
Journaux
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
Résultat de la recherche (908 notes) :
Dimanche 15 février 2026
Journal du dimanche 15 février 2026 à 15:23
#JaiDécouvert l'effet Zeigarnik que je n'arrive pas encore à bien maîtriser.
#JaiDécouvert aussi l'effet What the hell ou en français l'effet "Et puis merde".
Mardi 10 février 2026
Vendredi 9 janvier 2026
Journal du vendredi 09 janvier 2026 à 10:11
Dans Nouvelles sur l’IA de décembre 2025 #JaiDécouvert METR - Model Evaluation & Threat Research :
Claude Opus 4.5 rejoint la maintenant célèbre évaluation du METR. Il prend largement la tête (sachant que ni Gemini 3 Pro, ni ChatGPT 5.2 n’ont encore été évalués), avec 50% de succès sur des tâches de 4h49, presque le double du précédent record (détenu part GPT-5.1-Codex-Max, avec 50% de succès sur des tâches de 2h53). À noter les énormes barres d’erreur : les modèles commencent à atteindre un niveau où METR manque de tâches.
Lundi 29 décembre 2025
J'ai découvert upterm qui permet de partager facilement une session terminal à distance
J'ai cherché une solution pour partager facilement une session shell de ma workstation à un collègue.
Je connais les solutions suivantes :
$ ngrok tcp 22
Donne : tcp://0.tcp.ngrok.io:12345
# Connexion : ssh user@0.tcp.ngrok.io -p 12345
- Tmate, un fork de tmux patché, en C, projet qui a débuté en 2007
- cloudflared
#JaiDécouvert aujourd'hui les solutions upterm et bore.
Le projet upterm a commencé en 2019 et est codé en Golang. Le projet bore est plus jeune, il a commencé 2022 et est codé en rust.
J'ai testé bore puis upterm. J'ai retenu upterm pour les raisons suivantes :
- upterm propose directement un package rpm, contrairement à bore
- Le serveur relais public de upterm était significativement plus réactif que celui de bore lors de mes tests
- upterm propose nativement une session partagée entre deux utilisateurs, alors que bore est spécialisé dans la création de tunnels TCP. Il est possible de configurer bore pour lancer automatiquement des sessions partagées via un script tmux lancé par ssh, mais c'est moins pratique que upterm
Voici une démonstration de upterm :
$ sudo dnf install -y https://github.com/owenthereal/upterm/releases/download/v0.20.0/upterm_linux_amd64.rpm
Je peux ensuite autoriser la clé publique ssh de l'utilisateur invité :
$ upterm host --authorized-keys PATH_TO_PUBLIC_KEY
ou directement via son username GitHub :
$ upterm host --github-user username
Pour donner accès à une session terminal :
$ upterm host
The authenticity of host 'uptermd.upterm.dev (2a09:8280:1::3:4b89)' can't be established.
ED25519 key fingerprint is SHA256:9ajV8JqMe6jJE/s3TYjb/9xw7T0pfJ2+gADiBIJWDPE.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
╭─ Session: LiZaF6eKfCTxNeFSEt7B ─╮
┌──────────────────┬─────────────────────────────────────────────┐
│ Command: │ /usr/bin/zsh │
│ Force Command: │ n/a │
│ Host: │ ssh://uptermd.upterm.dev:22 │
│ Authorized Keys: │ n/a │
│ │ │
│ ➤ SSH Command: │ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev │
└──────────────────┴─────────────────────────────────────────────┘
╰─ Run 'upterm session current' to display this again ─╯
🤝 Accept connections? [y/n] (or <ctrl-c> to force exit)
✅ Starting to accept connections...
L'utilisateur invité accède à ce terminal simplement avec :
$ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev
upterm maintient une liste de sessions ouvertes, consultable avec :
$ upterm session list
📡 Active Sessions (1)
═══════════════════════
┌───┬──────────────────────┬──────────────┬─────────────────────────────┐
│ │ SESSION ID │ COMMAND │ HOST │
├───┼──────────────────────┼──────────────┼─────────────────────────────┤
│ * │ DumRFGF6AuinQjzwBf0E │ /usr/bin/zsh │ ssh://uptermd.upterm.dev:22 │
└───┴──────────────────────┴──────────────┴─────────────────────────────┘
💡 Tips:
• Use 'upterm session current' to see details
• Use 'upterm session info <SESSION_ID>' for specific session
Mercredi 24 décembre 2025
J'ai découvert AIChat, alternative à llm cli
Dans ce thread, #JaiDécouvert AIChat (https://github.com/sigoden/aichat), une alternative à llm (cli) codée en Rust.
AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
En parcourant le README.md, j'ai l'impression que AIChat propose une meilleure UX que llm (cli).
Je constate aussi que AIChat offre plus de fonctionnalités que llm (cli) :
- AI Tools & MCP
- AI Agents
- LLM Arena
- La partie RAG semble plus avancée
Ce qui attire le plus mon attention, c'est le sous-projet llm-functions qui, d'après ce que j'ai lu, permet de créer très facilement des tools en Bash, Python ou Javascript. Exemples :
J'ai hâte de tester ça 🙂 ( #JaimeraisUnJour ).
Par contre, llm-functions ne semble pas encore permettre la configuration de Remote MCP server.
Je suis aussi intéressé par cette issue : TUI for managing, searching, and switching between chat sessions.
Un point qui m'inquiète un peu : le projet semble peu actif ces derniers mois.
Mardi 23 décembre 2025
J'ai découvert la méthode NVIM_APPNAME qui permet de lancer des instances cloisonnées de Neovim
Il y a plus d'un an, j'ai écrit cette note où je décrivais la méthode que j'avais trouvée après plusieurs itérations pour lancer plusieurs instances Neovim cloisonnées.
J'ai publié cette méthode dans neovim-playground, qui ressemble à ceci :
export XDG_CONFIG_HOME=$(PWD)/config/
export XDG_DATA_HOME=$(PWD)/local/share/
export XDG_STATE_HOME=$(PWD)/local/state/
export XDG_CACHE_HOME=$(PWD)/local/cache/
Je me suis senti un peu bête aujourd'hui en découvrant dans la documentation officielle de Neovim qu'il existe une méthode officielle pour isoler une instance Neovim :
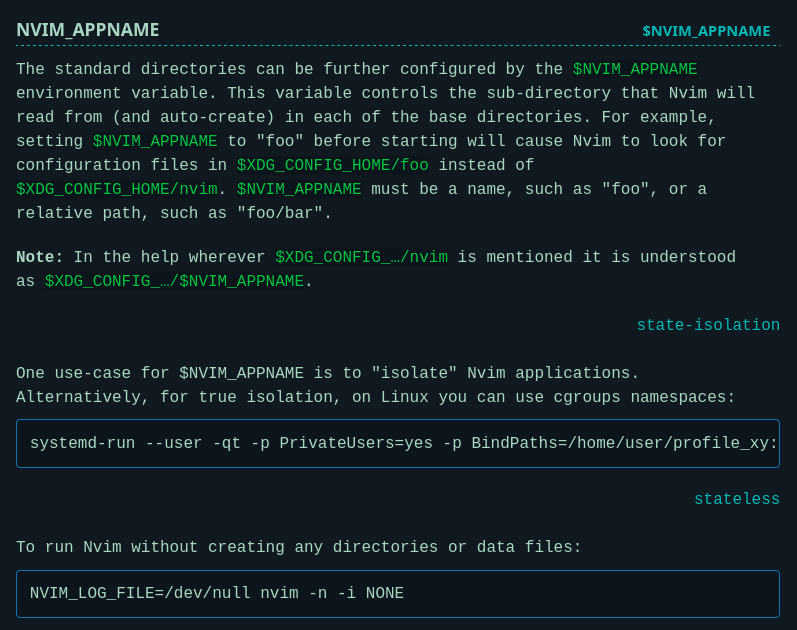
Cette fonctionnalité a été ajoutée dans la version 0.9.0 d'avril 2023, suite à une demande d'utilisateurs qui avaient le même besoin que moi, décrite dans cette issue : NVIM_APPNAME: isolated configuration profiles
Dans cette documentation, #JaiDécouvert comment lancer une application dans un namespace cgroups :
$ systemd-run --user -qt -p PrivateUsers=yes -p BindPaths=/home/user/profile_xy:/home/user/.config/nvim nvim
Je trouve cela plutôt simple.
Coïncidence : j'ai découvert systemd-run il y a 3 mois et depuis, je croise cette commande de plus en plus souvent.
Comme je souhaite lancer un environnement cloisonné Neovim tout en conservant l'accès aux outils de mon terminal (comme ceux installés avec Mise), j'ai choisi d'utiliser la méthode basée sur NVIM_APPNAME.
J'ai testé cette méthode avec succès dans neovim-playground (commit).
Lundi 22 décembre 2025
J'ai découvert le concept de "catch up culture"
J'ai été heureux de découvrir le 5 décembre dernier, #NouveauMot pour exprimer un concept que j'observe depuis des années : "catch up culture".
Voici le parcours médiatique du concept :
- mai 2025, publication du livre Bad Friend qui formalise le concept de "catch up culture"
- 23 occtobre sur Reddit : Tired of being the « catch-up » friend instead of the one people create new memories with
- 30 octobre sur Dazed : Are we caught in a culture of never-ending catch-ups?
- 20 novembre sur France Inter : "Catch up culture", quand l'amitié devient artificielle
- 30 novembre sur Huffington Post : Si vos discussions entre amis sont de moins en moins profondes, c’est à cause de la « catch up culture »
- 5 décembre sur Madame Figaro : Qu’est-ce que la «catch up culture», quand nos amitiés ne consistent plus qu’à se voir pour faire des «mises à jour» de nos vies ?
Et le 5 décembre, ma compagne me fait découvrir le terme catch up culture.
La "catch up culture" c'est quand on voit ses amis uniquement pour se raconter ce qu'on a fait depuis la dernière fois, plutôt que de vivre des moments ensemble. Les amitiés deviennent alors des séances de rattrapage espacées (que ce soit de 2 mois, 6 mois, 1 an ou 2 ans) où on échange surtout des anecdotes et des souvenirs communs. On reste sur les grandes lignes sans rentrer dans les détails importants, de peur d'ennuyer l'autre, parce qu'au fond on ne fait plus vraiment partie de sa vie.
Je le vis régulièrement quand je retourne à Metz une à deux fois par an, pour voir mes amis pongistes par exemple, avec qui j'ai vécu pendant parfois plus de 10 ans des aventures humaines mémorables. Même chose avec d'anciens collègues.
J'ai énormément de mémoire transactive avec eux. Quand je les revois, c'est fluide, ils me sont familiers, j'ai l'impression de les avoir vus hier. Ils sont importants pour moi. J'ai l'impression de les connaître avec un assez haut niveau d'intimité. Je connais leurs forces et faiblesses, j'ai confiance en eux, ce sont de vrais amis.
Par contre, à chaque fois que je les vois, j'ai la même sensation : on tourne en rond, on pratique du "catch up". On se raconte encore et encore nos anecdotes communes, nos souvenirs communs. On ne fait plus rien ensemble à part partager un bon repas. Plus de nouveaux "faits d'arme" !
Je n'aime pas et je n'ai jamais aimé pratiquer le small talk ou faire du baratinage. J'aime apprendre des choses des autres, et pour ça j'aime aller dans le détail, dépasser le catalogue de leurs dernières vacances ou de leurs aménagements de maison secondaire. Pour cela, j'essaie de privilégier des rencontres one-on-one (en tête-à-tête). J'ai découvert cela notamment dans le livre Never Eat Alone que j'ai survolé en 2016.
Je constate que les discussions en tête-à-tête sont d'autant plus intéressantes avec des amis avec qui on est en très forte confiance. Elles permettent :
- Profondeur de connexion : Les conversations en tête-à-tête permettent d'aller au-delà des banalités, et donc des échanges purement catch up, pour vraiment comprendre les motivations, défis et aspirations de l'autre personne.
- Vulnérabilité et confiance : Il est plus facile d'être authentique et de partager des choses personnelles dans un cadre intimiste.
- Attention non divisée : On peut vraiment écouter et être présent, sans les distractions d'un groupe et surtout, sans avoir peur d'ennuyer tout le monde en entrant dans les détails.
C'est un peu dans l'espoir de passer tout de suite au-delà de l'étape "catch up" que j'ai créé ma page NowNowNow, sans toutefois me faire d'illusion. En dehors de 1 ou 2 amis, personne ne connaît ou ne consulte cette page. Mais ça n'a pas d'importance pour moi, je le fais quand même, l'idée me plaît.
Quelques jours avant un dîner en tête-à-tête, j'aime prendre le temps de penser aux sujets de conversation qui pourraient nous intéresser tous les deux : partager mes nouvelles découvertes, mes nouveaux concepts et avoir le point de vue de la personne. J'aime savoir quels sont ses défis actuels, et j'essaie de lui poser des questions dans ce sens, pour lui permettre de formaliser sa pensée et pour apprendre d'elle, découvrir de nouvelles situations.
La prochaine fois que je vous propose une rencontre en tête-à-tête, vous saurez pourquoi 🙂.
Jeudi 11 décembre 2025
J'ai découvert l'extension Firefox Unlock Medium Article
#JaiDécouvert extension Firefox pour bypass l'obligation de créer un compte Medium pour consulter un article des articles Medium : Unlock Medium article.
L'extension se base sur le site web : https://freedium.cfd.
Mercredi 3 décembre 2025
Journal du mercredi 03 décembre 2025 à 06:58
#JaiDécouvert usql (https://github.com/xo/usql) qui semble être une alternative à pgcli, écrit en Golang.
Je ne l'ai pas encore testé.
Lundi 1 décembre 2025
J'ai découvert class-variance-authority et tailwinds-variants
Jusqu'à présent, pour la gestion conditionnelle des classes CSS dans mes projets ReactJS ou Svelte, j'utilisais clsx.
Pour Svelte en particulier, j'utilise souvent directement le mécanisme conditionnel natif de l'attribut "class" du framework.
Aujourd'hui, dans un projet professionnel ReactJS, #JaiDécouvert la librairie conditionnelle class-variance-authority.
Cette librairie existe depuis debut 2022 et voici un exemple d'utilisation de class-variance-authority :
<script>
import { cva } from 'class-variance-authority';
const button = cva(
'font-semibold rounded', // équivalent au paramètre `base:` utlisé par tailwind-variants
{
variants: {
intent: {
primary: 'bg-blue-500 text-white hover:bg-blue-600',
secondary: 'bg-gray-200 text-gray-900 hover:bg-gray-300'
},
size: {
sm: 'px-3 py-1 text-sm',
md: 'px-4 py-2 text-base',
lg: 'px-6 py-3 text-lg'
}
},
compoundVariants: [
{
intent: 'primary',
size: 'lg',
class: 'uppercase tracking-wide' // <= appliqué seulement si intent="primary" et size="lg"
}
],
defaultVariants: {
intent: 'primary',
size: 'md'
}
}
);
export let intent = 'primary';
export let size = 'md';
</script>
<button class={button({ intent, size })}>
<slot />
</button>
Je trouve cette approche plus élégante que clsx pour des besoins complexes, comme la création d'un design system.
Dans la même famille de librairie, il existe aussi tailwind-merge que j'avais déjà identifié mais sans avoir jamais pris le temps d'étudier. Ses fonctionnalités sont très simples et minimalistes :
Merge Tailwind CSS classes without style conflicts
Claude Sonnet 4.5 m'a fait découvrir tailwind-variants, une alternative à class-variance-authority. Cette lib est spécifique à Tailwind CSS mais offre de meilleures performances et des fonctionnalités supplémentaires par rapport à class-variance-authority.
Le projet a été créé début 2023, soit environ 1 an après class-variance-authority.
Voici un tableau comparant les fonctionnalités de tailwind-variants et class-variance-authority :
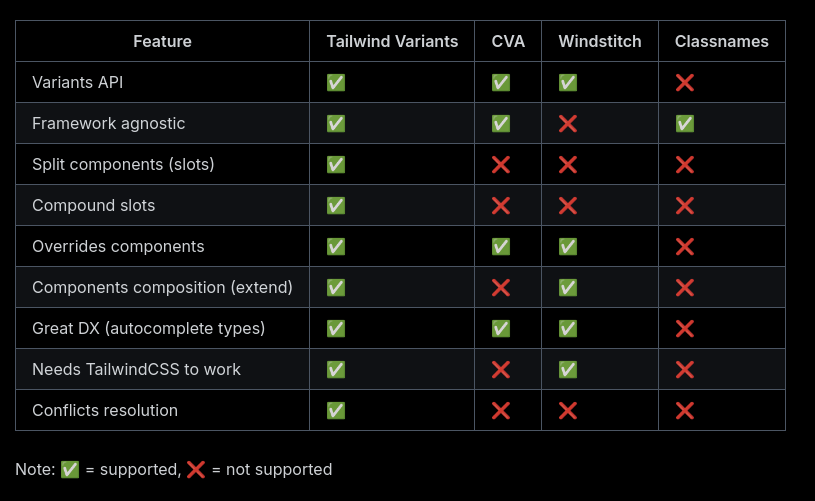
La dernière section de la page Tailwind Variants - Comparison explique l'historique de la lib avec class-variance-authority et les raisons qui ont motivé sa création.
Après quelques difficultés, je pense avoir saisi l'intérêt de la fonctionnalité "slots", disponible dans tailwind-variants mais absente de class-variance-authority.
Si un jour je dois créer des composants de design system avancés dans un projet ReactJS ou Svelte, je pense que j'utiliserai tailwind-variants.
J'ai découvert Adminer, alternative à PhpMyAdmin et je me suis intéressé à OPCache
En travaillant sur un playground d'étude de Podman Quadlets, dans le README.md de l'image Docker mariadb, #JaiDécouvert le projet Adminer (https://www.adminer.org) qui semble être l'équivalent de PhpMyAdmin, mais sous la forme d'un fichier unique.
Je découvre aussi que contrairement à PhpMyAdmin, Adminer n'est pas limité à Mysql / MariaDB, il supporte aussi PostgreSQL.
En regardant le dépôt GitHub d'Adminer, je découvre que le gros fichier PHP de 496 kB est le résultat de la concaténation de nombreux fichiers php.
Ça me rassure, parce que je me demandais comment l'édition d'un fichier unique de cette taille pouvait être humainement gérable.
Je trouve astucieux ce mode de déploiement d'un projet PHP sous forme d'un seul fichier qui me fait penser à la méthode Golang. Cependant, je me pose des questions sur la performance de cette technique étant donné que PHP fonctionne en mode process-per request (CGI), ce qui signifie que ce gros fichier PHP est interprété à chaque action sur la page 🤔.
En creusant un peu le sujet avec Claude Sonnet 4.5, je découvre que depuis la version 5.5 de PHP, OPCache améliore significativement la vitesse des requêtes PHP, sans pour autant atteindre celle de Golang, NodeJS, Python ou Ruby qui utilisent des serveurs HTTP intégrés. La consommation mémoire reste supérieure dans des conditions d'implémentation comparables.
Avec OPCache, Adminer semble rester performant malgré l'utilisation d'un fichier unique.
Vendredi 21 novembre 2025
Journal du vendredi 21 novembre 2025 à 14:32
Via Claude Sonnet 4.5, #JaiDécouvert le projet Massive Text Embedding Benchmark qui compare les embeddings Models.
Voici le site de documentation, son dépôt GitHub, et son leaderboard qui liste actuellement 319 models, dont 180 supportant le français.
Journal du vendredi 21 novembre 2025 à 13:56
Dans ce commentaire, #JaiDécouvert le site models.dev (https://models.dev) qui est entre autres une alternative à llm-prices.
Journal du vendredi 21 novembre 2025 à 12:03
Dans ce thread, #JaiDécouvert OpenCode (https://github.com/sst/opencode) qui semble être une alternative à Aider et Claude Code.
Après avoir parcouru la documentation, j'ai l'impression qu'OpenCode propose des fonctionnalités et une User experience plus avancées qu'Aider.
Le projet est récent (démarré en mars 2025) et publié sous licence MIT.
D'après le footer du site de documentation, je comprends qu'OpenCode est développé par l'entreprise Anomaly, financée par du Venture capital.
#JaiLu ce commentaire à propos d'OpenCode dans les issues d'Aider.
En cherchant sur Hacker News, je suis tombé sur ce thread de juillet 2025.
J'ai retenu ce commentaire :
Two big differences:
opencode is much more "agentic": It will just take off and do loads of stuff without asking, whereas aider normally asks permission to do everything. It will make a change, the language server tells it the build is broken, it goes and searches for the file and line in the error message, reads it, and tries to fix it; rinse repeat, running (say) "go vet" and "go test" until it doesn't see anything else to do. You can interrupt it, of course, but it won't wait for you otherwise.
aider has much more specific control over the context window. You say exactly what files you want the LLM to be able to see and/or edit; and you can clear the context window when you're ready to move on to the next task. The current version of opencode has a way to "compact" the context window, where it summarizes for itself what's been done and then (it seems) drops everything else. But it's not clear exactly what's in and out, and you can't simply clear the chat history without exiting the program. (Or if you can, I couldn't find it documented anywhere.)
Je retiens donc qu'Aider offre un contrôle plus précis qu'OpenCode. OpenCode fonctionne de manière plus autonome.
Pour ma part, je préfère contrôler finement les actions d'un AI code assistant sur mon code, à la fois pour comprendre ses interventions et pour gérer ma consommation de tokens.
Je n'ai pas envie de tester OpenCode pour le moment, je vais continuer avec Aider.
Dimanche 16 novembre 2025
Journal du dimanche 16 novembre 2025 à 19:18
En faisant des recherches à propos de Tailscale, netbird et headscale, #JaiDécouvert : frp, rathole, pangolin et Traefik Sablier Plugin.
Journal du dimanche 16 novembre 2025 à 13:25
Dans la vidéo de Monsieur Phi "L'autonomie des IA expliquée aux humains", #JaiDécouvert le service Mammouth, qui me rappelle un peu OpenRouter.
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
L'objectif produit de Mammouth ressemble pas mal au projet Albert Conversation sur lequel j'ai travaillé à la DINUM entre avril et août 2025.
Samedi 15 novembre 2025
Journal du samedi 15 novembre 2025 à 14:23
Dans ce commentaire, #JaiDécouvert une alternative à Grafana (partie dashboard) : Perses (https://github.com/perses/perses).
For exclusively dashboards, the CNCF has https://perses.dev/, which supports Prometheus Loki and Pyroscope, and has a Grafana importer but I haven't given it a shot.
Jeudi 13 novembre 2025
Journal du jeudi 13 novembre 2025 à 09:26
Dans mon activité professionnelle, #JaiDécouvert cerbos (https://github.com/cerbos/cerbos).
Cerbos is an authorization layer that evolves with your product. It enables you to define powerful, context-aware access control rules for your application resources in simple, intuitive YAML policies; managed and deployed via your Git-ops infrastructure. It provides highly available APIs to make simple requests to evaluate policies and make dynamic access decisions for your application.
Pour le moment je n'ai aucun avis sur cette technologie. Je ne l'ai pas encore étudié.
Ce projet est codé en Golang et a débuté en 2021.
Jeudi 6 novembre 2025
Journal du jeudi 06 novembre 2025 à 13:23
#JaiDécouvert le concept philosophique Homo faber.
En philosophie, la notion d'homo faber fait référence à l'Homme en tant qu'être susceptible de fabriquer des outils.
Journal du jeudi 06 novembre 2025 à 10:28
Dans mon activité professionnelle, #JaiDécouvert Bicep (https://github.com/Azure/bicep) équivalent pour Microsoft Azure de Terraform et CloudFormation.
Je découvre aussi le format ARM Template JSON :
Bicep code is transpiled to standard ARM Template JSON files, which effectively treats the ARM Template as an Intermediate Language (IL).
Dans ce contexte, j'apprends qu'ARM signifie Azure Resource Manager.
Je comprends que le suffixe "rm" dans le nom du provider Terraform d'Azure terraform-provider-azurerm fait référence à "Resource Manager".
Jeudi 30 octobre 2025
Journal du jeudi 30 octobre 2025 à 15:58
#JaiDécouvert le nom officielle de Evil maid attack (from "Is luks unlock with TPM2 more secure?").
#JaiDécouvert Cold boot attack (from "ArchWiki - Trusted Platform Module").
Jeudi 23 octobre 2025
J'ai découvert les types "unknown" et "never" en TypeScript
En TypeScript, dans mon projet professionnel, #JaiDécouvert le type unknown qui ressemble à any mais qui est différent.
Exemple (produit par Claude Sonnet 4.5) avec any :
let value: any;
value.foo.bar(); // No error, even if it crashes at runtime
value.trim(); // No error, even if value is a number
Exemple avec unknown :
let value: unknown;
value.trim(); // Error: Object is of type 'unknown'
// You must narrow the type first
if (typeof value === 'string') {
value.trim(); // OK, TypeScript knows it's a string
}
unknown a été introduit dans la version 3.0 de TypeScript en 2018 : Announcing TypeScript 3.0 - The unknown type.
J'ai trouvé les réponses à cette question StackOverflow intéressantes : 'unknown' vs. 'any'.
C'est peut-être parce que je ne suis pas habitué à la documentation de TypeScript , mais j'ai l'impression que la fonctionnalité unknown n'est pas correctement documentée. Par exemple, je suis surpris de trouver presque rien à son sujet dans la page Everyday-types , ni dans les chapitres "Reference" :
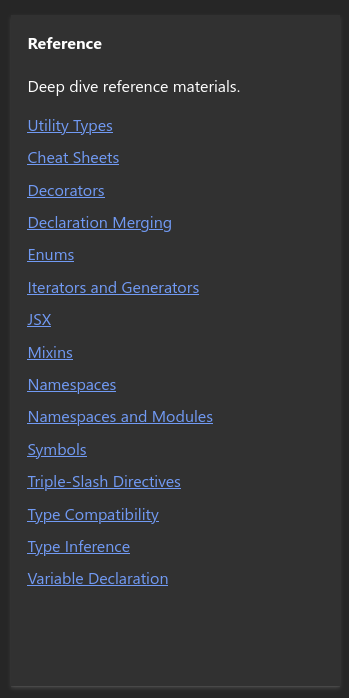
Et rien non plus dans les tutoriels.
Au passage, j'ai aussi découvert le type never.
#JaimeraisUnJour prendre le temps de parcourir la documentation de TypeScript de manière exhaustive. Jusqu'à présent, je n'en ai jamais eu réellement besoin, car je n'ai jamais contribué à de projet écrit en TypeScript. Mais maintenant, cela devient une nécessité pour mon projet professionnel.
Dimanche 19 octobre 2025
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Je fais mon retour dans l'écosystème React, j'ai découvert Jotai et Zustand
Dans le code source de mon projet professionnel, #JaiDécouvert la librairie ReactJS nommée Jotai (https://jotai.org).
Les atom de Jotai ressemblent aux fonctionnalités Svelte Store. Jotai permet entre autres d'éviter de faire du props drilling.
Pour en savoir plus sur l'intérêt de Jotai versus "React context (useContext + useState)", je vous conseille la lecture d'introduction de la page Comparison de la documentation Jotai. J'ai trouvé la section "Usage difference" très simple à comprendre.
Cette découverte est une bonne surprise pour moi, car les atom de Jotai reproduisent l'élégance syntaxique des Store de Svelte, ce qui améliore mon confort de développement en ReactJS. #JaiLu ce thread Hacker News en lien avec le sujet : "I like Svelte more than React (it's store management)".
Je tiens toutefois à préciser que si Jotai améliore significativement mon expérience de développeur (DX) avec ReactJS, cela reste une solution de gestion d'état au sein du runtime ReactJS. En comparaison, le compilateur Svelte génère du code optimisé natif qui reste intrinsèquement plus performant à l'exécution.
Exemple Svelte :
import { writable, derived } from 'svelte/store';
const count = writable(0);
const doubled = derived(count, $count => $count * 2);
// Usage dans component
$count // auto-subscription
Exemple ReactJS basé sur Jotai :
import { atom } from 'jotai';
const countAtom = atom(0);
const doubledAtom = atom(get => get(countAtom) * 2);
// Usage dans component
const [count] = useAtom(countAtom);
J'ai lu la page "Comparison" de Jotai pour mieux comprendre la place qu'a Jotai dans l'écosystème ReactJS.
#JaiDécouvert deux autres librairies développées par la même personne, Daishi Kato : Zustand et Valtio. D'après ce que j'ai compris, Daishi a développé ces librairies dans cet ordre :
- Zustand en juin 2019 - voir "How Zustand Was Born"
- La première version de Jotai en septembre 2020 - voir "How Jotai Was Born"
- La première version de Valtio en mars 2021 - voir "How Valtio Was Born"
J'ai aussi découvert Recoil développé par Facebook, mais d'après son entête GitHub celle-ci semble abandonnée. Une migration de Recoil vers Jotai semble être conseillée.
J'aime beaucoup comment Daishi Kato choisit le nom de ses librairies, la méthode est plutôt simple 🙂 :
Comme mentionné plus haut, Jotai ressemble à Recoil alors que Zustand ressemble à Redux :
Analogy
Jotai is like Recoil. Zustand is like Redux.
...
How to structure state
Jotai state consists of atoms (i.e. bottom-up). Zustand state is one object (i.e. top-down).
Même en lisant la documentation Comparison, j'ai eu de grandes difficulté à comprendre quand préférer Zustand à Jotai.
En lisant la documentation, Jotai me semble toujours plus simple à utiliser que Zustand.
Avec l'aide de Claude Sonnet 4.5, je pense avoir compris quand préférer Zustand à Jotai.
Exemple Zustand
Dans l'exemple Zustand suivant, la fonction addToCart modifie plusieurs parties du state useCartStore en une seule transaction :
import { create } from 'zustand'
const useCartStore = create((set) => ({
user: null,
cart: [],
notifications: [],
addToCart: (product) => set((state) => {
return {
cart: [...state.cart, product],
notifications: (
state.user
? [...state.notifications, { type: 'cart_updated' }]
: state.notifications
)
};
};
}));
Et voici un exemple d'utilisation de addToCart dans un composant :
function ProductCard({ product }) {
// Sélectionner uniquement l'action addToCart
const addToCart = useCartStore((state) => state.addToCart);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Exemple Jotai
Voici une implémentation équivalente basée sur Jotai :
import { atom } from 'jotai';
const userAtom = atom(null);
const cartAtom = atom([]);
const notificationsAtom = atom([]);
export const addToCartAtom = atom(
null,
(get, set, product) => {
const user = get(userAtom);
const cart = get(cartAtom);
const notifications = get(notificationsAtom);
set(cartAtom, [...cart, product]);
if (user) {
set(notificationsAtom, [...notifications, { type: 'cart_updated' }]);
}
}
);
Et voici un exemple d'utilisation de useToCartAtom dans un composant :
import { useSetAtom } from 'jotai';
import { addToCartAtom } from 'addToCartAtom';
function ProductCard({ product }) {
// Récupérer uniquement l'action (pas la valeur)
const addToCart = useSetAtom(addToCartAtom);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Ces deux exemples montrent que Zustand est plus élégant et probablement plus performant que Jotai pour gérer des actions qui conditionnent ou modifient plusieurs parties du state simultanément.
#JaiLu le thread SubReddit ReactJS "What do you use for global state management? " et j'ai remarqué que Zustand semble plutôt populaire.
En rédigeant cette note, j'ai découvert Valtio qui semble être une alternative à MobX. Je prévois d'étudier ces deux librairies dans une future note.
Journal du dimanche 19 octobre 2025 à 11:20
Dans l'historique de mon projet professionnel, #JaiDécouvert immer. J'ai constaté que Jotai propose une extension permettant d'utiliser immer. Pour le moment, je n'ai aucune idée de son intérêt, je n'ai pas pris le temps d'étudier ce sujet.
Journal du dimanche 19 octobre 2025 à 11:16
Ici dans la documentation Jotai, #JaiDécouvert Waku. Je n'ai pas pris le temps de l'étudier.
Samedi 18 octobre 2025
Journal du samedi 18 octobre 2025 à 12:18
En étudiant la librairie Jotai, #JaiDécouvert le terme "props drilling" :
Passing props is a great way to explicitly pipe data through your UI tree to the components that use it.
But passing props can become verbose and inconvenient when you need to pass some prop deeply through the tree, or if many components need the same prop. The nearest common ancestor could be far removed from the components that need data, and lifting state up that high can lead to a situation called “prop drilling”.
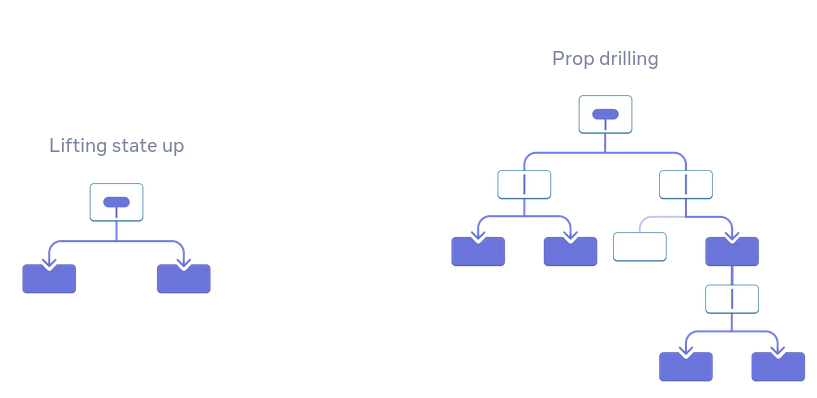
Le terme props drilling est très présent dans le SubReddit ReactJS : https://old.reddit.com/r/reactjs/search?q=drilling&restrict_sr=on&include_over_18=on.
Jeudi 16 octobre 2025
Journal du jeudi 16 octobre 2025 à 00:32
#JaiDécouvert les conférences Fedora annuelles nommées : Flock (https://fedoraproject.org/flock/)
Lundi 13 octobre 2025
Journal du lundi 13 octobre 2025 à 22:12
Dans cette issue, #JaiDécouvert le projet Kairos (https://kairos.io).
Samedi 11 octobre 2025
Journal du samedi 11 octobre 2025 à 10:27
À la position 24min20 de la vidéo This Week in Svelte, Ep. 119 , #JaiDécouvert la nouvelle section "Packages" du site officiel de Svelte. Cette initiative me semble utile : elle offre une liste de packages considérés comme "standard" par la communauté Svelte.
J'ai consulté la Merge Request qui ajoute la section "Packages" en pensant y trouver des explications sur le process et les critères d'inclusion d'un package dans cette liste, mais je n'ai rien trouvé 🤷♂️.
Mercredi 8 octobre 2025
Journal du mercredi 08 octobre 2025 à 14:29
#JaiDécouvert le nom officiel des attaques par social engineering suivantes :
Mercredi 24 septembre 2025
Journal du mercredi 24 septembre 2025 à 18:03
Dans ce billet du blog de Bluefin #JaiDécouvert Bazaar (https://github.com/kolunmi/bazaar).
Bazaar is a new app store for GNOME with a focus on discovering and installing applications and add-ons from Flatpak remotes, particularly Flathub ...
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Bazaar est une alternative à l'application officielle GNOME nommée gnome-software.
Contrairement à gnome-software qui est basée sur PackageKit et gère différents types de packages (rpm, DEB, Flatpak, Snap, etc.), Bazaar a un périmètre plus limité et se concentre exclusivement sur les packages Flatpak.
Dans un premier temps, je me suis demandé quel était l'intérêt de créer une nouvelle GUI pour installer des packages, pourquoi l'auteur n'a pas choisi de contribuer à gnome-software ?
J'ai trouvé une réponse dans ce thread.
Bazaar est une application avec une vision tranchée :
- support uniquement le repository Flathub (qui contient seulement des packages Flatpak) ;
- mise en avant de solution pour faire des donations.
Cette vision a permis à l'auteur de créer Bazaar en mai 2025, à partir de zéro, avec une implémentation plus direct (pas de support PackageKit…).
Cela lui a permis aussi de se consacrer fortement sur l'expérience utilisateur.
Après avoir testé l'application, je constate que contrairement à gnome-software, toutes les tâches s'exécutent de manière asynchrone. À la différence de gnome-software, Bazaar évite de recharger constamment l'index des packages après chaque opération , ce qui rend l'expérience utilisateur excellente 🙂.
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Je tiens tout de même à préciser que la version 49 de gnome-software a fait des progrès à ce sujet, un gros travail de refactoring a été fait sur 3 ans (73 Merge Request 😮) pour apporter le support de threading dans gnome-software.
Je pense utiliser Bazaar dans Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora".
Journal du mercredi 24 septembre 2025 à 17:11
Dans la documentation de Flight Control #JaiDécouvert le terme ClickOps :
Features and use cases Flight Control aims to support:
- Declarative APIs well-suited for GitOps management.
- ...
- Web UI to manage and monitor devices and applications for ClickOps management.
- ...
Je trouve que ClickOps constitue une terminologie plus rigoureuse pour désigner ce qu'on appelle communément clickodrome.
Mardi 23 septembre 2025
Journal du mardi 23 septembre 2025 à 16:23
En vrac, quelques projets que je viens de découvrir :
J'ai découvert Podman Quadlets
Dans ce thread du Subreddit self hosted, #JaiDécouvert Podman Quadlets, une fonctionnalité de podman.
D'après ce que j'ai compris, Podman Quadlets est un système qui permet de lancer des containers podman via systemd de manière déclarative.
Techniquement, Podman Quadlets transforme des fichiers .container en fichier unit files systemd classique.
Exemple d'un fichier .container :
# ~/.config/containers/systemd/nginx.container
[Unit]
Description=Nginx web server
After=network-online.target
[Container]
Image=docker.io/library/nginx:latest
PublishPort=8080:80
Volume=/srv/www:/usr/share/nginx/html:ro,Z
[Service]
Restart=always
[Install]
WantedBy=default.target
Et pour ensuite lancer ce container :
$ systemctl --user daemon-reload
$ systemctl --user start nginx
$ systemctl --user enable nginx
J'ai aussi découvert le projet podlet, (https://github.com/containers/podlet) qui permet de générer des fichiers Podman Quadlets à partir de fichiers docker compose.
J'apprécie que podman incarne la philosophie Unix en s'intégrant nativement aux composants Linux comme systemd, plutôt que de réinventer la roue comme Docker.
Lundi 22 septembre 2025
Journal du lundi 22 septembre 2025 à 17:50
#JaiDécouvert la page Project MINI RACK : https://mini-rack.jeffgeerling.com
Ce sujet m'intéresse, car je cherche une solution élégante pour remplacer ce bazar !

Journal du lundi 22 septembre 2025 à 16:27
Dans le projet Homepage, #JaiDécouvert le projet Open-Meteo : https://open-meteo.com
Open-Meteo is an open-source weather API and offers free access for non-commercial use. No API key required. Start using it n
Vendredi 19 septembre 2025
Dans l'épisode "141 L’IA c’est comme les patates, il faut la faire garder pour la faire adopter" du podcast Clever Cloud, #JaiDécouvert la spécification agents.md (https://agents.md).
J'ai l'impression que AGENTS.md ressemble à la fonctionnalité CONVENTIONS.md du projet Aider.
J'ai trouvé une issue à ce sujet dans le projet Aider : Does Aider support AGENT.md or PLAN.md?.
Journal du vendredi 19 septembre 2025 à 11:21
En mars 2025, j'ai pris la décision de contribuer financièrement à la hauteur de 10$ par mois au projet Servo (via Open Collective).
Aujourd'hui, j'ai eu la bonne surprise de découvrir l'article "Your Donations at Work: Funding Josh Matthews' Contributions to Servo".
The Servo project is excited to share that long-time maintainer Josh Matthews (@jdm) is now working part-time on improving the Servo contributor experience.
À l'heure actuelle, 287 contributeurs soutiennent Servo sur GitHub (montant non communiqué) et 388 personnes sur Open Collective pour 67 404 $ par an.
Je pense que la somme totale entre Open Collective et GitHub atteint probablement les 120 000 $ annuels.
Comparé aux 670 000 $ de revenus de Zig, les contributions pour Servo restent nettement plus modestes.
J'espère que la communauté Servo s'inspirera de la transparence de Zig : 2025 Financial Report and Fundraiser .
Dans cet article, #JaiDécouvert l'initiative Outreachy.
Jeudi 11 septembre 2025
Mercredi 3 septembre 2025
J'ai découvert l'outil de build Javascript avec cache remote nommé "nx"
En étudiant un projet privé professionnel, #JaiDécouvert le projet nx qui est comme Turborepo un outil de build pour Javascript et TypeScript.
Pour commencer, je dois préciser que je n'apprécie pas du tout comment le projet se présente. On voit partout :
Cela me donne l'impression que ce "pitch" a été créé par une équipe marketing 🙉 !
J'ai découvert ce tout petit thread Hacker News qui date du 18 août 2022 sur Hacker News qui, je trouve, explique très bien le but de Nx :
I'm a core team member of Nx (nx.dev) and one of the core features we implemented quite a while ago, is "computation caching". Basically to speed up things, we get all the input to a given computation, which our case as a devtool means running your Jest tests, Webpack/esbuild/... build etc, and cache the result (logs & potential build artifacts).
Next time when the same computation is run, we look it up and restore it from the cache, obviously tremendously improving the speed of the run. The real value is when you distribute that cache among co-workers, CI agents etc., which you can do with Nx Cloud (nx.app).
We had played with the idea of potentially mapping this to CO2 emissions. If you start saving a lot of computation, this reduces the number of times a machine gets spin up & executed on your CI. Well, earlier this week we aggregated some stats of how much time we saved and we were pretty by the result ourselves!
I summed it up in this blog article: https://blog.nrwl.io/helping-the-environment-by-saving-two-centuries-of-compute-time-feea8e1ce22?source=friends_link&sk=9b1259d0b171a7b95ebe95b3795660b5
But basically we saved:
- last 7 days: ~5 years of compute time
- last 30 days: ~23 years
- since beginning of Nx Cloud: ~200 years
Je pense que ces mesures font référence à ce qu'on peut voir dans ce screenshot :
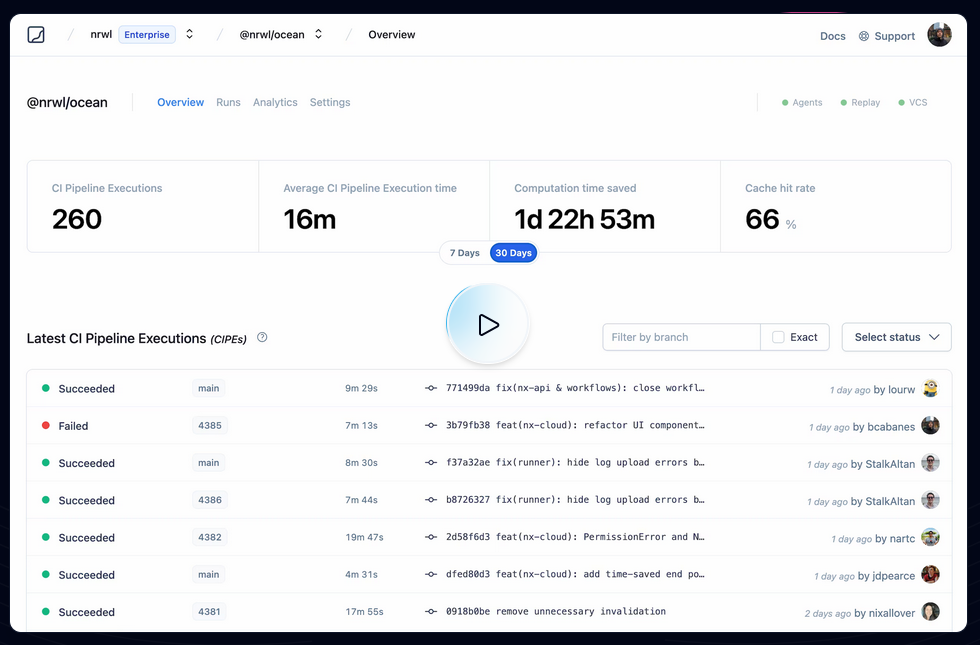
Je trouve cela très intéressant. Après avoir testé Bazel sans résultat concluant, sur la période 2018 à 2022, j'ai souvent cherché un outil comme Nx ou Turborepo, c'est-à-dire :
- Build distribué en parallèle sur différentes machines
- Partage de cache entre l'équipe de développement et les pipelines CI/CD
By default, Nx caches task results locally. The biggest benefit of caching comes from using remote caching in CI, where you can share the cache between different runs. Nx comes with a managed remote caching solution built on top of Nx Cloud.
To enable remote caching, connect your workspace to Nx Cloud by running the following command...
Je me demande si Nx permet de self host un composant de remote caching et si oui, je me demande si ce composant est open source ou non 🤔.
À noter que Turborepo permet de self host son propre service de remote cache : voir Turborepo - Remote Cache Self-hosting.
D'après mes recherches, Nx a été créé en juillet 2017, par Victor Savkin, un ancien développeur d'Angular chez Google. Selon cette description :
Software Engineer at Google (San Francisco Bay Area) between Jul 2014 - Dec 2016
One of the main developers of Angular 2. I've developed the dependency injection, change detection, forms, and router modules.
je pense que c'est pendant cette mission qu'il a eu l'idée de créer nx.
En janvier 2018, un second développeur Jason Jean, l'a rejoint sur le projet.
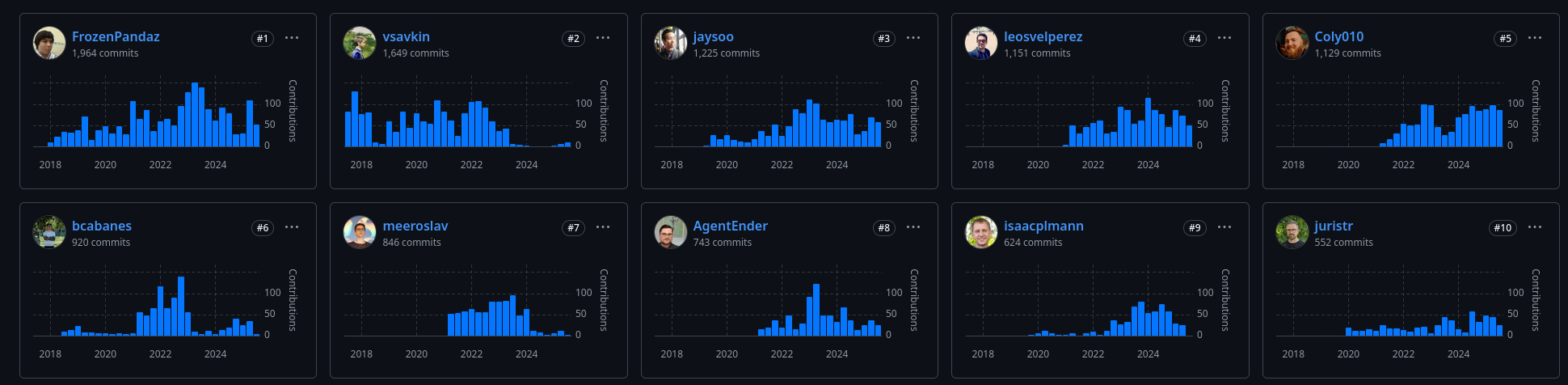
J'ai l'impression que Victor Savkin le CEO, n'a plus le temps de développer sur le projet depuis juillet 2023. Je pense que c'est à partir de là que le projet a eu de la traction.
Samedi 30 août 2025
Journal du samedi 30 août 2025 à 16:50
#JaiDécouvert la formalisation du concept de content-modeling as code :
Mercredi 27 août 2025
Journal du mercredi 27 août 2025 à 09:57
Dans le livre "Politikon - Tout ce qu'il faut savoir sur les idéologies qui ont façonné notre monde", #JaiDécouvert le mouvement philosopique nommé le "convivialisme".
Autour du noyau du M.A.U.S.S. s'élabore depuis quelques années une idéologie politique qui ambitionne de s'opposer massivement à l'idéologie économique dominante : le convivialisme. Plusieurs manifestes et ouvrages sont parus et ont été soutenus par de nombreuses personnalités internationales aussi différentes que Noam Chomsky, Jean-Claude Michéa, Chantal Mouffe ou Edgar Morin.
Le terme « convivialisme » trouve sa source dans l'ouvrage La convivialité du philosophe Ivant Illich.
Il s'agit ici de penser une société fondée sur une volonté commune de vivre ensemble en dehors du principe de l'utilité à maximiser et de l'illimitation de la croissance économique.
Samedi 23 août 2025
Journal du samedi 23 août 2025 à 14:13
Dans l'épisode "Une nouvelle histoire du Moyen Âge, avec Florian Mazel " de la web radio Storiavoce, #JaiDécouvert l'ouvrage collectif dirigé par Florian Mazel : "Nouvelle Histoire du Moyen Âge" (https://www.seuil.com/ouvrage/nouvelle-histoire-du-moyen-age-collectif/9782021460353 ).
L'émission m'a donné envie de l'acheter et de le feuilleter.
Dimanche 17 août 2025
J'ai découvert Badsender, une agence spécialisée en e-mailing et email deliverability
Il y a quelques semaines, un ami m'a demandé si je connaissais quelqu'un pour réaliser un audit Email deliverability. N'ayant personne de confiance à lui recommander dans ce domaine, je lui ai proposé de faire moi-même une prestation d'une demi-journée sur le sujet, malgré le fait que ce ne soit pas mon cœur de métier.
Pendant mes études, pour monter en compétence sur ce sujet (voir mes notes dans Email deliverability), j'ai découvert l'agence "d'emailing" nommée Badsender (https://www.badsender.com) via leur excellent billet sur BIMI.
Badsender, c’est une équipe de 10 spécialistes du numérique dotés d’une forte expertise en emailing et newsletter. Nous intervenons sur toute la chaîne email : délivrabilité, conseils stratégiques, rédaction, conception et production de campagnes.
J'ai beaucoup apprécié leur démarche de transparence : "Cap à 9 mois : Quel cap dans les 9 prochains mois ?".
J'ai beaucoup aimé le contenu de leurs billets d'analyse de newletters : https://www.badsender.com/newsletter/exemples/.
J'ai l'impression que Sébastien Fischer a produit la majorité des bons articles de Badsender pendant sa période chez eux (2021-2024).
En étudiant les dépôts de comptes sur INPI jusqu'à 2019 et les profils LinkedIn, il me semble que Badsender repose principalement sur 3 experts, notamment Jonathan Loriaux , le fondateur qui paraît avoir une solide expérience en Email deliverability.
Avec leur marge brute de 2019 d'environ 220 K€ et un panier moyen qui tourne autour de 2000 €, j'estime leur portefeuille client entre 100 et 150 comptes.
Après mon audit de délivrabilité d'e-mail pour mon client, si mon tarif à la journée est trop élevé, si mes disponibilités ne correspondent pas à ses besoins, ou s'il souhaite établir un partenariat à long terme avec un prestataire, alors je lui recommanderai sans doute de se tourner vers l'agence Badsender ou Sébastien Fischer.
Je vais informer Badsender de la publication de cette note pour savoir si elle contient des informations qui leur posent un problème.
Vendredi 15 août 2025
Journal du vendredi 15 août 2025 à 08:59
En étudiant le service DMARCwise, #JaiDécouvert et étudié le mécanisme SMTP MTA Strict Transport Security.
Lundi 4 août 2025
J'ai découvert la spécification "Brand Indicators for Message Identification"
En travaillant sur une mission freelance d'audit de délivrabilité d'e-mail, #JaiDécouvert la spécification "Brand Indicators for Message Identification".
Il s'agit de la spécification la plus récente qui s'ajoute aux spécifications de lutte contre l'usurpation d'identité email : SPF, DKIM, DMARC, ARC.
BIMI permet d'afficher le logo "certifié" de l'expéditeur du mail dans un certain nombre de clients mails (Apple, Fastmail, Gmail, La Poste, Yahoo).
Par exemple, cela donne ceci pour l'email noreply@notif-colissimo-laposte.info avec mon client mail Fastmail :
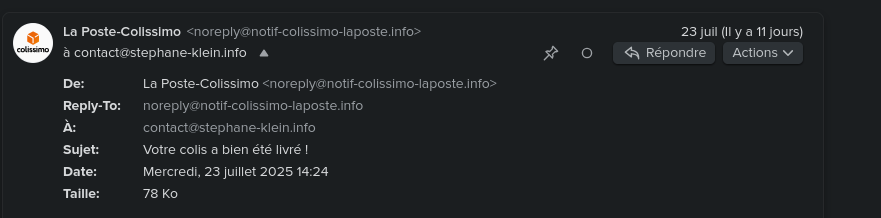
Autre exemple avec Gmail avec le "badge certifié" :
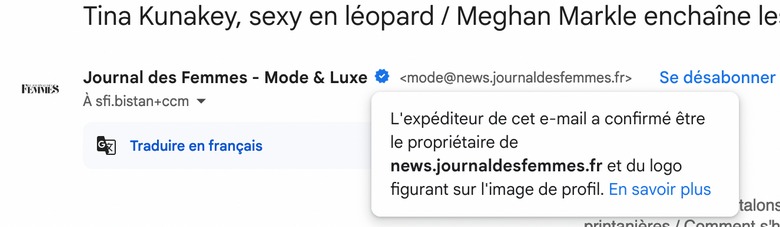
Pour avoir plus d'exemples concrets, je vous conseille de consulter la section [« Quelques exemples d’affichage de BIMI chez les fournisseurs de messagerie »](https://www.badsender.com/guides/bimi-pourquoi-et-comment-le-deployer/#:~:text=les fournisseurs de-,messagerie,-Apple Icloud (Mail) de l'excellent article « Formation BIMI : pourquoi et comment déployer BIMI ? » de l'agence française Badsender, qui offre entre autre des services d'audit de délivrabilité d'e-mail.
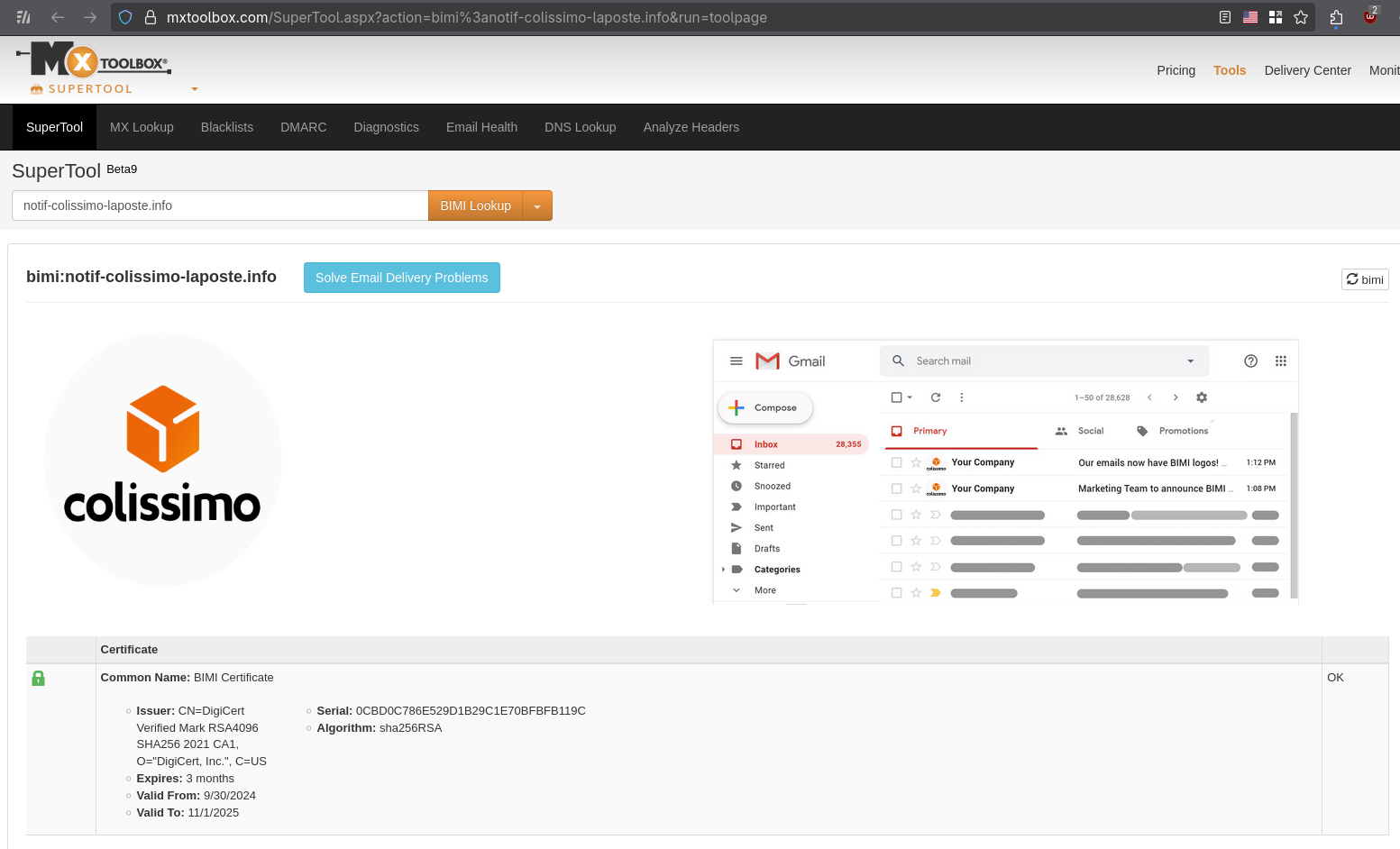
Vous pouvez, par exemple, vérifier la configuration BIMI sur cette page, voici le résultat, toujours avec l'adresse mail noreply@notif-colissimo-laposte.info :
Voici la configuration DNS TXT BIMI du domaine notif-colissimo-laposte.info :
$ dig TXT default._bimi.notif-colissimo-laposte.info +short
"v=BIMI1;l=https://notif-colissimo-laposte.info/logo.svg;a=https://notif-colissimo-laposte.info/la_poste_sa.pem;"
v=BIMI1indique le numéro de version de la spécification.l=https://notif-colissimo-laposte.info/logo.svgcontient l'URL vers le logo au format SVGa=https://notif-colissimo-laposte.info/la_poste_sa.pemcontient l'URL du certificat qui permet de certifier que l'expéditeur d'un email est autorisé à utiliser le logo Colissimo.
Voici ce que contient le certificat :
Issuer: CN=DigiCert Verified Mark RSA4096 SHA256 2021 CA1, O="DigiCert, Inc.", C=US
Expires: 3 months
Valid From: 9/30/2024
Valid To: 11/1/2025
Ce certifact a été généré par DigiCert.
Liste des entreprises de type Mark Verifying Authority pouvant actuellement générer des Verified Mark Certificate ou Common Mark Certificate :
D'après ce que j'ai compris, pour obvenir un Verified Mark Certificate, il est nécessaire de fournir au Mark Verifying Authority une preuve de dépôt de marque, par exemple via l'INPI.
Je pense que "Common" dans Common Mark Certificate est en lien avec le système juridique "Common law". Pour obtenir un Common Mark Certificate, il suffit de prouver qu'on utilise le logo depuis plus de 12 mois. DigiCert indique qu'ils effectuent une vérification en utilisant archive.org.
Depuis fin 2024, un autre type de certificat est disponible. C’est le CMC(Common Mark Certificate). Celui-ci permet de s’affranchir du dépôt de marque. Avoir une marque et un logo déposé sont donc maintenant optionnels. Néanmoins, le certificat CMC ne permet pas de garantir le même niveau de légitimité au destinataire. Certaines messageries, même si elles afficheront le logo BIMI dans le cas d’un certificat CMC n’ajouteront pas de certification de la marque (par exemple, dans Gmail, le checkmark bleu n’est pas affiché en cas de certificat CMC).
Lorsqu’un certificat VMC est choisi, une marque bleue est affichée dans Gmail afin de renforcer le sentiment de légitimité pour le destinataire. Ce qui ne sera pas le cas avec un certificat CMC.
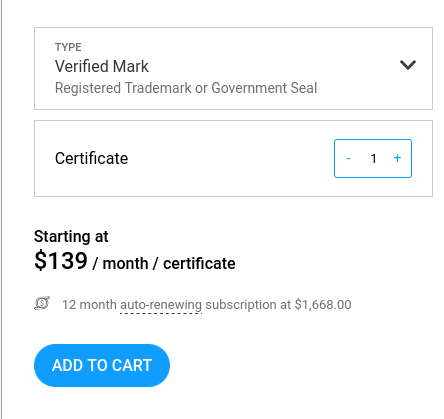
Voici les prix d'un Verified Mark Certificate chez DigiCert : 1668 € par an.
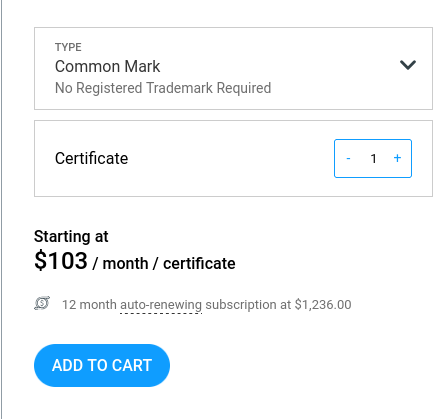
Et 1236 € par an pour un Common Mark Certificate.
Jusqu'à maintenant, je croyais que les services Gravatar ou Libravatar permettaient d'afficher un avatar dans les clients mail, mais je réalise que ce n'est pas le cas et il semble que je ne sois pas le seul à avoir cette idée fausse :
Many users set up their Gravatar expecting it to be shown when sending emails from their email address. This is not always the case, this page explains why.
Truth be told, there aren’t many email clients (meaning the app or platform your users use to read their emails) that support Gravatar. Most popular email services (like Gmail, Outlook or Apple Mail) don’t. Unfortunately there is nothing we can do.
If you have confirmed your reader’s email client support, then there might be some setting (or addon) that your readers will need to tweak.
Je me suis demandé si BIMI pouvait améliorer l'Email deliverability.
En parcourant le Subreddit EmailMarketing, j'ai découvert ce thread : Is BIMI & VMC worth it? . Tous les contributeurs s'accordent à dire que BIMI n'apporte aucune amélioration à l'Email deliverability.
Pour le moment, aucune information ne suggère que BIMI présente un avantage pour l'Email deliverability.
À ce stade, il me semble que la mise en place d'un Verified Mark Certificate est pertinente pour tout service ciblé par des attaques d'arnaque numérique.
Pour les autres services aux moyens limités, je pense qu'investir 1668 € annuels dans un Verified Mark Certificate n'est probablement pas justifié.
Je conseille néanmoins de configurer un logo BIMI sans certificat. Cette approche permet d'améliorer l'User experience en affichant le logo dans les boîtes mail avec un effort minimal.
Je compte configurer prochainement un logo BIMI sans certificat pour mon domaine personnel stephane-klein.info.
Pendant que j'écrivais cette note, je me suis encore interrogé sur l'absence d'acteurs qui tentent d'intégrer correctement une authentification mail via PKI étatique 🤔.
#JaimeraisUnJour creuser cette question dans une note dédiée.
Dimanche 27 juillet 2025
Journal du dimanche 27 juillet 2025 à 21:38
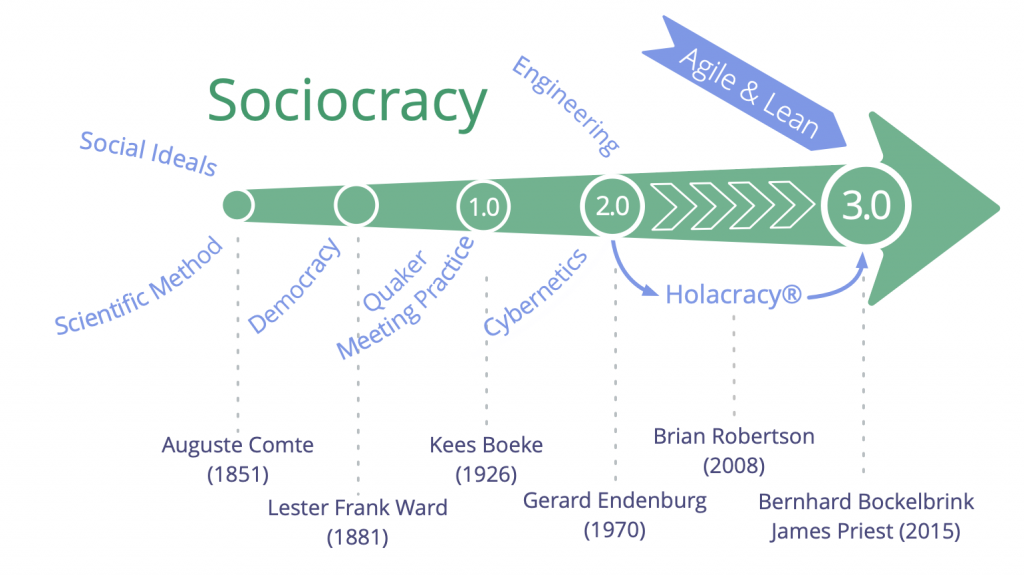
#JaiDécouvert la technologie sociale "Sociocratie 3.0" qui, d'après ce que j'ai compris, est une évolution de la sociocratie de Gerard Endenburg.
Toutes les ressources qui décrivent la "Sociocratie 3.0" sont diffusées sous licence Creative Commons.
Mardi 22 juillet 2025
Journal du mardi 22 juillet 2025 à 14:16
Dans la vidéo "Entretiens philosophiques, épisode 2 : Michéa et la critique du libéralisme" de Philo-Man et Le Précepteur, j'ai découvert la signification de mot "conséquent".
- Qui raisonne, qui agit avec un esprit de suite, rationnel, logique dans ses actions et sa conduite.
- (Philosophie) Qui qualifie une démarche logique avec soi-même, cohérent.
- Qui est la suite raisonnable de quelque chose, en accord avec elle, qui peut être logiquement déduit.
Dimanche 20 juillet 2025
J'ai découvert ContainerLab, un projet qui permet de simuler des réseaux
Pendant mon travail d'étude pratique de IPv6, #JaiDécouvert le projet Containerlab :
Containerlab was meant to be a tool for provisioning networking labs built with containers. It is free, open and ubiquitous. No software apart from Docker is required! As with any lab environment it allows the users to validate features, topologies, perform interop testing, datapath testing, etc. It is also a perfect companion for your next demo. Deploy the lab fast, with all its configuration stored as a code -> destroy when done.
Projet qui a commencé en 2020 et semble principalement développé par un développeur de chez Nokia.
D'après ce que j'ai compris, Containerlab me permet de facilement créer des réseaux dans un simulateur.
Je me souviens que je cherchais ce type d'outil en 2018, quand je travaillais sur un projet baremetal as service chez Scaleway.
Voici un exemple de fichier créé par Claude.ia pour simuler un environnement composé de deux réseaux IPv6 connectés entre eux : 3 serveurs sur le premier réseau et 2 serveurs sur le second.
Je précise que je n'ai pas encore testé ce fichier. J'ignore donc s'il fonctionne correctement.
name: dual-network-ipv6-lab
topology:
nodes:
# Routeur avec IPv6
router:
kind: linux
image: alpine:latest
exec:
# Activer IPv6
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- sysctl -w net.ipv6.conf.all.forwarding=1
# Adresses IPv6 sur les interfaces
- ip -6 addr add 2001:db8:1::1/64 dev eth1
- ip -6 addr add 2001:db8:2::1/64 dev eth2
# IPv4 en parallèle (dual-stack)
- ip addr add 192.168.1.1/24 dev eth1
- ip addr add 192.168.2.1/24 dev eth2
- echo 1 > /proc/sys/net/ipv4/ip_forward
# Réseau A (2001:db8:1::/64)
vm-a1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::10/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.10/24 dev eth1
- ip route add default via 192.168.1.1
vm-a2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::11/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.11/24 dev eth1
- ip route add default via 192.168.1.1
vm-a3:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:1::12/64 dev eth1
- ip -6 route add default via 2001:db8:1::1
- ip addr add 192.168.1.12/24 dev eth1
- ip route add default via 192.168.1.1
# Réseau B (2001:db8:2::/64)
vm-b1:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::10/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.10/24 dev eth1
- ip route add default via 192.168.2.1
vm-b2:
kind: linux
image: alpine:latest
exec:
- sysctl -w net.ipv6.conf.all.disable_ipv6=0
- ip -6 addr add 2001:db8:2::11/64 dev eth1
- ip -6 route add default via 2001:db8:2::1
- ip addr add 192.168.2.11/24 dev eth1
- ip route add default via 192.168.2.1
links:
# Réseau A
- endpoints: ["router:eth1", "vm-a1:eth1"]
- endpoints: ["router:eth1", "vm-a2:eth1"]
- endpoints: ["router:eth1", "vm-a3:eth1"]
# Réseau B
- endpoints: ["router:eth2", "vm-b1:eth1"]
- endpoints: ["router:eth2", "vm-b2:eth1"]
Pas de notes plus récentes | [ Notes plus anciennes (429) >> ]