
Journaux
Cliquez sur un ou plusieurs tags pour appliquer un filtre sur la liste des notes de type "Journaux" :
[ << Notes plus récentes (201) ] [ Notes plus anciennes (748) >> ]
Lundi 6 janvier 2025
Journal du lundi 06 janvier 2025 à 12:35
#JaiDécouvert Vast.ai (https://vast.ai/) :
Vast.ai is the market leader in low-cost cloud GPU rental.
Use one simple interface to save 5-6X on GPU compute.
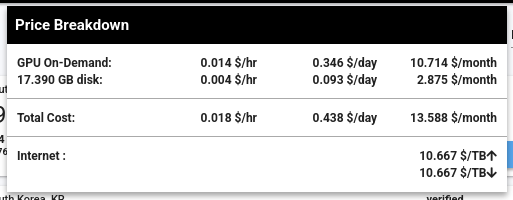
J'aimerais faire des Benchmarks de Inference Engines sur le serveur suivant à 14 $ par mois, qui contient une RTX 4090 avec 24 GB de Ram.

Dimanche 5 janvier 2025
Journal du dimanche 05 janvier 2025 à 13:51
Note de type #mémento.
Bien que gnome-software prenne en charge (code source) l'upgrade des firmware avec fwupd en mode GUI, j'aime effectuer ces mises à jour en ligne de commande.
Voici les commandes fwupd utiles.
Tout d'abord, pour m'aider à retenir le nom de cet outil : "fwupd" est tout simplement la contraction de "firmware update".
Pour rafraîchir la liste des firmwares disponibles :
$ sudo fwupdmgr refresh
Pour obtenir la liste des mises à jour disponibles :
$ sudo fwupdmgr get-updates
Pour installer les mises à jour disponibles :
$ sudo fwupdmgr update
Samedi 4 janvier 2025
Journal du samedi 04 janvier 2025 à 16:43
#JaiDécouvert l'opérateur satisfies en TypeScript, ajouté en novembre 2022, dans la version 4.9.
Je pense avoir compris son utilité et son usage.
Vendredi 3 janvier 2025
Journal du vendredi 03 janvier 2025 à 15:45
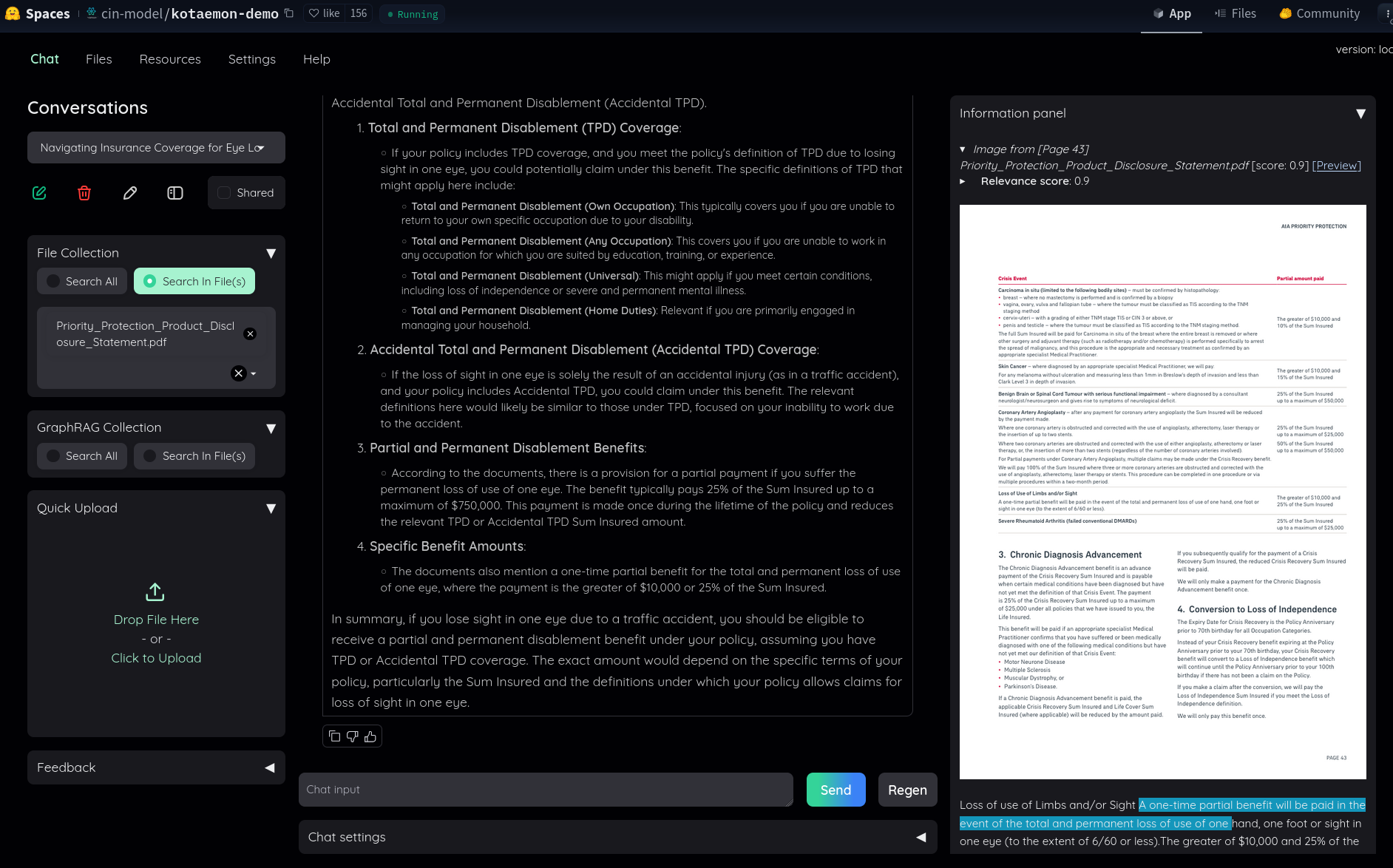
Dans ce thread Hacker News, #JaiDécouvert le RAG kotaemon (https://github.com/Cinnamon/kotaemon).
J'ai fait un simple test sur "Live Demo", j'ai trouvé le résultat très intéressant :
Dans le README, #JaiDécouvert GraphRAG (https://github.com/microsoft/graphrag), nano-graphrag (https://github.com/gusye1234/nano-graphrag) et LightRAG (https://github.com/HKUDS/LightRAG).
J'ai compris que kotaemon peut fonctionner avec nano-graphrag, LightRAG et GraphRAG et que nano-graphrag était recommandé.
J'ai lu :
Support for Various LLMs: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via
ollamaandllama-cpp-python).
J'ai l'impression que kotaemon est un outil de RAG complet, prêt à l'emploi, contrairement à llama_index qui se positionne davantage comme une bibliothèque de plus bas niveau.
Dans le Projet 20 - "Créer un POC d'un RAG", je pense commencer par tester kotaemon.
Je me demande si Obsidian ou SilverBullet pourraient tirer parti de la norme "URL text fragment" 🤔
#JeMeDemande si Obsidian ou SilverBullet.mb supportent la syntax URL text fragment 🤔.
Claude.ia m'a appris que les URL text fragment se nomment aussi des "deep linking to text".
J'ai effectué les recherches suivantes sur GitHub :
- « obsidian deep linking » et j'ai trouvé :
deep-notesmais le README "vide" ne m'a pas donné envie de le tester
- « obsidian fragment » mais je n'ai rien trouvé de pertinent
J'ai effectué les recherches suivantes sur https://forum.obsidian.md :
- « deep link » et j'ai trouvé :
- En lisant "Link to Block does not work with non-default themes" #JaiDécouvert la fonctionnalité d'Obsidian nommée "Link to a block in a note" qui est à l'usage très pratique.
- « fragment » et j'ai trouvé :
- "I think text fragment could be very useful in Obsidian" qui correspond à la question que je me pose.
Pour le moment, je pense qu'avec Obsidian la seule solution est d'utiliser la fonctionnalité "Link to a block in a note".
Voici mes recherches concernant SilverBullet.mb.
Dans la page "Links" j'ai trouvé la fonctionnalité "Anchors."
J'ai effectué les recherches suivantes sur https://community.silverbullet.md:
et je n'ai rien trouvé d'intéressant.
J'ai ensuite effectué des recherches sur GitHub :
je n'ai rien trouvé d'intéressant non plus.
J'ai posté le message suivant sur « I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔 ».
Version française :
Il y a quelques jours, j'ai découvert la fonctionnalité URL text fragment (ma note à ce sujet en français). Depuis, j'utilise l'extension Firefox "Link to Text Fragment" pour partager des liens précis et je trouve cela très simple d'usage.
J'ai bien identifié la fonctionnalité Anchors de Silverbullet pour créer un lien vers une position précise dans une page interne à SilverBullet.
Je me demande si SilverBullet pourrait tirer parti de la norme "URL text fragment" 🤔.
J'imagine une syntaxe du type
[[MyPage#:~:text=foobar]].Pour le moment, j'ai du mal à imaginer les avantages /inconvénients de cette idée de fonctionnalité par rapport à l'utilisation de "Anchors".
J'ai cherché si Obsidian supportait les URL text fragment, je constate que non.
Chez Obsidian l'équivalent de Anchors semble être Link to a block in a note.Quelle est votre intuition à ce sujet ?
Version anglaise :
A few days ago, I discovered the URL text fragment feature (my note about this in french). Since then, I've been using the Firefox extension “Link to Text Fragment” to share specific links, and I find it very easy to use.
I did identify Silverbullet's Anchors feature for linking to a specific position on a SilverBullet internal page.
I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔.
I can imagine a syntax like
[[MyPage#:~:text=foobar]].For now, I'm struggling to imagine the advantages/disadvantages of this feature idea compared to using “Anchors”.
I've looked to see if Obsidian supports URL text fragments, and find that it doesn't.
Obsidian's equivalent of Anchors seems to be Link to a block in a note.What's your feeling about this?
Journal du vendredi 03 janvier 2025 à 12:59
Dans ce thread du forum de SilverBullet.mb #JaiDécouvert l'outil Nutshell (https://ncase.me/nutshell/) :

Je trouve cela très ingénieux.
#JeMeDemande comment je pourrais tirer parti de cette fonctionnalité dans notes.sklein.xyz 🤔.
Mardi 31 décembre 2024
J'ai publié deux nouveaux playgrounds :
Cela fait depuis 2018 que je souhaite tester la génération d'un certificat de type "wildcard" avec le challenge DNS-01 de la version 2 de ACME.
Bonne nouvelle, j'ai testé avec succès cette fonctionnalité dans le playground : dnsrobocert-playground.
Est-ce que je vais généraliser l'usage de certificats wildcard générés avec un challenge DNS-01 à la place de multiples challenge HTTP-01 ?
Pour le moment, je n'en ai aucune idée. J'ai utilisé un challenge DNS-01 pour déployer sish.
L'avantage d'un certificat wildcard réside dans le fait qu'il n'a besoin d'être généré qu'une seule fois et peut ensuite être utilisé pour tous les sous-domaines. Toutefois, il doit être mis à jour tous les 90 jours.
Actuellement, je n'ai pas trouvé de méthode pratique pour automatiser son déploiement.
Par exemple, pour nginx, il serait nécessaire d'automatiser l'upload du certificat dans le volume du conteneur nginx, ainsi que l'exécution de la commande nginx -s reload pour recharger le certificat.
Concernant le second playground, j'ai réussi à déployer avec succès sish.
Voici un exemple d'utilisation :
$ ssh -p 2222 -R test:80:localhost:8080 playground.stephane-klein.info
Press Ctrl-C to close the session.
Starting SSH Forwarding service for http:80. Forwarded connections can be accessed via the following methods:
HTTP: http://test.playground.stephane-klein.info
HTTPS: https://test.playground.stephane-klein.info
Je trouve l'usage plutôt simple.
Je compte déployer sish sur sish.stephane-klein.info pour mon usage personnel.
Journal du mardi 31 décembre 2024 à 18:21
Suite à la lecture de ce pouet, #JaiLu le billet de blog d'Emmanuele Bassi "The Mirror" qui traite de GObject et d'une stratégie d'amélioration.
Je n'ai pas compris l'intégralité de ce que j'ai lu. Cependant, l'écosystème Linux Desktop est un sujet qui me passionne depuis des années et je continue à me cultiver sur le sujet.
Journal du mardi 31 décembre 2024 à 17:12
Dans le billet de blog d'Emmanuele Bassi "The Mirror", j'ai découvert l'expression informatique "Flag day".
Releasing GLib 3.0 today would necessitate breaking API in the entirety of the GNOME stack and further beyond; it would require either a hard to execute “flag day”, or an impossibly long transition, reverberating across downstreams for years to come.
L'article Wikipédia donne la définition suivante :
A flag day, as used in system administration, is a change which requires a complete restart or conversion of a sizable body of software or data. The change is large and expensive, and—in the event of failure—similarly difficult and expensive to reverse.
D'après ce que j'ai compris, un "Flag day" désigne un déploiement complexe où plusieurs systèmes doivent être mis à jour simultanément, sans possibilité de retour en arrière. C'est une approche risquée, car elle implique une transition brutale entre l'ancien et le nouveau système, souvent difficile à gérer dans des environnements interdépendants.
Un "Flag day" s'oppose à une migration en douceur.
C'est une situation que j'essaie d'éviter autant que possible. Des méthodes comme les Feature toggle ou l'introduction d'un système de versionnement permettent d'effectuer des migrations douces, par petites itérations, testables et sans interruption de service.
Concernant l'origine de cette expression, je lis :
This systems terminology originates from a major change in the Multics operating system's definition of ASCII, which was scheduled for the United States holiday, Flag Day, on June 14, 1966.
Je pense qu'à l'avenir, je vais utiliser cette expression.
Samedi 28 décembre 2024
Journal du samedi 28 décembre 2024 à 17:10
Comme mentionné dans la note 2024-12-28_1621, j'ai implémenté un playground nommé powerdns-playground.
J'ai fait le triste constat de découvrir encore un projet (PowerDNS-Admin) qui ne supporte pas une "automated and unattended installation" 🫤.
PowerDNS-Admin ne permet pas de créer automatiquement un utilisateur admin.
Pour contourner cette limitation, j'ai implémenté un script configure_powerdns_admin.py qui permet de créer un utilisateur basé sur les variables d'environnement POWERDNS_ADMIN_USERNAME, POWERDNS_ADMIN_PASSWORD, POWERDNS_ADMIN_EMAIL.
Le script ./scripts/setup-powerdns-admin.sh se charge de copier le script Python dans le container powerdns-admin et de l'exécuter.
J'ai partagé ce script sur :
- le SubReddit self hosted : https://old.reddit.com/r/selfhosted/comments/1hocrjm/powerdnsadmin_a_python_script_for_automating_the/?
- et le Discord de PowerDNS-Admin : https://discord.com/channels/1088963190693576784/1088963191574376601/1322661412882874418
Journal du samedi 28 décembre 2024 à 16:21
Je viens de tomber dans un Yak! 🙂.
Je cherchais des alternatives Open source à ngrok et j'ai trouvé sish (https://docs.ssi.sh/).
Côté client, sish utilise exclusivement ssh pour exposer des services (lien la documentation).
Voici comment exposer sur l'URL http://hereiam.tuns.sh le service HTTP exposé localement sur le port 8080 :
$ ssh -R hereiam:80:localhost:8080 tuns.sh
Je trouve cela très astucieux 👍️.
Après cela, j'ai commencé à étudier comment déployer sish et j'ai lu cette partie :
This includes taking care of SSL via Let's Encrypt for you. This uses the adferrand/dnsrobocert container to handle issuing wildcard certifications over DNS.
Après cela, j'ai étudié dnsrobocert qui permet de générer des certificats SSL Let's Encrypt avec la méthode DNS challenges, mais pour cela, il a besoin d'insérer et de modifier des DNS Record sur un serveur DNS.
Je n'ai pas envie de donner accès à l'intégralité de mes zones DNS à un script.
Pour éviter cela, j'ai dans un premier temps envisagé d'utiliser un serveur DNS managé de Scaleway, mais j'ai constaté que le provider Scaleway n'est pas supporté par Lexicon (qui est utilisé par dnsrobocert).
Après cela, j'ai décidé d'utiliser PowerDNS et je viens de publier ce playground : powerdns-playground.
Vendredi 27 décembre 2024
Journal du vendredi 27 décembre 2024 à 11:23
#iteration Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor.
Note de type #mémento à propos de la configuration de l'icône et du splash screen d'une application Capacitor.
J'utilise le plugin @capacitor/splash-screen.
Ce plugin offre de nombreuses options de configuration : https://capacitorjs.com/docs/apis/splash-screen#configuration.
Les paramètres de configuration du splash screen sont définis ici dans mon POC poc-capacitor.
Cela m'a pris du temps pour trouver comment modifier l'icône et le splash screen de l'application.
Cette opération est documentée sur la page suivante : "Splash Screens and Icons".
Dans poc-capacitor, j'ai documenté cette opération ici.
La commande npx capacitor-assets generate prend en entrée mon fichier logo ./assets/logo.png et génère automatiquement de nombreux fichiers assets dans les dossiers suivants :
./android/app/src/main/res/./ios/App/App/Assets.xcassets/./src/assets/
Pour plus d'informations au sujet de cette commande, je vous invite à consulter : https://github.com/ionic-team/capacitor-assets.
Jeudi 26 décembre 2024
Journal du jeudi 26 décembre 2024 à 15:03
J'ai partagé Projet 20 - "Créer un POC d'un RAG" à un ami, il m'a dit « Pourquoi ne pas entraîner directement un modèle ? ».
Voici ma réponse sous forme de note.
Je tiens à préciser que je ne suis pas un expert du domaine.
Dans le manuscrit de l'épisode Augmenter ChatGPT avec le RAG de Science4All, je lis :
Quatre grandes catégories de solutions ont été proposées pour faire en sorte qu'un algorithme de langage apprenne une information.
Voici cette liste :
-
- le pré-entraînement, ou "pre-training" en anglais
-
- "peaufinage", qu'on appelle "fine-tuning" en anglais
Concernant le pre-training, je lis :
En pratique, ce pré-entraînement est toutefois très insuffisant pour que les algorithmes de langage soient capables de se comporter de manière satisfaisante.
Ensuite, je lis au sujet du fine-tuning :
Pour augmenter la fiabilité de l'algorithme, on peut alors effectuer un "peaufinage", qu'on appelle "fine-tuning" en anglais, et qui consiste typiquement à demander à des humains d'évaluer différentes réponses de l'algorithme.
...
Cependant, cette approche de peaufinage est coûteuse, à la fois en termes de ressources humaines et de ressources en calculs, et son efficacité est loin d'être suffisante pour une tâche aussi complexe que le langage.
Notez qu'on parle aussi de "peaufinage" pour la poursuite du pré-entraînement, mais cette fois sur des données proches du cas d'usage de l'algorithme. C'est typiquement le cas quand on part d'un algorithme open-weight comme Llama, et qu'on cherche à l'adapter aux contextes d'utilisation d'une entreprise particulière. Mais là encore, le coût de cette approche est important, et son efficacité est insuffisante.
Ensuite, au sujet du pré-prompting, je lis :
si cette approche est la plus efficace et la moins coûteuse, elle demeure encore très largement non-sécurisée ; et il faut s'attendre à ce que le chatbot déraille. Mais surtout, le pré-prompting est nécessairement limité car il ne peut pas être trop long.
Et, pour finir, je lis :
Je trouve que le paragraphe suivant donne une bonne explication du fonctionnement d'un RAG :
L'idée du RAG est la suivante : on va indexer tout un tas de documents qu'on souhaite enseigner à l'algorithme, et on va définir des méthodes pour lui permettre d'identifier, étant donné une requête d'un utilisateur, les bouts de documents qui sont les plus pertinents pour répondre à la requête de l'utilisateur. Ces bouts de documents sont ainsi "récupérés", et ils seront alors ajoutés à un preprompt fourni à l'algorithme, d'où "l'augmentation". Enfin, on va demander à l'algorithme de générer une réponse avec ce préprompt, d'où le nom de "Retrieval Augmented Generation". La boucle est bouclée !
Après lecture de ces informations, je pense qu'entrainer directement un modèle est une solution moins efficace qu'utiliser un RAG pour les objectifs décrits dans le Projet 20 - "Créer un POC d'un RAG".
Journal du jeudi 26 décembre 2024 à 14:25
En faisant des recherches sur les cours d'Algèbre linéaire, #JaiDécouvert la home page du professeur de #mathématique Bruno Vallette de l'unversité Sorbonne Paris.
Sa "home page" contient beaucoup de ressources, dont :
Journal du jeudi 26 décembre 2024 à 12:27
Dans la vidéo "L'intelligence artificielle en 2024: COT, Q*, Agents, Gaussian Splatting, Video Generation, Robotics" de Thibault Neveu, j'ai découvert le papier de recherche GAIA: a benchmark for General AI Assistants qui date de novembre 2023, qui semble être un autre test de AGI, comme ARC Prize.
Mardi 24 décembre 2024
Journal du mardi 24 décembre 2024 à 10:59
En écoutant la vidéo "La réduction de la dimensionnalité (ACP et SVD)", #JaiDécouvert la vidéo "Deux (deux ?) minutes pour l'éléphant de Fermi & Neumann" de la chaine YouTube nommée El Jj (lien direct), à laquelle je viens de m'abonner 🙂.
J'ai été époustouflé par cette vidéo ! Ce qui y est présenté m'impressionne profondément et m'aide à comprendre de nombreuses choses qui m'étaient jusqu'à présent inconnues.
Cette vidéo traite entre autres des Épicycloïde, qui me font penser aux rosaces que je dessinais en école primaire.
Je ne pensais pas que l'étude et l'utilisation de ces courbes étaient aussi intéressantes !
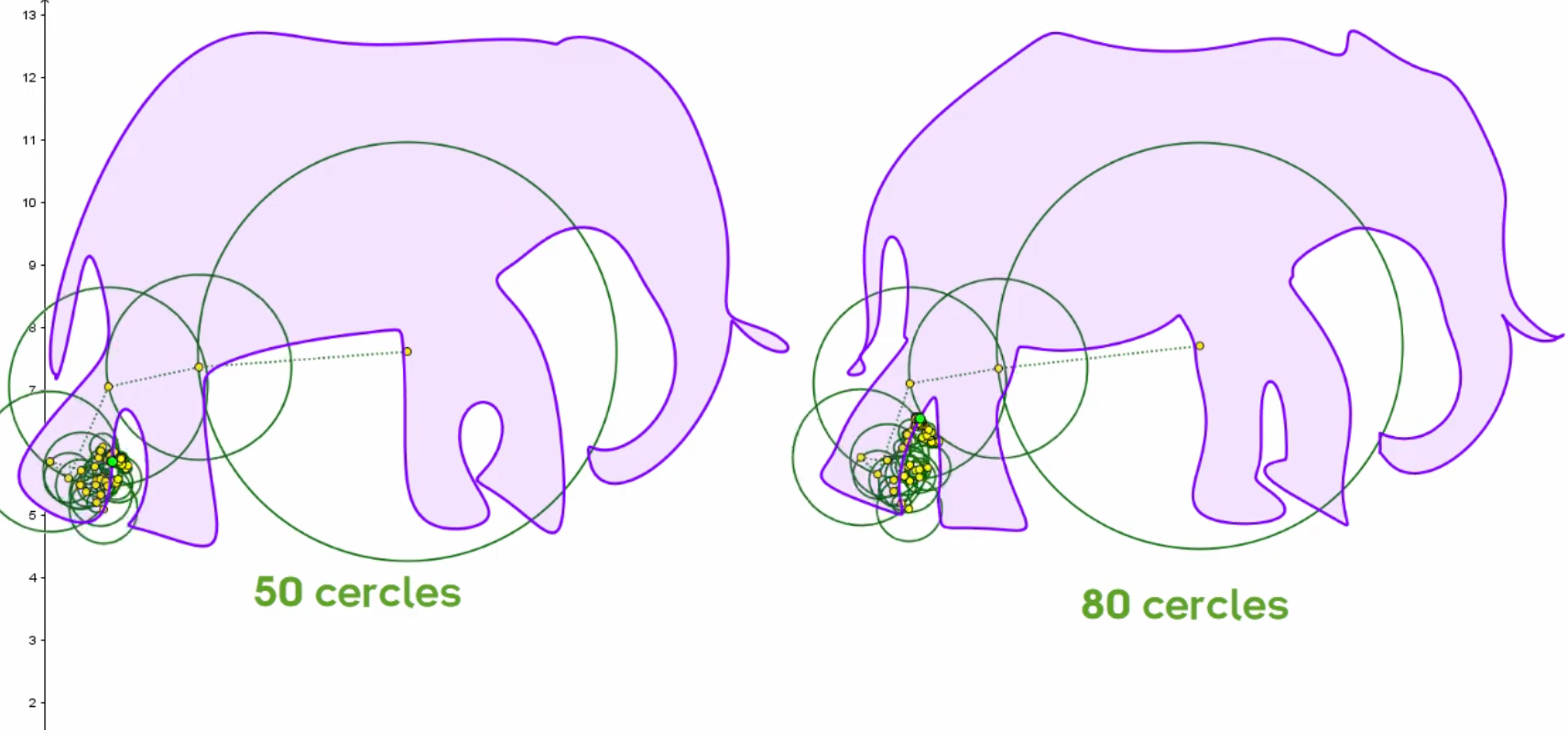
Ce que je retiens :
- Il est possible de représenter n'importe quelle forme avec des épicycloïdes
- Le nombre de cercles permet d'augmenter ou de réduire la précision de la forme, ce qui est utile pour "compresser" le nombre de paramètres nécessaires — avec perte — pour dessiner une forme.
Dans la vidéo, j'ai découvert WolframAlpha (https://www.wolframalpha.com/).
Je n'ai pas réellement compris l'utilité de ce site 😔.
L'article Wikipédia classe ce site dans la catégorie "Moteur de recherche" ou "Base de connaissance" 🤔.
Journal du mardi 24 décembre 2024 à 10:34
En travaillant sur la note 2024-12-26_1503, j'ai essayé de retrouver la vidéo qui est mentionnée dans l'épisode Augmenter ChatGPT avec le RAG de Science4All :
Pour cela, j'ai commencé à réécouter l'épisode "La réduction de la dimensionalité (ACP et SVD)" (voir ma note à ce sujet 2024-12-24_1057). Mais je constate qu'elle ne traite pas de word2vec.
Ensuite, j'ai écouté "L'IA sait-elle lire ? Intelligence Artificielle 21" (lien direct). Je pense que c'est cette vidéo qui est mentionnée par Lê. Cette vidéo traite du papier de recherche nommé "Efficient Estimation of Word Representations in Vector Space" qui, d'après ce que j'ai compris, est implémenté dans word2vec.
Lundi 23 décembre 2024
Journal du lundi 23 décembre 2024 à 19:39
J'ai commencé le Projet GH-271 - Installer Proxmox sur mon serveur NUC Intel i3-5010U, 8Go de Ram le 9 octobre.
Le 27 octobre, j'ai publié la note 2024-10-27_2109 qui contient une erreur qui m'a fait perdre 14h !
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
[ 0.0] Examining the guest ...
[ 4.5] Setting a random seed
virt-customize: warning: random seed could not be set for this type of
guest
[ 4.5] Setting the machine ID in /etc/machine-id
[ 4.5] Installing packages: qemu-guest-agent
[ 32.1] Running: systemctl enable qemu-guest-agent.service
[ 32.6] Finishing off
Je n'avais pas fait attention au message Setting the machine ID in /etc/machine-id 🙊.
Conséquence : le template Proxmox Ubuntu contenait un fichier /etc/machine-id avec un id.
Conséquence : toutes les Virtual machine que je créais sous Proxmox avaient la même valeur machine-id.
J'ai découvert que l'option 61 "Client identifier" du protocole DHCP permet de passer un client id au serveur DHCP qui sera utilisé à la place de l'adresse MAC.
Conséquence : le serveur DHCP assignait la même IP à ces Virtual machine.
J'ai pensé que le serveur DHCP de mon router BBox avait un problème. J'ai donc décidé d'installer Projet 15 - Installation et configuration de OpenWrt sur Xiaomi Mi Router 4A Gigabit pour avoir une meilleure maitrise du serveur DHCP.
Problème : j'ai fait face au même problème avec le serveur DHCP de OpenWrt.
Après quelques recherches, j'ai découvert que contrairement à virt-customize la commande virt-sysprep permet d'agir sur des images qui ont vocation à être clonées.
"Sysprep" stands for "system preparation" tool. The name comes from the Microsoft program sysprep.exe which is used to unconfigure Windows machines in preparation for cloning them.
Pour corriger le problème, j'ai remplacé cette ligne :
# virt-customize -a noble-server-cloudimg-amd64.img --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
Par ces deux lignes :
# virt-sysprep -a noble-server-cloudimg-amd64.img --network --install qemu-guest-agent --run-command 'systemctl enable qemu-guest-agent.service'
# virt-sysprep --operation machine-id -a noble-server-cloudimg-amd64.img
La seconde commande permet de supprimer le fichier /etc/machine-id, ce qui corrige le problème d'attribution d'IP par le serveur DHCP.
À noter que je ne comprends pas pourquoi il est nécessaire de lancer explicitement cette seconde commande, étant donné que la commande virt-sysprep est destinée aux images de type "template". Le fichier /etc/machine-id ne devrait jamais être créé, ou tout du moins, automatiquement supprimé à la fin de chaque utilisation de virt-sysprep.
Maintenant, l'instanciation de Virtual machine fonctionne bien, elles ont des IP différentes 🙂.
Prochaine étape du Projet GH-271 :
Je souhaite arrive à effectuer un déploiement d'une Virtual instance via cli de Terraform.
Dimanche 22 décembre 2024
Journal du dimanche 22 décembre 2024 à 18:11
Alexandre m'a partagé l'article "Proxmox - Activer les mises à jour sans abonnement (no-subscription)".
Élément que je retiens :
Le processus de validation des paquets chez Proxmox est le suivant : Test -> No-Subscription -> Enterprise. Le dépôt No-Suscription est donc suffisamment stable. L'avertissement est à mon avis pour mettre hors cause l'équipe de Proxmox en cas de trou dans la raquette lors des tests de validation.
$ ssh root@192.168.1.43
# echo EOF
# cat <<EOF > /etc/apt/sources.list.d/proxmox.list
> deb http://download.proxmox.com/debian/pve bookworm pve-no-subscription
> EOF
# apt update -y
# apt upgrade -y
...
# reboot
Pour supprimer le message de warning au login, sur la version 8.3.2, j'ai appliqué le patch suivant :
# patch /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js <<EOF
--- /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js.old 2024-12-22 18:23:48.951557867 +0100
+++ /usr/share/javascript/proxmox-widget-toolkit/proxmoxlib.js 2024-12-22 18:18:50.509376748 +0100
@@ -563,6 +563,7 @@
let res = response.result;
if (res === null || res === undefined || !res || res
.data.status.toLowerCase() !== 'active') {
+ /*
Ext.Msg.show({
title: gettext('No valid subscription'),
icon: Ext.Msg.WARNING,
@@ -575,6 +576,7 @@
orig_cmd();
},
});
+ */
} else {
orig_cmd();
}
EOF
# systemctl restart pveproxy
Samedi 21 décembre 2024
Journal du samedi 21 décembre 2024 à 20:40
Chose amusante, alors que ce matin même, j'ai découvert l'existence de o1, sortie il y a seulement quelques jours, le 5 décembre 2024.
Voilà que je découvre ce soir, dans ce thread Hacker News la sortie de o3 le 20 décembre 2024 : "OpenAI O3 breakthrough high score on ARC-AGI-PUB".
Les releases sont très réguliers en ce moment, il est difficile de suivre le rythme 😮 !
Dans ce thread, j'ai découvert le prix ARC (https://arcprize.org), lancé le 11 juin 2024, par le français Francois Chollet, basé sur le papier de recherche "On the Measure of Intelligence" sorti en 2019, il y a 5 ans.
ARC est un outil de mesure de AGI.
#JaimeraisUnJour prendre le temps de lire On the Measure of Intelligence.
Je lis ici :
OpenAI o3 Breakthrough High Score on ARC-AGI-Pub
OpenAI's new o3 system - trained on the ARC-AGI-1 Public Training set - has scored a breakthrough 75.7% on the Semi-Private Evaluation set at our stated public leaderboard $10k compute limit. A high-compute (172x) o3 configuration scored 87.5%.
This is a surprising and important step-function increase in AI capabilities, showing novel task adaptation ability never seen before in the GPT-family models. For context, ARC-AGI-1 took 4 years to go from 0% with GPT-3 in 2020 to 5% in 2024 with GPT-4o. All intuition about AI capabilities will need to get updated for o3.
Plus loin, je lis :
However, it is important to note that ARC-AGI is not an acid test for AGI – as we've repeated dozens of times this year. It's a research tool designed to focus attention on the most challenging unsolved problems in AI, a role it has fulfilled well over the past five years.
Passing ARC-AGI does not equate to achieving AGI, and, as a matter of fact, I don't think o3 is AGI yet. o3 still fails on some very easy tasks, indicating fundamental differences with human intelligence.
Donc, j'en conclus qu'il ne faut pas s'emballer outre mesure sur les résultats de ce test, bien que les progrès soient impressionnants.
La première partie du thread semble aborder la thématique du coût financier de o3 versus un humain : 309 commentaires.
Dans ce commentaire #JaiDécouvert le papier de recherche "H-ARC: A Robust Estimate of Human Performance on the Abstraction and Reasoning Corpus Benchmark" qui date de 2024.
Journal du samedi 21 décembre 2024 à 16:10
Je viens d'améliorer l'implémentation du moteur de recherche de mon sklein-pkm-engine.
Voici un screencast de présentation du résultat :
Le commit de changement : https://github.com/stephane-klein/sklein-pkm-engine/commit/71210703fe626bd455b2ec7774167d9a637e4972
Je suis passé de :
query_string: {
query: queryString,
default_field: "content_html"
}
à ceci :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Les fonctionnalités de recherche d'Elasticsearch sont nombreuses. Pour les parcourir, je conseille ce point d'entrée de la documentation Search in Depth.
Même après avoir fini mon implémentation de la fonction recherche, je dois avouer que je tâtonne sur le sujet. Je suis loin de maitriser le sujet.
Au départ, après lecture de ce paragraphe :
If you don’t need to support a query syntax, consider using the
matchquery. If you need the features of a query syntax, use thesimple_query_stringquery, which is less strict.
J'ai fait un refactoring de query_string vers simple_query_string (lien vers la documentation).
Mon objectif était d'arriver à implémenter la fonctionnalité Query-Time Search-as-You-Type avec de la recherche floue (fuzzy).
J'ai commencé par essayer la syntax foobar~* mais j'ai appris qu'il n'était pas possible d'utiliser ~ (fuzzy) en couplé avec * 😔 (documentation vers la syntax). Sans doute pour de bonnes raisons, liées à des problèmes de performance.
J'ai ensuite découpé ma requête en 3 conditions :
baseQuery.body.query.bool.must.push({
bool: {
should: [
{
simple_query_string: {
query: queryString,
fields: ["content_html"],
boost: 3
}
},
{
simple_query_string: {
query: queryString.split(' ').map(word => (word.length >= 3) ? `${word}*` : undefined).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
},
{
simple_query_string: {
query: queryString.split(' ').map(
word => {
if (word.length >= 5) { return `${word}~2`; }
else if (word.length >= 3) { return `${word}~1`; }
else return undefined;
}
).join(' ').trim(),
fields: ["content_html"],
boost: 1
}
}
],
minimum_should_match: 1
}
}
Cette implémentation fonctionne, mais je rencontrais des problèmes de performance aléatoires que je n'ai pas pris le temps d'essayer de comprendre la cause.
À force de tâtonnement, j'ai fini par choisir la solution basée sur multi_match (documentation de référence) :
multi_match: {
query: queryString,
fields: ["title^2", "content_html"],
fuzziness: "AUTO",
type: "best_fields"
}
Documentation de référence du paramètre fuzziness : Fuzzy query.
Documentation de la valeur AUTO : Common options - Fuzziness
Malheureusement, ici aussi, je ne peux pas utiliser fuzziness avec phrase_prefix :
The fuzziness parameter cannot be used with the phrase or phrase_prefix type.
En finissant cette note, je viens de découvrir cet exemple dans la documentation.
J'ai l'impression de comprendre qu'en utilisant le tokenizer ngram je pourrais faire des Fuzzy Search sans utiliser l'option fuzziness 🤔.
J'ai commencé l'implémentation dans la branche ngram-tokenizer mais je m'arrête là pour aujourd'hui. En tout, ce weekend, j'ai passé 4h30 sur ce sujet 😮.
J'espère tester cette implémentation d'ici à quelques jours.
Je souhaite aussi essayer prochainement de migrer de Elasticsearch vers OpenSearch.
Journal du samedi 21 décembre 2024 à 14:17
Je viens de corriger dans mon sklein-pkm-engine, un problème d'expérience utilisateur que m'avait remonté Alexandre sur la page détail d'une note.
Par exemple sur la note : https://notes.sklein.xyz/2024-12-19_1709/

Le lien sur le tag dev-kit pointait vers https://notes.sklein.xyz/diaries/?tags=dev-kit. Conséquence : les Evergreen Note n'étaient pas listés dans les résultats. Ce comportement était perturbant pour l'utilisateur.
J'ai modifié l'URL sur les tags pour les faire pointer vers https://notes.sklein.xyz/search/?tags=dev-kit, page qui affiche tous types de notes.
Journal du samedi 21 décembre 2024 à 13:02
J'ai écouté la vidéo "o1 et Claude sont-ils capables de nous MANIPULER ? Deux études récentes aux résultats troublants" de Monsieur Phi au sujet de o1 de OpenAI.
Vraiment passionnant !
Vendredi 20 décembre 2024
Journal du vendredi 20 décembre 2024 à 18:22
#JaiDécouvert Breitbart News (https://fr.wikipedia.org/wiki/Breitbart_News) (from)
Breitbart News est un média politique ultra-conservateur américain créé en 2007 par Andrew Breitbart. Il est qualifié d'extrême droite par de nombreux commentateurs, considéré comme suprémaciste et complotiste.
Jeudi 19 décembre 2024
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞
Le 6 novembre 2024, j'ai publié la note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
L'issue indiquée dans cette note a été cloturée il y a 3 jours : Use mise tools in env template · Issue #1982.
Voici le contenu de changement de la documentation : https://github.com/jdx/mise/pull/3598/files#diff-e8cfa8083d0343d5a04e010a9348083f7b64035c407faa971074c6f0e8d0d940
Ce qui signifie que je vais pouvoir maintenant utiliser terraform installé via Mise dans le fichier .envrc :
[env]
_.source = { value = "./.envrc.sh", tools = true }
[tools]
terraform="1.9.8"
Après avoir installé la dernière version de Mise, j'ai testé cette configuration dans repository suivant : install-and-configure-mise-skeleton.
Le fichier .envrc suivant a fonctionné :
export HELLO_WORLD=foo3
export NOW=$(date)
export TERRAFORM_VERSION=$(terraform --version | head -n1)
Exemple :
$ mise trust
$ echo $TERRAFORM_VERSION
Terraform v1.9.8
Je n'ai pas trouvé de commande Mise pour recharger les variables d'environnement du dossier courant, sans quitter le dossier. Avec direnv, pour effectuer un rechargement je lançais : direnv allow.
À la place, j'ai trouvé la méthode suivante :
$ source .envrc
Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Journal du jeudi 19 décembre 2024 à 16:40
#JaiDécouvert le format de fichier Bake de Docker : https://docs.docker.com/build/bake/introduction/.
Je ne comprends pas bien son utilité 🤔.
La commande suivante me convient parfaitement :
$ docker build \
-f Dockerfile \
-t myapp:latest \
--build-arg foo=bar \
--no-cache \
--platform linux/amd64,linux/arm64 \
.
J'ai essayé de trouver l'issue d'origine du projet Bake, pour connaitre ses motivations, mais je n'ai pas trouvé.
Comment lancer une image Docker de l'architecture "arm64" sous Intel ?
#JeMeDemande comment lancer une image Docker pour l'architecture arm64 sur une architecture Intel sous Fedora ?
Par défaut, l'exécution de cette image Docker sous Intel avec l'option --platform linux/arm64 ne fonctionne pas :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
exec /usr/bin/bash: exec format error
J'ai consulté et suivi la documentation Docker officielle suivante : Install QEMU manually.
$ docker run --privileged --rm tonistiigi/binfmt --install all
installing: arm64 OK
installing: arm OK
installing: ppc64le OK
installing: riscv64 OK
installing: mips64le OK
installing: s390x OK
installing: mips64 OK
{
"supported": [
"linux/amd64",
"linux/arm64",
"linux/riscv64",
"linux/ppc64le",
"linux/s390x",
"linux/386",
"linux/mips64le",
"linux/mips64",
"linux/arm/v7",
"linux/arm/v6"
],
"emulators": [
"qemu-aarch64",
"qemu-arm",
"qemu-mips64",
"qemu-mips64el",
"qemu-ppc64le",
"qemu-riscv64",
"qemu-s390x"
]
}
Après cela, je constate que j'arrive à lancer avec succès une image arm64 sous processeur Intel :
$ docker run --rm -it --platform linux/arm64 hasura/graphql-engine:v2.43.0 bash
root@bf74bfb8bc35:/# graphql-engine version
Hasura GraphQL Engine (Pro Edition): v2.43.0
J'ai pris un peu de temps pour explorer le repository tonistiigi/binfmt.
Je n'ai pas compris quelle est l'interaction entre les éléments installés par cette image et docker-engine.
Je constate que cette image a été créée en 2019 par deux développeurs de Docker : CrazyMax (un Français) et Tõnis Tiigi.
Mercredi 18 décembre 2024
Qu'est-ce qu'un "Script Helper" ?
J'utilise souvent le terme "Script Helper". Dans cette note, je vais tenter de le définir.
Un script dit « helper » est un script qui n'est pas essentiel au cœur du projet et qui ne contient pas de code métier. Son rôle est d’automatiser des tâches courantes et réutilisables pour le développeur.
L’écriture de ces scripts permet de centraliser et de versionner leur contenu, tout en réduisant les risques d’erreurs d’exécution.
Ma définition et objectif d'un "Workspace" dans un "environnement de développement" ?
Dans une note précédente, j'ai donné ma définition et les objectifs d'un "Development kit".
Dans cette note, je souhaite donner ma définition et les objectifs d'un workspace dans un "environnements de développement".
Un workspace est un dossier, qui contient des paramètres de configuration spécifiques — généralement sous la forme de variables d'environnements — qui permettent d'interagir sur une ou plusieurs instances de services, d'un environnement précis.
Généralement ce dossier contient des guides d'instructions pour réaliser des actions spécifiques sur le workspace et des scripts de type "helpers".
Exemple de workspaces :
staging/remote-workspace/: un workspace utilisé pour effectuer des actions sur les services déployés en staging sur des serveurs distants ;staging/local-workspace/: un workspace d'installer localement des services dans les mêmes conditions que sur l'environnement staging ;development/local-workspace/: un dossier workspace, qui permet de travailler — contribuer — localement sur le ou les services.
Voir aussi :
Jeudi 12 décembre 2024
Journal du jeudi 12 décembre 2024 à 11:10
La découverte du service deces.matchid.io (voir la note 2024-12-12_1020) m'a donné l'idée d'un service web qui permettrait d'être alerté en cas de décès d'un proche.
User Story (gestion de projet logiciel) :
- En tant que visiteur non connecté, je peux créer un compte utilisateur
- En tant qu'utilisateur, je peux saisir la liste des personnes que je souhaite surveiller
Le code source serait libre, mais la base de données serait privée.
J'ai trouvé un service qui permet de « S’abonner à une alerte des décès sur un nom » au prix de 18 € par an 😮 : https://www.libramemoria.com/etre-alerte-des-deces.
Journal du jeudi 12 décembre 2024 à 10:20
#JaiDécouvert le projet Match ID (https://matchid.io/) et plus précisément l'instance deces.matchid.io (https://deces.matchid.io/search).
Le projet matchID a été initié au ministère de l'Intérieur dans le contexte des challenges d' Entrepreneur d'intérêt général. La réconciliation des personnes décédées avec le permis de conduire a été le premier cas d'usage réalisé avec matchID.
Le projet a été libéré et mis en open source. L'équipe est maintenant composée de développeurs, anciens du ministère de l'Intérieur, contribuant bénévolement au service sur leur temps libre.
Nous avons créé ce service en complément, car il semblait d'utilité publique notamment pour la lutte contre la fraude, ou pour la radiation des décédés aux différents fichiers clients (e.g. hôpitaux).
L'exposition sur deces.matchid.io au profit du public est assurée par Fabien ANTOINE, avec le soutien de Cristian Brokate notamment pour le soutien technique à l'API. Le service est offert sans garantie de fonctionnement, nous nous efforçons de répondre aux messages (hors "absence du fichier") sur notre temps libre, faut de support officiel par les services de l'Administration.
Pour en savoir plus sur le projet matchID, consultez notre site https://matchid.io.
#Jadore ❤️
Le site exploite les fichiers des personnes décédées, disponibles en open data sur data.gouv.fr et recueillies par l'INSEE.
Les fichiers des personnes décédées sont établis par l’INSEE à partir des informations reçues des communes dans le cadre de leur mission de service public.
Quelques informations sur le fichier :
le fichier comporte 27983578 décès et NaN doublons (stricts)
il comporte les décès de 1970 à aujourd'hui (jusqu'au 31/10/2024)
il a été mis à jour le 05/11/2024
Un projet open source du Ministère de l'Intérieur.
Mercredi 11 décembre 2024
Journal du mercredi 11 décembre 2024 à 17:51
#JaiDécouvert OpenPhone (https://www.openphone.com) qui semble être une alternative à AirCall.
Journal du mercredi 11 décembre 2024 à 17:08
En étudiant les Web Components, #JaiDécouvert wired-elements (demo : https://wiredjs.com/).
J'adore, je pense utiliser ces composants à l'avenir pour réaliser des prototypes d'applications. Je trouve que cela permet de bien exprimer l'idée qu'aucun travail n'a été fait sur le design de l'interface utilisateur et que ce n'était pas l'objectif.
wired-elements fait partie de l'organisation rough-stuff qui a aussi développé Rough.js que j'avais déjà croisé, mais également rough-notation (démo : https://roughnotation.com) que je viens de découvrir et que je pense utiliser à l'avenir.
Je pourrais peut-être m'en inspirer pour implémenter l'issue "Je souhaite arriver à afficher un { en svg entre les lignes du mois de juillet et décembre et d'y afficher un texte".
Journal du mercredi 11 décembre 2024 à 16:56
Je pense m'insprirer de article "Technologies I Don't Want to Work With Again" de Lloyd Atkinson pour réaliser une note personnelle sur ce sujet.
Journal du mercredi 11 décembre 2024 à 11:22
#JaiDécouvert ArchieML (https://archieml.org/) qui est un markup language créé en 2015 par Michael Strickland qui travaille chez The New York Times.
Mon premier sentiment a été « pourquoi ne pas utiliser du Markdown ».
Ensuite, en lisant la documentation, j'ai compris que ce markup language était utilisé pour renseigner des valeurs dans différents champs. Comme le dit la documentation, ArchieML est une alternative à JSON ou YAML.
En explorant la section « Why not YAML? Or JSON? », j'ai compris la philosophie fondamentale d'ArchieML : offrir un langage de balisage qui soit particulièrement tolérant aux erreurs de syntaxe, notamment concernant l'indentation.
Cette approche répond spécifiquement aux besoins des journalistes qui, contrairement aux développeurs, ne sont généralement pas familiers avec les conventions strictes d'indentation que l'on trouve dans d'autres langages de balisage.
Ensuite, je me suis demandé : « Pourquoi ne pas demander aux journalistes de saisir leur article dans une page d'édition web, qui présente différents champs bien distincts ? ».
Je pense que la réponse se trouve ici :
And finally, because we make extensive use of Google Documents's concurrent-editing features…
Tout comme j'aime travailler avec des documents "plain text", peut-être que les journalistes préfèrent finalement travailler sur de simples documents textes plutôt qu'une page web d'édition, pour des raisons de rapidité d'utilisation : copier-coller rapide, fonctionnalité de commentaire collaboratif de Google Docs…
Je découvre dans la section ressources différentes librairies d'intégration à Google Docs.
Je découvre aussi que ArchieML est utilisé par d'autres journaux :
- Quartz
- The Atlanta Journal-Constitution
- Fusion
- The Wall Street Journal
Au final, je n'ai pas d'opinion définitive au sujet de cette méthode d'édition d'article 🤔.
Journal du mercredi 11 décembre 2024 à 11:03
Je viens de croiser pour la première fois la propriété windom.customElements (from).
Elle fait partie de l'ensemble des technologies qui composent ce que l'on appelle les Web Components.
Je connais depuis longtemps les Web Components, mais je n'ai jamais essayé de mettre en œuvre cette technologie. Je me suis contenté de lire et d'écouter des retours d'expérience et de suivre l'évolution des spécifications.
#JaiDécouvert que je peux facilement créer des Web Components en Svelte : https://svelte.dev/docs/svelte/custom-elements.
Custom elements can be a useful way to package components for consumption in a non-Svelte app, as they will work with vanilla HTML and JavaScript as well as most frameworks.
#JaiDécouvert le site Custom Elements Everywhere (https://custom-elements-everywhere.com/). Je lis que les Web Components sont maintenant parfaitement supportés par les frameworks majeurs : ReactJS, VueJS, Angular, Svelte, Solid… Ce qui est une très bonne nouvelle 🙂.
Je vais essayer de garder cette information à l'esprit, les Web Components me seront sans doute utile à l'avenir.
Avec Svelte, j'apprécie une sorte de "retour aux sources", c'est-à-dire, vers un web un peu plus "vannila", celui que j'ai connu au début des années 2000.
Je pense que Web Components vont encore renforcer cette sensation, comme par exemple le fait que si j'utilise la fonctionnalité développeur "inspection" du navigateur sur un Web Component, je vais voir, par exemple, la balise <button>....</button> du Web Component et non sa "soupe" HTML, comme c'est le cas avec un composant ReactJS ou Svelte (je sais qu'il existe des extensions navigateur pour éviter cela).
#JaimeraisUnJour prendre le temps d'étudier les performances des Web Components versus les composants de ReactJS, Svelte et Solid.
#JaiLu le thread du Subreddit ReactJS : Is it worth learning Web Components?. Voici quelques extraits :
Not worth it to be quite honest. I expect to get some hate for this.
I worked on a design system for three years that was written in Stencil (web component framework) that was used by multiple teams all using React, Angular, Vue. I regret everything, it should have all been react but the dumb decision to allow different teams to use different frameworks in order to do "micro frontend architecture" was the reason web components were picked shortly before I joined and took the lead.
Web components are also impossible to version and whichever one loads first is going to be the one that is globally used. This means production breaking changes without teams even knowing their breaking changes were going to fuck over another team.
Un peu plus loin du même auteur :
No, I view “micro frontend architecture” as a total disaster and it usually is implemented badly. When each application is a different framework too it’s quite honestly so difficult as to not even be worth entertaining.
Web components can be a great way to add functionality to legacy web apps. I don't know if I'd set out to use them in any other scenario though. I suppose you could, but I don't know many people writing vanilla HTML/JS apps these days.
J'ai effectué une recherche GitHub sur le topic "web-components" et j'ai trouvé des choses intéressantes :
- wired-elements - j'adore ! ( Voir note la 2024-12-11_1708)
- Open UI (https://open-ui.org) - cela semble être intéressant
- https://github.com/github/github-elements
- https://github.com/nolanlawson/emoji-picker-element
- https://atomicojs.dev
Lundi 9 décembre 2024
Journal du lundi 09 décembre 2024 à 15:50
J'utilise la fonctionnalité Docker volume mounts dans tous mes projets depuis septembre 2015.
Généralement, sous la forme suivante :
services:
postgres:
image: postgres:17
...
volumes:
- ./volumes/postgres/:/var/lib/postgresql/data/
D'après mes recherches, la fonctionnalité volumes mounts a été introduite dans la version 0.5.0 en juillet 2013.
À cette époque, je crois me souvenir que Docker permettait aussi de créer des volumes anonymes.
Je n'ai jamais apprécié les volumes anonymes, car lorsqu'un conteneur était supprimé, il devenait compliqué de retrouver le volume associé.
À cette époque, Docker était nouveau et j'avais très peur de perdre des données, par exemple, les volumes d'une instance PostgreSQL.
J'ai donc décidé qu'il était préférable de renoncer aux volumes anonymes et d'opter systématiquement pour des volume mounts.
Ensuite, peut-être en janvier 2016, Docker a introduit les named volumes, qui permettent de créer des volumes avec des noms précis, par exemple :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
name: postgres
$ docker volume ls
DRIVER VOLUME NAME
local postgres
Ce volume est physiquement stocké dans le dossier /var/lib/docker/volumes/postgres/_data.
Depuis, j'ai toujours préféré les volumes mounts aux named volumes pour les raisons pratiques suivantes :
- Travaillant souvent sur plusieurs projets, j'utilise les volume mounts pour éviter les collisions. Lorsque j'ai essayé les named volumes, une question s'est posée : quel nom attribuer aux volumes PostgreSQL ? «
postgres» ? Mais alors, quel nom donner au volume PostgreSQL dans le projet B ? Avec les volume mounts, ce problème ne se pose pas. - J'apprécie de savoir qu'en supprimant un projet avec
rm -rf ~/git/github.com/stephan-klein/foobar/, cette commande effacera non seulement l'intégralité du projet, mais également ses volumes Docker. - Avec les mounted volume, je peux facilement consulter le contenu des volumes. Je n'ai pas besoin d'utiliser
docker volume inspectpour trouver le chemin du volume.
La stratégie que j'ai choisie basée sur volumes mounts a quelques inconvénients :
- Le owner du dossier
volumes/, situé dans le répertoire du projet, estroot. Cela entraîne fréquemment des problèmes de permissions, par exemple lors de l'exécution des scripts de linter dans le dossier du projet. Pour supprimer le projet, je dois donc utilisersudo. Je précise que ce problème n'existe pas sous MacOS. Je pense que ce problème pourrait être contourné sous Linux en utilisant podman. - La commande
docker compose down -vne détruit pas les volumes.
Je suis pleinement conscient que ma méthode basée sur les volume mounts est minoritaire. En revanche, j'observe qu'une grande majorité des développeurs privilégie l'utilisation des named volumes.
Par exemple, cet été, un collègue a repris l'un de mes projets, et l'une des premières choses qu'il a faites a été de migrer ma configuration de volume mounts vers des named volumes pour résoudre un problème de permissions lié à Prettier, eslint ou Jest. En effet, la fonctionnalité ignore de ces outils ne fonctionne pas si NodeJS n'a pas les droits d'accès à un dossier du projet 😔.
Aujourd'hui, je me suis lancé dans la recherche d'une solution me permettant d'utiliser des named volumes tout en évitant les problèmes de collision entre projets.
Je pense que j'ai trouvé une solution satisfaisante 🙂.
Je l'ai décrite et testée dans le repository docker-named-volume-playground.
Ce repository d'exemple contient 2 projets distincts, nommés project_a et project_b.
J'ai instancié deux fois chacun de ces projets. Voici la liste des dossiers :
$ tree
.
├── project_a_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_a_instance_2
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_1
│ ├── docker-compose.yml
│ └── .envrc
├── project_b_instance_2
│ ├── docker-compose.yml
│ └── .envrc
└── README.md
Ce repository illustre l'organisation de plusieurs instances de différents projets sur la workstation du développeur.
Il ne doit pas être utilisé tel quel comme base pour un projet.
Par exemple, le "vrai" repository du projet projet_a se limiterait aux fichiers suivants : docker-compose.yml et .envrc.
Voici le contenu d'un de ces fichiers .envrc :
export PROJECT_NAME="project_a"
export INSTANCE_ID=$(pwd | shasum -a 1 | awk '{print $1}' | cut -c 1-12) # Used to define docker volume path
export COMPOSE_PROJECT_NAME=${PROJECT_NAME}_${INSTANCE_ID}
L'astuce que j'utilise est au niveau de INSTANCE_ID. Cet identifiant est généré de telle manière qu'il soit unique pour chaque instance de projet installée sur la workstation du développeur.
J'ai choisi de générer cet identifiant à partir du chemin complet vers le dossier de l'instance, je le passe dans la commande shasum et je garde les 12 premiers caractères.
J'utilise ensuite la valeur de COMPOSE_PROJECT_NAME dans le docker-compose.yml pour nommer le named volume :
services:
postgres:
image: postgres:17
environment:
POSTGRES_USER: postgres
POSTGRES_DB: postgres
POSTGRES_PASSWORD: password
ports:
- 5432
volumes:
- postgres:/var/lib/postgresql/data/
healthcheck:
test: ["CMD", "sh", "-c", "pg_isready -U $$POSTGRES_USER -h $$(hostname -i)"]
interval: 10s
start_period: 30s
volumes:
postgres:
name: ${COMPOSE_PROJECT_NAME}_postgres
Exemples de valeurs générées pour l'instance installée dans /home/stephane/git/github.com/stephane-klein/docker-named-volume-playground/project_a_instance_1 :
INSTANCE_ID=d4cfab7403e2COMPOSE_PROJECT_NAME=project_a_d4cfab7403e2- Nom du container postgresql :
project_a_d4cfab7403e2-postgres-1 - Nom du volume postgresql :
project_a_a04e7305aa09_postgres
Conclusion
Cette méthode me permet de suivre une pratique plus mainstream — utiliser les named volumes Docker — tout en évitant la collision des noms de volumes.
Je suis conscient que ce billet est un peu long pour expliquer quelque chose de simple, mais je tenais à partager l'historique de ma démarche.
Je pense que je vais dorénavant utiliser cette méthode pour tous mes nouveaux projets.
20224-12-10 11h27 : Je tiens à préciser qu'avec la configuration suivante :
services:
postgres:
image: postgres:17
...
volumes:
- postgres:/var/lib/postgresql/data/
volumes:
postgres:
Quand le nom du volume postgres n'est pas défini, docker-compose le nomme sous la forme ${COMPOSE_PROJECT_NAME}_postgres. Si le projet est stocké dans le dossier foobar, alors le volume sera nommé foobar_postgres.
$ docker volume ls
DRIVER VOLUME NAME
local foobar_postgres
Dimanche 8 décembre 2024
Journal du dimanche 08 décembre 2024 à 22:19
Je viens de rencontrer l'outil envdir (à ne pas confondre avec direnv) et son modèle de stockage de variables d'environnement, que je trouve très surprenant !
direnv ou dotenv utilisent de simples fichiers texte pour stocker les variables d'environnements, par exemple :
export POSTGRES_URL="postgres://postgres:password@localhost:5432/postgres"
export SMTP_HOST="127.0.0.1"
export SMTP_PORT="1025"
export MAIL_FROM="noreply@example.com"
Contrairement à ces deux outils, pour définir ces quatre variables, le modèle de stockage de envdir nécessite la création de 4 fichiers :
$ tree .
.
├── MAIL_FROM
├── POSTGRES_URL
├── SMTP_HOST
└── SMTP_PORT
1 directory, 4 files
$ cat POSTGRES_URL
postgres://postgres:password@localhost:5432/postgres
$ cat SMTP_HOST
127.0.0.1
$ cat SMTP_PORT
1025
$ cat MAIL_FROM
127.0.0.1
Je trouve ce modèle fort peu pratique. Contrairement à un simple fichier unique, le modèle de envdir présente certaines limitations :
- Organisation : il ne permet pas de structurer librement l'ordre ou de regrouper visuellement les variables.
- Lisibilité : l'ensemble de la configuration est plus difficile à visualiser d'un seul coup d'œil.
- Manipulation : copier ou coller son contenu n'est pas aussi direct qu'avec un fichier texte.
- Documentation : les commentaires ne peuvent pas être inclus pour expliquer les variables.
- Rapidité : la saisie ou la modification de plusieurs variables demande plus de temps, chaque variable étant dans un fichier distinct.
J'ai été particulièrement intrigué par le choix fait par l'auteur de envdir. Sa décision semble vraiment surprenante.
envdir fait partie du projet daemontools, créé en 1990. Ainsi, il est bien plus ancien que dotenv, qui a été lancé autour de 2010, et direnv, qui date de 2014.
Si je me remets dans le contexte des années 1990, je pense que le modèle de envdir a été avant tout motivé par une simplicité d'implémentation plutôt que d'utilisation. En effet, il est plus facile de lister les fichiers d'un répertoire et de charger leur contenu que de développer un parser de fichiers.
Je pense qu'en 2024, envdir n'a plus sa place dans un environnement informatique moderne. Je recommande vivement de le remplacer par des solutions plus récentes, comme devenv ou direnv.
Personnellement, j'utilise direnv dans tous mes projets.
Samedi 7 décembre 2024
Journal du samedi 07 décembre 2024 à 21:18
Dans le repository poc-git-monorepo-multirepos-sync, j'ai pour la première fois expérimenté l'utilisation d'un script Bash qui génère dynamiquement le contenu d'une démo d'un terminal.
Le contenu du fichier README.md est généré par /generate-readme.sh qui exécute demo.sh et qui enregistre la sortie standard dans README.md.
À l'usage, l'expérience était agréable.
Journal du samedi 07 décembre 2024 à 20:49
Je pense être arrivé à une solution plus ou moins satisfaisante pour le Projet 19 - "Documenter une méthode pour synchroniser un monorepo vers des multirepos qui fonctionne dans les deux sens".
Voici-ci, ci-dessous, les étapes de la démonstration qui sont détaillées dans le README.md du repository poc-git-monorepo-multirepos-sync.
- Je crée deux repositories :
frontendetbackend(multi repositories) ; - J'utilise le script tomono pour les intégrer dans un monorepo nommé
monorepo; - J'ajoute deux fichiers à la racine de
monorepo:README.mdet.mise.toml; - J'effectue des changements dans le repository
frontend, je commit ; - Je pull les changements du repository
frontendversmonorepo; - Dans
monorepo, j'effectue des changements dans le dossierfrontend/, je commit ; - J'utilise
cd frontend/; git format-patch --relative -1 HEADpour générer un patch qui contient les changements que j'ai effectués dans le dossierfrontend/; - Je vais dans le repository
frontendet j'applique les changements contenus dans ce patch avec la commandgit apply monpatch.patchou avecgit am monptach.patch.
Pour le moment, j'ai privilégié l'option git patch, parce que je souhaite suivre la méthode la plus "manuelle" que j'ai pu trouver lorsque je dois intervenir sur les repositories upstream, parce que je ne veux prendre aucun risque de perturber mes collègues avec mon initiative de monorepo.
Le repository GitHub suivant contient le résultat final du monorepo : https://github.com/stephane-klein/poc-git-monorepo-multirepos-sync-result-example/.
Est-ce que je suis satisfait du résultat de cette démo ?
La réponse est oui, bien que je ne sois pas satisfait de quelques éléments.
Par exemple, les fichiers de frontend présents dans ce commit ne sont pas dans le dossier frontend.
J'aimerais que ces titres de commits contiennent un prefix [frontend] ... et [backend].... Je pense que cela doit être possible à implémenter en modifiant le script tomono.
Est-ce que c'est pénible à utiliser ? Pour le moment, ma réponse est « je ne sais pas ».
Je vais tester cette méthode avec deux projets. Je pense écrire une note de bilan de cette expérience d'ici à quelques semaines.
Journal du samedi 07 décembre 2024 à 19:04
En travaillant sur Projet 19, #JaiDécouvert le projet git-branchless (https://github.com/arxanas/git-branchless).
High-velocity, monorepo-scale workflow for Git.
Je n'ai pas encore compris à quoi cela sert.
Vendredi 6 décembre 2024
Je découvre l'utilisation des URLs "text fragments" 😍
#OnMaPartagé l'article "Lier un fragment de texte dans une page web - Le carnet de Joachim".
Je suis trop heureux de découvrir cette fonctionnalité 😍.
#JaiLu la documentation de référence sur MDN Web Docs : "Text fragments - URIs".
Lien direct vers la syntaxe : https://developer.mozilla.org/en-US/docs/Web/URI/Fragment/Text_fragments#syntax.
Je découvre aussi qu'il est possible de sélectionner plusieurs fragments simultanément :
You can specify multiple text fragments to highlight in the same URL by separating them with ampersand (
&) characters.
J'apprends que cette fonctionnalité est disponible sous Chrome depuis février 2020 ! Firefox depuis le 1ᵉʳ octobre 2024, Safari depuis le 24 octobre 2024.
J'ai installé et testé l'extension Firefox Link to Text Fragment et cela fonctionne parfaitement 👌.
Sur la page suivante, vous pourrez trouver les liens vers cette même extension pour Chrome et Safari : https://github.com/GoogleChromeLabs/link-to-text-fragment?tab=readme-ov-file#installation.
Journal du vendredi 06 décembre 2024 à 12:03
Je viens de rédiger le Projet 18 - "Créer un skeleton pour l'anonymisation des dumps de bases de données PostgreSQL".
Jeudi 5 décembre 2024
Journal du jeudi 05 décembre 2024 à 23:10
Ce matin, lors d'une discussion avec un client, le sujet de la densité des User Interface a été abordé. Cela m'a rappelé une note que j'avais rédigée le 2024-07-27.
Suite à cela, je me suis lancé dans des recherches en lien avec les grilles de Perspective que j'aime beaucoup (https://perspective.finos.org/blocks/editable/index.html).
#JaiDécouvert Glide Data Grid (https://grid.glideapps.com/) :
A ReactJS data grid with no compromises, outrageous performance, rich rendering and full TypeScript support.
Apparement, cette librairie utiliser HTML Canvas pour son rendering.
Dans ce thread Hacker News, #JaiDécouvert l'article "The Design Philosophy of Great Tables" (https://posit-dev.github.io/great-tables/blog/design-philosophy/).
J'ai consulter la page Components > Data Table de Evidence. J'aime beaucoup.
Mercredi 4 décembre 2024
Journal du mercredi 04 décembre 2024 à 14:56
Alexandre a eu un breaking change avec Mise : https://github.com/jdx/mise/issues/3338.
Suite à cela, j'ai découvert que Mise va prévilégier l'utilisation du backend aqua plutôt que Asdf :
we are actively moving tools in the registry away from asdf where possible to backends like aqua and ubi which don't require plugins.
J'ai découvert au passage que Mise supporte de plus en plus de backend, par exemple Ubi et vfox.
Je constate qu'il commence à y avoir une profusion de "tooling version management" : Asdf,Mise, aqua, Ubi, vfox !
Je pense bien qu'ils ont chacun leurs histoires, leurs forces, leurs faiblesses… mais j'ai peur que cela me complique mon affaire : comment arriver à un consensus de choix de l'un de ces outils dans une équipe 🫣 ! Chaque développeur aura de bons arguments pour utiliser l'un ou l'autre de ces outils.
Constatant plusieurs fois que le développeur de Mise a fait des breaking changes qui font perdre du temps aux équipes, mon ami et moi nous sommes posés la question si, au final, il ne serait pas judicieux de revenir à Asdf.
D'autre part, au départ, Mise était une simple alternative plus rapide à Asdf, mais avec le temps, Mise prend en charge de plus en plus de fonctionnalités, comme une alternative à direnv , un système d'exécution de tâches, ou mise watch.
Souvent, avec des petits défauts très pénibles, voir par exemple, ma note "Le support des variables d'environments de Mise est limité, je continue à utiliser direnv".
Alexandre s'est ensuite posé la question d'utiliser un jour le projet devenv, un outil qui va encore plus loin, basé sur le système de package Nix.
Le projet devenv me fait un peu peur au premier abord, il gère "tout" :
- Comme Asdf et Mise : l'installation des outils, packages et langages
- Support de scripts "helper"
- Intégration de Docker
- Support de process
- Support du SDK Android
Il fait énormément de choses et je crains que la barrière à l'entrée soit trop haute et fasse fuir beaucoup de développeurs 🤔.
Tout cela me fait un peu penser à Bazel (utilisé par Google), Pants (utilisé par Twitter), Buck (utilisé par Facebook) et Please.
Tous ces outils sont puissants, je les ai étudiés en 2018 sans arrivée à les adopter.
Pour le moment, mes development kit nécessitent les compétences suivantes :
- Comprendre les rudiments d'un terminal Bash ;
- Arriver à installer et à utiliser Mise et direnv ;
- Maitriser Docker ;
- Savoir lire et écrire des scripts Bash de niveau débutant.
Déjà, ces quatre prérequis posent quelques fois des difficultés d'adoption.
Journal du mercredi 04 décembre 2024 à 10:14
#JaiDécouvert l'outil de "version manager" nommé aqua, une alternative à Mise et Asdf codé en Golang.
Ce projet semble avoir débuté en août 2021.
J'ai fait quelques recherches au sujet d'aqua sur Hacker News, j'ai trouvé très peu d'occurrences. J'ai trouvé "Ask HN: Homebrew, Asdf, Nix, or Other?".
Je pense qu'aqua est bien moins populaire que Asdf et Mise.
Au 4 décembre 2024 :
Mardi 3 décembre 2024
Journal du mardi 03 décembre 2024 à 23:57
Suite de 2024-12-03_2213. J'ai réussi à implémenter le support Pandoc style markdown attributes dans sklein-pkm-engine.
Le package markdown-it-attrs fonctionne parfaitement bien.
Par contre, le plugin markdown-attributes semble ne pas fonctionner sur les dernières versions de Obsidian.
Journal du mardi 03 décembre 2024 à 22:13
Suite à 2024-11-13_2147, j'ai implémenté l'amélioration du rendu des "citations", voici un exemple :
Texte de la citation.
J'ai utilisé la librairie markdown-it-callouts.
Par contre, l'implémentation actuelle contient un bug. Je souhaite appliquer ce style css uniquement au lien de la source de la citation :

Pour cela, j'aimerais pouvoir spécifier en markdown une classe source sur le lien qui pointe vers la source de la citation.
J'ai trouvé markdown-it-attrs qui me permettrait d'implémenter une syntax Pandoc-style markdown attributes :
> [!quote]
>
> Texte de la citation.
>
> [source](http://example.com){.source}
Le plugin Obsidian markdown-attributes semble implémenter cette syntax.
Je souhaite tester si ce plugin fonctionne bien et si oui, je vais essayer d'intégrer markdown-it-attrs dans sklein-pkm-engine.
Journal du mardi 03 décembre 2024 à 21:57
Dans l'article "Dependency management fatigue, or why I forever ditched React for Go+HTMX+Templ" (from), #JaiDécouvert :
- templ, qui permet de générer du code HTML SSR avec Golang en utilisant une syntax proche de JSX ;
- Datastar :
Cela me donne envie d'essayer ces technologies 🙂.
[ << Notes plus récentes (201) ] | [ Notes plus anciennes (748) >> ]