
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (806) ] [ Notes plus anciennes (856) >> ]
Samedi 29 juin 2024
Journal du samedi 29 juin 2024 à 23:31
#JaiDécouvert un nouveau Wayland Window Manager, nommé Niri d'un type particulier, c'est un scrollable-tiling Window Manager.
Journal du samedi 29 juin 2024 à 11:22
#JaiDécouvert https://rustdesk.com/ une solution alternative à TeamViewer.
J'ai décidé de tester RustDesk :
- J'ai installé avec succès RustDesk sous MacOS : https://rustdesk.com/docs/en/client/mac/
- J'ai installé RustDesk sous Fedora en installant directement le fichier Flatpak téléchargeable sur https://github.com/rustdesk/rustdesk/releases/tag/1.2.6
- J'ai vérifié, au moment où j'écris ces lignes, RustDesk ne semble pas disponible sur https://flathub.org/apps/search?q=rustdesk
- J'ai trouvé un Thread à ce sujet https://discourse.flathub.org/t/remote-desktop-control-rustdesk/2605/5
J'ai testé un accès via RustDesk depuis mon laptop Fedora vers un MacbookAir, via un réseau externe — j'ai utilisé ma connexion 4G — et cela a parfaitement fonctionné.
J'ai pu configurer un mot de passe permanent sur l'instance du MacbookAir, ainsi que le démarrage automatique RustDesk.
Tout semble parfait pour le moment.
Je constate que ce projet a démarré en septembre 2020.
J'ai installé et utilisé avec succès RustDesk pour contrôler un Desktop Windows à distance ainsi qu'un Smartphone Android à distance.
Journal du samedi 29 juin 2024 à 11:13
#JaiLu l'article intitulé Why the next GNOME Release will be one of the Best Ever.
Je pense que cet article offre une excellente vue d'ensemble des améliorations apportées à GNOME.
Vendredi 28 juin 2024
Journal du vendredi 28 juin 2024 à 17:07
#JaiDécouvert ce service en ligne pour payer des personne partout dans le monde https://www.deel.com/
Deel helps tens of thousands of companies expand globally with unmatched speed, flexibility and compliance. Get our all-in-one Global People Platform that simplifies the way you onboard, offboard, and everything else in between.
Ici je découvre des services alternatifs :
Mercredi 26 juin 2024
Journal du mercredi 26 juin 2024 à 13:31
Au mois de janvier 2024, #JaiDécouvert Slivev un outil alternatif à Reveal.js.
Presentation slides for developers 🧑💻👩💻👨💻
Lundi 24 juin 2024
Journal du lundi 24 juin 2024 à 11:56
#OnMaPartagé cette Étude de UFC-Que Choisir : Dark Pattens Dans l'E-Commerce. - Les interfaces trompeuses sur les places de marché en ligne.
Je ne l'ai pas encore lu, mais le sujet des dark pattern m'intéresse beaucoup.
#JaimeraisUnJour prendre le temps de lire l'intégralité de cette étude.
Dimanche 23 juin 2024
Journal du dimanche 23 juin 2024 à 22:22
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211 et 2024-06-23_1057.
#JaiCompris en lisant ceci que pg_search se nommait apparavant pg_bm25.
#JaiDécouvert que Tantivy — lib sur laquelle est construit pg_search — et Apache Lucene utilisent l'algorithme de scoring nommé BM25.
Okapi BM25 est une méthode de pondération utilisée en recherche d'information. Elle est une application du modèle probabiliste de pertinence, proposé en 1976 par Robertson et Jones. (from)
Je suis impressionné qu'en 2024, l'algorithme qui je pense est le plus performant utilisé dans les moteurs de recherche ait été mis au point en 1976 😮.
#JaiDécouvert pgfaceting - Faceted query acceleration for PostgreSQL using roaring bitmaps .
J'ai finallement réussi à installer pg_search à l'image Docker postgres:16 : https://github.com/stephane-klein/pg_search_docker.
J'ai passé 3h pour réaliser cette image Docker, je trouve que c'est beaucoup trop 🫣.
Journal du dimanche 23 juin 2024 à 11:20
#JaiDécouvert l'extension PostgreSQL : https://github.com/sraoss/pg_ivm (from)
Journal du dimanche 23 juin 2024 à 10:57
#iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et plus précisément la suite de 2024-06-20_2211, #JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
Je lis ici :
#JePense que c'est un synonyme de pg_search mais je n'en suis pas du tout certain.
En regardant la documetation de ParadeDB, je lis :
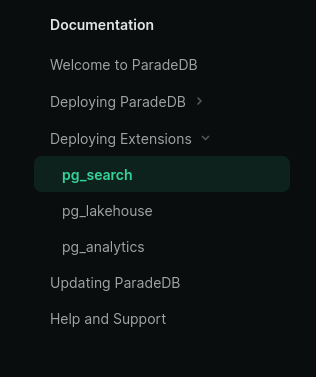
J'en conclu que ParadeDB est un projet qui regroupe plusieurs extensions PostgreSQL : pg_search, pg_lakehouse et pg_analytics.
Pour le Projet 5, je suis intéressé seulement par pg_search.
#JeMeDemande si pg_search dépend de pg_vector mais je pense que ce n'est pas le cas.
#JeMeDemande comment créer une image Docker qui intègre l'extension pg_search ou autrement nommé ParadeDB.
J'ai commencé par essayer de créer cette image Docker en me basant sur ce Dockerfile mais j'ai trouvé cela pas pratique. Je constaté que j'avais trop de chose à modifier.
Suite à cela, je pense que je vais essayer d'installer pg_search avec PGXN.
Lien vers l'extension pg_search sur PGXN : https://pgxn.org/dist/pg_bm25/
Sur GitHub, je n'ai trouvé aucun exemple de Dockerfile qui inclue pgxn install pg_bm25.
J'ai posté https://github.com/paradedb/paradedb/issues/1019#issuecomment-2184933674.
I've seen this PGXN extension https://pgxn.org/dist/pg_bm25/
But for the moment I can't install it:
root@631f852e2bfa:/# pgxn install pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: unpacking: /tmp/tmpvhb7eti5/pg_bm25-9.9.9.zip INFO: building extension ERROR: no Makefile found in the extension root
J'ai posté pgxn install pg_bm25 => ERROR: no Makefile found in the extension root #1287.
I think I may have found my mistake.
Should I not use
pgxn installbut should I usepgxn download:root@28769237c982:~# pgxn download pg_bm25 INFO: best version: pg_bm25 9.9.9 INFO: saving /root/pg_bm25-9.9.9.zip@philippemnoel Can you confirm my hypothesis?
J'ai l'impression que https://pgxn.org/dist/pg_bm25/ n'est buildé que pour PostgreSQL 15.
root@4c6674286839:/# unzip pg_bm25-9.9.9.zip
Archive: pg_bm25-9.9.9.zip
creating: pg_bm25-9.9.9/
creating: pg_bm25-9.9.9/usr/
creating: pg_bm25-9.9.9/usr/lib/
creating: pg_bm25-9.9.9/usr/lib/postgresql/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/
creating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/
inflating: pg_bm25-9.9.9/usr/lib/postgresql/15/lib/pg_bm25.so
creating: pg_bm25-9.9.9/usr/share/
creating: pg_bm25-9.9.9/usr/share/postgresql/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/
creating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25.control
inflating: pg_bm25-9.9.9/usr/share/postgresql/15/extension/pg_bm25--9.9.9.sql
inflating: pg_bm25-9.9.9/META.json
Je pense que je dois changer de stratégie 🤔.
Je ne pensais pas rencontrer autant de difficultés pour installer cette extension 🤷♂️.
Ce matin, j'ai passé 1h30 sur ce sujet.
J'ai trouvé ce Dockerfile https://github.com/kevinhu/pgsearch/blob/48c4fee0b645fddeb7825802e5d1a4a2beb9a99b/Dockerfile#L14
Je pense pouvoir installer un package Debian présent dans la page release : https://github.com/paradedb/paradedb/releases
Jeudi 20 juin 2024
Journal du jeudi 20 juin 2024 à 22:11
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
Dans cette version du 20 juin j'ai implémenté :
- Importation des fichiers dans des nodes de type
notesdans un graph. - Le contenu des notes dans une table
public.notes - Les aliases dans la table
public.note_aliases - Importation des tags et leurs liaisons vers les notes dans un graph.
Au stade où j'en suis, je suis encore loin d'être en capacité de juger si le moteur de graph — Age — me sera utile ou non pour réaliser des requêtes simplement 🤔.
Prochaine fonctionnalités que je souhaite implémenter dans ce projet :
- [ ] Recherche de type fuzzy search sur les
Note.title,aliasetTag.namebasé sur la méthode Levenshtein du module fuzzystrmatch - [ ] Recherche plain text sur le contenu des Notes basé sur pg_search
Dans la liste des features de pg_search je lis :
- Autocomplete
- Fuzzy search
Je pense donc intégrer pg_search avant fuzzystrmatch. Peut-être que je n'aurais pas besoin d'utiliser fuzzystrmatch.
Journal du jeudi 20 juin 2024 à 18:36
Je ne sais pas quoi en pensé Argos Panoptès : la supervision de sites web simple et efficace - LinuxFr.org 🤔.
Journal du jeudi 20 juin 2024 à 00:14
#JaiLu Ask HN: Why do message queue-based architectures seem less popular now? | Hacker News.
Je trouve la question très intéressante.
Ce commentaire m'a bien fait rire :
Going to give the unpopular answer. Queues, Streams and Pub/Sub are poorly understood concepts by most engineers. They don't know when they need them, don't know how to use them properly and choose to use them for the wrong things. I still work with all of the above (SQS/SNS/RabbitMQ/Kafka/Google Pub/Sub).
I work at a company that only hires the best and brightest engineers from the top 3-4 schools in North America and for almost every engineer here this is their first job.
My engineers have done crazy things like:
- Try to queue up tens of thousands of 100mb messages in RabbitMQ instantaneously and wonder why it blows up.
- Send significantly oversized messages in RabbitMQ in general despite all of the warnings saying not to do this
- Start new projects in 2024 on the latest RabbitMQ version and try to use classic queues
- Creating quorum queues without replication policies or doing literally anything to make them HA.
- Expose clusters on the internet with the admin user being guest/guest.
- The most senior architect in the org declared a new architecture pattern, held an organization-wide meeting and demo to extol the new virtues/pattern of ... sticking messages into a queue and then creating a backchannel so that a second consumer could process those queued messages on demand, out of order (and making it no longer a queue). And nobody except me said "why are you putting messages that you need to process out of order into a queue?"...and the 'pattern' caught on!
- Use Kafka as a basic message queue
- Send data from a central datacenter to globally distributed datacenters with a global lock on the object and all operations on it until each target DC confirms it has received the updated object. Insist that this process is asynchronous, because the data was sent with AJAX requests.
As it turns out, people don't really need to do all that great of a job and we still get by. So tools get misused, overused and underused.
In the places where it's being used well, you probably just don't hear about it.
Edit: I forgot to list something significant. There's over 30 microservices in our org to every 1 engineer. Please kill me. I would literally rather Kurt Cobain myself than work at another organization that has thousands of microservices in a gigantic monorepo.
Mercredi 19 juin 2024
Journal du mercredi 19 juin 2024 à 10:56
Voici une liste de plateformes qui hébergent des publications scientiques dans le domaine des sciences socales :
En faisant cette recherche, #JaiDécouvert cette page Wikipedia : List of academic databases and search engines.
Mardi 18 juin 2024
Journal du mardi 18 juin 2024 à 22:09
#JaiDécouvert ici que le Le Parti radical est le premier partie politique qui a été fondé en France.
Journal du mardi 18 juin 2024 à 18:12
J'essaie de mettre de l'ordre dans ma configuration eslint et pour cela, j'essaie de migrer de l'ancien format de fichier de configuration .eslint.config.js vers le nouveau.
Le nouveau format de configuration est nommé "Flat Config" et l'ancien "Legacy Config".
Mon constat après avoir travaillé une demi-heure sur le sujet : je pense que je suis tombé dans un Yak! 🤣.
Pour le moment, j'ai l'impression que tout change. Pour arriver à effectuer la migration, je repars de zéro. J'ajoute un paramètre après l'autre afin d'avoir un truc fonctionnel et d'y comprendre quelque chose 🤷♂️.
"env": {
browser: true,
node: true,
es6: true,
es2020: true
}
semble être remplacer par des imports de https://github.com/sindresorhus/globals :
import globals from "globals";
export default [
{
languageOptions: {
ecmaVersion: 2022,
sourceType: "module",
globals: {
...globals.browser,
}
}
}
];
linebreak-style est déprécié, cette règle est déplacé dans le package ESLint Stylistic.
Je n'ai pas besoin de convertir la règle suivante :
linebreak-style: [error, unix]
étant donné qu'elle est activée par défaut.
#JeLis https://eslint.style/guide/why
With stylistic rules in ESLint, we are able to achieve similar formatting compatibility while retaining the original code style that reflects the authors/teams' intentions, and apply fixes in one go.
et je comprends que eslint semble pouvoir remplacer Prettier.
J'observe que eslint-stylistic est un nouveau projet qui date de septembre 2023.
Journal du mardi 18 juin 2024 à 17:39
J'utilise encore eslint 8.57.0 et non pas la version 9 et #JaiDécidé d'arrêter d'utiliser le format #YAML (.eslintrc.yaml) pour configurer eslint pour les raisons suivantes :
- eslint version 9 ne supporte le format #YAML .
- Je souhaite utiliser le fichier
svelte.config.jsdans la configuration eslint et cela n'est possible qu'avec le formateslint.config.js.
Journal du mardi 18 juin 2024 à 14:22
J'utilise ma nouvelle configuration Neovim basé sur lazy.nvim et je n'arrive pas à faire fonctionner eslint dans mon projet Value Props.
J'ai essayé :
- eslint-lsp et j'ai un message d'erreur, qui m'indique qu'il ne trouve pas de fichier de configuration. Je me demande si il ne supporte pas format
.eslintrc.yaml🤔. - eslint_d.js : quand je consulte le resélutat retournée par
LSPInfo, je constate queeslint_dn'est pas lancé, je ne sais pas pourquoi 🤔.
Je souhaite que mon instance Neovim lance précisément le eslint configuré dans mon projet.
J'ai commencé à faire de recherche à propos de ce que j'utilisais avant, c'est à dire null-ls.nvim et je constate que ce projet est archivé.
Je constate que le projet null-ls.nvim continue à vivre à travers le fork nommé none-ls.nvim.
Je lis dans ce thread que plusieurs personnes conseillent : conform.nvim.
Lightweight yet powerful formatter plugin for Neovim
Je comprends que conform.nvim propose une fonctionnalité de formatage mais pas de "linting".
Mais ici je vois qu'il supporte eslint_d 🤔.
En lisant ce thread j'ai beaucoup de difficulté à me faire un avis entre "conform+mvim-lint" versus "null-ls".
#JaiDécidé de tester conform.nvim + nvim-lint.
Après 1h de difficulté avec nvim-lint., #JaiDécidé par pragmatisme d'utiliser none-ls.nvim.
https://github.com/stephane-klein/dotfiles/commit/dc781db2deefaefe0d96d6160baf0d05eae39812
Journal du mardi 18 juin 2024 à 10:57
#JaiÉcouté la vidéo Enthoven vs. ChatGPT : Qui est l'imposteur ? de Monsieur Phi. Je l'ai appricié.
Suite à cela, j'ai pris l'initiative de créer la page Liste de philosophes contemporains.
J'y ai ajouté :
J'ai rédigé la note antidaté 2024-04-13.
Journal du mardi 18 juin 2024 à 09:24
A lightweight, framework-agnostic database migration tool.
Ce projet a commencé en 2015.
Je viens de voir dans mes notes que j'avais déjà regardé ce projet le 15 octobre 2023, donc ce n'est pas vraiment une découverte 🤣.
Il est codé en Golang, chose que j'apprécie pour ce genre d'outil.
Depuis septembre 2022, j'utilise l'outil de migration graphile-migrate. Avant cela j'utilisais Migrate.
Dans ce thread j'ai été surpris de voir ce commentaire :
I’ve always wondered why tools like this cannot become stateless. Most have an up and down action, but I haven’t seen one yet that can run a query to determine if a migration has been applied or not. Then no state tables/artifacts are needed.
Instead of one file with an up and down, there could be two files where each has a predicate and then an action, where the predicate would run to determine if the migration has been applied or not.
En quelques secondes, je pense être capable d'imaginer plusieurs scénarios — que je ne souhaite pas lister ici — pour lesquels son idée ne pourrait pas fonctionner 🤔.
Dimanche 16 juin 2024
Journal du dimanche 16 juin 2024 à 17:08
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
#JeMeDemande si la convention est de nommer les nodes au singulier ou au pluriel, par exemple Note ou Notes 🤔.
D'après cette documentation, je comprends que la convention semble être le singulier.
Jeudi 13 juin 2024
Journal du jeudi 13 juin 2024 à 10:48
Dans l'Œuvre de philosophie morale : Réflexions ou sentences et maximes morales.
« Notre défiance justifie la tromperie d’autrui » (source)
De La Rochefoucauld.
- Vauvenargues (p. 81) : « L’expérience justifie notre défiance ; mais rien ne peut justifier la tromperie. »
- Sénèque (épitre iii) : Multi fallere docuerunt, dum timent falli, et aliis jus peccandi suspicando fecerunt. « Plus d’un, en craignant qu’on ne le trompe, enseigne aux autres à le tromper, et par ses soupçons autorise le mal qu’on lui fait. »
- Charron (de la Sagesse, livre II, chapitre x) : « Il se faut bien garder de faire démonstration aulciuie de deffiance, quand bien elle y seroit et juslement, car c’est desplaire, voire offenser, et donner occasion de nous estre contraire. »
Autre citation :
« Il est plus honteux de se défier de ses amis que d’en être trompé. » (source)
Mardi 11 juin 2024
Journal du mardi 11 juin 2024 à 22:21
J'essaie d'utiliser lazygit.
Lundi 10 juin 2024
Journal du lundi 10 juin 2024 à 17:22
#JaiDécouvert cette puce AMD APU (from)
Journal du lundi 10 juin 2024 à 15:49
#JaiDécouvert ce #hardware qui semble spécialisé pour exécuter des Inference Engines https://coral.ai/products (from)
Samedi 8 juin 2024
Journal du samedi 08 juin 2024 à 17:08
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Alors que je travaille sur cette partie du projet, je relis la documentation de pg_dumpall et je constate à nouveau que cette commande ne supporte pas les différents formats de sortie que propose pg_dump 😡.
C'est pénible… du coup, j'ai enfin pris le temps de chercher si il existe une solution alternative et #JaiDécouvert pg_back :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
C'est parfait, c'est exactement ce que je cherche 👌.
Mais je découvre aussi les fonctionnalités suivantes :
- Pre-backup and post-backup hooks
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure or a remote host with SFTP
Conséquence : #JeMeDemande si j'ai encore besoin de restic dans Projet 7 🤔.
Je viens de lire ici :
In addition to the N previous backups, it would be nice to keep N' weekly backups and N'' monthly backups, to be able to look back into the far past.
C'est une fonctionnalité supporté par restic, donc pour le moment, je choisis de continuer à utiliser restic.
Pour le moment, #JaiDécidé d'intégrer simplement pg_back dans restic-pg_dump-docker en remplacement de pg_dumpall et de voir par la suite si je simplifie ce projet ou non.
Journal du samedi 08 juin 2024 à 17:04
#JeLis pour la première fois https://github.com/postgrespro/pg_probackup
J'ai en même temps découvert https://github.com/postgrespro/ptrack mais je n'ai pas pris le temps de bien comprendre son rôle.
Journal du samedi 08 juin 2024 à 11:38
Dans 2024-06-08_1056 j'ai listé la puissance en TOPS de NPU AMD.
Suite à cela, j'ai eu envie de comparer la puissance de ces NPU à des puces Apple et Intel ainsi qu'à des GPU de NVidia.
Concernant Apple
Ici je lis :
- M1, M1 Pro, M1 Max : NPU à 11 TOPS
- M1 Ultra : NPU à 22 TOPS
Ici je lis :
- M2, M2 Pro, M2 Max : NPU à 15,8 TOPS
- M2 Ultra : NPU à 31,6 TOPS
Ici je lis :
- M3, M3 Pro, M3 Max : NPU à 18 TOPS
Ici je lis :
- M4 (sortie en mai 2024) : NPU à 38 TOPS
Concernant AMD
Dans cet article je lis :
- Des puces de la série Ryzen 7040 intègrent des NPU à 10 TOPS
- Des puces de la série Ryzen 8000 intègrent des NPU à 16 TOPS
- Des puces de la série Ryzen AI 300 intègrent des NPU à 50 TOPS
Concernant Intel
J'ai l'impression que ce sont les puces Intel Core Ultra qui intègrent des NPU.
- Ici je lis :
For the Ultra 7 165H chip, you get roughly up to 34 TOPS with 11 TOPS for the NPU, 18 TOPS for the GPU and the rest for the CPU.
- Ici je lis que les prochaines puces de Intel basé sur l'architecture Lunar Lake intégre un NPU de 48 TOPS
Concernant Nvidia
Je ne sais pas si les TOPS d'un NPU sont comparables aux TOPS de GPU mais d'après ce document je lis qu'une puce Nvidia T4 :
- Single-Precision : 8.1 TFLOPS
- Mixed-Precision (FP16/FP32) : 65 TFLOPS
- INT8 : 130 TOPS
- INT4 : 260 TOPS
Conclusion
J'ai l'impression qu'ici les ratios de puissances en TOPS entre des NPU et GPU tournent autour de x5 et x30.
Journal du samedi 08 juin 2024 à 10:56
En lisant ceci :
AI accelerators are used in mobile devices, such as neural processing units (NPUs) in Apple iPhones, AMD Laptops or Huawei cellphones, and personal computers such as Apple silicon Macs, to cloud computing servers such as tensor processing units (TPU) in the Google Cloud Platform.
#JaiDécouvert que AMD XDNA semble être l'architecture des puces NPU de AMD.
Je lis ici que Ryzen AI est le nom commercial du matériel AMD qui implémente l'architecture XDNA.
La première puce qui intégrèe AMD XDNA est le Ryzen 7040 sorti 2023.
Dans cet article je lis :
- Des puces de la série Ryzen 7040 intègrent des NPU à 10 TOPS
- Des puces de la série Ryzen 8000 intègrent des NPU à 16 TOPS
- Des puces de la série Ryzen AI 300 intègrent des NPU à 50 TOPS
Journal du samedi 08 juin 2024 à 10:35
Dans 2024-06-06_1047 #JaiDécidé d'utiliser le terme Inference Engines pour définir la fonction ou la catégorie de Llama.cpp.
J'ai échangé avec un ami au sujet des NPU et j'ai dit que j'avais l'impression que ces puces sont spécialés pour exécuter des Inference Engines, c'est-à-dire, effectuer des calculs d'inférence à partir de modèles.
Après vérification, dans cet article je lis :
An AI accelerator, deep learning processor, or neural processing unit (NPU) is a class of specialized hardware accelerator or computer system designed to accelerate artificial intelligence and machine learning applications, including artificial neural networks and machine vision.
et je comprends que mon impression était fausse. Il semble que les NPU ne sont pas seulement dédiés aux opérations d'exécution d'inférence, mais semblent être optimisés aussi pour faire de l'entrainement 🤔.
Un ami me précise :
Inference Engines
Pour moi, c'est un terme très générique qui couvre tous les aspects du machine learning, du deep learning et des algorithmes type LLM mis en œuvre.
et il me partage l'article Wikipedia Inference engine que je n'avais pas lu quand j'avais rédigé 2024-06-06_1047, honte à moi 🫣.
Dans l'article Wikipedia Inference engine je lis :
In the field of artificial intelligence, an inference engine is a software component of an intelligent system that applies logical rules to the knowledge base to deduce new information.
et
Additionally, the concept of 'inference' has expanded to include the process through which trained neural networks generate predictions or decisions. In this context, an 'inference engine' could refer to the specific part of the system, or even the hardware, that executes these operations.
Je comprends qu'un Inference Engines n'effectue pas l'entrainement de modèles.
Pour éviter la confusion, #JaiDécidé d'utiliser à l'avenir le terme "Inference Engine (comme LLama.cpp)".
Le contenu de l'article Wikipedia Llama.cpp augmente mon niveau de confiance dans ce choix de vocabulaire :
llama.cpp is an open source software library written in C++, that performs inference on various Large Language Models such as Llama
Obsidian ne souhaite jamais croitre au-delà de 12 personnes
#OnMaPartagé au sujet de Obsidian : https://x.com/kepano/status/1694731713686196526
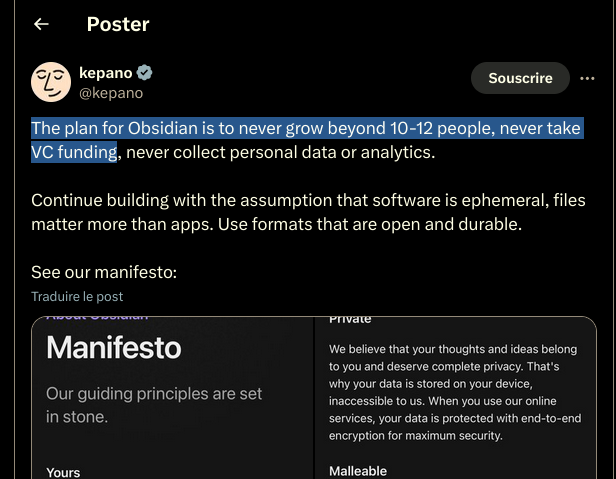
The plan for Obsidian is to never grow beyond 10-12 people, never take VC funding, never collect personal data or analytics.
#Jadore cela me fait penser à Basecamp.
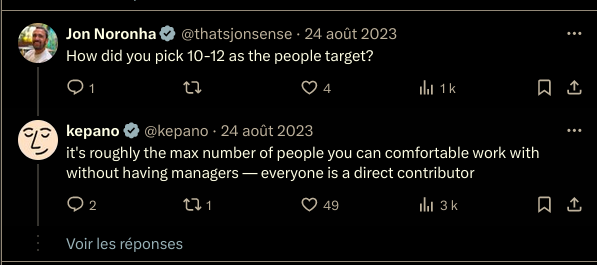
How did you pick 10-12 as the people target?
it's roughly the max number of people you can comfortable work with without having managers — everyone is a direct contributor
👍️👌
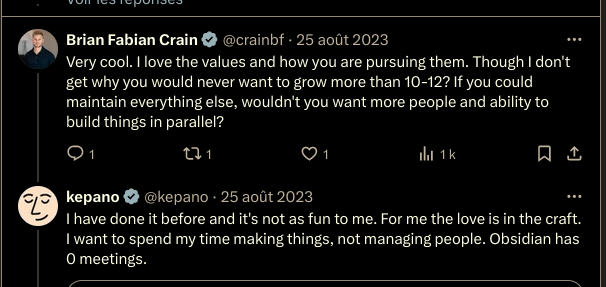
Though I don't get why you would never want to grow more than 10-12? If you could maintain everything else, wouldn't you want more people and ability to build things in parallel?
I have done it before and it's not as fun to me. For me the love is in the craft. I want to spend my time making things, not managing people. Obsidian has 0 meetings.
🙂
Vendredi 7 juin 2024
Journal du vendredi 07 juin 2024 à 17:12
Nouvelle #iteration sur Projet 7 - "Améliorer et mettre à jour le projet restic-pg_dump-docker".
Hasard du calendrier, mon ami Alexandre travaille en ce moment sur un projet nommé restic-ftp-docker.
Quelle différence avec restic-pg_dump-docker ?
Principale différence d'objectif entre ces deux projets :
restic-ftp-dockersauvegarde via restic le contenu d'un dossier vers un espace FTP.restic-pg_dump-dockersauvegarde via restic le contenu d'une base de données PostgreSQL. Le contenu de la base de données est exporté avec la commande standard pg_dump de PostgreSQL. La sauvegarde peut être envoyée vers tous les storages supportés par rclone.
#JaiDécidé de reprendre un maximum d'élément du projet restic-ftp-docker dans restic-pg_dump-docker.
#JeSouhaite proposer une Pull Request à restic-ftp-docker pour étendre ce projet à tous les storages supporté par rclone et ne plus le limité au storage ftp.
Jeudi 6 juin 2024
Journal du jeudi 06 juin 2024 à 22:57
#JeMeDemande quelles sont les différences entre les modèles qui terminent par "rien", par -instruct et par -chat.
This brings us to the heart of the innovation behind the wildly popular ChatGPT: it uses an enhancement of GPT3 that (besides having a lot more parameters), was explicitly fine-tuned on instructions (and dialogs more generally) -- this is referred to as instruction-fine-tuning or IFT for short. In addition to fine-tuning instructions/dialogs, the models behind ChatGPT (i.e., GPT-3.5-Turbo and GPT-4) are further tuned to produce responses that align with human preferences (i.e. produce responses that are more helpful and safe), using a procedure called Reinforcement Learning with Human Feedback (RLHF). (from)
Journal du jeudi 06 juin 2024 à 19:49
Suite à la lecture de Intel Unveils Lunar Lake Architecture #JaiLu l'article Wikipedia au sujet de NPU : https://en.wikipedia.org/wiki/AI_accelerator.
#JaiLu l'article Wikipedia au sujet des TPU de Google : https://en.wikipedia.org/wiki/Tensor_Processing_Unit
Il y a quelques jours, je me posais des questions au sujet du matériel spécialisé pour exécuter des Inference Engines. La page Puce d'accélération de réseaux de neurones est très intéressante à ce sujet.
Journal du jeudi 06 juin 2024 à 19:42
#OnMaPartagé Analyse • Lunar Lake, ou le x86 plus efficient que jamais, j'ai appris beaucoup de choses intéressantes 👌.
Sur le même sujet, voici le thread Hacker News : Intel Unveils Lunar Lake Architecture
Sujet : Lunar Lake
Journal du jeudi 06 juin 2024 à 18:41
Un ami vient de me partager https://fr.wikivoyage.org.
Je connais ce site depuis longtemps, mais je me souviens d'une histoire de rachat par une société commerciale qui avait tué le projet. Depuis, je ne l'utilisais plus.
Je viens de prendre le temps de rechercher des informations à ce sujet et voici ce que j'ai trouvé.
J'ai découvert Wikitravel en 2004 en même temps que Wiktionary et tous les autres projets de la fondation Wikimedia.
La société Internet Brands annonce l'acquisition de la marque Wikitravel et des serveurs qui hébergent le wiki, de même que World66 (world66.com), le 20 avril 2006 ; le projet devient donc commercial. Cette évolution a été décidée par les fondateurs de Wikitravel et non par la communauté des contributeurs du guide. Une conséquence directe de cette décision est le départ de la plupart des administrateurs et de certains auteurs de la section allemande, qui fondent le 10 décembre 2006 la section allemande d'un fork appelé Wikivoyage. Lors de ce branchement, l'intégralité des articles du Wikitravel allemand a été importée. (from)
Je me souviens donc de cette histoire.
À la mi-2012, la majorité de la communauté des éditeurs de Wikitravel a décidé de se réunir à nouveau avec Wikivoyage et proposé à la Wikimedia Foundation d'héberger le nouveau projet, sous le nom de Wikivoyage. Cette proposition a été acceptée en octobre 2012. (from)
J'avais loupé cet épisode.
Journal du jeudi 06 juin 2024 à 16:20
En travaillant sur 2024-06-06_1047 :
- #JaiDécouvert https://github.com/PABannier/bark.cpp - Suno AI's Bark model in C/C++ for fast text-to-speech (from)
- #JaiDécouvert https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from)
- #JaiLu au sujet de GGUF :
Hugging Face Hub supports all file formats, but has built-in features for GGUF format, a binary format that is optimized for quick loading and saving of models, making it highly efficient for inference purposes. GGUF is designed for use with GGML and other executors. GGUF was developed by @ggerganov who is also the developer of llama.cpp, a popular C/C++ LLM inference framework.
https://huggingface.co/docs/hub/gguf
- #JaiDécouvert llama : add pipeline parallelism support by slaren autrement dit « Multi-GPU pipeline parallelism support » (from)
- #JaiDécouvert https://github.com/ggerganov/whisper.cpp de Georgi Gerganov
- #JaiDécouvert https://github.com/ggerganov/llama.cpp/discussions/3471
- #JaiDécouvert la Merge Request d'ajout du support de ROCm Port : ROCm Port 1087 (from)
- #JaiDécouvert Basic Vim plugin for llama.cpp
- #JaiDécouvert https://github.com/rgerganov/ggtag par le même auteur que Llama.cpp, c'est-à-dire Georgi Gerganov
- #JaiDécouvert Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- #JaiDécouvert : d'après ce que j'ai compris la librairie ggml est le composant de base de Llama.cpp et Whisper.cpp
- #JaiDécouvert que Georgi Gerganov a lancé sa société nommée https://ggml.ai (from) et que celle-ci est financé entre autre part Nat Friedman ! Ha ha, encore lui 😍.
ggml.ai is a company founded by Georgi Gerganov to support the development of ggml. Nat Friedman and Daniel Gross provided the pre-seed funding.
We are currently seeking to hire full-time developers that share our vision and would like to help advance the idea of on-device inference. If you are interested and if you have already been a contributor to any of the related projects, please contact us at jobs@ggml.ai
- #JaiDécouvert Text-to-phoneme-to-speech https://twitter.com/ConcreteSciFi/status/1641166275446714368, j'adore 🙂
Déjeuner avec un ami sur le thème, auto-hébergement de LLMs
Cette semaine, j'ai déjeuné avec un ami dont les connaissances dans le domaine du #MachineLearning et des #llm dépassent largement les miennes... J'en ai profité pour lui poser de nombreuses questions.
Voici ci-dessous quelques notes de ce que j'ai retenu de notre discussion.
Avertissement : Le contenu de cette note reflète les informations que j'ai reçues pendant cette conversation. Je n'ai pas vérifié l'exactitude de ces informations, et elles pourraient ne pas être entièrement correctes. Le contenu de cette note est donc à considérer comme approximatif. N'hésitez pas à me contacter à contact@stephane-klein.info si vous constatez des erreurs.
Histoire de Llama.cpp ?
Question : quelle est l'histoire de Llama.cpp ? Comment ce projet se positionne dans l'écosystème ?
D'après ce que j'ai compris, début 2023, PyTorch était la solution "mainstream" (la seule ?) pour effectuer de l'inférence sur le modèle LLaMa — sortie en février 2023.
PyTorch — écrit en Python et C++ — est optimisée pour les GPU, plus précisément pour le framework CUDA.
PyTorch est n'est pas optimisé pour l'exécution sur CPU, ce n'est pas son objectif.
Georgi Gerganov a créé Llama.cpp pour pouvoir effectuer de l'inférence sur le modèle LLaMa sur du CPU d'une manière optimisé. Contrairement à PyTorch, plus de Python et des optimisations pour Apple Silicon, utilisation des instructions AVX / AVX2 sur les CPU x86… Par la suite, « la boucle a été bouclée » avec l'ajout du support GPU en avril 2023.
À la question « Maintenant que Llama.cpp a un support GPU, à quoi sert PyTorch ? », la réponse est : PyTorch permet beaucoup d'autres choses, comme entraîner des modèles…
Aperçu de l'historique du projet :
- 18 septembre 2022 : Georgi Gerganov commence la librairie ggml, sur laquelle seront construits Llama.cpp et Whisper.cpp.
- 4 mars 2023 : Georgi Gerganov a publié le premier commit de llama.cpp.
- 10 mars 2023 : je crois que c'est le premier poste Twitter de publication de Llama.cpp https://twitter.com/ggerganov/status/1634282694208114690.
- 13 mars 2023 : premier post à propos de LLama.cpp sur Hacker News qui fait zéro commentaire - Llama.cpp can run on Macs that have 64G of RAM (40GB of Free memory).
- 14 mars 2023 : second poste, toujours zéro commentaire - Run a GPT-3 style AI on your local machine, fully on premise.
- 31 mars 2023 : premier thread sur Llama.cpp qui fait le buzz avec 414 commentaires - Llama.cpp 30B runs with only 6GB of RAM now.
- 12 avril 2023 : d'après ce que je comprends, voici la Merge Request d'ajout du support GPU à Llama.cpp # Add GPU support to ggml (from).
- 6 juin 2023 : Georgi Gerganov lance sa société nommée https://ggml.ai (from) .
- 10 juillet 2023 : Distributed inference via MPI - Model inference is currently limited by the memory on a single node. Using MPI, we can distribute models across a locally networked cluster of machines.
- 24 juillet 2023 : llama : add support for llama2.c models (from).
- 25 août 2023 : ajout du support ROCm (AMD).
Comment nommer Llama.cpp ?
Question : quel est le nom d'un outil comme Llama.cpp ?
Réponse : Je n'ai pas eu de réponse univoque à cette question.
C'est un outil qui effectue des inférences sur un modèle.
Voici quelques idées de nom :
- Moteur d'inférence (Inference Engines) ;
- Exécuteur d'inférence (Inference runtime) ;
- Bibliothèque d'inférence.
Personnellement, #JaiDécidé d'utiliser le terme Inference Engines.
Autre projet comme Llama.cpp ?
Question : Existe-t-il un autre projet comme Llama.cpp
Oui, il existe d'autres projets, comme llm - Large Language Models for Everyone, in Rust. Article Hacker News publié le 14 mars 2023 sous le nom LLaMA-rs: a Rust port of llama.cpp for fast LLaMA inference on CPU.
Et aussi, https://github.com/karpathy/llm.c - LLM training in simple, raw C/CUDA (from).
Le README de ce projet liste de nombreuses autres implémentations de Inference Engines.
Mais, à ce jour, Llama.cpp semble être l'Inference Engines le plus complet et celui qui fait consensus.
GPU vs CPU
Question : Jai l'impression qu'il est possible de compiler des programmes généralistes sur GPU, dans ce cas, pourquoi ne pas remplacer les CPU par des GPU ? Pourquoi ne pas tout exécuter par des GPU ?
Mon ami n'a pas eu une réponse non équivoque à cette question. Il m'a répondu que l'intérêt du CPU reste sans doute sa faible consommation énergique par rapport au GPU.
Après ce déjeuner, j'ai fait des recherches et je suis tombé sur l'article Wikipedia nommé General-purpose computing on graphics processing units (je suis tombé dessus via l'article ROCm).
Cet article contient une section nommée GPU vs. CPU, mais qui ne répond pas à mes questions à ce sujet 🤷♂️.
ROCm ?
Question : J'ai du mal à comprendre ROCm, j'ai l'impression que cela apporte le support du framework CUDA sur AMD, c'est bien cela ?
Réponse : oui.
J'ai ensuite lu ici :
HIPIFY is a source-to-source compiling tool. It translates CUDA to HIP and reverse, either using a Clang-based tool, or a sed-like Perl script.
RAG ?
Question : comment setup facilement un RAG ?
Réponse : regarde llama_index.
#JaiDécouvert ensuite https://github.com/abetlen/llama-cpp-python
Simple Python bindings for @ggerganov's llama.cpp library. This package provides:
- Low-level access to C API via ctypes interface.
- High-level Python API for text completion
- OpenAI-like API
- LangChain compatibility
- LlamaIndex compatibility
- ...
dottextai / outlines
Il m'a partagé le projet https://github.com/outlines-dev/outlines alias dottxtai, pour le moment, je ne sais pas trop à quoi ça sert, mais je pense que c'est intéressant.
Embedding ?
Question : Thibault Neveu parle souvent d'embedding dans ses vidéos et j'ai du mal à comprendre concrètement ce que c'est, tu peux m'expliquer ?
Le vrai terme est Word embedding et d'après ce que j'ai compris, en simplifiant, je dirais que c'est le résultat d'une "sérialisation" de mots ou de textes.
#JaiDécouvert ensuite l'article Word Embeddings in NLP: An Introduction (from) que j'ai survolé. #JaimeraisUnJour prendre le temps de le lire avec attention.
Transformers ?
Question : et maintenant, peux-tu me vulgariser le concept de transformer ?
Réponse : non, je t'invite à lire l'article Natural Language Processing: the age of Transformers.
Entrainement décentralisé ?
Question : existe-t-il un système communautaire pour permettre de générer des modèles de manière décentralisée ?
Réponse - Oui, voici quelques liens :
- BigScience Research Workshop/
- Distributed Deep Learning in Open Collaborations
- Deep Learning over the Internet: Training Language Models Collaboratively
Au passage, j'ai ajouté https://huggingface.co/blog/ à mon agrégateur RSS (miniflux).
La suite…
Nous avons parlé de nombreux autres sujets sur cette thématique, mais j'ai décidé de m'arrêter là pour cette note et de la publier. Peut-être que je publierai la suite un autre jour 🤷♂️.
Mercredi 5 juin 2024
Journal du mercredi 05 juin 2024 à 14:42
#JaimeraisUnJour suivre le tutoriel https://github.com/srush/GPU-Puzzles - Solve puzzles. Learn #CUDA.
#GPU architectures are critical to machine learning, and seem to be becoming even more important every day. However, you can be an expert in machine learning without ever touching GPU code. It is hard to gain intuition working through abstractions.
Journal du mercredi 05 juin 2024 à 11:29
#JeMeDemande s'il existe un meilleur moteur de recherche que https://www.postgresql.org/search/?u=%2Fdocs%2F16%2F&q=on+conflict 🤔.
J'ai fait quelques recherches, pour le moment, je n'ai rien trouvé 😟.
Lundi 3 juin 2024
Journal du lundi 03 juin 2024 à 17:39
#JaiLu la page https://liquidex.house/programming/languages/lua (from) et au passage #JaiDécouvert le site perso https://liquidex.house/ que je trouve très intéressant dans sa forme.
Journal du lundi 03 juin 2024 à 15:28
#OnMaPartagé que le projet https://github.com/dylanaraps/pure-bash-bible est archivé 😥.
Je constate que l'auteur — dylanaraps — de "pure bash bible" a aussi archivé https://github.com/dylanaraps/neofetch.
Je me souviens d'avoir lu le thread Neofetch development discontinued, repository archived il y a quelques jours.
Vendredi 31 mai 2024
Journal du vendredi 31 mai 2024 à 20:02
J'ai commencé à écouter « Votre mission ? Découvrir Haskell et le mettre en prod - Céline Louvet » parce que je ne comprends rien à Haskell. Je ne vois pas ce que ce langage peut m'apporter. Je ne vois pas sa puissance, mais comme beaucoup de bons codeurs adorent Haskellet les langages fonctionnels, je suis presque certain que je passe à côté de quelque chose de très puissant.
Dans cette vidéo, Céline Louvet dit qu'elle est la première dev, la seule dev de sa startup et se lance avec un langage qu'elle ne maîtrise pas et que très peu de développeurs maîtrisent.
Je trouve qu'elle est très audacieuse !
Cette vidéo date de 2019, j'ai regardé son LinkedIn et je constate que l'expérience a tourné court. Peut-être pour plein de raisons non liées à Haskell. Et depuis je constate qu'elle n'a plus fait de Haskell 🤔.
Lecture active de l'article « LLM auto-hébergés ou non : mon expérience » de LinuxFr
#JaiLu l'article "LLM auto-hébergés ou non : mon expérience - LinuxFr.org" https://linuxfr.org/users/jobpilot/journaux/llm-auto-heberges-ou-non-mon-experience.
Cependant, une question cruciale se pose rapidement : faut-il les auto-héberger ou les utiliser via des services en ligne ? Dans cet article, je partage mon expérience sur ce sujet.
Je me suis plus ou moins posé cette question il y a 15 jours dans la note suivante : 2024-05-17_1257.
Ces modèles peuvent également tourner localement si vous avez un bon GPU avec suffisamment de mémoire (32 Go, voire 16 Go pour certains modèles quantifiés sur 2 bits). Ils sont plus intelligents que les petits modèles, mais moins que les grands. Dans mon expérience, ils suffisent dans 95% des cas pour l'aide au codage et 100% pour la traduction ou la correction de texte.
Intéressant comme retour d'expérience.
L'auto-hébergement peut se faire de manière complète (frontend et backend) ou hybride (frontend auto-hébergé et inférence sur un endpoint distant). Pour le frontend, j'utilise deux containers Docker chez moi : Chat UI de Hugging Face et Open Webui.
Je pense qu'il parle de :
Je suis impressionné par la taille de la liste des features de Open WebUI
J'ai acheté d'occasion un ordinateur Dell Precision 5820 avec 32 Go de RAM, un CPU Xeon W-2125, une alimentation de 900W et deux cartes NVIDIA Quadro P5000 de 16 Go de RAM chacune, pour un total de 646 CHF.
#JeMeDemande comment se situe la carte graphique NVIDIA Quadro P5000 sur le marché 🤔.
J'ai installé Ubuntu Server 22.4 avec Docker et les pilotes NVIDIA. Ma machine dispose donc de 32 Go de RAM GPU utilisables pour l'inférence. J'utilise Ollama, réparti sur les deux cartes, et Mistral 8x7b quantifié sur 4 bits (2 bits sur une seule carte, mais l'inférence est deux fois plus lente). En inférence, je fais environ 24 tokens/seconde. Le chargement initial du modèle (24 Go) prend un peu de temps. J'ai également essayé LLaMA 3 70b quantifié sur 2 bits, mais c'est très lent (3 tokens/seconde).
Benchmark intéressant.
En inférence, la consommation monte à environ 420W, soit une puissance supplémentaire de 200W. Sur 24h, cela représente une consommation de 6,19 kWh, soit un coût de 1,61 CHF/jour.
Soit environ 1,63 € par jour.
Together AI est une société américaine qui offre un crédit de 25$ à l'ouverture d'un compte. Les prix sont les suivants :
- Mistral 8x7b : 0,60$/million de tokens
- LLaMA 3 70b : 0,90$/million de tokens
- Mistral 8x22b : 1,20$/million de tokens
#JaiDécouvert https://www.together.ai/pricing
Comparaison avec les prix de OpenIA API :

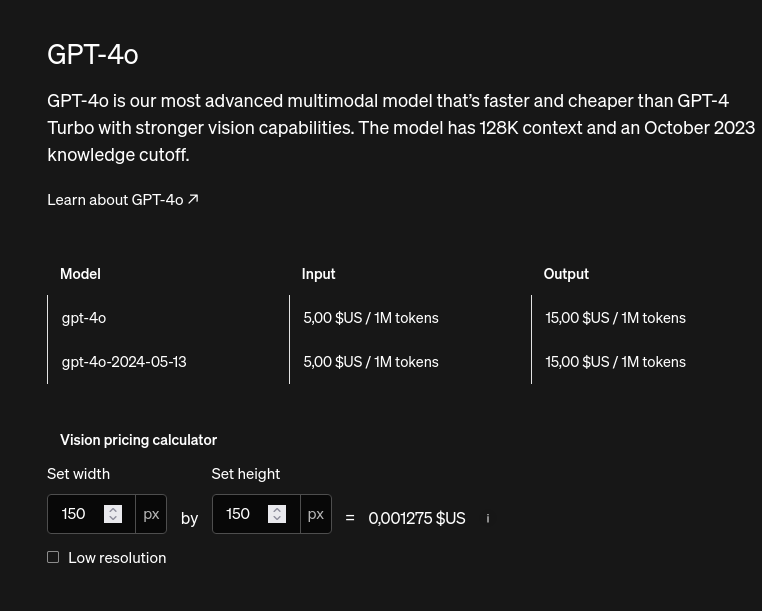
#JeMeDemande si l'unité tokens est comparable entre les modèles 🤔.
[ << Notes plus récentes (806) ] | [ Notes plus anciennes (856) >> ]