
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (50) ] [ Page suivante (379) >> ]
J'ai découvert la chaine YouTube Plantophage
Dans la vidéo "Le bio, c'est du 💩 ?" de L'Argumentarium, #JaiDécouvert une nouvelle Chaine YouTube : Plantophage.
Chaîne de vulgarisation scientifique sur les thèmes de l'agriculture, de l'agronomie et du jardinage.
Je précise que je n'ai pas encore regardé de contenu de cette chaîne, qui existe depuis le 21 mai 2023.
La première vidéo de cette chaine a été publiée le 21 mai 2023.
En parcourant la liste des vidéos, j'ai été particulièrement intrigué par "LIVE - Monsieur Phi et le spécisme " (3h34). C'est probablement par celle-ci que je vais commencer à découvrir cette chaîne.
Journal du vendredi 11 juillet 2025 à 23:11
Pendant mon apprentissage d'Observable, #JaiDécouvert les concepts de Wide data et Long data.
Je connaissais ces différentes façons d'organiser des données tabulaires, mais j'ignorais jusqu'à présent leurs noms, apparemment issus de l'article Tidy Data - Hadley Wickham - 12 septembre 2014 .
D'après ce que j'ai compris, les bibliothèques comme d3js ou Observable Plot privilégient le format Long data.
Il me semble que même si le format Wide data est plus intuitif pour les humains (présenté en tableau à plusieurs colonnes, plus lisible), il est généralement plus simple d'effectuer des opérations de traitement sur des données au format Long data.
J'ai découvert Kiln, un outil de gestion de secret basé sur Age
#JaiDécouvert dans ce thread Hacker News le projet kiln (https://kiln.sh/).
kiln is a secure environment variable management tool that encrypts your sensitive configuration data using age encryption. It provides a simple, offline-first alternative to centralized secret management services, with role-based access control and support for both age and SSH keys, making it perfect for team collaboration and enterprise environments.
Je n'ai pas encore testé kiln mais j'ai l'intuition qu'il pourrait remplacer le workflow que j'ai présenté il y a quelque mois dans cette note : "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh".
Voici les informations que j'ai identifiées au sujet de kiln :
- Ce projet est très jeune
- Écrit en Golang
- Supporte des clés age ou des clés ssh.
- « Team Collaboration: Fine-grained role-based access control for team members and groups »
- What happens if someone leaves the team?
La lecture de la faq m'a fait penser que je n'ai toujours pas pris le temps d'étudier SOPS 🫣.
J'ai hâte de tester kiln qui grâce à Age me semble plus simple que le workflow basé sur pass, que j'ai utilisé professionnellement de 2019 à 2023.
bridge-utils est déprécié, je dois remplacer "brctl" par "ip link"
En étudiant IPv6 et Linux bridge, j'ai découvert que le projet bridge-utils est déprécié. À la place, il faut utiliser iproute2.
Ce qui signifie que je ne dois plus utiliser la commande brctl, chose que j'ignorais jusqu'à ce matin.
iproute2 remplace aussi le projet net-tools. Par exemple, les commandes suivantes sont aussi dépréciées :
ifconfigremplacé parip addretip linkrouteremplacé parip routearpremplacé parip neighbrctlremplacé parip linkiptunnelremplacé parip tunnelnameifremplacé parip link set nameipmaddrremplacé parip maddr
Au-delà des aspects techniques — iproute2 utilise Netlink plutôt que ioctl — l'expérience utilisateur me semble plus cohérente.
J'ai une préférence pour une commande unique ip accompagnée de sous-commandes plutôt que pour un ensemble de commandes disparates.
Cette logique de sous-commandes s'inscrit dans une tendance générale de l'écosystème Linux, et je pense que c'est une bonne direction.
Je pense notamment à systemctl, timedatectl, hostnamectl, localectl, loginctl, apt, etc.
Quand j'ai débuté sous Linux en 1999, j'ai été habitué à utiliser les commande ifup et ifdown qui sont en réalité des scripts bash qui appellent entre autre ifconfig.
Ces scripts ont été abandonnés par les distributions Linux qui sont passées à systemd et NetworkManager.
En simplifiant, l'équivalent des commandes suivantes avec NetworkManager :
$ ifconfig
$ ifup eth0
$ ifdown eth0
est :
$ nmcli device status
$ nmcli connection up <nom_de_connexion>
$ nmcli connection down <nom_de_connexion>
Contrairement à mon intuition initiale, NetworkManager n'est pas un simple "wrapper" de la commande ip d'iproute2.
En fait, nmcli fonctionne de manière totalement indépendante d'iproute2, il utilise l'interface Netlink comme l'illustre cet exemple de la commande nmcli device show :
nmcli device show
↓ (Method call via D-Bus)
org.freedesktop.NetworkManager.Device.GetProperties()
↓ (NetworkManager traite la requête)
nl_send_simple(sock, RTM_GETLINK, ...)
↓ (Socket netlink vers kernel)
Kernel: netlink_rcv() → rtnetlink_rcv()
↓ (Retour des données)
RTM_NEWLINK response
↓ (libnl parse la réponse)
NetworkManager met à jour ses structures
↓ (Réponse D-Bus)
nmcli formate et affiche les données
Autre différence, contrairement à iproute2, les changements effectués par NetworkManager sont automatiquement persistants et il peut réagir à des événements, tel que le branchement d'un câble réseau et la présence d'un réseau WiFi connu.
Les paramètres de configuration de NetworkManager se trouvent dans les fichiers suivants :
- Fichiers de configuration globale de NetworkManager :
# Fichier principal
/etc/NetworkManager/NetworkManager.conf
# Fichiers de configuration additionnels
/etc/NetworkManager/conf.d/*.conf
- Fichiers de configuration des connexions NetworkManager :
# Configurations système (root)
/etc/NetworkManager/system-connections/
# Configurations utilisateur
~/.config/NetworkManager/user-connections/
Comme souvent, Ubuntu propose un outil "maison", nommé netplan qui propose un autre format de configuration. Mais je préfère utiliser nmcli qui est plus complet et a l'avantage d'être la solution mainstream supportée par toutes les distributions Linux.
Journal du vendredi 04 juillet 2025 à 14:46
En étudiant IPv6 et Linux bridge, j'ai découvert que Netlink a été introduit pour remplacer ioctl et procfs.
Netlink permet à des programmes user-land de communiquer avec le kernel via une API asynchrone. C'est une technologie de type inter-process communication (IPC).
La partie "Net" de "Netlink" s'explique par l'histoire : au départ, Netlink servait exclusivement à iproute2 pour la configuration réseau.
L'usage de Netlink s'est ensuite généralisé à d'autres aspects du kernel.
Journal du mardi 01 juillet 2025 à 12:25
#JaiDécouvert le mot et le concept d'Obeya :
J'ai participé à 2 Obeya.
Cela me donne l'impression que c'est comme un Standup Meeting géant, cross team.
Pour le moment, je ne suis pas convaincu de son efficience 🤔.
Journal du lundi 23 juin 2025 à 13:34
#JaiDécouvert de nombreuses informations intéressantes au sujet de Cloud Nubo dans les slides Nubo - A French government sovereign cloud du FOSDEM 2025.
#JaiDécouvert la fondation OpenInfra qui gouverne, entre autres, le projet OpenStack.
#JaiDécouvert l'existance des projets : Airship, Starlingx, Zuul. Je ne les ai pas étudiés.
Journal du dimanche 22 juin 2025 à 23:34
Un collègue m'a fait découvrir Vercel Chat SDK (https://github.com/vercel/ai-chatbot) :
Chat SDK is a free, open-source template built with NextJS and the AI SDK that helps you quickly build powerful chatbot applications.
#JaimeraisUnJour prendre le temps de le décliner vers SvelteKit.
Journal du dimanche 22 juin 2025 à 15:02
Je viens de découvrir les quatre premiers articles de la série "Nouvelle sur l'IA" sur LinuxFr :
- Nouvelles sur l’IA de février 2025
- Nouvelles sur l’IA de mars 2025
- Nouvelles sur l’IA d’avril 2025
- Nouvelles sur l’IA de mai 2025
L'auteur de ces articles indique en introduction :
Avertissement : presque aucun travail de recherche de ma part, je vais me contenter de faire un travail de sélection et de résumé sur le contenu hebdomadaire de Zvi Mowshowitz.
Je viens d'ajouter ces deux feed à ma note "Mes sources de veille en IA".
Prise de note de lecture de : Nouvelles sur l’IA de février 2025
Je découvre la signification de l'acronyme STEM : Science, technology, engineering, and mathematics.
Une procédure standard lors de la divulgation d’un nouveau modèle (chez OpenAI en tout cas) est de présenter une "System Card", aka "à quel point notre modèle est dangereux ou inoffensif".
#JaiDécouvert le concept de System Card, concept qui semble avoir été introduit par Meta en février 2022 : « System Cards, a new resource for understanding how AI systems work » (je n'ai pas lu l'article).
#JaiDécouvert ChatGPT Deep Research.
Je retiens :
Derya Unutmaz, MD: J'ai demandé à Deep Researchh de m'aider sur deux cas de cancer plus tôt aujourd'hui. L'un était dans mon domaine d'expertise et l'autre légèrement en dehors. Les deux rapports étaient tout simplement impeccables, comme quelque chose que seul un médecin spécialiste pourrait écrire ! Il y a une raison pour laquelle j'ai dit que c'est un changement radical ! 🤯
Et
Je suis quelque peu déçu par Deep Research d'@OpenAI. @sama avait promis que c'était une avancée spectaculaire, alors j'y ai entré la plainte pour notre procès guidé par o1 contre @DCGco et d'autres, et lui ai demandé de prendre le rôle de Barry Silbert et de demander le rejet de l'affaire.
Malheureusement, bien que le modèle semble incroyablement intelligent, il a produit des arguments manifestement faibles car il a fini par utiliser des données sources de mauvaise qualité provenant de sites web médiocres. Il s'est appuyé sur des sources comme Reddit et ces articles résumés que les avocats écrivent pour générer du trafic vers leurs sites web et obtenir de nouveaux dossiers.
Les arguments pour le rejet étaient précis dans le contexte des sites web sur lesquels il s'est appuyé, mais après examen, j'ai constaté que ces sites simplifient souvent excessivement la loi et manquent des points essentiels des textes juridiques réels.
#JaiDécouvert qu'il est possible de configurer la durée de raisonnement de Clause Sonnet 3.7 :
Aujourd'hui, nous annonçons Claude Sonnet 3.7, notre modèle le plus intelligent à ce jour et le premier modèle de raisonnement hybride sur le marché. Claude 3.7 Sonnet peut produire des réponses quasi instantanées ou une réflexion approfondie, étape par étape, qui est rendue visible à l'utilisateur. Les utilisateurs de l'API ont également un contrôle précis sur la durée de réflexion accordée au modèle.
#JaiDécouvert que l'offre LLM par API de Google se nomme Vertex AI.
#JaiDécouvert que les System Prompt d'Anthropic sont publics : https://docs.anthropic.com/en/release-notes/system-prompts#feb-24th-2025
J'ai trouvé la section "Gradual Disempowerement" très intéressante. #JaimeraisUnJour prendre le temps de faire une lecture active de l'article : Gradual Disempowerment.
Je viens de consacrer 1h30 de lecture active de l'article de février 2025. Je le recommande fortement pour ceux qui s'intéressent au sujet. Merci énormément à son auteur Moonz.
Je vais publier cette note et ensuite commencer la lecture de l'article de mars 2025.
Journal du dimanche 22 juin 2025 à 12:43
Je viens de découvrir sur LMArena un nouveau LLM développé par Google : flamesong.
Pour le moment, ce thread est la seule information que j'ai trouvé à ce sujet : https://old.reddit.com/r/Bard/comments/1lg48l9/new_model_flaamesong/.
Toujours via LMArena, j'ai découvert le modèle MinMax-M1 développé par une équipe basé à Singapore.
Dans le cadre de ma mission à la DINUM, #JaiDécouvert les clouds internes dédiés aux services sensibles de l'État : π (Pi), Cloud Nubo.
Ce cloud interne se décline en deux offres :
- Nubo, opérée par la Direction générale des Finances publiques (DGFiP), adaptée à l’hébergement de données sensibles,
- π (Pi), opérée par le Ministère de l'Intérieur, adaptée à l’hébergement de données sensibles jusqu’au niveau Diffusion restreinte.
"Nubo" signifie "Nuage" en esperanto.
Cloud Nubo ne doit pas être confondu avec la coopérative Nubo qui propose, elle aussi, des offres de services "cloud".
En consultant le profil LinkedIn de Renaud Chaillat, je découvre que le projet Cloud Nubo a été lancé en 2015 et s'appuie sur une expérience de 14 ans dans ce domaine, débutée en 2001.
 (source)
(source)
Ressources que j'ai trouvées intéressantes sur ce sujet :
#JaiDécouvert le référentiel SecNumCloud de l'ANSSI, qui définit les règles de sécurité que doivent respecter les Cloud providers pour obtenir le Visa de sécurité ANSSI.
Élaboré par l’Agence nationale de la sécurité des systèmes d’information (ANSSI), le référentiel SecNumCloud propose un ensemble de règles de sécurité à suivre garantissant un haut niveau d’exigence tant du point de vue technique, qu’opérationnel ou juridique.
... en conformité avec le droit européen.
Les solutions ayant passé avec succès la qualification obtiennent le Visa de sécurité ANSSI.
... L’obtention du Visa permet … de répondre aux exigences de la doctrine « cloud au centre » de l’État imposant aux administrations le recours à des solutions SecNumCloud pour l’hébergement de données qualifiées de sensibles.
Voici la documentation de ce référentiel : https://cyber.gouv.fr/sites/default/files/document/secnumcloud-referentiel-exigences-v3.2.pdf
J'ai consulté la liste des 8 prestataires SecNumCloud qualifiés. J'ai identifié Outscale, OVH (les offres OVH WMWare et OVH Bare Metal Pod), mais les 6 autres me sont totalement inconnues.
J'ai appris que le 8 janvier 2025, Scaleway a annoncé son entrée dans le processus de qualification SecNumCloud.
Voici la liste officielle des prestataires en cours de qualification.
Journal du samedi 21 juin 2025 à 12:45
Dans ce commentaire, #JaiDécouvert la page Models Table de LifeArchitect.ai d'Alan D. Thompson.
La page contient énormément d'information à propos des LLM !
Bien que je ne sois pas sûr de moi, pour le moment, je classe cette page dans la catégorie des leaderboard.
Journal du vendredi 20 juin 2025 à 17:28
#JaiDécouvert un autre leaderboard : Political Email Extraction Leaderboard (from).
Journal du vendredi 20 juin 2025 à 16:46
#JaiDécouvert le projet communautaire LLM-Stats.com (https://llm-stats.com/)
A comprehensive set of LLM benchmark scores and provider prices.
J'observe que LLM-Stats.com se base principalement sur le benchmark : A Graduate-Level Google-Proof Q&A Benchmark (GPQA).
En creusant le sujet, j'ai découvert cette page Wikipédia qui liste les principaux outils de LLM Benchmark : Language model benchmark.
Je pense avoir compris que le benchmark MMLU était populaire, utilisé par pratiquement tous les développeurs de LLM jusqu'en 2024, mais peu à peu remplacé par GPQA, qui est plus récent et plus compliqué.
Par exemple, GPQA est "Google-proof", ce qui signifie que les questions de GPQA sont difficiles à trouver en ligne, ce qui réduit le risque de contamination des données d'entraînement.
Journal du vendredi 20 juin 2025 à 16:37
#JaiDécouvert "Leaderboard des modèles de langage pour le français" : https://fr-gouv-coordination-ia-llm-leaderboard-fr.hf.space
C’est dans cette dynamique que la Coordination Nationale pour l’IA, le Ministère de l’Éducation nationale, Inria, le LNE et GENCI ont collaboré avec Hugging Face pour créer un leaderboard de référence dédié aux modèles de langage en français. Cet outil offre une évaluation de leurs performances, de leurs capacités et aussi de leurs limites.
Journal du vendredi 20 juin 2025 à 15:49
Il y a quelques mois, j'ai publié la note : J'ai découvert « Timeline of AI model releases in 2024 ».
Aujourd'hui, #JaiDécouvert le site The Road To AGI 2015 - 2025 (https://ai-timeline.org/).
Ce projet est Open source, voici son repository : jam3scampbell/ai-timeline.

Il me permet d'avoir une d'ensemble des publications des 6 premiers mois de l'année 2025 :
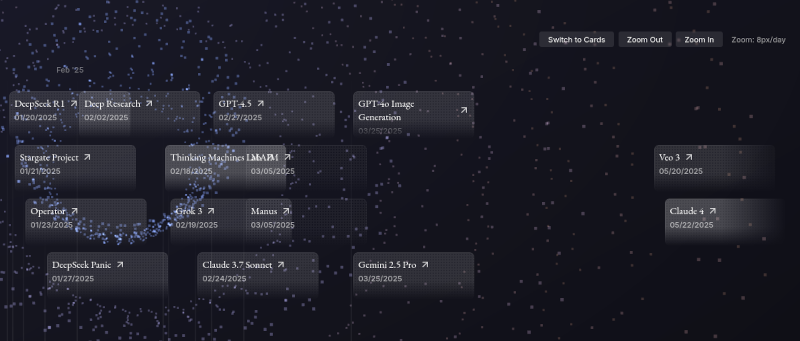
Bien que la réalisation de ce site soit techniquement réussie, après utilisation, je trouve qu'une simple liste Wikipedia répond mieux à mes besoins : https://en.wikipedia.org/wiki/List_of_large_language_models
J'ai lu le très bon billet d'Athoune sur Kloset, moteur de stockage de backup de Plakar
Il y a un an, Alexandre m'avait fait découvrir Kopia : Je découvre Kopia, une alternative à Restic.
Ma conclusion était :
Ma doctrine pour le moment : je vais rester sur restic.
En septembre 2024, j'ai découvert rustic, un clone de restic recodé en Rust. Pour le moment, je n'ai aucun avis sur rustic.
Il y a quelques semaines, Athoune m'a fait découvrir Plakar, mais je n'avais pas encore pris le temps d'étudier ce que cet outil de backup apportait de plus que restic que j'ai l'habitude d'utiliser.
Depuis, Athoune a eu la bonne idée d'écrire un article très détaillé sur Plakar, enfin, surtout son moteur de stockage avant-gardiste nommé Kloset : "Kloset sur la table de dissection" (au minimum 30 minutes de lecture).
Ce que je retiens, c'est que Kloset propose un système de déduplication plus performant que par exemple celui de restic qui est basé sur Rabin Fingerprints :
For creating a backup, restic scans the source directory for all files, sub-directories and other entries. The data from each file is split into variable length Blobs cut at offsets defined by a sliding window of 64 bytes. The implementation uses Rabin Fingerprints for implementing this Content Defined Chunking (CDC). An irreducible polynomial is selected at random and saved in the file config when a repository is initialized, so that watermark attacks are much harder.
Files smaller than 512 KiB are not split, Blobs are of 512 KiB to 8 MiB in size. The implementation aims for 1 MiB Blob size on average.
For modified files, only modified Blobs have to be saved in a subsequent backup. This even works if bytes are inserted or removed at arbitrary positions within the file.
Au moment où j'écris ces lignes, je n'ai aucune idée des différences ou des points communs entre l'algorithme Rolling hash dont parle l'article et Rabin Fingerprints qu'utilise restic.
Chose suprernante, je trouve très peu de citations de Plakar ou kloset sur Hacker News ou Lobster :
- Recherche avec "Plakar"
- Hacker News
- dans les stories
- Mars 2021 : March 2021: backups with Plakar – poolp.org : 0 commentaire
- Octobre 2024 : Open source distributed, versioned backups with encryption and deduplication : 0 commentaires
- Mars 2025 : CDC Attack Mitigation in Plakar : 0 commentaires
- dans les commentaires
- dans les stories
- Lobsters => rien
- Hacker News
- Recherche avec "Kloset"
- Hacker News :
- Lobsters => rien
Je tiens à remercier Athoune pour l'écriture, qui m'a permis de découvrir de nombreuses choses 🤗.
Journal du dimanche 15 juin 2025 à 11:02
En étudiant l'article Wikipedia "Base de données vectorielle", je découvre la liste de différents algorithmes Approximate Nearest Neighbor.
#JaiDécouvert feature extraction algorithms.
These feature vectors may be computed from the raw data using machine learning methods such as feature extraction algorithms, word embeddings or deep learning networks. The goal is that semantically similar data items receive feature vectors close to each other.
J'apprends :
Je lis :
Databases that use HNSW as search index include:
En interrogeant Claude Sonnet 4, j'apprends :
Benchmark indicatif (1M vecteurs 768D) :
Métrique Qdrant pgvector Elasticsearch Temps indexation 15 min 45 min 25 min Requête/sec 2000+ 500-800 800-1200 RAM utilisée 4 GB 6 GB 8 GB+ Précision @10 0.95 0.92 0.94 Date création 2021 2021 2022 (support HNSW) Langage Rust C Java Open Source Open Source Open Source
Journal du samedi 14 juin 2025 à 00:06
#JaiDécouvert OmniPoly (https://github.com/kWeglinski/OmniPoly)
Welcome to a solution for translation and language enhancement tool. This project integrates LibreTranslate for accurate translations, LanguageTool for grammar and style checks, and AI Translation for modern touch of sentiment analysis and interesting sentences extraction.
Je souhaite intégrer cet outil au dépôt sklein-open-webui-instance.
Comme ce projet ne sera plus exclusivement dédié à Open WebUI, il me semble qu'un changement de nom s'impose.
Journal du vendredi 13 juin 2025 à 22:32
Dans cette fonction filtre Open WebUI, #JaiDécouvert Detoxify (https://github.com/unitaryai/detoxify).
Trained models & code to predict toxic comments on 3 Jigsaw challenges: Toxic comment classification, Unintended Bias in Toxic comments, Multilingual toxic comment classification.
#JaimeraisUnJour prendre le temps de le tester.
Journal du vendredi 13 juin 2025 à 14:37
Je viens de découvrir la fonction inspect.cleandoc de la librairie standard de Python.
Exemple :
# foobar.py
from inspect import cleandoc
def foobar(body):
print(body)
foobar(
body=cleandoc("""
My text, with indentation
- item 1
- item 1.1
- item 2
Last line
""")
)
$ python foobar.py
My text, with indentation
- item 1
- item 1.1
- item 2
Last line
Je trouve cela très pratique pour améliorer la lisibilité du code source sans générer des indentations qui ne devraient pas être présentes dans les données.
Voir aussi, string-dedent, l'équivalent en Javascript : 2025-08-14_1120.
Journal du jeudi 12 juin 2025 à 21:38
Je me pose souvent des questions sur l'histoire des notations mathématiques. Quelle est l'origine d'une notation, pourquoi avoir fait ce choix, etc.
Comprendre comment une notation a émergé m'aide à la retenir.
Au cours de mes recherches par sérendipité sur ce sujet, #JaiDécouvert Florian Cajori :
Florian Cajori est un historien des mathématiques, véritable fondateur de cette discipline aux États-Unis, et auteur dans ce domaine d'ouvrages qui ont fait date.
Il a, entre autres, écrit le livre : "A History of Mathematical Notations".
Je suis ensuite tombé sur cette excellente page Wikipedia nommée "Table de symboles mathématiques", (et surtout sa version anglaise) que j'aurais adoré avoir quand je faisais mes études.
Autres ressources que j'ai croisées :
Alexandre m'a partagé le projet LocalAI (https://localai.io/).
Ce projet a été mentionné une fois sur Lobster dans un article intitulé Everything I’ve learned so far about running local LLMs, et quatre fois sur Hacker News (recherche pour "localai.io"), mais avec très peu de commentaires.
C’est sans doute pourquoi je n'ai jamais remarqué ce projet auparavant.
Pourtant, il ne s’agit pas d’un projet récent : son développement a débuté en mars 2023.
J'ai l'impression que LocalAI propose à la fois des interfaces web comme Open WebUI, mais qu'il est aussi une sorte de "wrapper" au-dessus de nombreux Inference Engines comme l'illustre cette longue liste.
Pour le moment, j'ai vraiment des difficultés à comprendre son positionnement dans l'écosystème.
LocalAI versus vLLM ou Ollama ? LocalAI versus Open WebUI ?, etc.
Je vais garder ce projet dans mon radar.
J'ai découvert le support SSH agent de Bitwarden et ses conséquences sur l'utilisation de Age
J'ai utilisé le "Workflow de gestion des secrets d'un projet basé sur Age et des clés ssh" dans un projet professionnel et un collègue a rencontré un problème au niveau du script /scripts/decrypt_secrets.sh :
#!/usr/bin/env bash
set -e
cd "$(dirname "$0")/../"
# Prepare identity arguments for age
identity_args=()
for key in ~/.ssh/id_*; do
if [ -f "$key" ] && ! [[ "$key" == *.pub ]]; then
identity_args+=("-i" "$key")
fi
done
# Execute age with all identity files
age -d "${identity_args[@]}" -o .secret .secret.age
cat << EOF
Secret decrypted in .secret
Don't forget to run the command:
$ source .envrc
EOF
Sa clé privée ssh n'était pas présente dans ~./ssh/ parce qu'il utilise "1Password SSH agent" (disponible depuis mars 2022).
Je ne connaissais pas cette fonctionnalité (merci).
#JaiDécouvert que cette fonctionnalité existe aussi dans Bitwarden depuis février 2025 : "SSH Agent".
#JaiDécouvert qu'une solution alternative pour Bitwarden existait depuis 2020 : bitwarden-ssh-agent. Mais beaucoup moins bien intégré à Bitwarden.
Au cours des 15 dernières années, j'ai régulièrement reçu des demandes de redéploiement de clés SSH de la part des développeurs, parfois plusieurs mois après leur onboarding. La cause principale : la plupart des développeurs ne pensent pas à sauvegarder leurs clés SSH dans leur gestionnaire de password et les perdent inévitablement lors du changement de workstation ou de réinstallation de leur système.
Face à ce constat récurrent, j'envisageais depuis plusieurs années de créer une issue chez Bitwarden pour leur proposer d'implémenter un système de sauvegarde automatique des clés SSH.
L'approche basée sur un ssh-agent ne m'avait jamais traversé l'esprit.
À l'avenir, j'envisage d'intégrer l'usage de Bitwarden SSH Agent (ou équivalent) dans les processus d'onboarding dont j'ai la responsabilité.
J'ai tenté d'ajouter le support de ssh-agent au script /scripts/decrypt_secrets.sh, mais d'après le thread "ssh-agent support", age ne semble pas supporter ssh-agent.
Conséquence : en attendant, j'ai demandé à mon collègue de placer sa clé privée ssh dans ~/.ssh/.
Journal du vendredi 06 juin 2025 à 10:22
À ma connaissance, par défaut, sur la plupart des smartphones Android, Google Discover est affiché sur la page d'accueil après un swipe vers la gauche.
Je déteste cette fonctionnalité : elle détourne mon attention vers des informations futiles.
Comme je n'avais pas trouvé comment désactiver cette fonctionnalité sur mon précédent smartphone Oppo Find X3 Lite 5G, j'avais remplacé le launcher Android par défaut par Neo-Launcher.
Suite à ma migration vers un Fairphone 5, j'ai pris un peu de temps pour chercher des Android Launcher Open source et #JaiDécouvert ici le projet kvaesitso.
Je viens de l'installer avec succès et je peux enfin désactiver Google Discover 🙂.
Journal du lundi 02 juin 2025 à 08:00
#JaiDécouvert Datatracker de IETF. Voici un exemple d'utilisation : https://datatracker.ietf.org/doc/rfc8292/
J'ai découvert la fonctionnalité SvelteKit Shared hooks init
J'ai bien fait de partager poc-sveltekit-custom-server dans la section discussion GitHb de Sveltekit car cela m'a permis de découvrir via ce commentaire l'existence de la fonctionnalité native SvelteKit nommée Shared hooks init.
This function runs once, when the server is created or the app starts in the browser, and is a useful place to do asynchronous work such as initializing a database connection.
Cette fonctionnalité a été introduite dans la version 2.10.0 de SvelteKit publiée le 10 décembre 2024.
C'est particulièrement frustrant car j'ai cherché cette fonctionnalité à plusieurs reprises entre mi-2022 et mi-2024, sans la trouver. Je me souviens même avoir lu une issue de Rich Harris expliquant que cette fonctionnalité était complexe à implémenter.
Il y a quelques semaines, lors du développement de poc-sveltekit-custom-server, j'ai refait une recherche de fonctionnalité "init", mais en me limitant à la documentation "Node servers". La présence de "Graceful shutdown" m'a paradoxalement induit en erreur : j'en ai déduit que s'il n'y avait pas d'équivalent pour l'initialisation sur cette page, c'est que la fonctionnalité n'existait toujours pas 😔.
Conséquence de tout cela :
- Je vais utiliser Shared hooks init dans gibbon-replay ;
- J'ai indiqué dans
poc-sveltekit-custom-serverque je recommande d'utiliser "Shared hooks init"
Journal du vendredi 23 mai 2025 à 18:22
#JaiDécouvert l'origine du nom du projet Flatpak :
Flatpak was originally developed by Alexander Larsson, who had been working on similar projects stretching back to 2007. The first release was as XDG-App in 2015. It was renamed to Flatpak in 2016, a nod to IKEA's "flatpacks" for delivering furniture.
J'adore l'idée derrière ce nom !
Journal du mercredi 21 mai 2025 à 14:25
#JaiDécouvert le concept de LLM-as-a-Judge.
#JaiLu l'article Wikipédia à ce sujet "LLM-as-a-Judge".
"Abstract" du papier de recherche Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena datant du 24 décembre 2023 :
Evaluating large language model (LLM) based chat assistants is challenging due to their broad capabilities and the inadequacy of existing benchmarks in measuring human preferences. To address this, we explore using strong LLMs as judges to evaluate these models on more open-ended questions. We examine the usage and limitations of LLM-as-a-judge, including position, verbosity, and self-enhancement biases, as well as limited reasoning ability, and propose solutions to mitigate some of them. We then verify the agreement between LLM judges and human preferences by introducing two benchmarks: MT-bench, a multi-turn question set; and [[Chatbot Arena]], a crowdsourced battle platform. Our results reveal that strong LLM judges like GPT-4 can match both controlled and crowdsourced human preferences well, achieving over 80% agreement, the same level of agreement between humans. Hence, LLM-as-a-judge is a scalable and explainable way to approximate human preferences, which are otherwise very expensive to obtain. Additionally, we show our benchmark and traditional benchmarks complement each other by evaluating several variants of LLaMA and Vicuna. The MT-bench questions, 3K expert votes, and 30K conversations with human preferences are publicly available at https://github.com/lm-sys/FastChat/tree/main/fastchat/llm_judge.
J'ai parcouru rapidement l'article "Evaluating RAG with LLM as a Judge" du blog de Mistral AI. Je n'ai pas pris le temps d'étudier les concepts que je ne connaissais pas dans cet article, par exemple RAG Triad.
J'ai effectué une recherche sur « LLM as Judge » sur le blog de Simon Willison.
Journal du mardi 20 mai 2025 à 17:03
#JaiLu la discussion GitHub du projet nginx-proxy : "How can we scapre metrics from nginx-proxy container".
J'y ai découvert le Prometheus exporter : nginx-prometheus-exporter (https://github.com/nginx/nginx-prometheus-exporter). Il semble être l'exporter officiel de nginx pour Prometheus.
Je pense tester son installation et sa configuration d'ici à quelques jours.
Liste des éléments que je souhaite étudier :
- Est-ce qu'il existe un dashboard Grafana qui permet de consulter par domaine et peut-être par URLs :
- le temps moyen de réponse
- la mediane de temps de réponse
- le temps de réponse au 90ème percentile (p90)
- le temps de réponse au 95ème percentile (p95)
Je pense que la metric nginxplus_upstream_server_response_time me permettra peut-être d'obtenir cette information.
J'ai identifié ce dashboard Grafana mais il ne semble pas afficher les informations dont j'ai besoin.
Faut-il encore configurer du swap en 2025, même sur des serveurs avec beaucoup de RAM ?
Aujourd'hui, j'ai implémenté des tests de montée en charge à l'aide de Grafana k6. En ciblant un site web hébergé sur un petit serveur Scaleway DEV1-M, j'ai constaté que le serveur est devenu inaccessible à la fin des tests. Aucun swap n'était configuré sur cette Virtual machine de 4Go de RAM.
Je me suis souvenu qu'en 2019, j'ai rencontré aussi des problèmes de freeze sur une VM AWS EC2 que j'ai corrigés en ajoutant un peu de swap au serveur. Après cela, je n'ai constaté plus aucun freeze de VM pendant 4 ans.
Ce sujet de swap m'a fait penser à la question qu'un ami m'a posée en octobre 2024 :
Désactiver le swap sur une Debian, recommandé ou pas ?
Alors que j'ai 29Go utilisé sur 64, le swap était plein (3,5Go occupé à 100%), les 12 cœurs du serveur partaient dans les tours. J'ai désactivé le swap et me voilà gentiment avec un load average raisonnable, pour les tâches de cette machine.
C'est une très bonne question que je me pose depuis longtemps. J'ai enfin pris un peu de temps pour creuser ce sujet.
Sept mois plus tard, voici ma réponse dans cette note 😉.
#JaiDécouvert le paramètre kernel nommé Swappiness.
swappiness
This control is used to define how aggressive the kernel will swap memory pages. Higher values will increase aggressiveness, lower values decrease the amount of swap. A value of 0 instructs the kernel not to initiate swap until the amount of free and file-backed pages is less than the high water mark in a zone.
The default value is 60.
Dans la documentation SwapFaq d'Ubuntu j'ai lu :
The swappiness parameter controls the tendency of the kernel to move processes out of physical memory and onto the swap disk. Because disks are much slower than RAM, this can lead to slower response times for system and applications if processes are too aggressively moved out of memory.
- swappiness can have a value of between
0and100swappiness=0tells the kernel to avoid swapping processes out of physical memory for as long as possibleswappiness=100tells the kernel to aggressively swap processes out of physical memory and move them to swap cacheThe default setting in Ubuntu is
swappiness=60. Reducing the default value of swappiness will probably improve overall performance for a typical Ubuntu desktop installation. A value ofswappiness=10is recommended, but feel free to experiment. Note: Ubuntu server installations have different performance requirements to desktop systems, and the default value of60is likely more suitable.
D'après ce que j'ai compris, plus swappiness tend vers zéro, moins le swap est utilisé.
J'ai lu ici :
vm.swappiness = 60: Valeur par défaut de Linux : à partir de 40% d’occupation de Ram, le noyau écrit sur le disque.
Cependant, je n'ai pas trouvé d'autres sources qui confirment cette correspondance entre la valeur de swappiness et un pourcentage précis d'utilisation de la RAM.
J'ai ensuite cherché à savoir si c'était encore pertinent de configurer du swap en 2025, sur des serveurs qui disposent de beaucoup de RAM.
#JaiLu ce thread : "Do I need swap space if I have more than enough amount of RAM?", et voici un extrait qui peut servir de conclusion :
In other words, by disabling swap you gain nothing, but you limit the operation system's number of useful options in dealing with a memory request. Which might not be, but very possibly may be a disadvantage (and will never be an advantage).
Je pense que ceci est d'autant plus vrai si le paramètre swappiness est bien configuré.
Concernant la taille du swap recommandée par rapport à la RAM du serveur, la documentation de Ubuntu conseille les ratios suivants :
RAM Swap Maximum Swap 256MB 256MB 512MB 512MB 512MB 1024MB 1024MB 1024MB 2048MB 1GB 1GB 2GB 2GB 1GB 4GB 3GB 2GB 6GB 4GB 2GB 8GB 5GB 2GB 10GB 6GB 2GB 12GB 8GB 3GB 16GB 12GB 3GB 24GB 16GB 4GB 32GB 24GB 5GB 48GB 32GB 6GB 64GB 64GB 8GB 128GB 128GB 11GB 256GB 256GB 16GB 512GB 512GB 23GB 1TB 1TB 32GB 2TB 2TB 46GB 4TB 4TB 64GB 8TB 8TB 91GB 16TB
#JaiDécouvert aussi que depuis le kernel 2.6, les fichiers de swap sont aussi rapides que les partitions de swap :
Definitely not. With the 2.6 kernel, "a swap file is just as fast as a swap partition."
Suite à ces apprentissages, j'ai configuré et activé un swap de 2G sur la VM Scaleway DEV1-L équipée de 4G de RAM, avec le paramètre swappiness réglé à 10.
J'ai relancé mon test Grafana k6 et je n'ai constaté plus aucun freeze, je n'ai pas perdu l'accès au serveur.
De plus, probablement grâce au paramètre swappiness fixé à 10, j'ai observé que le swap n'a pas été utilisé pendant le test.
Suite à ces lectures et à cette expérience concluante, j'ai décidé de désormais configurer systématiquement du swap sur tous mes serveurs de la manière suivante :
if swapon --show | grep -q "^/swapfile"; then
echo "Swap is already configured"
else
get_swap_size() {
local ram_gb=$(free -g | awk '/^Mem:/ {print $2}')
# Why this values? See https://help.ubuntu.com/community/SwapFaq#How_much_swap_do_I_need.3F
if [ $ram_gb -le 1 ]; then
echo "1G"
elif [ $ram_gb -le 2 ]; then
echo "1G"
elif [ $ram_gb -le 6 ]; then
echo "2G"
elif [ $ram_gb -le 12 ]; then
echo "3G"
elif [ $ram_gb -le 16 ]; then
echo "4G"
elif [ $ram_gb -le 24 ]; then
echo "5G"
elif [ $ram_gb -le 32 ]; then
echo "6G"
elif [ $ram_gb -le 64 ]; then
echo "8G"
elif [ $ram_gb -le 128 ]; then
echo "11G"
else
echo "11G"
fi
}
SWAP_SIZE=$(get_swap_size)
fallocate -l $SWAP_SIZE /swapfile
chmod 600 /swapfile
mkswap /swapfile
swapon /swapfile
if ! grep -q "^/swapfile.*swap" /etc/fstab; then
echo "/swapfile none swap sw 0 0" >> /etc/fstab
fi
fi
# Why 10 instead default 60? see https://help.ubuntu.com/community/SwapFaq#:~:text=a%20value%20of%20swappiness%3D10%20is%20recommended
echo 10 | tee /proc/sys/vm/swappiness
echo "vm.swappiness=10" | tee -a /etc/sysctl.conf
Journal du lundi 19 mai 2025 à 15:38
#JaiDécouvert la définition du mot "Bastide" :
Une bastide peut être aussi bien la maison d'habitation des maitres d'une exploitation agricole que l'ensemble d'une exploitation agricole, puis plus tardivement, une maison rurale bourgeoise provençale.
Le terme bastide désigne aussi un type de villes, créées au Moyen Âge, dans l'objectif de constituer de nouveaux foyers de population. Les bastides, nombreuses dans le Sud-Ouest de la France, étaient le plus souvent fondées sur initiative seigneuriale, royale ou ecclésiastique (parfois conjointement). Des privilèges fiscaux furent généralement octroyés aux personnes qui acceptaient de peupler les bastides nouvellement construites.
Journal du jeudi 15 mai 2025 à 11:59
Un ami m'a partagé la chaine YouTube "Le lab du vieux geek" :
Chaine YouTube consacrée à l'IA l'IT la culture Geek et de nombreux autres sujets autour de l'IA. Je m'appelle Jerome Fortias, je suis français vivant en Belgique, et j'ai utilisé mon premier robot en 1986, depuis je travaille dans le monde de l'IT et de l'IA. Cette chaine c'est un peu une expérimentation d'un youtuber amateur.
J'ai écouté "La fin des LLM (Yann LeCun a raison)" et ensuite "Comment les machines pourraient-elles atteindre l'intelligence humaine ? Conférence de Yann LeCun".
Énormément de contenu, j'en ai saisi qu'une petite partie.
#JaimeraisUnJour prendre le temps de lire les 509 commentaires sous la vidéo "La fin des LLM (Yann LeCun a raison)".
L'écoute de ces vidéos m'a fait penser aux vidéos suivantes de Thibault Neveu que j'ai écoutées il y a un an :
Journal du mercredi 14 mai 2025 à 11:48
Un collègue m'a partagé le projet Marker (https://github.com/VikParuchuri/marker) :
Marker converts documents to markdown, JSON, and HTML quickly and accurately.
- Converts PDF, image, PPTX, DOCX, XLSX, HTML, EPUB files in all languages
- Formats tables, forms, equations, inline math, links, references, and code blocks
- Extracts and saves images
- Removes headers/footers/other artifacts
- Extensible with your own formatting and logic
- Optionally boost accuracy with LLMs
- Works on GPU, CPU, or MPS
Voici comment fonctionne Marker :
Journal du mercredi 07 mai 2025 à 14:22
Ici dans le code source de Open WebUI, #JaiDécouvert Pyodide :
Pyodide is a Python distribution for the browser and NodeJS based on WebAssembly.
Journal du mardi 06 mai 2025 à 13:42
Suite à la lecture du thread "jj tips and tricks" Lobster, je suis tombé dans un rabbit hole (1h30) : #JaiLu les articles ci-dessous au sujet de Jujutsu.
- "What I've learned from jj" (134 commentaires Hacker News et 57 commentaires Lobster)
- Et ses sous-articles :
- "jj tips and tricks"
Quelques commentaires au sujet de l'article "What I've learned from jj"
Along with describing and making new changes, jj squash allows you to take some or all of the current change and “squash” it into another revision. This is usually the immediate parent, but can be any revision.
...
With jj squash, the current change is pushed into whatever target revision you want. And if that change has children, they’ll all be automatically rebased to incorporate the updated code, no additional work is needed.
J'ai hâte de tester si, à l'usage, c'est sensiblement plus simple qu'avec Git 🤔.
Conflict resolution
One of the consequences of being able to modify changes in-place is that all subsequent changes need to be rebased to account for the updated parent. If there were a sequence
s -> t -> u -> vand you’d modifiedt, jj will automatically rebase the rest:s -> t' -> u' -> v'. This includes conflicts, if any arise. The difference from git is that conflicts are not a stop-the-world event! You’ll see in the jj log output that changes have a conflict, but it won’t prevent a command (like an explicit or implicit rebase) from running to completion. You get to choose when and how to resolve the conflicts afterward. I found this a surprising benefit: rebases are already less stressful because of how easyundois, but now I’m no longer interrupted and forced to resolve conflicts immediately.
Cette simplicité annoncée me surprend vraiment. J'ai du mal à imaginer le fonctionnement, sans doute parce que je suis trop habitué à utiliser Git. J'ai l'impression que c'est de la magie !
J'ai hâte de tester !
... efforts to add
Change-IDas a supported header in git itself to enable durable change tracking on top of commits.
J'ai découvert cette initiative, je trouve cela très intéressant👌.
Un commentaire au sujet de l'article "First-class conflicts"
First-class conflicts
...
Unlike most other VCSs, Jujutsu can record conflicted states in commits. For example, if you rebase a commit and it results in a conflict, the conflict will be recorded in the rebased commit and the rebase operation will succeed. You can then resolve the conflict whenever you want. Conflicted states can be further rebased, merged, or backed out. Note that what's stored in the commit is a logical representation of the conflict, not conflict markers; rebasing a conflict doesn't result in a nested conflict markers (see technical doc for how this works).
Je trouve cela très intéressant.
Voici une commande pour extraire un patch avec l'inclusion des "Conflict markers" (je n'ai pas encore testé) :
$ jj diff --include-conflicts > conflicts.patch
Un commentaire au sujet de l'article "In Praise of Stacked PRs"
“Stacked PRs” is the practice of breaking up a large change into smaller, individually reviewable PRs which can depend on each other, forming a DAG.
Je suis ravi de découvrir que le terme "Stacked PRs" existe pour décrire le concept que j'expliquais souvent quand j'étais chez Spacefill.
En lisant ces articles, #JaiDécouvert :
git-rerere- Mercurial Changset Evolution
git-machete- git-stack (
git-stack) - GitBulter (https://github.com/gitbutlerapp/gitbutler)
et j'ai "redécouvert" :
Journal du jeudi 01 mai 2025 à 16:22
Je continue mon travail de mise à niveau en Kubernetes.
Je viens de réaliser que Helmfile ne fait pas directement partie du projet Helm. Je trouve cela surprenant. Ces deux projets sont réalisés par deux equipes différentes :
- Dépôt GitHub de Helm : https://github.com/helm/helm/
- Développeurs principaux :
- Matt Butcher basé aux États-Unis
- Adam Reese basé aux États-Unis
- Développeurs principaux :
- Dépôt GitHub de Helmfile : https://github.com/helmfile/helmfile/
- Développeurs principaux :
- Yusuke Kuoka basé au Japon
- yxxhero basé en Chine
- Développeurs principaux :
D'après ce que je comprends, si je simplifie, Helmfile est pour Helm l'équivalent de ce qu'est docker-compose.yml pour Docker.
Je m'intéresse aujourd'hui à Helmfile parce que je souhaite effectuer une tâche qui correspond au use-case numéro 2 décrit dans la documentation :
ArgoCD has support for kustomize/manifests/helm chart by itself. Why bother with Helmfile?
The reasons may vary:
1.You do want to manage applications with ArgoCD, while letting Helmfile manage infrastructure-related components like Calico/Cilium/WeaveNet, Linkerd/Istio, and ArgoCD itself.2.You want to review the exact K8s manifests being applied on pull-request time, before ArgoCD syncs.3.This is often better than using a kind of HelmRelease custom resources that obfuscates exactly what manifests are being applied, which makes reviewing harder.
Suite à cette lecture, voici comment j'ai mis en application une partie du use-case 2.
J'ai ce helmfile.yaml :
environments:
dev:
values:
- version: 6.1.0
production:
values:
- version: 6.1.0
---
repositories:
- name: open-webui
url: https://helm.openwebui.com/
---
releases:
- name: openwebui
namespace: {{ .Namespace }}
chart: open-webui/open-webui
values:
- ./env.d/{{ .Environment.Name }}/values.yaml
version: {{ .Values.version }}
Et ensuite, j'ai exécuté :
$ helmfile template -e dev --output-dir-template $(pwd)/gitops/{{.Release.Name}}
Adding repo open-webui https://helm.openwebui.com/
"open-webui" has been added to your repositories
Templating release=openwebui, chart=open-webui/open-webui
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/templates/service-account.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/service.yaml
wrote .../gitops/openwebui/open-webui/templates/service.yaml
wrote .../gitops/openwebui/open-webui/charts/pipelines/templates/deployment.yaml
wrote .../gitops/openwebui/open-webui/templates/workload-manager.yaml
wrote .../gitops/openwebui/open-webui/templates/ingress.yaml
Cela me permet ensuite de pouvoir observer avec précision ce qui va être déployé par ArgoCD.
Journal du mardi 29 avril 2025 à 11:05
Alexandre m'a partagé kubectx et kubens (https://github.com/ahmetb/kubectx) :
What are kubectx and kubens?
kubectx is a tool to switch between contexts (clusters) on kubectl faster. kubens is a tool to switch between Kubernetes namespaces (and configure them for kubectl) easily.
#JaiDécouvert Kubebuilder (https://github.com/kubernetes-sigs/kubebuilder) (from)
Kubebuilder is a framework for building Kubernetes APIs using custom resource definitions (CRDs).
Journal du lundi 28 avril 2025 à 23:34
#JaiDécouvert Krew (https://github.com/kubernetes-sigs/krew) :
#JaiDécouvert MetalLB (https://metallb.io/) :
#JaiDécouvert cert-manager (https://github.com/cert-manager/cert-manager)
cert-manager adds certificates and certificate issuers as resource types in Kubernetes clusters, and simplifies the process of obtaining, renewing and using those certificates.
It supports issuing certificates from a variety of sources, including Let's Encrypt (ACME), HashiCorp Vault, and Venafi TPP / TLS Protect Cloud, as well as local in-cluster issuance.
Journal du mardi 22 avril 2025 à 17:57
J'ai un collègue qui utilise Terragrunt (https://terragrunt.gruntwork.io/).
Je pense que j'ai déjà croisé cet outil mais sans trop y prêter attention.
Pour le moment, je ne comprends pas très bien l'intérêt de Terragrunt, j'ai l'impression que c'est un wrapper au-dessus de Terraform ou OpenTofu.
#JaimeraisUnJour prendre le temps de faire un POC de Terragrunt.
Journal du lundi 21 avril 2025 à 11:34
#JaiDécouvert l'extension GNOME Shell : astra-monitor (from).
J'ai bien aimé le contenu de la page "Project Comparison". Par exemple, ce paragraphe :
Introduction
Secondly, it acts as a guide for users, offering greater insights and assisting them in making an informed decision when choosing the ideal tool for their needs. By highlighting the unique features, performance benchmarks, and key differences between Astra Monitor and its alternatives, we hope to foster a transparent and informative environment for both our development team and the user community at large.
Voici en screenshot le résultat de mon installation :
![]()
Dépendances que j'ai installées sous ma Fedora Workstation (commit dans mon repository dotfiles) :
$ sudo dnf install \
libgtop2-devel \
nethogs \
iotop \
libdrm-devel \
https://github.com/Umio-Yasuno/amdgpu_top/releases/download/v0.10.4/amdgpu_top-0.10.4-1.x86_64.rpm
#JaiDécouvert https://github.com/Umio-Yasuno/amdgpu_top
Voici ce que retourne la commande sensors sur mon laptop :
$ sensors
thinkpad-isa-0000
Adapter: ISA adapter
fan1: 65535 RPM
CPU: +63.0°C
GPU: N/A
temp3: +63.0°C
temp4: +0.0°C
temp5: +63.0°C
temp6: +63.0°C
temp7: +63.0°C
temp8: +0.0°C
amdgpu-pci-3300
Adapter: PCI adapter
vddgfx: 1.45 V
vddnb: 734.00 mV
edge: +51.0°C
PPT: 19.18 W
BAT0-acpi-0
Adapter: ACPI interface
in0: 15.14 V
power1: 11.96 W
ath11k_hwmon-pci-0100
Adapter: PCI adapter
temp1: +41.0°C
k10temp-pci-00c3
Adapter: PCI adapter
Tctl: +62.9°C
nvme-pci-0200
Adapter: PCI adapter
Composite: +33.9°C (low = -273.1°C, high = +80.8°C)
(crit = +84.8°C)
Sensor 1: +33.9°C (low = -273.1°C, high = +65261.8°C)
Sensor 2: +45.9°C (low = -273.1°C, high = +65261.8°C)
acpitz-acpi-0
Adapter: ACPI interface
temp1: +63.0°C
temp2: +20.0°C
Voici comment j'ai configuré la température du haut (45°C) et du bas (44°C) du screenshot :
- En haut, j'ai sélectionné le paramètre
acpitz-acpi-0/temp1qui contient la température du CPU - En bas, j'ai sélectionné le paramètre
amdgpu-pci-3300/edgequi contient la température du GPU
Voici mon fichier de configuration pour astra-monitor astra-monitor-settings.json.
Il est possible de facilement l'importer dans la section "Utility" de astra-monitor.
Journal du jeudi 17 avril 2025 à 21:11
#JaiDécouvert la chaine YouTube de randonnée : Anna Chrosto.
J'ai entre autres regardé :
Journal du jeudi 17 avril 2025 à 12:02
Alexandre m'a partagé le projet Postgres Operator, que j'avais peut-être croisé par le passé, mais que j'avais oublié.
Postgres Operator permet entre autres de déployer des instances PostgreSQL dans un cluster Kubernetes mais aussi de mettre en place des systèmes de backup logique et backup binaire.
Journal du jeudi 10 avril 2025 à 22:48
Dans la documentation de restic, #JaiDécouvert resticprofile :
Scheduling backups
Restic does not have a built-in way of scheduling backups, as it’s a tool that runs when executed rather than a daemon. There are plenty of different ways to schedule backup runs on various different platforms, e.g. systemd and cron on Linux/BSD and Task Scheduler in Windows, depending on one’s needs and requirements. If you don’t want to implement your own scheduling, you can use resticprofile.
Le projet resticprofile a commencé en 2019, tout comme restic, il est écrit en Golang.
resticprofile permet de lancer restic à partir d'un fichier de configuration. D'après l'extrait ci-dessous, l'équipe de restic ne semble pas vouloir intégrer un système de fichiers de configuration.
Configuration profiles manager for restic backup
resticprofile is the missing link between a configuration file and restic backup. Creating a configuration file for restic has been discussed before, but seems to be a very low priority right now.
Journal du jeudi 10 avril 2025 à 20:34
Je me relance sur mes sujets de backup de PostgreSQL.
Au mois de février dernier, j'ai initié le « Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker" ».
J'ai ensuite publié les notes suivantes à ce sujet :
À ce jour, je n'ai pas fini mes POC suivants :
poc-pg_basebackup_incremental est la seule méthode que j'ai réussi à faire fonctionner totalement.
#JaimeraisUnJour terminer ces POC.
Aujourd'hui, je m'interroge sur les motivations qui m'ont conduit en 2020 à intégrer restic dans mon projet restic-pg_dump-docker. Avec le recul, l'utilisation de cet outil pour la simple sauvegarde d'archives pg_dump me semble désormais moins évidente qu'à l'époque.
J'ai fait ce choix peut-être pour bénéficier directement du support des fonctionnalités suivantes :
- Uploader vers différents Object Storage : S3-compatible Storage
- Le système de rétention : Removing snapshots according to a policy
- Le chiffrement : Encryption
- Et naïvement, je pensais peut-être pouvoir utiliser le système de déduplication des données : Backups and Deduplication
Après réflexion, je pense que pour la sauvegarde d'archives pg_dump, les fonctionnalités de déduplication et de sauvegarde incrémentale offertes par restic génèrent en réalité une surconsommation d'espace disque et de ressources CPU sans apporter aucun bénéfice.
J'ai ensuite effectué quelques recherches pour savoir s'il existait un système de sauvegarde PostgreSQL basé sur pg_dump et un système d'upload vers Object Storage et #JaiDécouvert pg_back (https://github.com/orgrim/pg_back/).
En 2020, quand j'ai créé restic-pg_dump-docker, je pense que je n'avais pas retenu pg_back car celui-ci était minimaliste et ne supportait pas encore l'upload vers de l'Object Storage.
En 2025, pg_back supporte toutes les fonctionnalités dont j'ai besoin :
pg_back is a dump tool for PostgreSQL. The goal is to dump all or some databases with globals at once in the format you want, because a simple call to pg_dumpall only dumps databases in the plain SQL format.
Behind the scene, pg_back uses pg_dumpall to dump roles and tablespaces definitions, pg_dump to dump all or each selected database to a separate file in the custom format. ...
Features
- ...
- Choose the format of the dump for each database
- ...
- Dump databases concurrently
- ...
- Purge based on age and number of dumps to keep
- Dump from a hot standby by pausing replication replay
- Encrypt and decrypt dumps and other files
- Upload and download dumps to S3, GCS, Azure, B2 or a remote host with SFTP
Je souhaite :
- Créer et publier un playground pour tester pg_back
- Si le résultat est positif, alors je souhaite ajouter une note en introduction de
restic-pg_dump-dockerpour inviter à ne pas utiliser ce projet et renvoyer les lecteurs vers le projet pg_back.
Journal du jeudi 10 avril 2025 à 08:44
#JaiDécouvert ici la fonctionnalité "Incremental Static Regeneration (ISR)" de NextJS.
L'Incremental Static Regeneration (ISR) est un mélange de génération static et de régénération dynamique.
Lors du build du site toutes les pages sont générées de manière statique. Cependant, certaines peuvent être "marquées" : ces pages clairement identifiées seront régénérées à intervalle régulier après le déploiement du site, faisant appel à des API ou une base de données pour garder la donnée à jour.
Lors de la visite d'une page à régénérer, une version "ancienne" de la page s'affiche, mais une demande de régénération est envoyée au serveur. La page est ainsi régénérée et renvoyée instantanément au visiteur, et prête à être affichée au visiteur suivant. Le cycle peut alors recommencer.
J'ai aussi lu cette page de documentation de Vercel :
Incremental Static Regeneration (ISR) allows you to create or update content on your site without redeploying. ISR's main benefits for developers include:
- Better Performance: Static pages can be consistently fast because ISR allows Vercel to cache generated pages in every region on our global Edge Network and persist files into durable storage
- Reduced Backend Load: ISR helps reduce backend load by using cached content to make fewer requests to your data sources
- Faster Builds: Pages can be generated when requested by a visitor or through an API instead of during the build, speeding up build times as your application grows
ISR is available to applications built with:
J'ai étudié le support ISR de SvelteKit. Il semble que cette fonctionnalité soit supportée uniquement par l'adapter-vercel.
J'ai identifié l'issue suivante : Would revalidating a static page work when self-hosted?.
#JaimeraisUnJour prendre le temps de creuser plus en profondeur ce sujet.