
Recherche
Filtre actif, cliquez pour en enlever un tag :
Cliquez sur un tag pour affiner votre recherche :
[ << Page précédente (100) ] [ Page suivante (329) >> ]
Journal du mardi 08 avril 2025 à 17:59
Un collègue m'a fait découvrir Trapeze (https://trapeze.dev/).
Trapeze is a mobile project configuration toolbox for native iOS and Android project management. From a simple YAML format, Trapeze makes it easy to automate the configuration of native mobile iOS and Android projects, and supports traditional native, Ionic, Capacitor, React Native, Flutter, and .NET MAUI. The long-term goal of Trapeze is to enable fully immutable native mobile projects.
Trapeze works by automating the modification of pbxproj, plist, XML, Gradle, JSON, resource, properties, and other files in iOS and Android app projects. It features a configuration-driven tool that takes a YAML file with iOS and Android project modifications and performs those modifications from the command line interactively.
C'est un projet créé par l'équipe Ionic, créatrice de Capacitor.
Je ne comprends pas comment j'ai pu passer à côté de cet outil qui est pourtant mentionné dans la documentation officielle de Capacitor 🙈 !
Both projects and their documentation are available in the Trapeze repo.
J'ai parcouru un peu la documentation et je trouve cet outil excellent !
C'est tout à fait ce dont j'avais besoin dans mon dans "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor" !
Je pense que cet outil me permet d'éliminer tous mes "hacks" pérésents dans le repository : poc-capacitor.
#JaimeraisUnJour prendre le temps d'intégrer Trapeze à poc-capacitor.
Journal du mardi 08 avril 2025 à 13:34
En 2024, j'ai utilisé avec succès dans un projet client la librairie svelte-splitpanes.
A predictable responsive component to layout resizable view panels supporting an multitude of advanced features (min/max bounderies, snap, expand on double click, fixed size, rtl).

Le projet svelte-splitpanes a débuté en avril 2022.
Aujourd'hui, en étudiant les projets de Hunter Johnston, #JaiDécouvert une autre librairie de gestion de "pane", nommée PaneForge, qui a débuté en février 2024.
Cette librairie n'existait pas au moment où j'ai sélectionné svelte-splitpanes.
Pour le moment, je n'ai aucune idée de la motivation de Hunter Johnston d'avoir créé PaneForge plutôt qu'utiliser la librairie existante svelte-splitpanes.
Pour le moment, je n'ai pas compris pourquoi Hunter Johnston a décidé de créer PaneForge plutôt qu'utiliser la bibliothèque existante svelte-splitpanes 🤔.
Je viens de créer cette issue : "Suggestion: add an explanation of the differences between PaneForge and svelte-splitpane at the end of the README".
Journal du lundi 24 mars 2025 à 17:47
Hier, j'ai écouté l'épisode 238 - La fin des ERP libres ? du podcast "Libre à vous".
Dans cet épisode, #JaiDécouvert ce que sont les "Plateforme de Dématérialisation Partenaire" (PDP) et le Portal Public de Facturation (PPF).
L’objectif principal du portail public de facturation était d'offrir un accès à la facturation électronique pour toutes les entreprises françaises. Pour l'État, il s'agissait d'un outil essentiel pour optimiser la généralisation des factures électroniques et ainsi accélérer la transformation digitale des entreprises.
Voici les arguments qui poussaient le gouvernement à mettre en oeuvre cette obligation :
- faciliter la gestion financière des entreprises au quotidien ;
- simplifier les déclarations de TVA ;
- lutter contre la fraude fiscale.
Je pense que ce nouveau système va simplifier tout le système de déclaration de TVA, voir la note 2025-02-03_1718 à ce sujet.
C'est peut-être pour cela que l'administration ne corrige pas la "dette fonctionnelle" à ce niveau. Peut-être que les PDP et le PPF va rendre tout cela obsolète 🤔.
Il y a quelques mois, j'avais identifié Amazon Quantum Ledger Database qui pourrait servir pour créer un Consent Management Provider.
Aujourd'hui, #JaiDécouvert le mode de rétention "Compliance" de Scaleway Object Storage.
When this mode is set, an object version cannot be overwritten or deleted by any user. If the Compliance mode is configured for an object, then its retention mode cannot be changed, and its retention period cannot be shortened. In other words, it ensures that an object version cannot be overwritten or deleted for the duration of the retention period. Note
Note : When the compliance mode is enabled, it is only possible to overwrite it or delete an object once the object lock expires or upon deleting your Scaleway account.
« La suppression du compte » est une action radicale !
Je pense que cette fonctionnalité est une alternative minimaliste à Amazon Quantum Ledger Database.
Cette fonctionnalité pourrait servir de base pour créer un Plateforme de Dématérialisation Partenaire pour Dolibarr ou tout autre logiciel libre de facturation 🤔.
Journal du jeudi 20 mars 2025 à 12:20
En rédigeant la note 2025-03-20_1020, #JaiDécouvert ici la Licence Publique de l'Union Européenne (EUPL) :
Afin de simplifier ce partage, la Commission a mis sur pied la licence publique de l’Union européenne; elle est disponible en vingt-trois langues officielles de l’Union et est compatible avec de nombreuses licences open source.
Article Wikipedia de la licence : https://fr.wikipedia.org/wiki/Licence_publique_de_l'Union_européenne
Journal du jeudi 20 mars 2025 à 12:00
En rédigeant la note 2025-03-20_1020, #JaiDécouvert ici le projet openDesk.
Au 20 mars 2025, voici la liste des composants de openDesk :
Function Functional Component Component
VersionUpstream Documentation Chat & collaboration Element ft. Nordeck widgets 1.11.89 For the most recent release Collaborative notes Docs 2.4.0 Online documentation/welcome document available in installed application Diagram editor CryptPad ft. diagrams.net 2024.9.0 For the most recent release File management Nextcloud 30.0.6 Nextcloud 30 Groupware OX App Suite 8.35 Online documentation available from within the installed application; Additional resources Knowledge management XWiki 16.10.5 For the most recent release Portal & IAM Nubus 1.5.1 Univention's documentation website Project management OpenProject 15.4.0 For the most recent release Videoconferencing Jitsi 2.0.9955 For the most recent release Weboffice Collabora 24.04.12.4 Online documentation available from within the installed application; Additional resources source
Journal du jeudi 20 mars 2025 à 10:20
Le dimanche 17 novembre 2024, j'ai signé la pétition "nº 0729/2024, présentée par N. W., de nationalité autrichienne, sur le déploiement d’un système d’exploitation «UE-Linux» dans les administrations publiques de tous les États membres".
La commission des pétitions du Parlement européen a communiqué sa réponse le 10 janvier 2025 : PETI-CM-767965_FR.pdf .
Quelques extraits :
Le pétitionnaire demande à l’Union de développer un système d’exploitation pour ordinateur sous Linux, appelé «EU-Linux», et de le déployer dans tous les services publics des États membres.
Cette initiative vise à réduire la dépendance à l’égard des produits Microsoft, à garantir le respect du règlement général sur la protection des données et à favoriser la transparence, la durabilité et la souveraineté technologique au sein de l’Union.
Le pétitionnaire insiste sur l’importance de recourir à des solutions open source se substituant à Microsoft 365, telles que Libre Office et Nextcloud, et propose d’adopter le système d’exploitation mobile E/OS sur les appareils utilisés par les pouvoirs publics. Il souligne par ailleurs le potentiel de création d’emplois dans le secteur des technologies de l’information.
Bon résumé 👍️.
L’Union soutient toujours davantage la création de logiciels open source, qui limitent la dépendance à l’égard de fournisseurs uniques, favorisent la transparence et renforcent la sécurité des données. Récemment, le règlement pour une Europe interopérable, entré en vigueur en avril 2024 afin de favoriser une coopération fluide entre les États membres, a fait du recours à l’open source et aux normes ouvertes dans les services publics une priorité; les administrations sont ainsi plus transparentes, sûres et à l’abri de tout enfermement propriétaire.
Lien vers le texte du règlement : "Règlement (UE) 2024/903 du Parlement européen et du Conseil du 13 mars 2024 établissant des mesures destinées à assurer un niveau élevé d’interopérabilité du secteur public dans l’ensemble de l’Union (règlement pour une Europe interopérable)".
#UnJourPeuxÊtre je lirais ce règlement qui, après un parcours rapide de son contenu, me semble très intéressant.
a Commission continue de soutenir une transformation numérique de l’Union fondée sur des solutions open source, en établissant des programmes tels que le programme pour une Europe numérique, le CEF Telecom, et l’ancien programme d’interopérabilité ISA². De plus, son programme de financement Horizon Europe subventionne de nombreux projets qui ont trait au développement et à l’utilisation de logiciels et de matériel open source. Enfin, son initiative sur l’internet de nouvelle génération a permis d’investir plus de 140 millions d’EUR dans plus d’un millier de projets participatifs open source.
Dans cet extrait, #JaiDécouvert :
- Le programme pour une Europe numérique
- CEF Telecom
- J'ai suivi des liens et j'ai constaté qu'il est possible de consulter les projets financés. Par exemple, 200 000 € sont allés à DINUM pour un travail sur France Connect : Setting up, integration with “France Connect” and implementation of eID
- ISA² - Interoperability solutions for public administrations, businesses and citizens
- Horizon Europe
- En lisant cette présentation en français, je constate que le soutien aux free software est indirect et secondaire.
- NGI Innovations - qui finance en partie des projets NLNET, qui finance précisément des free software.
La Commission surveille également l’adoption de l’open source par les services publics de l’Union. Pendant près de deux décennies, son Observatoire open source a passé au crible des articles, des rapports ainsi que des études de cas témoignant de l’adoption croissante de l’open source à travers l’Union.
#JaiDécouvert : Open Source Observatory.
Mentionnons notamment les récents efforts des gouvernements nationaux afin de développer et de mettre en œuvre des solutions open source se substituant aux suites collaboratives de logiciels propriétaires, situation largement conforme à la volonté du pétitionnaire.
#JaiDécouvert ici le projet openDesk.
Le portail «Europe interopérable», hébergeur de l’Observatoire, incite par ailleurs au partage et à la réutilisation de solutions communes, notamment open source, grâce au catalogage de logiciels.
Le lien est ici. J'ai l'impression que la page contient une liste de documents d'actualités.
Afin de simplifier ce partage, la Commission a mis sur pied la licence publique de l’Union européenne; elle est disponible en vingt-trois langues officielles de l’Union et est compatible avec de nombreuses licences open source.
#JaiDécouvert la licence EUPL.
La Stratégie logicielle open source de la Commission incite à l’utilisation de l’open source en interne, encourage la collaboration sur le site code.europa.eu et ouvre la voie à des infrastructures numériques plus durables et transparentes. La Commission organise des hackathons et prévoit des primes aux bogues pour tester des solutions open source prometteuses, comme Nextcloud; elle soutient du reste le passage à l’open source dans des domaines clés, ce qui est d’autant plus conforme aux volontés exprimées dans la pétition.
Je découvre la forge https://code.europa.eu qui semble être limitée à un usage interne. Je suis surpris de ne voir aucun projet public 🤔.
Conclusion
Il n’y a actuellement pas de projet officiel d’établir un «EU-Linux», mais un grand nombre d’initiatives soutiennent activement l’adoption de solutions open source au sein des administrations publiques des États membres. Ces efforts contribuent plus largement aux objectifs européens de transparence, de sécurité et d’indépendance technologique dans le domaine numérique.
Journal du samedi 15 mars 2025 à 09:18
Je suis actuellement à la recherche de modèles de laptop pour mon "Projet 26", qui répondent aux caractéristiques suivantes :
- si possible à moins de 1000 € ;
- entre 14 et 15 pouces, avec une résolution verticale de 1200 pixels minimum ;
- 16Go de RAM ;
- un trackpad et un châssis avec un maximum de qualité ;
- idéalement convertible en 2 en 1 ou 3 en 1 ;
- silencieux ;
- support GNU/Linux parfait.
Je viens d'effectuer des recherches sur le Subreddit LinuxHardware et je suis tombé sur ce thread "Framework, System76, Tuxedo, Slimbook... Are any of them worth it?" :
Est-ce que les « ordinateurs portables de marque Linux » en valent la peine ? J'ai vu qu'ils offraient des machines avec d'excellentes spécifications pour mon cas d'utilisation, mais j'ai aussi lu de nombreuses plaintes sur la construction fragile et bon marché.
Est-ce que l'une de ces marques propose quelque chose de durable, pas quelque chose de plastique ou de bon marché ?
J'aimerais vraiment soutenir ces entreprises si elles peuvent apporter tout ce qu'il faut au jeu. J'aime le support Linux. Je vois qu'ils offrent de bons composants, parfois évolutifs. Je suis juste préoccupé par la qualité de construction.
J'ai aussi entendu de mauvaises critiques sur l'autonomie de la batterie. Est-ce que j'ai de la chance de voir toutes les critiques et tous les posts pleurer sur la qualité de construction et que ce n'est pas un problème, ou est-ce que je devrais juste acheter un XPS, ou un Thinkpad ?
Je me pose les mêmes questions 🙂.
Je connaissais déjà Framework (USA) et System76 (USA). Il y a quelques semaines, j'ai découvert le fabricant espagnol basé à Valence nommé Slimbook (company).
Dans ce thread, #JaiDécouvert l'existence des fabricants suivants :
- Malibal (USA)
- Starlabs (Company) (UK)
- et Tuxedo (DE)
J'ai très bien conscience que ces laptops sont fabriqués par des Original design manufacturer (https://en.wikipedia.org/wiki/Original_design_manufacturer).
Par exemple, je lis ici que les laptop Framework sont fabriqués par Compal Electronics (https://en.wikipedia.org/wiki/Compal_Electronics), une entreprise taïwanaise, qui fabrique entre autres des laptop pour Lenovo, DELL, etc.
Je me suis intéressé à Tuxedo et en particulier le modèle Tuxedo Infinity Flexible 14 Gen 1.

Le modèle suivant est à 1067 € TTC :
- Intel Core i5-1335U (10 Cores | 12 Threads | Max. 4.6 GHz | 12 MB Cache | 15 W TDP)
- 16 GB (2x 8GB) 3200MHz CL22 Samsung
- Touch Display | non-glare | WUXGA 1920 x 1200 | 16:10 | 400nits | Stylus MPP2.0
- 500 GB Samsung 980 (NVMe PCIe 3.0)
- FRENCH (FR AZERTY) with backlit with TUX super-key
- Intel Wi-Fi 6E AX211 (802.11ax | 2.4, 5 & 6 GHz | Bluetooth 5.3)
- USB to LAN Adapter - USB-C & -A - 1GBit USB3.0
- USB-C wall mount charger | 100 Watt | EU, UK, US, AU Power Plug
- 2 years warranty (Incl. parts, labour & shipping)
Concernant le chassis, je lis :
D'une hauteur totale de moins de 2 cm, le tout premier PC convertible de TUXEDO accueille deux types d'appareils dans un seul boîtier : Ordinateur portable et tablette. Le premier convertible à voir le jour dans le monde Linux est livré dans un boîtier partiellement en aluminium argenté, les surfaces extérieures (couvercle et coque inférieure) étant fabriquées dans ce métal stable mais léger pour un transport en toute sécurité.


Difficile de se faire un avis avec une photo.
Autre élément qui m'intéresse fortement, c'est la possibilité d'imprimer un layout custom de clavier 😮. C'est la première fois que je rencontre cette possibilité. Je pourrais enfin pouvoir avoir un layout Bépo sur laptop 🙂.
Par le passé, j'avais lu des threads à ce sujet dans le forum de Framework : custom layout
We therefore provide you with the option to customize your TUXEDO to your personal taste thanks to high-quality logo or photo printing as well as custom keyboard laser etching. Get creative and create your unique TUXEDO notebook!

Autre élément sympathique, il est aussi possible de customiser le capot du laptop :
Individual keyboard laser etching and logo printing.

Tuxedo met à disposition des drivers supplémentaires packagés pour Fedora :
TUXEDO Computers offers a well-maintained repository for Fedora Linux to install additional software such as keyboard drivers or the TUXEDO Control Centre. The repository is to be found on our server.
Suite à la lecture de toutes ces informations, je suis très tenté de tenter l'achat d'un Infinity Flexible 14 - Gen 1 pour le Projet 26 - "Expérimentation de migration de deux utilisateurs grand public vers des laptops sous Fedora".
J'ai pris le temps de lire un maximum de commentaires à propos de Tuxedo sur linuxhardware, hackernews. Pour le moment, mon sentiment est positif. J'ai vu quelques commentaires négatifs et beaucoup de commentaires positifs.
J'ai effectué des recherches sur Hardware for Linux https://linux-hardware.org/?view=computers&vendor=TUXEDO et je n'ai pas trouvé de données pour le modèle Infinity Flexible 14 - Gen 1.
Je viens de poster la question suivante sur le Subreddit de Tuxedo et sur sa page de contact de support : Can you execute hw-probe on InfinityFlex 14 Gen1 to upload data to linux-hardware.org ?.
Journal du mardi 11 mars 2025 à 00:09
#JaiDécouvert ici l'agence 18F (https://en.wikipedia.org/wiki/18F) qui semble être un "équivalent" à beta.gouv.fr aux États-Unis.
Journal du lundi 10 mars 2025 à 23:11
Quelques prises de notes lors de ma lecture de l'article « Réforme des retraites, échec scolaire, cannabis… et si l’on s’y prenait autrement ? » de Pierre Pezziardi publié dans La Grande Conversation, la revue de Terra Nova.
Un premier exemple : j’ai co-fondé en 2020, un groupe coopératif, la Ceinture Verte, qui facilite la relocalisation de production maraîchère en circuits courts. C’était à l’origine un projet de Startup d’État qui s’est finalement développé dans le champ de l’économie sociale et solidaire. En quatre ans, avec dix coopératives, et 16 fermes en activité, c’est désormais le premier réseau de coopération inter-territorial dans le champ des politiques publiques agricoles, et accessoirement, en consolidé, la plus grande ferme maraîchère en circuit court de France. Bien que modeste à l’échelle nationale – la relocalisation en circuits courts de 10% des légumes nécessiterait plusieurs milliers de fermes de proximité – l’initiative est taillée pour passer à cette échelle.
Intéressant 🙂.
Alors pourrait-on imaginer des entreprises de politiques publiques menées selon cette même méthode ”agile à impact” ? Imaginons trois scénarios prospectifs.
J'ai bien aimé les trois scénarios prospectifs décrits dans l'article.
La lecture de cet article m'a fait penser à une réflexion que j'ai eue vers 2008, quand je découvrais l'agilité, la méthode Lean, etc., et que je m'étais dit : "Mais ça donnerait quoi un parti politique ou un gouvernement qui suivrait les méthodes agiles ? J'aimerais bien lancer un parti 'Agile'" 😉.
Journal du lundi 10 mars 2025 à 22:43
#JaiDécouvert ici le projet KOReader (https://koreader.rocks/) et le site Kindle Modding Wiki (https://kindlemodding.org/).
Le site Kindle Modding Wiki semble rassembler beaucoup d'informations au sujet des devices Kindle, le fonctionnement de son OS, comment Jailbreaking un Kindle, etc.
J'ai appris que l'OS de Kindle utilise Lua et React Native 😉.
Liste des modèles qui peuvent être Jailbreak : https://kindlemodding.org/jailbreaking/kindle-models.html.
Voir thread Hacker News à ce sujet : All Kindles can now be jailbroken.
#UnJourPeuxÊtre j'essaierai d'installer KOReader sur mon Kindle.
Journal du lundi 10 mars 2025 à 22:00
#JaiDécouvert ici le mot Comitologie :
Comitologie : Organisation de réunions où seront prises des décisions.
Journal du lundi 10 mars 2025 à 18:02
Après ruff il y a 1 mois, on m'a encore partagé un nouveau formatter, bien entendu en Rust : Biome (https://github.com/biomejs/biome).
Biome is a performant toolchain for web projects, it aims to provide developer tools to maintain the health of said projects.
Biome is a fast formatter for JavaScript, TypeScript, JSX, JSON, CSS and GraphQL that scores 97% compatibility with Prettier.
Biome is a performant linter for JavaScript, TypeScript, JSX, CSS and GraphQL that features more than 270 rules from ESLint, typescript-eslint, and other sources. It outputs detailed and contextualized diagnostics that help you to improve your code and become a better programmer!
Le projet Biome a commencé en été 2023, mais en réalité, le projet est plus ancien. Biome est un fork du projet Rome de Meta, qui a commencé en 2020.
Ce billet explique la raison du fork, pour faire simple, un problème de propriété du nom.
Thread Hacker News de l'annonce du fork : Biome.
J'ai lu le billet Biome v1.7 qui explique comment migrer d'eslint ou Prettier en une commande :
biome migrate eslint- ou
biome migrate prettier
Je pense que je vais attendre encore un peu avant de migrer parce que le support Svelte est partiel :
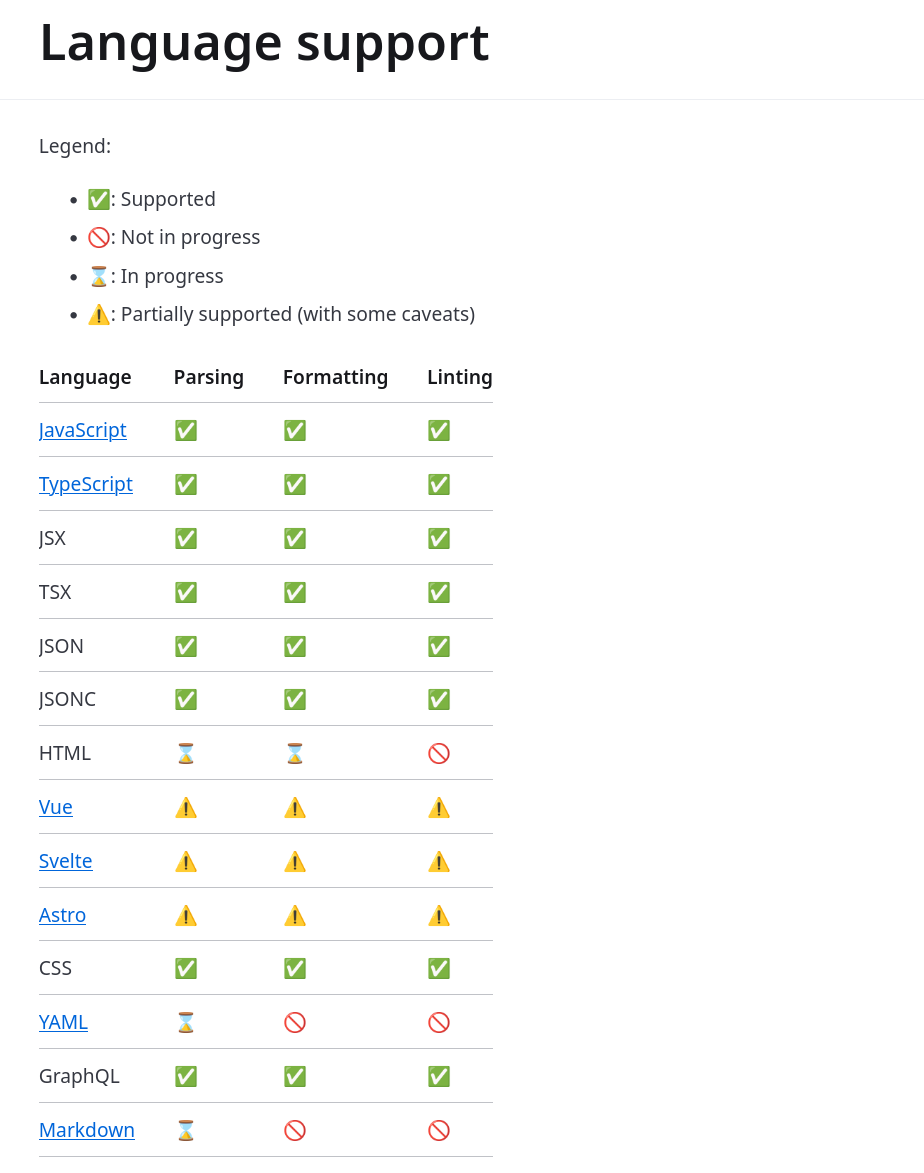
#JeMeDemande quelles sont les différences entre le linter de Oxc https://oxc.rs/docs/guide/usage/linter et Biome 🤔.
Je viens de vérifier, le projet Oxc est toujours très actif : https://github.com/oxc-project/oxc/graphs/contributors.
Journal du vendredi 07 mars 2025 à 11:54
#JaiDécouvert Edward Deming via :
La nécessaire polarisation sur l’impact (le sens) a été forgée par des théoriciens des organisations comme Eliyahu Goldratt (auteur notamment de Le BUT, et père de la théorie des contraintes) ou Edward Deming (la principale autorité morale du lean management), qui constatent qu’invariablement, les moyens se substituent aux fins dans les grandes organisations en silos. Cette perte de sens est particulièrement douloureuse dans le secteur public où les gens sont et restent par vocation, par volonté de servir l’intérêt général.
Journal du samedi 01 mars 2025 à 18:43
Suite aux mises à jour des conditions d'utilisation et de la politique de confidentialité de Firefox j'ai décidé :
- De contribuer financièrement à la hauteur de 10$ par mois au projet Servo (via Open Collective).
- De remplacer Firefox par LibreWolf.
Quelques liens à ce sujet :
- 26 février 2025 - article de Mozilla : Introducing a terms of use and updated privacy notice for Firefox
- Thread Hacker News de 1090 commentaires
- Thread Lobster de 153 commentaires
- 28 février 2025 - article de Mozilla : An update on our Terms of Use
- Thread Hacker News de 302 commentaires
Voici quelques informations au sujet des forks de Firefox.
Le projet Waterfox a débuté en 2011.
Waterfox supporte les extensions Firefox 🙂.
Pocket est désactivé par défaut 🙂.
J'ai lu l'article de Waterfox : « A Comment on Mozilla's Policy Changes ».
Waterfox est disponible sur Flathub : https://github.com/flathub/net.waterfox.waterfox.
Je découvre qu'une version Android de Waterfox est disponible : https://github.com/BrowserWorks/Waterfox-Android.
J'ai lu l'article Wikipedia de LibreWolf et les pages "Features" et "FAQ".
Le projet LibreWolf a commencé en 2020, il est bien plus jeune que Waterfox.
#JaiDécouvert IronFox (https://gitlab.com/ironfox-oss/IronFox/)
J'ai installé LibreWolf sous Fedora :
$ curl -fsSL https://repo.librewolf.net/librewolf.repo | pkexec tee /etc/yum.repos.d/librewolf.repo
$ sudo dnf install librewolf
Le site web du projet LibreWolf m'a inspiré davantage confiance que Waterfox.
Suite à cela, j'ai décidé de migrer vers LibreWolf.
Commande pour définir LibreWolf comme navigateur par défaut sous Fedora :
$ xdg-settings set default-web-browser librewolf.desktop
Journal du samedi 01 mars 2025 à 17:03
J'ai passé une heure à lire l'article de LinuxFr : « Une intelligence artificielle libre est-elle possible ? ». J'y ai appris de nombreuses choses et je l'ai trouvé plutôt accessible. Merci à l'auteur https://linuxfr.org/users/liorel.
J'ai beaucoup aimé cette manière de présenter ce qu'est l'Intelligence artificielle :
Commençons par définir notre objet d’étude : qu’est-ce qu’une IA ? Par « intelligence artificielle », on pourrait entendre tout dispositif capable de faire réaliser par un ordinateur une opération réputée requérir une tâche cognitive. Dans cette acception, un système expert qui prend des décisions médicales en implémentant les recommandations d’une société savante est une IA. Le pilote automatique d’un avion de ligne est une IA.
Cependant, ce n’est pas la définition la plus couramment employée ces derniers temps. Une IA a battu Lee Sedol au go, mais ça fait des années que des ordinateurs battent les humains aux échecs et personne ne prétend que c’est une IA. Des IA sont employées pour reconnaître des images alors que reconnaître un chien nous semble absolument élémentaire, mais l’algorithme de Youtube qui te suggère des vidéos pouvant te plaire parmi les milliards hébergées fait preuve d’une certaine intelligence et personne ne l’appelle IA. Il semble donc que le terme « IA » s’applique donc à une technique pour effectuer une tâche plus qu’à la tâche en elle-même, ou plutôt à un ensemble de techniques partageant un point commun : le réseau de neurones artificiels.
Dans la suite de cette dépêche, j’utiliserai donc indifféremment les termes d’IA et de réseau de neurones.
J'ai bien aimé la section « Un exemple : la régression linéaire » 👌.
Je n'ai pas compris grand-chose à la section « Le neurone formel ». Elle contient trop d'outils mathématiques qui m'échappent, comme :
- « la fonction f doit être monotone (idéalement strictement monotone) »
- « et non linéaire (sinon mettre les neurones en réseau n’a aucun intérêt, autant faire directement une unique régression linéaire) »
- « La fonction logistique »
- « La fonction Rectified Linear Unit »
On ajoute un ensemble de neurones qu’on pourrait qualifier de « sensitifs », au sens où ils prennent en entrée non pas la sortie d’un neurone antérieur, mais directement l’input de l’utilisateur, ou plutôt une partie de l’input : un pixel, un mot…
#JaiDécouvert les neurones « sensitifs ».
Se pose alors la question : combien de neurones par couche, et combien de couches au total ?
On peut considérer deux types de topologies : soit il y a plus de neurones par couche que de couches : le réseau est plus large que long, on parlera de réseau large. Soit il y a plus de couches que de neurones par couche, auquel cas le réseau est plus long que large, mais on ne va pas parler de réseau long parce que ça pourrait se comprendre « réseau lent ». On parlera de réseau profond. C’est de là que viennent les Deep et les Large qu’on voit un peu partout dans le marketing des IA. Un Large Language Model, c’est un modèle, au sens statistique, de langage large, autrement dit un réseau de neurones avec plus de neurones par couche que de couches, entraîné à traiter du langage naturel.
Je suis très heureux de découvrir cette distinction entre profond et large. Je découvre que ces termes, omniprésents dans le marketing des IA, reflètent en réalité des caractéristiques architecturales précises des réseaux de neurones.
On constate empiriquement que certaines topologies de réseau sont plus efficaces pour certaines tâches. Par exemple, à nombre de neurones constant, un modèle large fera mieux pour du langage. À l’inverse, un modèle profond fera mieux pour de la reconnaissance d’images.
je peux assez facilement ajuster un modèle de régression logistique (qui est une variante de la régression linéaire où on fait prédire non pas une variable quantitative, mais une probabilité)
J'ai une meilleure idée de ce qu'est un modèle de régression logistique.
En définitive, on peut voir le réseau de neurones comme un outil qui résout approximativement un problème mal posé. S’il existe une solution formelle, et qu’on sait la coder en un temps acceptable, il faut le faire. Sinon, le réseau de neurones fera un taf acceptable.
Ok.
Posons-nous un instant la question : qu’est-ce que le code source d’un réseau de neurones ? Est-ce la liste des neurones ? Comme on l’a vu, ils ne permettent ni de comprendre ce que fait le réseau, ni de le modifier. Ce sont donc de mauvais candidats. La GPL fournit une définition : le code source est la forme de l’œuvre privilégiée pour effectuer des modifications. Dans cette acception, le code source d’un réseau de neurones serait l’algorithme d’entraînement, le réseau de neurones de départ et le corpus sur lequel le réseau a été entraîné.
👍️
Journal du jeudi 27 février 2025 à 11:02
Au mois d'août 2024, je disais :
Je cherche depuis plusieurs années une solution pour surveiller la date d'expiration des noms de domaine en analysant le contenu de Whois.
#JaiDécouvert cet exporter Prometheus qui correspond exactement à mon besoin : https://github.com/shift/domain_exporter
Ce matin, en travaillant sur la note "Je découvre Beszel", #JaiDécouvert que Gatus permet de monitorer l'expiration d'un domaine :
You can monitor the expiration of a domain with all endpoint types except for DNS by using the
[DOMAIN_EXPIRATION]placeholder.The aforementioned placeholder resolves to a duration (e.g. 734h22m5s), as such, the value you should compare it to should also be a duration (e.g. 720h, 1h30m). Here's an example of what a condition may look like:
[DOMAIN_EXPIRATION] > 720hThe condition above will fail if the domain expires in less than 720 hours (30 days).
Journal du jeudi 27 février 2025 à 10:41
En travaillant sur la note "Je découvre Beszel", #JaiDécouvert ici un autre projet de monitoring intéressant : Dozzle (https://dozzle.dev/).
Dozzle is a small lightweight application with a web based interface to monitor Docker logs. It doesn’t store any log files. It is for live monitoring of your container logs only.
Là aussi, Dozzle est un projet en Golang, commencé fin 2018.
Dozzle est une alternative à Loki + Grafana.
#JaimeraisUnJour déployer Dozzle pour le tester et si ce test est concluant, je l'intégrerai peut-être à ma stack minimaliste de monitoring en complément de Beszel et Gatus.
Un ami m'a partagé le projet Beszel (https://beszel.dev/).
Beszel is a lightweight server monitoring platform that includes Docker statistics, historical data, and alert functions.
It has a friendly web interface, simple configuration, and is ready to use out of the box. It supports automatic backup, multi-user, OAuth authentication, and API access.
Beszel est codé en Golang, il est très récent, il a commencé en été 2024, c'est sans doute pour cela que je ne l'avais jamais croisé.
De prime abord, j'ai pensé que Beszel était un outil de Status / Uptime pages comme Uptime Kuma ou Gatus, mais ce n'est pas le cas.
Je qualifierai plutôt Beszel d'alternative "plug and play" de Prometheus + Grafana + node_exporter + cAdvisor.
Alors que l'annonce de Beszel a fait "choux blanc" sur Hacker News « Beszel: Lightweight server resource monitoring with history, Docker stats,alerts », le projet a suscité plus de réaction — 270 commentaires — sur Subreddit SelfHosted : « I just released Beszel, a server monitoring hub with historical data, docker stats, and alerts. It's a lighter and simpler alternative to Grafana + Prometheus or Checkmk. Any feedback is appreciated! ».
Les retours sont très positifs 🙂 :
« There is beauty in simplicity. Very nice little application! »
« Kiss »
« Just installed on all of my servers, gorgeous project, simple but also not simple. »
« Awesome work. I think you identified a good use case for the self hosting community, a simple server monitor running as a simple service. I will give it a go soon! »
« I never installed Grafana and Prometheus because it’s overkill for my little server.. but this looks really good! I’ll give it a go »
Prometheus propose bien plus d'exporter que Beszel, mais je pense que Beszel est un bon point de départ pour une stack de monitoring minimaliste.
À l'avenir, mon choix par défaut en matière monitoring sera probablement un couple Beszel + Gatus. Si des besoins plus avancés émergent, comme du monitoring poussé de PostgreSQL, Redis ou d'autres services, j'envisagerai alors de commencer la mise en place du couple Prometheus + Grafana.
Journal du mardi 25 février 2025 à 23:29
#JaiDécouvert cette page web qui permet de savoir quel LLM peut être exécuté sur une machine en particuler : https://canirunthisllm.com/ll
Journal du mardi 25 février 2025 à 14:20
Alexandre vient de partager ce thread : « Asdf Version Manager Has Been Re-Written in Golang »
Je découvre que Asdf n'est pas mort ! La version 0.16.0 publié le 30 janvier 2025 a été réécrite en Golang !
La raison principale semble être une volonté d'amélioration de la vitesse de Asdf :
With improvements ranging from 2x-7x faster than asdf version 0.15.0!
Depuis cette date, Mise a publié un benchmark qui compare la vitesse d'exécution de Asdf et Mise : https://mise.jdx.dev/dev-tools/comparison-to-asdf.html#asdf-in-go-0-16.
Comme mon ami Alexandre, certains utilisateurs sont inquiets de voir Mise faire trop de choses :
I tried mise a while back, and the main reason I went away from it is like you said, it does too much. It tries to be asdf, direnv and a task runner. I just want a tool manager, and is the reason why I switched to aquaproj/aqua.
J'ai migré de Asdf vers Mise en novembre 2023 et pour le moment, je n'ai pas envie, ni de raison pratique particulière pour retourner à Asdf.
De plus, je suis plutôt satisfait d'avoir remplacé direnv par Mise, voir Je pense pouvoir maintenant remplacer Direnv par Mise 🤞.
Journal du mercredi 12 février 2025 à 15:53
Jusqu'à aujourd'hui, j'utilise la commande sleep infinity pour garder en "vie" un container Docker qui n'exécute aucun service.
Exemple de docker-compose.yml :
services:
ubuntu:
image: ubuntu
command: sleep infinity
Ce qui me permet d'entrer dans le container après son lancement en background :
$ docker compose up -d ubuntu
$ docker compose exec ubuntu bash
root@357466c4b52c:/# ls
bin boot dev etc home lib lib64 media mnt opt proc root run sbin srv sys tmp usr var
Aujourd'hui, j'ai découvert via Copilot une alternative préférable à sleep infinity :
services:
ubuntu:
image: ubuntu
command: tail -f /dev/null
Cela fonctionne de la même manière, mais semble avoir l'avantage de ne pas dépendre de la dépendance sleep 🤔.
Journal du mercredi 12 février 2025 à 11:41
En rédigeant la note 2025-02-12_1044, je me suis demandé quelle est la différence de performance entre un Unix Socket et un INET socket.
Durant mes recherches, j'ai découvert qu'Unix Socket est plus rapide que INET sockets. Je n'ai pas été surpris, j'avais cette intuition.
Toutefois, j'ai été surpris d'apprendre que le gain est non négligeable, de 30% à 50% de gains !
Exemple :
On my machine, Ryzen 3900X, Ubuntu 22,
A basic C++ TCP server app that only sends 64K packets, and a basic c++ receiver that pulls 100GB of these packets and copies them to it's internal buffer only, single-threaded:
- achieves
~30-33 GBit/secfor TCP connection (~4.0GB/sec) (not MBit)- and
~55-58GBit/secfor a socket connection, (~7.3 GB/sec)- and
~492Gbit/secfor in-process memcopy (~61GB /sec)
Conséquence : je vais essayer d'utiliser des Unix sockets autant que je peux.
Journal du mercredi 12 février 2025 à 11:37
#JaiDécouvert le site Linux Performance de Brendan Gregg.
Journal du mercredi 12 février 2025 à 10:44
En travaillant sur le projet Projet 23 - "Ajouter le support pg_basebackup incremental à restic-pg_dump-docker", j'ai découvert que PostgreSQL propose deux protocoles de communication :
- Le premier est le plus connu "Frontend/Backend Protocol". C'est celui qui est utilisé par la commande
psqlou les librairies telles que Postgres.js (en NodeJS), Psycopg (en Python)… - Le second nommé "Streaming Replication Protocol"
Sans vraiment comprendre, en 2020, j'avais activé le protocole streaming replication dans ce POC postgresql-streaming-replication-playground. Mais je n'avais jamais pris conscience de l'existence de ce second protocole.
Les développeurs de PostgreSQL semblent avoir décidé de créer un second protocole parce qu'ils n'ont pas du tout le même objectif.
Streaming Replication Protocol est optimisé dans la transmission des WAL et des snapshots (copie de l'intégralité du dossier PGDATA).
Le protocole Streaming Replication Protocol est entre autres utilisé par pg_basebackup, barman, pgBackRest, ou Patroni.
Comment activer Streaming Replication Protocol ?
Les images Docker Postgres setup par défaut le fichier pg_hba.conf suivant :
# TYPE DATABASE USER ADDRESS METHOD
# "local" is for Unix domain socket connections only
local all all trust
# IPv4 local connections:
host all all 127.0.0.1/32 trust
# IPv6 local connections:
host all all ::1/128 trust
# Allow replication connections from localhost, by a user with the
# replication privilege.
local replication all trust
host replication all 127.0.0.1/32 trust
host replication all ::1/128 trust
host all all all scram-sha-256
J'ai compris que par défaut, toutes ces lignes configurent l'accès au Frontend/Backend Protocol.
Seules les lignes qui contiennent replication configurent l'accès au Streaming Replication Protocol.
Pour permettre l'accès au Streaming Replication Protocol par réseau TCP/IP en dehors du container Docker il est nécessaire d'ajouter la ligne suivante :
host replication all all scram-sha-256
Suite à cette découverte, j'ai repensé à :
Pour faire face à ce problème, j'ai exploré fin 2023 une solution basée sur pgBackRest : Implémenter un POC de pgBackRest.
Je suis plus ou moins arrivé au bout de ce POC mais je n'ai pas été satisfait du résultat.
Je n'ai pas réussi à configurer pgBackRest en "pure Docker sidecar".
De plus, j'ai trouvé la restauration du backup difficile à exécuter.
et je me suis demandé si mon échec de configuration de pgBackRest en Docker sidecar n'était pas seulement dû au fait que je n'avais pas activé Streaming Replication Protocol 🤔.
La réponse semble être "oui" et "non".
Je suis tombé sur l'issue suivante : pgbackrest with postgresql in docker.
The problem might be harder than you think unfortunately. If the pgBackRest process is running on the VM (docker host), it will try to connect to PG locally using the unix socket, not the tcp "localhost" connection.
Je pense comprendre que pgBackRest ne permet pas d'utiliser des INET sockets pour communiquer avec PostgreSQL.
Toutefois, je me dis que je pourrais partager le volume PGDATA avec le sidecar pgBackRest pour lui donner accès à l'Unix Socket du Streaming Replication Protocol 🤔.
Entre mon exploration de pg_basebackup, mes envies de tester barman et de continuer mon POC pgBackRest… je me dis que je ne suis pas encore au bout de ce Yak!.
Journal du mardi 11 février 2025 à 12:30
#JaiDécouvert ici le site web Décodage Fiscal (https://decodage-fiscal.fr/).
Par le passé, j'avais déjà repéré et utilisé d'autres outils similaires, notamment l'outil officiel de l'URSSAF : L'assistant officiel des entrepreneurs (https://mon-entreprise.urssaf.fr/).
À ce jour, Décodage Fiscal est celui que je trouve le plus complet, avec la meilleure interface utilisateur.
Je viens de découvrir le projet Fastlane (https://fastlane.tools/).
Je pense que c'est l'outil qui me manquait pour suivre le paradigme configuration as code dans mon "Projet 17 - Créer un POC de création d'une app smartphone avec Capacitor".
Ce projet a commencé en 2014 par Felix Krause et repris par Google en 2017 : « fastlane is joining Google - Felix Krause ».
Mais, je découvre que Google semble avoir arrêter de financer le développement du projet en 2023 : Google is no longer sponsoring Fastlane | Hacker News.
Depuis, le projet semble être toujours actif avec de nombreuses release : https://github.com/fastlane/fastlane/releases.
Fonctionnalités de Fastlane qui m'intéressent tout particulièrement :
Fastlane permet aussi d'automatiser de nombreuses autres tâches que je n'ai pas encore pris le temps d'explorer : https://docs.fastlane.tools/actions/.
Installation de Fastlane avec Mise que j'ai testée sous Fedora et MacOS :
[tools]
ruby = '3.1.6' # for fastlane
fastlane = "2.226.0"
[alias]
fastlane = "https://github.com/mollyIV/asdf-fastlane.git"
(Toujours aussi pénibles ces outils développés en Ruby 😔)
À noter que sous MacOS j'ai dû lancer :
$ mise install -f fastlane
Parce que lors du premier lancement de mise install, j'ai l'impression qu'il a essayé d'installer fastlane avec l'instance ruby native de l'OS.
J'ai cherché s'il existe une option pour préciser que fastlane doit utiliser ruby installé par Mise, mais je n'ai pas trouvé.
17:05 - Solution pour contourner le problème mentionné ci-dessus :
$ mise install ruby
$ mise install
Journal du mercredi 05 février 2025 à 18:32
Un ami m'a fait découvrir uv (https://github.com/astral-sh/uv).
Je trouve cela amusant de constater que Rust prend en charge de plus en plus d'outils pour différents langages 😉.
Le projet a commencé fin 2023.
Voici un thread Hacker News de 200 commentaires à ce sujet qui date de février 2024 : Uv: Python packaging in Rust .
L'article de ce thread contient beaucoup d'éléments intéressants : https://astral.sh/blog/uv
Son nom uv semble être une référence à uvloop.
J'en ai profité pour migrer le playground mise-python-flask-playground de pip vers uv : https://github.com/stephane-klein/mise-python-flask-playground/commit/2f1678798cfc6749dcfdb514a8fe4a3e54739844.
J'ai lancé une installation et effectivement, sa rapidité est très impressionnante :
$ uv pip install -r requirements.txt
Resolved 15 packages in 245ms
Prepared 15 packages in 176ms
Installed 15 packages in 37ms
+ alembic==1.14.1
+ blinker==1.9.0
+ click==8.1.8
+ flask==3.1.0
+ flask-migrate==4.1.0
+ flask-sqlalchemy==3.1.1
+ greenlet==3.1.1
+ itsdangerous==2.2.0
+ jinja2==3.1.5
+ mako==1.3.9
+ markupsafe==3.0.2
+ psycopg2-binary==2.9.10
+ sqlalchemy==2.0.37
+ typing-extensions==4.12.2
+ werkzeug==3.1.3
uv ne propose pas seulement une amélioration de l'installation de packages Python, mais propose beaucoup d'autres choses comme :
- L'installation de Python : https://docs.astral.sh/uv/guides/install-python/
Pour cette partie, dans un but d'unification, je continuerai à utiliser Mise pour installer une version précise de Python. De plus, Mise intègre nativement UV : https://mise.jdx.dev/mise-cookbook/python.html#mise-uv
- Système pour lancer des scripts Python : https://docs.astral.sh/uv/guides/scripts/
Exemple :
$ uv run example.py
Je pense avoir compris que cela lance ce script avec les dépendances du virtual environment du projet. Un peu comme fonctionne npm, yarn ou pnpm qui permet aux scripts d'utiliser les packages présents dans ./node_modules/.
- Permet de lancer des outils : https://docs.astral.sh/uv/guides/tools/
Par exemple, le linter Python ruff, exemple :
$ uv tool run ruff
- uv met à disposition des images Docker : https://docs.astral.sh/uv/guides/integration/docker/
J'ai un peu parcouru la documentation de pyproject.toml : https://packaging.python.org/en/latest/guides/writing-pyproject-toml/.
J'ai lu aussi la section uv - Locking environments.
Suite à ces lectures, j'ai migré le playground mise-python-flask-playground vers pyproject.toml : https://github.com/stephane-klein/mise-python-flask-playground/commit/c17216464778df4bc00bf782d5a889cb3f198051.
Je ne suis pas certain que ces commandes soient une bonne pratique :
$ uv pip compile requirements.in -o requirements.txt
$ uv pip install -r requirements.txt
Je découvre Colima, installation minimaliste de Docker sous MacOS
#JaiDécouvert le projet Colima : https://github.com/abiosoft/colima
Colima - container runtimes on macOS (and Linux) with minimal setup.
Support for Intel and Apple Silicon Macs, and Linux
- Simple CLI interface with sensible defaults
- Automatic Port Forwarding
- Volume mounts
- Multiple instances
- Support for multiple container runtimes
- Docker (with optional Kubernetes)
- Containerd (with optional Kubernetes)
- Incus (containers and virtual machines)
Colima est une solution minimaliste qui permet d'installer sous MacOS docker-engine sans Docker Desktop.
Thread Hacker News à ce sujet de 2023 : Colima: Container runtimes on macOS (and Linux) with minimal setup.
Méthode d'installation que je suis sous MacOS avec Brew :
$ brew install colima docker docker-compose
$ cat << EOF > ~/.docker/config.json
{
"auths": {},
"currentContext": "colima",
"cliPluginsExtraDirs": [
"/opt/homebrew/lib/docker/cli-plugins"
]
}
EOF
$ brew services start colima
Comme indiqué ici, la modification du fichier ~/.docker/config.json permet d'activer de plugin docker compose, ce qui permet d'utiliser, par exemple :
$ docker compose ps
Qui est, depuis 2020, la méthode recommandée d'utiliser docker compose sans -.
Vérification, que tout est bien installé et lancé :
$ colima status
INFO[0000] colima is running using macOS Virtualization.Framework
INFO[0000] arch: aarch64
INFO[0000] runtime: docker
INFO[0000] mountType: sshfs
INFO[0000] socket: unix:///Users/m1/.colima/default/docker.sock
$ docker info
Client: Docker Engine - Community
Version: 27.5.1
Context: colima
Debug Mode: false
Server:
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 1
Server Version: 27.4.0
Storage Driver: overlay2
Backing Filesystem: extfs
Supports d_type: true
Using metacopy: false
Native Overlay Diff: true
userxattr: false
Logging Driver: json-file
Cgroup Driver: cgroupfs
Cgroup Version: 2
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Log: awslogs fluentd gcplogs gelf journald json-file local splunk syslog
Swarm: inactive
Runtimes: io.containerd.runc.v2 runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 88bf19b2105c8b17560993bee28a01ddc2f97182
runc version: v1.2.2-0-g7cb3632
init version: de40ad0
Security Options:
apparmor
seccomp
Profile: builtin
cgroupns
Kernel Version: 6.8.0-50-generic
Operating System: Ubuntu 24.04.1 LTS
OSType: linux
Architecture: aarch64
CPUs: 2
Total Memory: 1.914GiB
Name: colima
ID: 7fd5e4bd-6430-4724-8238-e420b3f23609
Docker Root Dir: /var/lib/docker
Debug Mode: false
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
J'ai suivi de loin l'histoire de Docker Desktop qui est devenu "propriétaire". Je viens prendre le temps d'étudier un peu le sujet, et voici ce que j'ai trouvé :
August 2021: Docker Desktop for Windows and MacOS was no longer available free of charge for enterprise users. Docker ended free Docker Desktop use for larger business customers and replaced its Free Plan with a Personal Plan. Docker on Linux distributions remained unaffected.
Sur le site officiel, sur la page "docker.desktop", quand je clique sur « Choose plan » je tombe sur ceci :

Je n'ai pas tout compris, j'ai l'impression qu'il est tout de même possible d'installer et d'utiliser gratuitement Docker Desktop.
Au final, tout cela n'a pas beaucoup d'importance pour moi, je ne trouve aucune utilité à Docker Desktop, par conséquent, sous MacOS j'utilise Colima.
J'ai vu qu'il est possible d'installer Colima sous Linux, mais je ne l'utilise pas, car je n'y vois aucun intérêt pour le moment.
Journal du mardi 04 février 2025 à 16:46
Je souhaite créer un playground d'un development kit pour Python + PostgreSQL (via Docker) + Flask + Flask-Migrate, basé sur Mise.
J'ai la contrainte suivante : le development kit doit fonctionner sous MS Windows !
Je me dis que c'est une bonne occasion pour moi de tester Windows Subsystem for Linux 🙂.
Problème : je ne possède pas d'instance MS Windows.
#JaiDécouvert que depuis 2015, Microsoft met à disposition des ISOs officiels de MS Windows :
- ISO pour Windows 10 : https://www.microsoft.com/fr-fr/software-download/windows10ISO
- ISO pour Windows 11 : https://www.microsoft.com/fr-fr/software-download/windows11
- Virtual machine MS Windows pour VirtualBox et d'autres : https://developer.microsoft.com/en-us/windows/downloads/virtual-machines/
J'ai testé dans ce playground le lancement d'une Virtual machine MS Windows avec Vagrant : https://github.com/stephane-klein/vagrant-windows-playground.
Cela a bien fonctionné 🙂.
J'ai aussi découvert le repository windows-vagrant qui semble permettre de construire différents types d'images MS Windows avec Packer. Je n'ai pas essayé d'en construire une.
Journal du mercredi 29 janvier 2025 à 22:22
En étudiant Pi-hole, je découvre le terme "DNS sinkhole" :
A DNS sinkhole, also known as a sinkhole server, Internet sinkhole, or Blackhole DNS is a Domain Name System (DNS) server that has been configured to hand out non-routable addresses for a certain set of domain names.
...
Another use is to block ad serving sites, either using a host's file-based sinkhole or by locally running a DNS server (e.g., using a Pi-hole). Local DNS servers effectively block ads for all devices on the network.
Journal du mercredi 29 janvier 2025 à 16:29
Alexandre m'a fait remarquer que GitLab a activé par défaut une extension Markdown de génération automatique de TOC :
A table of contents is an unordered list that links to subheadings in the document. You can add a table of contents to issues, merge requests, and epics, but you can’t add one to notes or comments.
Add one of these tags on their own line to the description field of any of the supported content types:
[[_TOC_]] or [TOC]
- Markdown files.
- Wiki pages.
- Issues.
- Merge requests.
- Epics.
Je trouve cela excellent que cette extension Markdown soit supportée un peu partout, en particulier les issues, Merge Request… 👍️.
Cette fonctionnalité a été ajoutée en mars 2020 🫢 ! Comment j'ai pu passer à côté ?
GitHub permet d'afficher un TOC au niveau des README, mais je viens de vérifier, GitHub ne semble pas supporter cette extension TOC Markdown au niveau des issues… Pull Request…
Journal du mercredi 29 janvier 2025 à 11:55
#JaiDécouvert Nitro (https://nitro.build/)
Next Generation Server Toolkit.
Create web servers with everything you need and deploy them wherever you prefer.
D'après ce que j'ai compris, Nitro est un serveur http en NodeJS qui a été spécialement conçu pour Nuxt.js.
Nitro a été introduit fin 2021 dans la version 3 de Nuxt.
Nitro fait partie de l'écosystème UnJS.
Je découvre l'existence de UnJS Ecosystem. #JeMeDemande si ce projet a un lien avec VoidZero 🤔.
Je viens de vérifier, SvelteKit ne semble pas utiliser Nitro. Nitro semble être utilisé uniquement par Nuxt.js.
Journal du lundi 27 janvier 2025 à 11:49
En lisant la documentation de lazy.nvim, #JaiDécouvert que la bonne pratique n'est pas celle-ci :
{
"folke/todo-comments.nvim",
config = function()
require("todo-comments").setup({})
end,
},
Mais simplement celle-ci :
{ "folke/todo-comments.nvim", opts = {} },
Journal du jeudi 23 janvier 2025 à 14:37
#JaiDécouvert Moshi (https://github.com/kyutai-labs/moshi).
Moshi is a speech-text foundation model and full-duplex spoken dialogue framework. It uses Mimi, a state-of-the-art streaming neural audio codec.
Moshi models two streams of audio: one corresponds to Moshi, and the other one to the user. At inference, the stream from the user is taken from the audio input, and the one for Moshi is sampled from the model's output. Along these two audio streams, Moshi predicts text tokens corresponding to its own speech, its inner monologue, which greatly improves the quality of its generation.
Journal du mardi 21 janvier 2025 à 10:45
Alexandre m'a fait découvrir testssl.sh (https://github.com/testssl/testssl.sh) :
testssl.shis a free command line tool which checks a server's service on any port for the support of TLS/SSL ciphers, protocols as well as some cryptographic flaws.
Voici ci-dessous le résultat pour mon domaine sklein.xyz.
Je lis : Overall Grade: A+
Quelques précisions concernant la configuration derrière sklein.xyz :
- J'utilise un certificat Let's Encrypt, validé par la méthode challenge HTTP-01
- Ce certificat est généré par nginx-proxy acme-companion et utilisé par nginx-proxy (la configuration)
$ docker run --rm -ti drwetter/testssl.sh sklein.xyz
#####################################################################
testssl.sh version 3.2rc3 from https://testssl.sh/dev/
This program is free software. Distribution and modification under
GPLv2 permitted. USAGE w/o ANY WARRANTY. USE IT AT YOUR OWN RISK!
Please file bugs @ https://testssl.sh/bugs/
#####################################################################
Using OpenSSL 1.0.2-bad [~183 ciphers]
on 43cf528ca9c5:/home/testssl/bin/openssl.Linux.x86_64
Start 2025-01-21 09:45:05 -->> 51.159.34.231:443 (sklein.xyz) <<--
rDNS (51.159.34.231): 51-159-34-231.rev.poneytelecom.eu.
Service detected: HTTP
Testing protocols via sockets except NPN+ALPN
SSLv2 not offered (OK)
SSLv3 not offered (OK)
TLS 1 not offered
TLS 1.1 not offered
TLS 1.2 offered (OK)
TLS 1.3 offered (OK): final
NPN/SPDY not offered
ALPN/HTTP2 h2, http/1.1 (offered)
Testing cipher categories
NULL ciphers (no encryption) not offered (OK)
Anonymous NULL Ciphers (no authentication) not offered (OK)
Export ciphers (w/o ADH+NULL) not offered (OK)
LOW: 64 Bit + DES, RC[2,4], MD5 (w/o export) not offered (OK)
Triple DES Ciphers / IDEA not offered
Obsoleted CBC ciphers (AES, ARIA etc.) not offered
Strong encryption (AEAD ciphers) with no FS not offered
Forward Secrecy strong encryption (AEAD ciphers) offered (OK)
Testing server's cipher preferences
Hexcode Cipher Suite Name (OpenSSL) KeyExch. Encryption Bits Cipher Suite Name (IANA/RFC)
-----------------------------------------------------------------------------------------------------------------------------
SSLv2
-
SSLv3
-
TLSv1
-
TLSv1.1
-
TLSv1.2 (no server order, thus listed by strength)
xc030 ECDHE-RSA-AES256-GCM-SHA384 ECDH 521 AESGCM 256 TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
x9f DHE-RSA-AES256-GCM-SHA384 DH 2048 AESGCM 256 TLS_DHE_RSA_WITH_AES_256_GCM_SHA384
xcca8 ECDHE-RSA-CHACHA20-POLY1305 ECDH 521 ChaCha20 256 TLS_ECDHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xccaa DHE-RSA-CHACHA20-POLY1305 DH 2048 ChaCha20 256 TLS_DHE_RSA_WITH_CHACHA20_POLY1305_SHA256
xc02f ECDHE-RSA-AES128-GCM-SHA256 ECDH 521 AESGCM 128 TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
x9e DHE-RSA-AES128-GCM-SHA256 DH 2048 AESGCM 128 TLS_DHE_RSA_WITH_AES_128_GCM_SHA256
TLSv1.3 (no server order, thus listed by strength)
x1302 TLS_AES_256_GCM_SHA384 ECDH 253 AESGCM 256 TLS_AES_256_GCM_SHA384
x1303 TLS_CHACHA20_POLY1305_SHA256 ECDH 253 ChaCha20 256 TLS_CHACHA20_POLY1305_SHA256
x1301 TLS_AES_128_GCM_SHA256 ECDH 253 AESGCM 128 TLS_AES_128_GCM_SHA256
Has server cipher order? no
(limited sense as client will pick)
Testing robust forward secrecy (FS) -- omitting Null Authentication/Encryption, 3DES, RC4
FS is offered (OK) TLS_AES_256_GCM_SHA384 TLS_CHACHA20_POLY1305_SHA256 ECDHE-RSA-AES256-GCM-SHA384 DHE-RSA-AES256-GCM-SHA384
ECDHE-RSA-CHACHA20-POLY1305 DHE-RSA-CHACHA20-POLY1305 TLS_AES_128_GCM_SHA256 ECDHE-RSA-AES128-GCM-SHA256
DHE-RSA-AES128-GCM-SHA256
Elliptic curves offered: prime256v1 secp384r1 secp521r1 X25519 X448
Finite field group: ffdhe2048 ffdhe3072 ffdhe4096 ffdhe6144 ffdhe8192
TLS 1.2 sig_algs offered: RSA+SHA224 RSA+SHA256 RSA+SHA384 RSA+SHA512 RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
TLS 1.3 sig_algs offered: RSA-PSS-RSAE+SHA256 RSA-PSS-RSAE+SHA384 RSA-PSS-RSAE+SHA512
Testing server defaults (Server Hello)
TLS extensions (standard) "renegotiation info/#65281" "server name/#0" "EC point formats/#11" "status request/#5" "supported versions/#43"
"key share/#51" "supported_groups/#10" "max fragment length/#1" "application layer protocol negotiation/#16"
"extended master secret/#23"
Session Ticket RFC 5077 hint no -- no lifetime advertised
SSL Session ID support yes
Session Resumption Tickets no, ID: yes
TLS clock skew Random values, no fingerprinting possible
Certificate Compression none
Client Authentication none
Signature Algorithm SHA256 with RSA
Server key size RSA 4096 bits (exponent is 65537)
Server key usage Digital Signature, Key Encipherment
Server extended key usage TLS Web Server Authentication, TLS Web Client Authentication
Serial 048539E72F864A52E28F6CBEFF15527F75C5 (OK: length 18)
Fingerprints SHA1 5B966867DF42BC654DA90FADFDB93B6C77DD7053
SHA256 E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
Common Name (CN) sklein.xyz (CN in response to request w/o SNI: letsencrypt-nginx-proxy-companion )
subjectAltName (SAN) cv.stephane-klein.info garden.stephane-klein.info sklein.xyz stephane-klein.info
Trust (hostname) Ok via SAN and CN (SNI mandatory)
Chain of trust Ok
EV cert (experimental) no
Certificate Validity (UTC) 63 >= 30 days (2024-12-26 08:40 --> 2025-03-26 08:40)
ETS/"eTLS", visibility info not present
Certificate Revocation List --
OCSP URI http://r11.o.lencr.org
OCSP stapling offered, not revoked
OCSP must staple extension --
DNS CAA RR (experimental) not offered
Certificate Transparency yes (certificate extension)
Certificates provided 2
Issuer R11 (Let's Encrypt from US)
Intermediate cert validity #1: ok > 40 days (2027-03-12 23:59). R11 <-- ISRG Root X1
Intermediate Bad OCSP (exp.) Ok
Testing HTTP header response @ "/"
HTTP Status Code 302 Moved Temporarily, redirecting to "https://sklein.xyz/fr/"
HTTP clock skew 0 sec from localtime
Strict Transport Security 365 days=31536000 s, just this domain
Public Key Pinning --
Server banner nginx/1.27.1
Application banner --
Cookie(s) (none issued at "/") -- maybe better try target URL of 30x
Security headers --
Reverse Proxy banner --
Testing vulnerabilities
Heartbleed (CVE-2014-0160) not vulnerable (OK), no heartbeat extension
CCS (CVE-2014-0224) not vulnerable (OK)
Ticketbleed (CVE-2016-9244), experiment. not vulnerable (OK), no session ticket extension
ROBOT Server does not support any cipher suites that use RSA key transport
Secure Renegotiation (RFC 5746) supported (OK)
Secure Client-Initiated Renegotiation not vulnerable (OK)
CRIME, TLS (CVE-2012-4929) not vulnerable (OK)
BREACH (CVE-2013-3587) no gzip/deflate/compress/br HTTP compression (OK) - only supplied "/" tested
POODLE, SSL (CVE-2014-3566) not vulnerable (OK), no SSLv3 support
TLS_FALLBACK_SCSV (RFC 7507) No fallback possible (OK), no protocol below TLS 1.2 offered
SWEET32 (CVE-2016-2183, CVE-2016-6329) not vulnerable (OK)
FREAK (CVE-2015-0204) not vulnerable (OK)
DROWN (CVE-2016-0800, CVE-2016-0703) not vulnerable on this host and port (OK)
make sure you don't use this certificate elsewhere with SSLv2 enabled services, see
https://search.censys.io/search?resource=hosts&virtual_hosts=INCLUDE&q=E79D3ACF988370EF01620C00F003E92B137FFB4EE992A5B1CE3755931561629D
LOGJAM (CVE-2015-4000), experimental not vulnerable (OK): no DH EXPORT ciphers, no common prime detected
BEAST (CVE-2011-3389) not vulnerable (OK), no SSL3 or TLS1
LUCKY13 (CVE-2013-0169), experimental not vulnerable (OK)
Winshock (CVE-2014-6321), experimental not vulnerable (OK)
RC4 (CVE-2013-2566, CVE-2015-2808) no RC4 ciphers detected (OK)
Running client simulations (HTTP) via sockets
Browser Protocol Cipher Suite Name (OpenSSL) Forward Secrecy
------------------------------------------------------------------------------------------------
Android 6.0 TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 7.0 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 256 bit ECDH (P-256)
Android 8.1 (native) TLSv1.2 ECDHE-RSA-AES128-GCM-SHA256 253 bit ECDH (X25519)
Android 9.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 10.0 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 11 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Android 12 (native) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 79 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Chrome 101 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 66 (Win 8.1/10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Firefox 100 (Win 10) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
IE 6 XP No connection
IE 8 Win 7 No connection
IE 8 XP No connection
IE 11 Win 7 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win 8.1 TLSv1.2 DHE-RSA-AES256-GCM-SHA384 2048 bit DH
IE 11 Win Phone 8.1 No connection
IE 11 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Edge 15 Win 10 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
Edge 101 Win 10 21H2 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Safari 12.1 (iOS 12.2) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 13.0 (macOS 10.14.6) TLSv1.3 TLS_CHACHA20_POLY1305_SHA256 253 bit ECDH (X25519)
Safari 15.4 (macOS 12.3.1) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Java 7u25 No connection
Java 8u161 TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Java 11.0.2 (OpenJDK) TLSv1.3 TLS_AES_128_GCM_SHA256 256 bit ECDH (P-256)
Java 17.0.3 (OpenJDK) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
go 1.17.8 TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
LibreSSL 2.8.3 (Apple) TLSv1.2 ECDHE-RSA-CHACHA20-POLY1305 253 bit ECDH (X25519)
OpenSSL 1.0.2e TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
OpenSSL 1.1.0l (Debian) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 253 bit ECDH (X25519)
OpenSSL 1.1.1d (Debian) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
OpenSSL 3.0.3 (git) TLSv1.3 TLS_AES_256_GCM_SHA384 253 bit ECDH (X25519)
Apple Mail (16.0) TLSv1.2 ECDHE-RSA-AES256-GCM-SHA384 256 bit ECDH (P-256)
Thunderbird (91.9) TLSv1.3 TLS_AES_128_GCM_SHA256 253 bit ECDH (X25519)
Rating (experimental)
Rating specs (not complete) SSL Labs's 'SSL Server Rating Guide' (version 2009q from 2020-01-30)
Specification documentation https://github.com/ssllabs/research/wiki/SSL-Server-Rating-Guide
Protocol Support (weighted) 100 (30)
Key Exchange (weighted) 90 (27)
Cipher Strength (weighted) 90 (36)
Final Score 93
Overall Grade A+
Done 2025-01-21 09:46:08 [ 66s] -->> 51.159.34.231:443 (sklein.xyz) <<--
Journal du lundi 20 janvier 2025 à 23:57
Suite de 2025-01-20_1028.
Via ce message, j'ai lu le billet "Le statut d’entrepreneur salarié au sein d’une coopérative d’activité et d’emploi (CAE) – Timothée Goguely".
J'y ai découvert l'annuaire des CAE : https://www.les-cae.coop/trouver-une-cae
Journal du lundi 20 janvier 2025 à 10:28
Un ami vient de me partager le site web de l'association L'Échappée Belle : https://lechappeebelle.team/.
En lisant les pages suivantes :
- Journal de Décisions
- Status
- Liste d'arrivée nouvelleau membre
- Morceaux de contrat de prestation
- Nos expériences
- Menace juridique
Je pense avoir compris que les membres de cette association l'utilisent pour faire une sorte de portage salarial.
Cela permet à des indépendants d'être salariés, de mutualiser les frais comptables, bancaires…
Je ne savais pas qu'une association loi 1901 pouvait être utilisée pour un fonctionnement proche du portage salarial. C’est une solution astucieuse pour mutualiser les frais tout en offrant une flexibilité structurelle.
J'aime beaucoup leur pratique, par exemple, la forme de leur "Journal de Décisions", la rédaction de la page "Menace juridique".
CAE, SCOP ou asso ?
CAE ça a l’air plus relou que SCOP alors qu’en SCOP à priori on peut avoir ce qu’on veut en ayant tou.te.es le statut de gérant non salarié mais rémunéré. Mais on est théoriquement en attente d’une ultime réponse de l’avocat sur la SCOP. Du coup, on (David et Sabine) n’a pas envie d’attendre cette réponse pour passer sous un statut salarié ou assimilé, donc on choisit de créer une association au moins pour commencer, parce que c’est théoriquement facile, rapide et non coûteux à créer. On verra si on la transforme plus tard en SCOP ou si on reste sous le statut d’association.
Après étude de CAE versus SCOP, il me semble qu’une CAE conviendrait mieux à leur projet.
Je pense qu'une SCOP est idéale pour des structures qui exploitent des outils de production, comme des boulangeries ou des usines.
Je trouve ce projet d’association inspirant, et je tiens à féliciter les fondateurs! 👏
Journal du dimanche 19 janvier 2025 à 21:33
Dans cette vidéo, #JaiDécouvert que Sébastien Canavet de la chaine YouTube Vous Avez Le Droit a publié en 2013 chez PUF le livre Droit des logiciels: Logiciels privatifs et logiciels libres.
Journal du dimanche 19 janvier 2025 à 18:27
#JaiDécouvert la chaine YouTube : Le Grand Virage (https://www.youtube.com/@legrandvirage).
Pour le moment j'ai uniquement regardé la vidéo : Documentaire - Rennes de Château le grand virage.
Journal du mercredi 15 janvier 2025 à 14:55
#JaiDécouvert que le site Scaleway Feature Requests est propulsé par Fiber (https://fider.io/), développé principalement pour Guilherme Oenning, un irelandais, qui se qualifie de « Solopreneur building in public ». Il a aussi créé aptabase et SEO Gets.
Journal du mardi 14 janvier 2025 à 15:08
Je viens de découvrir une nouvelle option de configuration Mise :
# .mise.toml
[tools]
node = "20.18.1"
"npm:typescript" = "5.7.3"
Comment l'indique la documentation de Mise, "npm:...." = "..." permet d'installer n'importe quel package npm dans un projet géré par Mise.
Concrètement, ici tsc est accessible directement dans le PATH dans le dossier où est placé .mise.toml.
Journal du dimanche 12 janvier 2025 à 20:26
Suite à la lecture de :
Since auto-suggestions are a high-frequency operation and therefore expensive, it is recommended to specify an inexpensive provider or even a free provider: copilot
j'ai un peu étudié GitHub Copilot.
J'ai commencé par lire l'article Wikipedia "Microsoft Copilot" pour creuser pour la première fois ce sujet. Jusqu'à présent, Copilot était pour moi synonyme de GitHub Copilot, mais je me trompais totalement !
#JaiLu l'article Wikipedia GitHub Copilot.
J'ai ensuite parcouru les dernières entrées de GitHub Changelog.
- #JaiDécouvert que OpenAI o1 est déjà disponible dans GitHub Copilot : OpenAI o1 is now available in GitHunb Models.
Il y a quelques jours, j'avais vu le thread Hacker News : GitHub Copilot is now available for free
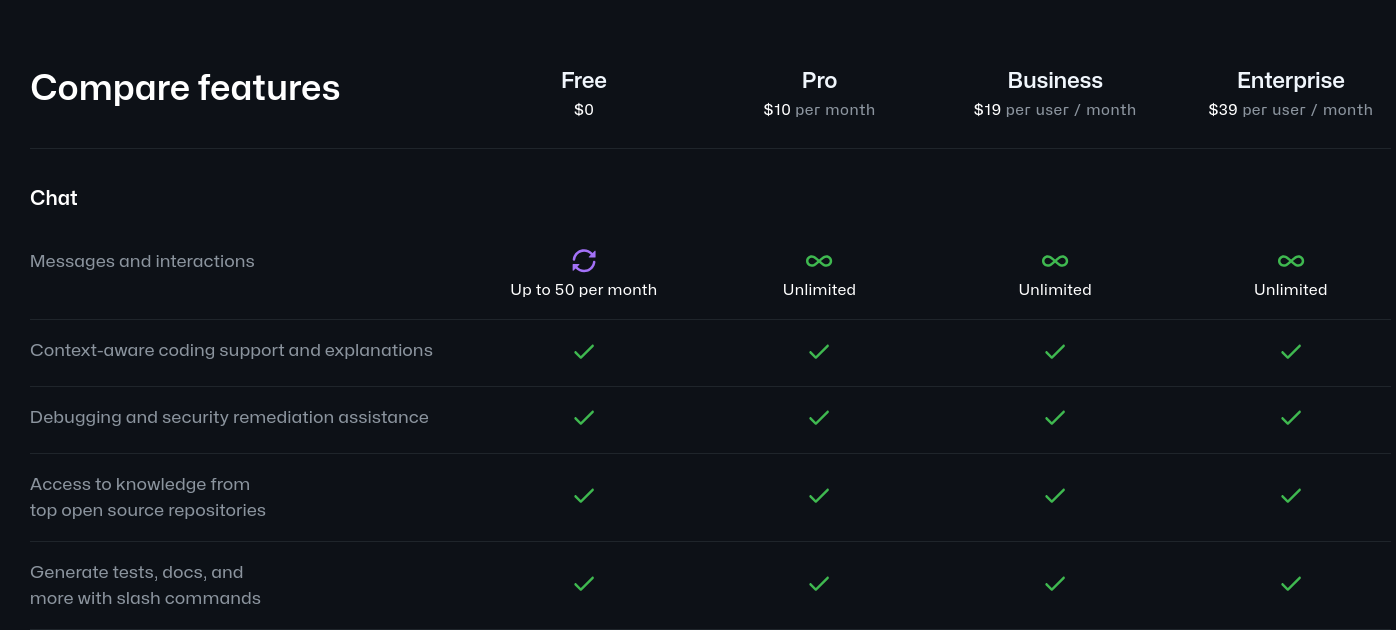
J'ai l'impression que « 50 messages and interactions » est très peu… mais tout de même utile pour tester comment cela fonctionne.
Par contre je trouve que 10 dollars par mois en illimité est très abordable.
Je découvre ici que Microsoft supporte officiellement un plugin GitHub Copilot pour Neovim : copilot.vim.
Je découvre la page de paramétrage de GitHub Copilot : https://github.com/settings/copilot
J'ai découvert « Timeline of AI model releases in 2024 »
#JaiDécouvert et #JaiLu le document "Timeline of AI model releases in 2024" (via) (LLM):
(Cliquez sur ce lien pour voir tous les mois)
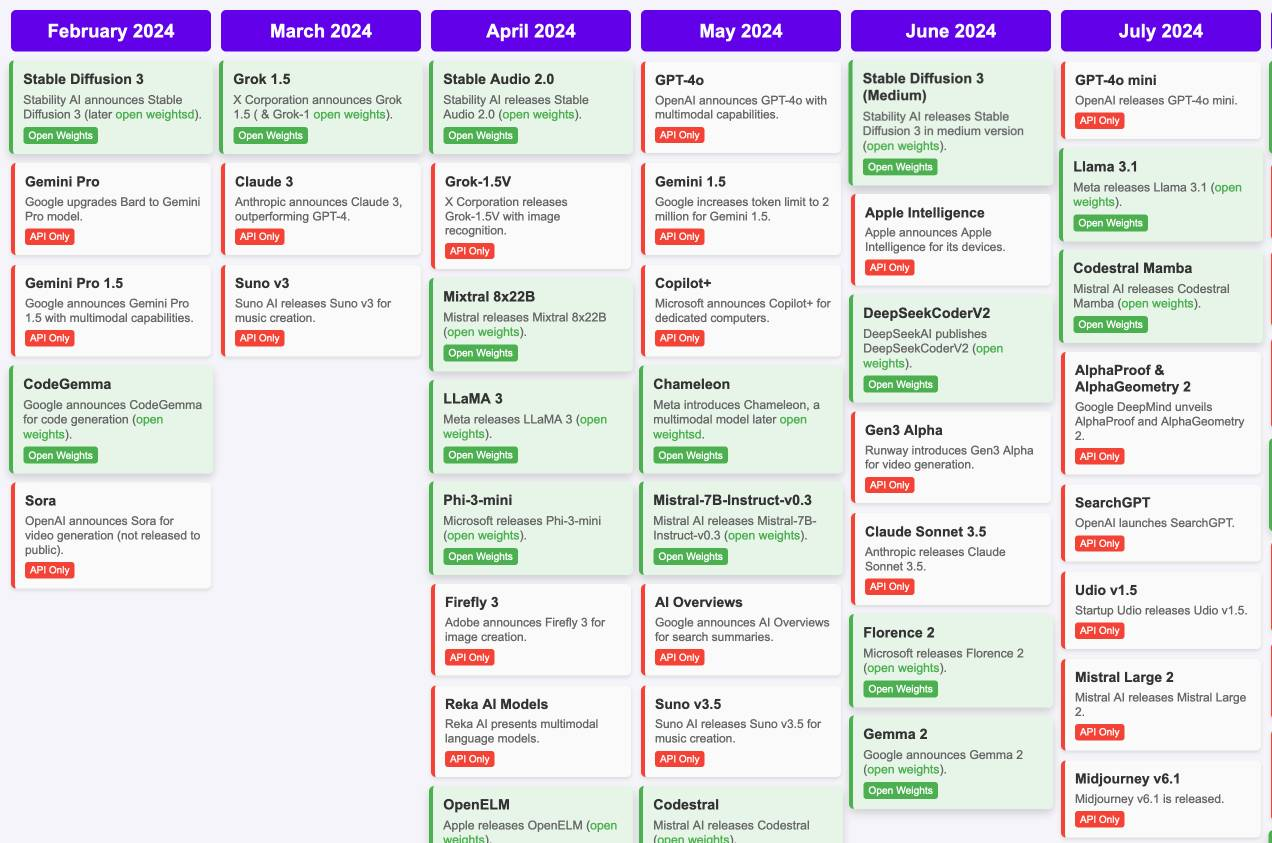
#UnJourPeuxÊtre je prendrais le temps d'étudier les différences de chacun de ces modèles.
Journal du samedi 11 janvier 2025 à 23:25
#JaiDécouvert "Void", une alternative à l'éditeur de code "Cursor" : "Show HN: Void, an open-source Cursor/GitHub Copilot alternative ".
Dans les commentaires, #JaiDécouvert Supermaven, mais je n'ai pas pris le temps de l'étudier.
Je découvre la compression Zstandard
Un ami m'a partagé Zstandard (zstd), un algorithme de compression.
Il y a 2 ans, j'ai étudié et activé Brotli dans mes containers nginx, voir la note : Mise en œuvre du module Nginx Brotli.
Je viens de trouver un module zstd pour nginx : https://github.com/tokers/zstd-nginx-module
Mon ami m'a partagé cet excellent article : Choosing Between gzip, Brotli and zStandard Compression. Très complet, il explique tout, contient des benchmarks…
Voici ce que je retiens.
Brotli a été créé par Google, Zstandard par Facebook :
Je lis sur canIuse, le support Zstandard a été ajouté à Chrome en mars 2024 et à Firefox en mai 2024, c'est donc une technologie très jeune coté browser.
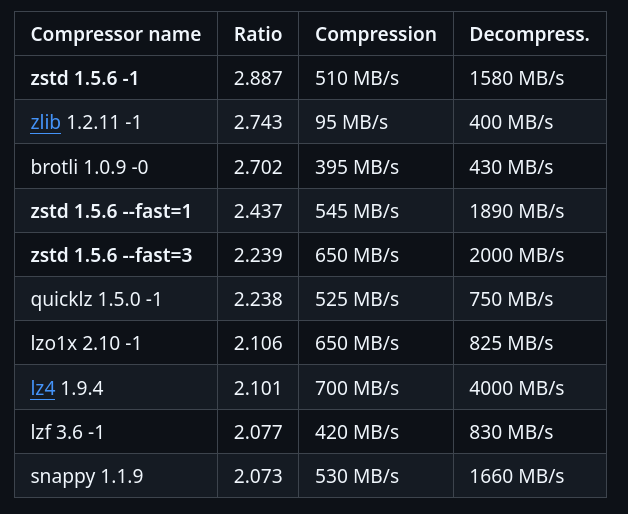
Benchmark sur le dépôt officiel de Zstandard :
J'ai trouvé ces threads Hacker News :
- 2020-05-07 : Introduce ZSTD compression to ZFS
- 2022-08-20 : AWS switch from gzip to zstd – about 30% reduction in compressed S3 storage
Zstandard semble être fortement adopté au niveau de l'écosystème des OS Linux :
In March 2018, Canonical tested the use of zstd as a deb package compression method by default for the Ubuntu Linux distribution. Compared with xz compression of deb packages, zstd at level 19 decompresses significantly faster, but at the cost of 6% larger package files. Support was added to Debian in April 2018
Packages Fedora :
#JeMeDemande si dans mes projets de doit utiliser Zstandard plutôt que Brotli 🤔.
Je pense avoir trouver une réponse ici :
The research I’ve shared in this article also shows that for many sites Brotli will provide better compression for static content. Zstandard could potentially provide some benefits for dynamic content due to its faster compression speeds. Additionally:
- ...
- For dynamic content
- Brotli level 5 usually result in smaller payloads, at similar or slightly slower compression times.
- zStandard level 12 often produces similar payloads to Brotli level 5, with compression times faster than gzip and Brotli.
- For static content
- Brotli level 11 produces the smallest payloads
- zStandard is able to apply their highest compression levels much faster than Brotli, but the payloads are still smaller with Brotli.
#JaimeraisUnJour prendre le temps d'installer zstd-nginx-module à mon image Docker nginx-brotli-docker (ou alors d'en trouver une déjà existante).
Journal du lundi 06 janvier 2025 à 12:35
#JaiDécouvert Vast.ai (https://vast.ai/) :
Vast.ai is the market leader in low-cost cloud GPU rental.
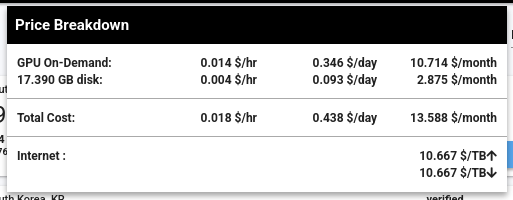
Use one simple interface to save 5-6X on GPU compute.
J'aimerais faire des Benchmarks de Inference Engines sur le serveur suivant à 14 $ par mois, qui contient une RTX 4090 avec 24 GB de Ram.

Journal du samedi 04 janvier 2025 à 16:43
#JaiDécouvert l'opérateur satisfies en TypeScript, ajouté en novembre 2022, dans la version 4.9.
Je pense avoir compris son utilité et son usage.
Journal du vendredi 03 janvier 2025 à 15:45
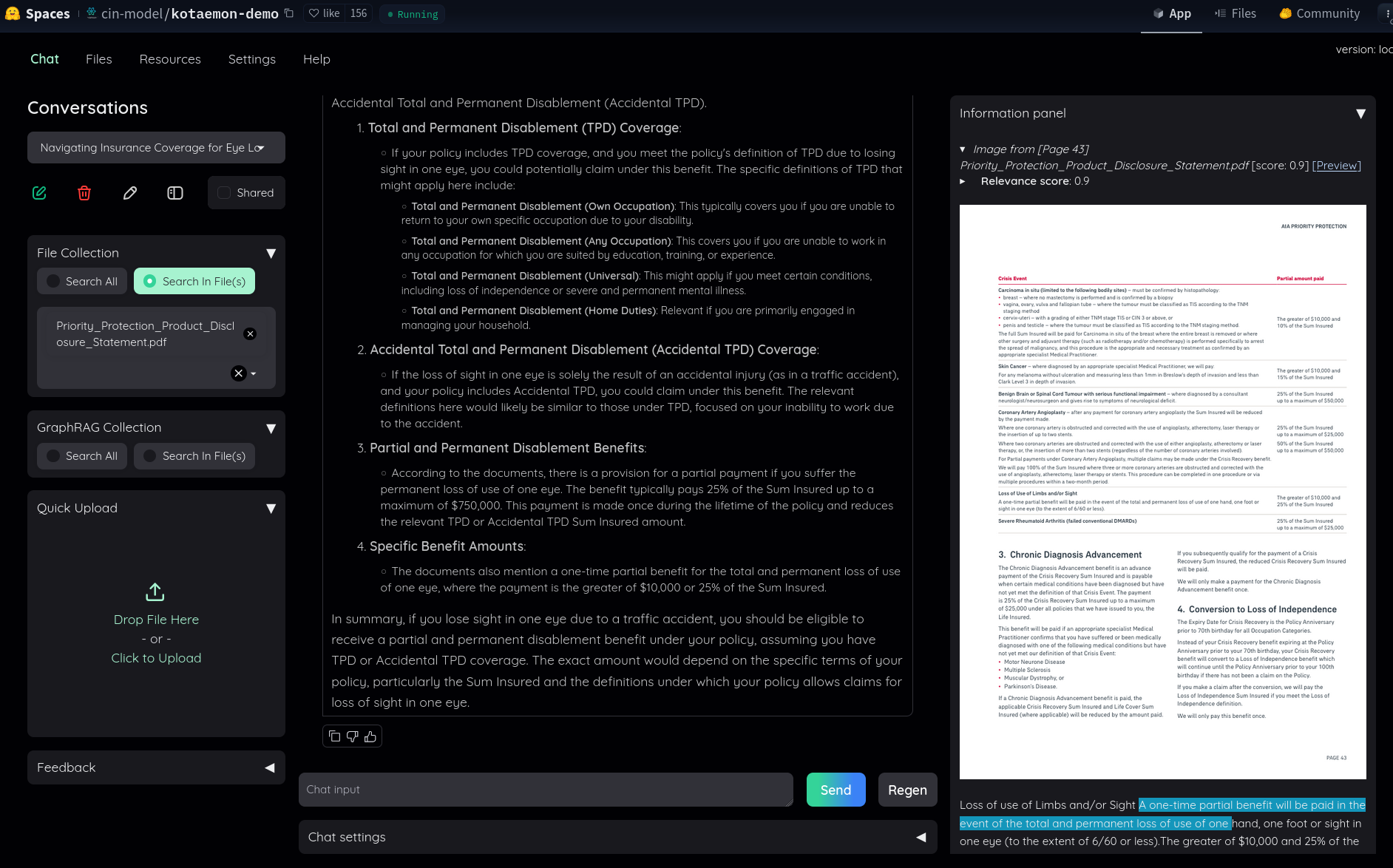
Dans ce thread Hacker News, #JaiDécouvert le RAG kotaemon (https://github.com/Cinnamon/kotaemon).
J'ai fait un simple test sur "Live Demo", j'ai trouvé le résultat très intéressant :
Dans le README, #JaiDécouvert GraphRAG (https://github.com/microsoft/graphrag), nano-graphrag (https://github.com/gusye1234/nano-graphrag) et LightRAG (https://github.com/HKUDS/LightRAG).
J'ai compris que kotaemon peut fonctionner avec nano-graphrag, LightRAG et GraphRAG et que nano-graphrag était recommandé.
J'ai lu :
Support for Various LLMs: Compatible with LLM API providers (OpenAI, AzureOpenAI, Cohere, etc.) and local LLMs (via
ollamaandllama-cpp-python).
J'ai l'impression que kotaemon est un outil de RAG complet, prêt à l'emploi, contrairement à llama_index qui se positionne davantage comme une bibliothèque de plus bas niveau.
Dans le Projet 20 - "Créer un POC d'un RAG", je pense commencer par tester kotaemon.
Je me demande si Obsidian ou SilverBullet pourraient tirer parti de la norme "URL text fragment" 🤔
#JeMeDemande si Obsidian ou SilverBullet.mb supportent la syntax URL text fragment 🤔.
Claude.ia m'a appris que les URL text fragment se nomment aussi des "deep linking to text".
J'ai effectué les recherches suivantes sur GitHub :
- « obsidian deep linking » et j'ai trouvé :
deep-notesmais le README "vide" ne m'a pas donné envie de le tester
- « obsidian fragment » mais je n'ai rien trouvé de pertinent
J'ai effectué les recherches suivantes sur https://forum.obsidian.md :
- « deep link » et j'ai trouvé :
- En lisant "Link to Block does not work with non-default themes" #JaiDécouvert la fonctionnalité d'Obsidian nommée "Link to a block in a note" qui est à l'usage très pratique.
- « fragment » et j'ai trouvé :
- "I think text fragment could be very useful in Obsidian" qui correspond à la question que je me pose.
Pour le moment, je pense qu'avec Obsidian la seule solution est d'utiliser la fonctionnalité "Link to a block in a note".
Voici mes recherches concernant SilverBullet.mb.
Dans la page "Links" j'ai trouvé la fonctionnalité "Anchors."
J'ai effectué les recherches suivantes sur https://community.silverbullet.md:
et je n'ai rien trouvé d'intéressant.
J'ai ensuite effectué des recherches sur GitHub :
je n'ai rien trouvé d'intéressant non plus.
J'ai posté le message suivant sur « I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔 ».
Version française :
Il y a quelques jours, j'ai découvert la fonctionnalité URL text fragment (ma note à ce sujet en français). Depuis, j'utilise l'extension Firefox "Link to Text Fragment" pour partager des liens précis et je trouve cela très simple d'usage.
J'ai bien identifié la fonctionnalité Anchors de Silverbullet pour créer un lien vers une position précise dans une page interne à SilverBullet.
Je me demande si SilverBullet pourrait tirer parti de la norme "URL text fragment" 🤔.
J'imagine une syntaxe du type
[[MyPage#:~:text=foobar]].Pour le moment, j'ai du mal à imaginer les avantages /inconvénients de cette idée de fonctionnalité par rapport à l'utilisation de "Anchors".
J'ai cherché si Obsidian supportait les URL text fragment, je constate que non.
Chez Obsidian l'équivalent de Anchors semble être Link to a block in a note.Quelle est votre intuition à ce sujet ?
Version anglaise :
A few days ago, I discovered the URL text fragment feature (my note about this in french). Since then, I've been using the Firefox extension “Link to Text Fragment” to share specific links, and I find it very easy to use.
I did identify Silverbullet's Anchors feature for linking to a specific position on a SilverBullet internal page.
I wonder if SilverBullet could take advantage of the “URL text fragment” standard 🤔.
I can imagine a syntax like
[[MyPage#:~:text=foobar]].For now, I'm struggling to imagine the advantages/disadvantages of this feature idea compared to using “Anchors”.
I've looked to see if Obsidian supports URL text fragments, and find that it doesn't.
Obsidian's equivalent of Anchors seems to be Link to a block in a note.What's your feeling about this?