constate aussi que mon expérience utilisateur n'est pas optimale : je dois effectuer de nombreux copier-coller pour donner du contexte à l'agent conversationnel.
Je lui donne du code source, je lui indique le nom des fichiers…
#JeMeDemande aussi si l'agent conversationnel pourrait me donner de meilleures réponses s'il a accès à l'intégralité du code source de projet 🤔.
Fonctionnalités
Exemples de tâches que j'aimerais facilement effectuer avec le AI code assistant, directement dans Neovim :
- Avoir des suggestions de code sur des projets : Javascript, TypeScript, Bash, Ansible, Svelte, Tailwind CSS
- Avoir des suggestions de corrections de bug
- Génération de message de Git commit à partir du contenu modifié et d'une explication du commit que j'aurais rédigé en français
- Suggestion / correction de documentation en Markdown, en anglais et français
- Suggestion de namming de variables
- Suggestion de refactoring
- Me donner les explications macro ou micro d'un projet
- Correction de fautes d'orthographe et de grammaire en français et anglais
Les questions que je me pose
Comme je le disais en août 2024 :
Cependant, une question me revient sans cesse à l'esprit en voyant ce genre d'outil utilisant les API d'AI Provider : est-ce que le coût d'utilisation de ce type de service ne risque pas d'être exorbitant ? 🤔
#JeMeDemande combien un AI code assistant va me coûter par mois 🤔.
Sur la page de pricing de Cursor, je lis :
$20/month :
- Unlimited completions
- 500 fast premium requests per month
- Unlimited slow premium requests
- 10 o1-mini uses per day
#JeMeDemande si Cursor a des réductions sur les volumes ou si je peux avoir le même prix en utilisant directement les API des AI Provider OpenAI ou Anthropic.
Est-ce que la location d'un serveur GPU sur Vast.ai pourrait être un choix plus économique 🤔.
Choix de modèle
#JeMeDemande quel modèle AI code assistant offre le meilleur rapport coût/performance ? Quel est le plus performant ?
J'ai lu ici que Salvatore Sanfilippo conseille Claude Sonnet 3.5 :
About "people still thinking LLMs are quite useless", I still believe that the problem is that most people are exposed to ChatGPT 4o that at this point for my use case (programming / design partner) is basically a useless toy. And I guess that in tech many folks try LLMs for the same use cases. Try Claude Sonnet 3.5 (not Haiku!) and tell me if, while still flawed, is not helpful.
Repository de ce projet :
- La branche
neovim-avante-pocdu repository https://github.com/stephane-klein/dotfiles
Ressources :
Dernière page.