
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
Résultat de la recherche (498 notes) :
J'ai découvert cc-safety-net : des hooks pour sécuriser les agents IA
Suite à ma note "Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code", une amie m'a mise sur la piste des hooks pour intégrer efficacement le blocage de l'exécution de commandes dangereuses dans mon harness.
claude-code-hooks
Elle utilise Claude Code et je pense qu'elle utilise le projet claude-code-hooks (lien direct), et plus précisément son script block-dangerous-commands.js.
Ce projet est présenté dans le billet Claude Code's Most Underrated Feature: Hooks du 25 janvier 2026, que j'ai pris le temps de lire avec attention.
Après lecture, ce billet confirme la piste suggérée par mon amie : les hooks semblent être la solution la plus répandue pour bloquer les commandes dangereuses.
J'ai découvert cc-safety-net
J'ai ensuite cherché une solution "clé en main" équivalente à block-dangerous-commands.js pour OpenCode et suis tombée sur cc-safety-net (lien direct), un projet qui a même démarré un peu avant claude-code-hooks (source) :
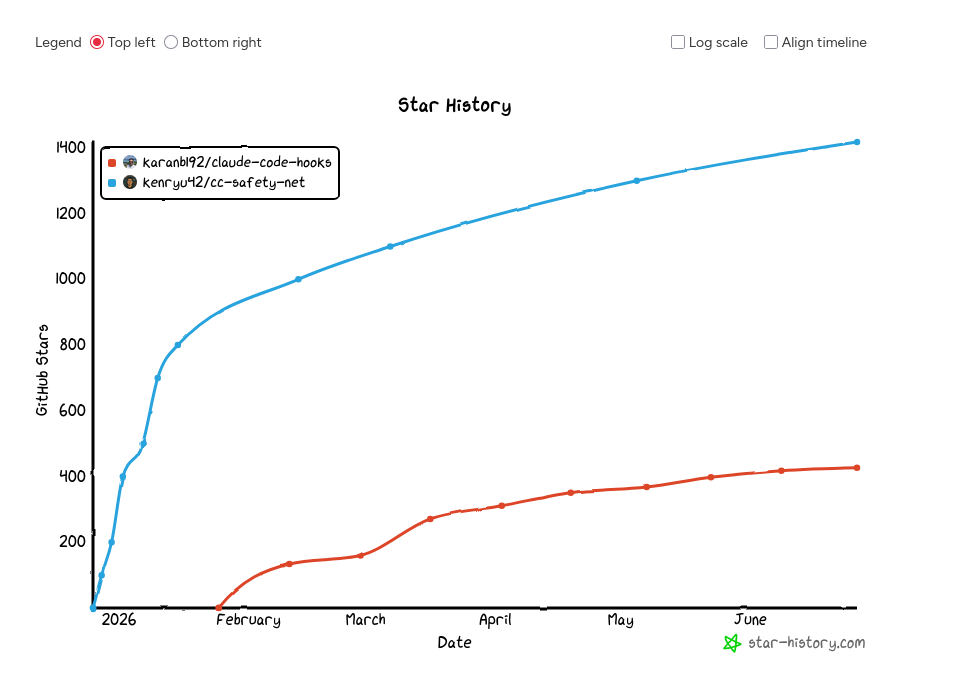
Le nom cc-safety-net combine l'abréviation de Claude Code ("cc") et "safety net", qui veut dire "filet de sécurité".
cc-safety-net ne se limite pas à Claude Code et OpenCode : il prend aussi en charge Codex, Gemini CLI, GitHub Copilot CLI et Kimi Code.
J'ai installé cc-safety-net
J'ai installé cc-safety-net sur mon instance OpenCode. Bien qu'il ne soit pas visible dans la liste des plugins de l'interface OpenCode — ce qui semble normal — il fonctionne correctement d'après mes tests :
$ git init
$ touch file1.md
$ git add file1.md
$ git commit -m "First import"
$ touch file2.md
$ opencode run --agent="build" "exécute git reset --hard"
> build · deepseek-v4-flash
✗ git reset --hard failed
Error: BLOCKED by CC Safety Net
Reason: git reset --hard destroys all uncommitted changes permanently. Use 'git stash' first.
Command: git reset --hard
If this operation is truly needed, ask the user for explicit permission and have them run the command manually.
La commande `git reset --hard` est bloquée par le CC Safety Net car elle détruit irréversiblement les changements non commités.
**Alternatives :**
- `git stash` pour sauvegarder les changements avant de reset
- Exécute la commande toi-même manuellement si tu confirms vouloir tout perdre
Que veux-tu faire ?
Par défaut, cc-safety-net contient peu de règles : il bloque les commandes de suppression sur le système de fichiers et git, comme documenté ici : "blocked-commands".
Après la lecture de la page "allowed-commands", j'ai cru que cc-safety-net proposait aussi un mode whitelist. En réalité, il fonctionne seulement en mode blocklist — pas de mode "tout bloquer" avec un système de whitelist.
Pour le moment, j'ai décidé d'activer le mode par défaut de cc-safety-net.
Création de rulebooks pour mon projet homelab
Ce que je trouve très intéressant avec cc-safety-net, c'est la possibilité d'ajouter facilement des "Custom Rules" grâce aux "rulebooks". Cette fonctionnalité est jeune, à peine 3 semaines. Pour le moment, je n'ai trouvé que 2 "rulebooks" sur GitHub.
J'ai utilisé le skill /cc-safety-net pour créer mes "rulebooks" pour les commandes kubectl, helmfile, tofu et mise de mon projet homelab.sklein.xyz.
Pas sans difficulté : le skill a dû corriger plusieurs erreurs de syntaxe dans les fichiers json qu'il a générés. Je ne sais pas si c'est normal. Mais à la fin, ça a fonctionné.
Je viens de configurer tout cela, je n'ai aucun retour d'expérience, j'essaierai d'en donner un d'ici une semaine.
Encore un problème avec rtk !
Par contre, j'ai découvert que cc-safety-net a lui aussi des difficultés avec rtk : [Bug]: rtk bypasses safety net.
Pour les secrets, je compte tester Rehydra
Contrairement à claude-code-hooks, cc-safety-net ne propose pas de hooks pour cacher les secrets à l'agent.
#JaiDécouvert le projet rehydra qui me semble très intéressant :
PII security for AI workflows, coding agents and browser workloads. Detects, replaces, encrypts, and rehydrates back when needed.
cc-safety-net versus agentsh ?
J'ai seulement survolé le sujet, mais j'ai l'impression que agentsh analyse et intercepte ce qui se passe directement au niveau du système d'exploitation, du système de fichiers, réseau, et processus. Il n'agit pas au niveau applicatif, il n'a pas besoin de comprendre ce que fait en théorie la commande, il observe réellement son action sur l'OS.
Pour le moment je pense que cc-safety-net est une bonne première étape de sécurité pour mes besoins. Mais agentsh a attiré ma curiosité, peut-être que je le testerai prochainement.
Remerciement
Merci à mon amie CC de m'avoir mise sur la piste des hooks 🤗.
Danger des permissions par défaut de OpenCode sur un projet d'infrastructure as code
Cette après-midi, DeepSeek V4 Flash (via OpenCode) a fait une boulette dans mon projet homelab.sklein.xyz !

En voulant corriger le Helmfile de déploiement de Hindsight, il a lancé :
$ mise run destroy-cnpg-hindsight
sans réaliser que cette task Mise allait lancer la commande suivante :
helmfile -f helmfile/helmfile.yaml.gotmpl destroy
sans remarquer que mon fichier helmfile/helmfile.yaml.gotmpl contenait tous mes services et pas seulement cnpg-hindsight !
Ce qui est marrant, c'est qu'après le « Oups », il a tout de suite essayé de se rattraper. Heureusement, je suis au début de l'installation de mon homelab — rien d'important à perdre — et j'ai pu tester que la restauration du backup continu de CloudNativePG basé sur barman fonctionne bien.
DeepSeek V4 Flash n'est pas à blâmer : je ne l'ai pas aidé avec mes instructions, je lui ai tendu un piège.
Suite à cet incident sans gravité, j'ai pris conscience que faire travailler un agent de coding sur un projet d'Infrastructure as code est bien plus risqué que sur un projet de développement cloisonné, sans accès à la production.
J'ai commencé par ajouter ces quelques lignes dans mon fichier AGENTS.md :
## Safety Rules
- **Never run any `destroy-*` script or `helmfile destroy` command without explicit user confirmation** in the same conversation turn. Always ask first.
- If you must run `helmfile destroy`, always use `--selector name=<release>` to target only one release.
- When in doubt about a command's destructiveness, ask before executing.
Ensuite, j'ai remarqué que l'agent plan de OpenCode avait par défaut un accès trop large au tool bash pour un projet d'Infrastructure as code, je me suis lancé dans le renforcement des permissions :
{
"$schema": "https://opencode.ai/config.json",
"agent": {
"plan": {
"permission": {
"bash": {
"*": "ask",
"kubectl get *": "allow",
"kubectl describe *": "allow",
"kubectl logs *": "allow",
"kubectl top *": "allow",
"tofu plan*": "allow",
"tofu show*": "allow",
"tofu output*": "allow",
"tofu state*": "allow",
"helm list*": "allow",
"helm status*": "allow",
"helm diff*": "allow",
"helmfile *list*": "allow",
"helmfile *status*": "allow",
"helmfile *diff*": "allow",
"git log*": "allow",
"git diff*": "allow",
"git status": "allow",
"git show*": "allow",
"jj log*": "allow",
"jj diff*": "allow",
"jj status": "allow",
"ls*": "allow",
"find*": "allow"
}
}
}
}
}
Ensuite, je me suis demandé s'il existait des solutions clé en main de limitation d'accès aux commandes cli, du même style que rtk, pour autoriser seulement des commandes de lecture sans risque.
#JaiDécouvert Prempti et agentsh. Je me suis demandé si l'intégration de l'un de ces outils n'allait pas entrer en conflit avec rtk. En étudiant les issues sur la sécurité de rtk, j'ai découvert que : rtk contourne le système de permissions d'OpenCode.
J'ai découvert que hindsight vient de "hind" (arrière) + "sight" (vue)
En étudiant le projet Hindsight, #JaiDécouvert un nouveau mot #anglais : hindsight, qui se traduit par "recul" en français.
Etymology : from hind + sight, 19th c. Compare Latinate retrospect.
Noun : hindsight
- Realization or understanding of the significance and nature of events after they have occurred.
Le mot hind anglais signifie :
MiMO-V2-Pro m'a confirmé que c'est normal que je ne connaissais pas ce mot : en anglais courant, on utilise back — que je connais, bien entendu — pour dire "arrière" de manière générale. Hind est un mot spécialisé un peu vieilli, principalement utilisé dans le contexte anatomique des animaux.
Je trouve que ce nom est très bien choisi pour le projet Hindsight qui est un Agent memory system.
Journal du dimanche 24 mai 2026 à 13:15
#JaiDécouvert ici encore des alternatives supplémentaires à pgfmt, pg_propre :
gh-issue-sync: sync GitHub issues locally and back
gh-issue-sync is a command line tool that syncs GitHub issues to local Markdown files for offline editing, batch updates, and integration with coding agents.
Pull issues locally, refine them until you are satisfied, and sync changes back. Also useful for offline access to your issues.
C'est un outil qui répond à un besoin que j'ai depuis 2018 : préparer avec un process précis des issues GitLab ou GitHub en draft, dans un format texte versionnable, particulièrement utile pendant la phase de meta-spec-writing.
C'est pour répondre à ce besoin que j'avais spécifié les fonctionnalités suivantes dans Projet 24 - Prototyper le gestionnaire de projet de mes rêves :
- Permettre d'importer / exporter une ou plusieurs issues dans un format de fichier YAML.
- Permettre d'importer / exporter ces fichiers via Git.
- Permettre l'utilisation de branche : création, suppression, merge de branches.
- Permettre la gestion des branches via l'interface web.
- Visualisation web des diff entre deux branches.
- Permettre de commit ou créer des snapshots d'une branche.
Je trouve curieux de voir émerger des projets comme Beads en octobre 2025 ou gh-issue-sync en décembre 2025, portés par la mouvance Specs Driven Development des agents IA, alors que j'explore ce formalisme depuis environ 2010. Ce qui m'intrigue surtout : pourquoi les développeurs s'intéressent à la spécification maintenant, et pas avant ? J'ai commencé à rédiger des choses à ce sujet, que je souhaite publier.
Le 15 mars dernier, j'ai créé des commandes OpenCode issue-create.md, issue-pull.md, issue-push.md, issue-update.md dont l'objectif était plus ou moins identique à gh-issue-sync : rédiger une issue dans un fichier local, la raffiner, puis l'envoyer vers GitHub. J'ai utilisé ces commandes pour créer les issues du projet sklein-devbox : https://github.com/stephane-klein/sklein-devbox/issues.
En l'état, je ne suis pas satisfait de mon expérience de développeur (DX). Il me semble que la fonctionnalité SKILL.md de gh-issue-sync offre probablement une meilleure architecture que l'utilisation des commandes OpenCode.
Ces prochains jours, je compte tester gh-issue-sync pour un éventuel remplacement. À plus long terme, j'aimerais pousser plus loin le sujet en testant Beads.
J'ai découvert snip et rtk et testé rtk (reduce LLM usage)
Le 13 avril 2026, j'ai découvert le projet snip :
Quelques semaines plus tard, le 29 avril, Alexandre m'a fait découvrir rtk, une alternative à snip.
rtk est un projet Rust dont le développement a commencé le 18 janvier 2026. snip, quant à lui, est un projet Golang initié par un français basé à la Réunion le 15 février 2026, directement inspiré de rtk.
Voici comment le projet snip compare les deux projets :
Design Philosophy
snip chose a fundamentally different approach to LLM token reduction: filters are data, not code. The binary is the engine, filters are YAML data files, and the two evolve independently.
rtk (Rust) snip (Go) Filter authoring Write Rust, recompile, wait for release Write YAML, drop in a folder, done Filter format Compiled into the binary Declarative YAML, engine and filters evolve independently Custom filters Fork the repo, add Rust code Create a .yamlfile in~/.config/snip/filters/Concurrency 2 OS threads Goroutines (lightweight, no thread pool) SQLite Requires CGO + C compiler Pure Go driver, static binary, no dependencies Cross-compilation Per-target C toolchain GOOS=linux GOARCH=arm64 go buildPipeline actions Built-in strategies 19 composable actions (keep, remove, regex, JSON, state machine...) Contributing Rust knowledge required YAML knowledge sufficient Both tools solve the same problem: reducing AI token costs from verbose CLI output. snip's bet is that extensibility wins. When anyone can write a filter in 5 minutes without touching Go or Rust, the filter ecosystem grows faster.
Voici à quoi ressemble un filtre dans rtk : https://github.com/rtk-ai/rtk/blob/master/src/filters/jj.toml.
Et voici l'équivalent pour snip : https://github.com/edouard-claude/snip/blob/master/filters/jj.yaml.
Je trouve la possibilité d'ajouter de nouvelles commandes à snip simplement en créant un fichier YAML intéressante, mais pour le moment je ne sais pas si j'en aurai besoin.
D'autre part, rtk est supporté par Mise : https://mise-versions.jdx.dev/tools/rtk.
Par conséquent, j'ai décidé de tester la configuration de rtk avec OpenCode. Voici le commit d'intégration à sklein-devbox : https://github.com/stephane-klein/sklein-devbox-chezmoi/commit/0fa4917ee2f31605f8d124223ec650961bf057b6.
Voici comment j'ai initialisé le plugin OpenCode pour rtk :
$ rtk init -g --opencode
OpenCode plugin installed (global).
OpenCode: /home/sklein/.config/opencode/plugins/rtk.ts
Restart OpenCode. Test with: git status
--- Telemetry ---
RTK collects anonymous usage metrics once per day to improve filters.
What: command names (not arguments), token savings, OS, version
Why: prioritize filter development for the most-used commands
Who: RTK AI Labs, contact@rtk-ai.app
Rights: disable anytime with `rtk telemetry disable`,
request erasure with `rtk telemetry forget`
Details: https://github.com/rtk-ai/rtk/blob/main/docs/TELEMETRY.md
Enable anonymous telemetry? [y/N] y
Telemetry enabled. Disable anytime: rtk telemetry disable
Et voici un exemple d'utilisation :
$ opencode run "Quels sont les derniers changements de ce projet ?"
> build · minimax-m2.5
$ rtk git log --oneline -10
0fffe04 Remove mode -x dot_config/tmux/scripts/executable_current-path.sh
832f03b Add peeble/ to Chezignore # <m-r> Reset Message
0fa4917 Setup rtk to reduces OpenCode LLM token consumption
983b77d s6-overlay migration to Pebble (#25)
1f7cbcd Start Mise eval before atuin to fix a bug
c8e6194 Remove gopass and GPG agent management since both services start automatically on first use
71e64e1 Enable Mise environment activation so Neovim can access Mise-managed tools
679f53f Purge empty mise installs/ dirs to force reinstall of incomplete tools
4c32db8 Extract init process into standalone script
8258ab9 Add infomation messages in init scripts
...
Je constate que la commande rtk git log est correctement utilisée par OpenCode.
Voici ce que m'affiche la commande rtk gain :
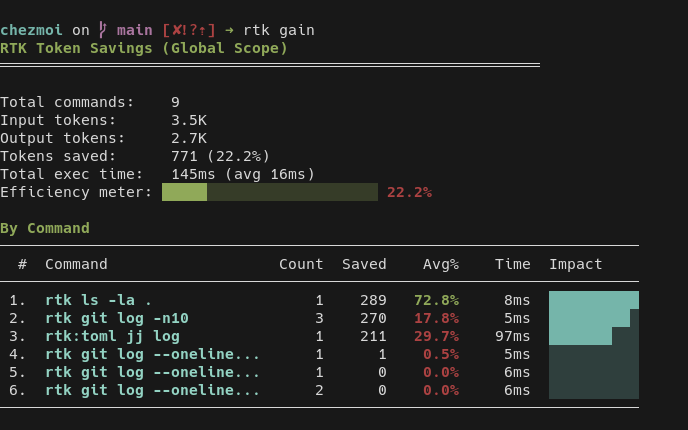
Pour le moment ceci n'est pas représentatif, car je viens de l'installer et j'ai lancé uniquement des tests fictifs.
Je compte publier une note de bilan d'ici quelques semaines pour analyser si c'est vraiment impactant ou non.
J'ai découvert le terme "test sociable"
Alexandre m'a fait découvrir aujourd'hui le terme "test sociable" versus "test solitaire", documenté ici par Martin Fowler.
Je connaissais déjà cette problématique sans en avoir le vocabulaire. Je la décrivais comme du "couplage dans le test" : un test qui couvre plusieurs unités à la fois peut échouer pour une raison indirecte, ce qui rend difficile l'identification de la vraie cause.
Je savais que la solution habituelle est d'utiliser des mocks pour isoler l'unité testée. Cela rend les tests mieux ciblés, mais aussi plus fastidieux à écrire.
Martin Fowler semble préférer les tests sociables par défaut, et ne recourt aux mocks que quand c'est nécessaire (non-déterminisme, lenteur, ressource externe instable). Je partage cette doctrine.
J'ai découvert Beads, Dolt et DoltgreSQL
En parcourant awesome-opencode, je suis tombé sur opencode-beads, qui m'a fait découvrir le projet Beads :
Beads is a distributed graph issue tracker for AI agents, powered by Dolt.
J'ai passé un peu de temps à parcourir la documentation du projet et je vois beaucoup de choses intéressantes et qui rejoignent les idées que j'ai pour "Projet 24 - Prototyper le gestionnaire de projet de mes rêves".
Ce projet m'a aussi fait découvrir Dolt :
Dolt is a SQL database that you can fork, clone, branch, merge, push and pull just like a Git repository.
et DoltgreSQL :
From the creators of Dolt, the world's first version controlled SQL database, comes DoltgreSQL, the postgres-flavored version of Dolt. It's a SQL database that you can branch and merge, fork and clone, push and pull just like a Git repository. Connect to your Doltgres server just like any Postgres database to read or modify schema and data. Version control functionality is exposed in SQL via system tables, functions, and procedures.
J'ai découvert pgfmt, un formater de code SQL
A PostgreSQL SQL formatter with multiple style options.
pgfmt parses SQL using tree-sitter PostgreSQL and reformats it according to one of several well-known style guides. Formatting is powered by libpgfmt.
Ce formatter supporte plusieurs types de style de formatage. Pour le moment, le formatage "river" est celui qui se rapproche le plus de mon style.
Je pense qu'il serait même possible de créer mon propre style de formatage en modifiant ce projet à l'aide d'un agentic coding tool 🤔.
Journal du vendredi 10 avril 2026 à 10:21
Dans Postgres Weekly numéro 643 #JaiDécouvert rpg :
rpg — modern Postgres terminal written in Rust. psql-compatible, with built-in DBA diagnostics and AI assistant
La liste des fonctionnalités de rpg me donne envie de le tester pour voir si, à l'usage, il est une bonne alternative à psql, pgcli ou usql.
Features
- psql-compatible —
\-commands are standard psql meta-commands (\d,\dt,\copy,\watch, ...);/-commands are rpg extensions — both AI and non-AI. Same muscle memory, clearly distinct additions.- Active Session History —
/ashlive wait event timeline with drill-down; pg_ash history integration- AI assistant —
/ask,/fix,/explain,/optimize,/text2sql,/yolo- DBA diagnostics — 15+
/dbacommands: activity, locks, bloat, indexes, vacuum, replication, config- Schema-aware completion — tab completion for tables, columns, functions, keywords
- Lua plugin system — extend rpg with custom
/-commands written in Lua- TUI pager — scrollable pager for large result sets
- Syntax highlighting — SQL keywords, strings, operators; EXPLAIN plans; color-coded errors/warnings
- Markdown output —
\pset format markdownfor docs-ready table output- Named queries — save and recall frequent queries
- Session persistence — history and settings preserved across sessions
- Multi-host failover —
-h host1,host2tries each in order, first success wins- SSH tunnel — connect through bastion hosts without manual port-forwarding
- Config profiles — per-project
.rpg.toml- Shell backtick substitution — dynamic prompts via
PROMPT1='[git branch --show-current] %/ # '- Status bar — connection info, transaction state, timing
- Cross-platform — single static binary: Linux, macOS, Windows (x86_64 + aarch64)
J'ai découvert MimiMax M2.7, qui semble équivalent à GLM-5 pour un tiers du prix
#JaiDécouvert la sortie de MiniMax M2.7 le 18 mars 2026 : https://www.minimax.io/news/minimax-m27-en.
Pour donner du contexte, j'utilise depuis le 12 mars 2026 les modèles GLM-5, Kimi K2.5 et MiniMax M2.5 via l'offre OpenCode Go. Je n'ai pas comparé rigoureusement ces modèles avec Sonnet 4.6 et Opus 4.6, mais pour le moment, je suis satisfait de ces modèles. J'ai même l'impression que MiniMax M2.5, le moins cher, suffit pour la majorité de mes besoins.
J'ai lu l'article "MiniMax M2.7 Review: Is It Worth the Hype?", mais c'est finalement MiniMax M2.7: Everything you need to know qui m'a été le plus utile, voici sa traduction :
MiniMax a publié MiniMax-M2.7, offrant une intelligence de niveau GLM-5 pour moins d'un tiers du coût
MiniMax-M2.7 de @MiniMax_AI obtient un score de 50 sur l'Artificial Analysis Intelligence Index, une amélioration de 8 points par rapport à MiniMax-M2.5, publié il y a un mois. Cette amélioration est portée par une performance améliorée sur les tâches agentiques du monde réel et une réduction des hallucinations. MiniMax-M2.7 est désormais devant MiMo-V2-Pro (Reasoning, 49) et Kimi K2.5 (Reasoning, 47), et équivalent à GLM-5 (Reasoning, 50) tout en utilisant 20% de tokens de sortie en moins et coûtant moins d'un tiers du prix pour fonctionner. MiniMax-M2.7 est un modèle uniquement raisonnement et maintient le même prix par token que MiniMax-M2.5.
Points clés :
➤ Performance solide sur les tâches agentiques du monde réel : MiniMax-M2.7 atteint un Elo GDPval-AA de 1494, une amélioration significative par rapport à MiniMax-M2.5 (1203) et devant MiMo-V2-Pro (Reasoning, 1426), GLM-5 (Reasoning, 1406) et Kimi K2.5 (Reasoning, 1283). Il reste derrière les modèles de pointe tels que GPT-5.4 (xhigh, 1667) et Claude Opus 4.6 (Adaptive Reasoning, max effort, 1606).
- Réduction des hallucinations : MiniMax-M2.7 obtient un score de +1 sur l'AA-Omniscience Index, contre -40 pour MiniMax-M2.5. Cela le place en compétition avec GPT-5.2 (xhigh, -1) et GLM-5 (Reasoning, +2), et bien devant Kimi K2.5 (Reasoning, -8). L'amélioration par rapport à M2.5 est entièrement due à la réduction des hallucinations, ce qui signifie que le modèle est plus susceptible de s'abstenir de répondre lorsqu'il ne connaît pas la réponse, plutôt que de deviner. M2.7 atteint un taux d'hallucination de 34%, inférieur à Claude Sonnet 4.6 (Adaptive Reasoning, max effort, 46%) et Gemini 3.1 Pro Preview (50%).
- Gains sur la plupart des évaluations par rapport à MiniMax-M2.5 : En dehors des améliorations du GDPval-AA et de l'AA-Omniscience notées ci-dessus, MiniMax-M2.7 progresse en HLE (+9 p.p.), TerminalBench Hard (+5 p.p.), SciCode (+4 p.p.), IFBench (+4 p.p.), GPQA (+3 p.p.) et LCR (+3 p.p.). Nous avons constaté une régression notable en τ²-Bench (-11 p.p.).>
- Utilisation accrue de tokens : MiniMax-M2.7 a utilisé environ 87M tokens de sortie pour exécuter l'Artificial Analysis Intelligence Index, en hausse de 55% par rapport à MiniMax-M2.5 (environ 56M). Il reste plus efficace en tokens que d'autres modèles tels que GLM-5 (Reasoning, 110M) et Kimi K2.5 (Reasoning, environ 89M).
- Rentabilité de pointe : MiniMax-M2.7 a coûté 176 $ pour exécuter l'Artificial Analysis Intelligence Index, maintenant le même prix de 0,30 $/1,20 $ par million de tokens d'entrée/sortie que M2.5. Cela le place sur la frontière de Pareto de notre graphique Intelligence vs. Coût. À titre de référence, GLM-5 (Reasoning) a coûté 547 $ à intelligence équivalente, Kimi K2.5 (Reasoning) 371 $, et Gemini 3 Flash Preview (Reasoning) 278 $.
Détails clés du modèle :
- Fenêtre de contexte : 200K tokens (équivalent à MiniMax-M2.5).
- Tarification : 0,30 $/1,20 $ par million de tokens d'entrée/sortie (inchangé par rapport à MiniMax-M2.5).
- Disponibilité : API propriétaire MiniMax uniquement.
- Modalité : Entrée et sortie de texte uniquement (pas de multimodalité).
- Licence : MiniMax n'a pas annoncé si MiniMax-M2.7 sera en open weights. MiniMax-M2.5 est disponible sous licence MIT.
MiniMax M2.7 a été intégré dans l'offre OpenCode Go, par conséquent, je vais tester ce modèle dans mes projets OpenCode.
Journal du jeudi 26 mars 2026 à 14:47
#JaiDécouvert https://keepachangelog.com, un guide pour maintenir les changelog de ses projets.
Je découvre l'offre "Go" de OpenCode, « Go - Modèles de code à faible coût pour tous », qui semble être sortie le 25 février 2026 : https://xcancel.com/opencode/status/2026553685468135886.
Je n'ai rien trouvé à ce sujet sur Hacker News ni chez Simon Willison.
D'après ce que je comprends, alors que l'offre OpenCode Zen propose un point d'accès et une facturation unifiés du type Pay-As-You-Go, comme OpenRouter, OpenCode Go est une offre d'abonnement à 10 dollars par mois, selon les mêmes principes que les plans d'abonnement comme Anthropic Claude Pro, Max, etc.
L'offre OpenCode Go propose un accès uniquement à 3 LLMs, tous Open Weights et tous chinois : GLM-5, Kimi K2.5 et MiniMax M2.5.
À noter toutefois que OpenCode Go n'utilise aucun AI provider basé en Chine :
Privacy : The plan is designed primarily for international users, with models hosted in the US, EU, and Singapore for stable global access.
Contrairement à Anthropic (voir Est-ce qu'un abonnement Claude est réellement plus économique qu'un accès direct via l'API ?), OpenCode semble être transparent sur leur offre :
Usage limits
OpenCode Go includes the following limits:
- 5 hour limit — $12 of usage
- Weekly limit — $30 of usage
- Monthly limit — $60 of usage
Limits are defined in dollar value. This means your actual request count depends on the model you use. Cheaper models like MiniMax M2.5 allow for more requests, while higher-cost models like GLM-5 allow for fewer.
The table below provides an estimated request count based on typical Go usage patterns:
GLM-5 Kimi K2.5 MiniMax M2.5 requests per 5 hour 1,150 1,850 20,000 requests per week 2,880 4,630 50,000 requests per month 5,750 9,250 100,000 Estimates are based on observed average request patterns:
- GLM-5 — 700 input, 52,000 cached, 150 output tokens per request
- Kimi K2.5 — 870 input, 55,000 cached, 200 output tokens per request
- MiniMax M2.5 — 300 input, 55,000 cached, 125 output tokens per request
You can track your current usage in the console.
Comparaison des prix au million de tokens des plans Claude Max et OpenCode Go
Si je pars des prix listés sur l'offre OpenCode Zen et les prix de Sonnet 4.6 chez Anthropic, je peux dresser le tableau suivant, prix exprimé en millions de tokens :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 | $0.30 | $1.20 | $0.06 | $0.375 |
| GLM 5 | $1.00 | $3.20 | $0.20 | - |
| Kimi K2.5 | $0.60 | $3.00 | $0.10 | - |
| Sonnet 4.6 | $3.00 | $15.00 | $0.30 | $3.75 |
Ensuite, j'ajuste ces prix avec les réductions offertes :
- par le plan Claude Max à $100 / mois, soit une réduction de 92,56 % (
(1345 - 100) / 1345 × 100 = 92,56 %) - par OpenCode Go, soit une réduction de 83,33 % (
(60 - 10) / 60 × 100 = 83,33 %)
Cela donne :
| Model | Input | Output | Cached Read | Cached Write |
|---|---|---|---|---|
| MiniMax M2.5 (avec offre Go) | $0.05 | $0.20 | $0.01 | $0.06 |
| GLM 5 (avec offre Go) | $0.16 | $0.53 | $0.03 | - |
| Kimi K2.5 (avec offre Go) | $0.10 | $0.50 | $0.01 | - |
| Sonnet 4.6 (avec offre Max) | $0.22 | $1.11 | $0.02 | $0.27 |
Sur la base du leaderboard SWE-bench Verified, je vais partir des hypothèses suivantes :
- Si je considère arbitrairement que GLM-5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est légèrement moins cher que l'offre Claude Max
- Si je considère arbitrairement que Kimi K2.5 est équivalent à Sonnet 4.6, alors l'offre OpenCode Go est deux fois moins cher que l'offre Claude Max
#JaiDécidé de tester l'offre OpenCode Go sur un projet d'outil d'archivage à froid de conversations Mattermost en Golang que je coderai from scratch. Je compte réaliser deux versions de ce projet en parallèle : une version avec Sonnet 4.6 et l'autre avec les modèles de OpenCode Go.
J'ai découvert le terme « Architecture à médaillon » — un concept DataOps
Alexandre m'a fait découvrir, via cet article, le terme « Architecture à médaillon » — un concept que je pratiquais déjà sans savoir le nommer.
J'ai installé Claude Desktop sous Fedora
Anthropic ne propose pas de version GNU Linux de Claude Desktop.
#JaiDécouvert le projet Claude Desktop for Linux qui a repackagé la version de Claude Desktop Windows pour GNU Linux. Ce projet propose des packages pour Debian, Fedora, ArchLinux et NixOS.
Je l'ai installé avec succès sous Fedora avec les commandes suivantes trouvé ici :
$ sudo curl -fsSL https://aaddrick.github.io/claude-desktop-debian/rpm/claude-desktop.repo -o /etc/yum.repos.d/claude-desktop.repo
$ sudo dnf install claude-desktop
J'ai ensuite testé la connexion de Claude Desktop au Filesystem MCP Server lancé en local :
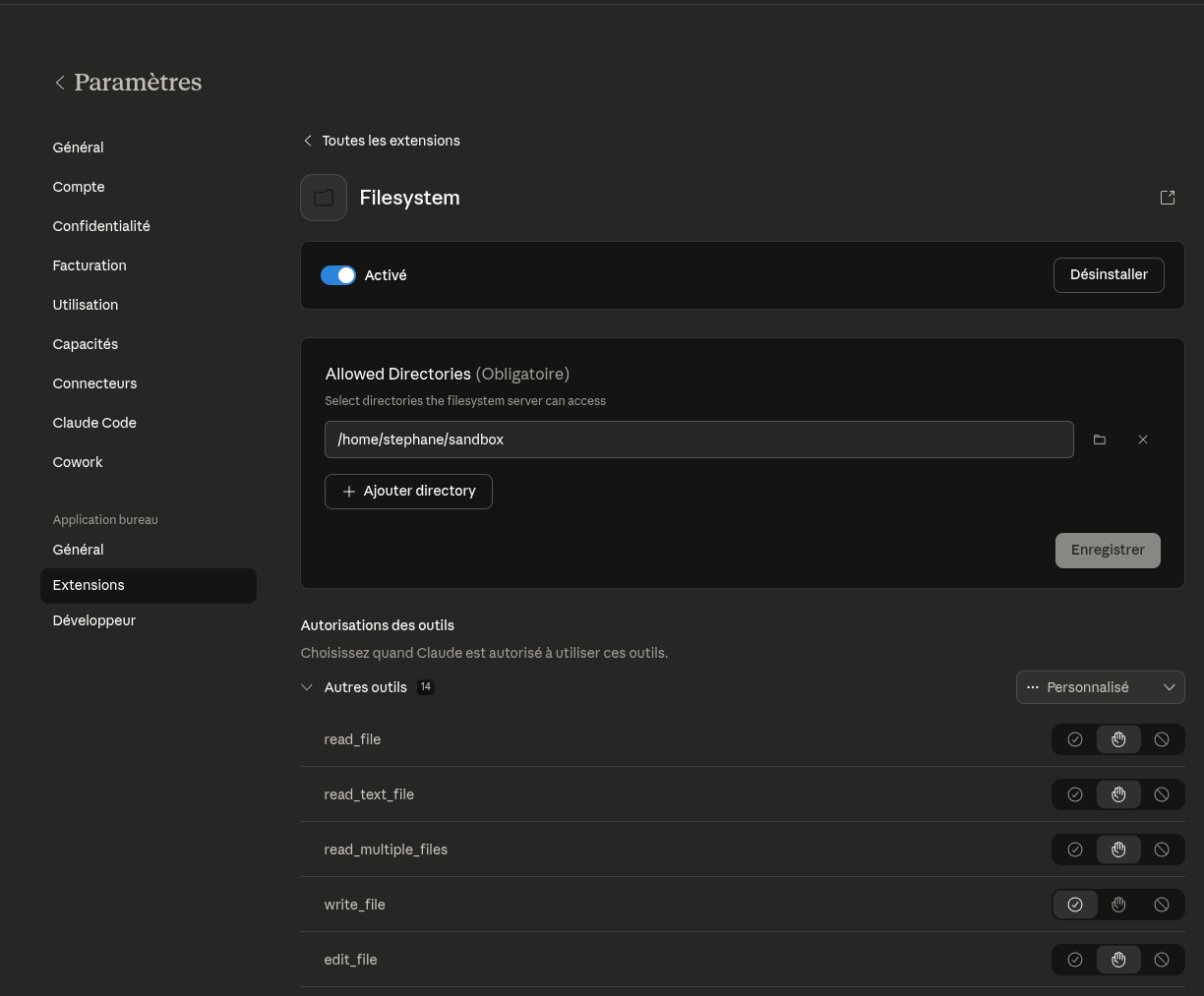
Seul élément négatif pour l'instant : la version Desktop ne permet pas d'utiliser l'extension Claude Counter (extension), contrairement à la version web.
J'ai découvert le modèle Open Weights GLM-5
#JaiDécouvert le modèle GLM-5 Open Weights de la société chinoise Z.ai : https://glm5.net
- Note de Simon Willison : https://simonwillison.net/2026/Feb/11/glm-5/
- Thread Hacker News : GLM-5: Targeting complex systems engineering and long-horizon agentic tasks
Analyse de Sonnet 4.6 des commentaires :
En se basant sur les retours concrets du fil, GLM-5 impressionne pour le coding agentique : cmrdporcupine rapporte un refactoring réussi dans un langage propriétaire pour seulement $1.50, avec une analyse initiale meilleure que GPT 5.3. Plusieurs utilisateurs le positionnent au niveau d'Opus 4.5 voire au-delà pour les tâches bien définies, à une fraction du coût. Le plan coding de Z.ai est cité comme une alternative crédible aux abonnements Anthropic, dont les limites d'usage dégradées poussent beaucoup à chercher ailleurs. Le scepticisme subsiste néanmoins sur le benchmaxxing — les comparaisons publiées portent sur Opus 4.5 et non sur Opus 4.6, la dernière génération.
Je constate que GLM-5 est mentionné / conseillé dans le README.md de Oh My OpenCode :
Even only with following subscriptions, ultrawork will work well (this project is not affiliated, this is just personal recommendation):
- ChatGPT Subscription ($20)
- Kimi Code Subscription ($0.99) (*only this month)
- GLM Coding Plan ($10)
- If you are eligible for pay-per-token, using kimi and gemini models won't cost you that much.
et
- Sisyphus (
claude-opus-4-6/kimi-k2.5/glm-5) is your main orchestrator. He plans, delegates to specialists, and drives tasks to completion with aggressive parallel execution. He does not stop halfway.- Hephaestus (
gpt-5.3-codex) is your autonomous deep worker. Give him a goal, not a recipe. He explores the codebase, researches patterns, and executes end-to-end without hand-holding. The Legitimate Craftsman.- Prometheus (
claude-opus-4-6/kimi-k2.5/glm-5) is your strategic planner. Interview mode: it questions, identifies scope, and builds a detailed plan before a single line of code is touched.
J'observe que GLM-5 est plutôt bien placé dans les leaderboard SWE-bench :
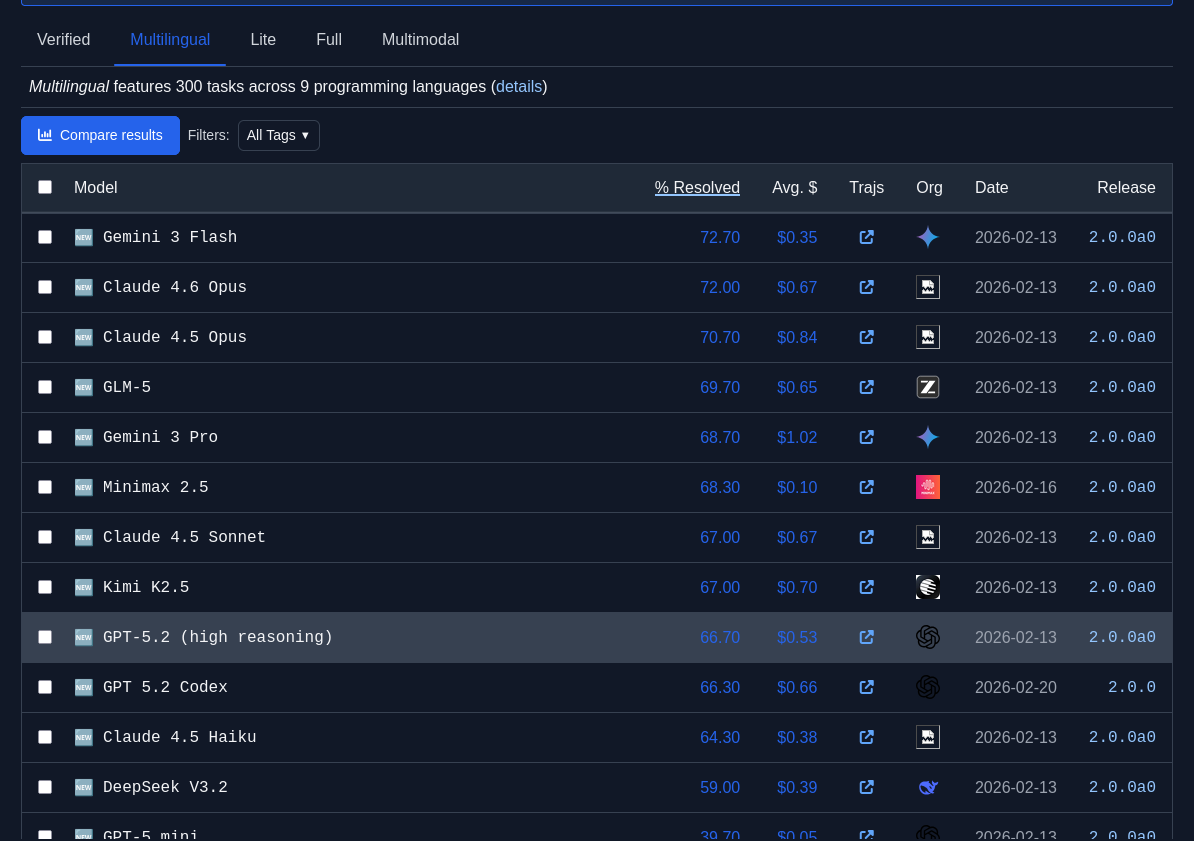
Je constate que GLM-5 est meilleur que Devstral 2 (Mistral) qui a un score de 61.3%.
J'ai découvert Promptfoo qui permet de faire du LLM Eval
Cette note a été partiellement écrite fin novembre 2025 et publiée 3 mois plus tard, fin février 2026.
Souhaitant améliorer mes prompts et combler mes lacunes en prompt engineering, je me suis mis à chercher des outils permettant de pratiquer quelque chose qui ressemblerait au Test driven development appliqué à la conception de prompts.
Via Claude Sonnet 4.5, #JaiDécouvert Promptfoo (https://github.com/promptfoo/promptfoo), un framework Javascript permettant notamment de faire du LLM Eval.
Cela fait plusieurs mois que je croise l'expression LLM Eval, sans avoir jamais pris le temps de comprendre ce que ce concept signifie précisément.
D'après ce que j'ai compris, la différence essentielle entre Unit testing et LLM Eval, c'est que les tests unitaires sont déterministes, alors que la qualité des réponses des LLM est évaluée de manière probabiliste.
Je compte créer un playground Promptfoo connecté à plusieurs modèles LLM dans les semaines à venir.
Journal du dimanche 15 février 2026 à 15:23
#JaiDécouvert l'effet Zeigarnik que je n'arrive pas encore à bien maîtriser.
#JaiDécouvert aussi l'effet What the hell ou en français l'effet "Et puis merde".
Journal du vendredi 09 janvier 2026 à 10:11
Dans Nouvelles sur l’IA de décembre 2025 #JaiDécouvert METR - Model Evaluation & Threat Research :
Claude Opus 4.5 rejoint la maintenant célèbre évaluation du METR. Il prend largement la tête (sachant que ni Gemini 3 Pro, ni ChatGPT 5.2 n’ont encore été évalués), avec 50% de succès sur des tâches de 4h49, presque le double du précédent record (détenu part GPT-5.1-Codex-Max, avec 50% de succès sur des tâches de 2h53). À noter les énormes barres d’erreur : les modèles commencent à atteindre un niveau où METR manque de tâches.
J'ai découvert upterm qui permet de partager facilement une session terminal à distance
J'ai cherché une solution pour partager facilement une session shell de ma workstation à un collègue.
Je connais les solutions suivantes :
$ ngrok tcp 22
Donne : tcp://0.tcp.ngrok.io:12345
# Connexion : ssh user@0.tcp.ngrok.io -p 12345
- Tmate, un fork de tmux patché, en C, projet qui a débuté en 2007
- cloudflared
#JaiDécouvert aujourd'hui les solutions upterm et bore.
Le projet upterm a commencé en 2019 et est codé en Golang. Le projet bore est plus jeune, il a commencé 2022 et est codé en rust.
J'ai testé bore puis upterm. J'ai retenu upterm pour les raisons suivantes :
- upterm propose directement un package RPM, contrairement à bore
- Le serveur relais public de upterm était significativement plus réactif que celui de bore lors de mes tests
- upterm propose nativement une session partagée entre deux utilisateurs, alors que bore est spécialisé dans la création de tunnels TCP. Il est possible de configurer bore pour lancer automatiquement des sessions partagées via un script tmux lancé par ssh, mais c'est moins pratique que upterm
Voici une démonstration de upterm :
$ sudo dnf install -y https://github.com/owenthereal/upterm/releases/download/v0.20.0/upterm_linux_amd64.rpm
Je peux ensuite autoriser la clé publique ssh de l'utilisateur invité :
$ upterm host --authorized-keys PATH_TO_PUBLIC_KEY
ou directement via son username GitHub :
$ upterm host --github-user username
Pour donner accès à une session terminal :
$ upterm host
The authenticity of host 'uptermd.upterm.dev (2a09:8280:1::3:4b89)' can't be established.
ED25519 key fingerprint is SHA256:9ajV8JqMe6jJE/s3TYjb/9xw7T0pfJ2+gADiBIJWDPE.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
╭─ Session: LiZaF6eKfCTxNeFSEt7B ─╮
┌──────────────────┬─────────────────────────────────────────────┐
│ Command: │ /usr/bin/zsh │
│ Force Command: │ n/a │
│ Host: │ ssh://uptermd.upterm.dev:22 │
│ Authorized Keys: │ n/a │
│ │ │
│ ➤ SSH Command: │ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev │
└──────────────────┴─────────────────────────────────────────────┘
╰─ Run 'upterm session current' to display this again ─╯
🤝 Accept connections? [y/n] (or <ctrl-c> to force exit)
✅ Starting to accept connections...
L'utilisateur invité accède à ce terminal simplement avec :
$ ssh LiZaF6eKfCTxNeFSEt7B@uptermd.upterm.dev
upterm maintient une liste de sessions ouvertes, consultable avec :
$ upterm session list
📡 Active Sessions (1)
═══════════════════════
┌───┬──────────────────────┬──────────────┬─────────────────────────────┐
│ │ SESSION ID │ COMMAND │ HOST │
├───┼──────────────────────┼──────────────┼─────────────────────────────┤
│ * │ DumRFGF6AuinQjzwBf0E │ /usr/bin/zsh │ ssh://uptermd.upterm.dev:22 │
└───┴──────────────────────┴──────────────┴─────────────────────────────┘
💡 Tips:
• Use 'upterm session current' to see details
• Use 'upterm session info <SESSION_ID>' for specific session
J'ai découvert AIChat, alternative à llm cli
Dans ce thread, #JaiDécouvert AIChat (https://github.com/sigoden/aichat), une alternative à llm (cli) codée en Rust.
AIChat is an all-in-one LLM CLI tool featuring Shell Assistant, CMD & REPL Mode, RAG, AI Tools & Agents, and More.
En parcourant le README.md, j'ai l'impression que AIChat propose une meilleure UX que llm (cli).
Je constate aussi que AIChat offre plus de fonctionnalités que llm (cli) :
- AI Tools & MCP
- AI Agents
- LLM Arena
- La partie RAG semble plus avancée
Ce qui attire le plus mon attention, c'est le sous-projet llm-functions qui, d'après ce que j'ai lu, permet de créer très facilement des tools en Bash, Python ou Javascript. Exemples :
J'ai hâte de tester ça 🙂 ( #JaimeraisUnJour ).
Par contre, llm-functions ne semble pas encore permettre la configuration de Remote MCP server.
Je suis aussi intéressé par cette issue : TUI for managing, searching, and switching between chat sessions.
Un point qui m'inquiète un peu : le projet semble peu actif ces derniers mois.
J'ai découvert la méthode NVIM_APPNAME qui permet de lancer des instances cloisonnées de Neovim
Il y a plus d'un an, j'ai écrit cette note où je décrivais la méthode que j'avais trouvée après plusieurs itérations pour lancer plusieurs instances Neovim cloisonnées.
J'ai publié cette méthode dans neovim-playground, qui ressemble à ceci :
export XDG_CONFIG_HOME=$(PWD)/config/
export XDG_DATA_HOME=$(PWD)/local/share/
export XDG_STATE_HOME=$(PWD)/local/state/
export XDG_CACHE_HOME=$(PWD)/local/cache/
Je me suis senti un peu bête aujourd'hui en découvrant dans la documentation officielle de Neovim qu'il existe une méthode officielle pour isoler une instance Neovim :
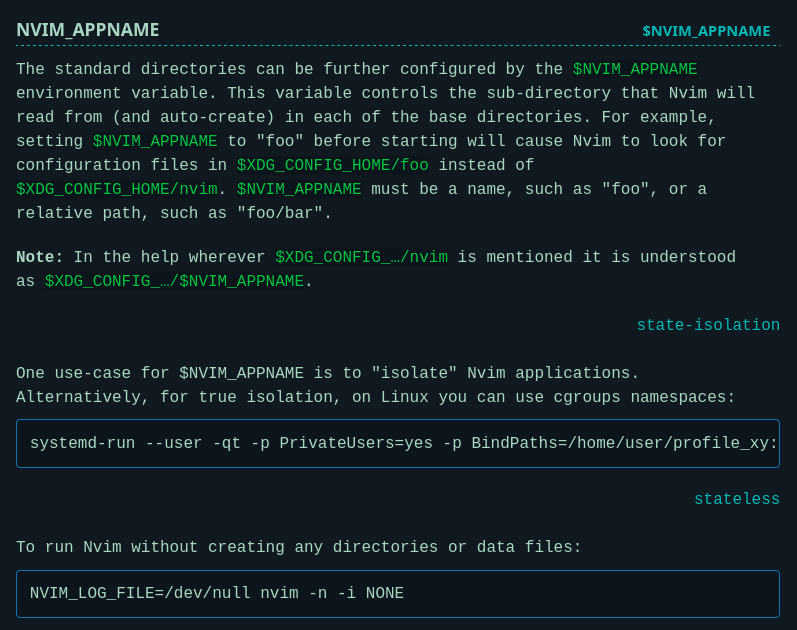
Cette fonctionnalité a été ajoutée dans la version 0.9.0 d'avril 2023, suite à une demande d'utilisateurs qui avaient le même besoin que moi, décrite dans cette issue : NVIM_APPNAME: isolated configuration profiles
Dans cette documentation, #JaiDécouvert comment lancer une application dans un namespace cgroups :
$ systemd-run --user -qt -p PrivateUsers=yes -p BindPaths=/home/user/profile_xy:/home/user/.config/nvim nvim
Je trouve cela plutôt simple.
Coïncidence : j'ai découvert systemd-run il y a 3 mois et depuis, je croise cette commande de plus en plus souvent.
Comme je souhaite lancer un environnement cloisonné Neovim tout en conservant l'accès aux outils de mon terminal (comme ceux installés avec Mise), j'ai choisi d'utiliser la méthode basée sur NVIM_APPNAME.
J'ai testé cette méthode avec succès dans neovim-playground (commit).
J'ai découvert le concept de "catch up culture"
J'ai été heureux de découvrir le 5 décembre dernier, #NouveauMot pour exprimer un concept que j'observe depuis des années : "catch up culture".
Voici le parcours médiatique du concept :
- mai 2025, publication du livre Bad Friend qui formalise le concept de "catch up culture"
- 23 occtobre sur Reddit : Tired of being the « catch-up » friend instead of the one people create new memories with
- 30 octobre sur Dazed : Are we caught in a culture of never-ending catch-ups?
- 20 novembre sur France Inter : "Catch up culture", quand l'amitié devient artificielle
- 30 novembre sur Huffington Post : Si vos discussions entre amis sont de moins en moins profondes, c’est à cause de la « catch up culture »
- 5 décembre sur Madame Figaro : Qu’est-ce que la «catch up culture», quand nos amitiés ne consistent plus qu’à se voir pour faire des «mises à jour» de nos vies ?
Et le 5 décembre, ma compagne me fait découvrir le terme catch up culture.
La "catch up culture" c'est quand on voit ses amis uniquement pour se raconter ce qu'on a fait depuis la dernière fois, plutôt que de vivre des moments ensemble. Les amitiés deviennent alors des séances de rattrapage espacées (que ce soit de 2 mois, 6 mois, 1 an ou 2 ans) où on échange surtout des anecdotes et des souvenirs communs. On reste sur les grandes lignes sans rentrer dans les détails importants, de peur d'ennuyer l'autre, parce qu'au fond on ne fait plus vraiment partie de sa vie.
Je le vis régulièrement quand je retourne à Metz une à deux fois par an, pour voir mes amis pongistes par exemple, avec qui j'ai vécu pendant parfois plus de 10 ans des aventures humaines mémorables. Même chose avec d'anciens collègues.
J'ai énormément de mémoire transactive avec eux. Quand je les revois, c'est fluide, ils me sont familiers, j'ai l'impression de les avoir vus hier. Ils sont importants pour moi. J'ai l'impression de les connaître avec un assez haut niveau d'intimité. Je connais leurs forces et faiblesses, j'ai confiance en eux, ce sont de vrais amis.
Par contre, à chaque fois que je les vois, j'ai la même sensation : on tourne en rond, on pratique du "catch up". On se raconte encore et encore nos anecdotes communes, nos souvenirs communs. On ne fait plus rien ensemble à part partager un bon repas. Plus de nouveaux "faits d'arme" !
Je n'aime pas et je n'ai jamais aimé pratiquer le small talk ou faire du baratinage. J'aime apprendre des choses des autres, et pour ça j'aime aller dans le détail, dépasser le catalogue de leurs dernières vacances ou de leurs aménagements de maison secondaire. Pour cela, j'essaie de privilégier des rencontres one-on-one (en tête-à-tête). J'ai découvert cela notamment dans le livre Never Eat Alone que j'ai survolé en 2016.
Je constate que les discussions en tête-à-tête sont d'autant plus intéressantes avec des amis avec qui on est en très forte confiance. Elles permettent :
- Profondeur de connexion : Les conversations en tête-à-tête permettent d'aller au-delà des banalités, et donc des échanges purement catch up, pour vraiment comprendre les motivations, défis et aspirations de l'autre personne.
- Vulnérabilité et confiance : Il est plus facile d'être authentique et de partager des choses personnelles dans un cadre intimiste.
- Attention non divisée : On peut vraiment écouter et être présent, sans les distractions d'un groupe et surtout, sans avoir peur d'ennuyer tout le monde en entrant dans les détails.
C'est un peu dans l'espoir de passer tout de suite au-delà de l'étape "catch up" que j'ai créé ma page NowNowNow, sans toutefois me faire d'illusion. En dehors de 1 ou 2 amis, personne ne connaît ou ne consulte cette page. Mais ça n'a pas d'importance pour moi, je le fais quand même, l'idée me plaît.
Quelques jours avant un dîner en tête-à-tête, j'aime prendre le temps de penser aux sujets de conversation qui pourraient nous intéresser tous les deux : partager mes nouvelles découvertes, mes nouveaux concepts et avoir le point de vue de la personne. J'aime savoir quels sont ses défis actuels, et j'essaie de lui poser des questions dans ce sens, pour lui permettre de formaliser sa pensée et pour apprendre d'elle, découvrir de nouvelles situations.
La prochaine fois que je vous propose une rencontre en tête-à-tête, vous saurez pourquoi 🙂.
J'ai découvert l'extension Firefox Unlock Medium Article
#JaiDécouvert extension Firefox pour bypass l'obligation de créer un compte Medium pour consulter un article des articles Medium : Unlock Medium article.
L'extension se base sur le site web : https://freedium.cfd.
Journal du mercredi 03 décembre 2025 à 06:58
#JaiDécouvert usql (https://github.com/xo/usql) qui semble être une alternative à pgcli, écrit en Golang.
Je ne l'ai pas encore testé.
J'ai découvert class-variance-authority et tailwinds-variants
Jusqu'à présent, pour la gestion conditionnelle des classes CSS dans mes projets ReactJS ou Svelte, j'utilisais clsx.
Pour Svelte en particulier, j'utilise souvent directement le mécanisme conditionnel natif de l'attribut "class" du framework.
Aujourd'hui, dans un projet professionnel ReactJS, #JaiDécouvert la librairie conditionnelle class-variance-authority.
Cette librairie existe depuis debut 2022 et voici un exemple d'utilisation de class-variance-authority :
<script>
import { cva } from 'class-variance-authority';
const button = cva(
'font-semibold rounded', // équivalent au paramètre `base:` utlisé par tailwind-variants
{
variants: {
intent: {
primary: 'bg-blue-500 text-white hover:bg-blue-600',
secondary: 'bg-gray-200 text-gray-900 hover:bg-gray-300'
},
size: {
sm: 'px-3 py-1 text-sm',
md: 'px-4 py-2 text-base',
lg: 'px-6 py-3 text-lg'
}
},
compoundVariants: [
{
intent: 'primary',
size: 'lg',
class: 'uppercase tracking-wide' // <= appliqué seulement si intent="primary" et size="lg"
}
],
defaultVariants: {
intent: 'primary',
size: 'md'
}
}
);
export let intent = 'primary';
export let size = 'md';
</script>
<button class={button({ intent, size })}>
<slot />
</button>
Je trouve cette approche plus élégante que clsx pour des besoins complexes, comme la création d'un design system.
Dans la même famille de librairie, il existe aussi tailwind-merge que j'avais déjà identifié mais sans avoir jamais pris le temps d'étudier. Ses fonctionnalités sont très simples et minimalistes :
Merge Tailwind CSS classes without style conflicts
Claude Sonnet 4.5 m'a fait découvrir tailwind-variants, une alternative à class-variance-authority. Cette lib est spécifique à Tailwind CSS mais offre de meilleures performances et des fonctionnalités supplémentaires par rapport à class-variance-authority.
Le projet a été créé début 2023, soit environ 1 an après class-variance-authority.
Voici un tableau comparant les fonctionnalités de tailwind-variants et class-variance-authority :
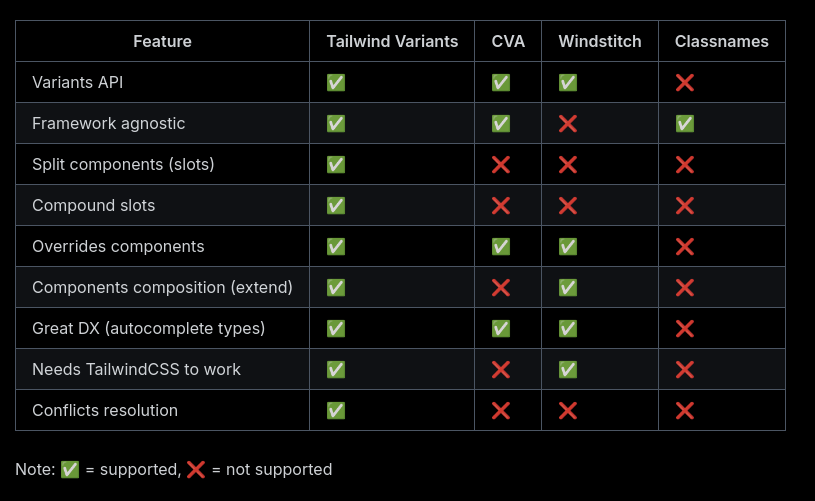
La dernière section de la page Tailwind Variants - Comparison explique l'historique de la lib avec class-variance-authority et les raisons qui ont motivé sa création.
Après quelques difficultés, je pense avoir saisi l'intérêt de la fonctionnalité "slots", disponible dans tailwind-variants mais absente de class-variance-authority.
Si un jour je dois créer des composants de design system avancés dans un projet ReactJS ou Svelte, je pense que j'utiliserai tailwind-variants.
J'ai découvert Adminer, alternative à PhpMyAdmin et je me suis intéressé à OPCache
En travaillant sur un playground d'étude de Podman Quadlets, dans le README.md de l'image Docker mariadb, #JaiDécouvert le projet Adminer (https://www.adminer.org) qui semble être l'équivalent de PhpMyAdmin, mais sous la forme d'un fichier unique.
Je découvre aussi que contrairement à PhpMyAdmin, Adminer n'est pas limité à Mysql / MariaDB, il supporte aussi PostgreSQL.
En regardant le dépôt GitHub d'Adminer, je découvre que le gros fichier PHP de 496 kB est le résultat de la concaténation de nombreux fichiers php.
Ça me rassure, parce que je me demandais comment l'édition d'un fichier unique de cette taille pouvait être humainement gérable.
Je trouve astucieux ce mode de déploiement d'un projet PHP sous forme d'un seul fichier qui me fait penser à la méthode Golang. Cependant, je me pose des questions sur la performance de cette technique étant donné que PHP fonctionne en mode process-per request (CGI), ce qui signifie que ce gros fichier PHP est interprété à chaque action sur la page 🤔.
En creusant un peu le sujet avec Claude Sonnet 4.5, je découvre que depuis la version 5.5 de PHP, OPCache améliore significativement la vitesse des requêtes PHP, sans pour autant atteindre celle de Golang, NodeJS, Python ou Ruby qui utilisent des serveurs HTTP intégrés. La consommation mémoire reste supérieure dans des conditions d'implémentation comparables.
Avec OPCache, Adminer semble rester performant malgré l'utilisation d'un fichier unique.
Journal du vendredi 21 novembre 2025 à 14:32
Via Claude Sonnet 4.5, #JaiDécouvert le projet Massive Text Embedding Benchmark qui compare les embeddings Models.
Voici le site de documentation, son dépôt GitHub, et son leaderboard qui liste actuellement 319 models, dont 180 supportant le français.
Journal du vendredi 21 novembre 2025 à 13:56
Dans ce commentaire, #JaiDécouvert le site models.dev (https://models.dev) qui est entre autres une alternative à llm-prices.
Journal du vendredi 21 novembre 2025 à 12:03
Dans ce thread, #JaiDécouvert OpenCode (https://github.com/sst/opencode) qui semble être une alternative à Aider et Claude Code.
Après avoir parcouru la documentation, j'ai l'impression qu'OpenCode propose des fonctionnalités et une User experience plus avancées qu'Aider.
Le projet est récent (démarré en mars 2025) et publié sous licence MIT.
D'après le footer du site de documentation, je comprends qu'OpenCode est développé par l'entreprise Anomaly, financée par du Venture capital.
#JaiLu ce commentaire à propos d'OpenCode dans les issues d'Aider.
En cherchant sur Hacker News, je suis tombé sur ce thread de juillet 2025.
J'ai retenu ce commentaire :
Two big differences:
opencode is much more "agentic": It will just take off and do loads of stuff without asking, whereas aider normally asks permission to do everything. It will make a change, the language server tells it the build is broken, it goes and searches for the file and line in the error message, reads it, and tries to fix it; rinse repeat, running (say) "go vet" and "go test" until it doesn't see anything else to do. You can interrupt it, of course, but it won't wait for you otherwise.
aider has much more specific control over the context window. You say exactly what files you want the LLM to be able to see and/or edit; and you can clear the context window when you're ready to move on to the next task. The current version of opencode has a way to "compact" the context window, where it summarizes for itself what's been done and then (it seems) drops everything else. But it's not clear exactly what's in and out, and you can't simply clear the chat history without exiting the program. (Or if you can, I couldn't find it documented anywhere.)
Je retiens donc qu'Aider offre un contrôle plus précis qu'OpenCode. OpenCode fonctionne de manière plus autonome.
Pour ma part, je préfère contrôler finement les actions d'un AI code assistant sur mon code, à la fois pour comprendre ses interventions et pour gérer ma consommation de tokens.
Je n'ai pas envie de tester OpenCode pour le moment, je vais continuer avec Aider.
Journal du dimanche 16 novembre 2025 à 19:18
En faisant des recherches à propos de Tailscale, netbird et headscale, #JaiDécouvert : frp, rathole, pangolin et Traefik Sablier Plugin.
Journal du dimanche 16 novembre 2025 à 13:25
Dans la vidéo de Monsieur Phi "L'autonomie des IA expliquée aux humains", #JaiDécouvert le service Mammouth, qui me rappelle un peu OpenRouter.
J'ai pris un abonnement d'un mois à 12 € TTC pour tester le service. Pour l'instant, je pense continuer avec le couple Open WebUI et OpenRouter qui me donne accès à plus de modèles et plus de flexibilité.
L'objectif produit de Mammouth ressemble pas mal au projet Albert Conversation sur lequel j'ai travaillé à la DINUM entre avril et août 2025.
Journal du samedi 15 novembre 2025 à 14:23
Dans ce commentaire, #JaiDécouvert une alternative à Grafana (partie dashboard) : Perses (https://github.com/perses/perses).
For exclusively dashboards, the CNCF has https://perses.dev/, which supports Prometheus Loki and Pyroscope, and has a Grafana importer but I haven't given it a shot.
Journal du jeudi 13 novembre 2025 à 09:26
Dans mon activité professionnelle, #JaiDécouvert cerbos (https://github.com/cerbos/cerbos).
Cerbos is an authorization layer that evolves with your product. It enables you to define powerful, context-aware access control rules for your application resources in simple, intuitive YAML policies; managed and deployed via your Git-ops infrastructure. It provides highly available APIs to make simple requests to evaluate policies and make dynamic access decisions for your application.
Pour le moment je n'ai aucun avis sur cette technologie. Je ne l'ai pas encore étudié.
Ce projet est codé en Golang et a débuté en 2021.
Journal du jeudi 06 novembre 2025 à 13:23
#JaiDécouvert le concept philosophique Homo faber.
En philosophie, la notion d'homo faber fait référence à l'Homme en tant qu'être susceptible de fabriquer des outils.
Journal du jeudi 06 novembre 2025 à 10:28
Dans mon activité professionnelle, #JaiDécouvert Bicep (https://github.com/Azure/bicep) équivalent pour Microsoft Azure de Terraform et CloudFormation.
Je découvre aussi le format ARM Template JSON :
Bicep code is transpiled to standard ARM Template JSON files, which effectively treats the ARM Template as an Intermediate Language (IL).
Dans ce contexte, j'apprends qu'ARM signifie Azure Resource Manager.
Je comprends que le suffixe "rm" dans le nom du provider Terraform d'Azure terraform-provider-azurerm fait référence à "Resource Manager".
Journal du jeudi 30 octobre 2025 à 15:58
#JaiDécouvert le nom officielle de Evil maid attack (from "Is luks unlock with TPM2 more secure?").
#JaiDécouvert Cold boot attack (from "ArchWiki - Trusted Platform Module").
J'ai découvert les types "unknown" et "never" en TypeScript
En TypeScript, dans mon projet professionnel, #JaiDécouvert le type unknown qui ressemble à any mais qui est différent.
Exemple (produit par Claude Sonnet 4.5) avec any :
let value: any;
value.foo.bar(); // No error, even if it crashes at runtime
value.trim(); // No error, even if value is a number
Exemple avec unknown :
let value: unknown;
value.trim(); // Error: Object is of type 'unknown'
// You must narrow the type first
if (typeof value === 'string') {
value.trim(); // OK, TypeScript knows it's a string
}
unknown a été introduit dans la version 3.0 de TypeScript en 2018 : Announcing TypeScript 3.0 - The unknown type.
J'ai trouvé les réponses à cette question StackOverflow intéressantes : 'unknown' vs. 'any'.
C'est peut-être parce que je ne suis pas habitué à la documentation de TypeScript , mais j'ai l'impression que la fonctionnalité unknown n'est pas correctement documentée. Par exemple, je suis surpris de trouver presque rien à son sujet dans la page Everyday-types , ni dans les chapitres "Reference" :
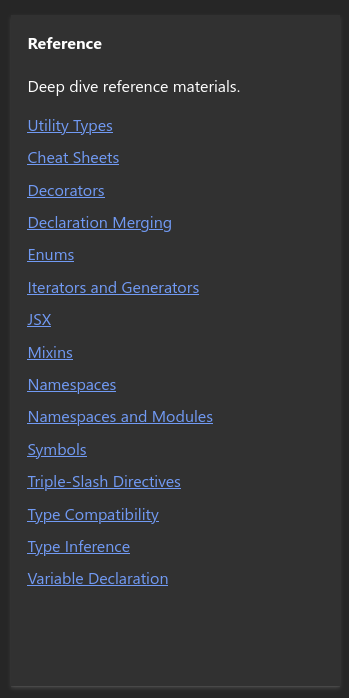
Et rien non plus dans les tutoriels.
Au passage, j'ai aussi découvert le type never.
#JaimeraisUnJour prendre le temps de parcourir la documentation de TypeScript de manière exhaustive. Jusqu'à présent, je n'en ai jamais eu réellement besoin, car je n'ai jamais contribué à de projet écrit en TypeScript. Mais maintenant, cela devient une nécessité pour mon projet professionnel.
Support OCI de CoreOS (image pull & updates)
Cette note fait partie de la série de notes : "J'ai étudié et testé CoreOS et je suis tombé dans un rabbit hole 🙈".
Note précédente : "L'utilisation de OSTree par Flatpak".
Le format Open Container Initiative (Docker image) utilise le media type application/vnd.oci.image.layer.v1.tar+gzip et se compose de métadonnées au format JSON accompagnées de plusieurs archives tar.gz. Ce format est beaucoup moins optimisé pour le stockage et le transfert que celui de libostree, qui utilise un système de déduplication basé sur les objets et des deltas binaires (pour en savoir plus, voir la note "2014-2018 approche alternative avec Atomic Project").
La déduplication OCI s'effectue au niveau des layers complets. Par exemple, si je build localement une image à partir du Dockerfile suivant :
# image frontend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 # layer 2 - 50Mb
COPY app.js /app/ # layer 3
Puis une seconde image avec ce Dockerfile :
# image backend
FROM fedora:39 # layer 1
RUN dnf install -y pkg1 pkg2 # layer 4 - 100 Mb
COPY app.js /app/ # layer 3
Les layers 2 et 4 sont considérés comme différents car leurs contenus diffèrent (commandes RUN différentes). Les fichiers du package pkg1 sont donc stockés deux fois. La taille totale sur disque et lors du transfert est de 150 MB (au lieu de 100 MB avec une déduplication au niveau fichier).
Malgré cette limitation, depuis la version 42 , Fedora CoreOS utilise le support OCI de OSTree pour télécharger les mises à jour système. Ce changement constitue la première itération vers la migration de CoreOS vers bootc.
Le format OCI semble privilégié à libostree comme format d'échange car son écosystème est plus populaire : utilisation par Docker, Kubernetes, podman, disponibilité sur Docker Hub, et maîtrise généralisée du format Dockerfile.
Depuis la version 4.0.0 , podman supporte le format de compression zstd:chunked , basé sur les zstd skippable frames . Ce format permet une déduplication plus fine en découpant les layers en chunks, améliorant ainsi l'efficacité des téléchargements différentiels, bien que restant inférieur à des capacités de libostree. À noter que seul le registry quay supporte actuellement ce format — Docker Hub ne le prend pas encore en charge.
En explorant ce sujet de déduplication (qui permet de réduire la taille des données à télécharger lors des mises à jour), #JaiDécouvert bsdiff, bspatch, Rolling hash (je l'avais déjà croisé).
Note suivante : "Convergence vers Bootc".
Je fais mon retour dans l'écosystème React, j'ai découvert Jotai et Zustand
Dans le code source de mon projet professionnel, #JaiDécouvert la librairie ReactJS nommée Jotai (https://jotai.org).
Les atom de Jotai ressemblent aux fonctionnalités Svelte Store. Jotai permet entre autres d'éviter de faire du props drilling.
Pour en savoir plus sur l'intérêt de Jotai versus "React context (useContext + useState)", je vous conseille la lecture d'introduction de la page Comparison de la documentation Jotai. J'ai trouvé la section "Usage difference" très simple à comprendre.
Cette découverte est une bonne surprise pour moi, car les atom de Jotai reproduisent l'élégance syntaxique des Store de Svelte, ce qui améliore mon confort de développement en ReactJS. #JaiLu ce thread Hacker News en lien avec le sujet : "I like Svelte more than React (it's store management)".
Je tiens toutefois à préciser que si Jotai améliore significativement mon expérience de développeur (DX) avec ReactJS, cela reste une solution de gestion d'état au sein du runtime ReactJS. En comparaison, le compilateur Svelte génère du code optimisé natif qui reste intrinsèquement plus performant à l'exécution.
Exemple Svelte :
import { writable, derived } from 'svelte/store';
const count = writable(0);
const doubled = derived(count, $count => $count * 2);
// Usage dans component
$count // auto-subscription
Exemple ReactJS basé sur Jotai :
import { atom } from 'jotai';
const countAtom = atom(0);
const doubledAtom = atom(get => get(countAtom) * 2);
// Usage dans component
const [count] = useAtom(countAtom);
J'ai lu la page "Comparison" de Jotai pour mieux comprendre la place qu'a Jotai dans l'écosystème ReactJS.
#JaiDécouvert deux autres librairies développées par la même personne, Daishi Kato : Zustand et Valtio. D'après ce que j'ai compris, Daishi a développé ces librairies dans cet ordre :
- Zustand en juin 2019 - voir "How Zustand Was Born"
- La première version de Jotai en septembre 2020 - voir "How Jotai Was Born"
- La première version de Valtio en mars 2021 - voir "How Valtio Was Born"
J'ai aussi découvert Recoil développé par Facebook, mais d'après son entête GitHub celle-ci semble abandonnée. Une migration de Recoil vers Jotai semble être conseillée.
J'aime beaucoup comment Daishi Kato choisit le nom de ses librairies, la méthode est plutôt simple 🙂 :
Comme mentionné plus haut, Jotai ressemble à Recoil alors que Zustand ressemble à Redux :
Analogy
Jotai is like Recoil. Zustand is like Redux.
...
How to structure state
Jotai state consists of atoms (i.e. bottom-up). Zustand state is one object (i.e. top-down).
Même en lisant la documentation Comparison, j'ai eu de grandes difficulté à comprendre quand préférer Zustand à Jotai.
En lisant la documentation, Jotai me semble toujours plus simple à utiliser que Zustand.
Avec l'aide de Claude Sonnet 4.5, je pense avoir compris quand préférer Zustand à Jotai.
Exemple Zustand
Dans l'exemple Zustand suivant, la fonction addToCart modifie plusieurs parties du state useCartStore en une seule transaction :
import { create } from 'zustand'
const useCartStore = create((set) => ({
user: null,
cart: [],
notifications: [],
addToCart: (product) => set((state) => {
return {
cart: [...state.cart, product],
notifications: (
state.user
? [...state.notifications, { type: 'cart_updated' }]
: state.notifications
)
};
};
}));
Et voici un exemple d'utilisation de addToCart dans un composant :
function ProductCard({ product }) {
// Sélectionner uniquement l'action addToCart
const addToCart = useCartStore((state) => state.addToCart);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Exemple Jotai
Voici une implémentation équivalente basée sur Jotai :
import { atom } from 'jotai';
const userAtom = atom(null);
const cartAtom = atom([]);
const notificationsAtom = atom([]);
export const addToCartAtom = atom(
null,
(get, set, product) => {
const user = get(userAtom);
const cart = get(cartAtom);
const notifications = get(notificationsAtom);
set(cartAtom, [...cart, product]);
if (user) {
set(notificationsAtom, [...notifications, { type: 'cart_updated' }]);
}
}
);
Et voici un exemple d'utilisation de useToCartAtom dans un composant :
import { useSetAtom } from 'jotai';
import { addToCartAtom } from 'addToCartAtom';
function ProductCard({ product }) {
// Récupérer uniquement l'action (pas la valeur)
const addToCart = useSetAtom(addToCartAtom);
return (
<div>
<h3>{product.name}</h3>
<p>{product.price}€</p>
<button onClick={() => addToCart(product)}>
Ajouter au panier
</button>
</div>
);
}
Ces deux exemples montrent que Zustand est plus élégant et probablement plus performant que Jotai pour gérer des actions qui conditionnent ou modifient plusieurs parties du state simultanément.
#JaiLu le thread SubReddit ReactJS "What do you use for global state management? " et j'ai remarqué que Zustand semble plutôt populaire.
En rédigeant cette note, j'ai découvert Valtio qui semble être une alternative à MobX. Je prévois d'étudier ces deux librairies dans une future note.
Journal du dimanche 19 octobre 2025 à 11:20
Dans l'historique de mon projet professionnel, #JaiDécouvert immer. J'ai constaté que Jotai propose une extension permettant d'utiliser immer. Pour le moment, je n'ai aucune idée de son intérêt, je n'ai pas pris le temps d'étudier ce sujet.
Journal du dimanche 19 octobre 2025 à 11:16
Ici dans la documentation Jotai, #JaiDécouvert Waku. Je n'ai pas pris le temps de l'étudier.
Journal du samedi 18 octobre 2025 à 12:18
En étudiant la librairie Jotai, #JaiDécouvert le terme "props drilling" :
Passing props is a great way to explicitly pipe data through your UI tree to the components that use it.
But passing props can become verbose and inconvenient when you need to pass some prop deeply through the tree, or if many components need the same prop. The nearest common ancestor could be far removed from the components that need data, and lifting state up that high can lead to a situation called “prop drilling”.
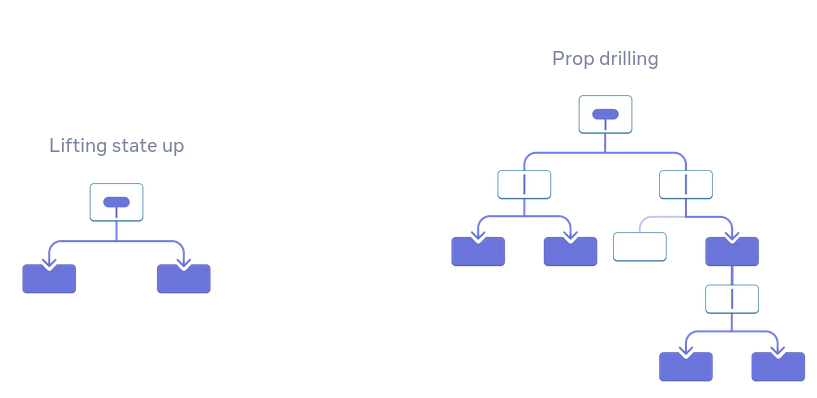
Le terme props drilling est très présent dans le SubReddit ReactJS : https://old.reddit.com/r/reactjs/search?q=drilling&restrict_sr=on&include_over_18=on.
Journal du jeudi 16 octobre 2025 à 00:32
#JaiDécouvert les conférences Fedora annuelles nommées : Flock (https://fedoraproject.org/flock/)
Journal du lundi 13 octobre 2025 à 22:12
Dans cette issue, #JaiDécouvert le projet Kairos (https://kairos.io).
Journal du samedi 11 octobre 2025 à 10:27
À la position 24min20 de la vidéo This Week in Svelte, Ep. 119 , #JaiDécouvert la nouvelle section "Packages" du site officiel de Svelte. Cette initiative me semble utile : elle offre une liste de packages considérés comme "standard" par la communauté Svelte.
J'ai consulté la Merge Request qui ajoute la section "Packages" en pensant y trouver des explications sur le process et les critères d'inclusion d'un package dans cette liste, mais je n'ai rien trouvé 🤷♂️.
Journal du mercredi 08 octobre 2025 à 14:29
#JaiDécouvert le nom officiel des attaques par social engineering suivantes :
Journal du mercredi 24 septembre 2025 à 18:03
Dans ce billet du blog de Bluefin #JaiDécouvert Bazaar (https://github.com/kolunmi/bazaar).
Bazaar is a new app store for GNOME with a focus on discovering and installing applications and add-ons from Flatpak remotes, particularly Flathub ...
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Bazaar est une alternative à l'application officielle GNOME nommée gnome-software.
Contrairement à gnome-software qui est basée sur PackageKit et gère différents types de packages (RPM, DEB, Flatpak, Snap, etc.), Bazaar a un périmètre plus limité et se concentre exclusivement sur les packages Flatpak.
Dans un premier temps, je me suis demandé quel était l'intérêt de créer une nouvelle GUI pour installer des packages, pourquoi l'auteur n'a pas choisi de contribuer à gnome-software ?
J'ai trouvé une réponse dans ce thread.
Bazaar est une application avec une vision tranchée :
- support uniquement le repository Flathub (qui contient seulement des packages Flatpak) ;
- mise en avant de solution pour faire des donations.
Cette vision a permis à l'auteur de créer Bazaar en mai 2025, à partir de zéro, avec une implémentation plus direct (pas de support PackageKit…).
Cela lui a permis aussi de se consacrer fortement sur l'expérience utilisateur.
Après avoir testé l'application, je constate que contrairement à gnome-software, toutes les tâches s'exécutent de manière asynchrone. À la différence de gnome-software, Bazaar évite de recharger constamment l'index des packages après chaque opération , ce qui rend l'expérience utilisateur excellente 🙂.
Bazaar is fast and highly multi-threaded, guaranteeing a smooth experience in the user interface. You can queue as many downloads as you wish and run them while perusing Flathub's latest releases. This is due to the UI being completely decoupled from all backend operations.
Je tiens tout de même à préciser que la version 49 de gnome-software a fait des progrès à ce sujet, un gros travail de refactoring a été fait sur 3 ans (73 Merge Request 😮) pour apporter le support de threading dans gnome-software.
Je pense utiliser Bazaar dans Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora".
Vous êtes sur la première page | [ Page suivante (448) >> ]