
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (856) ] [ Notes plus anciennes (124) >> ]
Vendredi 31 mai 2024
Journal du vendredi 31 mai 2024 à 15:24
À la fin de l'épisode Et si Shape Up avait raison de faire des pauses ? de Scrum Life #JaiDécouvert le néologisme one piece flow où une équipe travaille sur un problème à la fois, tout ensemble.
Jeudi 30 mai 2024
Journal du jeudi 30 mai 2024 à 15:42
Je viens de finir l'écoute de le l'épisode "Le détournement de fonds qui traumatise la tech française - Nicolas Colin - The Family". J'ai trouvé cela intéressant.
Journal du jeudi 30 mai 2024 à 11:40
#OnMaPartagé https://github.com/quickwit-oss/tantivy is a Full-text search engine #library inspired by Apache Lucene and written in Rust.
Mardi 28 mai 2024
Journal du mardi 28 mai 2024 à 12:29
Sur gwern.net #JaiDécouvert :
- Tests de lisibilité Flesch-Kincaid (from) ( #PasEncoreLu ).
- proselint, je l'avais déjà croisé mais je l'avais oublié. #JeMeDemande si il est possible de supporter le français 🤔 (from).
- Loi de Benford (from) ( #PasEncoreLu )
Journal du mardi 28 mai 2024 à 11:37
Au sujet de règle de platine, un ami vient de me dire :
Est-ce que tu dois appliquer la règle de platine ou / et la règle d'or avec les personnes qui ne veulent pas l'appliquer ?
Je trouve que c'est une très bonne question dont je n'ai pas la réponse.
Première idée qui me vient à l'esprit : est-ce qu'une réponse à ce problème serait d'organiser une discussion en tête-à-tête au début de la collaboration avec une personne afin de se mettre d'accord sur protocole de travail, dans le même esprit que The Core Protocols.
Lors de cette discussion, l'objectif serait que les deux personnes se mettent d'accord pour utiliser soit la la règle d'or soit la règle de platine soit aucune des deux — dans ce cas de figure, je pense que la relation est mal partie 😉.
#JeMePoseLaQuestion de comment organiser cela sans passer pour un ovni 🤔.
Journal du mardi 28 mai 2024 à 11:27
Ce matin #JaiDécouvert le site site perso gwern.net ( #blog ) et je déclare que « #Jadore ce site » !
J'aime le fond, la forme, l'attention aux détails, la rationalisation des décisions… 👌.
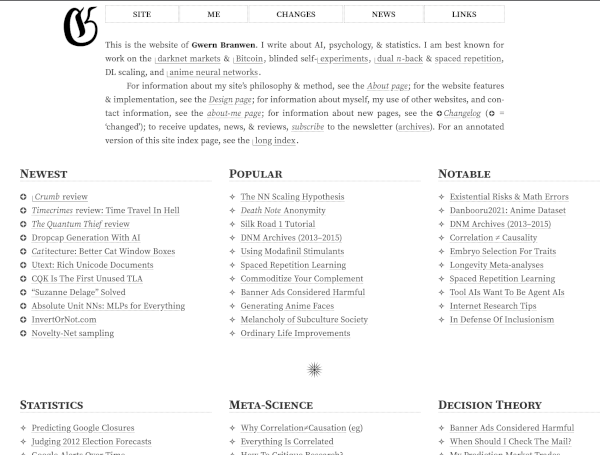
Voici quelques exemples de choses que j'apprécie.
Par exemple, sur la page https://gwern.net/about :

a.Je pense que cela signifie que l'article a été commencé en 2010 et a évolué jusqu'en 2022.b.Je trouve cela très simple pour indiquer que la page n'est plus en work in progress.
Je me suis souvent demandé comment je pouvais gérer mes notes mutables. Je considère qu'un article daté se doit être autant que possible immutable.
J'aime ces choix UX a et b pour indiquer ces informations au lecteur.
c.J'adore ❤️, ce tag permet d'indiquer le niveau de credence de l'article, c'est une version de marqueur de modestie épistémique.
#JeSouhaite m'inspirer des éléments UX a, b et c pour mon site sklein.xyz.
mention any use of Fermi estimates in Fermi calculations (from)
J'adore 🙂.
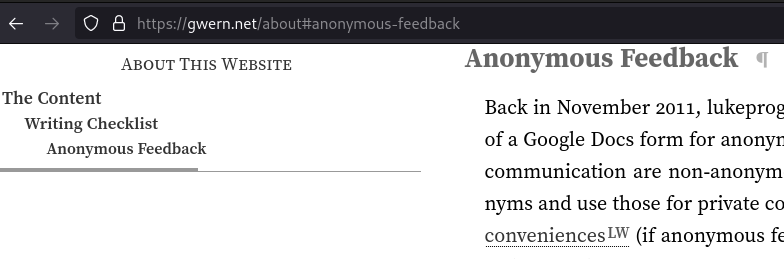
J'adore cette UX d'affichage de breadcrumb pour la raison suivante : les breadcrumb sont généralement affichés sur une ligne, ce qui pose souvent un problème pour les longs titres.
Ici l'affichage sur plusieurs lignes règle ce problème et transmet bien l'idée de hiérarchie 👌.
Il y a tant de bonnes choses à dire sur ce site, mais je m'arrête là pour cette note.
Lundi 27 mai 2024
Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo
Je vous partage une réflexion que je viens d'avoir.
- Je constate que j'utilise de plus en plus ChatGPT à la place de DuckDuckGo (mon moteur de recherche actuel).
- Je commence souvent par dégrossir une question avec ChatGPT, puis j'utilise mon moteur de recherche pour vérifier l'information avec une source que je juge "fiable".
- À d'autres moments, je préfère un article Wikipédia ou une documentation de référence plus exhaustive ou structurée — question d'habitude, sans doute — que la réponse de ChatGPT.
Suite à cela, je me suis dit que Google doit très rapidement revoir ses produits. Sinon, il est fort probable que Google perde énormément de revenus.
Je me suis ensuite demandé à quoi pourrait ressembler un produit Google basé sur un LLM qui remplacerait totalement ou en partie Google Search. Là, j'ai pensé directement à l'intégration de publicité à l'intérieur des réponses du LLM de Google 😱.
- Les publicités pourraient être intégrées de manière subtile sous forme de conseil dans les réponses.
- Je ne pourrais plus utiliser de bloqueurs de publicité comme uBlock Origin 😟.
- La situation pourrait être encore pire : Google pourrait se faire financer par des États, des grandes entreprises ou des milliardaires pour nous influencer légèrement via les réponses du LLM.
Je pense plus que jamais qu'il est important pour l'avenir de construire des modèles #open-source, auditables et reproductibles.
Dimanche 26 mai 2024
Journal du dimanche 26 mai 2024 à 23:06
Le 1er octobre 2023, on m'a demandé pourquoi j'utilisais neo-tree.nvim plutôt que nvim-tree.lua.
En été 2022, je pense avoir choisi neo-tree.nvim après avoir lu ce commentaire :
After adding soo many "nvim-tree does it" enhancements, I think it has all the features that nvim-tree has at this point, plus some more that nvim-tree doesn't have. (from)
Sur le GitHub officiel le neo-tree.nvim, je lis :
Why?
There are many tree plugins for (neo)vim, so why make another one? Well, I wanted something that was:
- Easy to maintain and enhance.
- Stable.
- Easy to customize.
Easy to maintain and enhance
This plugin is designed to grow and be flexible. This is accomplished by making the code as decoupled and functional as possible. Hopefully new contributors will find it easy to work with.
One big difference between this plugin and the ones that came before it, which is also what finally pushed me over the edge into making a new plugin, is that we now have libraries to build upon that did not exist when other tree plugins were created. Most notably, nui.nvim and plenary.nvm. Building upon shared libraries will go a long way in making neo-tree easy to maintain.
En lisant ces paragraphes, je pense comprendre que neo-tree.nvim a été créé après et en s'inspirant de nvim-tree.lua. Je suppose qu'il est plus moderne 🤔.
En 2022 une discussion a eu lieu pour merger les plugins neo-tree.nvim et nvim-tree.lua, les échanges entre les auteurs étaient chaleureux et constructif. Après beaucoup d'hésitation, la fusion ne s'est pas faite.
Le créateur de neo-tree.nvim explique dans une issue nvim-tree.lua pourquoi il a créé neo-tree.nvim.
L'auteur de nvim-tree.lua dit :
neo-tree as you said is more modular, leaning towards power users. (from)
Je lis ici :
NvimTree is faster (if performance matters to you...)
et ici
I've used nvim-tree for years and switched to neo-tree a while ago to try it out. At first I thought the buffers and git feature are cool, but then I barely used them, because I already have lazygit and telescope for that. Also neo-tree is considerably slower and was quite buggy for me. So I switched back to nvim-tree, honestly think it's just better.
Après avoir comparé la documentation de neo-tree.nvim avec celle de nvim-tree.lua, je constate :
- Les deux plugins supportent un mode "netrw or vinegar".
- Les deux plugins supportent un mode "floating window".
- neo-tree.nvim propose une fonctionnalité de fuzzy_finder que je n'ai pas trouvée dans nvim-tree.lua.
- J'ai une petite préférence pour les choix de key mapping de neo-tree.nvim mais c'est un avis subjectif, sans doute basé sur mon habitude.
En conclusion, je pense qu'il n'y pas d'argument frappant en faveur de l'un de ces deux plugins.
Journal du dimanche 26 mai 2024 à 10:52
Quand je travaille sur le refactoring de ma configuration Neovim, par exemple un passage de packer.nvim à lazy.nvim, je souhaite absolument éviter de perturber mon instance Neovim courante — que je qualifie de stable.
Pour cela, j'ai cherché des solutions pour lancer plusieurs instances de Neovim.
Mon point de départ dans cette quête était trop ambitieux : je souhaitais mettre en place un environemment de travail pour tester la globalité de mes dotfiles basé sur chezmoi.
J'ai explorer les pistes suivantes :
- Travailler dans la session d'un autre utilisateur Unix : je trouve cela vraiment pas pratique.
- J'ai testé une méthode basé sur Distrobox.
- J'ai testé une méthode basé sur Docker.
Finalement, si je me limite à un travail sur ma configuration Neovim, j'ai trouvé la solution suivante minimaliste pour lancer une instance de Neovim cloisonée :
$ export XDG_CONFIG_HOME=$PWD/config/
$ export XDG_DATA_HOME=$PWD/share/
$ nvim
Pour rendre mon quotidien plus agréable, j'exécute ce script ./start_sandboxed_neovim.sh — qui intègre ces instructions.
Je n'utilise pas direnv dans cet environnement de travail parce que je souhaite continuer à pouvoir éditer les fichiers de configuration avec mon instance de Neovim "stable".
En pratique, j'ouvre deux panels tmux verticaux, à gauche j'édite la configuration avec mon instance Neovim stable et à droite je lance l'instance Neovim cloisonée.
Vendredi 24 mai 2024
Journal du vendredi 24 mai 2024 à 16:05
#Jessaie d'utiliser l'instance https://searx.ox2.fr/ du meta moteur de recherche SearXNG.
Journal du vendredi 24 mai 2024 à 13:32
Cela fait depuis décembre 2023 que je souhaite traduire l'article The Platinum Rule de Shawn Wang (dit swyx), c'est chose faite :
Voici la Traduction de "The Platinum Rule" 🙂.
Pourquoi avoir traduit cet article ?
Parce que quand je l'ai lu, il m'a fait beaucoup réfléchir parce que j'ai réalisé que j'ai été depuis tout petit très conditionné par la règle d'or. J'essayais au maximum de la respecter et j'imaginais que si tout le monde la respectait, tout irait pour le mieux… mais avant de lire cet article, c'est bête à dire, mais je n'avais pas réalisé qu'en pratique, cela ne fonctionnait pas.
En lisant cet article, je pense qu'il est bon de garder à l'esprit que Shawn Wang (dit swyx) est un développeur et je pense qu'il a écrit cet article en rapport à des difficultés de travailler en équipe sur des projets de développement.
Pensez, par exemple, aux conventions de coding style et à bien d'autre sujets !
N'hésitez pas à venir échanger avec moi pour me partager votre avis sur le sujet, cela m'intéresse 🙂.
Journal du vendredi 24 mai 2024 à 11:56
Je viens de découvrir l'existence de l'article Wikipedia Redécentralisation d'Internet : https://fr.wikipedia.org/wiki/Redécentralisation_d'Internet
À noter que ce n'est pas une nouvelle idée pour moi, car je suis sensibilisé à ce sujet depuis le milieu des années 2000.
#JeSuisPrescripteur : En tant que prescripteur et soutien — non extrémiste — de ce principe, je suis favorable à une augmentation de la décentralisation d' #Internet.
Journal du vendredi 24 mai 2024 à 11:01
#JaiDécouvert La loi du Ripolin :
En 1925, l’architecte Le Corbusier publie L’Art décoratif d’aujourd’hui, ouvrage dans lequel il développe une Loi du Ripolin qui établit un parallèle entre le nettoyage des murs et celle de l’esprit. Passer une couche de blanc sur ses murs serait, pour lui, une opération de renouveau à la fois concret et moral. Cette loi lui permet également de donner sa définition de l’art. (from)
#JaimeraisUnJour lire Le Corbusier, L’Art décoratif d’aujourd’hui et « la loi du ripolin »
Un ami me fait découvrir "ripoliner" dans le sens suivant :
(Sens figuré) Farder, masquer, rafraîchir une image politique.
Journal du vendredi 24 mai 2024 à 10:56
Sur cette page : L’industrie française du meuble face à la concurrence européenne et chinoise je lis :
En 2018, la production française de meubles représente 6 % de la production de l’Union européenne à 28 pays (UE). La France occupe le cinquième rang, après l’Allemagne (21 %), l’Italie (20 %), la Pologne (15 %) et le Royaume-Uni (9 %). Avec la France et l’Espagne (6 % chacun), ces pays se partagent 80 % de la production européenne.
Une balance commerciale largement déficitaire
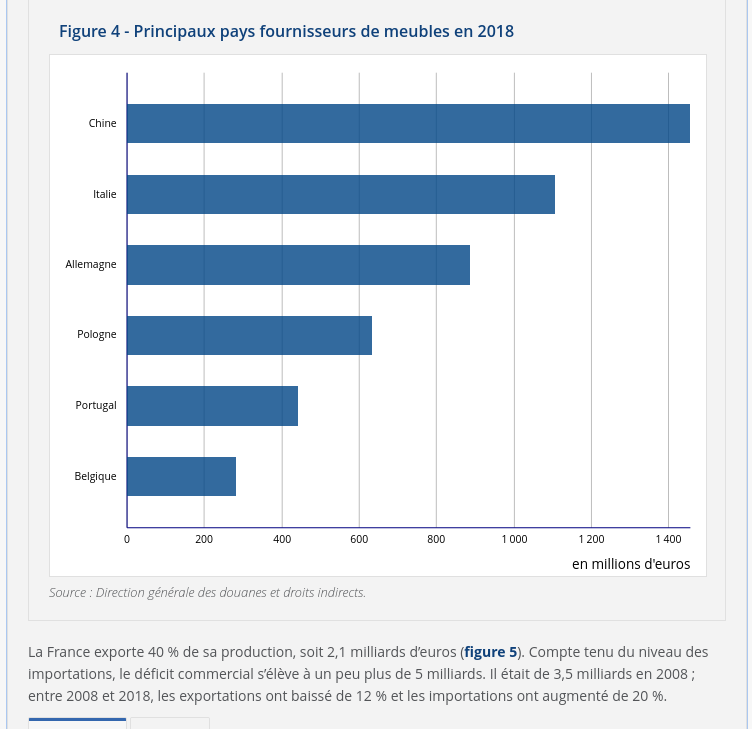
Journal du vendredi 24 mai 2024 à 10:36
Quand j'observe des phénomènes sociaux, par exemple, les chiffres de ventes de meubles de détail en France présentés ci-dessous, je suis toujours émerveillé par la régularité des cycles.
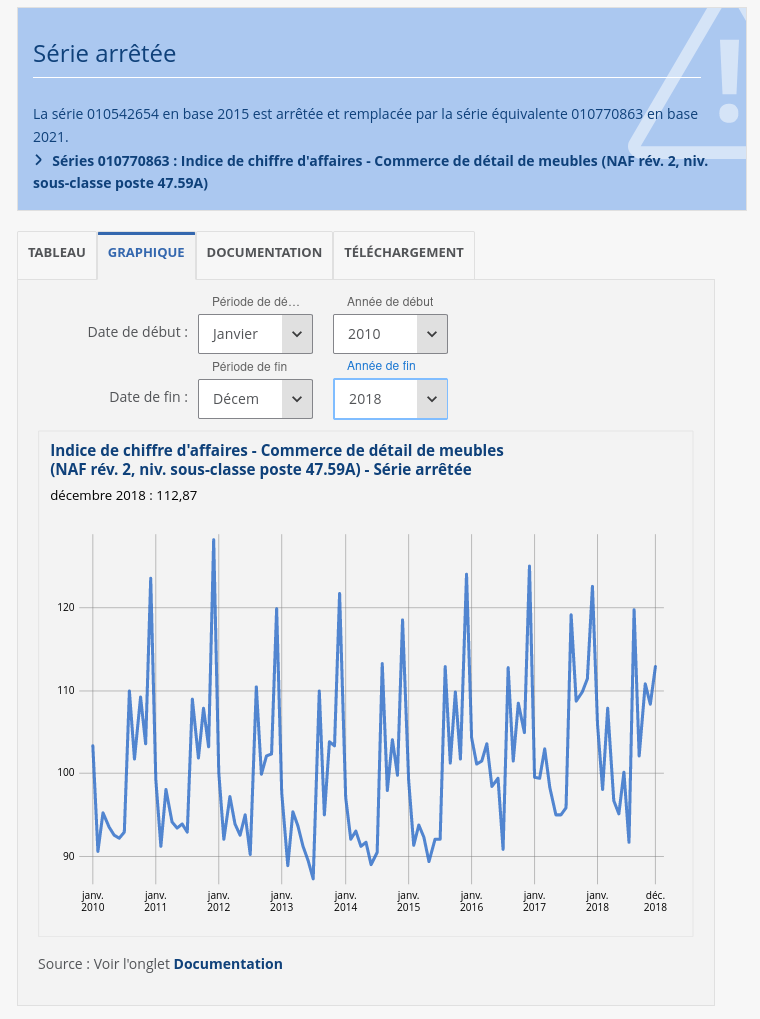
(Source)
Cela me fait penser à la Loi de Poisson ou à la Loi de Bernoulli qui sont dans mon esprit contre-intuitives. J'ai des difficultés à réaliser que l'univers dans lequel je vis est autant déterminé 🤔.
Jeudi 23 mai 2024
Journal du jeudi 23 mai 2024 à 21:55
#JeSouhaite tester le plugin Neovim https://github.com/nvim-telescope/telescope-file-browser.nvim.
Journal du jeudi 23 mai 2024 à 21:49
#JeMeDemande comment sous Neovim, je peux lister avec telescope l'historique de mes recherches live_grep_args.live_grep_args 🤔.
22:10 : J'ai trouvé ceci https://github.com/nvim-telescope/telescope.nvim/blob/5665d93988acfbb0747bdbf4f4cb583bcebc8930/lua/telescope/actions/history.lua#L11 mais je ne sais pas encore comment l'utiliser.
22:12 : Je vais essayer https://github.com/nvim-telescope/telescope-live-grep-args.nvim/issues/33
Commit : https://github.com/stephane-klein/dotfiles/commit/c36515c5055a31ecc51e9f08ab02cdb8acdaac69
Journal du jeudi 23 mai 2024 à 21:39
#OnMaPartagé https://www.ubicloud.com
Ubicloud offers infrastructure-as-a-service (IaaS) features on providers that lease bare metal instances, such as Hetzner, OVH, and AWS Bare Metal. It’s also available as a managed service.
Journal du jeudi 23 mai 2024 à 10:08
#idée de Projets : #JeMeDemande quelles méthodes utiliser pour implémenter un éditeur web de type texte à trous basé sur les librairies CodeMirror et ProseMirror.
Voici les premiers résultats de recherche que j'ai trouvés.
Pour ProseMirror, j'ai trouvé ceci :
Pour CodeMirror, j'ai trouvé ceci :
#JeMeDemande quelles sont les forces et faiblesses des deux idées d'implémentations suivantes :
a.Texte à trous implémenté par une seule instance d'éditeur CodeMirror/ProseMirror.b.Plusieurs instances d'éditeur CodeMirror/ProseMirror dans une page HTML. Dans cette implémentation les éléments en readonly ne seraient pas présents dans l'éditeur, mais seraientt de simples composants HTML de la page.
Mercredi 22 mai 2024
Journal du mercredi 22 mai 2024 à 12:45
On me demande où j'en suis dans mon expérience notes.sklein.xyz ?
Comment il est déployé ? Pour le moment, d'une manière très minimaliste et assez manuelle comme décrit ici : https://github.com/stephane-klein/obsidian-quartz-playground/tree/main/deployment
Aujourd'hui c'est toujours le cas. Quand je veux déployer je lance le script deployment/scripts/build-and-push.sh.
Je disais aussi :
Est-ce que j'en suis satisfait ? Pour le moment, la réponse est non, parce que je ne le maitrise pas assez.
Je ne suis toujours pas satisfait du rendu de notes.sklein.xyz mais je suis satisfait de l'expérience car j'arrive à produire et partager du contenu facilement.
Pour le moment, je pense que produire du contenu est plus important que de soigner le rendu. Le jour où j'aurai beaucoup de contenu, une amélioration de la forme, de la navigation et des fonctionnalités aura alors plus de valeur pour moi.
Je disais aussi :
J'ai une grande envie d'implémenter une version personnelle basée sur SvelteKit et Apache Age, mais j'essaie de ne pas tomber dans ce Yak!.
Suite à cela, j'ai créé Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et j'ai seulement travailé un tout petit peu sur cette expérience.
#JaimeraisUnJour un jour setup un RAG sur notes.sklein.xyz.
Est-ce que je suis satisfait du client Obsidian ? Je réponds que parfois oui, parfois non. Il m'agace par moments, et j'aimerais prendre le temps de "parfaitement configurer" Obsidian.nvim.
Journal du mercredi 22 mai 2024 à 11:57
Alexandre vient de me donner le conseil Bash suivant.
De remplacer mon usage de :
set -e`
par :
set -euo pipefail
e=> Arrête l'exécution à la première erreuru=> Génère une erreur si une variable n'est pas définie (il faut mettre des valeurs par défaut aux variables d'env)o pipefail=> Renvoie une erreur si une commande dans un pipe échoue
Je lui dit merci 🙂.
Journal du mercredi 22 mai 2024 à 11:33
J'ai rapidement parcouru l'article "What UI density means and how to design for it" ainsi que les discussions sur HackerNews et Lobsters.
#JePense : En tant que utilisateur hacker, je suis attristé de constater — ce n'est qu'une impression — que les UI des applications mainstream semblent de plus en plus appauvries en termes de densité d'information. Mon propos concerne spécifiquement les applications desktop ; les applications smartphone ont d'autres contraintes, notamment la sélection avec le doigt.
#JeMeDemande si les contraintes des interfaces utilisateur en mode texte (TUI) permettent généralement une densité d'information plus élevée 🤔.
J'ai partagé cette réflexion dans ces deux commentaires : HackerNews et Lobsters
Journal du mercredi 22 mai 2024 à 10:33
Je viens de finir Projet 6 - "SvelteFlow playground", voici un screencast de démonstration du résultat :
J'ai passé 5h27 sur ce projet.
Code source de ce projet https://github.com/stephane-klein/svelteflow-playground
Ma plus grosse difficulté a été de trouver comment implémenter les containtes liaison.
Pour le moment, je doute que mon implémentation respecte les bonnes pratiques d'utilisation de la librairie. Je pense que je vais découvrir le "bon" usage — tel que imaginé par Moritz Klack — de la librarie au fur et à mesure de mon utilisation.
Mardi 21 mai 2024
Journal du mardi 21 mai 2024 à 23:09
Dans la page suivante Elkjs Tree – Svelte Flow #JaiDécouvert la librarie Javascript elkjs :
ELK's layout algorithms for JavaScript
Journal du mardi 21 mai 2024 à 16:22
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
17:00 : J'ai réussi à ajouter un CustomNode (commit).
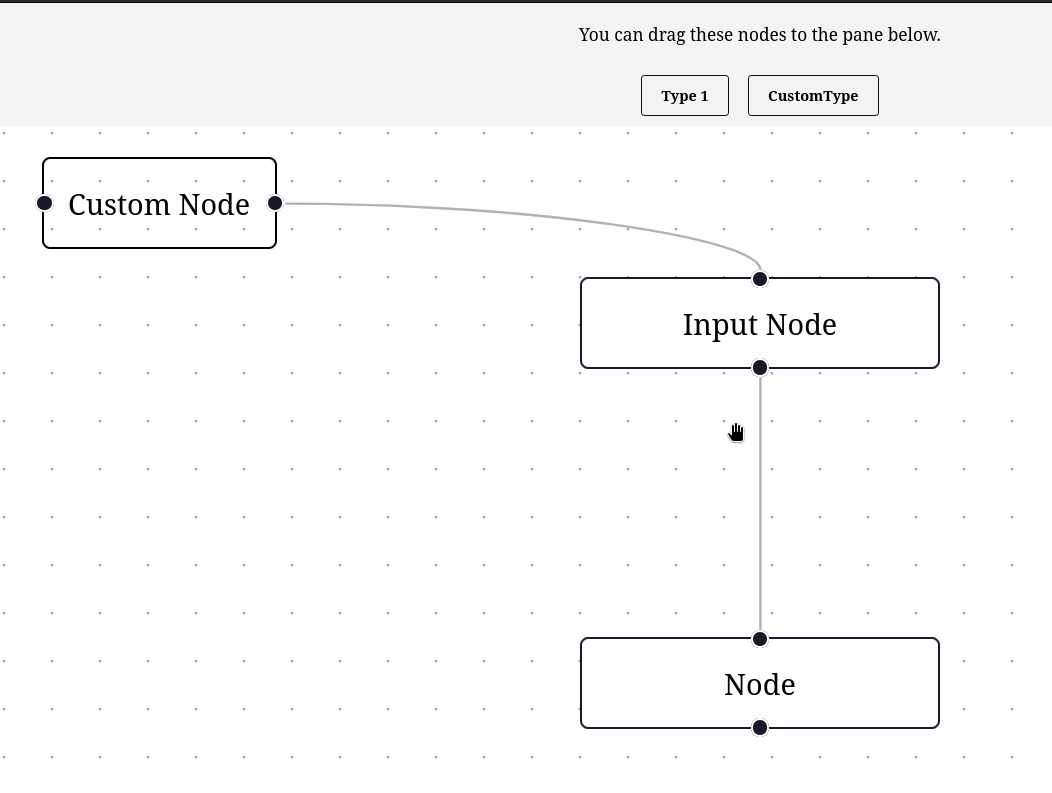
23:00 : Dans ce commit, j'ai réussi à définir des contraintes de liaisons. Il n'est plus possible de lier deux nodes du même type.

Journal du mardi 21 mai 2024 à 11:58
Dans ce thread je lis :
Linus Torvalds himself uses Fedora
et aussi un peu plus bas, je lis :
the second guy in linux (greg k.-h.) uses arch though 😊
Linus vient s'ajouter aux nombreux developeurs mainstreams qui utilisent Fedora.
#JaimeraisUnJour commencer à dresser cette liste (chose que j'ai commencé à faire avec cette note).
Journal du mardi 21 mai 2024 à 11:51
Sur Reddit, je suis tombé sur le thread concernant l'article de David Heinemeier Hansson (DHH de Basecamp) intitulé « Open source is neither a community nor a democracy ». Après lecture, je pense être en accord avec son contenu.
Lundi 20 mai 2024
Journal du lundi 20 mai 2024 à 18:38
Pour la première fois, j'ai pris le temps de faire quelque recherche pour comprendre l'origine de la différence de pratique de l'utilisation des majusques des titres en anglais et en français.
- La pratique anglais se nomme Title case.
- La pratique française se nomme Sentence case
#JaiDécouvert qu'il existe plusieurs règle de Title case :
- AP Stylebook
- Chicago Manual of Style
- APA Style
- ...
Journal du lundi 20 mai 2024 à 18:30
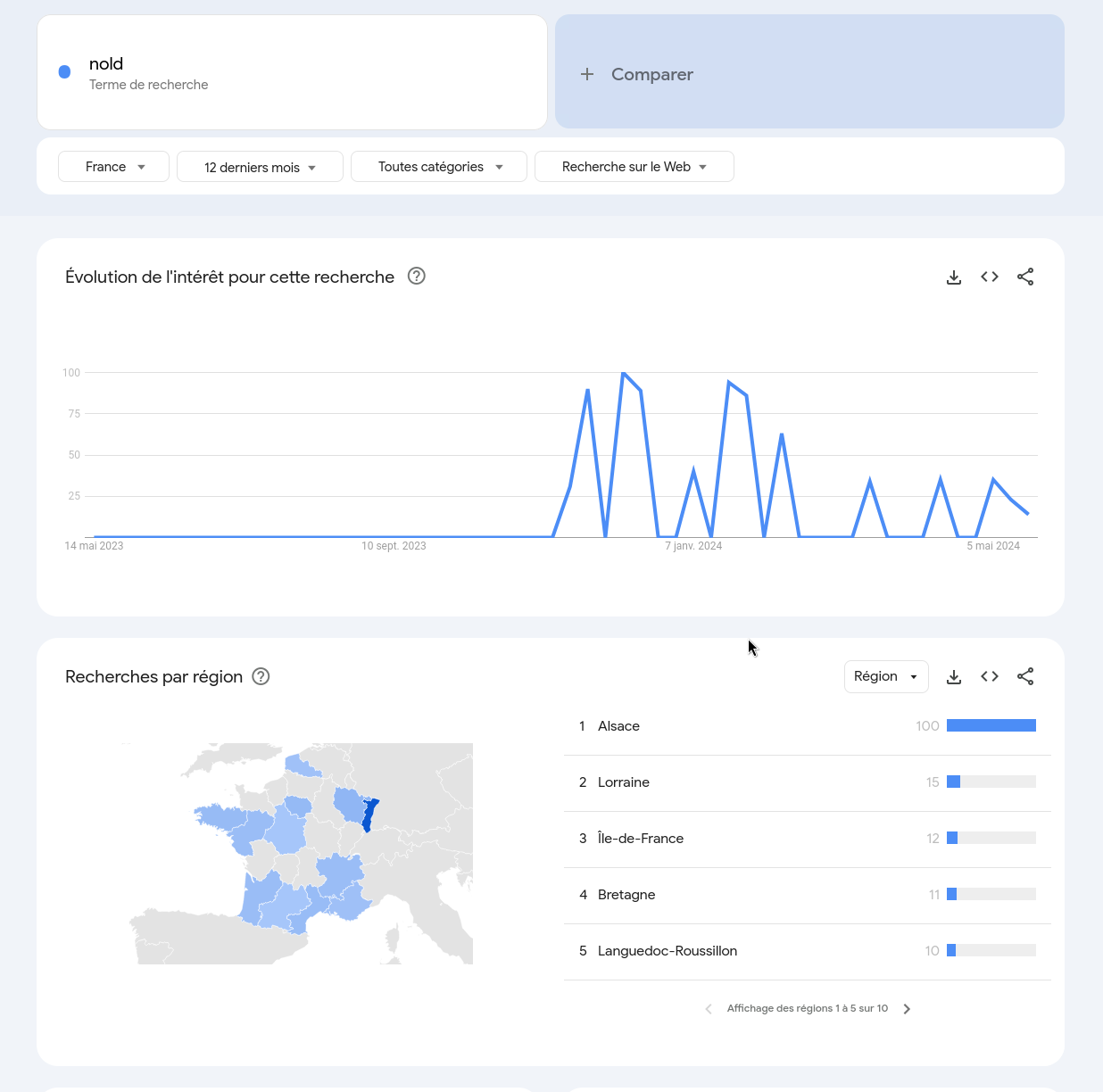
Une amie m'a fait découvrir ( #JaiDécouvert ) l'expression "NOLD" qui veut dire "Never Old".
L'expression "nold", contraction de "never" et de "old", autrement dit les "jamais vieux", désigne les 45-65 ans. Une génération qui ne se sent pas du tout vieille, bien décidée à ne pas être étiquetée "senior" passé la cinquantaine. Qu'est-ce qu'être nold, et d'où vient le concept ? Explications. - (from)"
Je pense que cette expression est pour le moment très confidentiel, je ne trouve rien sur :
En faisant une recherche sur Google Trend, je pense que cette expression est vraiment confidentiel :
Journal du lundi 20 mai 2024 à 15:13
Les deux fois où j'ai essayé d'utiliser Jupyter pour réaliser, par exemple, une calculatrice financière, j'ai fini par constater que je ne trouve pas cet outil pratique. Après quelques heures, je retourne soit à un script Python classique, soit à la création d'une page web basée sur HTML et JavaScript, qui me donne bien plus de flexibilité que Jupyter.
Il est possible que ce soit parce que je connais mal Jupyter, mais j'y ai tout de même consacré plus de deux heures hier soir, explorant notamment les Jupyter Widgets (ipywidgets).
Journal du lundi 20 mai 2024 à 11:17
Commande #cli pour convertir un fichier .mp4 en un .gif de 640px de largeur :
$ ffmpeg -i input.mp4 -vf "fps=10,scale=640:-1:flags=lanczos" -c:v pam -f image2pipe - | \
convert -delay 5 -layers Optimize - output.gif
Journal du lundi 20 mai 2024 à 11:01
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
Je me suis inspiré de l'exemple Drag and Drop pour implémenter ce commit, ce qui donne ceci :
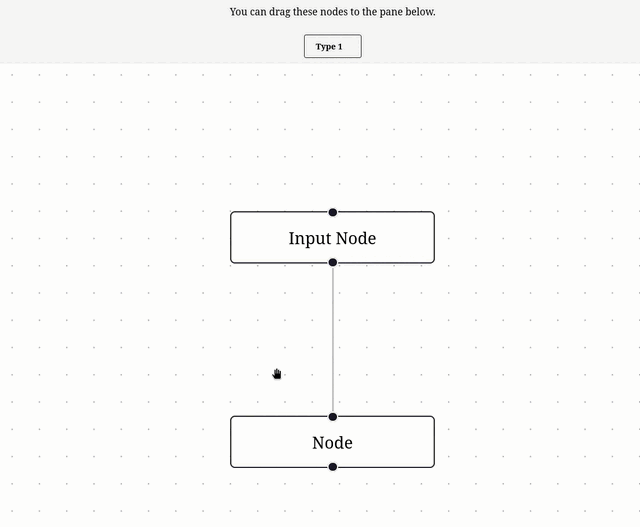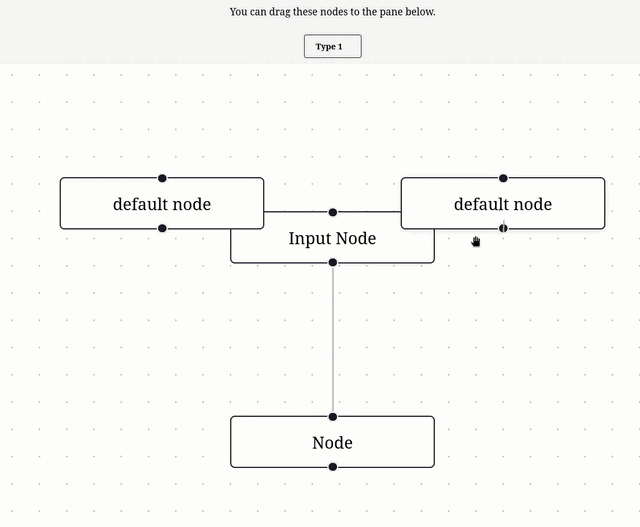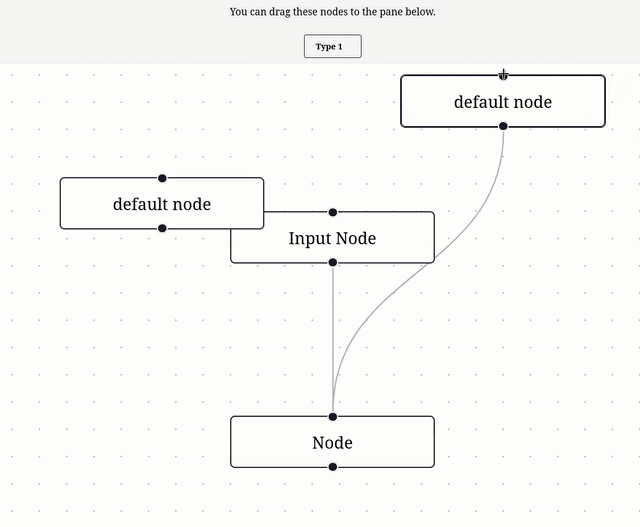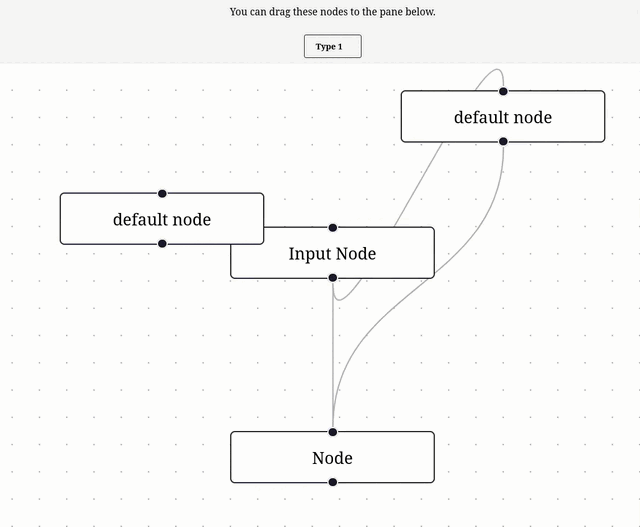
11:19 : Prochaine étape, lire et comprendre Theming – Svelte Flow.
11:32 :
- J'ai trouvé ce projet https://github.com/theonlytechnohead/patchcanvas/ qui peut me servir de source d'inspiration.
- #JeMeDemande si je dois implémenter un composant de type
<Handle />pour définir des contraintes de liaisons entre les nodes 🤔.
12:29 :
Journal du lundi 20 mai 2024 à 10:56
#JaiDécouvert https://keyshorts.com/ et #JeMeDemande si les stickers sont de meilleurs qualités que ceux de https://beaujoie.com/.
Vendredi 17 mai 2024
Upgrade de ma workstation de Fedora 39 vers 40
Fedora 40 version stable est sortie le 23 avril 2024 et presque un mois plus tard, j'ai upgrade mon Thinkpad T14s de la version 39 vers la version 40.
Que ce soit par le passé avec MacOS et maintenant avec Fedora, pour éviter d'être impacté par des bugs, ou des régressions, j'ai pris l'habitude d'attendre quelques semaines avant d'effectuer un upgrade d'OS majeur de ma workstation.
J'ai suivi la méthode officielle de mise à jour :
# dnf install dnf-plugin-system-upgrade
# dnf upgrade --refresh
# dnf clean all
# dnf system-upgrade download --releasever=40
# dnf system-upgrade reboot
et cela c'est déroulé avec succès.
Après 1h d'utilisation, je n'ai observé aucune régression.
Je me demande combien me coûterait l'hébergement de Lllama.cpp sur une GPU instance de Scaleway
#JeMeDemande combien me coûterait la réalisation du #POC suivant :
- Déploiement de Llama.cpp sur une GPU Instances de Scaleway;
- 3h d'expérimentation;
- Shutdown de l'instance.
🤔.
Tarifs :
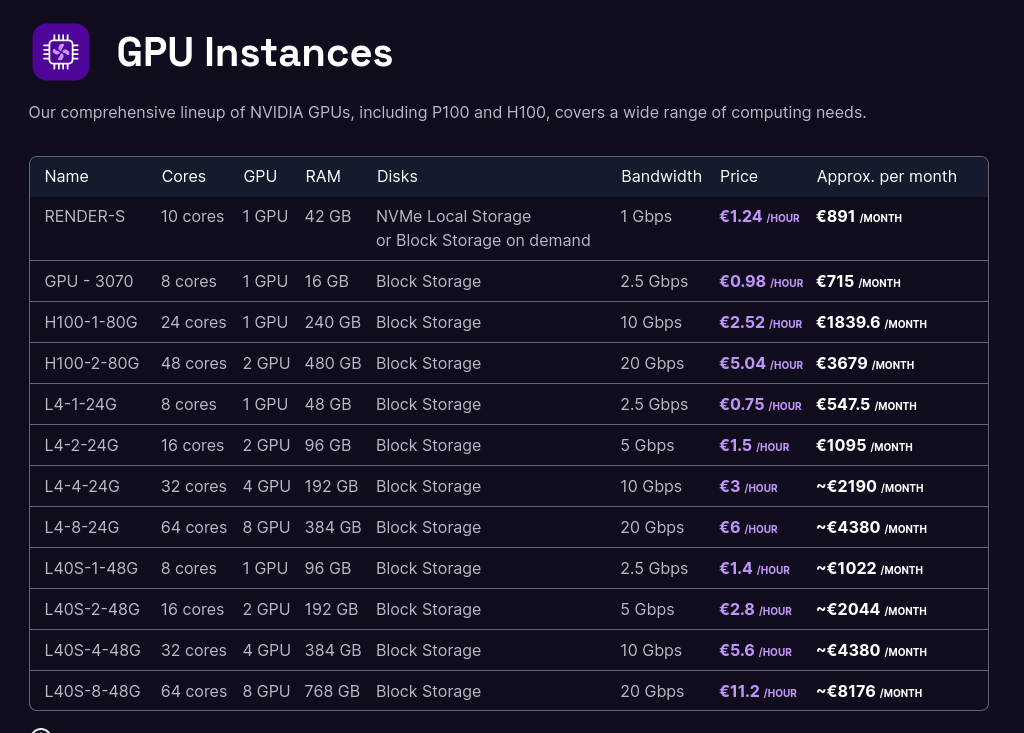
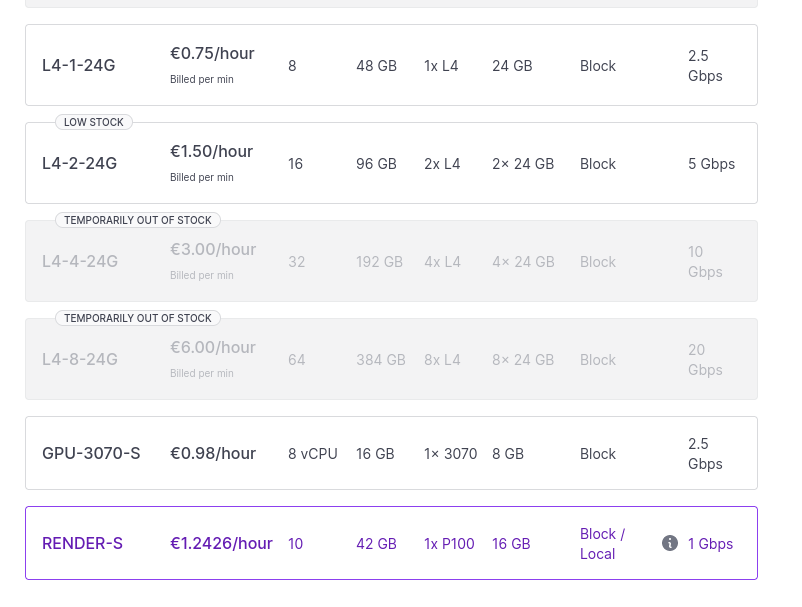
Dans un premier temps, j'aimerais me limiter aaux instances les moins chères :
- GPU-3070 à environ 1 € / heure
- L4-1-24G à 0.75 € / heure
- et peut-être RENDER-S à 1,24 € / heure
Tous ces prix sont hors taxe.
- L'instance GPU-3070 a seulement 16GB de Ram, #JeMeDemande si le résultat serait médiocre ou non.
- Je lis que l'instance L4-1-24G contient un GPU NVIDIA L4 Tensor Core GPU avec 24GB de Ram.
- Je lis que l'instance Render S contient un GPU Dedicated NVIDIA Tesla P100 16GB PCIe avec 42GB de Ram.
Au moment où j'écris ces lignes, Scaleway a du stock de ces trois types d'instances :
- #JeMeDemande comment je pourrais me préparer en amont pour installer rapidement sur le serveur un environnement pour faire mes tests.
- #JeMeDemande s'il existe des tutoriaux tout prêts pour faire ce type de tâches.
- #JeMeDemande combien de temps prendrait le déploiement.
Si je prends 2h pour l'installation + 3h pour faire des tests, cela ferait 5h au total.
J'ai cherché un peu partout, je n'ai pas trouvé de coût "caché" de setup de l'instance.
Le prix de cette expérience serait entre 4,5 € et 7,44 € TTC.
- #PremièreActionConcrète pour réaliser cette expérimentation : chercher s'il existe des tutoriaux d'installation de Llama.cpp sur des instances GPU Scaleway.
- #JeMeDemande combien me coûterait l'achat de ce type de machine.
- #JeMeDemande à partir de combien d'heures d'utilisation l'achat serait plus rentable que la location.
- Si par exemple, j'utilise cette machine 3h par jour, je me demande à partir de quelle date cette machine serait rentabilisée et aussi, #JeMeDemande si cette machine ne serait totalement obsolète ou non à cette date 🤔.
Journal du vendredi 17 mai 2024 à 12:07
Dans le Projet 6 - "SvelteFlow playground" je dis :
Glisser / déposer 2 types d'objets vers un flow container.
Je pense me servir de l'exemple Drag and Drop comme source d'inspiration.
Je dis aussi :
Interdire les liaisons entre des objets de même type.
Je pense me servir de l'exemple Validation comme source d'inspiration.
Je dis aussi :
Idéalement j'aimerais que les objets soient placés "harmonieusement" entre eux dans le flow container.
Peut-être que le système de layout de SvelteFlow pourra m'être utile :
🤔
Journal du vendredi 17 mai 2024 à 11:57
Issue intéressante au sujet RAG LLM IA for documentation learning · Issue #25 · Its-Alex/backlog · GitHub.
Journal du vendredi 17 mai 2024 à 11:05
Dans l'article "Qu'est-ce que la génération augmentée de récupération (RAG, retrieval-augmented generation) ?" je découvre l'acronyme Génération Augmentée de Récupération.
Je constate qu'il existe un paragraphe à ce sujet sur Wikipedia.
The initial phase utilizes dense embeddings to retrieve documents.
Je tombe encore une fois sur "embeddings", #JaimeraisUnJour prendre le temps de comprendre correctement cette notion.
Prenez l'exemple d'une ligue sportive qui souhaite que les fans et les médias puisse utiliser un chat pour accéder à ses données et obtenir des réponses à leurs questions sur les joueurs, les équipes, l'histoire et les règles du sport, ainsi que les statistiques et les classements actuels. Un LLM généralisé pourrait répondre à des questions sur l'histoire et les règles ou peut-être décrire le stade d'une équipe donnée. Il ne serait pas en mesure de discuter du jeu de la nuit dernière ou de fournir des informations actuelles sur la blessure d'un athlète, parce que le LLM n'aurait pas ces informations. Étant donné qu'un LLM a besoin d'une puissance de calcul importante pour se réentraîner, il n'est pas possible de maintenir le modèle à jour.
Le contenu de ce paragraphe m'intéresse beaucoup, parce que c'était un de mes objectifs lorsque j'ai écrit cette note en juin 2023.
Sans avoir fait de recherche, je pensais que la seule solution pour faire apprendre de nouvelles choses — injecter de nouvelle données — dans un modèle était de faire du fine-tuning.
En lisant ce paragraphe, je pense comprendre que le fine-tuning n'est pas la seule solution, ni même, j'ai l'impression, la "bonne" solution pour le use-case que j'aimerais mettre en pratique.
En plus du LLM assez statique, la ligue sportive possède ou peut accéder à de nombreuses autres sources d'information, y compris les bases de données, les entrepôts de données, les documents contenant les biographies des joueurs et les flux d'actualités détaillées concernant chaque jeu.
#JaimeraisUnJour implémenter un POC pour mettre cela en pratique.
Dans la RAG, cette grande quantité de données dynamiques est convertie dans un format commun et stockée dans une bibliothèque de connaissances accessible au système d'IA générative.
Les données de cette bibliothèque de connaissances sont ensuite traitées en représentations numériques à l'aide d'un type spécial d'algorithme appelé modèle de langage intégré et stockées dans une base de données vectorielle, qui peut être rapidement recherchée et utilisée pour récupérer les informations contextuelles correctes.
Intéressant.
Il est intéressant de noter que si le processus de formation du LLM généralisé est long et coûteux, c'est tout à fait l'inverse pour les mises à jour du modèle RAG. De nouvelles données peuvent être chargées dans le modèle de langage intégré et traduites en vecteurs de manière continue et incrémentielle. Les réponses de l'ensemble du système d'IA générative peuvent être renvoyées dans le modèle RAG, améliorant ses performances et sa précision, car il sait comment il a déjà répondu à une question similaire.
Ok, si je comprends bien, c'est la "kill feature" du RAG versus du fine-tuning.
bien que la mise en oeuvre de l'IA générative avec la RAG est plus coûteux que l'utilisation d'un LLM seul, il s'agit d'un meilleur investissement à long terme en raison du réentrainement fréquent du LLM
Ok.
Bilan de cette lecture, je dis merci à Alexandre de me l'avoir partagé, j'ai appris RAG et #JePense que c'est une technologie qui me sera très utile à l'avenir 👌.
Jeudi 16 mai 2024
Journal du jeudi 16 mai 2024 à 15:17
Voici une première liste de prestations freelance que je propose.
Le 16 mai, j'ai publié cette liste à l'adresse suivante : https://sklein.xyz/fr/services-freelance/
Pour en savoir plus à mon sujet, vous pouvez consulter https://sklein.xyz ou mon CV .
Prestation de développement
- Lancement d'une application web de type MVP (Produit Minimum Viable) soignée, développée de déployée à partir de zéro sans bug.
- Développement et déploiement à partir de zéro d'une Web API publique documentée, connectée à votre modèle de données.
- Amélioration de la vitesse d'exécution de votre backend, qui peut passer par des optimisations des requêtes SQL, ajout d'index, adaptation du modèle de données…
- Migration de votre projet de MySQL vers PostgreSQL.
- Votre application a beaucoup de bugs… vous ne savez plus comment traiter ce problème ? Je peux vous aider à stabiliser votre application suivant une stratégie de court ou moyen terme.
- Développement et déploiement d'une API GraphQL basé, sur PostGraphile ou Hasura.
- Mise en place de tests d'User Interface automatisés de votre application, basés sur PlayWright.
- Adaptation de votre frontend web codé en ReactJS, VueJS ou Svelte vers TailwindCSS et TailwindUI.
Prestation "pompier"
- Correction de bugs sous forme de "quickwin".
- Réduction des lenteurs de votre application sous forme de "quickwin".
- Traitement en urgence de problèmes d'hébergement (hosting).
Prestation de conseil
- Étude si une migration de votre projet d'une architecture monolithique vers une architecture en microservices est pertinente ou non.
- Étude de réduction de la facture de votre infrastructure d'hébergement (cloud hosting).
- Je peux vous aider à définir une stratégie de refactoring en douceur de votre projet, sans casser l'existant en migrant petite partie par petite partie.
- Vous êtes enlisé dans de la dette technique, vous ne savez pas comment vous sortir de cette impasse ? Je peux peut-être vous aider.
- Étude pour déterminer si l'utilisation d'une base de données orientée Graph type Neo4j peut être utile pour votre besoin métier, si c'est adapté à votre modèle de données.
- Réalisation un prototype permettant de tester si l'utilisation d'une base de données OLAP, type ClickHouse pourrait être pertinente pour améliorer la performance de moteur de base de données.
Prestation de DataOps
- Développement de scripts de data scraping, Web scrapping, automatisation d'action sans API...
Prestation d'infrastructure
- Création ou amélioration d'un « Development Kit » pour votre ou vos projets informatiques.
L'objectif de ce DevKit et d'accélérer l'intégration (onboarding) de vos développeurs, de rendre leur environnement de travail plus agréable et de faciliter la prise en main des projets en équipe. - Mise en place de processus automatisés ou semi-automatisés de "Continuous Delivery" basés sur GitLab-CI/CD ou GitHub Actions pour déployer votre projet sur des serveurs AWS, OVH, Scaleway, Hetzner, Vultr, ou DigitalOcean…
- Migration de projets multi-repository vers un monorepo.
- Adaptation de vos projets à Docker, création d'images Docker ("Dockerisation") de vos applications.
- Migration de votre projet d'une architecture monolithique vers une architecture en microservices.
- Peut-être que l'architecture microservices n'était pas adaptée au niveau de maturité de votre projet ; dans ce cas, je peux vous aider à migrer votre projet d'une architecture en microservices vers une architecture plus simple de type monolithique.
- Refactoring de votre infrastructure d'hébergement afin d'en réduire le coût.
Pour toutes ces prestations, mes livrables sont des Merge Request / Pull Request avec descriptions explicites prêtes à être review par votre équipe. J'aime pratiquer la méthode #WorkInPublic; par conséquent, l'évolution de mon travail est visible en continu via des commits, des commentaires ou des questions tout au long de la mission.
Journal du jeudi 16 mai 2024 à 09:44
Voici ma dernière itération du Projet -1 "CodeMirror, autocomplétion, Svelte".
Code source https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc
Journal du jeudi 16 mai 2024 à 09:36
Article que je trouve intéressant au sujet du le découpage des commit #git When to split patches for PostgreSQL | Peter Eisentraut
Journal du jeudi 16 mai 2024 à 08:36
#pensée : je travaille depuis plusieurs jours sur Projet -1 "CodeMirror, autocomplétion, Svelte" et je fais le constat que j'ai énormément de difficultés à comprendre et à utiliser la librairie #codemirror .
Bien que la documentation contienne déjà un certain nombre d'exemples, je constate que j'en ai besoin de beaucoup plus.
La documentation contient des exemples, mais la librairie est vaste et j'ai besoin de beaucoup plus d'exemples !
Comme je ne trouve pas mes réponses dans les exemples, je passe beaucoup de temps à :
- chercher dans le forum https://discuss.codemirror.net/
- chercher dans le code source https://github.com/codemirror/
- chercher dans les issues, par exemple https://github.com/search?q=org%3Acodemirror+bracket&type=issues
- à chercher dans le moteur de recherche global de GitHub https://github.com/search?q=codemirror+bracket&type=code
- à poser des questions à ChatGPT mais il me donne des réponses qui ne fonctionnent généralement pas
#JeMeDemande si je dois essayer de passer du temps à lire et comprendre le code source de #codemirror 🤔.
Mais, je sais qu'il m'est difficile de comprendre et de me faire une carte mentale d'une librairie de cette taille 🤔.
#JeMeDemande si mes amis développeurs arriveraient plus facilement que moi à comprendre le code source de #codemirror 🤔.
Mercredi 15 mai 2024
Journal du mercredi 15 mai 2024 à 22:45
Réflexion en travaillant sur 2024-05-15_2159 :
tmux is designed to be easy to script. Almost all commands work the same way when run using the
tmuxbinary as when run from a key binding or the command prompt inside tmux. (from)
Voici un exemple de ce que je trouve élégant dans le design de tmux.
Les commandes tmux, comme par exemple set :
- peut être exécuté via le shell avec l'exécutable
tmux:
$ tmux set -g window-status-current-format "Foobar"
- peut être utilisé dans le fichier de configuration
tmux.conf:
set -g window-status-current-format "Foobar"
- mais aussi en configurant un raccourcie clavier (ici cet exemple n'a pas trop de sens) :
bind-key x set -g window-status-current-format "Foobar"
C'est ce qui est expliqué ici :
Each command is named and can accept zero or more flags and arguments. They may be bound to a key with the bind-key command or run from the shell prompt, a shell script, a configuration file or the command prompt. For example, the same
set-optioncommand run from the shell prompt, from~/.tmux.confand bound to a key may look like:
$ tmux set-option -g status-style bg=cyanset-option -g status-style bg=cyanbind-key C set-option -g status-style bg=cyan
Le fonctionnement de tmux me fait aussi penser à i3 et sway…, plus précisément, les commandes utilisés dans leurs fichiers de configuration sont aussi exécutables via i3-msg commandname ou swaymsg commandename.
#JePense que c'est "çà" l'esprit Unix, des logiciels pour les utilisateurs qui ont un hacker mindset 🤔.
#JeMeDemande quels sont les autres logiciels qui suivent cet adn de tmux 🤔.
Journal du mercredi 15 mai 2024 à 21:59
Je viens de modifier ma configuration (dotfiles) tmux :
https://github.com/stephane-klein/dotfiles/commit/f370721781f6ea1b72c1954f43ce50196112e72e
La configuration suivante
set -g window-status-current-format "#[fg=colour231,bg=colour33,bold] #{?window_name,#{window_name},#{b:pane_current_path}} #[nobold]"
set -g window-status-format "#[fg=colour33,bg=colour254,bold] #{?window_name,#{window_name},#{b:pane_current_path}} #[nobold]"
permet de définir cette ligne status :

Pour chaque fenêtre est affichée soit le nom de la fenêtre, soit le nom du dossier courant du shell actif dans la fenêtre.
La syntaxe suivante est documentée ici :
#{?window_name,#{window_name},#{b:pane_current_path}}
Ce qui signife #{?condition,true_value,false_value}.
La configuration suivante
bind-key c new-window -c "#{pane_current_path}" -n ""
-n "" permet de définir par défaut le nom des nouvelles fenêtres avec un chaine vide.
Journal du mercredi 15 mai 2024 à 18:25
#JeMeDemande quel est le #browser utilisé dans ce screencast : https://www.youtube.com/watch?v=ZiM1RM0DCgo

Je viens de lui poser la question : https://mamot.fr/@stephane_klein/112446033714935652
[ << Notes plus récentes (856) ] | [ Notes plus anciennes (124) >> ]