
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (251) ] [ Notes plus anciennes (723) >> ]
Jeudi 19 décembre 2024
Comment lancer une image Docker de l'architecture "arm64" sous Intel ?
#JeMeDemande comment lancer une image Docker pour l'architecture arm64 sur une architecture Intel sous Fedora ?
Par défaut, l'exécution de cette image Docker sous Intel avec l'option --platform linux/arm64 ne fonctionne pas :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
exec /usr/bin/bash: exec format error
J'ai consulté et suivi la documentation Docker officielle suivante : Install QEMU manually.
$ docker run --privileged --rm tonistiigi/binfmt --install all
installing: arm64 OK
installing: arm OK
installing: ppc64le OK
installing: riscv64 OK
installing: mips64le OK
installing: s390x OK
installing: mips64 OK
{
"supported": [
"linux/amd64",
"linux/arm64",
"linux/riscv64",
"linux/ppc64le",
"linux/s390x",
"linux/386",
"linux/mips64le",
"linux/mips64",
"linux/arm/v7",
"linux/arm/v6"
],
"emulators": [
"qemu-aarch64",
"qemu-arm",
"qemu-mips64",
"qemu-mips64el",
"qemu-ppc64le",
"qemu-riscv64",
"qemu-s390x"
]
}
Après cela, je constate que j'arrive à lancer avec succès une image arm64 sous processeur Intel :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
root@bf74bfb8bc35:/# graphql-engine version
Hasura GraphQL Engine (Pro Edition): v2.43.0
J'ai pris un peu de temps pour explorer le repository tonistiigi/binfmt.
Je n'ai pas compris quelle est l'interaction entre les éléments installés par cette image et docker-engine.
Je constate que cette image a été créée en 2019 par deux développeurs de Docker : CrazyMax (un Français) et Tõnis Tiigi.
Mercredi 18 décembre 2024
Qu'est-ce qu'un "Script Helper" ?
J'utilise souvent le terme "Script Helper". Dans cette note, je vais tenter de le définir.
Un script dit « helper » est un script qui n'est pas essentiel au cœur du projet et qui ne contient pas de code métier. Son rôle est d’automatiser des tâches courantes et réutilisables pour le développeur.
L’écriture de ces scripts permet de centraliser et de versionner leur contenu, tout en réduisant les risques d’erreurs d’exécution.
Ma définition et objectif d'un "Workspace" dans un "environnement de développement" ?
Dans une note précédente, j'ai donné ma définition et les objectifs d'un "Development kit".
Dans cette note, je souhaite donner ma définition et les objectifs d'un workspace dans un "environnements de développement".
Un workspace est un dossier, qui contient des paramètres de configuration spécifiques — généralement sous la forme de variables d'environnements — qui permettent d'interagir sur une ou plusieurs instances de services, d'un environnement précis.
Généralement ce dossier contient des guides d'instructions pour réaliser des actions spécifiques sur le workspace et des scripts de type "helpers".
Exemple de workspaces :
staging/remote-workspace/: un workspace utilisé pour effectuer des actions sur les services déployés en staging sur des serveurs distants ;staging/local-workspace/: un workspace d'installer localement des services dans les mêmes conditions que sur l'environnement staging ;development/local-workspace/: un dossier workspace, qui permet de travailler — contribuer — localement sur le ou les services.
Voir aussi :
Jeudi 12 décembre 2024
Journal du jeudi 12 décembre 2024 à 11:10
La découverte du service deces.matchid.io (voir la note 2024-12-12_1020) m'a donné l'idée d'un service web qui permettrait d'être alerté en cas de décès d'un proche.
User Story (gestion de projet logiciel) :
- En tant que visiteur non connecté, je peux créer un compte utilisateur
- En tant qu'utilisateur, je peux saisir la liste des personnes que je souhaite surveiller
Le code source serait libre, mais la base de données serait privée.
J'ai trouvé un service qui permet de « S’abonner à une alerte des décès sur un nom » au prix de 18 € par an 😮 : https://www.libramemoria.com/etre-alerte-des-deces.
Journal du jeudi 12 décembre 2024 à 10:20
#JaiDécouvert le projet Match ID (https://matchid.io/) et plus précisément l'instance deces.matchid.io (https://deces.matchid.io/search).
Le projet matchID a été initié au ministère de l'Intérieur dans le contexte des challenges d' Entrepreneur d'intérêt général. La réconciliation des personnes décédées avec le permis de conduire a été le premier cas d'usage réalisé avec matchID.
Le projet a été libéré et mis en open source. L'équipe est maintenant composée de développeurs, anciens du ministère de l'Intérieur, contribuant bénévolement au service sur leur temps libre.
Nous avons créé ce service en complément, car il semblait d'utilité publique notamment pour la lutte contre la fraude, ou pour la radiation des décédés aux différents fichiers clients (e.g. hôpitaux).
L'exposition sur deces.matchid.io au profit du public est assurée par Fabien ANTOINE, avec le soutien de Cristian Brokate notamment pour le soutien technique à l'API. Le service est offert sans garantie de fonctionnement, nous nous efforçons de répondre aux messages (hors "absence du fichier") sur notre temps libre, faut de support officiel par les services de l'Administration.
Pour en savoir plus sur le projet matchID, consultez notre site https://matchid.io.
#Jadore ❤️
Le site exploite les fichiers des personnes décédées, disponibles en open data sur data.gouv.fr et recueillies par l'INSEE.
Les fichiers des personnes décédées sont établis par l’INSEE à partir des informations reçues des communes dans le cadre de leur mission de service public.
Quelques informations sur le fichier :
le fichier comporte 27983578 décès et NaN doublons (stricts)
il comporte les décès de 1970 à aujourd'hui (jusqu'au 31/10/2024)
il a été mis à jour le 05/11/2024
Un projet open source du Ministère de l'Intérieur.
Mercredi 11 décembre 2024
Journal du mercredi 11 décembre 2024 à 17:51
#JaiDécouvert OpenPhone (https://www.openphone.com) qui semble être une alternative à AirCall.
Journal du mercredi 11 décembre 2024 à 17:08
En étudiant les Web Components, #JaiDécouvert wired-elements (demo : https://wiredjs.com/).
J'adore, je pense utiliser ces composants à l'avenir pour réaliser des prototypes d'applications. Je trouve que cela permet de bien exprimer l'idée qu'aucun travail n'a été fait sur le design de l'interface utilisateur et que ce n'était pas l'objectif.
wired-elements fait partie de l'organisation rough-stuff qui a aussi développé Rough.js que j'avais déjà croisé, mais également rough-notation (démo : https://roughnotation.com) que je viens de découvrir et que je pense utiliser à l'avenir.
Je pourrais peut-être m'en inspirer pour implémenter l'issue "Je souhaite arriver à afficher un { en svg entre les lignes du mois de juillet et décembre et d'y afficher un texte".
Journal du mercredi 11 décembre 2024 à 16:56
Je pense m'insprirer de article "Technologies I Don't Want to Work With Again" de Lloyd Atkinson pour réaliser une note personnelle sur ce sujet.
Journal du mercredi 11 décembre 2024 à 11:22
#JaiDécouvert ArchieML (https://archieml.org/) qui est un markup language créé en 2015 par Michael Strickland qui travaille chez The New York Times.
Mon premier sentiment a été « pourquoi ne pas utiliser du Markdown ».
Ensuite, en lisant la documentation, j'ai compris que ce markup language était utilisé pour renseigner des valeurs dans différents champs. Comme le dit la documentation, ArchieML est une alternative à JSON ou YAML.
En explorant la section « Why not YAML? Or JSON? », j'ai compris la philosophie fondamentale d'ArchieML : offrir un langage de balisage qui soit particulièrement tolérant aux erreurs de syntaxe, notamment concernant l'indentation.
Cette approche répond spécifiquement aux besoins des journalistes qui, contrairement aux développeurs, ne sont généralement pas familiers avec les conventions strictes d'indentation que l'on trouve dans d'autres langages de balisage.
Ensuite, je me suis demandé : « Pourquoi ne pas demander aux journalistes de saisir leur article dans une page d'édition web, qui présente différents champs bien distincts ? ».
Je pense que la réponse se trouve ici :
And finally, because we make extensive use of Google Documents's concurrent-editing features…
Tout comme j'aime travailler avec des documents "plain text", peut-être que les journalistes préfèrent finalement travailler sur de simples documents textes plutôt qu'une page web d'édition, pour des raisons de rapidité d'utilisation : copier-coller rapide, fonctionnalité de commentaire collaboratif de Google Docs…
Je découvre dans la section ressources différentes librairies d'intégration à Google Docs.
Je découvre aussi que ArchieML est utilisé par d'autres journaux :
- Quartz
- The Atlanta Journal-Constitution
- Fusion
- The Wall Street Journal
Au final, je n'ai pas d'opinion définitive au sujet de cette méthode d'édition d'article 🤔.
Journal du mercredi 11 décembre 2024 à 11:03
Je viens de croiser pour la première fois la propriété windom.customElements (from).
Elle fait partie de l'ensemble des technologies qui composent ce que l'on appelle les Web Components.
Je connais depuis longtemps les Web Components, mais je n'ai jamais essayé de mettre en œuvre cette technologie. Je me suis contenté de lire et d'écouter des retours d'expérience et de suivre l'évolution des spécifications.
#JaiDécouvert que je peux facilement créer des Web Components en Svelte : https://svelte.dev/docs/svelte/custom-elements.
Custom elements can be a useful way to package components for consumption in a non-Svelte app, as they will work with vanilla HTML and JavaScript as well as most frameworks.
#JaiDécouvert le site Custom Elements Everywhere (https://custom-elements-everywhere.com/). Je lis que les Web Components sont maintenant parfaitement supportés par les frameworks majeurs : ReactJS, VueJS, Angular, Svelte, Solid… Ce qui est une très bonne nouvelle 🙂.
Je vais essayer de garder cette information à l'esprit, les Web Components me seront sans doute utile à l'avenir.
Avec Svelte, j'apprécie une sorte de "retour aux sources", c'est-à-dire, vers un web un peu plus "vannila", celui que j'ai connu au début des années 2000.
Je pense que Web Components vont encore renforcer cette sensation, comme par exemple le fait que si j'utilise la fonctionnalité développeur "inspection" du navigateur sur un Web Component, je vais voir, par exemple, la balise <button>....</button> du Web Component et non sa "soupe" HTML, comme c'est le cas avec un composant ReactJS ou Svelte (je sais qu'il existe des extensions navigateur pour éviter cela).
#JaimeraisUnJour prendre le temps d'étudier les performances des Web Components versus les composants de ReactJS, Svelte et Solid.
#JaiLu le thread du Subreddit ReactJS : Is it worth learning Web Components?. Voici quelques extraits :
Not worth it to be quite honest. I expect to get some hate for this.
I worked on a design system for three years that was written in Stencil (web component framework) that was used by multiple teams all using React, Angular, Vue. I regret everything, it should have all been react but the dumb decision to allow different teams to use different frameworks in order to do "micro frontend architecture" was the reason web components were picked shortly before I joined and took the lead.
Web components are also impossible to version and whichever one loads first is going to be the one that is globally used. This means production breaking changes without teams even knowing their breaking changes were going to fuck over another team.
Un peu plus loin du même auteur :
No, I view “micro frontend architecture” as a total disaster and it usually is implemented badly. When each application is a different framework too it’s quite honestly so difficult as to not even be worth entertaining.
Web components can be a great way to add functionality to legacy web apps. I don't know if I'd set out to use them in any other scenario though. I suppose you could, but I don't know many people writing vanilla HTML/JS apps these days.
J'ai effectué une recherche GitHub sur le topic "web-components" et j'ai trouvé des choses intéressantes :
- wired-elements - j'adore ! ( Voir note la 2024-12-11_1708)
- Open UI (https://open-ui.org) - cela semble être intéressant
- https://github.com/github/github-elements
- https://github.com/nolanlawson/emoji-picker-element
- https://atomicojs.dev
Lundi 9 décembre 2024
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres
Dimanche 8 décembre 2024
Journal du dimanche 08 décembre 2024 à 22:19
Je viens de rencontrer l'outil envdir (à ne pas confondre avec direnv) et son modèle de stockage de variables d'environnement, que je trouve très surprenant !
direnv ou dotenv utilisent de simples fichiers texte pour stocker les variables d'environnements, par exemple :
export POSTGRES_URL="postgres://postgres:password@localhost:5432/postgres"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export MAIL_FROM="noreply@example.com"
Contrairement à ces deux outils, pour définir ces quatre variables, le modèle de stockage de envdir nécessite la création de 4 fichiers :
$ tree .
.
├── MAIL_FROM
├── POSTGRES_URL
├── SMTP_HOST
└── SMTP_PORT
1 directory, 4 files
$ cat POSTGRES_URL
postgres://postgres:password@localhost:5432/postgres
$ cat SMTP_HOST
127.0.0.1
$ cat SMTP_PORT
1025
$ cat MAIL_FROM
127.0.0.1
Je trouve ce modèle fort peu pratique. Contrairement à un simple fichier unique, le modèle de envdir présente certaines limitations :
- Organisation : il ne permet pas de structurer librement l'ordre ou de regrouper visuellement les variables.
- Lisibilité : l'ensemble de la configuration est plus difficile à visualiser d'un seul coup d'œil.
- Manipulation : copier ou coller son contenu n'est pas aussi direct qu'avec un fichier texte.
- Documentation : les commentaires ne peuvent pas être inclus pour expliquer les variables.
- Rapidité : la saisie ou la modification de plusieurs variables demande plus de temps, chaque variable étant dans un fichier distinct.
J'ai été particulièrement intrigué par le choix fait par l'auteur de envdir. Sa décision semble vraiment surprenante.
envdir fait partie du projet daemontools, créé en 1990. Ainsi, il est bien plus ancien que dotenv, qui a été lancé autour de 2010, et direnv, qui date de 2014.
Si je me remets dans le contexte des années 1990, je pense que le modèle de envdir a été avant tout motivé par une simplicité d'implémentation plutôt que d'utilisation. En effet, il est plus facile de lister les fichiers d'un répertoire et de charger leur contenu que de développer un parser de fichiers.
Je pense qu'en 2024, envdir n'a plus sa place dans un environnement informatique moderne. Je recommande vivement de le remplacer par des solutions plus récentes, comme devenv ou direnv.
Personnellement, j'utilise direnv dans tous mes projets.
Samedi 7 décembre 2024
Journal du samedi 07 décembre 2024 à 21:18
Dans le repository poc-git-monorepo-multirepos-sync, j'ai pour la première fois expérimenté l'utilisation d'un script Bash qui génère dynamiquement le contenu d'une démo d'un terminal.
Le contenu du fichier README.md est généré par /generate-readme.sh qui exécute demo.sh et qui enregistre la sortie standard dans README.md.
À l'usage, l'expérience était agréable.
Journal du samedi 07 décembre 2024 à 20:49
Je pense être arrivé à une solution plus ou moins satisfaisante pour le Projet 19 - "Documenter une méthode pour synchroniser un monorepo vers des multirepos qui fonctionne dans les deux sens".
Voici-ci, ci-dessous, les étapes de la démonstration qui sont détaillées dans le README.md du repository poc-git-monorepo-multirepos-sync.
- Je crée deux repositories :
frontendetbackend(multi repositories) ; - J'utilise le script tomono pour les intégrer dans un monorepo nommé
monorepo; - J'ajoute deux fichiers à la racine de
monorepo:README.mdet.mise.toml; - J'effectue des changements dans le repository
frontend, je commit ; - Je pull les changements du repository
frontendversmonorepo; - Dans
monorepo, j'effectue des changements dans le dossierfrontend/, je commit ; - J'utilise
cd frontend/; git format-patch --relative -1 HEADpour générer un patch qui contient les changements que j'ai effectués dans le dossierfrontend/; - Je vais dans le repository
frontendet j'applique les changements contenus dans ce patch avec la commandgit apply monpatch.patchou avecgit am monptach.patch.
Pour le moment, j'ai privilégié l'option git patch, parce que je souhaite suivre la méthode la plus "manuelle" que j'ai pu trouver lorsque je dois intervenir sur les repositories upstream, parce que je ne veux prendre aucun risque de perturber mes collègues avec mon initiative de monorepo.
Le repository GitHub suivant contient le résultat final du monorepo : https://github.com/stephane-klein/poc-git-monorepo-multirepos-sync-result-example/.
Est-ce que je suis satisfait du résultat de cette démo ?
La réponse est oui, bien que je ne sois pas satisfait de quelques éléments.
Par exemple, les fichiers de frontend présents dans ce commit ne sont pas dans le dossier frontend.
J'aimerais que ces titres de commits contiennent un prefix [frontend] ... et [backend].... Je pense que cela doit être possible à implémenter en modifiant le script tomono.
Est-ce que c'est pénible à utiliser ? Pour le moment, ma réponse est « je ne sais pas ».
Je vais tester cette méthode avec deux projets. Je pense écrire une note de bilan de cette expérience d'ici à quelques semaines.
Journal du samedi 07 décembre 2024 à 19:04
En travaillant sur Projet 19, #JaiDécouvert le projet git-branchless (https://github.com/arxanas/git-branchless).
High-velocity, monorepo-scale workflow for Git.
Je n'ai pas encore compris à quoi cela sert.
Vendredi 6 décembre 2024
Je découvre l'utilisation des URLs "text fragments" 😍
#OnMaPartagé l'article "Lier un fragment de texte dans une page web - Le carnet de Joachim".
Je suis trop heureux de découvrir cette fonctionnalité 😍.
#JaiLu la documentation de référence sur MDN Web Docs : "Text fragments - URIs".
Lien direct vers la syntaxe : https://developer.mozilla.org/en-US/docs/Web/URI/Fragment/Text_fragments#syntax.
Je découvre aussi qu'il est possible de sélectionner plusieurs fragments simultanément :
You can specify multiple text fragments to highlight in the same URL by separating them with ampersand (
&) characters.
J'apprends que cette fonctionnalité est disponible sous Chrome depuis février 2020 ! Firefox depuis le 1ᵉʳ octobre 2024, Safari depuis le 24 octobre 2024.
J'ai installé et testé l'extension Firefox Link to Text Fragment et cela fonctionne parfaitement 👌.
Sur la page suivante, vous pourrez trouver les liens vers cette même extension pour Chrome et Safari : https://github.com/GoogleChromeLabs/link-to-text-fragment?tab=readme-ov-file#installation.
Journal du vendredi 06 décembre 2024 à 12:03
Je viens de rédiger le Projet 18 - "Créer un skeleton pour l'anonymisation des dumps de bases de données PostgreSQL".
Jeudi 5 décembre 2024
Journal du jeudi 05 décembre 2024 à 23:10
Ce matin, lors d'une discussion avec un client, le sujet de la densité des User Interface a été abordé. Cela m'a rappelé une note que j'avais rédigée le 2024-07-27.
Suite à cela, je me suis lancé dans des recherches en lien avec les grilles de Perspective que j'aime beaucoup (https://perspective.finos.org/blocks/editable/index.html).
#JaiDécouvert Glide Data Grid (https://grid.glideapps.com/) :
A ReactJS data grid with no compromises, outrageous performance, rich rendering and full TypeScript support.
Apparement, cette librairie utiliser HTML Canvas pour son rendering.
Dans ce thread Hacker News, #JaiDécouvert l'article "The Design Philosophy of Great Tables" (https://posit-dev.github.io/great-tables/blog/design-philosophy/).
J'ai consulter la page Components > Data Table de Evidence. J'aime beaucoup.
Mercredi 4 décembre 2024
Journal du mercredi 04 décembre 2024 à 14:56
Alexandre a eu un breaking change avec Mise : https://github.com/jdx/mise/issues/3338.
Suite à cela, j'ai découvert que Mise va prévilégier l'utilisation du backend aqua plutôt que Asdf :
we are actively moving tools in the registry away from asdf where possible to backends like aqua and ubi which don't require plugins.
J'ai découvert au passage que Mise supporte de plus en plus de backend, par exemple Ubi et vfox.
Je constate qu'il commence à y avoir une profusion de "tooling version management" : Asdf,Mise, aqua, Ubi, vfox !
Je pense bien qu'ils ont chacun leurs histoires, leurs forces, leurs faiblesses… mais j'ai peur que cela me complique mon affaire : comment arriver à un consensus de choix de l'un de ces outils dans une équipe 🫣 ! Chaque développeur aura de bons arguments pour utiliser l'un ou l'autre de ces outils.
Constatant plusieurs fois que le développeur de Mise a fait des breaking changes qui font perdre du temps aux équipes, mon ami et moi nous sommes posés la question si, au final, il ne serait pas judicieux de revenir à Asdf.
D'autre part, au départ, Mise était une simple alternative plus rapide à Asdf, mais avec le temps, Mise prend en charge de plus en plus de fonctionnalités, comme une alternative à direnv , un système d'exécution de tâches, ou mise watch.
Souvent, avec des petits défauts très pénibles, voir par exemple, ma note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
Alexandre s'est ensuite posé la question d'utiliser un jour le projet devenv, un outil qui va encore plus loin, basé sur le système de package Nix.
Le projet devenv me fait un peu peur au premier abord, il gère "tout" :
- Comme Asdf et Mise : l'installation des outils, packages et langages
- Support de scripts "helper"
- Intégration de Docker
- Support de process
- Support du SDK Android
Il fait énormément de choses et je crains que la barrière à l'entrée soit trop haute et fasse fuir beaucoup de développeurs 🤔.
Tout cela me fait un peu penser à Bazel (utilisé par Google), Pants (utilisé par Twitter), Buck (utilisé par Facebook) et Please.
Tous ces outils sont puissants, je les ai étudiés en 2018 sans arrivée à les adopter.
Pour le moment, mes development kit nécessitent les compétences suivantes :
- Comprendre les rudiments d'un terminal Bash ;
- Arriver à installer et à utiliser Mise et direnv ;
- Maitriser Docker ;
- Savoir lire et écrire des scripts Bash de niveau débutant.
Déjà, ces quatre prérequis posent quelques fois des difficultés d'adoption.
Journal du mercredi 04 décembre 2024 à 10:14
#JaiDécouvert l'outil de "version manager" nommé aqua, une alternative à Mise et Asdf codé en Golang.
Ce projet semble avoir débuté en août 2021.
J'ai fait quelques recherches au sujet d'aqua sur Hacker News, j'ai trouvé très peu d'occurrences. J'ai trouvé "Ask HN: Homebrew, Asdf, Nix, or Other?".
Je pense qu'aqua est bien moins populaire que Asdf et Mise.
Au 4 décembre 2024 :
Mardi 3 décembre 2024
Journal du mardi 03 décembre 2024 à 23:57
Suite de 2024-12-03_2213. J'ai réussi à implémenter le support Pandoc style markdown attributes dans sklein-pkm-engine.
Le package markdown-it-attrs fonctionne parfaitement bien.
Par contre, le plugin markdown-attributes semble ne pas fonctionner sur les dernières versions de Obsidian.
Journal du mardi 03 décembre 2024 à 22:13
Suite à 2024-11-13_2147, j'ai implémenté l'amélioration du rendu des "citations", voici un exemple :
Texte de la citation.
J'ai utilisé la librairie markdown-it-callouts.
Par contre, l'implémentation actuelle contient un bug. Je souhaite appliquer ce style css uniquement au lien de la source de la citation :

Pour cela, j'aimerais pouvoir spécifier en markdown une classe source sur le lien qui pointe vers la source de la citation.
J'ai trouvé markdown-it-attrs qui me permettrait d'implémenter une syntax Pandoc-style markdown attributes :
> [!quote]
>
> Texte de la citation.
>
> [source](http://example.com){.source}
Le plugin Obsidian markdown-attributes semble implémenter cette syntax.
Je souhaite tester si ce plugin fonctionne bien et si oui, je vais essayer d'intégrer markdown-it-attrs dans sklein-pkm-engine.
Journal du mardi 03 décembre 2024 à 21:57
Dans l'article "Dependency management fatigue, or why I forever ditched React for Go+HTMX+Templ" (from), #JaiDécouvert :
- templ, qui permet de générer du code HTML SSR avec Golang en utilisant une syntax proche de JSX ;
- Datastar :
Cela me donne envie d'essayer ces technologies 🙂.
Journal du mardi 03 décembre 2024 à 16:31
#JaiDécouvert la fonctionnalité "Table Partitioning" de PostgreSQL.
Je connaissais la possibilité de faire du database sharding avec PostgreSQL, en utilisant la fonctionnalité create_distributed_table de Citus — je n'ai jamais mis cela en pratique — mais je ne connaissais pas fonctionnalité native PostgreSQL de Table Partitining.
En PostgreSQL, une table partitionnée est une table divisée en plusieurs sous-tables appelées partitions, qui permettent de gérer efficacement de grandes quantités de données. Cette fonctionnalité est utile pour améliorer les performances des requêtes, simplifier l'archivage, ou encore gérer la répartition des données.
Avantages des tables partitionnées
Performances améliorées :
- Les requêtes peuvent être plus rapides grâce au pruning des partitions (PostgreSQL n'interroge que les partitions pertinentes).
- Les index sont plus légers car chaque partition peut avoir ses propres index.
Maintenance simplifiée :
- Vous pouvez archiver ou supprimer des partitions entières sans impacter le reste des données.
- Les opérations comme
VACUUMouANALYZEsont effectuées indépendamment sur chaque partition.
Cette fonctionnalité a été ajoutée dans la version 10 de PostgreSQL, en 2017.
J'ai aussi découvert qu'il est possible d'utiliser des Table Partitioning avec des Foreign Data Wrapper, par exemple, pour stocker certaines partitions sur des serveurs distants. Je pense que c'est une alternative à Citus, sans doute moins performante.
Lundi 2 décembre 2024
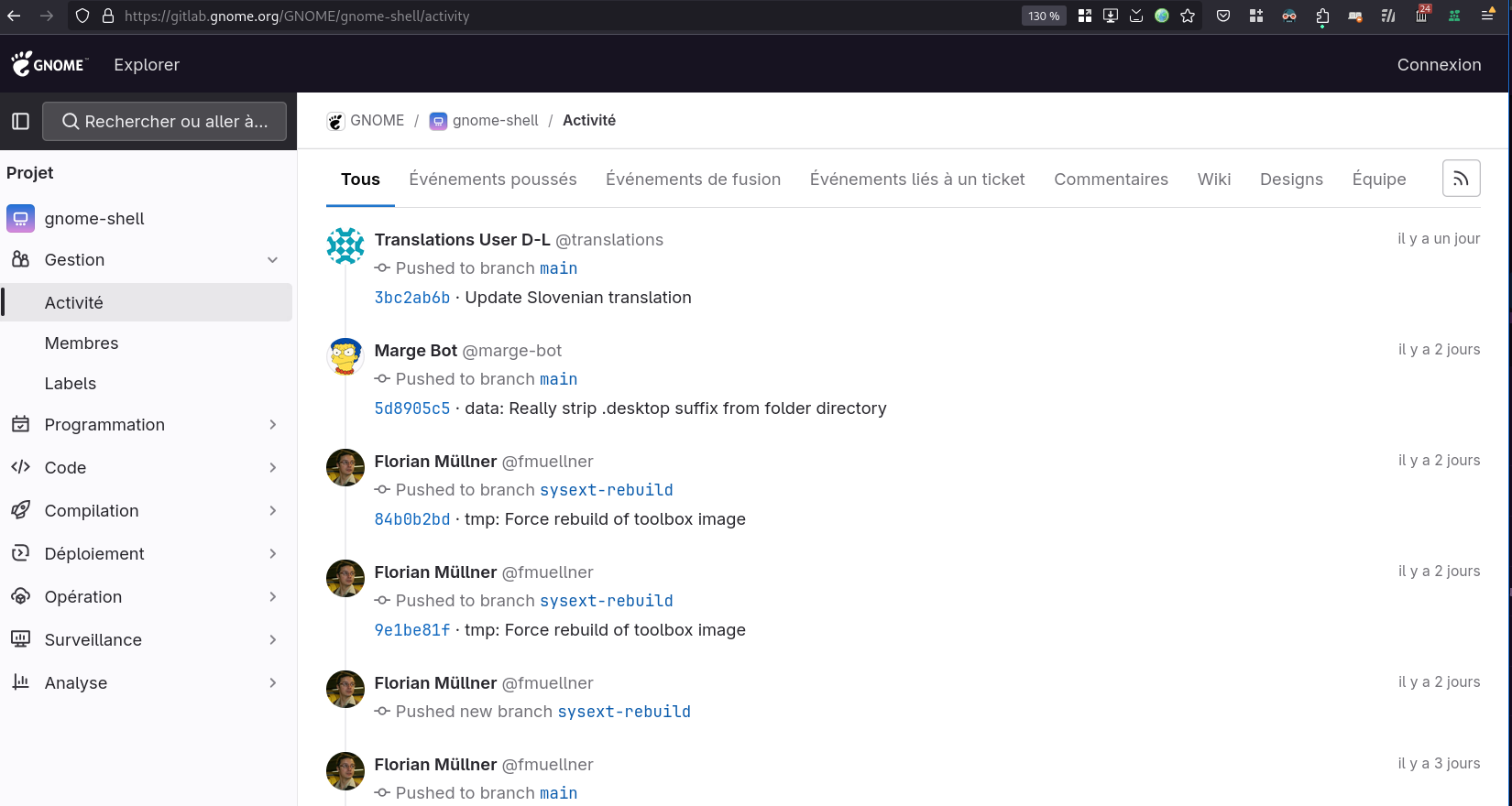
La fonctionnalité "Activité" de GitLab me manque dans GitHub
La fonctionnalité "Activité" de GitLab me manque dans GitHub.
Voici trois exemples concrets de fonctionnement de cette fonctionnalité, dans trois contextes différents.
Le premier, dans le projet GNOME Shell :
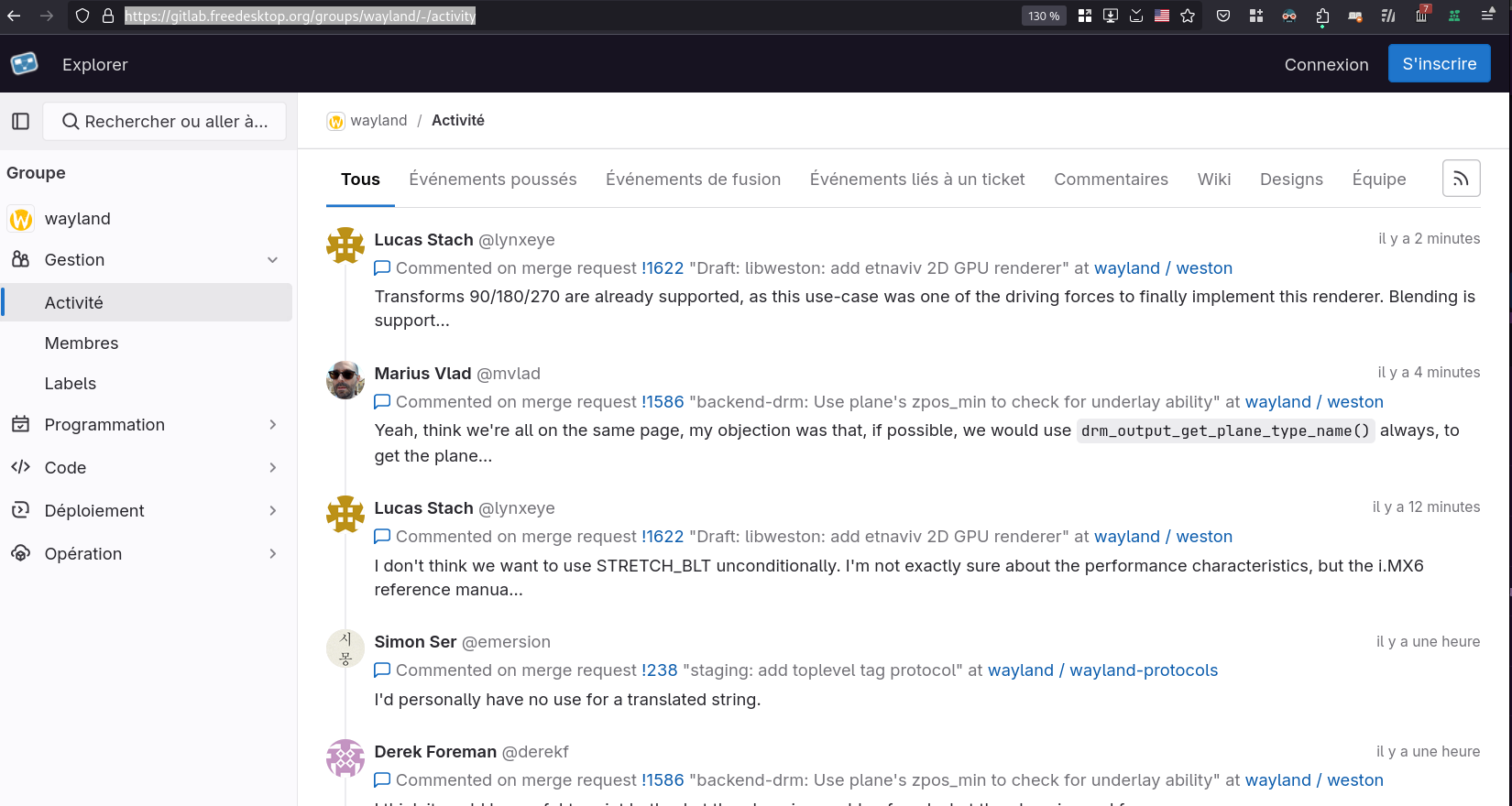
Le second, dans le groupe Wayland : https://gitlab.freedesktop.org/groups/wayland/-/activity
Et le troisième, pour l'utilisateur Lucas Stach: https://gitlab.freedesktop.org/users/lynxeye/activity
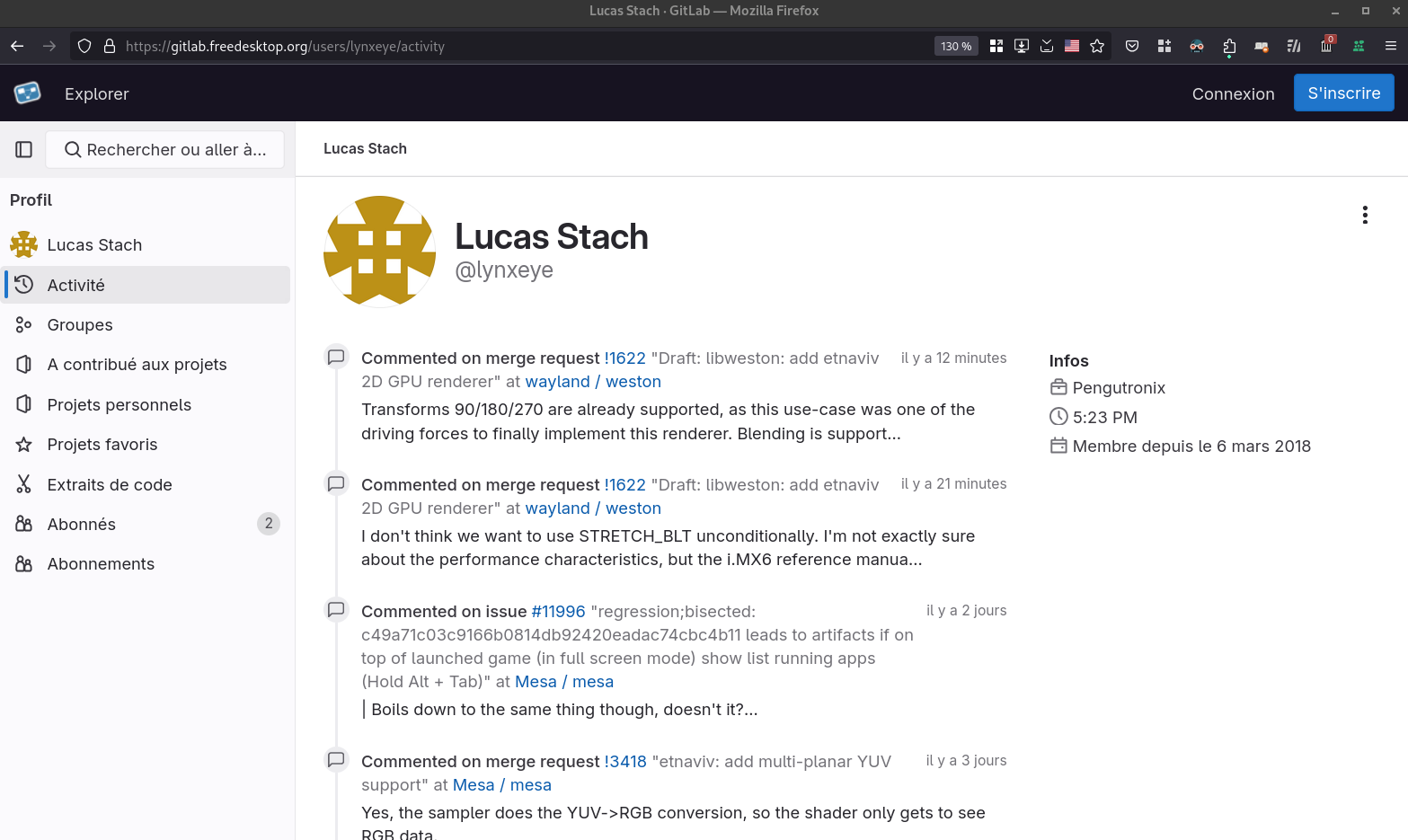
Je trouve cette fonctionnalité très utile quand on travaille sur un projet. Elle permet d'avoir une vue d'ensemble de ce qui s'est passé sur un projet sur une période. Elle vient en complément de l'historique Git qui est limité aux changements effectués sur le code source.
Dans certaines situations, je sais qu'un collègue travaille sur un sujet qui me concerne et la fonctionnalité "Activité" me permet de mieux comprendre où il en est, de suivre facilement ce qu'il fait.
Cette fonctionnalité "Activité" permet de pratiquer la stigmergie.
J'utilise aussi cette fonctionnalité lors de la rédaction d'un rapport d'activité ou d'un message de Daily Scrum. Elle m'aide à retrouver précisément ce que j'ai fait dernièrement.
Je trouve la page "Contribution activity" d'un user GitHub limité, par exemple, elle ne contient pas l'historique des commentaires.
Même chose au niveau d'un projet, dans la page "Pulse", par exemple : https://github.com/sveltejs/kit/pulse.
Je viens de regarder du côté de Codeberg / Forgejo : <https://codeberg.org/forgejo/forgejo/activity. Même constat que pour GitHub, les informations sont très réduites.
Environ 10 ans après la création du Coworking Metz, je suis très heureux de constater que ce projet a été utile :

Dimanche 1 décembre 2024
Journal du dimanche 01 décembre 2024 à 19:33
Je viens de regarder le #film "En fanfare" et j'ai vraiment passé un excellent moment. Une belle découverte que je recommande chaudement !
Samedi 30 novembre 2024
Mercredi 27 novembre 2024
Journal du mercredi 27 novembre 2024 à 22:56
J'ai apprécié la lecture sur LinuxFr d'un commentaire au sujet de GTK 4 posté par un core développeur de Gimp : https://linuxfr.org/news/gimp-3-0-rc1-est-sorti#comment-1975019.
Journal du mercredi 27 novembre 2024 à 20:45
#JaiDécouvert le service Fediverse People Directory, j'ai mis à jour mes tags et j'ai soumis mon compte Mastodon, je suis le seul avec le tag "Metz" 🤣 : https://fediverse.info/explore/people?t=metz.
Journal du mercredi 27 novembre 2024 à 14:37
J'utilise SearXNG depuis avril 2024. J'adore cet outil !
Depuis cette date, j'utilise l'instance https://searx.ox2.fr malheursement cette instance ne fonctionne plus depuis 4 jours.
Pour sélectionner une nouvelle instance, je suis partie de la liste officielle suivante : https://searx.space
Mes critères de sélection :
- Support IPv6
- Version la plus récente de SearXNG
- Proche de la France
- Utime proche de 100%
- Temps de réponse
Résultat de mon premier filtre :
- https://priv.au (DE)
- https://search.sapti.me (DE)
- https://search.projectsegfau.lt (DE)
- https://www.gruble.de (DE)
- https://searx.namejeff.xyz (Suisse)
J'ai fini par choisir l'instance https://priv.au parce qu'elle propose une extension Firefox de configuration automatique : https://addons.mozilla.org/en-US/firefox/addon/searxng-priv-au/.
Attention à bien supprimer l'ancienne extension Firefox SearXNG avant d'en installer une nouvelle afin de pouvoir utiliser la nouvelle instance SearXNG.
Journal du mercredi 27 novembre 2024 à 14:33
Un ami m'a partagé ce thread au sujet de l'IP fixe chez Bouygues qui semble indiquer que l'offre fibre de Bouygues ne propose pas d'IP fixe ?
En pratique, je constate que l'IP publique de ma fibre est fixe depuis plus d'un an : 176.142.86.141.
Voici, ci-dessous, les informations que j'ai trouvées à ce sujet.
Dans le document "Comparatif des offres en fibre optique des principaux opérateurs grand public en France, au 15 juillet 2024" du site lafibre.info, concernant la fibre de Bouygues, je lis :
- IPv4 fixe (dédiée ou mutualisée 8 064 ports.
- IPv4 dédiée gratuite sur demande.
- Plage IPv6 /60 fixe pour tous les clients
Dans le document "2024-07 ARCEP Baromètre ipv6 - partage ipv4" du site lafibre.info, je lis, concernant la fibre de Bouygues :
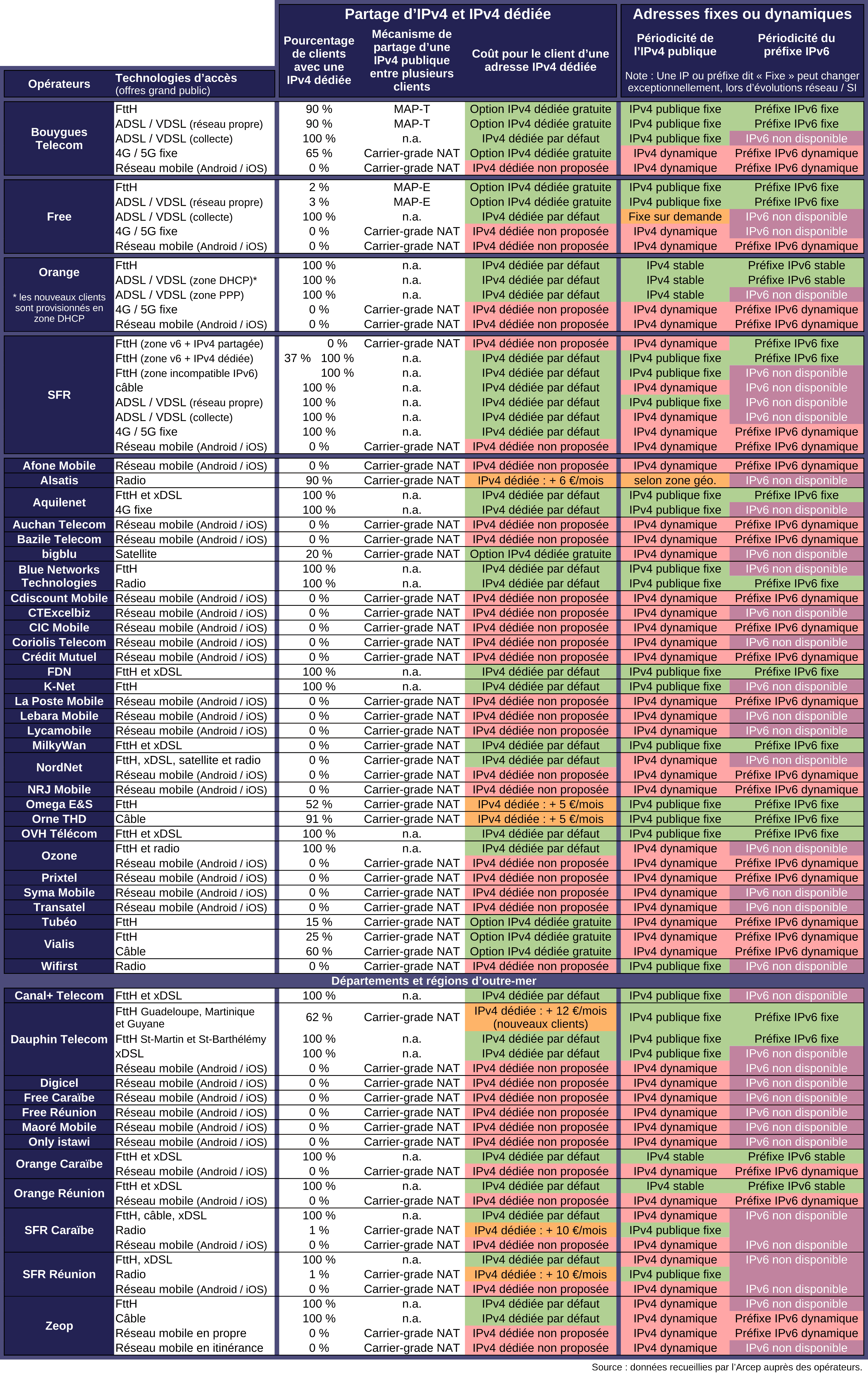{kind=link}
- Option IPv4 dédié gratuite.
- Pourcentage de clients avec une IPv4 dédiée : 90 %.
- Adresse fixes ou dynamiques (une IP ou prefixe dit « fixe » peut changer exceptionnelement, lors d'évolutions réseau / SI) :
- IPv4 publique fixe
- Préfixe IPv6 fixe
Voici mon interprétation : je pense que l'IP de l'offre fibre de Bouygues est fixe, mais peut exceptionnellement changer.
C'est ce que semble confirmer la personne membre du support technique de Bouygues dans le thread mentionné en début de cette note :
Journal du mercredi 27 novembre 2024 à 11:29
Il y a quelques jours, j'ai écrit une note au sujet des stratégies de versionning et aujourd'hui, #JaiDécouvert le site TrunkVer (https://trunkver.org/) (from).
We have identified a frequent source of avoidable confusion, conflict and cost in the software delivery process caused by versioning software that should not be versioned - or rather, the versioning should be automated.
👍️
However, we keep encountering teams and organizations that apply semantic versioning or a custom versioning scheme to software that does not need any of that - and through this, they create an astonishing amount of unnecessary work such as arguing whether or not a certain piece of software should be called “alpha”, “beta”, “rho”, “really final v4” etc, manually creating tickets listing the changes or even specialized gatekeeper roles such as “release engineer” - in the worst case a single person in the whole organization. Because this makes it harder, boring and costly to deploy, it systematically reduces the number of deployments, and through this the delivery performance of the organization.
👍️
Depuis 20 ans, j'ai rarement développé des librairies ou des API REST utilisées par des tiers.
Par conséquent, je n'ai pratiquement jamais eu besoin d'utiliser Semantic Versioning dans mes projets.
La plupart des projets sur lesquels je travaille suivent le modèle "Rolling release".
Je croise trop souvent des développeurs utilisant la spécification Semantic Versioning alors que leur projet suit le modèle Rolling release et je pense que TrunkVer serait bien plus adapté à leur contexte.
Cela fait plusieurs années maintenant que j'utilise la méthode suivante pour identifier "la version" de ce que je déploie.
Dans mes scripts de déploiement, je génère un fichier version.json, comme ceci (example) :
cat <<EOF > version.json
{
"environment": "prod",
"branch": "$(git rev-parse --abbrev-ref HEAD)",
"gitDate": "$(git show -s --format=%ci | sed "s/ /_/g")",
"buildStamp": "$(env TZ=Europe/Paris date '+%Y-%m-%d_%H:%M:%S-%Z')",
"gitHash": "$(git rev-parse HEAD)"
}
EOF
Ensuite je l'insert au moment du docker build et je l'expose sur une URL http.
Ce qui donne, par exemple, ceci :
$ curl https://notes.sklein.xyz/version.json
{
"environment": "prod",
"branch": "main",
"gitDate": "2024-12-03_23:43:26_+0100",
"buildStamp": "2024-12-03_23:51:09-CET",
"gitHash": "04c83c82a663260626e02502be1015d23b4859c2"
}
Ma méthode ne correspond pas exactement dans la forme à la méthode TrunkVer mais cela s'en rapproche.
Journal du mercredi 27 novembre 2024 à 10:52
Depuis des années, j'hésite toujours entre get et fetch lors du naming de fonctions.
Je viens de demander à ChatGPT la différence entre ces deux verbes et quand est-ce qu'il est préférable d'utiliser l'un ou l'autre.
Voici sa réponse :
Pour
get:
- Signification : Indique une opération simple pour récupérer ou accéder à des données.
- Contexte d'utilisation :
- Utilisé pour des accès rapides et directs à des données qui sont déjà disponibles localement (en mémoire, en cache, etc.).
- Souvent employé dans des fonctions "getter" ou des méthodes utilitaires simples.
Pour
fetch:
- Signification : Suggère une opération potentiellement asynchrone ou coûteuse, comme récupérer des données d'une source externe.
- Contexte d'utilisation :
- Lorsqu'une action supplémentaire est requise pour obtenir les données, comme un appel réseau ou une requête vers une API.
- Implique souvent un effort ou une complexité plus grande que
get.
J'ai essayé d'obtenir plus de ressources concernant cette déclaration.
J'ai trouvé ceci :
Example: fetch implies that some entity needs to go and get something that is remote and bring it back. Dogs fetch a stick, and retrieve is a synonym for fetch with the added semantic that you may have had possession of the thing prior as well. get is a synonym for obtain as well which implies that you have sole possession of something and no one else can acquire it simultaneously.
-
Ma recherche "
fetch get" sur English Language and Usage Stack Exchange : -
Sur MDN Web Docs, j'ai effectué des recherches de fonctions qui commencent par
getoufetch. Je constate que le verbefetchest utilisé lorsque la fonction va chercher des données sur le réseau.
Suite à cette étude, j'ai décidé d'utiliser fetch plutôt que get pour toutes les fonctions allant chercher des données en dehors du "processus local". Quelques exemples :
- Utilisation de
fetchpour nommer une fonction javascript frontend ou backend, qui effectue des requêtes REST ou GraphQL. - Utilisation de
getpour nommer une fonction PL/pgSQL qui effectue uniquement des requêtes SQL sur la base de données locale (pas de requêtes vers des Foreign Data (PostgreSQL)). Ici "locale" signifie que l'instance qui exécute la fonction PL/pgSQL est la même que celle qui contient les tables requêtées (voir cet échange).
Mardi 26 novembre 2024
Lundi 25 novembre 2024
Journal du lundi 25 novembre 2024 à 19:05
#JaiLu "Derrière le succès des microentrepreneurs, des conditions de travail et une protection dégradée" en lien avec ma note 2024-07-12_1346.
« J'ai reçu près d'un millier de messages en quelques jours et beaucoup d'insultes. » Députée (dissidente socialiste, siégeant dans le groupe LIOT) de l'Ariège, Martine Froger n'imaginait pas que sa proposition de loi visant à limiter le régime de la micro-entreprise à deux ans, déposée le 17 septembre, déchaînerait autant les passions. « Cela partait du constat que certains artisans de ma région ne trouvent pas de personnel, car les indépendants leur prennent des chantiers. Il y a une concurrence déloyale » , explique-t-elle. Exposée sur les réseaux sociaux par des microentrepreneurs expliquant leur attachement à ce statut et par une pétition ayant recueilli plus de 60 000 signatures, l'élue a finalement retiré son projet.
😮
La FNAE se satisfait d'avoir obtenu, en juillet, l'augmentation des cotisations de certaines catégories de microentrepreneurs, pour financer leur retraite complémentaire, « soit 600 000 personnes », selon Grégoire Leclercq. Seul problème, le taux de prélèvement passera progressivement de 21 % à 26 %, d'ici à 2026, ce qui risque paradoxalement de mettre en danger la viabilité de certaines entreprises.
Pour le président de la fédération des autoentrepreneurs, le régime peut être encore amélioré. « Demain, tout le monde cumulera des boulots, c'est le sens de l'histoire, imagine-t-il. On aura peut-être 80 % de la population, dans vingt ou trente ans, qui aura été microentrepreneur à un moment. Il faut que le régime perdure, mais en renforçant les droits à la formation et la protection sociale. »
« On ne résoudra pas la précarisation du marché de l'emploi en supprimant le statut, mais, en l'état, on crée des cohortes à venir de retraités précaires, juge, de son côté, le chercheur Jean-Yves Ottmann, qui a travaillé sur le recours à l'autoentrepreneuriat chez les agents commerciaux dans l'immobilier. Le statut devrait être réservé aux activités transitoires et d'appoint, avec un plafond illimité la première année et très bas ensuite, pour éviter que les gens y restent longtemps. »
« Il y a du travail à faire sur ce statut, résume la députée Martine Froger, qui va lancer des auditions pour affiner sa proposition de loi. J'ai compris que, dans certains secteurs, cela avait apporté beaucoup de bonnes choses, mais on a un modèle social à porter : si tout le monde devient autoentrepreneur, on est mal. Il faut juste réguler un peu les choses. »
Journal du lundi 25 novembre 2024 à 10:34
Dans ce post Fediverse #JaiDécouvert :
- doocteur.fr : pour faire une recherche sans tomber sur des sites comme doctissimo. Indispensable (beaucoup de résultats avec la revue médicale suisse, qui est très chouette) ;
- compendium.ch pour se renseigner sur ses médicaments ;
- theriaque.org (création de compte gratuit pour accéder à l'analyse) pour analyser les interactions entre tes médicaments ;
- igorthiriez.com : des fiches sur la santé mentale (pathologies, tips, médicaments) ;
- nofakemed.fr : pour savoir si le truc qui a bien marché sur ton voisin est du placebo ou pas.
Et aussi :
sur le site Haute Autorité de Santé.
Dimanche 24 novembre 2024
Journal du dimanche 24 novembre 2024 à 18:39
#OnMaPartagé le projet Speek, mais il n'a pas particulièrement retenu mon attention.
Journal du dimanche 24 novembre 2024 à 18:15
#JaiÉtudié Decentralized Identifiers (DID).
#JaiDécouvert Trinsic, Sidetree, uPort et Evernym.
Pour le moment, je n'ai étudié aucun de ces projets.
Journal du dimanche 24 novembre 2024 à 17:53
J'ai lu "How decentralized is Bluesky really? (from)", écrit par Christine Lemmer-Webber, co-autrice de ActivityPub.
J'ai trouvé cet article précis, il explore de nombreuses thématiques avec objectivité.
J'ai retenu cette déclaration, que je vais sans doute retenir pour donner mon point de vue sur Bluesky :
In my opinion, this should actually be the way Bluesky brands itself, which I believe would be more honest: an open architecture (that's fair to say!) with the possibility of credible exit. This would be more accurate and reflect better what is provided to users.
-- from
« Une solution ouverte qui permet de quitter facilement Twitter dès maintenant ».
#JaiDécouvert Zooko's triangle.
Je suis une nouvelle fois tombé sur l'article "Petnames: A humane approach to secure, decentralized naming".
Samedi 23 novembre 2024
Journal du samedi 23 novembre 2024 à 00:06
#JaiLu le thread Hacker News : What's Next for WebGPU (WebGPU).
Vendredi 22 novembre 2024
Journal du vendredi 22 novembre 2024 à 21:37
Voici une stratégie pour contourner dans une certaine mesure la limitation Hasura que j'ai décrite dans la note 2024-11-22_1703.
Remplacer :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
par :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
GRANT SELECT ON TABLE foobar TO hasurauser;
ALTER TABLE foobar ENABLE ROW LEVEL SECURITY;
CREATE POLICY deny_untrusted_user ON foobar
FOR SELECT USING (current_user != 'hasurauser');
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
Journal du vendredi 22 novembre 2024 à 17:03
Je découvre une nouvelle limitation de Hasura par rapport à PostGraphile.
Hasura permet d'exécuter des fonctions PostgreSQL seulement si leur type de retour est une table. De plus, cette table doit être tracked par Hasura.
Return type: MUST be
SETOF <table-name>OR<table-name>where<table-name>is already tracked.Return type workaround: If the required SETOF table doesn't already exist or your function needs to return a custom type i.e. row set, you can create and track an empty table with the required schema to support the function.
-- from
D'autre part, Hasura doit avoir des permissions d'accès à cette table utilisée en retour de fonction.
Par exemple, Hasura ne supporte pas ce type de configuration :
REVOKE ALL PRIVILEGES ON TABLE foobar FROM hasurauser;
CREATE FUNCTION myfunction() RETURNS SETOF foobar
LANGUAGE sql VOLATILE SECURITY DEFINER
AS $$
SELECT * FROM foobar
$$;
Cette limitation, parmi d'autres, renforce ma préférence pour PostGraphile plutôt que Hasura dans un contexte d'utilisation avec PostgreSQL — PostGraphile supporte uniquement PostgreSQL.
Jeudi 21 novembre 2024
Journal du jeudi 21 novembre 2024 à 17:49
#JaiDécouvert le magazine "Paged Out" « one article == one page » : https://pagedout.institute/ 🙂.
Journal du jeudi 21 novembre 2024 à 17:36
Dans la note 2024-11-20_1102, je disais :
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
C'est chose faite 🙂.
Le repository poc-capacitor contient maintenant un script ./scripts/deploy-ios-requirements.sh qui permet d'exécuter ce script de provisioning sur le serveur Scaleway Apple Silicon distant : /provisioning/_ios.sh.
Ensuite, j'ai détaillé les étapes pour :
- Uploader le projet sur le Scaleway Apple Silicon distant
- Démarrer l'émulation d'un iPhone 15
- Compiler et lancer l'application Capacitor dans l'émulateur iPhone 15
- Et visualiser l'émulateur via VNC
Tout cela est détaillé ici : https://github.com/stephane-klein/poc-capacitor/tree/f109fb23dc612f486fad0d55ba939b4679841d06?tab=readme-ov-file#launch-application-on-ios
Mercredi 20 novembre 2024
Je teste l'offre Scaleway Apple Silicon
Dans le projet "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor" je disais :
- Essayer d'utiliser l'offre Apple Mac mini M1 de Scaleway pour builder l'app pour iOS
Voici mon retour d'expérience d'utilisation de l'offre Scaleway Apple Silicon.
Voici la liste des images MacOS disponibles :
$ scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
7a8d85fb-781a-4212-8e47-240ec0c3d23f macos-sequoia-15.0 macOS Sequoia 15.0 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sequoia.png Sequoia true 15.0 16
Voici la liste des types de serveurs disponibles dans la zone fr-par-3 :
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M1-M Apple M1 (8 cores) 8.0 GB 256 GB high stock 1 days
Et la liste dans la zone fr-par-1 :
$ SCW_DEFAULT_ZONE="fr-par-1" scw apple-silicon server-type list
Name CPU Memory Disk Stock Minimum Lease Duration
M2-M Apple M2 (8 cores) 16 GB 256 GB high stock 1 days
M2-L Apple M2 Pro (10 cores) 16 GB 512 GB high stock 1 days
Je souhaite installer un serveur de type M1-M à 0,11 € HT / heure, soit 2,64 € HT / jour, 80,3 € HT / mois.
Lors de ma première tentative, j'ai essayé de créer un serveur avec la commande suivante :
$ scw apple-silicon server create name=capacitor zone=fr-par-3 "$SCW_PROJECT_ID" M1-M 7a8d85fb-781a-4212-8e47-240ec0c3d23f
Invalid argument '46ad009f-xxxxxx': arg name must only contain lowercase letters, numbers or dashes
Suite à cette erreur, j'ai créé l'issue siuvante : Reduce"scw apple-silicon server create" helper message ambiguity.
$ scw apple-silicon server create name=capacitor project-id=${SCW_PROJECT_ID} type=M1-M os-id=7a8d85fb-781a-4212-8e47-240ec0c3d23f zone=fr-par-3
Mais l'OS n'était pas trouvé, je me suis rendu compte que cette image OS n'était pas disponible dans la zone fr-par-3.
$ SCW_DEFAULT_ZONE="fr-par-3" scw apple-silicon os list
ID NAME LABEL IMAGE URL FAMILY IS BETA VERSION XCODE VERSION
59bf09f1-5584-469d-a0f6-55c8fee1ab81 macos-ventura-13.6 macOS Ventura 13.6 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-ventura.png Ventura false 13.6 14
e08d1e5d-b4b9-402a-9f9a-97732d17e374 macos-sonoma-14.4 macOS Sonoma 14.4 https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png Sonoma false 14.4 15
Voici finalement la commande de création de serveur qui a fonctionné avec succès :
$ scw apple-silicon server create name=capacitor project-id=$SCW_PROJECT_ID type=M1-M os-id=e08d1e5d-b4b9-402a-9f9a-97732d17e374 zone=fr-par-3
ID bb34d8ef-6305-4104-801c-1cf1b6b0f99f
Type M1-M
Name capacitor
ProjectID 46ad009f-xxxx
OrganizationID 215d7434-xxxx
IP 51.xxx.xxx.xxx
VncURL vnc://m1:xxxx@51.xxx.xxx.121:5900
SSHUsername m1
SudoPassword xxxxxxx
Os ID e08d1e5d-b4b9-402a-9f9a-97732d17e374
Name macos-sonoma-14.4
Label macOS Sonoma 14.4
ImageURL https://scw-apple-silicon.s3.fr-par.scw.cloud/scw-console/os/macos-sonoma.png
Family Sonoma
IsBeta false
Version 14.4
XcodeVersion 15
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status starting
CreatedAt now
UpdatedAt now
DeletableAt 23 hours from now
DeletionScheduled false
Zone fr-par-3
Voici le serveur créé :
$ scw apple-silicon server list
ID TYPE NAME PROJECT ID
bb34d8ef-6305-xxxxx M1-M capacitor 46ad009f-54bc-4125-xxxxxx
Le serveur est passé en ready après environ 1min.
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx
...
CompatibleServerTypes:
[M1-M M2-M M2-L]
Status ready
...
DeletableAt 23 hours from now
DeletionScheduled false
...
Je peux me connecter directement en ssh au serveur :
$ ssh m1@xxx.xxx.xx.xxx
Last login: Wed Nov 20 16:22:10 2024
m1@bb34d8ef-6305-4104-801c-1cf1b6b0f99f ~ % uname -a
Darwin bb34d8ef-6305-4104-801c-1cf1b6b0f99f 23.4.0 Darwin Kernel Version 23.4.0: Fri Mar 15 00:12:41 PDT 2024; root:xnu-10063.101.17~1/RELEASE_ARM64_T8103 arm64
Je peux aussi me connecter au serveur via VNC (lien vers la documentation à ce sujet).
Installation des dépendances sous Fedora :
$ sudo dnf install -y remmina remmina-plugins-vnc
J'utilise le client VNC nommé Remmina.
$ remmina -c vnc://m1:xxxxx@51.xxxx.xxx.xxxx:5900
Les paramètres vnc et le mot de passe de l'user m1 sont disponibles dans la sortie de :
$ scw apple-silicon server get bb34d8ef-6305-xxxxxxx -o json
{
"id": "bb34d8ef-6305-4104-xxxx-xxxxxxxxx",
...
"vnc_url": "vnc://m1:xxxx@xxx.xxx.xxx.xxx:5900",
"ssh_username": "m1",
"sudo_password": "bTgkdiVUs7yT",
...
}
Il est possible de coller le mot de passe via la fonctionnalité « Envoyer le contenu du presse-papiers comme une saisie au clavier » de Remmina :
Attention, la réinstallation d'un serveur Apple Silicon prend au moins 45min.
J'ai implémenté des scritps de déploiement d'un Apple Silicon dans le POC : poc-capacitor.
Prochaine étape du Projet 17 : Setup les iOS Requirements de Capacitor sur ce serveur Apple Silicon.
Mardi 19 novembre 2024
Journal du mardi 19 novembre 2024 à 23:50
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Dans la note 2024-11-19_1029, je disais :
Pour utiliser Capacitor, j'ai besoin d'installer certains éléments.
In order to develop Android applications using Capacitor, you will need two additional dependencies:
- Android Studio
- An Android SDK installation
Je me demande si Android Studio est optionnel ou non.
La réponse est non, Android Studio n'est pas nécessaire, ni pour compiler l'application, ni pour la lancer dans un émulateur Android. Android SDK est suffisant.
J'ai utilisé le plugin Mise https://github.com/Syquel/mise-android-sdk pour installer les "Android Requirements" de Capacitor. Les instructions détaillées pour Fedora sont listées dans le README.md du repository : https://github.com/stephane-klein/poc-capacitor/tree/4238e80f84a248fdb9e5bb86c10bea8b9f0fdade.
Installation de Android Studio sous Fedora
Dans le Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor, il semble que j'ai besoin d'installer Android Studio.
J'ai exploré la méthode Asdf / Mise, mais j'ai rencontré des difficultés : 2024-11-19_1029 et 2024-11-19_1102.
J'ai ensuite constaté ici que RPM Fusion ne propose pas de package Android Studio. J'ai ensuite cherché sur Fedora COPR, mais j'ai trouvé uniquement de très vieux packages.
J'ai lu ici qu'Android Studio est disponible via Flatpak sur Flathub : https://flathub.org/apps/com.google.AndroidStudio. Je n'avais pas pensé à Flatpak 🙊.
Après réflexion, je trouve cela totalement logique que Android Studio soit distribué via Flatpak.
Voici le repository GitHub de ce package : https://github.com/flathub/com.google.AndroidStudio. Il semble être bien maintenu par Alessandro Scarozza « Senior Android Developer, Android Studio Flatpak Mantainer and old Debian Linux user ».
Le package contient la version 2024.2.1.11 d'Android Studio, j'ai vérifié, elle correspond bien à la dernière version disponible sur https://developer.android.com/studio.
Voici ce que donne l'installation :
$ flatpak install com.google.AndroidStudio
Looking for matches…
Remotes found with refs similar to ‘com.google.AndroidStudio’:
1) ‘flathub’ (system)
2) ‘flathub’ (user)
Which do you want to use (0 to abort)? [0-2]: 1
com.google.AndroidStudio permissions:
ipc network pulseaudio ssh-auth x11 devices multiarch file access [1]
dbus access [2]
[1] home
[2] com.canonical.AppMenu.Registrar, org.freedesktop.Notifications, org.freedesktop.secrets
ID Branch Op Remote Download
1. [✓] com.google.AndroidStudio.Locale stable i flathub 5,6 Ko / 57,2 Ko
2. [✓] com.google.AndroidStudio stable i flathub 1,3 Go / 1,3 Go
Installation complete.
Journal du mardi 19 novembre 2024 à 11:02
Suite de 2024-11-19_1029.
J'ai testé https://github.com/Syquel/mise-android-sdk. Il dépend de yq. Cela m'embête un peu d'ajouter cette dépendance dans les "Prerequisite" de mon projet.
À la suite de cela, j'ai testé https://github.com/huffduff/asdf-android-sdk, mais je suis tombé sur le problème suivant, ce qui ne m'a pas donné confiance : "Bad URL in "asdf plugin add android-sdk https://github.com/tommyo/asdf-android-sdk.git" instruction".
Échec avec arcticShadow/asdf-android
Ensuite, j'ai testé https://github.com/arcticShadow/asdf-android.
$ mise plugins install https://github.com/arcticShadow/asdf-android.git
$ mise ls-remote android
1
#JeMeDemande pourquoi version 1 ? 🤔
$ mise install android latest
mise ERROR latest not found in mise tool registry
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
$ mise install android 1
curl: (22) The requested URL returned error: 404
mise ERROR ~/.local/share/mise/plugins/android/bin/download failed
* Downloading android release 1...
curl: (22) The requested URL returned error: 404
asdf-android: Could not download https://dl.google.com/android/repository/commandlinetools-linux-1_latest.zip
mise ERROR failed to install android@1
mise ERROR ~/.local/share/mise/plugins/android/bin/download exited with non-zero status: exit code 1
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
Suite à cela, j'ai posté cette issue : "mise ERROR latest not found in mise tool registry · Issue #6 · arcticShadow/asdf-android · GitHub".
À ce moment précis, je me suis dit que je suis en train de tomber dans un Yak!.
Échec avec huffduff/asdf-android-sdk
Je retourne au projet https://github.com/huffduff/asdf-android-sdk.
$ mise plugin add android-sdk https://github.com/huffduff/asdf-android-sdk
$ mise ls-remote android-sdk
2.1
J'ai consulté la page https://github.com/AndroidSDKSources/android-sdk-sources-list et je ne comprends pas à quoi correspond la version 2.1 🤔.
Ensuite, j'ai rencontré ces erreurs :
$ mise install android-sdk latest
mise ERROR latest not found in mise tool registry
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
$ mise install android-sdk 2.1
Warning: Errors during XML parse:
Warning: Additionally, the fallback loader failed to parse the XML.
cp: impossible d'évaluer '/home/stephane/.local/share/mise/downloads/android-sdk/2.1/*': Aucun fichier ou dossier de ce nom
mise ERROR ~/.local/share/mise/plugins/android-sdk/bin/install failed
cp: impossible d'évaluer '/home/stephane/.local/share/mise/downloads/android-sdk/2.1/*': Aucun fichier ou dossier de ce nom
asdf-android-sdk: Expected /home/stephane/.local/share/mise/installs/android-sdk/2.1/cmdline-tools/2.1/bin/sdkmanager to be executable.
asdf-android-sdk: An error occurred while installing android-sdk 2.1.
mise ERROR failed to install android-sdk@2.1
mise ERROR ~/.local/share/mise/plugins/android-sdk/bin/install exited with non-zero status: exit code 1
mise ERROR Run with --verbose or MISE_VERBOSE=1 for more information
Suite à cela, j'ai posté cette issue : "Add mise support? « mise ERROR latest not found in mise tool registry »"
Succès avec Syquel/mise-android-sdk
Je retourne sur le premier projet https://github.com/Syquel/mise-android-sdk et j'installe yq :
$ sudo dnf install yq
$ mise plugins install android-sdk https://github.com/Syquel/mise-android-sdk.git
mise plugin:android-sdk ✓ https://github.com/Syquel/mise-android-sdk.git#a44eb2b
$ mise ls-remote android-sdk
1.0
2.0
2.1
3.0
4.0
5.0
6.0
7.0
8.0
9.0
10.0
11.0
12.0
13.0-rc01
13.0
14.0-alpha01
16.0-alpha01
16.0
Je pense que ces versions correspondent à https://github.com/AndroidSDKSources/android-sdk-sources-list, mais #JeMeDemande pourquoi la version 15 est absente de cette liste.
J'ai configuré mon fichier .mise.toml
$ cat .mise.toml
[tools]
android-sdk = "13.0"
Et ensuite :
$ mise install
$ rehash
$ sdkmanager --version
13.0
Ensuite je ne sais pas trop quoi faire avec sdkmanager mais c'est une autre histoire 🙂.
[ << Notes plus récentes (251) ] | [ Notes plus anciennes (723) >> ]