
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (31 notes) :
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
Comment j'ai perdu ma discipline en décembre et janvier
Jusqu'à mi-décembre 2025, cela faisait environ 2 ans que j'arrivais à rester concentré sur un sujet à la fois. J'avais réussi à éviter de papillonner d'un sujet à l'autre. Pour moi, un sujet n'est vraiment terminé que lorsque j'ai publié la note correspondante.
Le dernier sujet que j'avais exploré avec succès était mon étude de Fedora CoreOS.
Je me suis ensuite lancé dans l'étude pratique approfondie de Podman Quadlets. J'ai réussi à publier coreos-quadlet-playground, mais avant même d'avoir commencé à rédiger ma note de synthèse, j'ai perdu ma discipline.
Dans cette note, je vais tenter d'expliquer comment et pourquoi j'ai "dérapé" et faire un bilan des side-projects sur lesquels j'ai papillonné pendant ces deux derniers mois (depuis mi-décembre).
Lors de mon travail sur Podman Quadlets, j'ai découvert comment ce projet utilise avec élégance systemd-run et le mécanisme des generators (systemd-run-generator) de systemd pour incarner la philosophie Unix.
Suite à cette découverte, j'ai repensé aux scripts manuels que j'utilisais ces derniers mois pour lancer mes VM QEMU. Exemple : up-qemu-vm.sh. Je me suis dit qu'il serait élégant de lancer des VM QEMU de la même manière que Podman Quadlets.
Je n'ai pas réussi à résister à cette idée. Le 10 décembre au soir, je me suis dit que j'allais consacrer une petite heure à tester cette idée via du vibe coding avec Aider et Claude Sonnet 4.5.
Cette heure s'est transformée en 12h de session non-stop. J'ai réussi à publier une première version de qemu-compose, mais je venais de rompre ma discipline : je n'avais toujours pas écrit ma note sur Podman Quadlets.
Depuis, je n'ai pas réussi à retrouver ma discipline. Je suis tombé dans une spirale de papillonnage qui a duré deux mois 🙈.
En rédigeant cette note, j'ai essayé de comprendre pourquoi j'avais dérapé.
Je pense que c'était la combinaison de plusieurs facteurs :
- Le déclencheur : Ma première expérience réelle de vibe coding sur un projet complet. Cette expérience m'a tellement excité et en même temps tellement perturbé que j'ai perdu la motivation de rédiger ma note sur Podman Quadlets.
- La cascade : Une fois le premier écart fait, l'effet "What the hell" s'est enclenché : mon cerveau a rationalisé la continuation du comportement déviant par un "de toute façon, c'est déjà foutu, autant continuer".
- Le contexte : J'étais dans une période de stress et de frustration. L'illusion de toute-puissance qu'offrent les derniers modèles 4.5 d'Anthropic — obtenir des résultats rapides — m'a poussé dans une fuite en avant, un échappatoire pour combler mes frustrations du moment.
Depuis 2 ans, j'utilise trois garde-fous (circuit breakers) pour m'empêcher de démarrer un nouveau projet sans avoir terminé le précédent — autrement dit, pour éviter de papillonner et de survoler les sujets :
- Je tracke toutes mes activités via Toggl. Quand je démarre une activité, je lance consciemment le chronomètre. Cette friction me force à nommer ce que je fais et à rester conscient du temps que j'y consacre. C'est un premier filtre contre les distractions impulsives.
- Tous les matins, je rédige mes todo lists pro et perso dans Obsidian. L'élément clé est une section "Je ne veux pas faire" où je liste explicitement les tâches tentantes mais hors priorité. C'est mon exutoire pour les idées qui me donnent envie sans pour autant y céder.
- La publication de notes sur notes.sklein.xyz me force à définir ma "Definition of Done". Une itération (un sujet) n'est terminée que quand la note est publiée.
En analysant mes notes, je constate que j'ai progressivement abandonné la rédaction de mes todo lists quotidiennes à partir du 5 décembre — soit 5 jours avant mon dérapage sur qemu-compose.
Je pense que ce n'est pas un hasard.
#JaiDécidé de reprendre cette routine dès demain. C'est mon garde-fou le plus important.
Voici les sujets en vrac que j'ai survolés pendant ces 2 derniers mois — tous sans note de synthèse publiée :
- Réimplémentation complète de ma configuration chezmoi (inachevée)
- Développement de
gnome-settings-import-export
- Développement de
- Étude de timeshift et snapper
- Installation et configuration de netbird sur mes NUC
- Tentative d'installation de Kodi sur un de mes NUC (inachevée)
- Nouvelle configuration Neovim from scratch basée sur LazyVim (inachevée) :
lazyvim-playground - Migration de Fugitive vers Neogit
- Développement et publication du plugin
neo-tree-session.nvim - Étude puis abandon d'une migration Alacritty + tmux → wezterm (branche WIP)
- Étude puis abandon d'une migration Alacritty + tmux → kitty
- Étude d'une migration Alacritty → foot + tmux (en cours)
- Contribution au projet foot avec 2 Merge Requests :
- Test d'avante.nvim, notamment Avante Zen Mode — piste abandonnée
- Migration de Aider vers OpenCode
- Adoption de Jujutsu à la place de Git — utilisation quotidienne depuis plus d'un mois, progression continue mais pas encore fluide
Bilan : 13 explorations, 2 contributions open source, 1 plugin publié, 0 note de synthèse 😔.
En publiant cette note, je souhaite casser cet effet "What the hell".
Je vais sans doute accepter de ne pas publier de notes sur les sujets que j'ai abandonnés. Par contre, je souhaite à l'avenir publier des notes au sujet de :
Journal du samedi 01 mars 2025 à 18:43
Suite aux mises à jour des conditions d'utilisation et de la politique de confidentialité de Firefox j'ai décidé :
- De contribuer financièrement à la hauteur de 10$ par mois au projet Servo (via Open Collective).
- De remplacer Firefox par LibreWolf.
Quelques liens à ce sujet :
- 26 février 2025 - article de Mozilla : Introducing a terms of use and updated privacy notice for Firefox
- Thread Hacker News de 1090 commentaires
- Thread Lobster de 153 commentaires
- 28 février 2025 - article de Mozilla : An update on our Terms of Use
- Thread Hacker News de 302 commentaires
Voici quelques informations au sujet des forks de Firefox.
Le projet Waterfox a débuté en 2011.
Waterfox supporte les extensions Firefox 🙂.
Pocket est désactivé par défaut 🙂.
J'ai lu l'article de Waterfox : « A Comment on Mozilla's Policy Changes ».
Waterfox est disponible sur Flathub : https://github.com/flathub/net.waterfox.waterfox.
Je découvre qu'une version Android de Waterfox est disponible : https://github.com/BrowserWorks/Waterfox-Android.
J'ai lu l'article Wikipedia de LibreWolf et les pages "Features" et "FAQ".
Le projet LibreWolf a commencé en 2020, il est bien plus jeune que Waterfox.
#JaiDécouvert IronFox (https://gitlab.com/ironfox-oss/IronFox/)
J'ai installé LibreWolf sous Fedora :
$ curl -fsSL https://repo.librewolf.net/librewolf.repo | pkexec tee /etc/yum.repos.d/librewolf.repo
$ sudo dnf install librewolf
Le site web du projet LibreWolf m'a inspiré davantage confiance que Waterfox.
Suite à cela, j'ai décidé de migrer vers LibreWolf.
Commande pour définir LibreWolf comme navigateur par défaut sous Fedora :
$ xdg-settings set default-web-browser librewolf.desktop
En gestion de projet logiciel, quelle est la définition de "Theme" ?
J'ai du mal à bien définir le terme thème en gestion de projet logiciel.
Dans cette note, je vais décrire les deux définitions que je connais.
Voici une définition de Ken Rubin, auteur du livre Essential Scrum :
A collection of related user stories. A theme provides a convenient way to indicate that a set of stories have something in common, such as being in the same functional area.
Un Theme peut-être assigné à tout type d'issue, par exemple Epic ou User Story.
Les auteurs du livre Product Roadmaps Relaunched ont une autre définition de Theme :
As we’ve touched on, in the relaunched roadmapping process we use themes and subthemes to express customer needs. This is probably a new concept for many of you, so let’s define what we mean by these terms.
Themes are an organizational construct for defining what’s important to your customers at the present time.
...
So, again, themes and subthemes represent the needs and problems your product will solve for. A need is generally something the customer doesn’t have yet, whereas a problem is something that’s not working right (with the existing product, or whatever substitute they might currently be using). Even though these two terms suggest subtle differences, the important point is that both refer to a gap or pain in the customer’s experience. When identifying the themes and subthemes for your roadmap, remember to consider both needs and problems from all angles.
Jared Spool, paraphrasing our very own Bruce McCarthy, says, “Themes help teams stay focused without prematurely committing to a solution that may not be the best idea later on.” As Spool points out, it is important to focus most of the roadmapping effort on customer needs and problems because “the viability of a feature may shift dramatically, while the nature of an important customer problem will likely remain the same.”
Dans ce livre, un Theme représente un besoin client important à un instant donné.
D'après ce que j'ai compris, Product Roadmaps Relaunched adopte une définition plus restrictive du concept de thème que Essential Scrum. Dans Product Roadmaps Relaunched, un thème sert uniquement à décrire des fonctionnalités de façon imprécise.
Exemple tiré du livre Product Roadmaps Relaunched :
- Theme: Billing & payments
- Subtheme: Billing & payments API integration
- Subtheme: API integration testing
Pour résumer :
- Essential Scrum inclut des thèmes qui ne sont pas seulement liés aux fonctionnalités, mais aussi à la stratégie globale, à l’organisation, voire aux aspects techniques et processus internes.
- Product Roadmaps Relaunched reste focalisé sur l'expérience utilisateur et les besoins clients, avec des thèmes qui expriment des fonctionnalités sans trop rentrer dans les considérations techniques ou organisationnelles.
#JaiDécidé d'adopter la définition de "Theme" donnée dans Essential Scrum.
Journal du mercredi 12 février 2025 à 15:11
Je pense comprendre que pgBackRest ne permet pas d'utiliser des INET sockets pour communiquer avec PostgreSQL.
Toutefois, je me dis que je pourrais partager le volume
PGDATAavec le sidecar pgBackRest pour lui donner accès à l'Unix Socket du Streaming Replication Protocol 🤔.
Je viens de me rappeler que pgBackRest a une seconde contrainte qui semble l'empêcher de fonctionner en Docker sidecar :
Backing up a running PostgreSQL cluster requires WAL archiving to be enabled. Note that at least one WAL segment will be created during the backup process even if no explicit writes are made to the cluster.
pg-primary:/etc/postgresql/15/demo/postgresql.conf⇒ Configure archive settings :archive_command = 'pgbackrest --stanza=demo archive-push %p' archive_mode = on max_wal_senders = 3 wal_level = replica
Cela signifie que l'exécutable pgbackrest doit être installé dans l'image Docker PostgreSQL.
Cela me pose un problème parce que mon objectif est de pouvoir utiliser un système de sauvegarde en Docker sidecar sans avoir à utiliser une image Docker PostgreSQL modifiée.
Cette contrainte ne semble pas présente avec barman qui propose 3 méthodes de backup :
La méthode postgres utilise pg_basebackup et je pense qu'elle peut fonctionner en Docker sidecar.
#JaiDécidé d'explorer cette piste.
Journal du dimanche 09 février 2025 à 17:05
J'utilise depuis 2019 les containers Docker suivant en sidecar pour sauvegarder automatiquement et régulièrement directement un volume Docker et un volume PostgreSQL :
restic-pg_dump-docker est très pratique et facile d'usage, voici un exemple d'utilisation dans un docker-compose.yml :
restic-pg-dump:
image: stephaneklein/restic-pg_dump:latest
environment:
AWS_ACCESS_KEY_ID: "admin"
AWS_SECRET_ACCESS_KEY: "password"
RESTIC_REPOSITORY: "s3:http://minio:9000/bucket1"
RESTIC_PASSWORD: secret
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
POSTGRES_HOST: postgres
POSTGRES_DB: postgres
postgres:
image: postgres:16.1
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- "5432:5432"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Il suffit de configurer les paramètres d'accès à l'instance PostgreSQL à sauvegarder et ceux de l'Object Storage où uploader les backups. Rien de plus, 😉.
Pour plus de paramètres, voir la section Configuration du README.md.
Cependant, je ne suis pas totalement satisfait de restic-pg_dump-docker. Cet outil effectue seulement des sauvegardes complètes de la base de données.
Ceci ne pose généralement pas trop de problème quand la base de données est d'une taille modeste, mais c'est bien plus compliqué dès que celle-ci fait, par exemple, plusieurs centaines de mégas.
Pour faire face à ce problème, j'ai exploré fin 2023 une solution basée sur pgBackRest : Implémenter un POC de pgBackRest.
Je suis plus ou moins arrivé au bout de ce POC mais je n'ai pas été satisfait du résultat.
Je n'ai pas réussi à configurer pgBackRest en "pure Docker sidecar".
De plus, j'ai trouvé la restauration du backup difficile à exécuter.
Un élément a changé depuis septembre 2024. Comme je le disais dans cette note 2024-11-03_1151, la version 17 de PostgreSQL propose de nouvelles options de sauvegarde :
- l'outil pg_basebackup qui permet de réaliser les sauvegardes incrémentales,
- et un nouvel utilitaire, pg_combinebackup, qui permet de reconstituer une sauvegarde complète à partir de sauvegardes incrémentales.
Cette nouvelle méthode semble apporter certains avantages par rapport aux solutions basées sur WAL comme pgBackRest ou barman.
Une consommation d'espace réduite :
In this mailing list thread on the Postgres-hackers mailing list, Jakub from EDB ran a test. This is a pgbench test. The idea is that the data size doesn't really change much throughout this test. This is a 24 hour long test. At the start the database is 3.3GB. At the end, the database is 4.3GB. Then, as it's running, it's continuously running pgbench workloads. In those 24 hours, if you looked at the WAL archive, there were 77 GB of WAL produced.
That's a lot of WAL to replay if you wanted to restore to a particular point in time within that timeframe!
Jakub ran one full backup in the beginning and then incremental backups every two hours. The full backup in the beginning is 3.4 GB, but then all the 11 other backups are 3.5 in total, they're essentially one 10th of a full backup size.
Une vitesse de restauration grandement accélérée :
A 10x time safe
What Jakub tested then was the restore to a particular point in time. Previously, to restore to a particular point in time would take more than an hour to replay the WAL versus in this case because we have more frequent, incremental backups, it's going to be much, much faster to restore. In this particular test case 78 minutes compared to 4 minutes. This is a more than a 10 times improvement in recovery time. Of course you won't necessarily always see this amount of benefit, but I think this shows why you might want to do this. It is because you want to enable more frequent backups and incremental backups are the way to do that.
Nombre 2024 j'ai passé un peu de temps à étudier les solutions de backup qui utilisent la nouvelle fonctionnalité de PostgreSQL 17, mais je n'avais rien trouvé
Je viens à nouveau de chercher dans les archives de Postgre Weely, sur GitHub, sur le forum de Restic, etc., et je n'ai rien trouvé d'intéressant.
#JaiDécidé de prendre les choses en main et de faire évoluer le projet restic-pg_dump-docker pour y ajouter le support du backup incrémental de PostgreSQL 17.
Voir : Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker".
Journal du lundi 27 janvier 2025 à 10:51
Il y a plus de deux ans, j'avais écrit la note suivante :
En plus de les oublier régulièrement, je trouve ces deux commandes pas pratiques.
Je dois utiliser ctrl-w H pour transformer des windows horizontaux en verticaux et ctrl-w J pour transformer des windows verticaux en horizontaux. Cela fait deux raccourcis alors que j'aimerais en utiliser un seul.
Ce matin, #JaiDécidé d'essayer d'utiliser winshift.nvim (https://github.com/sindrets/winshift.nvim).
Voici mon commit de changement de mon dotfiles : https://github.com/stephane-klein/dotfiles/commit/5d6f798538ac16ab8a308d4da26913306b0cff82
J'ai testé un peu winshift.nvim. C'est parfait 🙂, ce plugin correspond parfaitement à mes besoins et il est très facile à utiliser !
J'ai réussi à configurer Avante.nvim connecté à Claude Sonnet via le provider Copilot
Note d' #iteration du Projet 21 - "Rechercher un AI code assistant qui ressemble à Cursor mais pour Neovim".
J'ai réussi à installer avante.nvim, voici le commit de changement de mon dotfiles : "Add Neovim Avante AI Code assistant".
Suite à la lecture de :
Since auto-suggestions are a high-frequency operation and therefore expensive, it is recommended to specify an inexpensive provider or even a free provider: copilot
et ma note 2025-01-12_2026, #JaiDécidé de connecter avante.nvim à GitHub Copilot.
J'ai suivi les instructions de README.md de avante.nvim et voici les difficultés que j'ai rencontrées.
Contexte : j'utilise lazy.nvim avec la méthode kickstart.nvim.
- Ici j'ai appliqué cette configuration :
opts = {
provider = "copilot",
auto_suggestions_provider = "copilot",
copilot = {
model = "claude-3.5-sonnet"
}
},
- Ce commentaire n'indique pas explicitement que je devais ajouter ici cette initialisation de copilot.lua :
{
"zbirenbaum/copilot.lua",
config = function()
require("copilot").setup({})
end
},
Après installation des plugins (Lazy sync), il faut lancer :Copilot auth pour initialiser l'accès à votre instance de GitHub Copilot. C'est très simple, il suffit de suivre les instructions à l'écran.
Pour le moment, j'ai uniquement fait un test de commentaire d'un script : « Est-ce que ce script contient des erreurs ? » :
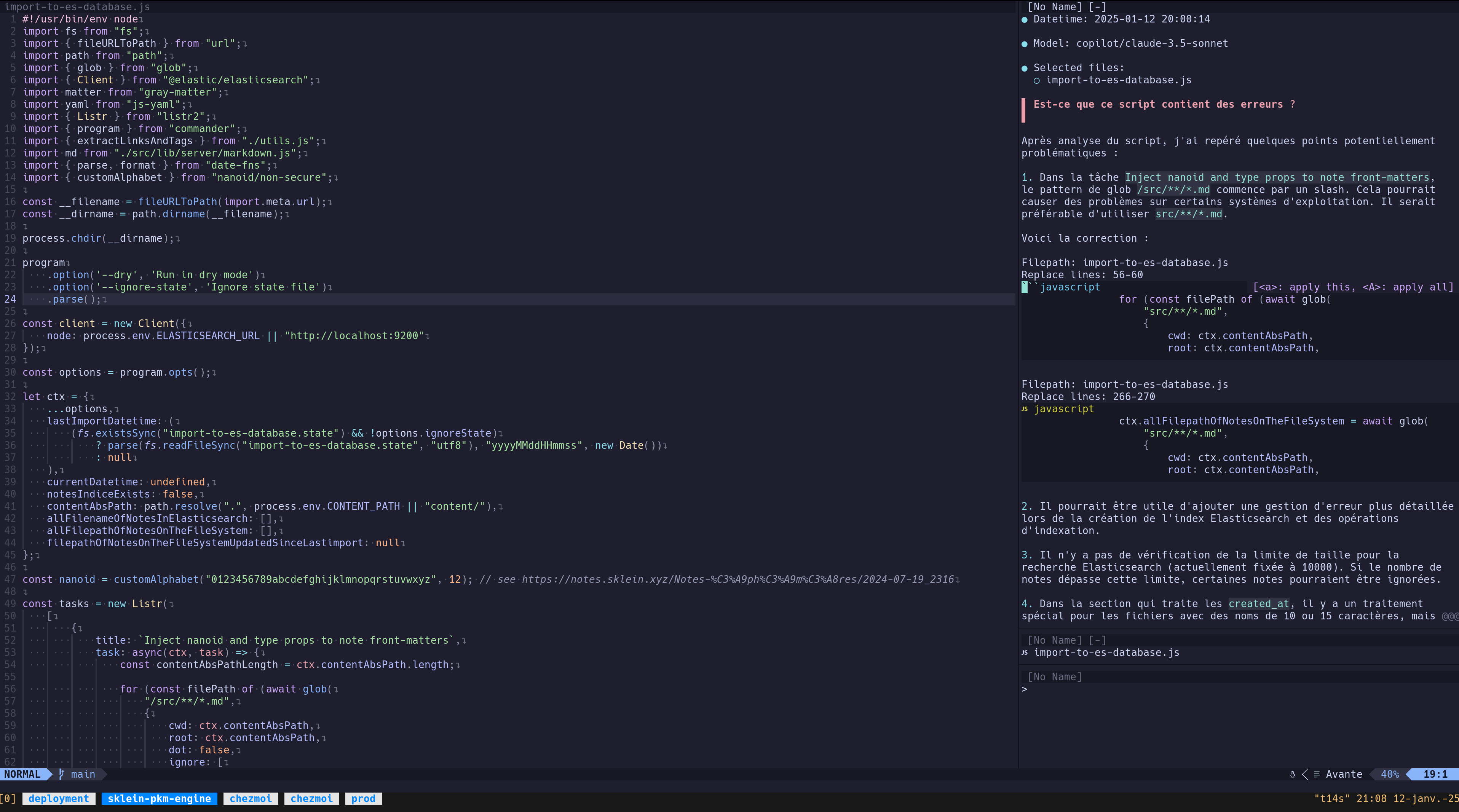
J'ai ensuite tenté de consulter mon rapport d'utilisation de GitHub Copilot pour vérifier l'état de mes quotas, mais je n'ai pas réussi à trouver ces informations :
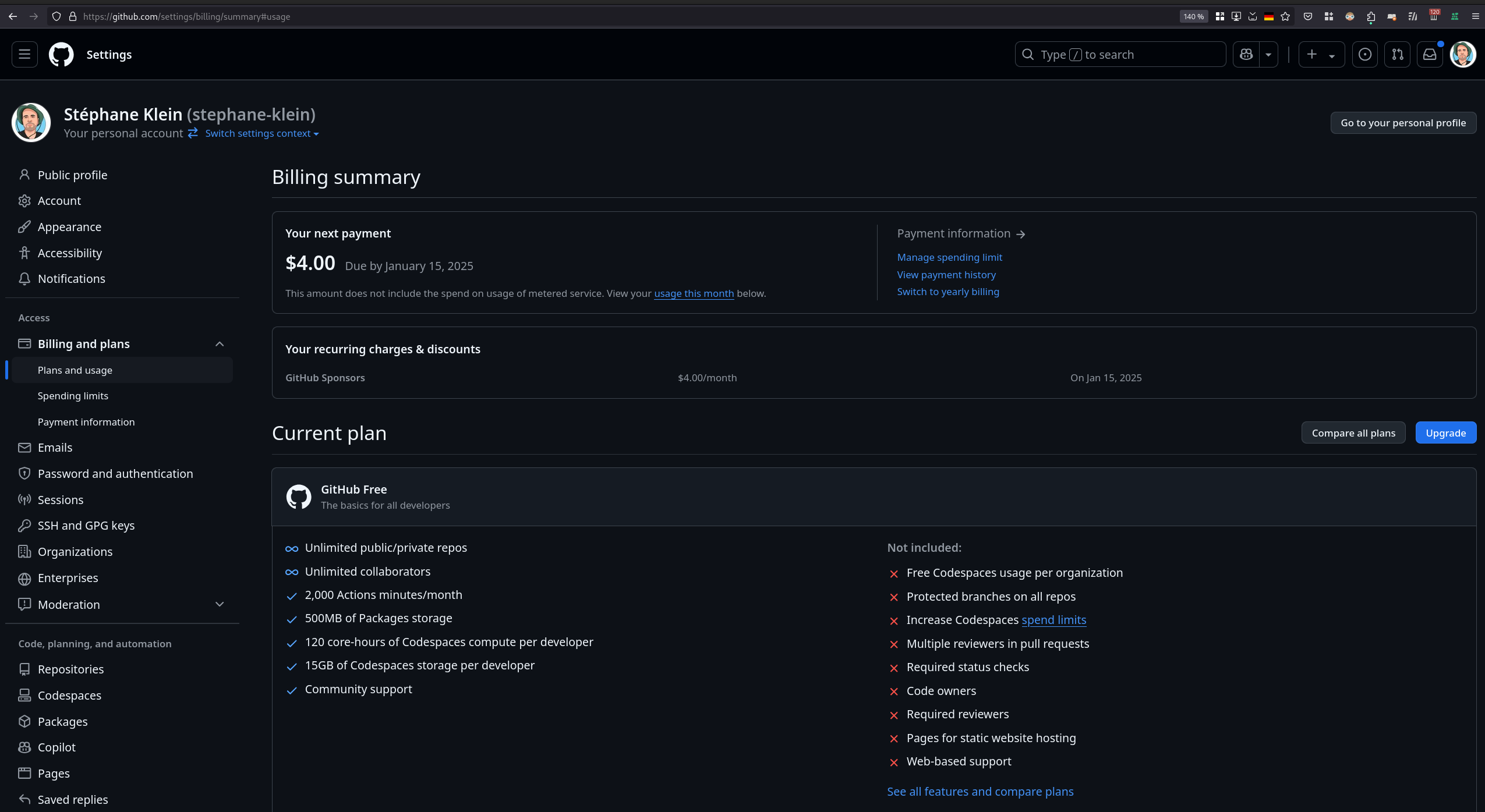
D'ici quelques jours, je prévois de rédiger un bilan d'utilisation de avante.nvim pour faire le point sur mon expérience avec cet outil.
Journal du mercredi 23 octobre 2024 à 10:53
#JaiDécidé d'utiliser dans mes README l'expression figurée anglaise "Smoke test".
Inscription et migration vers social.coop
Suite à l'étude de social.coop, #JaiDécidé de migrer mon compte Mastodon de l'instance Mamot.fr administré par La Quadrature du Net vers social.coop.
J'ai rempli le formulaire Registration Form.
À la question :
In up to 500 characters (the maximum length of a toot on Mastodon), can you tell us a bit about yourself? For instance, why you wish to join social.coop, and what hopes or aspirations you have for the site and/or your participation?
J'ai répondu :
Bonjour,
Je suis membre de la communauté Fediverse depuis 2018 (https://mamot.fr/@stephane_klein). J'ai décidé en novembre 2022 de réduire au maximum mon activité sur Twitter.
Cela fait plusieurs années que j'envisage de rejoindre une instance à laquelle je pourrais contribuer financièrement.
J'ai découvert social.coop et j'apprécie la gestion financière transparente du projet via https://opencollective.com/socialcoop ainsi que le mode de gouvernance basé sur Loomio.
Je serais ravi de rejoindre votre communauté.
Je suis français, basé à Paris. Plus d'informations sur https://sklein.xyz.
Bonne soirée, Stéphane
En rédigeant ce texte, je me demande s'il existe une communauté identique à social.coop, mais 100% francophone 🤔.
Traduction en anglais :
Hello,
I am a member of the Fediverse community since 2018 (https://mamot.fr/@stephane_klein). I decided in November 2022 to reduce my Twitter activity as much as possible.
For several years now, I've been considering joining an organization to which I could contribute financially.
I discovered social.coop and appreciate the transparent financial management of the project via https://opencollective.com/socialcoop as well as the mode of governance based on Loomio.
I would be happy to join your community.
I am French, based in Paris. More information on https://sklein.xyz.
Have a nice evening, Stéphane
J'attends la réponse à mon inscription.
Première itération de mon aventure Malt
Il y a quelques mois, j'ai envisagé de créer plusieurs profils sur Malt pour me présenter sous différentes "casquettes". Par exemple :
- CTO as a Service
- CPTO
- DevOps
- Expert en Web Scraping
- Développeur Frontend
- Développeur Backend
- Développeur Fullstack
- …
Cette idée m'est venue en 2022, lorsque j'étais CTO chez Spacefill et que je recrutais des freelances pour des missions très spécifiques.
Je m'étais alors rendu compte que la sélection des profils était fastidieuse et que je passais à côté de candidats intéressants simplement à cause de problèmes liés aux mots-clés.
C'est à ce moment-là que je me suis dit que si un jour je m'inscrivais sur une place de marché de freelances, il serait judicieux de créer plusieurs types de profils pour contourner ces limitations de filtres.
En août dernier, j'ai fait quelques recherches sur la possibilité de créer plusieurs profils sur Malt et je suis tombé sur cette page (webarchive):
Créer plusieurs profils dans Malt ?
Vous pouvez créer plusieurs profils dans Malt. Chaque compte doit être associé à une adresse e-mail différente.
Chez Malt, nous déconseillons de créer deux profils différents sur la marketplace sauf si vous avez deux activités très différentes, par exemple si vous êtes développeur et graphiste.
Vos filleuls et gains cumulés seront alors répartis entre plusieurs profils.
Si vous exercez deux activités indépendantes très différentes, nous vous conseillons de créer deux comptes distincts en prenant soin de télécharger les documents liés à votre(vos) activité(s).
Nous ne pourrons pas fusionner vos notes et projets entre vos deux profils.
Création de mon compte Malt
Je me suis ensuite dit qu'avant de mettre en place une stratégie complexe, qu'il serait plus judicieux de commencer par créer et publier un simple profil.
En remplissant ce profil, j'ai constaté que je pouvais renseigner une longue liste de compétences. J'ai alors pensé que l'idée de créer plusieurs profils n'était finalement plus nécessaire.
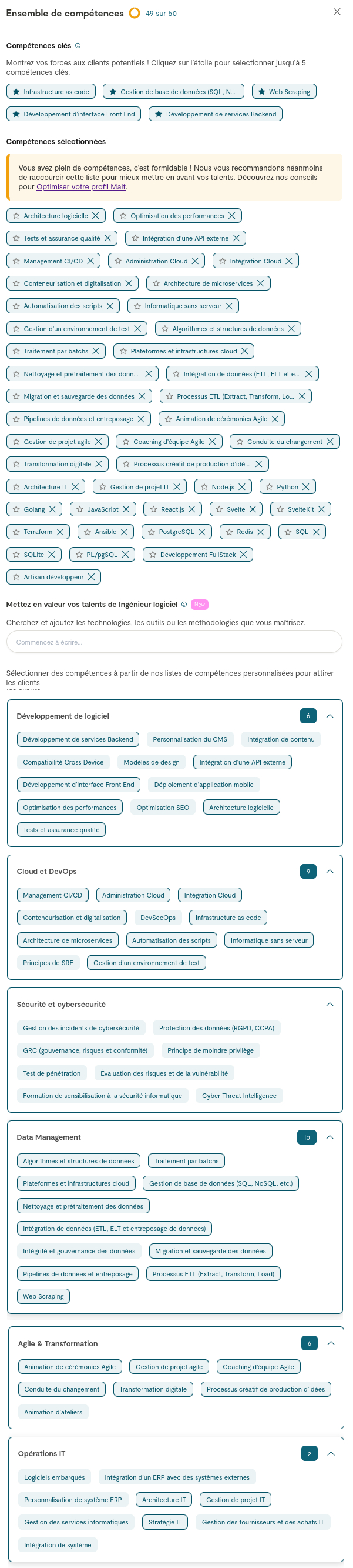
Premier point de difficulté, le choix de la catégorie :
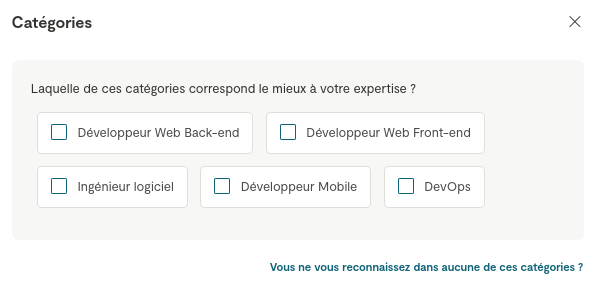
J'ai opté pour une catégorie générique, celle de "Ingénieur logiciel".
Cependant, je doute fortement que ce soit le premier choix d'une personne que utilise le recherche de Malt 🤔 :
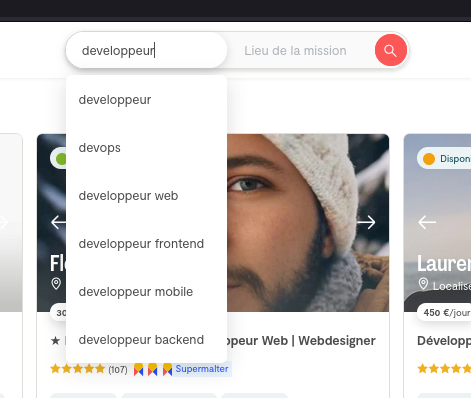
'ai fait un test en choisissant l'intitulé "Développeur". Après avoir filtré par mon tarif journalier exact et mon niveau d'expérience, je suis présent en page 6 des résultats.
Si je sélectionne la catégorie "Développeur Web Back-end" ou "Développeur Web Front-end" je ne suis plus présente dans la liste des résultats 😟.
Bilan Malt après 25 jours
Mon bilan Malt après 25 jours ? Pour le moment, personne ne m'a contacté. J'observe que mes statistiques sont plutôt mauvaises. De plus, je pense que les 3 personnes qui ont vu mon profil sont des amis.
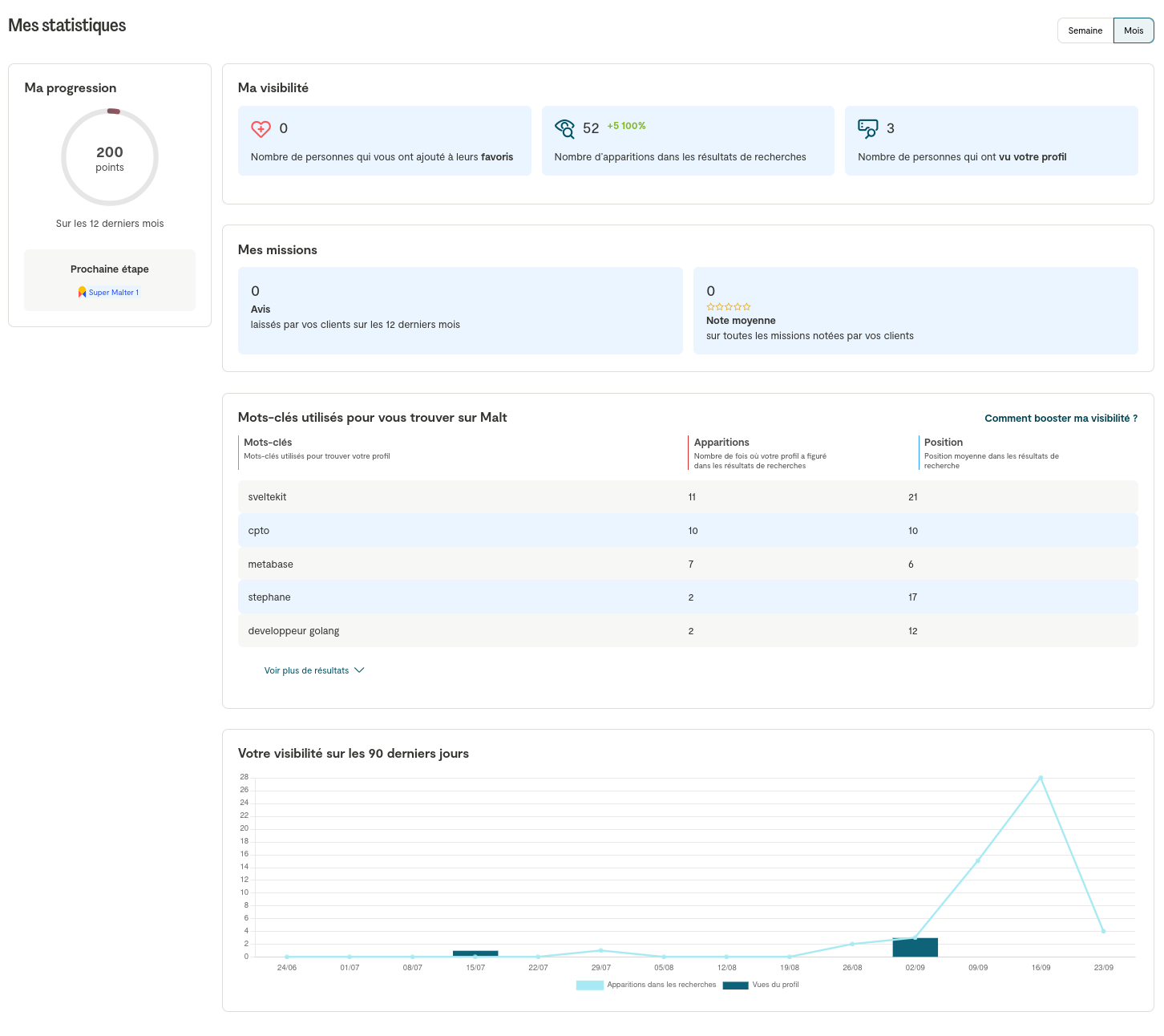
Un ami freelance m'a confié qu'il n'avait reçu qu'une seule proposition de mission sur Malt en plus de trois ans.
Un autre ami freelance m'a confié avoir eu, sur un an, sur Malt, environ 40 propositions de mission, 5 échanges constructifs et signé deux missions.
Suite de stratégie Malt ?
Il est clair que mon profil Malt n'est pas optimisé.
J'ai visé trop large en listant mes compétences, et je pense que ce n'est pas la meilleure stratégie.
Le problème, c'est que si je veux rendre mon profil plus spécialisé, je vais devoir faire des choix et retirer des compétences que je ne souhaite pas supprimer 😞.
Pour éviter cela, je vois deux stratégies :
- Modifier mon profil chaque semaine, en ajustant les technologies, les catégories et le tarif journalier ;
- Créer plusieurs profils.
#JeMeDemande si l'étape de vérification des documents d'entreprise va m'empêcher de créer plusieurs profils 🤔.
#JeMeDemande s'il est préférable que je consacre prioritairement du temps à l'optimisation de mon profil Malt ou alors de travailler sur ma Stratégie de promotion de mon activité freelance sur LinkedIn 🤔.
#JaiDécidé de reporter l'optimisation de mon profil Malt.
Journal du lundi 02 septembre 2024 à 15:31
J'utilise souvent le terme "rationale" pour donner une explication raissonnée d'une proposition.
Dans la description d'une issue, on trouve souvent une section intitulée "Motivation" et "Rationale", comme dans cette PEP : https://peps.python.org/pep-0625/
Pour être plus clair avec mes interlocuteurs moins familiers avec le vocabulaire des hackers, #JaiDécidé de remplacer « Rationale » par « raisons qui justifient cette proposition ».
Journal du lundi 02 septembre 2024 à 10:32
Depuis janvier 2022, j'ai pris l'habitude de publier quotidiennement par écrit le contenu de mon Standup Meeting ou Daily Scrum.
Dans certaines situations, je publie ce message sans participer à un meeting synchrone.
En l'absence de réunion, l'appellation "standup meeting" ne semble pas appropriée. Je me pose la question de savoir comment nommer ce type de message, par exemple pour l'utiliser comme nom de channel.
Après quelques recherches sémantiques, #JaiDécidé d'utiliser les termes suivants :
Journal du mardi 20 août 2024 à 14:35
#OnMaPartagé la pratique suivante quand un projet utilise Mise : convertir tous les fichiers .tool-versions vers le format de configuration natif de Mise.mise.toml. Cette conversion permet d'éviter d'éventuels problèmes de compatibilité entre Mise et Asdf.
It supports the same .tool-versions files that you may have used with asdf and uses asdf plugins. It will not, however, reuse existing asdf directories (so you'll need to either reinstall them or move them), and 100% compatibility is not a design goal.
-- from
En utilisant le format .mise.toml l'utilisateur comprends qu'il doit utiliser Mise.
#JaiDécidé d'ajouter cette pratique dans ma doctrine d'artisan développeur.
Journal du jeudi 15 août 2024 à 20:00
Depuis que j'utilise @tabler/icons-svelte pour intégrer des tabler-icons sur un projet SvelteKit SSR, je rencontre d'énormes problèmes de performance en mode développement (pnpm run dev).
Pour traiter le problème, j'ai essayé ce hack indiqué dans l'issue Slow experience in SvelteKit, mais cela ne fonctionne pas.
Toujours dans cette issue, #JaiDécouvert Iconify.
Je pense me souvenir d'avoir commencé à utiliser tabler-icons comme alternative Open source à Font Awesome.
J'ai lu la page page raconte l'histoire du projet et j'apprends que le projet s'est réellement lancé en 2020.
Iconify est devenu un projet Open source en 2021 :
In mid 2022 plans changed, thanks to people showing interest in sponsoring open source development.
The new plan is to:
- Open source everything, encourage developers to create their own open source solutions that use Iconify.
- Rely on sponsors to finance development.
-- from
Mais, d'après la page contributors le projet semble toujours très majoritairement développé par Vjacheslav Trushkin.
Je lis aussi :
Unlike fonts, it downloaded data only for icons used on page, rendered pixel perfect SVG. (from)
Par contre, je pense comprendre qu'Iconify n'est pas un projet de création d'icônes, mais un framework qui regroupe énormément d'icônes.
Par exemple, j'ai constaté qu'Iconify intègre entre autres :
Iconify propose des composants icônes pour Svelte : Iconify for Svelte.
Mais, je lis :
Loads icons on demand. No need to bundle icons, component will automatically load icon data for icons that you use from Iconify API. -- from
Cette technique « Loads icons on demand » ne me plait pas. Je souhaite réduire au maximum les latences dans mes applications web.
J'ai continué mes recherches.
#JaiLu Icon library for svelte? : sveltejs
#JaiDécouvert unplugin-icons (from).
unplugin-icons est un projet qui a commencé en 2021 et qui est basé sur Iconify.
Je constate que unplugin-icons propose une configuration SvelteKit.
J'ai testé et cela semble très bien fonctionner 🙂.
Le site https://icones.js.org permet de facilement copier-coller le code Javascript pour intégrer une icône. Par exemple, un click sur "Unplugin Icons" :
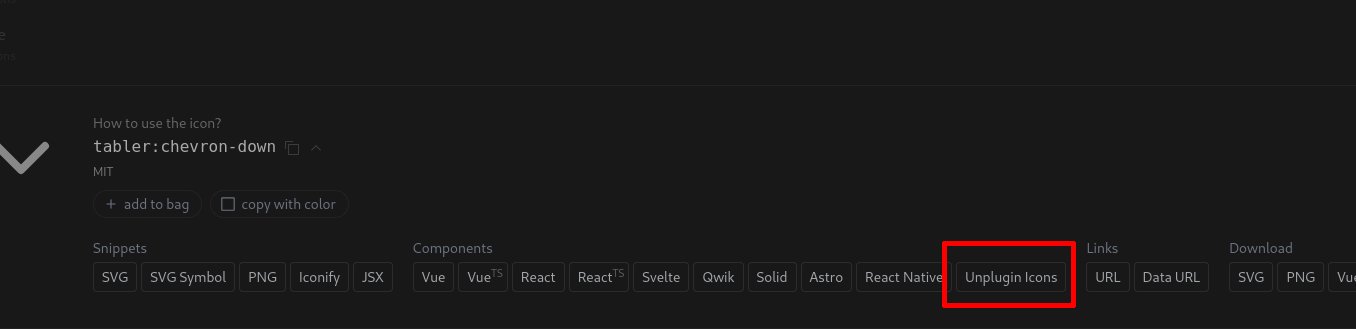
permet de copier :
import TablerChevronDown from '~icons/tabler/chevron-down'
Je ne constate aucun problème de lenteur au mode développement (pnpm run dev) et aucun chargement réseau externe des icônes dans la version de production.
#JaiDécidé d'adopter cette librairie pour gérer les icons de mes projets SvelteKit.
Journal du dimanche 11 août 2024 à 21:20
Suite à ma note 2024-08-10_1726 en lien avec le Projet 11 - "Première version d'un moteur web PKM", #JaiDécidé de ne pas implémenter les pages /tags/{tag_name}/. À la place, je souhaite que les a href des tags point vers l'url suivante : /search/?tags=tagname.
Journal du samedi 10 août 2024 à 12:45
Depuis avril 2024, je m'intéresse au sujet des Personal knowledge management et Zettelkasten. J'ai remarqué que Zotero occupe une place importante dans les workflows des utilisateurs de PKM.
Conséquence : #JaiDécidé de tester Zotero , afin de déterminer s'il peut m'être utile et comment l'intégrer efficacement dans mon propre workflow.
Journal du samedi 06 juillet 2024 à 15:15
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, 2024-06-23_1057 et 2024-06-23_2222.
Pour le projet obsidian-vault-to-apache-age-poc je souhaite créer une image Docker qui intègre les extensions pg_search et Apache Age à une image PostgreSQL.
Pour réaliser cela, je vais me baser sur ce travail préliminaire https://github.com/stephane-klein/pg_search_docker.
#JaiDécidé de créer un repository GitHub nommé apache-age-docker, qui contiendra un Dockerfile pour builder une image Docker PostgreSQL 16 qui intègre la release "Release v1.5.0 for PG16" de l'extension Postgres Apage Age.
Journal du mardi 18 juin 2024 à 17:39
J'utilise encore eslint 8.57.0 et non pas la version 9 et #JaiDécidé d'arrêter d'utiliser le format #YAML (.eslintrc.yaml) pour configurer eslint pour les raisons suivantes :
- eslint version 9 ne supporte le format #YAML .
- Je souhaite utiliser le fichier
svelte.config.jsdans la configuration eslint et cela n'est possible qu'avec le formateslint.config.js.
Journal du mardi 18 juin 2024 à 14:22
J'utilise ma nouvelle configuration Neovim basé sur lazy.nvim et je n'arrive pas à faire fonctionner eslint dans mon projet Value Props.
J'ai essayé :
- eslint-lsp et j'ai un message d'erreur, qui m'indique qu'il ne trouve pas de fichier de configuration. Je me demande si il ne supporte pas format
.eslintrc.yaml🤔. - eslint_d.js : quand je consulte le resélutat retournée par
LSPInfo, je constate queeslint_dn'est pas lancé, je ne sais pas pourquoi 🤔.
Je souhaite que mon instance Neovim lance précisément le eslint configuré dans mon projet.
J'ai commencé à faire de recherche à propos de ce que j'utilisais avant, c'est à dire null-ls.nvim et je constate que ce projet est archivé.
Je constate que le projet null-ls.nvim continue à vivre à travers le fork nommé none-ls.nvim.
Je lis dans ce thread que plusieurs personnes conseillent : conform.nvim.
Lightweight yet powerful formatter plugin for Neovim
Je comprends que conform.nvim propose une fonctionnalité de formatage mais pas de "linting".
Mais ici je vois qu'il supporte eslint_d 🤔.
En lisant ce thread j'ai beaucoup de difficulté à me faire un avis entre "conform+mvim-lint" versus "null-ls".
#JaiDécidé de tester conform.nvim + nvim-lint.
Après 1h de difficulté avec nvim-lint., #JaiDécidé par pragmatisme d'utiliser none-ls.nvim.
https://github.com/stephane-klein/dotfiles/commit/dc781db2deefaefe0d96d6160baf0d05eae39812
Journal du samedi 08 juin 2024 à 17:08
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Alors que je travaille sur cette partie du projet, je relis la documentation de pg_dumpall et je constate à nouveau que cette commande ne supporte pas les différents formats de sortie que propose pg_dump 😡.
C'est pénible… du coup, j'ai enfin pris le temps de chercher si il existe une solution alternative et #JaiDécouvert pg_back :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
C'est parfait, c'est exactement ce que je cherche 👌.
Mais je découvre aussi les fonctionnalités suivantes :
- Pre-backup and post-backup hooks
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure or a remote host with SFTP
Conséquence : #JeMeDemande si j'ai encore besoin de restic dans Projet 7 🤔.
Je viens de lire ici :
In addition to the N previous backups, it would be nice to keep N' weekly backups and N'' monthly backups, to be able to look back into the far past.
C'est une fonctionnalité supporté par restic, donc pour le moment, je choisis de continuer à utiliser restic.
Pour le moment, #JaiDécidé d'intégrer simplement pg_back dans restic-pg_dump-docker en remplacement de pg_dumpall et de voir par la suite si je simplifie ce projet ou non.
Journal du samedi 08 juin 2024 à 10:35
Dans 2024-06-06_1047 #JaiDécidé d'utiliser le terme Inference Engines pour définir la fonction ou la catégorie de llama.cpp.
J'ai échangé avec un ami au sujet des NPU et j'ai dit que j'avais l'impression que ces puces sont spécialés pour exécuter des Inference Engines, c'est-à-dire, effectuer des calculs d'inférence à partir de modèles.
Après vérification, dans cet article je lis :
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed to accelerate artificial intelligence and machine learning applications, including artificial neural networks and machine vision.
et je comprends que mon impression était fausse. Il semble que les NPU ne sont pas seulement dédiés aux opérations d'exécution d'inférence, mais semblent être optimisés aussi pour faire de l'entrainement 🤔.
Un ami me précise :
Inference Engines
Pour moi, c'est un terme très générique qui couvre tous les aspects du machine learning, du deep learning et des algorithmes type LLM mis en œuvre.
et il me partage l'article Wikipedia Inference engine que je n'avais pas lu quand j'avais rédigé 2024-06-06_1047, honte à moi 🫣.
Dans l'article Wikipedia Inference engine je lis :
In the field of artificial intelligence, an inference engine is a software component of an intelligent system that applies logical rules to the knowledge base to deduce new information.
et
Additionally, the concept of 'inference' has expanded to include the process through which trained neural networks generate predictions or decisions. In this context, an 'inference engine' could refer to the specific part of the system, or even the hardware, that executes these operations.
Je comprends qu'un Inference Engines n'effectue pas l'entrainement de modèles.
Pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Le contenu de l'article Wikipedia Llama.cpp augmente mon niveau de confiance dans ce choix de vocabulaire :
llama.cpp is an open source software library written in C++, that performs inference on various Large Language Models such as Llama
Journal du vendredi 07 juin 2024 à 17:12
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Hasard du calendrier, mon ami Alexandre travaille en ce moment sur un projet nommé restic-ftp-docker.
Quelle différence avec restic-pg_dump-docker ?
Principale différence d'objectif entre ces deux projets :
restic-ftp-dockersauvegarde via restic le contenu d'un dossier vers un espace FTP.restic-pg_dump-dockersauvegarde via restic le contenu d'une base de données PostgreSQL. Le contenu de la base de données est exporté avec la commande standard pg_dump de PostgreSQL. La sauvegarde peut être envoyée vers tous les storages supportés par rclone.
#JaiDécidé de reprendre un maximum d'élément du projet restic-ftp-docker dans restic-pg_dump-docker.
#JeSouhaite proposer une Pull Request à restic-ftp-docker pour étendre ce projet à tous les storages supporté par rclone et ne plus le limité au storage ftp.
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age", j'utilise les librairies remark mais pour le moment, je les trouve bien plus difficiles à utiliser que gray-matter couplé avec markdown-it.
Par exemple, je souhaite extraire dans un dict le contenu frontmatter de fichiers markdown, ainsi que la partie body.
Avec remark j'ai écrit avec difficulté le code suivant :
#!/usr/bin/env node
import { glob } from "glob";
import fs from 'fs';
import { unified } from 'unified';
import markdown from 'remark-parse';
import frontmatter from 'remark-frontmatter';
import extract from 'remark-extract-frontmatter';
import { parse } from 'yaml';
import stringify from 'remark-stringify';
const processor = unified()
.use(markdown)
.use(frontmatter, ['yaml'])
.use(extract, { yaml: parse })
.use(stringify);
const processMarkdown = async (filename) => {
const fileContent = fs.readFileSync(filename);
const result = await processor.process(fileContent);
const body = result.toString().split(/---\s*$/m)[2] || '';
return {
frontmatter: result.data,
body: body.trim()
};
};
for (const filename of (await glob("content/**/*.md"))) {
processMarkdown(filename).then(data => {
console.log('Frontmatter:', data.frontmatter);
console.log('Body:', data.body);
});
}
Et voici mon implémentation avec gray-matter :
#!/usr/bin/env node
import { glob } from "glob";
import matter from "gray-matter";
import yaml from "js-yaml";
for (const filename of (await glob("content/**/*.md"))) {
console.log(matter.read(filename, {
engines: {
yaml: (s) => yaml.load(s, { schema: yaml.JSON_SCHEMA })
}
}));
}
Je préfère sans hésitation cette seconde implémentation.
#JaiDécidé d'utiliser gray-matter.
#JeMeDemande quels seraient les avantages que j'aurai à utiliser remark 🤔.
Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Finalement, contraiment à ce que j'avais décidé ici, je n'ai pas utilisé Convict dans mon application Value Props propulsé par SvelteKit.
J'ai "simplement" utilisé la vite-plugin-environment pour définir la valeur par défaut des variables d'environnement de configuration utilisées par l'application.
Exemple :
// vite.config.js
import { defineConfig } from "vite";
import EnvironmentPlugin from 'vite-plugin-environment'
import { sveltekit } from "@sveltejs/kit/vite";
export default defineConfig({
plugins: [
EnvironmentPlugin({
POSTGRES_URL: "postgres://webapp:password@localhost:5432/myapp",
Y_WEBSOCKET_URL: "ws://localhost:1234",
SMTP_HOST: "127.0.0.1",
SMTP_POST: 1025,
SECRET: "secret"
}),
sveltekit()
]
});;
Et voici un exemple d'utilisation de ces paramètres de configuration :
// src/lib/server/db.js
import postgres from "postgres";
const sql = postgres(process.env.POSTGRES_URL);
export default sql;
Rien de plus, je n'ai ni utilisé Convict ni dotenv, j'ai pu suivre le principe KISS.
J'ai décidé de continuer à utiliser la lib Convict de configuration management
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Après avoir parcouru la documentation de env-cmd et dotenv
Après avoir réalisé que je n'avais rencontré aucun problème avec node-convict et que j'avais même pris du plaisir à l'utiliser.
Suite au feedback d'un ami qui me dit :
J'aime beaucoup convict qu'on a utilisé dans gibbon-mail
Et qui me rappelle que dotenv est très orienté "fichier de conf" alors que lui comme moi suivons plutôt la doctrine "variable d'env" (The Twelve-Factors App).
#JaiDécidé que je n'allais suivre la mode, que je vais continuer à utiliser Convict.
Une heure plus tard, j'ai changé d'avis Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Je commence à utiliser Toggl pour analyser la répartition de mon temps
Je suis président du club de Tennis de Table d'Issy-les-Moulineaux depuis le début de l'année. Cette fonction me prend beaucoup plus de temps que je ne l'imaginais initialement, et j'ai du mal à quantifier précisément cette charge de travail. J'ai l'impression qu'elle est importante, mais j'hésite : représente-t-elle un jour par semaine ? Deux jours ? Ou est-ce simplement ma perception qui me trompe ?
J'ai l'intuition que cette mission est trop lourde pour quelqu'un qui exerce une activité professionnelle. Je pense qu'elle ne peut être remplie efficacement que par une personne à la retraite, disposant de suffisamment de temps et d'énergie pour gérer tous les aspects administratifs et organisationnels.
Si je dois prématurément démissionner, je souhaite pouvoir rationaliser ma décision. Je veux la fonder sur des mesures concrètes et précises, et non sur un simple sentiment.
Pour cela, #JaiDécidé d'essayer d'utiliser l'application quantified self de suivi du temps nommée Toggl Track pendant 1 mois, afin d'avoir des données précises pour analyser la répartition de mon temps sur différentes activités :
- Tâches domestiques (préparation des repas, ménage, vaisselle) ;
- Mon emploi en CDI ;
- Lecture ;
- Hobbie : coding, apprentissage, veille technologique ;
- Sport (Footing, Tennis de Table) ;
- Repas et restaurant ;
- Transports ;
- Tâches liées à mon rôle de président de club ;
- Temps de sommeil.
Je me demande si je vais être assez discipliné pour faire ce suivi.
Je suis curieux de savoir ce que vont m'apprendre ces mesures !
#JaiDécouvert le concept de marqueur de modestie épistémique en mai 2019 dans cette vidéo de Lê Nguyên Hoang : « Modestie épistémique #DébattonsMieux ».
#JaiDécidé d'essayer à partir d'aujourd'hui de mettre cela en pratique autant que possible dans ma communication.
Mon intuition, c'est que cela va être très difficile à l'oral, dans le flux de la communication, mais je pense qu'il n'y a aucune raison que je n'y arrive pas à l'écrit.
Pour l'écrit, j'aurais tendance à dire que c'est une question de rigueur, équivalente à ma rigueur d'utilisation des conventional comments quand je poste des commentaires de review.
Voici quelques exemples de marqueurs de modestie épistémique que je pourrais utiliser :
- il me semble que …, ça serait …
- j'aurais tendance à dire que …
- peut-être ...
- probablement ...
- sans doute ...
- si je devais parier ...
- mon intuition dirait que ...
- je me trompe sans doute…
- il me semble extrêmement probable …
- il semble que …
- selon cette article ....
- je pense que .....
- j'ai entendu dire que ....
- il paraît ......
- selon ce consensus ....
Projet 12 - "Implémentation nodemailer-scaleway-transport"
Date de la création de cette note : 2024-07-30.
Quel est l'objectif de ce projet ?
Implémenter et publier un plugin Nodemailer de transport pour l'API HTTP Transactional Email de Scaleway.
Pourquoi je souhaite réaliser ce projet ?
Les ports SMTP des instances computes de Scaleway sont par défaut fermés. Pour contourner cette contrainte, il est nécessaire d'effectuer une demande au support pour les ouvrir.
Partant de ce constat, #JaiDécidé d'utiliser le protocole HTTP autant que possible pour envoyer des e-mails.
Problème : je n'ai pas trouvé de plugin de transport Nodemailer pour Scaleway, ce qui a motivé la création de ce projet.
Repository de ce projet :
https://github.com/stephane-klein/nodemailer-scaleway-transport (non publié au moment de la rédaction de cette note)
Ressources :
Nom alternatifs à "Inference Engines" :
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, j'ai décidé d'utiliser le terme Inference Engines.
Update du 2024-06-08 : suite à 2024-06-08_1035, pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Exemples de "Inference Engines" :
Dernière page.