
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (7) >> ]
Journal du mardi 18 juin 2024 à 18:12
J'essaie de mettre de l'ordre dans ma configuration eslint et pour cela, j'essaie de migrer de l'ancien format de fichier de configuration .eslint.config.js vers le nouveau.
Le nouveau format de configuration est nommé "Flat Config" et l'ancien "Legacy Config".
Mon constat après avoir travaillé une demi-heure sur le sujet : je pense que je suis tombé dans un Yak! 🤣.
Pour le moment, j'ai l'impression que tout change. Pour arriver à effectuer la migration, je repars de zéro. J'ajoute un paramètre après l'autre afin d'avoir un truc fonctionnel et d'y comprendre quelque chose 🤷♂️.
"env": {
browser: true,
node: true,
es6: true,
es2020: true
}
semble être remplacer par des imports de https://github.com/sindresorhus/globals :
import globals from "globals";
export default [
{
languageOptions: {
ecmaVersion: 2022,
sourceType: "module",
globals: {
...globals.browser,
}
}
}
];
linebreak-style est déprécié, cette règle est déplacé dans le package ESLint Stylistic.
Je n'ai pas besoin de convertir la règle suivante :
linebreak-style: [error, unix]
étant donné qu'elle est activée par défaut.
#JeLis https://eslint.style/guide/why
With stylistic rules in ESLint, we are able to achieve similar formatting compatibility while retaining the original code style that reflects the authors/teams' intentions, and apply fixes in one go.
et je comprends que eslint semble pouvoir remplacer Prettier.
J'observe que eslint-stylistic est un nouveau projet qui date de septembre 2023.
Journal du mardi 18 juin 2024 à 17:39
J'utilise encore eslint 8.57.0 et non pas la version 9 et #JaiDécidé d'arrêter d'utiliser le format #YAML (.eslintrc.yaml) pour configurer eslint pour les raisons suivantes :
- eslint version 9 ne supporte le format #YAML .
- Je souhaite utiliser le fichier
svelte.config.jsdans la configuration eslint et cela n'est possible qu'avec le formateslint.config.js.
Journal du mardi 18 juin 2024 à 09:24
A lightweight, framework-agnostic database migration tool.
Ce projet a commencé en 2015.
Je viens de voir dans mes notes que j'avais déjà regardé ce projet le 15 octobre 2023, donc ce n'est pas vraiment une découverte 🤣.
Il est codé en Golang, chose que j'apprécie pour ce genre d'outil.
Depuis septembre 2022, j'utilise l'outil de migration graphile-migrate. Avant cela j'utilisais Migrate.
Dans ce thread j'ai été surpris de voir ce commentaire :
I’ve always wondered why tools like this cannot become stateless. Most have an up and down action, but I haven’t seen one yet that can run a query to determine if a migration has been applied or not. Then no state tables/artifacts are needed.
Instead of one file with an up and down, there could be two files where each has a predicate and then an action, where the predicate would run to determine if the migration has been applied or not.
En quelques secondes, je pense être capable d'imaginer plusieurs scénarios — que je ne souhaite pas lister ici — pour lesquels son idée ne pourrait pas fonctionner 🤔.
Journal du dimanche 16 juin 2024 à 17:08
Nouvelle #iteration du Projet 5 - "Importation d'un vault Obsidian vers Apache Age".
#JeMeDemande si la convention est de nommer les nodes au singulier ou au pluriel, par exemple Note ou Notes 🤔.
D'après cette documentation, je comprends que la convention semble être le singulier.
Journal du vendredi 31 mai 2024 à 20:02
J'ai commencé à écouter « Votre mission ? Découvrir Haskell et le mettre en prod - Céline Louvet » parce que je ne comprends rien à Haskell. Je ne vois pas ce que ce langage peut m'apporter. Je ne vois pas sa puissance, mais comme beaucoup de bons codeurs adorent Haskellet les langages fonctionnels, je suis presque certain que je passe à côté de quelque chose de très puissant.
Dans cette vidéo, Céline Louvet dit qu'elle est la première dev, la seule dev de sa startup et se lance avec un langage qu'elle ne maîtrise pas et que très peu de développeurs maîtrisent.
Je trouve qu'elle est très audacieuse !
Cette vidéo date de 2019, j'ai regardé son LinkedIn et je constate que l'expérience a tourné court. Peut-être pour plein de raisons non liées à Haskell. Et depuis je constate qu'elle n'a plus fait de Haskell 🤔.
Journal du dimanche 26 mai 2024 à 10:52
Quand je travaille sur le refactoring de ma configuration Neovim, par exemple un passage de packer.nvim à lazy.nvim, je souhaite absolument éviter de perturber mon instance Neovim courante — que je qualifie de stable.
Pour cela, j'ai cherché des solutions pour lancer plusieurs instances de Neovim.
Mon point de départ dans cette quête était trop ambitieux : je souhaitais mettre en place un environemment de travail pour tester la globalité de mes dotfiles basé sur chezmoi.
J'ai explorer les pistes suivantes :
- Travailler dans la session d'un autre utilisateur Unix : je trouve cela vraiment pas pratique.
- J'ai testé une méthode basé sur Distrobox.
- J'ai testé une méthode basé sur Docker.
Finalement, si je me limite à un travail sur ma configuration Neovim, j'ai trouvé la solution suivante minimaliste pour lancer une instance de Neovim cloisonée :
$ export XDG_CONFIG_HOME=$PWD/config/
$ export XDG_DATA_HOME=$PWD/share/
$ nvim
Pour rendre mon quotidien plus agréable, j'exécute ce script ./start_sandboxed_neovim.sh — qui intègre ces instructions.
Je n'utilise pas direnv dans cet environnement de travail parce que je souhaite continuer à pouvoir éditer les fichiers de configuration avec mon instance de Neovim "stable".
En pratique, j'ouvre deux panels tmux verticaux, à gauche j'édite la configuration avec mon instance Neovim stable et à droite je lance l'instance Neovim cloisonée.
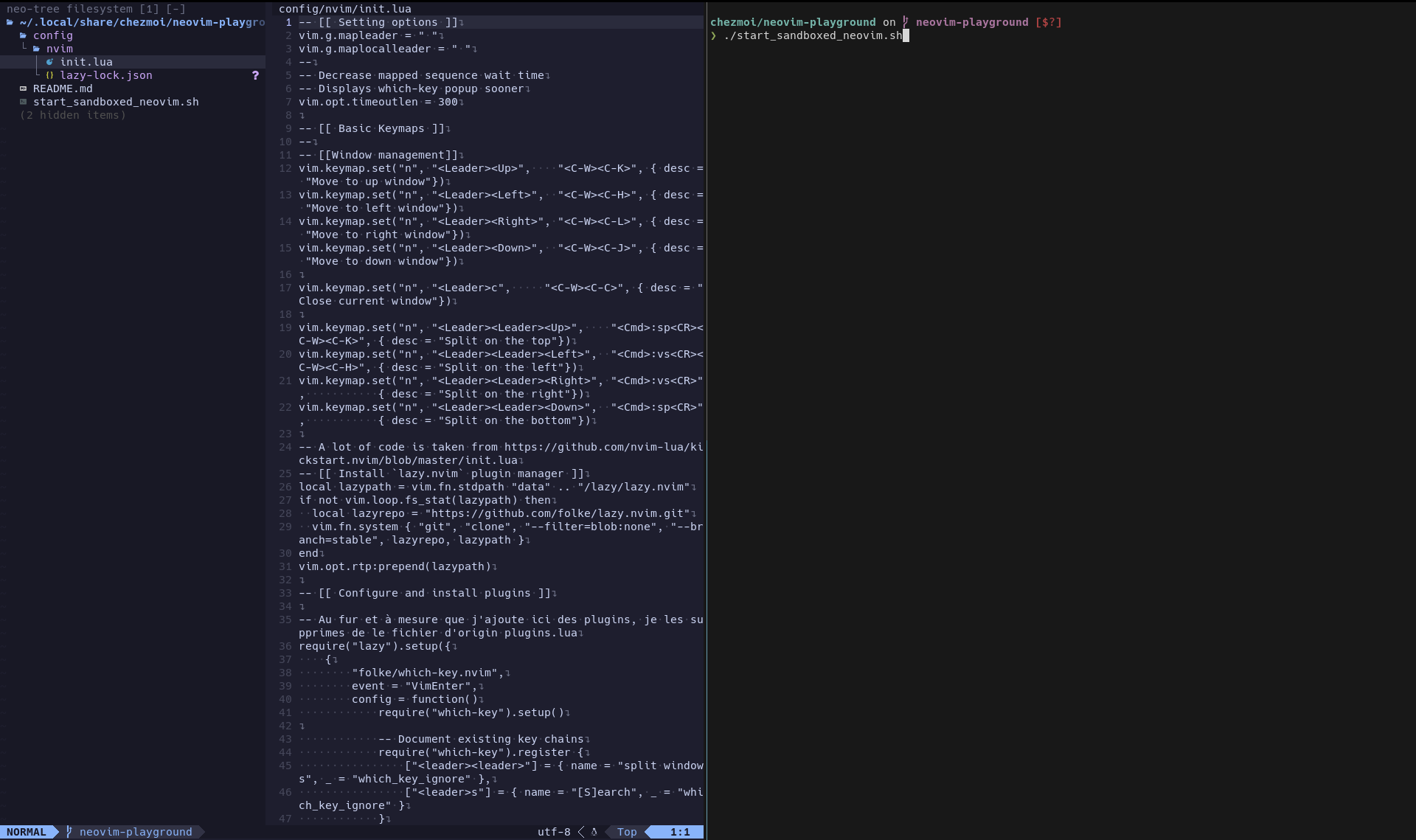
2025-11-28 : j'ai publié le playground suivant basé sur la méthode décrite dans cette note https://github.com/stephane-klein/neovim-playground
Journal du mercredi 22 mai 2024 à 11:57
Alexandre vient de me donner le conseil Bash suivant.
De remplacer mon usage de :
set -e`
par :
set -euo pipefail
e=> Arrête l'exécution à la première erreuru=> Génère une erreur si une variable n'est pas définie (il faut mettre des valeurs par défaut aux variables d'env)o pipefail=> Renvoie une erreur si une commande dans un pipe échoue
Je lui dit merci 🙂.
Journal du mercredi 22 mai 2024 à 10:33
Je viens de finir Projet 6 - "SvelteFlow playground", voici un screencast de démonstration du résultat :
J'ai passé 5h27 sur ce projet.
Code source de ce projet https://github.com/stephane-klein/svelteflow-playground
Ma plus grosse difficulté a été de trouver comment implémenter les containtes liaison.
Pour le moment, je doute que mon implémentation respecte les bonnes pratiques d'utilisation de la librairie. Je pense que je vais découvrir le "bon" usage — tel que imaginé par Moritz Klack — de la librarie au fur et à mesure de mon utilisation.
Journal du mardi 21 mai 2024 à 23:09
Dans la page suivante Elkjs Tree – Svelte Flow #JaiDécouvert la librarie Javascript elkjs :
ELK's layout algorithms for JavaScript
Journal du mardi 21 mai 2024 à 16:22
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
17:00 : J'ai réussi à ajouter un CustomNode (commit).
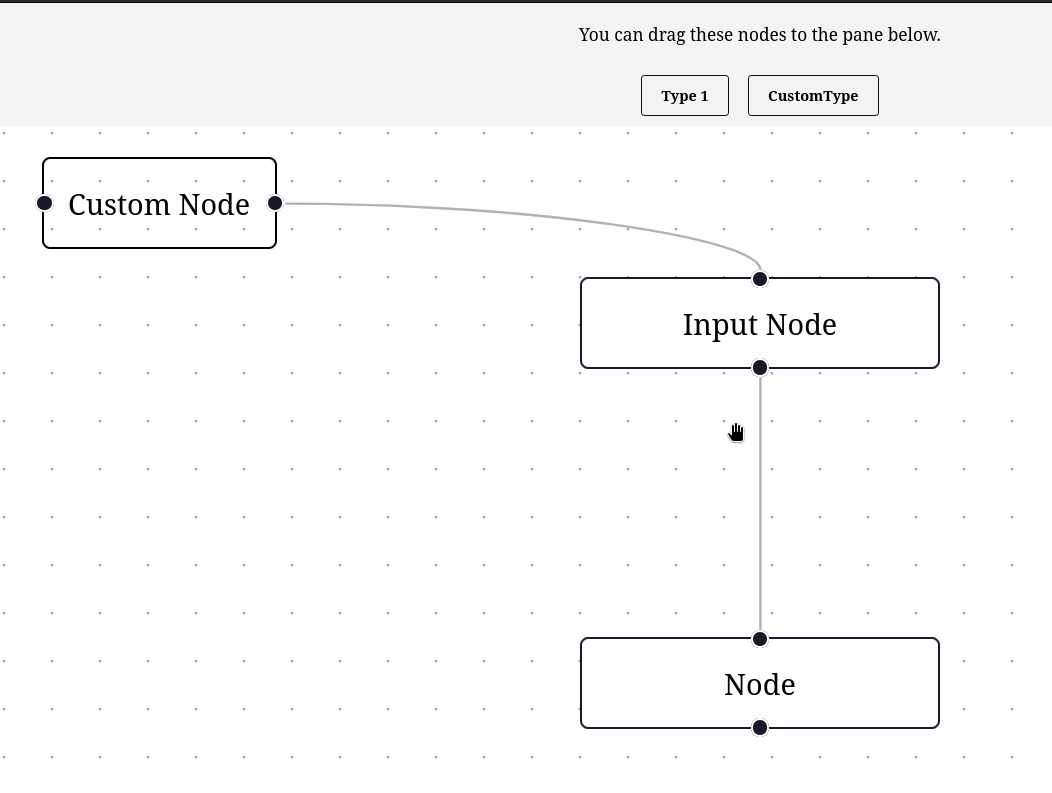
23:00 : Dans ce commit, j'ai réussi à définir des contraintes de liaisons. Il n'est plus possible de lier deux nodes du même type.

Journal du lundi 20 mai 2024 à 15:13
Les deux fois où j'ai essayé d'utiliser Jupyter pour réaliser, par exemple, une calculatrice financière, j'ai fini par constater que je ne trouve pas cet outil pratique. Après quelques heures, je retourne soit à un script Python classique, soit à la création d'une page web basée sur HTML et JavaScript, qui me donne bien plus de flexibilité que Jupyter.
Il est possible que ce soit parce que je connais mal Jupyter, mais j'y ai tout de même consacré plus de deux heures hier soir, explorant notamment les Jupyter Widgets (ipywidgets).
Journal du lundi 20 mai 2024 à 11:01
Nouvelle #iteration sur Projet 6 - "SvelteFlow playground".
Je me suis inspiré de l'exemple Drag and Drop pour implémenter ce commit, ce qui donne ceci :
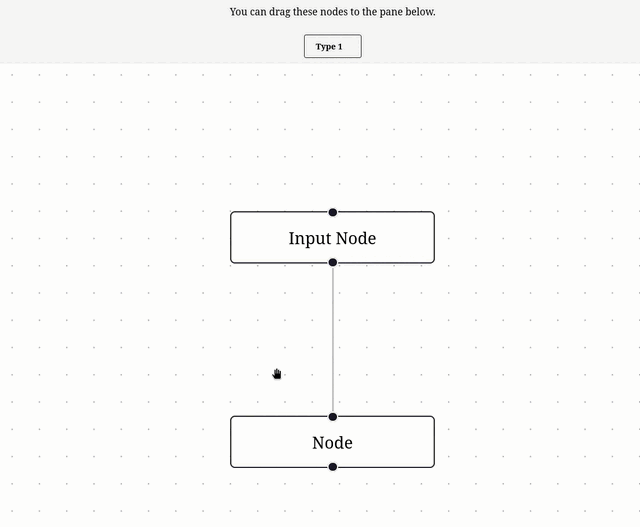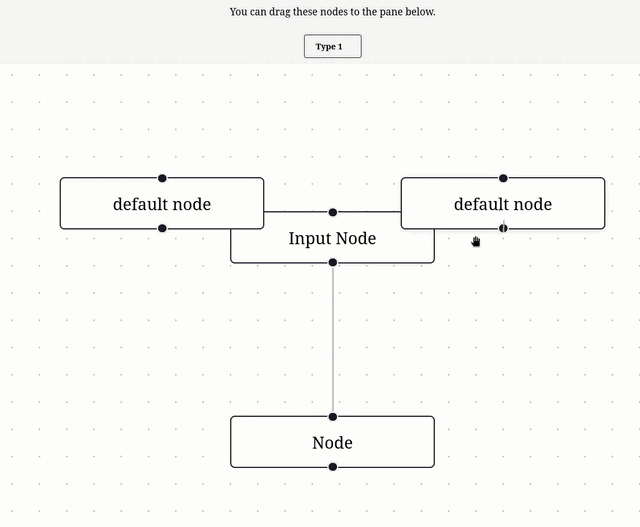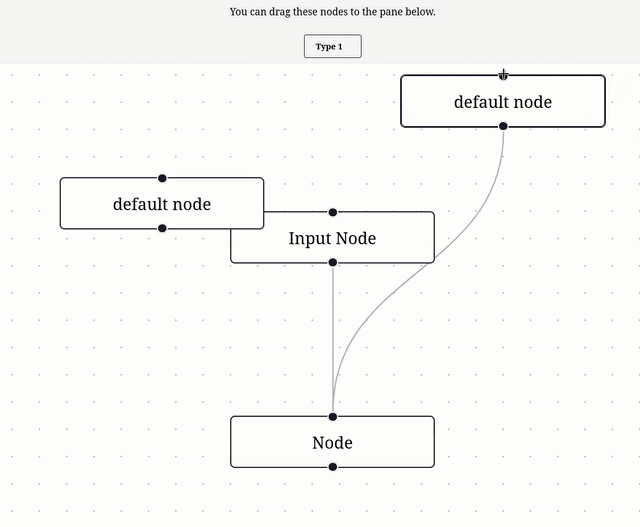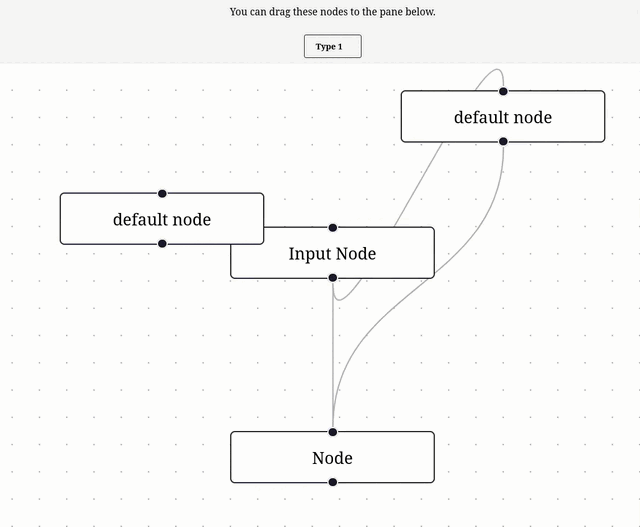
11:19 : Prochaine étape, lire et comprendre Theming – Svelte Flow.
11:32 :
- J'ai trouvé ce projet https://github.com/theonlytechnohead/patchcanvas/ qui peut me servir de source d'inspiration.
- #JeMeDemande si je dois implémenter un composant de type
<Handle />pour définir des contraintes de liaisons entre les nodes 🤔.
12:29 :
Journal du jeudi 16 mai 2024 à 09:44
Voici ma dernière itération du Projet -1 "CodeMirror, autocomplétion, Svelte".
Code source https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc
Journal du jeudi 16 mai 2024 à 09:36
Article que je trouve intéressant au sujet du le découpage des commit #git When to split patches for PostgreSQL | Peter Eisentraut
Journal du jeudi 16 mai 2024 à 08:36
#pensée : je travaille depuis plusieurs jours sur Projet -1 "CodeMirror, autocomplétion, Svelte" et je fais le constat que j'ai énormément de difficultés à comprendre et à utiliser la librairie #codemirror .
Bien que la documentation contienne déjà un certain nombre d'exemples, je constate que j'en ai besoin de beaucoup plus.
La documentation contient des exemples, mais la librairie est vaste et j'ai besoin de beaucoup plus d'exemples !
Comme je ne trouve pas mes réponses dans les exemples, je passe beaucoup de temps à :
- chercher dans le forum https://discuss.codemirror.net/
- chercher dans le code source https://github.com/codemirror/
- chercher dans les issues, par exemple https://github.com/search?q=org%3Acodemirror+bracket&type=issues
- à chercher dans le moteur de recherche global de GitHub https://github.com/search?q=codemirror+bracket&type=code
- à poser des questions à ChatGPT mais il me donne des réponses qui ne fonctionnent généralement pas
#JeMeDemande si je dois essayer de passer du temps à lire et comprendre le code source de #codemirror 🤔.
Mais, je sais qu'il m'est difficile de comprendre et de me faire une carte mentale d'une librairie de cette taille 🤔.
#JeMeDemande si mes amis développeurs arriveraient plus facilement que moi à comprendre le code source de #codemirror 🤔.
Journal du lundi 13 mai 2024 à 19:07
Suite de Je m'interroge, pourquoi tant de beaux projets sont codés en Closure ?.
Encore Nautilus time-blocking tool que je trouve intéressant, codé en Closure : https://nautilus-omnibus.web.app
Voici les arguments que donne ici l'auteur de ce logiciel pour expliquer pourquoi il a choisi Closure :
It has to be said that Clojurescript is an excellent fit for text-based Roam. The Nautilus code in Clojurescript is, in a way, one “big function,” transforming text (task list) into another text (SVG code), which renders the spiral. What I enjoy most about working with Clojure is the mindset where code and data are almost one. With REPL, you can easily evaluate parts of the code for debugging and even rewrite code on the fly.
Hooray, and now Nautilus is finally part of the extensions menu in Roam Depot and it already has several hundred users. More are joining daily.
Journal du vendredi 10 mai 2024 à 08:37
#JeMeDemande si le code de SilverBullet.mb pourrait m'inspirer dans mon travail sur Projet -1 "CodeMirror, autocomplétion, Svelte" 🤔.
J'ai l'impression que le code qui m'intéresse se trouve vers ici.
Je pense que CompletionTooltip est la classe qui est responsable de l'affichage du "completion picker".
09:56 : J'ai réussi à afficher un "completion picker" minimaliste :
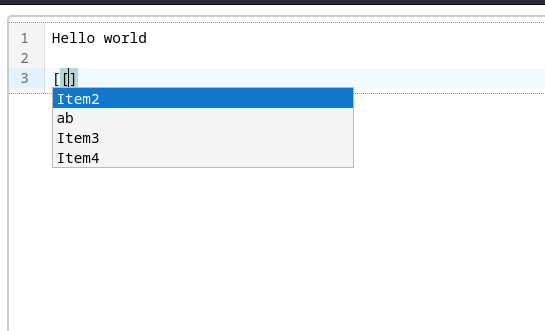
10:02 : Prochaines itérations :
- [ ] Essayer d'implémenter le chargement de la liste d'items de suggestion de manière dynamique. Je souhaite obtenir cette liste via une requête GET http, sur l'url
/get-suggestions/. Cette fonctionnalité est souvent nommée « remote data fetch » (exemple ici). - [ ] Essayer d'implémenter un chargement dynamique d'items de manière progressif. Au lieu de charger toutes la listes des items, l'objectif et de les charger au fur et à mesure, par exemple en petit paquets de 100 items). L'objectif de cette tache ressemble à https://github.com/vtaits/react-select-async-paginate.
Le paramétrage de `search_path` PostgreSQL dans docker-compose ne fonctionne pas 🤨
Je suis en train de travailler sur Projet 5 - "Importation d'un vault Obsidian vers Apache Age" et je rencontre une difficulté.
J'utilise cette configuration docker-compose.yml :
services:
postgres:
image: apache/age:PG16_latest
restart: unless-stopped
ports:
- 5432:5432
environment:
POSTGRES_DB: postgres
POSTGRES_USER: postgres
POSTGRES_PASSWORD: password
PGOPTIONS: "--search_path='ag_catalog,public'"
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
Je ne comprends pas pourquoi, j'ai l'impression que le paramètre PGOPTIONS: "--search_path=''" ne fonctionne plus.
$ ./scripts/enter-in-pg.sh
postgres=# SHOW search_path ;
search_path
-----------------
"$user", public
(1 ligne)
postgres=#
La valeur de search_path devrait être ag_catalog,public.
J'ai testé avec l'image Docker image: postgres:16, j'observe le même problème.
Je suis surpris parce que je pense me souvenir que cette syntaxe fonctionnait ici en septembre 2023 🤔.
#JeMeDemande comment corriger ce problème 🤔.
#JaiLu docker - Can't set schema_name in dockerized PostgreSQL database - Stack Overflow
09:07 : #ProblèmeRésolu par https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/commit/0b1cef3a725550269583ddb514fa3fff1932e89d
Journal du lundi 06 mai 2024 à 15:23
#JaiPublié le playground https://github.com/stephane-klein/mermaid-sveltekit-playground parce que j'ai besoin de faire une intégration Mermaid dans mon projet Value Props.
Ce playground n'a que peu d'intérêt pour le moment, mis à part de confirmer que je n'ai pas eu de difficulté à initialiser Mermaid dans un projet SvelteKit.
Dans Projet 5 - "Importation d'un vault Obsidian vers Apache Age", j'utilise les librairies remark mais pour le moment, je les trouve bien plus difficiles à utiliser que gray-matter couplé avec markdown-it.
Par exemple, je souhaite extraire dans un dict le contenu frontmatter de fichiers markdown, ainsi que la partie body.
Avec remark j'ai écrit avec difficulté le code suivant :
#!/usr/bin/env node
import { glob } from "glob";
import fs from 'fs';
import { unified } from 'unified';
import markdown from 'remark-parse';
import frontmatter from 'remark-frontmatter';
import extract from 'remark-extract-frontmatter';
import { parse } from 'yaml';
import stringify from 'remark-stringify';
const processor = unified()
.use(markdown)
.use(frontmatter, ['yaml'])
.use(extract, { yaml: parse })
.use(stringify);
const processMarkdown = async (filename) => {
const fileContent = fs.readFileSync(filename);
const result = await processor.process(fileContent);
const body = result.toString().split(/---\s*$/m)[2] || '';
return {
frontmatter: result.data,
body: body.trim()
};
};
for (const filename of (await glob("content/**/*.md"))) {
processMarkdown(filename).then(data => {
console.log('Frontmatter:', data.frontmatter);
console.log('Body:', data.body);
});
}
Et voici mon implémentation avec gray-matter :
#!/usr/bin/env node
import { glob } from "glob";
import matter from "gray-matter";
import yaml from "js-yaml";
for (const filename of (await glob("content/**/*.md"))) {
console.log(matter.read(filename, {
engines: {
yaml: (s) => yaml.load(s, { schema: yaml.JSON_SCHEMA })
}
}));
}
Je préfère sans hésitation cette seconde implémentation.
#JaiDécidé d'utiliser gray-matter.
#JeMeDemande quels seraient les avantages que j'aurai à utiliser remark 🤔.
Journal du jeudi 02 mai 2024 à 23:15
#JeMeDemande les librairies qui existent pour afficher des graphes basés sur les résultats retournées par une base de données orienté graphe, comme Apache Age.
#JeMeDemande si je peux arriver à faire quelque chose avec la librairie Svelte suivante : https://svelteflow.dev/
Autre librairies :
Obsidian Quartz utilise d3js : https://github.com/jackyzha0/quartz/blob/v4/quartz/components/scripts/graph.inline.ts
Journal du jeudi 02 mai 2024 à 22:57
J'ai traité Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age".
Le résultat se trouve ici https://github.com/stephane-klein/apache-age-playground.
J'ai réussi à écrire plusieurs requêtes Cypher, mais je suis très loin de maitriser ce langage. Pour le moment, je me base principalement sur les exemples donnés dans la documentation.
Journal du jeudi 02 mai 2024 à 21:34
Je suis en train de travailler sur Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age" mais pour le moment, je regrette de ne pas prendre le temps de bien lire toute cette documentation https://age.apache.org/age-manual/master/index.html pour apprendre Cypher. Je ne comprends pas pourquoi je ne fais pas cette effort alors que le sujet m'intéresse 🤔.
Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Finalement, contraiment à ce que j'avais décidé ici, je n'ai pas utilisé Convict dans mon application Value Props propulsé par SvelteKit.
J'ai "simplement" utilisé la vite-plugin-environment pour définir la valeur par défaut des variables d'environnement de configuration utilisées par l'application.
Exemple :
// vite.config.js
import { defineConfig } from "vite";
import EnvironmentPlugin from 'vite-plugin-environment'
import { sveltekit } from "@sveltejs/kit/vite";
export default defineConfig({
plugins: [
EnvironmentPlugin({
POSTGRES_URL: "postgres://webapp:password@localhost:5432/myapp",
Y_WEBSOCKET_URL: "ws://localhost:1234",
SMTP_HOST: "127.0.0.1",
SMTP_POST: 1025,
SECRET: "secret"
}),
sveltekit()
]
});;
Et voici un exemple d'utilisation de ces paramètres de configuration :
// src/lib/server/db.js
import postgres from "postgres";
const sql = postgres(process.env.POSTGRES_URL);
export default sql;
Rien de plus, je n'ai ni utilisé Convict ni dotenv, j'ai pu suivre le principe KISS.
J'ai décidé de continuer à utiliser la lib Convict de configuration management
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Après avoir parcouru la documentation de env-cmd et dotenv
Après avoir réalisé que je n'avais rencontré aucun problème avec node-convict et que j'avais même pris du plaisir à l'utiliser.
Suite au feedback d'un ami qui me dit :
J'aime beaucoup convict qu'on a utilisé dans gibbon-mail
Et qui me rappelle que dotenv est très orienté "fichier de conf" alors que lui comme moi suivons plutôt la doctrine "variable d'env" (The Twelve-Factors App).
#JaiDécidé que je n'allais suivre la mode, que je vais continuer à utiliser Convict.
Une heure plus tard, j'ai changé d'avis Comment définir la valeur par défaut des variables d'environement dans SvelteKit ?
Journal du mercredi 01 mai 2024 à 16:06
Je suis en train de lire la documentation de dotenv-vault, j'ai beau relire plusieurs fois cette documentation, je n'arrive pas à comprendre où est stocker la configuration 🤔.
5 minutes après, je pense avoir compris, la libraire dotenv-vault est basé sur le service SaaS https://www.dotenv.org/.
5 minutes après, #JaiLu Dotenv Vault vs Infisical | Dotenv.
En 2024, quelle est la librairie JavaScript de configuration management la plus populaire ?
Dans l'application web que je développe pour Value Props, je n'utilise actuellement aucune librairie de configuration pour l'app.
J'utilise uniquement process.env.CONFIG_PARAM || "default value".
En contexte, cela ressemble à ceci.
import nodemailer from "nodemailer";
let transporter;
if (process.env?.SMTP_USER && process.env?.SMTP_PASS) {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: true,
auth: {
user: process.env.SMTP_USER,
pass: process.env.SMTP_PASS
}
});
} else {
transporter = nodemailer.createTransport({
host: process.env.SMTP_HOST || "127.0.0.1",
port: process.env.SMTP_POST || 1025,
secure: false
});
}
export default transporter;
Je commence maintenant à utiliser des paramètres de configuration à différents endroits. Conséquence, je me dis que c'est peut-être maintenant le bon moment pour utiliser une librairie de configuration du type Convict.
Pourquoi j'ai cité Convict ? Parce que c'était le choix que j'avais fait en 2019, dans le projet gibbon-mail.
#JeMeDemande qu'elle est en 2024, la librairie [Javascript] de type environment-variables, configuration-management la plus populaire actuellement.
Pour répondre à cette question, j'ai commencé à faire une recherche sur npm trends et il m'a proposé la suggestion suivante config vs configstore vs convict vs cross-env vs dotenv
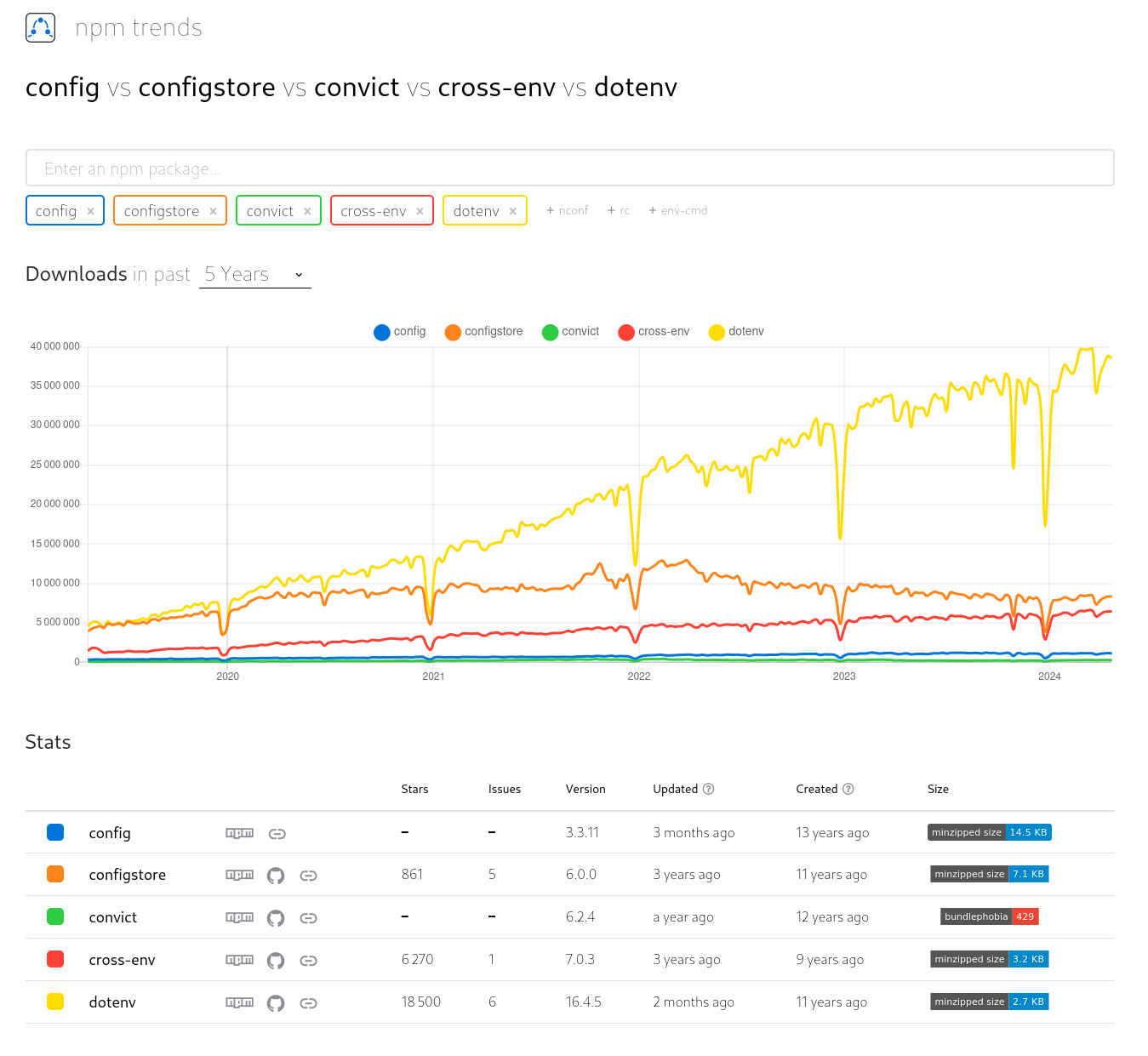
dotenv semble se détacher assez franchement.
dotenv et cross-env sont listés dans Delightful Node.js packages and resources.
Je constate que cross-env est abandonné et conseille ici de migrer vers env-cmd.
Je vais demander avis à des amis, mais pour le moment, je pense que je vais utiliser dotenv.
Quelque heure plus tard :
Journal du mercredi 01 mai 2024 à 14:05
En lien avec 2024-05-01_1205 :
#JeMeDemande si je peux utiliser le moteur de template EJS pour parser et render le template présent dans le markdown pour ensuite lancer le rendu markdown.
Je n'ai pas réussi à trouver mention de fonctionnalité de loop ou condition dans la documentation du plugin Obsidian Templater mais après lecture de ces deux threads :
il semble que Templater supporte bien les fonctionnalités permettant d'implémenter des loop et condition dans un template.
Je pense que cela va me servir de source d'inspiration pour 2024-05-01_1205.
Journal du mercredi 01 mai 2024 à 13:05
En lien avec 2024-05-01_1205, dans le code source du plugin Obsidian nommé Templater, #JaiDécouvert la librairie Javascript rusty_engine :
A Javascript templating engine in WASM
En dehors de l'aspect performance, je me demande si cette librairie serait plus adaptée à mes besoins que EJS 🤔.
D'après toi, quel problème a cherché à résoudre Svelte ?
D'après toi, quel problème a cherché à résoudre Svelte ?
Comme le dit ici Richard Harris :
The first version of Svelte was all about testing a hypothesis — that a purpose-built compiler could generate rock-solid code that delivered a great user experience. The second was a small upgrade that tidied things up a bit.
Je pense que la réponse se trouve dans ce billet https://svelte.dev/blog/frameworks-without-the-framework
D'après ce que j'ai compris il voulait tester si une librairie compilé pourrait :
- Générer des projets plus petit
- Générer des projets plus rapide
- Apporté des choses élégantes
Après les résultats de ce POC et 8 ans plus tard, je pense que les réponses à ces questions étaient oui.
J'ai lu ce billet il y a plusieurs année, je n'ai pas pris le temps de le relire.
Je me demande si LogSeq utilise CodeMirror 🤔
En pensant au projet Projet -1 "CodeMirror, autocomplétion, Svelte", je me suis demandé si le projet OpenSource LogSeq utilise ou non CodeMirror.
Je suis aller voir le code source et j'ai constaté que la réponse est oui, LogSeq utilise CodeMirror. J'ai un peu plus creusé et je suis tombé dans cette partie du code qui je pense implémente la fonctionnalité d'auto complétion de l'éditeur de LogSeq.
Problème 😔, je n'ai aucune connaissance dans le langage Closure et il m'est difficile de comprendre cette implémentation et de m'en servir dans mon POC.
Pourquoi j'apprécie le framework SvelteKit ?
La partie que je préfère de plus dans le framework SvelteKit ce sont les fonctionnalités décrient dans la section Routing et Advanced routing de la documentation de SvelteKit.
Si vous survolez ces pages de documentation, vous allez peut-être me poser la question « ok et alors, c'est quoi le truc cool ? ». Je ne vais pas vous répondre maintenant, parce que c'est intégralité de ces deux pages de documentations qui faut lire avec une très grande attention. En utilisant SvelteKit dans plusieurs projets, j'ai appris à découvrir toutes les petites subtilités du système de rooting de SvelteKit.
#JaimeraisUnJour prendre le temps de paraphraser avec mes mots cette documentation pour partager avec vous l'enthousiasme que j'ai à l'égard de SvelteKit.
Est-ce que Nuxt ou NextJS sont moins élégants que SvelteKit ? Pour le moment, je ne sais pas, je n'ai pas pris assez de temps pour pousser assez loin la comparaison. C'est l'objectif de Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit".
Un ami est heureux d'utiliser Nuxt (VueJS), je suis heureux pour lui 🙂
Un ami me partage la satisfaction qu'il a à utiliser la version 3 de Nuxt :
Nuxt3 est devenu magnifique avec le combo Nuxt/Font, Nuxt/i18n, Tailwind CSS, sa couche server pour proxy une api sous le boisseau. Ça en fait un framework redoutable.
Suite à la lecture de ce commentaire, #JeMeDemande s'il est autant satisfait de Nuxt3 que je le suis de SvelteKit 🤔.
Je souhaite depuis longtemps — début 2023 — réaliser ces deux projets :
- Projet - 2 "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit"
- Projet 3 - "Réaliser un petit projet basé sur Nuxt pour le comparer avec SvelteKit"
pour être en capacité de donner mon opinion éclairée de comparaison entre ces trois frameworks NextJS, Nuxt et SvelteKit.
Pour le moment, je me contente de recevoir avec plaisir le bonheur de mon ami et je garde en mémoire son expérience, pour la partager le jour où un ami de demandera mon avis au sujet de Nuxt.
Première itération d'un POC de CodeMirror avec l'autocomplétion
#JaiPublié https://github.com/stephane-klein/svelte-codemirror-autocomplete-poc qui contient mes 2 premières heures de travail sur le #POC Projet 1 - "CodeMirror, autocomplétion, Svelte".
J'ai réussi à setup le projet, mais pour le moment, je n'arrive pas à bien configurer la fonctionnalité autocomplete de CodeMirror. Par exemple, je n'arrive pas à ne pas afficher les caractères [[ dans le popup qui affiche la liste des suggestions.
Idéalement, pour expliquer, j'aimerais réaliser un screencast.
Je pense que ce POC va me prendre du temps. Je pense que je vais devoir étudier en profondeur l'API de @codemirror/autocomplete.
#SiJeDevaisParier, mon estimation de durée 🤔 serait de 8h à 20h de travail.
Journal du lundi 29 avril 2024 à 11:04
Dans l'application web de mon projet Value Props, j'utilise la librairie sveltekit-i19n qui propose la fonctionnalité suivante :
Module-based – your translations are loaded for visited pages only (and only once!)
Actuellement, j'ai configuré les modules suivants :
❯ tree src/lib/translations
src/lib/translations
├── en
│ ├── all_data.json
│ ├── buttons.json
│ ├── login.json
│ ├── menu.json
│ ├── my_password.json
│ ├── my_preferences.json
│ ├── question_answers.json
│ ├── question_setup.json
│ ├── question_status.json
│ ├── space_data.json
│ ├── space_edit.json
│ ├── space.json
│ ├── space_members.json
│ ├── space_questions.json
│ ├── spaces.json
│ ├── space_slides.json
│ └── space_status.json
├── fr
│ ├── all_data.json
│ ├── buttons.json
│ ├── login.json
│ ├── menu.json
│ ├── my_password.json
│ ├── my_preferences.json
│ ├── question_answers.json
│ ├── question_setup.json
│ ├── question_status.json
│ ├── space_data.json
│ ├── space_edit.json
│ ├── space.json
│ ├── space_members.json
│ ├── space_questions.json
│ ├── spaces.json
│ ├── space_slides.json
│ └── space_status.json
├── index.js
├── lang.json
└── README.md
3 directories, 37 files
Je viens à nouveau de me casser la tête parce que j'ai besoin d'une traduction présente dans le module space_data dans une page qui ne fait pas partie de ce module.
Cela m'arrive très très souvent et je m'en veux, je n'ai pas respecté le principe YAGNI !
Dès le début d'l'implémentation de cette application, j'ai voulu faire les choses "bien" et j'ai commencé à utiliser la fonctionnalité "module" de la librairie !
Je suis persuadé que c'est une optimisation inutile pour le moment. Le découpage en module est difficile.
Encore une expérience qui me confirme que je dois toujours suivre par défaut le principe suivant du Zen of Python :
Flat is better than nested.
Je pense me créer pour ce projet une tâche de dette technique, de refactoring dont le but sera de migrer tous les modules vers un seul module — un seul fichier).
Seulement, le jour où je travaillerai sur la performance de chargement des pages, je réfléchirai à un découpage "intelligent" des traductions en modules.
Journal du lundi 25 mars 2024 à 20:00
Après 11 mois de procrastination, j'ai enfin pris le temps de faire ce script https://github.com/stephane-klein/toggl-report-helper-script
Au départ, j'hésitais entre une implémentation en Python ou en JavaScript. J'ai finalement opté pour JavaScript, car cela correspond à ma nouvelle doctrine.
Même si Python reste le langage que j'affectionne profondément, que je trouve toujours aussi élégant, j'ai pris la décision de me consacrer pleinement à JavaScript.
Journal du vendredi 06 octobre 2023 à 20:00
Cette après midi, j'hésite à migrer le projet sveltekit-tendaro-webshell-skeleton de Javascript vers TypeScript.
Je me demande si :
- cela en vaut la peine ;
- étant donné que je n'ai jamais fait pour de vrai un projet en TypeScript, est-ce que je ne risque pas de tomber dans un Yak! 🤔.
Actuellement ma doctrine concernant TypeScript est la suivante.
Si je dois coder et publier une librairie sur npm alors, je choisis TypeScript.
Quand je dis librairie, je parle de librairie qui contient des classes, des fonctions ou des composants importés par d'autres projets.
Pourquoi est-ce que je choisis d'utiliser TypeScript pour les librairies ?
- Je permets aux développeurs qui utilisent TypeScript dans leur projet, de pouvoir bénéficier de la documentation, l'autocomplétion, la détection des erreurs… de la librairie que j'aurais mise à disposition ;
- Je n'ai pas vérifié, mais je pense que le typage de TypeScript permet à des outils d'auto générer une grande partie de la documentation d'une librairie.
Si je dois coder une application web, alors pour le moment, je choisis JavaScript.
Le code implémenté dans une application web, n'est généralement pas utilisé par des utilisateurs "externes". Par conséquent, je ne trouve pas très important de mettre à disposition une documentation aux autres développeurs. Je pense qu'à petite taille, l'effort ne vaut pas la peine. Ma réponse est peut-être différente si 10, 20… développeurs contribuent à la même base code 🤔.
- Généralement, le code d'une application web est plutôt simple, beaucoup de CRUD et peu de librairie complexe.
- Pour le moment, je pense que l'effort d'ajouter le boilerplate code de typage TypeScript (importer les types, d'ajouter le typage dans le code) ne sera pas compensé par les fonctionnalités de détection d'erreurs , d'autocomplétions et de refactoring que permet TypeScript.
Mais je me dis que je me trompe peut-être, peut-être que si j'essaie, je vais me rendre compte que j'aime bien cela et que cela me fera gagner du temps ou alors améliorera mon confort, mon plaisir de développement 🤔.
Tâches à faire si je souhaite migrer à TypeScript :
- [ ] Implémenter une déclinaison de
sveltekit-ssr-skeletonen TypeScript - [ ] Modifier mon environnement Neovim pour activer les fonctionnalités suivantes :
- [ ] Support de l'autocomplétion TypeScript
- [ ] Support de la détection des erreurs TypeScript
- [ ] Support des fonctions de refactoring TypeScript
- [ ] Affichage en "live" de la documentation des composants, fonctions…
Ressources à lire avant pour avancer sur ce sujet :
Projet 6 - "SvelteFlow playground"
Date de la création de cette note : 2024-05-17 .
Quel est l'objectif de ce projet ?
Je souhaite essayer de réaliser avec Svelte Flow, une page web qui permet de :
- Glisser / déposer 2 types d'objets vers un flow container.
- Permettre de saisir du texte dans ces deux types d'objets.
- Permettre de relier les objets de type 1 vers ceux de type 2 et inversement.
- Interdire les liaisons entre des objets de même type.
Idéalement j'aimerais que les objets soient placés "harmonieusement" entre eux dans le flow container.
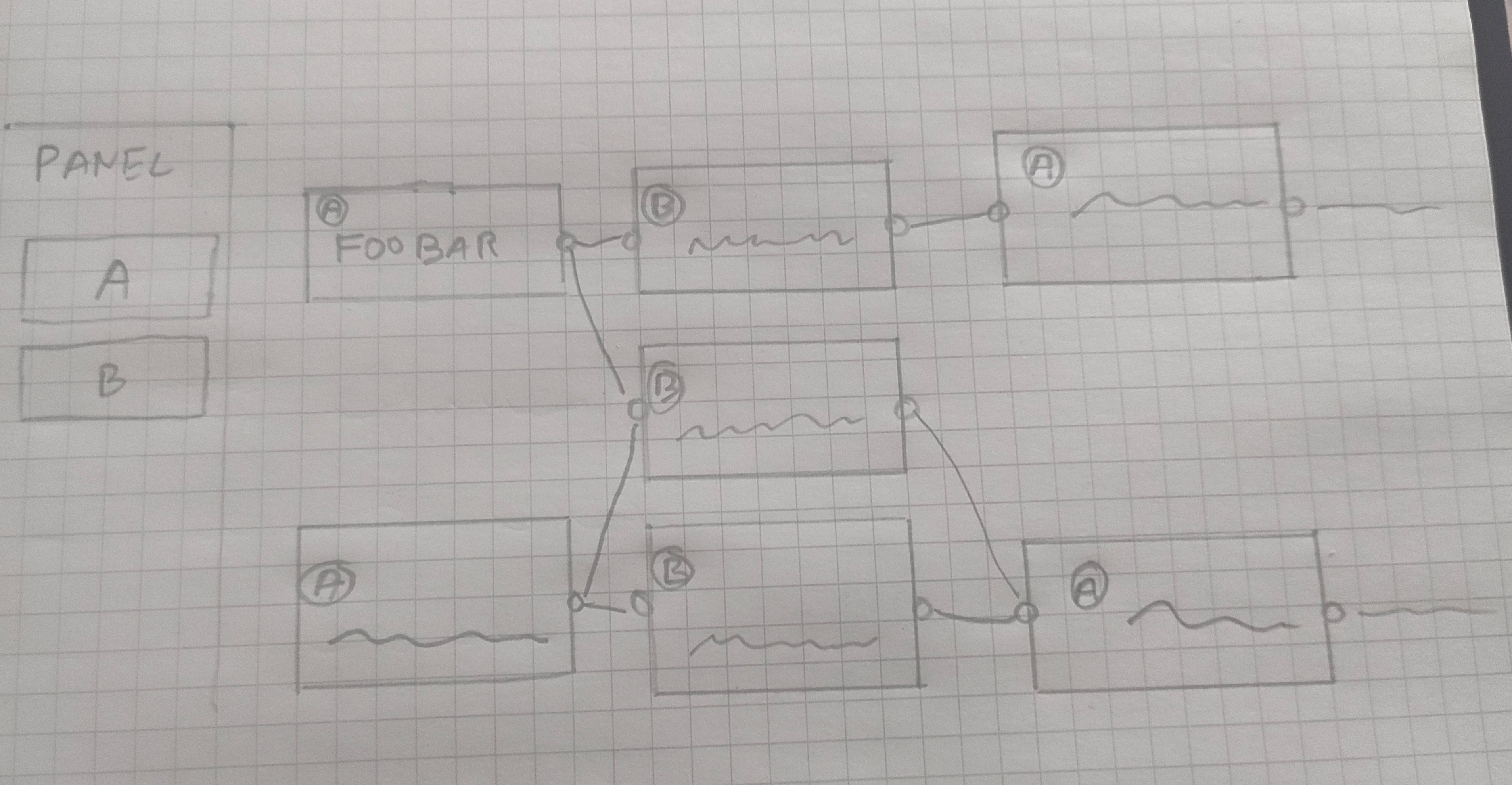
Pourquoi je souhaite réaliser ce projet ?
Je besoin de créer ce type d'éditeur dans mon projet Value Props
Repository de ce projet :
Ressources :
- Documentation de SvelteFlow : https://svelteflow.dev/learn
Résultat
2024-05-22 : je déclare le projet terminé.
Voir détail dans cette note : 2024-05-22_1033
Projet 5 - "Importation d'un vault Obsidian vers Apache Age"
Date de la création de cette note : 2024-05-02.
Quel est l'objectif de ce projet ?
Je souhaite essayer d'implémenter un script d’importation d’un vault Obsidian vers la Base de données Graph Apache Age, avec importation des tags, alias.
Pourquoi je souhaite réaliser ce projet ?
Pour progresser en Cypher. À cause de 2024-04-30_1704.
Repository de ce projet :
https://github.com/stephane-klein/obsidian-vault-to-apache-age-poc/
Plus d'informations sur ce projet :
Projet 4 - "Je souhaite apprendre les bases d'utilisation de Apache Age"
Date de la création de cette note : 2024-05-02
J'ai commencé ce projet le 20 avril 2024
Quel est l'objectif de ce projet ?
Je souhaite dans un premier temps être capable de reproduire ce que j'avais fait dans le projet neo4j-playground et peut être même ensuite d'aller un peu plus loin dans mon apprentissage du langage de Query Cypher.
Pourquoi je souhaite réaliser ce projet ?
J'ai envie d'ajouter à ma stack de compétence, un moteur de base de données orienté Graph. Idéalement, j'aimerais que ça soit Apache Age parce que c'est un projet libre et basé sur PostgreSQL. Cela me permettrait de facilement coupler les avantages d'une base de données relationnel avec une base de données Graph.
Repository de ce projet :
https://github.com/stephane-klein/apache-age-playground
Idées après ce projet :
Si j'arrive à terminer ce projet, j'ai les idées suivantes :
- Écrire un script d'importation d'un vault Obsidian vers Apache Age, avec importation des tags, alias. => voir Projet 5
- Écrire des scripts de benchmark pour comparer PostgreSQL vs Apache Age sur les aspects suivants : vitesse de lecture, vitesse d'écriture et espace disque consommé.
Projet 2 - "Réaliser un petit projet basé sur NextJS pour le comparer avec SvelteKit"
Date de la création de cette note : mardi 30 avril 2024.
Quel est l'objectif de ce projet ?
Ce projet remplace l'issue Étudier la version 12 de NextJS que j'ai créé en mars 2023.
Contexte : J'utilise SvelteKit depuis avril 2022, j'apprécie très fortement l'élégence de toutes les fonctionnalités de routing de SvelteKit.
Mon objectif est de créer un projet de type #POC pour apprendre les bases de NextJS et de comparer ce framework avec SvelteKit.
Artefacts à produire :
- Un repository GitHub qui contient le projet de type POC que j'aurais réaliser pour apprendre à utiliser NextJS
- Une note d'opinion qui présente ma comparaison entre SvelteKit et NextJS
Objectif secondaire de ce projet:
Je pense pas dire de bétise, en déclarant qu'en 2024 ReactJS est plus populaire que VueJS et Svelte, par conséquent, je pense que maitriser Nuxt me sera utile à l'avenir, par exemple pour des projets en freelance.
Je souhaite ajouter Nuxt sur mon CV.
Repository de ce projet :
Aucun pour le moment.
Ressources :
- Voir les notes que j'ai prise dans l'issue Étudier la version 12 de NextJS
🏛️ The fastest and tiniest utility for conditionally joining classNames.
Article wikipedia : https://en.wikipedia.org/wiki/You_aren't_gonna_need_it
[ << Page précédente (50) ] | [ Page suivante (7) >> ]